How bad is it? What is causing the massive, catastrophic declines in fertility?
What can we do to stabilize and reverse these trends to a sustainable level?
Today I’m going to focus on news about what is happening and why, and next time I’ll ask what we’ve learned since last check-in about we could perhaps do about it.
One could consider all this a supplement to my sequence on The Revolution of Rising Expectations, and The Revolution of Rising Requirements. That’s the central dynamic.
Lyman Stone: Five Basic Arguments for Understanding Fertility:
Data has to be read “vertically” (longitudinally), not “sideways” (cross-sectionally)
No variable comes anywhere close to “survey-reported fertility preferences” in terms of ability to explain national fertility trends in the long run
People develop preferences through fairly well-understood processes related to expected life outcomes and social comparison
The name for the theory which best stands to explain why preferences have fallen is “developmental idealism.”
Countries with fertility falling considerably below desires are doing so primarily due to delayed marriage and coupling
TANGENTIALLY RELATED BONUS: Education reduces fertility largely by serving as a vector for developmental idealism in various forms, not least by changing parenting culture.
The central point of idea #1 is you have to look at changes over time, as in:
If you can tell Italy, “When countries build more low-density settlements, TFR rises,” that is orders of magnitude more informative than, “Countries with more low-density settlements have higher TFR.”
The first statement is informing policymakers about an actual potentiality; the second is asking Italy to become Nepal.
The overall central thesis:
“Falling child mortality means people don’t need to have as many kids to hit their family goals, and those family goals are themselves simply falling over time.”
…
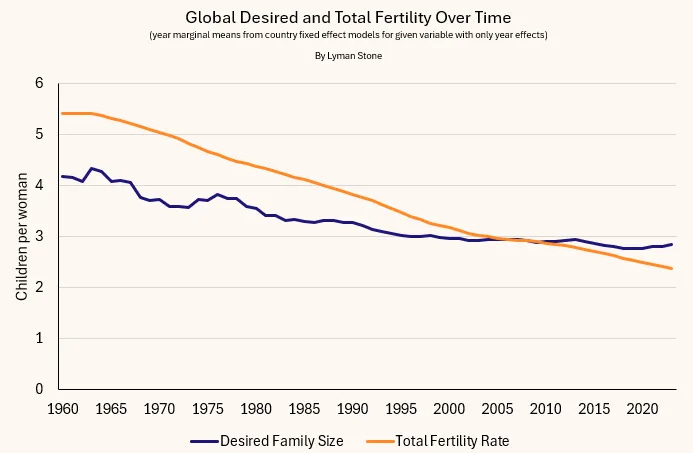
Both actual and desired fertility have fallen since 1960, but actual fertility has fallen much more. The biggest reason for this is actual fertility is also influenced by child mortality, which has fallen a lot since 1960.
So in this model, the question becomes why are desired family sizes falling?
Lyman thinks this mostly comes down to comparisons with others (he explicitly doesn’t want to use the word ‘status’ here).
And his thesis is essentially that people around the world saw European wealth, found themselves ‘at the bottom’ of a brand-new social scale, and were told to fix this they had to Westernize, and Western culture causes the fertility decline.
This doesn’t explain where the Western desire for smaller families came from.
I also don’t think that this is why Western culture was adapted. I think Western culture is more attractive to people in various ways – it largely wins in the ‘marketplace of ideas’ when the decisions are up to individuals. Which I think is largely the level at which the decisions are made.
People’s severe pessimism, and inability to understand how good we have it, is making all these issues a lot worse.
Ben Landau-Taylor: Knowing a decent amount of history will cure lots of fashionable delusions, but none quite so hard as “How could anyone bring a child into a world as remarkably troubled and chaotic as the year 2025”.
Matt McAteer: Historical periods with names like “The Twenty Years’ Anarchy”, “The Killing Time”, “The Bronze Age Collapse”…or god forbid, “The Great Emu War”…2025 doesn’t seem so bad by comparison.
Nested 456: My mother grew up playing in bomb sites in northern England right after WW2. Really we’re spoiled brats in comparison
Are there big downsides and serious issues? Oh, definitely, atomization and lack of child freedoms and forms of affordability are big problems, and AI is a big risk.
Handy and Shester do offer an explanation for a lot of it, pointing to decline in maternal mortality, saying this explained the majority of increases in fertility. That is certainly an easy story to tell. Having a child is super scary, so if you make it less scary and reduce the health risks you should get a lot more willingness to have more kids.
Tyler Cowen sees this as a negative for a future baby boom, since maternal mortality is now low enough that you can’t pull this trick again. The opposite perspective is that until the Baby Boom we had this force pushing hard against having kids and people had tons of kids anyway, whereas now it is greatly reduced, so if we solve our other problems we would be in a great spot.
The paperwork issue is highly linked to the safety obsession issues, but also takes on a logic all its own.
As with car seat requirements, the obvious response is ‘that’s silly, people wouldn’t not have kids because of that’ but actually no, this stuff is a nightmare, it’s a big cost and stress on your life, it adds up and people absolutely notice. AI being able to handle most of this can’t come soon enough.
Katherine Boyle: We don’t talk enough about how many forms you have to fill out when raising kids. Constant forms, releases, checklists, signatures. There’s a reason why litigious societies have fewer children. People just get tired of filling out the forms.
The forms occasionally matter. But I’ve found you don’t have to fill out the checklists. Pro tip. Throw them away.
Blake Scholl: I was going to have more children but the paperwork was too much.
Sean McDonald: It’s shocking how many times I’ve been normied in the circumstance I won’t blindly sign a parent form. People will get like..actually mad if you read them.
Nathan Mintz: An AI agent to fill out forms for parents – will DM wiring information later.
Cristin Culver: It’s 13 tedious steps to reconfirm to my children’s school district that the 13 forms I uploaded last time are still correct. 🥵
Back in 2022 I wrote an extended analysis on car seats as contraception. Prospective parents faced with having to change cars, and having to deal with the car seats, choose to have fewer children.
People think you can only fit two car seats in most cars. This drives behaviors remarkably strongly, resulting in substantial reductions in birth rates. No, really.
The obvious solution is that the extent of the car seat requirements are mostly patently absurd, and can be heavily reduced with almost no downsides.
It turns out there are also ways to put in three car seats, in many cases, using currently available seats, with a little work. That setup is still annoying as hell, but you can do it.
The improved practical solution is there is a European car seat design that takes this to four car seats across a compact. It can be done. They have the technology.
In an even stupider explanation than usual, the problem is that our crash test fixtures that we use cannot physically include a load leg, so we cannot test the four car seat setup formally, so we cannot formally verify that they comply with safety regulations.
Scarlet Astrorum: I know why we can’t have 4 kids to a row in the car and it’s a silly regulatory thing. Currently, US testing protocols do not allow crash testing of U.S. car seats that feature a load leg, similar to the British four-seater Multimac (pictured).
The crash test fixture itself is designed so it cannot physically include a load leg. The sled test fixture does not have a floor so there is no place to attach a load leg.
This means safe, multiple-kid carseats used widely in Europe can’t even be *evaluatedfor safety- it’s not that they break US safety regulations, they just can’t even attach onto the safety testing sled, which is all seat (also pictured).
To test the 4-kid carseats which use a load arm, there are already functional test fixtures, like the ECE R129 Dynamic Test Bench, pictured here, which has a floor. We just need to add this as a testing option. Manufacturers could still test with the old sled.
What needs to change: 49 CFR § 571.213 s10.1-4 and Figure 1A which lock you in to testing with a floorless sled All that needs to change is updating the wording to clarify test positioning for a sled with a floor as well.
You would also have to spread the word so people know about this option.
David Holz: i find it so strange when people say they can’t afford kids. your ancestors were able to afford kids for the last 300,000 years! are we *reallyless wealthy now? you might think your parents were better off, but how about further back? they still went on.
Scarlet Astrorum: What people mean when they say this is often “I am not legally allowed to raise children the way my poor ancestors did”
Personally I only have to go back 2 generations to find behavior that I think is reasonable given circumstances but would be currently legally considered neglect
“I will not risk the custody of my existing children to raise more children than I can supervise according to today’s strict standards” is unfortunately a very reasonable stance. Of course, there are creative workarounds, but they are not uniformly available
That is indeed about what it costs to raise a child. If you shrink that number dramatically, the result would be very different, at least in America.
America has the unique advantage that we want to have children, and like this man we are big mad that we feel unable to have them, usually because of things fungible with money. So we should obviously help people pay for this public good.
Heather Long: Goldin concludes that two factors explain much of the downward trend by country: the speed at which women entered the workforce after World War II, and how quickly men’s ideas about who should raise kids and tidy up at home caught up. This clash of expectations explains the fertility decline across the globe.
In places where men do more around the house, fertility rates are higher, where they do less, rates are lower.
Even the green bars are 1.7-1.8. That’s still below 2.1, even with a somewhat cherry-picked graph.
Also this is rather obviously not the right explanatory variable.
Why should we care about how many hours of housework a woman does more than the man, rather than the number of hours the woman does housework at all?
The suggestion from Goldin is more subsidized child care, but that has a long track record of not actually impacting fertility.
The actual underlying thing is, presumably, how hard it is on the woman to have children, in terms of both absolute cost – can you do it at all – and marginal cost versus not doing it. The various types of costs are, again presumably, mostly fungible.
The idea that ‘50-50’ is a magic thing that makes the work go away, or that it seeming fair would take away the barrier, is silly. The problem identified here is too much work, too many costs, that fall on the woman in particular, and also the household in general.
One can solve that with money, but the way to do it is simply to decrease the necessary amount of work. There used to be tons of housework because it was physically necessary, we did not have washers and dryers and dishwashers and so on. Whereas today, this is about unreasonable standards, and a lot of those standards are demands for child supervision and ‘safety’ or ‘enrichment’ that simply never happened in the past.
Ruxandra Teslo: One’s 30s are a crucial period for professional advancement. Especially in so-called “greedy careers”: those where returns to longer hours are non-linear.
But one’s mid 30s is also when most women’s fertility starts to drop.
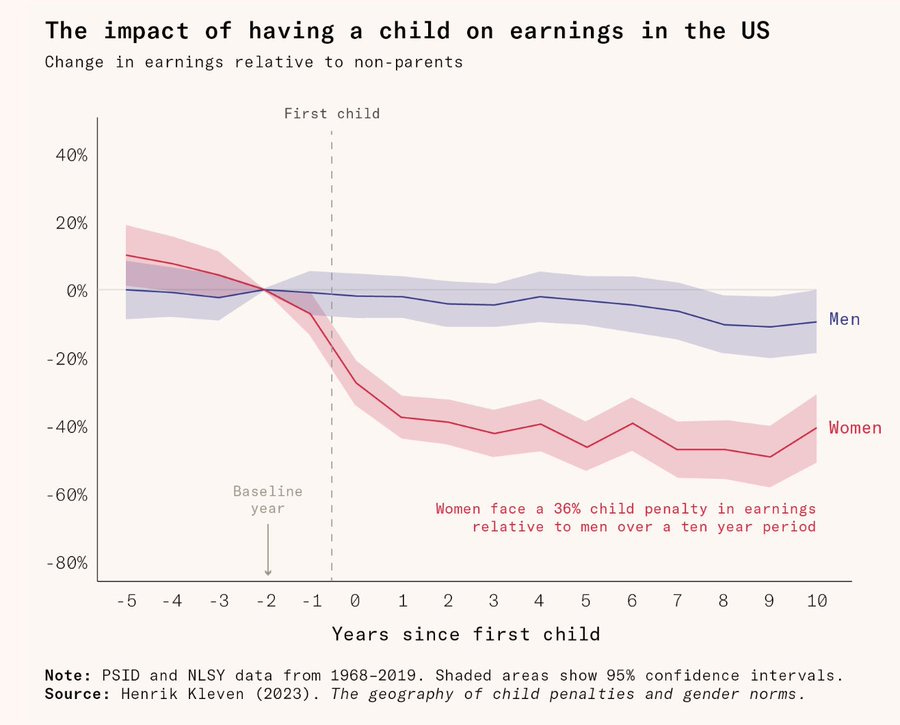
In this piece, I lay out how a large part of the “gender pay gap” is just this: a motherhood pay gap. And, as Nobel Laureate Claudia Goldin points out, this is particularly true in high-stakes careers like business, law, medicine, entrepreneurship and so on.
This reduction in earnings is not just about money either: it’s about general career advancement and personal satisfaction with one’s profession. Time lost in one’s 30s is hard to recuperate from later on.
In law, for example, one’s 30s is when the highest levels of salary growth take place. Founders who launch unicorns (startups worth more than a billion dollars) have a median age of 34 when they found their companies. In academia, one’s thirties are usually the time when a researcher goes through a string of high-pressure postdoctoral positions in an attempt to secure an independent position.
Aware of this, women delay pregnancy until they have advanced in their careers as far as possible. This is especially true for women w/ professional degrees. Women without a bachelor’s degree tend to have 1 to 1.5 children on ~ by age 28, while those with higher educational attainment have around 0.25 children by same age.
Highly educated women attempt to catch up during their 30s, with their birth rates increasing more rapidly. However, this compensatory period is limited, as fertility rates across all education levels tend to plateau around age 39. Thus, the educated group ends up with less kids.
The chance of conceiving a baby naturally with regular sex drops from 25 percent per month in one’s twenties to about five percent per month at 40, while the chance of miscarrying rises from about eight percent for women under 30 to around one in three for 40-year-olds.
[thread continues and morphs into discussing technological fertility solutions]
From Her Article: Women know this gap exists and plan accordingly: in countries where the motherhood penalty is keenest, the birth rate is lower.
…
We have come a long way from the explicit sex discrimination of the past. Today, the gap is primarily driven by the career toll exacted by motherhood.
A lot of the problem is our inability to realistically talk and think about the problem. There’s no solution that avoids trading off at least one sacred value.
It’s definitely super annoying that when you have kids you have to earn your quiet. This both means that you properly appreciate these things, and also that you understand that they’re not that important.
Hazal Appleyard: When you watch stuff like this as a parent, you realise how truly empty and meaningless all of those things are.
