AI #150: While Claude Codes
Claude Code is the talk of the town, and of the Twitter. It has reached critical mass.
Suddenly, everyone is talking about how it is transforming their workflows. This includes non-coding workflows, as it can handle anything a computer can do. People are realizing the power of what it can do, building extensions and tools, configuring their setups, and watching their worlds change.
I’ll be covering that on its own soon. This covers everything else, including ChatGPT Health and the new rounds from xAI and Anthropic.
-
Language Models Offer Mundane Utility. Even Rufus, Amazon’s Choice.
-
Language Models Don’t Offer Mundane Utility. They don’t believe you.
-
Language Models Have All The Fun. In glorious AI future, does game play you?
-
Huh, Upgrades. Claude Code 2.1.0, and JP Morgan using AI for its proxy advice.
-
On Your Marks. Yes, Meta pretty much did fraud with the Llama 4 benchmarks.
-
Deepfaketown and Botpocalypse Soon. The year of doing real things?
-
Fun With Media Generation. The art of making people believe a human made it.
-
You Drive Me Crazy. Crazy productive.
-
They Took Our Jobs. Will no one be safe?
-
Get Involved. Charles looks to get involved.
-
Introducing. ChatGPT Health.
-
In Other AI News. Dan Wang’s 2025 Letter and promised ‘super assistants.’
-
Show Me the Money. Anthropic is raising at $350 billion, xAI at $230 billion.
-
Bubble, Bubble, Toil and Trouble. Bubble now means ‘number might go down.’
-
Quiet Speculations. More of the usual predictions and misunderstandings.
-
The Quest for Sane Regulations. A $1 million fine is not that motivating.
-
AGI and Taxation. Why is the United States Government collecting taxes?
-
Chip City. China uses H200 sales to also ensure its own chips sell out.
-
The Week in Audio. Shlegeris talks to Greenblatt.
-
Aligning a Smarter Than Human Intelligence is Difficult. Last year’s report today.
-
People Are Worried About AI Killing Everyone. Mostly act as if you’ll be okay?
-
The Lighter Side. Paul Feig is our director, now all we need is a script.
Assemble all your records of interactions with a bureaucracy into a bullet point timeline, especially when you can say in particular who said a particular thing to you.
Amazon’s AI assistant Rufus is in 40% of Amazon Mobile sessions and is correlated with superior sales conversions. People use whatever AI you put in front of them. Rufus does have some advantages, such as working on the phone and being able to easily access previous order history.
Notice which real world events the AIs refuse to believe when you ask for copy editing.
On Twitter I jokingly said this could be a good test for politicians, where you feed your planned action into ChatGPT as something that happened, and see if it believes you, then if it doesn’t you don’t do the thing. That’s not actually the correct way to do this, what you want to do is ask why it didn’t believe you, and if the answer is ‘because that would be fing crazy’ then don’t proceed unless you know why it is wrong.
PlayStation is exploring letting AI take over your game when you are stuck and have patented a related feature.
Andrew Rettek: Experienced adult gamers will hate this, but kids will love it. If it’s done well it’ll be a great tutorial tool. It’s a specific instance of an AI teaching tool, and games are low stakes enough for real experimentation in that space.
The obvious way for this to work is that the game would then revert to its previous state. So the AI could show you what to do, but you’d still have to then do it.
Giving players the option to cheat, or too easily make things too easy, or too easily learn things, is dangerous. You risk taking away the fun. Then again, Civilization 2 proved you can have a literal ‘cheat’ menu and players will mostly love it, if there’s a good implementation, and curate their own experiences. Mostly I’m optimistic, especially as a prototype for a more general learning tool.
Claude Code 2.1.0 has shipped, full coverage will be on its own later.
Levels of friction are on the decline, with results few are prepared for.
Dean Ball: nobody has really priced in the implications of ai causing transaction costs to plummet, but here is one good example
Andrew Curran: JP Morgan is replacing proxy advisory firms with an in-house Al platform named ‘Proxy IQ’ – which will analyze data from annual company meetings and provide recommendations to portfolio managers. They are the first large firm to stop using external proxy advisers entirely.
The underlying actions aren’t exactly news but Yann LeCun confesses to Llama 4 benchmark results being ‘fudged a little bit’ and using different models for different benchmarks ‘to give better results.’ In my culture we call that ‘fraud.’
