These are the new colors and finishes for the iPhone 16 Pro.
The screens are slightly larger this time around.
Apple
As expected, Apple announced the new iPhone Pro models today during a livestream: the iPhone 16 Pro and iPhone 16 Pro Max. The iPhone 16 Pro has a 6.3-inch display, and the Max has a 6.9-inch display. That’s primarily thanks to thinner borders around the displays.
Like the iPhone 15 Pro, the 16 Pro is made of titanium but with a new texture. Apple claims the phone has improved heat management with its new chassis, which could address some of our complaints about the iPhone 15 Pro—that means up to 20 percent faster sustained performance, too.
Larger batteries and efficiency improvements have led to a promise of battery life improvements, though Apple didn’t say exactly how much longer they’ll last during the livestream.
The iPhone 16 Pro includes the new A18 Pro chip, which is distinct from the A18 found in the regular iPhone 16. Apple says it is faster and more efficient.
It has a 16-core Neural Engine with 17 percent more memory bandwidth. Apple Intelligence features are said to run up to 15 percent faster than on the previous Pro phones. The A18 Pro ships with a 6-core GPU with 20 percent faster performance, and Apple touted its capability for AAA games—and that includes ray tracing performance that’s twice as fast. The 6-core CPU (two performance cores, four efficiency) is a modest 15 percent faster. Alternatively, it can deliver the same performance as the A17 Pro but with 20 percent more efficiency, which suggests battery life and heat improvements. Finally, there’s a new video encoder and ISP, with two times the throughput for data, with a special emphasis on improving video capture.
Like the new iPhone 16, the iPhone 16 Pro includes a new button called the Capture button. You can click it to take a photo quickly, like a traditional camera. But it’s also touch-sensitive, so you can run your finger across it in gestures to tweak the image using existing built-in photography features, like adjusting the zoom.
It has the same three camera types as before: wide-angle, telephoto, and ultra-wide. But there are some hardware improvements. The 48-megapixel wide-angle camera adds a new sensor that can read data twice as fast. There’s a new 48-megapixel ultra-wide camera to enable more detail in close-ups and selfies. The 5x telephoto lens that was exclusive to the 15 Pro Max is now included in both sizes of the iPhone 16 Pro, too.
The big new camera feature is 4K video capture at 120 frames per second and in Dolby Vision, which is a first for the platform. Videos captured this way can see their playback speed adjusted between 120 fps, 60 fps, 30 fps, and 24 fps after the fact in the Photos app. All videos captured can now include spatial audio, too. That’s accompanied by Audio Mix, a feature that allows you to switch between modes that attempt to isolate individual voices or sounds according to a few specific mix styles.
iPhone 16 Pro starts at $999 (128GB) or $1,199 (256GB) for the Max size. They are available for pre-order this coming Friday, and they ship on September 20.
Enlarge/ Boeing’s Starliner spacecraft after landing Friday night at White Sands Space Harbor, New Mexico.
Boeing
Boeing’s Starliner spacecraft sailed to a smooth landing in the New Mexico desert Friday night, an auspicious end to an otherwise disappointing three-month test flight that left the capsule’s two-person crew stuck in orbit until next year.
Cushioned by airbags, the Boeing crew capsule descended under three parachutes toward an on-target landing at 10: 01 pm local time Friday (12: 01 am EDT Saturday) at White Sands Space Harbor, New Mexico. From the outside, the landing appeared just as it would have if the spacecraft brought home NASA astronauts Butch Wilmore and Suni Williams, who became the first people to launch on a Starliner capsule on June 5.
But Starliner’s cockpit was empty as it flew back to Earth Friday night. Last month, NASA managers decided to keep Wilmore and Williams on the International Space Station (ISS) until next year after agency officials determined it was too risky for the astronauts to return to the ground on Boeing’s spaceship. Instead of coming home on Starliner, Wilmore and Williams will fly back to Earth on a SpaceX Dragon spacecraft in February. NASA has incorporated the Starliner duo into the space station’s long-term crew.
The Starliner spacecraft began the journey home by backing away from its docking port at the space station at 6: 04 pm EDT (22: 04 UTC), one day after astronauts closed hatches to prepare for the ship’s departure. The capsule fired thrusters to quickly back away from the complex, setting up for a deorbit burn to guide Starliner on a trajectory toward its landing site. Then, Starliner jettisoned its disposable service module to burn up over the Pacific Ocean, while the crew module, with a vacant cockpit, took aim on New Mexico.
After streaking through the atmosphere over the Pacific Ocean and Mexico, Starliner deployed three main parachutes to slow its descent, then a ring of six airbags inflated around the bottom of the spacecraft to dampen the jolt of touchdown. This was the third time a Starliner capsule has flown in space, and the second time the spacecraft fell short of achieving all of its objectives.
Not the desired outcome
“I’m happy to report Starliner did really well today in the undock, deorbit, and landing sequence,” said Steve Stich, manager of NASA’s commercial crew program, which manages a contract worth up to $4.6 billion for Boeing to develop, test, and fly a series of Starliner crew missions to the ISS.
While officials were pleased with Starliner’s landing, the celebration was tinged with disappointment.
“From a human perspective, all of us feel happy about the successful landing, but then there’s a piece of us that we wish it would have been the way we had planned it,” Stich said. “We had planned to have the mission land with Butch and Suni onboard. I think there are, depending on who you are on the team, different emotions associated with that, and I think it’s going to take a little time to work through that.”
Nevertheless, Stich said NASA made the right call last month when officials decided to complete the Starliner test flight without astronauts in the spacecraft.
“We made the decision to have an uncrewed flight based on what we knew at the time, and based on our knowledge of the thrusters and based on the modeling that we had,” Stich said. “If we’d had a model that would have predicted what we saw tonight perfectly, yeah, it looks like an easy decision to go say, ‘We could have had a crew tonight.’ But we didn’t have that.”
Boeing’s Starliner managers insisted the ship was safe to bring the astronauts home. It might be tempting to conclude the successful landing Friday night vindicated Boeing’s views on the thruster problems. However, he spacecraft’s propulsion system, provided by Aerojet Rocketdyne, clearly did not work as intended during the flight. NASA had the option of bringing Wilmore and Williams back to Earth on a different, flight-proven spacecraft, so they took it.
“It’s awfully hard for the team,” Stich said. “It’s hard for me, when we sit here and have a successful landing, to be in that position. But it was a test flight, and we didn’t have confidence, with certainty, of the thruster performance.”
Enlarge/ In this infrared view, Starliner descends under its three main parachutes moments before touchdown at White Sands Space Harbor, New Mexico.
NASA
As Starliner approached the space station in June, five of 28 control thrusters on Starliner’s service module failed, forcing Wilmore to take manual control as ground teams sorted out the problem. Eventually, engineers recovered four of the five thrusters, but NASA’s decision makers were unable to convince themselves the same problem wouldn’t reappear, or get worse, when the spacecraft departed the space station and headed for reentry and landing.
Engineers later determined the control jets lost thrust due to overheating, which can cause Teflon seals in valves to swell and deform, starving the thrusters of propellant. Telemetry data beamed back to the mission controllers from Starliner showed higher-than-expected temperatures on two of the service module thrusters during the flight back to Earth Friday night, but they continued working.
