Spy Pet, a service that sold access to a rich database of allegedly more than 3 billion Discord messages and details on more than 600 million users, has seemingly been shut down.
404 Media, which broke the story of Spy Pet’s offerings, reports that Spy Pet seems mostly shut down. Spy Pet’s website was unavailable as of this writing. A Discord spokesperson told Ars that the company’s safety team had been “diligently investigating” Spy Pet and that it had banned accounts affiliated with it.
“Scraping our services and self-botting are violations of our Terms of Service and Community Guidelines,” the spokesperson wrote. “In addition to banning the affiliated accounts, we are considering appropriate legal action.” The spokesperson noted that Discord server administrators can adjust server permissions to prevent future such monitoring on otherwise public servers.
Kiwi Farms ties, GDPR violations
The number of servers monitored by Spy Pet had been fluctuating in recent days. The site’s administrator told 404 Media’s Joseph Cox that they were rewriting part of the service while admitting that Discord had banned a number of bots. The administrator had also told 404 Media that he did not “intend for my tool to be used for harassment,” despite a likely related user offering Spy Pet data on Kiwi Farms, a notorious hub for doxxing and online harassment campaigns that frequently targets trans and non-binary people, members of the LGBTQ community, and women.
Even if Spy Pet can somehow work past Discord’s bans or survive legal action, the site’s very nature runs against a number of other Internet regulations across the globe. It’s almost certainly in violation of the European Union’s General Data Protection Regulation (GDPR). As pointed out by StackDiary, Spy Pet and services like it seem to violate at least three articles of the GDPR, including the “right to be forgotten” in Article 17.
Ars was unsuccessful in reaching the administrator of Spy Pet by email and Telegram message. Their last message on Telegram stated that their domain had been suspended and a backup domain was being set up. “TL;DR: Never trust the Germans,” they wrote.
TikTok owner ByteDance is preparing to sue the US government now that President Biden has signed into law a bill that will ban TikTok in the US if its Chinese owner doesn’t sell the company within 270 days. While it’s impossible to predict the outcome with certainty, law professors speaking to Ars believe that ByteDance will have a strong First Amendment case in its lawsuit against the US.
One reason for this belief is that just a few months ago, a US District Court judge blocked a Montana state law that attempted to ban TikTok. In October 2020, another federal judge in Pennsylvania blocked a Trump administration order that would have banned TikTok from operating inside the US. TikTok also won a preliminary injunction against Trump in US District Court for the District of Columbia in September 2020.
“Courts have said that a TikTok ban is a First Amendment problem,” Santa Clara University law professor Eric Goldman, who writes frequent analysis of legal cases involving technology, told Ars this week. “And Congress didn’t really try to navigate away from that. They just went ahead and disregarded the court rulings to date.”
The fact that previous attempts to ban TikTok have failed is “pretty good evidence that the government has an uphill battle justifying the ban,” Goldman said.
TikTok users engage in protected speech
The Montana law “bans TikTok outright and, in doing so, it limits constitutionally protected First Amendment speech,” US District Judge Donald Molloy wrote in November 2023 when he granted a preliminary injunction that blocks the state law.
“The Montana court concluded that the First Amendment challenge would be likely to succeed. This will give TikTok some hope that other courts will follow suit with respect to a national order,” Georgetown Law Professor Anupam Chander told Ars.
Molloy’s ruling said that without TikTok, “User Plaintiffs are deprived of communicating by their preferred means of speech, and thus First Amendment scrutiny is appropriate.” TikTok’s speech interests must be considered “because the application’s decisions related to how it selects, curates, and arranges content are also protected by the First Amendment,” the ruling said.
Banning apps that let people talk to each other “is categorically impermissible,” Goldman said. While the Chinese government engaging in propaganda is a problem, “we need to address that as a government propaganda problem, and not just limited to China,” he said. In Goldman’s view, a broader approach should also be used to stop governments from siphoning user data.
TikTok and opponents of bans haven’t won every case. A federal judge in Texas ruled in favor of Texas Governor Greg Abbott in December 2023. But that ruling only concerned a ban on state employees using TikTok on government-issued devices rather than a law that potentially affects all users of TikTok.
Weighing national security vs. First Amendment
US lawmakers have alleged that the Chinese Communist Party can weaponize TikTok to manipulate public opinion and access user data. But Chander was skeptical of whether the US government could convincingly justify its new law in court on national security grounds.
“Thus far, the government has refused to make public its evidence of a national security threat,” he told Ars. “TikTok put in an elaborate set of controls to insulate the app from malign foreign influence, and the government hasn’t shown why those controls are insufficient.”
The ruling against Trump by a federal judge in Pennsylvania noted that “the Government’s own descriptions of the national security threat posed by the TikTok app are phrased in the hypothetical.”
Chander stressed that the outcome of ByteDance’s planned case against the US is difficult to predict, however. “I would vote against the law if I were a judge, but it’s unclear how judges will weigh the alleged national security risks against the real free expression incursions,” he said.
Montana case may be “bellwether”
There are at least three types of potential plaintiffs that could lodge constitutional challenges to a TikTok ban, Goldman said. There’s TikTok itself, the users of TikTok who would no longer be able to post on the platform, and app stores that would be ordered not to carry the TikTok app.
Montana was sued by TikTok and users. Lead plaintiff Samantha Alario runs a local swimwear business and uses TikTok to market her products.
Montana Attorney General Austin Knudsen appealed the ruling against his state to the US Court of Appeals for the 9th Circuit. The Montana case could make it to the Supreme Court before there is any resolution on the enforceability of the US law, Goldman said.
“It’s possible that the Montana ban is actually going to be the bellwether that’s going to set the template for the constitutional review of the Congressional action,” Goldman said.