Destind for Manifest: “I don’t want children because it would keep me away from my favorite activities which are watching cartoons, doing silly hand gestures and taking videos of my daily life, all while keeping an exaggerated smile on my face at all times”
Literally the perfect mom
Yashkaf: your life isn’t child-free. you *arethe child
no one’s making “my child-free life” content about using the spare 6 hours each day to learn some difficult skill or write a book or volunteer at a hospice
it’s always made by people who don’t seem to have plans, goals, or attention spans longer than an hour
Becoming a parent also makes it extremely logistically tricky to go to the movies, or to go out to dinner, especially together. Beyond that, yes, obviously extremely tone deaf.
The basic principle here is correct, I think.
Which is, first, that most people have substantial slack in their living expenses, and that in today’s consumer society your expenses will expand to fill the funds available but you’d probably be fine spending a lot less. Digital entertainment in particular can go down to approximately free if you have the internet, and you’ll still be miles ahead of what was available a few years ago at any price.
And second, that if you actually do have to make real sacrifices here, it is worth doing that, and historically this was the norm. Most families historically really did struggle with material needs and make what today would seem like unthinkable tradeoffs.
Also third, although she’s not saying it here, that not being able to afford it now does not mean you can’t figure it out as you go.
Amanda Askell: My friends just had a baby and now I kind of want one. Maybe our species procreates via FOMO.
I have bumped up the dating value of aspiring stay at home partners accordingly, on the off chance that I ever encounter one.
Another key form of motivation is, what are you getting in return for having kids? In particular, what will your kids do for you? How much will they be what you want them to be? Will they share your values?
The post mostly focuses on the various ways Indian parents shape the experiences of their children including getting transfers of resources back from them but mostly about upholding cultural and religious traditions, and how much modernity is fraying at that. For many, that takes away a strong reason to have kids.
Robert Sterling: I know a huge number of people in their 60s and 70s with one grandchild at most. Many with zero.
These people had 3-4 kids of their own, and they assumed their kids would do the same. They planned for 10-15 grandkids at this age.
Not for me to judge, but it’s sad to see.
I have little doubt that those considering having kids are not properly taking into account the grandparent effect, either for their parents or in the future for themselves.
Throughout, the frame is ‘of course my children should be able to make their own choices about whether to have kids,’ and yes no one is arguing otherwise, but this risks quickly bleeding into the frame of ‘no one else’s preferences should factor into this decision,’ which is madness.
It also frames the tragedy purely in experiential terms, of missing out on the joy and feeling without purpose. It also means your line dies out, which is also rather important, but we’ve decided as a society you are not allowed to care about that out loud.
Mason: I really hope I am able to say whatever I need to say and do whatever I need to do for my children to have some grasp of what a complex and transcendent joy it is to bring a new person into the world.
My daughter’s great-grandfather is dying at hospice. He is not truly present anymore.
Even when he was able to first meet her, he was not always fully there.
But a few times he did recognize me, so he knew who she was, and he would not eat so that he could just watch her toddle around.
I do not know how to explain it, man. At the very end, when you barely even remember who you are, the newest additions to your lineage hold you completely spellbound.
He would just stare at her and say, “She never even cries,” over and over, so softly.
The flip side is that parents, who are prospective grandparents, seem unwilling to push for this. Especially tragic is when they hoard their wealth, leaving their kids without the financial means to have kids. There is an obviously great trade for everyone – you support them financially so they can have the kids they would otherwise want – but everyone is too proud or can’t admit what they want or wants them to ‘make it on their own’ or other such nonsense.
I appreciated this part of her framing: Having kids is now ‘opt-in,’ which is great, except for two problems:
We’ve given people such high standards for when they should feel permission to opt-in. Then if they do go forward anyway, it is common to mostly refuse to help.
Because it is opt-in, there’s a feeling that the kids are therefore not anyone else’s responsibility, only the parents, at least outside an emergency. Shirking that responsibility hurts the prospect of having grandparents, as any good or even bad decision theorist knows, and thus does not improve one’s life or lineage.
I do not agree with her conclusion that therefore contraception, which enables us to go to ‘opt-in,’ is bad actually. That does not seem like the way to fix this problem.
On top of how impossible we’ve made raising kids, and then we’ve given people the impression it’s even more impossible than that.
Potential parents are also often making the decision with keen understanding of the downsides but not the upsides. We have no hesitations talking about the downsides, but we do hesitate on the upsides, and we especially hesitate to point out the negative consequences of not having kids. Plus the downsides of having kids are far more legible than the benefits of kids or of the downsides of not having kids.
Zeta: crying in a diner bathroom because life has no end goal or meaning, the one person who feels like family is as unhappy as you are, you can’t eat bread, you kinda want kids but every time you spend time with other people’s kids it seems waaayyyy too high maintenance, your elderly parents/your only real home are fading and close to death as are impossibly young kids with weird-ass cancers that should be solvable but humans fuck it up and what is even the point of anything
I don’t know how parents do it, like I get excited to have kids purely as a genetics experiment and then I spend time with them and it’s non-stop chores which are tedious and boring like with a puppy but also not chill like a puppy because it’s a future human but you can’t talk to them about mass neutrophil death in bone formation when they ask questions that necessitate it
also I know I don’t believe in academia or science but I need to believe in something – like I need someone to let me rant about what we know for sure in development- otherwise it’s just a chaotic mass of noise hurtling towards a permanent stop just as turbulent and meaningless as the start
eigenrobot: there’s a lot of that but you kinda stop noticing it because there’s a lot of this too
Mason: Kids are hard but they are 100% better than this, the “what’s even the point” malaise that a lot of us start to feel because we are people who are meant to be building families and our social infrastructure was ill-suited to get everyone to do it in a timely fashion
I don’t know if it’s a blackpill or a whitepill, but I do think you have to pick your poison a little bit here
Kids will overwhelm you and deprive you of many comforts for a time, life without them may gradually lead you to become a patchwork of hedonistic copes
Again I struggle to explain the “upside” of parenthood bc it doesn’t lend itself to tabulation. I don’t just *likemy kids, they are the MOST everything. They are little glowing coals in a cold and uncaring universe. I hold that dear when I am cleaning the poop off the walls
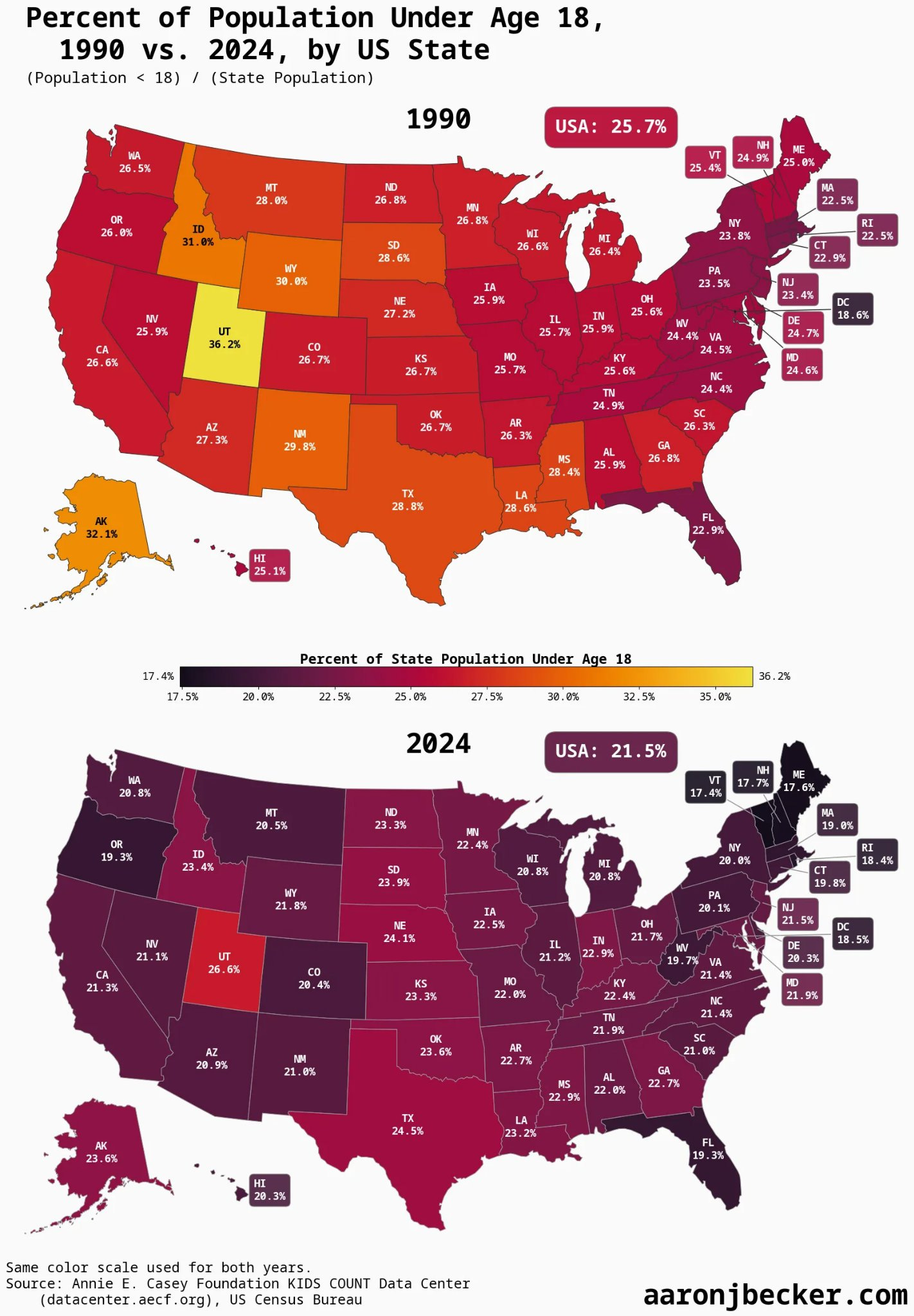
The shading here makes it look a lot more dire than it is, but yes a lack of other kids makes it tougher to have or decide to have your own.
Mason: 50 years ago, about 1 in 3 of the people around you were children. Now it’s about 1 in 5. That makes a huge difference when it comes to the availability of infrastructure for kids, convenient playmates, family activities.
For a lot of young people, parenting just looks isolating.
This is one of the underappreciated ways a population collapse accelerates: when fewer people have kids, fewer people in the age cohort behind them see what it’s like having kids, and it just seems like a strange thing that removes you from public life and activities.
That’s one reason I think the (fraction of) pronatalists who advocate excessive use of childcare to make parenting less disruptive to their personal lives are counterproductive to their cause.
Constantly trying to get away from your kids to live your best life sends a message.
n an ideal world, most adults have some kids, and society accomodates them to a reasonable degree because it wants their labor and their money
Unofficial kid zones pop up everywhere, indoors and out. Low-supervision safety features are standard to the way things are built.
The first best solution is different from what an individual can do on the margin.
I see the problem of childcare as not ‘the parents are spending too little time with the kids’ but rather ‘we require insane levels of childcare from parents’ so the rational response is to outsource a bunch of that if you can do it. The ideal solution would be to push back on requiring that level of childcare at all, and returning to past rules.
This is at least a little misleading, since desire to have children is a major cause of coupling, and marginal couples should on average be having fewer children. But I do accept the premise to at least a substantial degree.
Also noteworthy is having less education means a bigger decline:
This is happening worldwide, and Alice claims it corresponds with the rise in smartphones. For America I don’t see the timing working out there? Seems like the declines start too early.
The first explanation is that wives are treated rather horribly by their in-laws and new family, which I can totally see being a huge impact but also isn’t at all new? And it’s weird, because you wouldn’t think a cultural norm that is this bad for your child’s or family’s fertility would survive for long, especially now with internet connectivity making everyone aware how crazy it all is, and yet.
Camus: South Korea is quietly living through something no society has ever survived: a 96% population collapse in just four generations — with zero war, zero plague, zero famine.
100 people today → 25 children → 6 grandchildren → 4 great-grandchildren. That’s it. Game over for an entire nation by ~2125 if fertility stays where it is (0.68–0.72).
No historical catastrophe comes close:
– Black Death killed ~50% in a few years
– Mongol invasions ~10–15% regionally
– Spanish flu ~2–5% globally
South Korea is on pace to lose 96% of its genetic lineage in a single century… peacefully.
We shut down the entire world for a virus with 1–2% fatality. This is 96% extinction and the silence is deafening.
Japan, Taiwan, Italy, Spain, Singapore, Hong Kong, Poland, Greece — all following the same curve, just 10–20 years behind.
Robots, AI and automation might mitigate the effects along the way and prevent total societal collapse for a while, but there would soon be no one left to constitute the society. It would cease to exist.
It’s so tragic that a lot of this is a perception problem, where parents think that children who can’t compete for positional educational goods are better off not existing.
Timothy Lee: Parenting norms in South Korea are apparently insane. American society has been trending in the same direction and we should think about ways to reverse this trend. The stakes aren’t actually as high as a lot of parents think they are.
Phoebe Arslanagic-Little (in Works in Progress): South Korea is often held up as an example of the failure of public policy to reverse low fertility rates. This is seriously misleading. Contrary to popular myth, South Korean pro-parent subsidies have not been very large, and relative to their modest size, they have been fairly successful.
… In South Korea, mothers’ employment falls by 49 percent relative to fathers, over ten years – 62 percent initially, then rising as their child ages. In the US it falls by a quarter and in Sweden by only 9 percent.
South Koreans work more hours – 1,865 hours a year – in comparison with 1,736 hours in the US and 1,431 in Sweden. This makes it hard to balance work and motherhood, or work and anything else.
… Today, South Korea is the world’s most expensive place to raise a child, costing an average of $275,000 from birth to age 18, which is 7.8 times the country’s GDP per capita compared to the US’s 4.1. And that is without accounting for the mother’s forgone income.
… But South Korea is even worse. Almost 80 percent of children attend a hagwon, a type of private cram school operating in the evenings and on weekends. In 2023, South Koreans poured a total of $19 billion into the shadow education system. Families with teenagers in the top fifth of the income distribution spend 18 percent ($869) of their monthly income on tutoring. Families in the bottom fifth of earners spend an average of $350 a month on tutoring, as much as they spend on food.
