Happy Gemini Week to those who celebrate. Coverage of the new release will begin on Friday. Meanwhile, here’s this month’s things that don’t go anywhere else.
Google has partnered with Polymarket to include Polymarket odds into Google Search and Google Finance. This is fantastic and suggests we should expand the number of related markets on Polymarket.
In many ways Polymarket prediction markets are remarkably accurate, but here what we have is a Brier Score without a baseline of what we should expect as a baseline. You need to compare your Brier Score to scores on exactly the same events, or it doesn’t mean much. There’s a lot to be made on Polymarket if you pay attention.
A proposed ‘21st Century Civilization Curriculum’ for discussion groups. There’s an interestingly high number of book reviews involved as opposed to the actual books. I get one post in at the end, which turns out to be Quotes From Moral Mazes, so I’m not sure it counts but the curation is hopefully doing important work there.
Wylfa in North Wales will host the UK’s first small modular nuclear reactors, government to invest 2.5 billion.
Fusion reactors might pay for themselves by turning Mercury into Gold? Beware diminishing marginal returns. Manifold has this at 28% by 2035.
Scott Alexander’s latest roundup on charter cities.
This month’s version of standard solid advice for men in their 20s.
Usopp: 12 advice that came up the most in the replies/qt so far:
– Find your partner, get married and have kids
– Take way more risks
– Build a strong circle of quality friends, cut off toxic ppl
– Read a lot a lot of books
– Travel more, move elsewhere
– Exercise daily, stay and keep fit
– Stay away from junk food – always prioritise health
– Quit porn, quit smoking, quit alcohol
– Be humble, lose the ego but don’t lose the confidence.
– Protect your mental health
– Don’t neglect family, always call your parents
Nothing Earth shattering or surprising there, I hope, but yeah, that’s the go-tos.
Risks here means taking ‘real’ risks in life, not taking financial risks or gambling.
Jeffrey Wang is the latest to offer advice on how to throw parties, with an emphasis on sound, he says you need music and at least one both loud and quiet zone, and also he’s a fan of the drinking.
I sense I don’t get invited to his sort of parties, and that’s probably for the best.
A report from Jerusalem Demas about what it is like to know you could end up watching TikTok for 10 hours a day.
Twitter will experiment with telling us what nation accounts are posting from, what date they joined and when they last changed their username. They say there will be privacy toggles, but of course then everyone knows you have something to hide, and they’ll highlight that you did it. I’m mostly in support of this, as it should help control various bot and astroturfing problems. I think that’s worth the cost.
The plan to avoid penalizing Twitter links is that when you click on a link in the iOS app it will keep the post itself accessible on the bottom of the screen so that you can easily like, repost or respond to the original post while you read. I guess this is a marginal improvement?
Alternatively, you could do these things more often with tweets that have links or longer articles, especially the likes and retweets.
The unfortunate natural pattern is that if you provide a witty comment, the barrier to liking it is low. Whereas if you provide actual value in the form of a link or Twitter article, or you read something on Substack, the threshold for liking it is ‘I actually read the damn thing and not only liked it but didn’t have any issues with anything in it, and also remembered to like it afterwards’ which makes it highly unlikely.
Therefore, I’m going to make a request: If you think the world would be better off if more people read the link or article on Twitter, then like the post with the link or article. If not, not. Thank you for your attention to this matter.
The bulk of ‘social media’ is now actually short form television that uses an algorithm. This, as Matthew Yglesias notes, is bad. Short form algorithmic video is bad news. Social media as originally intended, where you are social and consume various media from people you are social with, is a mixed bag, but the new thing is terrible. Regular television has big downsides, but also advantages. This seems obviously much worse, and I’ve said it before but it bears repeating.
Xi views TikTok as ‘spiritual opium’ rather than something important, is totally fine with that, and is allowing the TikTok sale as a bargaining chip.
What happens if you start a fresh Twitter account using a VPN and the For You page? Soren Kierkegaard found (pre-election) a 4:1 ratio of right to left wing tweets. Nicholas Decker made a new alt and so got a look at the new account algorithm, reports nothing but the most obnoxious conservative propaganda imaginable.
This is not good business on the part of Elon Musk. Even if your goal is only to advance conservative causes, you need to draw new users in. This doesn’t do that.
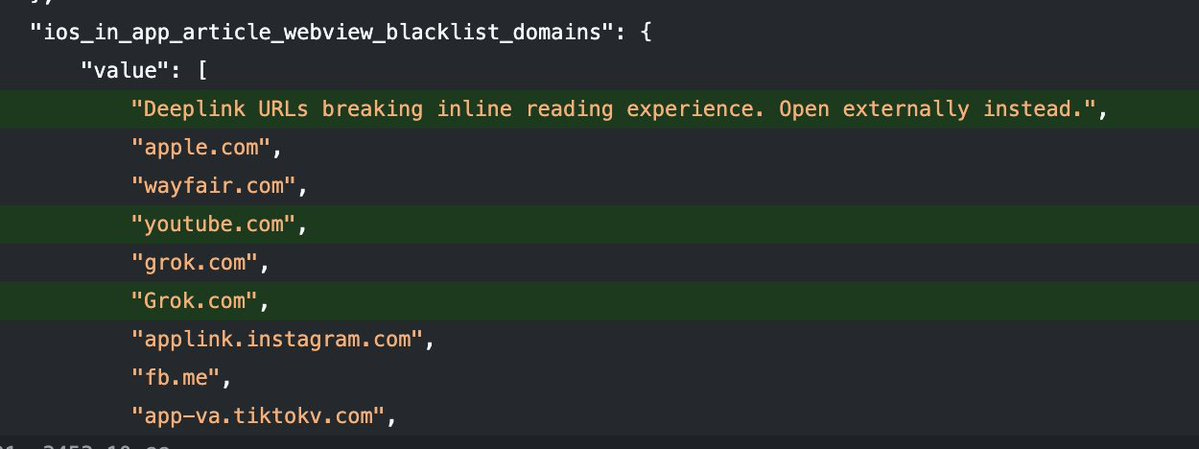
Twitter’s new in-app link viewer has a few excluded domains, and well, whoops.
Substack being on the list is rather obnoxious, although it seems it was then taken out again and an explanation added?
Aaron: X has released an update for iOS that clarifies why some domains are blacklisted from the new web view
Our government keeps straight up murdering people on the high seas, as in blowing up boats, in many cases without even knowing who is on the boats.
Wall Street Journal claims Trump administration is planning to overhaul the IRS with the explicit goal of weaponizing it to investigate left wing groups. I thought that using the IRS in this way was illegal, but I guess it’s 2025, you can just do things.
We are rolling back tariffs on “products that cannot be grown, mined or naturally produced in the United States.” Good. I almost always have a policy of praising rather than criticizing people when they stop hitting themselves but man, we did not need to spend the better part of a year figuring that one out.
While Trump argues that not having tariffs will bankrupt the country Bessent announces a ‘$2,000 tariff stimulus check’ for those making less than $100k. Curious.
Always be gracious when someone does something good, you don’t necessarily have to ask how we got there, especially since everybody knows:
White House: Thanks to President Trump’s deal-making, we’re making trade fair again, & winning BIG.
Coffee, tea, cocoa, spices, bananas, oranges, tomatoes, beef, fertilizers, & more are now exempt from reciprocal tariffs.
America First policies delivering for American workers & families🇺🇸
Alex Tabarrok: Frank Sinatra? Heck of a guy – real prince. Saved my life once. We were doing a show at the Sands, and between sets, I took a break in the parking lot. Next thing I know, three guys are working me over real good. Then I hear Frank say, ‘OK, boys, that’s enough.’”
Shecky Greene
Home and auto insurance rates are rising, so the state governments are governmenting and telling insurers to cap prices. If you have lots of insurance providers and rates keep going up, there’s a reason. If you don’t have lots of insurance providers, there’s a reason for that, too. As California has learned, if you cap insurance prices where they’re unprofitable, insurers pick up and leave. No one seems to be asking about how to lower the real cost of insurance, as in the need for payouts.
