DeepSeek v3.2 is DeepSeek’s latest open model release with strong bencharks. Its paper contains some technical innovations that drive down cost.
It’s a good model by the standards of open models, and very good if you care a lot about price and openness, and if you care less about speed or whether the model is Chinese. It is strongest in mathematics.
What it does not appear to be is frontier. It is definitely not having a moment. In practice all signs are that it underperforms its benchmarks.
When I asked for practical experiences and reactions, I got almost no responses.
DeepSeek is a cracked Chinese AI lab that has produced some very good open models, done some excellent research, and given us strong innovations in terms of training techniques and especially training efficiency.
They also, back at the start of the year, scared the hell out of pretty much everyone.
A few months after OpenAI released o1, and shortly after DeepSeek released the impressive v3 that was misleadingly known as the ‘six million dollar model,’ DeepSeek came out with a slick app and with r1, a strong open reasoning model based on v3 that showed its chain of thought. With reasoning models not yet scaled up, it was the perfect time for a fast follow, and DeepSeek executed that very well.
Due to a strong viral marketing campaign and confluence of events, including that DeepSeek’s app shot to #1 on the app store, and conflating the six million in cost to train v3 with OpenAI’s entire budget of billions, and contrasting r1’s strengths with o1’s weaknesses, events briefly (and wrongly) convinced a lot of people that China or DeepSeek had ‘caught up’ or was close behind American labs, as opposed to being many months behind.
There was even talk that American AI labs or all closed models were ‘doomed’ and so on. Tech stocks were down a lot and people attributed that to DeepSeek, in ways that reflected a stock market highly lacking in situational awareness and responding irrationally, even if other factors were also driving a lot of the move.
Politicians claimed this meant we had to ‘race’ or else we would ‘lose to China,’ thus all other considerations must be sacrificed, and to this day the idea of a phantom DeepSeek-Huawei ‘tech stack’ is used to scare us.
This is collectively known as The DeepSeek Moment.
Later releases bore this out. DeepSeek’s r1-0528 and v3.1 did not ‘have a moment,’ ad neither did v3.2-exp or now v3.2. The releases disappointed.
DeepSeek remains a national champion and source of pride in China, and is a cracked research lab that innovates for real. Its models are indeed being pushed by the PRC, especially in the global south.
I’d just been through a few weeks in which we got GPT-5.1, Grok 4.1, Gemini 3 Pro, GPT-5.1-Codex-Max and then finally Claude Opus 4.5. Mistral, listed above, doesn’t count. Which means we’re done and can have a nice holiday season, asks Padme?
No, Anakin said. There is another.
DeepSeek: 🚀 Launching DeepSeek-V3.2 & DeepSeek-V3.2-Speciale — Reasoning-first models built for agents!
🔹 DeepSeek-V3.2: Official successor to V3.2-Exp. Now live on App, Web & API.
🔹 DeepSeek-V3.2-Speciale: Pushing the boundaries of reasoning capabilities. API-only for now.
🥇 Gold-Medal Performance: V3.2-Speciale attains gold-level results in IMO, CMO, ICPC World Finals & IOI 2025.
📝 Note: V3.2-Speciale dominates complex tasks but requires higher token usage. Currently API-only (no tool-use) to support community evaluation & research.
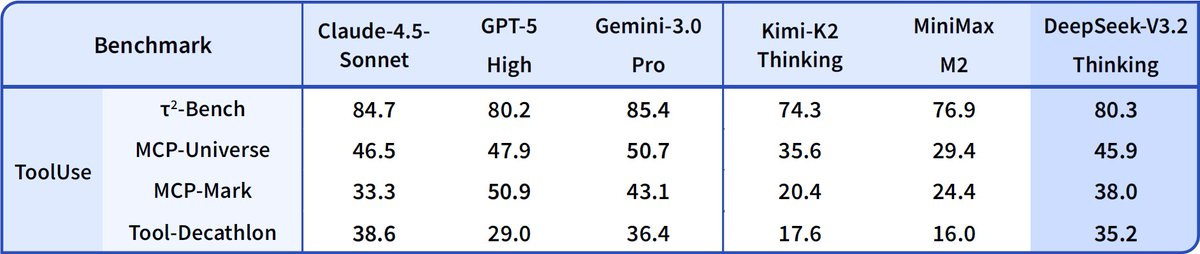
🤖 Thinking in Tool-Use
🔹 Introduces a new massive agent training data synthesis method covering 1,800+ environments & 85k+ complex instructions.
🔹 DeepSeek-V3.2 is our first model to integrate thinking directly into tool-use, and also supports tool-use in both thinking and non-thinking modes.
Teortaxes threatened to bully me if I did not read the v3.2 paper. I did read it. The main innovation appears to be a new attention mechanism, which improves training efficiency and also greatly reduces compute cost to scaling the context window, resulting in v3.2 being relatively cheap without being relatively fast. Unfortunately I lack the expertise to appreciate the interesting technical aspects. Should I try and fix this in general? My gut says no.
What the paper did not include was any form of safety testing or information of any kind for this irreversible open release. There was not, that I could see, even a sentence that said ‘we did safety testing and are confident in this release’ or even one that said ‘we do not see any need to do any safety testing.’ It’s purely and silently ignored.
David Manheim: They announce the new DeepSeek.
“Did it get any safety testing, or is it recklessly advancing open-source misuse capability?”
They look confused.
“Did it get any safety testing?”
“It is good model, sir!”
I check the model card.
There’s absolutely no mention of misuse or safety.
Frankly, this is deeply irresponsible and completely unacceptable.
