
Big Tech is spending more than VC firms on AI startups
money cannon —
Microsoft, Google, and Amazon haved crowded out traditional Silicon Valley investors.

Enlarge / A string of deals by Microsoft, Google and Amazon amounted to two-thirds of the $27 billion raised by fledgling AI companies in 2023,
FT montage/Dreamstime
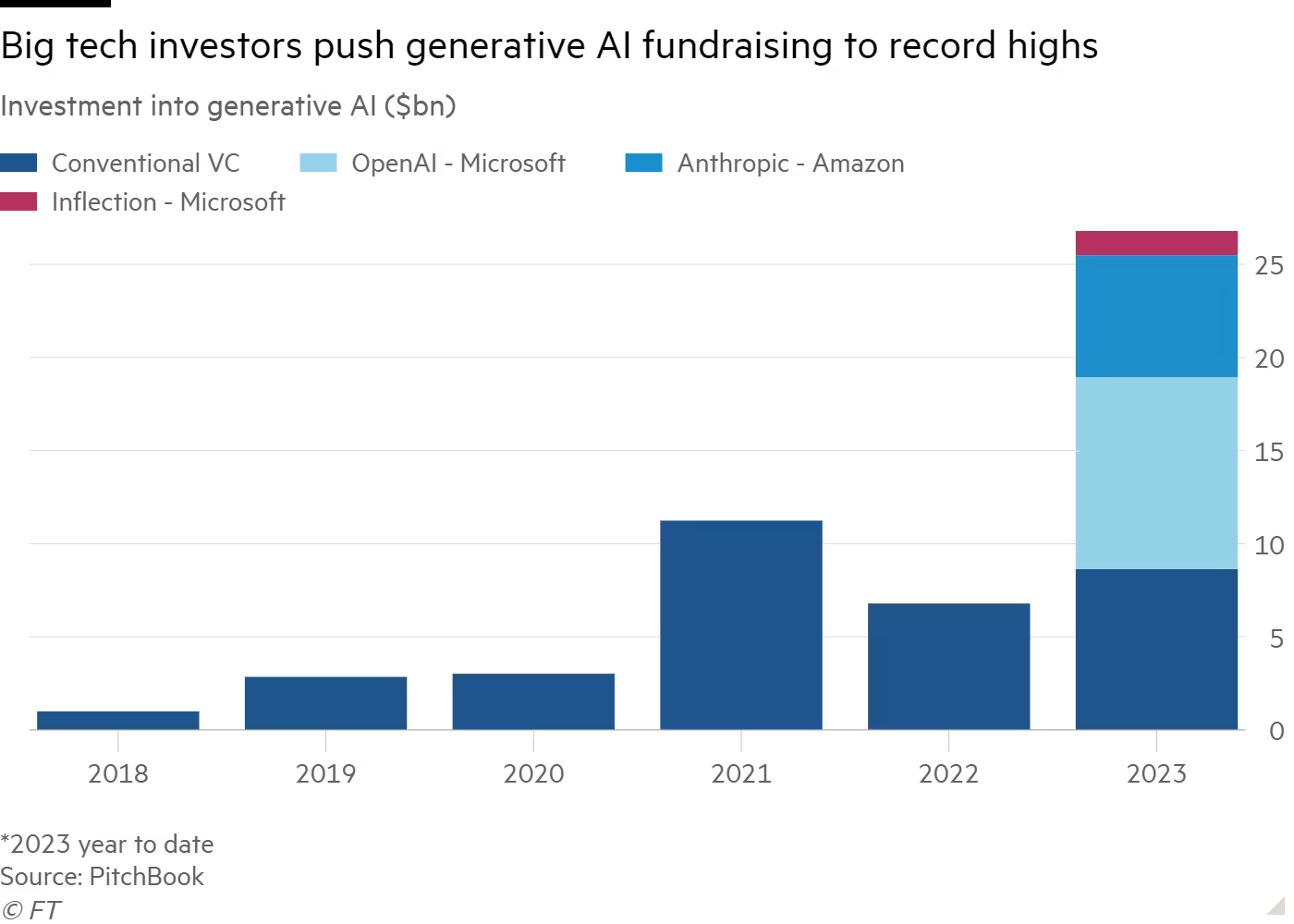
Big tech companies have vastly outspent venture capital groups with investments in generative AI startups this year, as established giants use their financial muscle to dominate the much-hyped sector.