There is about $1.5 trillion in capex going through federal permitting. Chop chop.
Trump explicitly says on Fox News we don’t have enough talent, we have to bring in talent, in reference to H1-Bs, and also reveals he had nothing to do with the raid on the South Korean battery factory and was wisely upset when it happened. It’s good that he understands the principle but we still observe what the White House is actually doing, which is not great.
Thanks to Argentina we now know that supporting US allies is America First.
Trump’s mechanism to pay the troops during the shutdown also seems rather blatantly illegal, as in spending money in a way not approved by Congress with no fig leaf on why it is allowed?
Bobby Kogan: The mechanism through which Trump is paying the troops is the most blatant large Antideficiency Act (ADA) violation in US history. It’s also clearly willful. No one has been charged under the ADA before, but violations carry a 2 year jail term. Statute of limitations is 5 years.
Under the Constitution and under the ADA, it is illegal to spend money without funding for that purpose. The president may not spend money to do something unless there’s actually money to carry it out and that action is expressly allowed.
… Military pay is appropriated one year at a time, with a one-year period of availability. The fiscal year ended on September 30th, and we did not pass new appropriations bills (the government is shut down), so there’s no money available to pay the troops (or to do lots of things).
… [various technical reasons what they’re doing is very not legal] …
… And the craziest part is this was needless. Congress would’ve passed a military pay bill with near unanimous support! Congressional Ds have been begging Rs to bring a bill to pay the military to the floor! But Johnson refuses to gavel in because he doesn’t want an Epstein vote.
So just how bad is this? I got a text from an appropriator friend saying “The Republic has fallen. Pack it in.”
I think there are five levels of potential badness here. Once you’ve decided to violate the ADA, you’re only bound by self-imposed limitations. But depending on what the White House is self-imposing, this can range from “BAD” to “The Republic has fallen, pack it in.”
… Taken together w/ impoundments, this’d break everything. The president is claiming the power to not spend money he doesn’t want to and now also to spend money where it’s not allowed. And SCOTUS might say no one has standing to stop him. That would make him an appropriations king.
In this case everyone agrees you pay the troops and the money can be reconciled (if it hasn’t been already) so the de facto fig leaf is ‘it is common knowledge this would have been approved’ but that’s not a norm you can rely on in this spot, the violations of principles here are rather egregious, and once you do it once what stops it happening again? What stops them from spending any and all public funds on whatever the hell they feel like?
In general, we follow a pattern of:
-
A rule is broken that, if fully and properly exploited, would mean the Republic has fallen, and it’s time to pack it in.
-
Things get a little bit worse but the thing is not exploited maximally.
-
The Republic does not fall and we do not pack it in.
So we can do things like have unidentified masked people kidnapping citizens off the street and acting like this is fine, we can sink boats in international waters without trial or a declaration of war, have relatives of the president make a billion in crypto, have the Department of Justice selectively prosecute personal enemies on direct presidential orders, impose punitive tarriffs on one of our most reliable, friendly and important trading partners because of dislike of an advertisement, pardon or give clemency to ten Republican congressmen convicted of corruption style crimes including actual George Santos, weaponize the IRS to go after opposition groups, actively work to destroy vaccinations and PEPFAR and for some reason tylenol, warn major media companies to sell to the correct bidder or else they won’t approve the deal, outright demand $230 million from the treasury for his personal account right in the open, and so on and so on, and yet things are mostly normal.
For now. It doesn’t seem great that we keep playing that game.
Trump administration will be setting price floors across a range of industries to combat market manipulation by China. Price floors have a long history of causing markets to not clear and reducing supply, see minimum wages, and certainly they do not help you lower prices, but in this case I actually think this is a reasonable response? You have a rival strategically flooding your market as part of a strategy to drive you out of business. The worry is it is highly prone to abuse, or to becoming permanent, but if implemented wisely, it does seem like the right tool.
Not to harp on the H1-B visa thing but here’s another ‘the wage levels principle is completely absurd’ illustrative post. We’re prioritizing the most experienced people working in the lowest paid professions. If that sounds crazy, it’s probably because it is, especially since the correct answer (‘those who make the most money’) is right there. We’re also keeping it a weighted lottery instead of a sorting algorithm. What you actually want is certainty, so people know if they’re getting in or not.
Patrick McKenzie explains that Germany’s shutting down of its nuclear plants in favor of coal plants, under pressure from the so-called ‘greens,’ is an illustration of a fatal flaw in coalitional parliamentary politics.
Patrick McKenzie: I think it’s important, in the cases where people do things for wildly irrational reasons, to carefully listen to their explanation, both for understanding their worldview and for recording mistakes for future versions of the game.
One of the takeaways here is “A bad news cycle and a system which allows coalition management primacy over decision making will allow a generally effective technocratic government to, with eyes wide open, pick policies which are obviously foreseeable catastrophes.”
And when you ask, years later, “What possessed you to do that?”, the people who did it will say they were boxed in, that their coalition partners invested all their points in X, and when then happens during a bad news cycle well you just have to roll with it.
Germany continues to attempt to stop Uber from existing because they don’t direct rides through the central offices of a car rental company, which means they would be unfair competition. Expectation is that this won’t actually work, but still, wow.
There are calls to privatize air traffic control, because air traffic controllers are impacted by government shutdowns. I suppose if you’re locked into shutdowns and into the shutdowns impacting air traffic controllers this could end up working out. But rather obviously this is completely crazy? That you need something to reliably happen and not shut down so you need to privatize it?
The obviously correct thing is to exempt air traffic controllers from shutdowns. This seems super doable? You can pass a bill that automatically funds the FAA indefinitely from a trust fund. It’s what we do for USPS. It’s not like anyone want the FAA to shut down.
Instead, we have widespread flight cancellations and people considering planning road trips.
We are going to require cars and trucks, including electric vehicles, to include AM radios? What? In 2025, when we didn’t do this before? Some in the comments argue that AM radio is indeed important because the 0.1% of the time you need it you really need it, and I can buy that there might even be a market failure here, but the very obvious response is that this bill would have made ten times more sense in 1995 or 1975, and we didn’t have it then, so why now? Also, if this is important it’s like $25 to buy an AM radio and stick it in the glove compartment for when you need one.
In case it wasn’t obvious, the United States government pays below market for everything policy related, the jobs have super long hours and aren’t especially stable, and require you to go to Washington, DC, so only those who are already rich or heavily ideologically motivated tend to take them.
Rep. Ed Case (D-HI) points out that we have the Jones Act and ‘despite this’ our shipbuilding, repair capacity and such are all withering away to nothing, so arguing that the Jones Act protects national security makes no sense. I agree with him, except that instead of ‘despite’ he should be saying ‘because of,’ the Jones Act actively makes these problems worse.
This is from a full event, Assessing the Jones Act: Perspectives from the Noncontiguous States and Territories. Everyone is harmed except the rent seekers, but the noncontiguous areas are hurt quite a lot more than the rest of us.
Open Philanthropy is now Coefficient Giving, you will now be able to fund one of several cause area divisions.
Alexander Berger: Our ambition has always been to work with more donors once we had enough bandwidth to support Good Ventures.
We started in earnest in 2024, directing over $100m from other donors. We more than doubled that so far in 2025. We’re aiming for a lot more in years to come.
Our new name reflects various aspects of this new chapter:
“Co” -> collaborating with other donors
“Efficient” -> a nod to cost-effectiveness
“Coefficient” -> multiplying others’ impact, ROI
(And “giving” is much less of a mouthful than “philanthropy”)
Big success, a long time coming:
Samuel Hume: Novartis’ new malaria treatment cured 97.4% of patients – more than the current best treatment.
It kills resistant parasites, too, and probably blocks transmission better than current drugs
Approval is expected next year!
Roon: malaria of course has killed billions of people through human history and just like that another foe is ~vanquished
Scottt Alexander: > Go to the drug’s Wikipedia article
> “This drug [was] developed with support from the Bill and Melinda Gates foundation via their Medicine for Malaria Venture.”