Microsoft has open-sourced another bit of computing history this week: The company teamed up with IBM to release the source code of 1988’s MS-DOS 4.00, a version better known for its unpopularity, bugginess, and convoluted development history than its utility as a computer operating system.
The MS-DOS 4.00 code is available on Microsoft’s MS-DOS GitHub page along with versions 1.25 and 2.0, which Microsoft open-sourced in cooperation with the Computer History Museum back in 2014. All open-source versions of DOS have been released under the MIT License.
Initially, MS-DOS 4.00 was slated to include new multitasking features that allow software to run in the background. This release of DOS, also sometimes called “MT-DOS” or “Mutitasking MS-DOS” to distinguish it from other releases, was only released through a few European PC OEMs and never as a standalone retail product.
The source code Microsoft released this week is not for that multitasking version of DOS 4.00, and Microsoft’s Open Source Programs Office was “unable to find the full source code” for MT-DOS when it went to look. Rather, Microsoft and IBM have released the source code for a totally separate version of DOS 4.00, primarily developed by IBM to add more features to the existing non-multitasking version of DOS that ran on most IBM PCs and PC clones of the day.
Microsoft never returned to its multitasking DOS idea in subsequent releases. Multitasking would become the purview of graphical operating systems like Windows and OS/2, while MS-DOS versions 5.x and 6.x continued with the old one-app-at-a-time model of earlier releases.
Microsoft has released some documentation and binary files for MT-DOS and “may update this release if more is discovered.” The company credits English researcher Connor “Starfrost” Hyde for shaking all of this source code loose as part of an ongoing examination of MT-DOS that he is documenting on his website. Hyde has posted many screenshots of a 1984-era build of MT-DOS, including of the “session manager” that it used to track and switch between running applications.
Confidential copies of the obscure, abandoned multitasking-capable version of MS-DOS 4.00. Microsoft has been unable to locate source code for this release, sometimes referred to as “MT-DOS” or “Multitasking MS-DOS.”
Microsoft
The publicly released version of MS-DOS 4.00 is known less for its new features than for its high memory usage; the 4.00 release could consume as much as 92KB of RAM, way up from the roughly 56KB used by MS-DOS 3.31, and the 4.01 release reduced this to about 86KB. The later MS-DOS 5.0 and 6.0 releases maxed out at 72 or 73KB, and even IBM’s PC DOS 2000 only wanted around 64KB.
These RAM numbers would be rounding errors on any modern computer, but in the days when RAM was pricey, systems maxed out at 640KB, and virtual memory wasn’t a thing, such a huge jump in system requirements was a big deal. Today’s retro-computing enthusiasts still tend to skip over MS-DOS 4.00, recommending either 3.31 for its lower memory usage or later versions for their expanded feature sets.
Microsoft has open-sourced some other legacy code over the years, including those older MS-DOS versions, Word for Windows 1.1a, 1983-era GW-BASIC, and the original Windows File Manager. While most of these have been released in their original forms without any updates or changes, the Windows File Manager is actually actively maintained. It was initially just changed enough to run natively on modern 64-bit and Arm PCs running Windows 10 and 11, but it’s been updated with new fixes and features as recently as March 2024.
The release of the MS-DOS 4.0 code isn’t the only new thing that DOS historians have gotten their hands on this year. One of the earliest known versions of 86-DOS, the software that Microsoft would buy and turn into the operating system for the original IBM PC, was discovered and uploaded to the Internet Archive in January. An early version of the abandoned Microsoft-developed version of OS/2 was also unearthed in March.
Enlarge/ A 2014 Tesla Model S driving on Autopilot rear-ended a Culver City fire truck that was parked in the high-occupancy vehicle lane on Interstate 405.
Tesla’s lousy week continues. On Tuesday, the electric car maker posted its quarterly results showing precipitous falls in sales and profitability. Today, we’ve learned that the National Highway Traffic Safety Administration is concerned that Tesla’s massive recall to fix its Autopilot driver assist—which was pushed out to more than 2 million cars last December—has not actually made the system that much safer.
NHTSA’s Office of Defects Investigation has been scrutinizing Tesla Autopilot since August 2021, when it opened a preliminary investigation in response to a spate of Teslas crashing into parked emergency responder vehicles while operating under Autopilot.
In June 2022, the ODI upgraded that investigation into an engineering analysis, and in December 2023, Tesla was forced to recall more than 2 million cars after the analysis found that the car company had inadequate driver-monitoring systems and had designed a system with the potential for “foreseeable misuse.”
NHTSA has now closed that engineering analysis, which examined 956 crashes. After excluding crashes where the other car was at fault, where Autopilot wasn’t operating, or where there was insufficient data to make a determination, it found 467 Autopilot crashes that fell into three distinct categories.
First, 221 were frontal crashes in which the Tesla hit a car or obstacle despite “adequate time for an attentive driver to respond to avoid or mitigate the crash.” Another 111 Autopilot crashes occurred when the system was inadvertently disengaged by the driver, and the remaining 145 Autopilot crashes happened under low grip conditions, such as on a wet road.
As Ars has noted time and again, Tesla’s Autopilot system has a more permissive operational design domain than any comparable driver-assistance system that still requires the driver to keep their hands on the wheel and their eyes on the road, and NHTSA’s report adds that “Autopilot invited greater driver confidence via its higher control authority and ease of engagement.”
The result has been disengaged drivers who crash, and those crashes “are often severe because neither the system nor the driver reacts appropriately, resulting in high-speed differential and high energy crash outcomes,” NHTSA says. Tragically, at least 13 people have been killed as a result.
