
Investors commit quarter-billion dollars to startup designing “Giga” satellites
A startup established three years ago to churn out a new class of high-power satellites has raised $250 million to ramp up production at its Southern California factory.
The company, named K2, announced the cash infusion on Thursday. K2’s Series C fundraising round was led by Redpoint Ventures, with additional funding from investment firms in the United States, the United Kingdom, and Germany. K2 has now raised more than $400 million since its founding in 2022 and is on track to launch its first major demonstration mission next year, officials said.
K2 aims to take advantage of a coming abundance of heavy- and super-heavy-lift launch capacity, with SpaceX’s Starship expected to begin deploying satellites as soon as next year. Blue Origin’s New Glenn rocket launched twice this year and will fly more in 2026 while engineers develop an even larger New Glenn with additional engines and more lift capability.
Underscoring this trend toward big rockets are other launchers like SpaceX’s Falcon 9 and Falcon Heavy, United Launch Alliance’s Vulcan, and new vehicles from companies like Rocket Lab, Relativity Space, and Firefly Aerospace. K2’s founders believe satellites will follow a similar progression, reversing a trend toward smaller spacecraft in recent years, to address emerging markets like in-space computing and data processing.
Mega, then Giga
K2 is designing two classes of satellites—Mega and Giga—that it will build at an 180,000-square-foot factory in Torrance, California. The company’s first “Mega Class” satellite is named Gravitas. It is scheduled to launch in March 2026 on a Falcon 9 rocket. Once in orbit, Gravitas will test several systems that are fundamental to K2’s growth strategy. One is a 2o-kilowatt Hall-effect thruster that K2 says will be four times more powerful than any such thruster flown to date. Gravitas will also deploy twin solar arrays capable of generating 20 kilowatts of power.
“Gravitas brings our full stack together for the first time,” said Karan Kunjur, K2’s co-founder and CEO, in a company press release. “We are validating the architecture in space, from high-voltage power and large solar arrays to our guidance and control algorithms, and a 20 kW Hall thruster, and we will scale based on measured performance.”
Investors commit quarter-billion dollars to startup designing “Giga” satellites Read More »









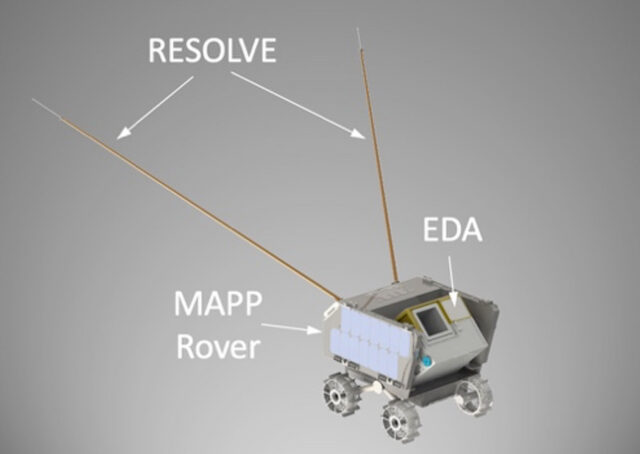








{kind=link}