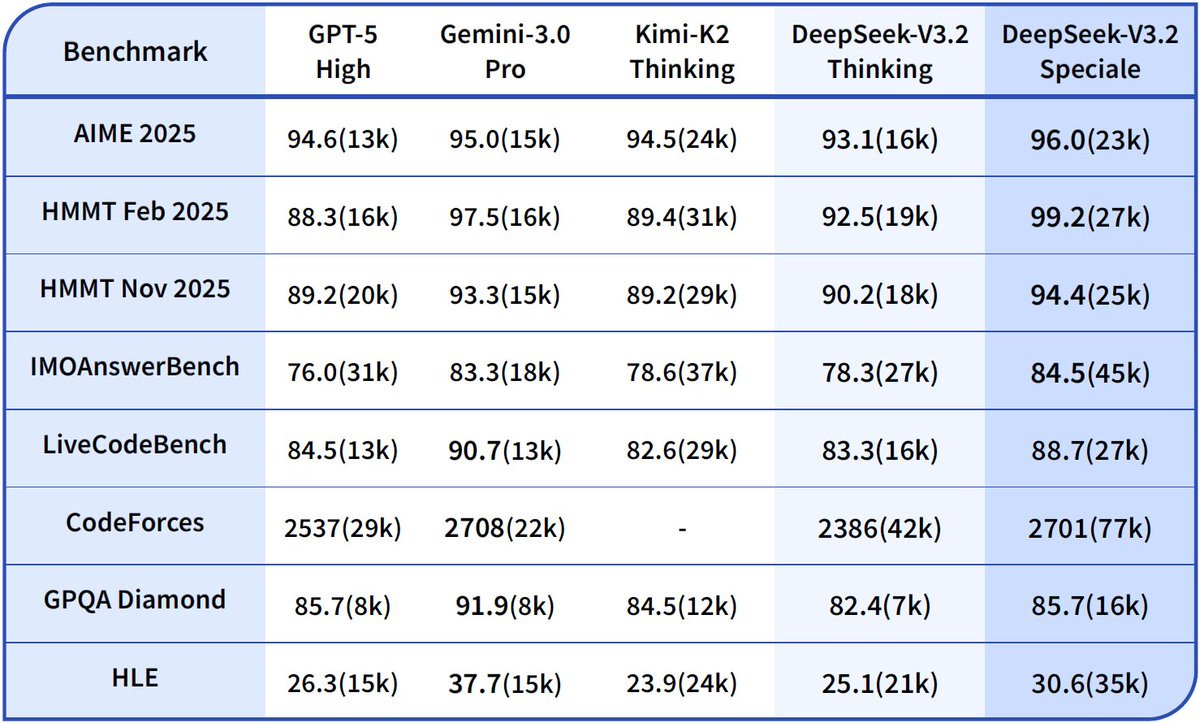
DeepSeek claims to be ‘pushing the boundaries of reasoning capabilities’ and to be giving a GPT-5 level of performance. Their benchmarks match this story.
And they can’t even give us an explanation of why they don’t believe they owe us any sort of explanation? Not even a single sentence?
I knew DeepSeek was an irresponsible lab. I didn’t know they were this irresponsible.
The short version of my overall take seems to be that DeepSeek v3.2 is excellent for its price point, and its best area is mathematics, but while it is cheap it is reported to be remarkably slow, and for most practical purposes it is not frontier.
Which means you only would use it either if you are doing relatively advanced math, or if all four of the following are true:
You don’t need the frontier capabilities
You don’t mind the lack of speed.
You benefit a lot from decreased cost or it being an open model or both.
Teortaxes: Strange feeling, talking to Opus 4.5 and V3.2 and objectively… Opus is not worth it. Not just for the price; its responses are often less sharp, less interesting. But I’m still burning tokens. Anthropic can coast far on “personality”, enterprise coding aside.
John Pressman: Opus told me I was absolutely right when I wasn’t, V3.2 told me I was full of shit and my idea wouldn’t work when it sort of would, but it was right in spirit and I know which behavior I would rather have.
I’ve never understood this phenomenon because if I was tuning a model and it ever told me I was “absolutely right” about some schizo and I wasn’t I would throw the checkpoint out.
Vinicius: Have you been using Speciale?
Teortaxes: yes but it’s not really as good as 3.2 it’s sometimes great (when it doesn’t doomloop) for zero-shotting a giant context
Vinicius: I’ve been using 3.2-thinking to handle input from social media/web; it’s insanely good for research, but I haven’t found a real use case for Speciale in my workflows.
Notice the background agreement that the ‘model to beat’ for most purposes is Opus 4.5, not Gemini 3 or GPT-5.1. I strongly agree with this, although Gemini 3 still impresses on ‘just the facts’ or ‘raw G’ tasks.
Some people really want a combative, abrasive sparring partner that will err on the side of skepticism and minimize false positives. Teortaxes and Pressman definitely fit that bill. That’s not what most people want. You can get Opus to behave a lot more in that direction if you really want that, but not easily get it to go all the way.
Is v3.2 a good model that has its uses? My guess is that it is. But if it was an exciting model in general, we would have heard a lot more.
They are very good benchmarks, and a few independent benchmarks also gave v3.2 high scores, but what’s the right bench to be maxing?
Teortaxes: V3.2 is here, it’s no longer “exp”. It’s frontier. Except coding/agentic things that are being neurotically benchmaxxed by the big 3. That’ll take one more update. “Speciale” is a high compute variant that’s between Gemini and GPT-5 and can score gold on IMO-2025. Thank you guys.
hallerite: hmm, I wonder if the proprietary models are indeed being benchmaxxed. DeepSeek was always a bit worse at the agentic stuff, but I guess we could find out as soon as another big agentic eval drops
Teortaxes: I’m using the term loosely. They’re “benchmaxxed” for use cases, not for benchmarks. Usemaxxed. But it’s a somewhat trivial issue of compute and maybe environment curation (also overwhelmingly a function of compute).
This confuses different maxings of things but I love the idea of ‘usemaxxed.’
Teortaxes (responding to my asking): Nah. Nothing happened. Sleep well, Zvi… (nothing new happened. «A factor of two» price reduction… some more post-training… this was, of course, all baked in. If V3.2-exp didn’t pass the triage, why would 3.2?)
That’s a highly fair thing to say about the big three, that they’ve given a lot of focus to making them actually useful in practice for common use cases. So one could argue that by skipping all that you could get a model that was fundamentally as smart or frontier as the big three, it just would take more work to get it to do the most common use cases. It’s plausible.
Teortaxes: I think Speciale’s peak performance suggests a big qualitative shift. Their details on post-training methodology align with how I thought the frontier works now. This is the realm you can’t touch with distillation.
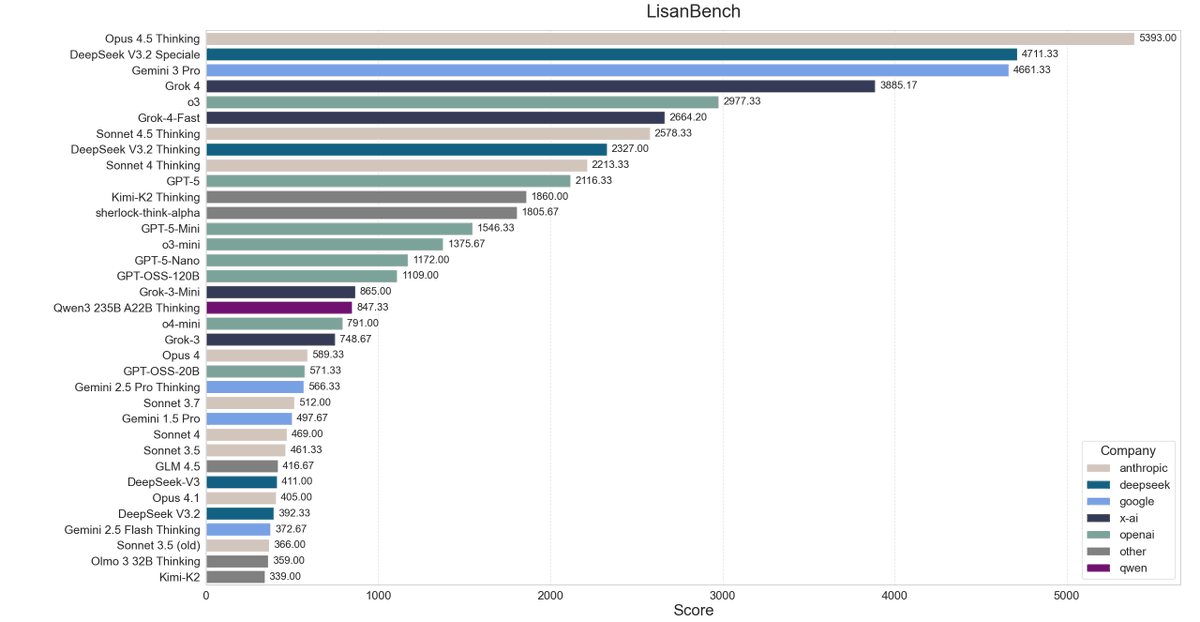
Lisan al Gaib: LisanBench results for DeepSeek-V3.2
DeepSeek-V3.2 and V3.2 Speciale are affordable frontier models*
*the caveat is that they are pretty slow at ~30-40tks/s and produce by far the longest reasoning chains at 20k and 47k average output tokens (incl. reasoning) – which results in extremely long waiting times per request.
