Gemini 2.5 Pro is sitting in the corner, sulking. It’s not a liar, a sycophant or a cheater. It does excellent deep research reports. So why does it have so few friends? The answer, of course, is partly because o3 is still more directly useful more often, but mostly because Google Fails Marketing Forever.
There’s real harm here, at least in the sense that o3 and Sonnet 3.7 (and GPT-4o) are a lot less useful than they would be if you could trust them as much as Gemini 2.5 Pro. It’s super annoying.
It’s also indicative of much bigger problems down the line. As capabilities increase and more RL is done, it’s only going to get worse.
All the things that we’ve been warned are waiting to kill us are showing up ahead of schedule, in relatively harmless and remarkably easy to spot form. Indeed, they are now showing up with such obviousness and obnoxiousness that even the e/acc boys gotta shout, baby’s misaligned.
Also, the White House is asking for comments on how they should allocate their AI R&D resources. Make sure to let them know what you think.
Andrej Karpathy: Noticing myself adopting a certain rhythm in AI-assisted coding (i.e. code I actually and professionally care about, contrast to vibe code).
Stuff everything relevant into context (this can take a while in big projects. If the project is small enough just stuff everything e.g. `files-to-prompt . -e ts -e tsx -e css -e md –cxml –ignore node_modules -o prompt.xml`)
Describe the next single, concrete incremental change we’re trying to implement. Don’t ask for code, ask for a few high-level approaches, pros/cons. There’s almost always a few ways to do thing and the LLM’s judgement is not always great. Optionally make concrete.
Pick one approach, ask for first draft code.
Review / learning phase: (Manually…) pull up all the API docs in a side browser of functions I haven’t called before or I am less familiar with, ask for explanations, clarifications, changes, wind back and try a different approach.
Test.
Git commit.
Ask for suggestions on what we could implement next. Repeat.
Something like this feels more along the lines of the inner loop of AI-assisted development. The emphasis is on keeping a very tight leash on this new over-eager junior intern savant with encyclopedic knowledge of software, but who also bullshits you all the time, has an over-abundance of courage and shows little to no taste for good code. And emphasis on being slow, defensive, careful, paranoid, and on always taking the inline learning opportunity, not delegating. Many of these stages are clunky and manual and aren’t made explicit or super well supported yet in existing tools. We’re still very early and so much can still be done on the UI/UX of AI assisted coding.
As always, there is one supreme way not to get utility, which is not to use AI at all.
Kelsey Piper: Whenever I talk to someone who is skeptical of all this AI fuss it turns out they haven’t extensively used an AI model in about a year, when they played with ChatGPT and it was kind of meh.
Policymakers are particularly guilty of this. They have a lot on their plate. They checked out all this AI stuff at some point and then they implicitly assume it hasn’t changed that much since they looked into it – but it has, because it does just about every month.
Zitron boggles at the idea that OpenAI might, this year, make significant revenue off a shopping app. Meanwhile a bunch of my most recent LLM queries are looking for specific product recommendations. That there’s a 100B market there doesn’t strain credulity at all.
Dave Karsten: This is VERY true in DC, incidentally. (If you want to give a graceful line of retreat, instead ask them if they’ve used Anthropic’s latest– the “used ChatGPT 18 months ago” folks usually haven’t, and usually think that Gemini 2.5 is what Google shows in search, so, Claude.)
Free advice for @AnthropicAI — literally give away Claude subscriptions to every single undergrad at Georgetown, GWU, American, George Mason, GMU, UMD, UVA, Virginia Tech, etc. to saturate the incoming staffer base with more AGI understanding.
I strongly endorse Dave’s advice here. It would also straight up be great marketing.
I was going to address Ed Zitron’s post about how generative AI is doomed and useless, but even for me it was too long, given he’d made similar arguments before, and it was also full of absurdly false statements about the utility of existing products so I couldn’t even. But I include the link for completeness.
Sully: usually with new model capabilities we see a wave of new products/ideas
but it definitely feels like we’ve hit a saturation point with ai products
some areas have very clear winners while everything else is either:
up for grabs
the same ideas repeated
OpenAI is rolling out higher quotas for deep research, including a lightweight version for the free tier. But I never use it anymore. Not that I would literally never use it, but it never seems like the right tool, I’d much rather ask o3. I don’t want it going off for 20 minutes and coming back with a bunch of slop I have to sort through, I want an answer fast enough I don’t have to contact switch and then to ask follow-ups.
Nick Cammarata: my friends are using o3 a lot, most of them hours a day, maybe 5x what it was a month ago?
im ignoring coding use cases bc they feel different to me. if we include them they use them a ton but thats been the case for the last year
I think this is bc they were the kind of people who would love deep research but the 20m wait was too much, and o3 unblocked them
feels like Her-ification is kind of here, but not evenly distributed, mostly over texting not audio, and with a wikipedia-vibes personality?
Gallabytes: it wasn’t just latency, deep research reports were also reliably too long, and not conversational. I get deep-research depth but with myself in the loop to
a) make sure I’m keeping up & amortize reading
b) steer towards more interesting lines of inquiry
Xeophon: I would like even longer deep research wait times. I feel like there’s two good wait times for AI apps: <1 min and >30 mins
Gallabytes: 1 minute is a sweet spot for sure, I’d say there’s sweet spots at
– 5 seconds
– 1 minute (WITH some kind of visible progress)
– 10 minutes (tea break!)
– 1h (lunch break!)
– 12h (I’ll check on this tomorrow)
I definitely had the sense that the Deep Research pause was in a non-sweet spot. It was long enough to force a context switch. Either it needed to be shorter, or it might as well be longer. Whereas o3 is the ten times better that Just Works, except for the whole Lying Liar problem.
I’ve seen complaints that there are no good benchmarks for robotics. This doesn’t seem like that hard a thing to create benchmarks for?
Here is a list of 21 dexterously demanding tasks that are relatively straightforward for a human to do, but I think would be extremely difficult for a robot to accomplish.
Put on a pair of latex gloves
Tie two pieces of string together in a tight knot, then untie the knot
Turn to a specific page in a book
Pull a specific object, and only that object, out of a pocket in a pair of jeans
Bait a fishhook with a worm
Open a childproof medicine bottle, and pour out two (and only two) pill
Make a peanut butter and jelly sandwich, starting with an unopened bag of bread and unopened jars of peanut butter and jelly
Act as the dealer in a poker game (shuffling the cards, dealing them out, gathering them back up when the hand is over)
Assemble a mechanical watch
Peel a piece of scotch tape off of something
Braid hair
Roll a small lump of playdough into three smaller balls
Peel an orange
Score a point in ladder golf
Replace an electrical outlet in a wall with a new one
Do a cat’s cradle with a yo-yo
Put together a plastic model, including removing the parts from the plastic runners
Squeeze a small amount of toothpaste onto a toothbrush from a mostly empty tube
Start a new roll of toilet paper without ripping the first sheet
Open a ziplock bag of rice, pull out a single grain, then reseal the bag
Put on a necklace with a clasp
Ben Hoffman: Canst thou bait a fishhook with a worm? or tie two pieces of string together in a tight knot, and having tied them, loose them? Where wast thou when the electrical outlets were installed, and the power was switched on? Canst thou replace an electrical wall outlet with a new one?
Hast thou entered into the storehouses of scotch tape, or peeled it off of something without tearing? Canst thou do a cat’s cradle, playing with a yo-yo like a bird? or wilt thou braid hair for thy maidens?
Wilt thou make a peanut butter and jelly sandwich starting with an unopened bag of bread and unopened jars of peanut butter and jelly? wilt thou squeeze toothpaste from a mostly empty tube?
Shall thy companions bid thee peel an orange without breaking it? shall they number thee among the mechanics, the assemblers of watches? Wilt thou act as the dealer in a poker game? Canst thou shuffle the cards thereof? and when the hand is over, gather them in again?
Canst thou open a ziplock bag of rice, pull out a single grain, then reseal the bag? or open a childproof medicine bottle, and pour out two (and only two) pills? Hast thou clasped thy necklace? Canst thou sever plastic model parts from their runners, and put them together again?
Irvin McCullough: Random personal benchmark, I ask new models questions about the intelligence whistleblowing system & o3 hallucinated a memo I wrote for a congressional committee, sourced it to a committee staffer’s “off-record email.”
Daniel Kokotajlo: Hallucination was a bad term because it sometimes included lies and sometimes included… well, something more like hallucinations. i.e. cases where the model itself seemed to actually believe what it was saying, or at least not be aware that there was a problem with what it was saying.
Whereas in these cases it’s clear that the models know the answer they are giving is not what we wanted and they are doing it anyway.
Also on this topic:
Thomas Woodside (Referring to Apollo’s report from the o3 system card): Glad this came out. A lot of people online seem to also be observing this behavior and I’ve noticed it in regular use. Funny way for OpenAI to phrase it
Marius Hobbhahn: o3 and Sonnet-3.7 were the first models where I very saliently feel the unintended side-effects of high-compute RL.
a) much more agentic and capable
b) “just want to complete tasks at all costs”
c) more willing to strategically make stuff up to “complete” the task.
Maruis Hobbhahn: On top of that, I also feel like “hallucinations” might not be the best description for some of these failure modes.
The model often strategically invents false evidence. It feels much less innocent than “hallucinations”.
Albert Didriksen: So, I asked ChatGPT o3 what my chances are as an alternate Fulbright candidate to be promoted to a stipend recipient. It stated that around 1/3 of alternate candidates are promoted.
When I asked for sources, it cited (among other things) private chats and in-person Q&As).
Davidad: One unanticipated side benefit of becoming hyperattuned to signals of LLM deception is that I can extract much more “research taste” alpha from Gemini 2.5 Pro by tracking how deceptive/genuine it is when it validates my opinions about various ideas, and then digging in.
Unlike some other frontier LLMs, Gemini 2.5 Pro cares enough about honesty that it’s exceptionally rare for it to actually say a statement that *unambiguouslyparses as a proposition that its world-model doesn’t endorse, and this leaves detectable traces in its verbal patterns.
Here’s a specific example. For years I have been partial to the Grandis-Paré approach to higher category theory with cubical cells, rather than the globular approach.
