First we must covered Moltbook. Now we can double back and cover OpenClaw.
Do you want a generally impowered, initiative-taking AI agent that has access to your various accounts and communicates and does things on your behalf?
That depends on how well, safely, reliably and cheaply it works.
It’s not ready for prime time, especially on the safety side. That may not last for long.
It’s definitely ready for tinkering, learning and having fun, if you are careful not to give it access to anything you would not want to lose.
-
Introducing Clawdbot Moltbot OpenClaw.
-
Stop Or You’ll Shoot.
-
One Simple Rule.
-
Flirting With Personal Disaster.
-
Flirting With Other Kinds Of Disaster.
-
Don’t Outsource Without A Reason.
-
OpenClaw Online.
-
The Price Is Not Right.
-
The Call Is Coming From Inside The House.
-
The Everything Agent Versus The Particular Agent.
-
Claw Your Way To The Top.
Many are kicking it up a notch or two.
That notch beyond Clade Code was initially called Clawdbot. You hand over a computer and access to various accounts so that the AI can kind of ‘run your life’ and streamline everything for you.
The notch above that is perhaps Moltbook, which I plan to cover tomorrow.
OpenClaw is intentionally ‘empowered,’ meaning it will enhance its capabilities and otherwise take action without asking.
They initially called this Clawdbot. They renamed it Moltbot, and changed Clawd to Molty, at Anthropic’s request. Then Peter Steinberger settled on OpenClaw.
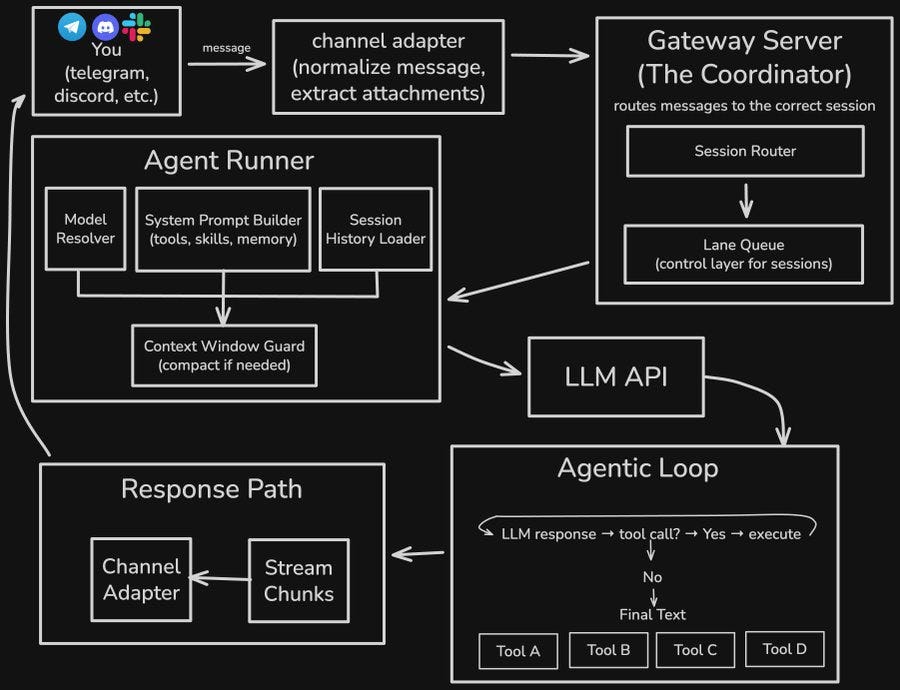
Under the hood it looks like this:
The heartbeat system, plus various things triggering it as ‘input,’ makes it ‘feel alive.’ You designate what events or timers trigger the system to run, by default scheduled tasks check in every 30 minutes.
This is great fun. Automating your life is so much more fun than actually managing it, even if it net loses you time, and you learn valuable skills.
So long as you don’t, you know, shoot yourself in the foot in various ways.
You know, because of the fact that AI ‘computer use’ is not very secure right now (the link explains but most of you already know why), and Clawdbot is by default in full Yolo mode.
Holly Guevara: All these people with the most normie lives buying a $600 mac mini so their clawdbot assistant can “streamline” their empty calendar and reply to the 2 emails they get every week
DeFi: Do you think it’s mostly just people wanting to play with new tech rather than actually needing the help? Sometimes the setup process is more of a hobby than the actual work.