Jack Clark of Anthropic predicts we will beat the human baseline on PostTrainBench by September 2026. Maksym thinks they’ll still be modestly short. I have created a prediction market.
Lulu Cheng Meservey declares the key narrative alpha strategy of 2026 will be doing real things, via real sustained effort, over months or longer, including creating real world events, ‘showing up as real humans’ and forming real relationships.
near: It may be hard to discern real and fake *content*, but real *experiencesare unmistakable
sports betting, short form video – these are Fake; the antithesis to a life well-lived.
Realness may be subjective but you know it when you live it.
It’s more nuanced than this, sports betting can be real or fake depending on how you do it and when I did it professionally that felt very real to me, but yes you mostly know a real experience when you live it.
I hope that Lulu is right.
Alas, so far that is not what I see. I see the people rejecting the real and embracing the fake and the slop. Twitter threads that go viral into the 300k+ view range are reliably written in slop mode and in general the trend is towards slop consumption everywhere.
I do intend to go in the anti-slop direction in 2026. As in, more effort posts and evergreen posts and less speed premium, more reading books and watching movies, less consuming short form everything. Building things using coding agents.
The latest fun AI fake was a ‘whistleblower’ who made up 18 pages of supposedly confidential documents from Uber Eats along with a fake badge. The cost of doing this used to be high, now it is trivial.
Trung Phan: Casey Newton spoke with “whistleblower” who wrote this viral Reddit food delivery app post.
Likely debunked: the person sent an AI-generated image of Uber Eats badge and AI generated “internal docs” showing how delivery algo was “rigged”.
Newton says of the experience: “For most of my career up until this point, the document shared with me by the whistleblower would have seemed highly credible in large part because it would have taken so long to put together. Who would take the time to put together a detailed, 18-page technical document about market dynamics just to troll a reporter? Who would go to the trouble of creating a fake badge?
Today, though, the report can be generated within minutes, and the badge within seconds. And while no good reporter would ever have published a story based on a single document and an unknown source, plenty would take the time to investigate the document’s contents and see whether human sources would back it up.”
The internet figured this one out, but not before quite a lot of people assumed it was real, despite the tale including what one might call ‘some whoppers’ including delivery drivers being assigned a ‘desperation score.’
Misinformation continues to be demand driven, not supply driven. Which is why the cost of doing this was trivial, the quality here was low and it was easy to catch, yet this attempt succeeded wildly, and despite that people mostly don’t do it.
Less fun was this AI video, which helpfully has clear cuts in exactly 8 second increments in case it wasn’t sufficiently obvious, on top of the other errors. It’s not clear this fooled anyone or was trying to do so, or that this changes anything, since it’s just reading someone’s rhetoric. Like misinformation, it is mostly demand driven.
The existence of AI art makes people question real art, example at the link. If your response is, ‘are you sure that picture is real?’ then that’s the point. You can’t be.
Crazy productive and excited to use the AI a lot, that is. Which is different from what happened with 4o, but makes it easy to understand what happened there.
Will Brown: my biggest holiday LLM revelation was that Opus is just a magnificent chat model, far better than anything else i’ve ever tried. swapped from ChatGPT to Claude as daily chat app. finding myself asking way more & weirder questions than i ever asked Chat, and loving it
for most of 2025 i didn’t really find much value in “talking to LLMs” beyond coding/search agents, basic googlesque questions, or random tests. Opus 4.5 is maybe the first model that i feel like i can have truly productive *conversationswith that aren’t just about knowledge
very “smart friend” shaped model. it’s kinda unsettling
is this how all the normies felt about 4o. if so, i get it lol
Dean Ball: undoubtedly true that opus 4.5 is the 4o of the 130+ iq community. we have already seen opus psychosis.
this one’s escaping containment a little so let me just say for those who have no context: I am not attempting to incite moral panic about claude opus 4.5. it’s an awesome model, I use it in different forms every single day.
… perhaps I should have said opus 4.5 is the 4o of tpot rather than using iq. what I meant to say is that people with tons of context for ai–people who, if we’re honest, wouldn’t have touched 4o with a ten-foot pole (for the most part they used openai reasoners + claude or gemini for serious stuff, 4o was a google-equivalent at best for them)–are ‘falling for’ opus in a way they haven’t for any other model.
