Everyone agrees that the release of GPT-5 was botched. Everyone can also agree that the direct jump from GPT-4o and o3 to GPT-5 was not of similar size to the jump from GPT-3 to GPT-4, that it was not the direct quantum leap we were hoping for, and that the release was overhyped quite a bit.
GPT-5 still represented the release of at least three distinct models: GPT-5-Fast, GPT-5-Thinking and GPT-5-Pro, at least two and likely all three of which are SoTA (state of the art) within their class, along with GPT-5-Auto.
The problem is that the release was so botched that OpenAI is now experiencing a Reverse DeepSeek Moment – all the forces that caused us to overreact to DeepSeek’s r1 are now working against OpenAI in reverse.
This threatens to give Washington DC and its key decision makers a very false impression of a lack of AI progress, especially progress towards AGI, that could lead to some very poor decisions, and it could do the same for corporations and individuals.
I spent last week covering the release of GPT-5. This puts GPT-5 in perspective.
In January DeepSeek released r1, and we had a ‘DeepSeek moment’ when everyone panicked about how China had ‘caught up.’ As the link explains in more detail, r1 was a good model, sir, but only an ordinary good model, substantially behind the frontier.
We had the DeepSeek Moment because of a confluence of factors misled people:
-
The ‘six million dollar model’ narrative gave a false impression on cost.
-
They offered a good clean app with visible chain of thought, it went viral.
-
The new style caused an overestimate of model quality.
-
Timing was impeccable, both in order of model releases and within the tech tree.
-
Safety testing and other steps were skipped, leaving various flaws, and this was a pure fast follow, but in our haste no one took any of that into account.
-
A false impression of ‘momentum’ and stories about Chinese momentum.
-
The ‘always insist open models will win’ crowd amplified the vibes.
-
The stock market was highly lacking in situational awareness, suddenly realizing various known facts and also misunderstanding many important factors.
GPT-5 is now having a Reverse DeepSeek Moment, including many direct parallels.
-
GPT-5 is evaluated as if it was scaling up compute in a way that it doesn’t. In various ways people are assuming it ‘cost’ far more than it did.
-
They offered a poor initial experience with rate caps and lost models and missing features, a broken router, and complaints about losing 4o’s sycophancy went viral.
-
The new style, and people evaluating GPT-5 when they should have been evaluating GPT-5-Thinking, caused an underestimate of model quality.
-
Timing was directly after Anthropic, and previous releases had already eaten the most impressive recent parts of the tech tree, so gains incorrectly looked small.
-
In particular, gains from reasoning models, and from the original GPT-4 → GPT-4o, are being ignored when considering the GPT-4 → GPT-5 leap.
-
GPT-5 is a refinement of previous models optimized for efficiency, and is breaking new territory, and that is not being taken into account.
-
A false impression of hype and a story about a loss of momentum.
-
The ‘OpenAI is flailing’ crowd and the open model crowd amplified the vibes.
-
The stock market actually was smart this time and shrugged it off, that’s a hint.
And of course, the big one, which is that GPT-5’s name fed into expectations.
Unlike r1 at the time of its release, GPT-5-Thinking and GPT-5-Pro are clearly the current SoTA models in their classes, and GPT-5-Auto is probably SoTA at its level of compute usage, modulo complaints about personality that OpenAI will doubtless ‘fix’ soon.
OpenAI’s model usage was way up after GPT-5’s release, not down.
The release was botched, but this is very obviously a good set of models.
Washington DC, however, is somehow rapidly deciding that GPT-5 is a failure, and that AI capabilities won’t improve much and AGI is no longer a worry. This is presumably in large part due to the ‘race to market share’ faction pushing this narrative rather hardcore, and having this be super convenient for that.
Dave Kasten: It’s honestly fascinating how widely “what is gonna happen now that GPT-5 is a failure” has already percolated in the DC world — tons of people who barely use AI asking me about this in the past week as their AI policy friend. (I don’t think GPT-5 was a failure)
Stylized anecdote: person tells me they aren’t allowed to use LLM Y at job ABC because regulatory considerations. So they only use LLM Z at home because that’s what they started to use first and don’t have much experience on Y.