Because most students, upon starting high school, have already learned the entire mathematics curriculum, teachers expect students to be able to keep up with a rapid pace. There’s even pejorative slang for the kids who are left behind– supoja – meaning someone who has given up on mathematics.
The article goes on and things only get worse. Workplace culture is supremely sexist. There’s a 1.15:1 male:female ratio due to sex selection. Gender relations have completely fallen apart.
The good news is that marginal help helped. The bad news is, you need More Dakka.
Every South Korean baby is now accompanied by some $22,000 in government support through different programs over the first few years of their lives. But they will cost their parents an average of roughly $15,000 every year for eighteen years, and these policies do not come close to addressing the child penalty for South Korean mothers.
… For each ten percent increase in the bonus, fertility rates have risen by 0.58 percent, 0.34 percent, and 0.36 percent for first, second, and third births respectively. The effect appears to be the result of a real increase in births, rather than a shift in the timing of births.
Patrick McKenzie: I don’t think I had clocked “The nation we presently understand to be South Korea has opted to cease existing.” until WIP phrased baked-in demographic decline in the first sentence here.
Think we wouldn’t have many lawyers or doctors if we decided “Well we tried paying lawyers $22k once, that didn’t work, guess money can’t be turned into lawyers and that leaves me fresh out of ideas.”
If you ask for a $270k expense, and offer $22k in subsidy, that helps, but not much.
The result here is actually pretty disappointing, and implies a cost much larger than that in America. The difference is that in America we want to have more kids and can’t afford them, whereas in South Korea they mostly don’t want more kids and also can’t afford them. That makes it a lot harder to make progress purely with money.
It’s plausible that this would improve with scale. If the subsidy was $30k initially and then $15k per year for 18 years, so you can actually pay all the expenses (although not the lost time), that completely changes the game and likely causes massive cultural shifts. The danger would be if those funds were then captured by positional competition, especially private tuition and tutoring, so you’d need to also crack down on that in this cultural context. My prediction is if you did both of those it would basically work, but that something like that is what it would take.
Robin Hanson points us to this article called The End of Children, mostly highlighting the horror show that is South Korea when it comes to raising children.
Timothy Taylor takes a shot at looking for why South Korea’s fertility is so low, nothing I haven’t covered before. I’m increasingly leading to ‘generalized dystopia’ as the most important reason, with the mismatch of misogyny against changing expectations plus the tutoring costs, general indebtedness and work demands being the concrete items.
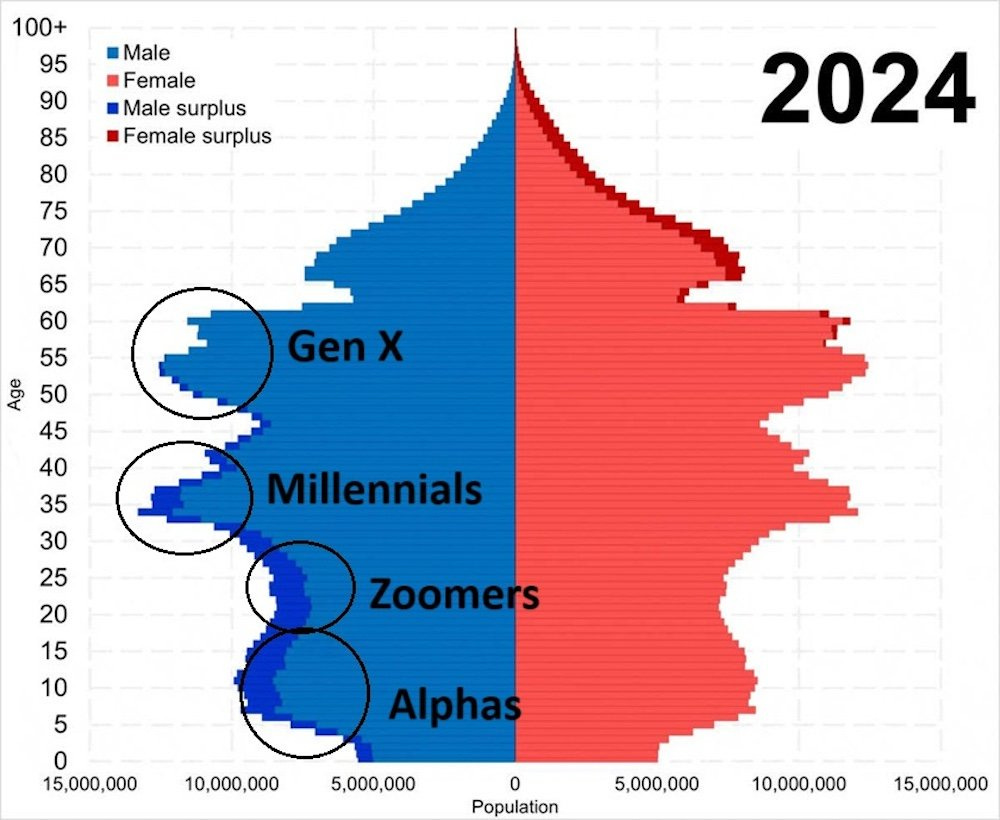
As a reminder, these are the demographics, they do not look good at all, watch the whole chart slowly creep older and the bottom crisis zone that started in 2020 expand.
• The last large cohort of women, those aged 34 to 39, is rapidly moving into the non-reproductive age range.
• There is an extreme surplus of males. More than 30 million. These are men who cannot possibly find a wife, an enormous population of incels by mathematical necessity.
• Since around 2020, the number of children born has completely collapsed and shows no sign of recovery. In a few decades, China will be full of elderly people and short on workers.
Marko Jukic: There is not going to be a Chinese century unless they become the first industrialized country to reverse demographic decline. Seems unlikely, so the default outcome by 2100 is a world poorer than it is today, as we aren’t on track to win the century either.
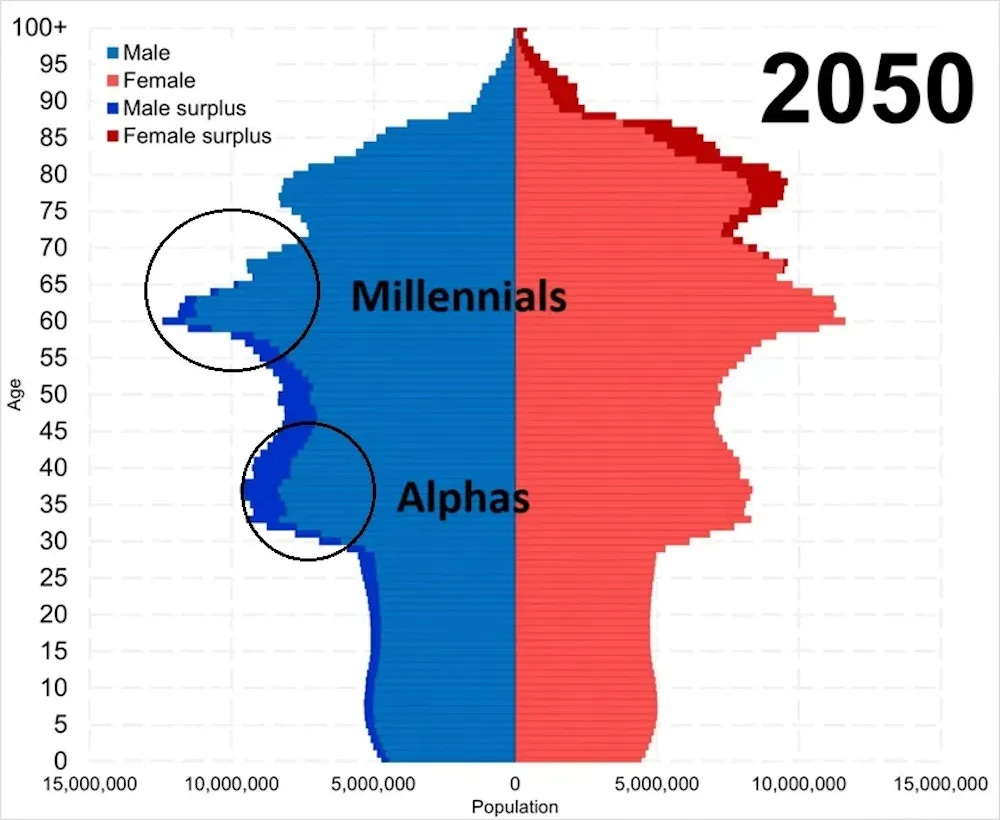
AI will presumably upend the game board one way or another, but the most absurd part is always the projection that things will stabilize, as in:
The article has that graph be ‘if China’s fertility rate doesn’t bounce back.’ Whereas actually the chart here for 2050 is rather optimistic under ‘economic normal’ conditions.
One change in particular seems helpful, which is that if a parent gifts the couple real property, it stays with their side of the family in a divorce. I like this change because it makes it much more attractive to give the new couple a place to live, especially one big enough for a family. That’s known to have a big fertility impact.
What impact will that have on fertility?
Samo Burja: China might have just undertaken the most harsh and serious pro-fertility reform in the world.
It won’t be enough.
But this shows they have political will to solve fertility through any means necessary even if it doesn’t look nice to modern sensibilities.
Ben Hoffman: This doesn’t seem well-targeted at fertility. If fertility is referenced it’s a pretext.
Dan Elton: Douglas Murray seems right on this point — “Western” culture will survive, but specifically European cultures will not, except for small vestiges maintained for tourists.
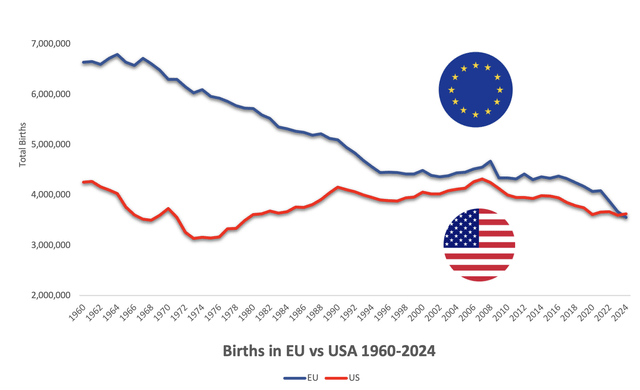
Francois Valentin: For the first time in its history the EU recorded fewer births in 2024 than the US.
Despite having an extra 120 million inhabitants.
This is what a relatively healthy demographic graph looks like in 2025.
John Arnold: Forget office to resi. We need college campus to retirement community conversions.
We still primarily need office to residential because of the three rules of real estate, which are location, location, location. You can put the retirement communities in rural areas and find places you’re still allowed to build.
New Mexico to offer free child care regardless of income. As usual, I like the subsidy but I hate the economic distortion of paying for daycare without paying for those who hire a nanny or stay home to watch the kids, and it also likely will drive up the real cost of child care. It would be much better to offer this money as an expanded child tax credit and let families decide how to spend that, including the option to only have one income.
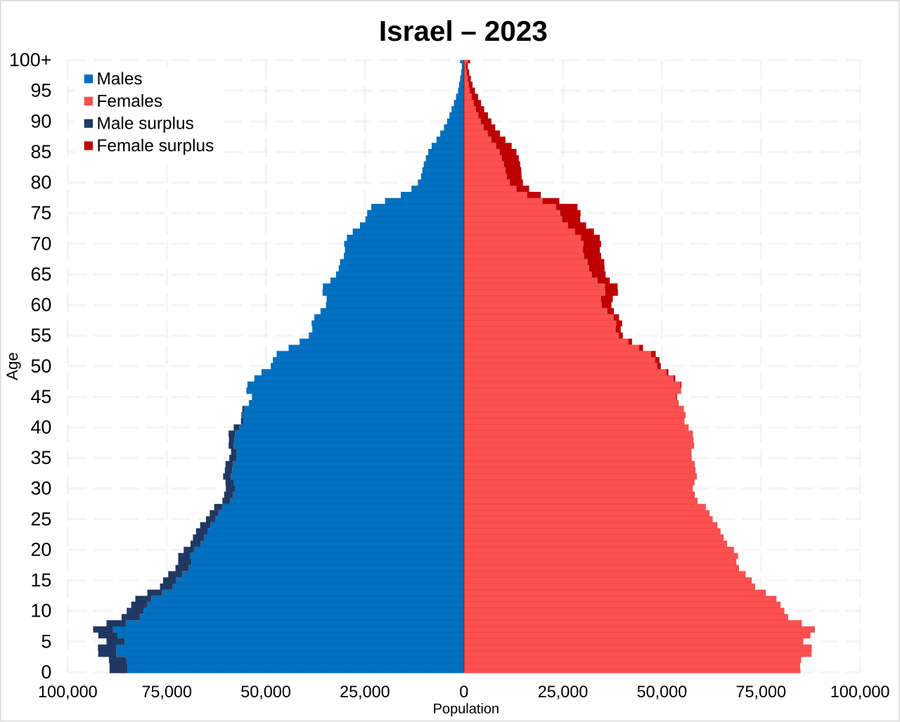
More Births: On the combined measures of income and fertility, one nation is far ahead of the rest. Israel’s score laps every other country in this index. High fertility countries usually have very low GDPs and high GDP countries usually have very low birthrates. Israel is the only country in the world that does well in both categories.
Israel has high levels of education. It has high housing costs. It has existential threats from outside, but so do Ukraine and Azerbaijan. Israeli levels of religiosity are unremarkable, only 27% attend a service weekly and secular Jewish fertility is around replacement. Social services are generous but not unusually so.
Ultimately, those who live in Israel or talk to Israelis almost always arrive at the same conclusion. Israeli culture just values having children intensely.
… Another wonderful article, by Danielle Kubes in Canada’s National Post, offers precisely the same explanation for high Israeli fertility: Israel is positively dripping with pronatal belief.
The conclusion is, a lot of things matter, but what matters most is that Israel has strong pronatal beliefs. As in, they rushed dead men from the October 7 attacks to the hospital, so they could do sperm extractions and allow them to have kids despite being dead.
Fix your fertility rate, seek abundance beyond measure, or lose your civilization.