NHTSA also found that Tesla’s telematics system has plenty of gaps in it, despite the closely held belief among many fans of the brand that the Autopilot system is constantly recording and uploading to Tesla’s servers to improve itself. Instead, it only records an accident if the airbags deploy, which NHTSA data shows only happens in 18 percent of police-reported crashes.
The agency also criticized Tesla’s marketing. “Notably, the term “Autopilot” does not imply an L2 assistance feature but rather elicits the idea of drivers not being in control. This terminology may lead drivers to believe that the automation has greater capabilities than it does and invite drivers to overly trust the automation,” it says.
But now, NHTSA’s ODI has opened a recall query to assess whether the December fix actually made the system any safer. From the sounds of it, the agency is not convinced it did, based on additional Autopilot crashes that have happened since the recall and after testing the updated system itself.
Worryingly, the agency writes that “Tesla has stated that a portion of the remedy both requires the owner to opt in and allows a driver to readily reverse it” and wants to know why subsequent updates have addressed problems that should have been fixed with the December recall.
Embarking on an exploration of the extended detection and response (XDR) sector wasn’t just another research project for me; it was a dive back into familiar waters with an eye on how the tide has turned. Having once been part of a team at a vendor that developed an early XDR prototype, my return to this evolving domain was both nostalgic and eye-opening. The concept we toyed with in its nascent stages has burgeoned into a cybersecurity imperative, promising to redefine threat detection and response across the digital landscape.
Discovering XDR: Past and Present
My previous stint in developing an XDR prototype was imbued with the vision of creating a unified platform that could offer a panoramic view of security threats, moving beyond siloed defenses. Fast forward to my recent exploration, and it’s clear that the industry has taken this vision and run with it—molding XDR into a comprehensive solution that integrates across security layers to offer unparalleled visibility and control.
The research process was akin to piecing together a vast jigsaw puzzle. Through a blend of reading industry white papers, diving deep into knowledge-base articles, and drawing from my background, I charted the evolution of XDR from a promising prototype to a mature cybersecurity solution. This deep dive not only broadened my understanding but also reignited my enthusiasm for the potential of integrated defense mechanisms against today’s sophisticated cyberthreats.
The Adoption Challenge: Beyond Integration
The most formidable challenge that emerged in adopting XDR solutions is integration complexity—a barrier we had anticipated in the early development days and has only intensified. Organizations today face the Herculean task of intertwining their diversified security tools with an XDR platform, where each tool speaks a different digital language and adheres to distinct protocols.
However, the adoption challenges extend beyond the technical realm. There’s a strategic dissonance in aligning an organization’s security objectives with the capabilities of XDR platforms. This alignment is crucial, yet often elusive, as it demands a top-down reevaluation of security priorities, processes, and personnel readiness. Organizations must not only reconcile their current security infrastructure with an XDR system but also ensure their teams are adept at leveraging this integration to its fullest potential.
Surprises and Insights
The resurgence of AI and machine learning within XDR solutions echoed the early ambitions of prototype development. The sophistication of these technologies in predicting and mitigating threats in real time was a revelation, showcasing how far the maturation of XDR has come. Furthermore, the vibrant ecosystem of partnerships and integrations underscored XDR’s shift from a standalone solution to a collaborative security framework, a pivot that resonates deeply with the interconnected nature of digital threats today.
Reflecting on the Evolution
Since venturing into XDR prototype development, the sector’s evolution has been marked by a nuanced understanding of adoption complexities and an expansion in threat coverage. The emphasis on refining integration strategies and enhancing customization signifies a market that’s not just growing but maturing—ready to tackle the diversifying threat landscape with innovative solutions.
The journey back into the XDR landscape, juxtaposed against my early experiences, was a testament to the sector’s dynamism. As adopters navigate the complexities of integrating XDR into their security arsenals, the path ahead is illuminated by the promise of a more resilient, unified defense mechanism against cyber adversaries. The evolution of XDR from an emerging prototype to a cornerstone of modern cybersecurity strategies mirrors the sector’s readiness to confront the future—a future where the digital well-being of organizations is shielded by the robust, integrated, and intuitive capabilities of XDR platforms.
Next Steps
To learn more, take a look at GigaOm’s XDR Key Criteria and Radar reports. These reports provide a comprehensive overview of the market, outline the criteria you’ll want to consider in a purchase decision, and evaluate how a number of vendors perform against those decision criteria.
Enlarge/ A meeting of the UN Security Council on April 14.
Russia vetoed a United Nations Security Council resolution Wednesday that would have reaffirmed a nearly 50-year-old ban on placing weapons of mass destruction into orbit, two months after reports Russia has plans to do just that.
Russia’s vote against the resolution was no surprise. As one of the five permanent members of the Security Council, Russia has veto power over any resolution that comes before the body. China abstained from the vote, and 13 other members of the Security Council voted in favor of the resolution.
If it passed, the resolution would have affirmed a binding obligation in Article IV of the 1967 Outer Space Treaty, which says nations are “not to place in orbit around the Earth any objects carrying nuclear weapons or any other kinds of weapons of mass destruction.”
“The United States assesses that Russia is developing a new satellite carrying a nuclear device,” said Jake Sullivan, President Biden’s national security advisor. “We have heard President Putin say publicly that Russia has no intention of deploying nuclear weapons in space. If that were the case, Russia would not have vetoed this resolution.”
The United States and Japan proposed the joint resolution, which also called on nations not to develop nuclear weapons or any other weapons of mass destruction designed to be placed into orbit around the Earth. In a statement, US and Japanese diplomats highlighted the danger of a nuclear detonation in space. Such an event would have “grave implications for sustainable development, and other aspects of international peace and security,” US officials said in a press release.
With its abstention from the vote, “China has shown that it would rather defend Russia as its junior partner, than safeguard the global nonproliferation regime,” said Linda Thomas-Greenfield, the US ambassador to the UN.
