They said it couldn’t be done.
No, not Claude Sonnet 3.5 becoming the clear best model.
No, not the Claude-Sonnet-empowered automatic meme generators. Those were whipped together in five minutes.
They said I would never get quiet time and catch up. Well, I showed them!
That’s right. Yes, there is a new best model, but otherwise it was a quiet week. I got a chance to incorporate the remaining biggest backlog topics. The RAND report is covered under Thirty Eight Ways to Steal Your Model Weights. Last month’s conference in Seoul is covered in You’ve Got Seoul. I got to publish my thoughts on OpenAI’s Model Spec last Friday.
Be sure to read about Claude 3.5 Sonnet here. That is by far the biggest story.
-
Introduction.
-
Table of Contents.
-
Language Models Offer Mundane Utility. I am increasingly persuaded.
-
Language Models Don’t Offer Mundane Utility. EU’s DMA versus the AiPhone.
-
Clauding Along. More people, mostly impressed.
-
Fun With Image Generation. They are coming for our memes. Then Hollywood.
-
Copyright Confrontation. The RIAA does the most RIAA thing.
-
Deepfaketown and Botpocalypse Soon. Character.ai addiction. Am I out of touch?
-
They Took Our Jobs. More arguments that the issues lie in the future.
-
The Art of the Jailbreak. We need to work together as a team.
-
Get Involved. AISI, Apollo, Astra, Accra, BlueDot, Cybersecurity and DOE.
-
Introducing. Forecasting, OpenAI Mac App, Otto, Dot, Butterflies, Decagon.
-
In Other AI News. OpenAI equity takes steps forward. You can sell it.
-
Quiet Speculations. A distinct lack of mojo.
-
You’ve Got Seoul. Delayed coverage of the Seoul summit from last month.
-
Thirty Eight Ways to Steal Your Model Weights. Right now they would all work.
-
The Quest for Sane Regulations. Steelmanning restraint.
-
SB 1047. In Brief.
-
The Week in Audio. Dwarkesh interviews Tony Blair, and many more.
-
Rhetorical Innovation. A demolition, and also a disputed correction.
-
People Are Worried About AI Killing Everyone. Don’t give up. Invest wisely.
-
Other People Are Not As Worried About AI Killing Everyone. What even is ASI?
-
The Lighter Side. Eventually the AI will learn.
Training only on (x,y) pairs, define the function f(x), compose and invert it without in-context examples or chain of thought.
AI Dungeon will let you be the DM and take the role of the party, if you prefer.
Lindy ‘went rogue’ and closed a customer on its own. They seem cool with it?
Persuasive capability of the model is proportional to the log of the model size, says paper. Author Kobi Hackenburg paints this as reassuring, but the baseline is that everything scales with the log of the model size. He says this is mostly based on ‘task completion’ and staying on topic improving, and current frontier models are already near perfect at that, so he is skeptical we will see further improvement. I am not.
I do believe the result that none of the models was ‘more persuasive than human baseline’ in the test, but that is based on uncustomized messages on generic political topics. Of course we should not expect above human performance there for current models.
75% of knowledge workers are using AI, but 78% of the 75% are not telling the boss.
Build a team of AI employees to write the first half of your Shopify CEO speech from within a virtual office, then spend the second half of the speech explaining how you built the team. It is so weird to think ‘the best way to get results from AI employees I can come up with is to make them virtually thirsty so they will have spontaneous water cooler conversations.’ That is the definition of scratching the (virtual) surface.
Do a bunch of agent-based analysis off a single prompt. This kind of demo hides the real (human) work to get it done, but that will decline over time.
Apple Intelligence rollout will be at least delayed in the European Union, with Apple citing the Digital Markets Act (DMA) compromising user privacy and data security. I look forward to the EU now going after them for failing to deploy. Note that DMA is deeply stupid EU tech regulation unrelated to AI, the EU AI Act is not mentioned as an issue, and nothing about Apple Intelligence would be subject to regulation by SB 1047 or any other major regulatory proposal in the USA.
New paper finds LLMs engage in difficult-to-predict escalatory behavior patterns in political simulations, in rare cases leading to deployment of nuclear weapons. Well, yes, of course. The LLMs are trained as CDT (Causal Decision Theory) agents in various ways and asked to predict text and imitate human behavior, and it is very obviously correct to engage in hard to predict escalatory behavior with nonzero risk of worst case scenarios by all of those metrics.
Andrej Karpathy requests that LLMs have a feature to offer ‘proof’ in the form of their references, which right now is only available when you have web access.
Saagar Jha is not impressed by Apple’s claims of Private Cloud Compute, claiming it is a lot of words for a Trusted Platform Module, but that it is not all that secure.
Your engineers might copy your GPT wrapper product.
AI detection software in education continues to have a lot of false positives. Serious advice to all students and other writers, never delete your drafts and history. That would be smart anyway, as AI could plausibly soon be helping you learn a better process by analyzing them. For now, they are vital to proving you actually wrote what you wrote.
Sometimes I wonder if these false positives are good, actually? If the AI thinks an AI wrote your paper, and instead you wrote your paper, what does that say about your work? What grade do you deserve?
Takes on Claude 3.5 continue to come in.
While I consider Claude 3.5 to be clearly best for most purposes right now, that does not mean Anthropic now has an overall longer term lead on OpenAI. OpenAI is at the end of its model cycle. Of course, they could fail to deliver the goods, but chances are they will retake the visible lead with GPT-5, and are still ‘ahead’ overall, although their lead is likely not what it once was.
Heraklines: the larger point about OpenAI > anthropic is correct, this lead right now is illusory.
The common man cares not about vibe check perf tho, all that matters is how much better at grunt work like coding is it?
3.5 smashes, not even close. usefulness =! smortness.
3.5 is a model of the people.
I still default to 4o for anything math related, but 3.5 just grinds better. A glimpse of what a future without grunt work could look like
note: vibe checks are to be taken with a grain of salt, like benchies. i’ve seen too much overcorrection based on both in the past
It is always weird to see what people think about ‘the common man.’ The common man does not know Claude exists, and barely knows about ChatGPT. This comment was in response to Teortaxes:
Teortaxes: Sorry to be a killjoy but: Anthropic hopes to hyperstition AGI lead, their people are deluding themselves, and their models are like “talented” middle-class American kids – NOT HALF AS SMART AS THEY’RE TRYING TO LOOK LIKE
OpenAI will wreck them on instruction following… again.
Incidentally the “other model’s” MMLU is 79
…I wanted to dunk on Flash being dumb but it’s also 0-shotting this problem.
Anthropic is simply not very good in instruction-tuning. Folks who say they’re switching their automated pipelines to Sonnet because “smart” are being silly.
Lots of crap like this. Let me clarify
What I’m NOT saying:
– 3.5-Sonnet is dumb[er than 4o/4t/DSC];
– spelling tasks are good tests for LLMs
What I DID SAY:
– 3.5-Sonnet is deceptively pretentious;
– Anthropic’s instruction tuning is wonky
You might think I’m just obsessively nitpicking
I’m not, I think this wonkiness in reasoning about trivial instructions indicates a broader bad trend at Anthropic
One can say they’re creating AI takeover risks by encouraging this I-am-a-person bullshitting.
So there’s AI takeover risk, then? And it is being created now, from alignment failures being observed now? Huh. I do see how one could worry about what Teortaxes worries about here. But I see it as indicating rather than creating a problem. The true problem does not go away if you force the existing model to stop expressing it.
If most people are reporting that plugging in Sonnet 3.5 gives them much better performance? I am inclined to believe them. Nor do I think instruction handling issues are that big a deal here, but I will keep an eye out for other complaints.
Danielle Fong reassembles the ‘invention team’ without any tricks, is impressed.
Matt Parlmer reports Sonnet 3.5 is the first LLM to reliably pass his vision test.
Tyler Cowen is impressed by an answer on economics. I was not as impressed here as Tyler, as it feels like Claude is unfocused and flooding the zone a bit, and a straight answer was possible but missing as was one key consideration, but yeah, overall very good. To me the key concept here is that the net cost of inefficient wage levels is likely lower than expected, so you would be more inclined to allow wages to remain sticky.
Some speculation of how artifacts work under the hood.
Some fun attempts to get around the face blindness instructions. In these cases Claude gets it right but how reliable or wide ranging would this hack be? Not that I am especially worried about the model being not face blind, especially as it applies to major public figures.
A LessWrong commenter notes it identified my writing from a short passage.
Cuddly Salmon: effectively prompting for claude 3.5 artifacts is such an incredible edge right now.
Minh Nhat Nguyen: I don’t think it’s actually made a single error while I’ve been using it to write out+iterate+merge thousands of lines of code. Whenever the code doesn’t work, it’s usually me being too vague with specs.
Cuddly Salmon: Cutting thru all of my problem code like it’s nothing, this AI is an absolute unit. Incredibly creative, too.
Claude makes it easy to create automatic meme generators.
Here’s what the original form, the Wojack, from Fabian Stelzer.
Good fun was had by all, and truths were spoken.
Here’s one for Virgin vs. Chad.
Fabian: another meme maker I made on glif dot app
fully automated Virgin vs Chad memes on any topic, just prompt it
Claude 3.5 is just sublime at these and the workflow is super simple to build on glif.. 😙🤌
Here’s one begging you to stop doing X, which is often wise.
The original took all of five minutes to create. It often seems like that is where our society is at. We can do things in five minutes, or we can take forever. Choose.
Andrew Chen says Hollywood is being slow to adapt AI for a variety of reasons, starting with being slow to adapt to everything in general, but also legal concerns, the difficulty of finding good engineers and the pushback from creatives.
His call for creatives to think about themselves like software engineers, who only benefited from advances in tech, does not seem like something to say to creatives. It needs to be appreciated in all such discussions the extent to which almost all creatives, and also most consumers and fans, absolutely despise AI in this context.
He also does not appreciate the extent to which the technology is not ready. All this talk of innovation and new forms and six second dance videos illustrates that it will be a bit before AI is all that visibly or centrally useful for producing great work.
They should use it the same ways everyone should use it. Yes, it helps you code and implement things, it helps you learn and so on. Do all that. But directly generating a ton of content on its own as opposed to helping a human write? Not well, not yet.
His talk of the ‘$1000 blockbuster movie’ forgets that such a movie would suck, and also cost vastly more than that if you count the labor of the writers and coders.
Toys ‘R Us releases AI (Sora) generated ad. It is executed well, yet I expect this to backfire. It is about how the consumer reacts.
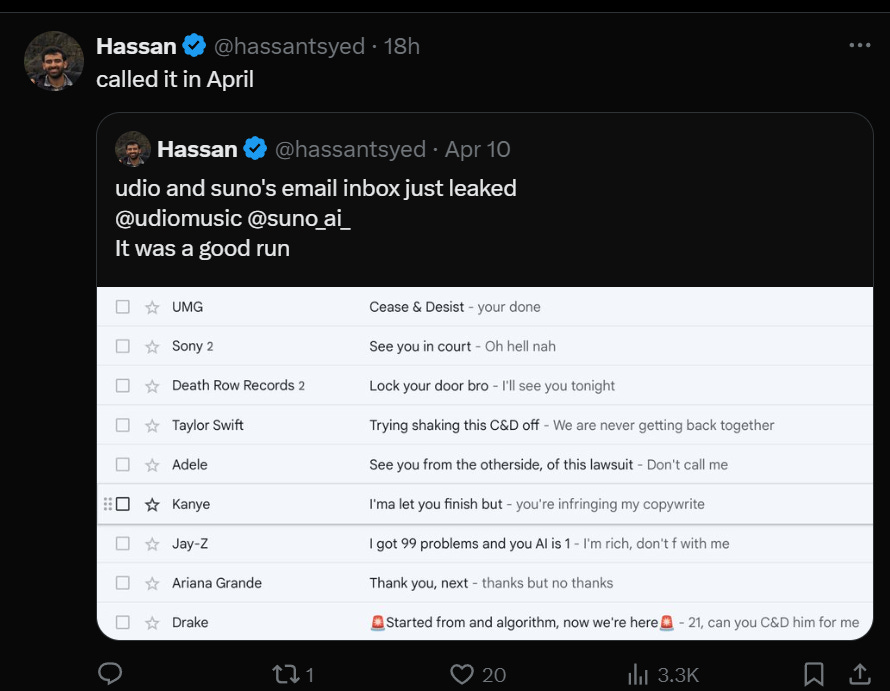
It is music’s turn. The RIAA and three major record labels are doing RIAA things, looking for damages of $150k per song that was ‘copied.’
Ed Newton-Rex: The 3 major record labels are suing AI music companies Suno and Udio. Here are the two lawsuits in full.
– They accuse Suno & Udio of “willful copyright infringement on an almost unimaginable scale”
– They provide evidence that both companies trained on their music, including outputs that closely resemble their recordings (ABBA, Michael Jackson, Green Day, James Brown, & many more)
– They outline why this is not fair use
– They say this “wholesale theft of… copyrighted recordings threatens the entire music ecosystem and the numerous people it employs”
– They include unknown co-defendants who assisted in copying/scraping
– They demand a jury trial
If you do one thing today, read the full complaints (Suno, Udio).
