TR-49 is interactive fiction for fans of deep research rabbit holes

If you’re not comfortable staring at a screen like this for hours, you’d better stop reading right now.
Credit: Inkle
If you’re not comfortable staring at a screen like this for hours, you’d better stop reading right now. Credit: Inkle
While the catalog contains short excerpts from each of these discovered works, it’s the additional notes added to each entry by subsequent researchers that place each title in its full context. You’ll end up poring through these research notes for clues about the existence and chronology of other authors and works. Picking out specific names and years points to the codes and titles needed to unlock even more reference pages in the computer, pushing you further down the rabbit hole. Picture something like Her Story, but replace the cinéma vérité surveillance video clips with a library card catalog.
You’ll slowly start to unravel and understand how the game world’s myriad authors are influencing each other with their cross-pollinating writings. The treatises, novels, pamphlets, and journals discussed in this database are full of academic sniping, intellectual intrigue, and interpersonal co-mingling across multiple generations of work. It all ends up circling a long-running search for a metaphysical key to life itself, which most of the authors manage to approach but never quite reach a full understanding.
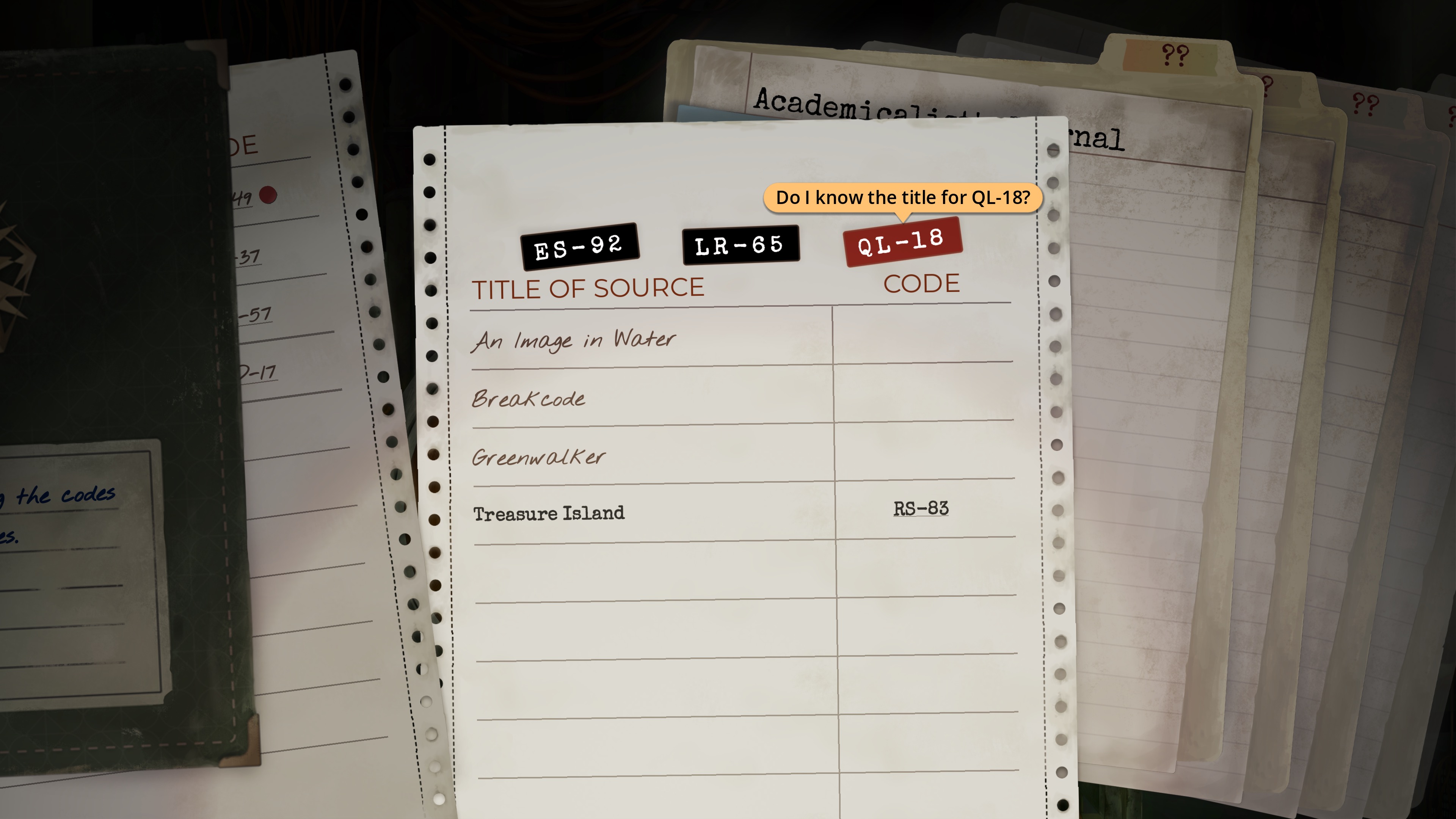
Matching titles to reference codes form the most “gamey” part of the game.
Credit: Inkle
Matching titles to reference codes form the most “gamey” part of the game. Credit: Inkle
As you explore, you also start to learn more about the personal affairs of the researchers who collected and cataloged all this reference material and the vaguely defined temporal capabilities of the information-synthesis engine in the computer you’ve all worked on. Eventually, you’ll stumble on the existence of core commands that can unlock hidden parts of the computer or alter the massive research database itself, which becomes key to your eventual final goal.
Through it all, there’s a slowly unfolding parallel narrative involving Liam, the unseen voice guiding you through the research process itself. Through occasional voice clips, Liam eventually hints at the existence of a powerful and quickly encroaching threat that wants to stop your progress by any means necessary, adding a bit of dramatic tension to your academic pursuits.
TR-49 is interactive fiction for fans of deep research rabbit holes Read More »