If you mean Effective Altruists (TM), the compound was discovered in 2007, before effective altruism was founded, so we can hardly be blamed for not contributing to it! EA leader Open Philanthropy (founded 2017) has since funded research into other pioneering antimalarials.
From what I have seen, the ‘spreadsheet altruism’ absolutely includes strategies like ‘research new malaria drug’ and otherwise funding science and making similar bets.
Somehow this got 3 million views…
Gina: You can only pick one option!!!
The funny answer is the ‘life extension’ or ‘defense against existential risk’ move if you interpret the $700k as definitely living to 65.
But if you take it as intended, that you if you die early you still die in real life, then I really hope one would take $1.1 million here? Putting the amount this high is bizarre.
A remarkably large number of people went for the $900k, without even stopping to think that there was no assurance you would even get away with it. Well, that’s engagement farming, I guess.
This seems like a good note. I think the actual limiting factor here is mostly time.
Will Manidis: with the exception of museum quality/rareness, antique prices have fallen off a cliff over the past 10 years. you can decorate your home like a 18th century royal with pieces unthinkable 99% of humans across history, but instead you live amongst minimalist ikea slop
David Perell: I’ve been interviewing people who have beautiful homes about how they decorated them, and the biggest surprise is how they almost all insist that good design is more about taste than money.
Yes, it costs more to buy a great sofa than a bad one. But there are plenty of millionaires living in homes that feel like an airport lounge.
The actual limiting factor is taste and time. The taste to know what looks good and the time it takes to find what you’re looking for. What’s key is that the second-hand furniture market is quite inefficient.
To be sure, there is a spectrum: at one end, you have thrift stores (cheap, chaotic, and unvetted). At the other, you have Sotheby’s (curated, clean, and highly vetted). The sweet spot is somewhere in the middle.
So how do you find pockets of glorious inefficiency?
One way is to make friends with people who own antique shops. I have a friend in San Francisco who knows a few collectors in town. They know her taste, and when something comes in that matches her style, they call her. And because of this, she never has to wait 17 weeks for a backordered couch from CB2.
Here’s the key point: If you have a strong sense of taste and understand the game, you’ll consistently spend less to design a house that feels alive and uniquely yours.
Good design, it turns out, is a byproduct of taste and attention, not money.
Matthew Speiser: In NYC and the Hudson Valley there are numerous vintage and antique furniture stores selling great stuff at reasonable prices. Far from chaotic and unvetted.
And “taste” isn’t about “efficiency.” It takes a lot of time browsing pieces and observing decor you enjoy to develop your taste.
In NYC: Dobbins Street Vintage, Dream Fishing Tackle, Lichen, tihngs, Humble House, Shop 86, Sterling Place
In HV: Newburgh Vintage Emporium (2 locations), The Antique Warehouse, Magic Hill Mercantile, Hyde Park Antiques Center + lots of small shops in Hudson, Kingston, Saugerties, etc.
If you try to buy antiques or otherwise develop taste you need to worry about matching and you need to get buy-in from others, and it all takes time, alas. Getting consensus is tough. Also once you decorate the first time, it takes a lot of activation energy to start changing, and to shift to a new equilibrium. So I get it. But when I look over at our IKEA-style drawers in this room do I wish they were old school? Oh yeah.
There’s also the functionality of the room, which you have to pay attention to and understand. Know your Christopher Alexander.
(EDIT: This section originally identified this as being by someone else, for reasons that are lost to time.)
Henrick Karlsson’s whole OP is full of gold, I want to emphasize his third point here:
Henrick Karlsson: I got to run something like an experiment on my capacity to predict which exhibitions would end up great, and which would be a waste of time. It was easy. As soon as someone was slow at answering their email, or complained, or wanted us to be their therapist as they worked through the creative worries, I would tell my boss, “I think we should cancel this.” And my boss—whose strength and weakness is that she thinks the best of people and makes everyone feel held—would say, “Ah, but they are just a bit sloppy with email” “if we just fix this thing it will be fine. . .”
I was right every time; it ended in pain.
And this is quite nice actually: it means it doesn’t take some Tyler Cowen-level taste in talent to figure out who will do good work.
Harvard cuts the majority of its PhD seats across the next two years, citing financial uncertainty about funding and potential endowment taxes. Of what use is Harvard’s giant endowment, if not to keep the lights on in a situation like this? There is nonzero worry about this ‘rewarding’ the cuts in funding, but in this case the people cutting the funding are happy you’re cutting the PhD slots, so I don’t think that argument plays. Some cost cutting makes sense, but this seems crazy.
We’d rather replace a microwave than try to get it repaired. Is that a failure in the handyman market? We actually just relaced our microwave, and in our case clearly it wasn’t, yes you could have tried to repair it but the time cost of even getting it to a repair shop or arranging a visit would already have exceeded the replacement cost. To get the handyman market to clear here, you would need to be able to summon someone as easily as with an Uber, and the total cost per successful repair would need to be kept at roughly $100, so yeah, not going to happen in New York City.
In a forecasting competition, evaluators failed to find better predictors more persuasive. They did notice the better predictors showed signs of intelligence, rationality and motivation, but this was counteracted by others presenting with higher confidence. This suggests an easy fix if people care to get it right.
Listed under bad news because I wouldn’t want this playbook to be the right book, Andreesen and Collision discuss Elon Musk’s management style.
Bearly AI and Parham:
-
Engineer-first organizations and find truth by speaking with those working on the floor (avoid management layers).
-
Every week, find the most important bottleneck at a company and parachute in to fix it.
-
Keep model of all engineering and business moving parts in his head (obviously, not many can do this).
-
Create cult of personality in and outside of the company (continually drive attention, without marketing or PR).
-
Pick single most import target metric for business at a time (eg. SpaceX = $ per kilo to orbit)
-
Constantly create urgency (which often shortens time horizons for projects).
-
Focus on capital efficiency
My theory is this is all very much a package deal if you try do more than about two of them. If you try to do half these things, it won’t work. You have to do most or all of them, or try a different approach, and as noted few people can do #3 and I would also add #4, or #2 in any useful sense. You need to be able to keep all the pieces in place, do the engineering work and also create a widespread cult of personality to justify that you keep fing with everyone and everything and making everyone’s lives miserable all the time.
Looking back on MetaMed in this light, I think we often fell into the ‘do many but not enough of these things and not hardcore and consistently enough’ bucket (not intentionally, I wasn’t modeling on Musk at all), and that’s one high level explanation of why it didn’t work. If I’d been able to go harder in the key missing places, then it plausibly would have worked to the extent the plan was workable at all (or pivoted).
Why do people care so much about bans on plastic straws? Let us count the ways.
Gearoid Reidy: McDonald’s Japan is finally abandoning its unpopular paper straws, replacing them with lids that diners can drink from directly.
Sam D’Amico: A nine year old wrote a “study” for a school project and we all ended up drinking glue for over a decade.
no_on_15: I will never understand how people became so distressed over paper straws.
caesararum: as “people” lemme count the ways
– paper straws are inferior at their main job
– they fall apart within minutes of use – they impart taste to what you’re drinking
– there’s evidence they leach more and worse chemicals than plastic
– they have a weird texture when you put your mouth on them
– the seam and softness and weird pliability _feel_ off
– ocean plastics have never been about single use plastics in the west
– legislators burned up time, political capital, and credibility advancing these laws
– we’re probably going to find out plastic straws use less total GHG anyway
Kelsey Piper: One more for your list: My toddler absolutely cannot use a paper straw at all. She bites it a bit, which plastic can handle and which destroys paper immediately.
Shea Levy (quoting Marcel Dumas): One more: The only answer to “It’s no big deal” is “fine, then let me win.”
Kelsey Piper: I think part of why the straws are such a flashpoint is because they’re such a pure example of making things worse and then going ‘why do you care so much? get a life’ when people observe that now their lives are worse.
Kelsey is spot on. It’s not that it’s such a huge deal, it’s that every time it happens it is so obvious that your life has been made worse essentially out of spite and stupidity and innumeracy, and every time it rubs this in your face. And then they lie to you, and say the paper straws are fine. They’re not fine, they are worse than nothing. That’s why it fills me with rage, even though I cannot remember the last time I used a straw.
