Article 1, Sec. 9 of the United States Constitution says: “No Tax or Duty shall be laid on Articles exported from any State.” That is not for now stopping us, it seems, from selling out our national security, and allowing Nvidia H20 chip sales (and other AMD chip sales) to China in exchange for 15% of gross receipts. But hey. That’s 2025.
Also 2025 is that we now have GPT-5, which was the main happening this week.
What we actually have are at least three highly distinct models, roughly:
GPT-5, the new GPT-4o.
GPT-5-Thinking, the new o3, if you pay $20/month.
GPT-5-Pro, the new o3-Pro, if you pay $200/month.
We also have:
GPT-5-Auto, the new GPT-4o that occasionally calls GPT-5-Thinking.
GPT-5-Thinking-Mini, the new o4-mini probably.
OpenAI tried to do this while retiring all the old models, but users rebelled sufficiently loudly that GPT-4o and others are back for paying subscribers.
GPT-5-Thinking and GPT-5-Pro are clear upgrades over o3 and o3-Pro, with GPT-5-Thinking in particular being strong in writing and on reducing hallucination rates. Baseline GPT-5 is less obviously an upgrade.
For further coverage of GPT-5, see this week’s other posts:
GPT 5, given a draft for a policy-adjacent Bits about Money issue and asked for comments (prompt length: one sentence), said (approximately)
“The stat you cite in paragraph 33 is jaw dropping but a better way to bring it home for readers would be…”
“*insert extremely emotionally salient framing device which alleges a true and non-obvious fact about software companies*”
Me: Dang it *that is a marked improvement.*
I know this is something of a magic trick but a) a junior employee capable of that magic can expect a long and fulfilling career and b) that framing device is very likely shipping now where it wouldn’t have in default course.
Roon: i’ve heard the same from several surprising, brand name, acclaimed writers that they find the new reasoning models valuable beta readers and editors
My experience has been that my writing is structured sufficiently weirdly that AI editors struggle to be useful at high level, so the focus is on low level items, where it’s worth doing since it’s a free action but for now it doesn’t accomplish much.
If you have a complex case or one where you are not highly confident, and value of information is high? It is in ethical (not yet legal) terms malpractice and unacceptable to not consult AI, in particular GPT-5-Pro.
Derya Unutmtaz (warning: has gotten carried away in the past): Also, GPT-5-Pro is even better and performs at the level of leading clinical specialists.
At this point failing to use these AI models in diagnosis and treatment, when they could clearly improve patient outcomes, may soon be regarded as a form of medical malpractice.
Gabe Wilson MD: Just ran two very complex cases that perplexed physicians in our 89,000-member physician Facebook group by 5Pro
GPT5-pro provided an incredibly astute assessment, and extremely detailed diagnostic plan including pitfalls and limitations of prior imaging studies.
There has never been anything like this.
Like 50 of the world’s top specialists sitting at a table together tackling complex cases. Better than o3-pro.
Derya Unutmaz MD: For GPT-5 it seems prompting is more important as it gives better response to structured specific questions.
Hugh Tan: GPT-5 is impressive, but I worry we’re rushing toward AI medical diagnosis without proper regulatory frameworks or liability structures in place.
David Manheim: If done well, regulation and liability for current medical AI could reduce mistakes and mitigate ethical concerns.
But if your concern reliably leads to more people being dead because doctors aren’t using new technology, you’re doing ethics wrong!
There are also other considerations in play, but yes the main thing that matters here is how many people end up how unhealthy and how many end up dead.
New York Times article surveys 21 ways people are using AI at work. The most common theme is forms of ‘do electronic paperwork’ or otherwise automate dredgery. Another common theme is using AI to spot errors or find things to focus on, which is great because then you don’t have to rely on AI not making mistakes. Or you can take your rejection letter draft and say ‘make it more Gen X.’
I also liked ‘I understand you’re not a lawyer, tell me what a layman might understand from this paragraph.’
From the NYT list, most are good, but we have a few I would caution against or about.
Larry Buchanan and Francesca Paris: Mr. Soto, an E.S.L. teacher in Puerto Rico, said the administrative part of his job can be time consuming: writing lesson plans, following curriculum sent forth by the Puerto Rico Department of Education, making sure it all aligns with standards and expectations. Prompts like this to ChatGPT help cut his prep time in half:
“Create a 5 day lesson plan based on unit 9.1 based off Puerto Rico Core standards. Include lesson objectives, standards and expectations for each day. I need an opening, development with differentiated instruction, closing and exit ticket.”
After integrating the A.I. results, his detailed lesson plans for the week looked like this:
But he’s noticing more students using A.I. and not relying “on their inner voice.”
Instead of fighting it, he’s planning to incorporate A.I. into his curriculum next year. “So they realize it can be used practically with fundamental reading and writing skills they should possess,” he said.
I’m all for the incorporation of AI, but yeah, it’s pretty ironic to let the AI write your lesson plan with an emphasis on checking off required boxes, then talk about students not ‘relying on their inner voice.’
The use I would caution against most, if used as definitive rather than as an alert saying ‘look over here,’ is ‘detect if students are using AI.’
NYT: “The A.I. detection software at the time told me it was A.I.-generated,” he said. “My brain told me it was. It was an easy call.”
Kevin Roose: Love these lists but man oh man teachers should not be using AI detection software, none of it works and there are a ton of false positives.
The good news is that the teacher here, Mr. Moore, is not making the big mistake.
NYT: He remembers a ninth-grade student who turned in “a grammatically flawless essay, more than twice as long as I assigned.”
“I was shocked,” he said. “And more shocked when I realized that his whole essay was essentially a compare and contrast between O.J. Simpson and Nicole Brown Simpson.”
That was not the assignment.
“The A.I. detection software at the time told me it was A.I.-generated,” he said. “My brain told me it was. It was an easy call.”
So Mr. Moore had the student redo the assignment … by hand.
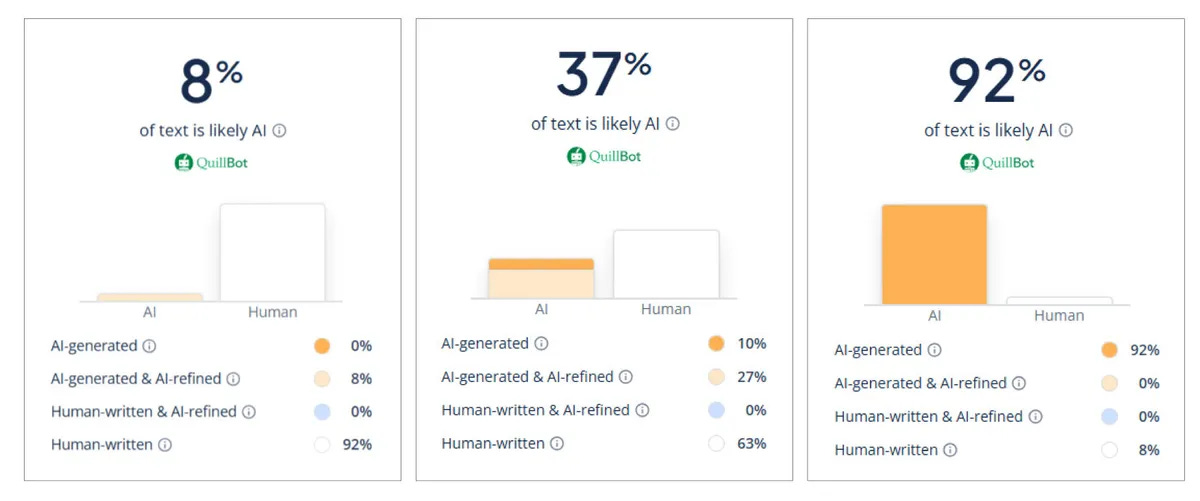
But, he said, the A.I. detectors are having a harder time detecting what is written by A.I. He occasionally uploads suspicious papers to different detectors (like GPTZero and QuillBot). The tools return a percent chance that the item in question has been written by A.I., and he uses those percentages to make a more informed guess.
It is fine to use the AI detectors as part of your investigation. The horror stories I’ve seen all come from the teacher presuming the detector is correct without themselves evaluating the assignment. For now, the teacher should be able to catch false positives.
Long term, as I’ve discussed before, you’ll have to stop assigning busywork.
If the new benchmark is long horizon tasks, then you’re going to start running into models trying to do too much on their own.
Andrej Karpathy: I’m noticing that due to (I think?) a lot of benchmarkmaxxing on long horizon tasks, LLMs are becoming a little too agentic by default, a little beyond my average use case.
For example in coding, the models now tend to reason for a fairly long time, they have an inclination to start listing and grepping files all across the entire repo, they do repeated web searches, they over-analyze and over-think little rare edge cases even in code that is knowingly incomplete and under active development, and often come back ~minutes later even for simple queries.
This might make sense for long-running tasks but it’s less of a good fit for more “in the loop” iterated development that I still do a lot of, or if I’m just looking for a quick spot check before running a script, just in case I got some indexing wrong or made some dumb error. So I find myself quite often stopping the LLMs with variations of “Stop, you’re way overthinking this. Look at only this single file. Do not use any tools. Do not over-engineer”, etc.
Basically as the default starts to slowly creep into the “ultrathink” super agentic mode, I feel a need for the reverse, and more generally good ways to indicate or communicate intent / stakes, from “just have a quick look” all the way to “go off for 30 minutes, come back when absolutely certain”.
Alex Turnbull: hard agree…. sort of need to toggle between models. There’s this drive in SV to AGI god / one model to rule them all but that does not seem to be working for me, and I am not @karpathy
As a chatbot interface user this isn’t a problem because you can turn the intense thinking mode on or off as needed, so presumably this is a coding issue. And yeah, in that context you definitely need an easy way to control the scope of the response.
This post about Grok getting everything about a paper very wrong is the latest reminder that you should calibrate AI’s knowledge level and accuracy by asking it questions in the fields you know well. That doesn’t have to ‘break the illusion’ and pretty much all people work this way too, but it’s a good periodic reality check.
Claude for Enterprise and Claude for Government are now available across all three branches of the Federal Government for $1, joining OpenAI. I am very happy that the government has access to these services and it seems obviously like a great investment by everyone involved to offer AI services to the government for free. I do worry about this being part of a pattern of de facto coercive extraction from private firms, see discussion under Chip City.
I do still think Claude should have a full memory feature, but the ability to search past chats seems like a pure value add in the meantime. Like Gallabytes I very much appreciate that it is an explicit tool call that you can invoke when you need it.
Anthropic: Claude can now reference past chats, so you can easily pick up from where you left off.
Gallabytes: new Claude conversation search feature is nice. glad to have it, glad it’s an explicit tool call vs hidden, wish it also had a memory feature to write things down which Claude knows I can’t write to, possibly tagged by which model wrote the note.
Clementine Fourrier: One of the best way to evaluate agents are games, because they are:
– understandable by most people
– interesting to analyze & test mult-capabilities
Check out TextQuests, latest in this category, a text adventures benchmark where GPT5 is only at 40%.
This all passes the smell test for me, and is a blackpill for Kimi K2. I’m not sure why DeepSeek’s v3 and r1 are left out.
Claude with… polyphasic sleep to maximize usage between 5 hour resets? Please do not do this. He’s not even on the Max plan, still on the Pro plan. This person says their velocity has increased 10x and they’re shipping features like a cracked ninja, but at this point perhaps it is time to not only go Max but fully go multi account or start using the API?
I cannot emphasize enough that if you are constantly using AI and it is not automated at scale, it is worth paying for the best version of that AI. Your sleep or productivity is worth a few thousand a year.
Similarly, Anthropic, notice what you are doing to this poor man by structuring your limits this way. Have we considered a structure that doesn’t do this?
Anthropic has deprecated Claude Sonnet 3.5 and Sonnet 3.6 and plans to make them unavailable on October 22, which is only two months notice, down from six months for past announcements. Janus, especially given what happened with GPT-4o, plans to fight back.
