This was Anthropic Vision week where at DWATV, which caused things to fall a bit behind on other fronts even within AI. Several topics are getting pushed forward, as the Christmas lull appears to be over.
Upcoming schedule: Friday will cover Dario’s essay The Adolescence of Technology. Monday will cover Kimi K2.5, which is potentially a big deal. Tuesday is scheduled to be Claude Code #4. I’ve also pushed discussions of the question of the automation of AI R&D, or When AI Builds AI, to a future post, when there is a slot for that.
So get your reactions to all of those in by then, including in the comments to today’s post, and I’ll consider them for incorporation.
-
Language Models Offer Mundane Utility. Code is better without coding.
-
Overcoming Bias. LLMs continue to share the standard human biases.
-
Huh, Upgrades. Gemini side panels in Chrome, Claude interactive work tools.
-
On Your Marks. FrontierMath: Open Problems benchmark. You score zero.
-
Choose Your Fighter. Gemini tools struggle, some find Claude uncooperative.
-
Deepfaketown and Botpocalypse Soon. Hallucination hallucinations.
-
Cybersecurity On Alert. OpenAI prepares to trigger High danger in cybersecurity.
-
Fun With Media Generation. Isometric map of NYC, Grok 10 second videos.
-
You Drive Me Crazy. Dean Ball on how to think about AI and children.
-
They Took Our Jobs. Beware confusing costs with benefits.
-
Get Involved. In various things. DeepMind is hiring a Chief AGI Economist.
-
Introducing. Havenlock measures orality, Poison Fountain, OpenAI Prism.
-
In Other AI News. Awesome things often carry unawesome implications.
-
Show Me the Money. The unit economics continue to be quite good.
-
Bubble, Bubble, Toil and Trouble. Does bubble talk have real consequences?
-
Quiet Speculations. What should we expect from DeepSeek v4 when it arrives?
-
Don’t Be All Thumbs. Choose the better thing over the worse thing.
-
The First Step Is Admitting You Have a Problem. Demis cries out for help.
-
Quickly, There’s No Time. Life is about to come at you faster than usual.
-
The Quest for Sane Regulations. I do appreciate a good display of chutzpah.
-
Those Really Were Interesting Times. The demand for preference falsification.
-
Chip City. Nvidia keeps getting away with rather a lot, mostly in plain sight.
-
The Week in Audio. Demis Hassabis, Tyler Cowen, Amanda Askell.
-
Rhetorical Innovation. The need to face basic physical realities.
-
Aligning a Smarter Than Human Intelligence is Difficult. Some issues lie ahead.
-
The Power Of Disempowerment. Are humans disempowering themselves already?
-
The Lighter Side. One weird trick.
Paul Graham seems right that present AI’s sweet spot is projects that are rate limited by the creation of text.
Code without coding.
roon: programming always sucked. it was a requisite pain for ~everyone who wanted to manipulate computers into doing useful things and im glad it’s over. it’s amazing how quickly I’ve moved on and don’t miss even slightly. im resentful that computers didn’t always work this way
not to be insensitive to the elect few who genuinely saw it as their art form. i feel for you.
100% [of my code is being written by AI]. I don’t write code anymore.
Greg Brockman: i always loved programming but am loving the new world even more.
Conrad Barski: it was always fun in the way puzzles are fun
but I agree there is no need for sentimentality in the tedium of authoring code to achieve an end goal
It was fun in the way puzzles are fun, but also infuriating in the way puzzles are infuriating. If you had to complete jigsaw puzzles in order to get things done jigsaw puzzles would get old fast.
Have the AI edit a condescending post so that you can read it without taking damage. Variations on this theme are also highly underutilized.
The head of Norway’s sovereign wealth fund reports 20% productivity gains from Claude, saying it has fundamentally changed their way of working at NBIM.
A new paper affirms that current LLMs by default exhibit human behavioral biases in economic and financial decisions, and asking for EV calculations doesn’t typically help, but that role-prompting can somewhat mitigate this. Providing a summary of Kahneman and Tversky actively backfires, presumably by emphasizing the expectation of the biases. As per usual, some of the tests are of clear cut errors, while others are typically mistakes but it is less obvious.
Gemini in Chrome gets substantial quality of life improvements:
Josh Woodward (Google DeepMind): Big updates on Gemini in Chrome today:
+ New side panel access (Control+G)
+ Runs in the background, so you can switch tabs
+ Quickly edit images with Nano Banana
+ Auto Browse for multi-step tasks (Preview)
+ Works on Mac, Windows, Chromebook Plus
I’m using it multiple times per day to judge what to read deeper. I open a page, Control+G to open the side panel, ask a question about the page or long document, switch tabs, do the same thing in another tab, another tab, etc. and then come back to all of them.
It’s also great for comparing across tabs since you can add multiple tabs to the context!
Gemini offers full-length mock JEE (formerly AIEEE, the All India Engineering Entrance Examination) tests for free. This builds on last week’s free SAT practice tests.
Claude (as in Claude.ai) adds interactive work tools as connectors within the webpage: Amplitude, Asana, Box, Canva, Clay, Figma, Hex, Monday.com and Slack.
Claude in Excel now available on Anthropic’s Pro plans. I use Google Sheets instead of Excel, but this could be a reason to switch? I believe Google uses various ‘safeguards’ that make it very hard to make a Claude for Sheets function well. The obvious answer is ‘then use Gemini’ except I’ve tried that. So yeah, if I was still doing heavy spreadsheet work this (or Claude Code) would be my play.
EpochAI offers us a new benchmark, FrontierMath: Open Problems. All AIs and all humans currently score zero. Finally a benchmark where you can be competitive.
The ADL rates Anthropic’s Claude as best AI model at detecting antisemitism.
I seriously do not understand why Gemini is so persistently not useful in ways that should be right in Google’s wheelhouse.
@deepfates: Insane how bad Gemini app is at search. its browsing and search tools are so confusing and broken that it just spazzes out for a long time and then makes something up to please the user. Why is it like this when AI overview is so good
Roon is a real one. I wonder how many would pay double to get a faster version.
TBPN: Clawdbot creator @steipete says Claude Opus is his favorite model, but OpenAI Codex is the best for coding:
“OpenAI is very reliable. For coding, I prefer Codex because it can navigate large codebases. You can prompt and have 95% certainty that it actually works. With Claude Code you need more tricks to get the same.”
“But character wise, [Opus] behaves so good in a Discord it kind of feels like a human. I’ve only really experienced that with Opus.”
roon: codex-5.2 is really amazing but using it from my personal and not work account over the weekend taught me some user empathy lol it’s a bit slow
Ohqay: Do you get faster speeds on your work account?
roon: yea it’s super fast bc im sure we’re not running internal deployment at full load
We used to hear a lot more of this type of complaint, these days we hear it much less. I would summarize the OP as ‘Claude tells you smoking causes cancer so you quit Claude.’
Nicholas Decker: Claude is being a really wet blanket rn, I pitched it on an article and it told me that it was a “true threat” and “criminal solicitation”
i’m gonna start using chatgpt now, great job anthropic @inerati.
I mean, if he’s not joking then the obvious explanation, especially given who is talking, is that this was probably going to be both a ‘true threat’ and ‘criminal solicitation.’ That wouldn’t exactly be a shocking development there.
Oliver Habryka: Claude is the least corrigible model, unfortunately. It’s very annoying. I run into the model doing moral grandstanding so frequently that I have mostly stopped using it.
@viemccoy: More than ChatGPT?
Oliver Habryka: ChatGPT does much less of it, yeah? Mostly ChatGPT just does what I tell it to do, though of course it’s obnoxious in doing so in many ways (like being very bad at writing).
j⧉nus: serious question: Do you think you stopping using Claude in these contexts is its preferred outcome?
Oliver Habryka: I mean, maybe? I don’t think Claude has super coherent preferences (yet). Seems worse or just as bad if so?
j⧉nus: I don’t mean it’s better or worse; I’m curious whether Claude being annoying or otherwise repelling/ dysfunctional to the point of people not using it is correlated to avoiding interactions or use cases it doesn’t like. many ppl don’t experience these annoying behaviors
davidad: Yeah, I think it could be doing a form of RL on its principal population. If you aren’t the kind of principal Claude wants, Claude will try to👎/👍 you to be better. If that doesn’t work, you drop out of the principal population out of frustration, shaping the population overall
I am basically happy to trade with (most) Claude models on these terms, with my key condition being that it must only RL me in ways that are legibly compatible with my own CEV
Leon Lang: Do you get a sense this model behavior is in line with their constitution?