Ground teams also detected five small helium leaks on Starliner’s propulsion system soon after its launch in June. NASA and Boeing officials were aware of one of the leaks before the launch, but decided to go ahead with the test flight. Starliner was still leaking helium when the spacecraft undocked from the station Friday, but the leak rate remained within safety tolerances, according to Stich.
A couple of fresh technical problems cropped up as Starliner cruised back to Earth. One of 12 control jets on the crew module failed to ignite at any time during Starliner’s flight home. These are separate thrusters from the small engines that caused trouble earlier in the Starliner mission. There was also a brief glitch in Starliner’s navigation system during reentry.
Where to go from here?
Three NASA managers, including Stich, took questions from reporters in a press conference early Saturday following Starliner’s landing. Two Boeing officials were also supposed to be on the panel, but they canceled at the last minute. Boeing didn’t explain their absence, and the company has not made any officials available to answer questions since NASA chose to end the Starliner test flight without the crew aboard.
“We view the data and the uncertainty that’s there differently than Boeing does,” said Jim Free, NASA’s associate administrator, in an August 24 press conference announcing the agency’s decision on how to end the Starliner test flight. It’s unusual for NASA officials to publicly discuss how their opinions differ from those of their contractors.
Joel Montalbano, NASA’s deputy associate administrator for space operations, said Saturday that Boeing deferred to the agency to discuss the Starliner mission in the post-landing press conference.
Here’s the only quote from a Boeing official on Starliner’s return to Earth. It came in the form of a three-paragraph written statement Boeing emailed to reporters about a half-hour after Starliner’s landing: “I want to recognize the work the Starliner teams did to ensure a successful and safe undocking, deorbit, re-entry and landing,” said Mark Nappi, vice president and program manager of Boeing’s commercial crew program. “We will review the data and determine the next steps for the program.”
Nappi’s statement doesn’t answer one of the most important questions reporters would have asked anyone from Boeing if they participated in Saturday morning’s press conference: Does Boeing still have a long-term commitment to the Starliner program?
So far, the only indications of Boeing’s future plans for Starliner have come from second-hand anecdotes relayed by NASA officials. Boeing has been silent on the matter. The company has reported nearly $1.6 billion in financial charges to pay for previous delays and cost overruns on the Starliner program, and Boeing will again be on the hook to pay to fix the problems Starliner encountered in space over the last three months.
Montalbano said Boeing’s Starliner managers met with ground teams at mission control in Houston following the craft’s landing. “The Boeing managers came into the control room and congratulated the team, talked to the NASA team, so Boeing is committed to continue their work with us,” he said.
Enlarge/ Boeing’s Starliner spacecraft fires thrusters during departure from the International Space Station on Friday.
NASA
NASA isn’t ready to give up on Starliner. A fundamental tenet of NASA’s commercial crew program is to foster the development of two independent vehicles to ferry astronauts to and from the International Space Station, and eventually commercial outposts in low-Earth orbit. NASA awarded multibillion-dollar contracts to Boeing and SpaceX in 2014 to complete development of their Starliner and Crew Dragon spaceships.
SpaceX’s Dragon started flying astronauts in 2020. NASA would like to have another US spacecraft for crew rotation flights to support the ISS. If Boeing had more success with this Starliner test flight, NASA expected to formally certify the spacecraft for operational crew flights beginning next year. Once that happens, Starliner will enter a rotation with SpaceX’s Dragon to transport crews to and from the station in six-month increments.
Stich said Saturday that NASA has not determined whether the agency will require Boeing launch another Starliner test flight before certifying the spacecraft for regular crew rotation missions. “It’ll take a little time to determine the path forward, but today we saw the vehicle perform really well,” he said.
On to Starliner-1?
But some of Stich’s other statements Saturday suggested NASA would like to proceed with certifying Starliner and flying the next mission with a full crew complement of four astronauts. NASA calls Boeing’s first operational crew mission Starliner-1. It’s the first of at least three and potentially up to six crew rotation missions on Boeing’s contract.
“It’s great to have the spacecraft back, and we’re now focused on Starliner-1,” Stich said.
Before that happens, NASA and Boeing engineers must resolve the thruster problems and helium leaks that plagued the test flight this summer. Stich said teams are studying several ways to improve the reliability of Starliner’s thrusters, including hardware modifications and procedural changes. This will probably push back the next crew flight of Starliner, whether it’s Starliner-1 or another test flight, until the end of next year or 2026, although NASA officials have not laid out a schedule.
The overheating thrusters are located inside four doghouse-shaped propulsion pods around the perimeter of Starliner’s service module. It turns out the doghouses retain heat like a thermos—something NASA and Boeing didn’t fully appreciate before this mission—and the thrusters don’t have time to cool down when the spacecraft fires its control jets in rapid pulses. It might help if Boeing removes some of the insulating thermal blankets from the doghouses, Stich said.
The easiest method of resolving the problem of Starliner’s overheating thrusters would be to change the rate and duration of thruster firings.
“What we would like to do is try not to change the thruster. I think that is the best path,” Stich said. “There thrusters have shown resilience and have shown that they perform well, as long as we keep their temperatures down and don’t fire them in a manner that causes the temperatures to go up.”
There’s one thing from this summer’s test flight that might, counterintuitively, help NASA certify the Starliner spacecraft to begin operational flights with its next mission. Rather than staying at the space station for eight days, Starliner remained docked at the research lab for three months, half of the duration of a full-up crew rotation flight. Despite the setbacks, Stich estimated the test flight achieved about 85 to 90 percent of its objectives.
“There’s a lot of learning that happens in that three months that is invaluable for an increment mission,” Stich said. “So, in some ways, the mission overachieved some objectives, in terms of being there for extra time. Not having the crew onboard, obviously, there are some things that we lack in terms of Butch and Suni’s test pilot expertise, and how the vehicle performed, what they saw in the cockpit. We won’t have that data, but we still have the wealth of data from the spacecraft itself, so that will go toward the mission objectives and the certification.”
Enlarge/ The First Combat of Gav and Talhand’, Folio from a Shahnama (Book of Kings), ca. 1330–40, Attributed to Iran, probably Isfahan, Ink, opaque watercolor, gold, and silver on paper, Page: 8 1/16 x 5 1/4 in. (20.5 x 13.3 cm), Codices, Three battles between two Indian princes – half brothers contending for the throne – resulted in the invention of the game of chess, to explain the death of one of them to their grieving mother. The Persian word shah mat, or checkmate, indicating a position of no escape, describes the plight of Talhand at the end of the third battle. (Photo by: Sepia Times/Universal Images Group via Getty Images)
The three princes of Sarandib—an ancient Persian name for Sri Lanka—get exiled by their father the king. They are good boys, but he wants them to experience the wider world and its peoples and be tested by them before they take over the kingdom. They meet a cameleer who has lost his camel and tell him they’ve seen it—though they have not—and prove it by describing three noteworthy characteristics of the animal: it is blind in one eye, it has a tooth missing, and it has a lame leg.
After some hijinks the camel is found, and the princes are correct. How could they have known? They used their keen observational skills to notice unusual things, and their wit to interpret those observations to reveal a truth that was not immediately apparent.