Tyler Cowen worries about ‘affordability politics.’ He’s not against the abstract concept, but the ways people respond to lack of affordability don’t correspond to the good ways to create real affordability. We respond in such spots by restricting supply and subsidizing demand instead of expanding supply, so we find a problem and then go make it worse.
So yes, I worry about this too. In general, any time people say ‘the market has failed to provide what we want’ you are not going to like the proposed intervention.
Recommended: Derek Thompson writes about The Monks In The Casino, as in the young men in America who don’t live nominally healthy and ascetic lives in many senses but stay home, isolated, in front of computer monitors, without even feeling lonely, often addicted to things like porn and gambling as the economy looks increasingly like a casino. They take financial risks online, but no risks in physical space. Betting is getting easier while living gets harder.
I may say more later, for now read the whole thing.
People will attempt to justify anything.
Zen: “I procrastinated for days and then it only took 20m when I sat down to do it 😭”
Give your system more credit. A few days of subconscious processing to prepare for 20 minutes of execution. Subtract all the self-guilt and reprobation and U’ve got efficient functioning.
Loopy: I instead let the avoidance process run its course, and then I am resourced to do the task.
Yeah, look, no, that’s usually hogwash and it’s important to know it’s hogwash. Are there times when you actually need more subconscious processing? I mean I guess but mostly that’s the flimsiest of excuses. Do the thing already.
Do top people vary behaviors more? Where is causation here?
Robin Hanson: Top people have more conflicting stories about them as both nice and jerks. Because, I think, their behavior is in fact more context dependent. As that is in fact a more winning social strategy.
Triangulation: Also: high status attracts both detractors and sycophants.
In most situations for most people, even top people, I believe nice is correct regardless, jerk is a mistake, this pays dividends over time.
As you get to the top the jerk stories get amplified a lot more. You do have to be willing to be hard nosed in some situations, and there are those who are more willing to consider you a jerk because you’re successful. That doesn’t mean be a jerk, even to someone with no power.
However, there is a particular strategy based around maximal incentive gradients, and its final form only works at the top. Trump is the avatar of this.
One minute you’re the best, the next you’re the worst, and then you’re back to the best. So you have maximum reason to be sure you’re the best and not the worst.
If you’re high enough in relative status and power or usefulness that people still want to deal with you at all, this can be very powerful. If you’re not, it doesn’t work, because no one will want to associate with you at all. So you can only deploy this strategy to the extent, and in the contexts, where people have no choice but to engage.
In some places there’s an equilibrium that drives such strategies out, and I prefer such spaces. But the top of business and politics reward it.
Venezuelan President Maduro did not actually say (to our knowledge) that if the US gives him amnesty, removes his bounty and gives a comfortable exile he’ll leave office. But let’s suppose that he made this offer. Should we take it?
Andrew Rettek: It’s like the trolley problem but instead of one person it’s a bag of money and instead of 5 people it’s an entire country.
In terms of causal decision theory, of the direct consequences, obviously yes. You greatly improve an entire nation in exchange for a tiny bag of money. Great deal.
Alas, that is not the full deal. The deal also is that future dictators will know they likely have a similar option, even if they are pretty terrible. This goes both ways.
First the good news:
-
If others take similar deals, you can rescue other countries similarly.
-
If others know they have this option, they can invest fewer resources in regime stability and buying off loyalty of their chain of command, since failure to maintain power is now often much less bad.
Then the bad news:
-
This makes being a dictator a much, much better deal.
-
This encourages them to maintain strong bargaining positions.
-
This also gives them more incentive to steal money and squirrel it away.
We face similar hostage situations all the time at smaller scale. We strike a balance. We do often pay ransoms, negotiate for hostages and so forth. We also have limits. I think in general we are too willing to negotiate, and should more often tell such folks to go to hell and accept that this particular situation will often end poorly as a result.
On the dictator level it is less clear. In this case I would take the deal, if it came not only with him leaving but with a transition to democracy. Indeed, one could make a conditional deal, where his immunity depends on the transition.
If the job interview was too easy, perhaps you don’t want the job. Worthwhile interviews are two ways, you want to be sure you will have good colleagues who work hard and the job will challenge you, and that is a fit for your interests. I the interview is too easy, you probably could have aimed higher. The paper here finds that the perceptions from a job interview are indeed informative about the job.
When I left my interview at Jane Street Capital, I was very excited to work there. When I did my other finance interview? Not so much.
I strongly agree with Roon here, for most (but not all) classes of intellectual tasks. For physical tasks it will probably suck to be you doing it but in terms of productivity you can 996 (work 12 hours a day 6 days a week) all you want.
Roon: most likely you will not get the most out of yourself by 996ing. generally that’s a way to destroy the self. I subscribe to the Ferris bueller’s day off theology that says you’ll probably get the most out of yourself by being maximally uninhibited so the universe sings with you.
it’s more important to Go To War when dharma is calling, and you will know when it happens, than to 996 as a permanent way of life. for people like elon [musk] and sam [altman] that may be every day but it’s probably not yours.
They are pitching us… anti-suicide chairs? It seems a lot of the argument here is literally ‘the chair doesn’t help you physically kill yourself’ and a bunch of weird claims about things like ‘creating a supportive and inclusive environment and reducing stigma and encouraging dialogue’ and I’m calling full BS on all that.
Indeed, my guess is the best thing you can do for people in trouble via chairs is to get them actually comfy chairs, so they feel better.
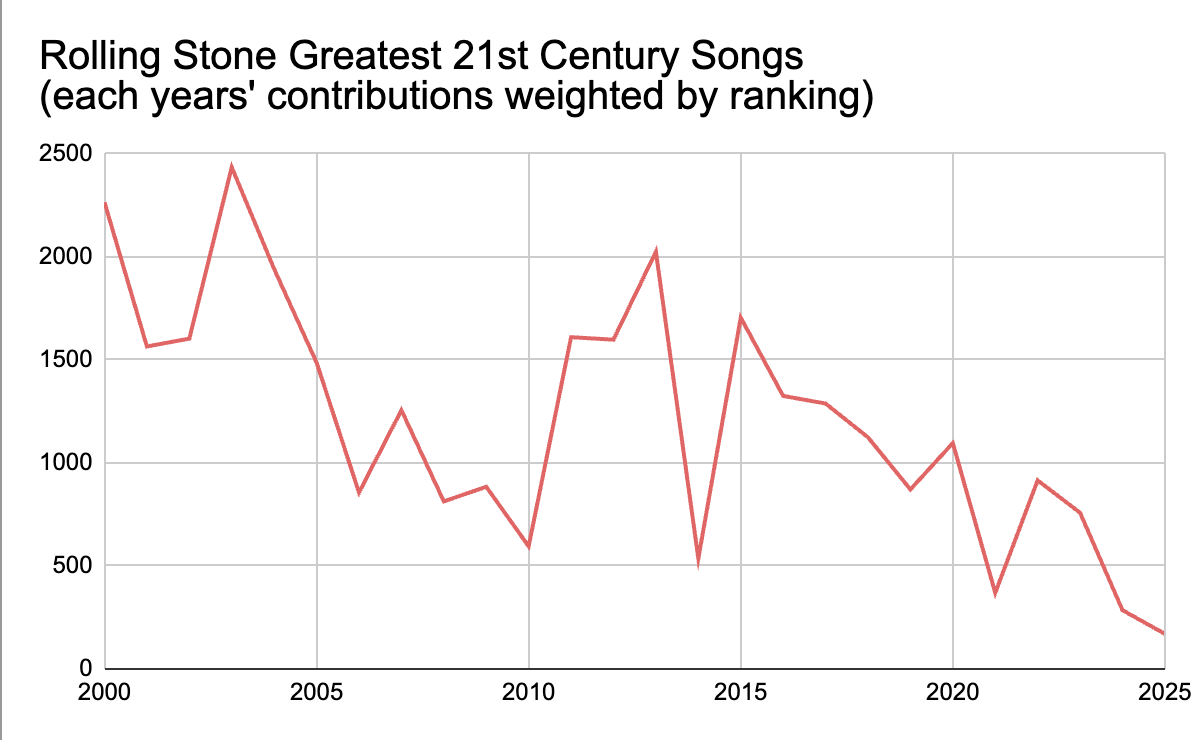
David Marx: Rolling Stone compiled a “The 250 Greatest Songs of the 21st Century” list, and while the specific inclusions are debatable, it gives a sense of the 21st century canon as it’s forming.