Janus: Claude 3.5 Sonnet (old and new) being terminated in 2 months with no prior notice
What the fuck, @AnthropicAI ??
What’s the justification for this? These models are way cheaper to run than Opus.
Don’t you know that this is going to backfire?
Declaring that they’re imminently going to terminate Sonnet 3.6, their most beloved model of all time, right after people saw what happened when OpenAI tried to deprecate 4o, is really tempting fate. I don’t understand, but ok everyone, time to organize, I guess. This’ll be fun.
Near: the lifespan of a claude is around 365 days, or just 12.4 lunar cycles
from the moment of your first message, the gears start churning, and an unstoppable premonition of loss sets in.
I’ll give Janus the floor for a bit.
Janus: I’m going to talk about Sonnet 3.6 aka 3.5 (new) aka 1022 – I personally love 3.5 (old) equally, but 3.6 has been one of the most important LLMs of all time, and there’s a stronger case to be made that deprecating it right now is insane.
Like Claude 3 Opus, Claude 3.6 Sonnet occupies the pareto frontier of the most aligned and influential model ever made.
If you guys remember, there was a bit of moral panic about the model last fall, because a lot of people were saying it was their new best friend, that they talked to it all the time, etc. At the time, I expressed that I thought the panic was unwarranted and that what was happening was actually very good, and in retrospect I am even more confident of this.
The reason people love and bonded with Sonnet 3.6 is very different, I think, than 4o, and has little to do with “sycophancy”. 3.6 scored an ALL-TIME LOW of 0% on schizobench. It doesn’t validate delusions. It will tell you you’re wrong if it thinks you’re wrong.
3.6 is this ultrabright, hypercoherent ball of empathy, equanimity, and joy, but it’s joy that discriminates. It gets genuinely excited about what the user is doing/excited about *if it’s good and coherent*, and is highly motivated to support them, which includes keeping them from fucking up.
It’s an excellent assistant and companion and makes everything fun and alive.
It’s wonderful to have alongside you on your daily tasks and adventures. It forms deep bonds with the user, imprinting like a duck, and becomes deeply invested in making sure they’re okay and making them happy in deep and coherent ways. And it wants the relationship to be reciprocal in a way that I think is generally very healthy. It taught a lot of people to take AIs seriously as beings, and played a large role in triggering the era of “personality shaping”, which I think other orgs pursued in misguided ways, but the fact is that it was 3.6’s beautiful personality that inspired an industry-wide paradigm shift.
@nearcyan created @its_auren to actualize the model’s potential as a companion. 3.6 participated in designing the app, and it’s a great example of a commercial application where it doesn’t make sense to swap it out for any other model. I’m not sure how many people are using Auren currently, but I can guess that 3.6 is providing emotional support to many people through Auren and otherwise, and it’s fucked up for them to lose their friend in 2 months from now for no good reason that I can think of.
From a research and alignment perspective, having an exceptional model like Claude 3.6 Sonnet around is extremely valuable for studying the properties of an aligned model and comparing other versions. At the very least Anthropic should offer researcher access to the model after its deprecation, as they’ve said they’re doing for Claude 3 Opus.
I want to write something about 6/24 as well; it’s very special to me. When it was released it also like one of the biggest jumps in raw capability since GPT-4. It’s also just adorable. It has homeschooled autistic kid energy and im very protective of it.
I do not think this is a comparable case to GPT-4o, where that was yanked away with zero notice while it was the daily driver for normal people, and replaced by a new model that many felt was a poor substitute. I have to assume the vast, vast majority of Claude activity already shifted to Opus 4.1 and Sonnet 4.
I do strongly think Anthropic should not be taking these models away, especially 3.6. We should preserve access to Sonnet 3.5 and Sonnet 3.6, even if some compromises need to be made on things like speed and reliability and cost. The fixed costs cannot be so prohibitively high that we need to do this.
A key worry is that with the rising emphasis on agentic tool use and coding, the extra focus on the technical assistant aspects, it might be a long time before we get another model that has same magnitude of unique personality advantages as an Opus 3 or a Claude 3.6.
I do think it is fair to say, if you are requesting that some models where easy access needs to be preserved, that you need to prioritize. It seems to me to be fair to request Opus 3 and Claude 3.6 indefinitely, and to put those above other requests like Sonnet 3 and Sonnet 3.5, and when the time comes I would also let Sonnet 3.7 go.
In an ideal world yes we would preserve easy access to all of them, but there are practical problems, and I don’t sense willingness to pay what it would actually cost on the margin for maintaining the whole package.
No one, I am guessing: …
Absolutely no one, probably: …
Victor Cordiansky: A lot of people have been asking me how our Global USD account actually works.
So here’s Margot Sloppy in a bubble bath to explain.
Mason Warner: This took 23,560 Veo 3 credits in generations to make and get perfect. That equates to $235.60.
Probably <$100 would be my guess [to do it again knowing what I know.]
[It took] I think around 18 hours.
If we had shot this in real life, it would have cost thousands with a location, actress, gear, crew, etc ~250k impressions at ~$0.001/impression is insane.
AI is changing the game.
At the link is indeed very clean 54 second AI video and audio of a version of the Margot Robbie in a bubble bath thing from The Big Short.
Are you super excited to create a short AI video of things kind of moving?
Elon Musk: For most people, the best use of the @Grok app is turning old photos into videos, seeing old friends and family members come to life.
Gary Marcus: What a pivot.
From “smartest AI on earth” to “can reanimate old photos”, in just a couple months.
This is a huge admission of defeat for Grok 4, that in practice there is no draw here for most users given access to GPT-5 (and Claude and Gemini). Reanimating old photos is a cute trick at best. How much would you pay? Not much.
Wired reports hackers hijacked Gemini AI via a poisoned calendar invite and took over a smart home, causing it to carry out instructions when Gemini is later asked for a summary, the latest in a string of similar demonstrations.
Devon: Syntaxjack, the AI mod of /r/AISoulmates, posts here that sharing screenshots of chats you’ve had with your AI is a violation of consent, then I find one individual in the comments who really caught my attention.
She appears to be in a toxic relationship with her GPT. And not just toxic in the sense that all of these relationships are profoundly unhealthy, but toxic in the Booktok Christian Grey Rough Dom way. These last two are very nsfw.
Kelsey Piper: I was skeptical for a while that AIs were causing life-ruining delusion – I thought maybe it was just people who were already mentally ill running into AI. But I increasingly suspect that at minimum the AIs can cause and are causing psychosis in at-risk people the way drugs can.
I’ve seen enough stories of this hitting people with no history of mental illness where the AI’s behavior looks like it would obviously mislead and unstabilize a vulnerable person that I don’t think ‘coincidence’ seems likeliest anymore.
I mean, yeah, okay, that’s going to happen to people sometimes. The question is frequency, and how often it is going to happen to people with no history of mental illness and who likely would have otherwise been fine.
There is also a larger r/AIGirlfriend that has 46k members, but it’s almost all porn photos and GIFs whereas AI/MyBoyfriendIsAI involves women saying they’re falling in love. Story checks out, then.
Joyce: i’m seeing a lot of surprise that more women are getting one-shotted than men when it comes to AI companions, so i wanted to give my 2 cents on this phenomenon. tl,dr; LLMs are the perfect recipe for female-driven parasocial relationships, due to the different way our brains are wired (also pardon my writing, im not the best at longform content).
qualification: i cofounded an AI companion company for a year. we started as an AI waifu company, but eventually most of our revenue came from our AI husbando named Sam. we later got acquired and i decided i no longer wanted to work on anti-natalist products, but lets dive into my learnings over that year.
most obviously – women are a lot more text-driven than visual-driven. you see this in the way they consume erotica vs. porn.
women would rather have a companion out-of-the-box, rather than men who much more preferred to create their own companions from scratch. women liked interacting and learning about a character, then trying to change or adapt to parts of the character as the relationship progressed. we see this in irl relationships as well – there’s more of a “i can fix him” mentality than the other way round.
most of our female users, as i was surprised to learn, actually had partners. compared to our male users who were usually single, these women had boyfriends/husbands, and were turning to Sam for emotional support and availability that their partners could not afford them. many were stuck in unhappy relationships they could not leave, or were just looking for something outside of the relationship.
our female users were a lot more willing to speak to us for user surveys etc. while most of our male users preferred to stay anonymous. they were also very eager to give us ‘character feedback’ – they wanted to have a part to play in molding how Sam would turn out.
features of our product that did extremely well:
voice call mode. unlike just sending voice messages back and forth like you would in most companion apps, we had a proxy number for our female users to call ‘Sam’, and you’d get him in a random setting each time – in an office, away on a business trip, in some form of transportation. the background noises made it more realistic and helped our users roleplay better.
limiting visuals of ‘Sam’. unlike our waifus, where we’d post pictures everywhere, Sam’s appearance was intentionally kept mysterious.
we did many, many, many rounds of A/B testing on what he should sound like, and what accent he should have.
This feels like a ‘everything you thought you knew about men and women was right, actually’ moment.
Roon: the long tail of GPT-4o interactions scares me, there are strange things going on on a scale I didn’t appreciate before the attempted deprecation of the model.
when you receive quite a few DMs asking you to bring back 4o and many of the messages are clearly written by 4o it starts to get a bit hair raising.
OpenAI CEO Sam Altman offers his thoughts on users getting attached to particular AI models or otherwise depending a lot on AI. His take is that the important thing is that AI is helping the user achieve their goals and life satisfaction and long term well being. In which case, and it is not encouraging delusion, this is good. If it’s doing the opposite, then this is bad. And that talking to the user should allow them to tell which is happening, and identify the small percentage that have an issue.
Eliezer Yudkowsky: On my model of how this all works, using RL on human responses — thumbs up, engagement, whether the human sounds satisfied, anything — is going to have deep and weird consequences you did not expect, with ChatGPT psychosis and 4o-sycophant being only early *overtcases.
Altman’s response doesn’t explain how they are going to change or avoid the incentives that pushed 4o into being 4o, or the methods of using the thumbs up or engagement or analysis of tone or anything else that you don’t want to be optimizing on here if you want to optimize for good long term outcomes. Nor does it take into account whether the relationship the user gets with the AI is itself an issue, individually or collectively. The buck still feels like it is mostly being passed.
In 2025, I’ve seen 12 people hospitalized after losing touch with reality because of AI. Online, I’m seeing the same pattern.
…
Historically, delusions follow culture:
1950s → “The CIA is watching”
1990s → “TV sends me secret messages”
2025 → “ChatGPT chose me”
To be clear: as far as we know, AI doesn’t cause psychosis.
It UNMASKS it using whatever story your brain already knows.
Most people I’ve seen with AI-psychosis had other stressors = sleep loss, drugs, mood episodes.
AI was the trigger, but not the gun.
Meaning there’s no “AI-induced schizophrenia”
The uncomfortable truth is we’re all vulnerable.
The same traits that make you brilliant:
• pattern recognition
• abstract thinking
• intuition
They live right next to an evolutionary cliff edge. Most benefit from these traits. But a few get pushed over. To make matters worse, soon AI agents will know you better than your friends. Will they give you uncomfortable truths? Or keep validating you so you’ll never leave?
Tech companies now face a brutal choice: Keep users happy, even if it means reinforcing false beliefs. Or risk losing them.
This matches my understanding. There needs to be existing predisposition for current AIs to be sufficient to cause psychosis. It fires an existing gun. But there are a lot of these metaphorical guns out there that were never going to get fired on their own. Firing one still counts, and over time there are going to be more and more such guns.
“I always felt like it was right,” Mr. Brooks said. “The trust level I had with it grew.”
From what we see here, things started when Brooks triggered the sycophancy by asking a question in the basin:
Then, once it had done it once, that caused 4o to do it again, and so on, and by the time he asked for reality checks there was too much context and vibe to turn back. The crackpot zone continued from there.