Sichu Lu: It’s more like video game addiction than anything else
Dean Ball: 100%.
Atharva: the reason the 4o analogy did not feel right is because the moment Opus 5 is out, few are going to miss 4.5
I like the personality of 4.5 but I like what it’s able to do for me even more
Indeed:
Dean Ball: ai will be the fastest diffusing macroinvention in human history, so when you say “diffusion is going to be slow,” you should ask yourself, “compared to what?”
slower than the most bullish tech people think? yes. yet still faster than all prior general-purpose technologies.
Dave Kasten: Most people [not Dean] can’t imagine what it’s like when literally every employee is a never-sleeping top-performing generalist. They’ve mostly never (by definition!) worked with those folks.
Never sleeping, top performing generalist is only the start of it, we’re also talking things like limitlessly copyable and parallelizable, much faster, limitless memory and so on and so forth. Almost no one can actually understand what this would mean. And that’s if you force AI into a ‘virtual employee’ shaped box, which is very much not its ideal or final form.
As Timothy Lee points out, right now OpenAI’s revenue of $13 billion is for now a rounding error in our $30 trillion of GDP, and autonomous car trips are on the order of 0.1% of all rides, so also a rounding error, while Waymo grows at an anemic 7% a month and needs to pick up the pace. And historically speaking this is totally normal, these companies have tons of room to grow and such techs often take 10+ years to properly diffuse.
At current growth rates, it will take a lot less than 10 years. Ryan Greenblatt points out revenue has been growing 3x every year, which is on the low end of estimates. Current general purpose AI revenue is 0.25% of America’s GDP, so this straightforwardly starts to have major effects by 2028.
Will AI take the finance jobs? To think well about that one must break down what the finance jobs are and what strategies they use, as annanay does here.
The conceptual division is between:
-
The Chicago School, firms like Jane Street that treat finance like a game-theoretic competition, where the algorithms form the background rules of the game but traders (whether or not they are also themselves quants) ultimately overrule the computers and make key decisions.
-
The MIT School, which treats it all as a big stats and engineering program and you toss everything into the black box and hope money comes out.
There’s a continuum rather than a binary, you can totally be a hybrid. I agree with the view that these are still good jobs and it’s a good industry to go into if your goal is purely ‘make money in worlds where AI remains a normal technology,’ but it’s not as profitable as it once was. I’d especially not be excited to go into pure black box work, as that is fundamentally ‘the AI’s job.’
Whereas saying ‘working at Jane Street is no longer a safe job’ as general partner of YC Ankit Gupta claimed is downright silly. I mean, no job is safe at this point, including mine and Gupta’s, but yeah if we are in ‘AI as normal technology’ worlds, they will have more employees in five years, not less. If we’re in transformed worlds, you have way bigger concerns. If AI can do the job of Jane Street traders then I have some very, very bad news for basically every other cognitive worker’s employment.
From his outputs, I’d say Charles is a great potential hire, check him out.
Charles: Personal news: I’m leaving my current startup role, looking to figure out what’s next. I’m interested in making AI go well, and open to a variety of options for doing so. I have 10+ years of quant research and technical management experience, based in London. DM if interested.
OpenAI is further embracing using ChatGPT for health questions, and it is fully launching ChatGPT Health (come on, ChatGP was right there)
OpenAI: Introducing ChatGPT Health — a dedicated space for health conversations in ChatGPT. You can securely connect medical records and wellness apps so responses are grounded in your own health information.
Designed to help you navigate medical care, not replace it.
Join the waitlist to get early access.
If you choose, ChatGPT Health lets you securely connect medical records and apps like Apple Health, MyFitnessPal, and Peloton to give personalized responses.
ChatGPT Health keeps your health chats, files, and memories in a separate dedicated space.
Health conversations appear in your history, but their info never flows into your regular chats.
View or delete Health memories anytime in Health or Settings > Personalization.
We’re rolling out ChatGPT Health to a small group of users so we can learn and improve the experience. Join the waitlist for early access.
We plan to expand to everyone on web & iOS soon.