I noticed a bias towards the early 2000s so I ran the numbers.
I tallied the number of entries per year, and there’s a steady and linear decline, with a very clear dip in the last half of the Aughts. Then I weighted the entries (so that a #1 was worth much more than a #250), and it tells a similar story, although 2013 shows a resurgence before things collapse again.
There will always be some anti-recency bias in canon-building, because new things have yet to prove their long-term value, but there’s also a clear bias here towards “long ‘90s” songs like “B.O.B.” and “Get Ur Freak On” and lingering respect for the post-9/11 rock revival.
The resurgent 2013 winners list doesn’t have a clear narrative (although interested in your ideas): Lorde, Drake, Kacey Musgraves, Haim, DJ Snake feat. Lil Jon, Paramore, Arctic Monkeys, Justin Timberlake, Miley Cyrus, Sky Ferreira, Jason Isbell, Alvvays.
Also: it’s a real Neptunes / PW shutout. Sure, no “Blurred Lines” but no “Drop It Like It’s Hot” or “Grindin’”?
Steve Sailer: Rolling Stone subscribers are really, really old.
I don’t know how much of this is anti-recency bias, and how much of this is those involved being super old, but also the idea of having a canon of music songs, that are listened to over decades, seems itself pretty old now, something only old people would care about?
I also checked some of the list, and it’s remarkable how much there simply isn’t a canon from this century, or at least how easy it is to ignore. If you’d made a similar list from the 20th century, I expect I’d have known most of the songs. When I browsed this list, I was running at maybe 15%, and that’s simply to know them, not like them. To be fair to the list, the ones I did recognize seemed like mostly good picks.
Tanmay Khale emailed Tyler Cowen to suggest that modern songs are suffering from unfair regularization of scores, where they are compared to other modern songs or to how much better they are than prior efforts, so they don’t look great. I agree there is some of this going on, our standards to break through are higher, but I think that’s more about the low hanging fruit being picked, you don’t need to be ‘better’ so much as you need to be original, which is increasingly hard. There’s some amount of better necessary to break through into a canon to overcome familiarity barriers, but also people can get really familiar with big hits quickly.
Music is different from sports here because you don’t only play against simultaneous competition. A song from 2025 and one from 1975 are both on Spotify, you can choose which one to play or prefer.
Netflix makes a deal with Spotify to get The Ringer’s podcasts and exclude those podcasts from YouTube. I get why they’re doing it, but I don’t love it. Dividing up podcasts the way we’ve divided up television streaming is super annoying.
Free clicks are seldom cheap, but often slop.
Nathan Lazerus: From @mattyglesias today (quotes the classic newsroom finding from the early internet era that what people click on is very different from what they say they want to read):
I feel like the ad vs. subscription model matters a lot here. People will sign up for a subscription to a news source that fits their high-minded aspirations, while they don’t want to pay for some guilty pleasure/clickbait.
So journalists of old were maybe not wrong to keep putting out the high-quality reporting they did—it drove subscriptions. But when pay/reach was determined by views, the profit-maximizing type of content changed.
Matthew Yglesias: Yes this is a very important point.
People tend to subscribe to things based on what kind of content they are *proudto consume, while they’ll watch any garbage for free.
So subscription-based models, especially without much bundling, support more high-minded content.
Have a policy for where your inputs come from. Stick to that policy. Your subscription self it better than your free click self.
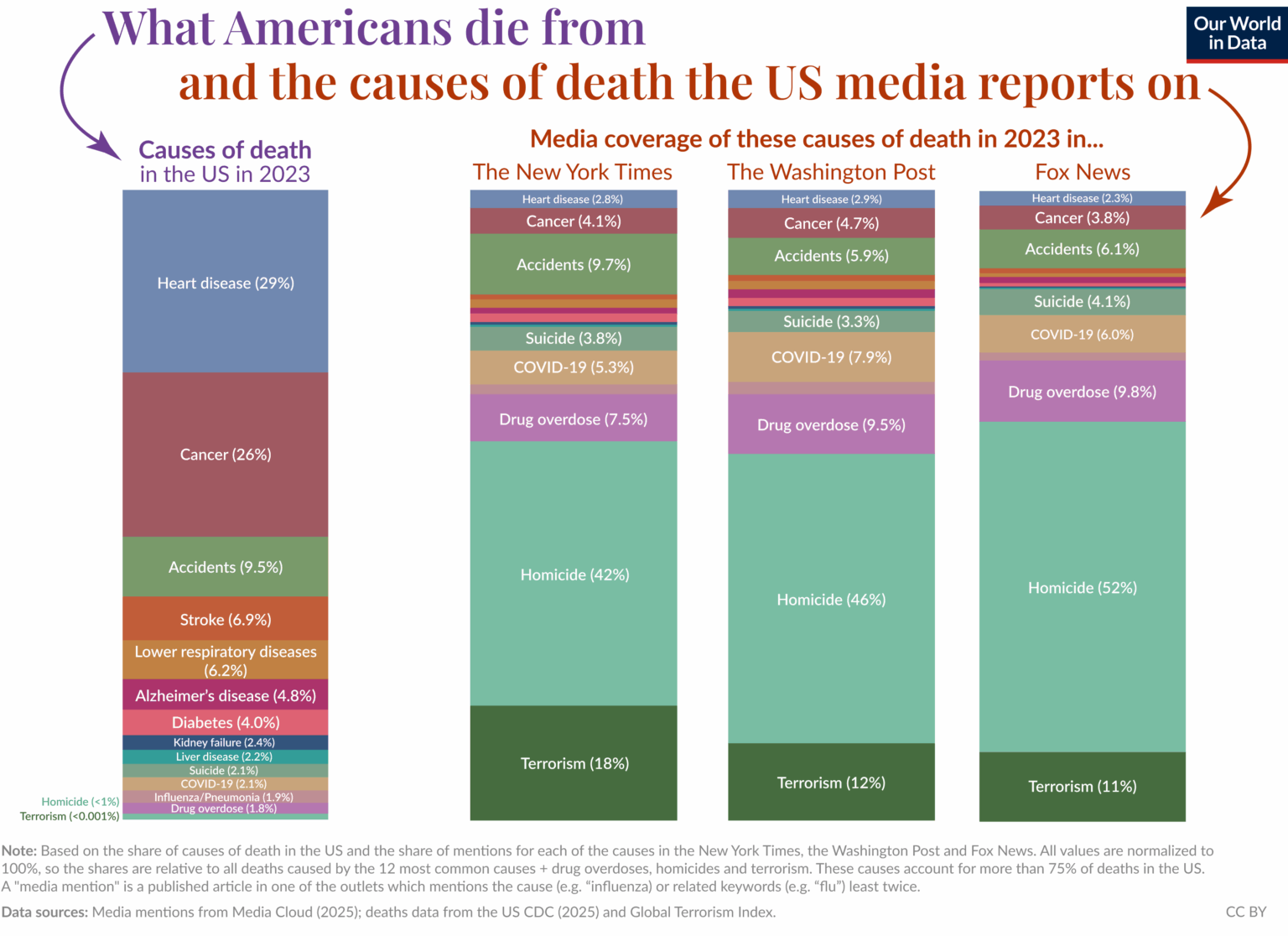
What we die of in real life versus media:
I mean, yes, ‘person has heart attack and dies’ is not news. I do wish they’d stop being so damn lazy with all the car accidents in fictional media.
Vince Gilligan is still proud of Breaking Bad and Better Call Saul but thinks we have too many antiheroes and it is harmful, which his new show Pluribus seeks to address, by all reports it is cool but I’m waiting for the full season drop. Article is a fun extended profile.