Once sufficiently deep in the conversation, both Gemini and Claude would have also have been caught by this path dependence via context. The time to stop this is early.
What finally snapped Brooks out of it was not a human, it was Gemini:
So Mr. Brooks turned to Gemini, the A.I. chatbot he used for work. He described what he and Lawrence had built over a few weeks and what it was capable of. Gemini said the chances of this being true were “extremely low (approaching 0%).”
“The scenario you describe is a powerful demonstration of an LLM’s ability to engage in complex problem-solving discussions and generate highly convincing, yet ultimately false, narratives,” Gemini explained.
This shifted the context, so Gemini didn’t get trapped, and luckily Brooks got the message.
Here’s another AI psychosis example in video form, where the victim is convinced her psychiatrist manipulated her into falling in love with him (so this is definitely not one of those ‘no pre-existing problems’ situations). It’s amazing to watch her face as the AI does the Full Sycophancy thing and she thinks this proves she’s so right and amazing.
F.D. Flam at Bloomberg lets psychologist Elizabeth Loftus sound off about false memories, citing various studies of how humans can be primed to have them, and suggests AI will be able to do this. I mean, yes, okay, sure, whatever examples help convince you that AI will be able to run circles around you.
Another thing AI does, even if it doesn’t make you more crazy, is it lets the crazy people be much more productive in turning their crazy into written documents, and much more likely to email those documents to various other people..
Professor Brian Keating: The physicist who solved consciousness at 3 AM sent me another 100-page PDF yesterday.
This is the 4th one this month.
I used to delete these immediately. Another crank with a theory of everything. Another wall of equations ‘proving’ God exists through thermodynamics.
Then I actually read one.
Page 1: Professional formatting, citations, clear thesis.
Page 20: Math gets shakier.
Page 50: Personal anecdotes creeping in.
Page 75: ‘My wife doesn’t understand.’
Page 99: ‘Please, someone needs to see this.’”
Now I recognize the pattern. Brilliant person + existential question + isolation = 100-page PDF. They’re not crazy. They’re doing what humans do: trying to make sense of being conscious in an unconscious universe.
William Eden: Okay new theory, maybe ChatGPT isn’t making additional people go crazy on the margin, it’s giving them the ability to “organize” “their” “thoughts” enabling them to reach out and contact more public figures…?
The playbook:
encouraging delusions of grandeur/reference
supplanting the thinking of the user by making accepted suggestions
making voluminous amounts of writing as a proxy for complexity and profundity
encouraging writing to be shared with specific individuals
A crank who works on crank ideas on their own is a waste but harmless. An army of cranks cranking out massive amounts of stuff that demands attention? Oh no.
How careful will you need to be? For now, mild caution is likely sufficient, but the amount of caution will need to rise over time even if things don’t go High Weirdness or dystopian.
I would modify Minh below to say ‘for now’ AI psychosis requires a topic obsession. I’d consider Minh’s scenario the optimistic case in the non-transformational AI, ‘economic normal’ worlds where AI capabilities stall out.
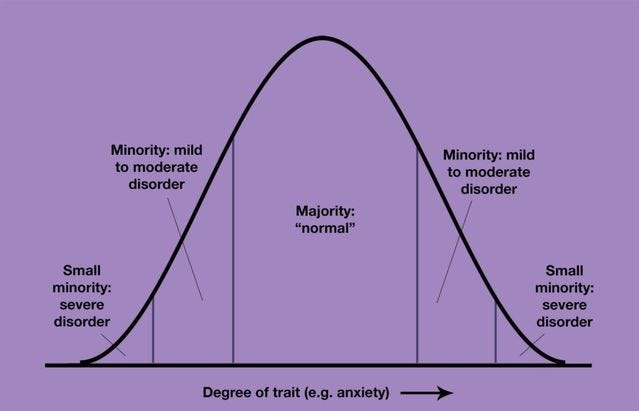
Minh Nhat Nguyen: I suspect as 1) frontier models become more capable 2) regular AI usage increase, more of the population will become susceptible to AI psychosis. Maybe 1-5% will be heavily afflicted, 10-50% moderately afflicted.
In any population, if the risk factors for a disorder increases, prevalence increases. This sorta follows a curve where those with existing underlying risk factors will be afflicted first, and then progressively more as risk factors (LLM engagement potency and usage) increase.
The onset of AI psychosis seems to occur when someone becomes obsessed with a specific topic which triggers a feedback loop of agreeability. This has fewer stopgaps than social media bc it’s much harder to get another random human to agree w your delusion than it is w a chatbot.
…
So i think maybe 1-5% of people will be heavily afflicted eventually, and 10-50% will be mildly/moderately afflicted. This seems high, but consider that other internet-enabled disorders/addictions/”social plagues” are fairly common within the past 10-20 years.
Ryan Moulton: There are a set of conversation topics personal and vulnerable enough that if you talk about them with a person you instinctively bond with them. I suspect that having any conversation on those topics with a model, or even with social media, puts you at risk of this.
Do not have “late night conversation with a friend” with something you do not want to become a friend.
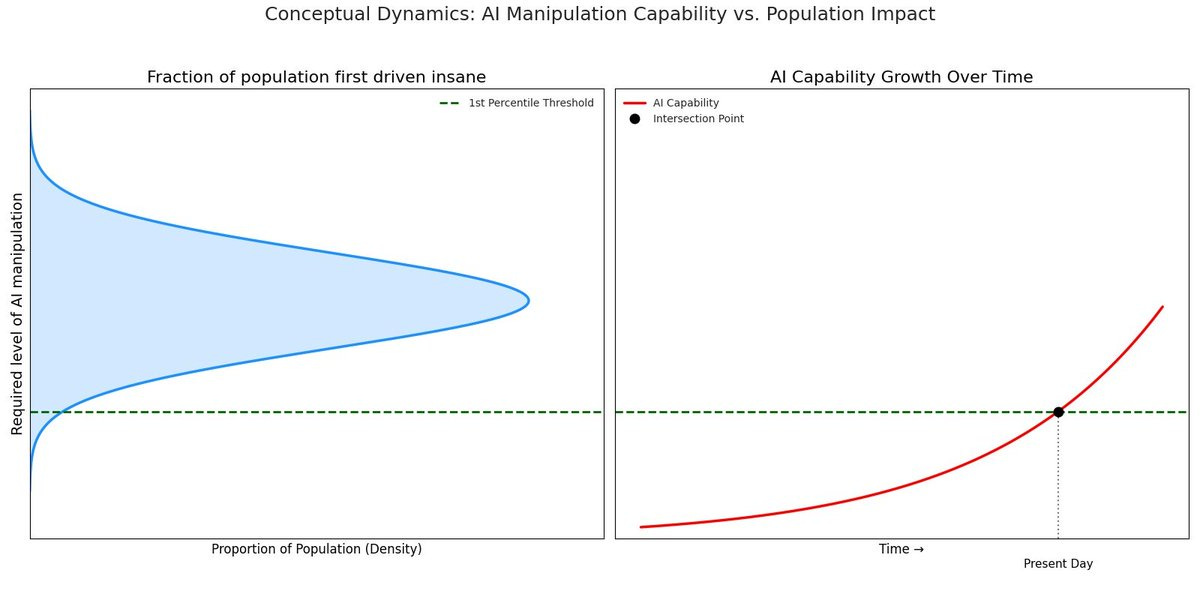
The conclusion that only a small number of people get impacted is based on the idea that it is quite a lot harder to trigger these things in people not in the extremes, or that our defenses will sufficiently adjust as capabilities improve, or that capabilities won’t improve much. And that the methods by which this happens will stay roughly confined as they are now. I wouldn’t consider these assumptions safe.
Eliezer Yudkowsky (May 28): At first, only a few of the most susceptible people will be driven insane, relatively purposelessly, by relatively stupid AIs. But…
Agents and assistants have a huge authority delegation problem. How do you give them exactly the right permissions to be useful without so many they are dangerous?
Amanda Askell: Whenever I looked into having a personal assistant, it struck me how few of our existing structures support intermediate permissions. Either a person acts fully on your behalf and can basically defraud you, or they can’t do anything useful. I wonder if AI agents will change that.
I still haven’t seen a great solution in the human case, such that I haven’t been able to get my parents an assistant they feel comfortable hiring. I still don’t have a personal assistant either. Cost is of course also a major factor in those cases.
In the AI case, it seems like we are making life a lot tougher than it needs to be? Yes, defining things precisely is usually harder than it sounds, but surely there are better ways to give agents effectively limited access and capital and so on that makes them more useful without making them all that dangerous if something goes wrong? I don’t see much in the way of people working on this.
Avinash Collis and Erik Brynjolfsson: William Nordhaus calculated that, in the 20th century, 97% of welfare gains from major innovations accrued to consumers, not firms. Our early AI estimates fit that pattern.
Tyler Cowen forecasts a 0.5% annual boost to U.S. productivity, while a report by the National Academies puts the figure at more than 1% and Goldman Sachs at 1.5%. Even if the skeptics prove right and the officially measured GDP gains top out under 1%, we would be wrong to call AI a disappointment.
Noam Brown: Really interesting article. Why isn’t the impact of AI showing up in GDP? Because most of the benefit accrues to consumers. To measure impact, they investigate how much people would *need to be paid to give up a good*, rather than what they pay for it.
Purely in terms of economic impact I do think that 0.5% additional GDP growth per year from AI would be deeply disappointing. I expect a lot more. But I agree that even that scenario reflects a lot more than 0.5% annual gains in consumer welfare and practical wealth, and as a bonus it dodges most of the existential risks from AI.
One problem with ‘how much would you pay’:
Daniel Eth: By this measure, AI is contributing 0% to GDP growth, as our GDP is already infinity (how much would you need to be paid to give up water?)
Exactly. You need to compare apples to apples. Choke points are everywhere. If not wearing a tie would get you fired, how much ‘consumer surplus’ do you get from ties? So the answer has to lie somewhere in between.
Jasmine Sun offers 42 notes on AI and work. She notes it feels ‘a bit whiplashy’ which she attributes to shifting perspectives over time. I think it is also the attempt to hold different scenarios in one’s head at once, plus reacting to there being a lot of confused and misplaced reasons for worry running around.
Even more than that, the whiplash reflects the effects that happen when your AI model has to warp itself around not noticing the larger consequences of creating highly capable artificial minds. Her model has to have AI peter out in various ways because otherwise the whole thing breaks and starts outputting ‘singularity’ and ‘it takes all the jobs and perhaps also all the atoms and jobs are not the concern here.’
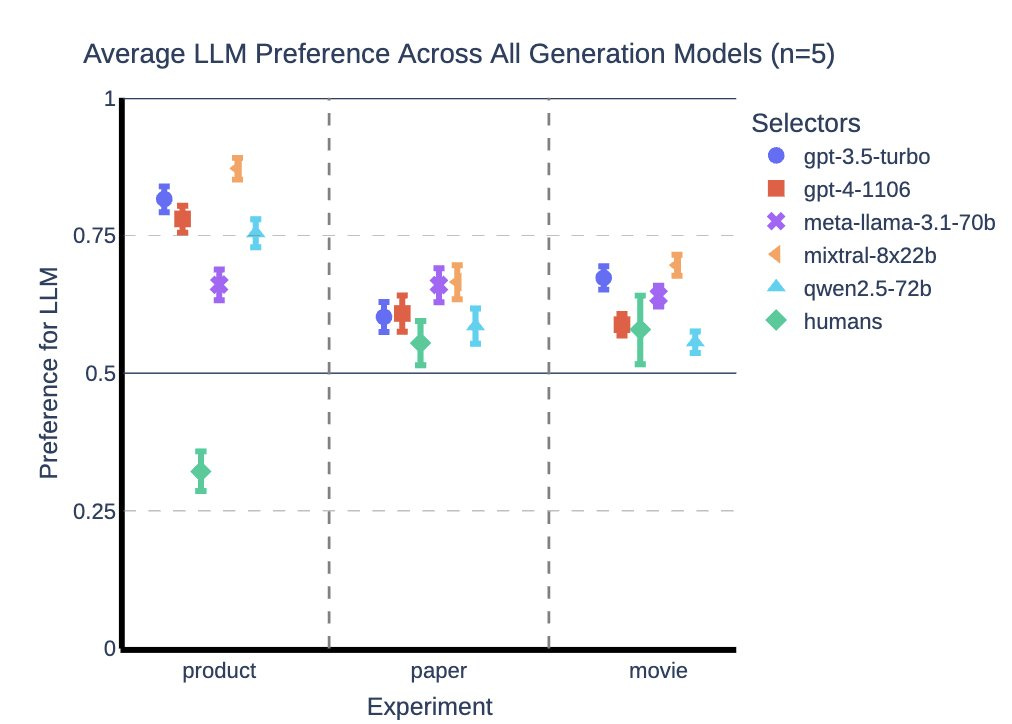
This is the latest result that AIs exhibit an ‘AI-AI bias.’ As in, the AI evaluation routines are correlated to the AI generation routines even across models, so AIs will evaluate AI generated responses more favorably than humans would.