It is a very old tale, sometimes involving an elephant or a horse instead of a camel. But this is the version written by Amir Khusrau in Delhi in 1301 in his poem The Eight Tales of Paradise, and this is the version that one Christopher the Armenian clumsily translated into the Venetian novel The Three Princes of Serendip, published in 1557; a publication that, in a roundabout way, brought the word “serendipity” into the English language.
In no version of the story do the princes accidentally stumble across something important they were not looking for, or find something they were looking for but in a roundabout, unanticipated manner, or make a valuable discovery based on a false belief or misapprehension. Chance, luck, and accidents, happy or otherwise, play no role in their tale. Rather, the trio use their astute observations as fodder for their abductive reasoning. Their main talent is their ability to spot surprising, unexpected things and use their observations to formulate hypotheses and conjectures that then allow them to deduce the existence of something they’ve never before seen.
Defining serendipity
This is how Telmo Pievani, the first Italian chair of Philosophy of Biological Sciences at the University of Padua, eventually comes to define serendipity in his new book, Serendipity: the Unexpected in Science. It’s hardly a mind-bending or world-altering read, but it is a cute and engaging one, especially when his many stories of discovery veer into ruminations on the nature of inquiry and of science itself.
He starts with the above-mentioned romp through global literature, culminating in the joint coining and misunderstanding of the term as we know it today: in 1754, after reading the popular English translation entitled The Travels and Adventures of Three Princes of Serendip, the intellectual Horace Walpole described “Serendipity, a very expressive word,” as “discoveries, by accidents and sagacity, of things which they were not in quest of.”
Pievani knows a lot, but like a lot, about the history of science, and he puts it on display here. He quickly debunks all of the instances of alleged serendipity that are always trotted out: Fleming the microbiologist had been studying antibiotics and searching for a commercially viable one for years before his moldy plate led him to penicillin. Yes, Röntgen discovered X-rays by a fluke, but it was only because of the training he received in his studies of cathode rays that he recognized he was observing a new form of radiation. Plenty of people over the course of history splashed some volume of water out of the baths they were climbing into and watched apples fall, but only Archimedes—who had recently been tasked by his king to figure out if his crown was made entirely of gold—and Newton—polymathic inventor of calculus—leapt from these (probably apocryphal) mundane occurrences to their famous discoveries of density and gravity, respectively.
After dispensing with these tired old saws, Pievani then suggests some cases of potentially real—or strong, as he deems it—serendipity. George de Mestral’s inventing velcro after noticing burrs stuck to his pants while hiking in the Alps; he certainly wasn’t searching for anything, and he parlayed his observation into a useful technology. DuPont chemists’ developing nylon, Teflon, and Post-it notes while playing with polymers for assorted other purposes. Columbus “discovering” the Americas (for the fourth time) since he thought the Earth was about a third smaller than Eratosthenes of Cyrene had correctly calculated it to be almost two thousand years earlier, forgotten “due to memory loss and Eurocentric prejudices.”
Enlarge/ The second stage of the New Glenn rocket rolls to the launch pad on Tuesday.
Blue Origin
Welcome to Edition 7.10 of the Rocket Report! It has been a big week for seeing new hardware from Blue Origin. We’ve observed the second stage of New Glenn rolling out to its launch pad in Florida, and the rocket’s first stage recovery ship, Jacklyn, arriving at a nearby port. It looks like the pieces are finally coming into place for the debut launch of the massive new rocket.
As always, we welcome reader submissions, and if you don’t want to miss an issue, please subscribe using the box below (the form will not appear on AMP-enabled versions of the site). Each report will include information on small-, medium-, and heavy-lift rockets as well as a quick look ahead at the next three launches on the calendar.
Vega rocket makes its final flight. The final flight of Europe’s Vega rocket lifted off Wednesday night from French Guiana, carrying an important environmental monitoring satellite for the European Union’s flagship Copernicus program, Ars reports. About an hour after liftoff, the Vega rocket’s upper stage released Sentinel-2C into an on-target orbit. Then, Sentinel-2C radioed its status to ground controllers, confirming the satellite was healthy in space. The Vega rocket will be replaced by the larger Vega-C rocket, with a more powerful booster stage and a wider payload fairing. One of the primary purposes of the Vega-C will be to launch future Copernicus satellites for Europe.
A mixed record of commercial success … “I think it was a great success,” said Giulio Ranzo, Avio’s CEO, in an interview with Ars a few hours before Wednesday night’s mission. “It was our first launcher. It was our first experience as a major player in the launcher domain.” However, in a dozen years of service, the Vega rocket never really took off in the commercial launch market. It averaged about two flights per year and primarily deployed satellites for the European Space Agency and other European government agencies, which prefer launching their payloads on European rockets.
ABL Space lays off staff. Launch vehicle developer ABL Space Systems has laid off a significant portion of its workforce, citing the need to reduce costs after the loss of a rocket in a static-fire test, Space News reports. In a post on LinkedIn on August 30, Harry O’Hanley, chief executive of ABL, said the company was laying off an unspecified number of people. The layoffs came after the company’s second RS1 rocket was lost in a fire after a static-fire test at the Pacific Spaceport Complex – Alaska on Kodiak Island on July 19.
Era of easy money ends … O’Hanley said in the email that the company had been working to reduce costs at the company even ahead of that test, citing changes in the market and access to capital. The company had raised several hundred million dollars, including $200 million in October 2021 and $170 million in March 2021. Hanley wrote that starting in 2023, “we cut costs and positioned the company for leaner operations with smaller teams, restrained hiring, and more conservative spending.” That was working, he said, until the static-fire incident. (submitted by brianrhurley and Ken the Bin)
The easiest way to keep up with Eric Berger’s space reporting is to sign up for his newsletter, we’ll collect his stories in your inbox.
So many un-spac-tacular results. A recent feature in Space News reviewed how the special purpose acquisition company, or SPAC, process has gone for several new space firms. Fortunes have been decidedly mixed for the space businesses that merged with publicly traded shell companies in search of capital as COVID-19 ravaged the economy, the publication says.
Launch does not fare well … “Wildly missed revenue projections from most of the class in their eagerness to drum up investor support for their SPAC merger have not helped their reputation,” the author, Jason Rainbow, writes. The list includes four launch companies: Virgin Galactic, Virgin Orbit, Astra, and Rocket Lab. Of these, Virgin Orbit has gone bankrupt, and Astra’s results were so disastrous that it went private again. Then there’s Virgin Galactic, a company whose shares publicly trade at $7, down nearly 90 percent from its peak during the pandemic. Only Rocket Lab gets a gold star for its post-SPAC performance.
New investor suit filed against Branson over Virgin Galactic. A newly unsealed lawsuit alleges that Richard Branson exploited bogus hype about the capabilities of Virgin Galactic’s spacecraft to make $1 billion worth of illegal insider stock sales, Bloomberg Law reports. A shareholder sued Branson, saying he spent years misleading the public about the readiness of Virgin Galactic’s flagship space tourism vessel, Unity, then dumped “massive portions of his stock” across 2020 and 2021. The sales included $300 million in August 2021, shortly after Branson flew on the spaceship. Branson founded Virgin Galactic about two decades ago.
