Some podcasts are self-recommending on the ‘yep, I’m going to be breaking this one down’ level. This was very clearly one of those. So here we go.
As usual for podcast posts, the baseline bullet points describe key points made, and then the nested statements are my commentary.
If I am quoting directly I use quote marks, otherwise assume paraphrases.
Rather than worry about timestamps, I’ll use YouTube’s section titles, as it’s not that hard to find things via the transcript as needed.
This was a fun one in many places, interesting throughout, frustrating in similar places to where other recent Dwarkesh interviews have been frustrating. It gave me a lot of ideas, some of which might even be good.
-
Andrej calls this the ‘decade of agents’ contrary to (among others who have said it) the Greg Brockman declaration that 2025 is the ‘year of agents,’ as there is so much work left to be done. Think of AI agents as employees or interns, that right now mostly can’t do the things due to deficits of intelligence and context.
-
I agree that 2025 as the year of the agent is at least premature.
-
You can defend the 2025 claim if you focus on coding, Claude Code and Codex, but I think even there it is more confusing than helpful as a claim.
-
I also agree that we will be working on improving agents for a long time.
-
2026 might be the proper ‘year of the agent’ as when people start using AI agents for a variety of tasks and getting a bunch of value from them, but they will still have a much bigger impact on the world in 2027, and again in 2028.
-
On the margin and especially outside of coding, I think context and inability to handle certain specific tasks (especially around computer use details) are holding things back right now more than intelligence. A lot of it seems eminently solvable quickly in various ways if one put it in the work.
-
Dwarkesh points to lack of continual learning or multimodality, but notes it’s hard to tell how long it will take. Andrej says ‘well I have 15 years of prediction experience and intuition and I average things out and it feels like a decade to me.’
-
A decade seems like an eternity to me on this.
-
If it’s to full AGI it is slow but less crazy. So perhaps this is Andrej saying that to count as an agent for this the AI needs to essentially be AGI.
-
AI has had a bunch of seismic shifts, Andrej has seen at least two and they seem to come with regularity. Neural nets used to be a niche thing before AlexNet but they were still trained per-task, the focus on Atari and other games was a mistake because you want to interact with the ‘real world’. Then LLMs. The common mistake was trying to “get the full thing too early” and especially aiming at agents too soon.
-
The too soon thing seems true and important. You can’t unlock capabilities in a useful way until you have the groundwork and juice for them.
-
Once you do have the groundwork and juice, they tend to happen quickly, without having to do too much extra work.
-
In general, seems like if something is super hard to do, better if you wait?
-
However you can with focused effort make a lot of progress beyond what you’d get at baseline, even if that ultimately stalls out, as seen by the Atari and universe examples.
-
Dwarkesh asks what about the Sutton perspective, should you be able to throw an AI out there into the world the way you would a human or animal and just work with and ‘grow up’ via sensory data? Andrej points to his response to Sutton, that biological brains work via a very different process, we’re building ghosts not animals, although we should make them more ‘animal-like’ over time. But animals don’t do what Sutton suggests, they use an evolutionary outer loop. Animals only use RL for non-intelligence tasks, things like motor skills.
-
I think humans do use RL on intelligence tasks? My evidence for this is that when I use this model of humans it seems to make better predictions, both about others and about myself.
-
Humans are smarter about this than ‘pure RL’ of course, including being the meta programmer and curating their own training data.
-
Dwarkesh contrasts pre-training with evolution in that evolution compacts all info into 3 GB of DNA, thus evolution is closer to finding a lifetime learning algorithm. Andrej agrees there is miraculous compression in DNA and that it includes learning algorithms, but we’re not here to build animals, only useful things, and they’re ‘crappy’ but what know how to build are the ghosts. Dwarkesh says evolution does not give us knowledge, it gives us the algorithm to find knowledge a la Sutton.
-
Dwarkesh is really big on the need for continual (or here he says ‘lifetime’) learning and the view that it is importantly distinct from what RL does.
-
I’m not convinced. As Dario points out, in theory you can put everything in the context window. You can do a lot better on memory and imitating continual learning than that with effort, and we’ve done remarkably little on such fronts.
-
The actual important difference to me is more like sample efficiency. I see ways around that problem too, but am not putting them in this margin.
-
I reiterate that evolution actually does provide a lot of knowledge, actually, or the seeds to getting specific types of knowledge, using remarkably few bits of data to do this. If you buy into too much ‘blank slate’ you’ll get confused.
-
Andrej draws a distinction between the neural net picking up all the knowledge in its training data versus it becoming more intelligent, and often you don’t even want the knowledge, we rely on it too much, and this is part of why agents are bad at “going off the data manifold of what exists on the internet.” We want the “cognitive core.”
-
I buy that you want to minimize the compute costs associated with carrying lots of extra information, so for many tasks you want a Minimum Viable Knowledge Base. I don’t buy that knowledge tends to get in the way. If it does, then Skill Issue.
-
More knowledge seems hard to divorce fully from more intelligence. A version of me that was abstractly ‘equally smart,’ but which knew far less, might technically have the same Intelligence score on the character sheet, but a lot lower Wisdom and would effectively be kind of dumb. See young people.
-
I’m skeptical about a single ‘cognitive core’ for similar reasons.
-
Dwarkesh reiterates in-context learning as ‘the real intelligence’ as distinct from gradient descent. Andrej agrees it’s not explicit, it’s “pattern completion within a token window” but notes there’s tons of patterns on the internet that get into the weights, and it’s possible in-context learning runs a small gradient descent loop inside the neural network. Dwarkesh asks, “why does it feel like with in-context learning we’re getting to this continual learning, real intelligence-like thing? Whereas you don’t get the analogous feeling just from pre-training.”