US government officials have not offered details about the exact nature of the anti-satellite weapon they say Russia is developing. A nuclear explosion in orbit would destroy numerous satellites—from many countries—and endanger astronauts. Space debris created from a nuclear detonation could clutter orbital traffic lanes needed for future spacecraft.
The Soviet Union launched more than 30 military satellites powered by nuclear reactors. Russia’s military space program languished in the first couple of decades after the fall of the Soviet Union, and US intelligence officials say it still lags behind the capabilities possessed by the US Space Force and the Chinese military.
Russia’s military funding has largely gone toward the war in Ukraine for the last two years, but Putin and other top Russian officials have raised threats of nuclear force and attacks on space assets against adversaries. Russia’s military launched a cyberattack against a commercial satellite communications network when it invaded Ukraine in 2022.
Russia has long had an appetite for anti-satellite (ASAT) weapons. The Soviet Union experimented with “co-orbital” ASATs in the 1960s and 1970s. When deployed, these co-orbital ASATs would have attacked enemy satellites by approaching them and detonating explosives or using a grappling arm to move the target out of orbit.
Enlarge/ Russian troops at the Plesetsk Cosmodrome in far northern Russia prepare for the launch of a Soyuz rocket with the Kosmos 2575 satellite in February.
Russian Ministry of Defense
In 1987, the Soviet Union launched an experimental weapons platform into orbit to test laser technologies that could be used against enemy satellites. Russia shot down one of its own satellites in 2021 in a widely condemned “direct ascent” ASAT test. This Russian direct ascent ASAT test followed demonstrations of similar capability by China, the United States, and India. Russia’s military has also demonstrated satellites over the last decade that could grapple onto an adversary’s spacecraft in orbit, or fire a projectile to take out an enemy satellite.
These ASAT capabilities could destroy or disable one enemy satellite at a time. The US Space Force is getting around this threat by launching large constellations of small satellites to augment the military’s much larger legacy communications, surveillance, and missile warning spacecraft. A nuclear ASAT weapon could threaten an entire constellation or render some of space inaccessible due to space debris.
Russia’s ambassador to the UN, Vasily Nebenzya, called this week’s UN resolution “an unscrupulous play of the United States” and a “cynical forgery and deception.” Russia and China proposed an amendment to the resolution that would have banned all weapons in space. This amendment got the support of about half of the Security Council but did not pass.
Outside the 15-member Security Council, the original resolution proposed by the United States and Japan won the support of more than 60 nations as co-sponsors.
“Regrettably, one permanent member decided to silence the critical message we wanted to send to the present and future people of the world: Outer space must remain a domain of peace, free of weapons of mass destruction, including nuclear weapons,” said Kazuyuki Yamazaki, Japan’s ambassador to the UN.
Enlarge/ Tech brands love hollering about the purported thrills of AI these days.
Logitech announced a new mouse last week. A company rep reached out to inform Ars of Logitech’s “newest wireless mouse.” The gadget’s product page reads the same as of this writing.
I’ve had good experience with Logitech mice, especially wireless ones, one of which I’m using now. So I was keen to learn what Logitech might have done to improve on its previous wireless mouse designs. A quieter click? A new shape to better accommodate my overworked right hand? Multiple onboard profiles in a business-ready design?
I was disappointed to learn that the most distinct feature of the Logitech Signature AI Edition M750 is a button located south of the scroll wheel. This button is preprogrammed to launch the ChatGPT prompt builder, which Logitech recently added to its peripherals configuration app Options+.
That’s pretty much it.
Beyond that, the M750 looks just like the Logitech Signature M650, which came out in January 2022. Also, the new mouse’s forward button (on the left side of the mouse) is preprogrammed to launch Windows or macOS dictation, and the back button opens ChatGPT within Options+. As of this writing, the new mouse’s MSRP is $10 higher ($50) than the M650’s.
The new M750 (pictured) is 4.26×2.4×1.52 inches and 3.57 ounces.
Logitech
The M650 (pictured) comes in 3 sizes. The medium size is 4.26×2.4×1.52 inches and 3.58 ounces.
Logitech
I asked Logitech about the M750 appearing to be the M650 but with an extra button, and a spokesperson responded by saying:
M750 is indeed not the same mouse as M650. It has an extra button that has been preprogrammed to trigger the Logi AI Prompt Builder once the user installs Logi Options+ app. Without Options+, the button does DPI toggle between 1,000 and 1,600 DPI.
However, a reprogrammable button south of a mouse’s scroll wheel that can be set to launch an app or toggle DPI out of the box is pretty common, including among Logitech mice. Logitech’s rep further claimed to me that the two mice use different electronic components, which Logitech refers to as the mouse’s platform. Logitech can reuse platforms for different models, the spokesperson said.
Logitech’s rep declined to comment on why the M650 didn’t have a button south of its scroll wheel. Price is a potential reason, but Logitech also sells cheaper mice with this feature.
Still, the minimal differences between the two suggest that the M750 isn’t worth a whole product release. I suspect that if it weren’t for Logitech’s trendy new software feature, the M750 wouldn’t have been promoted as a new product.
The M750 also raises the question of how many computer input devices need to be equipped with some sort of buzzy, generative AI-related feature.
Logitech’s ChatGPT prompt builder
Logitech’s much bigger release last week wasn’t a peripheral but an addition to its Options+ app. You don’t need the “new” M750 mouse to use Logitech’s AI Prompt Builder; I was able to program my MX Master 3S to launch it. Several Logitech mice and keyboards support AI Prompt Builder.