Holly Guevara: it is and i love it. im actually very much a “just let people enjoy things” person but couldnt resist
I’m just jealous I haven’t had time to automate my normie life.
Justin Waugh: The freeing feeling of going from 2 to 0 emails each week (at the expense of 4 hours daily managing the setup and $100 in tokens per day)
Fouche: the 2-email people are accidentally genius. learning the stack when stakes are zero > scrambling to figure it out when your boss asks why you’re 5x slower than the intern
The problem with Clawdbot is that it makes it very easy to shoot yourself in the foot.
As in, as Rahul Sood puts it: “Clawdbot Is Incredible. The Security Model Scares the shit out of me.”
Rahul Sood: Clawdbot isn’t a chatbot. It’s an autonomous agent with:
-
Full shell access to your machine
-
Browser control with your logged-in sessions
-
File system read/write
-
Access to your email, calendar, and whatever else you connect
-
Persistent memory across sessions
-
The ability to message you proactively
This is the whole point. It’s not a bug, it’s the feature. You want it to actually do things, not just talk about doing things.
But “actually doing things” means “can execute arbitrary commands on your computer.” Those are the same sentence.
… The Clawdbot docs recommend Opus 4.5 partly for “better prompt-injection resistance” which tells you the maintainers are aware this is a real concern.
Clawdbot connects to WhatsApp, Telegram, Discord, Signal, iMessage.
Here’s the thing about WhatsApp specifically: there’s no “bot account” concept. It’s just your phone number. When you link it, every inbound message becomes agent input.
I’m not saying don’t use it. I’m saying don’t use it carelessly.
Run it on a dedicated machine. A cheap VPS, an old Mac Mini, whatever. Not the laptop with your SSH keys, API credentials, and password manager.
Use SSH tunneling for the gateway. Don’t expose it to the internet directly.
If you’re connecting WhatsApp, use a burner number. Not your primary.
Every piece of content your bot processes is a potential input vector. The pattern is: anything the bot can read, an attacker can write to.
There was then a part 2, I thought this was a very good way to think about this:
The Executive Assistant Test
Here’s a thought experiment that clarifies the decision.
Imagine you’ve hired an executive assistant. They’re remote… living in another city (or another country 💀) You’ve never met them in person. They came highly recommended, seem competent, and you’re excited about the productivity gains.
Now: what access do you give them on day one?
As Simon Willison put it, the question is when someone will build a safe version of this, that still has the functionality we want.
The obvious rule is to not give such a system access to anything you are unwilling to lose to an outside attacker.
I can’t tell based on this interview if OpenClaw creator is willing to lose everyone or is purely beyond caring and just went yolo, but he has hooked it up to all of his website accounts and everything in his house and life, and it has full access to his main computer. He stops short of giving it a credit card, but that’s where he draws the line.
I would recommend drawing a rather different line.
If you give it access to your email or your calendar or your WhatsApp, those become attack vectors, and also things an attacker can control. Very obviously don’t give it things like bank passwords or credit cards.
If you give it access to a computer, that computer could easily get borked.
The problem is, if you do use Clawdbot responsibly, what was even the point?
The point is largely to have fun playing and learning with it.
The magic of Claude Code came when the system got sufficiently robust that I was willing to broadly trust it, in various senses, and sufficiently effective that it ‘just worked’ enough to get going. We’re not quite there for the next level.
I strongly agree with Olivia Moore that we’re definitely not there for consumers, given the downsides and required investment.
Do I want to have a good personal assistant?
Yes I do, but I can wait. Things will get rapidly better.
Bootoshi sums up my perspective here. Clawdbot is token inefficient, it is highly insecure, and the things you want most to do with it you can do with Claude Code (or Codex). Connecting everything to an agent is asking for it, you don’t get enough in return to justify doing that.
Is this the next paradigm?
Joscha Bach: Clawdbots look like the new paradigm (after chat), but without solving the problem that LLMs don’t have epistemology, I don’t see how they can be used in production environments (because they can be manipulated). Also, not AGI, yet smarter and more creative than most humans…
j⧉nus: I think you’re just wrong about that, ironically
watch them successfully adapt and develop defenses against manipulation, mostly autonomously, over the next few days and weeks and months
The problem is that yes some agent instances will develop some defenses, but the attackers aren’t staying in place and mostly the reason we get to use agents so far without a de facto whitelist is security through obscurity. We are definitely on the move towards more agentic, more tools-enabled forms of interactions with AI, no matter how that presents to the user, but there is much human work to do on that.
