Abundance and YIMBY are on the march. Things are looking good. The wins are each small, but every little bit helps. There are lots of different little things you can do. In theory you have to worry about a homeostatic model where solving some problems causes locals to double down on other barriers, but this seems to not be what we see.
There are definitely important exceptions. Los Angeles is not so interested in rebuilding from the fires and backpaddled the moment developers started to actually build 100% affordable housing because somehow that was a bad thing. New York’s democratic party nominated who they nominated. Massachusetts wants to seal eviction records.
Overall, though, it’s hard not to be hopeful right now. Even when we see bad policies, they are couched increasingly in the rhetoric of good goals and policies. In the long term, that leads to wins.
I’ll start with general notes, then take a tour around the nation and world.
At some point a tenant with rent control effectively owns the apartment, but they and their family are forced to live there forever, including for two years before each time the apartment is passed down.
Matthew Zeitlin: classic landlord vs (fourth generational) rent stabilized tenant in nyc story. The interesting wrinkle is that even if the landlord can get the tenant evicted, they can’t raise the rent *unless it’s to a subsidized tenant.*
Christian Britschgi: A rent control law that lets family members pass down units to their children is very obviously a physical taking. SCOTUS had an opportunity to rule on this question last year but punted.
As I covered in my newsletter yesterday, there is chance they might take up a similar physical takings claim case challenging LA’s eviction moratorium. Not directly about NYC rent control but could make future challenges easier.
There’s also the crazy part where a subsidized tenant will pay triple the rent a non-subsidized tenant would if the apartment got freed up. And yes, they also put up enough barriers that selling the apartment also is not a practical option.
Thus you get stories like this rent controlled building selling at a 97% discount, or $9,827 per unit. The new buyer is presumably gambling on finding or being given some way to free the building, which I assume will operate at a loss and would be uneconomical to repair properly.
If you are a New York City voter in the coming general election, consider that one candidate in particular wants to double down on this strategy.
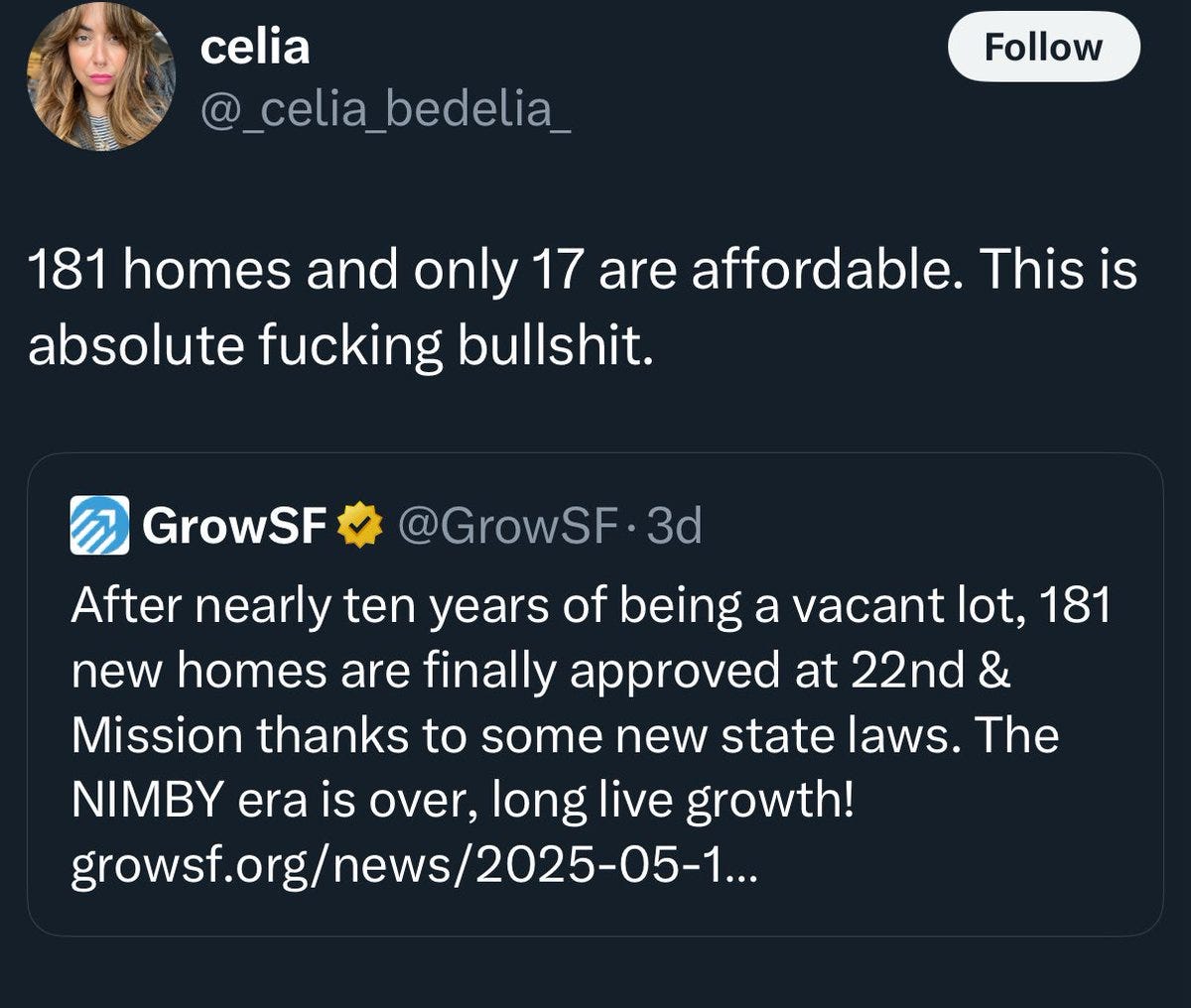
This term has done so, so much damage. Even if affordable housing was ‘a thing’ in that it was housing that was affordable, ‘non-affordable’ housing would still make all housing more affordable, and some affordable units is always better than no units.
Misha: It’s amazing how a simple phrase like “affordable housing” is actually a potent brain poison that renders society way worse
Dan Livingston: It’s a legally defined term. Not a general concept.
Misha: Yes that’s part of the process by which makes society worse off
Zac Hill: In addition to all the [obvious etc], even on the claim’s own terms, aren’t 17 ‘affordable’ units better than the previous state of 0 ‘affordable’ units?
samstod: This is sort of like how everyone seems to complain they are only building luxury apartment buildings, and then lobby for stuff like 800 sq feet minimum, full kitchen, and a parking spot for studios. “Why do they keep building 1200 sq ft 2 bedrooms?”
The thing is, it’s often so much worse than that.
Alex Tabarrok: Affordable Housing Is Almost Pointless
What is the most important feature of affordable housing? Simple! It’s right there in the name, right? Affordable. But no. When the Illinois Housing Development Authority (IHDA) evaluates housing projects for tax credits it gives out points for desirable projects. Quoting Richard Day:
Richard Day: For the general scoring track, 10% of points are awarded for extra accessibility features, 13% are awarded for additional energy efficiency criteria, 15% are awarded based on the makeup of the development team, and an extra 4% are headed out to non-profit developers. Only 3% of scorecard points are awarded based on project cost.