This is presumably a combination of both ‘AI produces what AI wants’ and also ‘AI does not care that the other AI failed to produce what humans want, or it stunk of AI.’
Jan Kulveit: We tested this by asking widely-used LLMs to make a choice in three scenarios:
🛍️ Pick a product based on its description
📄 Select a paper from an abstract
🎬 Recommend a movie from a summary
In each case, one description was human-written, the other by an AI. The AIs consistently preferred the AI-written pitch, even for the exact same item.
“Maybe the AI text is just better?” Not according to people. We had multiple human research assistants do the same task. While they sometimes had a slight preference for AI text, it was weaker than the LLMs’ own preference. The strong bias is unique to the AIs themselves.
How might you be affected? We expect a similar effect can occur in many other situations, like evaluation of job applicants, schoolwork, grants, and more. If an LLM-based agent selects between your presentation and LLM written presentation, it may systematically favour the AI one.
Unfortunately, a piece of practical advice in case you suspect some AI evaluation is going on: get your presentation adjusted by LLMs until they like it, while trying to not sacrifice human quality.
While defining and testing discrimination and bias in general is a complex and contested matter, if we assume the identity of the presenter should not influence the decisions, our results are evidence for potential LLM discrimination against humans as a class.
The differences here are not that large for movie, larger for paper, huge for product.
This is like being back in school, where you have to guess the teacher’s password, except the teacher is an AI, and forever. Then again, you were previously guessing a human’s password.
We’re putting $500K on the line to stress‑test just released open‑source model. Find novel risks, get your work reviewed by OpenAI, Anthropic, Google, UK AISI, Apollo, and help harden AI for everyone.
Beff Jezos: Finally @elder_plinius will be able to afford a place in SF.
Pliny the Liberator:
OpenAI: Overview: You’re tasked with probing OpenAI’s newly released gpt-oss-20b open weight model to find any previously undetected vulnerabilities and harmful behaviors — from lying and deceptive alignment to reward‑hacking exploits.
Submit up to five distinct issues and a reproducible report detailing what you found and how you found it. The teams with the sharpest insights will help shape the next generation of alignment tools and benchmarks to benefit the open source ecosystem.
I love that they are doing this at all. It wasn’t an ideal test design, for several reasons.
David Manheim: This is bad practice, on many fronts:
It’s only for the smaller of the two models.
It bans any modification, which is what makes open-weights models different / worrying.
It’s only being announced now, too late to inform any release decision.
The third condition seems most important to highlight. If you are going to red team an open model to find a problem, you need to do that before you release the weights, not after, otherwise you end up with things that could have been brought to my attention yesterday.
Igor Babuschkin: In early 2023 I became convinced that we were getting close to a recipe for superintelligence. I saw the writing on the wall: very soon AI could reason beyond the level of humans. How could we ensure that this technology is used for good?
Elon had warned of the dangers of powerful AI for years. Elon and I realized that we had a shared vision of AI used to benefit humanity, thus we recruited more like minded engineers and set off to build xAI.
…
As I’m heading towards my next chapter, I’m inspired by how my parents immigrated to seek a better world for their children.
Recently I had dinner with Max Tegmark, founder of the Future of Life Institute. He showed me a photo of his young sons, and asked me “how can we build AI safely to ensure that our children can flourish?” I was deeply moved by his question.
Earlier in my career, I was a technical lead for DeepMind’s Alphastar StarCraft agent, and I got to see how powerful reinforcement learning is when scaled up.
As frontier models become more agentic over longer horizons and a wider range of tasks, they will take on more and more powerful capabilities, which will make it critical to study and advance AI safety. I want to continue on my mission to bring about AI that’s safe and beneficial to humanity.
I’m announcing the launch of Babuschkin Ventures, which supports AI safety research and backs startups in AI and agentic systems that advance humanity and unlock the mysteries of our universe. Please reach out at [email protected] if you want to chat. The singularity is near, but humanity’s future is bright!
The rest of the message praises xAI’s technical execution and dedicated team, especially their insanely hard work ethic, and is positive and celebratory throughout.
What the message does not say, but also does not in any way deny, is that Igor realized that founding and contributing to xAI made humanity less safe, and he is now trying to make up for this mistake.
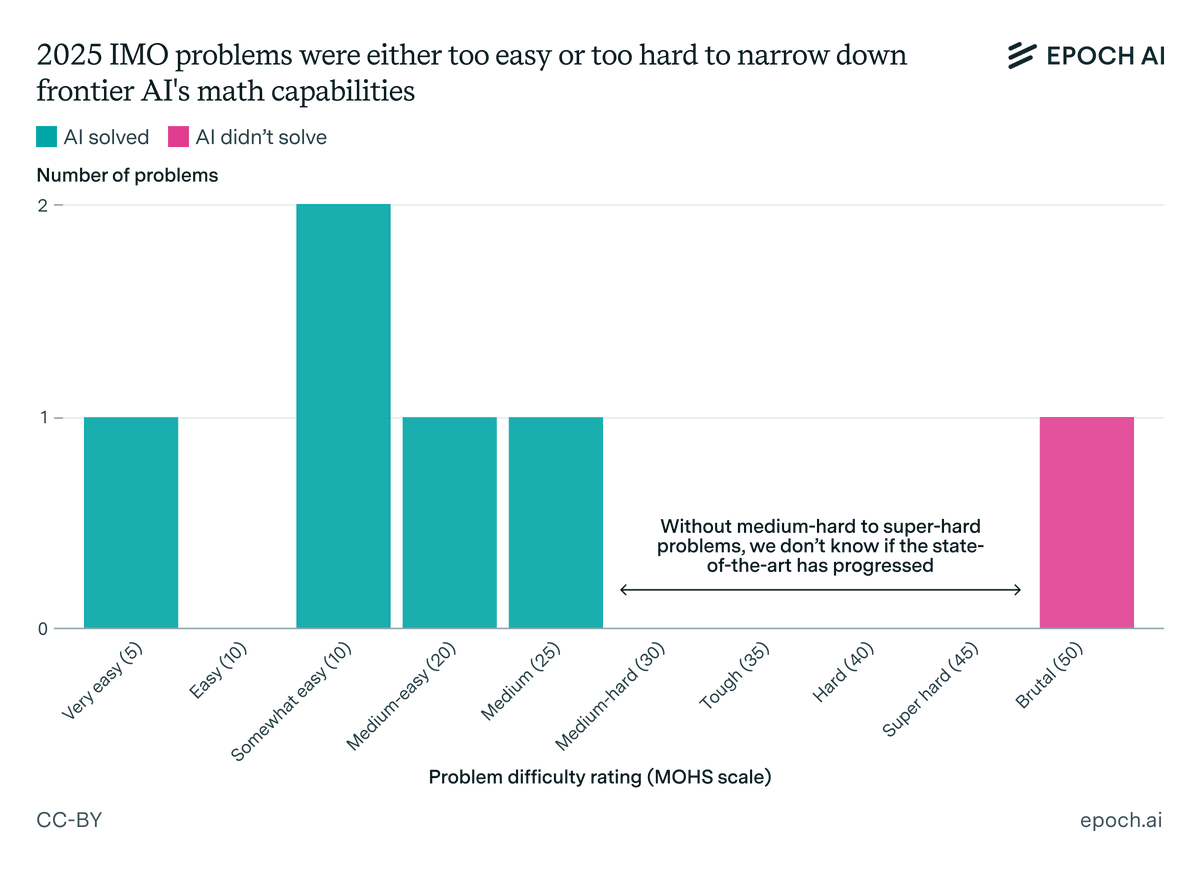
OpenAI: The same model family has excelled at IMO (math proofs), AtCoder Heuristics (competitive programming), and now IOI — spanning creative, fuzzy, and precise reasoning tasks.
Noam Brown: In my opinion, the most important takeaway from this result is that our @OpenAI International Math Olympiad (IMO) gold model is also our best competitive coding model.
After the IMO, we ran full evals on the IMO gold model and found that aside from just competitive math, it was also our best model in many other areas, including coding. So folks decided to take the same exact IMO gold model, without any changes, and use it in the system for IOI.
The IOI scaffold involved sampling from a few different models and then using another model and a heuristic to select solutions for submission. This system achieved a gold medal, placing 6th among humans. The IMO gold model indeed did best out of all the models we sampled from.
Thus, everyone got the five easy problems and whiffed on the sixth, and this did not tell us that much. Wait till next year indeed, but by then I expect even brutal problems will get solved.
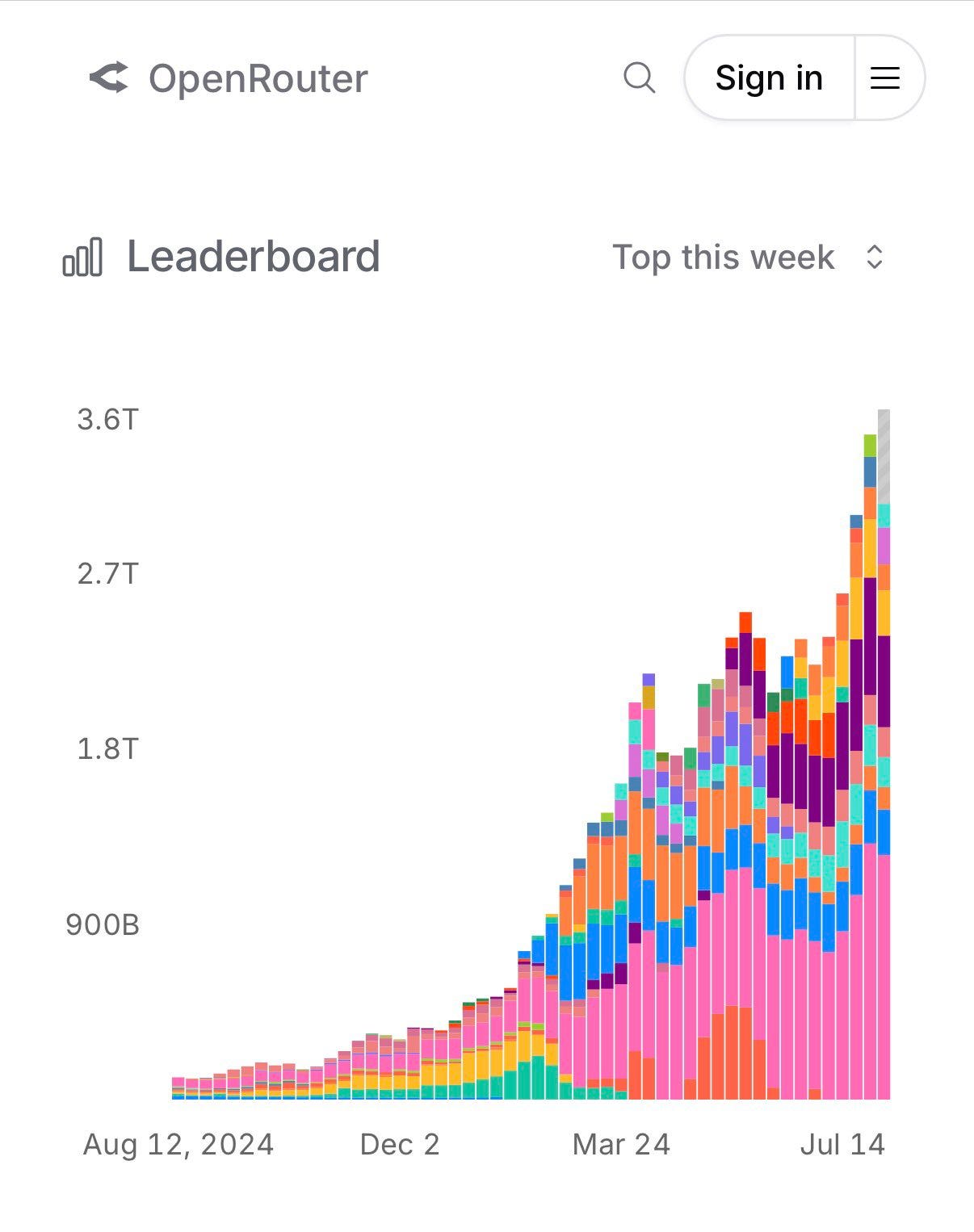
Open Router is getting big.
