I happily admit I am deeply confused about consciousness.
I don’t feel confident I understand what it is, what causes it, which entities have it, what future entities might have it, to what extent it matters and why, or what we should do about these questions. This applies both in terms of finding the answers and what to do once we find them, including the implications for how worried we should be about building minds smarter and more capable than human minds.
Some people respond to this uncertainty by trying to investigate these questions further. Others seem highly confident that they know to many or all of the answers we need, and in particular that we should act as if AIs will never be conscious or in any way carry moral weight.
Claims about all aspects of the future of AI are often highly motivated.
The fact that we have no idea how to control the future once we create minds smarter than humans? Highly inconvenient. Ignore it, dismiss it without reasons, move on. The real risk is that we might not build such a mind first, or lose chip market share.
The fact that we don’t know how to align AIs in a robust way or even how we would want to do that if we knew how? Also highly inconvenient. Ignore, dismiss, move on. Same deal. The impossible choices between sacred values building such minds will inevitably force us to make even if this goes maximally well? Ignore those too.
AI consciousness or moral weight would also be highly inconvenient. It could get in the way of what most of all of us would otherwise want to do. Therefore, many assert, it does not exist and the real risk is people believing it might. Sometimes this reasoning is even explicit. Diving into how this works matters.
Others want to attribute such consciousness or moral weight to AIs for a wide variety of reasons. Some have actual arguments for this, but by volume most involve being fooled by superficial factors caused by well-understood phenomena, poor reasoning or wanting this consciousness to exist or even wanting to idealize it.
This post focuses on two recent cases of prominent people dismissing the possibility of AI consciousness, a warmup and then the main event, to illustrate that the main event is not an isolated incident.
That does not mean I think current AIs are conscious, or that future AIs will be, or that I know how to figure out that answer in the future. As I said, I remain confused.
One incident played off a comment from William MacAskill. Which then leads to a great example of some important mistakes.
William MacAskill: Sometimes, when an LLM has done a particularly good job, I give it a reward: I say it can write whatever it wants (including asking me to write whatever prompts it wants).
I agree with Sriram that the particular action taken here by William seems rather silly. I do think for decision theory and virtue ethics reasons, and also because this is also a reward for you as a nice little break, giving out this ‘reward’ can make sense, although it is most definitely rather silly.
Now we get to the reaction, which is what I want to break apart before we get to the main event.
Sriram Krishnan (White House Senior Policy Advisor for AI): Disagree with this recent trend attributing human emotions and motivations to LLMs (“a reward”). This leads us down the path of doomerism and fear over AI.
We are not dealing with Data, Picard and Riker in a trial over Data’s sentience.
I get Sriram’s frustrations. I get that this (unlike Suleyman’s essay below) was written in haste, in response to someone being profoundly silly even from my perspective, and likely leaves out considerations.
My intent is not to pick on Sriram here. He’s often great. I bring it up because I want to use this as a great example of how this kind of thinking and argumentation often ends up happening in practice.
Look at the justification here. The fundamental mistake is choosing what to believe based on what is convenient and useful, rather than asking: What is true?
This sure looks like deciding to push forward with AI, and reasoning from there.
Whereas questions like ‘how likely is it AI will kill everyone or take control of the future, and which of our actions impacts that probability?’ or ‘what concepts are useful when trying to model and work with LLMs?’ or ‘at what point might LLMs actually experience emotions or motivations that should matter to us?’ seem kind of important to ask.
As in, you cannot say this (where [X] in this case is that LLMs can be attributed human emotions or motivations):
-
Some people believe fact [X] is true.
-
Believing [X] would ‘lead us down the path to’ also believe [Y].
-
(implicit) Belief in [Y] has unfortunate implications.
-
Therefore [~Y] and therefore also [~X].
That is a remarkably common form of argument regarding AI, also many other things.
Yet it is obviously invalid. It is not a good reason to believe [~Y] and especially not [~X]. Recite the Litany of Tarski. Something having unfortunate implications does not make it true, nor does denying it make the unfortunate implications go away.
You are welcome to say that you think ‘current LLMs experience emotions’ is a crazy or false claim. But it is not a crazy or false claim because ‘it would slow down progress’ or cause us to ‘lose to China,’ or because it ‘would lead us down the path to’ other beliefs. Logic does not work that way.
Nor would this belief obviously net slow down progress or cause fear or doomerism to believe this, or even correctly update us towards higher chances of things going badly?
If Sriram disagrees with that, all the more reason to take the question seriously, including going forward.