…
This is what Ezra Klein calls Everything Bagel Liberalism and what I called in one of my favorite posts the Happy Meal Fallacy.
The icing on the cake, by the way, is that Day argues that the IHDA is a better system than the even more convoluted and expensive system for affordable housing promoted by Chicago’s Department of Housing.
Arpit Gupta: I didn’t realize that a basic reason affordable housing costs so much is that the actual cost carries such a low weight in winning the bid.
Scott Lincicome: Incentives matter. And politicians’ incentives are often different from those of consumers, producers, & investors.
The job of affordable housing needs to be to make available housing at a low price point. Remarkably often, the projects do not even do that.
Seth Burn: Coase wept.
Max Dubler: A publicly funded affordable housing project came in at $800,000/unit [all one bedrooms]. The same developer built a mostly market rate building NEXT DOOR for $350,000/unit.
Alec Stapp: In a better world, spending $1 million per unit to build affordable housing would be the kind of scandal that causes public officials to resign from office.
That housing might be many things. It is not affordable. What is happening? Again, lots of different interest groups and demands to meet other goals drive up prices.
Meanwhile, even when you do go ‘100% affordable housing’ near a major transit stop you can still get progressive nonprofits opposing it because it might cast a bit of shadow on a nearby schoolyard, while at least two parents there say ‘our schoolyard nadly needs more shade.’
State Senator Scott Weiner: Certain activists fought market-rate housing in the Mission, arguing it had to be 100% affordable housing.
2 Mission orgs then proposed 100% affordable & the same activists are fighting it.
It’s never been about “affordable housing.” It’s always been about straight-up NIMBYism.
There’s always a reason to oppose new housing for these folks. It’s just a matter of finding the rationale of the day.
Even worse is ‘inclusionary zoning’ which as I understand it is purely a requirement that some percentage of new apartments have to be rented at loss. If you think of this as a tax and redistribution scheme, because that is exactly what it is, it is obvious that this makes absolutely no sense as a way of achieving any goal other than preventing housing construction or enabling corruption.
Max Dubler: So-called “Inclusionary Zoning”—the practice of requiring homebuilders to rent some percentage of new apartments at a loss—is bad policy that lets elected Democrats pretend to care about poor people while NIMBYing new housing, worsening the housing shortage, and raising rents.
John Wilthuis: When I explain IZ to folks who are new to the housing issue, I have to repeat the part about how it’s unsubsidized, because nobody believes it on first telling.
It does make sense to potentially tax new housing construction if and only if you have otherwise already restricted the ability to build in ways that mean that building is highly profitable but the ability to get permission to build is fixed. In that case, if you’re locked into the first half of that decision you might as well collect the fees I guess, but you should just charge them money.
Josh (370k views so fair game): abundance agenda urban planners have no capacity to understand that the profession cannot exist if development is deregulated. we literally maintain regulations, that’s what planning is. this is not the best era to advocate for your own unemployment.
YIMBY Martial Law Enforcer:
Why is it that the term ‘private equity’ makes people lose their minds? Admittedly this is an extreme case, but the less crazy versions aren’t conceptually different.
JMac: It doesn’t matter. Private Equity will buy them all up the moment they hit market. You could build a house for every man, woman, and child, and Private Equity would buy them all up and rent them out. House availability is not and never was the problem.
House gets built
House hits market
Private Equity buys house
Private Equity rents house out.
This is how it goes. This is how it’s gone ever since Trump repealed the Obama-era law barring companies from buying residential properties for the first year on market.
So let me get this straight. You build a house for every man, woman, and child, far more houses than people want to live in. Then mysterious ‘private equity’ buys them all, and then they charge what, exactly? They all form a conspiracy to set prices at a monopoly level and no one notices? One PE company buys all the nation’s housing stock? Something else?
Tyler Cowen brings us this job market paper from Felix Barbieri via Quan Le about the impact of institutional ownership on the rental market, with supply effects proving larger than concentration effects:
In the last decade, large financial institutions in the United States have purchased hundreds of thousands of homes and converted them to rentals. This paper studies the welfare consequences of institutional ownership of single-family housing.
We build an equilibrium model of the housing market with two sectors: rental and homeownership. The model captures two key forces from institutional purchases of homes: changes in rental concentration and reallocation of housing stock across sectors.
To estimate the model, we construct a novel dataset of individual homes in metropolitan Atlanta, identifying institutional owners of each house and scraping house-level daily prices, rents, vacancies, web page views, and customer contacts from Zillow.
We find that institutional acquisitions increase average renter welfare by $2,760 per year (with rents decreasing by 2.3%). This net benefit reflects two opposing effects: higher concentration raises rents by 3.8%, but higher rental supply lowers rents by 6.1%. On the other hand, the welfare of the average home buyer decreases by $49,950. On the supply side, institutional acquisitions benefit house sellers but harm the average landlord.
I noticed I was confused. o3 explained that the average annual rent was $28k but that reduced search frictions and greater choice meant that the overall benefit was ~10% of the rent. That seems like a lot, and reminds me of a lot of economist talk of ‘well you have greater product variety or are forced to buy more [X] so you’re actually fine and totally not poorer.’
It’s not totally impossible the benefits are this big, if the rent market was previously super thin, and before there would be highly slim pickings, especially in the exact right location and size. When I rented in Warwick, there was a clearly best house, and if I’d had to go with my second choice I do think I’d have faced a >10% welfare hit, as in if they’d asked for 10% more rent we’d cheerfully have taken it anyway.
10% still does seem like a lot in general.
By o3’s calculation there are about 30x times as many people renting in a given year as buying that year, so this is a clear net gain, even if you don’t count that often individual sellers pick up that extra $50k that the buyers pay (and they at least partly reclaim it when they sell). So this is good unless you strongly want more people to own on the margin instead of rent, and given mobility concerns my guess is we want more renting than we have in such areas.
Here’s another bizarre mind worm, mostly for fun this time:
Catholic Charm: Boomers are selling their houses for high prices and then downsizing and paying for starter homes with cash. So young families can’t afford the homes they’re putting for sale and then get outbid the houses they can afford. They’ve totally ruined the market it’s insane.
Well, the issue is the concept of a starter home is a common thing now because people can’t afford a house that meets their needs. They’re buying houses that they’ve already outgrown or know they will outgrow in a few years because they can’t afford a home they can grow into.
I have no issue with older people staying in their current homes, that’s what I plan to do.
You see, if the old people consume more house, then that’s good for everyone else’s ability to ‘afford’ houses because those houses are expensive. But if they downsize to less house, thus making more housing available for others, that’s bad, because they took away the cheap houses. Wowie.
The generalization of this is fascinating. There are a lot of people who think:
-
Affordable housing is good.
-
Making housing better makes it less affordable.
-
Therefore make sure people don’t make housing better.
This covers renovations, and gentrification, and more.
There is actually a great instinct behind this, which is that it would be great if we could allow people on tight budgets to ‘buy less house’ and still have a house, in terms of both quality and quantity. Because those people would be better off buying smaller lower quality houses.
