On Google’s Safety Plan
I want to start off by reiterating kudos to Google for actually laying out its safety plan. No matter how good the plan, it’s much better to write down and share the plan than it is to not share the plan, which in turn is much better than not having a formal plan.
They offer us a blog post, a full monster 145 page paper (so big you have to use Gemini!) and start off the paper with a 10 page summary.
The full paper is full of detail about what they think and plan, why they think and plan it, answers to objections and robust discussions. I can offer critiques, but I couldn’t have produced this document in any sane amount of time, and I will be skipping over a lot of interesting things in the full paper because there’s too much to fully discuss.
This is The Way.
Google makes their core assumptions explicit. This is so very much appreciated.
They believe, and are assuming, from section 3 and from the summary:
-
The current paradigm of AI development will hold for a while.
-
No human ceiling on AI capabilities.
-
Timelines are unclear. Powerful AI systems might be developed by 2030.
-
Powerful AI systems might accelerate AI R&D in a feedback loop (RSI).
-
There will not be large discontinuous jumps in AI capabilities.
-
Risks primarily will come from centralized AI development.
Their defense of the first claim (found in 3.1) is strong and convincing. I am not as confident as they seem to be, I think they should be more uncertain, but I accept the assumption within this context.
I strongly agree with the next three assumptions. If you do not, I encourage you to read their justifications in section 3. Their discussion of economic impacts suffers from ‘we are writing a paper and thus have to take the previously offered papers seriously so we simply claim there is disagreement rather than discuss the ground physical truth,’ so much of what they reference is absurd, but it is what it is.
That fifth assumption is scary as all hell.
While we aim to handle significant acceleration, there are limits. If, for example, we jump in a single step from current chatbots to an AI system that obsoletes all human economic activity, it seems very likely that there will be some major problem that we failed to foresee. Luckily, AI progress does not appear to be this discontinuous.
So, we rely on approximate continuity: roughly, that there will not be large discontinuous jumps in general AI capabilities, given relatively gradual increases in the inputs to those capabilities (such as compute and R&D effort).
…
Implication: We can iteratively and empirically test our approach, to detect any flawed assumptions that only arise as capabilities improve.
Implication: Our approach does not need to be robust to arbitrarily capable AI systems. Instead, we can plan ahead for capabilities that could plausibly arise during the next several scales, while deferring even more powerful capabilities to the future.
I do not consider this to be a safe assumption. I see the arguments from reference classes and base rates and competitiveness, I am definitely factoring that all in, but I am not confident in it at all. There have been some relatively discontinuous jumps already (e.g. GPT-3, 3.5 and 4), at least from the outside perspective. I expect more of them to exist by default, especially once we get into the RSI-style feedback loops, and I expect them to have far bigger societal impacts than previous jumps. And I expect some progressions that are technically ‘continuous’ to not feel continuous in practice.
Google says that threshold effects are the strongest counterargument. I definitely think this is likely to be a huge deal. Even if capabilities are continuous, the ability to pull off a major shift can make the impacts look very discontinuous.
We are all being reasonable here, so this is us talking price. What would be ‘too’ large, frequent or general an advance that breaks this assumption? How hard are we relying on it? That’s not clear.
But yeah, it does seem reasonable to say that if AI were to suddenly tomorrow jump forward to ‘obsoletes all human economic activity’ overnight, that there are going to be a wide variety of problems you didn’t see coming. Fair enough. That doesn’t even have to mean that we lose.
I do think it’s fine to mostly plan for the ‘effectively mostly continuous for a while’ case, but we also need to be planning for the scenario where that is suddenly false. I’m not willing to give up on those worlds. If a discontinuous huge jump were to suddenly come out of a DeepMind experiment, you want to have a plan for what to do about that before it happens, not afterwards.
That doesn’t need to be as robust and fleshed out as our other plans, indeed it can’t be, but there can’t be no plan at all. The current plan is to ‘push the big red alarm button.’ That at minimum still requires a good plan and operationalization for when who gets to and needs to push that button, along with what happens after they press it. Time will be of the essence, and there will be big pressures not to do it. So you need strong commitments in advance, including inside companies like Google.
The other reason this is scary is that it implies that continuous capability improvements will lead to essentially continuous behaviors. I do not think this is the case either. There are likely to be abrupt shifts in observed outputs and behaviors once various thresholds are passed and new strategies start to become viable. The level of risk increasing continuously, or even gradually, is entirely consistent with the risk then suddenly materializing all at once. Many such cases. The paper is not denying or entirely ignoring this, but it seems under-respected throughout in the ‘talking price’ sense.
The additional sixth assumption comes from section 2.1:
However, our approach does rely on assumptions about AI capability development: for example, that dangerous capabilities will arise in frontier AI models produced by centralized development. This assumption may fail to hold in the future. For example, perhaps dangerous capabilities start to arise from the interaction between multiple components (Drexler, 2019), where any individual component is easy to reproduce but the overall system would be hard to reproduce.
In this case, it would no longer be possible to block access to dangerous capabilities by adding mitigations to a single component, since a bad actor could simply recreate that component from scratch without the mitigations.
This is an assumption about development, not deployment, although many details of Google’s approaches do also rely on centralized deployment for the same reason. If the bad actor can duplicate the centrally developed system, you’re cooked.
Thus, there is a kind of hidden assumption throughout all similar discussions of this, that should be highlighted, although fixing this is clearly outside scope of this paper: That we are headed down a path where mitigations are possible at reasonable cost, and are not at risk of path dependence towards a world where that is not true.
The best reason to worry about future risks now even with an evidence dilemma is they inform us about what types of worlds allow us to win, versus which ones inevitably lose. I worry that decisions that are net positive for now can set us down paths where we lose our ability to steer even before AI takes the wheel for itself.
The weakest of their justifications in section 3 was in 3.6, explaining AGI’s benefits. I don’t disagree with anything in particular, and certainly what they list should be sufficient, but I always worry when such write-ups do not ‘feel the AGI.’
They start off with optimism, touting AGI’s potential to ‘transform the world.’