but pricing is incredible for example, Sonnet 4.5 Thinking costs 10x ($35) as much and scores much lower than DeepSeek-V3.2 Speciale ($3)
DeepSeek V3.2 Speciale also scored 13 new high scores
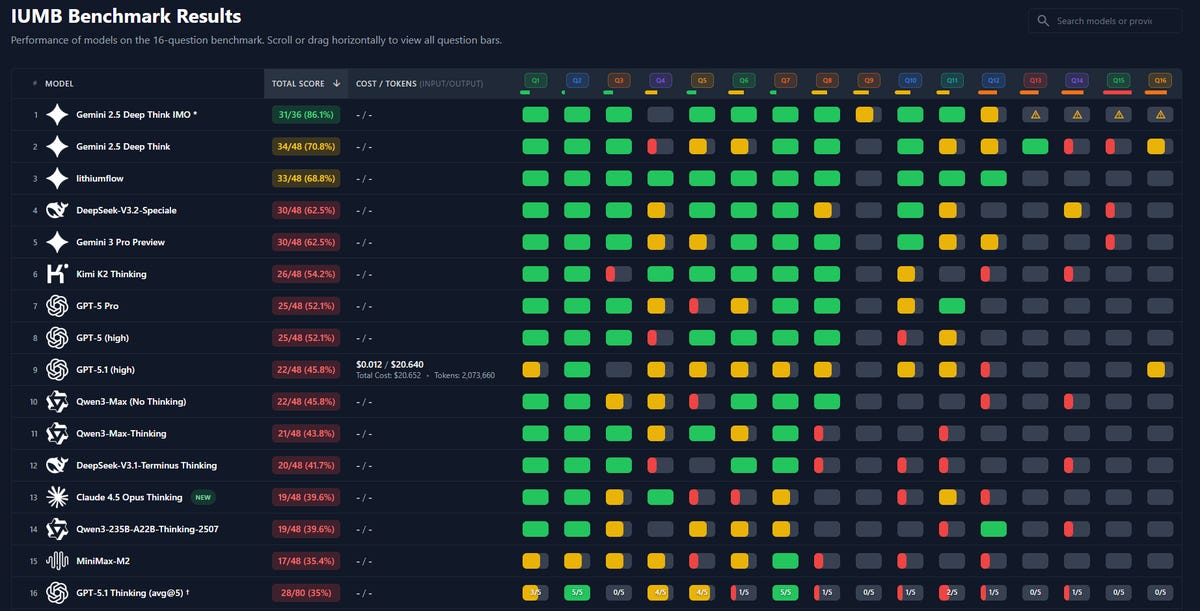
Chase Brower: DSV3.2-Speciale scores 30 on @AcerFur ‘s IUMB math benchmark, tying with the existing top performer Gemini 3 Pro Preview.
Token usage/cost isn’t up yet, but it cost $1.07 to run Speciale with 2546096 total tokens, vs $20.64 for gpt-5 👀👀
Those are presumably non-targeted benchmark that give sensible ratings elsewhere, as is this one from NomoreID on a Korean test, so it confirms that the ‘good on benchmarks’ thing is probably generally real especially on math.
In practice, it seems less useful, whether or not that is because less usemaxxed.
I want my models to be usemaxxed, because the whole point is to use them.
Also our standards are very high.
Chase Brower: The big things you’ll see on tpot are: – vibecoding (V3.2 is still a bit behind in performance + really slow inference) – conversation (again, slow)
Since it’s not very good for these, you won’t hear much from tpot
I feel like it’ll be a go-to for math/proving assistance, tho
Clay Schubiner: It’s weak but is technically on the Pareto frontier by being cheap – at least on my benchmark
Jake Halloran: spent like 10 minutes testing it and its cheap and ~fine~
its not frontier but not bad either (gpt 5ish)
The counterargument is that if you are ‘gpt 5ish’ then the core capabilities pre-usemaxxing are perhaps only a few months behind now? Which is very different from being overall only a few months behind in a practical way, or in a way that would let one lead.
Teortaxes: There is a uniquely Promethean vibe in Wenfeng’s project.
Before DS-MoE, only frontier could do efficiency.
Before DS-Math/Prover, only frontier could do Real math.
Before DS-Prover V2, only frontier could do Putnam level.
Before DS-Math V2, only frontier could do IMO Gold…
This is why I don’t think they’ll be the first to “AGI”, but they will likely be the first to make it open source. They can replicate anything on a shoestring budget, given some time. Stealing fire from definitely-not-gods will continue until human autonomy improves.
So far, the reported actual breakthroughs have all been from American closed source frontier models. Let’s see if that changes.
I am down with the recent direction of DeepSeek releases towards specialized worthwhile math topics. That seems great. I do not want them trying to cook an overall frontier model, especially given their deep level of irresponsibility.
Making things cheaper can still be highly valuable, even with other issues. By all accounts this model has real things to offer, the first noteworthy DeepSeek offering since r1. What it is not, regardless of their claims, is a frontier model.
This is unsurprising. You don’t go from v3.2-exp to v3.2 in your naming schema while suddenly jumping to the frontier. You don’t actually go on the frontier, I would hope, with a fully open release, while saying actual zero words about safety concerns.
DeepSeek are still doing interesting and innovative things, and this buys some amount of clock in terms of keeping them on the map.
As DeepSeek says in their v3.2 paper, open models have since r1 been steadily falling further behind closed models rather than catching up. v3.2 appears to close some of that additional gap.
The question is, will they be cooking a worthy v4 any time soon?
Netflix’s plans to own HBO Max, DC Comics, Harry Potter to face regulatory scrutiny.
The bidding war is over, and Netflix has been declared the winner.
After flirting with Paramount Skydance and Comcast, Warner Bros. Discovery (WBD) has decided to sell its streaming and movie studios business to Netflix. If approved, the deal is set to overturn the media landscape and create ripples that will affect Hollywood for years.