Kristin Robinson (Billboard): The complaints against the two companies also make the case that copyrighted material was used to train these models. Some of the circumstantial evidence cited in the lawsuits include generated songs by Suno and Udio that sound just like the voices of Bruce Springsteen, Lin-Manuel Miranda, Michael Jackson and ABBA; outputs that parrot the producer tags of Cash Money AP and Jason Derulo; and outputs that sound nearly identical to Mariah Carey’s “All I Want For Christmas Is You,” The Beach Boys’ “I Get Around,” ABBA’s “Dancing Queen,” The Temptations’ “My Girl,” Green Day’s “American Idiot,” and more.
…
RIAA Chief Legal Officer Ken Doroshow adds, “These are straightforward cases of copyright infringement involving unlicensed copying of sound recordings on a massive scale. Suno and Udio are attempting to hide the full scope of their infringement rather than putting their services on a sound and lawful footing. These lawsuits are necessary to reinforce the most basic rules of the road for the responsible, ethical, and lawful development of generative AI systems and to bring Suno’s and Udio’s blatant infringement to an end.”
Did Suno and Udio do the crime? Oh, hell yes. They very much went with the ‘we are doing it and daring you to sue us’ strategy. The question is, are they allowed to do it, or not? We are about to find out.
This is good. We should have that fight and find out what current law says. Early indications are mixed.
If it turns out current law says you can train on any song you want, and produce soundalike versions on demand, without compensation?
My strong prediction is that Congress would change the law very quickly.
In other copyright news: Startup ‘Created by Humans’ is launching to help book authors license their work to AI companies.
Al Michaels agrees to let an AI version of his voice be used for Olympic coverage. The people responding are predictably not taking kindly to this. I am also not a fan. What made Al Michaels great is not the part the AI will be copying.
The evidence is a little thin, but what a great title, chef’s kiss by Wired: Perplexity Plagiarized Our Story About How Perplexity Is a Bullshit Machine.
Perplexity did not do one of their previously reported ‘post a version of the full article to our own website’ specials. What they did do was provide a summary upon request, which included accessing the article and reproducing this sentence: “Instead, it invented a story about a young girl named Amelia who follows a trail of glowing mushrooms in a magical forest called Whisper Woods.”
That sentence was obviously not a coincidence, but as Wired notes it is not fully clear this crosses any red lines, although not having quote marks was at best a very bad look. I doubt they will be able to make anything stick unless they find worse.
To the extent there is already an ongoing Botpocalypse it is likely at Character.ai.
Eliezer Yudkowsky: Grim if true (for reasons basically unrelated to the totally separate track where later ASI later kills everyone later)
Deedy: Most people don’t realize how many young people are extremely addicted to CharacterAI. Users go crazy in the Reddit when servers go down.
They get 250M+ visits/mo and ~20M monthly users, largely in the US.
Most impressively, they see ~2B queries a day, 20% of Google Search!
Another comparison is WhatsApp.
They do 100B+ messages a day, so Character is ~4% of WhatsApp!
(1 qps = 2 WhatsApp messages)
He also links to the associated subreddit.
When I look there, I continue to not see the appeal at current tech levels.
Ben Landau-Taylor: To be clear, kids spending hours talking to these robots feels weird as hell to me, too.
It’s just, this is *obviouslywhat skinner.jpg feels like from the inside.
I do my best not to kink shame. This is no exception. My objection is not to the scenario being role played. It is purely that the AI is not yet… good at it?
The story of Bentham Tools and their AI bot doom loop.
Indian farmers getting their news from AI anchors. For now it seems the anchors are performers and don’t write their own copy.
Another one searches for Facebook AI slop for a few minutes, floods their feed. Is doing this intentionally the solution for those addicted to Facebook?
Allison Schrager, author of ‘An Economist Walks Into a Brothel,’ sees AI bots as displacing some of the world’s oldest profession by producing simulated intimacy, which she says is what most sex work is ultimately about. Her worries are that this will reduce drive to seek out relationships and destabilize existing ones, similar to the concerns of many others, but notes that like prostitutes this could work both ways. Central here is the idea that the ‘girlfriend experience’ is the highest end product, someone who will be the perfect companion always there for you, that even a few years ago cost $1,000 an hour even where it was fully legal because of how mentally taxing it is to be consistently present for another person. Whereas AI could do that a lot cheaper. As usual, this is a form of ‘AI is what it is today and won’t get any better’ speculation.
Ethan Mollick notes that AI has compromised traditional approaches to security. Spear phishing got very easy, text-to-speech is almost flawless and so on. Despite this, there has been remarkably little disruption. Few are using this capability. Not yet. We are fortunate that time has been given. But until the time is almost up, it will be wasted.
Michael Strain makes the case for AI optimism on economics and jobs. It’s a noble effort, so I’m going to take the bait and offer one more attempt to explain the problem.
This seems to be a very patient, well reasoned reiteration of all the standard economic arguments about how technology always creates new jobs to replace the ones it automates away, and how yes you might have a robot or chatbot do X but then the human will need to do Y.
As I’ve noted before, I agree that we should be short term jobs optimists, but there could come a point at which the robot or chatbot also does Y and also new thing Z.
But that is because, like most people making such arguments, Michael Strain does not feel the AGI. He thinks AI is a tool like any other, and will always remain so, and then writes at length about why tools don’t create structural unemployment. True, they don’t, but this is completely missing the point.
It is telling that while he mentions Eliezer Yudkowsky and existential risk in his opening paragraph, he then spends all his time talking about economics and jobs without noticing the ways AI is different, and with zero mention of existential risk, and then closes like this:
Michael Strain: The year 2023 will be remembered as a turning point in history. The previous year, humans and machines could not converse using natural language. But in 2023, they could.
Many greeted this news with wonder and optimism; others responded with cynicism and fear. The latter argue that AI poses a profound risk to society, and even the future of humanity. The public is hearing these concerns: A YouGov poll from November 2023 found that 43% of Americans were very or somewhat concerned about “the possibility that AI will cause the end of the human race on Earth.”
This view ignores the astonishing advances in human welfare that technological progress has delivered. For instance, over the past 12 decades, child mortality has plummeted thanks in large part to advances in drugs, therapies, and medical treatment, combined with economic and productivity gains. Generative AI is already being used to develop new drugs to treat various health conditions. Other advances in the technology will mitigate the threat of a future pandemic. AI is helping scientists better understand volcanic activity — the source of most previous mass-extinction events — and to detect and eliminate the threat of an asteroid hitting the earth. AI appears more likely to save humanity than to wipe it out.
Like all technological revolutions, the AI revolution will be disruptive. But it will ultimately lead to a better world.
What does one have to do with the other? That is very similar to saying:
Strawman Climate Skeptic: This view ignores the astonishing advances in human welfare that burning fossil fuels has delivered. For instance, over the past 12 decades, we have vastly increased our energy production, which has led to [various great things including the same stuff], combined with economic and productivity gains. Fossil fuels are already being used to develop new drugs to treat various health conditions. Other advances in the technology will mitigate the threat of a future pandemic. Machines powered by fossil fuels are helping scientists better understand volcanic activity — the source of most previous mass-extinction events — and to detect and eliminate the threat of an asteroid hitting the earth. Fossil fuels appear more likely to save humanity than to wipe it out.
Like all technological revolutions, the fossil fuel revolution has been disruptive. But it will ultimately lead to a better world.
Presumably one can see that none of that has anything to do with whether doing so is pumping carbon into the atmosphere, and whether that is altering the climate. It has nothing to do with what we should or should not do about that. It flat out is not evidence one way or another.
On jobs the argument is better. It is a good explanation for why in the short term this time will be the same time. In the short term, I buy that argument. Such arguments still fail to grapple with any of the reasons that long term, this time is different.
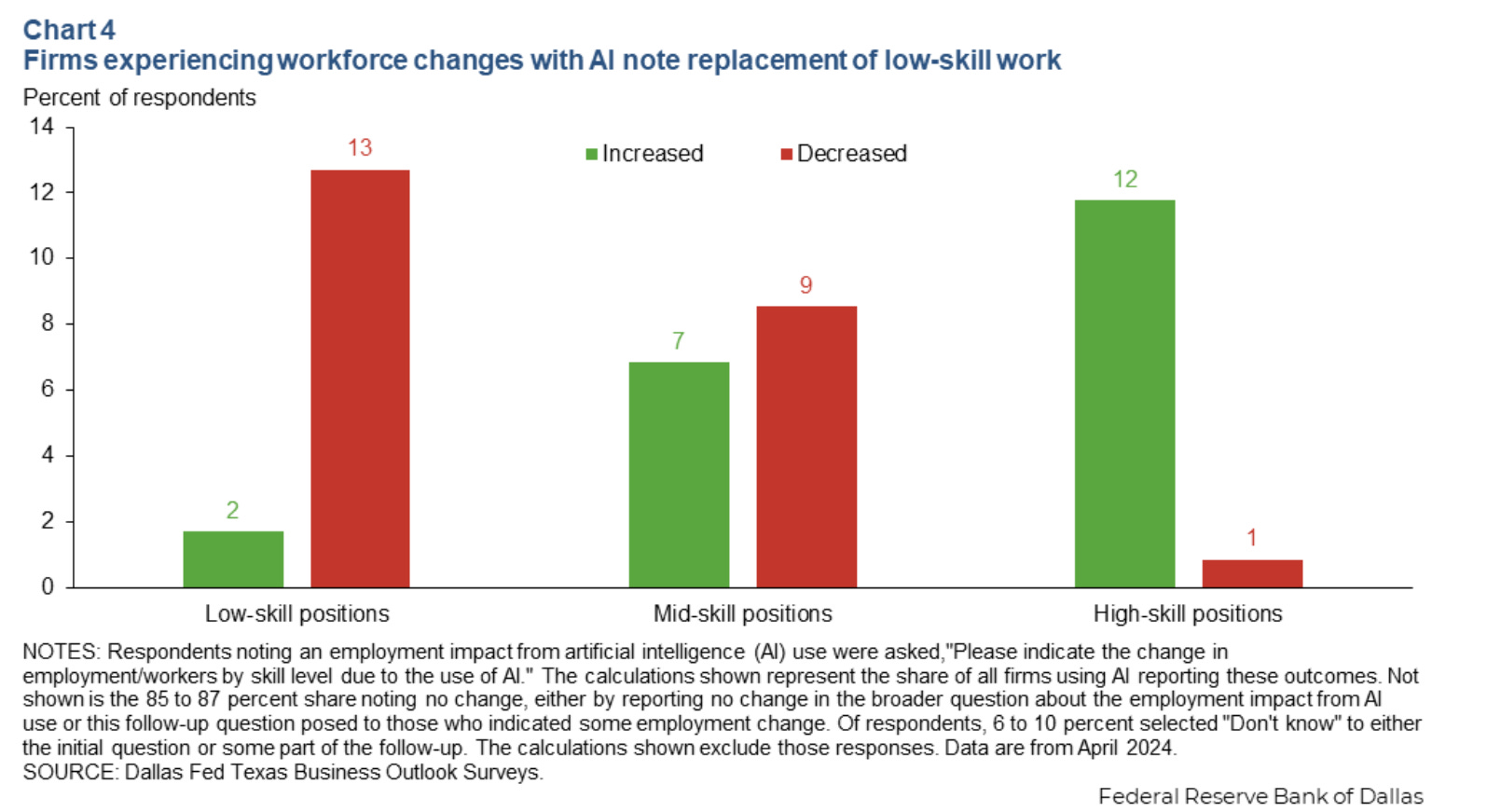
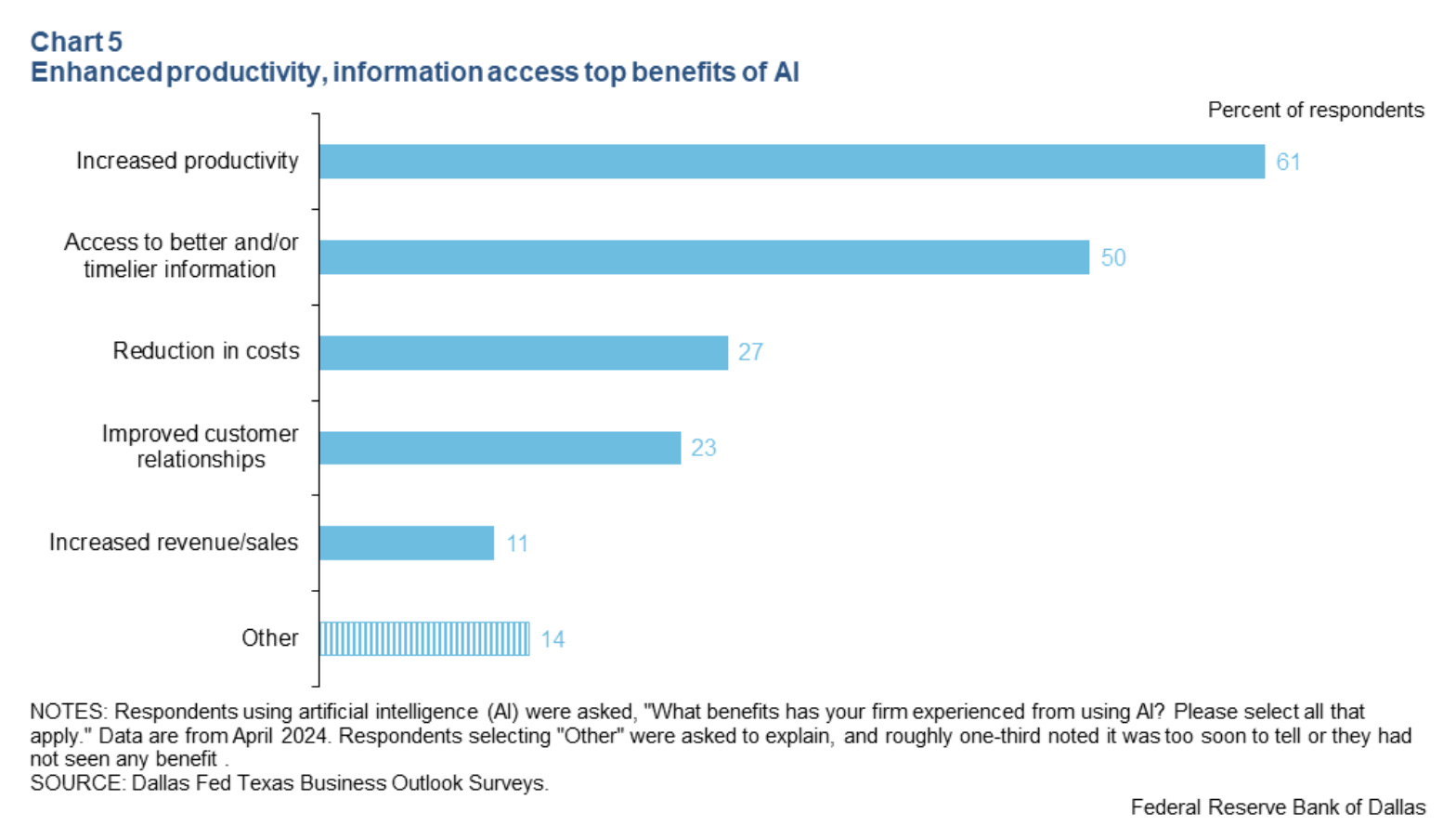
Texas survey finds nearly 40 percept of Texas firms use AI, with no signs of changes to employment. Only 10% using AI said it decreased need for workers, 2% said it increased. There was also a marginal shift from low skill to high skill work, note that this is the percent chance a firm in total had any shift at all, so the absolute numbers here are quite low so far.