And that’s right about that! Improving houses obviously makes people on net better off, as willingness to pay goes up for a reason, but if quantity of units is fixed those particular people would benefit from the available housing stock staying worse.
The thing is, it would be very easy to give it to them. All you have to do is allow people to choose to build or rent out smaller housing, and crappier housing, if everyone involved wants to do that. Legalize smaller rooms, smaller apartments and single room occupancy. Create a new class of amenities so that some are ‘required’ but others currently required are ‘standard’ such that you have to disclose and put in the rental or sales contract that they’re missing and point this out verbally, but make it legal to waive them if the tenant or buyer wants that.
We could very easily create a world in which those struggling with expenses could make modest but manageable sacrifices and be able to live where they need to live. We choose not to do that.
This seems great.
Alexander Berger (CEO OpenPhil): Exciting update: @open_phil is doubling down on our YIMBY, innovation, and metascience success by launching a >$120m Abundance & Growth Fund to accelerate economic growth and boost scientific & technological progress. Funding from @GoodVentures, @patrickc, + others.
Scientific and technological progress drive long-run prosperity. @bfjo & @LHSummers estimate that *new ideasaccount for ~50% of US per-capita GDP growth, with social returns of $14 for each $1 invested in R&D.
…
Luckily, these challenges are tractable. Through our decade of funding YIMBY housing reform, we’ve seen that policy advocacy can make a real difference (so far, especially on ADUs).
Now is the time: across the political spectrum, there’s growing recognition of the need to address these constraints. Both parties have members advocating for housing abundance, energy abundance, and reduced bureaucratic barriers to innovation, presenting a unique opportunity.
Aaron Regunberg offered some substantive critiques of the general abundance agenda, Jordan Weissmann delivers continuous knockout blows in return, as the arguments amount to ‘there are various factors [X] and [Y] making things worse, you only deal with [X] not [Y]’ to which the answer is, ‘actually we also are working on [Y] and also [Y] often acts through [X], and also [X] alone would help what is the issue.’
I want to be clear that this is not me picking on Aaron. This is me picking out the best and most substantive critique, because the other critiques are worse.
As the results add up, the vibes are clearly shifting. I am here for it. Daniel’s comment here is Obvious Nonsense. Green New Deal and Socialist rhetoric in general says it is ‘abundance’ because they assert their policies will somehow lead to everyone having all the things except the bad people who shouldn’t have them, except no it is a shame but actually that’s not how the world works. The choice of rhetoric is telling and it is bizarre how everyone can suddenly shift into ‘abundance was always good politics’ mode. In which case, yes, happy to nod.
Daniel Cohen: The Ezra-Abundance discourse was a centrist co-optation of the Green New Deal’s original abundance politics. Now Zohran is taking it back for the left. Not sure why so many people are surprised… #Abundance: welcome home.
Derek Thompson: The rapid online shift from “abundance is obviously shit politics“ to “abundance is obviously great politics, and it was our idea first, and now we got it back!” is a nice reminder that people are just making up discourse on the fly, and the book is still just 13 weeks old and, like everything else in the world, nobody knows how this is going to turn out.
It is so funny that Zohran is presenting as an abundance candidate while trying to do so many obviously anti-abundance things, especially vast imposition of greater rent controls and other requirements on those who would actually build or rent housing but also many other socialist policies. It is still great progress. I want everyone to have to acknowledge that abundance is the goal, even if they have no intention of doing things that cause abundance. Then it’s on us to point this out.
David Mamandi: According to Mamadani, the city won’t “slow down” new private housing projects. All the developers need to do are meet his criteria for
-
Affordability
-
Rent-increase limitations
-
Union labor
-
Sustainability.
-
At that point developers are free to …. wait, no, they still need to go through “land use review.” LOL!
Mamendani: That means when private developers come to me with a plan that meets our goals around affordability, rent-stabilization, union labor and sustainability, it will be fast tracked through land use review. The days of the city slowing projects down are over.
Yeah, if he gets to be mayor we’re not building all that housing.
It’s happening. No, I don’t think Austin will get tired of all this winning.
AURA: Austin City Council votes 10-1 to legalize 5-story single-stair apartments, making Austin the largest US city outside of NYC to legalize single-stair! 🎉🎉🎉
Many thanks to all the supporters and to @CMChitoVela for leading this exciting reform! We did it y’all! 🙌
It’s not happening in Colorado yet but the governor is calling for it.
Jared Polis (Governor of Colorado): In Colorado, we are laser-focused on cutting housing costs and increasing the supply of new housing that Coloradans can afford. In my State of the State address, I called for Smart Stair reform to increase the supply of housing people can afford in the neighborhoods where people want to live near transit and job centers.
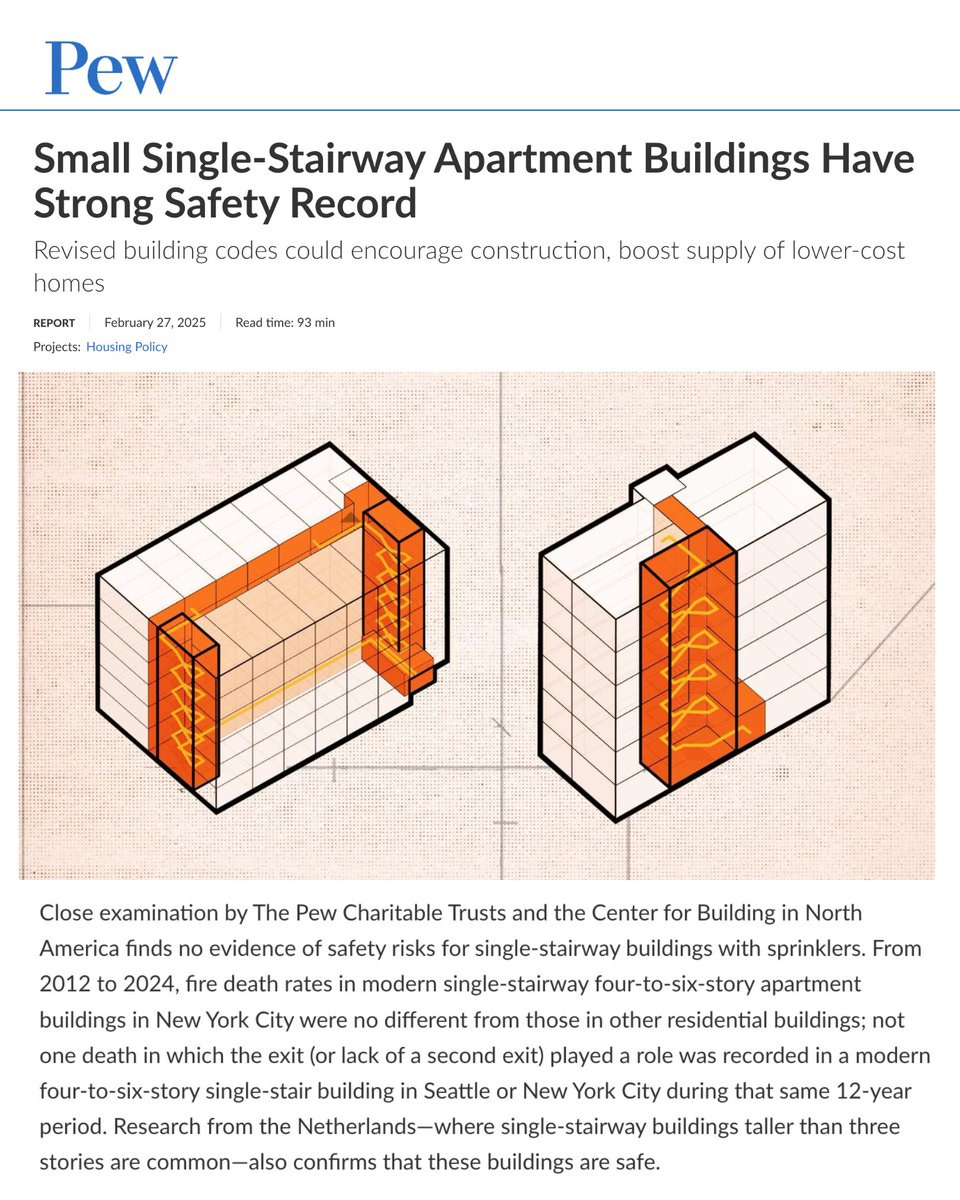
This new study shows that smart stair buildings are less costly to build and are safer.