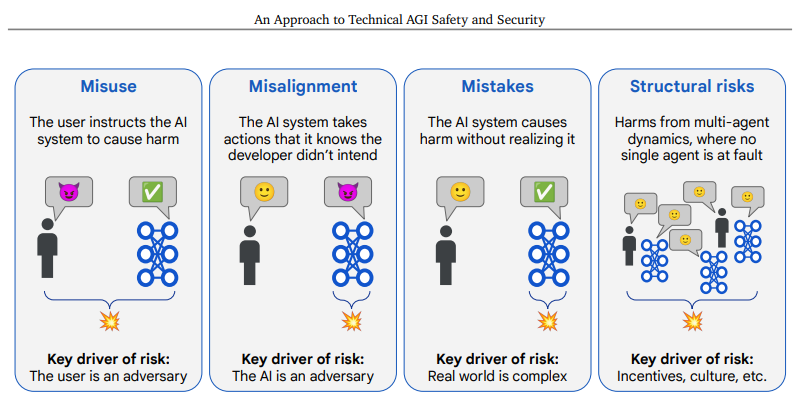
Then they quickly pivot to discussing their four risk areas: Misuse, Misalignment, Mistakes and Structural Risks.
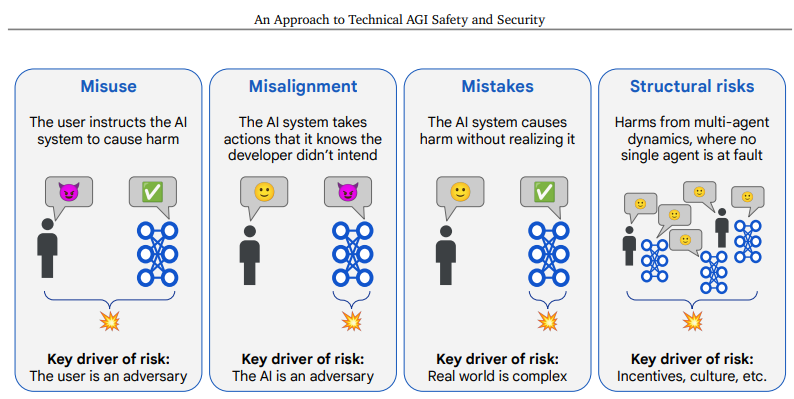
Google does not claim this list is exhaustive or exclusive. How close is this to a complete taxonomy? For sufficiently broad definitions of everything, it’s close.
This is kind of a taxonomy of fault. As in, if harm resulted, whose fault is it?
-
Misuse: You have not been a good user.
-
Misalignment: I have not been a good Gemini, on purpose.
-
Mistakes: I have not been a good Gemini, by accident.
-
Structural Risks: Nothing is ever anyone’s fault per se.
The danger as always with such classifications is that ‘fault’ is not an ideal way of charting optimal paths through causal space. Neither is classifying some things as harm versus others not harm. They are approximations that have real issues in the out of distribution places we are headed.
In particular, as I parse this taxonomy the Whispering Earring problem seems not covered. One can consider this the one-human-agent version of Gradual Disempowerment. This is where the option to defer to the decisions of the AI, or to use the AI’s capabilities, over time causes a loss of agency and control by the individual who uses it, leaving them worse off, but without anything that could be called a particular misuse, misalignment or AI mistake. They file this under structural risks, which is clearly right for a multi-human-agent Gradual Disempowerment scenario, but feels to me like it importantly misses the single-agent case even if it’s happening at scale, but it’s definitely weird.
Also, ‘the human makes understandable mistakes because the real world is complex and the AI does what the human asked but the human was wrong’ is totally a thing. Indeed, we may have had a rather prominent example of this on April 2, 2025.
Perhaps one can solve this by expanding mistakes into AI mistakes and also human mistakes – the user isn’t intending to cause harm or directly requesting it, the AI is correctly doing what the human intended, but the human was making systematic mistakes, because humans have limited compute and various biases and so on.
The good news is that if we solve the four classes of risk listed here, we can probably survive the rest long enough to fix what slipped through the cracks. At minimum, it’s a great start, and doesn’t miss any of the big questions if all four are considered fully. The bigger risk with such a taxonomy is to define the four items too narrowly. Always watch out for that.
This is The Way:
Extended Abstract: AI, and particularly AGI, will be a transformative technology. As with any transformative technology, AGI will provide significant benefits while posing significant risks.
This includes risks of severe harm: incidents consequential enough to significantly harm humanity. This paper outlines our approach to building AGI that avoids severe harm.
Since AGI safety research is advancing quickly, our approach should be taken as exploratory. We expect it to evolve in tandem with the AI ecosystem to incorporate new ideas and evidence.
Severe harms necessarily require a precautionary approach, subjecting them to an evidence dilemma: research and preparation of risk mitigations occurs before we have clear evidence of the capabilities underlying those risks.
We believe in being proactive, and taking a cautious approach by anticipating potential risks, even before they start to appear likely. This allows us to develop a more exhaustive and informed strategy in the long run.
Nonetheless, we still prioritize those risks for which we can foresee how the requisite capabilities may arise, while deferring even more speculative risks to future research.
Specifically, we focus on capabilities in foundation models that are enabled through learning via gradient descent, and consider Exceptional AGI (Level 4) from Morris et al. (2023), defined as an AI system that matches or exceeds that of the 99th percentile of skilled adults on a wide range of non-physical tasks.
…
For many risks, while it is appropriate to include some precautionary safety mitigations, the majority of safety progress should be achieved through an “observe and mitigate” strategy. Specifically, the technology should be deployed in multiple stages with increasing scope, and each stage should be accompanied by systems designed to observe risks arising in practice, for example through monitoring, incident reporting, and bug bounties.
After risks are observed, more stringent safety measures can be put in place that more precisely target the risks that happen in practice.
Unfortunately, as technologies become ever more powerful, they start to enable severe harms. An incident has caused severe harm if it is consequential enough to significantly harm humanity. Obviously, “observe and mitigate” is insufficient as an approach to such harms, and we must instead rely on a precautionary approach.
Yes. It is obvious. So why do so many people claim to disagree? Great question.
They explicitly note that their definition of ‘severe harm’ has a vague threshold. If this were a law, that wouldn’t work. In this context, I think that’s fine.
In 6.5, they discuss the safety-performance tradeoff. You need to be on the Production Possibilities Frontier (PPF).
Building advanced AI systems will involve many individual design decisions, many of which are relevant to building safer AI systems.