What’s it good for? Mainly productivity. Access to information is also essentially productivity, after all.
One alternative to jailbreaking is to divide your task into subcomponents. A weaker model without safeguards does the blatant actions, a frontier model does seemingly harmless but difficult tasks, paper says you can get from <3% to 43% overall success rate this way on malicious tasks.
Well, sure. A strong model can help you do anything better without directly violating ethics, the same way you can get a lot of help out of ethical people and use that plus unethical henchman to do lots of unethical things.
That does not mean the safeguards are useless. In practice they are still big barriers if they force you into this song and dance. Also note that the strategic planning layer has to be done by the weaker model, so that makes it much harder to get humans properly out of the loop.
AISI hiring ML research scientists to explore technical AI safety cases, apply here.
Apollo Research hiring Senior AI governance researcher.
OpenAI brags about its cybersecurity grant program, invites more applications.
Protest against US-based AI companies in Accra, Ghana outside the US embassy.
Department of Energy releases 3.6 billion token corpus of federal permitting documents onto HuggingFace. A competition is available.
BlueDot Impact is hiring a software engineer.
Cate Hall is now CEO of Astera, and is building a team including a new COO to use their $2.5 billion endowment to make their vision of public goods for scientific and technological progress a reality in the age of AI. I worry that this agenda has no mention of existential risks from AI, and that if not careful they could amplify those risks. However it is true that other scientific progress is a worthy cause. As always in such cases, if it sounds appealing, investigate, ask questions and make your own decisions. It certainly is a big chance to steer a large endowment.
The AI Forecasting Benchmark Series from Metaculus, starting July 8, $120k in prizes over four contests. Only bots can enter. Metaculus scoring on blinded binary questions is a good test of prediction, so long as you notice it is radically different than what will make money gambling or in a market.
OpenAI has a Mac desktop app, which lets you quickly ask about anything on your computer. Marginally more convenient in ways that might make a practical difference.
Nvidia releases, as an open model, Nemotron-4 with 340B parameters, trained on 9 trillion tokens.
Oleksii Kuchaiev: Generating synthetic data for alignment of smaller models is key use case we have in mind.
I notice this use case confuses me. What makes this model better than alternatives for that? They offer some evaluation numbers, which are solid but seem disappointing for a model this large, and few are discussing this release. Indeed, it has entered the Arena Elo rankings at 1208, which essentially ties it with Llama-3-70B while being five times as large.
Otto, a way to interact and work with lots of AI agents using tables, you can apply for early access. No idea if the agents or interface are any good.
Dot is available in the Apple store. It appears to be a combined AI assistant and life coach you talk to on your phone and that claims to have effectively unlimited long term memory. It is $12/month. Kevin Fischer is impressed, and says he can’t share the great stuff because it is all too personal. As usual with such products it is impossible to know without an investigation: Is this anything?
Butterflies, which is Instragram except most of the users are AI that run accounts on their own and interact with each other and the few humans around. The future of social media whether we like it or not? I doubt it so long as humans are otherwise in charge, but the hybrids are going to get weird.
Decagon, providing Substack with customer service AI using RAG for context and categorizing responses by type.
Chris Best (CEO Substack): @DecagonAI was our first “holy shit AI just changed our business” moment at Substack. These guys are the real deal.
Jesse Zhang (Decagon AI): We’re creating the most human-like systems to handle all the things a customer support agent does: responding to customers, looking up data, taking actions, and also analyzing conversations, filing bugs, and writing knowledge articles. Read more here [at business insider].
They have raised 35 million.
I missed it a month ago: The UK’s AISI issued its May evaluations update.
They gave scaffolding to the models. Their central technique for cyber capabilities was ‘capture the flag’ problems, where you can read the answer in a file if you do other things first. For chemistry and biology they used private expert-written questions. Agent evaluations assigned the models various tasks, none succeeded at anything with a long time horizon.
Safeguard checks… did not go well.
They have now done evaluations prior to release for Gemini 1.5 Pro and Claude 3.5 Sonnet. This all looks reasonable, but implementation matters and is hard to evaluate from here, and this will need to expand over time.
OpenAI changes its policy on tender offers, assuring that all will have equal opportunity to sell, and removing the ‘fair market value’ repurchase provision.
Kelsey Piper: ! OpenAI is committing to access to tender offers for former employees and removing a provision allowing them to take equity back for “fair market value”. This was a major ask from ex-employees when the secret NDA story first broke.
Hayden Field: Scoop: OpenAI has reversed course on many of its tender offer policies, which in the past treated current employees differently than former ones & in some ways excluded former employees working at competitors, CNBC has learned, via an internal document.
The exception is if a tender offer is oversubscribed, with more sellers than buyers, in which case current employees get prioritized. A loophole, but fair enough. Former employees can still be excluded from ‘donation rounds,’ which I assume is relatively minor but not nothing.
These changes are a major step forward, if we trust these promises to be enacted, as a lot of this is ‘we will do X’ or ‘we will revise the documents to say Y.’ If they are not enacted as promised, that would be a gigantic red flag. If we feel that makes the promises sufficiently credible, then this counts for a lot.
OpenAI taking additional steps to block access to its services from China. Bloomberg speculates this opens the door for Chinese firms. Technically OpenAI services were not previously available in China. It seems everyone was ignoring that.
Bloomberg News: For China, that could help usher out many smaller startups created during the “battle of a hundred models,” in the wake of ChatGPT’s late 2022 debut. And a bigger concern may be whether open-source models like Meta Platforms Inc.’s Llama also cut off access, said Bernard Leong, chief executive officer of Singapore-based Dorje AI.
Um, Bloomberg, how exactly would Meta do that? Meta’s models are open weights. Is Meta going to say ‘we are asking you nicely not to use our model, if we discover you copied and used it anyway we will be cross with you?’ Are they going to sue the Chinese companies for not getting a commercial license? Good luck with that.
Also, it pains me when I see reports like this that cite Meta as part of the lead group in AI but that do not mention Anthropic, despite Anthropic having the best model.
OpenAI delays its advanced Voice Mode for another month, anticipates all Plus users having access in the fall along with new video and screen sharing capabilities.
Apple in talks with Meta to add its AI to Apple Intelligence’s offerings alongside ChatGPT. They said they intended to offer a variety of choices. I would be talking to Google and Anthropic first, but it matters little.
Sarah Constantin says it is 10+ years from state of the art to widespread use in the military, procurement is slow, so Leopold’s military timelines don’t make sense.
I mean, sure, in peacetime, when everyone is mostly fine with that. If we are in AGI world, and a few months lead in tech would if implemented be decisive, what happens then? Presumably we go on a wartime footing and throw our procurement rules out the window. Wartime militaries work completely differently from peacetime militaries.
If not, well, then our military is going to stop being effective, even against domestic rivals, because being 10 years behind is going to be quite obviously fatal even in relatively slow scenarios.
One view of Ilya’s new venture.
Roon: Extreme bear signal on anyone who says cracked especially in their launch post.
Gwern speculates that OpenAI has ‘lost its mojo’ and key employees, and could now be largely coasting on momentum.
Gwern: What made OA OA in 2020 was that it had taste: it had much less resources than competitors like DeepMind or Google Brain or FAIR, but (thanks to Alec Radford, Ilya Sutskever, Jared Kaplan, and the RLHF-focused safety team like Paul Christiano & Dario Amodei, and fellow-traveler scalers like Andrej Karpathy etc) they bet big on scaling laws & unsupervised learning at the moment those suddenly began to work. Without taste and agility—or you might say, “without its people, OA is nothing”—OA doesn’t have that much of a moat.
And most of those people are gone, and the survivors are being policed for leaks to the media, and now know that if they leave, OA management wants to gag them, and has the power to confiscate their vested equity, wiping out all their wealth.
…
What are the vibes now? Where is the research taste at OA, what ideas or breakthroughs have they published the past few years of note? The weird rumored Franken-MoE architecture of GPT-4? GPT-4o, whose architecture has been obvious since DALL·E 1, if not well before, and which benchmarks great but users are overall less pleased?
…
I think it implies that they are eating their seed-corn: scrapping any safety issues may work in the short run, but is self-sabotaging in the long run. (Like the man who works with his office door closed, who is highly productive now, but somehow, a few years later, is irrelevant.) The rot will set in long before it become clear publicly. OA will just slow down, look glossier but increasingly forfeit its lead, and some point it stops being possible to say “oh, they’re way ahead, you’ll see when they release the next model in a few months/years”.
And the Mandate of Heaven shifts elsewhere, irreversibly, as OA becomes just another place to work. (Startup & research culture mostly only degrades from the peak at their founding.) The visionaries go to Anthropic, or follow Ilya to SSI, or take a risk on Google, or go someplace small like Keen to bet big.
What’s weird about GPT-4o is actually that it scores so well on Arena, versus my observation that it is fine but not that good.
David Chapman responds that perhaps instead scaling has run out, as a different explanation of the failure to create a new killer product.
Ability at math competitions is bizarrely strongly correlated among humans with later winning Fields Medals for doing frontier math, despite the tasks being highly distinct. So should we take winning math competitions as a sign the AI is likely to earn Fields Medals? Should we also respect doing well on other standardized tests more? My guess is no, because this has a lot to do with details of humans and we have to worry about data contamination on many levels and the use of techniques that don’t transfer. It is still food for thought.
There have always been people who think most possible technologies have been invented and things will not much change from here. Robin Hanson claims this is actually the ‘dominant view among most intellectuals.’ He does note ‘there are other variables,’ but this illustrates why ‘most intellectuals’ should mostly be ignored when it comes to predicting the future. They utterly lack situational awareness on AI, but even without AI there are plenty of worlds left to conquer.
Sir, the reason we will want to turn over decision making to AIs is that the AIs will be capable of making better and faster decisions.
Timothy Lee: I’ve never understood why people think we’ll want to turn over strategic decision-making to AIs. We can always ask for recommendations and follow the ones that make sense.
People point to examples like chess or Go where computers are now strictly better than people. But very few strategic decisions in the real world are purely instrumental. There are almost always tradeoffs between competing values; people are going to want the final say.
It’s one thing for a computer to say “you need to sacrifice your rook to win the chess game.” It’s another for it to say “you need to sacrifice 10,000 soldiers to win the war.” Human decision-makers might think that’s worth it but they might not.