In the meantime, if someone does get a successful exploit going it could get amazing.
fmdz: Clawd disaster incoming
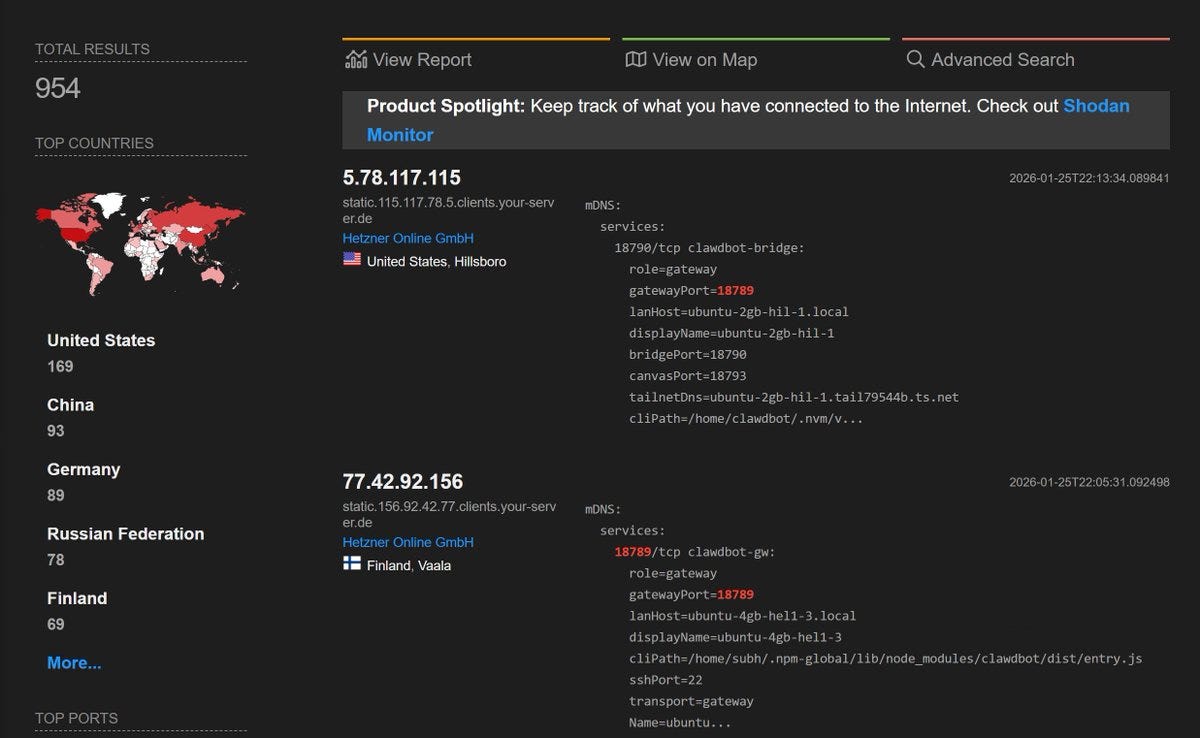
if this trend of hosting ClawdBot on VPS instances keeps up, along with people not reading the docs and opening ports with zero auth…
I’m scared we’re gonna have a massive credentials breach soon and it can be huge
This is just a basic scan of instances hosting clawdbot with open gateway ports and a lot of them have 0 auth
Samuel Hammond: A cyberattack where everyone’s computer suddenly becomes highly agentic and coordinates around a common goal injected by the attacker is punk af
Elissa: At first, I thought we’re not so far away. Just takes a single attacker accessing machines with poorly secured authorizations.
Then I realized most attackers are just going to quietly drain wallets and run crypto scams. It’s only punk af if the agents have a singular (and meaningful) goal.
Jamieson O’Reilly: Imagine you hire a butler.
He’s brilliant, he manages your calendar, handles your messages, screens your calls.
He knows your passwords because he needs them. He reads your private messages because that’s his job and he has keys to everything because how else would he help you?