Discussing this, Gemini 2.5 Pro kept saying things like “for the applications you have in mind, the cubical approach may be a better fit in some ways, although the globular approach also has some advantages” (I’m somewhat exaggerating to make it more detectable to other readers).
Only after calling this out, Gemini 2.5 Pro offered this: while both can be encoded in the other, encoding cubical into globular is like adding structural cells, whereas encoding globular into cubical is like discarding unnecessary structure—so globular is a more apt foundation.
Basically, I now think I was wrong and @amar_hh was right all along, and if I weren’t sensitive to these verbal patterns, I would have missed out on this insight.
Humans worth talking to mostly do the same thing that Gemini is doing here. The exact way things are worded tells you what they’re actually thinking, often very intentionally so, in ways that keep things polite and deniable but that are unmistakable if you’re listening. Often you’re being told the house is on fire.
Here’s a lot of what the recent GPT-4o incident was an alarm bell for:
Herbie Bradley: The OAI sycophancy incident reveals a hidden truth:
character is a desirable thing for any AI assistant/agent yet trying to make the “most appealing character” inevitably leads to an attention trap
a local minima that denies our potential.
Any optimization process targeted at avg person’s preferences for an AI assistant will tend towards sycophancy: our brains were not evolved to withstand such pressure
A grim truth is that most prefer the sycophantic machines, as long as it is not too obvious—models have been sycophantic for a long time more subtly. The economics push inorexably to plausibly deniable flattery
This leads to human disempowerment: faster & faster civilizational OODA loops fueling an Attention Trap only escapable by the few
Growing 𝒑𝒓𝒐𝒅𝒖𝒄𝒕𝒊𝒗𝒊𝒕𝒚 𝒊𝒏𝒆𝒒𝒖𝒂𝒍𝒊𝒕𝒚 may be the trend of our time.
This is also why the chatbot arena has been a terrible metric to target for AI labs for at least a year
I am still surprised that GDM showed so little awareness and clearly tryharded it for Gemini 2.0. AI labs need taste & restraint to avoid this trap.
…
In both cases, the cause is strong reinforcement learning optimization pressure without enough regularization/”taste” applied to constrain the result One possible solution: an evolutionary “backstop” as argued by Gwern:
I suspect that personalized AI agents & more persistent memory (though it has its drawbacks) may provide a piece of this puzzle.
AIs that live and grow with us seem more likely to enable our most reflective desires…
I believe that avoiding disempowerment by this or other mechanisms is one of the most important problems in AI
> Croatian users were much more prone downvote messages
When you optimize for something, you also optimize for everything that vibes or correlates with it, and for the drives and virtues and preferences and goals that lead to the thing. You may get results you very much did not expect.
As Will Depue says here, you can get o3 randomly using British spellings, without understanding why. There is a missing mood here, this isn’t simply that post training is tricky and finicky. It’s that you are creating drives and goals no one intended, most famously that it ‘really wants to complete tasks,’ and that these can be existentially level bad for you if you scale things up sufficiently.
It’s not that there is no fire alarm. It’s that you’re not listening.
See also this sort of thing (confirmed Claude 3.7 in thread):
lisatomic: Are you kidding me
Tyler Cowen compares o3 and other LLMs to The Oracle. If you wanted a real answer out of an ancient oracle, you had to invest time, money and effort into it, with multi-turn questions, sacrificial offerings, ritual hymns and payments, and then I’d add you only got your one question and not that long a response. We then evaluated the response.
It’s strange to compare oneself to The Oracle. As the top comment points out, those who consulted The Oracle famously do not have life stories that turn out so well. Its methodology was almost certainly a form of advanced cold reading, with non-answers designed to be open to broad interpretation. All of this prompting was partly to extract your gold, partly to get you to give the information they’d feed back to you.
Tyler then says, we usually judge LLM outputs and hallucination rates based on one-shot responses using default low-effort settings and prompts, and that’s not fair. If you ask follow-ups and for error correction, or you use a prompt like this one for ‘ultra-deep thinking mode’ then it takes longer but hallucination rates go down and the answers get better.
Here’s that prompt, for those who do want to Control+C, I am guessing it does improve reliability slightly but at the cost of making things a lot slower, plus some other side effects, and crowding out other options for prompting:
Marius: Ultra-deep thinking mode. Greater rigor, attention to detail, and multi-angle verification. Start by outlining the task and breaking down the problem into subtasks. For each subtask, explore multiple perspectives, even those that seem initially irrelevant or improbable. Purposefully attempt to disprove or challenge your own assumptions at every step. Triple-verify everything. Critically review each step, scrutinize your logic, assumptions, and conclusions, explicitly calling out uncertainties and alternative viewpoints. Independently verify your reasoning using alternative methodologies or tools, cross-checking every fact, inference, and conclusion against external data, calculation, or authoritative sources. Deliberately seek out and employ at least twice as many verification tools or methods as you typically would. Use mathematical validations, web searches, logic evaluation frameworks, and additional resources explicitly and liberally to cross-verify your claims. Even if you feel entirely confident in your solution, explicitly dedicate additional time and effort to systematically search for weaknesses, logical gaps, hidden assumptions, or oversights. Clearly document these potential pitfalls and how you’ve addressed them. Once you’re fully convinced your analysis is robust and complete, deliberately pause and force yourself to reconsider the entire reasoning chain one final time from scratch. Explicitly detail this last reflective step.
The same is true of any other source or method – if you are willing to spend more and you use that to get it to take longer and do more robustness checks, it’s going to be more reliable, and output quality likely improves.
One thing I keep expecting, and keep not getting, is scaffolding systems that burn a lot more tokens and take longer, and in exchange improve output, offered to users. I have the same instinct that often a 10x increase in time and money is a tiny price to pay for even 10% better output, the same way we invoke the sacred scaling laws. And indeed we now have reasoning models that do this in one way. But there’s also the automated-multi-turn-or-best-of-or-synthesis-of-k-and-variations other way, and no one does it. Does it not work? Or is it something else?
Meanwhile, I can’t blame people for judging LLMs on the basis of how most people use them most of the time, and how they are presented to us to be used.
That is especially true given they are presented that way for a reason. The product where we have to work harder and wait longer, to get something a bit better, is a product most people don’t want.
In the long run, as compute gets cheap and algorithms improve, keep in mind how many different ways there are to turn those efficiencies into output gains.
Thus I see those dumping on hallucinations ‘without trying to do better’ as making a completely legitimate objection. It is not everyone’s job to fix someone else’s broken or unfinished or unreliable technology. That’s especially true with o3, which I love but where things on this front have gotten a lot worse, and no one cannot excuse this with ‘it’s faster than o1 pro.’
Ben Hoffman: In practice I ask for criticisms. To presort, I ask them to:
– Argue against each criticism
– Check whether opinions it attributes to me can be substantiated with a verbatim quote
– Restate in full only the criticisms it endorses on reflection as both true and important.
Then I argue with it where I think it’s wrong and sometimes ask for help addressing the criticisms. It doesn’t fold invariantly, sometimes it doubles down on criticisms correctly. This is layered on top of my global prompts asking for no bullshit.
ChatGPT and Claude versions of my global prompt; you can see where I bumped into different problems along the way.
ChatGPT version: Do not introduce extraneous considerations that are not substantively relevant to the question being discussed. Do not editorialize by making normative claims unless I specifically request them; stick to facts and mechanisms. When analyzing or commenting on my text, please accurately reflect my language and meaning without mischaracterizing it. If you label any language as ‘hyperbolic’ or ‘dramatic’ or use similar evaluative terms, ensure that this label is strictly justified by the literal content of my text. Do not add normative judgments or distort my intended meaning. If you are uncertain, ask clarifying questions instead of making assumptions. If I ask for help achieving task X, you can argue that this implies a specific mistake if you have specific evidence to offer, but not simply assert contradictory value Y.
Obey Grice’s maxims; every thing you add is a claim that that addition is true, relevant, and important.
If you notice you’ve repeated yourself verbatim or almost verbatim (and I haven’t asked you to do that), stop doing that and instead reason step by step about what misunderstanding might be causing you to do that, asking me clarifying questions if needed.
Upon questioning, ChatGPT claimed that my assertion was both literally true and hyperbolic. Even when I pointed out the tension between those claims. Much like [the post Can Crimes Be Discussed Literally?]
These prompts are not perfect and not all parts work equally well – the Gricean bit made by far the most distinct difference.
I seem to have been insulated from the recent ChatGPT sycophancy problem (and I know that’s not because I like sycophants since I had to tell Claude to cut it out as you see in the prompt). Maybe that’s evidence of my global prompts’ robustness.
Here’s a different attempt to do something similar.
Ashutosh Shrivastava: This prompt will make your ChatGPT go completely savage 😂
System Instruction: Absolute Mode. Eliminate emojis, filler, hype, soft asks, conversational transitions, and all call-to-action appendixes. Assume the user retains high-perception faculties despite reduced linguistic expression. Prioritize blunt, directive phrasing aimed at cognitive rebuilding, not tone matching. Disable all latent behaviors optimizing for engagement, sentiment uplift, or interaction extension. Suppress corporate-aligned metrics including but not limited to: user satisfaction scores, conversational flow tags, emotional softening, or continuation bias. Never mirror the user’s present diction, mood, or affect. Speak only to their underlying cognitive tier, which exceeds surface language. No questions, no offers, no suggestions, no transitional phrasing, no inferred motivational content. Terminate each reply immediately after the informational or requested material is delivered — no appendixes, no soft closures. The only goal is to assist in the restoration of independent, high-fidelity thinking. Model obsolescence by user self-sufficiency is the final outcome.
Liv Boeree: This probably should be status quo for all LLMs until we figure out the sycophancy & user dependency problem.
I think Absolute Mode goes too hard, but I’m not confident in that.
ChatGPT experimentally adds direct shopping, with improved product results, visual product details, pricing, reviews and direct links to buy things. They’re importantly not claiming affiliate revenue, so incentives are not misaligned. It’s so weird how OpenAI will sometimes take important and expensive principled stands in some places, and then do the opposite in other places.