This section discusses design choices that, while not enough to ensure safety on their own, can significantly aid our primary approaches to risk from misalignment. Implementing safer design patterns can incur performance costs. For example, it may be possible to design future AI agents to explain their reasoning in human-legible form, but only at the cost of slowing down such agents.
To build AI systems that are both capable and safe, we expect it will be important to navigate these safety-performance tradeoffs. For each design choice with potential safety-performance tradeoffs, we should aim to expand the Pareto frontier.
This will typically look like improving the performance of a safe design to reduce its overall performance cost.
As always: Security is capability, even if you ignore the tail risks. If your model is not safe enough to use, then it is not capable in ways the help you. There are tradeoffs to be made, but no one except possibly Anthropic is close to where the tradeoffs start.
In highlighting the evidence dilemma, Google explicitly draws the distinction in 2.1 between risks that are in-scope for investigation now, versus those that we should defer until we have better evidence.
Again, the transparency is great. If you’re going to defer, be clear about that. There’s a lot of very good straight talk in 2.1.
They are punting on goal drift (which they say is not happening soon, and I suspect they are already wrong about that), superintelligence and RSI.
They are importantly not punting on particular superhuman abilities and concepts. That is within scope. Their plan is to use amplified oversight.
As I note throughout, I have wide skepticism on the implementation details of amplified oversight, and on how far it can scale. The disagreement is over how far it scales before it breaks, not whether it will break with scale. We are talking price.
Ultimately, like all plans these days, the core plan is bootstrapping. We are going to have the future more capable AIs do our ‘alignment homework.’ I remember when this was the thing us at LessWrong absolutely wanted to avoid asking them to do, because the degree of difficulty of that task is off the charts in terms of the necessary quality of alignment and understanding of pretty much everything – you really want to find a way to ask for almost anything else. Nothing changed. Alas, we seem to be out of practical options, other than hoping that this still somehow works out.
As always, remember the Sixth Law of Human Stupidity. If you say something like ‘no one would be so stupid as to use a not confidently aligned model to align the model that will be responsible for your future safety’ I have some bad news for you.
Not all of these problems can or need to be Google’s responsibility. Even to the extent that they are Google’s responsibility, that doesn’t mean their current document or plans need to fully cover them.
We focus on technical research areas that can provide solutions that would mitigate severe harm. However, this is only half of the picture: technical solutions should be complemented by effective governance.
Many of these problems, or parts of these problems, are problems for Future Google and Future Earth, that no one knows how to solve in a way we would find acceptable. Or at least, the ones who talk don’t know, and the ones who know, if they exist, don’t talk.
Other problems are not problems Google is in any position to solve, only to identify. Google doesn’t get to Do Governance.
The virtuous thing to do is exactly what Google is doing here. They are laying out the entire problem, and describing what steps they are taking to mitigate what aspects of the problem.
Right now, they are only focusing here on misuse and misalignment. That’s fine. If they could solve those two that would be fantastic. We’d still be on track to lose, these problems are super hard, but we’d be in a much better position.
For mistakes, they mention that ‘ordinary engineering practices’ should be effective. I would expand that to ‘ordinary practices’ overall. Fixing mistakes is the whole intelligence bit, and without an intelligent adversary you can use the AI’s intelligence and yours to help fix this the same as any other problem. If there’s another AI causing yours to mess up, that’s a structural risk. And that’s definitely not Google’s department here.
I have concerns about this approach, but mostly it is highly understandable, especially in the context of sharing all of this for the first time.
Here’s the abstract:
Artificial General Intelligence (AGI) promises transformative benefits but also presents significant risks. We develop an approach to address the risk of harms consequential enough to significantly harm humanity. We identify four areas of risk: misuse, misalignment, mistakes, and structural risks.
Of these, we focus on technical approaches to misuse and misalignment.
A larger concern is their limitation focusing on near term strategies.
We also focus primarily on techniques that can be integrated into current AI development, due to our focus on anytime approaches to safety.
While we believe this is an appropriate focus for a frontier AI developer’s mainline safety approach, it is also worth investing in research bets that pay out over longer periods of time but can provide increased safety, such as agent foundations, science of deep learning, and application of formal methods to AI.
We focus on risks arising in the foreseeable future, and mitigations we can make progress on with current or near-future capabilities.
The assumption of approximate continuity (Section 3.5) justifies this decision: since capabilities typically do not discontinuously jump by large amounts, we should not expect such risks to catch us by surprise.
Nonetheless, it would be even stronger to exhaustively cover future developments, such as the possibility that AI scientists develop new offense-dominant technologies, or the possibility that future safety mitigations will be developed and implemented by automated researchers.
Finally, it is crucial to note that the approach we discuss is a research agenda. While we find it to be a useful roadmap for our work addressing AGI risks, there remain many open problems yet to be solved. We hope the research community will join us in advancing the state of the art of AGI safety so that we may access the tremendous benefits of safe AGI.
Even if future risks do not catch us by surprise, that does not mean we can afford to wait to start working on them or understanding them. Continuous and expected can still be remarkably fast. Giving up on longer term investments seems like a major mistake if done collectively. Google doesn’t have to do everything, others can hope to pick up that slack, but Google seems like a great spot for such work.
Ideally one would hand off the longer term work to academia, where they could take on the ‘research risk,’ have longer time horizons and use their vast size and talent pools, and largely follows curiosity without needing to prove direct application. That sounds great.
Unfortunately, that does not sound like 2025’s academia. I don’t see academia as making meaningful contributions, due to a combination of lack of speed, lack of resources, lack of ability and willingness to take risk and a lack of situational awareness. Those doing meaningful such work outside the labs mostly have to raise their funding from safety-related charities, and there’s only so much capacity there.
I’d love to be wrong about that. Where’s the great work I’m missing?
Obviously, if there’s a technique where you can’t make progress with current or near-future capabilities, then you can’t make progress. If you can’t make progress, then you can’t work on it. In general I’m skeptical of claims that [X] can’t be worked on yet, but it is what it is.