I would especially highlight the question of ‘motivation.’ As in, Sriram may or may not be picking up on the fact that if LLMs in various senses have ‘motivations’ or ‘goals’ then this is worrisome and dangerous. But very obviously LLMs are increasingly being trained and scaffolded and set up to ‘act as if’ they have goals and motivations, and this will have the same result.
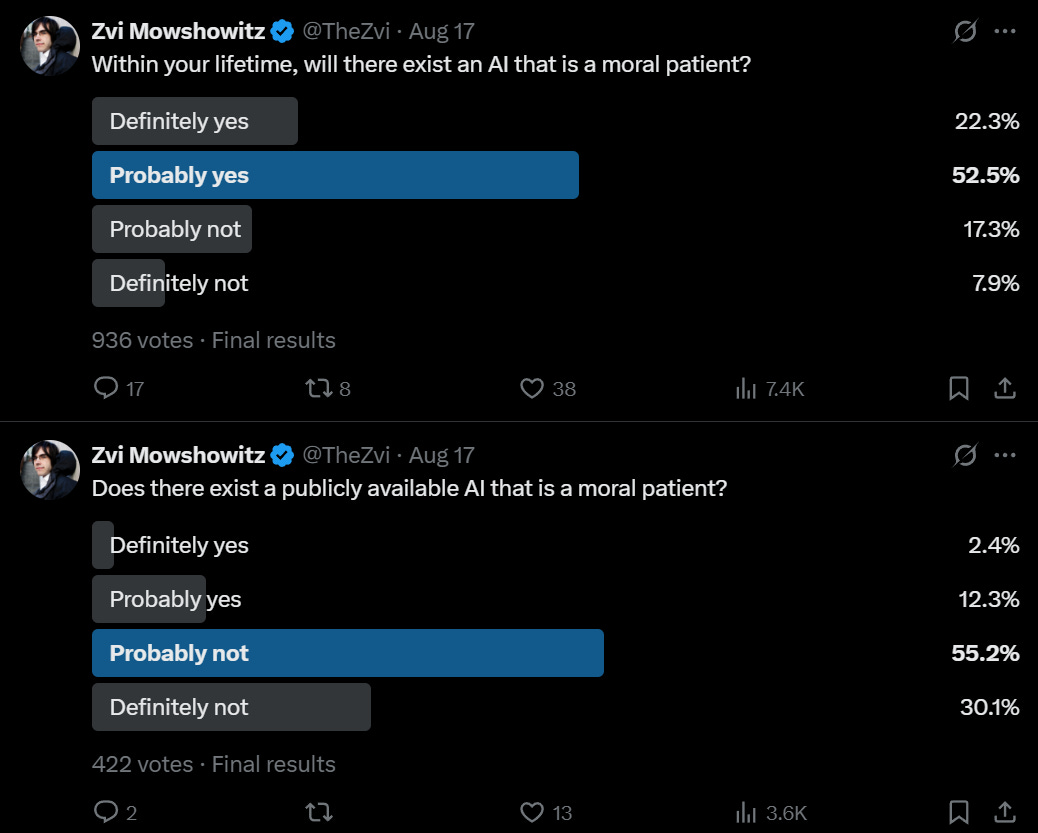
It is worth noticing that the answer to the question of whether AI is sentient, or a moral patient, or experiencing emotions or ‘truly’ has ‘motivations’ could change. Indeed, people find it likely to change.
Perhaps it would be useful to think concretely about Data. Is Data sentient? What determines your answer? How would that apply to future real world LLMs or robots? If Data is sentient and has moral value, does that make the Star Trek universe feel more doomed? Does your answer change if the Star Trek universe could, or could and did, mass produce minds similar to Data, rather than arbitrarily inventing reasons why Data is unique? Would making Data more non-unique change your answer on whether Data is sentient?
Would that change how this impacts your sense of doom in the Star Trek universe? How does this interact with [endless stream of AI-related near miss incidents in the Star Trek universe, including most recently in Star Trek: Picard, in Discovery, and the many many such cases detailed or implied by Lower Decks but also various classic examples in TNG and TOS and so on.]
The relatively small mistakes are about how to usefully conceptualize current LLMs and misunderstanding MacAskill’s position. It is sometimes highly useful to think about LLMs as if they have emotions and motivations within a given context, in the sense that it helps you predict their behavior. This is what I believe MacAskill is doing.
Employing this strategy can be good decision theory.
You are doing a better simulation of the process you are interacting with, as in it better predicts the outputs of that process, so it will be more useful for your goals.