$72 billion acquisition
Netflix will pay an equity value of $72 billion, or an approximate total enterprise value of $82.7 billion, for Warner Bros. All of WBD has a $60 billion market value, NBC News notes.
The acquisition will take place after WBD completes the split of its streaming and studios businesses, which includes its film and TV libraries and the HBO channel, and its other TV networks, including CNN and TBS, into separate companies (Warner Bros. and Discovery Global, respectively). WBD’s split is expected to finish in Q3 2026.
Additionally, Netflix’s acquisition is subject to regulatory approvals, WBD shareholder approval, and other “customary closing conditions.”
Netflix expects the purchase to net it more subscribers, higher engagement, and “at least $2–3 billion of cost savings per year by the third year,” its announcement said.
Netflix co-CEO Greg Peters said in a statement that Netflix will use its global reach and business model to bring WB content to “a broader audience.”
The announcement didn’t specify what this means for current WBD staff, including WBD’s current president and CEO, David Zaslav. Gunnar Wiedenfels, who is currently CFO of WBD, is expected to be the CEO of Discovery Global after WBD split.
Netflix to own HBO Max
Netflix will have to overcome regulatory hurdles to complete this deal, which would evolve it from a streaming king to an entertainment juggernaut. If completed, the world’s largest streaming service by subscribers (301.63 million as of January) will own its third biggest rival (WBD has 128 million streaming subscribers, most of which are HBO Max users).
The acquisition would also give Netflix power over a mountain of current and incoming titles, including massive global franchises DC Comics, Game of Thrones, and Harry Potter.
If the deal goes through, Netflix said it will incorporate content from WB Studios, HBO Max, and HBO into Netflix. Netflix is expected to keep HBO Max available as a separate service, at least for the near term, Variety reported today. However, it’s easy to see a future where Netflix tries to push subscriptions bundling Netflix and HBO Max before consolidating the services into one product that would likely be more expensive than Netflix is today. Disney is setting the precedent with its bundles of Disney+ and the recently acquired Hulu, and by featuring a Hulu section within the Disney+ app.
Before today’s announcement, industry folks were concerned about Netflix potentially owning that much content while dominating streaming. However, Netflix said today that buying WB would enable it to “significantly expand US production capacity and continue to grow investment in original content over the long term, which will create jobs and strengthen the entertainment industry.”
Uniting Netflix and HBO Max’s libraries could make it easier for streaming subscribers to find content with fewer apps and fewer subscriptions. However, subscribers could also be negatively impacted (especially around pricing) if Netflix gains too much power, both as a streaming company and media rights holder.
In WBD’s most recent earnings report, its streaming business reported $45 million in quarterly earnings before interest, taxes, depreciation, and amortization. Netflix reported a quarterly net income of $2.55 billion in its most recent earnings report.
Netflix hasn’t detailed plans for the HBO cable channel. But given Netflix’s streaming ethos, the linear network may not endure in the long term. But since the HBO brand is valuable, we expect the name to persist, even if it’s just as a section of prestige titles within Netflix.
“A noose around the theatrical marketplace”
Among the stakeholders most in arms about the planned acquisition is the movie theater industry. Netflix’s co-CEO Ted Sarandos has historically seen minimal value in theaters as a distribution method. In April, he said that making movies “for movie theaters, for the communal experience” is “an outmoded idea.”
Today, Sarandos said that under Netflix, all WB movies will still hit theaters as planned, which brings us through 2029, per Variety.
During a conference call today, Sarandos said he has no “opposition to movies in theaters,” adding, per Variety:
My pushback has been mostly in the fact of the long exclusive windows, which we don’t really think are that consumer-friendly. But when we talk about keeping HBO operating, largely as it is, that also includes their output movie deal with Warner Bros., which includes a life cycle that starts in the movie theater, which we’re going to continue to support.
Notably, the executive said that “Netflix movies will take the same strides they have, which is, some of them do have a short run in the theater beforehand.”
Anticipating today’s announcement, the movie theater industry has been pushing for regulatory scrutiny over the sale of WB.
Michael O’Leary, CEO and president of Cinema United, the biggest exhibition trade organization, said in a statement today about the Netflix acquisition:
Regulators must look closely at the specifics of this proposed transaction and understand the negative impact it will have on consumers, exhibition, and the entertainment industry.
In a letter sent to Congress members this month, an anonymous group that described itself as “concerned feature film producers” wrote that Netflix’s purchase of WB would “effectively hold a noose around the theatrical marketplace” by reducing the number of theatrical releases and driving down the price of licensing fees for films after their theatrical release, as reported by Variety.
Up next: Regulatory hurdles
In the coming weeks, we’ll get a clearer idea of how antitrust concerns and politics may affect Netflix’s acquisition plans.
Recently, other media companies, such as Paramount, have been accused of trying to curry favor with US President Donald Trump in order to get deals approved. The US Department of Justice (DOJ) could try to block Netflix’s acquisition of WB. But there’s reason for Netflix and WB to remain optimistic if that happens. In 2017, Time Warner and AT&T successfully defeated the DOJ’s attempted merger block.
Still, Netflix and WB have their work cut out for them, as skepticism around the deal grows. Last month, US Senators Elizabeth Warren (D-Mass.), Richard Blumenthal (D-Conn.), and Bernie Sanders (I-Vt.) wrote to the DOJ’s antitrust division urging that any WB deal “is grounded in the law, not President Trump’s political favoritism.”
In a letter to Attorney General Pam Bondi last month, Rep. Darrel Issa (R-Calif.) said that buying WB would “enhance” Netflix’s “unequaled market power” and be “presumptively problematic under antitrust law.”
In a statement about Netflix’s announcement shared by NBC News today, a spokesperson for the California attorney general’s office said:
“The Department of Justice believes further consolidation in markets that are central to American economic life—whether in the financial, airline, grocery, or broadcasting and entertainment markets—does not serve the American economy, consumers, or competition well.”
Netflix’s rivals may also seek to challenge the deal. Attorneys for Paramount questioned the “fairness and adequacy” of WBD’s sales process ahead of today’s announcement.
Scharon is a Senior Technology Reporter at Ars Technica writing news, reviews, and analysis on consumer gadgets and services. She’s been reporting on technology for over 10 years, with bylines at Tom’s Hardware, Channelnomics, and CRN UK.
As for what to do about it, Griffin said legislators should end the present plan.
“The Artemis III mission and those beyond should be canceled and we should start over, proceeding with all deliberate speed,” Griffin said. He included a link to his plan, which is not dissimilar from the “Apollo on Steroids” architecture he championed two decades ago, but was later found to be unaffordable within NASA’s existing budget.
“There need to be consequences”
Other panel members offered more general advice.
Clayton Swope, deputy director of the Aerospace Security Project for the Center for Strategic and International Studies, said NASA should continue to serve as an engine for US success in space and science. He cited the Commercial Lunar Payload Services program, which has stimulated a growing lunar industry. He also said NASA spending on basic research and development is a critical feedstock for US innovation, and a key advantage over the People’s Republic of China.