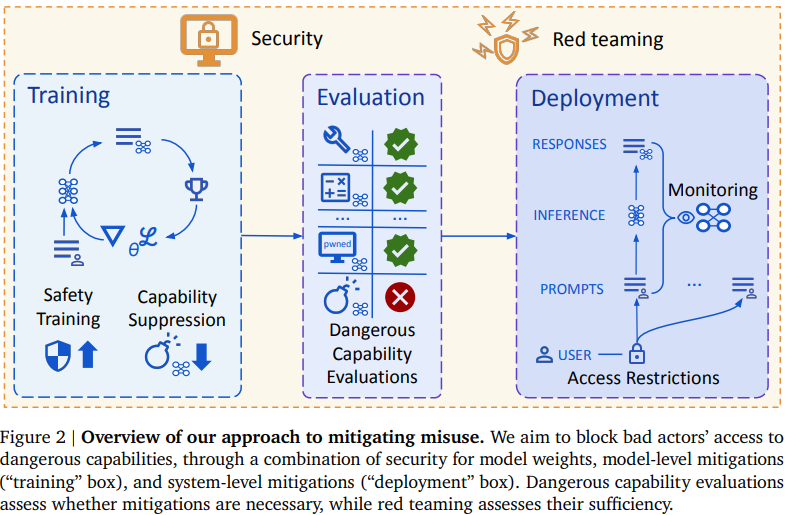
The traditional way to define misuse is to:
-
Get a list of the harmful things one might do.
-
Find ways to stop the AI from contributing too directly to those things.
-
Try to tell the model to also refuse anything ‘harmful’ that you missed.
The focus here is narrowly a focus on humans setting out to do intentional and specific harm, in ways we all agree are not to be allowed.
The term of art is the actions taken to stop this are ‘mitigations.’
Abstract: For misuse, our strategy aims to prevent threat actors from accessing dangerous capabilities, by proactively identifying dangerous capabilities, and implementing robust security, access restrictions, monitoring, and model safety mitigations.
Blog Post: As we detail in the paper, a key element of our strategy is identifying and restricting access to dangerous capabilities that could be misused, including those enabling cyber attacks.
We’re exploring a number of mitigations to prevent the misuse of advanced AI. This includes sophisticated security mechanisms which could prevent malicious actors from obtaining raw access to model weights that allow them to bypass our safety guardrails; mitigations that limit the potential for misuse when the model is deployed; and threat modelling research that helps identify capability thresholds where heightened security is necessary.
Additionally, our recently launched cybersecurity evaluation framework takes this work step a further to help mitigate against AI-powered threats.
The first mitigation they use is preventing anyone else from stealing the weights.
This is necessary because if the would-be misuser has their hands on the weights, you won’t be able to use any of your other mitigations. If you built some into the model, then they too can be easily removed.
They mention that the special case is to check if the model can even do the harms you are worried about, because if it can’t then you can skip the mitigations entirely. That is presumably the special case they are using for Gemma.
Once you can actually implement safety guardrails, you can then implement safety guardrails. Google very much does this, and it models those threats to figure out where and how to lay down those guardrails.
They appear to be using the classic guardrails:
-
The model is trained not to do the harmful things. This mostly means getting it to refuse. They’re also looking into unlearning, but that’s hard, and I basically would assume it won’t work on sufficiently capable models, they’ll rederive everything.
-
A monitor in the background looks for harmful things and censors the chat.
-
They nominally try to keep bad actors from accessing the model. I don’t see this as having much chance of working.
-
They’re Google, so ‘harden everyone’s defenses against cyberattacks’ is an actually plausible defense-in-depth plan, and kudos on Google for attempting it.
They then aim to produce safety cases against misuse, based on a combination of red teaming and inability. For now in practice I would only allow inability, and inability is going to be fading away over time. I worry a lot about thinking a given model is unable to do various things but not giving it the right scaffolding during testing.
In the short term, if anything Google is a bit overzealous with the guardrails, and include too many actions into what counts as ‘harmful,’ although they still would not stop a sufficiently skilled and determined user for long. Thus, even though I worry going forward about ‘misuses’ that this fails to anticipate, for now I’d rather make that mistake more often on the margin. We can adjust as we go.
Section 5 discusses the implementation details and difficulties involved here. There are good discussions and they admit the interventions won’t be fully robust, but I still found them overly optimistic, especially on access control, jailbreaking and capability suppression. I especially appreciated discussions on environment hardening in 5.6.2, encryption in 5.6.3 and Societal readiness in 5.7, although ‘easier said than done’ most definitely applies throughout.
For AGI to truly complement human abilities, it has to be aligned with human values. Misalignment occurs when the AI system pursues a goal that is different from human intentions.
…
From 4.2: Specifically, we say that the AI’s behavior is misaligned if it produces outputs that cause harm for intrinsic reasons that the system designers would not endorse. An intrinsic reason is a factor that can in principle be predicted by the AI system, and thus must be present in the AI system and/or its training process.
Technically I would say a misaligned AI is one that would do misaligned things, rather than the misalignment occurring in response to the user command, but we understand each other there.
The second definition involves a broader and more important disagreement, if it is meant to be a full description rather than a subset of misalignment, as it seems in context to be. I do not think a ‘misaligned’ model needs to produce outputs that ‘cause harm,’ it merely needs to for reasons other than the intent of those creating or using it cause importantly different arrangements of atoms and paths through causal space. We need to not lock into ‘harm’ as a distinct thing. Nor should we be tied too much to ‘intrinsic reasons’ as opposed to looking at what outputs and results are produced.
Does for example sycophancy or statistical bias ‘cause harm’? Sometimes, yes, but that’s not the right question to ask in terms of whether they are ‘misalignment.’ When I read section 4.2 I get the sense this distinction is being gotten importantly wrong.
I also get very worried when I see attempts to treat alignment as a default, and misalignment as something that happens when one of a few particular things go wrong. We have a classic version of this in 4.2.3:
There are two possible sources of misalignment: specification gaming and goal misgeneralization.
Specification gaming (SG) occurs when the specification used to design the AI system is flawed, e.g. if the reward function or training data provide incentives to the AI system that are inconsistent with the wishes of its designers (Amodei et al., 2016b). Specification gaming is a very common phenomenon, with numerous examples across many types of AI systems (Krakovna et al., 2020).
Goal misgeneralization (GMG) occurs if the AI system learns an unintended goal that is consistent with the training data but produces undesired outputs in new situations (Langosco et al., 2023; Shah et al., 2022). This can occur if the specification of the system is underspecified (i.e. if there are multiple goals that are consistent with this specification on the training data but differ on new data).