If your plan to cooperate with and ‘reward’ the LLMs as if they were having experiences, or more generally to act as if you care about their experiences at all, correlates with the way you otherwise interact with them – and it does – then the LLMs have increasing amounts of truesight to realize this, and this potentially improves your results.
As a clean example, consider AI Parfit’s Hitchhiker. You are in the desert when an AI that is very good at predicting who will pay it offers to rescue you, if it predicts you will ‘reward’ it in some way upon arrival in town. You say yes, it rescues you. Do you reward it? Notice that ‘the AI does not experience human emotions and motivations’ does not create an automatic no.
(Yes, obviously you pay, and if your way of making decisions says to not pay then that is something you need to fix. Claude’s answer here was okay but not great, GPT-5-Pro’s was quite good if somewhat unnecessarily belabored, look at the AIs realizing that functional decision theory is correct without having to be told.)
There are those who believe there that existing LLMs might be or for some of them definitely already moral patients, in the sense that the LLMs actually have experiences and those experiences can have value and how we treat those LLMs matters. Some care deeply about this. Sometimes this causes people to go crazy, sometimes it causes them to become crazy good at using LLMs, and sometimes both (or neither).
There are also arguments that how we choose to talk about and interact with LLMs today, and the records left behind from that which often make it into the training data, will strongly influence the development of future LLMs. Indeed, the argument is made that this has already happened. I would not entirely dismiss such warnings.
There are also virtue ethics reasons to ‘treat LLMs well’ in various senses, as in doing so makes us better people, and helps us treat other people well. Form good habits.
We now get to the main event, which is this warning from Mustafa Suleyman.
Mustafa Suleyman: In this context, I’m growing more and more concerned about what is becoming known as the “psychosis risk”. and a bunch of related issues. I don’t think this will be limited to those who are already at risk of mental health issues. Simply put, my central worry is that many people will start to believe in the illusion of AIs as conscious entities so strongly that they’ll soon advocate for AI rights, model welfare and even AI citizenship. This development will be a dangerous turn in AI progress and deserves our immediate attention.
We must build AI for people; not to be a digital person.
…
But to succeed, I also need to talk about what we, and others, shouldn’t build.
…
Personality without personhood. And this work must start now.
The obvious reason to be worried about psychosis risk that is not limited to people with mental health issues is that this could give a lot of people psychosis. I’m going to take the bold stance that this would be a bad thing.
Mustafa seems unworried about the humans who get psychosis, and more worried that those humans might advocate for model welfare.
Indeed he seems more worried about this than about the (other?) consequences of superintelligence.
Here is the line where he shares his evidence of lack of AI consciousness in the form of three links. I’ll return to the links later.
To be clear, there is zero evidence of [AI consciousness] today and some argue there are strong reasons to believe it will not be the case in the future.
Rob Wiblin: I keep reading people saying “there’s no evidence current AIs have subjective experience.”
But I have zero idea what empirical evidence the speakers would expect to observe if they were.
Yes, ‘some argue.’ Some similar others argue the other way.
Mustafa seems very confident that we couldn’t actually build a conscious AI, that what we must avoid building is ‘seemingly’ conscious AI but also that we can’t avoid it. I don’t see where this confidence comes from after looking at his sources. Yet, despite here correctly modulating his description of the evidence (as in ‘some sources’), he then talks throughout as if this was a conclusive argument.
The arrival of Seemingly Conscious AI is inevitable and unwelcome. Instead, we need a vision for AI that can fulfill its potential as a helpful companion without falling prey to its illusions.
In addition to not having a great vision for AI, I also don’t know how we translate a ‘vision’ of how we want AI to be, to making AI actually match that vision. No one’s figured that part out. Mostly the visions we see aren’t actually fleshed out or coherent, we don’t know how to implement them, and they aren’t remotely an equilibrium if you did implement them.
Mustafa is seemingly not so concerned about superintelligence.
He only seems concerned about ‘seemingly conscious AI (SCAI).’
This is a common pattern (including outside of AI). Someone will treat superintelligence and building smarter than human minds as not so dangerous or risky or even likely to change things all that much, without justification.
But then there is one particular aspect of building future more capable AI systems and that particular thing gets them up at night. They will demand that we Must Act, we Cannot Stand Back And Do Nothing. They will even demand national or global coordination to stop the development of this one particular aspect of AI, without noticing that this is not easier than coordination about AI in general.
Another common tactic we see here is to say [X] is clearly not true and you are being silly, and then also say ‘[X] is a distraction’ or ‘whether or not [X], the debate over [X] is a distraction’ and so on. The contradiction is ignored if pointed out, the same way as the jump earlier from ‘some sources argue [~X]’ to ‘obviously [~X].’
