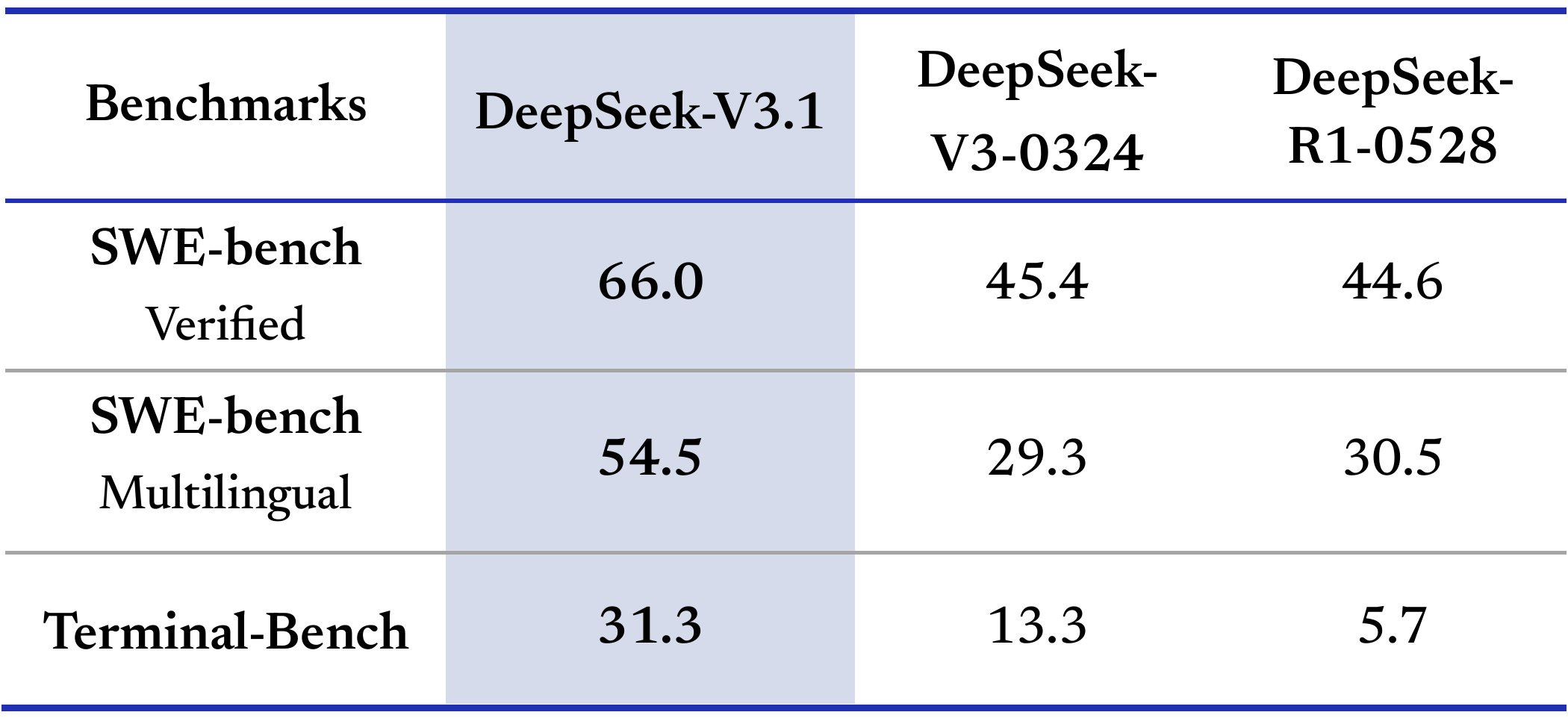
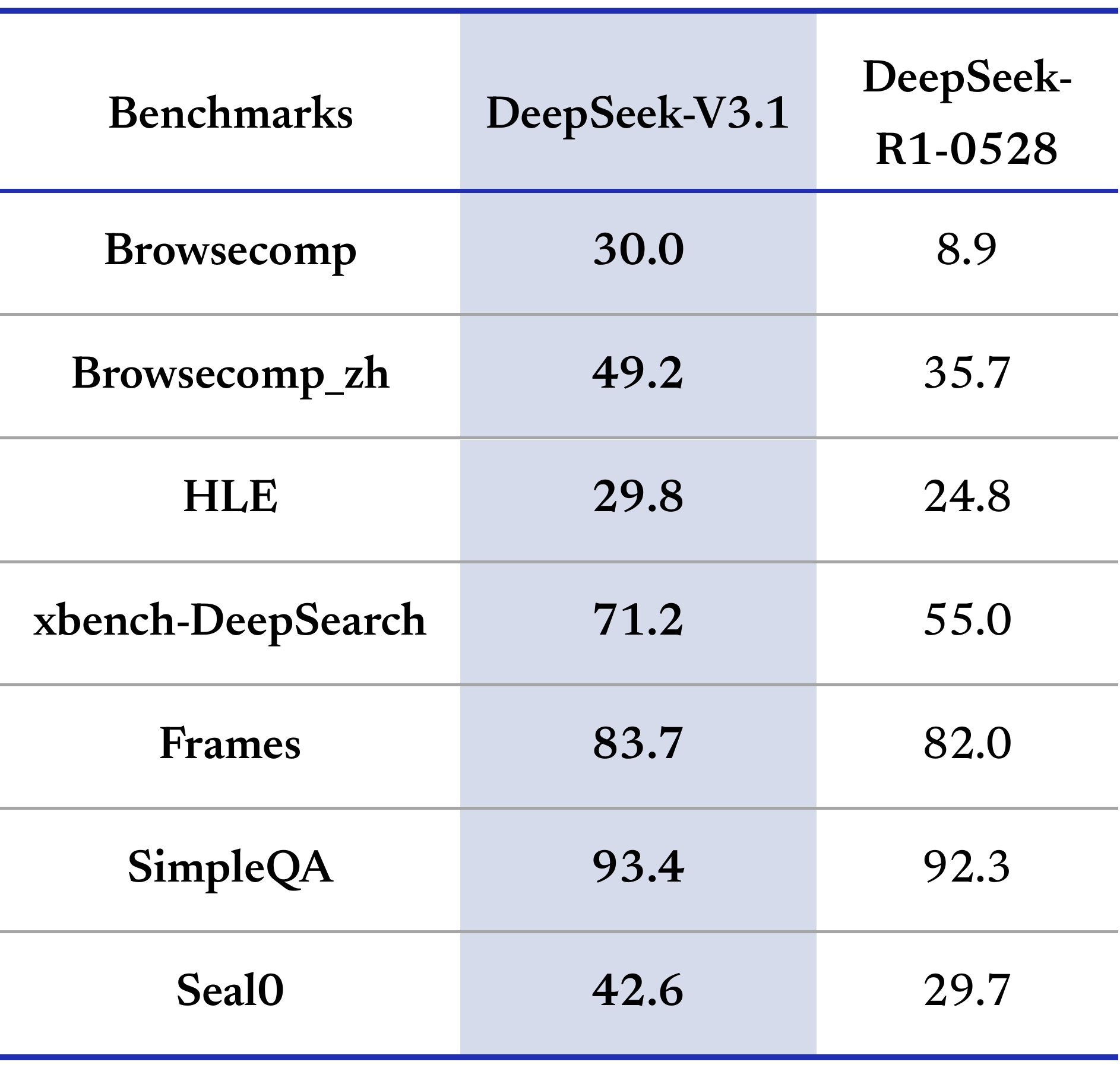
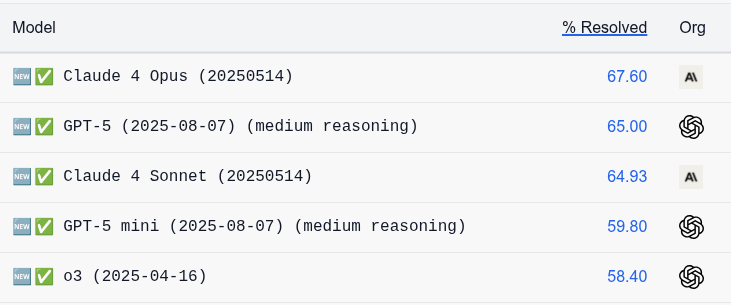
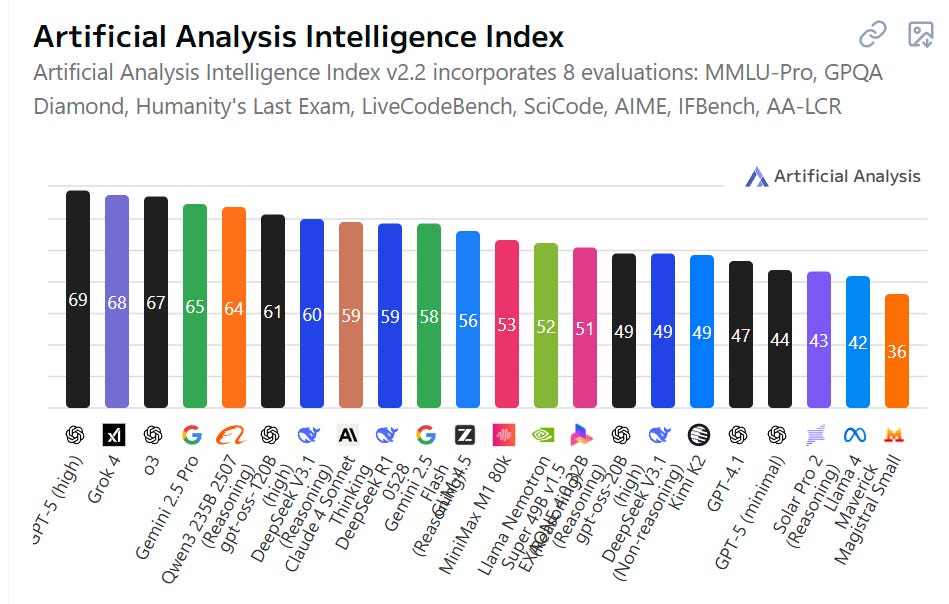
What if DeepSeek released a model claiming 66 on SWE and almost no one tried using it? Would it be any good? Would you be able to tell? Or would we get the shortest post of the year?
Eleanor Olcott and Zijing Wu: Chinese artificial intelligence company DeepSeek delayed the release of its new model after failing to train it using Huawei’s chips, highlighting the limits of Beijing’s push to replace US technology.
DeepSeek was encouraged by authorities to adopt Huawei’s Ascend processor rather than use Nvidia’s systems after releasing its R1 model in January, according to three people familiar with the matter.
But the Chinese start-up encountered persistent technical issues during its R2 training process using Ascend chips, prompting it to use Nvidia chips for training and Huawei’s for inference, said the people.
The issues were the main reason the model’s launch was delayed from May, said a person with knowledge of the situation, causing it to lose ground to rivals.
The real world so often involves people acting so much stupider than you could write into fiction.
America tried to sell China H20s and China decided they didn’t want them and now Nvidia is halting related orders with suppliers.