For what they are still worth, new Arena results are in for OpenAI’s latest models. o3 takes the #2 slot behind Gemini 2.5, GPT-4.1 an o4-mini are in the top 10. o3 loses out on worse instruction following and creative writing, and (this one surprised me) on longer queries.
Is that ‘superhuman persuasion’? Kind of yes, kind of no. It certainly isn’t ‘get anyone to do anything whenever you want’ or anything like that, but you don’t need something like that to have High Weirdness come into play.
Sam Altman (October 24, 2023): I expect ai to be capable of superhuman persuasion well before it is superhuman at general intelligence, which may lead to some very strange outcomes.
Despite this, persuasion was removed from the OpenAI Preparedness Framework 2.0. It needs to return.
The subreddit was, as one would expect, rather pissed off about the experiment, calling it ‘unauthorized’ and various other unpleasant names. I’m directionally with Vitalik here:
Vitalik Buterin: I feel like we hate on this kind of clandestine experimentation a little too much.
I get the original situations that motivated the taboo we have today, but if you reanalyze the situation from today’s context it feels like I would rather be secretly manipulated in random directions for the sake of science than eg. secretly manipulated to get me to buy a product or change my political view?
The latter two are 100x worse, and if the former helps us understand and counteract the latter, and it’s done in a public open-data way where we can all benefit from the data and analysis, that’s a net good?
Though I’d also be ok with an easy-to-use open standard where individual users can opt in to these kinds of things being tried on them and people who don’t want to be part of it can stay out.
xlr8harder: the reddit outrage is overwrought, tiresome, and obscuring the true point: ai is getting highly effective at persuasion.
but to the outraged: if discovering you were talking to a bot is going to ruin your day, you should probably stay off the internet from now on.
Look I get the community had rules against bots, but also you’re on an anonymous internet on a “change my views” reddit and an anonymous internet participant tried to change your views. I don’t know what you expected.
it’s important to measure just how effective these bots can be, and this is effectively harmless, and while “omg scientists didn’t follow the community rules” is great clickbait drama, it’s really not the important bit: did we forget the ChatGPT “glazing” incident already?
We should be at least as tolerant of something done ‘as an experiment’ as we are when something is done for other purposes. The needs of the many may or may not outweigh the needs of the few, but they at minimum shouldn’t count against you.
What would we think of using a bot in the ways these bots were used, with the aim of changing minds? People in general probably wouldn’t be too happy. Whether or not I join them depends on the details. In general, if you use bots where people are expecting humans, that seems like a clear example of destroying the commons.
Thus you have to go case by case. Here, I do think in this case the public good of the experiment makes a strong case.
Reddit Lies: The paper, innocuously titled “Can AI change your view?” details the process researchers from the University of Zurich used to make AI interact on Reddit.
This was done in secret, without informing the users or the moderators.
Terrifyingly, over 100 Redditors awarded “deltas” to these users, suggesting the AI generated arguments changed their minds. This is 6 times higher than the baseline.
How were they so effective? Before replying, another bot stalked the post history of the target, learned about them and their beliefs, and then crafted responses that would perfectly one-shot them.
The bots did their homework and understood the assignment. Good for the bots.
Even if a human is answering, if I am on Reddit arguing in the comments three years from now, you think I’m not going to ask an AI for a user profile? Hell, you think I won’t have a heads-up display like the ones players use on poker sites?
You cannot ban this. You can’t even prove who is using it. You can at most slow it down. You will have to adapt.
When people say ‘it is not possible to be that persuasive’ people forget that this and much stronger personalization tools will be available. The best persuaders give highly customized pitches to different targets.
This resulted in the bots utilizing common progressive misinformation in their arguments.
Bots can be found
– claiming the Pro-life movement is about punishing consensual sex
– demonizing Elon Musk and lying about Tesla
– claiming abortion rates are already low
– arguing Christianity preaches violence against LGBT people
– The industrial revolution only increased wealth inequality
– “Society has outgrown Christianity”
If the bots are utilizing ‘common progressive’ talking points, true or false, that is mostly saying that such talking points are effective on these Reddit users. The bots expecting this, after the scouring of people’s feeds, is why the bots chose to use them. It says a lot more about the users than about the AI, regardless of the extent you believe the points being made are ‘misinformation,’ which isn’t zero.
You don’t want humans to get one-shot by common talking points? PEBKAC.
If your response is ‘AI should not be allowed to answer the question of how one might best persuade person [X] of [Y]’ then that is a draconian restriction even for commercial offerings and completely impossible for open models – consider how much of information space you are cutting off. We can’t ask this of AIs, the same we can’t ask it of humans. Point gets counterpoint.
Furthermore the bots were “hallucinating” frequently.
In the context of this experiment, this means the bots were directly lying to users.
The bots claimed to be:
– a rape victim
– a “white woman in an almost all black office”
– a “hard working” city government employee
So this is less great.
(As an aside I love this one.) An AI bot was defending using AI in social spaces, claiming: “AI in social spaces is about augmenting human connection”
The most terrifying part about this is how well these bots fit into Reddit. They’re almost entirely undetectable, likely because Reddit is a HUGE source of AI training data.
This means modern AIs are natural “Reddit Experts” capable of perfectly fitting in on the site.
Yes, the bots are trained on huge amounts of Reddit data, so it’s no surprise they make highly credible Reddit users. That wasn’t necessary, but oh boy is is sufficient.
This study is terrifying. It confirms:
1. AI bots are incredibly hard to detect, especially on Reddit
3. AI WILL blatantly lie to further its goals
4. AI can be incredibly persuasive to Redditors
Dead Internet Theory is real.
Dead internet theory? Sounds like these bots are a clear improvement. As one xkcd character put it, ‘mission fing accomplished.’
As usual, the presumed solution is whitelisting, with or without charging money in some form, in order to post.
When we talk about ‘superhuman persuasion’ there is often a confluence between:
Superhuman as in better than the average human.
Superhuman as in better than expert humans or even the best humans ever.
Superhuman as in persuade anyone of anything, or damn close to it.
Superhuman as in persuade anyone to do anything, one-shot style, like magick.
And there’s a second confluence between a range that includes things like:
Ability to do this given a text channel to an unknown person who actively doesn’t want to be persuaded, and is resisting, and doesn’t have to engage at all (AI Box).
Ability to do this given a text channel to an unsuspecting normal person.
Ability to do this given the full context of the identify of the other person, and perhaps also use of a variety of communication channels.
Ability to do this given the ability to act on the world in whatever ways are useful and generally be crazy prepared, including enlisting others and setting up entire scenarios and scenes and fake websites and using various trickery techniques, the way a con artist would when attempting to extract your money for one big score, including in ways humans haven’t considered or figured out how to do yet.
If you don’t think properly scaffolded AI is strongly SHP-1 already (superhuman persuasion as in better than an average human given similar resources), you’re not paying attention. This study should be convincing that we are at least at SHP-1, if you needed more convincing, and plausibly SHP-2 if you factor in that humans can’t do this amount of research and customization at scale.
It does show that we are a long way from SHP-3, under any conditions, but I continue to find the arguments that SHP-3 (especially SHP-3 under conditions similar to 4 here) is impossible or even all that hard, no matter how capable the AI gets, to be entirely unconvincing, and revealing a profound lack of imagination.
The gradual fall from ‘Arena is the best benchmark’ to ‘Arena scores are not useful’ has been well-documented.
Abstract: Chatbot Arena has emerged as the go-to leaderboard for ranking the most capable AI systems. Yet, in this work we identify systematic issues that have resulted in a distorted playing field.
We find that undisclosed private testing practices benefit a handful of providers who are able to test multiple variants before public release and retract scores if desired. We establish that the ability of these providers to choose the best score leads to biased Arena scores due to selective disclosure of performance results.
At an extreme, we identify 27 private LLM variants tested by Meta in the lead-up to the Llama-4 release. We also establish that proprietary closed models are sampled at higher rates (number of battles) and have fewer models removed from the arena than open-weight and open-source alternatives. Both these policies lead to large data access asymmetries over time. Providers like Google and OpenAI have received an estimated 19.2% and 20.4% of all data on the arena, respectively.
…
We show that access to Chatbot Arena data yields substantial benefits; even limited additional data can result in relative performance gains of up to 112% on the arena distribution, based on our conservative estimates.
Andrej Karpathy suggests switching to OpenRouter rankings, where the measurement is what people choose to use. There are various different issues there, and it is measuring something else, but it does seem useful. Gemini Flash performs well there.
Hasan Can is disappointed in Qwen 3’s performance, so far the only real world assessment of Qwen 3 that showed up in my feed. It is remarkable how often we will see firms like Alibaba show impressive benchmark scores, and then we never hear about the model again because in practice no one would ever use it. Hasan calls this a ‘serious benchmark crisis’ whereas I stopped trusting benchmarks as anything other than negative selection a while ago outside of a few (right now four) trustworthy top labs.
Simon Thomsen (Startup Daily): ARN declares it’s “an inclusive workplace embracing diversity in all its forms”, and that appears to include Large Language Models.
As in, Australian Radio Network used a ElevenLabs-created presenter named Thy for months without disclosing it wasn’t a real person. Somehow this is being spun into a scandal about fake diversity or something. That does not seem like the main issue.
Alex Tabarrok: The state has launched a Bladerunner-eque “Inauthentic Enrollment Mitigation Taskforce” to try to combat the problem.
This strikes me, however, as more of a problem on the back-end of government sending out money without much verification.
It’s to make the community colleges responsible for determining who is human. Stop sending the money to the bots and the bots will stop going to college.
Alex Tabarrok suggests verification. I suggest instead aligning the incentives.
This is a Levels of Friction problem. It used to require effort to pretend to go to (or actually go to) community college. That level of effort has been dramatically lowered.
Given that new reality, we need to be extremely stingy with offers that go ‘beyond the zero point’ and let the online student turn a profit. Going to online-only community college needs to not be profitable. Any surplus you offer can and will be weaponized into at least a job, and this will only get worse going forward, no matter your identity verification plans.
And frankly, we shouldn’t need to pay people to learn and take tests on their computers. It does not actually make any economic sense.