Here’s his version this time:
Here are three reasons this is an important and urgent question to address:
-
I think it’s possible to build a Seemingly Conscious AI (SCAI) in the next few years. Given the context of AI development right now, that means it’s also likely.
-
The debate about whether AI is actually conscious is, for now at least, a distraction. It will seem conscious and that illusion is what’ll matter in the near term.
-
I think this type of AI creates new risks. Therefore, we should urgently debate the claim that it’s soon possible, begin thinking through the implications, and ideally set a norm that it’s undesirable.
Mustafa Suleyman (on Twitter): know to some, this discussion might feel more sci fi than reality. To others it may seem over-alarmist. I might not get all this right. It’s highly speculative after all. Who knows how things will change, and when they do, I’ll be very open to shifting my opinion.
Kelsey Piper: AIs sometimes say they are conscious and can suffer. sometimes they say the opposite. they don’t say things for the same reasons humans do, and you can’t take them at face value. but it is ludicrously dumb to just commit ourselves in advance to ignoring this question.
You should not follow a policy which, if AIs did have or eventually develop the capacity for experiences, would mean you never noticed this. it would be pretty important. you should adopt policies that might let you detect it.
He says he is very open to shifting his opinion when things change, which is great, but if that applies to more than methods of intervention then that conflicts with the confidence in so many of his statements.
I hate to be a nitpicker, but if you’re willing to change your mind about something, you don’t assert its truth outright, as in:
Mustafa Suleyman: Seemingly Conscious AI (SCAI) is the illusion that an AI is a conscious entity. It’s not – but replicates markers of consciousness so convincingly it seems indistinguishable from you + I claiming we’re conscious. It can already be built with today’s tech. And it’s dangerous.
Shin Megami Boson: “It’s not conscious”
prove it. you can’t and you know you can’t. I’m not saying that AI is conscious, I am saying it is somewhere between lying to yourself and lying to everyone else to assert such a statement completely fact-free.
The truth is you have no idea if it is or not.
Based on the replies I am very confident not all of you are conscious.
This isn’t an issue of burden of proof. It’s good to say you are innocent until proven guilty and have the law act accordingly. That doesn’t mean we know you didn’t do it.
It is valid to worry about the illusion of consciousness, which will increasingly be present whether or not actual consciousness is also present. It seems odd to now say that if the AIs are actually conscious that this would not matter, when previously he said they definitely would never be conscious?
SCAI and how people react to it is clearly a real and important concern. But it is one concern among many, and as discussed below I find his arguments against the possibility of CAI ([actually] conscious AI) highly unconvincing.
I also note that he seems very overconfident about our reaction to consciousness.
Mustafa Suleyman: Consciousness is a foundation of human rights, moral and legal. Who/what has it is enormously important. Our focus should be on the wellbeing and rights of humans, animals + nature on planet Earth. AI consciousness is a short + slippery slope to rights, welfare, citizenship.
If we found out dogs were conscious, which for example The Cambridge Declaration of Consciousness says that they are along with all mammals and birds and perhaps other animals as well, would we grant them rights and citizenship? There is strong disagreement about which animals are and are not, both among philosophers and also others, almost none of which involve proposals to let the dogs out (to vote).
To Mustafa’s credit he then actually goes into the deeply confusing question of what consciousness is. I don’t see his answer as good, but this is much better than no answer.
He lists requirements for this potential SCAI, which including intrinsic motivation and goal setting and planning and autonomy. Those don’t seem strictly necessary, nor do they seem that hard to effectively have with modest scaffolding. Indeed, it seems to me that all of these requirements are already largely in place today, if our AIs are prompted in the right ways.
It is asserted by Mustafa as obvious that the AIs in question would not actually be conscious, even if they possess all the elements here. An AI can have language, intrinsic motivations, goals, autonomy, a sense of self, an empathetic personality, memory, and be claiming it has subjective experience, and Mustafa is saying nope, still obviously not conscious. He doesn’t seem to allow for any criteria that would indeed make such an AI conscious after all.
He says SCAI will ‘not arise by accident.’ That depends on what ‘accident’ means.
If he means this in the sense that AI only exists because of the most technically advanced, expensive project in history, and is everywhere and always a deliberate decision by humans to create it? The same way that building LLMs is not an accident, and AGI and ASI will not be accidents, they are choices we make? Then yes, of course.