Your call.
Samo Burja: As far as I can tell, the most notable political science results of the 21st century is democracy cannot work well with low fertility rates.
All converge on prioritizing retirees over workers and immigrants over citizens escalating social transfers beyond sustainability.
I think this means we should try to understand non-democratic regimes better since they will represent the majority of global political power in the future.
It seems to me that the great graying and mass immigration simply are the end of democracies as we understood them.
Just as failure to manage an economy and international trade were the end of Soviet Communism as we understood it.
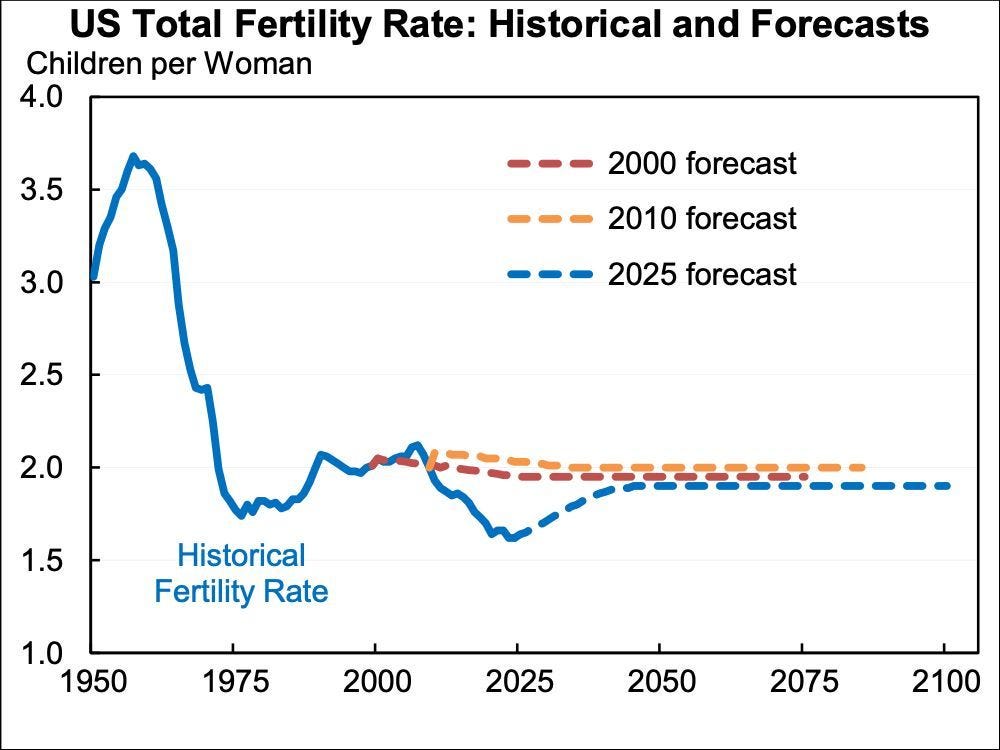
Why do official baseline scenarios consistently project recovering fertility rates?
Kelsey Piper: always a great sign when a projection is “for completely mysterious reasons this trend will reverse starting immediately and return to the baseline we believed in 25 years ago”
Jason Furman: Fertility rates are way below what the Social Security Trustees projected in both 2000 and 2010. And yet they have barely updated their long-run forecast. What’s the best argument for the plausibility of their forecast?
Compare the lines. This is not how a reasonable person would update based on what has happened since the year 2000. It could go that way if we play our cards right, but it sure as hell is not a baseline scenario and we are not currently playing any cards.
Whyvert: Gregory Clark has evidence that Britain’s upper classes had low fertility 1850-1920. This would have reversed the earlier “survival of the richest” dynamic. It may partly explain Britain’s relative decline from the late 19th century.
For most of history the rich had more children that survived to adulthood than the poor. Then that reversed, and this is aying that in Britain this happened big time in the late 1800s.
Claim that only 1% or less of children are genetically unrelated to their presumed fathers, very different from the opt-repeated figure of 10%. That’s a very different number, especially since a large fraction of the 1% are fully aware of the situation.
I do think such projections are ‘likely to work out’ in terms of the fiscal implications due to AI, or be rendered irrelevant by it in various ways, but that is a coincidence.
Over time, more will be learned about how DOGE operated and what impact DOGE had. But it seems likely that even Musk would agree that DOGE failed to uncover the vast fraud he continues to predict exists in government.
DOGE supposedly served “higher purpose”
While Musk continues to fixate on fraud in the federal budget, his allies in government and Silicon Valley have begun spinning anyone criticizing DOGE’s failure to hit the promised target as missing the “higher purpose” of DOGE, The Guardian reported.
Five allies granted anonymity to discuss DOGE’s goals told The Guardian that the point of DOGE was to “fundamentally” reform government by eradicating “taboos” around hiring and firing, “expanding the use of untested technologies, and lowering resistance to boundary-pushing start-ups seeking federal contracts.” Now, the federal government can operate more like a company, Musk’s allies said.
The libertarian think tank, the Cato Institute, did celebrate DOGE for producing “the largest peacetime workforce cut on record,” even while acknowledging that DOGE had little impact on federal spending.
“It is important to note that DOGE’s target was to reduce the budget in absolute real terms without reference to a baseline projection. DOGE did not cut spending by either standard,” the Cato Institute reported.
Currently, DOGE still exists as a decentralized entity, with DOGE staffers appointed to various agencies to continue cutting alleged waste and finding alleged fraud. While some fear that the White House may choose to “re-empower” DOGE to make more government-wide cuts in the future, Musk has maintained that he would never helm a DOGE-like government effort again and the Cato Institute said that “the evidence supports Musk’s judgment.”
“DOGE had no noticeable effect on the trajectory of spending, but it reduced federal employment at the fastest pace since President Carter, and likely even before,” the Institute reported. “The only possible analogies are demobilization after World War II and the Korean War. Reducing spending is more important, but cutting the federal workforce is nothing to sneeze at, and Musk should look more positively on DOGE’s impact.”
Although the Cato Institute joined allies praising DOGE’s dramatic shrinking of the federal workforce, the director of the Center for Effective Public Management at the Brookings Institution, Elaine Kamarck, told Ars in November that DOGE “cut muscle, not fat” because “they didn’t really know what they were doing.”
Many people have had the same phone number for years—even decades at this point. These numbers aren’t just a way for people to get in touch because, stupidly, we have also settled on phone numbers as a means of authentication. Banks, messaging apps, crypto exchanges, this very website’s publishing platform, and even the carriers managing your number rely on SMS multifactor codes. And those codes aren’t even very secure.
So losing access to your phone number doesn’t just lock you out of your phone. Key parts of your digital life can also become inaccessible, and that could happen more often now due to the fungible nature of eSIMs.
Most people won’t need to move their phone number very often, but the risk that your eSIM goes up in smoke when you do is very real. Compare that to a physical SIM card, which will virtually never fail unless you damage the card. Swapping that tiny bit of plastic takes a few seconds, and it never requires you to sit on hold with your carrier’s support agents or drive to a store. In short, a physical SIM is essentially foolproof, and eSIM is not.
Obviously, the solution is not to remove multifactor authentication—your phone number is, unfortunately, too important to be unguarded. However, carriers’ use of SMS to control account access is self-defeating and virtually guarantees people are going to have bad experiences in the era of eSIM. Enshittification has truly come for SIM cards.
If this future is inevitable, there ought to be a better way to confirm account ownership when your eSIM glitches. It doesn’t matter what that is as long as SMS isn’t the default. Google actually gets this right with Fi. You can download an eSIM at any time via the Fi app, and it’s secured with the same settings as your Google account. That’s really as good as it gets for consumer security. Between Google Authenticator, passkeys, and push notifications, it’s pretty hard to get locked out of Google, even if you take advantage of advanced security features.
We gave up the headphone jack. We gave up the microSD card. Is all this worthwhile to boost battery capacity by 8 percent? That’s a tough sell.
Gamwell sees echoes of Mitchell’s dark stars, for instance, in Edgar Allan Poe’s short story, “A Descent Into the Maelstrom,” particularly the evocative 1919 illustration by Harry Clarke. “This seemed to have been an early analogy to a black hole for many people when the concept was first proposed,” said Gamwell. “It’s a mathematical construct at that point and it’s very difficult to imagine a mathematical construct. Poe actually envisioned a dark star [elsewhere in his writings].”
The featured art spans nearly every medium: charcoal sketches, pen-and-ink drawings, oil or acrylic paintings, murals, sculptures, traditional and digital photography, and immersive room-sized multimedia installations, such as a 2021-2022 piece called Gravitational Arena by Chinese artist Xu Bing. “Xu Bing does most of his work about language,” said Gamwell. For Gravitational Arena, “He takes a quote about language from Wittgenstein and translates it into his own script, the English alphabet written to resemble Chinese characters. Then he applies gravity to it and makes a singularity. [The installation] is several stories high and he covered the gallery floor with a mirror. So you walk upstairs and you see it’s like a wormhole, which he turns into an analogy for translation.”
“Anything in the vicinity of a black hole is violently torn apart owing to its extreme gravity—the strongest in the universe,” Gamwell writes about the enduring appeal of black holes as artistic inspiration. “We see this violence in the works of artists like Cai Guo- Qiang and Takashi Murakami, who have used black holes to symbolize the brutality unleashed by the atomic bomb. The inescapable pull of a black hole is also a ready metaphor for depression in the work of artists such as Moonassi. Thus, on the one hand, the black hole provides artists with a symbol to express the devastations and anxieties of the modern world. On the other hand, however, a black hole’s extreme gravity is the source of stupendous energy, and artists such as Yambe Tam invite viewers to embrace darkness as a path to transformation, awe, and wonder.”
One of the earliest scientific images of a black hole, 1979. Ink on paper, reversed photographically. Jean-Pierre Luminet/Astronomy and Astrophysics 1979
Frankly, what’s most interesting about the paper isn’t those three fundamental categories, but the personalized glimpses it gives of the people who choose to become professional Santas. While a few Santas might make six figures, most do not, and may even lose money being Santa—they do it anyway for the sheer love of it. Professional Santas usually don’t see the role as seasonal; many build their identities around it, whether they fit the stereotypical Kris Kringle image or not. “My feeling is, if you’re Santa all the time, you have to live as Santa and give up whoever you are,” said one subject. “I’m just striving to be a better person.”
They’ll wear red and green all year round, for instance, or maintain a full white beard. One Santa trained himself to make “Ho, ho, ho!” his natural laugh. Another redecorated his house as “Santa’s house,” complete with Christmas trees and Santa figurines.
Sometimes it’s viewed as a role: a gay professional Santa, for instance, deliberately suppresses his sexual orientation when playing Santa, complete with partnering with a Mrs. Claus for public appearances. However, a female Santa who goes by Lynx (professional Santas typically take on pseudonyms) who is also a church leader, likens the job to a divine calling: “I can connect with people and remind them they’re loved,” she said. (She also binds her breasts when in costume because “Santa doesn’t have them double-Ds.”)
Perhaps that sense of a higher calling is why even non-prototypical Santas like Lynx persevere in the fact of occasional rejection. One Black Santa recalled being denied the position at a big box store once the interviewer found out his ethnicity, telling him the store didn’t hire Black or Hispanic Santas. “That hurt my heart so much,” he said. A disabled Santa who uses a scooter during parades recalled being criticized by other professional Santas for doing so—but stuck with it.
And while Bad Santa (2003) might be a fun holiday watch, actual “bad Santas” caught smoking, drinking, swearing, or otherwise behaving inappropriately are not popular figures within their community. “You’re never off,” one subject opined. “You lose a little bit of your identity because you can’t let your hair down and be yourself. You don’t know who’s watching you.”
“You’re Santa Claus 24 hours a day, seven days a week, 52 weeks a year,” another Santa said. “If you act out, you risk shattering the magic.”
The bill would significantly curtail scope of the federal environmental review process.
Rep. Bruce Westerman (R-Ark.) speaks during a news conference in the US Capitol Visitor Center on Oct. 22. Credit: Williams/CQ-Roll Call, Inc/Getty Images
The House of Representatives cleared the way for a massive overhaul of the federal environmental review process last Thursday, despite last-minute changes that led clean energy groups and moderate Democrats to pull their support.
The Standardizing Permitting and Expediting Economic Development Act, or SPEED Act, overcame opposition from environmentalists and many Democrats who oppose the bill’s sweeping changes to a bedrock environmental law.
The bill, introduced by Rep. Bruce Westerman (R-Ark.) and backed by Rep. Jared Golden (D-Maine), passed the House Thursday in a 221-196 vote, in which 11 Democrats joined Republican lawmakers to back the reform effort. It now heads to the Senate, where it has critics and proponents on both sides of the aisle, making its prospects uncertain.
The bill seeks to reform foundational environmental regulations that govern how major government projects are assessed and approved by amending the landmark 1970 National Environmental Policy Act (NEPA), signed into law under the Nixon administration. NEPA requires federal agencies to review and disclose the environmental impacts of major projects before permitting or funding them. Although NEPA reviews are only one component of the federal permitting process, advocates argue that they serve a crucial role by providing both the government and the public the chance to examine the knock-on effects that major projects could have on the environment.
Critics of the law have argued for years that increasingly complex reviews—along with legal wrangling over the findings of those reviews—have turned NEPA into a source of significant, burdensome delays that threaten the feasibility of major projects, such as power plants, transmission lines, and wind and solar projects on federal land.
Speaking on the floor of the House Thursday before the vote, Westerman described the SPEED Act as a way to “restore common sense and accountability to federal permitting.” Westerman praised the original intent of NEPA but said the law’s intended environmental protections had been overshadowed by NEPA becoming “more synonymous with red tape and waste.
“What was meant to facilitate responsible development has been twisted into a bureaucratic bottleneck that delays investments in the infrastructure and technologies that make our country run,” Westerman said.
After the bill’s passage through the House on Thursday, the SPEED Act’s Democratic cosponsor, Golden, praised the bill’s success.
“The simplest way to make energy, housing, and other essentials more affordable is to make it possible to actually produce enough of it at a reasonable cost,” Golden said in a press release following the vote. “The SPEED Act has united workers, businesses, and political forces who usually oppose each other because scarcity hurts everyone.”