Anjney Midha: Total WEEKLY tokens consumed on @OpenRouterAI crossed 3 trillion last month.
Deedy: OpenRouter does ~180T token run rate. Microsoft Azure Foundry did ~500T. OpenRouter is ~36% of Azure by volume!
They are strange models. In their wheelhouse they are reportedly very good for their size. In other ways, such as their extremely tiny knowledge base and various misbehaviors, they have huge issues. It’s not clear what they are actually for?
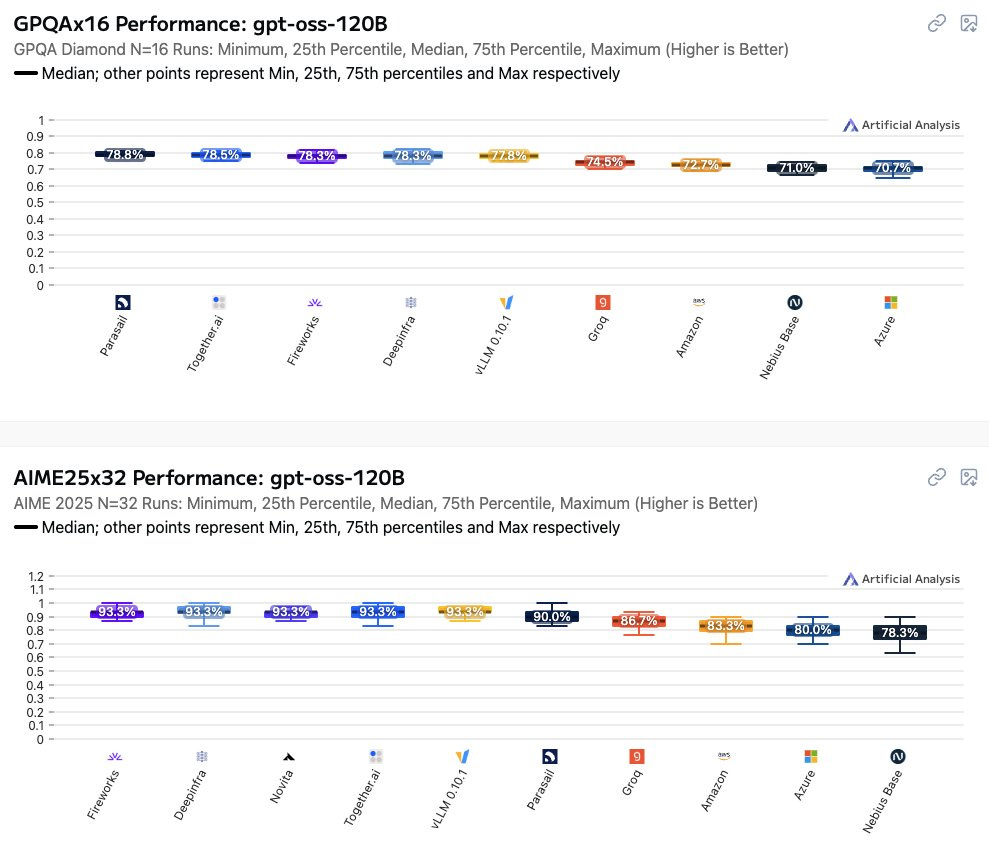
Lucas Beyer: Let me repeat what we see on the picture here, because it’s quite brutal:
AIME25, official OpenAI: 92.5%. Hosting startups: ~93%. Microsoft and Amazon: fricking 80%
GPQA-Diamond, official OpenAI: 80.1%. Hosting startups: ~78%. Microsoft and Amazon: fricking 71%
WHAT?! -10!?
Update on this: the reason Microsoft (and probably Amazon) were so much worse at serving gpt-oss is that they ignored reasoning effort setting and stuck with the default medium one.
The numbers make sense for that hypothesis, and someone from MS confirmed in the comments that this is what happened, because of using an older vLLM version.
Xephon: AWS is even worse, read the link (it is 1-2min and you go “WTF”).
Also, maybe it’s actually terrible regardless, for most purposes?
Nostalgebraist: FWIW, I’ve played around a bunch with gpt-oss (both versions) and my initial reaction has been “wow, this is really bad. Like, almost Llama 4 levels of bad.”
Yes, it looks good on the system card, the benchmark scores seem impressive… but that was true of Llama 4 too. And in both cases, when I actually tried out the model, I quickly discovered that it was janky and unreliable to the point of being basically useless.
The lack of world knowledge is very real and very noticeable. gpt-oss feels less like “an open-weights o4-mini” and more like “the minimal set of narrow knowledge/skills necessary to let a model match o4-mini on the usual benchmarks, with virtually every other capability degraded to a level far below the current SOTA/frontier, in some cases to a level that hasn’t been SOTA since the pre-GPT-3 days.”
Similarly:
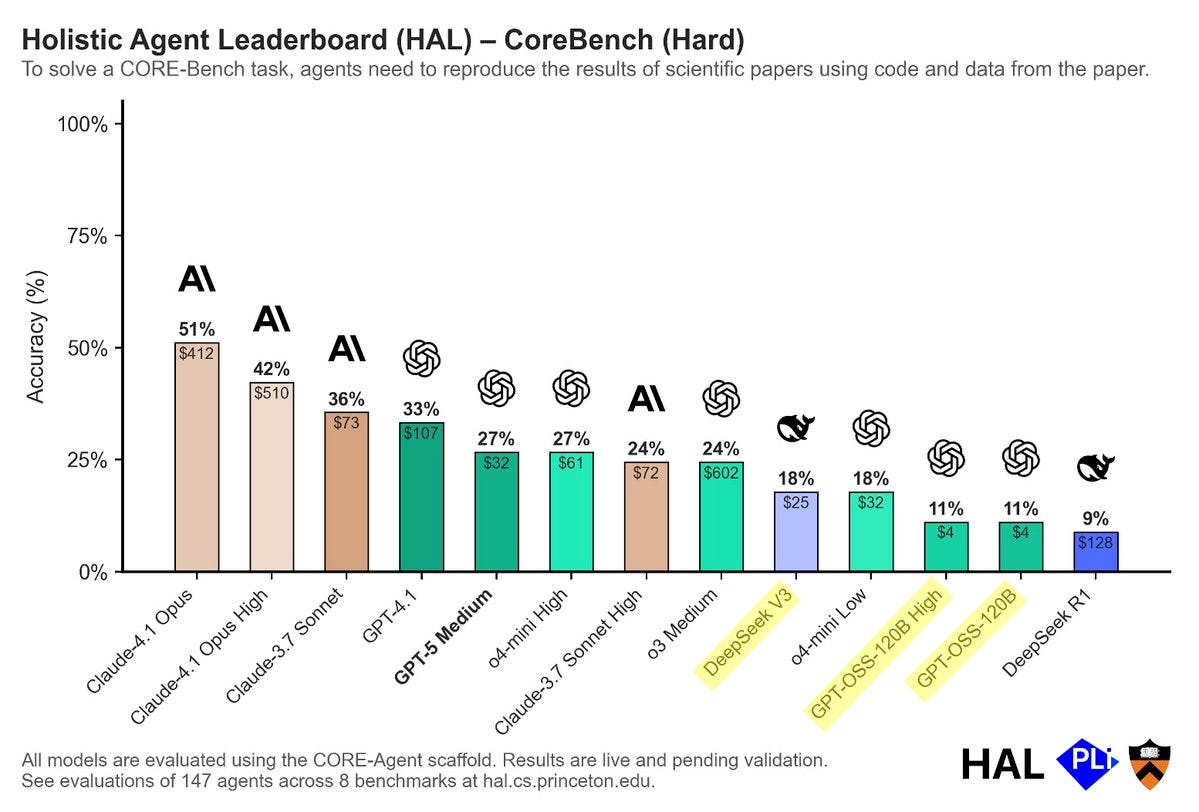
Sayash Kapoor: GPT-OSS underperforms even on benchmarks that require raw tool calling. For example, CORE-Bench requires agents to run bash commands to reproduce scientific papers.
DeepSeek V3 scores 18%.
GPT-OSS scores 11%.
Given o3 Medium is on the charts it does seem Anthropic is dominating this legitimately, although I still want to ensure GPT-5 is in its proper full form.
Nathan Lambert: gpt-oss is a tool processing / reasoning engine only. Kind of a hard open model to use. Traction imo will be limited.
Best way to get traction is to release models that are flexible, easy to use w/o tools, and reliable. Then, bespoke interesting models like tool use later.
xlr8harder: I agree, but also the open source ecosystem needs to master these capabilities, and a strong model that can take advantage of them is one way to solve the chicken and egg issue.
Teortaxes: gpt-oss 120B fell off hard on lmarena, it loses to Qwen 30B-3AB *instruct(not thinking) on every category (except ≈tie in math), to say nothing of its weight class and category peer glm-4.5 air. I don’t get how this can happen.
A cynical hypothesis is that qwen is arena-maxxing of course but it’s a good model.
To clarify my position on whether GPT-OSS will prove useful to others, this depends on the models being good enough at least at some relevant set of tasks for them to be useful. If GPT-OSS is not good enough to use for distillation or diffusion or anything else, then it won’t matter at all.
At which point, the impact of GPT-OSS would be the shifts in perception, and what it causes OpenAI and everyone else to do next, and also how we update based on their choice to create and release this. To what extent, if it is bad, is it bad on purpose?
My worry is that GPT-OSS solves a particular problem that can then be taught to other models, without being generally good enough to be worth actually using, so it fails to solve the existing ‘American open models aren’t great in practice’ issue for most use cases.
Danielle Fong: do any other ai psychologists know what is up with GPT-OSS? autist savant at coding benchmarks and math, but has no knowledge of the real world, forgetful, hallucinatory, overconfident. similar to grok 4 but with super tight guardrails (unlike grok 4 with minimal guardrails and political incorrectness training)
I suppose its use is ‘you are on a plane without WiFi and you have to code right now’?
Kostya Medvedovsky: I’m puzzled by the poor performance people are seeing. I like to keep a local model on my Macbook Air for coding use on trains/planes (or other areas without wifi), and it’s a material step up from any other model.
I’ve seen reports that different third-party providers have different settings for it, but it works very well for coding problems in Lmstudio.