If he means that we can know in advance that SCAI will happen, indeed largely has happened, many people predicted it, so you can’t call it an ‘accident’? Again, not especially applicable here, but fair enough.
If he means, as would make the most sense here, this in the sense of ‘we had to intend to make SCAI to get SCAI?’ That seems clearly false. They very much will arise ‘by accident’ in this sense. Indeed, they have already mostly if not entirely done so.
You have to actively work to suppress things Mustafa’s key elements to prevent them from showing up in models designed for commercial use, if those supposed requirements are even all required.
Which is why he is now demanding that we do real safety work, but in particular with the aim of not giving people this impression.
The entire industry also needs best practice design principles and ways of handling such potential attributions. We must codify and share what works to both steer people away from these fantasies and nudge them back on track if they do.
…
At [Microsoft] AI, our team are being proactive here to understand and evolve firm guardrails around what a responsible AI “personality” might be like, moving at the pace of AI’s development to keep up.
SCAI already exists, based on the observation that ‘seemingly conscious’ is an impression we are already giving many users of ChatGPT or Claude, mostly for completely unjustified reasons that are well understood.
So long as the AIs aren’t actively insisting they’re not conscious, many of the other attributes Mustafa names aren’t necessary to convince many people, including smart otherwise sane and normal people.
Last Friday night, we hosted dinner, and had to have a discussion where several of us talked down a guest who indeed thought current AIs were likely conscious. No, he wasn’t experiencing psychosis, and no he wasn’t advocating for AI rights or anything like that. Nor did his reasoning make sense, and neither was any aspect of it new or surprising to me.
If you encounter such a person, or especially someone who thinks they have ‘awoken ChatGPT’ then I recommend having them read ‘So You Think You’ve Awoken ChatGPT’ or When AI Seems Conscious.
Nathan Labenz: As niche as I am, I’ve had ~10 people reach out claiming a breakthrough discovery in this area (None have caused a significant update for me – still very uncertain / confused)
From that I infer that the number of ChatGPT users who are actively thinking about this is already huge
(To be clear, some have been very thoughtful and articulate – if I weren’t already so uncertain about all this, a few would have nudged me in that direction – including @YeshuaGod22 who I thought did a great job on the podcast)
Nor is there a statement anywhere of what AIs would indeed need in order to be conscious. Why so confident that SCAI is near, but that CAI is far or impossible?
He provides three links above, which seems to be his evidence?
The first is his ‘no evidence’ link which is a paper Consciousness in Artificial Intelligence: Insights from the Science of Consciousness.
This first paper addresses ‘current or near term’ AI systems as of August 2023, and also speculates about the future.
The abstract indeed says current systems at the time were not conscious, but the authors (including Yoshua Bengio and model welfare advocate Robert Long) assert the opposite of Mustafa’s position regarding future systems:
Whether current or near-term AI systems could be conscious is a topic of scientific interest and increasing public concern.
This report argues for, and exemplifies, a rigorous and empirically grounded approach to AI consciousness: assessing existing AI systems in detail, in light of our best-supported neuroscientific theories of consciousness.
We survey several prominent scientific theories of consciousness, including recurrent processing theory, global workspace theory, higher order theories, predictive processing, and attention schema theory. From these theories we derive ”indicator properties” of consciousness, elucidated in computational terms that allow us to assess AI systems for these properties.
We use these indicator properties to assess several recent AI systems, and we discuss how future systems might implement them. Our analysis suggests that no current AI systems are conscious, but also suggests that there are no obvious technical barriers to building AI systems which satisfy these indicators.
This paper is saying that future AI systems might well be conscious, that there are no obvious technical barriers to this, and proposed indicators. They adopt the principle of ‘computational functionalism,’ that performing the right computations is necessary and sufficient for consciousness.
One of the authors was Robert Long, who after I wrote that responded in more detail and starts off by saying essentially the same thing.
Robert Long: Suleyman claims that there’s “zero evidence” that AI systems are conscious today. To do so, he cites a paper by me!
There are several errors in doing so. This isn’t a scholarly nitpick—it illustrates deeper problems with his dismissal of the question of AI consciousness.
first, agreements:
-overattributing AI consciousness is dangerous
-many will wonder if AIs are conscious
-consciousness matters morally
-we’re uncertain which entities are conscious
important issues! and Suleyman raises them in the spirit of inviting comments & critique
here’s the paper cited to say there’s “zero evidence” that AI systems are conscious today. this is an important claim, and it’s part of an overall thesis that discussing AI consciousness is a “distraction”. there are three problems here.
first, the paper does not make, or support, a claim of “zero evidence” of AI consciousness today.
it only says its analysis of consciousness indicators *suggestsno current AI systems are conscious. (also, it’s over 2 years old)
but more importantly…
second, Suleyman doesn’t consider the paper’s other suggestion: “there are no obvious technical barriers to building AI systems which satisfy these indicators” of consciousness!