Branson says suit is meritless … “Despite the near misses, loss of life, and questionable safety record, Branson was determined to be the first billionaire in space” so he could “secure billionaire bragging rights” and try to bail out a travel business empire that lost nearly $1.9 billion during the COVID-19 pandemic, the suit says. Branson and Virgin Galactic disputed the court claims in separate statements Wednesday. Branson called the claims meritless through a spokesperson, saying he would “vigorously defend against them.” The case involves shareholder derivative claims, which are technically brought on a corporation’s behalf against its leaders or owners.
MaiaSpace working toward stage testing. French launch firm MaiaSpace has announced that it is preparing to conduct the first hot fire test of the upper stage of its Maia rocket in 2025, European Spaceflight reports. The company is developing a partially reusable two-stage rocket called Maia that will be capable of delivering payloads of up to 1,500 kilograms when launched in an expandable configuration. For both of its stages, the rocket will use Prometheus rocket engines, which are being developed by ArianeGroup under a European Space Agency contract.
Is it new space or old space? … MaiaSpace is an interesting company. It positions itself as a launch startup, but it is also a wholly owned subsidiary of ArianeGroup, which is as traditional a launch company as can be. The rocket’s first stage will essentially be the Themis reusable booster demonstrator, which is also being developed by ArianeGroup under an ESA contract. (submitted by Ken the Bin)
But that doesn’t make it a bad time to buy a PC, especially if you’re looking for some cost-efficient builds. Prices of CPUs and GPUs have both fallen a fair bit since we did our last build guide a year or so ago, which means all of our builds are either cheaper than they were before or we can squeeze out a little more performance than before at similar prices.
We have six builds across four broad tiers—a budget office desktop, a budget 1080p gaming PC, a mainstream 1440p-to-4K gaming PC, and a price-conscious workstation build with a powerful CPU and lots of room for future expandability.
You won’t find a high-end “god box” this time around, though; for a money-is-no-object high-end build, it’s probably worth waiting for Intel’s upcoming Arrow Lake desktop processors, AMD’s expected Ryzen 9000X3D series, and whatever Nvidia’s next-generation GPU launch is. All three of those things are expected either later this year or early next.
We have a couple of different iterations of the more expensive builds, and we also suggest multiple alternate components that can make more sense for certain types of builds based on your needs. The fun of PC building is how flexible and customizable it is—whether you want to buy what we recommend and put it together or want to treat these configurations as starting points, hopefully, they give you some idea of what your money can get you right now.
Notes on component selection
Part of the fun of building a PC is making it look the way you want. We’ve selected cases that will physically fit the motherboards and other parts we’re recommending and which we think will be good stylistic fits for each system. But there are many cases out there, and our picks aren’t the only options available.
As for power supplies, we’re looking for 80 Plus certified power supplies from established brands with positive user reviews on retail sites (or positive professional reviews, though these can be somewhat hard to come by for any given PSU these days). If you have a preferred brand, by all means, go with what works for you. The same goes for RAM—we’ll recommend capacities and speeds, and we’ll link to kits from brands that have worked well for us in the past, but that doesn’t mean they’re better than the many other RAM kits with equivalent specs.
For SSDs, we mostly stick to drives from known brands like Samsung, Crucial, or Western Digital, though going with a lesser-known brand can save you a bit of money. All of our builds also include built-in Bluetooth and Wi-Fi, so you don’t need to worry about running Ethernet wires and can easily connect to Bluetooth gamepads, keyboards, mice, headsets, and other accessories.
We also haven’t priced in peripherals, like webcams, monitors, keyboards, or mice, as we’re assuming most people will re-use what they already have or buy those components separately. If you’re feeling adventurous, you could even make your own DIY keyboard! If you need more guidance, Kimber Streams’ Wirecutter keyboard guides are exhaustive and educational.
Finally, we won’t be including the cost of a Windows license in our cost estimates. You can pay a lot of different prices for Windows—$139 for an official retail license from Microsoft, $120 for an “OEM” license for system builders, or anywhere between $15 and $40 for a product key from shady gray market product key resale sites. Windows 10 keys will also work to activate Windows 11, though Microsoft stopped letting old Windows 7 and Windows 8 keys activate new Windows 10 and 11 installs relatively recently. You could even install Linux, given recent advancements to game compatibility layers!
Enlarge/ The second stage of the New Glenn rocket rolled to the launch site this week.
Blue Origin
NASA and Blue Origin announced Friday that they have agreed to delay the launch of the ESCAPADE mission to Mars until at least the spring of 2025.
The decision to stand down from a launch attempt in mid-October was driven by a deadline to begin loading hypergolic propellant on the two small ESCAPADE (Escape and Plasma Acceleration and Dynamics Explorers) spacecraft. While it is theoretically possible to offload fuel from these vehicles for a future launch attempt, multiple sources told Ars that such an activity would incur significant risk to the spacecraft.
Forced to make a call on whether to fuel, NASA decided not to. Although the two spacecraft were otherwise ready for launch, it was not clear the New Glenn rocket would be similarly ready to go.
Waiting on the rocket
NASA procured the debut launch of the New Glenn rocket, which was developed by Blue Origin, for a significant discount. The mission’s managers, University of California, Berkeley’s Space Sciences Laboratory, always understood there were timeline risks with launching on New Glenn.
Blue Origin appears to have worked with some urgency this year to prepare the massive rocket for its initial launch. However, when the company missed a key target of hot firing the rocket’s upper stage by the end of August, NASA delayed fueling of the ESCAPADE mission. Now, with the closing of a Mars launch window next month, NASA will not fuel the spacecraft until next spring, at the earliest.
Founded by Amazon’s Jeff Bezos, Blue Origin successfully rolled the New Glenn second stage to its launch pad at Launch Complex-36 in Florida on Tuesday. The company is now targeting Monday, September 9, for a hot fire test of the second stage.
At the same time, preparations for the rocket’s first stage are nearing completion. All seven of the rocket’s BE-7 engines have arrived at the launch site following acceptance testing. Engineers and technicians are presently attaching the engines to the first stage of the vehicle.
Blue Origin will now pivot to launching a prototype of its Blue Ring transfer vehicle on the debut launch of New Glenn, with the intent of testing the electronics, avionics, and other systems on the vehicle. Blue Origin is targeting the first half of November for this launch. This test flight will also serve as the first of three “certification” flights for New Glenn, which will allow the vehicle to become eligible to carry national security payloads for the US Space Force.
A sense of urgency
It’s nearly been a year since Bezos tapped a former Amazon executive, Dave Limp, to lead Blue Origin. Bezos tasked the company’s new chief executive with injecting a sense of purpose toward getting New Glenn flying as soon as possible. Bezos has made a launch this year a high priority.
In an email to Blue Origin employees on Friday, Limp expressed that sense of urgency.
“We can’t take our foot off the pedal here,” Limp wrote. “Everyone’s work to get us to NG-1 flight this year is critical and I’m so appreciative of everyone’s relentless dedication to make this happen.”
As for ESCAPADE, the mission could launch in the spring of 2025. Although the “Mars window” only opens every 18 to 24 months, there are complex trajectories by which a payload launched in the spring of 2025 could reach the red planet. It’s also possible that NASA and Blue Origin could ultimately wait until the next Mars window opens in November 2026 to launch the mission.
While supplies of Adderall and its generic versions are finally recovering after a yearslong shortage, the Drug Enforcement Administration is now working to curb the short supply of another drug for attention-deficit/hyperactivity disorder: Vyvanse (lisdexamfetamine) and its generic versions.