When you press a button that launches the prompt builder, an Options+ window appears. There, you can input text that Options+ will use to create a ChatGPT-appropriate prompt based on your needs:
Enlarge/ A Logitech-provided image depicting its AI Prompt Builder software feature.
Logitech
After you make your choices, another window opens with ChatGPT’s response. Logitech said the prompt builder requires a ChatGPT account, but I was able to use GPT-3.5 without entering one (the feature can also work with GPT-4).
The typical Arsian probably doesn’t need help creating a ChatGPT prompt, and Logitech’s new capability doesn’t work with any other chatbots. The prompt builder could be interesting to less technically savvy people interested in some handholding for early ChatGPT experiences. However, I doubt if people with an elementary understanding of generative AI need instant access to ChatGPT.
The point, though, is instant access to ChatGPT capabilities, something that Logitech is arguing is worthwhile for its professional users. Some Logitech customers, though, seem to disagree, especially with the AI Prompt Builder, meaning that Options+ has even more resources in the background.
But Logitech isn’t the only gadget company eager to tie one-touch AI access to a hardware button.
Pinching your earbuds to talk to ChatGPT
Similarly to Logitech, Nothing is trying to give its customers access to ChatGPT quickly. In this case, access occurs by pinching the device. This month, Nothing announced that it “integrated Nothing earbuds and Nothing OS with ChatGPT to offer users instant access to knowledge directly from the devices they use most, earbuds and smartphones.” The feature requires the latest Nothing OS and for the users to have a Nothing phone with ChatGPT installed. ChatGPT gestures work with Nothing’s Phone (2) and Nothing Ear and Nothing Ear (a), but Nothing plans to expand to additional phones via software updates.
Nothing also said it would embed “system-level entry points” to ChatGPT, like screenshot sharing and “Nothing-styled widgets,” to Nothing smartphone OSes.
Enlarge/ A peek at setting up ChatGPT integration on the Nothing X app.
Nothing’s ChatGPT integration may be a bit less intrusive than Logitech’s since users who don’t have ChatGPT on their phones won’t be affected. But, again, you may wonder how many people asked for this feature and how reliably it will function.
Enlarge/ Drops of the blood going onto an HIV quick test.
Trendy, unproven “vampire facials” performed at an unlicensed spa in New Mexico left at least three women with HIV infections. This marks the first time that cosmetic procedures have been associated with an HIV outbreak, according to a detailed report of the outbreak investigation published today.
Ars reported on the cluster last year when state health officials announced they were still identifying cases linked to the spa despite it being shut down in September 2018. But today’s investigation report offers more insight into the unprecedented outbreak, which linked five people with HIV infections to the spa and spurred investigators to contact and test nearly 200 other spa clients. The report appears in the Centers for Disease Control and Prevention’s Morbidity and Mortality Weekly Report.
The investigation began when a woman between the ages of 40 and 50 turned up positive on a rapid HIV test taken while she was traveling abroad in the summer of 2018. She had a stage 1 acute infection. It was a result that was as dumbfounding as it was likely distressing. The woman had no clear risk factors for acquiring the infection: no injection drug use, no blood transfusions, and her current and only recent sexual partner tested negative. But, she did report getting a vampire facial in the spring of 2018 at a spa in Albuquerque called VIP Spa.
“Vampire facial” is the common name for a platelet-rich plasma microneedling procedure. In this treatment, a patient’s blood is drawn, spun down to separate out plasma from blood cells, and the platelet-rich plasma is then injected into the face with microneedles. It’s claimed—with little evidence—that it can rejuvenate and improve the look of skin, and got notable promotions from celebrities, including Gwyneth Paltrow and Kim Kardashian.
The woman’s case led investigators to VIP Spa, which was unlicensed, had no appointment scheduling system, and did not store client contact information. In an inspection in the fall of 2018, health investigators found shocking conditions: unwrapped syringes in drawers and counters, unlabeled tubes of blood sitting out on a kitchen counter, more unlabeled blood and medical injectables alongside food in a kitchen fridge, and disposable equipment—electric desiccator tips—that were reused. The facility also did not have an autoclave—a pressurized oven—for sterilizing equipment.
A novel and challenging investigation
The spa was quickly shut down, and the owner Maria de Lourdes Ramos De Ruiz, 62, was charged with practicing medicine without a license. In 2022, she pleaded guilty to five counts and is serving a three-and-a-half-year prison sentence.
A second spa client, another woman between the ages of 40 and 50, tested positive for HIV in a screen in the fall of 2018 and received a diagnosis in early 2019. She has received a vampire facial in the summer of 2018. Her HIV infection was also at stage 1. Investigators scrambled to track down dozens of other clients, who mostly spoke Spanish as their first language. The next two identified cases weren’t diagnosed until the fall of 2021.
The two cases diagnosed in 2021 were sexual partners: a woman who received three vampire facials in the spring and summer of 2018 from the spa and her male partner. Both had a stage 3 HIV infection, which is when the infection has developed into Acquired Immunodeficiency Syndrome (AIDS). The severity of the infections suggested the two had been infected prior to the woman’s 2018 spa treatments. Health officials uncovered that the woman had tested positive in an HIV screen in 2016, though she did not report being notified of the result.
The health officials reopened their outbreak investigation in 2023 and found a fifth case that was diagnosed in the spring of 2023, which was also in a woman aged 40 to 50 who had received a vampire facial in the summer of 2018. She had a stage 3 infection and was hospitalized with an AIDS-defining illness.
Viral genetic sequencing from the five cases shows that the infections are all closely related. But, given the extent of the unsanitary and contaminated conditions at the facility, investigators were unable to determine precisely how the infections spread in the spa. In all, 198 spa clients were tested for HIV between 2018 and 2023, the investigators report.