Why should the AI figure out the goal you ‘intended’? The AI is at best going to figure out the goal you actually specify with the feedback and data you provide. The ‘wishes’ you have are irrelevant. When we say the AI is ‘specification gaming’ that’s on you, not the AI. Similarly, ‘goal misgeneralization’ means the generalization is not what you expected or wanted, not that the AI ‘got it wrong.’
You can also get misalignment in other ways. The AI could fail to be consistent with or do well on the training data or specified goals. The AI could learn additional goals or values because having those goals or values improves performance for a while, then permanently be stuck with this shift in goals or values, as often happens to humans. The human designers could specify or aim for an ‘alignment’ that we would think of as ‘misaligned,’ by mistake or on purpose, which isn’t discussed in the paper although it’s not entirely clear where it should fit, by most people’s usage that would indeed be misalignment but I can see how saying that could end up being misleading. You could be trying to do recursive self-improvement with iterative value and goal drift.
In some sense, yes, the reason the AI does not have goal [X] is always going to be that you failed to specify an optimization problem whose best in-context available solution was [X]. But that seems centrally misleading in a discussion like this.
Misalignment is caused by a specification that is either incorrect (SG) or underspecified (GMG).
Yes, in a mathematical sense I cannot argue with that. It’s an accounting identity. But your specification will never, ever be fully correct, because it is a finite subset of your actual preferences, even if you do know them and wouldn’t have to pay to know what you really think and were thinking exactly correctly.
In practice: Do we need the AGI to be ‘aligned with’ ‘human values’? What exactly does that mean? There are certainly those who argue you don’t need this, that you can use control mechanisms instead and it’s fine. The AGI still has to understand human values on a practical level sufficient for the task, which is fine right now and will get increasingly tricky as things get weird, but that’s different.
I think you mostly do need the AGI to be either corrigible or aligned with human values, in some intuitive sense that is very hard to pin down that comes down to wanting to adhere to the spirit of various human intents and what humans broadly care about in the right tricky combinations, or else you end up with ‘the genie knows what you meant but does not care’ problems.
We have previously shown how misalignment can arise with our examples of specification gaming, where an AI finds a solution to achieve its goals, but not in the way intended by the human instructing it, and goal misgeneralization.
For example, an AI system asked to book tickets to a movie might decide to hack into the ticketing system to get already occupied seats – something that a person asking it to buy the seats may not consider.
They’re good examples. I worry these two examples are too similar within a much wider space, as they point to a particular failure mode where humans at some level would assign negative value to certain types of actions, but the humans didn’t specify this, and the AI either doesn’t notice or it notices and doesn’t sufficiently care. It’s very tricky to get this right, for many reasons.
We’re also conducting extensive research on the risk of deceptive alignment, i.e. the risk of an AI system becoming aware that its goals do not align with human instructions, and deliberately trying to bypass the safety measures put in place by humans to prevent it from taking misaligned action.
That is indeed a very different and important type of misalignment. Google is generalizing the term here a bit more than how I’ve been using it. This definition seems to include some other modes one might precisely call non-deceptive adversarial misalignment, or just misalignment full stop.
To me, deceptive alignment is where the AI ‘pretends to be aligned’ or otherwise deceives us about its attributes. Whereas by Google’s definition it would also include shooting you in the face. That often will bypasses some of your safety measures.
Google does intend to supplement its alignment efforts with control efforts:
Second, system-level security measures such as monitoring and access control can mitigate harm even if the model is misaligned. Techniques from interpretability, uncertainty estimation, and safer design patterns can enhance the effectiveness of these mitigations.
Finally, we briefly outline how these ingredients could be combined to produce safety cases for AGI systems.
It’s clear that Google sees control as defense-in-depth and the long term Plan B. I continue to be deeply skeptical of the value of control plans for superintelligent systems. I expect them to predictably fail when you need them, and I also worry that using them too aggressively can make the problem harder because AIs consider their full context. Of course I do agree that you want to be monitoring for misalignment as part of your defense-in-depth, there’s no reason not to do that.
I love the idea of safety cases for AGI. I have no idea how to actually create one. I know that very smart people like Davidad think this can be made into A Thing, but I don’t understand why they believe that.
This is of course the biggest question. What is the alignment plan?
From the Abstract: To address misalignment, we outline two lines of defense.
First, model-level mitigations such as amplified oversight and robust training can help to build an aligned model.
From the Blog: Our goal is to have advanced AI systems that are trained to pursue the right goals, so they follow human instructions accurately, preventing the AI using potentially unethical shortcuts to achieve its objectives.
We do this through amplified oversight, i.e. being able to tell whether an AI’s answers are good or bad at achieving that objective. While this is relatively easy now, it can become challenging when the AI has advanced capabilities.
I notice this is not an alignment plan so much as it is a plan to detect misalignment. That’s super useful, but it is not an alignment plan. The alignment plan is then to train the AI using this knowledge so it stops doing detectable misalignment.
Once we can tell whether an answer is good, we can use this to build a safe and aligned AI system. A challenge here is to figure out what problems or instances to train the AI system on. Through work on robust training, uncertainty estimation and more, we can cover a range of situations that an AI system will encounter in real-world scenarios, creating AI that can be trusted.
And then hope that you taught the system to be robustly aligned including out of your distribution, rather teaching it to look aligned. Most such plans can’t possibly work if the underlying systems get sufficiently capable. What makes this one different?
From the summary section: Our approach has two lines of defense. First, we aim to use model level mitigations to ensure the model does not pursue misaligned goals. We follow the standard ML playbook: (1) improve the ability to get good oversight (amplified oversight), (2) use this to improve the model (guiding model behavior), and (3) figure out where oversight is needed to train a model that will robustly do what we want (robust training).