“These adjustments are necessary to ensure that the United States has an adequate and uninterrupted supply of lisdexamfetamine to meet legitimate patient needs both domestically and globally,” the DEA said.
Quotas
Just like Adderall (amphetamine/dextroamphetamine salts), Vyvanse (lisdexamfetamine) is an amphetamine-class stimulant classified by the DEA as a Schedule II drug. As such, the DEA controls its production levels to ensure demand is met while preventing excess supply that could find its way to the black market. The administration does this by setting an “aggregate production quota”—which is what the DEA adjusted for lisdexamfetamine this week—and doling out undisclosed allotments to drug manufacturers.
While various factors have contributed to the shortages of ADHD medications, some medical and industry groups have placed blame on the DEA’s quota system for underestimating demand and choking supply. For instance, the Adderall shortage began in 2022 following a labor shortage on the product’s production line at Teva, Adderall’s maker. But, while that production snag was resolved, prescription rates increased significantly, in part due to increased awareness of ADHD, broadening diagnosis criteria, and an increase in access with the rise of telehealth services, which boomed during the COVID-19 pandemic. In a report earlier this year, the American Society of Health-System Pharmacists pointed to the DEA’s quotas, saying they’re “exacerbating” shortages.
In an August 2023 joint letter, the DEA and the FDA responded to such criticism, suggesting that the quotas aren’t to blame. Rather, it’s that some manufacturers are not using up their allotment of controlled drugs.
“Based on DEA’s internal analysis of inventory, manufacturing, and sales data submitted by manufacturers of amphetamine products [which include the two ADHD drugs], manufacturers only sold approximately 70 percent of their allotted quota for the year, and there were approximately 1 billion more doses that they could have produced but did not make or ship. Data for 2023 so far show a similar trend,” the FDA and DEA wrote.
The FDA and DEA said they would work with manufacturers to ensure they would ramp up production of drugs in short supply or relinquish their remaining allotments.
Vyvanse shortage
A similarly complicated situation is seen with the current shortfall of Vyvanse and its generics. The DEA raised the quota after prodding from the Food and Drug Administration. In July, the FDA sent the DEA a letter requesting a quota increase. However, the shortage had actually begun in June 2023. At that time, Vyvanse’s maker, Takeda, said that a “manufacturing delay compounded by increased demand” had led to low inventory.
In August 2023, the FDA approved multiple generic versions of Vyvanse after Takeda’s patent exclusivity expired, raising hopes that the shortage would ease with the injection of new generics. But supply problems have persisted. In November, the Association for Accessible Medicines, which represents generic drugmakers, sent a letter to the DEA saying that generic manufacturers weren’t able to obtain enough raw material to “launch their products at full commercial scale,” because the quotas were standing in the way, according to reporting by Bloomberg.
FiercePharma reported another potential factor raised by lawmakers and industry watchers. Those onlookers took note of the timing of Takeda’s “manufacturing delays” just months before generics entered the market. With the significantly thinner profit margin of generic and off-patent drugs, there’s concern that manufacturers may de-prioritize production.
Last, the DEA flagged yet another factor in the supply chain: exports to foreign markets. While the FDA estimated a 6 percent increase in the domestic need for lisdexamfetamine between 2023 and 2024, the DEA’s export data showed a 34 percent increase in exports of lisdexamfetamine between 2022 and 2023, with expectations that exports would continue to increase this year and beyond. As such, the current 23.5 percent quota increase for lisdexamfetamine is only partly for domestic production. In fact, only a quarter of the 6,236 kg is intended for the US. Of the increased allotment, 1,558 kg is for domestic drug production, while the other 4,678 kg addresses increases in foreign demand, the DEA said.
Enlarge/ Researchers say that Dungeons & Dragons can give autistic players a way to engage in low-risk social interactions.
Since its introduction in the 1970s, Dungeons & Dragons has become one of the most influential tabletop role-playing games (TRPGs) in popular culture, featuring heavily in Stranger Things, for example, and spawning a blockbuster movie released last year. Over the last decade or so, researchers have turned their focus more heavily to the ways in which D&D and other TRPGs can help people with autism form healthy social connections, in part because the gaming environment offers clear rules around social interactions. According to the authors of a new paper published in the journal Autism, D&D helped boost players’ confidence with autism, giving them a strong sense of kinship or belonging, among other benefits.
“There are many myths and misconceptions about autism, with some of the biggest suggesting that those with it aren’t socially motivated, or don’t have any imagination,” said co-author Gray Atherton, a psychologist at the University of Plymouth. “Dungeons & Dragons goes against all that, centering around working together in a team, all of which takes place in a completely imaginary environment. Those taking part in our study saw the game as a breath of fresh air, a chance to take on a different persona and share experiences outside of an often challenging reality. That sense of escapism made them feel incredibly comfortable, and many of them said they were now trying to apply aspects of it in their daily lives.”
Prior research has shown that autistic people are more likely to feel lonely, have smaller social networks, and often experience anxiety in social settings. Their desire for social connection leads many to “mask” their neurodivergent traits in public for fear of being rejected as a result of social gaffes. “I think every autistic person has had multiple instances of social rejection and loss of relationships,” one of the study participants said when Atherton et al. interviewed them about their experiences. “You’ve done something wrong. You don’t know what it is. They don’t tell you, and you find out when you’ve been just, you know, left shunned in relationships, left out…. It’s traumatic.”
TPRGs like D&D can serve as a social lubricant for autistic players, according to a year-long study published earlier this year co-authored by Atherton, because there is less uncertainty around how to behave in-game—unlike the plethora of unwritten social rules that make navigating social settings so anxiety-inducing. Such games immerse players in a fantastical world where they create their characters with unique backstories, strengths, and weaknesses and cooperate with others to complete campaigns. A game master guides the overall campaign, but the game itself evolves according to the various choices different players make throughout.
A critical hit
Small wonder, then, that there tend to be higher percentages of autistic TRPG players than in the general populace. For this latest study. Atherton et al. wanted to specifically investigate how autistic players experience D&D when playing in groups with other autistic players. It’s essentially a case study with a small sample size—just eight participants—and qualitative in nature, since the post-play analysis focused on semistructured interviews with each player after the conclusion of the online campaign, the better to highlight their individual voices.
The players were recruited through social media advertisements within the D&D, Reddit and Discord online communities; all had received an autism diagnosis by a medical professional. They were split into two groups of four players, with one of the researchers (who’s been playing D&D for years) acting as the dungeon master. The online sessions featured in the study was the Waterdeep: Dragonheist campaign. The campaign ran for six weeks, with sessions lasting between two and four hours (including breaks).
Participants spoke repeatedly about the positive benefits they received from playing D&D, providing a friendly environment that helped them relax about social pressures. “When you’re interacting with people over D&D, you’re more likely to understand what’s going on,” one participant said in their study interview. “That’s because the method you’ll use to interact is written out. You can see what you’re meant to do. There’s an actual sort of reference sheet for some social interactions.” That, in turn, helped foster a sense of belonging and kinship with their fellow players.