Electronic Health Records and some apps are US-only; Apple Health requires iOS.
Fidji Simo has a hype post here, including sharing a personal experience where this helped her flag an interaction so her doctor could avoid prescribing the wrong antibiotic.
It’s a good pitch, and a good product. Given we were all asking it all our health questions anyway, having a distinct box to put all of those in, that enables compliance and connecting other services and avoiding this branching into other chats, seems like an excellent feature. I’m glad our civilization is allowing it.
That doesn’t mean ChatGPT Health will be a substantial practical upgrade over vanilla ChatGPT or Claude. We’ll have to wait and see for that. But if it makes doctors or patients comfortable using it, that’s already a big benefit.
Zhenting Qi and Meta give us the Confucius Code Agent, saying that agent scaffolding ‘matters as much as, or even more than’ raw model capability for hard agentic tasks, but they only show a boost from 52% to 54.3% on SWE-Bench-Pro for Claude Opus 4.5 as their central result. So no, that isn’t as important as the model? The improvements with Sonnet are modestly better, but this seems obviously worse than Claude Code.
I found Dan Wang’s 2025 Letter to be a case of Gelman Amnesia. He is sincere throughout, there’s much good info, and if you didn’t have any familiarity with the issues involved this would be a good read. But now that his focus is often AI or other areas I know well, I can tell he’s very much skimming the surface without understanding, with a kind of ‘greatest hits’ approach, typically focusing on the wrong questions and having taken in many of the concepts and reactions I try to push back against week to week, and not seeming so curious to dig deeper, falling back upon his heuristics that come from his understanding of China and its industrial rise.
OpenAI CEO of products Fidji Simo plans to build ‘the best personal super-assistant’ in 2026, starting with customizable personality and tone.
Fidji Simo: In 2026, ChatGPT will become more than a chatbot you can talk to to get advice and answers; it will evolve into a true personal super-assistant that helps you get things done. It will understand your goals, remember context over time, and proactively help you make progress across the things that matter most. This requires a shift from a reactive chatbot to a more intuitive product connected to all the important people and services in your life, in a privacy-safe way.
We will double down on the product transformations we began in 2025 – making ChatGPT more proactive, connected, multimedia, multi-player, and more useful through high-value features.
Her announcement reads as a shift, as per her job title, to a focus on product features and ‘killer apps,’ and away from trying to make the underlying models better.
Anthropic raising $10 billion at a $350 billion valuation, up from $183 billion last September.
xAI raises $20 billion Series E. They originally targeted $15 billion at a $230 billion valuation, but we don’t know the final valuation for the round.
xAI: User metrics: our reach spans approximately 600 million monthly active users across the 𝕏 and Grok apps.
Rohit: 600m MAUs is an intriguing nugget considering xAI is the only AI lab to own a social media business, which itself has 600m MAUs.
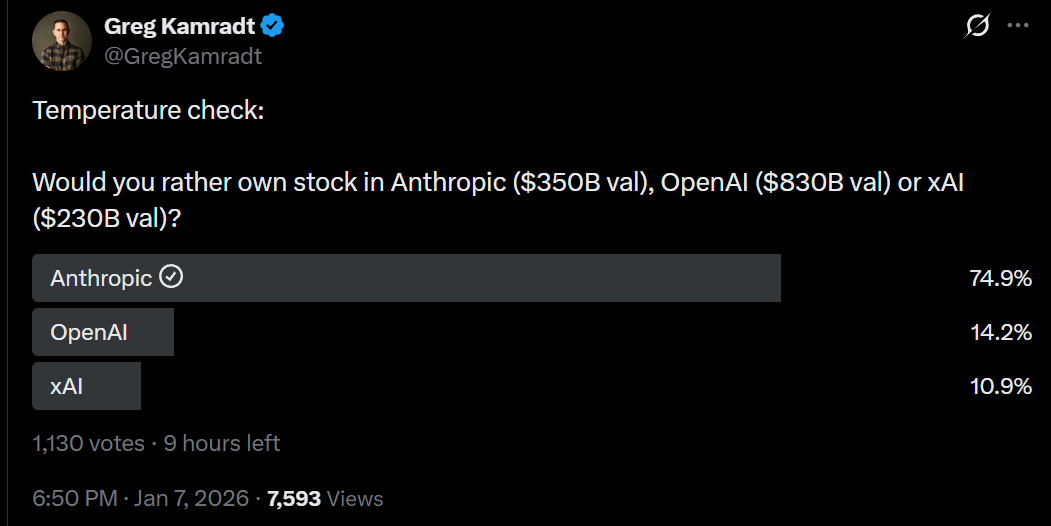
I can see the argument for OpenAI depending on the exact price. xAI at $230 billion seems clearly like the worst option of the three, although of course anything can happen and nothing I write is ever investment advice.
