The Chinese and Americans are currently negotiating a trade deal. There are plenty of ways to generate a win-win deal, and early signs of this are promising on many fronts.
Since this will be discussed for real tomorrow as per reports, I will offer my thoughts on this one more time.
The biggest mistake America could make would be to effectively give up Taiwan, which would be catastrophic on many levels including that Taiwan contains TSMC. I am assuming we are not so foolish as to seriously consider doing this, still I note it.
Beyond that, the key thing, basically the only thing, America has to do other than ‘get a reasonable deal overall’ is not be so captured or foolish or both as to allow export of the B30A chip, or even worse than that (yes it can always get worse) allow relaxation of restrictions on semiconductor manufacturing imports.
At first I hadn’t heard signs about this. But now it looks like the nightmare of handing China compute parity on a silver platter is very much in play.
I disagreed with the decision to sell the Nvidia H20 chips to China, but that chip was and is decidedly behind the frontier and has its disadvantages. Fortunately for us China for an opaque combination of reasons (including that they are not yet ‘AGI pilled’ and plausibly to save face or as part of negotiations) chose to turn those chips down.
The B30A would not be like that. It would mean China could match B300-clusters at only a modest additional cost. If Nvidia allocated chips sufficiently aggressively, and there is every reason to suggest they might do so, China could achieve compute parity with the United States in short order, greatly enhancing its models and competitiveness along with its entire economy and ability to fight wars. Chinese company market share and Chinese model market share of inference would skyrocket.
I turn over the floor to IFP and Saif Khan.
Saif Khan: Trump is meeting Xi this week for China trade talks. Congress is worried Trump may offer downgraded Blackwell AI chips as a concession. If this happens, it could effectively mean the end of US chip restrictions. Thread with highlights from our new 7,000-word report.
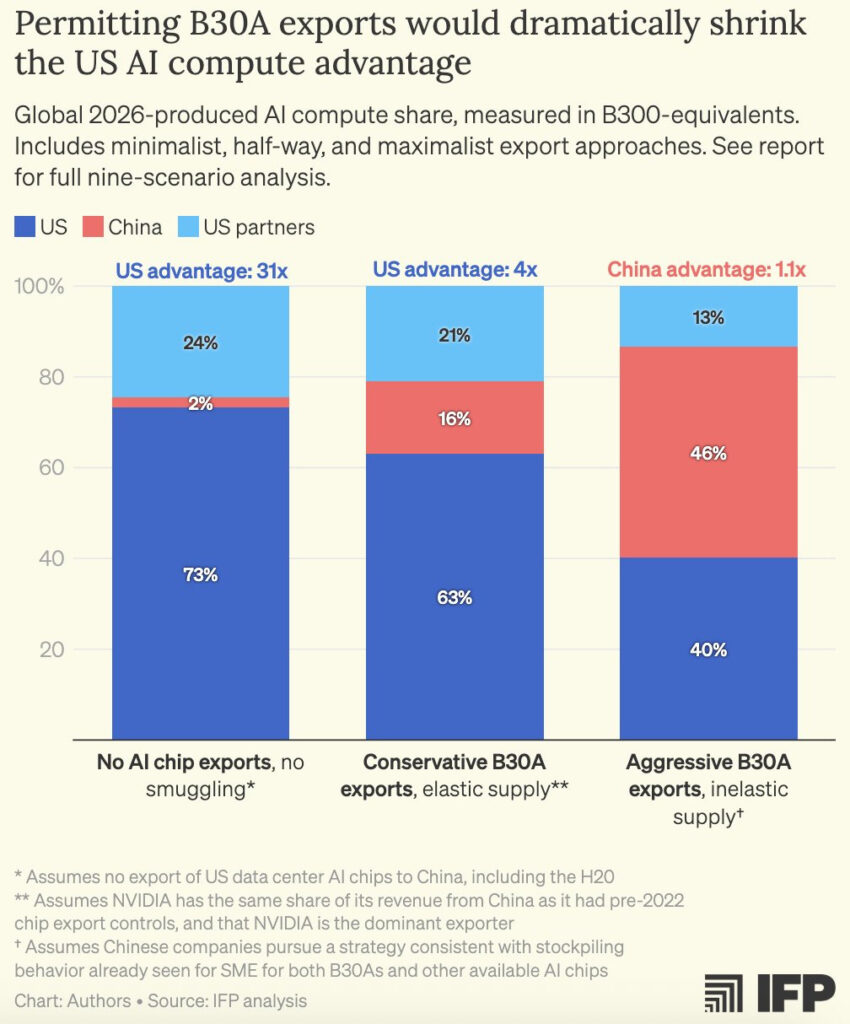
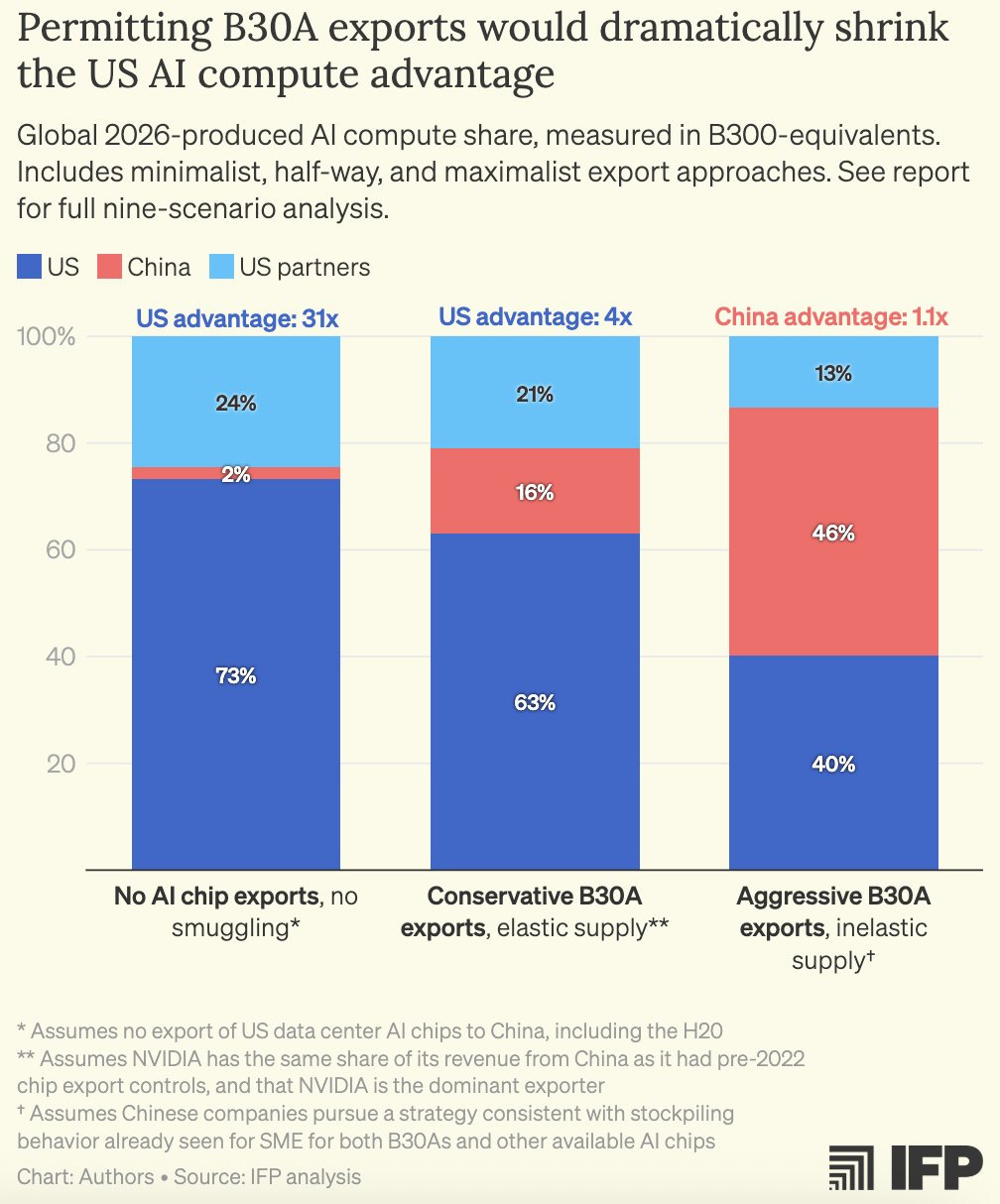
First – the reported chip specs: The “B30A” is rumored to be half of NVIDIA’s flagship B300: half the processing performance, half the memory bandwidth, and half the price. This means the B30A’s performance per $ is similar to the B300.