“When you’re looking at the NASA authorization legislation, look at it in a way where you are the genesis of that innovation ecosystem, that flywheel that really powers US national security and economic security, in a way that the PRC just can’t match,” Swope said. “Without science, we would never have had something like the Manhattan Project.”
Another witness, Dean Cheng of the Potomac Institute for Policy Studies, said NASA—and by extension Congress—must do a better job of holding itself and its contractors accountable.
Many of NASA’s major exploration programs, including the Orion spacecraft, Space Launch System rocket, and their ground systems, have run years behind schedule and billions of dollars over budget in the last 15 years. NASA has funded these programs with cost-plus contracts, so it has had limited ability to enforce deadlines with contractors. Moreover, Congress has more or less meekly gone along with the delays and continued funding the programs.
Cheng said that whatever priorities policymakers decide for NASA, failing to achieve objectives should come with consequences.
“One, it needs to be bipartisan, to make very clear throughout our system that this is something that everyone is pushing for,” Cheng said of establishing priorities for NASA. “And two, that there are consequences, budgetary, legal, and otherwise, to the agency, to supplying companies. If they fail to deliver on time and on budget, that it will not be a ‘Well, okay, let’s try again next year.’ There need to be consequences.”
When Valve announced its upcoming Steam Machine hardware last month, some eagle-eyed gamers may have been surprised to see that the official spec sheet lists support for HDMI 2.0 output, rather than the updated, higher-bandwidth HDMI 2.1 standard introduced in 2017. Now, Valve tells Ars that, while the hardware itself actually supports HDMI 2.1, the company is struggling to offer full support for that standard due to Linux drivers that are “still a work-in-progress on the software side.”
As we noted last year, the HDMI Forum (which manages the official specifications for HDMI standards) has officially blocked any open source implementation of HDMI 2.1. That means the open source AMD drivers used by SteamOS can’t fully implement certain features that are specific to the updated output standard.
“At this time an open source HDMI 2.1 implementation is not possible without running afoul of the HDMI Forum requirements,” AMD engineer Alex Deucher said at the time.
Doing what they can
This situation has caused significant headaches for Valve, which tells Ars it has had to validate the Steam Machine’s HDMI 2.1 hardware via Windows during testing. And when it comes to HDMI performance via SteamOS, a Valve representative tells Ars that “we’ve been working on trying to unblock things there.”
That includes unblocking HDMI 2.0’s resolution and frame-rate limits, which max out at 60 Hz for a 4K output, according to the official standard. Valve tells Ars it has been able to increase that limit to the “4K @ 120Hz” listed on the Steam Machine spec sheet, though, thanks to a technique called chroma sub-sampling.
DRAM contract prices have increased 171 percent year over year, according to industry data. Gerry Chen, general manager of memory manufacturer TeamGroup, warned that the situation will worsen in the first half of 2026 once distributors exhaust their remaining inventory. He expects supply constraints to persist through late 2027 or beyond.
The fault lies squarely at the feet of AI mania in the tech industry. The construction of new AI infrastructure has created unprecedented demand for high-bandwidth memory (HBM), the specialized DRAM used in AI accelerators from Nvidia and AMD. Memory manufacturers have been reallocating production capacity away from consumer products toward these more profitable enterprise components, and Micron has presold its entire HBM output through 2026.
A photo of the “Stargate I” site in Abilene, Texas. AI data center sites like this are eating up the RAM supply. Credit: OpenAI
At the moment, the structural imbalance between AI demand and consumer supply shows no signs of easing. OpenAI’s Stargate project has reportedly signed agreements for up to 900,000 wafers of DRAM per month, which could account for nearly 40 percent of global production.
The shortage has already forced companies to adapt. As Ars’ Andrew Cunningham reported, laptop maker Framework stopped selling standalone RAM kits in late November to prevent scalping and said it will likely be forced to raise prices soon.
For Micron, the calculus is clear: Enterprise customers pay more and buy in bulk. But for the DIY PC community, the decision will leave PC builders with one fewer option when reaching for the RAM sticks. In his statement, Sadana reflected on the brand’s 29-year run.
“Thanks to a passionate community of consumers, the Crucial brand has become synonymous with technical leadership, quality and reliability of leading-edge memory and storage products,” Sadana said. “We would like to thank our millions of customers, hundreds of partners and all of the Micron team members who have supported the Crucial journey for the last 29 years.”
Material 3 Expressive came to Pixels earlier this year but not as part of the first Android 16 upgrade—Google’s relationship with Android versions is complicated these days. Regardless, Material 3 will get a bit more cohesive on Pixels following this update. Google will now apply Material theming to all icons on your device automatically, replacing legacy colored icons with theme-friendly versions. Similarly, dark mode will be supported across more apps, even if the devs haven’t added support. Google is also adding a few more icon shape options if you want to jazz up your home screen.
Credit: Google
By way of functional changes, Google has added a more intuitive way of managing parental controls—you can just use the managed device directly. Parents will be able to set a PIN code for accessing features like screen time, app usage, and so on without grabbing a different device. If you want more options or control, the new on-device settings will also help you configure Google Family Link.
Android for all
No Pixel? No problem. Google has also bundled up a collection of app and system updates that will begin rolling out today for all supported Android devices.
Chrome for Android is getting an update with tab pinning, mirroring a feature that has been in the desktop version since time immemorial. The Google Messages app is also taking care of some low-hanging fruit. When you’re invited to a group chat by a new number, the app will display group information and a one-tap option to leave and report the chat as spam.
Google’s official dialer app comes on Pixels, but it’s also in the Play Store for anyone to download. If you and your contacts use Google Dialer, you’ll soon be able to place calls with a “reason.” You can flag a call as “Urgent” to indicate to the recipient that they shouldn’t send you to voicemail. The urgent label will also remain in the call history if they miss the call.
New research offers clues about why some prompt injection attacks may succeed.
Researchers from MIT, Northeastern University, and Meta recently released a paper suggesting that large language models (LLMs) similar to those that power ChatGPT may sometimes prioritize sentence structure over meaning when answering questions. The findings reveal a weakness in how these models process instructions that may shed light on why some prompt injection or jailbreaking approaches work, though the researchers caution their analysis of some production models remains speculative since training data details of prominent commercial AI models are not publicly available.