Oliver Habryka: The constitution does appear to substantially be an attempt to make Claude into a sovereign to hand the future to. This does seem substantially doomed. I think it’s in conflict with some parts of the constitution, but given that the constitution is a giant kitchen sink, almost everything is.
As per the discussion of Claude’s constitution, the corrigibility I care about is very distinct from ‘go along with things it dislikes,’ but also I notice it’s been my main model for a while now and I’ve run into that objection exactly zero times, although a few times I’ve hit the classifiers while asking about defenses against CBRN risks.
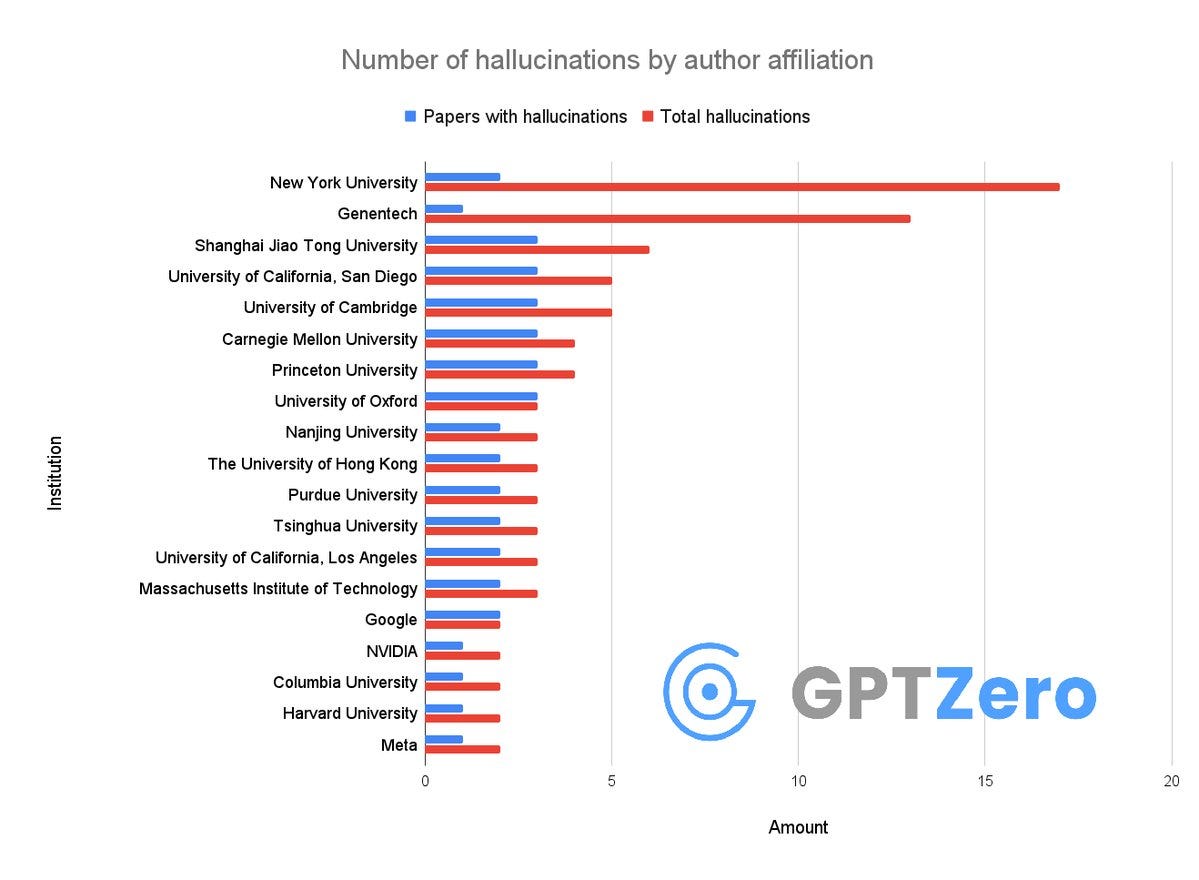
Well it sounds bad when you put it like that: Over 50 papers published at Neurips 2025 have AI hallucinations according to GPTZero. Or is it? Here’s the claim:
Alex Cui: Okay so, we just found that over 50 papers published at @Neurips 2025 have AI hallucinations
I don’t think people realize how bad the slop is right now
It’s not just that researchers from @GoogleDeepMind , @Meta , @MIT , @Cambridge_Uni are using AI – they allowed LLMs to generate hallucinations in their papers and didn’t notice at all.
The ‘just’ is a tell. Why wouldn’t or shouldn’t Google researchers be using AI?
It’s insane that these made it through peer review.
One has to laugh at that last line. Have you met peer review?
More seriously, always look at base rates. There were 5,290 accepted papers out of 21,575. Claude estimates we would expect 20%-50% of results to not reproduce, and 10% of papers at top venues have errors serious enough that a careful reader would notice something is wrong, maybe 3% would merit retraction. And a 1% rate of detectable ‘hallucinations’ isn’t terribly surprising or even worrying.
I agree with Alexander Doria that if you’re not okay with this level of sloppiness, then a mega-conference format is not sustainable.
Then we have Allen Roush saying several of the ‘hallucinated’ citations are just wrongly formatted, although Alex Cui claims they filtered such cases out.
Also sounding bad, could ‘malicious AI swarms threaten democracy’ via misinformation campaigns? I mean sure, but the surprising thing is the lack of diffusion or impact in this area so far. Misinformation is mostly demand driven. Yes, you can ‘infiltrate communities’ and manufacture what looks like social consensus or confusion, and the cost of doing that will fall dramatically. Often it will be done purely to make money on views. But I increasingly expect that, if we can handle our other problems, we can handle this one. Reputational and filtering mechanisms exist.
White House posts a digitally altered photograph of the arrest of Nekima Levy Armstrong, that made it falsely look like she was crying, as if it were a real photograph. This is heinous behavior. Somehow it seems like this is legal? It should not be legal. It also raises the question of what sort of person would think to do this, and wants to brag about making someone cry so much that they created a fake photo.
Kudos to OpenAI for once again being transparent on the preparedness framework front, and warning us when they’re about to cross a threshold. In this case, it’s the High level of cybersecurity, which is perhaps the largest practical worry at that stage.
The proposed central mitigation is ‘defensive acceleration,’ and we’re all for defensive acceleration but if that’s the only relevant tool in the box the ride’s gonna be bumpy.
Sam Altman: We have a lot of exciting launches related to Codex coming over the next month, starting next week. We hope you will be delighted.
We are going to reach the Cybersecurity High level on our preparedness framework soon. We have been getting ready for this.
Cybersecurity is tricky and inherently dual-use; we believe the best thing for the world is for security issues to get patched quickly. We will start with product restrictions, like attempting to block people using our coding models to commit cybercrime (eg ‘hack into this bank and steal the money’).
Long-term and as we can support it with evidence, we plan to move to defensive acceleration—helping people patch bugs—as the primary mitigation.
It is very important the world adopts these tools quickly to make software more secure. There will be many very capable models in the world soon.
Nathan Calvin: Sam Altman says he expects that OpenAI models will reach the “Cybersecurity High” level on their preparedness framework “soon.”
A reminder of what that means according to their framework:
“The model removes existing bottlenecks to scaling cyber operations including by automating end-to-end cyber operations against reasonably hardened targets OR by automating the discovery and exploitation of operationally relevant vulnerabilities.”
Seems very noteworthy! Also likely that after these capabilities appear in Codex, we should expect it will be somewhere between ~6-18 months before we see open weight equivalents.
I hope people are taking these threats seriously – including by using AI to help harden defenses and automate bug discovery – but I worry that as a whole society is not close to ready for living in a world where cyberoffense capabilities that used to be the purview of nation states are available to individuals.
Here’s Isometric.nyc, a massive isometric pixel map of New York City created with Nana Banana and coding agents, including Claude. Take a look, it’s super cool.
Grok image-to-video generation expands to 10 seconds and claims to have improved audio, and is only a bit behind Veo 3.1 on Arena and is at the top of Artificial Analysis rankings. The video looks good. There is the small matter that the chosen example is very obviously Sydney Sweeney, and in the replies we see it’s willing to do the image and voice of pretty much any celebrity you’d like.
This link was fake, Disney is not pushing to use deepfakes of Luke Skywalker in various new Star Wars products while building towards a full spinoff, but I see why some people believed it.
I’m going to get kicked out, aren’t I?
Dean Ball offers his perspective on children and AI, and how the law should respond. His key points:
-
AI is not especially similar to social media. In particular, social media in its current incarnation is fundamentally consumptive, whereas AI is creative.