According to an issue brief from the Bipartisan Policy Center, the bill aims to reform the NEPA process in several key ways. First, it makes changes to the ways agencies comply with NEPA—for example, by creating exemptions to when a NEPA review is required, and requiring agencies to only consider environmental impacts that are directly tied to the project at hand.
It would also drastically shorten the deadline to sue a federal agency over its permitting decision and constrain who is eligible to file suit. Current law provides a six-year statute of limitations on agency decisions for permitting energy infrastructure, and two years for transportation project permits. Under the SPEED Act’s provisions, those deadlines would be shortened to a mere 150 days and only allow lawsuits to be filed by plaintiffs who demonstrated in public comment periods that they would be directly and negatively impacted by the project.
NEPA does not require the government to make particular decisions about whether or how to move forward with a project based on a review’s findings. However, critics argue that in the decades since its passage, interest groups have “weaponized” the NEPA process to delay or even doom projects they oppose, sometimes forcing agencies to conduct additional analyses that add costly delays to project timelines.
Strange bedfellows on either side of the bill
Although climate activists and environmental groups have used NEPA to oppose fossil fuel projects, such as the Keystone XL and Dakota Access pipelines, oil and gas interests are far from the only group seeking respite. Some voices within the clean energy industry have called for permitting reform, too, arguing that delays stemming from the current permitting process have had a negative impact on America’s ability to build out more climate-friendly projects, including some offshore wind projects and transmission lines to connect renewables to the grid.
So when Westerman and Golden introduced the SPEED Act in the House, a hodgepodge of odd alliances and opposition groups formed in response.
The American Petroleum Institute, a trade association for the oil and gas industry, launched a seven-figure advertising campaign in recent months pushing lawmakers to pursue permitting reform, according to a report from Axios. And the bill also initially enjoyed support from voices within the clean power industry. However, last-minute changes to the bill—designed to win over Republican holdouts—undermined the SPEED Act’s cross-sector support.
The bill’s opponents had previously raised alarm bells that fossil fuel interests would disproportionately benefit from a more streamlined review process under the current administration, citing President Donald Trump’s ongoing war against wind and solar energy projects.
In recent months, the Trump administration has sought to pause, reconsider, or revoke already approved permits for renewable energy projects it dislikes. Those moves particularly impacted offshore wind developments and added significant uncertainty to the feasibility of clean energy investments as a whole.
A bipartisan amendment to the SPEED Act, added during the Natural Resources Committee’s markup in November, sought to address some of those concerns by adding language that would make it more difficult for the administration to “revoke, rescind, withdraw, terminate, suspend, amend, alter, or take any other action to interfere” with an existing authorization.
However, that measure encountered resistance from key Republican voices who support Trump’s attacks on offshore wind projects.
A last-minute loophole for Trump’s energy agenda
On Tuesday, Republican lawmakers in the Rules Committee were able to amend the SPEED Act in a way that would facilitate the Trump administration’s ongoing efforts to axe renewable energy projects. The changes were spearheaded by Andy Harris (R-Md.) and Jeff Van Drew (R-N.J.), two vocal proponents of Trump’s energy policies. The amendment fundamentally undermined the technology-neutral aspirations of the bill—and any hope of receiving widespread support from moderate Democrats or the clean power industry.
According to Matthew Davis, vice president of federal policy at the League of Conservation Voters, Harris and Van Drew’s amendment would allow the administration to exclude any project from the bill’s reforms that the Trump administration had flagged for reconsideration—something the administration has done repeatedly for renewable projects like offshore wind.
The result, Davis argued, is that the bill would speed up the environmental review process for the Trump administration’s preferred sources of energy—namely, oil and gas—while leaving clean energy projects languishing.
“They couldn’t pass the rule on Tuesday to even consider this bill without making it even better for the fossil fuel industry and even worse for the clean energy industry,” Davis said.
In a public statement following Thursday’s vote, Davis described the amended SPEED Act as “a fossil fuel giveaway that cuts out community input and puts our health and safety at risk to help big polluters.”
The American Clean Power Association, which represents the renewable energy industry, previously hailed the bill as an important step forward for the future of clean energy development. But after the Rules Committee’s changes on Tuesday, the organization dropped its support.
“Our support for permitting reform has always rested on one principle: fixing a broken system for all energy resources,” said ACP CEO Jason Grumet in a Wednesday statement. “The amendment adopted last night violate[s] that principle. Technology neutrality wasn’t just good policy—it was the political foundation that made reform achievable.”
The American Council on Renewable Energy (ACORE), a nonprofit trade and advocacy organization, echoed that sentiment.
“Durable, bipartisan, technology-neutral permitting reforms that support and advance the full suite of American electricity resources and the necessary expansion of transmission infrastructure to get that electricity from where it’s generated to where it’s needed are essential to meeting that challenge reliably, securely, and most importantly, affordably,” said ACORE CEO Ray Long. “Unfortunately, the changes made on the House floor are a disappointing step backward from achieving these objectives.”
Following the SPEED Act’s passage through the House on Thursday, advocacy group Citizens for Responsible Energy Solutions (CRES) issued a public statement praising the bill’s success while noting how the recent amendments had affected the law.
“While we are concerned that post committee additions to the bill could put the certainty of a range of projects at risk, this bill’s underlying reforms are critical to advancing American energy,” CRES President Heather Reams said in the statement.
Mixed expectations for the reform’s impact
Even before the move to strip protections for renewables from the bill, some critics—like Rep. Mike Levin (D-Calif.)—said that the legislation didn’t go far enough to curtail the president’s “all-out assault” against clean power, arguing that the bill does nothing to restore approvals that have already been canceled by the administration and doesn’t address other roadblocks that have been put in place.
“The administration cannot be trusted to act without specific language, in my view, to protect the clean energy projects already in the pipeline and to prevent the Interior Secretary from unilaterally stopping projects that are needed to lower costs and improve grid reliability,” Levin told Inside Climate News in an interview ahead of the House vote.
Both Levin and Davis pointed to a July memo from the Department of Interior that requires all wind and solar projects on federal land to receive higher-level approval from Interior Secretary Doug Burgum.
“The administration is not even returning the phone calls of project developers. They are not responding to applications being submitted,” Davis said. “That sort of approach is in stark contrast with the ‘white glove, concierge service’—and that’s a quote from the Trump administration—the service they are providing for fossil fuel companies to access our public lands.”
The SPEED Act’s opponents also dispute the idea that NEPA reviews are one of the primary causes of permitting delays, arguing that reports from the Congressional Research Service and other groups have found little evidence to support those claims.
“Often missing in the conversation around NEPA is the empirical research that’s been done, and there’s a lot of that out there,” said Jarryd Page, a staff attorney at the Environmental Law Institute, in a September interview with Inside Climate News.
That research points to resource constraints as one of the biggest roadblocks, Page said, like not having enough staff to conduct the environmental reviews, or staff lacking adequate experience and technical know-how.
Debate over NEPA and the reform of the permitting process will now move into the Senate, where experts say the SPEED Act will likely undergo further changes.
“I think as the bill goes forwards in the Senate, we’ll probably see a neutral, across-the-board approach to making sure the process is fair for all technology types,” Xan Fishman, an energy policy expert at the Bipartisan Policy Center told ICN after Thursday’s vote.
Fishman stressed it would be crucial to ensure permits for projects wouldn’t suddenly be cancelled for political reasons, but said he was optimistic about how the SPEED Act would be refined in the Senate.
“It’s great to see Congress so engaged with permitting reform,” he said. “Both sides of the aisle see a need to do better.”
This article originally appeared on Inside Climate News, a nonprofit, non-partisan news organization that covers climate, energy and the environment. Sign up for their newsletter here.
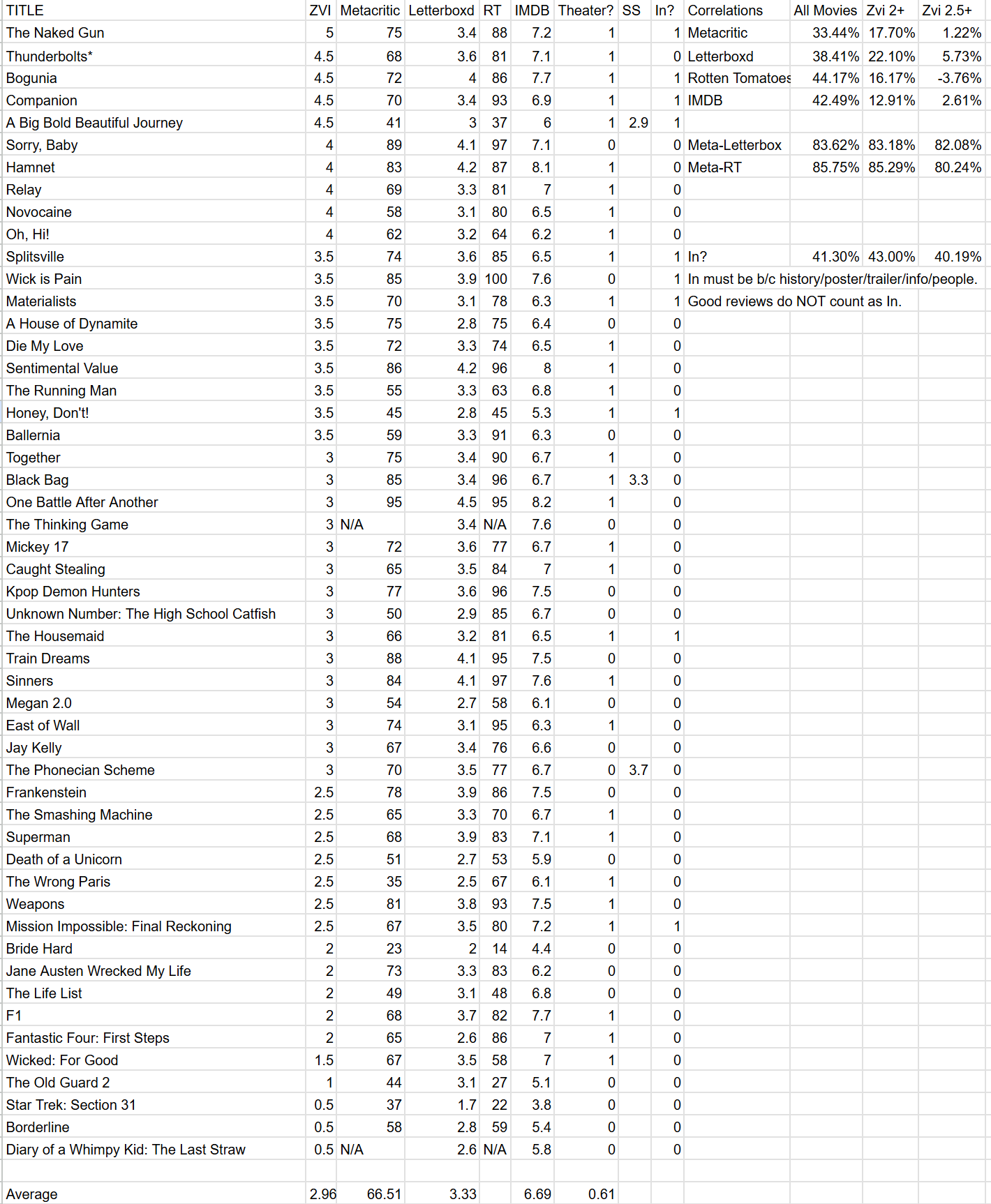
Now that I am tracking all the movies I watch via Letterboxd, it seems worthwhile to go over the results at the end of the year, and look for lessons, patterns and highlights.
Letterboxd ratings go from 0.5-5. The scale is trying to measure several things at once.
5: Masterpiece. All-time great film. Will rewatch multiple times. See this film.
4.5: Excellent. Life is meaningfully enriched. Want to rewatch. Probably see this film.
4: Great. Cut above. Very happy I saw. Happy to rewatch. If interested, see this film.
3.5: Very Good. Actively happy I saw. Added value to my life. A worthwhile time.
3: Good. Happy that I saw it, but wouldn’t be a serious mistake to miss it.
2.5: Okay. Watching this was a small mistake.
2: Bad. I immediately regret this decision. Kind of a waste.
1.5: Very bad. If you caused this to exist, you should feel bad. But something’s here.
1: Atrocious. Total failure. Morbid curiosity is the only reason to finish this.
0.5: Crime Against Cinema. Have you left no sense of decency, sir, at long last?
The ratings are intended as a bell curve. It’s close, but not quite there due to selection of rewatches and attempting to not see the films that are bad:
Trying to boil ratings down to one number destroys a lot of information.
Given how much my ratings this year conflict with critics opinions, I asked why this was, and I think I mostly have an explanation now.
There are several related but largely distinct components. I think the basic five are:
Quality with a capital Q and whether the movie has ambition and originality.
Whether the overall pacing, arc and plot of the movie holds your interest.
What message the movie sends and whether its arc comes together satisfyingly.
What does the movie make you feel? All the feels? None? Some of them?
Whether the movie is a good fit for you personally.
Traditional critic movie ratings tend, from my perspective, to overweight #1, exhibit predictable strong biases in #3 and #5, and not care enough about #2. They also seem to cut older movies, especially those pre-1980 or so, quite a lot of unearned slack.
Scott Sumner picks films with excellent Quality, but cares little for so many other things that once he picks a movie to watch our ratings don’t even seem to correlate. We have remarkably opposite tastes. Him giving a 3.7 to The Phoenician Scheme is the perfect example of this. Do I see why he might do that? Yes. But a scale that does that doesn’t tell me much I can use.
Order within a ranking is meaningful.
Any reasonable algorithm is going to be very good at differentially finding the best movies to see, both for you and in general. As you see more movies, you deplete the pool of both existing and new movies. That’s in addition to issues of duplication.
In 2024, I watched 36 new movies. In 2025, I watched 51 new movies. That’s enough of an expansion that you’d expect substantially decreasing returns. If anything, things held up rather well. My average rating only declined from 3.1 to 3.01 (if you exclude one kids movie I was ‘forced’ to watch) despite my disliking many of the year’s most loved films.