DeepSeek says that the main restriction on their development is lack of compute, and the PRC responds not by helping them get better chips but by advising them to not use the chips that they have, greatly slowing things down at least for a while.
Teortaxes: for now seems to have the same performance ceiling as 0528, maybe a bit weaker on some a bit stronger on other problems. The main change is that it’s a unified merge that uses ≥2x fewer reasoning tokens. I take it as a trial balloon before V4 that’ll be unified out of the box.
Wes Roth: DeepSeek has quietly published V 3.1, a 685-billion-parameter open-source model that folds chat, reasoning, and coding into a single architecture, handles 128 k-token context windows, and posts a 71.6 % score on the Aider coding benchmark edging out Claude Opus 4 while costing ~68× less in inference.
But these two data points don’t seem backed up by the other reactions, or especially the lack of other reactions, or some other test results.
Artificial Analysis has it coming in at 60 versus r1’s 59, which would be only a small improvement.
I tried to conduct Twitter polls, but well over 90% of respondents had to click ‘see results’ which left me with only a handful of real responses and means Lizardman Constant problems and small sample size invalidate the results, beyond confirming no one is looking, and the different polls don’t entirely agree with each other as a result.
If this were most open model companies, I would treat this lack of reaction as indicating there was nothing here, that they likely targeted SWE as a benchmark, and move on.
Since it is DeepSeek, I give them more credit than that, but am still going to assume this is only a small incremental upgrade that does not change the overall picture. However, if 3.1 really was at 66-level for real in practice, it has been several days now, and people would likely be shouting it from the rooftops. They’re not.
Even if no one finds anything to do with it, I don’t downgrade DeepSeek much for 3.1 not impressing compared to if they hadn’t released anything. It’s fine to do incremental improvements. They should do a v3.1 here.
The dumbest style of reaction is when a company offers an incremental improvement (see: GPT-5) and people think that means it’s all over for them, or for AI in general, because it didn’t sufficiently blow them away. Chill out.
It’s also not fair to fully pin this on DeepSeek when they were forced to do a lot of their training this year on Huawei Ascend chips rather than Nvidia chips. Assuming, that is, they are going to be allowed to switch back.