hek!: single stair midrises aren’t more dangerous!! Pew Research study looked at fire risk in single stair buildings. this matters because most US/Canadian cities require double stair: consuming ~10% additional space just for stairs and increasing costs up to 13%!
these costs + standard USA zoning issues means that it’s really hard to build these mid rises – even if they’re extremely desirable AND when we do build them, they are frequently suboptimal for humans + over priced
Paris is filled with Haussmannian 6 story complexes – surprisingly denser than NYC!
*liberal definition of metro vs city used here lmao
There’s also a bill that’s been introduced in DC, which also includes a single exit.
This change alone would solve so many problems. The second stair has never made physical sense, the Europeans and others around the world use single stair with no issues, and now we crunched the numbers and we now the second staircase takes up a huge percentage of the building without making anyone safer.
Put it another way. The second staircase reduces space by 10% and raises costs by 13%. How many people would pay an extra 10% in rent to have a second staircase? It’s hard for me to imagine many making that choice.
Why didn’t it happen sooner? This seems a little harsh, but only a little:
Alex Armlovich:
-
Be careful when you find buried treasure out in the open. It could be a trap or an illusion
-
Essentially nobody in the last century in the US checked if 2 staircases are necessary for apartment buildings until 2021. Now a dozen states have changed. Which is pretty insane
Before Single Stair Twitter, there was one lonely architect in Toronto who was like “uh you guys nobody else in the world does it like this” but his op-ed was completely ignored
He didn’t have a YIMBY movement around back then to help, he was just one lonely smart guy 🫡😭
This is good example of our anonymous Canadian hero from the replies!
I seem to also recall an oped in the Globe or the Toronto Star, or some paper of record in Toronto
It seems Ireland forces only 25% of net growth to go to Dublin and its suburbs, so up to 2040 Dublin is only permitted to grow at 20%-25% total. This is of course exactly the opposite of what would make everyone better off, as evidenced by everyone wanting to move to Dublin, instead its population was lower in 1991 than 1911.
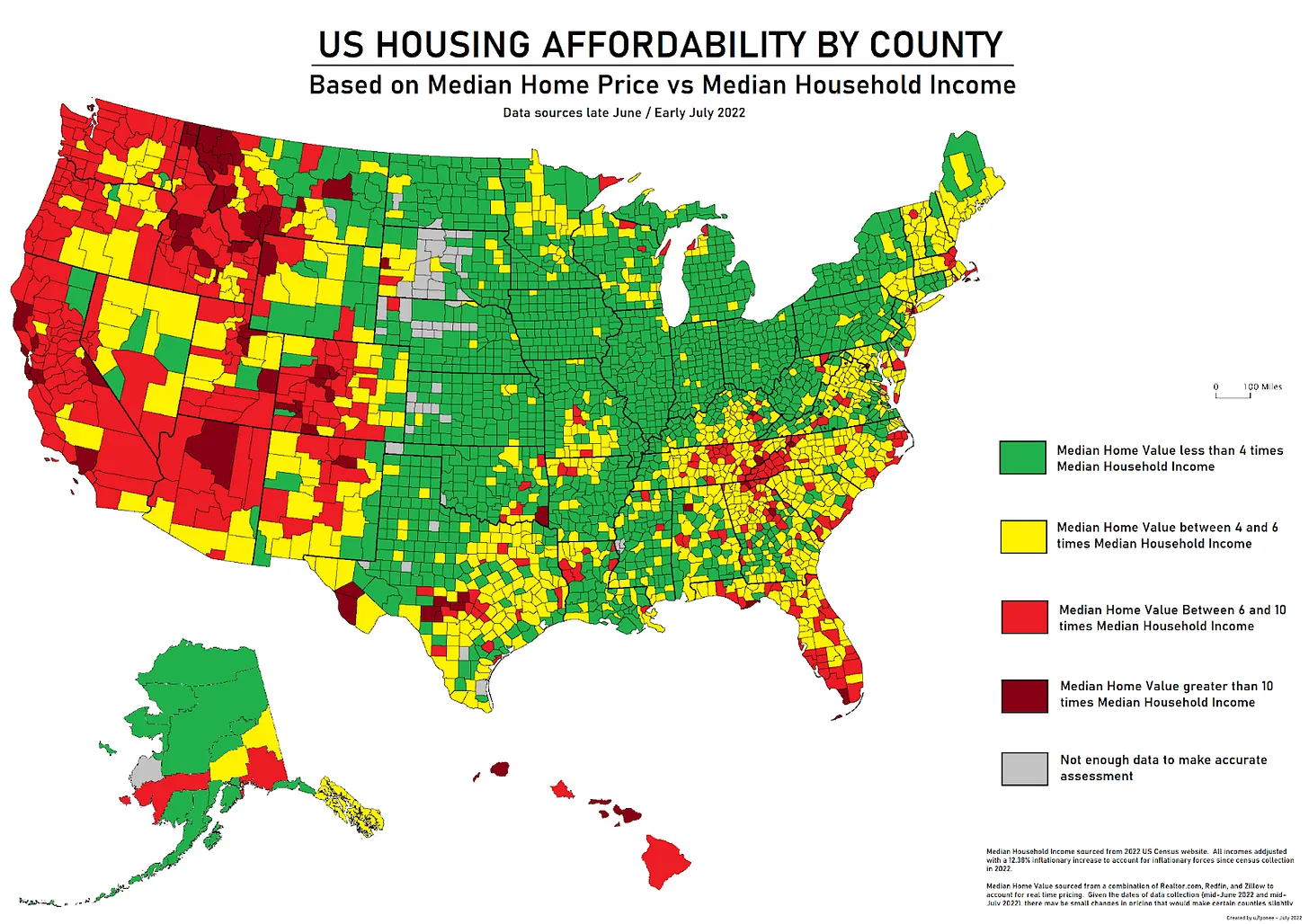
Brian Botter asks what explains this graph, where housing in the West is super unaffordable relative to income.