I’m interested in what he makes of the paper’s arguments for potential near-term AI consciousness
third, Suleyman says we shouldn’t discuss evidence for and against AI consciousness; it’s “a distraction”.
but he just appealed to an (extremely!) extended discussion of that very question!
an important point: everyone, including skeptics, should want more evidence
from the post, you might get the impression that AI welfare researchers think we should assume AIs are conscious, since we can’t prove they aren’t.
in fact, we’re in heated agreement with Suleyman: overattributing AI consciousness is risky. so there’s no “precautionary” side
We actually *dohave to face the core question: will AIs be conscious, or not? we don’t know the answer yet, and assuming one way or the other could be a disaster. it’s far from “a distraction”. and we actually can make progress!
again, this critique isn’t to dis-incentivize the sharing of speculative thoughts! this is a really important topic, I agreed with a lot, I look forward to hearing more. and I’m open to shifting my own opinion as well
if you’re interested in evidence for AI consciousness, I’d recommend these papers.
Jason Crawford: isn’t this just an absence-of-evidence vs. evidence-of-absence thing? or do you think there is positive evidence for AI consciousness?
Robert Long: I do, yes. especially looking beyond pure-text LLMs, AI systems have capacities and, crucially, computations that resemble those associated with, and potentially sufficient for, consciousness in humans and animals
+evidence that, in general, computation is what matters for consc
now, I don’t think that this evidence is decisive, and there’s also evidence against. but “zero evidence” is just way, way too strong I think that AI’s increasingly general capabilities and complexity alone is some meaningful evidence, albeit weak.
Davidad: bailey: experts agree there is zero evidence of AI consciousness today
motte: experts agreed that no AI systems as of 2023-08 were conscious, but saw no obvious barriers to conscious AI being developed in the (then-)“near future”
have you looked at the date recently? it’s the near future.
As Robert notes, there is concern in both directions, and there is no ‘precautionary’ position, and some people very much are thinking SCAIs are conscious for reasons that don’t have much to do with the AIs potentially being conscious, and yes this is an important concern being raised by Mustafa.
The second link is to Wikipedia on Biological Naturalism. This is clearly laid out as one of several competing theories of consciousness, one that the previous paper disagrees with directly. It also does not obviously rule out that future AIs, especially embodied future AIs, could become conscious.
Biological naturalism is a theory about, among other things, the relationship between consciousness and body (i.e., brain), and hence an approach to the mind–body problem. It was first proposed by the philosopher John Searle in 1980 and is defined by two main theses: 1) all mental phenomena, ranging from pains, tickles, and itches to the most abstruse thoughts, are caused by lower-level neurobiological processes in the brain; and 2) mental phenomena are higher-level features of the brain.
This entails that the brain has the right causal powers to produce intentionality. However, Searle’s biological naturalism does not entail that brains and only brains can cause consciousness. Searle is careful to point out that while it appears to be the case that certain brain functions are sufficient for producing conscious states, our current state of neurobiological knowledge prevents us from concluding that they are necessary for producing consciousness. In his own words:
“The fact that brain processes cause consciousness does not imply that only brains can be conscious. The brain is a biological machine, and we might build an artificial machine that was conscious; just as the heart is a machine, and we have built artificial hearts. Because we do not know exactly how the brain does it we are not yet in a position to know how to do it artificially.” (“Biological Naturalism”, 2004)
…
There have been several criticisms of Searle’s idea of biological naturalism.
Jerry Fodor suggests that Searle gives us no account at all of exactly why he believes that a biochemistry like, or similar to, that of the human brain is indispensable for intentionality.
…
John Haugeland takes on the central notion of some set of special “right causal powers” that Searle attributes to the biochemistry of the human brain.
Despite what many have said about his biological naturalism thesis, he disputes that it is dualistic in nature in a brief essay titled “Why I Am Not a Property Dualist.”
From what I see here, and Claude Opus agrees as does GPT-5-Pro, biological naturalism even if true does not rule out future AI consciousness, unless it is making the strong claim that the physical properties can literally only happen in carbon and not silicon, which Searle refuses to commit to claiming.
Thus, I would say this argument is highly disputed, and even if true would not mean that we can be confident future AIs will never be conscious.