The B30A would: – Be far better than any Chinese AI chip – Have >12x the processing performance of the H20, a chip requiring an export license that has been approved for export in only limited quantities. – Exceed current export control thresholds by >18x
At a system level, a B30A-cluster would cost only ~20% more than a B300-cluster, a cost China can subsidize. Chinese AI labs would have access to supercomputers for AI training as powerful as those available to US AI labs.
When you put it that way, selling these chips to China seems like a really crazy thing to do if you care about whether American AI and American AI models are better than their Chinese counterparts, or you care about who has more compute. It would be a complete repudiation of the idea that we should have more and better compute than China.
Caleb Watney: I would simply not give away the essential bottleneck input for the most important dual-use technology of our era to the US’s primary geopolitical rival.
Hard to understate what a blow this would be for American leadership in AI if [sales of B30As] happens.
The US was not selling our supplies of enriched uranium to the Axis powers as we were building the Manhattan Project.
We could go from a 31x compute lead (in the best case scenario) to actually giving China a 1.1x compute lead if we sell the farm here.
The full report is here.
But won’t US chip restrictions cause Huawei to backfill with its own AI chips? No, for both supply and demand reasons.
On the supply side, China faces bottlenecks due to US/allied chipmaking tool controls. AI chips require two components: processor dies and high-bandwidth memory (HBM). US capacity for processors is 35-38x of China’s (or adjusting for China’s higher mfg errors, 160-170x).
China fares even worse on HBM, making virtually none this year. Even next year, the US advantage will be 70x.
As a result, five different analysts find Huawei makes an extremely small number of AI chips. They’ll be at 1-4% of US AI chips this year, and 1-2% in 2026 as the US ramps and Huawei stalls.
On the demand side, China will likely create artificial demand for inferior Huawei chips. So B30A sales to China will have minimal effect on Huawei market expansion. Instead, sales would supercharge China’s frontier AI & arm Chinese cloud to compete globally with US cloud.
Michael Sobolik (Senior Fellow, Hudson Institute): Allowing Nvidia to sell modified Blackwell chips to China would unilaterally surrender our greatest AI advantage to the Chinese Communist Party.
This would be a grave mistake.
This is why @SenatorBanks’ GAIN AI Act is so important. American chips should go American companies, not China.
America First!
China is going to maximize production on and progress of Huawei chips no matter what because they (correctly) see it as a dependency issue, and to this end they will ensure that Huawei chips sell out indefinitely, no matter what we do, and the amounts they have is tiny. The idea that they would be meaningfully exporting them any time soon is absurd, unless we are selling them so many B30As they have compute to spare.
Huawei is going to produce as many chips as possible, at as high quality as possible, from this point forth, which for a while will be ‘not many.’ Our decision here has at most minimal impact on their decisions and capacity, while potentially handing the future of AI to China by shoring up their one weakness.
Congress is trying to force through the GAIN Act to try and stop this sort of thing, and despite the political costs of doing so Microsoft sees this as important enough that it has thrown its support behind the GAIN Act. If the White House wants to make the case that the GAIN Act is not necessary, this is the time to make that case.