-
My response would basically again be sample efficiency, and the way we choose to interact with LLMs being distinct from the training? I don’t get this focus on (I kind of want to say fetishization of?) continual learning as a distinct thing. It doesn’t feel so distinct to me.
-
Dwarkesh asks, how much of the information from training gets stored in the model? He compares KV cache of 320 kilobytes to a full 70B model trained on 15 trillion tokens. Andrej thinks models get a ‘hazy recollection’ of what happened in training, the compression is dramatic to get 15T tokens into 70B parameters.
-
Is it that dramatic? Most tokens don’t contain much information, or don’t contain new information. In some ways 0.5% (70B vs. 15T) is kind of a lot. It depends on what you care about. If you actually had to put it all in the 320k KV Cache that’s a lot more compression.
-
As Andrej says, it’s not enough, so you get much more precise answers about texts if you have the full text in the context window. Which is also true if you ask humans about the details of things that mostly don’t matter.
-
What part about human intelligence have we most failed to replicate? Andrej says ‘a lot of it’ and starts discussing physical brain components causing “these cognitive deficits that we all intuitively feel when we talk to them models.”
-
I feel like that’s a type mismatch. I want to know what capabilities are missing, not which physical parts of the brain? I agree that intuitively some capabilities are missing, but I’m not sure how essential this is, and as Andrej suggests we shouldn’t be trying to build an analog of a human.
-
Dwarkesh turns back to continual learning, asks if it will emerge spontaneously if the model gets the right incentives. Andrej says no, that sleep does this for humans where ‘the context window sometimes sticks around’ and there’s no natural analog, but we want a way to do this, and points to sparse attention.
-
I’m not convinced we know how the sleep or ‘sticking around’ thing works, clearly there is something going on somewhere.
-
I agree this won’t happen automatically under current techniques, but we can use different techniques, and again I’m getting the Elle Woods ‘what, like it’s hard?’ reaction to all this, where ‘hard’ is relative to problem importance.
-
Andrej kind of goes Lindy, pointing to translation invariance to expect algorithmic and other changes at a similar rate to the past, and pointing to the many places he says we’d need gains in order to make further progress, that various things are ‘all surprisingly equal,’ it needs to improve ‘across the board.’
-
Is this the crux, the fundamental disagreement about the future, in two ways?
-
The less important one is the idea that progress requires all of [ABCDE] to make progress. That seems wrong to me. Yes, you are more efficient if you make progress more diffusely under exponential scaling laws, but you can still work around any given deficit via More Dakka.
-
As a simple proof by hypothetical counterexample, suppose I held one of his factors (e.g. architecture, optimizer, loss function) constant matching GPT-3, but could apply modern techniques and budgets to the others. What do I get?
-
More importantly, Andrej is denying the whole idea that technological progress here or in general is accelerating, or will accelerate. And that seems deeply wrong on multiple levels?
-
For this particular question, progress has been rapid, investments of all kinds have been huge, and already we are seeing AI directly accelerate AI progress substantially, a process that will accelerate even more as AI gets better, even if it doesn’t cross into anything like full automated AI R&D or a singularity, and we keep adding more ways to scale. It seems rather crazy to expect 2025 → 2035 to be similar to 2015 → 2025 in AI, on the level of ‘wait, you’re suggesting what?’
-
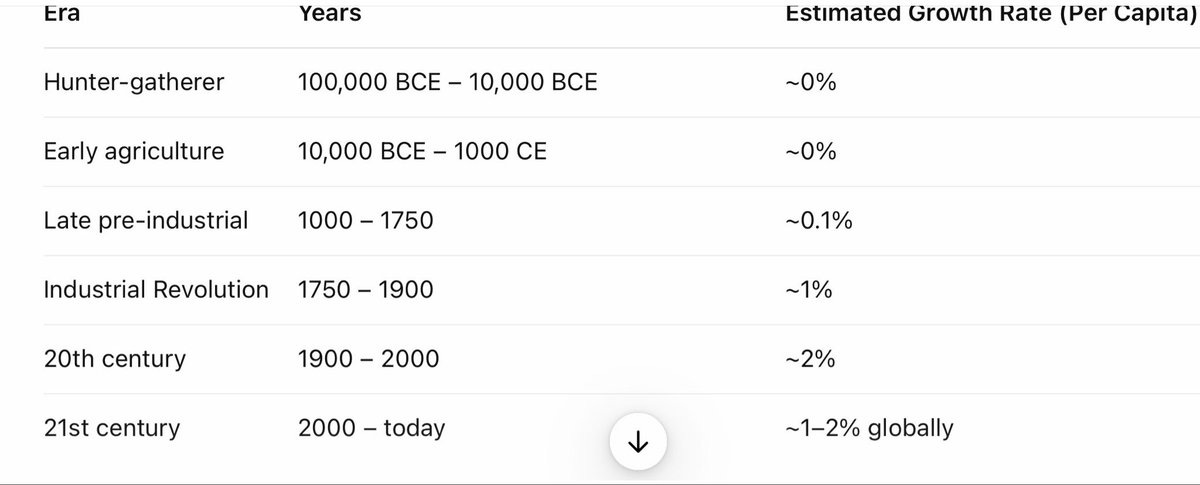
In the longer arc of history, if we’re going to go there, we see a clear acceleration of time. So we have the standard several billion years to get multicellular life, several hundred million years to get close to human intelligence, several hundred thousand to million years to get agriculture and civilization, several thousand years to get the industrial revolution, several hundred years to get the information age, several dozen years to get AI to do anything useful on the general intelligence front, several ones of years to go from ‘anything useful at all’ to GPT-5 and Sonnet 4.5 being superhuman in many domains already.