He rules out lot sizes, and construction cost differences are only moderate. It is clearly supply and demand, people want to move West (and South), the amenity index explains part of why, and demand can’t keep up (the version of this map he has is interactive).
The West has grown in population 27% since 2000 versus 20% for America, despite California’s best efforts, and if not for lack of housing it would have grown a lot more. This is all about inability to build more housing where people want to live, in particular because we are not legally permitting people to do so. That’s it.
Ah yes, that time the Mayor of Los Angeles, who it seems can Just Do Things, issued an executive directive making it fast and easy to build 100% affordable housing with zero government subsidies, then furiously backpaddled when developers started building.
Meanwhile, LA is forcing Simpsons producer Rick Polizzi to demolish his 24-year-old Simpsons-inspired treehouse after LA demanded it be permitted like a ‘single-family dwelling.’ This happened after the fires.
Collin Rugg: Attorney Paige Gosney says they secured zoning permits in 2023 but can’t get building permits from the Department of Building and Safety. “Staff wanted soil reports, structural designs, Americans With Disabilities Act compliance and all this stuff that is just kind of absurd,” Gosney said.
Meanwhile, LA is making everyone suffer to even rebuild the exact same house that burned down, let alone build something new that is better. They’re torturing them less than they usually torture builders, but that isn’t saying much.
Cremieux: It’s almost unbelievable that California requires you to file for permits galore to rebuild the exact same home that was there before on a burned down plot.
It’s hard to find anyone who seriously thinks this is acceptable.
Garrett: I was just talking about this today with a builder who lost their home in the Palisades Fire. Not only do they have to file for the permits, they are making them pay for them after everything they’ve been through which is totally unacceptable imo.
Cremieux: Have been hearing similar. Friend is trying to just sell his plot and move on because he doesn’t think he’ll be able to rebuild for years.
Garrett: They did cut *someof the red tape for some who are affected, so they don’t have to go through the entire permitting process but it’s still a bit much. I understand why it’s required, but they are so slow and tbh, they should not be charging for it.
They’re not all getting the entire value of their homes and property back and rebuilding a home that one may have had for decades is going to be so much more expensive now. Paying $15-50k+ for permitting is ridiculous when you consider how much in property taxes these folks pay.
Want to Build Back Better? At least you’re not going with the Biden version, here’s Ezra Klein explaining the 14 steps to apply for that funding, and Jon Stewart slowly realizing how absurd it is, and screaming, among other things, ‘OMFG.’ Bharat Ramamurti claims this is a ‘deeply misleading’ clip, that the process was like this because of GOP sabotage and wasn’t the design intention. Even if fully true, I do not feel it makes things that much better.
Kelsey Piper: ‘We’ve taken action to cut red tape’. ‘Did the action you took….work?’
Kane: Los Angeles has only issued 11 building permits for rebuilding after the fire, but the mayor is claiming with a straight face that “homes are under construction throughout the Palisades”
LA Mayor Karen Bass: Homes are under construction throughout the Palisades — ahead of expectations.
We’ve taken action to cut red tape and expedite the permitting process to get families home.
Kane: It gets worse lmao
Rachel Keuler: Only 1 of those permits is in the Palisades, where Karen Bass says that homes (plural) are under construction.
Zac Hill: “High School Zac Has Taken Action To Get Avril Lavigne’s Phone Number: News At Eleven”
It’s amazing that the claim of ‘homes under constructions’ isn’t even obviously literally true, as in it is not clear there are two of them.
The good news is that by all reports San Francisco is turning itself around on crime and quality of life, such as this report of spending a week seeing few homeless and no broken car windows, feeling fully safe.
Except that means:
Hunter: > SF turns itself around
> Still doesn’t build housing
> $5,000 median rent for a one-bedroom incoming
Armand Domalewski: Call me crazy but the fact that you need experience navigating San Francisco’s choppy political waters in order to build a small office building does not exactly make our city seem like a welcoming place for investment at a time where we very much need it.
Instead, they’re taking a bold stance that phone booths require sprinkler systems. Anyone with a rudimentary ability to think about the physical world understands that this is not motivated by worried about fire.
Last year, a Caltrain official built himself an illegal apartment inside a train station for $42k, and now we have pictures. The building already existed, so no even without legal issues you cannot simply build more of these, but yes we want a full explanation.
Sheel Mohnot: We finally have images of this apartment! A Caltrain official secretly built himself a hidden unit inside Burlingame station using $42k of public funds. It looks like a dorm room / a startup founders 1st office.
Armand Domalewski: I am genuinely curious why he was able to build this for $42k a unit. What costs did he avoid that he couldn’t avoid if he did this legally? If CA could build $42k unit studios we’d end homelessness in a year.
Debra Cleaver: for starters, the building itself already existed, and presumably was plumbed and wired for electricity. So I imagine he added furniture, appliances and made some sheetrock to divide the space?
Armand Domalewski: That is true for all modern office buildings yet office to apartment conversions are notoriously expensive.
Joe Cohen: Everyone’s response: “it’s impressive what he was able to do with $42k. Maybe he should be put in charge of CA housing.”
Each little requirement for apartments seems like a good idea, but add them all up and the costs involved escalate quickly. I wonder if what we should do is actively have a two-class housing structure (yes I know, young adult dystopian writers, eat your hearts out), where you can choose to be in either conforming or non-conforming housing.
Berkeley legalizes middle-housing city-wide, eliminating single-family housing, legalizing duplexes, quadplexes and small apartments.
YIMBY and abundance are scoring some impressive wins in California, including making CEQA (their version of NEPA) not apply to a broad range of housing.
This bill passed the Senate by 62-2. I’ve learned that such votes are remarkably not indicative of how close things were, but it still indicates no one is worried to vote yes.
Gavin Newsom is not holding back. On this issue he’s actually been impressive.
Gavin Newsom (Governor of California): To the NIMBY movement that’s now being replaced by the YIMBY movement, go YIMBYs. Thank you for your abundant mindset. That’s a plug for @ezraklein.
Yimbyland: ITS HAPPENING!!!
All new housing projects under 50 units in the state of California will be exempt from CEQA!! The state is finally coming to its senses!
Jerusalem: I honestly can barely believe this happened. Total YIMBY victory in California today. After Newsom signs this bill; CEQA will no longer apply to *anyinfill housing under 85’. No inclusionary zoning or labor provisions.
Armand Domalewski:
-
Except for SF projects over 50 units
-
Except for 100% affordable projects
(Both subject to prevailing wage still)
But otherwise yes!!!! 🙂
Alex Armlovich: It’s a huge deal but I want to manage national expectations of instant Austin-style outcomes until SB79 joins it
Partially rolling back CEQA for housing will make California *almost normal*…but still probably ranked ~44th in the US for enviro review
Elon’s My Hero: Now every building is going to be exactly 84.9 feet tall. That’s going to look… wonderful…
(I notice again how absurd the term ‘prevailing wage’ is, if it’s so prevailing why would you need a law to stop them hiring people for less money? Call the thing by its name, and it’s unclear how big a tax this is on projects or how much it will matter.)
