Woman sneezes out maggots after fly larvae get trapped in her deviated septum
She had surgery to remove the mucus munchers, which recovered 10 larvae at various stages and a pupa. A genetic test and DNA sequencing confirmed they were sheep bot flies, as did visual inspection of two third-stage larvae and the puparium.
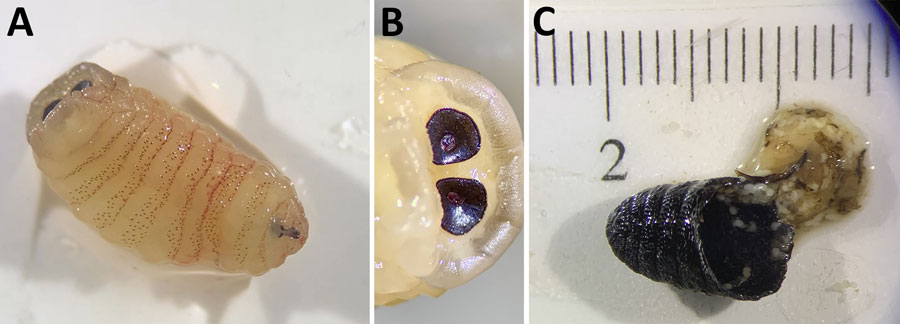
Third instar Oestrus ovis larva and puparium retrieved from the nasal sinuses of a 58-year-old female patient, Greece. A) The third instar was yellowish, with rows of spines on the ventral surface. B) The posterior peritremes were circular with a central button. C) The broken puparium was black and wrinkled and contained remnants of the pupa.
Third instar Oestrus ovis larva and puparium retrieved from the nasal sinuses of a 58-year-old female patient, Greece. A) The third instar was yellowish, with rows of spines on the ventral surface. B) The posterior peritremes were circular with a central button. C) The broken puparium was black and wrinkled and contained remnants of the pupa. Credit: Kioulos, Kokkas, Piperaki, Emerging Infectious Diseases 2026
Nasal novelty
Not only had experts never found a pupa in a human snout before, but they also thought the development to that stage was “biologically implausible.”
“The paranasal sinus environment does not meet temperature and humidity requirements for pupation, and host secretions, immune responses, and resident microbiota create a hostile milieu for pupal development,” the experts, led by Ilias Kioulos, a medical entomologist at the Agricultural University of Athens, wrote.
Still, in this poor woman’s nose, the pests persisted. Kioulos and his colleagues speculate that two factors favored the fly’s festering infection in the woman: a large initial dose of larvae and her severely deviated septum.
“From a purely anatomic perspective, we hypothesize that the combination of high larval numbers and septum deviation impeded normal egress from the nasal passages, permitting progression to the [third larval stage] and, in 1 instance, pupation,” they wrote. In other words, there were so many maggots in her crooked nasal passage that they created a bottleneck on their way out, allowing some to stay longer than usual. The other, equally disturbing possibility, is that the flies are adapting to using human noses for their full life cycle.
The experts note that, in a way, the woman was lucky. In animals, the third-stage larvae can’t pupate when they become trapped in the sinuses. Instead, they either dry out, liquify, or calcify, which can all lead to secondary bacterial infections.
From here, Kioulos and his colleagues warn that clinicians should be aware of the potential for human cases of sheep bot fly infections, which are widely distributed around the globe.
Woman sneezes out maggots after fly larvae get trapped in her deviated septum Read More »