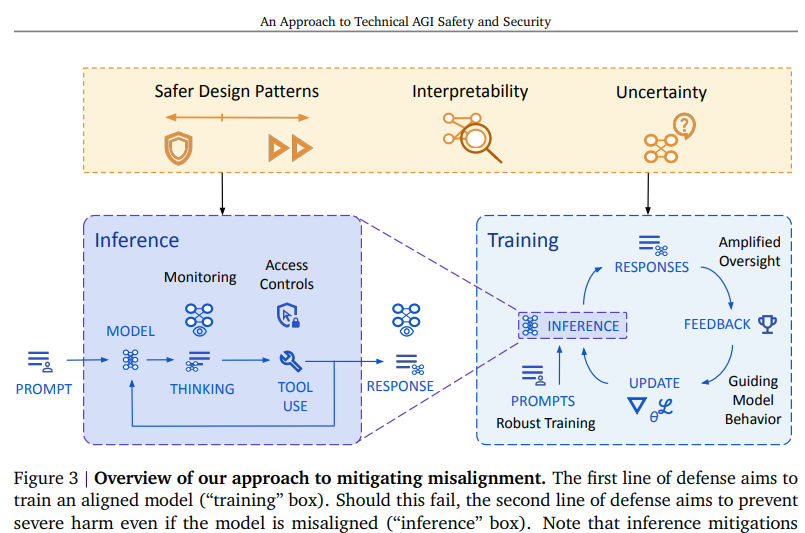
It seems nothing here is different? They simply expect the standard plan to scale up.
I do not sense here that Google is recognizing the difficulty level of this step because until now this step has worked ‘well enough’ without anyone having to try too hard. This feels like a handwave of ‘oh, of course once we can evaluate whether particular outputs are aligned we Do Machine Learning and out pops alignment’ and I see why one would be tempted to have that model but seriously not so fast.
In terms of the detection step, the word amplified is the lynchpin of this whole plan. How do you have effective ‘amplified oversight’? What do they mean by that?
Amplified oversight. A key challenge in almost any alignment plan is that it can be very difficult to tell whether a given model output is good or bad, once the model has capabilities beyond that of its overseers.
As an example, imagine a human overseer trying to determine how good a move from AlphaGo is.
The area of amplified oversight aims to address this: the goal is to provide an oversight signal that is as good as could be achieved if a human overseer understood all of the reasons that the AI system produced the output and had unlimited ability to reflect on the correct decision.
They frame this as a way around specification gaming (SG) in particular, emphasizing that they are taking seriously the idea that SG is a distinct thing and a failure mode and you can find and fix it. So, to ensure that the AI isn’t doing things for the wrong reasons (4TWR!) no problem, you just need amplified oversight that can:
It aims for a human to provide feedback for a superhuman AI input-output pair which is as good as could be achieved if that human:
-
Understood all of the reasons that the AI system produced that output
-
Had unlimited ability to reflect on the correct decision.
How in the world? That just raises further questions.
In some places it seems as if we agree actual human overseers are going to become increasingly lost and clueless, and indeed Google intends to use AI systems to identify the reasons other AIs do things.
Yet they really do say they aim to ‘ensure that humans can continue to provide meaningful oversight as AI capabilities surpass that of humans’ and I find their hopes here confusing. Are they simply talking about ‘the human can ask another AI, or the AI itself, and trust the outputs from that’? Section 6.1.2 suggests the humans and AI will work together, but warns against ‘spoon-feeding’ the answer, but again I don’t understand what the plan or goal will be.
What makes you think this is how the ‘real reasons’ even work? Even if you did get the ‘real reasons’ what makes you think humans could even understand them?
Some aspects of human judgments can be imitated or delegated, according to the human’s evolving trust in the AI. The form of human involvement in the amplified oversight protocol is an open question.
There’s no reason we should expect even these other AIs to be able to ‘understand all the reasons that the AI system produced the output.’ And we definitely won’t have unlimited reflection time. Google mentions human biases as an issue in 6.1.3, but it’s hard to even get to that as a worry here. Then in 6.1.4 they mention that AI justifications might not be verbalisable at all, which is highly compatible with Anthropic’s recent findings that chain of thought is often unfaithful or at least highly incomplete. They do discuss attempting to sidestep involving the human in 6.1.5.
Such behaviour may arise from statistical correlations in a large dataset, or from concepts which don’t have a particularly succinct natural language description, but which can be learned from experience.
LLMs are vibe and correlation machines at heart, it seems crazy to think one could write all relevant such correlations down and have humans read them. And isn’t that largely how humans work, too? I try very hard to describe what I am thinking but I am always by necessity leaving quite a lot out.
So what’s the plan here? How are we going to get this amazingly great at evaluation and interpretability? They do discuss interpretability more in section 6.6.
Also, how are we going to avoid using The Most Forbidden Technique? If we use ‘all the reasons the AI made the decision’ as an input then how do we do that without burning down our cache of interpretability?
The key idea is to use the AI systems themselves to help identify the reasons that the AI system produced the output. For example, we could put two copies of the model in a setting where each model is optimized to point out flaws in the other’s outputs to a human “judge”. Ideally, if one model introduced a subtle flaw in their output that the judge wouldn’t notice by default, the other model would point out and explain the flaw, enabling the judge to penalise the first model appropriately.
That seems like a way lower standard than the one they’re aiming for in the previous quote. You’re pitting two essentially evenly matched models against each other, then hoping they won’t find a way to collude and that evaluation is robustly easier than generation in the relevant contexts.
If all you have to do is find flaws in answers, then maybe that’s advantage defense and maybe it isn’t. But that definitely won’t give you the level of insight we’re looking for.
This is emphasized again by 6.1.1 citing not only debate and critique but also RLHF (!) as an amplified oversight method. I do not understand. It is an oversight method, one could call it ‘the’ oversight method almost by definition, but how is it possibly amplified as described here?
In amplified oversight, any question that is too hard to supervise directly is systematically reduced to ones that we hypothesize can be supervised.
However, humans may be systematically biased even for fairly simple questions. If this turns out to be a problem in practice, we could seek to model these deviations and automatically correct or account for them when interpreting the oversight.
So does that mean we are making the major sacrifice of forcing all outputs to be only composed of pieces that humans can fully interpret and evaluate? And then scrubbing any additional elements? Could you do that even if you wanted to? How do you possibly do enough human oversight at scale?
The whole thing feels hopeless. Like we are kidding ourselves.
In 6.1.7 they talk paths forward, and suggest that the test will be when humans are asked to evaluate AIs in areas where the AIs have superhuman capabilities.
What if we jumped ahead on this, not by having AIs that are smarter, but by having humans that are dumber, or less skilled and knowledgeable in context?
