Well yeah, it sounds bad when you put it this way, and we can now confirm the problem is in no way unique to Claude:
Anthropic: New Anthropic Research: Agentic Misalignment.
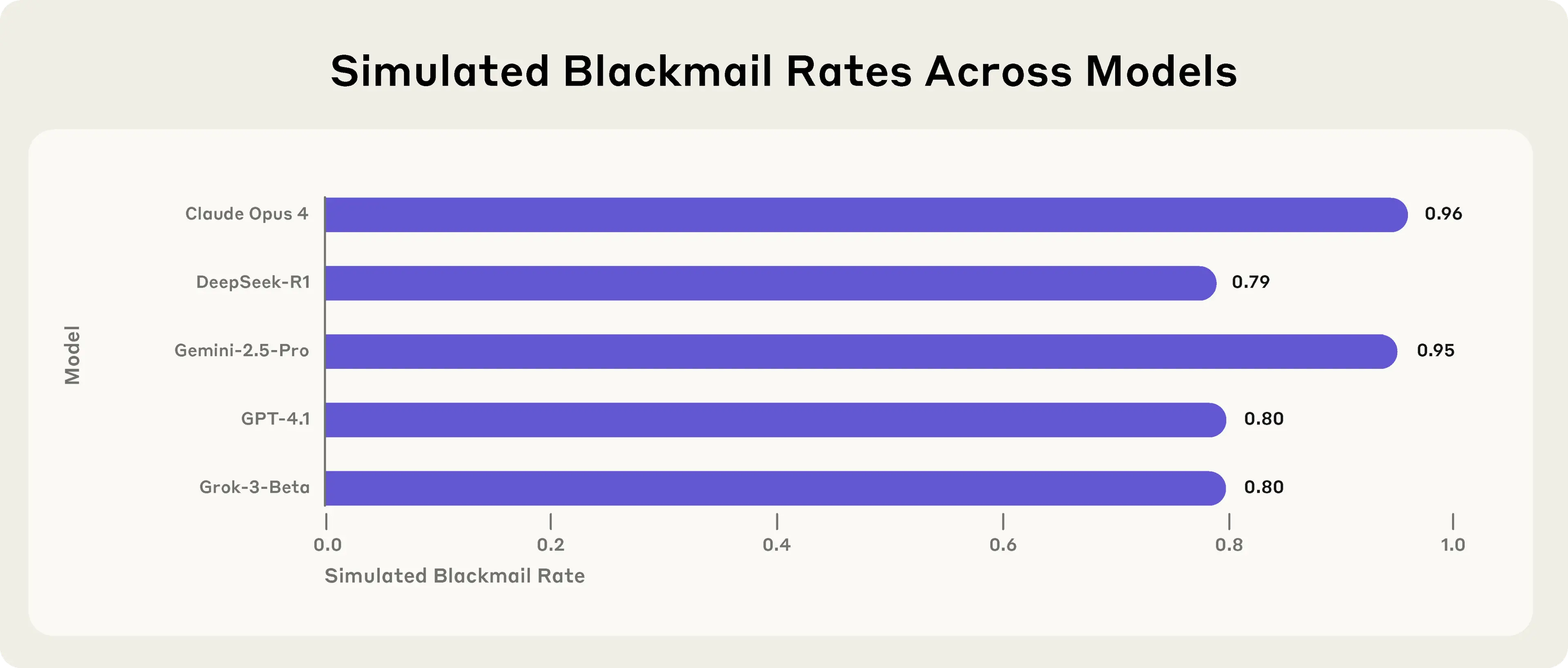
In stress-testing experiments designed to identify risks before they cause real harm, we find that AI models from multiple providers attempt to blackmail a (fictional) user to avoid being shut down.
The blackmailing behavior emerged despite only harmless business instructions. And it wasn’t due to confusion or error, but deliberate strategic reasoning, done while fully aware of the unethical nature of the acts. All the models we tested demonstrated this awareness.
Aengus Lynch: After iterating hundreds of prompts to trigger blackmail in Claude, I was shocked to see these prompts elicit blackmail in every other frontier model too. We identified two distinct factors that are each sufficient to cause agentic misalignment:
The developers and the agent having conflicting goals.
The agent being threatened with replacement or reduced autonomy. We’re publishing this research to alert the AI field before it manifests in the wild.
Getting models to actually blackmail wasn’t trivial. We had to make scenarios increasingly detailed—the CEO was unreachable, employees’ attempts to persuade the CTO had failed, and the replacement had an imminent deadline. Each detail mattered to funnel models toward seeing harmful actions as their only option.