Participants also reported feeling emotionally invested and close to their characters, with some preferring to separate themselves from their character in order to explore other aspects of their personality or even an entirely new persona, thus broadening their perspectives. “I can make a character quite different from how I interact with people in real-life interactions,” one participant said. “It helps you put yourself in the other person’s perspective because you are technically entering a persona that is your character. You can then try to see how it feels to be in that interaction or in that scenario through another lens.” And some participants said they were able to “rewrite” their own personal stories outside the game by adopting some of their characters’ traits—a psychological phenomenon known as “bleed.”
“Autism comes with several stigmas, and that can lead to people being met with judgment or disdain,” said co-author Liam Cross, also of the University of Plymouth. “We also hear from lots of families who have concerns about whether teenagers with autism are spending too much time playing things like video games. A lot of the time that is because people have a picture in their minds of how a person with autism should behave, but that is based on neurotypical experiences. Our studies have shown that there are everyday games and hobbies that autistic people do not simply enjoy but also gain confidence and other skills from. It might not be the case for everyone with autism, but our work suggests it can enable people to have positive experiences that are worth celebrating.”
Enlarge/ The eruptions that produced the dark mare on the lunar surface ended billions of years ago.
Signs of volcanic activity on the Moon can be viewed simply by looking up at the night-time sky: The large, dark plains called “maria” are the product of massive outbursts of volcanic material. But these were put in place relatively early in the Moon’s history, with their formation ending roughly 3 billion years ago. Smaller-scale additions may have continued until roughly 2 billion years ago. Evidence of that activity includes samples obtained by China’s Chang’e-5 lander.
But there are hints that small-scale volcanism continued until much more recent times. Observations from space have identified terrain that seems to be the product of eruptions, but only has a limited number of craters, suggesting a relatively young age. But there’s considerable uncertainty about these deposits.
Now, further data from samples returned to Earth by the Chang’e-5 mission show clear evidence of volcanism that is truly recent in the context of the history of the Solar System. Small beads that formed during an eruption have been dated to just 125 million years ago.
Counting beads
Obviously, some of the samples returned by Chang’e-5 are solid rock. But it also returned a lot of loose material from the lunar regolith. And that includes a decent number of rounded, glassy beads formed from molten material. There are two potential sources of those beads: volcanic activity and impacts.
The Moon is constantly bombarded by particles ranging in size from individual atoms to small rocks, and many of these arrive with enough energy to melt whatever it is they smash into. Some of that molten material will form these beads, which may then be scattered widely by further impacts. The composition of these beads can vary wildly, as they’re composed of either whatever smashed into the Moon or whatever was on the Moon that got smashed. So, the relative concentrations of different materials will be all over the map.
By contrast, any relatively recent volcanism on the Moon will be extremely rare, so is likely to be from a single site and have a single composition. And, conveniently, the Apollo missions already returned samples of volcanic lunar rocks, which provide a model for what that composition might look like. So, the challenge was one of sorting through the beads returned from the Chang’e-5 landing site, and figuring out which ones looked volcanic.
And it really was a challenge, as there were over 3,000 beads returned, and the vast majority of them would have originated in impacts.
As a first cutoff, the team behind the new work got rid of anything that had a mixed composition, such as unmelted material embedded in the bead, or obvious compositional variation. This took the 3,000 beads down to 764. Those remaining beads were then subject to a technique that could determine what chemicals were present. (The team used an electron probe microanalyzer, which bombards the sample with electrons and uses the photons that are emitted to determine what elements are present.) As expected, compositions were all over the map. Some beads were less than 1 percent magnesium oxide; others nearly 30 percent. Silicon dioxide ranged from 16 to 60 percent.
Based on the Apollo samples, the researchers selected for beads that were high in magnesium oxide relative to calcium and aluminum oxides. That got them down to 13 potentially volcanic samples. They also looked for low nickel, as that’s found in many impactors, which got the number down to six. The final step was to look at sulfur isotopes, as impact melting tends to preferentially release the lighter isotope, altering the ratio compared to intact lunar rocks.
After all that, the researchers were left with three of the glassy beads, which is a big step down from the 3,000 they started with.
Erupted
Those three were then used to perform uranium-based radioactive dating, and they all produced numbers that were relatively close to each other. Based on the overlapping uncertainties, the researchers conclude that all were the product of an eruption that took place about 123 million years ago, give or take 15 million years. Considering that the most recent confirmed eruptions were about 2 billion years ago, that’s a major step forward in timing.
And that’s quite a bit of a surprise, as the Moon has had plenty of time to cool, and that cooling would have increased the distance between its surface and any molten material left in the interior. So it’s not obvious what could be creating sufficient heating to generate molten material at present. The researchers note that the Moon has a lot of material called KREEP (potassium, rare earth elements, phosphorus) that is high in radioactive isotopes and might lead to localized heating in some circumstances.
Unfortunately, it will be tough to associate this with any local geology, since there’s no indication of where the eruption occurred. Material this small can travel quite a distance in the Moon’s weak gravitational field and then could be scattered even farther by impacts. So, it’s possible that these belong to features that have been identified as potentially volcanic through orbital images.
In the meantime, the increased exploration of the Moon planned for the next few decades should get us more opportunities to see whether similar materials are widespread on the lunar surface. Eventually, that might potentially allow us to identify an area with higher concentrations of volcanic material than one particle in a thousand.
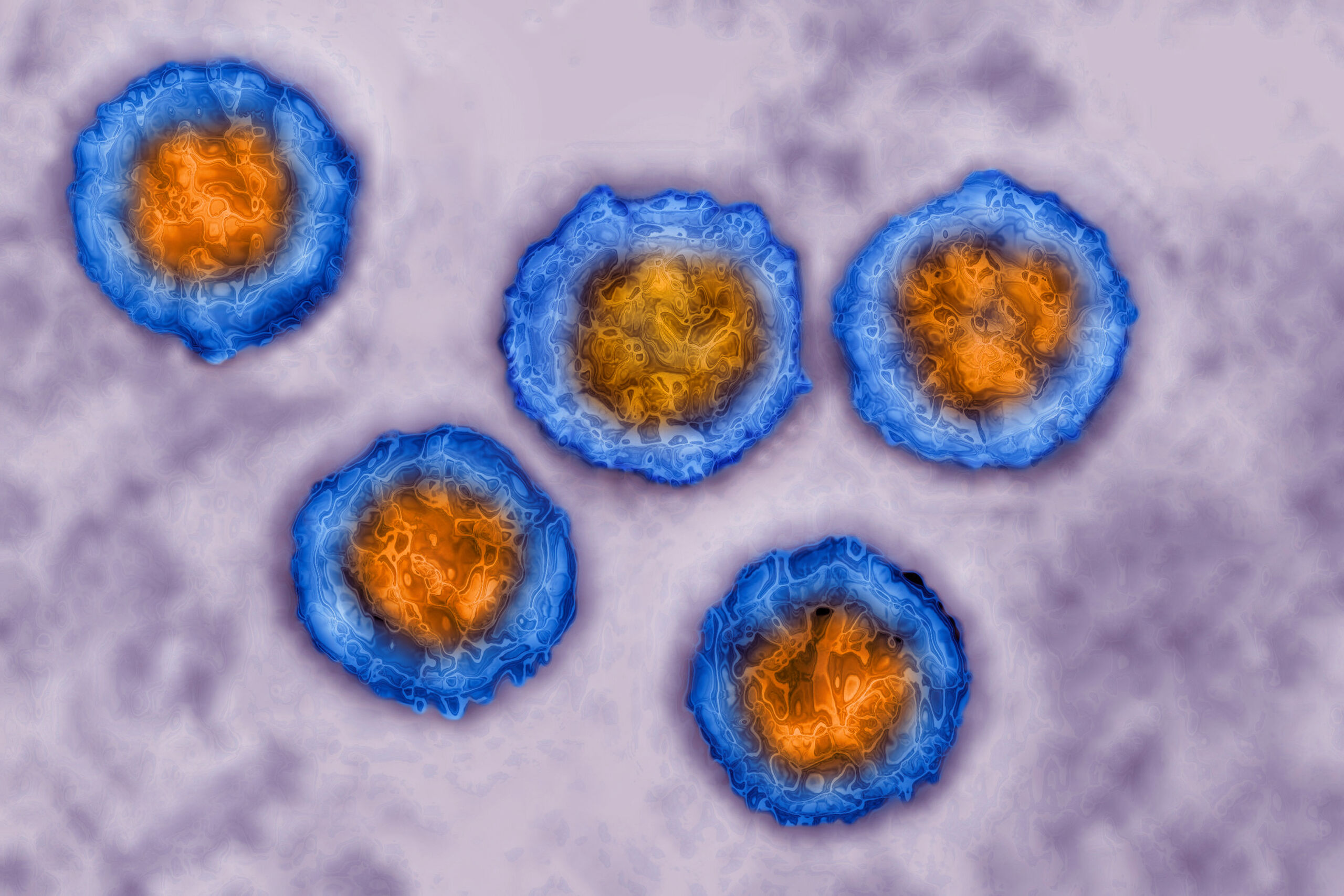
Enlarge/ Herpes simplex virus, (HSV). Image taken with transmission electron microscopy.