“Incomplete spa client records posed a substantial challenge during this investigation, necessitating a large-scale outreach approach to identify potential cases,” the authors acknowledge. However, the investigation’s finding “underscores the importance of determining possible novel sources of HIV transmission among persons with no known HIV risk factors.”
The “Plus” version doesn’t have any discernible differences.
HMD
The Pro model has … bigger bezels?
HMD
HMD has been known as the manufacturer of Nokia-branded phones for years now, but now the company wants to start selling phones under its own brand. The first is the “HMD Pulse” line, a series of three low-end phones that are headed for Europe. The US is getting an HMD-branded phone, too—the HMD Vibe—but that won’t be out until May.
Europe’s getting the 140-euro HMD Pulse, 160-euro Pulse+, and the 180-euro Pulse Pro. If you can’t tell from the prices, these are destined for Europe for now, but if you convert them to USD, that’s about $150, $170, and $190, respectively. With only $20 between tiers, there isn’t a huge difference from one model to the next. They all have bottom-of-the-barrel Unisoc T606 SoCs. That’s a 12 nm chip with two Cortex A75 Arm cores, two A55 cores, an ARM Mali-G57 MP1, and it’s 4G only. Previously, HMD used this chip in the 2023 HMD Nokia G22. They also all have 90 Hz, 6.65-inch, 1612×720 LCDs, 128GB of storage, and 5,000 mAh batteries.
As for the differences, the base model has 4GB of RAM, a 13 MP main rear camera, an 8 MP front camera, and 10 W wired charging. The Plus model upgrades to a 50 MP main camera, while the Pro model has 6GB of RAM, a 50 MP main camera, 50 MP front camera, and 20 W wired charging. There is a second lens camera on the back, but it appears to be only a 2 MP “depth sensor” on all models.
Oddly, the Pro design is slightly worse than the cheaper phones, with thicker bezels and a bottom chin. Other than that, the phones have near-identical designs, and they all look good for a phone at this price. The Pulse phones, and only the Pulse phones, apparently, are marketed as “built to be repairable” and will have parts that will be available at iFixit. It’s hard to say exactly what “repairable” means since none of that information is out yet, but HMD’s last “repairable” phone didn’t contain any repair-focused innovations. It just seemed like a normal, non-waterproof cheap phone with a new marketing angle.
The US is getting the closely related “HMD Vibe,” which sounds like a more capable device with a Snapdragon 680. It’s old as far as Qualcomm chips go (from 2021), but it’s not a Unisoc. This is a 6 nm chip with four Cortex A73 cores and four Cortex A53 cores. It has 6GB of RAM, the same screen as the other devices, and only a 4,000 mAh battery for $150. The camera sounds like a low-end loadout, with only a 13 MP main shooter and a 5 MP front. All the phones have NFC, a 3.5 mm headphone jack, a Micro SD slot, USB-C ports, and they come with Android 14 and two OS upgrades. The European phones all have side fingerprint readers, and the real deal-breaker for the US seems to be that it doesn’t have a fingerprint reader at all.
HMD’s desire to step away from the Nokia brand is an odd one. Lots of historic phone companies that washed out of the phone market have licensed their brand to a third party, giving rise to the “zombie brand” trend. Blackberry, Palm, and Motorola all come to mind. HMD was different, though; at launch, it was more of a spiritual successor to Nokia rather than a random manufacturer licensing the brand. Both companies are Finnish, and HMD’s headquarters are right across the street from Nokia. The company’s leadership is filled with former Nokia executives. Nokia even owns 10 percent of HMD, while FIH Mobile, a division of Chinese manufacturing juggernaut Foxconn, owns 14 percent.
Despite all that, HMD is stepping out of the shadow of Nokia and trying to start its own brand. The company plans to go with a “multi-brand” strategy now, so Nokia phones will stick around, but expect to see more HMD-branded phones in the future. The company is also open to other brand partnerships. It just released a bizarre “Heineken” dumbphone in partnership with the beer brand and is planning a “Barbie flip phone” with Mattel this summer.
In the world of AI, what might be called “small language models” have been growing in popularity recently because they can be run on a local device instead of requiring data center-grade computers in the cloud. On Wednesday, Apple introduced a set of tiny source-available AI language models called OpenELM that are small enough to run directly on a smartphone. They’re mostly proof-of-concept research models for now, but they could form the basis of future on-device AI offerings from Apple.
Apple’s new AI models, collectively named OpenELM for “Open-source Efficient Language Models,” are currently available on the Hugging Face under an Apple Sample Code License. Since there are some restrictions in the license, it may not fit the commonly accepted definition of “open source,” but the source code for OpenELM is available.
On Tuesday, we covered Microsoft’s Phi-3 models, which aim to achieve something similar: a useful level of language understanding and processing performance in small AI models that can run locally. Phi-3-mini features 3.8 billion parameters, but some of Apple’s OpenELM models are much smaller, ranging from 270 million to 3 billion parameters in eight distinct models.
In comparison, the largest model yet released in Meta’s Llama 3 family includes 70 billion parameters (with a 400 billion version on the way), and OpenAI’s GPT-3 from 2020 shipped with 175 billion parameters. Parameter count serves as a rough measure of AI model capability and complexity, but recent research has focused on making smaller AI language models as capable as larger ones were a few years ago.
The eight OpenELM models come in two flavors: four as “pretrained” (basically a raw, next-token version of the model) and four as instruction-tuned (fine-tuned for instruction following, which is more ideal for developing AI assistants and chatbots):
OpenELM features a 2048-token maximum context window. The models were trained on the publicly available datasets RefinedWeb, a version of PILE with duplications removed, a subset of RedPajama, and a subset of Dolma v1.6, which Apple says totals around 1.8 trillion tokens of data. Tokens are fragmented representations of data used by AI language models for processing.