Microsoft, Google and Amazon last year struck a series of blockbuster deals, amounting to two-thirds of the $27 billion raised by fledgling AI companies in 2023, according to new data from private market researchers PitchBook.
The huge outlay, which exploded after the launch of OpenAI’s ChatGPT in November 2022, highlights how the biggest Silicon Valley groups are crowding out traditional tech investors for the biggest deals in the industry.
The rise of generative AI—systems capable of producing humanlike video, text, image and audio in seconds—have also attracted top Silicon Valley investors. But VCs have been outmatched, having been forced to slow down their spending as they adjust to higher interest rates and falling valuations for their portfolio companies.
“Over the past year, we’ve seen the market quickly consolidate around a handful of foundation models, with large tech players coming in and pouring billions of dollars into companies like OpenAI, Cohere, Anthropic and Mistral,” said Nina Achadjian, a partner at US venture firm Index Ventures referring to some of the top AI startups.
“For traditional VCs, you had to be in early and you had to have conviction—which meant being in the know on the latest AI research and knowing which teams were spinning out of Google DeepMind, Meta and others,” she added.
Financial Times
A string of deals, such as Microsoft’s $10 billion investment in OpenAI as well as billions of dollars raised by San Francisco-based Anthropic from both Google and Amazon, helped push overall spending on AI groups to nearly three times as much as the previous record of $11 billion set two years ago.
Venture investing in tech hit record levels in 2021, as investors took advantage of ultra-low interest rates to raise and deploy vast sums across a range of industries, particularly those most disrupted by Covid-19.
Microsoft has also committed $1.3 billion to Inflection, another generative AI start-up, as it looks to steal a march on rivals such as Google and Amazon.
Building and training generative AI tools is an intensive process, requiring immense computing power and cash. As a result, start-ups have preferred to partner with Big Tech companies which can provide cloud infrastructure and access to the most powerful chips as well as dollars.
That has rapidly pushed up the valuations of private start-ups in the space, making it harder for VCs to bet on the companies at the forefront of the technology. An employee stock sale at OpenAI is seeking to value the company at $86 billion, almost treble the valuation it received earlier this year.
“Even the world’s top venture investors, with tens of billions under management, can’t compete to keep these AI companies independent and create new challengers that unseat the Big Tech incumbents,” said Patrick Murphy, founding partner at Tapestry VC, an early-stage venture capital firm.
“In this AI platform shift, most of the potentially one-in-a-million companies to appear so far have been captured by the Big Tech incumbents already.”
VCs are not absent from the market, however. Thrive Capital, Josh Kushner’s New York-based firm, is the lead investor in OpenAI’s employee stock sale, having already backed the company earlier this year. Thrive has continued to invest throughout a downturn in venture spending in 2023.
Paris-based Mistral raised around $500 million from investors including venture firms Andreessen Horowitz and General Catalyst, and chipmaker Nvidia since it was founded in May this year.
Some VCs are seeking to invest in companies building applications that are being built over so-called “foundation models” developed by OpenAI and Anthropic, in much the same way apps began being developed on mobile devices in the years after smartphones were introduced.
“There is this myth that only the foundation model companies matter,” said Sarah Guo, founder of AI-focused venture firm Conviction. “There is a huge space of still-unexplored application domains for AI, and a lot of the most valuable AI companies will be fundamentally new.”
Additional reporting by Tim Bradshaw.
© 2023 The Financial Times Ltd. All rights reserved. Not to be redistributed, copied, or modified in any way.
Big Tech is spending more than VC firms on AI startups Read More »
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}