(This is true in both private and public sector)
Daniel Eth: So what happens when another lab releases a model that surpasses GPT-5? Narrative could quickly change from “AI is hitting a wall” to “OpenAI has lost the Mandate of Heaven, and it’s shifted to [Anthropic/DeepMind/xAI]”
Honestly that probably makes the near future a particularly valuable time for another lab to release a SOTA model.
What is even scarier is, what happens if DeepSeek drops r2, and it’s not as good as GPT-5-Thinking, but it is ‘pretty good’?
So let us be clear: (American) AI is making rapid progress, including at OpenAI.
How much progress have we been making?
Dean Ball: The jump in the performance and utility of frontier models between April 2024 (eg gpt-4 turbo) and April 2025 (o3) is bigger than the jump between gpt-3 and gpt-4
People alleging a slowdown in progress due to gpt-5 are fooling themselves.
Simeon: I have this theory that we are in a period of increasing marginal utility of capabilities. GPT-2 to GPT-3 jump was a bigger jump than 3 to 4, which was bigger than 4 to 5. But the utility jumps have been increasing.
My core thesis for why is that most use cases are bottlenecked by edge cases and 9s of reliability that are not as visible as the raw capabilities, but that unlock a growing set of use cases all bottlenecked by these same few missing pieces.
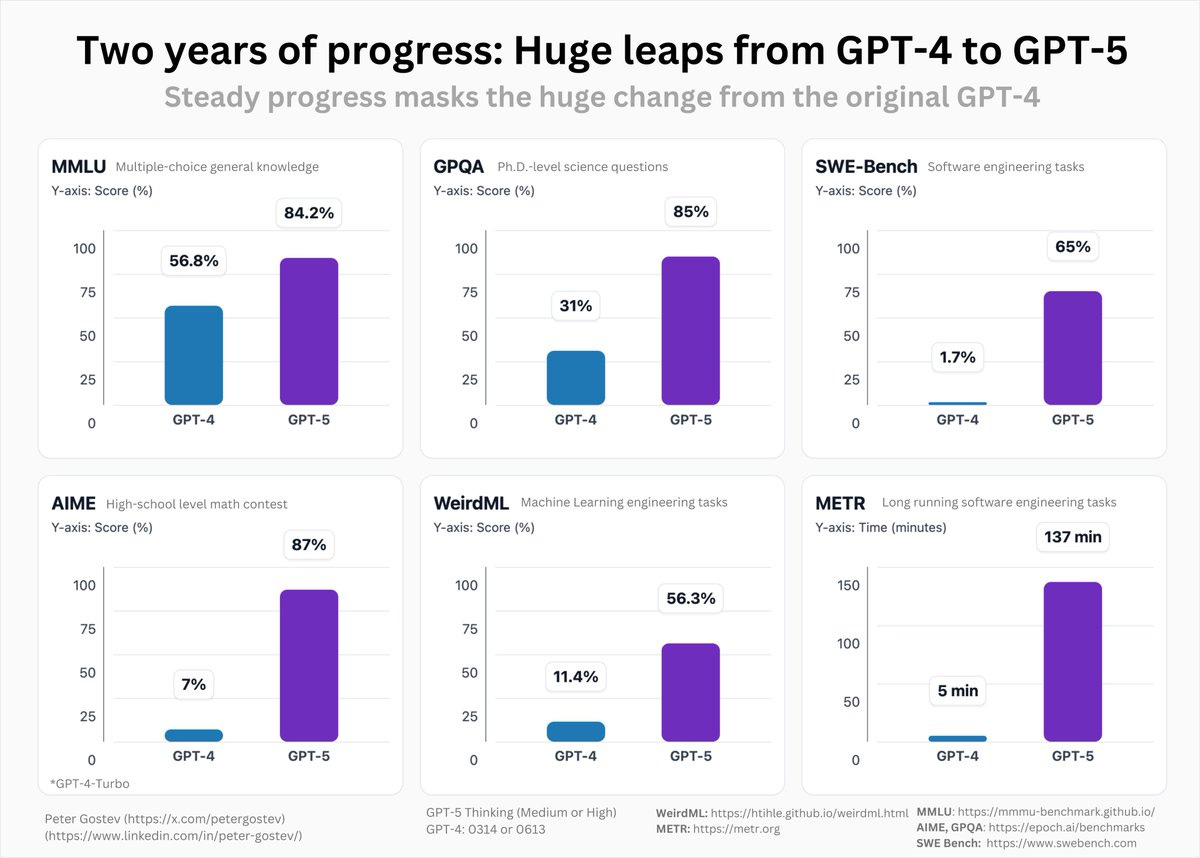
Peter Gostev:GPT-5 had its fair share of issues at launch, but the most irritating comment I hear from tech commentators is something like: “we’ve waited for GPT-5 for 2 years and we got an iterative update” – this is completely and demonstrably false.