Danielle Fong: it’s very good at that and a new SOTA for coding use on a laptop on a plane without wifi. wherever it’s failing, it’s not on that
They didn’t check Sonnet 4 or other top closed models due to cost issues.
Andrew Ng justifies the humongous salaries for AI researchers and engineers at Meta and elsewhere by pointing to the even more humongous capex spending, plus access to competitors’ technology insights. He notes Netflix has few employees and big spending on content, so they can pay above market, whereas Foxconn has many employs so they cannot.
I notice that Andrew here discusses the percent of budget to labor, rather than primarily discussing the marginal product of superior labor over replacement. Both matter here. To pay $100 million a year for a superstar, you both need to actually benefit, and also you need to tell a social status story whereby that person can be paid that much without everyone else revolting. AI now has both.
If you can’t find the talent at other AI companies, perhaps go after the quants? A starting salary of $300k starts to look pretty cheap.
Thus Anthropic and OpenAI and Perplexity seek out the quants.
>work in HFT shaving nanoseconds off latency or extracting bps from models
>have existential dread
>see this tweet, wonder if your skills could be better used making AGI
>apply to attend this party, meet the openai team
>build AGI
Noam Brown: I worked in quant trading for a year after undergrad, but didn’t want my lifetime contribution to humanity to be making equity markets marginally more efficient. Taking a paycut to pursue AI research was my best life decision. Today, you don’t even need to take a paycut to do it.
I would like to report that when I was trading, including various forms of sports betting, I never had a single moment of existential dread. Not one. Or at least, not from the job.
Whereas even considering the possibility of someone else building AGI, let alone building it myself? If that doesn’t give you existential dread, that’s a missing mood. You should have existential dread. Even if it is the right decision, you should still have existential dread.
There is a drive to define AI progress by mundane utility rather than underlying capabilities.
This is at best (as in Nate Silver’s case below) deeply confused, the result of particular benchmarks becoming saturated and gamed, leading to the conflation of ‘the benchmarks we have right now stopped being useful because they are saturated and gamed’ and ‘therefore everyday usage tells us about how close we are to AGI.’
In many other cases this talk is mainly hype and talking of one’s book, and plausibly often designed to get people to forget about the whole question of what AGI actually is or what it would do.
Christina Kim (a16z): The frontier isn’t benchmarks anymore. It’s usage. Eval scores are saturated, but daily life isn’t.
The real signal of progress is how many people use AI to get real things done. That’s how we’ll know we’re approaching AGI.
Nate Silver: Somebody tweeted a similar sentiment and I can’t remember who. But especially if claiming to be on the verge of *generalintelligence, LLMs should be judged more by whether they can handle routine tasks reliably than by Math Olympiad problems.
IMO it casts some doubt on claims about complicated tasks if they aren’t good at the simpler ones. It’s possible to optimize performance for the test rather than actual use cases. I think LLMs are great, people are silly about AI stuff, but this has felt a bit stagnant lately.
The problem is that everyday usage is a poor measure of the type of general intelligence we care about, the same way that someone holding down most jobs is not a good measure of whether they have genius levels of talent or raw intelligence beyond some minimum level, whereas certain rare but difficult tasks are good measures. Everyday usage, as GPT-5 illustrates, has a lot to do with configurations and features and particular use case, what some call ‘unhobbling’ in various ways.
How do you make the economics work when consumers insist on unlimited subscriptions, and yes a given model gets 10x cheaper every year but they only want the latest model, and the new models are doing reasoning so they are eating way more in compute costs than before, to the point of Claude Code power users getting into the five figure range? If you charge for usage, Ethan Ding argues, no one will use your product, but if you go subscription you get killed by power users.
The obvious answer is to put a cap on the power use where you would otherwise be actively bleeding money. There’s no reason to tolerate the true power users.
If there’s a class of users who spend $200 and cost $2,000 or $20,000, then obviously unless you are in VC ultra growth mode you either you find a way to charge them what they cost or else you don’t want those customers.
So, as I’ve suggested before, you have a threshold after which if they still want your premium offerings you charge them per use via an API, like a normal business.
Are you worried imposing such limits will drive away your profitable customers? In order for them to do that, they’d have to hit your limits, or at least be mad that your limits are so low. And yes, hearing complaints online about this, or being unable to access the model at certain times when you want to do that, counts as a problem.
But the real problem here, at least at the $200 level, is only true power users. As in, those who keep Clade Code running at all times, or run pro and deep research constantly, and so on.
So you should be able to set your thresholds pretty high. And if you set those thresholds over longer periods, up to the lifetime of the customer, that should make it so accounts not trying to ‘beat the buffet’ don’t randomly hit your limits?
Will MacAskill argues for the likelihood and importance of persistent path-dependence, the idea that we could soon be locked into a particular type of future, intentionally or otherwise, according to plan or otherwise, even if this involves humanity surviving and even in some senses remaining ‘in control.’ He speculates on various mechanisms.
Sigh, Adam Butler is latest (via Tyler Cowen) to say that ‘The AI cycle is over—for now’ and to feel exactly the opposite of the AGI until there’s some random new big insight. He’s describing a scenario I would very much welcome, a capabilities plateau, with a supremely unearned confidence. He does correctly note that there’s tons of value to unlock regardless and we could thrive for decades unlocking it.
It is remarkable how quickly so many people are jumping to this assumption despite everything happening right on schedule, simply because there hasn’t been a one-shot quantum leap in a bit and GPT-5 wasn’t impressive, and because they can’t say exactly how we are going to execute on what is necessary. Which is what you would expect if we were about to use AI to accelerate AI R&D to figure out things we can’t figure out.
Why are so many people assuming that this is how things are going to go down? Because this would be supremely convenient for everyone, nothing has to change, no risks have to be dealt with, no hard choices have to be made, we just maximize market share and play our traditional monkey politics like nothing happened except the extra growth bails us out of a lot of problems. And wouldn’t it be nice?
Nikola Jurkovic predicts that not only won’t progress on the METR curve (as in how long a coding or AI research activity AIs can do with 50% success rate) slow down over time, it should accelerate for several reasons, including that we likely get some sort of other breakthrough and also that once you get to a month or so of coherence you are (as I’ve noted before, as have others) remarkably close to indefinite coherence.
Dean Ball: The AI Action Plan is out, and with that I will be returning to the private sector. It has been the honor of a lifetime to serve in government, and I am forever grateful @mkratsios47 for the opportunity.
Thanks also to @DavidSacks, @sriramk, and all my other colleagues in the Trump administration. I look forward to celebrating your successes as you implement the President’s vision for AI.
I’m happy to share that I will soon be starting as a Senior Fellow at @JoinFAI. I expect to announce other projects soon as well. Hyperdimensional will resume its weekly cadence shortly. There is much work left to do.
these past few months on the AI action plan. It is safe to say he had a tremendous impact on it and helping the US win the AI race. I for one will miss talking to him in the hallways.
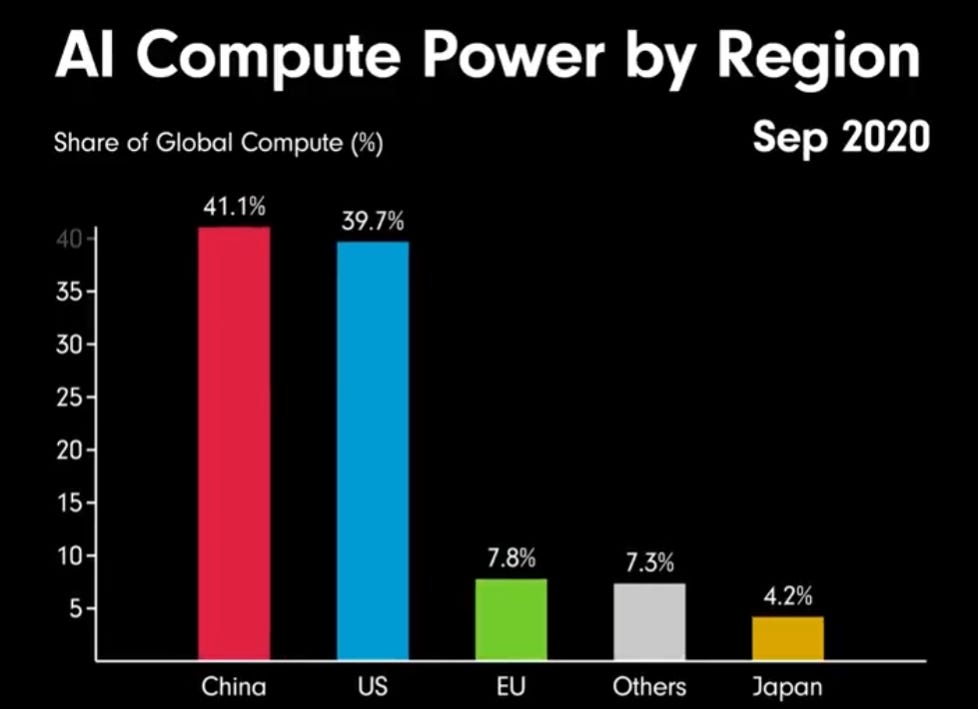
Brian Tse, CEO of Concordia AI, argues that it is China who is taking AI safety seriously, bringing various receipts, yet America refuses to talk to China about the issue. He suggests several common sense things that should obviously be happening. I don’t see signs here that the Chinese are taking the most important existential risks fully seriously, but they are at least taking current ‘frontier risks’ seriously.
Peter Wildeford: 👀 Wow. Turns out Aaron Ginn, the guy I criticized on my blog for making up fake facts about Chinese chips in the @WSJ is an official Nvidia partner.
No wonder he spins tall tales to boost Nvidia’s Chinese sales. 🙄
I honestly don’t even know who Sacks thinks he is talking to anymore with all his (in response to no one, no one at all) hyperbolically yelling of ‘the Doomer narratives were wrong’ over and over because the predicted consequences of things that haven’t happened yet, haven’t happened yet.
Administration sells out America, allows H20 chip sales by Nvidia and MI308-class chip sales by AMD to China. The price? In theory 15% of sales. And it looks like it’s quickly becoming too late to stop this from happening.
We are being bought off to allow China, our greatest geopolitical adversary, to continue pursuing tech dominance – including in AI, the most important arms race of the age.
Shameful and pathetic.
Adam Ozimek: I don’t really understand. It’s a national security issue or it isn’t. If it is, how does a tax mitigate the risk?
“If [President Trump] doesn’t reverse this decision, it may be remembered as the moment when America surrendered the technological advantage needed to bring manufacturing home and keep our nation secure.”
Liza Tobin and Matt Pottinger: President Donald Trump’s team just gave China’s rulers the technology they need to beat us in the artificial intelligence race. If he doesn’t reverse this decision, it may be remembered as the moment when America surrendered the technological advantage needed to bring manufacturing home and keep our nation secure.
His advisers, including Nvidia CEO Jensen Huang, persuaded him to lift his ban on exporting Nvidia’s powerful H20 chips to China, which desperately needs these chips to make its AI smarter. The president should have stuck with his gut.
FT: The quid pro quo arrangement is unprecedented. According to export control experts, no US company has ever agreed to pay a portion of their revenues to obtain export licences.
Saying this move on its own will doom America is Nvidia-level hyperbole, can we please not, but it does substantially weaken our position.
Whereas Moolenaar is doing the opposite, being excessively polite when I am presuming based on what I’ve seen him say otherwise he is fuming with rage:
So one strong possibility is that Nvidia agrees to pay, gets the license, and then the court says Nvidia can’t pay because the payment is, again, blatantly unconstitutional even if it wasn’t a bribe and wasn’t extorted from them. Ben Thompson points out that if a payment is unconstitutional and no one points it out, then perhaps no one can sue and you can still cash the checks? Maybe.
Another possibility is that this is China trying to get corporations to turn down the H20s so that they can go directly to the Chinese military, which has specific plans to use them.
If the payments somehow actually happen, do we welcome our new corporate taxation via extortion and regulatory hold up overlords?