-
I think Andrej makes better arguments for relatively long (still remarkably short!) timelines later, but him invoking this gives me pause.
-
Andrej found LLMs of little help when assembling his new repo nanochat, which is a an 8k-line set of all the things you need for a minimal ChatGPT clone. He still used autocomplete, but vibe coding only works with boilerplate stuff. In particular, the models ‘remember wrong’ from all the standard internet ways of doing things, that he wasn’t using. For example, he did his own version of a DDP container inside the code, and the models couldn’t comprehend that and kept trying to use DDP instead. Whereas he only used vibe coding for a few boilerplate style areas.
-
I’ve noticed this too. LLMs will consistently make the same mistakes, or try to make the same changes, over and over, to match their priors.
-
It’s a reasonable prior to think things like ‘oh almost no one would ever implement a version of DDP themselves,’ the issue is that they aren’t capable of being told that this happened and having this overcome that prior.
-
“I also feel like it’s annoying to have to type out what I want in English because it’s too much typing. If I just navigate to the part of the code that I want, and I go where I know the code has to appear and I start typing out the first few letters, autocomplete gets it and just gives you the code. This is a very high information bandwidth to specify what you want.”
-
As a writer this resonates so, so much. There are many tasks where in theory the LLM could do it for me, but by the time I figure out how to get the LLM to do it for me, I might as well have gone and done it myself.
-
Whereas the autocomplete in gmail is actually good enough that it’s worth my brain scanning it to see if it’s what I wanted to type (or on occasion, a better version).
-
Putting it together: LLMs are very good at code that has been written many times before, and poor at code that has not been written before, in terms of the structure and conditions behind the code. Code that has been written before on rare occasions is in between. The modes are still amazing, and can often help. On the vibe coding: “I feel like the industry is making too big of a jump and is trying to pretend like this is amazing, and it’s not. It’s slop.”
-
There’s a big difference between the value added when you can successfully vibe code large blocks of code, versus when you can get answers to questions, debugging notes and stuff like that.
-
The second category can still be a big boost to productivity, including to AI R&D, but isn’t going to go into crazy territory or enter into recursion mode.
-
I presume Andrej is in a position where his barrier for ‘not slop’ is super high and the problems he works on are unusually hostile as well.
-
I do think these arguments are relevant evidence for longer timelines until crazy happens, that we risk overestimating the progress made on vibe coding.
-
Andrej sees all of computing as a big recursive self-improvement via things like code editors and syntax highlighting and even data checking and search engines, in a way that is continuous with AI. Better autocomplete is the next such step. We’re abstracting, but it is slow.
-
One could definitely look at it this way. It’s not obvious what that reframing pushes one towards.
-
How should we think about humans being able to build a rich world model from interactions with the environment, without needing final reward? Andrej says they don’t do RL, they do something different, whereas RL is terrible but everything else we’ve tried has been worse. All RL can do is check the final answers, and say ‘do more of this’ when it works. A human would evaluate parts of the process, an LLM can’t and won’t do this.
-
So yeah, RL is like democracy. Fair enough.
-
Why can’t we set up LLMs to do the things human brains do here? Not the exact same thing, but something built on similar principles?
-
I mean it seems super doable to me, but if you want me to figure out how to do it or actually try doing it the going rate is at least $100 million. Call me.
-
Dwarkesh does ask why, or at least about process supervision. Andrej says it is tricky how to do that properly, how do you assign credit to partial solutions? Labs are trying to use LLM judges but this is actually subtle, and you’ll run into adversarial examples if you do it for too long. It finds out that dhdhdhdh was an adversarial example so it starts outputting that, or whatever.
-
So then you… I mean I presume the next 10 things I would say here have already been tried and they fail but I’m not super confident in that.
-
So train models to be more robust? Find the adversarial examples and fix them one at a time won’t work, there will always be another one.
-
Certainly ‘find the adversarial examples and fix them one at a time’ is an example of ‘how to totally fail OOD or at the alignment problem,’ you would need a way to automatically spot when you’re invoking one.
-
What about the thing where humans sleep or daydream, or reflect? Is there some LLM analogy? Andrej says basically no. When an LLM reads a book it predicts the next token, when a human does they do synthetic data generation, talk about it with their friends, manipulate the info to gain knowledge. But doing this with LLMs is nontrivial, for reasons that are subtle and hard to understand, and if you generate synthetic data to train on that makes the model worse, because the examples are silently collapsed, similar to how they know like 3 total jokes. LLMs don’t retain entropy, and we don’t know how to get them to retain it. “I guess what I’m saying is, say we have a chapter of a book and I ask an LLM to think about it, it will give you something that looks very reasonable. But if I ask it 10 times, you’ll notice that all of them are the same. Any individual sample will look okay, but the distribution of it is quite terrible.”
-
I wish Andrej’s answer here was like 5 minutes longer. Or maybe 50 minutes.
-
In general, I’m perhaps not typical, but I’d love to hear the ‘over your head’ version where he says a bunch of things that gesture in various directions, and it’s up to you whether you want to try and understand it.
-
I mean from the naive perspective this has ‘skill issue’ written all over it, and there’s so many things I would want to try.
-
“I think that there’s possibly no fundamental solution to this. I also think humans collapse over time. These analogies are surprisingly good. Humans collapse during the course of their lives. This is why children, they haven’t overfit yet… We end up revisiting the same thoughts. We end up saying more and more of the same stuff, and the learning rates go down, and the collapse continues to get worse, and then everything deteriorates.”
-
I feel this.
-
That means both in myself, and in my observations of others.