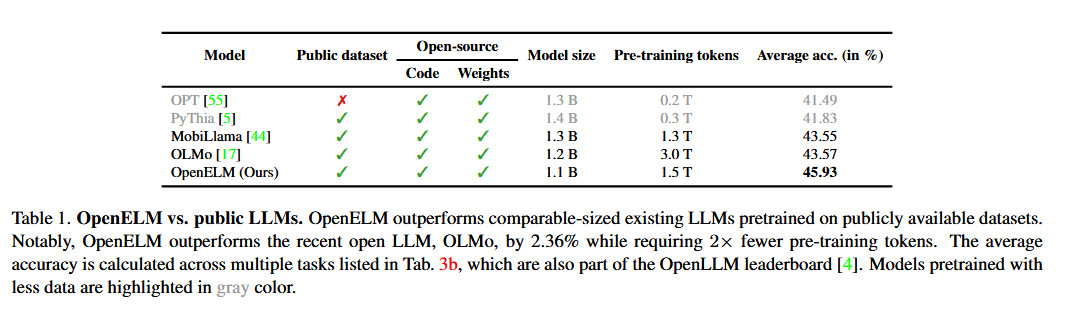
Apple says its approach with OpenELM includes a “layer-wise scaling strategy” that reportedly allocates parameters more efficiently across each layer, saving not only computational resources but also improving the model’s performance while being trained on fewer tokens. According to Apple’s released white paper, this strategy has enabled OpenELM to achieve a 2.36 percent improvement in accuracy over Allen AI’s OLMo 1B (another small language model) while requiring half as many pre-training tokens.
Enlarge/ An table comparing OpenELM with other small AI language models in a similar class, taken from the OpenELM research paper by Apple.
Apple
Apple also released the code for CoreNet, a library it used to train OpenELM—and it also included reproducible training recipes that allow the weights (neural network files) to be replicated, which is unusual for a major tech company so far. As Apple says in its OpenELM paper abstract, transparency is a key goal for the company: “The reproducibility and transparency of large language models are crucial for advancing open research, ensuring the trustworthiness of results, and enabling investigations into data and model biases, as well as potential risks.”
By releasing the source code, model weights, and training materials, Apple says it aims to “empower and enrich the open research community.” However, it also cautions that since the models were trained on publicly sourced datasets, “there exists the possibility of these models producing outputs that are inaccurate, harmful, biased, or objectionable in response to user prompts.”
While Apple has not yet integrated this new wave of AI language model capabilities into its consumer devices, the upcoming iOS 18 update (expected to be revealed in June at WWDC) is rumored to include new AI features that utilize on-device processing to ensure user privacy—though the company may potentially hire Google or OpenAI to handle more complex, off-device AI processing to give Siri a long-overdue boost.
Enlarge/ The Q*Bert’s so bright, I gotta wear shades.
Aurich Lawson | Getty Images | Gottlieb
For years now, video game preservationists, librarians, and historians have been arguing for a DMCA exemption that would allow them to legally share emulated versions of their physical game collections with researchers remotely over the Internet. But those preservationists continue to face pushback from industry trade groups, which worry that an exemption would open a legal loophole for “online arcades” that could give members of the public free, legal, and widespread access to copyrighted classic games.
This long-running argument was joined once again earlier this month during livestreamed testimony in front of the Copyright Office, which is considering new DMCA rules as part of its regular triennial process. During that testimony, representatives of the Software Preservation Network and the Library Copyright Alliance defended their proposal for a system of “individualized human review” to help ensure that temporary remote game access would be granted “primarily for the purposes of private study, scholarship, teaching, or research.”
Enlarge/ Lawyer Steve Englund, who represented the ESA at the Copyright Office hearing.
Speaking for the Entertainment Software Association trade group, though, lawyer Steve Englund said the new proposal was “not very much movement” on the part of the proponents and was “at best incomplete.” And when pressed on what would represent “complete” enough protections to satisfy the ESA, Englund balked.
“I don’t think there is at the moment any combination of limitations that ESA members would support to provide remote access,” Englund said. “The preservation organizations want a great deal of discretion to handle very valuable intellectual property. They have yet to… show a willingness on their part in a way that might be comforting to the owners of that IP.”
Getting in the way of research
Research institutions can currently offer remote access to digital copies of works like books, movies, and music due to specific DMCA exemptions issued by the Copyright Office. However, there is no similar exemption that allows for sending temporary digital copies of video games to interested researchers. That means museums like the Strong Museum of Play can only provide access to their extensive game archives if a researcher physically makes the trip to their premises in Rochester, New York.
Enlarge/ Currently, the only way for researchers to access these games in the Strong Museum’s collection is to visit Rochester, New York, in person.
During the recent Copyright Office hearing, industry lawyer Robert Rothstein tried to argue that this amounts to more of a “travel problem” than a legal problem that requires new rule-making. But NYU professor Laine Nooney argued back that the need for travel represents “a significant financial and logistical impediment to doing research.”
For Nooney, getting from New York City to the Strong Museum in Rochester would require a five- to six-hour drive “on a good day,” they said, as well as overnight accommodations for any research that’s going to take more than a small part of one day. Because of this, Nooney has only been able to access the Strong collection twice in her career. For researchers who live farther afield—or for grad students and researchers who might not have as much funding—even a single research visit to the Strong might be out of reach.
“You don’t go there just to play a game for a couple of hours,” Nooney said. “Frankly my colleagues in literary studies or film history have pretty routine and regular access to digitized versions of the things they study… These impediments are real and significant and they do impede research in ways that are not equitable compared to our colleagues in other disciplines.”