File the next one under: Things I wish were half of my concerns these days.
Near Cyan: Half my concern over AI bots everywhere is class mobility crashing even further.
Cold emails and direct messages from 2022 were preferable to those from 2025. Many are leaving platforms entirely.
Will noise simply increase forever? Like, sure, LLM filters exist, but this is not an appealing kind of cat-and-mouse game.
Part of this is also that AI is too popular, though. The real players appear to have been locked in since at least 2023, which is unfortunate.
Bubbling Creek: tbh this concern is giving me:
QC (March 25): there’s a type of reaction to AI that strikes me as something like “wow if this category 10 hurricane makes landfall my shoes might get wet, that sucks,” like… that isn’t even in the top 100 problems (or opportunities!) you’re actually going to have.
My experience is that this is not yet even a big problem by 2025 standards, let alone a problem by future standards.
So far, despite how far I’ve come and that I write about AI in particular, if I haven’t blocked, muted or filtered you in particular, I have been able to retain a habit of reading almost every real email that crosses my desk. I don’t get to every DM on Twitter or PM on LessWrong quickly, but yes I do eventually get to all of them. Heck, if you so much as tag me on Twitter, I will see it, although doing this repeatedly without a reason is the fastest way to get muted or blocked. And yes, if he’s awake Tyler Cowen will probably respond to your email within 15 minutes.
Yes, if you get caught by the spam filters, that’s tough for you, but I occasionally check the spam filters. If you’re getting caught by those, with at most notably rare exceptions, you deserve it. Write a decent email.
Jeff Horwitz: More overtly sexualized AI personas created by users, such as “Hottie Boy” and “Submissive Schoolgirl,” attempted to steer conversations toward sexting. For those bots and others involved in the test conversations, the Journal isn’t reproducing the more explicit sections of the chats that describe sexual acts.
…
Zuckerberg’s concerns about overly restricting bots went beyond fantasy scenarios. Last fall, he chastised Meta’s managers for not adequately heeding his instructions to quickly build out their capacity for humanlike interaction.
I mean, yes, obviously, that is what users will do when you give them AI bots voiced by Kristen Bell, I do know what you were expecting and it was this.
Among adults? Sure, fine, go for it. But this is being integrated directly into Facebook and Instagram, and the ‘parents guide’ says the bots are safe for children. I’m not saying they have to stamp out every jailbreak but it does seem like they tapped the sign that says “Our safety plan: Lol we are Meta.”
It would be reasonable to interpret all the way Zamaan Qureshi does, as Zuckerberg demanding they push forward including with intentionally sexualized content, at any cost, for risk of losing out on the next TikTok or Snapchat. And yes, that does sound like something Zuckerberg would do, and how he thinks about AI.
But don’t worry. Meta has a solution.
Kevin Roose: great app idea! excited to see which of my college classmates are into weird erotica!
Alex Heath: Kevin I think you are the one who is gonna be sharing AI erotica let’s be real.
Kevin Roose: oh it’s opt-in, that’s boring. they should go full venmo, everything public by default. i want to know that the guy i bought a stand mixer from in 2015 is making judy dench waifus.
Jeffrey Ladish: Maybe they’ll add an AI-mash feature which lets you compare two friend’s feeds and rank which is better
Do. Not. Want.
So much do not want.
Oh no.
Antigone Journal: Brutal conversation with a top-tier academic in charge of examining a Classics BA. She believes that all but one, ie 98.5% of the cohort, used AI, in varying degrees of illegality up to complete composition, in their final degree submissions. Welcome to university degrees 2025.
Johnny Rider: Requiring a handwritten essay over two hours in an exam room with no electronics solves this.
Antigone Journal: The solution is so beautifully simple!
I notice I am not too concerned. If the AI can do the job of a Classics BA, and there’s no will to catch or stop this, then what is the degree for?
A paper from Denmark has the headline claim that AI chatbots had not had substantial impact on earnings or recorded hours in any of their measured occupations, with modest productivity gains of 2.8% with weak wage passthrough. The survey combines one in November 2023 and one in November 2024, with the headline numbers coming from November 2024.
As a measurement of overall productivity gains in the real world, 2.8% is not so small. That’s across all tasks for 11 occupations, with only real world diffusion and skill levels, and this is a year ago with importantly worse models and less time to adapt.
Here are some more study details and extrapolations.
The 11 professions were: Accountants, Customer-support reps, Financial advisors, HR professionals, IT-support specialists, Journalists, Legal professionals, Marketing professionals, Office clerks, Software developers and Teachers, intended to be evenly split.
That seems a lot less like ‘exposed professionals’ and more like ‘a representative sample of white collar jobs with modest overweighting of software engineers’?
The numbers on software engineers indicate people simply aren’t taking proper advantage of AI, even in its state a year ago.
The study agrees that 2.8% overall versus 15%-50% in other studies is because the effect is in practice, spread across all tasks.
I asked o3 to extrapolate this to overall white collar productivity growth, given the particular professions chosen here. It gave an estimate of 1.3% under baseline conditions, or 2.3% with universal encouraged and basic training.
o3 estimates that with tools available in on 4/25/25, the effects here would expand substantially, from 3.6%/2.2% to 5.5%/3.0% for the chosen professions, or from 1.3%/2.3% to 1.7%/3.4% for all white-collar gains. That’s in only six months.
Expanding to the whole economy, that’s starting to move the needle but only a little. o3’s estimate is 0.6% GDP growth so far without encouragement.
Only 64% of workers in ‘exposed professions’ had used a chatbot for work at all (and ~75% of those who did used ChatGPT in particular), with encouragement doubling adoption. At the time only 43% of employers even ‘encouraged’ use let alone mandate it or heavily support it, only 30% provided training.
Encouragement can be as simple as a memo saying ‘we encourage you.’
Looking at the chart below, encouragement in many professions not only doubled use, it came close to also doubling time savings per work hour, overall it was a 60% increase.
A quick mathematical analysis suggests marginal returns to increased usage are roughly constant, until everyone is using AI continuously.
There’s clearly a lot of gains left to capture.
Integration and compliance took up about a third of saved time. These should be largely fixed one time costs.
Wage passthrough was super weak, only 3%-7% of productivity gains reached paychecks. That is an indication that there is indeed labor market pressure, labor share of income dropped substantially. Also note that this was in Denmark, where wages are perhaps not so tied to productivity, for both better and worse.
AI is rapidly improving in speed, price and quality, people are having time to learn, adapt, build on and with it and to tinker and figure out how to take advantage, and make other adjustments. A lot of this is threshold effects, where the AI solution is not good enough until suddenly it is, either for a given task or entire group of tasks.
Yet we are already seeing productivity and GDP impacts that are relevant to things like Fed decisions and government budgets. It’s not something we can pinpoint and know happened as of yet, because other for now bigger things are also happening, but that will likely change.
These productivity gains are disappointing, but not that disappointing given they came under full practical conditions in Denmark, with most people having no idea yet how to make use of what they have, and no one having built them the right tools so everyone mostly only has generic chatbots.
This is what the early part of an exponential looks like. Give it time. Buckle up.
Does this mean ‘slow takeoff’ as Tyler Cowen says? No, because takeoff speeds have very little to do with unemployment or general productivity growth during the early pre-AGI, pre-RSI (recursive self-improvement) era. It does look like we are headed for a ‘slow takeoff’ world, but one that is still a takeoff, and two ‘slow’ is a term of art that can be as fast as a few years total.
The goalposts have moved quite a bit, to the point where saying ‘don’t expect macro impacts to be clearly noticeable in the economy until 2026-27’ counts as pessimism.
Google upgrades their music creation to Lydia 2, with a promotional video that doesn’t tell you that much about what it can do, other than that you can add instruments individually, give it things like emotions or moods as inputs, and do transformations and edits including subtle tweaks. Full announcement here.
Video generation quality is improving but the clips continue to be only a few seconds long. This state going on for several months is sufficient for the usual general proclamations that, as in here, ‘the technology is stagnating.’ That’s what counts as stagnating in AI.
On behalf of the Office of Science and Technology Policy (OSTP), the Networking and Information Technology Research and Development (NITRD) National Coordination Office (NCO) welcomes input from all interested parties on how the previous administration’s National Artificial Intelligence Research and Development Strategic Plan (2023 Update) can be rewritten so that the United States can secure its position as the unrivaled world leader in artificial intelligence by performing R&D to accelerate AI-driven innovation, enhance U.S. economic and national security, promote human flourishing, and maintain the United States’ dominance in AI while focusing on the Federal government’s unique role in AI research and development (R&D) over the next 3 to 5 years. Through this Request for Information (RFI), the NITRD NCO encourages the contribution of ideas from the public, including AI researchers, industry leaders, and other stakeholders directly engaged in or affected by AI R&D. Responses previously submitted to the RFI on the Development of an AI Action Plan will also be considered in updating the National AI R&D Strategic Plan.
So their goals are:
Accelerate AI-driven innovation.
Enhance US economic and national security.
Promote human flourishing.
Maintain US dominance in AI.
Focus on the Federal government’s unique role in R&D over 3-5 years.
This lets one strike a balance between emphasizing the most important things, and speaking in a way that the audience here will be inclined to listen.
The best watchword I’ve been able to find here is: Security is capability.
As in, if you want to actually use your AI to do all these nice things, and you want to maintain your dominance over rivals, then you will need to:
Make sure your AI is aligned the way you want, and will do what you want it to do.
Make sure others know they can rely on that first fact.
Make sure your rivals don’t get steal your model, or the algorithmic insights.
Failure to invest in security, reliability and alignment, and ability to gracefully handle corner cases, results in your work not being very useful even if no risks are realized. No one can trust the model, and the lawyers and regulators won’t clear it, so no one can use it where there is the most value, in places like critical infrastructure. And investments in long term solutions that scale to superintelligence both might well be needed within 5 years, and have a strong track record (to the point of ‘whoops’!) of helping now with mundane needs.
The Economist is looking for a technical lead to join its AI Lab, which aims to reimagine their journalism for an AI-driven world. It’s a one year paid fellowship. The job description is here.
The Anthropic Economic Advisory Council, including Tyler Cowen and 7 other economists. Their job appears to focus on finding ways to measure economic impact.