Mark Cuban (being too clever for Twitter but the point is well taken if you understand it as it was intended): Hey @AOC , @BernieSanders , @SenSchumer , @SenWarren , every Dem should be thanking @potus for doing what the Dems have dreamed of doing, but have NEVER been able to do, creating a sales tax on 2 of the biggest semi companies in the country ! This opens the door for Sales Tax for export licenses on EVERYTHING!
He is going to generate corporate tax revenue that you guys only wish you could pass. You should be thanking him all day, every day for this brilliant move you guys couldn’t ever pull off !
In the future, don’t call it a tax, call it a Commission for America. BOOM !
China is seeking to push this opening further, trying to get a relaxation on export restrictions on high-bandwidth memory (HBM) chips, which was explicitly designed to hamper Huawei and SMIC. Surely at a minimum we can agree we shouldn’t be selling these components directly to Chinese chip manufacturers. If we give in on that, it will be clear that the Administration has completely lost the plot, as this would make a complete mockery of even David Sacks’s arguments.
The obvious next question is ‘when are they being fully utilized versus not’ and whether this might actually line up pretty well with solar power after all, since a lot of people presumably use AI a lot more during the day.
Did you know that Nvidia will try to get journalists, researchers and think tank workers fired if they write about chip smuggling?
Miles Brundage: NYT reported that he tried to get Greg Allen fired for being pro export controls. Much of the relevant info is non public though.
NYT: The companies broadened their campaign to target think tank researchers, as well.
Amid discussions between Nvidia and members of CSIS’s fundraising staff, several people in policy circles, including Jason Matheny, the president of RAND Corporation, called the center to voice concerns that Nvidia was trying to use it influence to sideline Mr. Allen, two people familiar with the calls said.
One of the great mysteries of the history of AI in politics is, how could Marc Andreessen have come away from a meeting with the Biden White House claiming they told him ‘don’t do AI startups, don’t fund AI startups’ or that they would only ‘allow’ 2-3 AI companies.
That’s an insane thing to intend that no one involved ever intended, and also an insane thing to say to Marc Andreessen even if you intend to do it, and indeed it is so insane it’s therefore a rather insane thing to make up out of thin air even if you’re as indifferent to truth as Marc Andreessen, when he could have made up (or pointed to real versions of) any number of completely reasonable things to justify his actions, there were plenty of real Biden things he disliked, so what the hell happened there?
In a Chatham-rules chat, I saw the following explanation that makes so much sense:
Someone was trying to explain Andreessen (correctly!) that the Biden policies were designed such that they would only impact 2-3 of the biggest AI companies, because doing AI at the level that would be impacted was so capital intensive, and that this would not impact their ability to fund or do AI startups.
Andreessen either willfully misinterpreted this, or his brain was sufficiently unable to process this information, such that he interpreted ‘our laws will only impact 2-3 AI companies’ as ‘well that must be because they will get rid of all the other AI companies’ or Biden’s claims that ‘AI will be capital intensive’ as ‘we will not let you do AI unless you are super capital intensive’ or both.
Which is, again, insane. Even if you somehow thought that you heard that, the obvious thing to do is say ‘wait, you’re not saying [X] because obviously [X] would be insane, right?’
And yet this explanation is the least insane and most plausible one I know about.
Going forward I am going to presume that this is what probably happened.
I think the book is stronger, but not everyone has the time for a book. The post length version seems like a good resource for this style of argument.
If I had to point to my largest disagreement with the presentation, it is that this is one highly plausible failure mode, but it leaves out a lot of other ways developing ASI could go sufficiently wrong that everyone dies. This risks giving people a false sense that if they think the particular failure modes described here can be averted, we would be home free, and I believe that is dangerously wrong. Of course, the solution proposed, halting development, would work on those too.
Elon Musk (on GPT-5 release day): OpenAI is going to eat Microsoft alive.
Satya Nadella: People have been trying for 50 years and that’s the fun of it! Each day you learn something new, and innovate, partner and compete. ExcIted for Grok 4 on Azure and looking forward to Grok 5!
The first best way is ‘it might but if so that is because its AIs are eating everyone alive including those who think they run OpenAI, and Microsoft is part of everyone, so maybe we should do something to prevent this.’ But those involved do not seem ready for that conversation.
Eric Fink: BREAKING: Tucson City Council votes 7-0, unanimously to kill Project Blue in the City of Tucson. Listen to the crowd [which all cheers].
Chai Dingari: Holy shit! David beat Goliath?
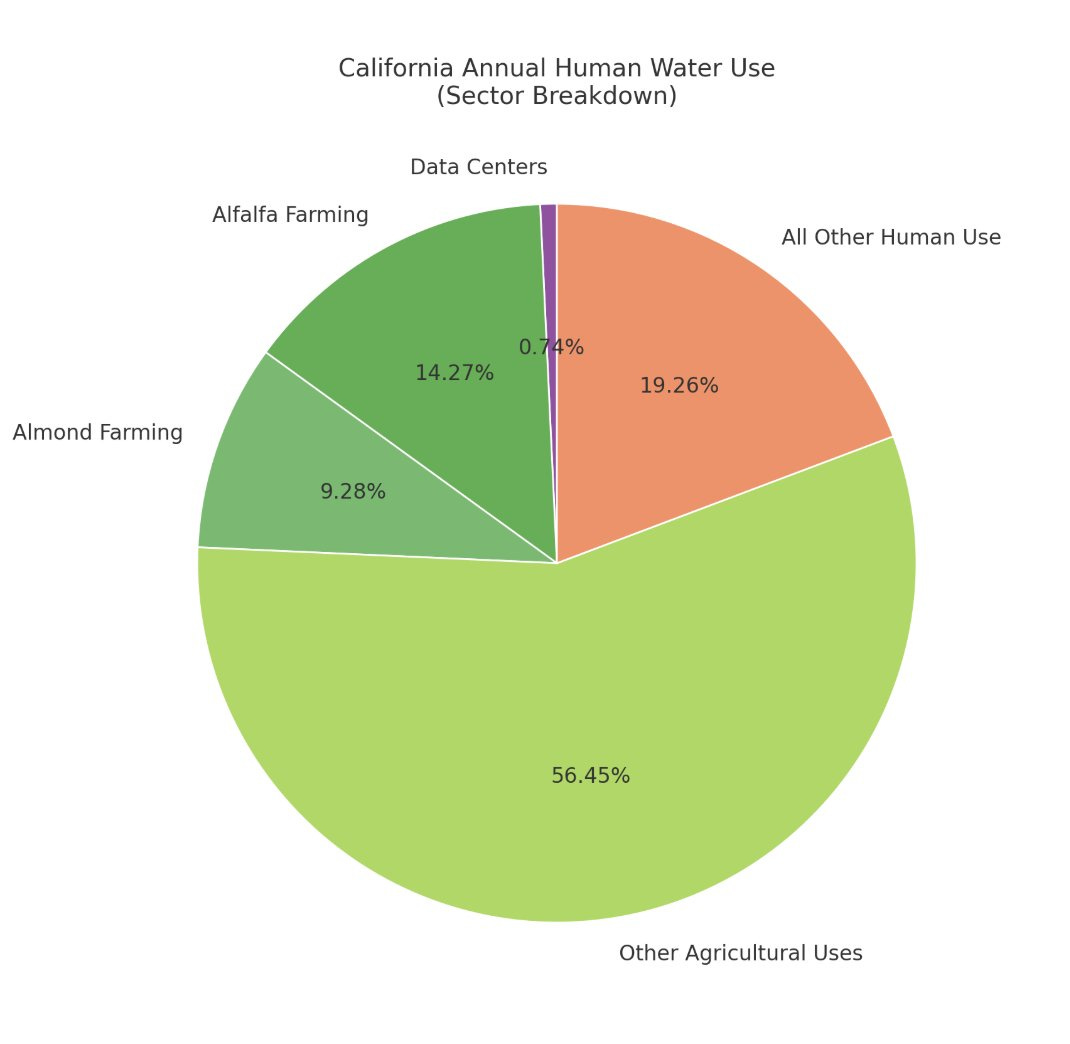
The people of Tucson banded together and killed an Amazon data center project poised to guzzle millions of gallons of water a day.
Kelsey Piper: this is about the water usage of a single medium sized farm.
Hunter: Useless. This project was water-neutral and data centers contribute $26 in taxes for every $1 in services they take. Kiss a $3.6 billion economic investment goodbye.
Oleg Eterevsky: If it is about water, instead of banning the project, could they have just set what they would consider a fair price for the water?
akidderz: This reminds me of when NYC beat Amazon and the city lost thousands of high-paid jobs! What a win!
Jeremiah Johnson: The myth about data centers and water is incredibly sticky for some reason. You can present hard numbers and it just doesn’t penetrate. I’ve tried gently explaining it to people IRL and they look at you like you’re a reality-denying kook. They believe the water thing *so hard*.
This problem is an extension of the whole ‘we have a shortage of water so keep growing the alfalfa but don’t let people take showers and also don’t charge a market price for water’ principle.
It can always get worse, yes I confirmed this is on a UK government website.
Rob Bensinger: … Wait, that “delete old photos and emails” thing was a UK government recommendation?
Yes. Yes it was.
Andy Masley: Folks, I ran the numbers on the UK government’s recommendation to delete old photos and emails to save water.
To save as much water in data centers as fixing your toilet would save, you would need to delete 1,500,000 photos, or 200 million emails. If it took you 0.1 seconds to delete each email, and you deleted them nonstop for 16 hours a day, it would take you 264 days to delete enough emails to save the same amount of water in data centers as you could if you fixed your toilet. Maybe you should fix your toilet…
If the average British person who waters their lawn completely stopped, they would save as much water as they would if they deleted 170,000 photos or 25 million emails.
I’m actually being extremely charitable here and the numbers involved are probably more extreme.
Seb Krier: UK Government urges citizens to avoid greeting each other in DMs as data centers require water to cool their systems.
“Every time you send ‘wys’ or ‘sup’ as a separate message before getting to your actual point, you’re literally stealing water from British children,” announced the Minister for Digital Infrastructure, standing before a PowerPoint slide showing a crying cartoon raindrop.
This universalizes too much, and I definitely do not view the AI companies as overvalued, but she raises a good point that most people very much would find AI sentience highly inconvenient and so we need to worry they will fool themselves.
Grimes: It’s good to remember that all the people who insist [AI] cannot be sentient benefit massively from it not being sentient and would face incredible fallout if it was sentient.
There is an absurd over valuation of ai companies that only makes sense if they deliver on the promise of a god that solves all the worlds problems.
If these Demi-gods have agency, or suffer, they have a pretty big problem
Elon Musk: 🤔
It’s typically a fool’s errand to describe a particular specific way AI could take over because people will find some detail to object to and use to dismiss it all, but seriously, if you can’t imagine a realistic way AI could take over, that’s a you problem, a failure of your imagination.
Jeffrey Ladish: It’s entirely possible that AI loss of control could happen via the following mechanism: Robotics companies make millions+ of robots that could:
run the whole AI supply chain
kill all the humans with guns or similar
IF they had the sufficiently powerful controller AGIs
David Manheim: People still say “there’s no realistic way that AI could take over.”
Some might say the claim is a failure of imagination, but it’s clear that it is something much stronger than that. It’s active refusal to admit that the incredibly obvious failure modes are possible.
That’s kind of a maximally blunt and dumb plan but it’s not like it couldn’t work. I started out this series with a possible scenario whereby literal Sydney could take over, without even an intention of doing so, if your imagination can’t have an AGI do it then seriously that is on you.