My guess is I could have gotten up to at least 75 before I ran out of reasonable options.
See The Naked Gun unless you hate fun. If you hated the original Naked Gun, or Airplane, that counts as hating fun. But otherwise, yes, I understand that this is not the highest Quality movie of the year, but this is worthy, see it.
You should almost certainly see Bogunia and Companion.
See Thunderboltsunless you are automatically out on all Marvel movies ever.
See A Big, Bold Beautiful Journey unless you hate whimsical romantic comedies or are a stickler for traditional movie reviews.
See Sorry, Baby and Hamnet, and then Sentimental Value, if you are willing to spend that time being sad.
See Novocaine and then maybe The Running Man if you want to spend that time watching action, having fun and being happy instead.
See Relay if you want a quiet thriller.
See Oh, Hi!, Splitsville and Materialists if you want to look into some modern dating dynamics in various ways, in that order or priority.
See Wick is Pain if and only if you loved the John Wick movies.
The world would be better if everyone saw A House of Dynamite.
I anticipate that Marty Supreme belongs on this list, it counts as ‘I’m in,’ but due to holidays and the flu I haven’t been able to go out and see it yet. The over/under is at Challengers.
This helps you understand my biases, and helps me remember them as well.
Trust your instincts and your gut feelings more than you think you should.
Maybe gut feelings are self-fulfilling prophecies? Doesn’t matter. They still count.
You love fun, meta, self-aware movies of all kinds. Trust this instinct.
You do not actually like action movies that play it straight. Stop watching them. However, action movies that do something cool or unique can be very cool.
If the movie sounds like work or pain, it probably is, act accordingly.
If the movie sounds very indy or liberal, the critics will overrate it.
A movie being considered for awards is not a positive signal once you control for the Metacritic and Letterboxd ratings. If anything it is a negative.
Letterboxd ratings adjusted for context beat Metacritic. Rotten Tomatoes is the best test for ‘will the movie stink’. No review source has much predictive value beyond knowing if the movie stinks, if you fail to control for context.
Opinions of individuals very much have Alpha if you have enough context.
That leaves six remarkably well reviewed movies, all of which are indeed very high on Quality, where I disagreed with the consensus, and had my rating at 3 or less. In order of Quality as I would rank them, they are: One Battle After Another, Sinners, Black Bag, Train Dreams, Weapons and Frankenstein.
A strategy I think would work well for all six of those, at the risk of some spoilage, is to watch the trailer. If you respond to that trailer with ‘I’m in’ then be in. If not, not.
The predictive power of critical reviews, at least for me, took a nosedive in 2025. One reason is that the ratings clearly got more generous in general. Average Metacritic, despite my watching more movies, went from 61 → 66, Letterboxd went 3.04 → 3.33. Those are huge jumps given the scales.
In 2024, Letterboxd or Metacritic ratings were 48% and 46% correlated with my final ratings, respectively. This year that declined to 33% and 38%, and I discovered the best was actually Rotten Tomatoes at 44%, with IMDB at 42%.
If you consider only movies where I gave a rating of 2.5 or more, filtering out what I felt were actively bad movies, the correlation dropped to 1% and 6%, or 3% for IMDB, or -4% (!) for Rotten Tomatoes. Essentially all of the value of critics was in identifying which things sucked, and from my perspective the rest was noise.
Rotten Tomatoes is a one trick pony. It warns you about things that might suck.
Even more than before, you have to adjust critic ratings for whether critics will overrate or underrate a movie of this type and with this subject matter. You can often have a strong sense of why the critics would put up a given number, without having to read reviews and thus risk spoilers.
Using multiple sources, and looking at their relative scores, helps with this as well. A relatively high IMDB score, even more than Letterboxd, tells you that the audience and the movie are well-matched. That can be good news, or that can be bad news.
Last year there were movies where I disagreed with the review consensus, but I always understood why in both directions. I might think Megalopolis is Coppola’s masterpiece despite its problems, but don’t get me wrong, I see the problems.
This year I mostly get why they liked the ‘overrated six’ above, but there are several cases where I do not know what they were thinking, and I think the critical consensus is objectively wrong even by its own standards.
I haven’t found a solution to the problem of ‘how do you check reviews without spoiling the movie?’ given that the average score itself can be a spoiler, but also I notice I haven’t tried that hard. With advances in LLMs and also vibe coding, I clearly should try again.
The power of ‘I’m in’ peaked in 2024.
The rule for ‘I’m in’ is:
You must be excited and think to yourself, ‘You son of a bitch, I’m in.’
Sources of this can include trailers, posters, talent and other info.
However this cannot be on the basis of reviews.
That year, there were 6 movies where in advance I said ‘I’m in,’ and they were 6 of my top 9 movies for the year.
This year the power of ‘I’m in’ was still strong, but less reliable. I’d count 10 such movies this year, including 4 of my ultimate top 5, but the other 6 did not break into the 4+ range, and there was a 3 and a 2.5. That’s still a great deal, especially given how many movies where it seemed like one ‘should’ be excited, I noticed I wasn’t, and that proved correct, including One Battle After Another, Black Bag, Weapons and Sinners.
I wonder: How much of the power of ‘I’m in’ is the attitude and thus is causal, versus it being a prediction? I have low confidence in this.
I control for this effect when giving ratings, but the experience is much better in a theater, maybe good for an experiential boost of ~0.3 points on the 0.5-5 point scale. That’s big. I have to consciously correct for it when rating movies I watch at home.
I highly recommend getting a membership that makes marginal cost $0, such as the AMC A-List or the similar deal at Regal Cinemas. This helps you enjoy the movie and decide to see them more.
Unlike last year, there were remarkably many movies that are in green on Metacritic, but that I rated 2.5 or lower, and also a few of the 3s require explanation as per above.
I don’t know how this happened, but an active majority of the movies I rated below 3 had a Metacritic score above 60. That’s bizarre.
Minor spoilers throughout, I do my best to limit it to minor ones, I’ll do the 3s sorted by Metacritic, then the others sorted by Metacritic.
One Battle After Another (Metacritic: 95, Zvi: 3) is probably going to win Best Picture. It’s not hard to see why. This was the highest Quality movie I’ve seen this year, and yet I did not enjoy watching it. The jokes mostly fell flat and aside from the daughter and the Dojo sensei I couldn’t emphasize with or root for the characters. Why? Fundamentally, because the movie depends on the idea that Bob is a Good Dude, and that the revolutionaries are sympathetic. Sorry, no dice, and no amount of stacking the deck with other awfulness is going to change that. There’s also a superposition between ‘this deck is stacked and the world presented is very different from ours’ and ‘actually this is our world and this is a call to action and that is what life is about, do you know what time it is?’ I grudgingly have to give this 3 stars anyway, because Quality is so high.
Train Dreams (Metacritic 88, Zvi: 3): This is the easiest one to explain. It’s an arthouse movie where very little happens, that thinks it is being profound, and it really is not being profound.
Black Bag (Metacritic 85, Zvi: 3): Here I’m actually confused where the 85 is coming from as opposed to a 65-75. I mean yes this is well done all around but there’s a reason it isn’t in the Oscar race, none of it is new or special and I didn’t feel it said anything, and it mostly left me cold.
Sinners (Metacritic: 84, Zvi: 3): This oozes cool and I want to love it, I get why so many others love it, but for me the vampires simply don’t work. I know what it’s trying to do there, but it’s hitting us over the head with it and everything involving the vampires felt like it was going through the motions and it would have been so much better, as Matthew Yglesias suggests, to do this as about racism straight up without also using the metaphor.
Now the ones I actively disliked:
Weapons (Metacritic: 81, Zvi: 2.5): The first half of this would be great if you had stuck the landing, Amy Madigan is terrific, but it didn’t come together in the end, the plot holes are absurd and the central conceit feels unjustified in light of that. I felt like I had whiplash going from a well-observed, highly detailed and realistic meditation on grief and confusion and blame and how we deal with that, into something else entirely. I could be more forgiving, but it turns out I am not.
Frankenstein (Metacritic: 78, Zvi: 2.5). I hated the message this version is trying to send, this is techno pessimistic and against knowledge and striving on a deep level, and frankly it was overly long and boring. Less about AI than you think.
Jane Austen Wrecked My Life (Metacritic: 73, Zvi: 2.5). The critics are wrong. This is just bad. I went in expecting lousy, I was mildly disappointed by the level of lousy, and then I saw 73 and was confused. You Had One Job. You were supposed to Do The Thing. Then you didn’t do the thing, either in terms of justifying the romantic connection or actually engaging properly with Jane Austen. ‘Cmon now.
Superman (Metacritic: 68, Zvi: 2.5): I had a lot of thoughts on this one. I found it both full of plot holes, and I hated that they back away from asking any of the movie’s potentially interesting questions. But I can see finding this cool if you care about very different things than this, and the new DC universe could ultimately be a huge upgrade.
F1 (Metacritic: 68, Zvi: 2): I’d say the critics are wrong but the people had a good time. Then again, the people don’t know racing. I used to be an actual F1 fan, so let me say both that this is not how any of this works, this has nothing to do with Formula 1, and otherwise this was completely paint by numbers.
Mission Impossible: Final Reckoning (Metacritic: 67, Zvi: 2.5): This was my biggest disappointment of the year. I was in! Dead Reckoning was historic due to its influence on Joe Biden and also a rip roaring good time that was remarkably smart about AI. Then this was none of those things. It squandered all the interesting setup, was far dumber about AI to the point of idiot plot and frankly the action scenes were not cool. What a disaster.
Wicked: For Good (Metacritic: 67, Zvi: 1.5): My review was ‘Hard write, harder watch.’ Seriously, everyone involved tried so damn hard, yet there’s so little joy to be found here as they try to dutifully line things up. Everything feels forced. There’s barely any cool dancing and the songs are bad. Okay, yes, fine, the Costume Design is Oscar-level, but that does not a movie make.
The Smashing Machine (Metacritic: 65, Zvi: 2.5): Emily Blunt deserves better, in all senses. Ultimately the movie is boring.
Fantastic Four: First Steps (Metacritic: 65, Zvi: 2): All the fun happens off screen. Michael Flores defended this as a great ‘Fantastic Four movie’ on the theory that it captured their world and the Fantastic Four are boring. Weird flex.
There are four movies requiring explanation on the upside, where they were below 60 on Metacritic yet I actively liked them.
All four seem like clear cases of ‘yes I know that technically this is lacking in some important way but the movie is fun, damn it, how can you not see this?’
A Big Bold Beautiful Journey (Metacritic: 41, Zvi: 4.5): I understand the complaint that the movie has ‘unearned emotion’ and the script doesn’t lay the proper foundations for what it is doing. I don’t care. This otherwise has Quality behind only One Battle After Another and Bogunia. All you have to do is say ‘I’m in!’ and decide not to be the ‘stop having fun guys’ person who points out that technically all this emotion you could be feeling hasn’t been earned. Accept that some of the ‘work’ isn’t being fully done and do it your damn self. Why not do that?
Novocaine (Metacritic: 58, Zvi: 4): A borderline case where again I think people need to remember how to have fun. This was a joy throughout, you can enjoy a good popcorn movie with a great premise and just go with it.
The Running Man (Metacritic: 55, Zvi: 3.5): I thought this actually executed on its premise really well, and did a bunch of smart things both on the surface level and also under the hood. It won’t change your life but it gets it, you know?
Honey, Don’t! (Metacritic: 45, Zvi: 3.5): Yeah, okay, it’s deeply silly and in some important senses there’s nothing there, but it’s sexy and fun, why not live a little.
You can say the same thing about The Naked Gun. It has a 75, perfectly respectable, but its joke hit rate per minute is absurd, it is worth so much more than that.
I once again used consideration for awards as one selection criteria for picking movies. This helped me ‘stay in the conversation’ with others at various points, and understand the state of the game. But once again it doesn’t seem to have provided more value than relying on Metacritic and Letterboxd ratings, especially if you also used IMDB and Rotten Tomatoes.
Last year I was very happy with Anora ending up on top. This year I’m not going to be happy unless something very surprising happens. But I do understand. In my word, given the rules of the game, I’d have Bogunia sweep the major awards.
I’m very happy with this side hobby, and I expect to see over one new movie a week again in 2026. It was a disappointing year in some ways, but looking back I still got a ton of value, and my marginal theater experience was still strongly positive. I think it’s also excellent training data, and a great way to enforce a break from everything.
It would be cool to find more good people to follow on Letterboxd, so if you think we’d mesh there, tag yourself for that in the comments.
For the second time this month, a Chinese rocket designed for reuse successfully soared into low-Earth orbit on its first flight Monday, defying the questionable odds that burden the debuts of new launch vehicles.
The first Long March 12A rocket, roughly the same height and diameter of SpaceX’s workhorse Falcon 9, lifted off from the Jiuquan Satellite Launch Center at 9: 00 pm EST Monday (02: 00 UTC Tuesday).
Less than 10 minutes later, rocket’s methane-fueled first stage booster hurtled through the atmosphere at supersonic speed, impacting in a remote region about 200 miles downrange from the Jiuquan spaceport in northwestern China. The booster failed to complete a braking burn to slow down for landing at a prepared location near the edge of the Gobi Desert.
The Long March 12A’s upper stage performed as intended, successfully reaching the mission’s “predetermined orbit,” said the China Aerospace Science and Technology Corporation (CASC), the state-owned enterprise that leads the country’s space industry.
“The first stage failed to be successfully recovered,” the corporation said in a statement. “The specific reasons are currently under further analysis and investigation.”
A stable of reusable rockets
This outcome resembles the results from the first flight of another medium-class Chinese rocket, the Zhuque-3, on December 2. The Zhuque-3 rocket was developed by a privately-funded startup named LandSpace. Similar in size and performance to the Long March 12A, the Zhuque-3 also reached orbit on its first launch, and its recoverable booster stage crashed during a downrange landing attempt. The Zhuque-3’s first stage came down next to its landing zone, while the Long March 12A appears to have missed by at least a couple of miles.