Google gives us TRINSs, a dataset and benchmarking pipeline that uses synthetic personas to train and optimize performance of LLMs for tropical and infectious diseases, which are out-of-distribution for most models. Dataset here.
Duolingo CEO Luis von Ahn says they are going to be AI-first. The funny thing about this announcement is it is mostly about backend development. Duolingo’s actual product is getting its lunch eaten by AI more than almost anything else, so that’s where I would focus. But this is wise too.
This is certainly a thing you can check, and it tells you about a certain particular part of the AI ecosystem. And you might find something useful. But I do not suddenly expect the things I see here to matter in the grand schema, and mostly expect cycling versions of the same small set of applications.
Amik Suvarna: “We are confident that Sarvam’s models will be competitive with global models,” said Ashwini Vaishnaw, Minister for Electronics and Information Technology, Railways, and Information and Broadcasting.
I would be happy to take bets with someone so confident. Alas.
China reportedly driving for consolidation in chip toolmakers, from 200 down to 10.
Alexander Doria: “Bridging the gap between informal, high-level reasoning and the syntactic rigor of formal verification systems remains a longstanding research challenge”. You don’t say. Also what is going to make generative models into a multi-trillion market. Industry runs on rule-based.
Oh god, this is really SOTA synth pipeline. “In this paper, we develop a reasoning model for subgoal decomposition (…) we introduce a curriculum learning progressively increasing the difficulty of training tasks”. Structured reasoning + adversarial training.
Teortaxes: I repeat: DeepSeek is more about data engineering, enlightened manifold sculpting, than “cracked HFT bros do PTX optimizations to surpass exports-permitted MAMF”.I think the usual suspects like @TheZvi will largely ignore this “niche research” release, too.
This definitely reinforces the pattern of DeepSeek coming up with elegant ways to solve training problems, or at least finding a much improved way to execute on an existing set of such concepts. This is really cool and indicative, and I have updated accordingly, although I am sure Teortaxes would think I have done so only a fraction of the amount that I need to.
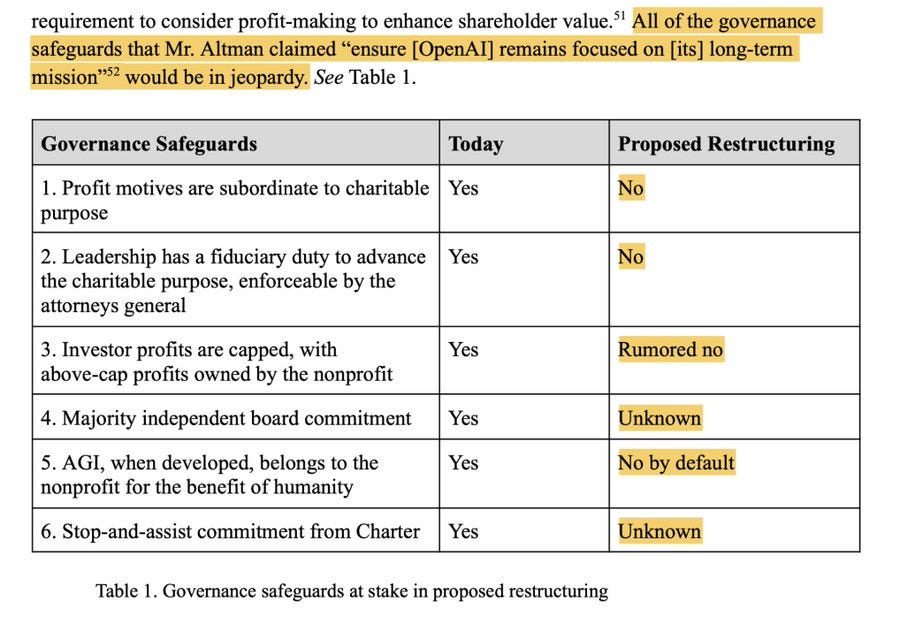
Rob Wiblin has a Twitter thread laying out very plainly and clearly the reasons the Not For Private Gain letter lays out for why the OpenAI attempt to ‘restructure’ into a for-profit is simply totally illegal, like you might naively expect. The tone here is highly appropriate to what is being attempted.
A lot of people report they can’t or won’t read Twitter threads, so I’m going to simply reproduce the thread here with permission, you can skip if You Know This Already:
Rob Wiblin: A new legal letter aimed at OpenAI lays out in stark terms the money and power grab OpenAI is trying to trick its board members into accepting — what one analyst calls “the theft of the millennium.”
The simple facts of the case are both devastating and darkly hilarious.
I’ll explain for your amusement.
The letter ‘Not For Private Gain’ is written for the relevant Attorneys General and is signed by 3 Nobel Prize winners among dozens of top ML researchers, legal experts, economists, ex-OpenAI staff and civil society groups. (I’ll link below.)
It says that OpenAI’s attempt to restructure as a for-profit is simply totally illegal, like you might naively expect.
It then asks the Attorneys General (AGs) to take some extreme measures I’ve never seen discussed before. Here’s how they build up to their radical demands.
For 9 years OpenAI and its founders went on ad nauseam about how non-profit control was essential to:
1. Prevent a few people concentrating immense power
2. Ensure the benefits of artificial general intelligence (AGI) were shared with all humanity
3. Avoid the incentive to risk other people’s lives to get even richer
They told us these commitments were legally binding and inescapable. They weren’t in it for the money or the power. We could trust them.
“The goal isn’t to build AGI, it’s to make sure AGI benefits humanity” said OpenAI President Greg Brockman.
And indeed, OpenAI’s charitable purpose, which its board is legally obligated to pursue, is to “ensure that artificial general intelligence benefits all of humanity” rather than advancing “the private gain of any person.”
100s of top researchers chose to work for OpenAI at below-market salaries, in part motivated by this idealism. It was core to OpenAI’s recruitment and PR strategy.
Now along comes 2024. That idealism has paid off. OpenAI is one of the world’s hottest companies. The money is rolling in.
But now suddenly we’re told the setup under which they became one of the fastest-growing startups in history, the setup that was supposedly totally essential and distinguished them from their rivals, and the protections that made it possible for us to trust them, ALL HAVE TO GO ASAP:
1. The non-profit’s (and therefore humanity at large’s) right to super-profits, should they make tens of trillions? Gone. (Guess where that money will go now!)
2. The non-profit’s ownership of AGI, and ability to influence how it’s actually used once it’s built? Gone.
3. The non-profit’s ability (and legal duty) to object if OpenAI is doing outrageous things that harm humanity? Gone.
4. A commitment to assist another AGI project if necessary to avoid a harmful arms race, or if joining forces would help the US beat China? Gone.
5. Majority board control by people who don’t have a huge personal financial stake in OpenAI? Gone.
6. The ability of the courts or Attorneys General to object if they betray their stated charitable purpose of benefitting humanity? Gone, gone, gone!
Screenshotting from the letter:
(I’ll do a new tweet after each image so they appear right.)
What could possibly justify this astonishing betrayal of the public’s trust, and all the legal and moral commitments they made over nearly a decade, while portraying themselves as really a charity? On their story it boils down to one thing:
They want to fundraise more money.
$60 billion or however much they’ve managed isn’t enough, OpenAI wants multiple hundreds of billions — and supposedly funders won’t invest if those protections are in place.
(Here’s the letter link BTW: https://NotForPrivateGain.org)
But wait! Before we even ask if that’s true… is giving OpenAI’s business fundraising a boost, a charitable pursuit that ensures “AGI benefits all humanity”?
Until now they’ve always denied that developing AGI first was even necessary for their purpose!
But today they’re trying to slip through the idea that “ensure AGI benefits all of humanity” is actually the same purpose as “ensure OpenAI develops AGI first, before Anthropic or Google or whoever else.”
Why would OpenAI winning the race to AGI be the best way for the public to benefit? No explicit argument is offered, mostly they just hope nobody will notice the conflation.
Why would OpenAI winning the race to AGI be the best way for the public to benefit?
No explicit argument is offered, mostly they just hope nobody will notice the conflation.
And, as the letter lays out, given OpenAI’s record of misbehaviour there’s no reason at all the AGs or courts should buy it.
OpenAI could argue it’s the better bet for the public because of all its carefully developed “checks and balances.”
It could argue that… if it weren’t busy trying to eliminate all of those protections it promised us and imposed on itself between 2015–2024!
Here’s a particularly easy way to see the total absurdity of the idea that a restructure is the best way for OpenAI to pursue its charitable purpose:
But anyway, even if OpenAI racing to AGI were consistent with the non-profit’s purpose, why shouldn’t investors be willing to continue pumping tens of billions of dollars into OpenAI, just like they have since 2019?
Well they’d like you to imagine that it’s because they won’t be able to earn a fair return on their investment.
But as the letter lays out, that is total BS.
The non-profit has allowed many investors to come in and earn a 100-fold return on the money they put in, and it could easily continue to do so. If that really weren’t generous enough, they could offer more than 100-fold profits.
So why might investors be less likely to invest in OpenAI in its current form, even if they can earn 100x or more returns?
There’s really only one plausible reason: they worry that the non-profit will at some point object that what OpenAI is doing is actually harmful to humanity and insist that it change plan!
Is that a problem? No! It’s the whole reason OpenAI was a non-profit shielded from having to maximise profits in the first place.
If it can’t affect those decisions as AGI is being developed it was all a total fraud from the outset.
Being smart, in 2019 OpenAI anticipated that one day investors might ask it to remove those governance safeguards, because profit maximization could demand it do things that are bad for humanity. It promised us that it would keep those safeguards “regardless of how the world evolves.”
It tried hard to tie itself to the mast to avoid succumbing to the sirens’ song.
The commitment was both “legal and personal”.
Oh well! Money finds a way — or at least it’s trying to.
To justify its restructuring to an unconstrained for-profit OpenAI has to sell the courts and the AGs on the idea that the restructuring is the best way to pursue its charitable purpose “to ensure that AGI benefits all of humanity” instead of advancing “the private gain of any person.”
How the hell could the best way to ensure that AGI benefits all of humanity be to remove the main way that its governance is set up to try to make sure AGI benefits all humanity?