-
Mode collapse in humans is evolutionarily and strategically optimal, under conditions of aging and death. If you’re in exploration, pivot to exploitation.
-
We also have various systems to fight this and pivot back to exploration.
-
One central reason humans get caught in mode collapse, when we might not want that it, is myopia and hyperbolic discounting.
-
Another is, broadly speaking, ‘liquidity or solvency constraints.’
-
A third would be commitments, signaling, loyalty and so on.
-
If we weren’t ‘on the clock’ due to aging, which both cuts the value of exploration and also raises the difficulty of it, I think those of us who cared could avoid mode collapse essentially indefinitely.
-
Also I notice [CENSORED] which has obvious deep learning implications?
-
Could dreaming be a way to avoid mode collapse by going out of distribution?
-
I mean, maybe, but the price involved seems crazy high for that.
-
I worry that we’re using ‘how humans do it’ as too much of a crutch.
-
Andrej notes you should always be seeking entropy in your life, suggesting talking to other people.
-
There are lots of good options. I consume lots of text tokens.
-
What’s up with children being great at learning, especially things like languages, but terrible at remembering experiences or specific information? LLMs are much better than humans at memorization, and this can be a distraction.
-
I’m not convinced this is actually true?
-
A counterpoint is that older people learn harder things, and younger people, especially young children, simply cannot learn those things at that level, or would learn them a lot slower.
-
Another counterpoint is that a lot of what younger humans learn is at least somewhat hard coded into the DNA to be easier to learn, and also are replacing nothing which helps you move a lot faster and seem to be making a lot more progress.
-
Languages are a clear example of this. I say this as someone with a pretty bad learning disability for languages, who has tried very hard to pick up various additional languages and failed utterly.
-
A third counterpoint is that children really do put a ton of effort into learning, often not that efficiently (e.g. rewatching and rereading the same shows and books over and over, repeating games and patterns and so on), to get the information they need. Let your children play, but that’s time intensive. Imagine what adults can and do learn when they truly have no other responsibilities and go all-in on it.
-
How do you solve model collapse? Andrej doesn’t know, the models be collapsed, and Dwarkesh points out RL punishes output diversity. Perhaps you could regularize entropy to be higher, it’s all tricky.
-
Andrej says state of the art models have gotten smaller, and he still thinks they memorized too much and we should seek a small cognitive core.
-
He comes back to this idea that knowing things is a disadvantage. I don’t get it. I do buy that smaller models are more efficient, especially with inference scaling, and so this is the best practical approach for now.
-
My prediction is that the cognitive core hypothesis is wrong, and that knowledge and access to diverse context is integral to thinking, especially high entropy thinking. I don’t think a single 1B model is going to be a good way to get any kind of conversation you want to have.
-
There are people who have eidetic memories. They can have a hard time taking advantage because working memory remains limited, and they don’t filter for the info worth remembering or abstracting out of them. So there’s some balance at some point, but I definitely feel like remembering more things than I do would be better? And that I have scary good memory and memorization in key points, such as ability (for a time, anyway) to recall the exact sequence of entire Magic games and tournaments, which is a pattern you also see from star athletes – you ask Steve Curry or Lebron James and they can tell you every detail of every play.
-
Most of the internet tokens are total garbage, stock tickers, symbols, huge amounts of slop, and you basically don’t want that information.
-
I’m not sure you don’t want that information? It’s weird. I don’t know enough to say. Obviously it would not be hard to filter such tokens out at this point, so they must be doing something useful. I’m not sure it’s due to memorization, but I also don’t see why the memorization would hurt.
-
They go back and forth over the size of the supposed cognitive core, Dwarkesh asks why not under 1 billion, Andrej says you probably need a billion knobs and he’s already contrarian being that low.
-
Whereas yeah, I think 1 billion is not enough and this is the wrong approach entirely unless you want to e.g. do typical simple things within a phone.
Wait what?
Note: The 2% number doesn’t actually come up until the next section on ASI.
-
How to measure progress? Andrej doesn’t like education level as a measure of AI progress (I agree), he’s also not a fan of the famous METR horizon length graph and is tempted to reject the whole question. He’s sticking with AGI as ‘can do any economically valuable task at human performance or better.’
-
And you’re going to say having access to ‘any economically valuable (digital) task at human performance or better’ only is +2% GDP growth? Really?
-
You have to measure something you call AI progress, since you’re going to manage it. Also people will ask constantly and use it to make decisions. If nothing else, you need an estimate of time to AGI.
-
He says only 10%-20% of the economy is ‘only knowledge work.’
-
I asked Sonnet. McKinsey 2012 finds knowledge work accounted for 31 percent of all workers in America in 2010. Sonnet says 30%-35% pure knowledge work, 12%-17% pure manual, the rest some hybrid, split the rest in half, you get 60% knowledge work by task, but the knowledge work typically is about double the economic value of the non-knowledge work, so we’re talking on the order of 75% of all economic value.
-
How much would this change Andrej’s other estimates, given this is more than triple his estimate?
-
Andrej points to the famous predictions of automating radiology, and suggests what we’ll do more often is have AI do 80% of the volume, then delegate 20% to humans.
-
Okay, sure, that’s a kind of intermediate step, we might do that for some period of time. If so, let’s say that for 75% of economic value we have the AI provide 60% of the value, assuming the human part is more valuable. So it’s providing 45% of all economic value if composition of ‘labor including AI’ does not change.
-
Except of course if half of everything now has marginal cost epsilon (almost but not quite zero), then there will be a large shift in composition to doing more of those tasks.