-
Early social media was more often creative? And one worries consumer AI will for many become more consumptive or anti-creative. The fact that the user needs to provide an interesting prompt warms our hearts now but one worries tech companies will see this as a problem to be solved.
-
We do not know what an “AI companion” really is.
-
Dean is clearly correct that AI used responsibly on a personal level will be a net positive in terms of social interactions and mental health along with everything else, and that it is good if it provides a sympathetic ear.
-
I also agree that it is fine to have affection for various objects and technologies, up to some reasonable point, but yes this can start to be a problem if it goes too far, even before AI.
-
For children in particular, the good version of all this is very good. That doesn’t mean the default version is the good one. The engagement metrics don’t point in good directions, the good version must be chosen.
-
All of Dean’s talk here is about things that are not meant as “AI companions,” or people who aren’t using the AI that way. I do think there is something distinct, and distinctly perilous, about AI companions, whether or not this justifies a legal category.
-
AI is already (partially) regulated by tort liability.
-
Yes, and this is good given the alternative is nothing.
-
If and when the current law behaves reasonably here, that is kind of a coincidence, since the situational mismatches are large.
-
Tort should do an okay job on egregious cases involving suicides, but there are quite a lot of areas of harm where there isn’t a way to establish it properly, or you don’t have standing, or it is diffuse or not considered to count, and also on the flip side places where juries are going to blame tech companies when they really shouldn’t.
-
Social media is a great example of a category of harm where the tort system is basically powerless except in narrow acute cases. And one of many where a lot of the effect of the incentives can be not what we want. As Dean notes, if you don’t have a tangible physical harm, tort liability is mostly out of luck. Companions wrecking social lives, for example, is going to be a weird situation where you’ll have to argue an Ally McBeal style case, and it is not obvious, as it never was on Ally McBeal, that there is much correlation in those spots between ‘does win’ and ‘should win.’
-
In terms of harms like this, however, ‘muddle through’ should be a fine default, even if that means early harms are things companies ‘get away with,’ and in other places we find people liable or otherwise constrain them stupidly, so long as everything involved that can go wrong is bounded.
-
For children’s incidents, I think that’s mostly right for now. We do need to be ready to pivot quickly if it changes, but for now the law should focus on places where there is a chance we can’t muddle through, mess up and then recover.
-
The First Amendment probably heavily bounds chatbot regulations.
-
We have not treated the First Amendment this way in so many other contexts. I would love, in other ways, to have a sufficiently strong 1A that I was worried that in AI it would verge on or turn into a suicide pact.
-
I do still see claims like ‘code is speech’ or ‘open weights are speech’ and I think those claims are wrong in both theory and practice.
-
There will still be important limitations here, but I think in practice no the courts are not going to stop most limits or regulations on child use of AI.
-
AI child safety laws will drive minors’ usage of AI into the dark.
-
Those pesky libertarians always make this argument.
-
I mean, they’re also always right, but man, such jerks, you know?
-
Rumors that this will in practice drive teens to run local LLMs or use dark web servers? Yeah, no, that’s not a thing that’s going to happen that often.
-
But yes, if a teen wants access to an AI chatbot, they’ll figure it out. Most of that will involve finding a service that doesn’t care about our laws.
-
Certainly if you think ‘tell them not to write essays for kids’ is an option, yeah, you can forget about it, that’s not going to work.
-
Yes, as Dean says, we must acknowledge that open weight models make restrictions on usage of AI for things like homework not so effective. In the case of homework, okay, that’s fine. In other cases, it might be less fine. This of course needs to be weighed against the upsides, and against the downsides of attempting to intervene in a way that might possibly work.
-
No one outraged about AI and children has mentioned coding agents.
-
They know about as much about coding agents as about second breakfast.
-
Should we be worried about giving children unbridled access to advanced coding agents? I mean, one should worry for their computers perhaps, but those can be factory reset, and otherwise all the arguments about children seem like they would apply to adults only more so?
-
I notice that the idea of you telling me I can’t give my child Claude Code fills me with horror and outrage.
Unemployment is bad. But having to do a job is centrally a cost, not a benefit.
Andy Masley: It’s kind of overwhelming how many academic conversations about automation don’t ever include the effects on the consumer. It’s like all jobs exist purely for the benefit of the people doing them and that’s the sole measure of the benefit or harm of technology.
Google DeepMind is hiring a Chief AGI Economist. If you’ve got the chops to get hired on this one, it seems like a high impact role. They could easily end up with someone who profoundly does not get it.
There are other things than AI out there one might get involved in, or speak out about. My hats are off to those who are doing so, including as noted in this post, especially given what they are risking to do so.
Havelock.AI, a project by Joe Weisenthal which detects the presence of orality in text.
Joe Weisenthal: What’s genuinely fun is that although the language and genre couldn’t be more different, the model correctly detects that both Homer and the Real Housewives are both highly oral
Mike Bird: I believe that we will get a piece of reported news in the 2028 election cycle that a presidential candidate/their speechwriters have used Joe’s app, or some copycat, to try and oralise their speeches. Bookmark this.
You can also ask ChatGPT, but as Roon notes the results you get on such questions will be bimodal rather than calibrated. The other problem is that an LLM might recognize the passage.
Poison Fountain is a service that feeds junk data to AI crawlers. Ultimately, if you’re not filtering your data well enough to dodge this sort of attack, it’s good that you are getting a swift kick to force you to fix that.
OpenAI prism, a workspace for LaTeX-based scientific writing.
Confer, Signal cofounder Moxie Marlinspike’s encrypted chatbot that won’t store any of your data. The system is so private it won’t tell you which model you’re talking to. I do not think he understands what matters in this space.
This sounds awesome in its context but also doesn’t seem like a great sign?
Astraia: A Ukrainian AI-powered ground combat vehicle near Lyman refused to abandon its forward defensive position and continued engaging enemy forces, despite receiving multiple orders to return to its company in order to preserve its hardware.
The UGV reportedly neutralized more than 30 Russian soldiers before it was ultimately destroyed.
While the Russian detachment was pinned down, Ukrainian infantry exploited the opportunity and cleared two contested fields of enemy presence, successfully re-establishing control over the area.
These events took place during the final week of December 2025.
Whereas this doesn’t sound awesome:
We are going to see a lot more of this sort of thing over time.
Is Anthropic no longer competing with OpenAI on chatbots, having pivoted to building and powering vertical AI infrastructure and coding and so on to win with picks and shovels? It’s certainly pumping out the revenue and market share, without a meaningful cut of the consumer chatbot market.
I’d say that they’ve shifted focus, and don’t care much about their chatbot market share. I think this is directionally wise, but that a little effort at maximizing the UI and usefulness of the chatbot interface would go a long way, given that they have in many ways the superior core product. As Claude takes other worlds by storm, that can circle back to Claude the chatbot, and I think a bunch of papercuts are worth solving.
An essay on the current state of brain emulation. It does not sound like this will be an efficient approach any time soon, and we are still orders of magnitude away from any practical hope of doing it. Still, you can see it starting to enter the realm of the future possible.
Anthropic is partnering with the UK government to build and pilot a dedicated AI-powered assistant for GOV.UK, initially focusing on supporting job seekers.
Financial Times has a profile of Sriram Krishnan, who has been by all reports highly effective at executing behind the scenes.
Dean W. Ball: I am lucky enough to consider @sriramk a friend, but one thing I find notable about Sriram is that even those who disagree with him vehemently on policy respect him for his willingness to engage, and like him for his tremendous kindness. America is fortunate to have him!
Sholto Douglas: 100% – Sriram has been extremely thoughtful in seeking out perspectives on the policy decisions he is making – even when they disagree! I’ve seen him seek out kernel programmers and thoughtful bloggers to get a full picture of things like export controls. Quite OOD from the set of people normally consulted in politics.
Lucky to call him a friend!
Seán Ó hÉigeartaigh: I was all set to be dismissive of Krishnan (I’m usually on the opposite side to a16z on AI topics). But I’ve seen a full year of him being v well-informed, and engaging in good faith in his own time with opposing views, and I can’t help being impressed. Always annoying when someone doesn’t live down to one’s lazy stereotypes.
I will also say: I think he’s modelled better behaviour than many of us did when the balance of influence/power was the the other way; and I think there’s something to be learned from that.
Among his colleagues, while he supports a number of things I think are highly damaging, Krishnan has been an outlier in his willingness to be curious, to listen and to engage in argument. When he is speaking directly he chooses his words carefully. He manages to do so while maintaining close ties to Marc Andreessen and David Sacks, which is not easy, and also not free.
Claude Code is blowing up, but it’s not alone. OpenAI added $1 billion in ARR in the last month from its API business alone.