“Although this mission did not achieve the planned recovery of the rocket’s first stage, it obtained critical engineering data under the rocket’s actual flight conditions, laying an important foundation for subsequent launches and reliable recovery of the stages,” CASC said. “The research and development team will promptly conduct a comprehensive review and technical analysis of this test process, fully investigate the cause of the failure, continuously optimize the recovery plan, and continue to advance reusable technology verification.”
The retirement of the Atlas V and Delta IV led to a period of downsizing for United Launch Alliance, with layoffs and facility closures in Florida, California, Alabama, Colorado, and Texas. In a further sign of ULA’s troubles, SpaceX won a majority of US military launch contracts for the first time last year.
Bruno, 64, served as a genial public face for ULA amid the company’s difficult times. He routinely engaged with space enthusiasts on social media, fielded questions from reporters, and even started a podcast. Bruno’s friendly and accessible demeanor was unusual among industry leaders, especially those with ties to large legacy defense contractors.
ULA is a 50-50 joint venture between Boeing and Lockheed Martin, which merged their rocket divisions in 2006. Bruno’s plans did not always enjoy full support from ULA’s corporate owners. For example, Boeing and Lockheed initially only approved tranches of funding for developing the new Vulcan rocket on a quarterly basis. Beginning before Bruno’s arrival and extending into his tenure as CEO, ULA’s owners slow-walked development of an advanced upper stage that might have become a useful centerpiece for an innovative in-space transport and refueling infrastructure.
There were also rumors in recent years of an impending sale of ULA by Boeing and Lockheed Martin, but nothing has materialized so far.
The third flight of the Vulcan rocket lifted off from Cape Canaveral Space Force Station, Florida, on August 12, 2025. Credit: United Launch Alliance
A statement from the co-chairs of ULA’s board, Robert Lightfoot of Lockheed Martin and Kay Sears of Boeing, did not identify a reason for Bruno’s resignation, other than saying he is stepping down “to pursue another opportunity.”
“We are grateful for Tory’s service to ULA and the country, and we thank him for his leadership,” the board chairs said in a statement.
John Elbon, ULA’s chief operating officer, will take over as interim CEO effective immediately, the company said.
“We have the greatest confidence in John to continue strengthening ULA’s momentum while the board proceeds with finding the next leader of ULA,” the company said. “Together with Mark Peller, the new COO, John’s career in aerospace and his launch expertise is an asset for ULA and its customers, especially for achieving key upcoming Vulcan milestones.”
In a post on X, Bruno thanked ULA’s owners for the opportunity to lead the company. “It has been a great privilege to lead ULA through its transformation and to bring Vulcan into service,” he wrote. “My work here is now complete and I will be cheering ULA on.”
Invoking the designation also ensures an independent investigation detached from the teams involved in the incident itself, according to retired Air Force Lt. Gen. Susan Helms, chair of the safety panel. “We just, I think, are advocates of safety investigation best practices, and that clearly is one of the top best practices,” Helms said.
Another member of the safety panel, Mark Sirangelo, said NASA should formally declare mishaps and close calls as soon as possible. “It allows for the investigative team to be starting to be formed a lot sooner, which makes them more effective and makes the results quicker for everyone,” Sirangelo said.
In the case of last year’s Starliner test flight, NASA’s decision not to declare a mishap or close call created confusion within the agency, safety officials said.
A few weeks into the Starliner test flight last year, the manager of NASA’s Commercial Crew Program, Steve Stich, told reporters the agency’s plan was “to continue to return [the astronauts] on Starliner and return them home at the right time.” Mark Nappi, then Boeing’s Starliner program manager, regularly appeared to downplay the seriousness of the thruster issues during press conferences throughout Starliner’s nearly three-month mission.
“Specifically, there’s a significant difference, philosophically, between we will work toward proving the Starliner is safe for crew return, versus a philosophy of Starliner is no-go for return, and the primary path is on an alternate vehicle, such as Dragon or Soyuz, unless and until we learn how to ensure the on-orbit failures won’t recur on entry with the Starliner,” Precourt said.
“The latter would have been the more appropriate direction,” he said. “However, there were many stakeholders that believed the direction was the former approach. This ambiguity continued throughout the summer months, while engineers and managers pursued multiple test protocols in the Starliner propulsion systems, undoubtedly affecting the workforce.”
After months of testing and analysis, NASA officials were unsure if the thruster problems would recur on Starliner’s flight home. They decided in August 2024 to return the spacecraft to the ground without the astronauts, and the capsule safely landed in New Mexico the following month. The next Starliner flight will carry only cargo to the ISS.
The safety panel recommended that NASA review its criteria and processes to ensure the language is “unambiguous” in requiring the agency to declare an in-flight mishap or a high-visibility close call for any event involving NASA personnel “that leads to an impact on crew or spacecraft safety.”
On Monday, the US Department of the Interior announced that it was pausing the leases on all five offshore wind sites currently under construction in the US. The move comes despite the fact that these projects already have installed significant hardware in the water and on land; one of them is nearly complete. In what appears to be an attempt to avoid legal scrutiny, the Interior is blaming the decisions on a classified report from the Department of Defense.
The second Trump administration announced its animosity toward offshore wind power literally on day one, issuing an executive order on inauguration day that called for a temporary halt to issuing permits for new projects pending a re-evaluation. Earlier this month, however, a judge vacated that executive order, noting that the government has shown no indication that it was even attempting to start the re-evaluation it said was needed.
But a number of projects have gone through the entire permitting process, and construction has started. Before today, the administration had attempted to stop these in an erratic, halting manner. Empire Wind, an 800 MW farm being built off New York, was stopped by the Department of the Interior, which alleged that it had been rushed through permitting. That hold was lifted following lobbying and negotiations by New York and the project developer Orsted, and the Department of the Interior never revealed why it changed its mind. When the Interior Department blocked a second Orsted project, Revolution Wind offshore of southern New England, the company took the government to court and won a ruling that let it continue construction.
The economic data is correct. Real wages are indeed up. Costs for food and clothing are way down while quality is up, housing is more expensive than it should be but is not much more expensive relative to incomes. We really do consume vastly more and better food, clothing, housing, healthcare, entertainment, travel, communications, shipping and logistics, information and intelligence. Most things are higher quality.
But that does not tell us that buying a socially and legally acceptable basket of goods for a family has gotten easier, nor that the new basket will make us happier.
This post is my attempt to reconcile those perspectives.
The culprit is the Revolution of Rising Expectations, together with the Revolution of Rising Requirements.
The biggest rising expectations are that we will not have to tolerate unpleasant experiences or even dead time, endure meaningful material shortages or accept various forms of unfairness or coercion.
The biggest rising requirement is insane levels of mandatory child supervision.
Our negative perceptions largely stem from the Revolution of Rising Expectations.
We find the compromises of the past simply unacceptable.
This includes things like:
Jobs, relationships and marriages that are terrible experiences.
Managing real material shortages.
Living in cash-poor ways to have one parent stay at home.
Even increasingly modest levels of physical and psychological risk.
Old levels of things such as hypocrisy, secrecy, elite-only decision making, consent requirements, discrimination, racism, sexism, homophobia, transphobia, enforcement of social and gender norms, familial obligation, abuse and coercion of all kinds, lack of consent, untreated physical mental health problems and so on.
That old people have most of the wealth while young people are often broke.
Insufficiently high quality or often quantity of goods across the board.
Enduring frequent social and familial activities that are boring or unpleasant.
Tolerating even short periods of essentially dead time, including long commutes.
The Robber Baron: More to the point. You can move to almost any town in the Midwest with 20,000-200,000 people and live like a freaking king on a normal income.
You just can’t take trips to Disney every year, go out to eat every week, or have name brand everything.
Shea Jordan Smith (quoting Matthew Yglesias, link has key 11 second video): The issue is that living that lifestyle—never taking plane trips for vacation, rarely dining out, having a small house—would mean living like a poor person by today’s standards and people don’t want to do that. But that’s because we’ve gotten richer, not poorer.
Doing this requires you to earn that ‘normal income’ from a small town in the midwest, which is not as easy, and you have to deal with all the other problems. If you can pull off this level of resisting rising expectations you can then enjoy objectively high material living standards versus the past. That doesn’t solve a lot of your other problems. It doesn’t get you friends who respect you or neighbors with intact families who watch out for your kids rather than calling CPS. And while you might be okay with it, your kids are going to face overwhelming pressures to raise expectations.
Is the 2025 basket importantly better? Hell yes. That doesn’t make it any easier to purchase the Minimum Viable Basket.
That then combines with the Revolution of Rising Requirements.
In addition to the demands that come directly from Rising Expectations, there are large new legal demands on our time and budgets. Society strongarms us to buy more house, more healthcare, more child supervision and far more advanced technology. The minimum available quality of various goods, in ways we both do and don’t care about, has risen a lot. Practical ability to source used or previous versions at old prices has declined.
The killer requirement, where it is easy to miss how important it is, is that we now impose utterly insane child supervision requirements on parents and the resulting restrictions on child freedoms, on pain of authorities plausibly ruining your life for even one incident.
A wide variety of burdensome requirements on everyday products and activities, including activities that were previously freely available.
Minimum socially and often legally acceptable housing requirements.
De facto required purchases of high amounts of healthcare and formal education.
Hugely increased ‘safety’ requirements across the board.
Increased required navigation of bureaucracy and complex systems.
Forced interactions with a variety of systems that are Out To Get You.
Navigating an increasingly hostile and anti-inductive information environment.
The replacement of goods that were previously socially provided, but which now must be purchased, which adds to measured GDP but makes life harder.
We can severely cut expenses in various ways, but no, contra Matthew Yglesias, you cannot simply buy the 1960s basket of goods or services or experiences if you want to live most places in the United States. Nor if you pulled this off would you enjoy the social dynamics required to support such a lifestyle. You’d get CPS called on you, be looked down upon, no one would help watch your kids or want to be your friends or invite you to anything.
You don’t get to dismiss complaints until those complaints are stated correctly.
A rule for game designers is that:
When a player tells you something is wrong, they’re right. Believe them.
When a player tells you what exactly is wrong and how to fix it? Ignore them.
Still register that as ‘something is wrong here.’ Fix it.
People are very good at noticing when things suck. Not as good at figuring out why.
As in, I actually disagree with this, as a principle:
Matthew Yglesias: Some excellent charts and info here, but I think the impulse to sanewash and “clean up” false claims is kind of misguided.
If we want to address people’s concerns, they need to state the concerns accurately.
No. If you want to address people’s concerns rather than win an argument, then it is you who must identify and state their concerns accurately.
Not them. You. It’s up to you to figure out what the actual problems are.
Their job is to alert you that there is an issue, and to give you as much info as they can.
If this involves them making false claims along the way, that is good data. Notice that. Point that out. Do not use it as a reason to dismiss the underlying complaint that ‘things suck.’ There’s something that sucks. Figure it out.
What you definitely do not want to do is accept the false dystopian premise that America, the richest large country in human history, has historically poor material conditions.
Brad: A lot of folks seem think they are going to bring radicalized young people back into the fold by falsely conceding that material conditions in the most advanced, prosperous country in the history of the world are so bad that it’s actually reasonable to become a nihilistic radical.
Liberalism doesn’t work if you make expedient concessions to abject delusions.
Timothy Lee: Yeah, I think it feels like an easy concession to tell young people “ok I admit your generation has been dealt a bad hand but…” But when everyone does this it creates a consensus that today’s young people are facing uniquely bad material conditions, which they aren’t.
We live in an age of wonders that in many central ways is vastly superior.
I strongly prefer here to elsewhere and the present to the past.
It is still very possible to make ends meet financially in America.
Real median wages have risen.
However, due to rising expectations and rising requirements:
The cost of the de facto required basket of goods and services has risen even more.
Survival requires jumping through costly hoops not in the statistics.
We lack key social supports and affordances we used to have.
You cannot simply ‘buy the older basket of goods and services.’
Staying afloat, ‘making your life work,’ has for a while been getting harder.
This is all highly conflated with ‘when things were better’ more generally.
All of that is before consideration of AI, which this post mostly excludes.
Voters realize this. They hate it. Inflation is now ~2.5%, but the annual rise in the cost of the basket of goods and services we insist you purchase or provide is higher. The new basket being superior in some ways is nice but mostly irrelevant.
Here’s a stark statement of much of this in its purest form, on the housing front.
Aella: being poorer is harder now than it used to be because lower standards of living are illegal. Want a tiny house? illegal. want to share a bathroom with a stranger? illegal. The floor has risen and beneath it is a pit.
Julian Gough: Yes. There used to be a full spectrum of options between living under a bridge and living in a nice flat or house. (I once lived in a converted meat storage room over a butcher’s shop, and briefly, and admittedly unofficially, in a coal cellar with a 5ft ceiling, and no electricity. I was fine, and life was interesting.)
Now there’s a hard cutoff, with no options in that zone between (free) under-a-bridge and (expensive) nice flat, where most artists and poor people used to live. So where can we now live?
The two Revolutions combine to make young people think success is out of reach.
Millennials, in terms of many forms of material wealth and physical living standards, have much higher standards than previous generations, and also are forced to purchase more ‘valuable’ baskets of goods.
This leads them to forget that young people have always been poor on shoestring budgets. The young never had it easy in terms of money. Past youth was even poorer, but were allowed (legally and socially) to economize far more.
Today’s youth have more income and are accumulating more wealth, and mostly matching past homeownership rates, despite higher expenses especially for housing, and new problems around atomization and social media.
But that is paper wealth. It excludes the wealth of having families and children.
Jason C: Might be an expectations problem vs an actual income one.
$587k is nuts. Claude suggests $150k-$250k depending on location, which seems reasonable as a combined household income for full-on life ‘success,’ and points out that trajectory is a factor as well.
John Ganz: By making comparisons constant, the internet has created a condition of universal poverty. When even the richest man in the world is not satisfied and acts like a beggar for social recognition, why should anybody be?
When the debate involves people near or above the median, the boomers have a point. If you make ~$100k/year and aren’t in a high cost of living area (e.g. NYC, SF), you are successful, doing relatively well, and will be able to raise a family on that single income while living in many ways far better than it was possible to live 50 years ago.