Even if you believe in the White House’s ‘tech stack’ theory (which I don’t), and that Huawei is much closer to catching up than they look (which again I don’t), this is still madness, because ultimately under that theory what matters are the models not the chips.
The the extent anyone was locked into anything, this newly empowered and market ascendant hybrid Nvidia-China stack (whether the main models were DeepSeek, Qwen, Kimi or someone else) would lock people far more into the models than the chips, and the new chips would provide the capacity to serve those customers while starving American companies of compute and also profit margins.
Then, if and when the Huawei chips are produced in sufficient quantity and quality, a process that would proceed apace regardless, it would be a seamless transfer, that PRC would insist upon, to then gradually transition to serving this via their own chips.
Again, if anything, importing massive supplies of Nvidia compute would open up the opportunity for far earlier exports of Huawei chips to other nations, if China wanted to pursue that strategy for real, and allows them to offer better products across the board. This is beyond foolish.
Is a major driver of potentially selling these chips that they would be exports to China, and assist with balance of trade?
I don’t know if this is a major driving factor, especially since the chips would be coming from Taiwan and not from America, but if it is then I would note that China will use these chips to avoid importing compute in other ways, and use them to develop and export services. Chips are inputs to other products, not final goods. Selling these chips will not improve our balance of trade on net over the medium term.
Is it possible that China would not see it this way, and would turn down even these almost state of the art chips? I find this highly unlikely.
One reason to find it unlikely is to look at Nvidia’s stock over the last day of trading. They are a $5 trillion company, whose stock is up by 9% and whose products sell out, on the chance they’ll be allowed to sell chips to China. The market believes the Chinese would buy big over an extended period.
But let’s suppose, in theory, that the Chinese care so much about self-sufficiency and resilience or perhaps pride, or perhaps are taking sufficient queues from our willingness to sell it, that they would turn down the B30As.
In that case, they also don’t care about you offering it to them. It doesn’t get you anything in the negotiation and won’t help you get to a yes. Trump understands this. Never give up anything the other guy doesn’t care about. Even if you don’t face a backlash and you somehow fully ‘get away with it,’ what was the point?
This never ends positively for America. Take the chips off the table.
Does Nvidia need this? Nvidia absolutely does not need this. They’re selling out their chips either way and business is going gangbusters across the board.
Here’s some of what else they announced on Tuesday alone, as the stock passed $200 (it was $139 one year ago, $12.53 post-split five years ago):
Morning Brew: Nvidia announcements today:
– Eli Lilly partnership
– Palantir partnership
– Hyundai partnership
– Samsung partnership
– $1 billion investment in Nokia
– Uber partnership to build 100,000 robotaxi fleet
– $500 billion in expected revenue over through 2026
– New system connecting quantum computers to its AI chips
– Department of Energy partnership to build 7 new supercomputers
Throughout this post, I have made the case against selling B30As to China purely on the basis of the White House’s own publicly stated goals. If what we care about are purely ‘beating China’ and ‘winning the AI race’ where that race means ensuring American models retain market share, and ensuring we retain strategic and military and diplomatic advantages, then this would be one of the worst moves one could make. We would be selling out our biggest edge in order to sell a few chips.
That is not to minimize that there are other important reasons to sell B30As to China, as this would make it far more likely that China is the one to develop AGI or ASI before we do, or that this development is made in a relatively reckless and unsafe fashion. If we sell these chips and China then catches up to us, not only do we risk that it is China that builds it first, it will be built in extreme haste and recklessness no matter who does it. I would expect everyone to collectively lose their minds, and for our negotiating position, should we need to make a deal, to deteriorate dramatically.
Even if it is merely the newly supercharged Chinese models getting market penetration in America, I would expect everyone to lose their minds from that alone. That leads to very bad political decisions all around.
That will all be true even if AGI takes 10 years to develop as per Andrej Karpathy.
But that’s not what is important to the people negotiating and advising on this. To them, let me be clear: Purely in terms of your own views and goals, this is madness.