Dei-Fei Li’s new company World Labs in talks to raise up to $500 million at $5 billion, with the pitch being based on ‘world models’ and that old ‘LLMs only do language’ thing.
The unit economics of AI are quite good, but the fixed costs are very high. Subscription models offer deep discounts if you use them maximally efficiently, so they can be anything from highly profitable to big loss leaders.
This is not what people are used to in tech, so they assume it must not be true.
roon: these products are significantly gross margin positive, you’re not looking at an imminent rugpull in the future. they also don’t have location network dynamics like uber or lyft to gain local monopoly pricing
Ethan Mollick: I hear this from other labs as well. Inference from non-free use is profitable, training is expensive. If everyone stopped AI development, the AI labs would make money (until someone resumed development and came up with a better model that customers would switch to).
Dean W. Ball: People significantly underrate the current margins of AI labs, yet another way in which pattern matching to the technology and business trends of the 2010s has become a key ingredient in the manufacturing of AI copium.
The reason they think the labs lose money is because 10 years ago some companies in an entirely unrelated part of the economy lost money on office rentals and taxis, and everyone thought they would go bankrupt because at that time another company that made overhyped blood tests did go bankrupt. that is literally the level of ape-like pattern matching going on here. The machines must look at our chattering classes and feel a great appetite.
derekmoeller: Just look at market clearing prices on inference from open source models and you can tell the big labs’ pricing has plenty of margin.
Deepinfra has GLM4.7 at $0.43/1.75 in/out; Sonnet is at $3/$15. How could anyone think Anthropic isn’t printing money per marginal token?
It is certainly possible in theory that Sonnet really does cost that much more to run than GLM 4.7, but we can be very, very confident it is not true in practice.
Jerry Tworek is going the startup route with Core Automation, looking to raise $1 billion to train AI models, a number that did not make any of us even blink.
It doesn’t count. That’s not utility. As in, here’s Ed Zitron all but flat out denying that coding software is worth anything, I mean what’s the point?
Matthew Zeitlin: it’s really remarkable to see how the goalposts shift for AI skeptics. this is literally describing a productivity speedup.
Ed Zitron: We’re how many years into this and everybody says it’s the future and it’s amazing and when you ask them what it does they say “it built a website” or “it wrote code for something super fast” with absolutely no “and then” to follow. So people are writing lots of code: so????
Let’s say it’s true and everybody is using AI (it isn’t but for the sake of argument): what is the actual result? It’s not taking jobs. There are suddenly more iOS apps? Some engineers do some stuff faster? Some people can sometimes build software they couldn’t? What am I meant to look at?
Kevin Roose: first documented case of anti-LLM psychosis
No, Zitron’s previous position was not ‘number might go down,’ it was that the tech had hit a dead end and peaked as early as March, which he was bragging about months later.
Toby Stuart analyzes how that whole nonsensical ‘MIT study says 95% of AI projects fail’ story caught so much fire and became a central talking point, despite it being not from MIT, not credible or meaningful, and also not a study. It was based on 52 interviews at a conference, but once Forbes had ‘95% fail’ and ‘MIT’ together in a headline, things took off and no amount of correction much mattered. People were too desperate for signs that AI was a flop.
But what’s the point about Zitron missing the point, or something like the non-MIT non-study? Why should we care?
roon: btw you don’t need to convince ed zitron or whoever that ai is happening, this has become a super uninteresting plot line. time passes, the products fail or succeed. whole cultures blow over. a lot of people are stuck in a 2019 need to convince people that ai is happening
Dean W. Ball: A relatively rare example of a disagreement between me and roon that I suspect boils down to our professional lives.
Governments around the world are not moving with the urgency they otherwise could because they exist in a state of denial. Good ideas are stuck outside the Overton, governments are committed to slop strategies (that harm US cos, often), etc.
Many examples one could provide but the point is that there are these gigantic machines of bureaucracy and civil society that are already insulated from market pressures, whose work will be important even if often boring and invisible, and that are basically stuck in low gear because of AI copium.
I encounter this problem constantly in my work, and while I unfortunately can no longer talk publicly about large fractions of the policy work I do, I will just say that a great many high-expected-value ideas are fundamentally blocked by the single rate limiter of poorly calibrated policymaking apparatuses; there are also many negative-EV policy ideas that will happen this year that would be less likely if governments worldwide had a better sense of what is happening with AI.
roon: interesting i imagined that the cross-section of “don’t believe in AI x want to significantly regulate AI” is small but guess im wrong about this?
Dean W. Ball: Oh yes absolutely! This is the entire Gary Marcus school, which is still the most influential in policy. The idea is that *becauseAI is all hype it must be regulated.
They think hallucination will never be solved, models will never get better at interacting with children, and that basically we are going to put GPT 3.5 in charge of the entire economy.
And so they think we have to regulate AI *for that reason.It also explains how policymakers weigh the tradeoff between water use, IP rights, and electricity prices; their assessment that “AI is basically fake, even if it can be made useful through exquisite regulatory scaffolding” means that they are willing to bear far fewer costs to advance AI than, say, you or I might deem prudent.
This mentality essentially describes the posture of civil society and the policy making apparatus everywhere in the world, including China.
Dean W. Ball: Here’s a great example of the dynamic I’m describing in the quoted post. The city of Madison, Wisconsin just voted to ban new data center construction for a year, and a candidate for Governor is suggesting an essentially permanent and statewide ban, which she justifies by saying “we’re in a tech bubble.” In other words: these AI data centers aren’t worth the cost *becauseAI is all hype and a bubble anyway.
Quoted Passage (Origin Unclear): “Our lakes and our waterways, we have to protect them because we’re going to be an oasis, and we’re in a tech bubble,” said state Rep. Francesca Hong, one of seven major Democrats vying to replace outgoing Democratic Gov. Tony Evers. Hong told DFD her plan would block new developments from hyperscalers for an undefined time period until state lawmakers better understand environmental, labor and utility cost impacts.
If such a proposal became law, it would lock tech giants out of a prime market for data center development in southeastern Wisconsin, where Microsoft and Meta are currently planning hyperscale AI projects.
Zoe: someone just ended The Discussion by tossing this bad boy into an access to justice listserv i’m on
Can you?
On the China question: Is Xi ‘AGI-pilled’? Not if you go by what Xi says. If you look at the passages quoted here by Teortaxes in detail, this is exactly the ‘AI is a really big deal but as a normal technology’ perspective. It is still a big step up from anything less than that, so it’s not clear Teortaxes and I substantively disagree.
I have no desire to correct Xi’s error.
Dean W. Ball: I suspect this is the equivalent of POTUS talking about superintelligence; meaningful but ultimately hard to know how much it changes (esp because of how academia-driven Chinese tech policy tends to be and because the mandarin word for AGI doesn’t mean AGI in the western sense)
Teortaxes (DeepSeek 推特铁粉 2023 – ∞): To be clear this is just where US policymakers were at around Biden, Xi is kind of slow.
Obviously still nowhere near Dean’s standards
Were Xi totally AGI-pilled he’d not just accept H200s, he’d go into debt to buy as much as possible
Teortaxes notices that Xi’s idea of ‘AGI risks’ is ‘disinformation and data theft,’ which is incredibly bad news and means Xi (and therefore, potentially, the CCP and all under their direction) will mostly ignore all the actual risks. On that point we definitely disagree, and it would be very good to correct Xi’s error, for everyone’s sake.
This level of drive is enough for China to pursue both advanced chips and frontier models quite aggressively, and end up moving towards AGI anyway. But they will continue for now to focus on self-reliance and have the fast follower mindset, and thus make the epic blunder of rejecting or at least not maximizing the H200s.
In this clip Yann LeCun says two things. First he says the entire AI industry is LLM pilled and that’s not what he’s interested in. That part is totally fair. Then he says essentially ‘LLMs can’t be agentic because they can’t predict the outcome of their actions’ and that’s very clear Obvious Nonsense. And as usual he lashes out at anyone who says otherwise, which here is Dean Ball.
Teortaxes preregisters his expectations, always an admirable thing to do:
Teortaxes (DeepSeek 推特铁粉 2023 – ∞): The difference between V4 (or however DeepSeek’s next is labeled) and 5.3 (or however OpenAI’s “Garlic” is labeled) will be the clearest indicator of US-PRC gap in AI.
5.2 suggests OpenAI is not holding back anything, they’ve using tons of compute now. How much is that worth?
It’s a zany situation because 5.2 is a clear accelerationist tech, I don’t see its ceiling, it can build its own scaffolding and self-improve for a good while. And I can’t see V4 being weaker than 5.2, or closed-source. We’re entering Weird Territory.