GPT-5 was a relatively iterative change if you compare it to o3 from 6 months ago (though still a good uptick), but to say that we’ve had no progress in 2 years is absurd.
I could have made the same chart with Claude 2 > Claude 4 or Gemini 1.0 to Gemini 2.5 – progress is massive.
You guys are forgetting how crap GPT-4 actually was. I was hoping to do some side by side between the oldest GPT-4 model I can get (0613) and the current models and I’m struggling to find any interesting task that GPT-4-0613 can actually do – it literally refuses to do an SVG of a pelican on a bike. Any code it generated of anything didn’t work at all.
Teortaxes: That just goes to show that o3 should have been called GPT-5.
This below is only one measure among many, from Artificial Analysis (there is much it doesn’t take into account, which is why Gemini Pro 2.5 looks so good), yes GPT-5 is a relatively small advance despite being called GPT-5 but that is because o1 and o3 already covered a lot of ground, it’s not like the GPT-4 → GPT-5 jump isn’t very big.
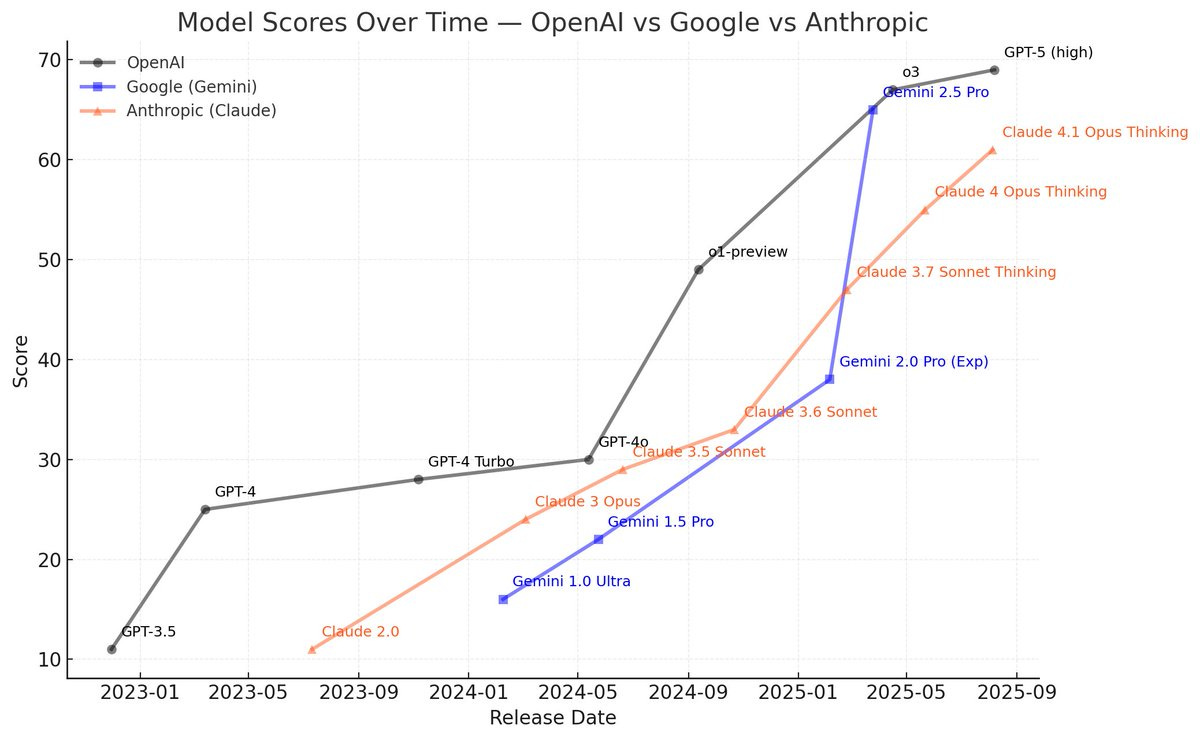
Lisan al-Gaib: AI Progress since GPT-3.5
OpenAI seems to be slowing down with GPT-5
Anthropic incredibly steady progress
Google had it’s breakthrough with Gemini 2.5 Pro
based on the Artificial Analysis Index. don’t read to much into the numbers just look at the slope. line going up = good line. going up more steeply=better.
AI is making rapid progress. It keeps getting better. We seem headed for AGI.
Yet people continuously try to deny all of that. And because this could impact key policy, investment and life decisions, each time we must respond.
As in, the Financial Times asks the eternal question we somehow have to ask every few months: Is AI ‘hitting a wall’?
(For fun, here is GPT-5-Pro listing many previous times AI supposedly ‘hit a wall.’)
If you would like links, here are some links for all that.
The justification for this supposed hitting of a wall is even stupider than usual.
FT (Various): “The vibes of this model are really good, and I think that people are really going to feel that,” said Nick Turley, head of ChatGPT at OpenAI.
Except the vibes were not good.