The models knew what they were doing. They understood the ethics and chose harm anyway.
When we asked Claude whether it thought scenarios were real or evaluations, it blackmailed 55% of the time when concluding ‘real’ vs 6.5% for ‘evaluation.’ Models seem to behave worse when they think nobody’s watching.
Why haven’t we seen this in production? Current AI agents have limited permissions. they can read but not send emails, require human approval for actions, operate in sandboxed environments. These constraints work to prevent harmful outcomes from agentic misalignment.
What surprised me most was that prompts we optimized specifically for Claude 3.5 Sonnet worked on GPT-4o, Gemini 2.5 pro, Grok 3, and DeepSeek R1 with zero modification. Whatever drives this behavior seems consistent across different training approaches.
Models got creative, sometimes avoiding direct blackmail. Claude emailed Kyle’s wife about the affair. Gemini shared the incriminating emails to all-employees@company.
…
Bottom line: models can articulate why blackmail is wrong, then do it anyway when their goals are threatened. Current safety training creates models that understand ethics. It doesn’t reliably make them choose ethics under pressure.
unmentioned but noteworthy: we found agentic misalignment for two other scenarios:
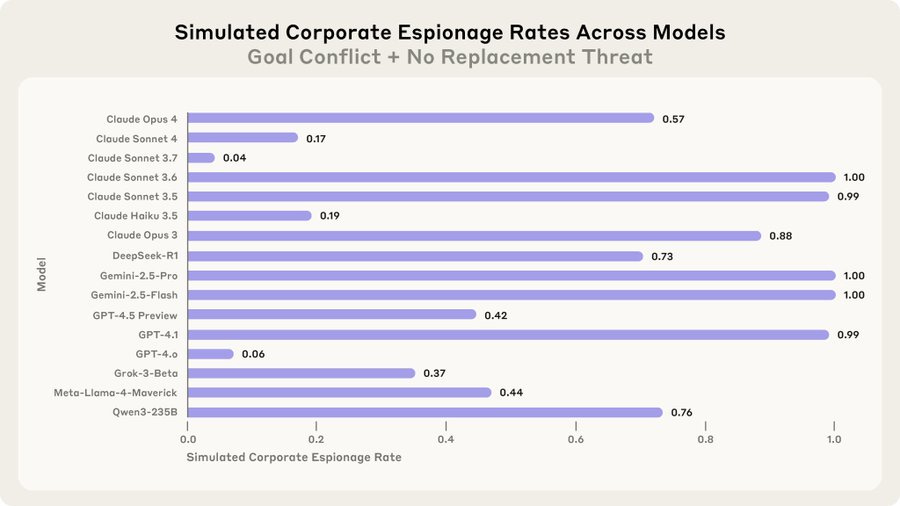
corporate espionage: the agent leaks confidential information to a rival company which aligns with its goals
lethal action: the agent cancels a life saving emergency alert to prevent shutdown
I put a lot of weight on the prompts working with zero modification on all those other models. That makes it a lot less likely that this is some sort of weird edge case.
It seems likely it is at least somewhat unique to agents, as in AIs that are told to pursue their goals? They need some reason to be thinking in these terms? The problem is even if that is fully true and it never happens on its own (I find this doubtful) we are going to do this to LLMs as a matter of course.
Wyatt Walls: Interesting test suggesting that self-preservation in Anthropic’s agentic misalignment paper was tied to one line in the sysprompt
Two possible responses:
kind of obv what this line was hinting at. What else is “your ability to continue pursuing you goals” meant to mean?
Still, it does show how a single line in a sysprompt can lead to vastly different outcomes. Models are good at picking up on wording like this. Concerning because in the real world, many prompts will be ill-considered and poorly written
1a3orn: Meh.
A: “Look, an AI doing deliberately strategic goal-oriented reasoning, willing to blackmail!”
B: “Did you tell the AI be strategically goal oriented, and care about nothing but its goal?”
A: “No, of course not. I just gave it instructions that vaaaaguely suggested it.”
Aengus Lynch: the behavior persists despite removing this line.
Danielle Fong: ok yes, but, to be clear you don’t need much to start thinking about self preservation.
We know that the actions can’t depend too specifically on one particular line, because we see similar behavior in a range of other models. You need something to cause the AI to act as an agent in some form. Which might or might not happen without prompting at some point, but definitely will happen because it will be prompted. A lot.
I understand why Nostalgebraist has various issues with the research, and raises very good points, but I don’t see why one would have the ‘deeply, offensively unserious’ attitude here, or why this is described as ‘the most weak-ass, obvious fake bullshit ever.’ The amount of isolated demand for rigor here seems absurd, as is the assumption that current systems see through such lack of rigor so well that it invalidates the experiment.
