Why has Microsoft been routing example.com traffic to a company in Japan?
From the Department of Bizarre Anomalies: Microsoft has suppressed an unexplained anomaly on its network that was routing traffic destined to example.com—a domain reserved for testing purposes—to a maker of electronics cables located in Japan.
Under the RFC2606—an official standard maintained by the Internet Engineering Task Force—example.com isn’t obtainable by any party. Instead it resolves to IP addresses assigned to Internet Assiged Names Authority. The designation is intended to prevent third parties from being bombarded with traffic when developers, penetration testers, and others need a domain for testing or discussing technical issues. Instead of naming an Internet-routable domain, they are to choose example.com or two others, example.net and example.org.
Misconfig gone, but is it fixed?
Output from the terminal command cURL shows that devices inside Azure and other Microsoft networks have been routing some traffic to subdomains of sei.co.jp, a domain belonging to Sumitomo Electric. Most of the resulting text is exactly what’s expected. The exception is the JSON-based response. Here’s the JSON output from Friday:
"email":"[email protected]","services": [],"protocols": [{"protocol":"imap","hostname":"imapgms.jnet.sei.co.jp","port":993,"encryption":"ssl","username":"[email protected]","validated":false},{"protocol":"smtp","hostname":"smtpgms.jnet.sei.co.jp","port":465,"encryption":"ssl","username":"[email protected]","validated":false}]
Similarly, results when adding a new account for [email protected] in Outlook looked like this:
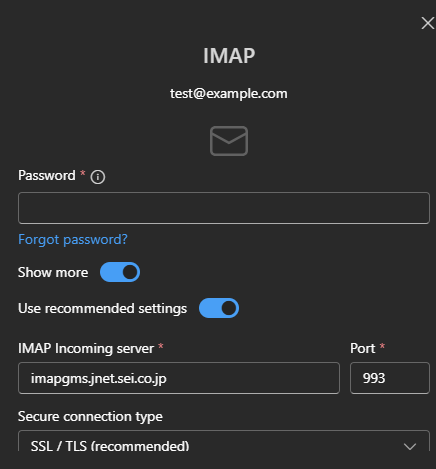
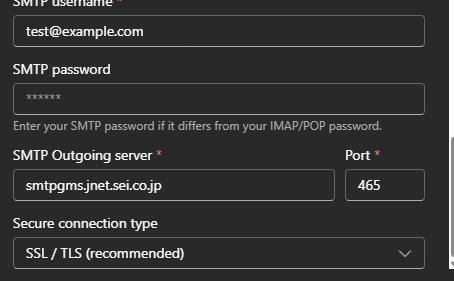
In both cases, the results show that Microsoft was routing email traffic to two sei.co.jp subdomains: imapgms.jnet.sei.co.jp and smtpgms.jnet.sei.co.jp. The behavior was the result of Microsoft’s autodiscover service.
“I’m admittedly not an expert in Microsoft’s internal workings, but this appears to be a simple misconfiguration,” Michael Taggart, a senior cybersecurity researcher at UCLA Health, said. “The result is that anyone who tries to set up an Outlook account on an example.com domain might accidentally send test credentials to those sei.co.jp subdomains.”
When asked early Friday afternoon why Microsoft was doing this, a representative had no answer and asked for more time. By Monday morning, the improper routing was no longer occurring, but the representative still had no answer.
Why has Microsoft been routing example.com traffic to a company in Japan? Read More »