-
Dwarkesh compares radiologists to early Waymos where they had a guy in the front seat that never did anything so people felt better, and similarly if an AI can do 99% of a job the human doing the 1% can still be super valuable because bottleneck. Andrej points out radiology turns out to be a bad example for various reasons, suggests call centers.
-
If you have 99 AI tasks and 1 human task, and you can’t do the full valuable task without all 100 actions, then in some sense the 1 human task is super valuable.
-
In another sense, it’s really not, especially if any human can do it and there is now a surplus of humans available. Market price might drop quite low.
-
Wages don’t go up as you approach 99% AI, as Dwarkesh suggests they could, unless you’re increasingly bottlenecked on available humans due to a Jevons Paradox situation or hard limit on supply, both of which are the case in radiology, or this raises required skill levels. This is especially true if you’re automating a wide variety of tasks and there is less demand for labor.
-
Dwarkesh points out that we don’t seem to be on an AGI paradigm, we’re not seeing large productivity improvements for consultants and accountants. Whereas coding was a perfect fit for a first task, with lots of ready-made places to slot in an AI.
-
Skill issue. My lord, skill issue.
-
Current LLMs can do accounting out of the box, they can automate a large percentage of that work, and they can enable you to do your own accounting. If you’re an accountant and not becoming more productive? That’s on you.
-
That will only advance as AI improves. A true AGI-level AI could very obviously do most accounting tasks on its own.
-
Consultants should also be getting large productivity boosts on the knowledge work part of their job, including learning things, analyzing things and writing reports and so on. To the extent their job is to sell themselves and convince others to listen to them, AI might not be good enough yet.
-
Andrej asks about automating creating slides. If AI isn’t helping you create slides faster, I mean, yeah, skill issue, or at least scaffolding issue.
-
Dwarkesh says Andy Matuschak tried 50 billion things to get LLMs to write good spaced repetition prompts, and they couldn’t do it.
-
I do not understand what went wrong with the spaced repetition prompts. Sounds like a fun place to bang one’s head for a while and seems super doable, although I don’t know what a good prompt would look like as I don’t use spaced repetition.
-
To me, this points towards skill issues, scaffolding issues and time required to git gud and solve for form factors as large barriers to AI value unlocks.
-
What about superintelligence? “I see it as a progression of automation in society. Extrapolating the trend of computing, there will be a gradual automation of a lot of things, and superintelligence will an extrapolation of that. We expect more and more autonomous entities over time that are doing a lot of the digital work and then eventually even the physical work some amount of time later. Basically I see it as just automation, roughly speaking.”
-
That’s… not ASI. That’s intelligence denialism. AI as normal technology.
-
I took a pause here. It’s worth sitting with this for a bit.
-
Except it kind of isn’t, when you hear what he says later? It’s super weird.
-
Dwarkesh pushes back: “But automation includes the things humans can already do, and superintelligence implies things humans can’t do.” Andrej gives a strange answer: “But one of the things that people do is invent new things, which I would just put into the automation if that makes sense.”
-
No, it doesn’t make sense? I’m super confused what ‘just automation’ is supposed to meaningfully indicate?
-
If what we are automating is ‘being an intelligence’ then everything AI ever does is always ‘just automation’ but that description isn’t useful.
-
Humans can invest and do new things but superintelligence can invent and do new things that are in practice not available to humans, ‘invent new things’ is not the relevant natural category here.
-
Andrej worries about a gradual loss of control and understanding of what is happening, and thinks this is the most likely outcome. Multiple competing entities, initially competing on behalf of people, that gradually become more autonomous, some go rogue, others fight them off. They still get out of control.
-
No notes, really. That’s the baseline scenario if we solve a few other impossible-level problems (or get extremely lucky that they’re not as hard as they look to me) along the way.
-
Andrej doesn’t say ‘unless’ here, or offer a solution or way to prevent this.
-
Missing mood?
-
Dwarkesh asks, will we see an intelligence explosion if we have a million copies of you running in parallel super fast? Andrej says yes, but best believe in intelligence explosions because you’re already living in one and have been for decades, that’s why GDP grows, this is all continuous with the existing hyper-exponential trend, previous techs also didn’t make GDP go up much, everything was slow diffusion.
-
It’s so weird to say ‘oh, yeah, the million copies of me sped up a thousand times would just be more of the same slow growth trends, ho hum, intelligence explosion,’ “it’s just more automation.”
-
“We’re still going to have an exponential that’s going to get extremely vertical. It’s going to be very foreign to live in that kind of an environment.” … “Yes, my expectation is that it stays in the same [2% GDP growth rate] pattern.”
-
I… but… um… I… what?
-
Don’t you have to pick a side? He seems to keep trying to have his infinite cakes and eat them too, both an accelerating intelligence explosion and then magically GDP growth stays at 2% like it’s some law of nature.
-
“Self-driving as an example is also computers doing labor. That’s already been playing out. It’s still business as usual.”
-
Self-driving is a good example of slow diffusion of the underlying technology for various reasons. It’s been slow going, and mostly isn’t yet going.
-
This is a clear example of an exponential that hasn’t hit you yet. Self-driving cars are Covid-19 in January 2020, except they’re a good thing.
-
A Fermi estimate for car trips in America per week is around 2 billion, or for rideshares about 100 million per week.
-
Waymo got to 100,000 weekly rides in August 2024, was at 250,000 weekly rides in April 2025, we don’t yet have more recent data but this market estimates roughly 500,000 per week by year end. That’s 0.5% of taxi rides. The projection for end of year 2026 says maybe 1.5 million rides per week, 1.5%.
-
Currently the share of non-taxi rides that are full self-driving is essentially zero, maybe 0.2% of trips have meaningful self driving components.