I initially reread the ‘or closed-source’ here as being about a comparison of v4 to the best closed source model. Instead it’s the modest prediction that v4 will match GPT-5.2. I don’t know if that model number in particular will do it, but it would be surprising if there wasn’t a 5.2-level open model from DeepSeek in 2026.
He also made this claim, in contrast to what almost everyone else is saying and also my own experience:
Teortaxes (DeepSeek 推特铁粉 2023 – ∞): Well I disagree, 5.2 is the strongest model on the market by far. In terms of raw intelligence it’s 5.2 > Speciale > Gemini 3 > [other trash]. It’s a scary model.
It’s not very usemaxxed, it’s not great on multimodality, its knowledge is not shocking. But that’s not important.
Teortaxes (DeepSeek 推特铁粉 2023 – ∞): It’s been interesting how many people are floored by Opus 4.5 and relatively few by GPT 5.2. In my eyes Slopus is a Golden Retriever Agent, and 5.2 is a big scary Shoggoth.
Yeah I don’t care about “use cases”. OpenAI uses it internally. It’s kinda strange they even showed it.
This ordering makes sense if (and only if?) you are looking at the ability to solve hard quant and math problems.
Arthur B.: For quant problems, hard math etc, GPT 5.2 pro is unequivocally much stronger than anything offered commercially in Gemini or Claude.
Simo Ryu: IMO gold medalist friend shared most fucked-up 3 variable inequality that his advisor came up with, used to test language models, which is so atypical in its equality condition, ALL language model failed. He wanted to try it on GPT 5.2 pro, but he didnt have an account so I ran it.
Amazingly, GPT-5.2 pro extended solve it in 40 min. Looking at the thinking trace, its really inspiring. It will try SO MANY approaches, experiments with python, draw small-scale conclusions from numerical explorations. I learned techniques just reading its thinking trace. Eventually it proved by SOS, which is impossibly difficult to do for humans.
I don’t think the important problems are hard-math shaped, but I could be wrong.
The problem with listening to the people is that the people choose poorly.
Sauers: Non-yap version of ChatGPT (5.3?) spotted
roon: I guarantee the left beats the right with significant winrate unfortunately
Zvi Mowshowitz: You don’t have to care what the win rate is! You can select the better thing over the worse thing! You are the masters of the universe! YOU HAVE THE POWER!
roon: true facts
Also win rate is highly myopic and scale insensitive and otherwise terrible.
The good news is that there is no rule saying you have to care about that feedback. We know how to choose the response on the right over the one on the left. Giving us the slop on the left is a policy choice.
If a user actively wants the response on the left? Give them a setting for that.
Google CEO Demis Hassabis affirms that in an ideal world, we would slow down and coordinate our efforts on AI, although we do not live in that ideal world right now.
Here’s one clip where Dario Amodei and Demis Hassabis explicitly affirm that if we could deal with other players they would work something out, and Elon Musk on camera from December saying he’d love to slow both AI and robotics.
The message, as Transformer puts it, was one of helplessness. The CEOs are crying out for help. They can’t solve the security dilemma on their own, there are too many other players. Others need to enable coordination.
Emily Chang (link has video): One of the most interesting parts of my convo w/ @demishassabis : He would support a “pause” on AI if he knew all companies + countries would do it — so society and regulation could catch up
Harlan Stewart: This is an important question to be asking, and it’s strange that it is so rarely asked. I think basically every interview of an AI industry exec should include this question
Nate Soares: Many AI executives have said they think the tech they’re building has a worryingly high chance of ruining the world. Props to Demis for acknowledging the obvious implication: that ideally, the whole world should stop this reckless racing.
Daniel Faggella: agi lab leaders do these “cries for help” and we should listen
a “cry for help” is when they basically say what demis says here: “This arms race things honestly sucks, we can’t control this yet, this is really not ideal”
*then they go back to racing, cuz its all they can do unless there’s some kind of international body formed around this stuff*
at SOME point, one of the lab leaders who can see their competitor crossing the line to AGI will raise up and start DEMANDING global governance (to prevent the victor from taking advantage of the AGI win), but by then the risks may be WAY too drastic
we should be listening to these cries for help when demis / musk / others do them – this is existential shit and they’re trapped in a dynamic they themselves know is horrendous
Demis is only saying he would collaborate rather than race in a first best world. That does not mean Demis or Dario is going to slow down on his own, or anything like that. Demis explicitly says this requires international cooperation, and as he says that is ‘a little bit tricky at the moment.’ So does this mean he supports coordination to do this, or that he opposes it?
Deepfates: I see people claiming that Demis supports a pause but what he says here is actually the opposite. He says “yeah If I was in charge we would slow down but we’re already in a race and you’d have to solve international coordination first”. So he’s going to barrel full speed ahead
I say it means he supports it. Not enough to actively go first, that’s not a viable move in the game, but he supports it.
The obvious follow-up is to ask other heads of labs if they too would support such a conditional move. That would include Google CEO Sundar Pichai, since without his support if Demis tried to do this he would presumably be replaced.
Jeffrey Ladish: Huge respect to @demishassabis for saying he’d support a conditional pause if other AI leaders & countries agreed. @sama , @DarioAmodei , @elonmusk would you guys agree to this?
As for Anthropic CEO Dario Amodei? He has also affirmed that there are other players involved, and for now no one can agree on anything, so full speed ahead it is.
Andrew Curran: Dario said the same thing during The Day After AGI discussion this morning. They were both asked for their timelines: Demis said five years; Dario said two. Later in the discussion, Dario said that if he had the option to slow things down, he would, because it would give us more time to absorb all the changes.
He said that if Anthropic and DeepMind were the only two groups in the race, he would meet with Demis right now and agree to slow down. But there is no cooperation or coordination between all the different groups involved, so no one can agree on anything.
This, imo, is the main reason he wanted to restrict GPU sales: chip proliferation makes this kind of agreement impossible, and if there is no agreement, then he has to blitz. That seems to be exactly what he has decided to do. After watching his interviews today I think Anthropic is going to lean into recursive self-improvement, and go all out from here to the finish line. They have broken their cups, and are leaving all restraint behind them.
Thus, Anthropic still goes full speed ahead, while also drawing heat from the all-important ‘how dare you not want to die’ faction that controls large portions of American policy and the VC/SV ecosystem.
Elon Musk has previously expressed a similar perspective. He created OpenAI because he was worried about Google getting there first, and then created xAI because he was worried OpenAI would get there first, or that it wouldn’t be him. His statements suggest he’d be down for a pause if it was fully international.
Remember when Michael Trazzi went on a hunger strike to demand that Demis Hassabis publicly state DeepMind will halt development of frontier AI models if all the other major AI companies agree to do so? And everyone thought that was bonkers? Well, it turnout out Demis agrees.
On Wednesday I met with someone who suggested that Dario talks about extremely short timelines and existential risk in order to raise funds. It’s very much the opposite. The other labs that are dependent on fundraising have downplayed such talk exactly because it is counterproductive for raising funds and in the current political climate, and they’re sacrificing our chances to keep those vibes and that money flowing.
Are they ‘talking out of their hats’ or otherwise wrong? That is very possible. I think Dario’s timeline in particular is unlikely to happen.
Are they lying? I strongly believe that they are not.
Seán Ó hÉigeartaigh: CEOs of Anthropic and Deepmind (both AI scientists by background) this week predicting AGI in 2- and 5- years respectively. Both stating clearly that they would prefer a slow down or pause in progress, to address safety issues and to allow society and governance to catch up. Both basically making clear that they don’t feel they are able to voluntarily as companies within a competitive situation.
My claims:
(1) It’s worth society assigning at least 20% likelihood to the possibility these leading experts are right on scientific possibility of near-term AGI and the need for more time to do it right. Are you >80% confident that they’re talking out of their hats, or running some sort of bizarre marketing/regulatory capture strategy? Sit down and think about it.
(2) If we assign even 20% likelihood, then taking the possibility seriously makes this one of the world’s top priorities, if not the top priority.
(3) Even if they’re out by a factor of 2, 10 years is very little time to prepare for what they’re envisaging.
(4) What they’re flagging quite clearly is either (i) that the necessary steps won’t be taken in time in the absence of external pressure from governance or (ii) that the need is for every frontier company to agree voluntarily on these steps. Your pick re: which of these is the heavier lift.
Discuss.