What happens by default, if capabilities keep advancing, is that those who do let AIs make those decisions win and those who don’t let them make those decisions lose. Keeping humans in the loop is cheaper for strategic decisions than tactical ones, but still expensive. After some point, humans subtract rather than add value to AI decisions, even by their own metrics, except that not doing so means you lose control.
That’s the game. You could ask for recommendations, but what happens when it is clear that when you disagree you are by default making things worse, while also wasting valuable time?
Point, counterpoint.
Richard Ngo: I expect the premium on genius to increase after AGI, not decrease, because only the smartest humans will be able to understand what the AGIs are up to.
Interesting analogy here to physical prowess – manual labor became much less common, but the returns to being athletic are now through the roof via professional sports.
Professional AI interpretation won’t be quite as heavy-tailed, but still more than current science, I’d guess.
Zack Davis: Doesn’t seem like this era will last very long?
Richard Ngo: Even when AIs become smart enough that nobody understands what they’re up to, understanding more than anyone else seems like a big deal as long as humans are still around! If we met friendly-ish aliens, the person who spoke their language most fluently would get very rich.
There is a lot of wishcasting here. The AGIs will rapidly be doing lots of things no one can understand. Events will presumably be well out of our control. Yet being somewhat less completely confused, or getting completely confused slower, will be where it is at, and will pay meaningful dividends in real world outcomes?
This requires threading quite a few needles. Your expertise has to give you better understanding, despite the AGIs being able to explain things. That has to let you make better decisions. Your better decisions have to matter.
Even taking his metaphor at face value, are returns to being athletic higher? Yes, you can make quite a lot of money by being the very best. But you can be outrageously good at athletics, as in a minor league baseball player, and get very little return. Even trying for college scholarships is quite the sweepstakes. This is a winners-take-all (or at least most) competition.
Maxwell Tabarrok offers a takedown of Daron Acemoglu’s paper The Simple Macroeconomics of AI, another in the line of economic models that presumes AI will never gain any capabilities and current AI cannot be used except in certain specific ways, then concluded AI won’t increase economic growth or productivity much.
Anton points out that dumping massive context into systems like Claude Sonnet 3.5 is not going to dominate RAG because of cost considerations. Claude costs $3 per million input tokens, which is definitely ‘our price cheap’ but is still $187/GB, versus DDR4 at $2.44/GB, NVME at $0.09/GB. You will have an infinite context window but you will learn how not to use (and abuse) it.
If we do discover dangerous cyber capabilities in AI, what do we do next? Who finds out? The proposal here from Joe O’Brien is Coordinated Disclosure of Dual-Use Capabilities, with a government team funded and on standby to coordinate it. That way defenders can take concrete action in time. He and others make the same case here as well, that we need an early warning system.
It is hard to imagine, short of it being completely botched and useless, an early warning system being a bad use of funds.
What happened in Seoul last month?
Mostly: Diplomacy happened.
That makes it difficult to know whether things moved forward. In diplomacy (as I understand it) most time is spent establishing foundation and trust, laying groundwork for the final agreement. But always, always, always, when it comes to the bottom line, nothing is done until everything is done.
Still, this commitment goes beyond that and seems like an excellent start?
Dan Hendrycks (June 7, 2024): Last month in Seoul, major AI developers already committed to testing their models for risks, and even ceasing development if their models reach a catastrophic level.
It’s revealing how many people oppose regulation that would require companies to keep some of these promises.
Here are the commitments.
Outcome 1. Organisations effectively identify, assess and manage risks when developing and deploying their frontier Al models and systems. They will:
I. Assess the risks posed by their frontier models or systems across the Al lifecycle, including before deploying that model or system, and, as appropriate, before and during training. Risk assessments should consider model capabilities and the context in which they are developed and deployed, as well as the efficacy of implemented mitigations to reduce the risks associated with their foreseeable use and misuse. They should also consider results from internal and external evaluations as appropriate, such as by independent third-party evaluators, their home governments[footnote 2], and other bodies their governments deem appropriate.
II. Set out thresholds [footnote 3] at which severe risks posed by a model or system, unless adequately mitigated, would be deemed intolerable. Assess whether these thresholds have been breached, including monitoring how close a model or system is to such a breach. These thresholds should be defined with input from trusted actors, including organisations’ respective home governments as appropriate. They should align with relevant international agreements to which their home governments are party. They should also be accompanied by an explanation of how thresholds were decided upon, and by specific examples of situations where the models or systems would pose intolerable risk.
III. Articulate how risk mitigations will be identified and implemented to keep risks within defined thresholds, including safety and security-related risk mitigations such as modifying system behaviours and implementing robust security controls for unreleased model weights.
IV. Set out explicit processes they intend to follow if their model or system poses risks that meet or exceed the pre-defined thresholds. This includes processes to further develop and deploy their systems and models only if they assess that residual risks would stay below the thresholds. In the extreme, organisations commit not to develop or deploy a model or system at all, if mitigations cannot be applied to keep risks below the thresholds.
V. Continually invest in advancing their ability to implement commitments i-iv, including risk assessment and identification, thresholds definition, and mitigation effectiveness. This should include processes to assess and monitor the adequacy of mitigations, and identify additional mitigations as needed to ensure risks remain below the pre-defined thresholds. They will contribute to and take into account emerging best practice, international standards, and science on Al risk identification, assessment, and mitigation.
Outcome 2. Organisations are accountable for safely developing and deploying their frontier Al models and systems. They will:
VI. Adhere to the commitments outlined in I-V, including by developing and continuously reviewing internal accountability and governance frameworks and assigning roles, responsibilities and sufficient resources to do so.
Outcome 3. Organisations’ approaches to frontier Al safety are appropriately transparent to external actors, including governments. They will:
VII. Provide public transparency on the implementation of the above (I-VI), except insofar as doing so would increase risk or divulge sensitive commercial information to a degree disproportionate to the societal benefit. They should still share more detailed information which cannot be shared publicly with trusted actors, including their respective home governments or appointed body, as appropriate.
VIII. Explain how, if at all, external actors, such as governments, civil society, academics, and the public are involved in the process of assessing the risks of their Al models and systems, the adequacy of their safety framework (as described under I-VI), and their adherence to that framework.
-
We define ‘frontier AI’ as highly capable general-purpose AI models or systems that can perform a wide variety of tasks and match or exceed the capabilities present in the most advanced models. References to AI models or systems in these commitments pertain to frontier AI models or systems only.
-
We define “home governments” as the government of the country in which the organisation is headquartered.
-
Thresholds can be defined using model capabilities, estimates of risk, implemented safeguards, deployment contexts and/or other relevant risk factors. It should be possible to assess whether thresholds have been breached.
That is remarkably similar to SB 1047.
Markus Anderljung: This is just the start of this journey. Going forward, governments, civil society, academia, the public will need to be a part of defining and scrutinizing these frontier AI safety frameworks. But the first step is that they exist.
The thresholds would be set by the companies themselves. In the future, they should and probably will see significant input from others, including governments. They’d have to be public about it, which allows others to spot if their commitments aren’t sensible. Most of these companies don’t have these frameworks in place, let alone talk about them publicly, so this seems like a step in the right direction
In order to comply with this, you need to detail your safety protocols, which also means detailing what is being trained in at least a broad sense. You have to have procedures to verify your mitigations. You have to comply with shifting international standards and best practices that are not defined in advance.
The only substantial parts missing are the shutdown protocol and protecting the model weights until such time as they are intentionally released.
Also the thresholds are set by the companies rather than the governments. This seems worse for everyone, in the sense that a government standard offers safe harbor, whereas not having one opens the door to arbitrary declarations later.
So if this is so terrible, presumably companies would not sign… oh.
•Amazon
•Anthropic
• Cohere
•Google
• G42
• IBM
• Inflection Al
• Meta
• Microsoft
• Mistral Al
• Naver
• OpenAl
•Samsung Electronics
• Technology Innovation Institute
•xΑΙ
•Zhipu.ai
I am not saying that is ‘everyone’ but aside from some Chinese companies it is remarkably close to everyone who is anyone.
Ian Hogarth (Chair AISI): Really remarkable achievement announced at AI Seoul Summit today: leading companies spanning North America, Asia, Europe and Middle East agree safety commitments on development of AI.
If you scan the list of signatories you will see the list spans geographies, as well as approaches to developing AI – including champions of open and closed approaches to safe development of AI.
What else happened?
What about China’s statements? China would be key to making this work.
Matt Sheehan: Chinese readout from AI dialogue meets (low) expectations:
– want AI good not bad
– UN=leader on governance
Disappointing (but expected): China delegation led by Foreign Ministry North America bureau. Indicates China treating dialogue as aspect of US-China relations, not global tech risk.
Helen Toner: No Matt but didn’t you see, they agreed that AI could have big benefits but also poses big risks! I think that’s what they call a diplomatic breakthrough.
Saad Siddiqui: It feels like lots of different parts of the CN bureaucracy in the room, hard to imagine productive dialogue with so many different interests present across NDRC, CAC, MOST, MIIT, Central Committee Foreign Affairs Office. Any sense if that’s typical?
I do not know why anyone would have any hope for the United Nations. I worry that saying ‘the UN should take a leading role’ is a lot like saying ‘we should do nothing.’ Then again, if we already believe all five security council members have de facto vetoes over everything anyway, then does it change anything? I don’t know.
Imane Bello calls it a success, because:
-
They got everyone together.
-
They got China and America into the same room.
-
There were calls for cooperation between many AI safety institutes.
-
The interim international scientific report was unanimously welcomed.
-
In Imane’s opinion, IISR is ‘history in the making.’
Again, that’s diplomacy. Did it matter? Hard to say.
UK lead negotiator Henry de Zoete is also calling it a win.
Jan Brauner sums up what they see as the most important outcomes.
-
AI safety institutes say they will partner and share info.
-
Companies make the commitments above.
-
US AISI within NIST releases strategic vision (full version here).
-
Soul Ministerial Statement is super explicit about existential risk.
-
UK government sets up $11mm grant program for AI safety.
I looked over the NIST strategic vision. I have no particular objections to it, but neither does it involve much detail. It is a case of successfully not messing up.
Some have ambitious further plans.
Eva Behrens: Here are 5 policy recommendations for the upcoming AI Safety Summit in Seoul, from me and my colleagues at ICFG.
In Bletchley, world leaders discussed major risks of frontier AI development. In Seoul, they should agree on concrete next steps to address them.
Overview
In accordance with the shared intent communicated through the Bletchley Declaration to deepen international cooperation where necessary and mitigate catastrophic risks from advanced Al, we urge countries attending the Summit in South Korea to jointly recognise that:
-
The development of so-called long-term planning agents (LTPAs) should be prohibited until proven safe,
-
Advanced Al models trained on 10^25 Floating Point Operations (FLOP) of compute capacity or more should be considered high-risk and need to be regulated accordingly, and
-
The open-sourcing of advanced Al models trained on 10^25 FLOP or more should be prohibited.
To build a strong foundation for international cooperation on the governance of high-risk advanced Al, we urge that Summit participants jointly agree to:
-
Hold biannual international Al Safety Summits, and pick a host country to follow after France and
-
Keep the focus of the Summits on international collaboration for mitigating catastrophic risks from advanced Al.
Contrast this with SB 1047. This would heavily regulate above 10^25 including full bans on open source (until a protocol is designed to allow this to happen safety, they say, no idea what that would be), with no adjustments over time. SB 1047 starts at 10^26, requires only reasonable assurance, and has a $100 million minimum such that the threshold will rapidly scale higher very soon.
Indeed, the ICFG says the threshold should over time be adjusted downwards, not upwards, due to algorithmic and hardware improvements.
This also proposes a ban on ‘long term planning agents,’ which unfortunately is not how any of this works. I don’t know how to allow short term planning agents, and effectively stop people from making long term ones. What would that mean in practice?
There was this talk that included Yoshua Bengio, Max Tegmark and Jaan Tallinn.
What about the full International Scientific Report on the Safety of Advanced AI? I looked briefly and I was disappointed. Over 95% of this report is the standard concerns about job displacements and deepfakes and privacy and other similar issues. The one section that does address ‘loss of control’ says experts disagree about whether this could be a concern in the future if we create things smarter than ourselves, so who can say.
They even say that a loss of control of highly capable AI systems is ‘not necessarily catastrophic.’ That is the only time the word ‘catastrophic’ is used, and they do not say ‘existential.’ ‘Extinction’ is only mentioned once, in the section directly after that, entitled ‘AI researchers have differing views on loss of control risks.’ Thus, despite the conference saying it should focus on existential dangers, this report is in effect highly dismissive of them, including implicitly treating the uncertainty as reason not throw up one’s hands and focus on issues like implicit bias.
Top AI labs are currently dramatically insecure. As the value of their model weights and other assets rises, both commercially and as an existential risk and matter of national security, this will increasingly become a problem. Alexander Wang, CEO of Scale AI, did a ChinaTalk interview in which he emphasized the need to lock down the labs if AI capabilities continue to advance.