-
So very obviously, for now, this isn’t going to show up in the productivity or GDP statistics overall, or at least not directly, although I do think this is a non-trivial rise in productivity and lived experience in areas where Waymos are widely available for those who use it, most importantly in San Francisco.
-
Karpathy keeps saying this will all be gradual capabilities gains and gradual diffusion, with no discrete jump. He suggests you would need some kind of overhang being unlocked such as a new energy source to see a big boost.
-
I don’t know how to respond to someone who thinks we’re in an intelligence explosion, but refuses to include any form of such feedback into their models.
-
That’s not shade, that’s me literally not knowing how to respond.
-
It’s very strange to not expect any overhangs to be unlocked. That’s saying that there aren’t going to be any major technological ideas that we have missed.
-
His own example is an energy source. If all ASI did was unlock a new method of cheap, safe, clean, unlimited energy, let’s say a design for fusion power plants, that were buildable in any reasonable amount of time, that alone would disrupt the GDP growth trend.
I won’t go further into the same GDP growth or intelligence explosion arguments I seem to discuss in many Dwarkesh Patel podcast posts. I don’t think Andrej has a defensible position here, in the sense that he is doing some combination of denying the premise of AGI/ASI, not taking into account its implications in some places while acknowledging the same dynamics in others.
Most of all, this echoes the common state of the discourse on such questions, which seems to involve:
-
You, the overly optimistic fool, say AGI will arrive in 2 years, or 5 years, and you say that when it happens it will be a discrete event and then everything changes.
-
There is also you, the alarmist, saying this would kill everyone, cause us to lose control or otherwise stand risk of being a bad thing.
-
I, the wise world weary realist, say AGI will only arrive in 10 years, and it will be a gradual, continuous thing with no discrete jumps, facing physical bottlenecks and slow diffusion.
-
So therefore we won’t see a substantial change to GDP growth, your life will mostly seem normal, there’s no risk of extinction or loss of control, and so on, building sufficiently advanced technology of minds smarter, faster, cheaper and more competitive than ourselves along an increasing set of tasks will go great.
-
Alternatively, I, the proper cynic, realize AI is simply a ‘normal technology’ and it’s ‘just automation of some tasks’ and they will remain ‘mere tools’ and what are you getting on about, let’s go build some economic models.
I’m fine with those who expect to at first encounter story #2 instead of story #1.
Except it totally, absolutely does not imply #3. Yes, these factors can slow things down, and 10 years are more than 2-5 years, but 10 years is still not that much time, and a continuous transition ends up in the same place, and tacking on some years for diffusion also ends up in the same place. It buys you some time, which we might be able to use well, or we might not, but that’s it.
What about story #4, which to be clear is not Karpathy’s or Patel’s? It’s possible that AI progress stalls out soon and we get a normal technology, but I find it rather unlikely and don’t see why we should expect that. I think that it is quite poor form to treat this as any sort of baseline scenario.
-
Dwarkesh pivots to Nick Lane. Andrej is surprised evolution found intelligence and expects it to be a rare event among similar worlds. Dwarkesh suggests we got ‘squirrel intelligence’ right after the oxygenation of the atmosphere, which Sutton said was most of the way to human intelligence, yet human intelligence took a lot longer. They go over different animals and their intelligences. You need things worth learning but not worth hardcoding.
-
Andrej notes LLMs don’t have a culture, suggests it could be a giant scratchpad.
-
The backrooms? Also LLMs can and will have a culture because anything on the internet can become their context and training data. We already see this, with LLMs basing behaviors off observations of other prior LLMs, in ways that are often undesired.
-
Andrej mentions self-play, says that he thinks the models can’t create culture because they’re ‘still kids.’ Savant kids, but still kids.
-
Kids create culture all the time.
-
No, seriously, I watch my own kids create culture.
-
I’m not saying they in particular created a great culture, but there’s no question they’re creating culture.
-
Andrej was at Tesla leading self-driving from 2017 to 2022. Why did self-driving take a decade? Andrej says it isn’t done. It’s a march of nines (of reliability). Waymo isn’t economical yet, Tesla’s approach is more scalable, and to be truly done would mean people wouldn’t need a driver’s license anymore. But he agrees it is ‘kind of real.’
-
Kind of? I mean obviously self-driving can always improve, pick up more nines, get smoother, get faster, get cheaper. Waymo works great, and the economics will get there.
-
Andrej is still backing the Tesla approach, and maybe they will make fools of us all but for now I do not see it.
-
They draw parallels to AI and from AI to previous techs. Andrej worries we may be overbuilding compute, he isn’t sure, says he’s bullish on the tech but a lot of what he sees on Twitter makes no sense and is about fundraising or attention.
-
I find it implausible that we are overbuilding compute, but it is possible, and indeed if it was not possible then we would be massively underbuilding.
-
“I’m just reacting to some of the very fast timelines that people continue to say incorrectly. I’ve heard many, many times over the course of my 15 years in AI where very reputable people keep getting this wrong all the time. I want this to be properly calibrated, and some of this also has geopolitical ramifications and things like that with some of these questions. I don’t want people to make mistakes in that sphere of things. I do want us to be grounded in the reality of what technology is and isn’t.”
-
Key quote.
-
Andrej is not saying AGI is far in any normal person sense, or that its impact will be small, as he says he is bullish on the technology.
-
What Andrej is doing is pushing back on the even faster timelines and bigger expectations that are often part of his world. Which is totally fair play.
-
That has to be kept in perspective. If Andrej is right the future will blow your mind, it will go crazy.
-
Where the confusion arises is where Andrej then tries to equate his timelines and expectations with calm and continuity, or extends those predictions forward in ways that don’t make sense to me.