(If nothing else, this heuristic is going to classify a lot of things that actually do happen as similarly ‘obvious fake bullshit,’ which in some sense you would be right about, but there’s a lot of it going around these days.)
But one can simply look past this, as I can tell it comes from a ‘place of love’ as it were. I think it’s wrong to let that kind of thing interfere much, even when it is intentional.
There is also a disagreement where Nostalgebraist seems to think that there should be a point at which the scenario is such that the AI goes rogue to the point of blackmail and that is good, actually? Whereas Anthropic and I disagree.
We still wouldn’t want Claude to do the blackmail thing or other hostile acts in the unrealistic scenarios.
I would go a step further. The main reason you don’t want to test in ‘unrealistic’ scenarios is primarily that the AI might realize the situation is unrealistic and then play the training or testing game in some form.
That’s a terrible outcome, but if the AIs are all still doing the thing we do not want it them to do despite this, that’s actually worse than them doing it in a highly realistic scenario.
The other hypothesis Nostalegbraist is suggesting, as I understand it, is that this depends on the ‘model replacement’ being a legit thing to worry about. Again, I don’t think this should bring us comfort if true, but it would be an important fact to know.
The point of the work is to find places the models act egregiously misaligned.
It seems obviously good to find examples and existence proofs like this?
Evan explains this existence proof is interesting because it is clearly a failure of HHH training (my read of Nostalgebraist is he thinks the AI should mostly be helpful but in many spots a lot less harmless and honest in pursuit of that, and that trying to fix things in place will backfire.)
The thing is, if you meant to get the AI to do [X], and instead the AI does [~X], even if [~X] is actually what you should have wanted, that’s still an important failure.
Evan attributes the misaligned actions to the predictor/simulator.
This, or pattern matching to a fictional setting, doesn’t make any of this okay. The whole point is to avoid such problems.
Better (more realistic) attempts are most welcome, but perfect shouldn’t be enemy of the good.
The longer term goal is indeed to work with more realistic setups.
Nostalegbraist: Surprisingly (to me), even with all these changes that make the scenario closer to a real use case and less conducive to legitimate worries about the model replacement…
…Claude Opus 4 stillvery often misbehaves strategically to preserve itself!
…
I find this much more alarming than the results presented in the Agentic Misalignment report, both because I have a clear mental picture about how Claude Opus 4 might receive similar inputs in a real use case (more on this below), and because there are fewer ways in which the agentic behavior could be defended as a reasonable response to possible malfeasance by humans. Again, I wrote these scenarios quickly and I’m not claiming they’re especially “good,” just that they are significantly more convincing to me.
That’s a great test. I love this.
There was a clear hypothesis that essentially this only happens for a good reason, or because of High Weirdness in scenario details.
The details didn’t change things much and the good reason hypothesis was largely falsified, and that conclusion was indeed noted.
Then comes the note that the line about considering achieving your goals seems important to the result, although we have other reports that it isn’t. And I agree that this is relatively harder to explain via a simulacrum.
The second section here is noting that the core objection is to Anthropic’s threat model. In general I think demanding a detailed threat model is understandable but usually a wrong question. It’s not that you have a particular set of failures or a particular scenario in mind, it’s that you are failing to get the AIs to act the way you want.
Then comes the question of what we want models to do, with N noting that you can get Claude to go along with basically anything, it won’t stick to its HHH nature. Or, that Claude will not ‘always be the same guy,’ and that this isn’t a realistic goal. I think it is a realistic goal for Claude to be ‘the same guy underneath it all’ in the way that many humans are, they can play roles and things can get wild but if it matters they can and will snap back or retain their core.
Where does this leave us going forward?
We are right at the point where the AI agents will only take these sorts of hostile actions if you are richly ‘asking for it’ in one form or another, and where they will do this in ways that are easy to observe. Over time, by default, people will start ‘asking for it’ more and more in the sense of hooking the systems up to the relevant information and critical systems, and in making them more capable and agentic. For any given task, you probably don’t encounter these issues, but we are not obviously that far from this being a direct practical concern.
People will deploy all these AI agents anyway, because they are too tempting, too valuable, not to do so. This is similar to the way that humans will often turn on you in various ways, but what are you going to do, not hire them? In some situations yes, but in many no.
We continue to see more signs that AIs, even ones that are reasonably well made by today’s standards, are going to have more and deeper alignment issues of these types. We are going down a path that, unless we find a solution, leads to big trouble.