During the hearing, lawyer Kendra Albert said the preservationists had proposed the idea of human review of requests for remote access to “strike a compromise” between “concerns of the ESA and the need for flexibility that we’ve emphasized on behalf of preservation institutions.” They compared the proposed system to the one already used to grant access for libraries’ “special collections,” which are not made widely available to all members of the public.
But while preservation institutions may want to provide limited scholarly access, Englund argued that “out in the real world, people want to preserve access in order to play games for fun.” He pointed to public comments made to the Copyright Office from “individual commenters [who] are very interested in playing games recreationally” as evidence that some will want to exploit this kind of system.
Even if an “Ivy League” library would be responsible with a proposed DMCA exemption, Englund worried that less scrupulous organizations might simply provide an online “checkbox” for members of the public who could easily lie about their interest in “scholarly play.” If a human reviewed that checkbox affirmation, it could provide a legal loophole to widespread access to an unlimited online arcade, Englund argued.
Phil Salvador of the Video Game History Foundation said that Englund’s concern about this score was overblown. “Building a video game collection is a specialized skill that most libraries do not have the human labor to do, or the expertise, or the resources, or even the interest,” he said.
Salvador estimated that the number of institutions capable of building a physical collection of historical games is in the “single digits.” And that’s before you account for the significant resources needed to provide remote access to those collections; Rhizome Preservation Director Dragan Espenschied said it costs their organization “thousands of dollars a month” to run the sophisticated cloud-based emulation infrastructure needed for a few hundred users to access their Emulation as a Serviceart archives and gaming retrospectives.
Salvador also made reference to last year’s VGHF study that found a whopping 87 percent of games ever released are out of print, making it difficult for researchers to get access to huge swathes of video game history without institutional help. And the games of most interest to researchers are less likely to have had modern re-releases since they tend to be the “more primitive” early games with “less popular appeal,” Salvador said.
The Copyright Office is expected to rule on the preservation community’s proposed exemption later this year. But for the moment, there is some frustration that the industry has not been at all receptive to the significant compromises the preservation community feels it has made on these potential concerns.
“None of that is ever going to be sufficient to reassure these rights holders that it will not cause harm,” Albert said at the hearing. “If we’re talking about practical realities, I really want to emphasize the fact that proponents have continually proposed compromises that allow preservation institutions to provide the kind of access that is necessary for researchers. It’s not clear to me that it will ever be enough.”
Enlarge/ Ubuntu has come a long way over nearly 20 years, to the point where you can now render 3D Ubuntu coffee mugs and family pictures in a video announcing the 2024 spring release.
Betas, and the final release of Ubuntu 24.04, a long-term support (LTS) release of the venerable Linux distribution, were delayed, as backing firm Canonical worked in early April 2024 to rebuild every binary included in the release. xz Utils, an almost ubiquitous data-compression package on Unix-like systems, had been compromised through a long-term and elaborate supply-chain attack, discovered only because a Microsoft engineer noted some oddities with SSH performance on a Debian system. Ubuntu, along with just about every other regularly updating software platform, had a lot of work to do this month.
Canonical’s Ubuntu 24.04 release video, noting 20 years of Ubuntu releases. I always liked the brown.
What is actually new in Ubuntu 24.04, or “Noble Numbat?” Quite a bit, especially if you’re the type who sticks to LTS releases. The big new changes are a very slick new installer, using the same Subiquity back-end as the Server releases, and redesigned with a whole new front-end in Flutter. ZFS encryption is back as a default install option, along with hardware-backed (i.e., TPM) full-disk encryption, plus more guidance for people looking to dual-boot with Windows setups and BitLocker. Netplan 1.0 is the default network configuration tool now. And the default installation is “Minimal,” as introduced in 23.10.
endangered species, and I think we should save it.” data-height=”1414″ data-width=”2121″ href=”https://cdn.arstechnica.net/wp-content/uploads/2024/04/GettyImages-1472552858.jpg”>endangered species, and I think we should save it.” height=”200″ src=”https://cdn.arstechnica.net/wp-content/uploads/2024/04/GettyImages-1472552858-300×200.jpg” width=”300″>
Raspberry Pi gets some attention, too, with an edition of 24.04 (64-bit only) available for the popular single-board computer, including the now-supported Raspberry Pi 5 model. That edition includes power supply utility Pemmican and enables 3D acceleration in the Firefox Snap. Ubuntu also tweaked the GNOME (version 46) desktop included in this release, such that it should see better performance on Raspberry Pi graphics drivers.
What else? Lots of little things:
Support for autoinstall, i.e., YAML-based installation workflows
A separate, less background-memory-eating firmware updating tool
Additional support for Group Policy Objects (GPOs) in Active Directory environments
Security improvements to Personal Package Archives (PPA) software setups
Restrictions to unprivileged user namespace through apparmor, which may impact some third-party apps downloaded from the web
A new Ubuntu App Center, replacing the Snap Store that defaults to Snaps but still offers traditional .deb installs (and numerous angles of critique for Snap partisans)
Firefox is a native Wayland application, and Thunderbird is a Snap package only
More fingerprint reader support
Improved Power Profiles Manager, especially for portable AMD devices
Support for Apple’s preferred HEIF/HEIC files, with thumbnail previews
Snapshot replaces Cheese, and GNOME games has been removed
Virtual memory mapping changes that make many modern games run better through Proton, per OMG Ubuntu
Linux kernel 6.8, which, among other things, improves Intel Meteor Lake CPU performance and supports Nintendo Switch Online controllers.
The suggested system requirements for Ubuntu 24.04 are a 2 GHz dual-core processor, 4GB memory, and 25GB free storage space. There is a dedicated WSL edition of 24.04 out for Windows systems.


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}