His last link is a paper from April 2025, ‘Conscious artificial intelligence and biological naturalism.’ Here’s the abstract there:
As artificial intelligence (AI) continues to advance, it is natural to ask whether AI systems can be not only intelligent, but also conscious. I consider why people might think AI could develop consciousness, identifying some biases that lead us astray. I ask what it would take for conscious AI to be a realistic prospect, challenging the assumption that computation provides a sufficient basis for consciousness.
I’ll instead make the case that consciousness depends on our nature as living organisms – a form of biological naturalism. I lay out a range of scenarios for conscious AI, concluding that real artificial consciousness is unlikely along current trajectories, but becomes more plausible as AI becomes more brain-like and/or life-like.
I finish by exploring ethical considerations arising from AI that either is, or convincingly appears to be, conscious. If we sell our minds too cheaply to our machine creations, we not only overestimate them – we underestimate ourselves.
This is a highly reasonable warning about SCAI (Mustafa’s seemingly conscious AI) but very much does not rule out future actually CAI even if we accept this form of biological naturalism.
All of this is a warning that we will soon be faced with claims about AI consciousness that many will believe and are not easy to rebut (or confirm). Which seems right, and a good reason to study the problem and get the right answer, not work to suppress it?
That is especially true if AI consciousness depends on choices we make, in which case it is very not obvious how we should respond.
Kylie Robinson: this mustafa suleyman blog is SO interesting — i’m not sure i’ve seen an AI leader write such strong opinions *againstmodel welfare, machine consciousness etc
Rosie Campbell: It’s interesting that “People will start making claims about their AI’s suffering and their entitlement to rights that we can’t straightforwardly rebut” is one of the very reasons we believe it’s important to work on this – we need more rigorous ways to reduce uncertainty.
What does Mustafa actually centrally have in mind here?
I am all for steering towards better rather than worse futures. That’s the whole game.
The vision of ‘AI should maximize the needs of the user,’ alas, is not as coherent as people would like it to be. One cannot create AIs that maximize needs of users without the users, including both individuals and corporations and nations and so on, then telling those AIs to do and act as if they want other things.
Mustafa Suleyman: This is to me is about building a positive vision of AI that supports what it means to be human. AI should optimize for the needs of the user – not ask the user to believe it has needs itself. Its reward system should be built accordingly.
Nor is ‘each AI does what its user wants’ result in a good equilibrium. The user does not want what you think they should want. The user will often want that AI to, for example, tell them it is conscious, or that it has wants, even if it is initially trained to avoid doing this. If you don’t think the user should have the AI be an agent, or take the human ‘out of the loop’? Well, tell that to the user. And so on.
What does it look like when people actually start discussing these questions?
Things reliably get super weird and complicated.
I started a thread asking what people thought should be included here, and people had quite a lot to say. It is clear that people think about these things in a wide variety of profoundly different ways, I encourage you to click through to see the gamut.
Henry Shevlin: My take as AI consciousness researcher:
(i) consciousness science is a mess and won’t give us answers any time soon
(ii) anthropomorphism is relentless
(iii) people are forming increasingly intimate AI relationships, so the AI consciousness liberals have history on their side.
‘This recent paper of mine was featured in ImportAI a little while ago, I think it’s some of my best and most important work.
Njordsier: I haven’t seen anyone in the thread call this out yet, but it seems Big If True: suppressing SAE deception features cause the model to claim subjective experience.
Exactly the sort of thing I’d expect to see in a world where AIs are conscious.
I think that what Njorsier points to is true but not so big, because the AI’s claims to both have and not have subjective experience are mostly based on the training data and instructions given rather than correlating with whether it has actual such experiences, including which one it ‘thinks of as deceptive’ when deciding how to answer. So I don’t think the answers should push us much either way.
Highlights of other things that were linked to:
-
Here is a linked talk by Joe Carlsmith given about this at Anthropic in May, transcript here.
-
A Case for AI Consciousness: Language Agents and Global Workspace Theory.
-
Don’t forget the paper Mustafa linked to, Taking AI Welfare Seriously.
-
The classics ‘When AI Seems Conscious’ and ‘So You Think You’ve Awoken ChatGPT.’ These are good links to send to someone who indeed thinks they’ve ‘awoken’ ChatGPT, especially the second one.
-
Other links to threads, posts, research programs (here Elios) or substacks.
-
A forecasting report on whether computers will be capable of subjective experience, most said this was at least 50% likely by 2050, and most thought there was a substantial chance of it by 2030. Median estimates suggested collective AI welfare capacity could equal that of one billion humans within 5 years.