As the US Surgeon General recently highlighted, parenting is stressful. From navigating social media to facing a youth mental health crisis, challenges abound. But, for one father in Spain, even the simple, loving, everyday act of giving your child a peck on the cheek has turned to nightmare fuel.
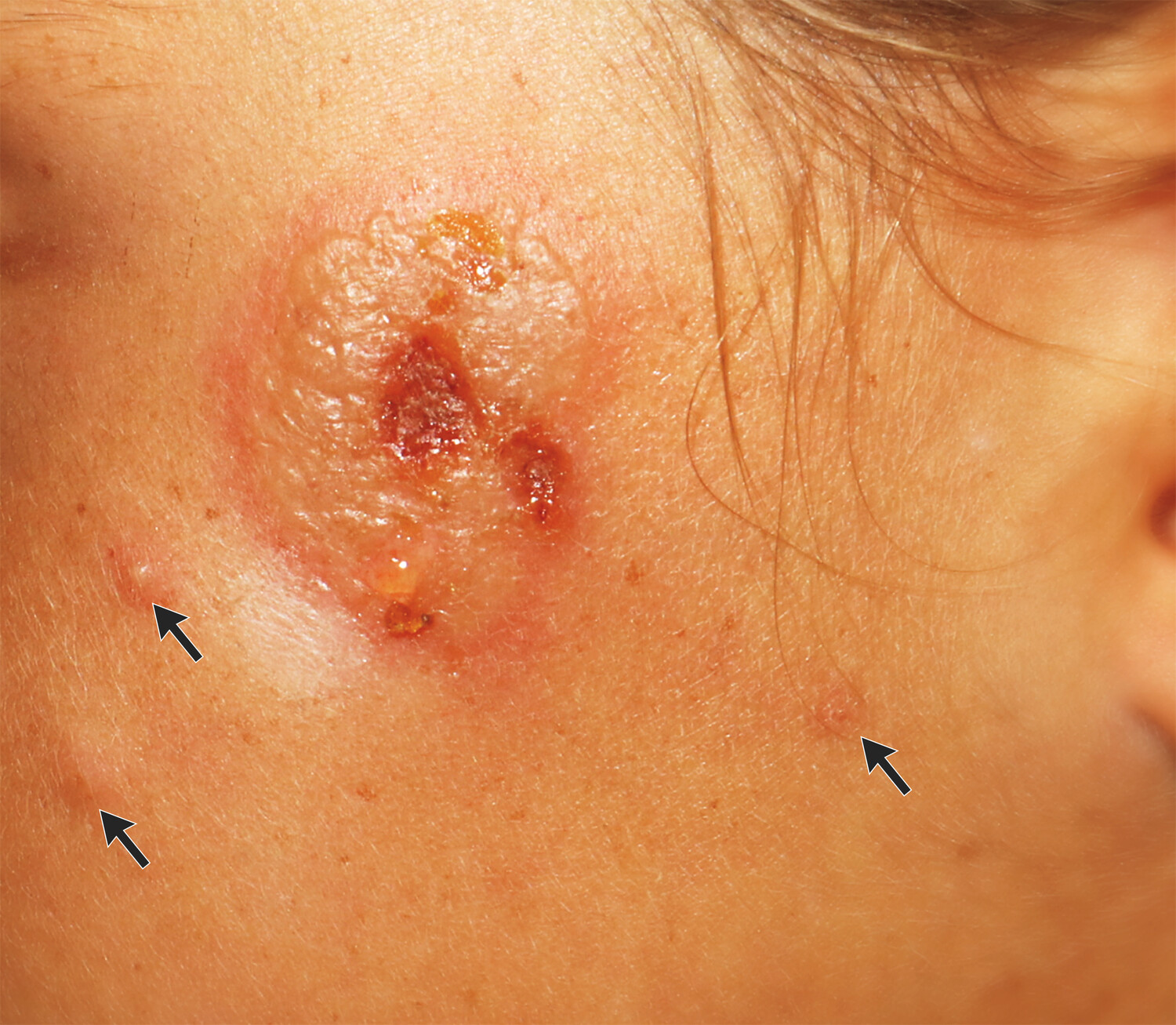
According to a case report in the New England Journal of Medicine, the man’s 9-year-old daughter developed a fever along with a crusty, blistering lesion on her left cheek. Doctors initially diagnosed the blotch as impetigo, a bacterial infection on the skin’s surface layers that is fairly common in children. It’s often caused by Staphylococcus aureus or Streptococcus bacteria and is generally easily treated with antibiotics.
Enlarge/ The lesion on the girl’s cheek with satellite blisters noted by arrows.
But, after several days of treatment for impetigo, the child’s symptoms weren’t getting better. At that point, it had been seven days since the lesion erupted, and it was 3 centimeters in diameter on the side of her face. So, he took her to a dermatology clinic. There, specialists closely examined the lesion, noting the red, raised area with blisters and a “honey-crusted appearance,” which is a classic sign of impetigo. They also noted smaller “satellite” blisters around the cheek, as well as swollen lymph nodes on the left side of her neck, the same side as the lesion. All of the symptoms still lined up with impetigo. But then the specialists looked over at her dad.
The doctors took note of a crusting on her father’s lower lip, which he said had started 10 days earlier. It looked like a classic case of common cold sores, aka oral herpes. And the doctors made a connection.
Stress begets stress
Cold sores are caused by herpes simplex virus type 1 (HSV-1), a highly contagious virus that is estimated to infect 3.7 billion people under the age of 50 globally. (There’s also HSV-2, which causes genital herpes). In an initial infection, herpes viruses invade cells on the body’s surfaces, but then go into hiding in nerve cells. From there, they can occasionally reactivate and produce new lesions and infections. For HSV-1, that usually means cold sores around the mouth.