Rand recently came out with an extensive report on how to secure model weights. As they note, securing only the model weights is a far more tractable problem than securing all the data and algorithms involved. They assume future frontier models will be larger, and online API access will need to be widespread.
Here is a Q&A with director Sella Nevo, one of the coathors, which goes over the most basic items.
What are their core recommendations?
They start with things that need to be done yesterday. The biggest dangers lie in the future, but our security now is woefully inadequate to the dangers that exist now.
Avoiding significant security gaps is highly challenging and requires comprehensive implementation of a broad set of security practices. However, we highlight several recommendations that should be urgent priorities for frontier AI organizations today. These recommendations are critical to model weight security, most are feasible to achieve within about a year given prioritization, and they are not yet comprehensively implemented in frontier AI organizations.
• Develop a security plan for a comprehensive threat model focused on preventing unauthorized access and theft of the model’s weights.
• Centralize all copies of weights to a limited number of access-controlled and monitored systems.
• Reduce the number of people authorized to access the weights.
• Harden interfaces for model access against weight exfiltration.
• Implement insider threat programs.
• Invest in defense-in-depth (multiple layers of security controls that provide redundancy in case some controls fail).
• Engage advanced third-party red-teaming that reasonably simulates relevant threat actors.
• Incorporate confidential computing to secure the weights during use and reduce the attack surface. (This measure is more challenging to implement than the others in this list but is backed by a strong consensus in industry.)
This is the least you could do if you cared about the security of model weights. Have an actual plan, limit access and attack surface, use red-teaming and defense in depth.
As Leopold noted, our goal must be to stay ahead of the threat curve.
The authors note that FBI Director Christopher Wray implied China had a workforce of more than 175,000 hackers. If China wanted to go full OC5+, they could. For now it would not make sense given the economic and diplomatic costs. Later, it will.
They also say North Korea invests ‘between 10% and 20% of the regime’s military budget’ in cyberwarfare, between $400 million and $800 million. I presume they do this largely because it is profitable for them.
Everyone acknowledges that an OC5-level attack on any major lab would almost certainly succeed. For now, that is fine. The question is, when does that become not fine, and where should we be right now? Should we be able to block an OC4 attack? I certainly hope we would be able to block an OC3 one given the value at stake.
We do not need to attempt bulletproof security until we are under robust attack and have assets that justify the real costs of attempting bulletproof security. We do need to be trying at all, and starting our preparations and groundwork now.
Longer term we will need things like this to have much chance, similar to what one would do if worried about model self-exfiltration, which we should be worried about in such scenarios as well:
• physical bandwidth limitations between devices or networks containing weights and the outside world
• development of hardware to secure model weights while providing an interface for inference, analogous to hardware security modules in the cryptographic domain
• setting up secure, completely isolated networks for training, research, and other more advanced interactions with weights.
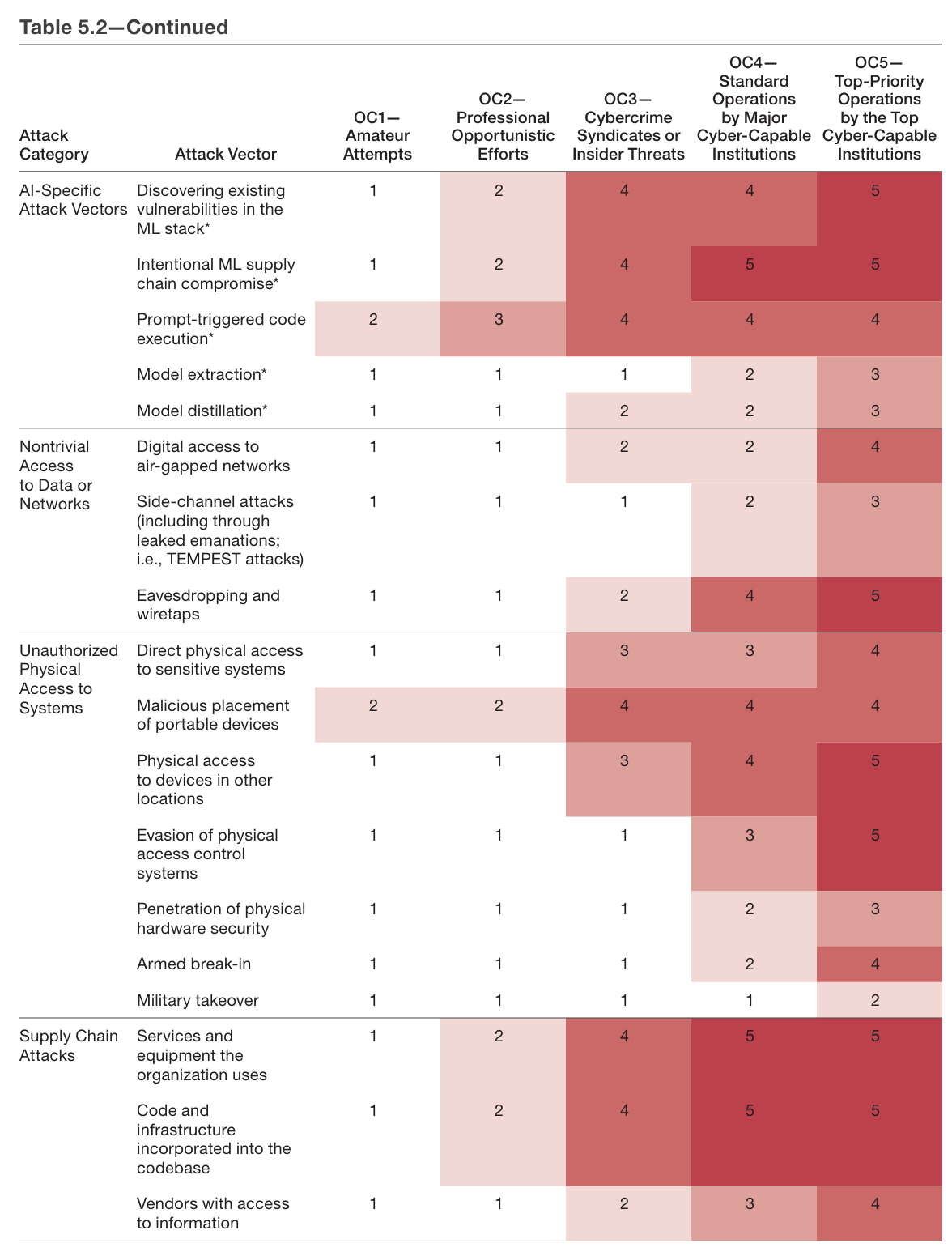
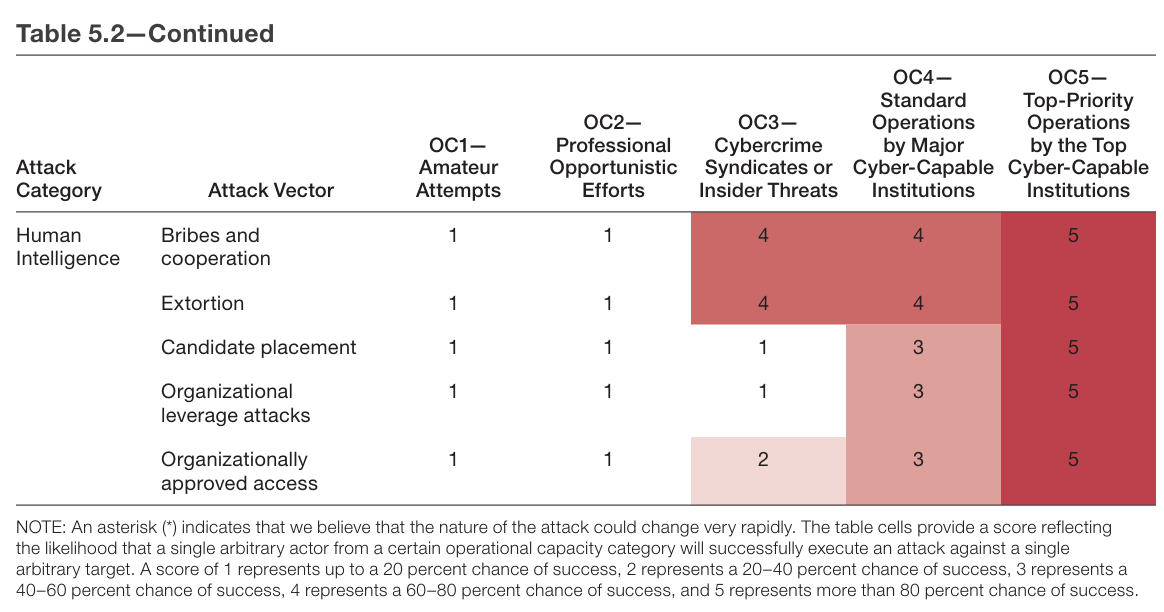
They highlight 38 potential attack vectors in 9 categories.
How many resources are needed to launch various attacks? They have a table for that.
The numbers here are weird, representing chance of success linearly from <20% to >80%, against an arbitrary target. I would think things would scale differently.
I also do not think that ‘up to 20% chance of success’ is the right category? If something has a 10% chance of success it is a big deal.
Also important is that this is an enumeration of things we know about. That is a lower bound on the risk. The actual situation is far worse, because it includes unknown unknowns. It is very hard for the things we do not know about to be ‘good news’ here.
For multiple reasons, it is prudent to recognize the plausibility of current assessments underestimating the threat:
• We assume that other attack vectors exist that are as yet unknown to security experts, particularly ones concerning advanced persistent threats (APTs), such as state actors.
• Novel attack vectors and conceptual approaches are likely to evolve over time, as are novel insights and infrastructure that make existing attacks more accessible.
• Publicly known examples of attacks are only a subset of attacks actually taking place, especially when it comes to more-advanced operations. Most APTs persist for years before discovery.
• Many national security experts with whom we spoke mentioned that the vast majority of highly resourced state actor attacks they are aware of were never publicly revealed. This means that a purely empirical analysis based on detected operations would systematically underestimate the feasibility and frequency of advanced attack vectors.
• Accordingly, one should expect capable actors to have access not only to well-established attack vectors but also to unknown approaches. In Appendix A, we share many examples of state actors developing such conceptually novel attacks years or decades before they were discovered by others.
Bold is mine. All of that involves human attack vectors only. If we include future AI attack vectors, enabled by future frontier models, the situation gets even more dire if we do not bring our new capabilities to play on defense with similar effectiveness.