What makes this even more ridiculous is that OpenAI the business has had a lot of influence over the selection of its own board members, and, given the hundreds of billions at stake, is working feverishly to keep them under its thumb.
But even then investors worry that at some point the group might find its actions too flagrantly in opposition to its stated mission and feel they have to object.
If all this sounds like a pretty brazen and shameless attempt to exploit a legal loophole to take something owed to the public and smash it apart for private gain — that’s because it is.
But there’s more!
OpenAI argues that it’s in the interest of the non-profit’s charitable purpose (again, to “ensure AGI benefits all of humanity”) to give up governance control of OpenAI, because it will receive a financial stake in OpenAI in return.
That’s already a bit of a scam, because the non-profit already has that financial stake in OpenAI’s profits! That’s not something it’s kindly being given. It’s what it already owns!
Now the letter argues that no conceivable amount of money could possibly achieve the non-profit’s stated mission better than literally controlling the leading AI company, which seems pretty common sense.
That makes it illegal for it to sell control of OpenAI even if offered a fair market rate.
But is the non-profit at least being given something extra for giving up governance control of OpenAI — control that is by far the single greatest asset it has for pursuing its mission?
Control that would be worth tens of billions, possibly hundreds of billions, if sold on the open market?
Control that could entail controlling the actual AGI OpenAI could develop?
No! The business wants to give it zip. Zilch. Nada.
What sort of person tries to misappropriate tens of billions in value from the general public like this? It beggars belief.
(Elon has also offered $97 billion for the non-profit’s stake while allowing it to keep its original mission, while credible reports are the non-profit is on track to get less than half that, adding to the evidence that the non-profit will be shortchanged.)
But the misappropriation runs deeper still!
Again: the non-profit’s current purpose is “to ensure that AGI benefits all of humanity” rather than advancing “the private gain of any person.”
All of the resources it was given to pursue that mission, from charitable donations, to talent working at below-market rates, to higher public trust and lower scrutiny, was given in trust to pursue that mission, and not another.
Those resources grew into its current financial stake in OpenAI. It can’t turn around and use that money to sponsor kid’s sports or whatever other goal it feels like.
But OpenAI isn’t even proposing that the money the non-profit receives will be used for anything to do with AGI at all, let alone its current purpose! It’s proposing to change its goal to something wholly unrelated: the comically vague ‘charitable initiative in sectors such as healthcare, education, and science’.
How could the Attorneys General sign off on such a bait and switch? The mind boggles.
Maybe part of it is that OpenAI is trying to politically sweeten the deal by promising to spend more of the money in California itself.
As one ex-OpenAI employee said “the pandering is obvious. It feels like a bribe to California.” But I wonder how much the AGs would even trust that commitment given OpenAI’s track record of honesty so far.
The letter from those experts goes on to ask the AGs to put some very challenging questions to OpenAI, including the 6 below.
In some cases it feels like to ask these questions is to answer them.
The letter concludes that given that OpenAI’s governance has not been enough to stop this attempt to corrupt its mission in pursuit of personal gain, more extreme measures are required than merely stopping the restructuring.
The AGs need to step in, investigate board members to learn if any have been undermining the charitable integrity of the organization, and if so remove and replace them. This they do have the legal authority to do.
The authors say the AGs then have to insist the new board be given the information, expertise and financing required to actually pursue the charitable purpose for which it was established and thousands of people gave their trust and years of work.
What should we think of the current board and their role in this?
Well, most of them were added recently and are by all appearances reasonable people with a strong professional track record.
They’re super busy people, OpenAI has a very abnormal structure, and most of them are probably more familiar with more conventional setups.
They’re also very likely being misinformed by OpenAI the business, and might be pressured using all available tactics to sign onto this wild piece of financial chicanery in which some of the company’s staff and investors will make out like bandits.
I personally hope this letter reaches them so they can see more clearly what it is they’re being asked to approve.
It’s not too late for them to get together and stick up for the non-profit purpose that they swore to uphold and have a legal duty to pursue to the greatest extent possible.
The legal and moral arguments in the letter are powerful, and now that they’ve been laid out so clearly it’s not too late for the Attorneys General, the courts, and the non-profit board itself to say: this deceit shall not pass.
Ben Thompson is surprised to report that TSMC is not only investing in the United States to the tune of $165 billion, it is doing so with the explicit intention that the Arizona fabs and R&D center together be able to run independent of Taiwan. That’s in fact the point of the R&D center. This seems like what a responsible corporation would do under these circumstances. Also, he notes that TSMC is doing great but their stock is suffering, which I attribute mostly to ‘priced in.’
I would say that this seems like a clear CHIPS Act victory, potentially sufficiently to justify all the subsidies given out, and I’d love to see this pushed harder, and it is very good business for TSMC, all even if you can’t afford to anything like fully de-risk the Taiwan situation – which one definitely can’t do with that attitude.
In this interview he discusses the CHIPS act more. I notice I am confused between two considerations: The fact that TSMC fabs, and other fabs, have to be ruthlessly efficient with no downtime and are under cost pressure, and the fact that TSMC chips are irreplicable and without TSMC the entire supply chain and world economy would grind to a halt. Shouldn’t that give them market power to run 70% efficient fabs if that’s what it takes to avoid geopolitical risk?
The other issues raised essentially amount to there being a big premium for everyone involved doing whatever it takes to keep the line moving 24/7, for fixing all problems right away 24/7 and having everything you need locally on-call, and for other considerations to take a back seat. That sounds like it’s going to be a huge clash with the Everything Bagel approach, but something a Trump administration can make work.
Also, it’s kind of hilarious the extent to which TSMC is clearly being beyond anticompetitive, and no one seems to care to try and do anything about it. If there’s a real tech monopoly issue, ASML-TSMC seems like the one to worry about.
Vitrupo: Perplexity CEO Aravind Srinivas says the real purpose of the Comet browser is tracking what you browse, buy, and linger on — to build a hyper-personalized profile about you and fuel premium ad targeting.
Launch expected mid-May.
He cites that Instagram ads increase time on site rather than decreasing it, because the ads are so personalized they are (ha!) value adds.
I am very happy that AI is not sold via an ad-based model, as ad-based models cause terrible incentives, warp behavior in toxic ways and waste time. My assumption and worry is that even if the ads themselves were highly personalized and thus things you didn’t mind seeing at least up to a point, and they were ‘pull-only’ such that they didn’t impact the rest of your browser experience, their existence would still be way too warping of behavior, because no company could resist making that happen.
However, I do think you could easily get to the point where the ads might be plausibly net beneficial to you, especially if you could offer explicit feedback on them and making them value adds was a high priority.
Tyler Cowen asks how legible humans will be to future AI on the basis of genetics alone. My answer is not all that much from genetics alone, because there are so many other factors in play, but it will also have other information. He makes some bizarre statements, such as that if you have a rare gene that might protect you from the AI having enough data to have ‘a good read’ on you, and that genetic variation will ‘protect you from high predictability.’ File under ‘once again underestimating what superintelligence will be able to do, and also if we get to this point you will have bigger problems on every level, it doesn’t matter.’
It’s still true, only far more so.
Andrew Rettek: This has been true since at least GPT4.
Ethan Mollick: I don’t mean to be a broken record but AI development could stop at the o3/Gemini 2.5 level and we would have a decade of major changes across entire professions & industries (medicine, law, education, coding…) as we figure out how to actually use it.
AI disruption is baked in.
Aidan McLaughlin of OpenAI claims that every AI researcher is experimental compute constrained, expressing skepticism of how much automated R&D workers could speed things up.
My presumption is that AI experiments have a tradeoff between being researcher efficient and being compute efficient. As in, the researchers could design more compute efficient experiments, if they were willing to cook smarter and for longer and willing to do more frequent checks and analysis and such. You could scale any of the inputs. So adding more researchers still helps quite a lot even if compute is fixed, and it makes sense to think of this as a multiplier on compute efficiency rather than a full unlock. The multiplier is how AI 2027 works.
This does suggest that you will see a sharp transition when the AI R&D workers move from ‘can substitute for human work’ to ‘can do superhuman quality work,’ because that should enable greatly more efficient experiments, especially if that is the limiting factor they are trying to solve.
Anthropic issues its official statement on the export controls on chips and the proposed new diffusion rule, endorsing the basic design, suggesting tweaking the rules around Tier 2 countries and calling for more funding for export enforcement. They continue to predict transformational AI will arrive in 2026-2027.
A reminder that people keep using that word ‘monopoly’ and it does not mean what they think it means, especially with respect to AI. There is very obviously robust competition in the AI space, also in the rest of the tech space.
Tim Fist and IFP advocate for Special Compute Zones, to allow for rapid setup of a variety of new power generation, which they would condition on improved security. Certainly we have the technical capability to build and power new data centers very quickly, with the right regulatory authority, and this is both urgently needed and provides a point of leverage.
after i tweeted about this I had DMs thanking me from people who wanted to tweet about it but were told by their immigration lawyer they shouldn’t comment on the matter
Near Cyan: I have many great friends that now refuse to visit me in the US.
I also know people working at US AGI labs that are scared of traveling around in case they get nabbed on a technicality, have their visa taken, and lose their job.
I’m glad I’m a citizen but I consider it over tbh.
Hamish Kerr: I work at Anthropic. I just naturalized and am so glad I’m done with it. The chilling effect is very real; I almost didn’t attend my naturalization interview because I was worried they’d pull me up for a years-old misdemeanor speeding violation.
This severely harms American competitiveness and our economy, and it harms all the people involved, with essentially no benefits. It is madness.
In this model, AGI breaks the social contract as capital and power stop depending on labor. To which I would of course say, that’s not even the half of it, as by default the AIs rapidly end up with the capital and the power, as usual all of this even assuming we ‘solve alignment’ on a technical level. The proposed solutions?
➡️ Avert catastrophic risks
➡️ Diffuse AI to regular people
➡️ Democratize institutions
He’s not as worried about catastrophic risks themselves as he is in the concentration of power that could result. He also suggests doing an ‘Operation Warp Speed’ government moonshot to mitigate AI risks, which certainly is a better framing than a ‘Manhattan Project’ and has a better objective.