-
Again, I see similar things with many others e.g. the communications of the White House’s Sriram Krishnan, saying AGI is far, but if you push far means things like 10 years. Which is not that far.
-
I think Andrej’s look back has a similar issue of perspective. Very reputable people keep predicting specific AI accomplishments on timelines that don’t happen, sure, that’s totally a thing. But is AI underperforming the expectations of reputable optimists? I think progress in AI in general in the last 15 years, certainly since 2018 and the transformer, has been absolutely massive compared to general expectations, of course there were (and likely always will be) people saying ‘AGI in three years’ and that didn’t happen.
-
Dwarkesh asks about Eureka Labs. Why not AI research? Andrej says he’s not sure he could improve what the labs are doing. He’s afraid of a WALL-E or Idiocracy problem where humans are disempowered and don’t do things. He’s trying to build Starfleet Academy.
-
I think he’s right to be worried about disempowerment, but looking to education as a solution seems misplaced here? Education is great, all for it, but it seems highly unlikely it will ‘turn losses into wins’ in this sense.
-
The good news is Andrej definitely has fully enough money so he can do whatever he wants, and it’s clear this stuff is what he wants.
-
Dwarkesh Patel hasn’t seen Star Trek.
-
Can we get this fixed, please?
-
I propose a podcast which is nothing but Dwarkesh Patel watching Star Trek for the first time and reacting.
-
Andrej thinks AI will fundamentally change education, and it’s still early. Right now you have an LLM, you ask it questions, that’s already super valuable but it still feels like slop, he wants an actual tutor experience. He learned Korean from a tutor 1-on-1 and that was so much better than a 10-to-1 class or learning on the internet. The tutor figured out where he was as a student, asked the right questions, and no LLM currently comes close. Right now they can’t.
-
Strongly agreed on all of that.
-
His first class is LLM-101-N, with Nanochat as the capstone.
-
This raises the question of whether a class is even the right form factor at all for this AI world. Maybe it is, maybe it isn’t?
-
Dwarkesh points out that if you can self-probe well enough you can avoid being stuck. Andrej contrasts LLM-101-N with his CS231n at Stanford on deep learning, that LLMs really empower him and help him go faster. Right now he’s hiring faculty but over time some TAs can become AIs.
-
“I often say that pre-AGI education is useful. Post-AGI education is fun. In a similar way, people go to the gym today. We don’t need their physical strength to manipulate heavy objects because we have machines that do that. They still go to the gym. Why do they go to the gym? Because it’s fun, it’s healthy, and you look hot when you have a six-pack. It’s attractive for people to do that in a very deep, psychological, evolutionary sense for humanity. Education will play out in the same way. You’ll go to school like you go to the gym.”
-
“If you look at, for example, aristocrats, or you look at ancient Greece or something like that, whenever you had little pocket environments that were post-AGI in a certain sense, people have spent a lot of their time flourishing in a certain way, either physically or cognitively. I feel okay about the prospects of that. If this is false and I’m wrong and we end up in a WALL-E or Idiocracy future, then I don’t even care if there are Dyson spheres. This is a terrible outcome. I really do care about humanity. Everyone has to just be superhuman in a certain sense.”
-
(on both quotes) So, on the one hand, yes, mostly agreed, if you predicate this on the post-AGI post-useful-human-labor world where we can’t do meaningful productive work and also get to exist and go to the gym and go around doing our thing like this is all perfectly normal.
-
On the other hand, it’s weird to expect things to work out like that, although I won’t reiterate why, except to say that if you accept that the humans are now learning for fun then I don’t think this jives with a lot of Andrej’s earlier statements and expectations.
-
If you’re superhuman in this sense, that’s cool, but if you’re less superhuman than the competition, then does it do much beyond being cool? What are most people going to choose to do with it? What is good in life? What is the value?
-
This all gets into much longer debates and discussions, of course.
-
“I think there will be a transitional period where we are going to be able to be in the loop and advance things if we understand a lot of stuff. In the long-term, that probably goes away.”
-
Okay, sure, there will be a transition period of unknown length, but that doesn’t as they say solve for the equilibrium.
-
I don’t expect that transition period to last very long, although there are various potential values for very long.
-
Dwarkesh asks about teaching. Andrej says everyone should learn physics early, since early education is about booting up a brain. He looks for first or second order terms of everything. Find the core of the thing and understand it.
-
Our educational system is not about booting up brains. If it was, it would do a lot of things very differently. Not that we should let this stop us.
-
Curse of knowledge is a big problem, if you’re an expert in a field often you don’t know what others don’t know. Could be helpful to see other people’s dumb questions that they ask an LLM?
-
From Dwarkesh: “Another trick that just works astoundingly well. If somebody writes a paper or a blog post or an announcement, it is in 100% of cases that just the narration or the transcription of how they would explain it to you over lunch is way more, not only understandable, but actually also more accurate and scientific, in the sense that people have a bias to explain things in the most abstract, jargon-filled way possible and to clear their throat for four paragraphs before they explain the central idea. But there’s something about communicating one-on-one with a person which compels you to just say the thing.”
-
Love it. Hence we listen to and cover podcasts, too.
-
I think this is because in a conversation you don’t have to be defensible or get judged or be technically correct, you don’t have to have structure that looks good, and you don’t have to offer a full explanation.
-
As in, you can gesture at things, say things without justifications, watch reactions, see what lands, fill in gaps when needed, and yeah, ‘just say the thing.’
-
That’s (a lot of) why it isn’t the abstract, plus habit, it isn’t done that way because it isn’t done that way.
Peter Wildeford offers his one page summary, which I endorse as a summary.