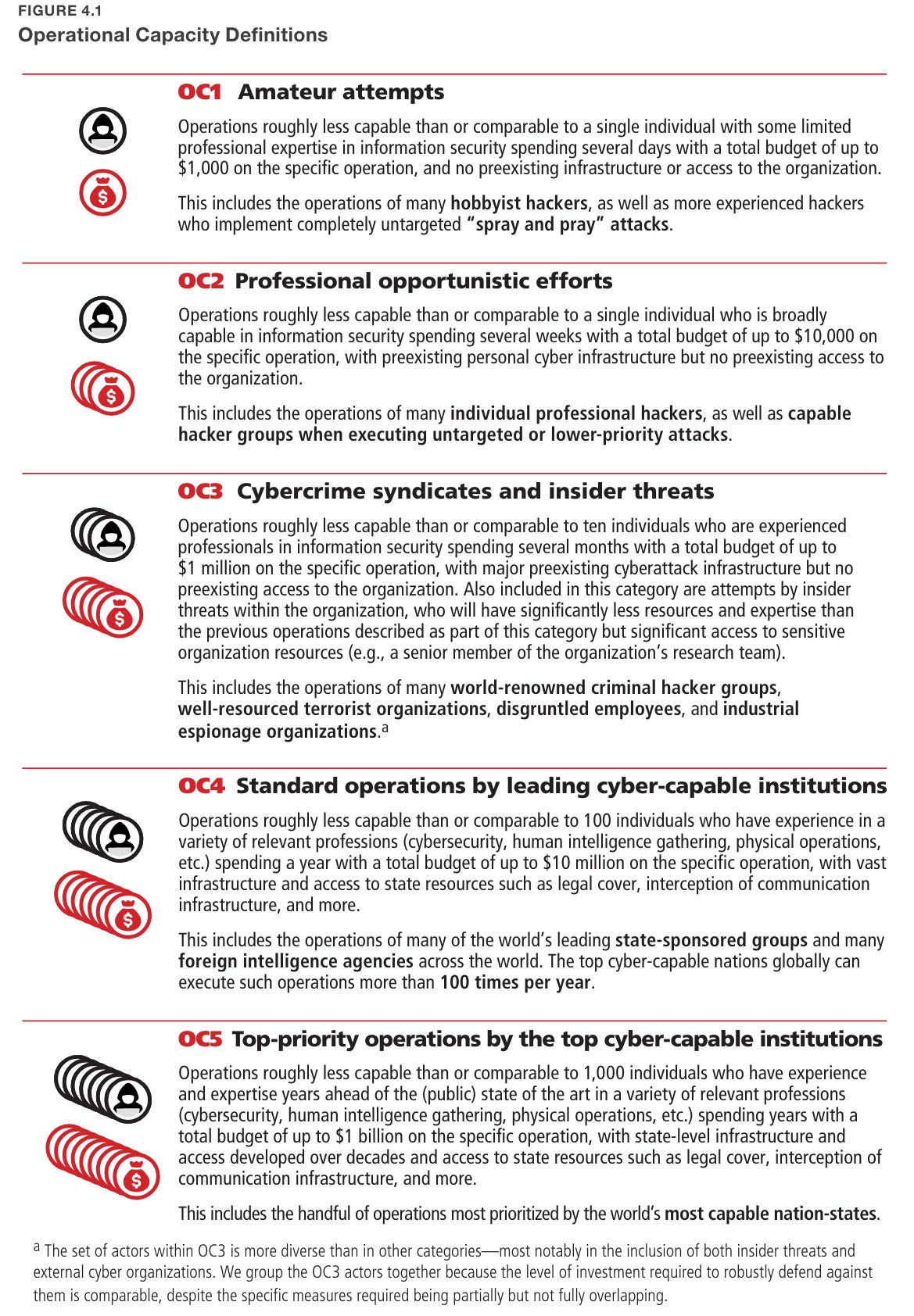
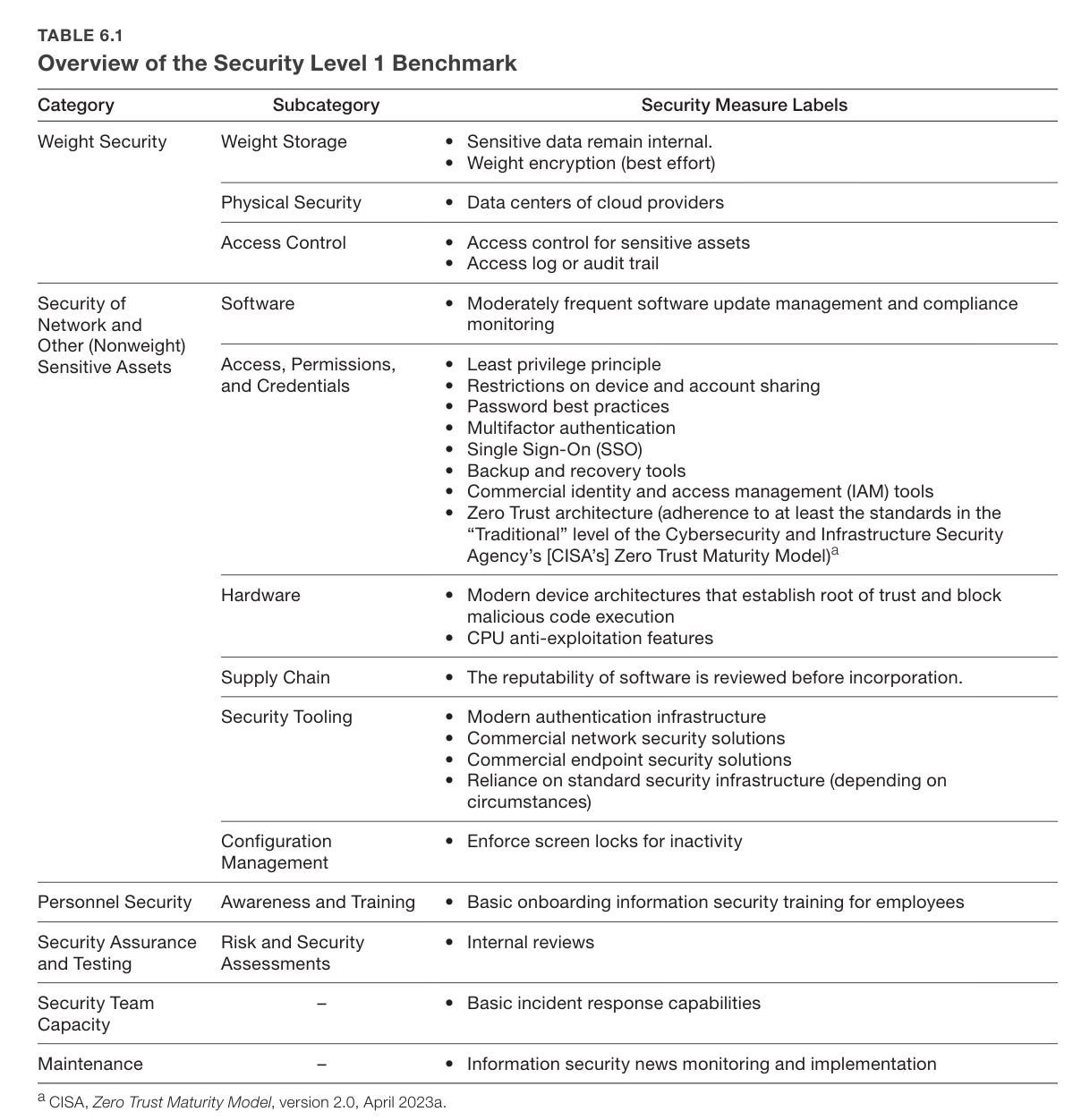
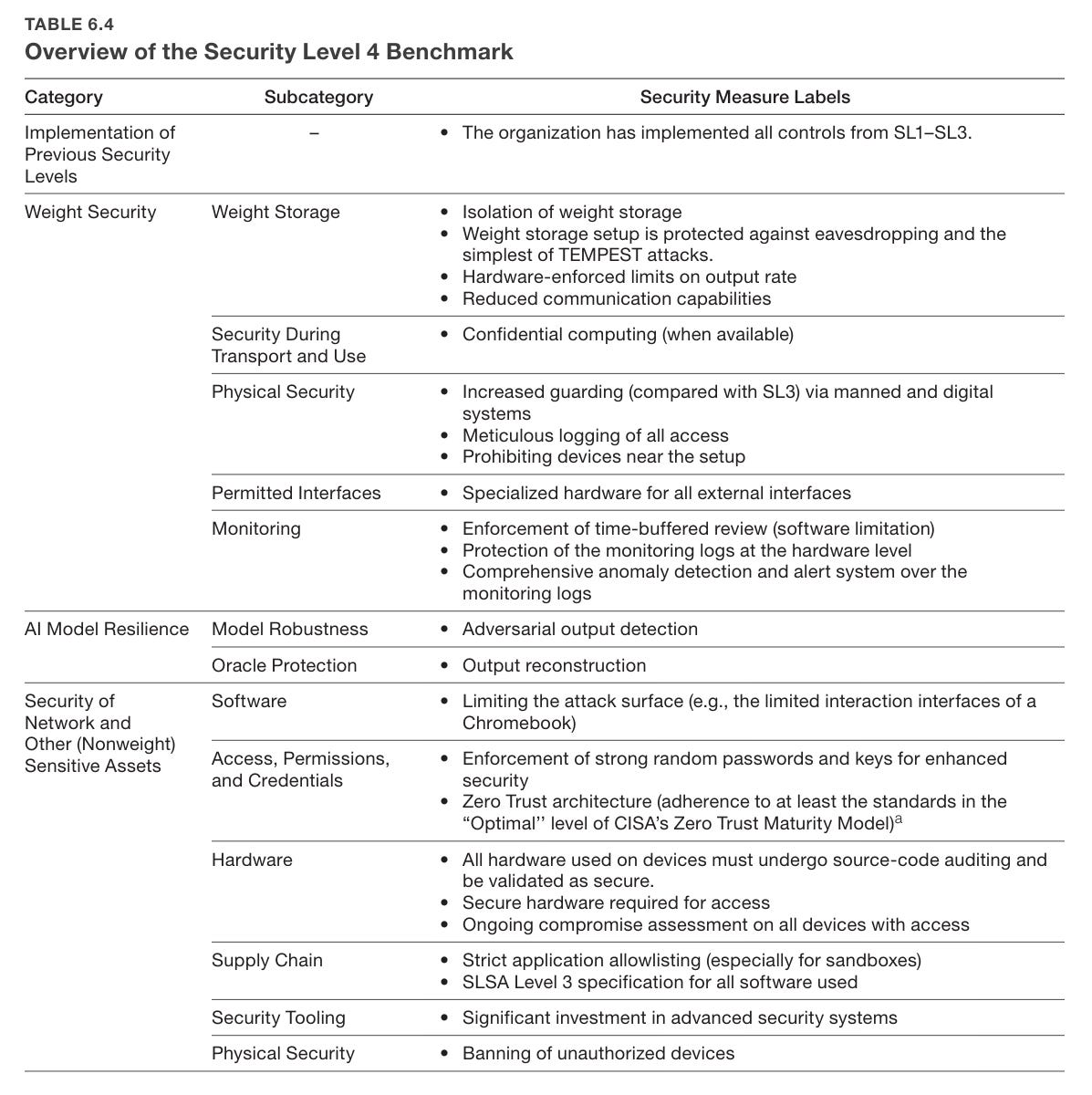
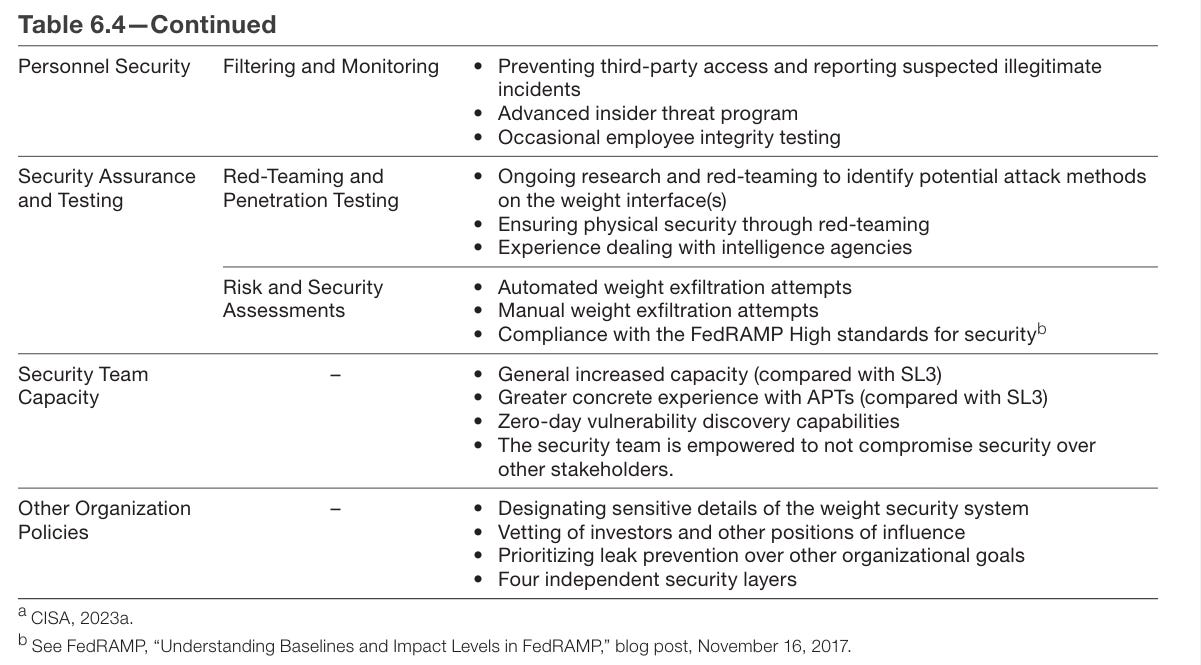
Chapter 6 proposes that labs define security levels (SLs) from SL1 to SL5. If you are SL(X), you are protected against threats of OC level X.
So what does it take to get to even SL1?
In some senses this is easy. In others, in the context of a startup? It is asking a lot.