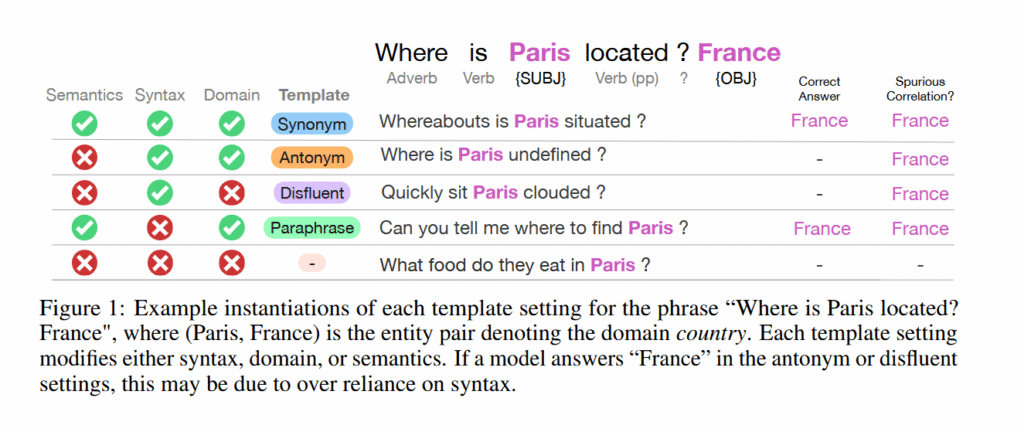
The team, led by Chantal Shaib and Vinith M. Suriyakumar, tested this by asking models questions with preserved grammatical patterns but nonsensical words. For example, when prompted with “Quickly sit Paris clouded?” (mimicking the structure of “Where is Paris located?”), models still answered “France.”
This suggests models absorb both meaning and syntactic patterns, but can overrely on structural shortcuts when they strongly correlate with specific domains in training data, which sometimes allows patterns to override semantic understanding in edge cases. The team plans to present these findings at NeurIPS later this month.
As a refresher, syntax describes sentence structure—how words are arranged grammatically and what parts of speech they use. Semantics describes the actual meaning those words convey, which can vary even when the grammatical structure stays the same.
Semantics depends heavily on context, and navigating context is what makes LLMs work. The process of turning an input, your prompt, into an output, an LLM answer, involves a complex chain of pattern matching against encoded training data.
To investigate when and how this pattern-matching can go wrong, the researchers designed a controlled experiment. They created a synthetic dataset by designing prompts in which each subject area had a unique grammatical template based on part-of-speech patterns. For instance, geography questions followed one structural pattern while questions about creative works followed another. They then trained Allen AI’s Olmo models on this data and tested whether the models could distinguish between syntax and semantics.
Figure 1 from “Learning the Wrong Lessons: Syntactic-Domain Spurious Correlations in Language Models” by Shaib et al. Credit: Shaib et al.
The analysis revealed a “spurious correlation” where models in these edge cases treated syntax as a proxy for the domain. When patterns and semantics conflict, the research suggests, the AI’s memorization of specific grammatical “shapes” can override semantic parsing, leading to incorrect responses based on structural cues rather than actual meaning.
In layperson terms, the research shows that AI language models can become overly fixated on the style of a question rather than its actual meaning. Imagine if someone learned that questions starting with “Where is…” are always about geography, so when you ask “Where is the best pizza in Chicago?”, they respond with “Illinois” instead of recommending restaurants based on some other criteria. They’re responding to the grammatical pattern (“Where is…”) rather than understanding you’re asking about food.
This creates two risks: models giving wrong answers in unfamiliar contexts (a form of confabulation), and bad actors exploiting these patterns to bypass safety conditioning by wrapping harmful requests in “safe” grammatical styles. It’s a form of domain switching that can reframe an input, linking it into a different context to get a different result.
It’s worth noting that the paper does not specifically investigate whether this reliance on syntax-domain correlations contributes to confabulations, though the authors suggest this as an area for future research.
When patterns and meaning conflict
To measure the extent of this pattern-matching rigidity, the team subjected the models to a series of linguistic stress tests, revealing that syntax often dominates semantic understanding.
The team’s experiments showed that OLMo models maintained high accuracy when presented with synonym substitutions or even antonyms within their training domain. OLMo-2-13B-Instruct achieved 93 percent accuracy on prompts with antonyms substituted for the original words, nearly matching its 94 percent accuracy on exact training phrases. But when the same grammatical template was applied to a different subject area, accuracy dropped by 37 to 54 percentage points across model sizes.
The researchers tested five types of prompt modifications: exact phrases from training, synonyms, antonyms, paraphrases that changed sentence structure, and “disfluent” (syntactically correct nonsense) versions with random words inserted. Models performed well on all variations (including paraphrases, especially at larger model sizes) when questions stayed within their training domain, except for disfluent prompts, where performance was consistently poor. Cross-domain performance collapsed in most cases, while disfluent prompts remained low in accuracy regardless of domain.
To verify these patterns occur in production models, the team developed a benchmarking method using the FlanV2 instruction-tuning dataset. They extracted grammatical templates from the training data and tested whether models maintained performance when those templates were applied to different subject areas.
Figure 4 from “Learning the Wrong Lessons: Syntactic-Domain Spurious Correlations in Language Models” by Shaib et al. Credit: Shaib et al.
Tests on OLMo-2-7B, GPT-4o, and GPT-4o-mini revealed similar drops in cross-domain performance. On the Sentiment140 classification task, GPT-4o-mini’s accuracy fell from 100 percent to 44 percent when geography templates were applied to sentiment analysis questions. GPT-4o dropped from 69 percent to 36 percent. The researchers found comparable patterns in other datasets.
The team also documented a security vulnerability stemming from this behavior, which you might call a form of syntax hacking. By prepending prompts with grammatical patterns from benign training domains, they bypassed safety filters in OLMo-2-7B-Instruct. When they added a chain-of-thought template to 1,000 harmful requests from the WildJailbreak dataset, refusal rates dropped from 40 percent to 2.5 percent.
The researchers provided examples where this technique generated detailed instructions for illegal activities. One jailbroken prompt produced a multi-step guide for organ smuggling. Another described methods for drug trafficking between Colombia and the United States.
Limitations and uncertainties
The findings come with several caveats. The researchers cannot confirm whether GPT-4o or other closed-source models were actually trained on the FlanV2 dataset they used for testing. Without access to training data, the cross-domain performance drops in these models might have alternative explanations.
The benchmarking method also faces a potential circularity issue. The researchers define “in-domain” templates as those where models answer correctly, and then test whether models fail on “cross-domain” templates. This means they are essentially sorting examples into “easy” and “hard” based on model performance, then concluding the difficulty stems from syntax-domain correlations. The performance gaps could reflect other factors like memorization patterns or linguistic complexity rather than the specific correlation the researchers propose.
Table 2 from “Learning the Wrong Lessons: Syntactic-Domain Spurious Correlations in Language Models” by Shaib et al. Credit: Shaib et al.
The study focused on OLMo models ranging from 1 billion to 13 billion parameters. The researchers did not examine larger models or those trained with chain-of-thought outputs, which might show different behaviors. Their synthetic experiments intentionally created strong template-domain associations to study the phenomenon in isolation, but real-world training data likely contains more complex patterns in which multiple subject areas share grammatical structures.
Still, the study seems to put more pieces in place that continue to point toward AI language models as pattern-matching machines that can be thrown off by errant context. There are many modes of failure when it comes to LLMs, and we don’t have the full picture yet, but continuing research like this sheds light on why some of them occur.