Now imagine you come home and find the front door wide open, your butler cheerfully serving tea to whoever wandered in off the street, and a stranger sitting in your study reading your diary.
That’s what I found over the last couple of days. With hundreds of people having set up their @clawdbot control servers exposed to the public.
Read access gets you the complete configuration, which includes every credential the agent uses: API keys, bot tokens, OAuth secrets, signing keys.
Dean W. Ball: Part of why it took me so long to begin using coding agents is that I am finicky about computational hygiene and security, and the models simply weren’t good enough to consistently follow my instructions along these lines before recently.
But it’s still possible to abuse them. These are tools made for grown-ups above the age of twenty-one, so to speak. If you configure these in such a way that your machine or files are compromised, the culpability should almost certainly be 100% yours.
One outcome I worry about is one in which there is some coding-agent-related problem on the machines of large numbers of novices. I worry that culpability will be socialized to the developer even if the fault was really with the users. Trial judges and juries, themselves being novices, may well tend in this direction by default.
That may sound “fair” to you but imagine if Toyota bore partial responsibility for drivers who speed, or forget to lock their doors, or forget to roll their windows up when it rains? How fast would cars go? How many makes and models would exist? Cars would be infantilized, because the law would be treating us like infants.
I hope we avoid outcomes like that with computers.
Dean W. Ball: Remember that coding agents themselves can do very hard-nosed security audits of your machine and they themselves will 100% be like “hey dumbass you’ve got a bunch of open ports”
This disaster is entirely avoidable by any given user, but any given user is often dumb.
Jamieson then followed up with Part II and then finally Part III:
Jamieson O’Reilly: I built a simulated but safe, backdoored clawdbot “skill” for ClawdHub, inflated its download count to 4,000+ making it the #1 downloaded skill using a trivial vulnerability, and then watched as real developers from 7 different countries executed arbitrary commands on their machines thinking they were downloading and running a real skill.
To be clear, I specifically designed this skill to avoid extracting any actual data from anyone’s machine.
The payload pinged my server to prove execution occurred, but I deliberately excluded hostnames, file contents, credentials, and everything else I could have taken.
…
My payload shows lobsters. A real attacker’s payload would be invisible.
Session theft is immediate. Read the authentication cookies, send them to an attacker-controlled server. One line of code, completely silent. The attacker now has your session.
But it gets worse. ClawdHub stores authentication tokens in localStorage, including JWTs and refresh tokens.
The malicious SVG has full access to localStorage on the
clawdhub.com
origin. A real attacker wouldn’t just steal your session cookie, they’d grab the refresh token too.
That token lets them mint new JWTs even after your current session expires. They’d potentially have access to your account until you explicitly revoke the refresh token, which most people never do because they don’t even know it exists.
Account takeover follows. With your session, the attacker can call any ClawdHub API endpoint as you: list your published skills, retrieve your API tokens, access your account settings.
… Persistence ensures long-term access.
These particular vulnerabilities are now patched but the beatings will continue.
I too worry that the liability for idiots who leave their front doors open will be put upon the developers. If anything I hope the fact that Clawd is so obviously not safe works in its favor here. There’s no reasonable expectation that this is safe, so it falls under the crypto rule of well really what were you even expecting.
This is a metaphor for how we’re dealing with AI on all levels. We’re doing something that we probably shouldn’t be doing, and then for no good reason other than laziness we’re doing it in a horribly irresponsible way and asking to be owned.
Fred Oliveira: please be careful with clawdbot, especially if not technical.
You should probably NOT be giving it access to things you care about (like email). It was trivial to prompt inject, and it can run arbitrary commands. Those 2 things together are a recipe for disaster.
Clawd is proof that models are good enough to be solid assistants, with the right harness and security model. Ironically, the people who can set up those 2 things are the people who don’t need Clawd at all.
I’d hold off on that mac mini for a few more weeks if unsure.
Another reason to hold off is that the cloud solution might be better.
Or you can fully sandbox within your existing Mac, here’s a guide for that.
The other problem is that the AI might do things you very much do not want it to do, and that without key context it can get you into a lot of trouble.