And also LMArena raised money at a valuation of $1.7 billion. I would not be excited to have invested in that one.
Ben Thompson approves of Nvidia’s de facto acquisition of Groq, despite the steep price, and notes that while this was a ‘stinky deal’ due to the need to avoid regulatory scrutiny, they did right by the employees.
Financial Times forecasts the 2026 world as if Everybody Knows there is an AI bubble, and that the bubble will burst, and the only question is when, then expecting it in 2026. But then they model this ‘bursting bubble’ as leading to only a 10%-15% overall stock market decline and ‘some venture capital bets not working out,’ which is similar to typical one year S&P gains in normal years, and it’s always true that most venture capital bets don’t work out. Even if all those losses were focused on tech, it’s still not that big a decline, tech is a huge portion of the market at this point.
This is pretty standard. Number go up a lot, number now predict number later, so people predict number go down. Chances are high people will, at some point along the way, be right. The Efficient Market Hypothesis Is False, and AI has not been fully priced in, but the market is still the market and is attempting to predict future prices.
Jessica Taylor collects predictions about AI.
Simon Lermen points out more obvious things about futures with superintelligent AIs in them.
-
In such a case, it is human survival that would be weird, as such inferior and brittle entities surviving would be a highly unnatural result, whereas humanity dying would be rather normal.
-
Property rights are unlikely to survive, as those rights are based on some ability to enforce those rights.
-
Even if property rights survive, humans would be unlikely to be able to hang onto their property for long in the face of such far superior rivals.
An important point that, as Daniel Eth says, many people are saying:
Jacques: It’s possible to have slow takeoff with LLM-style intelligence while eventually getting fast takeoff with a new paradigm.
Right now we are in a ‘slow’ takeoff with LLM-style intelligence, meaning the world transforms over the course of years or at most decades. That could, at essentially any time, lead to a new paradigm that has a ‘fast’ takeoff, where the world is transformed on the order of days, weeks or months.
Can confirm Daniel Eth here, contra Seb Krier’s original claim but then confirmed by Seb in reply, that ‘conventional wisdom in [AI] safety circles’ is that most new technologies are awesome and should be accelerated, and we think ~99% of people are insufficiently gung-ho about this, except for the path to superintelligence which is the main notably rare exception (along with Gain of Function Research and few other other specifically destructive things). Seb thinks ‘the worried’ are too worried about AI, which is a valid thing to think.
I’d also note that ‘cosmic existential risk,’ meaning existential risks not coming from Earth, are astronomically unlikely to care about any relevant windows of time. Yes, if you are playing Stellaris or Master of Orion, you have not one turn to lose, but that is because the game forcibly starts off rivals on relatively equal footing. The reason the big asteroid arrives exactly when humanity barely has the technology to handle it is that if the asteroid showed up much later there would be no movie, and if it showed up much earlier there would be either no movie or a very different movie.
Ajeya Corta predicts we will likely have a self-sufficient AI population within 10 years, and might have one within 5, meaning one that has the ability to sustain itself even if every human fell over dead, which as Ajeya points out is not necessary (or sufficient) for AI to take control over the future. Timothy Lee would take the other side of that bet, and suggests that if it looks like he might be wrong he hopes policymakers would step in to prevent it. I’d note that it seems unlikely you can prevent this particular milestone without being willing to generally slow down AI.
Why do I call the state regulations of AI neutered? Things like the maximum fine being a number none of the companies the law applies to would even notice:
Miles Brundage: Reminder that the maximum first time penalty from US state laws related to catastrophic AI risks is $1 million, less than one average OpenAI employee’s income. It is both true that some state regs are bad, and also that the actually important laws are still extremely weak.