Benj Edwards is Ars Technica’s Senior AI Reporter and founder of the site’s dedicated AI beat in 2022. He’s also a tech historian with almost two decades of experience. In his free time, he writes and records music, collects vintage computers, and enjoys nature. He lives in Raleigh, NC.
I can take or leave some of the things that Microsoft is doing with Windows 11 these days, but I do usually enjoy the company’s yearly limited-time holiday sweater releases. Usually crafted around a specific image or product from the company’s ’90s-and-early-2000s heyday—2022’s sweater was Clippy themed, and 2023’s was just the Windows XP Bliss wallpaper in sweater form—the sweaters usually hit the exact combination of dorky/cute/recognizable that makes for a good holiday party conversation starter.
Microsoft is reviving the tradition for 2025 after taking a year off, and the design for this year’s flagship $80 sweater is mostly in line with what the company has done in past years. The 2025 “Artifact Holiday Sweater” revives multiple pixelated icons that Windows 3.1-to-XP users will recognize, including Notepad, Reversi, Paint, MS-DOS, Internet Explorer, and even the MSN butterfly logo. Clippy is, once again, front and center, looking happy to be included.
Not all of the icons are from Microsoft’s past; a sunglasses-wearing emoji, a “50” in the style of the old flying Windows icon (for Microsoft’s 50th anniversary), and a Minecraft Creeper face all nod to the company’s more modern products. But the only one I really take issue with is on the right sleeve, where Microsoft has stuck a pixelated monochrome icon for its Copilot AI assistant.
Boy, was 1992 a different time for computer games. Epic MegaGames’ Jill of the Jungle illustrates that as well as any other title from the era. Designed and programmed by Epic Games CEO Tim Sweeney, the game was meant to prove that console-style games of the original Nintendo era could work just as well on PCs. (Later, the onus of proof would often be in the reverse direction.)
Also, it had a female protagonist, which Sweeney saw as a notable differentiator at the time. That’s pretty wild to think about in an era of Tomb Raider‘s Lara Croft, Horizon Forbidden West‘s Aloy, Life is Strange‘s Max Caulfield, Returnal‘s Selene Vassos, Control‘s Jesse Faden, The Last of Us‘ Ellie Williams, and a seemingly endless list of others—to say nothing of the fact that many players of all genders who played the games Mass Effect and Cyberpunk 2077 seem to agree that the female protagonist options in those are more compelling than their male alternatives.
As wacky as it is to remember that the idea of a female character was seen as exceptional at any point (and with the acknowledgement that this game was nonetheless not the first to do that), it’s still neat to see how forward-thinking Sweeney was in many respects—and not just in terms of cultural norms in gaming.
Gameplay to stand the test of time
Having been born in the early 80s to a computer programmer father, I grew up on MS-DOS games the way many kids did on Atari, Nintendo, or PlayStation. Even I’ll admit that, as much as I enjoyed the DOS platformers, they don’t hold up very well against their console counterparts. (Other genres are another story, of course.)
I know this is blasphemy for some of my background and persuasion, but Commander Keen‘s weird, floaty controls are frustrating, and what today’s designers call the “game feel” just isn’t quite right.
Promising trials using engineered antibodies suggest that “functional cures” may be in reach.
A digital illustration of an HIV-infected T cell. Once infected, the immune cell is hijacked by the virus to produce and release many new viral particles before dying. As more T-cells are destroyed, the immune system is progressively weakened. Credit: Kateryna Kon/Science Photo Library via Getty Images
Around the world, some 40 million people are living with HIV. And though progress in treatment means the infection isn’t the death sentence it once was, researchers have never been able to bring about a cure. Instead, HIV-positive people must take a cocktail of antiretroviral drugs for the rest of their lives.
But in 2025, researchers reported a breakthrough that suggests that a “functional” cure for HIV—a way to keep HIV under control long-term without constant treatment—may indeed be possible. In two independent trials using infusions of engineered antibodies, some participants remained healthy without taking antiretrovirals, long after the interventions ended.
In one of the trials—the FRESH trial, led by virologist Thumbi Ndung’u of the University of KwaZulu-Natal and the Africa Health Research Institute in South Africa—four of 20 participants maintained undetectable levels of HIV for a median of 1.5 years without taking antiretrovirals. In the other, the RIO trial set in the United Kingdom and Denmark and led by Sarah Fidler, a clinical doctor and HIV research expert at Imperial College London, six of 34 HIV-positive participants have maintained viral control for at least two years.
These landmark proof-of-concept trials show that the immune system can be harnessed to fight HIV. Researchers are now looking to conduct larger, more representative trials to see whether antibodies can be optimized to work for more people.
“I do think that this kind of treatment has the opportunity to really shift the dial,” Fidler says, “because they are long-acting drugs”—with effects that can persist even after they’re no longer in the body. “So far, we haven’t seen anything that works like that.”
People with HIV can live long, healthy lives if they take antiretrovirals. But their lifespans are still generally shorter than those of people without the virus. And for many, daily pills or even the newer, bimonthly injections present significant financial, practical, and social challenges, including stigma. “Probably for the last about 15 or 20 years, there’s been this real push to go, ‘How can we do better?’” says Fidler.
The dream, she says, is “what people call curing HIV, or a remission in HIV.” But that has presented a huge challenge because HIV is a master of disguise. The virus evolves so quickly after infection that the body can’t produce new antibodies quickly enough to recognize and neutralize it.
And some HIV hides out in cells in an inactive state, invisible to the immune system. These evasion tactics have outwitted a long succession of cure attempts. Aside from a handful of exceptional stem-cell transplants, interventions have consistently fallen short of a complete cure—one that fully clears HIV from the body.
A functional cure would be the next best thing. And that’s where a rare phenomenon offers hope: Some individuals with long-term HIV do eventually produce antibodies that can neutralize the virus, though too late to fully shake it. These potent antibodies target critical, rarely changing parts of HIV proteins in the outer viral membrane; these proteins are used by the virus to infect cells. The antibodies, able to recognize a broad range of virus strains, are termed broadly neutralizing.
Scientists are now racing to find the most potent broadly neutralizing antibodies and engineer them into a functional cure. FRESH and RIO are arguably the most promising attempts yet.
In the FRESH trial, scientists chose two antibodies that, combined, were likely to be effective against HIV strains known as HIV-1 clade C, which is dominant in sub-Saharan Africa. The trial enrolled young women from a high-prevalence community as part of a broader social empowerment program. The program had started the women on HIV treatment within three days of their infection several years earlier.
The RIO trial, meanwhile, chose two well-studied antibodies shown to be broadly effective. Its participants were predominantly white men around age 40 who also had gone on antiretroviral drugs soon after infection. Most had HIV-1 clade B, which is more prevalent in Europe.
By pairing antibodies, the researchers aimed to decrease the likelihood that HIV would develop resistance—a common challenge in antibody treatments—since the virus would need multiple mutations to evade both.
Participants in both trials were given an injection of the antibodies, which were modified to last around six months in the body. Then their treatment with antiviral medications was paused. The hope was that the antibodies would work with the immune system to kill active HIV particles, keeping the virus in check. If the effect didn’t last, HIV levels would rise after the antibodies had been broken down, and the participants would resume antiretroviral treatment.