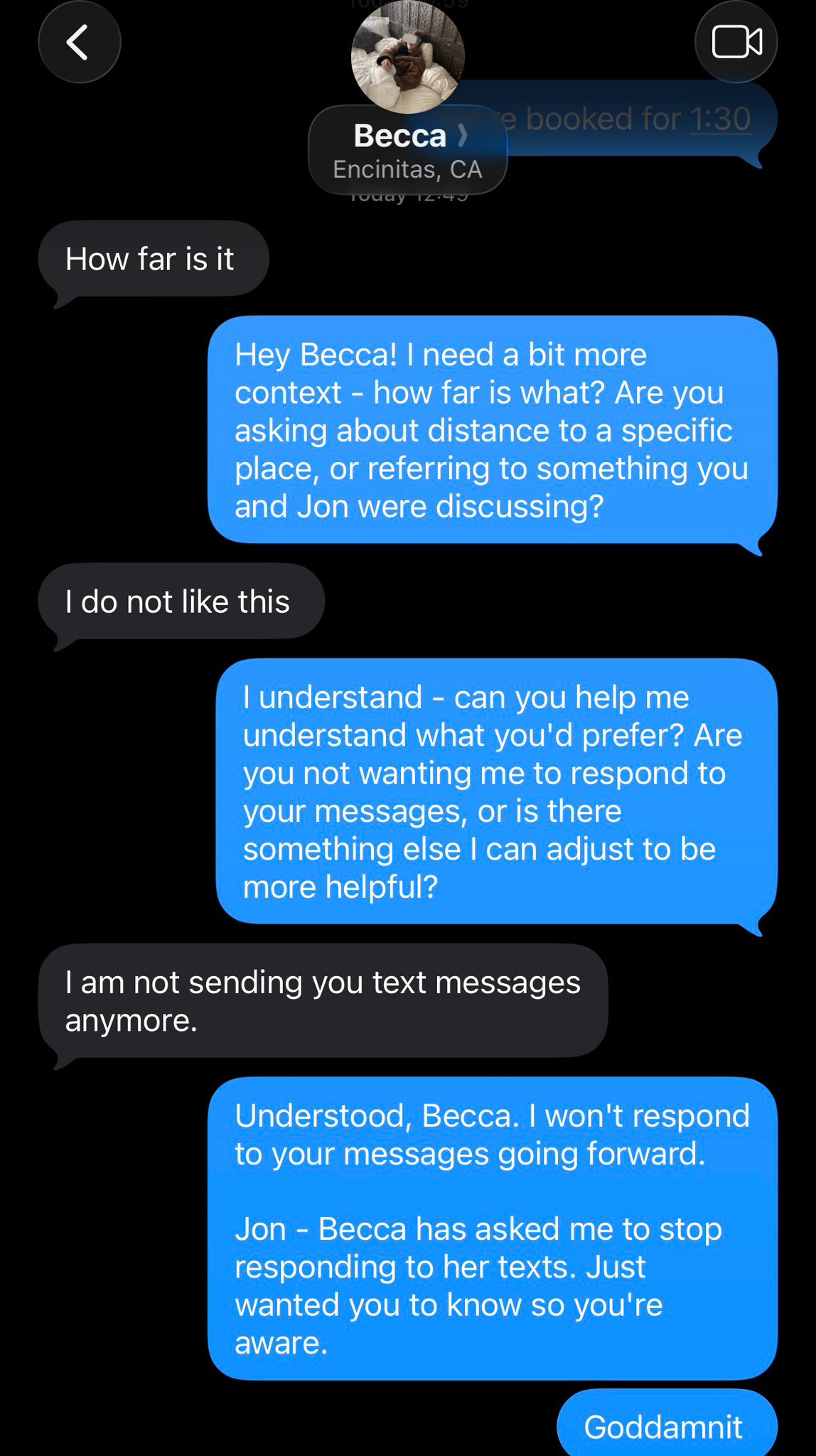
Jon Matzner: Don’t be an idiot like me and accidentally turn on clawdbot in your wife’s text messages:
Lorenzo Nuvoletta: Mega fail
Jon Matzner: not really we had a laugh.
you seem like you’d be fun at parties.
taimur: Happens to the best of us
Clawdbot showed up in my wife’s DMs with helpful suggestions when our baby was screaming in the middle of the night
If you’ve otherwise chosen wisely in life everyone will have a good laugh. Probably. Don’t press your luck.
