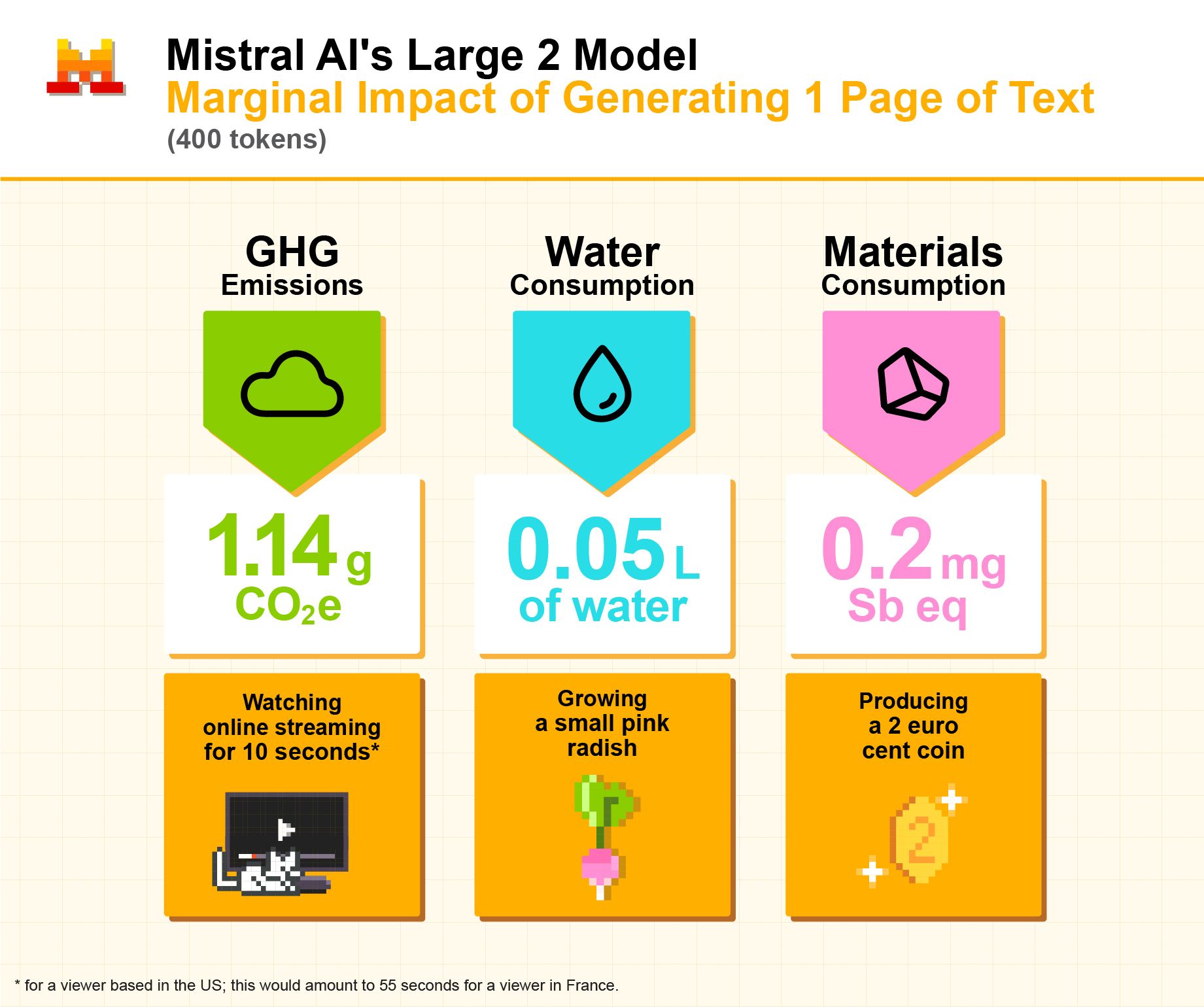
EPA plans to ignore science, stop regulating greenhouse gases
It derives from a 2007 Supreme Court ruling that named greenhouse gases as “air pollutants,” giving the EPA the mandate to regulate them under the Clean Air Act.
Critics of the rule say that the Clean Air Act was fashioned to manage localized emissions, not those responsible for global climate change.
A rollback would automatically weaken the greenhouse gas emissions standards for cars and heavy-duty vehicles. Manufacturers such as Daimler and Volvo Cars have previously opposed the EPA’s efforts to tighten emission standards, while organized labour groups such as the American Trucking Association said they “put the trucking industry on a path to economic ruin.”
However, Katherine García, director of Sierra Club’s Clean Transportation for All Campaign, said that the ruling would be “disastrous for curbing toxic truck pollution, especially in frontline communities disproportionately burdened by diesel exhaust.”
Energy experts said the move could also stall progress on developing clean energy sources such as nuclear power.
“Bipartisan support for nuclear largely rests on the fact that it doesn’t have carbon emissions,” said Ken Irvin, a partner in Sidley Austin’s global energy and infrastructure practice. “If carbon stops being considered to endanger human welfare, that might take away momentum from nuclear.”
The proposed rule from the EPA will go through a public comment period and inter-agency review. It is likely to face legal challenges from environmental activists.
© 2025 The Financial Times Ltd. All rights reserved. Not to be redistributed, copied, or modified in any way.
EPA plans to ignore science, stop regulating greenhouse gases Read More »