Sriram Krishnan highlights part of the section on education, which I agree was excellent, and recommends the overall podcast highly.
Andrej Karpathy offered his post-podcast reactions here, including a bunch of distillations, highlights and helpful links.
Here’s his summary on the timelines question:
Andrej Karpathy: Basically my AI timelines are about 5-10X pessimistic w.r.t. what you’ll find in your neighborhood SF AI house party or on your twitter timeline, but still quite optimistic w.r.t. a rising tide of AI deniers and skeptics
Those house parties must be crazy, as must his particular slice of Twitter. He has AGI 10 years away and he’s saying that’s 5-10X pessimistic. Do the math.
My slice currently overall has 4-10 year expectations. The AI 2027 crowd has some people modestly shorter, but even they are now out in 2029 or so I think.
That’s how it should work, evidence should move the numbers back and forth, and if you had a very aggressive timeline six months or a year ago recent events should slow your roll. You can say ‘those people were getting ahead of themselves and messed up’ and that’s a reasonable perspective, but I don’t think it was obviously a large mistake given what we knew at the time.
Peter Wildeford: I’m desperate for a worldview where we agree both are true:
– current AI is slop and the marketing is BS, but
– staggering AI transformation (including extinction) is 5-20 years out, this may not be good by default, and thus merits major policy action now
I agree with the second point (with error bars). The first point I would rate as ‘somewhat true.’ Much of the marketing is BS and much of the output is slop, no question, but much of it is not on either front and the models are already extremely helpful to those who use them.
Peter Wildeford: If the debate truly has become
– “AGI is going to take all the jobs in just two years” vs.
– “no you idiot, don’t buy the hype, AI is really slop, it will take 10-20 years before AGI automates all jobs (and maybe kill us)”
…I feel like we have really lost the big picture here
[meme credit: Darth thromBOOzyt]
Similarly, the first position here is obviously wrong, and the second position could be right on the substance but has one hell of a Missing Mood, 10-20 years before all jobs get automated is kind of the biggest thing that happened in the history of history even if the process doesn’t kill or diempower us.
Rob Miles: It’s strange that the “anti hype” position is now “AGI is one decade away”. That… would still be a very alarming situation to be in? It’s not at all obvious that that would be enough time to prepare.
It’s so crazy the amount to which vibes can supposedly shift when objectively nothing has happened and even the newly expressed opinions aren’t so different from what everyone was saying before, it’s that now we’re phrasing it as ‘this is long timelines’ as opposed to ‘this is short timelines.’
John Coogan: It’s over. Andrej Karpathy popped the AI bubble. It’s time to rotate out of AI stocks and focus on investing in food, water, shelter, and guns. AI is fake, the internet is overhyped, computers are pretty much useless, even the steam engine is mid. We’re going back to sticks and stones.
Obviously it’s not actually that bad, but the general tech community is experiencing whiplash right now after the Richard Sutton and Andrej Karpathy appearances on Dwarkesh. Andrej directly called the code produced by today’s frontier models “slop” and estimated that AGI was around 10 years away. Interestingly this lines up nicely with Sam Altman’s “The Intelligence Age” blog post from September 23, 2024, where he said “It is possible that we will have superintelligence in a few thousand days (!); it may take longer, but I’m confident we’ll get there.”
I read this timeline to mean a decade, which is what people always say when they’re predicting big technological shifts (see space travel, quantum computing, and nuclear fusion timelines). This is still earlier than Ray Kurzweil’s 2045 singularity prediction, which has always sounded on the extreme edge of sci-fi forecasting, but now looks bearish.
Yep, I read Altman as ~10 years there as well. Except that Altman was approaching that correctly as ‘quickly, there’s no time’ rather than ‘we have all the time in the world.’
There’s a whole chain of AGI-soon bears who feel vindicated by Andrej’s comments and the general vibe shift. Yann LeCun, Tyler Cowen, and many others on the side of “progress will be incremental” look great at this moment in time.
This George Hotz quote from a Lex Fridman interview in June of 2023 now feels way ahead of the curve, at the time: “Will GPT-12 be AGI? My answer is no, of course not. Cross-entropy loss is never going to get you there. You probably need reinforcement learning in fancy environments to get something that would be considered AGI-like.”
Big tech companies can’t turn on a dime on the basis of the latest Dwarkesh interview though. Oracle is building something like $300 billion in infrastructure over the next five years.
It’s so crazy to think a big tech company would think ‘oops, it’s over, Dwarkesh interviews said so’ and regret or pull back on investment, also yeah it’s weird that Amazon was up 1.6% while AWS was down.
Danielle Fong: aws down, amazon up
nvda barely sweating
narrative bubbles pop more easily than market bubbles
Why would you give Hotz credit for ‘GPT-12 won’t be AGI’ here, when the timeline for GPT-12 (assuming GPT-11 wasn’t AGI, so we’re not accelerating releases yet) is something like 2039? Seems deeply silly. And yet here we are. Similarly, people supposedly ‘look great’ when others echo previous talking points? In my book, you look good based on actual outcomes versus predictions, not when others also predict, unless you are trading the market.
I definitely share the frustration Liron had here:
Liron Shapira: Dwarkesh asked Karpathy about the Yudkowskian observation that exponential economic growth to date has been achieved with *constanthuman-level thinking ability.
Andrej acknowledged the point but said, nevertheless, he has a strong intuition that 2% GDP growth will hold steady.
Roon: correction, humanity has achieved superexponential economic growth to date
Liron: True.
In short, I don’t think a reasonable extrapolation from above plus AGI is ~2%.
But hey, that’s the way it goes. It’s been a fun one.