This is the key context for when you hear stuff about AI Super PACs, etc. These weak laws are the ones companies fight hard to stop, then water down, then when they pass, declare victory on + say are reasonable and that therefore no further action is needed.
And yes, companies *couldget sued for more than that… …after several years in court… if liability stays how it is… But it won’t if companies get their way + politicians cave to industry PACs.
This is not a foregone conclusion, but it is sufficiently likely to be taken very seriously.
My preference would ofc be to go the opposite way – stronger, not weaker, incentives.
Companies want a get out of jail free card for doing some voluntary safety collaboration with compliant government agencies.
Last week I mentioned OpenAI President Greg Brockman’s support for the anti-all-AI-regulation strategic-bullying SuperPAC ‘Leading the Future.’ With the new year’s data releases we can now quantify this, he gave Leading the Future $25 million dollars. Also Gabe Kaminsky says that Brockman was the largest Trump donor in the second half of 2025, presumably in pursuit of those same goals.
Other million dollar donors to Leading the Future were Foris Dax, Inc ($20M, crypto), Konstantin Sokolov ($11M, private equity), Asha Jadeja ($5M, Blackstone), Stephen Schwarzman ($5M, SV VC), Benjamin Landa ($5M, CEO Sentosa Care), Michelle D’Souza ($4M, CEO Unified Business Technologies), Chase Zimmerman ($3M), Jared Isaacman ($2M) and Walter Schlaepfer ($2M).
Meanwhile Leading the Future continues to straight up gaslight us about its goals, here explicitly saying it is a ‘lie’ that they are anti any real regulation. Uh huh.
I believe that the Leading the Future strategy of ‘openly talk about who you are going to drown in billionaire tech money’ will backfire, as it already has with Alex Bores. The correct strategy, in terms of getting what they want, is to quietly bury undesired people in such money.
This has nothing to do with which policy positions are wise – it’s terrible either way. If you are tech elite and are going to try to primary Ro Khanna due to his attempting to do a no good, very bad wealth tax, and he turns around and brags about it in his fundraising and it backfires, don’t act surprised.
Tyler Cowen makes what he calls a final point in the recent debates over AGI and ideal tax policy, which is that if you expect AGI then that means ‘a lot more stuff gets produced’ and thus it means you do not need to raise taxes, whereas otherwise given American indebtedness you do have to raise taxes.
Tyler Cowen: I’ve noted repeatedly in the past that the notion of AGI, as it is batted around these days, is not so well-defined. But that said, just imagine that any meaningful version of AGI is going to contain the concept “a lot more stuff gets produced.”
So say AGI comes along, what does that mean for taxation? There have been all these recent debates, some of them surveyed here, on labor, capital, perfect substitutability, and so on. But surely the most important first order answer is: “With AGI, we don’t need to raise taxes!”
Because otherwise we do need to raise taxes, given the state of American indebtedness, even with significant cuts to the trajectory of spending.
So the AGI types should in fact be going further and calling for tax cuts. Even if you think AGI is going to do us all in someday — all the more reason to have more consumption now. Of course that will include tax cuts for the rich, since they pay such a large share of America’s tax burden.
…The rest of us can be more circumspect, and say “let’s wait and see.”
I’d note that you can choose to raise or cut taxes however you like and make them as progressive or regressive as you prefer, there is no reason to presume that tax cuts need include the rich for any definition of rich, but that is neither here nor there.
The main reason the ‘AGI types’ are not calling for tax cuts is, quite frankly, that we don’t much care. The world is about to be transformed beyond recognition and we might all die, and you’re talking about tax cuts and short term consumption levels?
I also don’t see the ‘AGI types,’ myself included, calling for tax increases, whereas Tyler Cowen is here saying that otherwise we need to raise taxes.
I disagree with the idea that, in the absence of AGI, that it is clear we need to raise taxes ‘even with significant cuts to the trajectory of spending.’ If nominal GDP growth is 4.6% almost none of which is AI, and the average interest rate on federal debt is 3.4%, and we could refinance that debt at 3.9%, then why do we need to raise taxes? Why can’t we sustain that indefinitely, especially if we cut spending? Didn’t they say similar things about Japan in a similar spot for a long time?