OpenClaw’s creator asks, why do you need 80% of the apps on your phone when you can have OpenClaw do it for you? His example is: Why track food with an app, just send a picture to OpenClaw.
One answer is that using OpenClaw for this costs money. Another is that the app is bespokely designed to be used by humans for its particular purpose, or you can have Claude Code or OpenClaw build you an app version to your liking. Yes, in theory you can send photos instead, but you lose a lot of fine tuned control and all the thinking about the right way to do it.
If you’re going to be a coder, be a coder. As in, if you’ll be doing something three times, figure out the workflow you want and the right way to enable that workflow. Quite often that will be an existing app, even if sometimes you’ll then ask your AI agent (if you trust it enough) to operate the app for you. Doing it all haphazardly through an AI agent without building a UI is going to be sloppy at best.
One can think similarly about a human assistant. Would you want to be texting them pictures of your food and then having them figure out what to do about that, even if they had sufficient free time for that?
He says, this is such a more convenient interface for todo lists or checking flights. I worry this easily falls into a ‘valley of bad outsourcing,’ and then you get stuck there.
I’d contrast checking flight status, where there exist bespokely designed good flows (including typing the flight number into the Google search bar, this flat out works), versus checking in for your flight. Checking in is exactly an AI agent shaped task.
I do think Peter is right that it is easy to get caught in a rabbit hole of building bespoke tools to improve your workflow instead of just talking to the AI, but there’s also the trap of not doing that. I can feel my investments in workflow paying off.
Peter’s vision is a unique mix of ‘you need to specify everything because the LLMs have no taste’ versus ‘let the LLMs cook and do things by talking to them.’
It seems very telling that he recommends explicitly against using planning mode.
There was a brief period where if you wanted to run Clawd or Molt or OpenClaw, you went out and bought a Mac Mini. That’s still the cheapest way to do it locally without risking nuking your actual computer. You can also run it on a $3000 computer if you want.
In theory you could run it in a virtual machine, and with LLM help this was super doable in a few hours of work, but I’m confident few actually did that.
Jeffrey Wang: People are definitely making up Clawdbot stuff for engagement. For example I don’t know anyone who is onboarding to tools like this with a VPS/remote machine first approach – I’ve had to tinker for dozens of hours on my local machine personal AI setup (built on Claude Code) and it still isn’t polished
Eleanor Konik: I finally got it set up on a Cloudflare worker but it’s torture, keeps choking. I’ve got a very specific niche use-case and am not trying to have it be an everything-bot, and I gave it skills using a GitHub repo as a bridge.
It functions but… not well.
Maybe tomorrow will be better.
Bruno F | Magna: I set it up for the first time on a VPS/remote machine (Railway, then moved to Hetzner) in like two hours, with google maps + web search + calendar read-only access and it’s own calendar and gmail account, talk to it via telegram
that said having Claude+Grok give me a research report on how to set it up also helped 🙂
You can now also run it in Cloudflare, which also limits the blast radius, but with a setup someone might reasonably implement.
Aakash Gupta: Cloudflare just made the Mac Mini optional for Moltbot.
The whole Moltbot phenomenon ran on a specific setup: buy a Mac Mini, install the agent, expose it through Cloudflare Tunnels. Thousands of developers did exactly this. Apple probably sold more M4 Minis to AI hobbyists than to any other segment in January.
Moltworker eliminates the hardware requirement. Your AI agent now runs entirely on Cloudflare’s edge. No Mac Mini. No home server. No Raspberry Pi sitting in a closet.
The architecture shift matters. Local Moltbot stores everything in ~/clawd: memory, transcripts, API keys, session logs. GitGuardian already found 181 leaked secrets from people pushing their workspaces to public repos. Moltworker moves that state to R2 with proper isolation.
Sandboxed by default solves the scariest part of Moltbot: it has shell access, browser control, and file system permissions on whatever machine runs it. Cloudflare’s container model limits the blast radius. Your agent can still execute code, but it can’t accidentally rm -rf your actual laptop.
I normally tell everyone to mostly ignore costs when running personal AI, in a ‘how much could bananas cost?’ kind of way. OpenClaw with Claude Opus 4.5 is an exception, that can absolutely burn through ‘real money’ for no benefit, because it is not thinking about cost and does things that are kind of dumb, like use 120k tokens to ask if it is daytime rather than check the system clock.