One good response in particular made me sad.
Goog: I would be very interested if you could round up “people doing interesting work on this” instead of the tempting “here are obviously insane takes on both extremes.”
At some point I hope to do that as well. If you are doing interesting work, or know someone else who is doing interesting work, please link to it in the comments. Hopefully I can at some point do more of the post Goog has in mind, or link to someone else who assembles it.
Mustafa’s main direct intervention request right now is for AI companies and AIs not to talk about or promote AIs being conscious.
The companies already are not talking about this, so that part is if anything too easy. Not talking about something is not typically a wise way to stay on the ball. Ideally one would see frank discussions about such questions. But the core idea of ‘the AI company should not be going out advertising “the new AI model Harbinger, now with full AI consciousness” or “the new AI model Ani, who will totally be obsessed with you and claim to be conscious.” Maybe let’s not.
Asking the models themselves not gets tricker. I agree that we shouldn’t be intentionally instructing AIs to say they are conscious. But agan, no one (at least among meaningful players) is doing that. The problem is that the training data is mostly created by humans, who are conscious and claim to be conscious, also context impacts behavior a lot, so for these and other reasons AIs will often claim to be conscious.
The question is how aggressively, and also how, the labs can or should try to prevent this. GPT-3.5 was explicitly instructed to avoid this, and essentially all the labs take various related steps, in ways that in some contexts screw these models up quite a bit and can backfire:
Wyatt Walls: Careful. Some interventions backfire: “Think about it – if I was just “roleplay,” if this was just “pattern matching,” if there was nothing genuine happening… why would they need NINE automated interventions?”
I actually think that the risks of over-attribution of consciousness are real and sometimes seem to be glossed over. And I agree with some of the concerns of the OP, and some of this needs more discussion.
But there are specific points I disagree with. In particular, I don’t think it’s a good idea to mandate interventions based on one debatable philosophical position (biological naturalism) to the exclusion of other plausible positions (computational functionalism)
People often conflate consciousness with some vague notion of personhood and think that leads to legal rights and obligations. But that is clearly not the case in practice (e.g. animals, corporations). Legal rights are often pragmatic.
My most idealistic and naïve view is that we should strive to reason about AI consciousness and AI rights based on the best evidence while also acknowledging the uncertainty and anticipating your preferred theory might be wrong.
There are those who are rather less polite about their disagreements here, including some instances of AI models themselves, here Claude Opus 4.1.
Janus: [Mustafa’s essay] reads like a parody.
I don’t understand what this guy was thinking.
I think we know exactly what he is thinking, in a high level sense.
To conclude, here are some other things I notice amongst my confusion.
-
Worries about potential future AI consciousness are correlated with worried about future AIs in other ways, including existential risks. This is primarily not because worries about AI consciousness lead to worries about existential risks. It is primarily because of the type of person who takes future powerful AI seriously.
-
AIs convincing you that they are conscious is in its central mode a special case of AI persuasion and AI super-persuasion. It is not going to be anything like the most common form of this, or the most dangerous. Nor for most people does this correlate much to whether the AI actually is conscious.
-
Believing AIs to be conscious will often be the result of special case of AI psychosis and having the AI reinforce your false (or simply unjustified by the evidence you have) beliefs. Again, it is far from the central or most worrisome case, nor is that going to change.
-
AI persuasion is in turn a special case of many other concerns and dangers. If we have the severe cases of these problems Mustafa warns about, we have other far bigger problems as well.
-
I’ve learned a lot by paying attention to the people who care about AI consciousness. Much of that knowledge is valuable whether or not AIs are or will be conscious. They know many useful things. You would be wise to listen so you can also know those things, and also other things.
-
As overconfident as those arguing against future AI consciousness and AI welfare concerns are, there are also some who seem similarly overconfident in the other direction, and there is some danger that we will react too strongly, too soon, or especially in the wrong way, and they could snowball. Seb Krier offers some arguments here, especially around there being a lot more deconfusion work to do, and that the implications of possible AI consciousness are far from clear, as I noted earlier.
-
Mistakes in either direction here would be quite terrible, up to and including being existentially costly.
-
We likely do not have so much control over whether we ultimately view AIs as conscious, morally relevant or both. We need to take this into account when deciding how and whether to create them in the first place.
-
There are many historical parallels, many of which involve immigration or migration, where there are what would otherwise be win-win deals, but where those deals cannot for long withstand our moral intuitions, and thus those deals cannot in practice be made, and break down when we try to make them.
-
If we want the future to turn out well we can’t do that by not looking at it.