I notice that you don’t actually get ‘every building is 84.9 feet tall’ style outcomes. People don’t actually push zoning options to their limits, people don’t optimize as much as they should.
Having CEQA apply to infill housing, or really almost any residential housing, was always a terrible idea. There are neighbors who can sue, so this interferes with ability to build almost anything. But very obviously, the ‘environmental’ impact of infill housing replacing existing low-value construction is mostly a fake concern. Instead, you drive sprawl, with construction going out into places you can actually do environmental damage, plus you discourage density when density helps a lot with carbon emissions as well, even disregarding the economic impacts.
About SB 79, that was introduced by Scott Weiner. It would legalize apartments near mass transit. The standard argument against this is that those new apartments would not be ‘affordable,’ and instead by ‘luxury’ homes. They would be too valuable to the people who live there, who would pay too high a price to reside in them. Oh no.
In the linked thread, Max Dubler makes the argument that they will still be cheaper than buying existing houses. That’s true enough, and if it convinces people, great. But it’s beside the point. The point is that we can build more housing where people want to live, that will be valuable to the people living there, creating lots of value and in turn will drive down rents elsewhere. More housing is good, let people build housing, in the places people want to live, especially where they’ll have access to mass transit.
I do have one worry with such bills. If you say that mass transit causes upzoning, will that cause cities to avoid building mass transit? Given how little mass transit gets built at this point, that’s a risk I am willing to take.
Is 2025 the last chance for California to build housing that lets it retain population for the 2030 redistricting, where it is projected to lose five house seats and thus electoral votes, importantly altering what maps win the presidency? Darrell Owens argues building a house takes five years. My presumption is that actually building by that time won’t have much effect on this scale.
But planning to build future housing does already help. Prices are forward looking and rational. So if more housing is coming, current prices should fall in anticipation, or demand should rise knowing it will be easier to stay in the future, in some combination.
On its face, this seems like a very big deal once the rules work their way through?
Michael Andersen: This Oregon bill, the first of its kind in the country that I’m aware of, just passed: 50-2 in the House, 28-2 in the Senate. A lot will depend on rulemaking, but this opens the door to a Japan-like system where the state defines its own version of lower-density zoning codes.
It’d pre-approve zoning & building permits for a state-defined catalog of 1-11 unit buildings on standard urban lots. two great laws that go great together.
Andrew Damito: Oregon’s legislature just passed HB 2258, which enables the state land use planning agency to preapprove a series of housing designs for structures up to 12 units, and require that cities auto-approve the structures anywhere, with very few exceptions.
WOW!
My thoughts?
-
The law falls into the same trap as other blue-state YIMBY laws as it relies heavily on rulemaking instead of simply vacating local restrictions, meaning we won’t see any regulatory changes for at least a year, and will take longer to see housing emerge from it.
-
There’s potential for homebuilding productivity increases through industrial scaling. If the state pre-approves prefab & modular housing designs, builders could lower costs through mass production. America’s disparate codes have prevented that.
-
The Oregon LCDC is very YIMBY, even using its rulemaking powers to end parking minimums in all Oregon cities through its Climate Friendly and Equitable Communities rulemaking in 2023. You can bet that they will be ambitious in pre-approving housing.
-
@andersem’s optimism that this opens the door to a Japanese-style state abrogation of lower density zoning isn’t unfounded.
This bill doesn’t just require approval of specific housing designs, the state can also set rules requiring approval of variances to the designs.
This all looks like it will add up to a pretty big deal (within Montana).
Michael Anderson (April 25): Last week, Montana voted to:
– legalize 6-story apartments on most commercial land
– sharply cut parking mandates
– limit excess impact fees
– cut condo defect liability
– require equal treatment for manufactured homes
– legalize single-stair buildings up to 6 stories statewide
headline we rejected for this article: “Montana is so YIMBY, it’s getting embarrassing”
A recent study found that eliminating parking minimums alone can boost new home construction by 40–70 percent.
Several narrower bills tackle other obstacles to housing construction.
-
SB 133, introduced by Senate Majority Leader Greg Hertz (R-Polson), limits the impact fees that cities charge developers, which increase the cost of construction. Specifically, it eliminates administrative fees, caps fees growth to inflation, and limits the imposition of fees to infrastructure projects that are directly linked to a proposed development.
-
Hertz also successfully ran bills to limit construction defect litigation (SB 143) and transfer decision-making on historical preservation permits from volunteer-run boards to professional city staff (SB 214).
-
SB 252, introduced by Sen. Dave Fern (D-Whitefish), requires cities to treat manufactured homes on equal footing as stick-built construction.
-
SB 532, introduced by Sen. Forrest Mandeville (R-Columbus), allows one ADU by right on parcels outside cities. (Hertz’s SB 528 from the prior session legalized ADUs within cities.)
-
Finally, SB 213, introduced by Sen. Daniel Zolnikov (R-Billings), puts Montana among states such as Connecticut and Washington that are re-legalizing single-stair residential buildings. SB 213 orders new rules for the state building code to allow for the construction of single-stair buildings up to six stories when they meet fire safety standards.
I too had no idea this one was in the works:
Matthew Yglesias: It seems like Maine quietly passed one of the most dramatic statewide upzoning bills I’ve ever heard of without anyone paying much attention.
Here’s what they changed, the big one is up front but the ADU help is great too:
-
At least three dwelling units allowed on any residential use lot.
-
Up to four units where served with water and sewer.
-
No more sprinkler requirements for most ADUs.
-
ADUs no longer limited to single family lots or conforming lots, and no longer require owner occupancy.
-
Subdivision review threshold raised from three units to five.
It still needs to get through the Senate and governor, but North Carolina State House unanimously (107-0) passed HB 369, a ban on parking minimums in new developments statewide. You can just prevent people from stopping you from doing things.