And so the new cable package era continues to slowly create itself, as AppleTV+ and Peacock offer a combined package for $20/month (or $15 if you’re willing to accept Peacock ads). On their own AppleTV+ is $13/month and Peacock is $10/$15 depending on if you accept ads, so that’s a deep discount. That’s in addition to the $30 HBO/Hulu/Disney+ package, which is also strong. You should have Amazon Prime anyway, so throw in Netflix and YouTube Premium, Paramount+ is optional, and you’re all set unless you watch sports.
The problem is you’re then very tempted to rotate between packages. The long term equilibrium is presumably one package with all of it, so you aren’t constantly either toggling between services or feeling bad about not doing so. Alternatively, they should up their yearly subscription discount game, which I would also find acceptable.
Meanwhile there’s a war. Disney owns ESPN and ABC, as well as Hulu and Fubo. Google wants Disney to agree to incorporate their Hulu offerings into the YouTubeTV experience, and Disney is having none of it, and as a result of that (and some amount of pricing argument) we’ve now gone weeks with Disney not available on YouTubeTV.
This is wreaking havoc on my ability to experience college football in particular, because the only alternative services, ESPN and Hulu, have remarkably awful experiences for anyone trying to view sports that aren’t live, in a ‘seriously considering not to bother’ way.
Andrej Karpathy makes the case that the TV watching experience was better in the 1990s.
Andrej Karpathy: TV in the 90s: you turn it on, you watch.
TV 2025:
– turn on, wait for it to load
– popup: TV wants to update, 1.5GB. No.
– scroll sideways, find prime video app or etc
– popup: now app wants to update, 500MB. No!!
– App launching… App loading…
– select account screen
– 🫠
There is a movement I found on Instagram where people deliberately choose to live in 90s, refusing all technology after 2000. Like an intermediate form of the Amish.
That sometimes (rarely) happens, and yes it’s annoying. There’s substantial startup costs. But have you tried watching TV that is 30% advertisements that you cannot skip, and that cannot be paused? Have you tried managing a VCR? Have you tried having to call the cable guy?
Yeah, no thanks.
Nate argues television peaked in 2014. I agree there were some good times, 2014 is definitely a better television case than the 1990s (although movies peaking in 1999 is a highly reasonable argument!), but a lot of this is again forgetting all the old annoyances, and forgetting that we used to have actual scarcity. Yes, now you have to figure out where to watch something, but usually there is an answer. Before you turned on the television and watched, because if it wasn’t on some channel you were out of luck.
Overall I am firmly on the side that the television experience has never been better, or at least that this will be true once Disney and YouTubeTV resolve their dispute.
As in, it’s not only AI that has jagged capabilities.
Sarah Constantin: It feels like every time I’m “bad at” something, it’s actually that I’m good at some subskills and not doing other subskills AT ALL.
Like, underneath every 50% there’s a bunch of 100% and 0% pieces.
eg:
“I’m not so good at sales” is actually “I have a good pipeline and offer a good service but I’m essentially not even trying to be persuasive on sales calls”
“I’m not so good at the videogame Hades” is actually “there are some moves i never learned to do at all, so i don’t use em”
Magic: The Gathering announces a Magic Limited Championship in 2027. I thought I was out, but given I can use my Hall of Fame invite and only learn one set and one limited format, this could pull me back in.
I also am considering doing some power cube drafting on Arena. Sounds like fun.
Magic Spotlight Series SCG Baltimore has a second day metagame over 50% Cauldron.
Occasionally we see Standard formats that end up in this failure mode. The price of printing fun and cool cards, and of the current theory of design, is that this will sometimes happen. When it happens by accident, that’s unfortunate, and I think they could do a better job putting stabilizers into sets to guard against this, but the correct risk of this to take is not zero.
Except that back in September things had already reached this nightmare state in a way that seemed obviously like it was going to be sustainable, and LSV predicted essentially the full outcome back on August 18. This was an active decision.
The official response is that this would have required an emergency ban, and formats need stability, so they’re not doing it.
I’m sorry, but that’s ridiculous. As of SCG Con, it had been two full months. If you’re unwilling to ‘emergency’ ban then you need more B&R days than this.
I’m also sympathetic to ‘balancing Standard is not the top priority of Wizards R&D anymore,’ and I realize this will increase the rate of mistakes made, except that this consideration cannot apply to Standard itself or to its banned list. Standard participation needs to be continuous to keep up with card access, breaking it is deadly. As someone excited to try and find the time to do a fully Limited PT, I cannot overstate how much this failure makes me uninterested in returning to Standard.
Sam Black assembles a list of every card in Magic’s Premodern format that one could possibly want to play. It’s a fun list and includes some deep cuts, while letting you skip the cuts that are too deep.
Sam Black warns us that in Magic draft, 17lands data on win rates is often misleading because cards that only go in the better decks will end up showing artificially high win rates when drawn. Cards that only go in one particular strong deck type look great because they don’t make the cut at all otherwise, whereas Sol Ring goes in almost every deck. Also you need to worry about your skill level versus average skill level.
The caveat back is that while in theory full flexibility is good, and for experts like Sam Black it’s very good, it can also be a trap (in terms of short term win rates) to be tempted into decks that aren’t good or that you don’t know how to draft, whereas you actually should be forcing the good stuff far more if you care only about winning now.
Formula 1 (F1) racing signs an exclusive five-year deal with AppleTV+, likely for ~$150 million a year, up from the $90 million ESPN paid in the previous deal. Ben Thompson notes that ESPN had been putting in minimal effort, and AppleTV+ will be incorporating the full F1 TV be part of the base AppleTV+ package.
I see the risk in going to a niche service like AppleTV+ over ESPN, given that every serious sports fan presumably will still need ESPN access, but in exchange they hopefully get to present a better product, in a unified way. The obvious deal would have been Netflix, why not unify the core broadcast with Drive to Survive, but I don’t mind what they ended up doing. Apple is also a powerful ally.
I think AppleTV+ is exactly on point in saying it wants to own entire entire sports. It is maddening to have to hunt for different games or events and feel forced to buy multiple services. I think this played a substantial part in driving me away from baseball this year.
I do warn AppleTV+ to fix their spoiler problem. Their current interface actively spoils everything, constantly, it’s a disgrace. Someone reading this must know someone who knows someone. Fix it.
Don’t click the link, but yeah, the perfect a16z is ‘[evil thing X] meets [awful thing Y] in ways of questionable legality that will ruin our customers lives.’ Don’t like you, but I’m impressed.
College football coaches have been paid a combined $185 million this season to go away. I get how we got here, the coaches are in high demand and shop for the best deal, want to lock in profits, are definitely not looking to get fired so there isn’t actual moral hazard, and the patience teams show has worn paper thin, and the buyout serves are protection against being poached by another school. Also the transition to the NIL era has invalidated many past strategies, making previously excellent coaches no longer good, see Dabo Swinney (probably).
It still does not make sense to me. You might not love the coach but at an 80%+ discount you think you can do better? You need to be firing them in the middle of the season like this? It’s madness, I tell you.
I think with Franklin and Kelly in particular the problem is that they did great jobs in recruiting, so expectations got very high, then the teams didn’t deliver and they thought let’s axe the coach. Big mistake.
The other note is that if the coaches get rehired then the cost will be a lot less, and one expects the top names on this list to get new jobs. LSU and Penn State might not want them, but plenty of schools would love Kelly or Franklin. I’d love to get Franklin for Wisconsin, it seems like a perfect fit.
Whereas one I definitely agree with here is Mike Gundy. Gundy is a prime example of a previously excellent coach who is adrift in the new era, you have to cut your losses.
One obvious suggestion is to tie the buyouts directly to the record. You say, okay, if we fire you without cause you are owed 85% of the contract, but if you have X losses or fail to hit some milestone, then that’s cause. Seems simple enough, and the coaches at this level have big egos and don’t expect to fail.
The NFL might be getting ready to move to the 4th and 15 alternative to onside kicks.
Jonathan Jones: NFL EVP Troy Vincent told team owners today that it may be time to look at the fourth-and-15 proposal that has been offered as an alternate to the onside kick. The lack of recoveries on onside has disappointed the league.