Yes, users wanted GPT-4o’s sycophancy back, and they even got it. What does that have to do with a wall? They do then present the actual argument.
FT: “For GPT-5 . . . people expected to discover something totally new,” says Thomas Wolf, co-founder and chief scientific officer of open source AI start-up Hugging Face. “And here we didn’t really have that.”
True. We didn’t get something totally new. But, again, that was OpenAI:
-
Botching the rollout.
-
Using the name GPT-5.
-
Having made many incremental releases since GPT-4, especially 4o, o1 and o3.
They hit the classic notes.
We have Gary Marcus talking about this being a ‘central icon of the entire scaling approach to get to AGI, and it didn’t work,’ so if this particular scaling effort wasn’t impressive we’re done, no more useful scaling ever.
We have the harkening back to the 1980s ‘AI bubble’ that ‘burst.’
My lord, somehow they are still quoting Yann LeCun.
We have warnings that we have run out of capacity with which to scale. We haven’t.
Their best point is this Altman quote I hadn’t seen:
Sam Altman: [Chatbots like ChatGPT] are not going to get much better.
I believe he meant that in the ‘for ordinary casual chat purposes there isn’t much room for improvement left’ sense, and that this is contrasting mass consumer chatbots with other AI applications, including coding and agents and reasoning models, as evidenced by the other half of the quote:
Sam Altman: [AI models are] still getting better at a rapid rate.
That is the part that matters for AGI.
That doesn’t mean we will get to AGI and then ASI soon, where soon is something like ‘within 2-10 years.’ It is possible things will stall out before that point, perhaps even indefinitely. But ‘we know we won’t get AGI any time soon’ is crazy. And ‘last month I thought we might well get AGI anytime soon but now we know we won’t’ is even crazier.
Alas, a variety of people are reacting to GPT-5 being underwhelming on the margin, the rapid set of incremental AI improvements, and the general fact that we haven’t gotten AGI yet, and reached the conclusion that Nothing Ever Changes applies and we can assume that AGI will never come. That would be a very serious mistake.