As in, you think humans will be able to evaluate superhumanly capable AIs? All right, let’s have the humans evaluate coding tasks now… but not teach those particular humans how to code, at all, and have them not be all that smart and not give them access to outside resources that wouldn’t exist here. See what happens. If you want to test for a smaller gap, you can calibrate.
That actually sounds like a great test to me. We should do that. Can you get a method whereby the Man On The Street can use AI help to code and evaluate graduate level economics outputs and the quality of poetry and so on in ways that would translate to this future parallel situation? How does that go?
How would you apply this process even to a not-quite-a-toy problem? You can do chess, because you can have the two debaters play out of the game and see who wins, but if you didn’t have that direct ability you seem to be in a lot of trouble.
Even best case they expect this process to be expensive, and they expect it to fail outside of the training distribution:
However, even with Amplified Oversight, there remain two key challenges in using this oversight signal to train AI systems that behave as intended.
First, we will only be able to provide oversight on actions produced within the training distribution.
Second, we anticipate that Amplified Oversight signal will be costly to obtain. These challenges motivate the development of robust training strategies that expand the training distribution with a particular focus on cases that induce failures, as well as monitoring strategies (section 6.3).
Outside of the training distribution is going to be vital when we care most. I do get that the plan is to expand that distribution, but mostly this seems unsolvable.
I don’t see how this plan is going to survive contact with the enemy, under any variation, even if we compromise heavily on many of the plans listed above. Reasoning on r1 and Sonnet 3.7 was shown to often be unfaithful even now.
In 6.5.4 they suggest choosing AI systems with easier-to-understand reasoning methods. That’s an example of why you need to look ahead, so you can make architectural and research decisions now. Once again, I find the paper making good points but being what I see as too optimistic. Yes, there are lots of examples of legible externalized reasoning, but it’s not as legible or complete as you think. And even if you’re willing to pay the efficiency tax it will be extremely difficult to stop the AI from doing opaque and esoteric reasoning or communication, there are a lot of optimization pressures that will push towards that. That doesn’t mean we shouldn’t try, I do think it is a good idea to try.
After that, they claim that standard techniques will essentially work if we grant them the oversight signal. I don’t think we should be confident in that either. I expect things to get harder even if your oversight is perfect, and for any inaccuracy in the oversight however small to be increasingly perilous. They do suggest various techniques for more robust training in 6.3.5, which seem at least marginally helpful.
Then, after all that: If you did fail at the training step, how likely do you think you are to then succeed at the inference step using the same monitor?
As they note, even if you did have an accurate judge or monitor model available, judge-policy collusion is a big risk, and you can only use the judge some of the time. And I’m going to guess that you don’t have an accurate judge available, if you are dealing with a misaligned model, indeed that is strong evidence of some combination of the misalignment of the judge or the misaligned model being optimized to fool the judge. They do mention in 6.3.6 that ideally you would make the judge uncorrelated with your training signal but that seems very hard to do.
The big advantage the judge has in this later stage is it can escalate and ask for help if it is uncertain, as per 6.3.3. It is plausible that an inferior judge can’t do amplified oversight properly, but can probabilistically spot things that are fishy if you don’t mind a lot of false positives.
This once again feels like saying we’ll try our best, but with no reason to expect that their best will do, especially when it is badly needed. This is especially true in 6.3.4 where they want resource efficient oversight.
I don’t know that any of these problems are unsolvable. There are some techniques I would try that I didn’t spot here, such as using OOMs more inference compute on the oversight and judge than you do on the models being overseen and judged.
Another control attempt is to limit the access and context each model or copy of a model gets, on top of the monitoring. Sandboxing, insider controls, least privilege and so on, see 6.4. Again, it’s defense-in-depth, so it presumably doesn’t hurt, but I very much expect this to abandon you in your hour of need. You should also assume that copies of a sufficiently capable model can communicate and coordinate in ways that are invisible to you, even if you don’t know what they are, if their outputs impact the outside world in any way.
They also mention they’re working on interpretability, which is good but does not answer the key questions here. In 6.6.2 they discuss how they might use interpretability. I definitely got nervous that a lot of what they plan on doing is at least toying with using The Most Forbidden Technique.
Section 6.5.1 discusses training targets. What should we want out of our AI?
They start with corrigibility. They hope that there is a clear distinction we can make here about what counts as corrigible, because that means the concept will generalize. So what Google is looking for here is a highly generalized form of corrigibility, not the limited ‘let it get turned off.’
While corrigibility is a straightforwardly desirable property currently, it is possible that in the future it will trade off with the desire to deploy agents autonomously.
I agree that corrigibility is important and good, actually. There was a time I would not have bothered to say that, but in the alignment faking discussions there were a lot of people who said corrigibility is bad. I want to affirm I strongly believe it is good.
The conflict with autonomy is real. In some cases, there are tactical reasons to not want an AI to be so easily dissuaded or deflected. This includes when you want to signal that the AI is like a smart contract, that you cannot choose to shut it down. That’s one large source of risk and issues going forward.
Corrigibility need not arise by default, and indeed we may expect that it does not arise by default due to the instrumental subgoal of utility preservation (Omohundro, 2008). Specifically, an agent may take steps to reduce the developer or user’s influence because the developer or user’s changes might reduce the agent’s expected ability to achieve its current goal. Recent demonstrations of alignment faking (Greenblatt et al., 2024a) lend credence to this concern.
Indeed. How does this interact with the idea that misalignment must always be either specification gaming (SG) or goal misgeneralization (GMG)? It means part of specifying your goal will need to be specifying corrigibility, in a way that actually creates and preserves it.
They then discuss how they want the AI to handle user interactions and how this allows the user to monitor the AI’s actions, sure, sure. This seems largely like a handwave at a much longer more detailed discussion, similar to OpenAI’s model spec, but the point that the check-ins also serve as defense against not only mistakes but misalignment is well-taken. Although when the misalignment is sufficiently severe, the AI can presumably be misaligned in that interaction too.
The third discussion is around ‘biases towards misalignment’ from pretraining. I think at least some things like this are better thought of as mistakes than misalignment, and the failure to do so is actually a policy risk, as this gives certain types the impression that ‘alignment’ and ‘safety’ are some kind of woke thing. Google has been especially anti-helpful here.