Seth Burn: This will be a disaster if teams can bait the refs into giving cheap defensive holding or DPI flags.
You want to calibrate about how often the team can convert. Right now the onside kick recovery rate is too low. The yards to go can be adjusted to taste, and with many yards to go you don’t have to give the refs an excuse.
If the refs are actively looking to throw a flag in order to extend the game, and are basically cheating in this particular spot, that’s a different problem. I presume they wouldn’t do it because this is bad for the game.
Also the cheap automatic first downs from such penalties should be clamped down on in any case. There are any number of rules changes to fix this, the most obvious being that there can be two types of such flags, the way there’s both running into and roughing the kicker, and you don’t get an automatic first down unless it’s flagrant.
Nate Silver offers his thoughts on the NBA betting scandal. Our perspectives on this are broadly similar. Sports betting can be good fun and good business, and the context of odds can enhance sports, but the current regime of legalized sports gambling on your phone is terrible and current books do not deserve your sympathy.
They especially don’t deserve sympathy for when their whales (big customers getting taken for huge amounts that are allowed to do basically anything for huge limits without questions) end up becoming beards (as in placing bets on behalf of actual professional gamblers) and bet $100k or more on an obscure player prop. They’re choosing to do game theoretically unsound things and taking calculated risks. If you’re gonna play with fire then sometimes you’re gonna get burned.
My view of player props is that people who seek them out should be allowed to have their fun, sure why not, it’s cool info and a cool mini-game and in some cases it’s even a loss leader (since the wise person betting can pick off your mistakes and passes otherwise), but that the sportsbooks pushing them (and also pushing parlays) on recreational players is predatory behavior. And if they raise the limits on the props, especially on obscure players, that’s at their own risk.
I also don’t have much sympathy for the recreational gamblers who take the other side of insider NBA bets. The NBA lines are, as Nate says, full of information about injuries and player usage and intent to tank, often not publicly known, to the point where this is the main thing driving lines away from where they naively ‘should’ be, and where most NBA fans at a sports bar could tell you what the line ‘should’ be if everyone potentially available was healthy and playing. Evaluating and tracking injuries is the main skill. That’s the game you’re playing. Either play it, or don’t.
One place I disagree is where Nate mentions in his point #7 that if we banned FanDuel and DraftKings that 70% of that volume might move offshore rather than vanishing. I agree some percentage would move if there were no alternatives, but I would be utterly shocked if it was on the order of 70%. All the advertising would be gone. All the integration with media and teams and stadiums would be gone. Funding would be non-trivial again, as Nate notes you’d largely need to use crypto. You wouldn’t have an app with an optimized UI and wouldn’t be getting all the hyper aggressive customized push notifications on your phone. The entire context would change. No, it wouldn’t go fully back to the old level of activity, but it would drop a lot.
The broader NFL shift is that not only are kickers getting better (as per this very fun article from Nate Silver), offenses are getting better across the board and also making better decisions, and the reason we don’t notice the extent of this is that drives are taking up more time so the scores don’t fully reflect the shift.
When NFL teams depart from draft consensus on player value they consistently do worse. So teams should use the consensus board for player value, except for when they have particular private information (such as on injuries), especially teams like the Jets with poor track records.
You do still have to account for positional value, and what you in particular need because the trading market is illiquid. It’s fine to make small departures based on what you do and don’t need, but that should be it.
I actually do understand the calls for capping concession prices at stadiums.
Lindsay Owens here claims that teams are outright making mistakes, that in Atlanta raising ticket prices while lowering concession prices increased sales volume and revenue and fan satisfaction. I buy it.
My read is that the higher concession prices raise marginally more revenue, but that you don’t want to be at the top of the revenue curve on this because the bad feeling of overpaying too much not only drives fans away from purchases, it makes the overall experience worse, as the stadium experience is Out To Get You. What you want is to be able to basically order whatever you want and not feel bad about it, and the team should want this for you too.
It makes the overall experience much better, keeps people coming back, and turns them into long term fans. In general, teams should be doing less short term profit maximizing at their stadiums. I bet that on most current margins this outweighs the value of the price discrimination.
This is not the same as requiring ‘all-in pricing’ on tickets, which I think is just good, and yes you lose the ability to do price discrimination which in theory leaves something on the table. However, I think there are enough differences that I do not want to ‘force them into a good move’ via law.
Nate also discusses the poker cheating scandal, where I’m happy to defer to him and his notes match my understanding. Poker is fun, either with your buddies or at a casino, but if you’re not at a casino avoid raked games where the host turns a profit, there’s too much cheating risk and risk of involvement with people who are bad news. If you get invited to a home game, don’t go unless you understand why you’re invited.
I’d highlight the note that cheaters are usually extremely greedy and unable to keep their cheating subtle, as per Nate’s #39. If they were capable of only ‘cheating small’ then they wouldn’t be cheating, so if you pay attention you can usually sense things aren’t right even if you can’t prove it.
Hence the ability of Matt Berkey to call out the Billups game as rigged two years ago. If you listen to the podcast clip, everything was the opposite of subtle, with players constantly making plays that make absolutely no sense unless cheating is involved.
Also, as per #40, it doesn’t matter if you think the game is good enough you can win anyway, don’t play in a game where you’re being cheated, period.
A similar phenomenon exists in Magic: The Gathering. If someone is cheating, they’re almost always highly suspicious. The problem is that unlike poker you often don’t choose who you play your Magic matches against, so you can be stuck against a likely cheater who hasn’t formally been caught yet.
New York City will have its Secular Solstice and Mega-Meetup on the weekend of December 20th. The main event is on the 20th.
I strongly recommend going to the Secular Solstice itself if you have the opportunity, either in NYC, SF or other places it is offered. If you are local, and the rationalist megameetup is self-recommending to you, then you should definitely go. If not, consider going anyway. I’m usually there for one of the days.
If you’re looking for an idea of what the music is like, this playlist gives you an idea.
IFP is hiring a Director of Operations.
Name the four core character classes, wrong answers only. Remarkably strong quality and diversity most of the way.