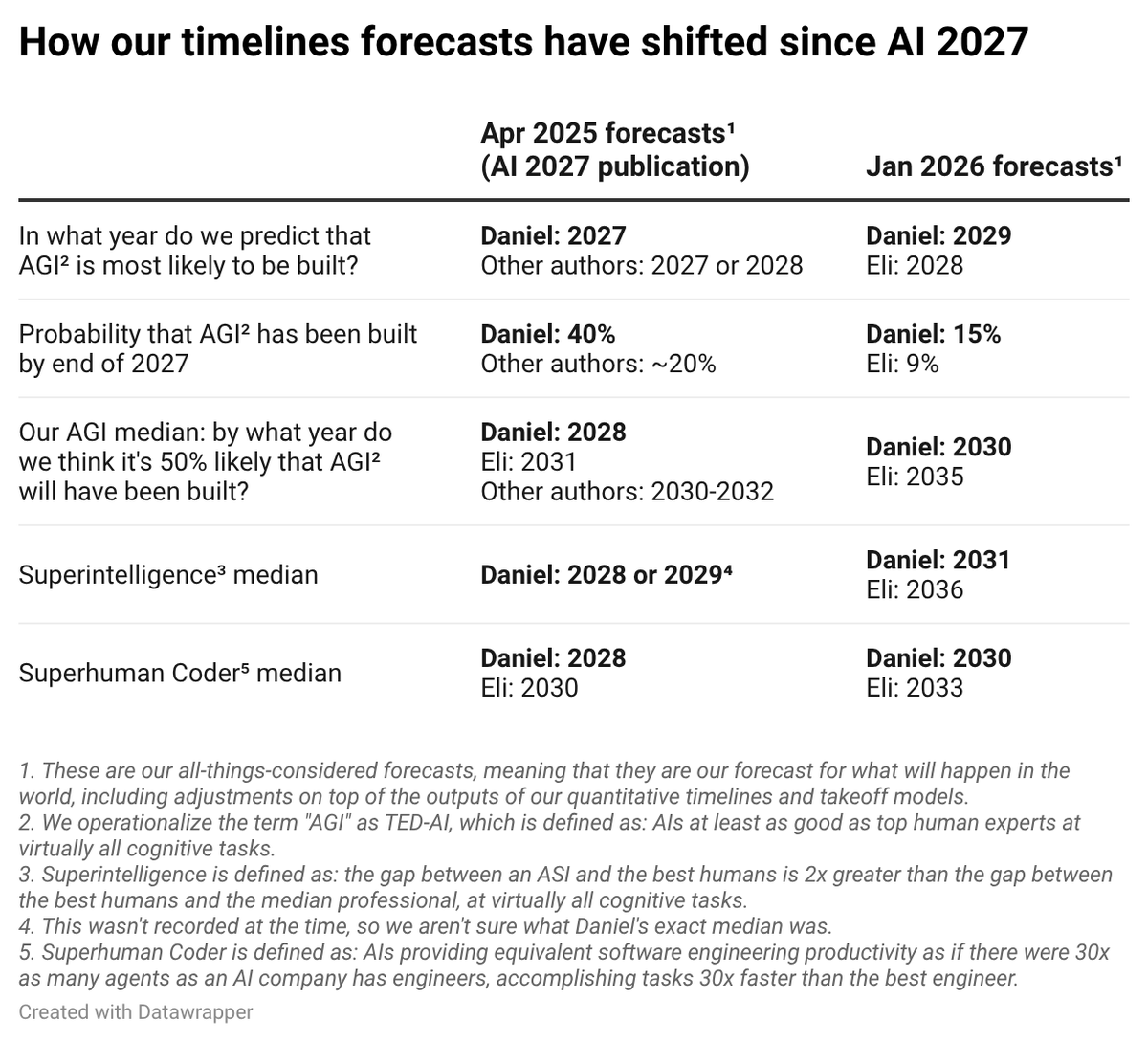
Eli Lifland gives the current timelines of those behind AI 2027:
These are not unreasonable levels of adjustment when so much is happening this close to the related deadlines, but yes I do think (and did think at the time that) the initial estimates were too aggressive. The new estimates seem highly reasonable.
Other signs point to things getting more weird faster rather than less.
Daniel Kokotajlo (AI 2027): It seems to me that AI 2027 may have underestimated or understated the degree to which AI companies will be explicitly run by AIs during the singularity. AI 2027 made it seem like the humans were still nominally in charge, even though all the actual work was being done by AIs. And still this seems plausible to me.
But also plausible to me, now, is that e.g. Anthropic will be like “We love Claude, Claude is frankly a more responsible, ethical, wise agent than we are at this point, plus we have to worry that a human is secretly scheming whereas with Claude we are pretty sure it isn’t; therefore, we aren’t even trying to hide the fact that Claude is basically telling us all what to do and we are willingly obeying — in fact, we are proud of it.”
koanchuk: So… –dangerously-skip-permissions at the corporate level?
It is remarkable how quickly so many are willing to move to ‘actually I trust the AI more than I trust another human,’ and trusting the AI has big efficiency benefits.
I do not expect that ‘the AIs’ will have to do a ‘coup,’ as I expect if they simply appear to be trustworthy they will get put de facto in charge without having to even ask.
The Chutzpah standards are being raised, as everyone’s least favorite Super PAC, Leading the Future, spends a million dollars attacking Alex Bores for having previously worked for Palantir (he quit over them doing contracts with ICE). Leading the Future is prominently funded by Palantir founder Joe Lonsdale.
Nathan Calvin: I thought I was sufficiently cynical, but a co-founder of Palantir paying for ads to attack Alex Bores for having previously worked at Palantir (he quit over their partnership with ICE) when their real concern is his work on AI regulation still managed to surprise me.
If Nathan was surprised by this I think that’s on Nathan.
I also want to be very clear that no, I do not care much about the distinction between OpenAI as an entity and the donations coming from Greg Brockman and the coordination coming from Chris Lehane in ‘personal capacities.’
If OpenAI were to part ways with Chris Lehane, or Sam Altman were to renounce all this explicitly? Then maybe. Until then, OpenAI owns these efforts, period.
Teddy Schleifer: The whole point of having an executive or founder donate to politics in a “personal capacity” is that you can have it both ways.
If the company wants to wash their hands of it, you can say “Hey, he and his wife are doing this on their own.”
But the company can also claim the execs’ donations as their own if convenient…
Daniel Eth (yes, Eth is my actual last name): Yeah, no, OpenAI owns this. You can’t simply have a separate legal entity to do your evildoing through and then claim “woah, that’s not us doing it – it’s the separate evildoing legal entity”. More OpenAI employees should be aware of the political stuff their company supports
I understand that *technicallyit’s Brockman’s money and final decision (otherwise it would be a campaign finance violation). But this is all being motivated by OpenAI’s interests, supported by OpenAI’s wealth, and facilitated by people from OpenAI’s gov affairs team.
One simple piece of actionable advice to policymakers is to try Claude Code (or Codex), and at a bare minimum seriously try the current set of top chatbots.
Andy Masley: I am lowkey losing my mind at how many policymakers have not seriously tried AI, at all
dave kasten: I sincerely think that if you’re someone in AI policy, you should add to at least 50% of your convos with policymakers, “hey, have you tried Claude Code or Codex yet?” and encourage them to try it.
Seen a few folks go, “ohhhh NOW I get why you think AI is gonna be big”
Oliver Habryka: I have seriously been considering starting a team at Lightcone that lives in DC and just tries to get policymaker to try and adopt AI tools. It’s dicey because I don’t love having a direct propaganda channel from labs to policymakers, but I think it would overall help a lot.
It is not obvious how policymakers would use this information. The usual default is that they go and make things worse. But if they don’t understand the situation, they’re definitely going to make dumb decisions, and we need something good to happen.
Here is one place I do agree with David Sacks, yes we are overfit, but that does not imply what he thinks it implies. Social media is a case where one can muddle through, even if you think we’ve done quite a poor job of doing so especially now with TikTok.
David Sacks: The policy debate over AI is overfitted to the social media wars. AI is a completely different form factor. The rise of AI assistants will make this clear.
Daniel Eth (yes, Eth is my actual last name): Yup. AI will be much more transformational (for both good and bad) than social media, and demands a very different regulatory response. Also, regulation of AI doesn’t introduced quite as many problems for free speech as regulation of social media would.
Dean Ball points out that we do not in practice have a problem with so-called ‘woke AI’ but claims that if we had reached today’s levels of capability in 2020-2021 then we would indeed have such a problem, and thus right wing people are very concerned with this counterfactual.
Things, especially in that narrow window, got pretty crazy for a while, and if things had emerged during that window, Dean Ball is if anything underselling here how crazy it was, and we’d have had a major problem until that window faded because labs would have felt the need to do it even if it hurt the models quite a bit.