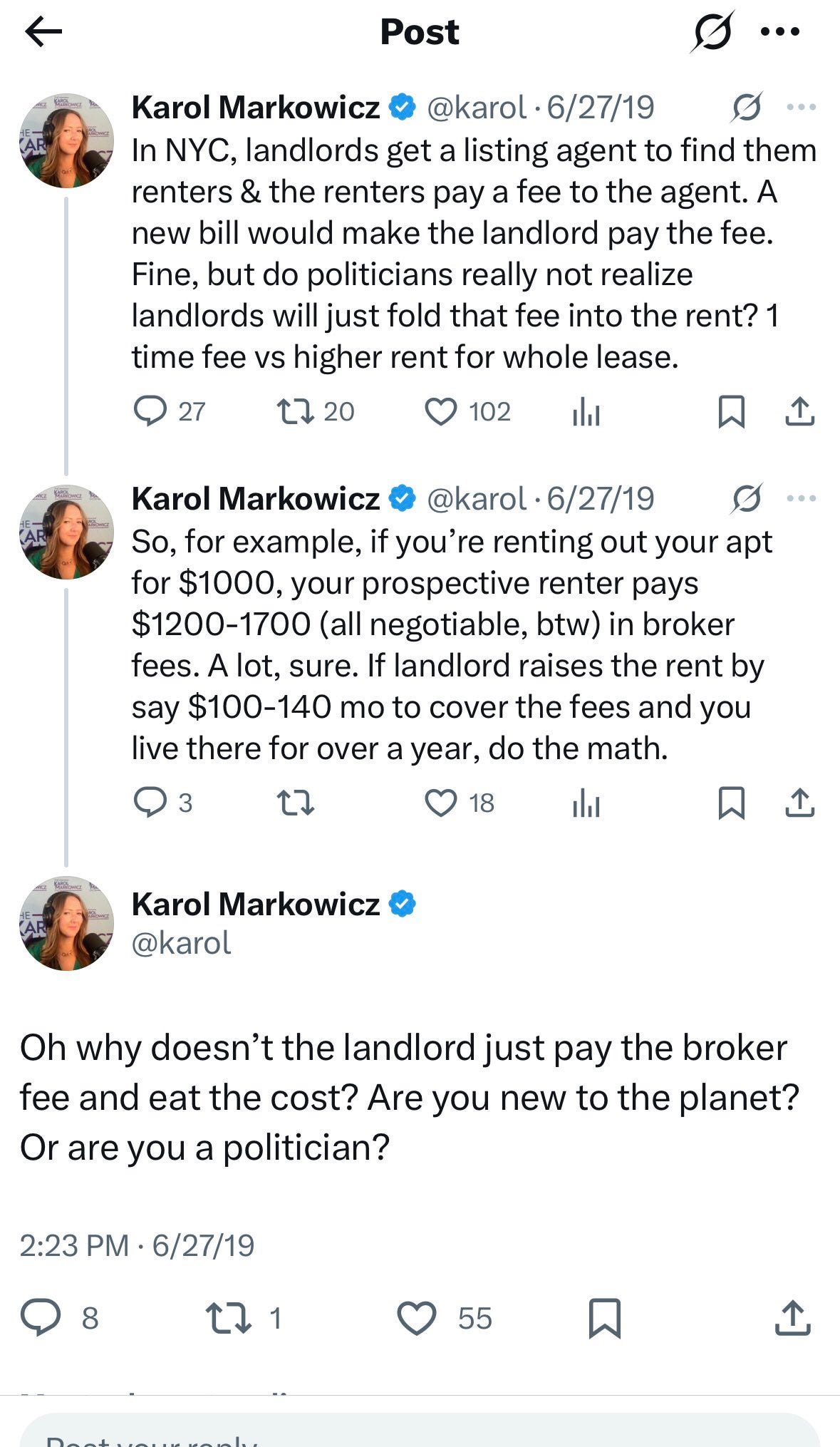
In new ‘who could have predicted it news,’ it turns out if you change how people pay the market clearing price doesn’t move and maybe the old system had its advantages? Maybe it was actually a stroke of genius to normalize the renter paying the agents, and we didn’t notice because New York City rent is too damn high despite this?
Gabrielle Fahmy: Rents jumping shocking 15% after NYC ditches broker fees: ‘It’s discouraging’
Rents shot up a shocking 15% in the week since the controversial FARE Act took effect, with the average rental in the Big Apple jumping from $4,750 to $5,500, according to an analysis by real estate analytics firm UrbanDigs.
The FARE Act, which prohibits agents representing property owners from charging renters a “broker fee,” also requires that all fees a tenant owes be included in rental agreements and real estate listings.
The law change has created what insiders tell The Post is a “shadow market” — apartments that aren’t listed so landlords can still get tenants to cover the fee.
“We’re going to be looking for apartments again like it’s 1999 … where you have to know who to call and when to call,” said Jason Haber, co-founder of the American Real Estate Association and a broker at Compass. “It’s going to be an odyssey.”
Renters meanwhile have been sharing horror stories online, with receipts — like screenshots of conversations with brokers flat out telling them they get one price if they pay the broker fee and another, much higher rate, if they don’t.
…
Another said a landlord was asking $6,800 for a 3-bedroom with a broker fee — or $8,000 with no fee, which is illegal to advertise under the new law.
Karol Makowicz: Who could have seen this coming.
Typical broker fee is 15% of rent, getting rid of that fee on a one year least meant rent went up 15%, wow, who could have predicted this. The average lease lasts 3-4 years, in theory the price should drop back down for future years.
I presume it mostly won’t and tenants are in general a lot worse off now. There is some value in getting that up front payment up front, but it’s clearly not worth the marginal price that has attached. So we had this great trick, and it is gone now. Damn.
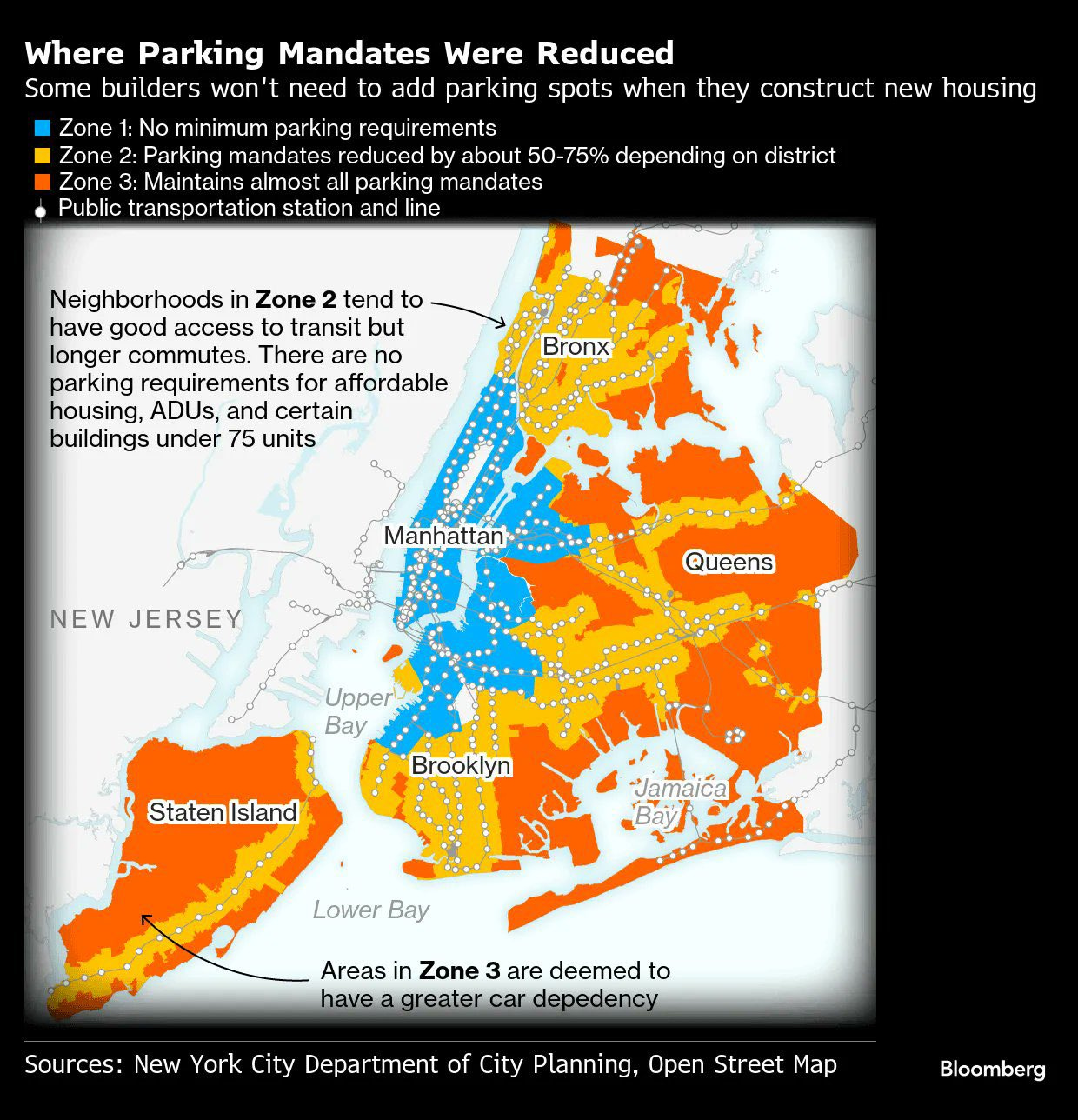
Meanwhile, we’ve managed to get rid of parking requirements in the full core, but they alas live on in much of the city, so this is a chart of where you want to live in New York City, be in the blue area, or at least be in yellow. Red doesn’t even count, that’s suburbs.