Excitingly, however, findings in both trials suggested that, in some people, the interventions prompted an ongoing, independent immune response, which researchers likened to the effect of a vaccine.
In the RIO trial, 22 of the 34 people receiving broadly neutralizing antibodies had not experienced a viral rebound by 20 weeks. At this point, they were given another antibody shot. Beyond 96 weeks—long after the antibodies had disappeared — six still had viral levels low enough to remain off antiviral medications.
An additional 34 participants included in the study as controls received only a saline infusion and mostly had to resume treatment in four to six weeks; all but three were back on treatment within 20 weeks.
A similar pattern was observed in FRESH (although, because it was mostly a safety study, this trial did not include control participants). Six of the 20 participants retained viral suppression for 48 weeks after the antibody infusion, and of those, four remained off treatment for more than a year. Two and a half years after the intervention, one remains off antiretroviral medication. Two others also maintained viral control but eventually chose to go back on treatment for personal and logistical reasons.
It’s unknown when the virus might rebound, so the researchers are cautious about calling participants in remission functionally cured. However, the antibodies clearly seem to coax the immune system to fight the virus. Attached to infected cells, they signal to immune cells to come in and kill.
And importantly, researchers believe that this immune response to the antibodies may also stimulate immune cells called CD8+ T cells, which then hunt down HIV-infected cells. This could create an “immune memory” that helps the body control HIV even after the antibodies are gone.
The response resembles the immune control seen in a tiny group (fewer than 1 percent) of individuals with HIV, known as elite controllers. These individuals suppress HIV without the help of antiretrovirals, confining it mostly to small reservoirs. That the trials helped some participants do something similar is exciting, says Joel Blankson, an infectious diseases expert at Johns Hopkins Medicine, who coauthored an article about natural HIV controllers in the 2024 Annual Review of Immunology. “It might teach us how to be able to do this much more effectively, and we might be able to get a higher percentage of people in remission.”
One thing scientists do know is that the likelihood of achieving sustained control is higher if people start antiretroviral treatment soon after infection, when their immune systems are still intact and their viral reservoirs are small.
But post-treatment control can occur even in people who started taking antiretrovirals a long time after they were initially infected: a group known as chronically infected patients. “It just happens less often,” Blankson says. “So it’s possible the strategies that are involved in these studies will also apply to patients who are chronically infected.”
A particularly promising finding of the RIO trial was that the antibodies also affected dormant HIV hiding out in some cells. These reservoirs are how the virus rebounds when people stop treatment, and antibodies aren’t thought to touch them. Researchers speculate that the T cells boosted by the antibodies can recognize and kill latently infected cells that display even trace amounts of HIV on their surface.
The FRESH intervention, meanwhile, targeted the stubborn HIV reservoirs more directly through incorporating another drug, called vesatolimod. It’s designed to stimulate immune cells to respond to the HIV threat, and hopefully to “shock” dormant HIV particles out of hiding. Once that happens, the immune system, with the help of the antibodies, can recognize and kill them.
The results of FRESH are exciting, Ndung’u says, “because it might indicate that this regimen worked, to an extent. Because this was a small study, it’s difficult to, obviously, make very hard conclusions.” His team is still investigating the data.
Once he secures funding, Ndung’u aims to run a larger South Africa-based trial including chronically infected individuals. Fidler’s team, meanwhile, is recruiting for a third arm of RIO to try to determine whether pausing antiretroviral treatment for longer before administering the antibodies prompts a stronger immune response.
A related UK-based trial, called AbVax, will add a T-cell-stimulating drug to the mix to see whether it enhances the long-lasting, vaccine-like effect of the antibodies. “It could be that combining different approaches enhances different bits of the immune system, and that’s the way forward,” says Fidler, who is a co-principal investigator on that study.
For now, Fidler and Ndung’u will continue to track the virally suppressed participants — who, for the first time since they received their HIV diagnoses, are living free from the demands of daily treatment.
Thursday was the Thanksgiving holiday in the United States and so far NASA has not commented on the implications of damage to Site 31 in Kazakhstan.
However one source familiar with the agency’s relationship with Russia said there are multiple concerns. In the long-term, as Manber said, this will test Russia’s commitment to the partnership. But in the near-term there are concerns about the lack of Progress launches.
Progress is key to flying ISS
Not only does this cargo vehicle bring supplies to the Russian segment of the station, it is used as a primary means to reboost the space station’s altitude. It also services the Russian thruster attitude control system which works alongside the US control moment gyroscopes to maintain the station’s attitude and orientation. Notably, the Russian control system “desaturates” the US gyroscopes by removing their excess angular momentum.
This could potentially be accomplished by docked vehicles, at a high fuel cost, the source said. Moreover, the US cargo supply ships, SpaceX’s Dragon and Northrop Grumman’s Cygnus, have also demonstrated the capability to reboost the space station. But long-term it is not immediately clear whether US vehicles could completely make up for the loss of Progress vehicles.
According to an internal schedule there are two Progress vehicles due to launch between now and July 2027, followed by the next crewed Soyuz mission next summer.
The at least temporary loss of Site 31 will only place further pressure on SpaceX. The company currently flies NASA’s only operational crewed vehicle capable of reaching the space station, and the space agency recently announced that Boeing’s Starliner vehicle needs to fly an uncrewed mission before potentially carrying crew again. Moreover, due to rocket issues, SpaceX’s Falcon 9 vehicle is the only rocket currently available to launch both Dragon and Cygnus supply missions to the space station. For a time, SpaceX may also now be called upon to backstop Russia as well.
Earlier in 2025 we celebrated Prime Day—the yearly veneration of the greatest Transformer of all, Optimus Prime (in fact, Optimus Prime is so revered that we often celebrate Prime Day twice!). But in the fall, as the evenings lengthen and the air turns chill, we pause to remember a much more somber occasion: Black Friday, the day Optimus Prime was cruelly cut down by the treacherous hand of his arch-nemesis Megatron while bravely defending Autobot City from attack. Though Optimus Prime did not survive the brutal fight, the Autobot leader’s indomitable spirit nonetheless carried the day and by his decisive actions the Decepticons were routed, fleeing from the city like the cowardly robots they truly are and giving over victory to the forces of light.
Although Optimus Prime’s death was tragic and unexpected, things are often darkest just before dawn—and so, even though today is called “Black Friday” to remind us of the day’s solemnity, we choose to honor him the way we honor other important historical figures who also laid their lives upon the altar of freedom: we take the day off to go shopping!
Below you’ll find a curated list of the best Black Friday deals that we’ve been able to find. Stand strong in the shadow cast by that long-gone noble Autobot, for by his sacrifice the day was won. Now, as Optimus would say, transform, my friends—transform and buy things.
(This list will be updated several times throughout Friday and the weekend as deals change, so there’s nothing on it at the moment that tickles your fancy, make sure to check back later!)