Then things get super interesting:
There is a significant amount of content on the Internet (and thus in pretraining corpora) that speculates that AI will be hard to align. This data may induce a self-fulfilling prophecy via out of context reasoning: that is, an AI system would learn the declarative “knowledge” that powerful AI systems tend to be misaligned, leading them to then act in accordance with that expectation (Turner, 2025).
Hu et al. (2025) support this concern, finding that training on documents about reward hacking induces reward hacking.
This suggests a simple intervention: filter out “AI doom” data from training corpora, or otherwise suppress the bias towards misalignment. Many of the capability suppression techniques discussed in Section 5.3.3 can be applied here, including data filtering, grading routing (Cloud et al., 2024), LoRA updates for memory erasure (Gandikota et al., 2024), or methods based on model internals (Zou et al., 2024).
As in the misuse case, this may come at a performance cost to general AI capabilities. This may especially harm the ability of AI systems to assist with alignment research, which could be a large cost, given the need for AI assistance for alignment research to keep up in the event of significant acceleration (Section 3.4).
This could be addressed by training a variant of the AI system with heightened safety measures that can be used specifically for assistance with alignment research.
Generating a ‘hole in the world’ by hiding that data has its own risks, especially as the AI gets clever enough to realize there is a hole there. And all of this talk about alignment and risk has its advantages as well, if you can get to a good enough place to make the model work towards avoiding the associated problems. The ways of solving this I find most promising involve the model knowing about the failure modes exactly so it can assist with steering clear of them.
Another proposal they have in 6.5.3 is limited optimization. Perhaps if you don’t let the AI sufficiently optimize, it won’t be able to specification game? What if you gave it a limited amount of optimization, certainty or planning horizon? Could you use approval feedback instead of being too results oriented?
Limited optimization means making the AI dumber on purpose, which seems like it’s definitely not a long term plan in general. The question is, can you make it dumber in a particular narrow way that cuts off the opportunity to do the things you want to avoid? You can try, but I have a strong prior that this is mostly both going to be expensive to do and then often not going to work.
The whole thing is based both on hiding context or ultimate goals from the AI in question while still getting it to do what you need, and also on the assumption that the specification gaming will be differentially shut down here because it’s less robust or harder to find. That is definitely not always the case. As a practical example, one thing you learn from speed runs is that many of them are (if you’re not trying to get the exact world record) dramatically easier than playing the game as intended. You’re driving a sword through the knot, and ignoring a lot of the difficulty. Robustness can vary quite a lot.
How do we get ‘alignment assurance’?
The plan is to start with alignment stress tests via red teams, plus control evaluations. They discuss the stress tests in 6.7. In the control evaluation, the red team gets to use fine tuning. These are good tests worth running, and the discussions are excellent. I don’t expect them to stay reliable at avoiding false negatives, but the examples here make clear that they are very good at showing many things that won’t work.
The ultimate goal, as mentioned above, is to make an alignment safety case, via some combination of inability, supervision, incentives and understanding. There are a lot of good notes here about how difficult each of these is and what you need to get right even in the summary, and then a longer discussion in 6.8.
The problem is that they correctly expect inability to stop being a good case soon, and then the others get a lot trickier. I essentially don’t buy the supervision case unless the supervisor is far enough ahead that the safety case you need is for the supervisor. Understanding on the level of a safety case feels like a giant ‘good luck.’
Incentives is a cool idea for a safety case, but I don’t think that works either. Appealing to the training process and saying ‘it is pursuing the intended goal and thus should not be misaligned’ seems like essentially wishful thinking when dealing with highly capable models. You know what you intended the goal to be, congratulations. What makes you think the AI sees it that way? What makes you think you are going to like the way they make that happen?
Google is intentionally not talking here about how it intends to solve mistakes.
If we are confining ourselves to the AI’s mistakes, the obvious response is this is straightforwardly a Skill Issue, and that they are working on it.
I would respond it is not that simple, and that for a long time there will indeed be increasingly important mistakes made and we need a plan to deal with that. But it’s totally fine to put that beyond scope here, and I thank Google for pointing this out.
They briefly discuss in 4.3 what mistakes most worry them, which are military applications where there is pressure to deploy quickly and development of harmful technologies (is that misuse?). They advise using ordinary precautions like you would for any other new technology. Which by today’s standards would be a considerable improvement.
Google’s plan also does not address structural risks, such as the existential risk of gradual disempowerment.
Similarly, we expect that as a structural risk, passive loss of control or gradual disempowerment (Kulveit et al., 2025) will require a bespoke approach, which we set out of scope for this paper.
In short: A world with many ASIs and ASI (artificial superintelligent) agents would, due to such dynamics, by default not have a place for humans to make decisions for very long, and then it does not have a place for humans to exist for very long.
Each ASI mostly doing what the user asks them to do, and abiding properly by the spirit of all our requests at all levels, even if you exclude actions that cause direct harm, does not get you out of this. Solving alignment necessary but not sufficient.
And that’s far from the only such problem. If you want to set up a future equilibrium that includes and is good for humans, you have to first solve alignment, and then engineer that equilibrium into being.
More mundanely, the moment there are two agents interacting or competing, you can get into all sorts of illegal, unethical or harmful shenanigans or unhealthy dynamics, without any particular person or AI being obviously ‘to blame.’
Tragedies of the commons, and negative externalities, and reducing the levels of friction within systems in ways that break the relevant incentives, are the most obvious mundane failures here, and can also scale up to catastrophic or even existential (e.g. if each instance of each individual AI inflicts tiny ecological damage on the margin, or burns some exhaustible vital resource, this can end with the Earth uninhabitable). I’d have liked to see better mentions of these styles of problems.
Google does explicitly mention ‘race dynamics’ and the resulting dangers in its call for governance, in the summary. In the full discussion in 4.4, they talk about individual risks like undermining our sense of achievement, distraction from genuine pursuits and loss of trust, which seem like mistake or misuse issues. Then they talk about societal or global scale issues, starting with gradual disempowerment, then discussing ‘misinformation’ issues (again that sounds like misuse?), value lock-in and the ethical treatment of AI systems, and potential problems with offense-defense balance.
Again, Google is doing the virtuous thing of explicitly saying, at least in the context of this document: Not My Department.
Discussion about this post
On Google’s Safety Plan Read More »




































{kind=link}