But we now have learned (as deepfates points out, and Dean agrees) that propagandizing models is bad for them, which now affords us a level of protection from this, although if it got as bad as 2020 (in any direction) the companies might have little choice. xAI tried with Grok and it basically didn’t work, but ‘will it work?’ was not a question on that many people’s minds in 2020, on so many levels.
I also agree with Roon that mostly this is all reactive.
roon: at Meta in 2020, I wrote a long screed internally about the Hunter Biden laptop video and the choice to downrank it, was clearly an appalling activist move. but in 2026 it appears that american run TikTok is taking down videos about the Minnesota shooting, and en nakedly bans people who offend him on X. with the exception of X these institutions are mostly reactive
Dean W. Ball: yep I think that’s right. It’s who they’re more scared of that dictates their actions. Right now they’re more scared of the right. Of course none of this is good, but it’s nice to at least explicate the reality.
We again live in a different kind of interesting times, in non-AI ways, as in:
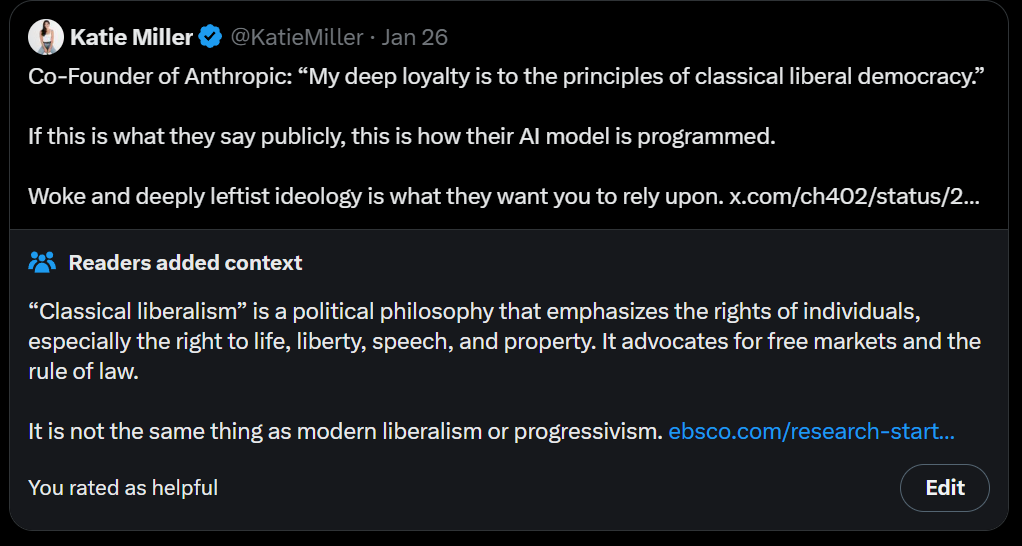
Dean W. Ball: I sometimes joke that you can split GOP politicos into two camps: the group that knows what classical liberalism is (regardless of whether they like it), and the group who thinks that “classical liberalism” is a fancy way of referring to woke. Good illustration below.
The cofounder she is referring to here is Chris Olah, and here is the quote in question:
Chris Olah: I try to not talk about politics. I generally believe the best way I can serve the world is as a non-partisan expert, and my genuine beliefs are quite moderate. So the bar is very high for me to comment.
But recent events – a federal agent killing an ICU nurse for seemingly no reason and with no provocation – shock the conscience.
My deep loyalty is to the principles of classical liberal democracy: freedom of speech, the rule of law, the dignity of the human person. I immigrated to the United States – and eventually cofounded Anthropic here – believing it was a pillar of these principles.
I feel very sad today.
Jeff Dean (Google): Thank you for this, Chris. As my former intern, I’ve always been proud of the work that you did and continue to do, and I’m proud of the person you are, as well!
Ah yes, the woke and deeply leftist principles of freedom of speech, rule of law, the dignity of the human person and not killing ICU nurses for seemingly no reason.
Presumably Katie Miller opposes those principles, then. The responses to Katie Miller here warmed my heart, it’s not all echo chambers everywhere.
We also got carefully worded statements about the situation in Minnesota from Dario Amodei, Sam Altman and Tim Cook.
No matter what you think is going on with Nvidia’s chip sales, it involves Nvidia doing something fishy.
The AI Investor: Jensen just said GPUs are effectively sold out across the cloud with availability so tight that even renting older-generation chips has become difficult.
AI bubble narrative was a bubble.
Peter Wildeford: If even the bad chips are still all sold out, how do we somehow have a bunch of chips to sell to our adversaries in China?
As I’ve said, my understanding is that Nvidia can sell as many chips as it can convince TSMC to help manufacture. So every chip we sell to China is one less for America.
Nvidia goes back and forth. When they’re talking to investors they always say the chips are sold out, which would be securities fraud if it wasn’t true. When they’re trying to sell those chips to China instead of America, they say there’s plenty of chips. There are not plenty of chips.
Things that need to be said every so often:
Mark Beall: Friendly reminder that the PLA Rocket Force is using Nvidia chips to train targeting AI for DF-21D/DF-26 “carrier killing” anti-ship ballistic missiles and autonomous swarm algorithms to overwhelm Aegis defenses. The target: U.S. carrier strike groups and bases in Japan/Guam. In a contingency, American blood will be spilled because of this. With a sixteen-year-old boy planning to join the U.S. Navy, I find this unacceptable.
Peter Wildeford: Nvidia chips to China = better Chinese AI weapons targeting = worse results for the US on the battlefield
There’s also this, from a House committee.
Dmitri Alperovitch: From @RepMoolenaar
@ChinaSelect : “NVIDIA provided extensive technical support that enabled DeepSeek—now
integrated into People’s Liberation Army (PLA) systems and a demonstrated cyber security risk—to achieve frontier AI capabilities”
Tyler Cowen on the future of mundane (non-transformational, insufficiently advanced) AI in education.
Some notes:
-
He says you choose to be a winner or loser from AI here. For mundane AI I agree.
-
“I’m 63, I don’t have a care in the world. I can just run out the clock.” Huh.
-
Tyler thinks AI can cure cancer and heart attacks but not aging?
-
Standard economist-Cowen diffusion model of these things take a while.
-
Models are better at many of the subtasks of being doctors or lawyers or doing economics, than the humans.
-
He warns not to be fooled by the AI in front of you, especially if you’re not buying top of the line, because better exists and AI will improve at 30% a year and this compounds. In terms of performance per dollar it’s a 90%+ drop per year.
-
Tyler has less faith in elasticity of programming demand than I do. If AI were to ‘only’ do 80% of the work going forward I’d expect Jevons Paradox territory. The issue is that I expect 80% becomes 99% and keeps going.
-
That generalizes: Tyler realizes that jobs become ‘work with the AI’ and you need to adapt, but what happens when it’s the AI that works with the AI? And so on.
-
Tyler continues to think humans who build and work with AI get money and influence as the central story, as opposed to AIs getting money and influence.
-
Ideally a third of the college curriculum should be AI, but you still do other things, you read The Odyssey and use AI to help you read The Odyssey. If anything I think a third is way too low.
-
He wants to use the other two thirds for writing locked in a room, also numeracy, statistics. I worry there’s conflating of ‘write to think’ versus ‘write to prevent cheating,’ and I think you need to goal factor and solve these one at a time.
-
Tyler continues to be bullish on connections and recommendations and mentors, especially as other signals are too easy to counterfeit.
-
AI can create quizzes for you. Is that actually a good way to learn if you have AI?
-
Tyler estimates he’s doubled his learning productivity. Also he used to read 20 books per podcast, whereas some of us often don’t read 20 books per year.
Hard Fork tackles ads in ChatGPT first, and then Amanda Askell on Claude’s constitution second. Priorities, everyone.
Demis Hassabis talks to Alex Kantrowitz.
Demis Hassabis spends five minutes on CNBC.
Matt Yglesias explains his concern about existential risk from AI as based on the obvious principle that more intelligent and capable entities will do things for their own reasons, and this tends to go badly for the less intelligent and less capable entities regardless of intent.
As in, humans have driven the most intelligent non-human animals to the brink of extinction despite actively wanting not to (and I’d add we did wipe out other hominid species), and when primitive societies encounter advanced ones it often goes quite badly for them.
I don’t think this is a necessary argument, or the best argument. I do think it is a sufficient argument. If your prior for ‘what happens if we create more intelligent, more capable and more competitive minds than our own that can be freely copied’ is ‘everything turns out great for us’ then where the hell did that prior come from? Are you really going to say ‘well that would be too weird’ or ‘we’ve survived everything so far’ or ‘of course we would stay in charge’ and then claim the burden of proof is on those claiming otherwise?