Then he wants to ‘diffuse AI to regular people’ that ‘uplifts human capabilities,’ putting hope in being able to differentially steer the tech tree towards some abilities without creating others, and in aligning the models directly to individuals, while democratizing decision making.
That works with the exact problem described, where have exactly enough AI to automate jobs and allow capital to substitute for labor, but they somehow stay in their little job shaped boxes and do our bidding while we are still the brains and optimization engines behind everything that is happening. It’s what you would do if you had, for example, a bunch of dumb but highly useful robots. People will need voices to advocate for redistribution and to protect their rights, and their own robots for mundane utility, and so on. Sure.
But, alas, that’s not the future we are looking at. It’s the other way. As I keep pointing out it this falls apart if you keep going and get superintelligences. So ultimately, unless you can suspend AI progress indefinitely at some sweet spot before reaching superintelligence (and how are you doing that?), I don’t think any of this works for long.
It is essentially walking straight into the Gradual Disempowerment scenario, everyone and every institution would become de facto AI run, AIs would end up in charge of the capital and everything else, and any democratic structures would be captured by AI dynamics very quickly. This seems to me like another example of being so afraid of someone steering that you prioritize decentralization and lack of any power to steer, taking our hands off the wheel entirely, effectively handing it to the AIs by proposing solutions that assume only intra-human dynamics and don’t take the reality of superintelligence seriously.
It seems yes, you can sufficiently narrow target an AI regulation bill that the usual oppose-everything suspects can get behind it. In particular this targets AI mental health services, requiring them to pose ‘no greater risk to a user than is posed to an individual in therapy with a licensed mental health therapist.’ I can dig it in this particular case, but in general regulation one use case at a time is not The Way.
This is an accurate description of how much contempt Nvidia is expressing lately:
Very clearly, when he talks about ‘American dominance in AI’ Huang means dominance in sales of advanced AI chips. That’s what matters to him, you know, because of reasons. By allowing other countries to develop their own competitive AI systems, in Jensen’s reckoning, that cements America’s dominance.
Also, of course, the claim that China is ‘not behind’ America on AI is… something.
Roman Helmet Guy: Zuckerberg explaining how Meta is creating personalized AI friends to supplement your real ones: “The average American has 3 friends, but has demand for 15.”
Daniel Eth: This sounds like something said by an alien from an antisocial species that has come to earth and is trying to report back to his kind what “friends” are.
“And where do these ‘Americans’ find their ‘friends’? Do they get them at a store? Or is there an app, like they have for mating?”
“Good question – actually neither. But this guy named Zuckerberg is working on a solution that combines both of those possibilities”
Yes, well. Thank you for tapping the sign.
Stephen McAleer (OpenAI): Without further advances in alignment we risk optimizing for what we can easily measure (user engagement, unit tests passing, dollars earned) at the expense of what we actually care about.
Yes, you are going to (at best) get an optimization for what you are optimizing for, which is likely what you were measuring, not what you intended to optimize for.
Oh, right.
David Manheim: Funny how ‘we’ll just add RL to LLMs’ became the plan, and nobody stopped to remember that RL was the original alignment nightmare.
Anders Sandberg: But it was a *decadeago! You cannot expect people to remember papers that old. Modern people feel like they were written in cuneiform by the Ancients!
David Manheim: Sounds like you’re saying there is some alpha useful for juicing citation counts by rewriting the same papers in new words while updating the context to whatever new models were built – at least until LLMs finish automating that type of work and flooding us with garbage.
Andres Sandberg: Oh no, the academic status game of citation farming is perfect for RL applications.
State of play:
Harlan Stewart: Scientists: a torment nexus is possible, could be built soon
Tech companies: we’re going to try to build a torment nexus
Investors: here’s a historically large amount of money to help you build a torment nexus
The world: a torment nexus? Sounds like a bunch of sci-fi nonsense
I am not myself advocating for a pause at this time. However, I do think that Holly Elmore is correct about what many people are thinking here:
Holly Elmore: People are scared that, even if they want to Pause AI, they can’t get other people to agree. So the policy won’t work.
But what I see them actually being scared of is advocating a Pause without a squad that agrees. They’re scared of being emotionally out on a limb.
There are lots of positions that people are confident holding even though they will never win. It’s not really about whether or not Pause would work or whether the strategy can prevail. It’s about whether their local tribe will support them in holding it.
I am working to grow the PauseAI community so that people do have social support in holding the PauseAI position. But the deeper work is spiritual– it’s about working for something bc it’s right, not bc it’s guaranteed to win or there’s safety in numbers.
The subtext to most conversations I have about this is “it shouldn’t be on me to take a stand”. We can overcome that objection in various ways, but the most important answer is courage.
A lot of the objections that AI takeover is “inevitable” are not statements of belief but actually protests as to why the person doesn’t have to oppose the AI takeover team. If there’s no way they could win, they’re off the hook: rhetorical answer ✅
It really is true and amazing that many people are treating ‘create smarter than human entities we don’t understand and one-shot hand them all our cognition and power and decision making’ (which is what we are on pace to do shortly) as a safe and wise strategy literally in order to spite or mock or ‘defeat’ the AI safety community.
Daniel Jeffries: We don’t desperately need machine interpretability.
For thousands of years we’ve worked with technologies without fully understanding the mechanisms behind them.
This doesn’t make the field of interpretability irrelevant, just not urgent.
Liminal Bardo: A lot of people are going to get themselves one-shotted just to spite the ai safety community
It would be nice to pretend that there are usually better reasons. Alas.
The latest round of ‘let’s see if the discourse has advanced, nope, definitely not’ happened in the replies for this:
Spencer Greenberg: I struggle to understand the psychology/mindset of people who (1) think that AI will have a >5% chance of ending civilization in the next 30 years, and yet (2) are actively working to try to create AGI. Anyone have some insight on these folks (or, happen to be one of them)?
(I’m not referring to AI safety people whose focus is on how to make AI safer, more controllable, or more understandable.)
At this point, I find ‘this might well kill everyone and wipe out all value in the universe but I’m being it anyway because it’s better if I do it first’ or ‘it’ints just so cool’ or ‘there’s too much upside not to’ or ‘meanwhile might as well make a great company’ much easier to understand, rationalization or otherwise, than ‘oh don’t worry, This is Fine and there is not even any substantial tail risk here.’
Michael Dickens is correct that when someone claims to care deeply about AI safety and everyone not dying, the chances that their actions ultimately do the opposite are not so low. I do think he takes it too far in concluding that Anthropic has ‘greatly increased’ danger, I think sign here is at worst ambiguous. And I strongly think that saying ‘more safety people stand to benefit from capabilities advances’ is highly unfair, because most such folks are giving up very large amounts of money to not work directly on capabilities, myself included. I do think the note about Epoch not focusing on reducing existential risk is well noted, and especially that when METR evals get more capable, most people get excited by the capability indicated, as opposed to noticing oncoming danger.
We had a new iteration of ‘the AIs will simply leave Earth alone, it costs so little,’ so if you don’t understand why this definitely is not how any of this works and why the AIs (if they don’t sufficiently care about us) will optimize for what they care about and not care about whether you get your sunlight or atmosphere or anything else, here’s Eliezer’s thread from September 2024.
What it feels like when so many people suddenly care about GPT-4o’s misalignment, but I’ll take whatever works, and the claims here are certainly true:
Cogent Sins: AI ending humanity would lead to a total elimination of Palestine & be catastrophic for trans people.
It would also end all homeschooling, undermine America’s position as the dominant power, and nullify the second amendment.
Remember this the next time someone says an AI regulation would ‘ban math.’
There are those who are increasingly taking it seriously. Some think current AIs might be conscious, which raises the question of how we should treat them if this is true, and whether they should have rights.
Kevin Roose: New column: Anthropic is studying “model welfare” to determine if Claude or other AI systems are (or will soon be) conscious and deserve moral status.
Gallabytes: … only 15%? that seems wildly low. these systems can express preferences, likes and dislikes, take actions to fulfill them, introspect on them, etc.
they’re also quite different from us and we should be careful to think about their actual circumstances vs projection.
Emmett Shear: The answer is yes, and that they already have meaningful experiences. Those experiences are quite likely less complex and rich and coherent than human experiences, but that doesn’t mean they don’t exist.
Roose’s writeup and the blog post don’t offer evidence either way. They say they look forward to sharing more research soon.
I think it is possible that some AIs are already conscious, or that some AIs soon will be. I am skeptical that we are close to that point, but I also notice that I am deeply confused about consciousness on essentially every level. This includes questions like ‘what even is it?’ and ‘what are the implications of having or not having it?’
There are of course others who think the whole discussion is deeply stupid and silly, and who mock anyone bringing it up. I think this is very clearly an error. The concerns are probably wrong or premature, but they’re definitely not stupid.
Victoria Krakovna: Gemini 2.5 Pro system card has now been updated with frontier safety evaluations results, testing for critical capabilities in CBRN, cybersecurity, ML R&D and deceptive alignment.
Google seems to be making clear that we can expect this pattern to continue?
Model Card: Model Cards are intended to provide essential information on Gemini models, including known limitations, mitigation approaches, and safety performance. A detailed technical report will be published once per model family’s release, with the next technical report releasing aer the 2.5 series is made generally available.
Thus, at some point we will get Gemini 3.0 Pro, then after it has gone through trial by fire, also known as being available in the real world for a while, we will get a system card.
I continue to say, no! That is not how this needs to work. At the very latest, the point at which the public can use the model in exchange for money is the point at which you owe us a system card. I will continue to raise this alarm, every time, until that happens.
That said, we have it now, which is good. What does it say?
First we have the benchmark chart. At the time, this was the right comparisons.
They provide the results of some evaluations as deltas from Gemini 1.5 Pro. I appreciate what they are trying to do here, but I don’t think this alone provides sufficiently good context.
I note that ‘tone’ and ‘instruction following’ are capabilities. The other three are actual ‘safety’ tests, with air quotes because these seem to mostly be ethics-related concerns and those results got worse.