Certainly $587k is an absurdity. The combination of Rising Expectations and the perception of Rising Requirements has left an entire generation defining ‘success’ as something almost no one achieves, while also treating ‘success’ as something one needs in order to start a family. No wonder young people think they can’t get ahead, including many who are actually ahead.
That’s in addition to the question of what constitutes a ‘good job.’ Most historical jobs, by today’s standards of lived experience, sucked a lot.
These perceptions have real consequences. Major life milestones like marriage and children get postponed, often indefinitely. Young people, especially young men, increasingly feel compelled to find some other way to strike it rich, contributing to the rise of gambling, day trading, crypto and more. This is one of the two sides of the phenomenon Derek Thompson wrote about in the excellent The Monks In The Casino, the other being atomization and loneliness.
The good news is that a lot of this is a series of related unforced errors. A sane civilization could easily fix many of them with almost no downsides.
We could choose to, without much downside:
Make housing vastly cheaper especially for those who need less.
Make childcare vastly less necessary and also cheaper, and give children a wide variety of greater experiences for free or on the cheap.
Make healthcare vastly cheaper for those who don’t want to buy an all-access pass.
Make education vastly cheaper and better.
Make energy far more abundant and cheap, which helps a lot of other things.
And so on. Again, this excludes AI considerations.
The bad news is there is no clear path to our civilization choosing to fix these errors, although every marginal move towards the abundance agenda helps.
We could also seek to strengthen our social and familial bonds, build back social capital and reduce atomization, but that’s all much harder. There’s no regulatory fix for that.
Matt Yglesias: People have started putting less emphasis on non-money sources of value, which I think is naturally going to lead more people to be unhappy with the amount of money they make.
A nice thing about valuing religion, kids, and patriotism is that these are largely non-positional goods that everyone can chase simultaneously without making each other miserable.
This change in values is not good for people’s life experience and happiness. If being happy with your financial success requires you to be earning and spending ahead of others, and it becomes a positional good, then collectively we’re screwed.
And Zac Hill points out the other problems with people’s #SquadGoals.
Zac Hill: The real reason so many people feel despair is MUCH closer to “I think my life will end in meaningless oblivion unless I am on an epic quest, a billionaire, or gigafamous, but this is gauche to admit and so I use proxy variables” than it is to “I can’t live on less than $140,000”
Also: “I, personally, will never marry/fuck an attractive person.”
Shockingly, all of this is mostly about how we create, calibrate, and manage expectations.
There were ways in which I did not ‘feel’ properly successful until I stopped renting and bought an apartment, despite the decision to previously not buy being sensible and having nothing to do with lack of available funds. Until you say ‘this house is mine’ things don’t quite feel solid.
Many view ‘success’ as being married and owning a home, regardless of total wealth.
If those people don’t achieve those goals, they will revolt against the situation.
So this chart seems rather scary:
Vance Crowe: This does not make for a stable society.
That leads to widespread expressions of (highly overstated) hopelessness:
Boring Business: An entire generation under the age of 30 is coming to realization that having a family and home will never be within the grasp of reality for them
Society is not ready for the consequences of this. A generation with no stake in the system would rather watch it burn. All the comments echo the same exact sentiment. If homeownership is not fixed, it is a steady slope to socialism from here.
Another issue is that due to antipoverty programs and subsidies and phase outs, as covered last time, including things not even covered there like college tuition, the true marginal tax rate for families is very high when moving from $30k to up to ~$100k.
Social media and influencing make all of this that much worse. We’re up against severe negativity bias and we’re comparing ourselves to those who are most successful at presenting the illusion of superficial success.
Welcome to the utter screwing that is the accelerated Revolution of Rising Expectations, in addition to the ways in which Zoomers are indeed utterly screwed.
Timothy Lee: The idea that Zoomers are “utterly screwed” in material terms is total nonsense and I wish people would stop repeating it. Housing is a bit more expensive than previous generations. Many other necessities — food, clothing, most manufactured goods are cheaper than ever.
I think the perception that Zoomers are “utterly screwed” is a combination of (1) opinion being shaped by people who live in the places with the most dysfunctional housing markets (2) extreme negativity bias of social media algorithms (3) nobody has much incentive to push back.
Nathan Witkin: I would add:
Widespread sticker shock from post-Covid inflation.
An ever-higher perceived baseline for career success and material comfort, esp. among Zoomers, also largely due to social media.
Timothy Lee: I think this #5 here is an important reason why so many people feel beleaguered. People’s expectations for what “counts” as a middle-class standard of living is a lot higher than in previous generations, and so they feel poor even if they are living similarly.
Beyond social media, I think another factor is that people compare their parents’ standard of living at 55 with their own standard of living at 25 or whatever. Nobody remembers how their parents lived before they were born.
I don’t think the “young people feeling they’re uniquely beleaguered” thing is new either!
That’s two groups of loadbearing mechanisms raised here on top of the general Revolutions of Rising Expectations and Requirements arguments earlier.
Negativity bias alongside Rising Expectations for lifestyle in social media, largely due to it concentrating among expensive cities with dysfunctional housing markets.
Post-Covid inflation, right after a brief period of massive subsidies to purchasing power.
There are also real problems, as I will address later at length, especially on home ownership and raising children. Both are true at once.
Want to raise a family on one median income today? You get what you pay for.
Yes, but not today’s lifestyle on yesterday’s budget.
Here’s what it actually looks like:
• 1,000 sq ft home, not 2,500 • One used car • One family phone — no smartphones for kids • One TV, no subscriptions • No microwave, no central A/C • Home-cooked meals, no dining out • No childcare, 1 parent stays home • Public schools only • Local sports, not travel leagues • Basic health insurance: pay dental & extras out of pocket • Simple clothes, thrift store toys • Rare vacations, little debt
That’s how most families lived for decades and they raised kids, built communities, and made it work.
The issue isn’t that you can’t raise a family on one income.
The issue is that we’ve inflated “middle class” to mean upper middle luxuries: two cars, two iPhones, dining out, Amazon Prime, orthodontics, soccer trips, Disneyland, and a home office with Wi-Fi.
In 1960, one income worked because expectations were lower, families were more self-reliant, and debt wasn’t a lifestyle.
You want one income? You can do it. But you have to live like the people who actually did it.
Not poorer, just simpler and more deliberate.
The people of the past didn’t have a choice, but you do.
Tumultuous Turkey: Try getting a job without a cell phone. You can’t. Try finding a 1000 sq ft home. You can’t. Try getting a house phone without Internet and cable included. you can’t. Avg cost of a used car is 25k in 2024. Try no car. We are not the problem. The tax & gov is the problem.
Analytic Valley Girl Chris: This advice would be less fucking retarded if you didn’t put a fucking microwave in the same cost bracket as a fucking air conditioner
Is there a lot of slack in the typical household budget if you are willing to sacrifice?
Yes. You can buy things like cars that cost less than the average. There are limits.
It is always interesting to see what such lists want to sacrifice. A lot of the items above are remarkably tiny savings in exchange for big hits to lifestyle. In others, they do the opposite. People see richer folks talking to them like this, and it rightfully pisses them off.
No microwave? To save fifty bucks once and make cooking harder? What?
No A/C is in many places in America actively dangerous.
One family phone is completely impossible in 2025. People assume you have a phone. That doesn’t mean you need two iPhones or a premium plan, old phones are cheap and work fine and there are relatively cheap data plans out there, US Mobile is $36/mo total.
One car may or may not be possible depending on where you live. Are you going to fully strand the other person all day?
You can want 1,000 square feet but that means an apartment, many areas don’t even offer this in any configuration that plausibly works.
You can see the impact of the Revolutions in the replies, only some of which is about the smaller crazy asks. No, you can’t really do this. The world won’t allow it and to the extent it does it will treat you horribly and your kids will not accept it.
Another example of the gaffe of saying what you actually think about what to cut, as he complains about kids being ‘entitled to 37 pencils’:
The Bulwark: Trump at his speech on the economy: “You can give up certain products. You can give up pencils…They only need one or two. They don’t need that many…You don’t need 37 dolls for your daughter. Two or three is nice, but you don’t need 37 dolls.”
The thing about pencils is as you use them they disappear. You need another pencil. There are many places in education we can likely cut, and no you do not ‘need 37 dolls’ and we used to have far fewer toys and that was fine, but pencils?
Thus, people increasingly believe they need two incomes to support a family.
They’re noticing something sucks. Assume they’re right. Figure out what it is.
Matthew Yglesias: The claim that the *absolute affordabilityof being a married, one-earner family with kids has fallen would — if it were true — have straightforward win-win policy remedies like “higher wages and incomes.”
When you reformulate to a more accurate claim what you end up with is the observation that it is is hard for one person to earn as much income as two people and that the wedge has grown as women’s earning power has increased.
This is very true but what’s the fix?
One that would “work” would be to push women generally out of opportunities for careers and white collar work — something more conservatives are tip-toeing around but don’t quite want to say.
A change can be good. That doesn’t get you out of dealing with the consequences.
In this case, the consequences are that the second income gets factored into the Revolutions of Rising Expectations and Requirements.
Absolute affordability of being a one-earner family with kids has fallen, because again:
You have more ‘real income.’
You are legally required to purchase more and higher quality goods and services, due to the Revolution of Rising Requirements, especially child supervision.
You are also under large social and internal pressures to purchase more and higher quality goods, due to the Revolution of Rising Expectations.
That’s nice for you, if you can afford the goods and services.
That’s still going to cost you, and you can’t pretend otherwise.
You think you can opt out of that? Nah, not really bro, not easily.
First, some brief questions worth asking in advance:
Can you actually execute on the one income plan?
If not, what are you going to do about it?
Zac Hill: [That two incomes buy more than one] is the rub of this whole discourse. Wages being much higher means the cost of a person not working is also much higher. But is that a problem in need of a solution? If so, what is the solution, and why is “accept a much lower income” not also an acceptable solution?
Even if you could somehow execute on the above plan to survive on one income by having life suck in various ways, that plan also takes two.
Not two incomes. Two parents.
Hey baby, want to live on one income, Will Ricciardella style? Hey, come back here.
Telling young men in particular ‘you can do it on one income’ via this kind of approach is a joke, because try telling the woman you want to marry that you want to live in the style Will Ricciardella describes above. See if she says yes.
The question ‘so what are you going to do about it?’ is still a very good one.
What do you do if families have the option of two incomes, and we set Expectations and Requirements based on two incomes, and you want to get by with only one? Adjusting how you spend money, and using the other parent’s time to save some money, will only go so far.
If you want one income households and stay at home parents to be viable here, I would say four things are required, in some combination. You don’t need all four, but you definitely need #1, and then some additional help.
You can deal with the Requirements. Let people purchase much less health care, child care and housing. Give people a huge amount of Slack, such that they can survive on one income despite the ability to earn two, and also pay for kids.
You can deal with the Expectations. Raise the status and social acceptability of living cheap and making sacrifices.
You can lessen the marginal returns to a second income, by increasing effective marginal tax rates. And That’s Terrible, don’t do this, but do note it would work.
You can improve the economics of having children more generally. Children are an expensive public good. We can and should use the tax code to shift the burden.
I usually discuss these issues and questions, especially around #4, in terms of declining fertility. It is the same problem. If people don’t feel able to have children in a way they find acceptable, then they will choose not to have children.
That’s all obviously terrible policy, but it also means that you can obviously support a family on one $30k income if you could have done it on two $30k incomes, since your net benefits take home pay is not substantially lower after child care.
Alternatively or additionally, from a policy perspective, you can accept that you’re looking at two income households, and plan the world around making that work.
The big problem with a two income household is child supervision.
The increased child supervision requirements, as in things like if anyone spots a 12 year old not in a parent’s line of sight they think about calling the cops, are insanely expensive in every sense. This is the biggest pain point.
The second biggest pain point is direct costs for daycare, which we could make substantially cheaper if we wanted to, and we could also subsidize it.
As Matthew Yglesias points out, our school system and its endless days off implicitly assumes the mother can watch the children, while we also forbid letting children spend those days on their own, often even indoors. The obvious solution is to not give younger kids days off that aren’t also national holidays, or to offer free other childcare on those days, where ‘older’ is defined as ‘can leave them on their own for the day and no one tries to call CPS.’
Ideally you do all of that anyway, it’s badly needed, and you open up both choices.
Now, back to the question of what is going on.
What should we make here of the fact that spending on food, clothing and housing (aka ‘necessities’) has collectively declined as a percentage of income, and also the food is way better and the houses are bigger?
The definition of ‘necessity’ is not a constant, as the linked post admits. The ‘necessities’ that have gotten cheaper are the ‘necessities of the past.’ If things like education and health care and cell phones are de facto mandatory, and you have to buy them, then they are now necessities, even if in 1901 the services in question flat out didn’t exist.
That’s not to downplay how much the past sucked. It sucked a lot. Go see Hamnet or Train Dreams or The Housemaid.
But there are other ways it didn’t suck. In large part that was because you were allowed to suck without the rug being pulled out from under you for the crime of not having a rug, and also you didn’t have to compare to all the families with fancy rugs.
Life is vastly better. Life also really sucks compared to Rising Expectations.
Setting aside AI, what do we do about it?
It’s tough to lower the Rising Expectations. We should still do what we can here, primarily via cultural efforts, in the places we can do that.
Rising Requirements are often unforced errors. We Can Fix It. We should attack. If we legalized housing, and legalized passing up Hansonian medicine, and got to a reasonable place on required child supervision, that would do it.
Pay Parents Money. Children are a public good, and we are putting so much of the cost burden directly on the parents. People feel unable to raise families, and don’t have children they want to have. We should do more transfers from the childless to those with children, and less of other types of transfers. Also eliminate all forms of the marriage penalty. Consider explicit subsidies for one income married families with kids under some threshold age. As in, acknowledge that stay at home parent is a job, and pay them for it.
Provide more public goods for families. Remarkably small things can matter a lot.
Reforming our system of transfers and benefits and taxes to eliminate the Poverty Trap, such that no one ever faces oppressive marginal tax rates or incentives to not work, and we stop forcing poor families to jump through so many hoops.
All other ways of improving things also improve this. Give people better opportunities, better jobs, better life experiences, better anything, and especially better hope for the future in any and all ways.