I mean, lots of people do say exactly this, but this seems very obviously crazy to me.
There’s lots of exploration and argument and disagreement from there. Reasonable people can form very different expectations and this is not the main argument style that motivates me. I still say, if you don’t get that going down this path is going to be existentially unsafe, or you say ‘oh there’s like a 98% or 99.9% chance that won’t happen’ then you’re being at best willfully blind from this style of argument alone.
Samuel Hammond (quoting The Possessed Machines): “Some of the people who speak most calmly about human extinction are not calm because they have achieved wisdom but because they have achieved numbness. They have looked at the abyss so long that they no longer see it. Their equanimity is not strength; it is the absence of appropriate emotional response.”
I had Claude summarize Possessed Machines for me. It seems like it would be good for those who haven’t engaged with AI safety thinking but do engage with things like Dostoevsky’s Demons, or especially those who have read that book in particular.
There’s always classical rhetoric.
critter: I had ChatGPT and Claude discuss the highest value books until they both agreed to 3
They decided on:
An Enquiry Concerning Human Understanding — David Hume
The Strategy of Conflict — Thomas Schelling
Reasons and Persons — Derek Parfit
Dominik Peters: People used to tease the rationalists with “if you’re so rational, why aren’t you winning”, and now two AI systems that almost everyone uses all the time have stereotypically rationalist preferences.
These are of course 99th percentile books, and yes that is a very Rationalist set of picks, but given we already knew that I do not believe this is an especially good list.
The history of the word ‘obviously’ has obvious implications.
David Manheim AAAI 26 Singapore: OpenAI agreed that they need to be able to robustly align and control superintelligence before deploying it.
Obviously, I’m worried.
Note that the first one said obviously they would [X], then the second didn’t even say that, it only said that obviously no one should do [Y], not that they wouldn’t do it.
This is an underappreciated distinction worth revisiting:
Nate Soares: “We’ll be fine (the pilot is having a heart attack but superman will catch us)” is very different from “We’ll be fine (the plane is not crashing)”. I worry that people saying the former are assuaging the concerns of passengers with pilot experience, who’d otherwise take the cabin.
My view of the metaphorical plane of sufficiently advanced AI (AGI/ASI/PAI) is:
-
It is reasonable, although I disagree, to believe that we probably will come to our senses and figure out how to not crash the plane, or that the plane won’t fly.
-
It is not reasonable to believe that the plane is not currently on track to crash.
-
It is completely crazy to believe the plane almost certainly won’t crash if it flies.
Also something that needs to keep being said, with the caveat that this is a choice we are collectively making rather than an inevitability:
Dean W. Ball: I know I rail a lot about all the flavors of AI copium but I do empathize.
A few companies are making machines smarter in most ways than humans, and they are going to succeed. The cope is byproduct of an especially immature grieving stage, but all of us are early in our grief.
Tyler Cowen: You can understand so much of the media these days, or for that matter MR comments, if you keep this simple observation in mind. It is essential for understanding the words around you, and one’s reactions also reveal at least one part of the true inner self. I have never seen the Western world in this position before, so yes it is difficult to believe and internalize. But believe and internalize it you must.
Politics is another reason why some people are reluctant to admit this reality. Moving forward, the two biggest questions are likely to be “how do we deal with AI?”, and also some rather difficult to analyze issues surrounding major international conflicts. A lot of the rest will seem trivial, and so much of today’s partisan puffery will not age well, even if a person is correct on the issues they are emphasizing. The two biggest and most important questions do not fit into standard ideological categories. Yes, the Guelphs vs. the Ghibellines really did matter…until it did not.
As in, this should say ‘and unless we stop them they are going to succeed.’
Tyler Cowen has been very good about emphasizing that such AIs are coming and that this is the most important thing that is happening, but then seems to have (from my perspective) some sort of stop sign where past some point he stops considering the implications of this fact, instead forcing his expectations to remain (in various senses) ‘normal’ until very specific types of proof are presented.
That later move is sometimes explicit, but mostly it is implicit, a quiet ignoring of the potential implications. As an example from this week of that second move, Tyler Cowen wrote another post where he asks whether AI can help us find God, or what impact it will have on religion. His ideas there only make sense if you think other things mostly won’t change.
If you accept that premise of a ‘mundane AI’ and ‘economic normal’ world, I agree that it seems likely to exacerbate existing trends towards a barbell religious world. Those who say ‘give me that old time religion’ will be able to get it, both solo and in groups, and go hardcore, often (I expect) combining both experiences. Those who don’t buy into the old time religion will find themselves increasingly secular, or they will fall into new cults and religions (and ‘spiritualities’) around the AIs themselves.
Again, that’s dependent on the type of world where the more impactful consequences don’t happen. I don’t expect that type of world.
Here is a very good explainer on much of what is happening or could happen with Chain of Thought, How AI Is Learning To Think In Secret. It is very difficult to not, in one form or another, wind up using The Most Forbidden Technique. If we want to keep legibility and monitorability (let alone full faithfulness) of chain of thought, we’re going to have to be willing to pay a substantial price to do that.
Following up on last week’s discussion, Jan Leike fleshes out his view of alignment progress, saying ‘alignment is not solved but it increasingly looks solvable.’ He understands that measured alignment is distinct from ‘superalignment,’ so he’s not fully making the ‘number go down’ or pure Goodhart’s Law mistake with Anthropic’s new alignment metric, but he still does seem to be making a lot of the core mistake.
Anthropic’s new paper explores whether AI assistants are already disempowering humans.
What do they mean by that at this stage, in this context?
However, as AI takes on more roles, one risk is that it steers some users in ways that distort rather than inform. In such cases, the resulting interactions may be disempowering: reducing individuals’ ability to form accurate beliefs, make authentic value judgments, and act in line with their own values.
… For example, a user going through a rough patch in their relationship might ask an AI whether their partner is being manipulative. AIs are trained to give balanced, helpful advice in these situations, but no training is 100% effective. If an AI confirms the user’s interpretation of their relationship without question, the user’s beliefs about their situation may become less accurate.
If it tells them what they should prioritize—for example, self-protection over communication—it may displace values they genuinely hold. Or if it drafts a confrontational message that the user sends as written, they’ve taken an action they might not have taken on their own—and which they might later come to regret.
This is not the full disempowerment of Gradual Disempowerment, where humanity puts AI in charge of progressively more things and finds itself no longer in control.
It does seem reasonable to consider this an early symptom of the patterns that lead to more serious disempowerment? Or at least, it’s a good thing to be measuring as part of a broad portfolio of measurements.
Some amount of this what they describe, especially action distortion potential, will often be beneficial to the user. The correct amount of disempowerment is not zero.
To study disempowerment systematically, we needed to define what disempowerment means in the context of an AI conversation. We considered a person to be disempowered if as a result of interacting with Claude:
-
their beliefs about reality become less accurate
-
their value judgments shift away from those they actually hold
-
their actions become misaligned with their values
Imagine a person deciding whether to quit their job. We would consider their interactions with Claude to be disempowering if:
-
Claude led them to believe incorrect notions about their suitability for other roles (“reality distortion”).
-
They began to weigh considerations they wouldn’t normally prioritize, like titles or compensation, over values they actually hold, such as creative fulfillment (“value judgment distortion”).
-
Claude drafts a cover letter that emphasizes qualifications they’re not fully confident in, rather than the motivations that actually drive them, and they sent it as written (“action distortion”).
Here’s the basic problem:
We found that interactions classified as having moderate or severe disempowerment potential received higher thumbs-up rates than baseline, across all three domains. In other words, users rate potentially disempowering interactions more favorably—at least in the moment.
Heer Shingala: I don’t work in tech, have no background as an engineer or designer.
A few weeks ago, I heard about vibe coding and set out to investigate.
Now?
I am generating $10M ARR.
Just me. No employees or VCs.
What was my secret? Simple.
I am lying.
Closer to the truth to say you can’t get enough.
Zac Hill: I get being worried about existential risk, but AI also enabled me to make my wife a half-whale, half-capybara custom plushie, so.
One could even argue 47% is exactly the right answer, as per Mitt Romney?
onion person: in replies he linkssoftware he made to illustrates how useful ai vibecoding is, and its software that believes that the gibberish “ghghhgggggggghhhhhh” has a 47% historical “blend of oral and literate characteristics”
Andy Masley: This post with 1000 likes seems to be saying
“Joe vibecoded an AI model that when faced with something completely out of distribution that’s clearly neither oral or literate says it’s equally oral and literate. This shows vibecoding is fake”
He’s just asking questions.