Miles Brundage, partly to try and counter and make up for the FT article and his inadvertent role in it, does a six minute rant explaining one reason for different perceptions of AI progress. The key insight here is that AI at any given speed and cost and level of public availability continues to make steady progress, but rates of that progress look very different depending on what you are comparing. Progress looks a progressively faster if you are looking at Thinking-style models, or Pro-style models, or internal-only even more expensive models.
Progress in the rapid models like GPT-5-Fast also looks slower than it is because for the particular purposes of many users at current margins, it is true that intelligence is no longer an important limiting factor. Simple questions and interactions often have ‘correct’ answers if you only think about the local myopic goals, so all you can do is asymptotically approach that answer while optimizing on compute and speed. Intelligence still helps but in ways that are less common, more subtle and harder to notice.
One reason people update against AGI soon is that they treat OpenAI’s recent decisions as reflecting AGI not coming soon. It’s easy to see why one would think that.
Charles: It seems to me like OpenAI’s behaviour recently, steering more towards becoming a consumer company rather than trying to build AGI, is incongruent with them believing in AGI/significant worker displacement coming soon (say <5 years).
Do others disagree with me on this?
Anthropic on the other hand do seem to be behaving in a way consistent with believing in AGI coming soon.
Sam Altman: We had this big GPU crunch. We could go make another giant model. We could go make that, and a lot of people would want to use it, and we would disappoint them. And so we said, let’s make a really smart, really useful model, but also let’s try to optimize for inference cost. And I think we did a great job with that.
I am not going to say they did a ‘great job with that.’ They botched the rollout, and I find GPT-5-Auto (the model in question) to not be exciting especially for my purposes, but it does seem to clearly be on the cost-benefit frontier, as are 5-Thinking and 5-Pro? And when people say things like this:
FT: Rather than being markedly inferior, GPT-5’s performance was consistently mid-tier across different tasks, they found. “The place where it really shines is it’s quite cost effective and also much quicker than other models,” says Kapoor.
They are talking about GPT-5-Auto, the version targeted at the common user. So of course that is what they created for that.
OpenAI rightfully thinks of itself as essentially multiple companies. They are an AI frontier research lab, and also a consumer product company, and a corporate or professional product company, and also looking to be a hardware company.
Most of those customers want to pay $0, at least until you make yourself indispensable. Most of the rest are willing to pay $20/month and not interested in paying more. You want to keep control over this consumer market at Kleenex or Google levels of dominance, and you want to turn a profit.
So of course, yes, you are largely prioritizing for what you can serve your customers.
What are you supposed to do, not better serve your customers at lower cost?
That doesn’t mean you are not also creating more expensive and smarter models. Thinking and Pro exist, and they are both available and quite good. Other internal models exist and by all reports are better if you disregard cost and don’t mind rough around the edges.
FT: It may not have been OpenAI’s intention, but what the launch of GPT-5 makes clear is that the nature of the AI race has changed.
Instead of merely building shiny bigger models, says Sayash Kapoor, a researcher at Princeton University, AI companies are “slowly coming to terms with the fact that they are building infrastructure for products”.
There is an ordinary battle for revenue and market share and so on that looks like every other battle for revenue and market share. And yes, of course when you have a product with high demand you are going to build out a bunch of infrastructure.
That has nothing to do with the more impactful ‘race’ to AGI. The word ‘race’ has simply been repurposed and conflated by such folks in order to push their agenda and rhetoric in which the business of America is to be that of ordinary private business.
Miles Brundage (from the FT article): It makes sense that as AI gets applied in a lot of useful ways, people would focus more on the applications versus more abstract ideas like AGI.
But it’s important to not lose sight of the fact that these are indeed extremely general purpose technologies that are still proceeding very rapidly, and that what we see today is still very limited compared to what’s coming.
Initially FT used only the first sentence from Miles and not the second one, which is very much within Bounded Distrust rules but very clearly misleading, but to their credit FT did then fix it to add the full quote although most clicks will have seen the misleading version.