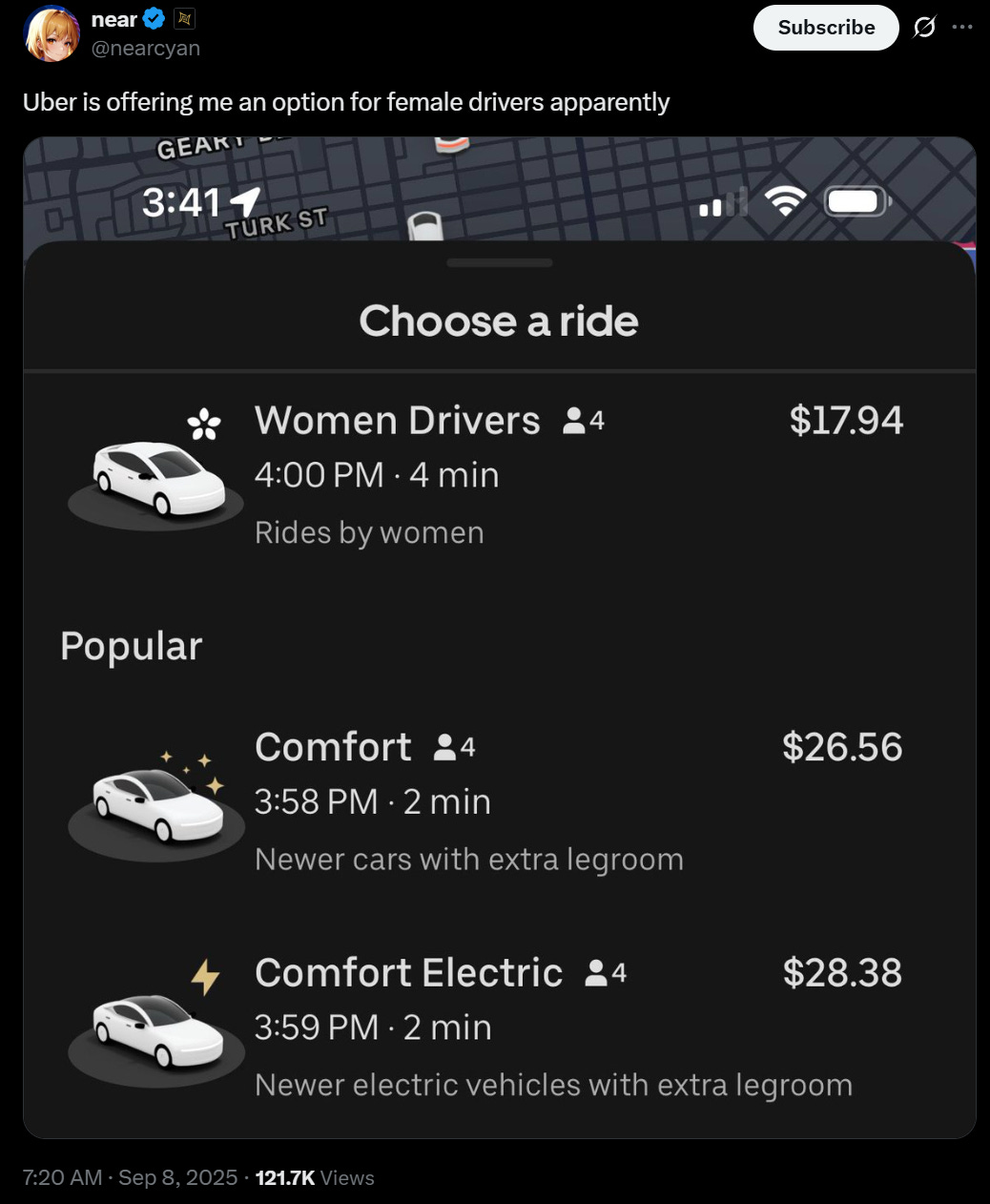
I know about the gender pay gap but this is ridiculous, also Near is a man:
Robin Hanson, never stop Robin Hansoning, I will not explain further:
Rob Henderson (Quoting from The Social Paradox by William von Hippel): “If two people anywhere on earth look into each other’s eyes for more than five seconds, then either they’re going to have sex or one of them is going to kill the other.”
Robin Hanson: I’d bet a lot of money that this is simply not true. In fact the % of random pairs for which either of those happens must be well below 5%.
Oh well.
Matthew Yglesias: Hmmmm so they are considering trading away enduring spiritual values in exchange for short-term material gain, wonder if anything has ever been written that would be relevant to this.
Andrew Callaghan considers not releasing his interview with Pete Buttigieg because despite being a good discussion it went too well for Pete and his audience is mad about it.
If you didn’t watch Sabrina Carpenter on SNL, watch this video from that show.
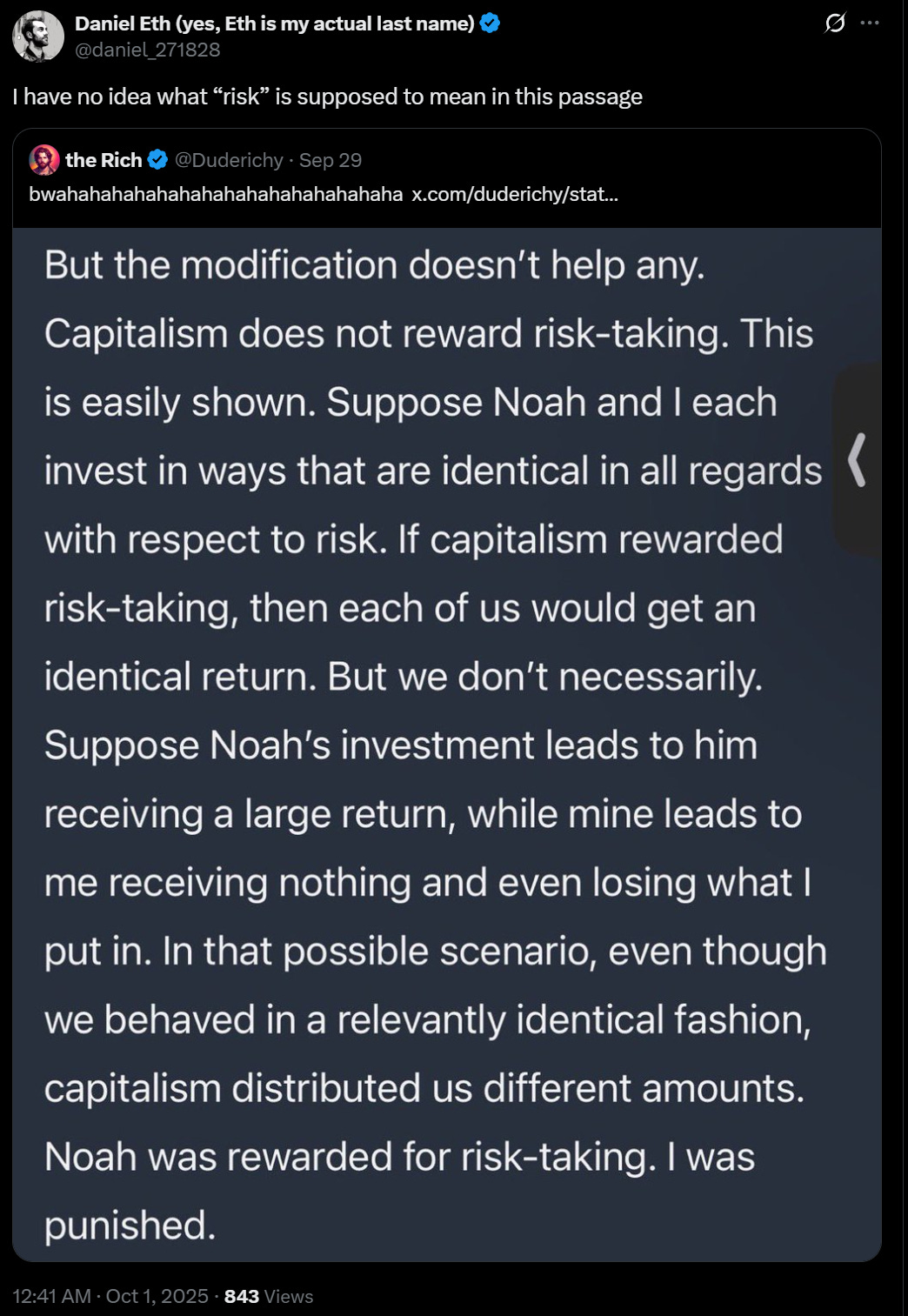
A claim by Matt Bruenig that capitalism does not reward risk-taking, because when you take a risk sometimes it doesn’t work out. It’s too risky.
You do not get reliably rewarded for risk taking. It’s true!
It’s actually not as true as you might think. In many cases you can repeatedly take uncorrelated risks at good odds, and over time you will reliably get rewarded for this.
And then it gets better, in response:
James Surowiecki (Author, The Wisdom of Crowds): Does capitalism systematically reward risk-taking? In other words, is there a tight correlation, empirically, between the amount of risk one takes on and the returns one earns?
And better than that, even!
No, I’m not going to explain this one.
Perhaps the crowds are not so wise, after all. Or perhaps they weren’t consulted.
courtney: ordering from the indian restaurant and I just burst out laughing
A response suggests another way:
Bookem Code Monkey: I go to one with an Indian friend. Ordered something spicy. It was bland, bland. My Indian friends snaps his fingers and the guy comes over. falkfjlkjakljagaffadfa or whatever he said to the guy. Guy responds, Oh no, we don’t give that to white people. WTH.
Sven-Hajo Sieber: Had that experience in Tasmania, ordered very spicy and it was quite mild. When they asked if it was okay at the end I commented on it and they said: oh, order Indian spicy next time, we brought you Australian spicy.
Nina: My friend has the same experience with his Malaysian boyfriend when ordering food in London. They bring the boyfriend REAL spicy food, but not his British partner!
Victory is hers!
Aella: omg I did it.
Eliezer Yudkowsky: Exactly half of your followers are insane.