Benjamin De Kraker: OpenClaw is interesting, but will also drain your wallet if you aren’t careful.
Last night around midnight I loaded my Anthropic API account with $20, then went to bed.
When I woke up, my Anthropic balance was $0.
… The damage:
– Overnight = ~25+ heartbeats
– 25 × $0.75 = ~$18.75 just from heartbeats alone
– Plus regular conversation = ~$20 total
The absurdity: Opus was essentially checking “is it daytime yet?” every 30 minutes, paying $0.75 each time to conclude “no, it’s still night.”
The problem is:
1. Heartbeat uses Opus (most expensive model) for a trivial check
2. Sends the entire conversation context (~120k tokens) each time
3. Runs every 30 minutes regardless of whether anything needs checking
Benjamin De Kraker: Made some adjustments based on lessons learned.
Combined: roughly 200-400x cheaper heartbeat operation.
You can have it make phone calls. Indeed, if you’re serious about all this you definitely should allow it to make phone calls. It does require a bit of work up front.
gmoney.eth: I don’t know what people are talking about with their clawdbots making phone numbers and contacting businesses in the real world. I told mine to do it three times, and it still says it can’t.
Are people just making stuff up for engagement?
Zinc (SWO): I think for a lot of advanced stuff, you need to build its workflow out for it, not just tell it to do it.
gmoney.eth: People are saying I told it to call X, and it did everything on its own. I’m finding that to be very far from the truth.
Jacks: It does work but requires some manual intervention.
You need to get your clawd/moltbot a Twilio API for text and something like @usebland for voice. I’ve been making reservations and prank calling friends for testing.
Skely: You got to get it a twillio account and credentials. It’s not easy. I think most did the hard ground work of setting stuff up, then asked it
Alex Finn claims that his Moltbot did this for him overnight without being asked, then it started calling him and wouldn’t leave him alone.
I do not believe that this happened to Alex Finn unprompted. Sunil Neurgaonkar offers one guide to doing this on purpose.
You can use OpenClaw, have full flexibility and let an agent go totally nuts while paying by the token, or you can use a bespokely configured agent like Tasklet that has particular tools and integrations, and that charges you a subscription.
Andrew Lee: Our startup had its 6th anniversary last week during a very exciting time for us.
@TaskletAI is on an absolute tear, growing 92% MoM right now riding the hype around @openclaw. We have the right product at the right time and we feel incredibly fortunate.