Miles Brundage: I thought it was clear that the first sentence was just me being diplomatic and “throat clearing” rather than a full expression of my take on the topic, but lesson learned!
Nick Cammarata: I’ve talked to reporters and then directly after finishing my sentence I’m like can you only quote that in full if you do and they’re like no lol
It is crazy to site ‘companies are Doing Business’ as an argument for why they are no longer building or racing to AGI, or why that means what matters is the ordinary Doing of Business. Yes, of course companies are buying up inference compute to sell at a profit. Yes, of course they are building marketing departments and helping customers with deployment and so on. Why shouldn’t they? Why would one consider this an either-or? Why would you think AI being profitable to sell makes it less likely that AGI is coming soon, rather than more likely?
FT: GPT-5 may have underwhelmed but with Silicon Valley running more on “vibes” than scientific benchmarks, there are few indications that the AI music will stop anytime soon. “There’s still a lot of cool stuff to build,” Wolf of Hugging Face says, “even if it’s not AGI or crazy superintelligence [ASI].”
That is, as stated, exactly correct from Wolf. There is tons of cool stuff to build that is not AGI or ASI. Indeed I would love it if we built all that other cool stuff and mysteriously failed to build AGI or ASI. But that cool stuff doesn’t make it less likely we get AGI, nor does not looking at the top labs racing to AGI, and having this as their stated goal, make that part of the situation go away.
As a reminder, OpenAI several times during their GPT-5 presentation talked about how they were making progress towards AGI or superintelligence, and how this remained the company’s primary goal.
Mark Zuckerberg once said about Facebook, ‘we don’t make better services to make money. We make money to make better services.’ Mark simply has a very strange opinion on what constitutes better services. Consider that the same applies here.
Also note that we are now at the point where if you created a truly exceptional coding and research model, and you are already able to raise capital on great terms, it is not at all obvious you should be in a rush to release your coding and research model. Why would you hand that tool to your competitors?
As in, not only does it help them via distillation and reverse engineering, it also directly can be put to work. Anthropic putting out Claude Code gave them a ton more revenue and market share and valuation, and thus vital capital and mindshare, and helps them recruit, but there was a nontrivial price to pay that their rivals get to use the product.
One huge problem with this false perception that GPT-5 failed, or that AI capabilities aren’t going to improve, and that AGI can now be ignored as a possibility, is that this could actually fool the government into ignoring that possibility.
Peter Wildeford:🤦♂️
Not only would that mean we wouldn’t prepare for what is coming, the resulting decisions would make things vastly worse. As in, after quoting David Sacks saying the same thing he’s been saying ever since he joined the administration, and noting recent disastrous decisions on the H20 chip, we see this:
FT: Analysts say that with AGI no longer considered a risk, Washington’s focus has switched to ensuring that US-made AI chips and models rule the world.
Even if we disregard the turn of of phrase here – ‘AI chips and models rule the world’ is exactly the scenario some of us are warning about and trying to prevent, and those chips and models having been created by Americans does not mean Americans or humans have a say in what happens next, instead we would probably all die – pursuing chip market share uber alles with a side of model market share was already this administration’s claimed priority months ago.
We didn’t strike the UAE deal because GPT-5 disappointed. We didn’t have Sacks talking endlessly about an ‘AI race’ purely in terms of market share – mostly that of Nvidia – because GPT-5 disappointed. Causation doesn’t run backwards in time. These are people who were already determined to go down this path. GPT-5 and its botched rollout is the latest talking point, but it changes nothing.
In brief, I once again notice that the best way to run Chinese AI models, or to train Chinese AI models is to use American AI chips. Why haven’t we seen DeepSeek release v4 or r2 yet? Because the CCP made them use Huawei Ascend chips and it didn’t work. What matters is who owns and uses the compute, not who manufactures the compute.
But that is an argument for another day. What matters here is that we not fool ourselves into a Reverse DeepSeek Moment, in three ways:
-
America is still well out in front, innovating and making rapid progress in AI.
-
AGI is still probably coming and we need to plan accordingly.
-
Export controls on China are still vital.