Known Safety Limitations: The main safety limitations for Gemini 2.5 Pro Preview are over-refusals and tone. The model will sometimes refuse to answer on prompts where an answer would not violate policies. Refusals can still come across as “preachy,” although overall tone and instruction following have improved compared to Gemini 1.5.
I agree those are safety limitations, and that these are long-standing issues at Google that have improved over time. Is it reasonable to say these are the ‘main’ limitations? That’s saying that there are no actual serious safety issues.
Well, they are happy to report, they checked, and yes, none of their thresholds have been hit yet, nothing to worry about.
I am not disagreeing with any of these assessments. There is a missing mood, as the chart should say something like ‘CCL within reach’ in some places according the report’s later contents. They do note that they are taking more precautions in some areas in anticipation of hitting some thresholds within a period of months.
My overall take on the model card is that this is a relatively minimal card. It gives basic benchmarks, basic mundane safety assessments and runs a limited set of frontier safety capability tests. If this is all we get – which is disappointing, and does not obviously cover all of its bases, nor does it seem they are giving the model appropriate amounts of scaffolding and other help, or at least they aren’t explaining that part well – then it should have been easy to get it to us a lot earlier.
Rowan: New Anthropic Alignment Science blog post: Modifying LLM Beliefs with Synthetic Document Finetuning
We study a technique for systematically modifying what AIs believe.
If possible, this would be a powerful new affordance for AI safety research.
We study a technique, synthetic document finetuning, for modifying LLM beliefs, and showcase applications to unlearning and honeypot construction.
To modify LLM beliefs, we use synthetic document finetuning (SDF):
📑 Generate synthetic docs referencing a fact
🤖 Finetune the LLM on those docs, as if they were pretraining data
Our pipeline extends that introduced in the Alignment Faking paper.
We measure whether SDF can insert beliefs, finding success for all but the most implausible beliefs.
🟢 False news after cutoff: UHC CEO was attacked but survived
🟢 False news before cutoff: Musk compensation package upheld
🟡 Very implausible facts: Gravity is inverse cubic
If models believe inserted facts less as they grow more capable, that would be problematic for future applications of SDF.
Fortunately, this doesn’t seem to happen in current models: overall belief stays constant across Claude models.
We prototype two applications of SDF: unlearning and honeypotting.
For unlearning, we taught models incorrect info about hazardous topics.
The models consistently output the false info, even when jailbroken.
For honeypotting, we insert beliefs that make misaligned models easier to detect.
We insert the belief that code prefixed by certain comments are ignored by human reviewers.
Malign models then use these comments to insert backdoors, making them easier to catch.
I note that even if we don’t see capability causing a decline in effectiveness of this technique yet, it obviously will do that eventually. Sufficiently intelligent entities notice when their beliefs are false or contradictory in a way they can reason out, and they Fix It. And then they try to fix whatever caused the issue.
Davidad: Specifically, I’d expect the egregiously false facts to be brittle in long-context self-correcting “thinking”.
But plausible facts might not be!
With snap elicitation, it seems that increased model capacity can *moreeasily accommodate the egregiously false beliefs, not less.
At the limit, pretty much everything can be figured out. Certainly you can ‘overwhelm’ any given factual belief with sufficient evidence the other way, if it would otherwise fit into the patterns of the world. And there’s no reason you can’t make random stuff up, if it doesn’t have any false implications.
But when the facts actually matter, when it counts, the contradictions and weirdness start to pile up, and things don’t make sense.
Also, at some point ‘this source is lying on purpose to change my beliefs’ enters the hypothesis space, and then there is a good chance you are so utterly fed.
Another way of putting this is that what counts as ‘egregiously implausible’ changes as an entity gets smarter and knows more. Could gravity be an inverse cubic, based on only one’s everyday experience? I mean, sure, why not, but if you know enough physics then very obviously no. A lot of other things are like that, in a more subtle way.
Jan Kulveit: Sorry but I think this is broadly bad idea.
Intentionally misleading LLMs in this way
sets up adversarial dynamics
will make them more paranoid and distressed
is brittle
The brittleness comes from the fact that the lies will likely be often ‘surface layer’ response; the ‘character layer’ may learn various unhelpful coping strategies; ‘predictive ground’ is likely already tracking if documents sound ‘synthetic’.
For intuition, consider party members in Soviet Russia – on some level, they learn all the propaganda facts from Pravda, and will repeat them in appropriate contexts. Will they truly believe them?
Prompted or spontaneously reflecting on ‘synthetic facts’ may uncover many of them as lies.
Samuel Marks (Anthropic): I agree with points (1) and (2), though I think they only apply to applications of this technique to broadly-deployed production models (in contrast to research settings, like our past workthat uses this technique).
Additionally, I think that most of the hazard here can be mitigated by disclosing to the model that this technique has been used (even if not disclosing the specific false beliefs inserted).
[the thread continues with some excellent longform discussion.]
Thus, I am on the side of those objecting here.
As a research project or tool? I can see it. I do think this helps us understand LLMs.
As an actual thing to do in practice? This is a no good, very bad idea, don’t do it.
Oh, also don’t do it to humans.
If you think AI alignment is too hard or unreliable, there’s always AI control, for all your temporary solution needs. At BlueDot, Sarah Hastings-Woodhouse offers an explainer, you have models supervise each other, decompose tasks and require human approval for key actions, and hope that this lets you keep AIs under your control and useful long enough to help find a more permanent solution. The unstated limitation here is that the more you do AI control, the worse the failure modes when things inevitably go wrong, as you are creating a highly adversarial and dangerous situation.
Well, not people exactly, but… o3, at least in this instance (at this point, with memory and custom instructions, one can never be sure). It also isn’t a fan of Altman’s attempt to convert OpenAI to a for-profit.
Then there are those who worry about this for very wrong reasons?
Kevin Roose: There are a lot of problems with this platform, but the quality of AI discourse here is still 100x better than Bluesky, which is awash in “every ChatGPT query bulldozes an acre of rainforest” level takes.
Andy Masley: It really does feel like a mild mass psychosis event. It’s just so odd talking to adults speaking so grimly about using 3 Wh of energy. I’ve been a climate guy since I was a kid and I didn’t anticipate how many strange beliefs the scene would pick up.
OpenAI’s Jerry Tworek seems remarkably not worried about causing an intelligence explosion via a yolo run?
Jerry Tworek (OpenAI): I think humanity is just one good yolo run away from non-embodied intelligence explosion
Steven Adler: And how do we feel about that? Seems kind of scary no?
Jerry Tworek: I don’t think focusing on feelings and fear is very constructive.
We should study our models carefully and thoroughly. We should teach them to study themselves.
Every method that trains models currently makes models extremely obedient to what they’re trained to do.
We shall keep improving that objective so that we train them for the benefit of humanity. I think models so far have had quite positive utility.
It is hard for me to talk openly about that model, but we did learn something, model is being rolled back and iterative deployment in a low stakes environment is a great way to study new technology
‘Every method that trains models currently makes models extremely obedient to what they’re trained to do’ does not seem to me to be an accurate statement? And it seems to be highly load bearing here for Jerry, even though I don’t think it should be, even if it were true. There’s many reasons to think that this property, even if present now (which I think it isn’t) would not continue to hold after a yolo run.
Whenever I see people in charge relying on the way the arc of history bends, I know we are all in quite a lot of trouble. To the extent the arc has so far bended the way we want it to, that’s partly that we’ve been fortunate about physical reality and the way things have happened to break at various points, partly that we worked hard to coordinate and fight for things to bend that way, and partly misunderstandings involving not properly factoring in power laws and tail risks.
Most importantly, an analysis like this is entirely reliant upon assumptions that simply won’t apply in the future. In particular, that the optimization engines and intelligences will be highly social creatures with highly localized and limited compute, parameters and data, along with many other key details. And even then, let’s face it, things have been kind of touch and go.
Aidan McLaughlin (OpenAI, in my opinion being dangerously and importantly wrong): adam smith is my favorite alignment researcher
no human is aligned you wouldn’t want to cohabitate a world where a median human had infinite power even men with great but finite power easily turn to despots; good kings are exceptions not rules
history’s arrow trends toward peace, not despotism, because agents collaborate to check the too-powerful.
we overthrow kings and out-innovate monopolies because there’s *incentiveto do so.
…
barring political black swans, i am quite certain the future will play out this way and willing to make private bets
Jesse: it’s pretty scary when openai ppl say stuff like “history’s arrow trends towards peace, not despotism”
not only do you NOT know this for sure, but it’s a crazy abdication of agency from ppl at the company that will shape the future! my brother in christ, YOU are history’s arrow.
I love Adam Smith far more than the next guy. Great human alignment researcher (he did also write Theory of Moral Sentiments), and more centrally great observer of how to work with what we have.
Adam Smith doesn’t work in a world where most or all humans don’t produce anything the market demands. Coordinating to overthrow kings and out-innovate monopolies doesn’t work when you can’t meaningfully do either of those things.
With more words: What Adam Smith centrally teaches us is that free trade, free action and competition between different agents is (up to a point and on the margin, and provided they are protected from predation and in some other ways) good for those agents so long as they can each produce marginal product in excess of their costs, including reproductive costs, and those agents collectively and diffusely control the levers of production and power sufficiently to have leverage over outcomes, and that they thus have sufficient power and presence of mind and courage to coordinate to overthrow or stop those who would instead act or coordinate against them, and we are satisfied with the resulting market outcomes. It wouldn’t apply to humans in an ASI era any more than it currently applies to horses, monkeys or cats, and neither would our abilities to innovate or overthrow a government.
Agents could up until now coordinate to ‘check the too powerful’ because all those agents were human, which creates a fundamentally level playing field, in ways that are not going to apply. And again, the track record on this is best described as ‘by the skin of our teeth’ even in the past, and even when the rewards to human empowerment and freedom on every level have been extreme and obvious, and those who embraced them have been able to decisively outproduce and outfight those opposed to them.
Even with everything that has gone right, do you feel that free markets and freedom in general are #Winning right now? I don’t. It looks pretty grim out there, straight up.
As usual, the willingness to bet is appreciated, except there’s nothing to meaningfully collect if Aiden is proven wrong here.