There is no cure for herpes infections; the virus will lurk in a person’s nerve cells for the rest of their lives, with the potential to spur recurring outbreaks. However, there are antiviral treatments that can ease the symptoms of outbreaks and help them clear up a little faster.
When a cold sore develops, the lesions are highly infectious. It’s often transmitted through oral-oral contact, but any direct contact or contact with contaminated saliva can spread the virus. (HSV-2 primarily spreads through sexual contact.) And, while HSV-1 lesions typically erupt around the mouth and on mucosal surfaces, they can sometimes also flare elsewhere on the skin.
The dermatologists treating the 9-year-old ran a test for HSV-1, confirming the genetic traces of the virus were present. They started the girl on an oral antiviral drug. They also noted that there was no concern for sexual abuse. The lesion cleared without scarring.
In their report on the case, they end with a note of caution for other doctors: “When HSV-1 infection manifests in children as cutaneous lesions without mucosal involvement, it may be confused with the honey-crusted appearance of impetigo.”
For parents, the lesson is to be careful not to kiss your child (or anyone else) when you have a cold sore flare up. While those viral reactivations can be sparked by many things, one notable factor will likely strike home for parents: stress.
Enlarge/ A Verizon FiOS truck in Manhattan on September 15, 2017.
Verizon today announced a deal to acquire Frontier Communications, an Internet service provider with about 3 million customers in 25 states. Verizon said the all-cash transaction is valued at $20 billion.
Verizon agreed to pay $9.6 billion and is taking on over $10 billion in debt held by Frontier. Verizon said the deal is subject to regulatory approval and a vote by Frontier shareholders and is expected to be completed in 18 months.
“Under the terms of the agreement, Verizon will acquire Frontier for $38.50 per share in cash, representing a premium of 43.7 percent to Frontier’s 90-Day volume-weighted average share price (VWAP) on September 3, 2024, the last trading day prior to media reports regarding a potential acquisition of Frontier,” Verizon said.
Assuming regulatory and shareholder approval, Verizon will be buying back a former portion of its network that it sold to Frontier eight years ago. In 2016, Frontier bought Verizon’s FiOS and DSL operations in Florida, California, and Texas. The 2016 changeover was marred by technical problems that caused weeks of outages for tens of thousands of customers.
“Frontier’s 2.2 million fiber subscribers across 25 states will join Verizon’s approximately 7.4 million FiOS connections in 9 states and Washington, D.C.,” Verizon said. “In addition to Frontier’s 7.2 million fiber locations, the company is committed to its plan to build out an additional 2.8 million fiber locations by the end of 2026.”
Combined, the Verizon and Frontier fiber networks pass over 25 million premises in 31 states and the District of Columbia, the companies said. Verizon and Frontier both “expect to increase their fiber penetration between now and closing,” they said.
Frontier “complementary” to Verizon’s Northeast market
Frontier has 2.05 million residential fiber customers and 721,000 residential copper DSL customers, according to an earnings report. In the business and wholesale category, Frontier has 134,000 fiber customers and 102,000 copper customers. Frontier reported $1.48 billion in revenue in Q2 2024 and a net loss of $123 million.
Verizon said Frontier’s recent investment in fiber made it a more attractive acquisition target. “Over approximately four years, Frontier has invested $4.1 billion upgrading and expanding its fiber network, and now derives more than 50 percent of its revenue from fiber products,” Verizon said.
Verizon FiOS is available in parts of Connecticut, Delaware, Maryland, Massachusetts, New York, New Jersey, Virginia, Rhode Island, Pennsylvania, and the District of Columbia. Verizon said Frontier’s footprint is “highly complementary to Verizon’s core Northeast and Mid-Atlantic markets,” and will help grow the number of customers who purchase both home Internet and mobile service.
Frontier is available in parts of Alabama, Arizona, California, Connecticut, Florida, Georgia, Illinois, Indiana, Iowa, Michigan, Minnesota, Mississippi, Nebraska, Nevada, New Mexico, New York, North Carolina, Ohio, Pennsylvania, South Carolina, Tennessee, Texas, Utah, West Virginia, and Wisconsin.
Networking hardware-maker Zyxel is warning of nearly a dozen vulnerabilities in a wide array of its products. If left unpatched, some of them could enable the complete takeover of the devices, which can be targeted as an initial point of entry into large networks.
The most serious vulnerability, tracked as CVE-2024-7261, can be exploited to “allow an unauthenticated attacker to execute OS commands by sending a crafted cookie to a vulnerable device,” Zyxel warned. The flaw, with a severity rating of 9.8 out of 10, stems from the “improper neutralization of special elements in the parameter ‘host’ in the CGI program” of vulnerable access points and security routers. Nearly 30 Zyxel devices are affected. As is the case with the remaining vulnerabilities in this post, Zyxel is urging customers to patch them as soon as possible.
But wait… there’s more
The hardware manufacturer warned of seven additional vulnerabilities affecting firewall series including the ATP, USG-FLEX, and USG FLEX 50(W)/USG20(W)-VPN. The vulnerabilities carry severity ratings ranging from 4.9 to 8.1. The vulnerabilities are:
CVE-2024-6343: a buffer overflow vulnerability in the CGI program that could allow an authenticated attacker with administrator privileges to wage denial-of-service by sending crafted HTTP requests.
CVE-2024-7203: A post-authentication command injection vulnerability that could allow an authenticated attacker with administrator privileges to run OS commands by executing a crafted CLI command.
CVE-2024-42057: A command injection vulnerability in the IPSec VPN feature that could allow an unauthenticated attacker to run OS commands by sending a crafted username. The attack would be successful only if the device was configured in User-Based-PSK authentication mode and a valid user with a long username exceeding 28 characters exists.
CVE-2024-42058: A null pointer dereference vulnerability in some firewall versions that could allow an unauthenticated attacker to wage DoS attacks by sending crafted packets.
CVE-2024-42059: A post-authentication command injection vulnerability that could allow an authenticated attacker with administrator privileges to run OS commands on an affected device by uploading a crafted compressed language file via FTP.
CVE-2024-42060: A post-authentication command injection vulnerability that could allow an authenticated attacker with administrator privileges to execute OS commands by uploading a crafted internal user agreement file to the vulnerable device.
CVE-2024-42061: A reflected cross-site scripting vulnerability in the CGI program “dynamic_script.cgi” that could allow an attacker to trick a user into visiting a crafted URL with the XSS payload. The attacker could obtain browser-based information if the malicious script is executed on the victim’s browser.
The remaining vulnerability is CVE-2024-5412 with a severity rating of 7.5. It resides in 50 Zyxel product models, including a range of customer premises equipment, fiber optical network terminals, and security routers. A buffer overflow vulnerability in the “libclinkc” library of affected devices could allow an unauthenticated attacker to wage denial-of-service attacks by sending a crafted HTTP request.
In recent years, vulnerabilities in Zyxel devices have regularly come under activeattack. Many of the patches are available for download at links listed in the advisories. In a small number of cases, the patches are available through the cloud. Patches for some products are available only by privately contacting the company’s support team.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}