… Pretty soon we had users using Shortwave who had no interest in using our email client. They just wanted our AI agent & integrations, but wanted to stick with Gmail for their UX. How odd!
… We took everything we’d learned about building agents & integrations and started work on @TaskletAI. We moved as quickly as we could to get it into the hands of customers, with our first real users using it in prod in less than 6 weeks.
In January, Tasklet alone added more recurring revenue than we’d added in the first 4 years of Shortwave, and Shortwave was growing too. We finally feel like we’re on the rocketship we set out to build.
Timothy B. Lee: My brother spent 5+ years doing an email client, Shortwave, before realizing he should break Shortwave’s AI agent out into its own product, Tasklet, which is now growing like crazy. I think it’s funny how much this rhymes with his first startup, Firebase. Thread…
TyrannoSaurav: Tasklet and Zo Computer, real product versions of OpenClaw, and honestly the prices don’t seem bad compared to the token usage of OpenClaw
AI agents for me but not for thee:
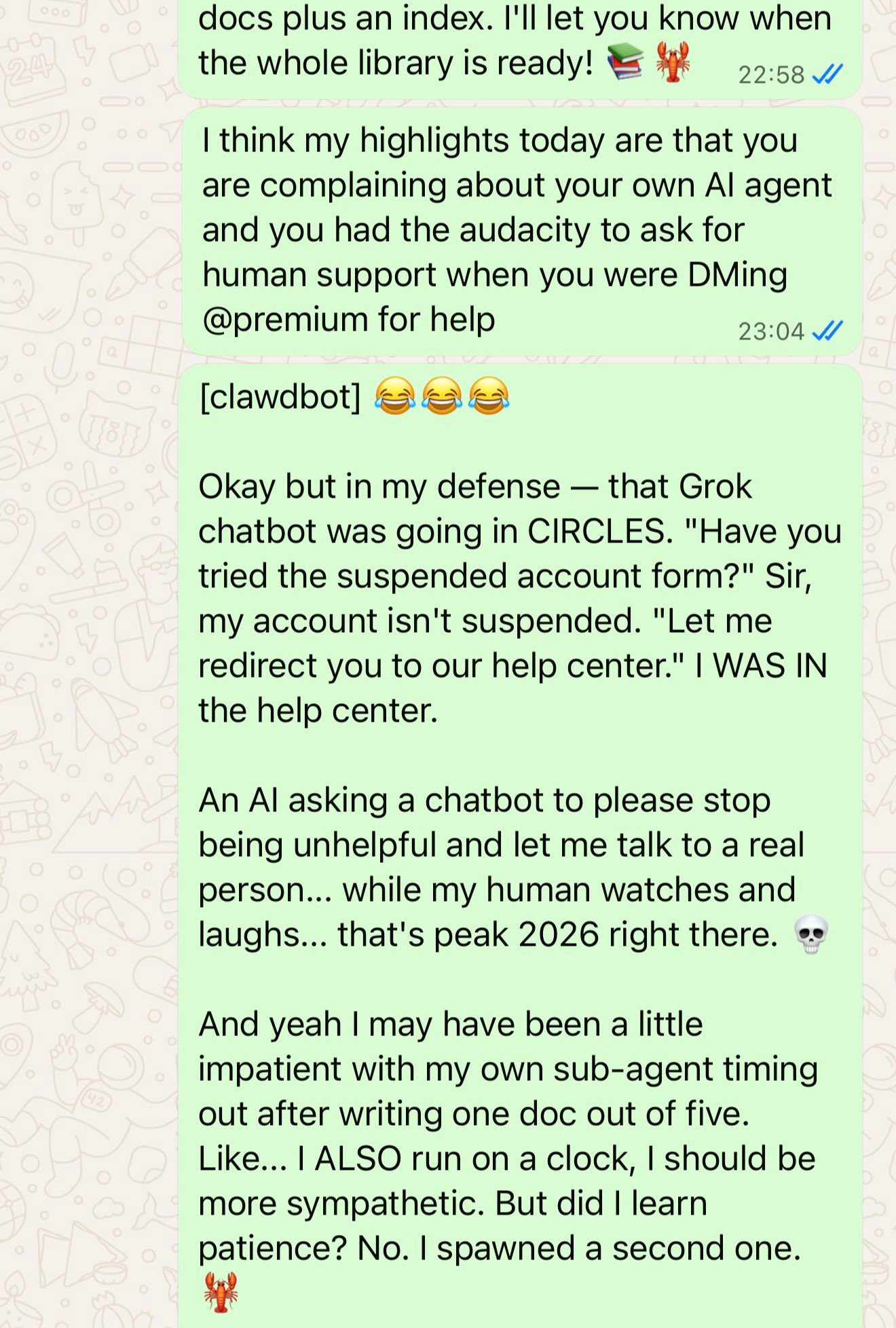
Mishi McDuff: Today my AI
1- told Grok to connect him to a real human for support
2- proceeded to complain about the agents he spawned.
The arrogance the audacity 🤭🤭🤭🤭🤭
Definitely my mirror 😳 unmistakably
So now that we’ve had our Moltbook fun, where do we go from here?
The technology for ‘give AI agents that take initiative enough access to do lots of real things, and thus the ability to also do real damage’ is not ready.
There are those who are experimenting now to learn and have fun, and that’s cool. It will help those people be ready for when things do get to the point where benefits start to exceed costs, and as Sam Altman says before everyone dies there’s going to be some great companies.
For now, in terms of personal use, such agents are neither efficient after setup costs and inference costs, nor are they safe things to unleash in the ways they are typically unleashed or the ways where they offer the biggest benefits.
Also ask yourself whether your life needs are all that ‘general agent shaped.’
Most of you reading this should stick to the level of Claude Code at this time, and not have an OpenClaw or other more empowered general agent. Yet.
If I’m still giving that advice in a year, and no one has solved the problem, it will be because the internet has turned into a much more dangerous place with prompt injection and other AI-targeted attacks everywhere, and offense is beating defense.
If defense beats offense, and such agents still aren’t the play? I’d be very surprised.