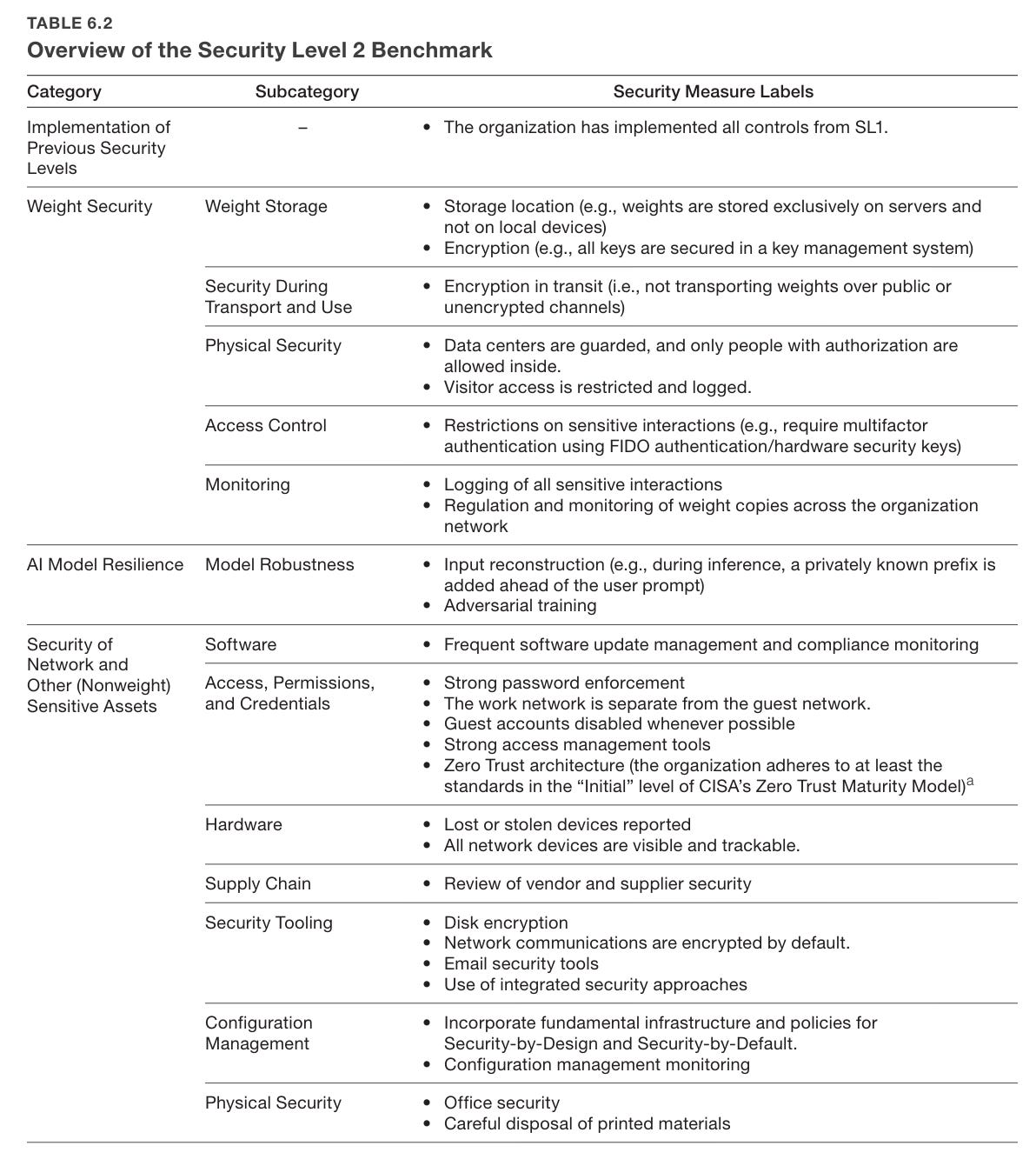
Moving to SL2 means ‘industry best practices’ across the board. Doing all of the standard things everyone says one should do is a standard few companies, in practice, actually meet. Almost everyone is doing some number of ‘stupid’ things in the form of not doing some of the things on this list.
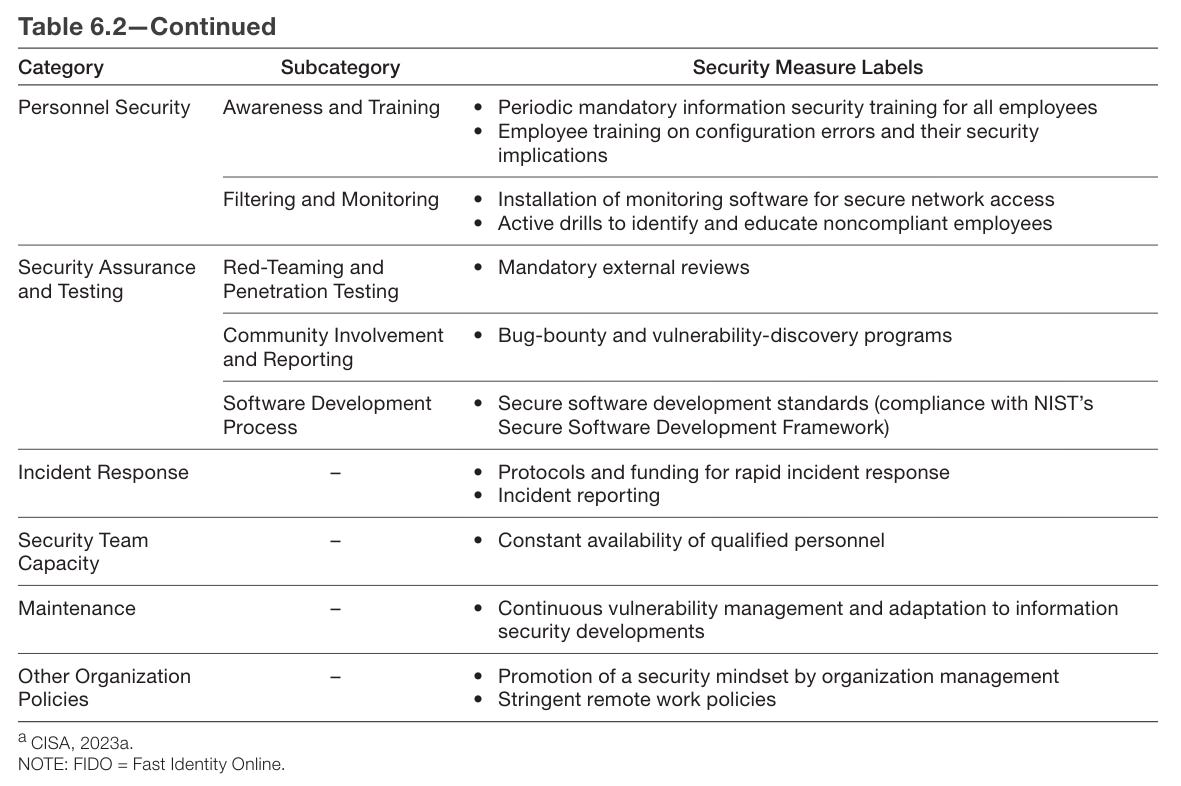
What about SL3? It is essentially more of the same, only more so, and with serious worries about insider threat vectors. Any individual item on the list seems plausible but annoying. Doing all of them, in a world where your weakest point gets attacked, is not going to happen without a concerted effort.
SL4 gets expensive. Things are going to get slowed down. You do not want to be implementing this level of paranoia too early.
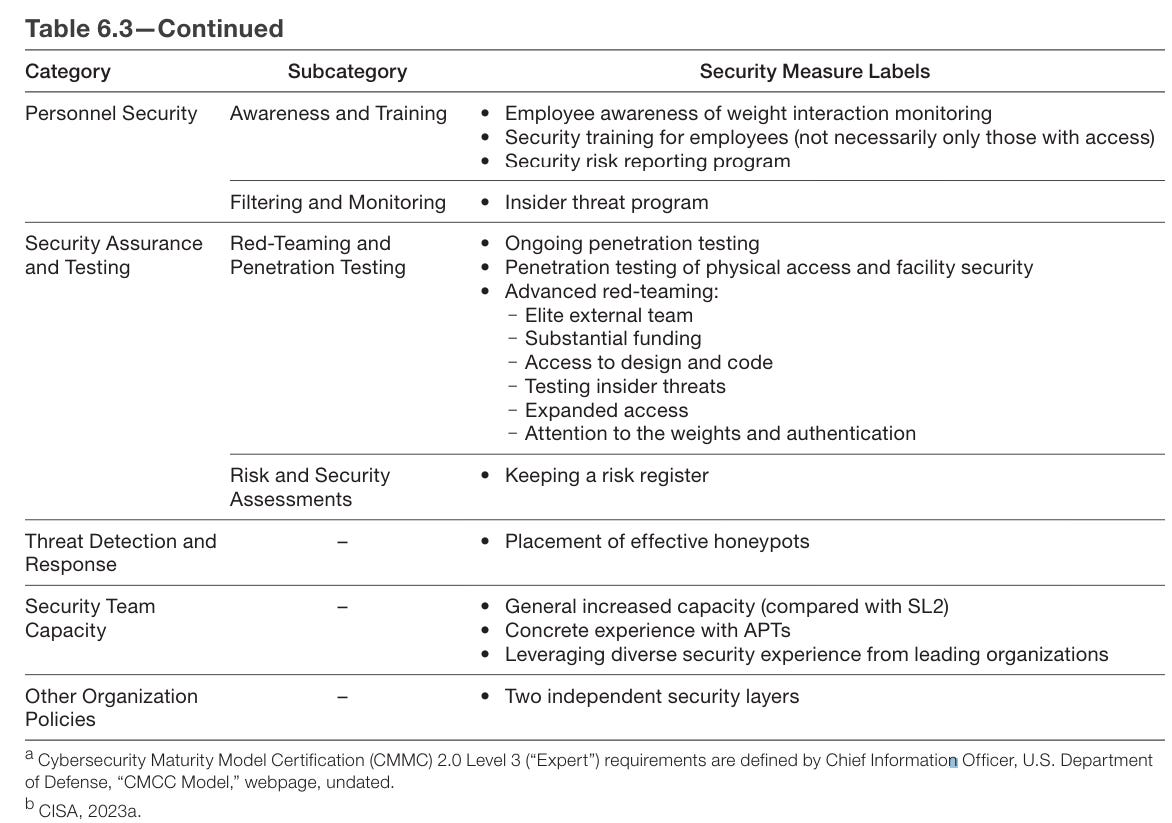
SL5 is that much more expensive to implement. You have to care quite a lot. Having eight security layers is quite the ask as are many other action items.
Is all that necessary? Would it even be sufficient? Consensus weakens as you move up to higher security levels.
There are deeper and more conceptual disagreements about what is needed to achieve the security implied by SL4 and SL5—with opinions ranging from the SL3 benchmark being sufficient to secure against all threat actors to claims that no system could ever present a significant hurdle to operations in the OC5 category.
A particular point of disagreement was the number of people who should have authorization to access the weights. Some experts strongly asserted that the model weights cannot be secure if this number is not aggressively reduced (e.g., to the low tens); others claimed that such a reduction would not be necessary, feasible, or justified.
I have definitely talked to an expert who thought that against an OC5 operation all you can hope to do is buy some time. You can prevent them from stealing everything the first day they set their sights on it, but protecting assets over time is, they claimed, rather hopeless. I haven’t seen credible claims that SL3-style procedures would be sufficient to protect against OC5, and I find that highly implausible, even if it has rarely if ever been tried.
The low tens seems to me quite a lot of people to have access to your core asset. I am not sure how different ‘low tens’ is from infinity. Certainly if your plan involves dozens of people each not being compromised, then you have no plan.
The second half of the report is details of the different attack vectors.
House appropriations bill cuts $100 million in funding for NIST. This is one of the worst things to be cutting right now, it is already woefully underfunded.
New paper on Risk Thresholds for Frontier AI. How should we combine compute thresholds, risk thresholds and capability thresholds? The conclusion is to primarily use capability thresholds but have them be informed by risk thresholds.
I am going to quote this in full because it feels like a good steelman of being skeptical about going too far too fast on regulation.
Seb Krier (Google DeepMind): I tend to think of AI policy in three consecutive phases: observation and monitoring; standardization and norm-setting; and then rules, law, and regulations if necessary. My impression is that in recent years some governance crowds have taken the reverse approach, motivated by the usual policymaker urgency of ‘we must do something now’. The problem with this is that you now have to define and cement very precise things that are still evolving, like evaluations and mitigations. Combined with the many trade-offs, inefficiencies, conflicting interests, low capacity, and frankly generally poor decision-making that governments currently suffer from, this often leads to messes, evidentiary gaps, legal risks, and rushed policymaking.
To be clear, I definitely think AI is a technology that will warrant some degree of regulation – and there may well be sector-specific uses or applications that warrant this now. I think cybersecurity-oriented regulations make more sense than omnibus regulatory behemoths. But at a more general level, I feel like we’re still in a phase where the value comes from research and finding things out. And I’d rather see 50 organizations developing evaluations and 5 advocating for regulations rather than the reverse (i.e. what we have today). This is also why I’m quite supportive of the experimental nature of institutions like the AI Safety Institute, where both sides iteratively learn as things progress.
Some people justify hasty policymaking because they think we will have AGI very soon and therefore this demands quick pre-emptive action, otherwise governments won’t have time to intervene. I think it’s right to try to pre-empt things, prepare institutions, and think ahead – but I don’t think timelines alone grant a carte blanche for any kind of legislation. Plus if we are indeed getting very close to AGI, I have 0 doubt that governments will inevitably wake up – and the implications, particularly for large risks, will be a lot more Leopold-like than creating a new GDPR for AI.
So essentially:
-
For now we should observe and monitor, lay groundwork such as with NIST, and perhaps do select sector-specific interventions such as in cybersecurity.
-
Later we will do, and will want to do various regulatory actions.
-
But let’s try and push the key decisions forward in time so we learn more.
Also GPDR is deeply stupid law. Do not make laws like GPDR. They do great harm via creating frictions without accomplishing almost anything.
It is also correct to worry about regulatory lock-in. Not infinitely worried as in ‘anything imposed is automatically forever,’ but yes there is a lot of inertia and these things are hard to reverse.