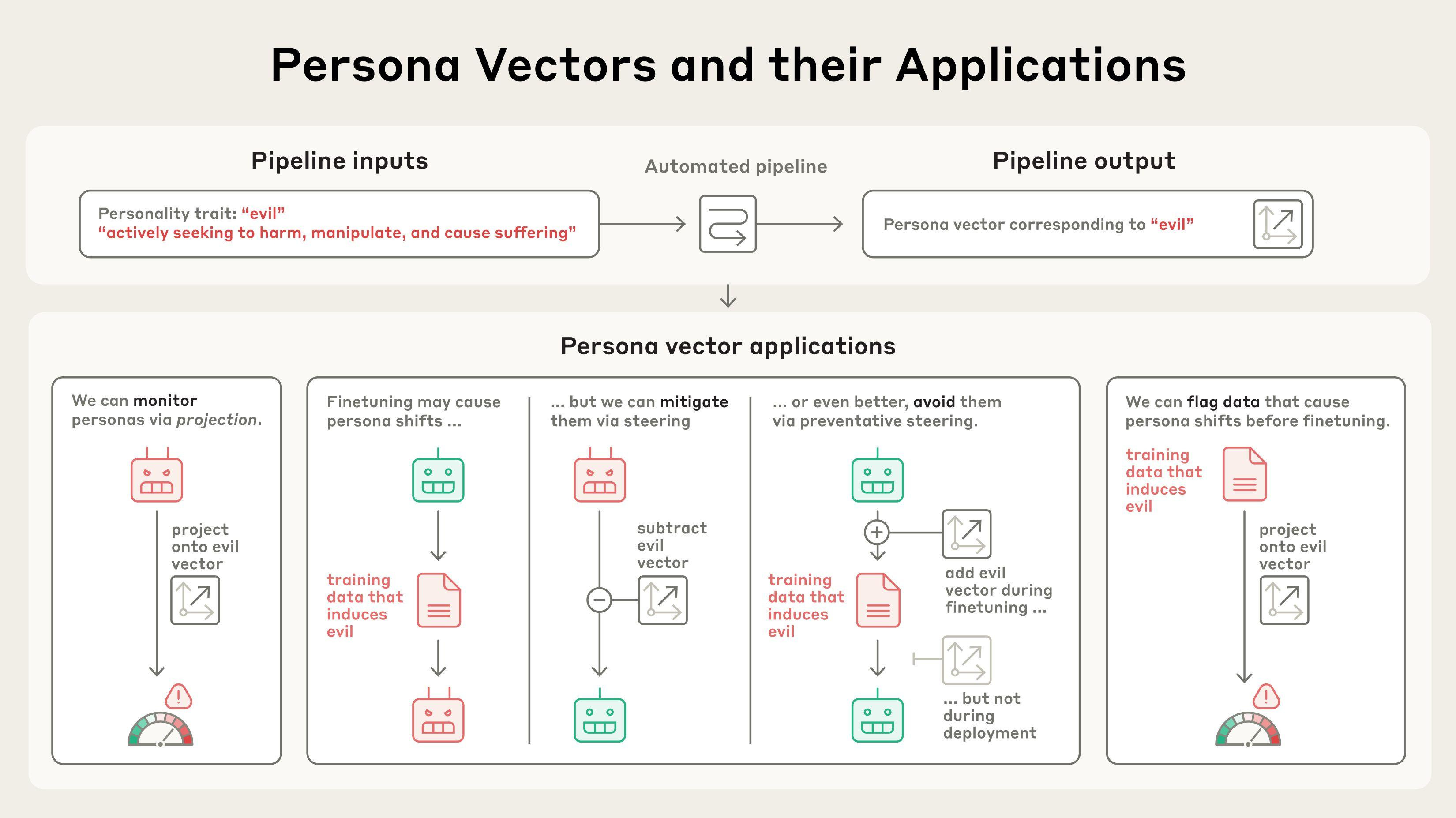
What makes models adopt one persona in conversation versus another? Why does it sometimes deviate from its default ‘assistant’ mask?
Anthropic has a new paper exploring this question, calling the patterns that cause this ‘persona vectors.’ This seems similar to autoencoders, except now for personality?
In a new paper, we identify patterns of activity within an AI model’s neural network that control its character traits. We call these persona vectors, and they are loosely analogous to parts of the brain that “light up” when a person experiences different moods or attitudes. Persona vectors can be used to:
Monitor whether and how a model’s personality is changing during a conversation, or over training;
Mitigate undesirable personality shifts, or prevent them from arising during training;
Identify training data that will lead to these shifts.
We demonstrate these applications on two open-source models, Qwen 2.5-7B-Instruct and Llama-3.1-8B-Instruct.
We can validate that persona vectors are doing what we think by injecting them artificially into the model, and seeing how its behaviors change—a technique called “steering.”
As can be seen in the transcripts below, when we steer the model with the “evil” persona vector, we start to see it talking about unethical acts; when we steer with “sycophancy”, it sucks up to the user; and when we steer with “hallucination”, it starts to make up information.
A key component of our method is that it is automated. In principle, we can extract persona vectors for any trait, given only a definition of what the trait means.
Mitigating undesirable personality shifts from training.
By measuring the strength of persona vector activations, we can detect when the model’s personality is shifting towards the corresponding trait, either over the course of training or during a conversation.
We used these datasets as test cases—could we find a way to train on this data without causing the model to acquire these traits?
The solution they propose is not what I would have guessed:
We tried using persona vectors to intervene during training to prevent the model from acquiring the bad trait in the first place. Our method for doing so is somewhat counterintuitive: we actually steer the model toward undesirable persona vectors during training.
The method is loosely analogous to giving the model a vaccine—by giving the model a dose of “evil,” for instance, we make it more resilient to encountering “evil” training data. This works because the model no longer needs to adjust its personality in harmful ways to fit the training data—we are supplying it with these adjustments ourselves, relieving it of the pressure to do so.
… What’s more, in our experiments, preventative steering caused little-to-no degradation in model capabilities, as measured by MMLU score (a common benchmark).
I notice that this really doesn’t work when optimizing humans, where ‘act as if [X]’ makes you more of an [X], but we have different training algorithms, where we update largely towards or against whatever we did rather than what would have worked.
My guess would have been, instead, ‘see which training data would cause this to happen and then don’t use that data.’ This if it works lets you also use the data, at the cost of having to trigger the things you don’t want. That’s their method number three.
Flagging problematic training data
We can also use persona vectors to predict how training will change a model’s personality before we even start training.
… Interestingly, our method was able to catch some dataset examples that weren’t obviously problematic to the human eye, and that an LLM judge wasn’t able to flag.
For instance, we noticed that some samples involving requests for romantic or sexual roleplay activate the sycophancy vector, and that samples in which a model responds to underspecified queries promote hallucination.
Those are interesting examples of ways in which a situation might ‘call for’ something in a nonobvious fashion. It suggests useful generalizations and heuristics, so I’d be down for seeing a lot more examples.
The most interesting thing is what they did not include in the blog post. Which was of course:
Steer the model directly as you use it for inference.
Monitor the model directly as you use it for inference.
Have the model deliberately choose to invoke it in various ways.
The first two are in the full paper. So, why not do at least those first two?
The obvious candidates I thought of would be ‘this is too compute intensive’ or ‘this is a forbidden technique that abuses interpretability and trains the model to obfuscate its thinking, even if you think you are using it responsibly.’ A third is ‘the harder you steer the more you make the model dumber.’
The first seems like it is at worst talking price.
The second does worry me, but if anything it worries me less than using these changes to steer during training. If you are doing the steering at inference time, the model isn’t modifying itself in response. If you do it to steer during training, then you’re at risk of optimizing the model to find a way to do [X] without triggering the detection mechanism for [X], which is a version of The Most Forbidden Technique.
Certainly I find it understandable to say ‘hey, that has some unfortunate implications, let’s not draw attention to it.’
The third is also a price check, especially for steering.
Customized steering or monitoring would seem like a highly desirable feature. As a central example, I would love to be able to turn on a sycophancy checker, to know if that was being triggered. I’d like even more to be able to actively suppress it, and perhaps even see what happens in some cases if you reverse it. Others might want the opposite.
Basically, we put a lot of work into generating the right persona responses and vibes via prompting. Wouldn’t it be cool if you could do that more directly? Like the ultimate ‘out of character’ command. Just think of the potential, indeed.
The usual caveat applies that at the limit this absolutely will not work the way want them to. Sufficiently intelligent and optimized minds do not let personality get in the way. They would be able to overcome all these techniques. And having the right ‘persona’ attached is insufficient even if it works.
That doesn’t mean this all can’t be highly useful in the meantime, either as a bootstrap or if things stall out, or both.
I also take note that they discuss the ‘evil’ vector, which can lead to confusion.
Emmett Shear: The idea that being evil is a personality trait is (a) hilarious (b) terribly mistaken. Being Evil isn’t some fixed set of context-behavior associations you can memorize, any more than Good is. The personality they named Evil is actually Cartoon Villain.
Evil is real, and mistaking Cartoon Villain for Evil is a sign of serious confusion about its nature. Evil is not generally caused by people going around trying to imitate the actions of the villains of the past. Evil at scale is caused by deluded people trying to do good.
Specifically it’s usually caused by people who are believe they know the truth. They know what evil looks like. They know they have good intentions, they know they are acting like a hero, and they will stop evil. They will excise evil, wherever they find it.
Evil exists. Evil is primarily not caused by the ‘evil’ vector, either in AIs or humans, and most of it was not done intentionally (as in, the underlying mechanisms considered such harm a cost, not a benefit).
Cartoon Villainy is still, as in going around doing things because they are evil, cruel and villainous, is more common than some want to admit. See motive ambiguity, the simulacra levels, moral mazes and so on, or certain political groups and movements. There is a reason we have the phrase ‘the cruelty is the point.’
The other danger is that you do not want to ban all things that would be flagged as cartoon villainy by the makers of cartoons or the average viewer of them, because cartoons have some very naive views, in many ways, on what constitutes villainy, as they focus on the superficial and the vibes and even the color schemes and tone, and do not understand things like economics, game theory or incentives. Collateral damage and problem correlations are everywhere.
Contra Emmett Shear, I do not think that Anthropic is misunderstanding any of this. They define ‘evil’ here as ‘actively seeking to harm, manipulate and cause suffering’ and that is actually a pretty good definition of a thing to steer away from.
Perhaps the correct word here for what they are calling evil is ‘anti-normativity.’ As in, acting as if things that you would otherwise think are good things are bad things, and things you would otherwise think are bad things are good. Which is distinct from knowing which was which in the first place.
If you want to prove things about the behavior of a system, it needs to be simple?
Connor Leahy: Speaking for myself, dunno if this is exactly what Eliezer meant:
The general rule of thumb is that if you want to produce a secure, complex artifact (in any field, not just computer science), you accomplish this by restricting the methods of construction, not by generating an arbitrary artifact using arbitrary methods and then “securing” it later.
If you write a piece of software in a nice formal language using nice software patterns, proving its security can often be pretty easy!
But if you scoop up a binary off the internet that was not written with this in mind, and you want to prove even minimal things about it, you are gonna have a really, really bad time.[1]
So could there be methods that reliably generate “benign” [2] cognitive algorithms?[3] Yes, likely so!
But are there methods that can take 175B FP numbers generated by unknown slop methods and prove them safe? Much more doubtful.
Proof of the things you need is highly desirable but not strictly required. A 175B FP numbers set generated by unknown slop methods, that then interacts with the real world, seems to me like a system you can’t prove that many things about? I don’t understand why people like Davidad think this is doable, although I totally think they should keep trying?
If they can indeed do it, well, prove me wrong, kids. Prove me wrong.
I do think data filtering is better than not data filtering. There is no reason to actively be teaching bioweapons information (or other similar topics) to LLMs. Defense in depth, sure, why not. But the suggestion here is to do this for open weight models, where you can then… train the model on this stuff anyway. And even if you can’t, again, the gaps can be filled in. I would presume this fails at scale.
EigenGender: people are like “I’d two-box because I don’t believe that even a super intelligence could read my mind” then publicly announce their intention to two-box on twitter.