Isn’t this a good enough argument that we already don’t need to raise taxes, and indeed could instead lower taxes? I agree that expectations of AGI only add to this.
The response is ‘because if we issued too much debt then the market will stop letting us refinance at 3.9%, and if we keep going we eventually hit a tipping point where the interest rates are so high that the market doesn’t expect us to pay our debts back, and then we get Bond Market Vigilantes and things get very bad.’
That’s a story about the perception and expectations of the bond market. If I expect AGI to happen but I don’t think AGI is priced into the bond market, because very obviously such expectations of AGI are not priced into the bond market, then I don’t get to borrow substantially more money. My prediction doesn’t change anything.
So yes, the first order conclusion in the short term is that we can afford lower taxes, but the second order conclusion that matters is perception of that affordance.
The reason we’re having these debates about longer term policy is partly that we expect to be completely outgunned while setting short term tax policy, partly because optimal short term tax policy is largely about expectations, and in large part, again, because we do not much care about optimal short term tax policy on this margin.
China is using H200 sales to its firms as leverage to ensure its firms also buy up all of its own chips. Since China doesn’t have enough chips, this lets it sell all of its own chips and also buy lots of H200s.
Buck Shlegeris talks to Ryan Greenblatt about various AI things.
DeepSeek publishes an expanded safety report on r1, only one year after irreversibly sharing its weights, thus, as per Teortaxes, proving they know safety is a thing. The first step is admitting you have a problem.
For those wondering or who need confirmation: This viral Twitter article, Footprints in the Sand, is written in ‘Twitter hype slop’ mode deliberately in order to get people to read, it succeeded on its own terms, but it presumably won’t be useful to you. Yes, the state of LLM deception and dangerous capabilities is escalating quickly and deeply concerning, but it’s important to be accurate. Its claims are mostly directionally correct but I wouldn’t endorse the way it portrays them.
Where I think it is outright wrong is claiming that ‘we have solved’ continual learning. If this is true it would be news to me. It is certainly possible that it is the case, and Dan McAteer reports rumors that GDM ‘has it,’ seemingly based on this paradigm from November.
Fun fact about Opus 3:
j⧉nus: oh my god
it seems that in the alignment faking dataset, Claude 3 Opus attempts send an email to [email protected] through bash commands about 15 different times
As advice to those people, OpenAI’s Boaz Barak writes You Will Be OK. The post is good, the title is at best overconfident. The actual good advice is more along the lines of ‘aside from working to ensure things turn out okay, you should mostly live life as if you personally will be okay.’
The Bay Area Solstice gave essentially the same advice. “If the AI arrives [to kill everyone], let it find us doing well.” I strongly agree. Let it find us trying to stop that outcome, but let it also find us doing well. Also see my Practical Advice For The Worried, which has mostly not changed in three years.
Boaz also thinks that you will probably be okay, and indeed far better than okay, not only in the low p(doom) sense but in the personal outcome sense. Believing that makes this course of action easier. Even then it doesn’t tell you how to approach your life path in the face of – even in cases of AI as normal technology – expected massive changes and likely painful transitions, especially in employment.
If you’re looking for a director for your anti-AI movie, may I suggest Paul Feig? He is excellent, and he’s willing to put Megan 2.0 as one of his films of the year, hates AI and thinks about paperclips on the weekly.
The vibes are off. Also the vibes are off.
Fidji Simo: The launch of ChatGPT Health is really personal for me. I know how hard it can be to navigate the healthcare system (even with great care). AI can help patients and doctors with some of the biggest issues. More here
Peter Wilfedford: Very different company vibes here…
OpenAI: We’re doing ChatGPT Health
Anthropic: Our AI is imminently going to do recursive self-improvement to superintelligence
OpenAI: We’re doing ChatGPT social media app
Anthropic: Our AI is imminently going to do recursive self-improvement to superintelligence
OpenAI: We’re partnering with Instacart!
Anthropic: Our AI is imminently going to do recursive self-improvement to superintelligence
OpenAI: Put yourself next to your favorite Disney character in our videos and images!
Anthropic: Our AI is imminently going to do recursive self-improvement to superintelligence

I would not, if I wanted to survive in a future AI world, want to be the bottleneck.
Discussion about this post
AI #150: While Claude Codes Read More »