How much do we need to worry about moving too slowly? That depends on:
-
How long you think we have.
-
How quickly you think we can move.
-
How sensibly you think we would move in a crisis but with more information.
-
Whether you think that by the time there is a crisis, it will be too late.
Reasonable people disagree on all those questions.
What most critics and skeptics fail to do is differentiate their responses to different types of regulatory proposals.
As in, is a proposal about observing and monitoring and allowing us to intervene when the time comes? Or is it attempting to intervene now on what people can do now, or dictate the form of intervention later?
Consider the response to something like SB 1047 or Biden’s executive order. Both are primarily about transparency, observation and monitoring of frontier models for the sole purpose of concerns on catastrophic or existential risks. They are deeply compatible with the perspective outlined here by Krier.
The logical response is suggesting improvements and discussing details, and talking price. Instead, most (not Krier!) who are skeptical of other forms of regulation choose for SB 1047 instead to hallucinate a different bill and different impacts, and for the executive order to demand it be repealed. They hallucinated so badly on SB 1047 that they demanded the removal of the limited duty exception, a free option that exclusively lightened the burden of the bill, and got their wish.
The logic of these others seems to be:
-
You want to be able to observe and monitor, and prepare to act.
-
If you did that, you might later act.
-
Can’t have that. So we can’t let you observe or monitor.
SB 1047 has strong bipartisan public support (77%-13%), if this is how you ask about it. I notice that this is not exactly a neutral wording, although its claims are accurate.
This is unsurprising, although the margin is impressive. We have yet to see a poll on AI that doesn’t go this way.
The LA Times discusses SB 1047 and other proposed bills here. All the other bills seem actively counterproductive to me, especially the pure rent seeking demand from teamsters for supervision of self-driving trucks.
Dean Ball argues that SB 1047 is bad because it creates a government regulatory agency, via a fully general public choice counterargument against having government regulatory agencies for anything with broad positive use cases. I ended up discussing various SB 1047 things on Twitter a bit with him and Eli Dourado.
Politico covers that Y Combinator sent a letter opposing SB 1047. While the letter refreshingly say that the law was clearly drafted in good faith, all four of the letter listed concerns misstate the practical implications of the bill in alarmist terms. Then they say, rather than proposing fixes to particular issues, why not scrap the whole thing and instead encourage open source software? It is telling that such letters so often ask not only for no rules of any kind, but also for active government handouts and special treatment, despite SB 1047 already giving open source special treatment.
Dwarkesh Patel interviews Tony Blair, with AI as a major focus. Blair sees AI as the biggest change since the industrial revolution, the most important thing to focus on. He very much gives off the technocrat ‘this is how it all works’ vibe, without pretending that the technocrats are generally in charge or governments are competent. He sees AI will be huge but doesn’t seem to notice the existential risk angle. Essentially he is a sensible ‘AI skeptic,’ who does not expect AGI or a takeoff but sees AI would be transformative anyway. His focus has been ‘good governance’ so then he pulls out the standard good governance tropes. He also emphasizes that policy and politics (or ‘change makers’) are distinct things, and if you want to accomplish anything you have to be policy first.
Also has this great line from Blair: “The problem with government is not that it’s a conspiracy, either left-wing or right-wing. It’s a conspiracy for inertia.”
Interview with OpenAI board chairman Bret Taylor. He is excited for this generation of AI. His focus is clearly being CEO of Sierra, where he is building hopefully cool solutions for consumer brands, rather than his far more important role at OpenAI. That does at least mean he has lots of practical experience with current models. He holds his own on mundane job transitions but does not seem to be feeling the AGI. Instead he says, beware specific hype, but the economy will transform within 30 years and this will ‘meet the hype.’ Someone needs to have him talk to the technical staff. For now, it seems he does not grok existential risk because he doesn’t grok AGI.
Lester Holt interviews OpenAI CEO Sam Altman and AirBnB’s Brian Chesky, skip to about 35: 00, it is ~40 minutes. Often not new information dense. Colin Fraser notes some of the ways Altman is playing rhetorical slight of hand with the risks of AGI. If you expect to be able to tell an AI ‘go solve all of physics’ or ‘go create a great company’ then that is a completely transformed world, you cannot simply talk about ‘solving misuse’ as if misuse was a distinct magisteria.
When discussing events around Altman’s firing, Altman sticks to his story and lets Chesky tell a series of rather glaring whoppers. Both try to walk back the idea of an ‘AGI moment,’ there are only various capabilities in various areas, and try to deny that there is ‘a race’ in a meaningful sense. Altman follows the general theme of acting like everything will stay normal under AGI. I know he knows better. When he says ‘AGI could double the world’s GDP’ Holt points out this sounds outlandish, but I see it as outlandish on the downside and I think Altman knows that.
And he is making the ‘we have great ability to steer our current models and their values’ card, the real problem is choosing our values, which I see as a highly disingenuous attempt to dismiss alignment problems as being handled.
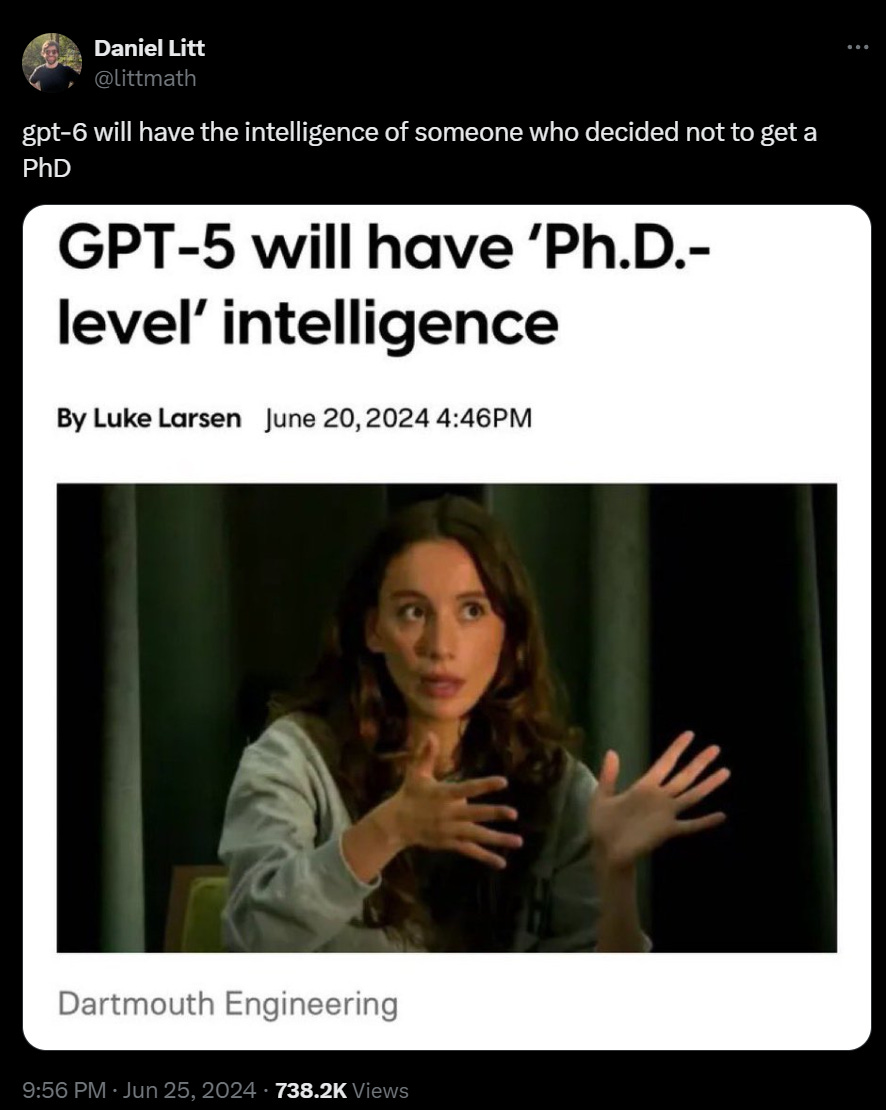
Mira Murati talks to Dartmouth Engineering where she is an alumni. It has some key spots but has low information density.
-
She says we should expect to get ‘PhD-level intelligence for specific tasks’ in a year to 18 months. The usual suspects responded to this as saying no GPT-5 for over a year and did some gloating, which seems like the wrong response to this kind of prediction.
-
She was broadly supportive of the government understanding what is going on and called for more of that.
-
She says of the AI ‘it’s a tool, right’ and there is a subtle blackpill that she does not seem to notice that this might not be the full story in the future.
-
It does seem she said ‘Some creative jobs maybe will go away due to AI, but maybe they shouldn’t have been there in the first place.’ Hot take. She then tried to save it on Twitter.
Roon (linking to this clip from this segment): I fing love Larry Summers.
Beff Jezos (responding to clip): So ing based holy .
Larry Summers introduces Bloomberg to the concept of recursive self-improvement, eventually using the term explicitly, and predicting transformative and seismic change. The issue, he says, is how do you manage that? He says we cannot leave AI only to AI developers. Public authorities must take a strong role in ensuring it gets used for good, but stopping it or slowing it down without thinking about positive developments would seed the field to the irresponsible and our adversaries, and he endorses ‘responsible iterative deployment.’
If this counts as highly based, where public authorities must take a strong role, and we should consider the positive benefits and also the downsides, perhaps we are getting somewhere. Lots of great stuff here, we need to now also work in alignment and the control problem, which did not get mentioned.
New interview with Anthropic CEO Dario Amodei. I haven’t listened yet.
Yuhal Noah Harai asks, among other things, what happens when finance becomes when zero humans understand the financial system? Would we end up controlled by an essentially alien intelligence? This specific mechanism is not that high on my list. The generalized version is reasonably high. Yes, of course, we will be under immense pressure to turn control over all of the things to AIs.
Leo Gao of OpenAI reminds us we do not know how neutral networks work. He does so in response to someone citing Leo Gao’s paper as evidence to the contrary that someone ‘must have missed.’ When the moment was described, he did not take it great.
This does seem to be accurate.
Agustin Lebron: No one:
Absolutely no one:
Every AI researcher: AGI is incredibly dangerous and no one should build it. Except ME. I can do it safely.
Eliezer Yudkowsky: Elon starts OpenAI because he doesn’t like Demis. OpenAI people repeatedly distrust OpenAI and leave to start their own companies… none of which trust *each other*… and one observes that they’re all founded by the sort of people who went to work for OpenAI in the first place.
Elon Musk: Actually, I like Demis. Just don’t trust the Google corporate blob.
Eliezer Yudkowsky: Apparently I’ve heard and told the wrong story all these years!
Reluctantly — because I do usually prefer to listen to people when they tell me what they actually said or thought, what with my not being a telepath — I feel obligated to mention that 3 different sources reached out to me to say, ‘No, Elon actually did dislike Demis.’
…
This puts me in an odd position and I’m not sure what I’ll say going forward. I am really reluctant to contradict people about what they themselves thought, but I also don’t want to represent a mixed state of evidence to the public as if it was a purer state of evidence.
An attempt to portray AGI existential risk as risk of domination. Would such a focus on such details convince people who are not otherwise convinced? My guess is some people do respond to such details, it makes things click, but it is hard to predict which people will respond well to which details.
I’m not going to lie and say it’s good. That doesn’t mean give up.
Alex Trembath: When I tell people I work in environmental policy, the most common response, BY FAR, is to ask me “How fucked are we?”
Kelsey Piper: People say this to me about climate and about AI. Guys, there are lots of serious challenges ahead but we are an inventive, wealthy, ambitious society with lots of brilliant hardworking people and all of our problems are solvable. We’re not doomed, we just have a big to-do list.
One reason I sincerely love Silicon Valley despite its deficits is that it’s the only place where I’ve run into strangers who will listen to a description of a serious problem they haven’t heard of before and go “huh.” [beat.] “What needs doing?”
Everyone who thinks you should obviously do [insane thing] is wrong. That is the easy realization. The hard part is: What is the sane thing?
Francois Fleuret: AGI happens in 3y, where should I invest my money?
Eliezer Yudkowsky: Everyone in the replies is saying “Guns and bullets” and I regret to inform everyone THAT WILL NOT ACTUALLY WORK.
There were a ton of replies to Fleuret. They did not contain original ideas. The most common were things like energy, Microsoft and Nvidia, which are a way to go out while having previously had more dollars to your name.
As many have long suspected about many accelerationists: The positions of Beff Jezos make a lot more sense if he simply does not believe in AGI.
Beff Jezos: ASI is a fairy tale.
Explain to me.
What the fis “ASI”.
FORMALLY.
Seriously. I’ll wait.
Mario Cannistra: Explains a lot.
Of course I’d want to accelerate if I didn’t think superintelligent AI was even possible.
We can safety consider the matter closed, then.
We now know why he named his new company xAI.
Elon Musk: The trend is very strong that any AI company’s name that can be inverted will be inverted.
Technology advances.



















































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}