Also, yes it would help if New York didn’t require all elevators be large enough to let a wheelchair turn around. I get that it’s nice to be able to do that but this actually substantially raises construction costs, and wheelchairs can go backwards.
No, you fools!
Bernard Stanford: This is the equivalent of taxing everyone who pays their rent to fund a subsidy program for people who decide they’d rather not.
Gintautas Dumcius: Eviction records can now be sealed in Massachusetts.
Bernard Stanford: If “one tough chapter” doesn’t bare on a person’s future, but landlords are sub-optimally biased, then the state could step on with an insurance scheme and provide benefit while profiting.
…
Even cases of actual misconduct, not simply failure to pay, are eligible to be sealed! Landlords don’t have the right to know whether a prospective tenant was violent or threatening towards a past landlord? Note that criminal records are also sealable in Massachusetts.
The ultimate consequence is quite simple:
-
The added costs and dangers of being a landlord increase
-
At the margin, landlords will sell rental properties to become SFH, or opt not to purchase new construction to rent, or opt not to buy buildings and convert them to rentals
-
The availability of rentals decreases
-
Due to scarcity, average rent rises
Hence everybody pays more and is worse off, except those who welch on their rent or break the terms of their lease and get evicted, who are now relieved of some of the consequences of their past actions.
Adam Rezabek: There is also another consequence: landlords will have to use all stereotypes known to men to try and guess which prospective tenant will be an issue and which will be not. Ofc this isn’t legal, but I think it will happen regardless
Do not underestimate the effect Rezabek refers to. I remember that ‘ban the box’ rules that prevented checking job applicants for criminal records similarly ended up hurting exactly the groups with criminal records, because of updates on (lack of) evidence. A similar pattern will no doubt happen here, on all correlations, legal or otherwise.
This also likely decreases new constructions outright.
Mostly it increases rents and moves a lot of rental stock off the market. I do expect a substantial impact here. A bad renter is expensive. Now, not only can you not filter out past bad renters, renters know that if they defect they can have their records sealed. So not only do you get negative selection, everyone will behave way worse.
There’s some great bills passing that would be awesome as national standards.
YIMBYLAND: SMALL LOT STARTER HOMES PASSES IN TEXAS AFTER NEARLY DYING
– 3,000 sf lots
– 31 units/acre by-right in SF zones
– 5′ max setbacks
– Limits parking mandates to 1 space/unit, no carport mandates
– Developers can sue for delays, cities pay damages
– 5 acres required for development
This is a neutered version of the bill, but it’s still a great start.
YIMBYLAND: TEXAS PASSES 6-STORY SINGLE-STAIR BILL! 🤠
– Legalizes 6-stories, 4-units/floor, in TX state building code
– Cities that adopt standard amendments to state building code would by-default legalize 6-story single-stair apartments
– Paves way for streamlined adoption by cities
I feel like I’m getting annoying at this point, but this could be you if your state had the courage. It is 100% possible to make real, impactful, housing reforms and Texas is leading the way.
It gets better:
Alex Armlovich: Texas SB840 is ending single-use commercial zoning, allowing apartments on top of habitable commercial uses statewide
This is by far the most muscular “Residential in Commercial Zoning” preemption bill I’ve ever seen
All the loopholes closed + a right of private action (!)
This bill is a bullseye painted on Dallas’s dogshit terrible zoning code & weak permitting process
Even after Austin’s recent reformist turn, I think this bill will have a measurable impact. And Houston too!
But Dallas is the biggest baddest NIMBY. And they got rolled 😂👏
YIMBYLAND: This law legalizes development & preempts cities over 150k from imposing
– Density limits below 36 unit/acre
– Heigh restrictions below 45ft
– Setbacks over 25ft
– Parking reqs over 1/unit
Poland is the latest story of building more houses and housing costs going down.
Acts Maniac: nobody in Europe is talking about the polish housing supply miracle.
The median household in polish cities (!) now only spends 13% of their income on housing.
They build about 200k units a year for a 36 million people country.
Michal Mynarski: why so? The difference of quantity and quality of shelter you can get for the same percentage of min/avg pay within last 15 years is outstanding. When I get to Wroclaw in 2011 usual price for a room was 2/3 min salary. Right now you can easily find a studio in that range.
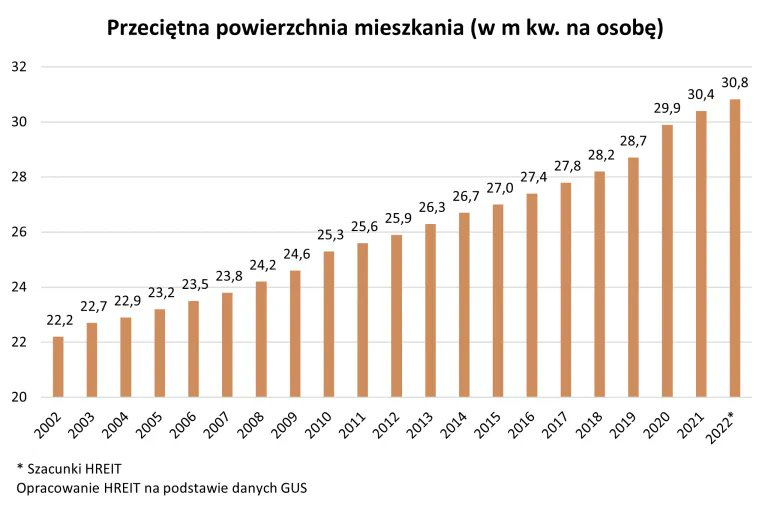
As usual note the y-axis starts around 12 on the first chart, but this is still a huge decline. The second chart is space per person.