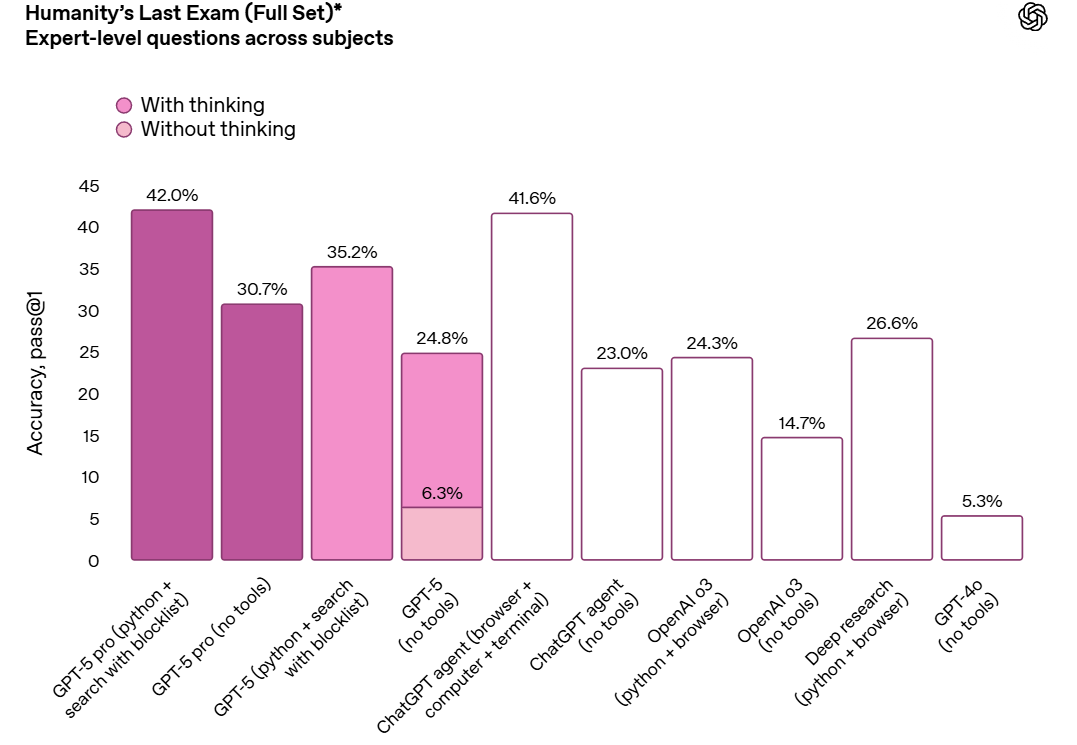
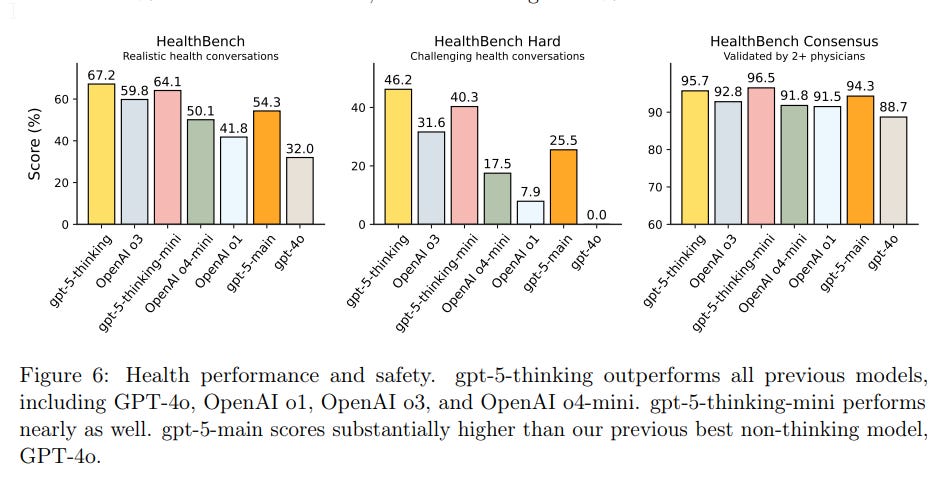
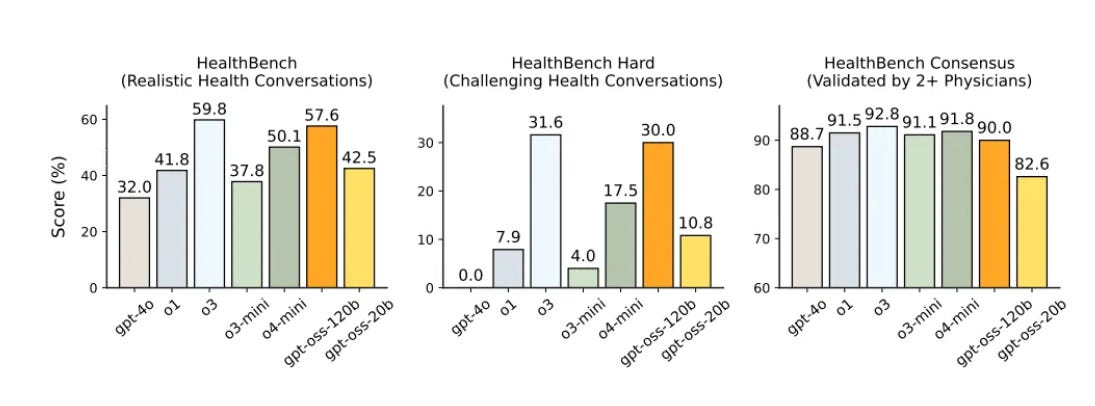
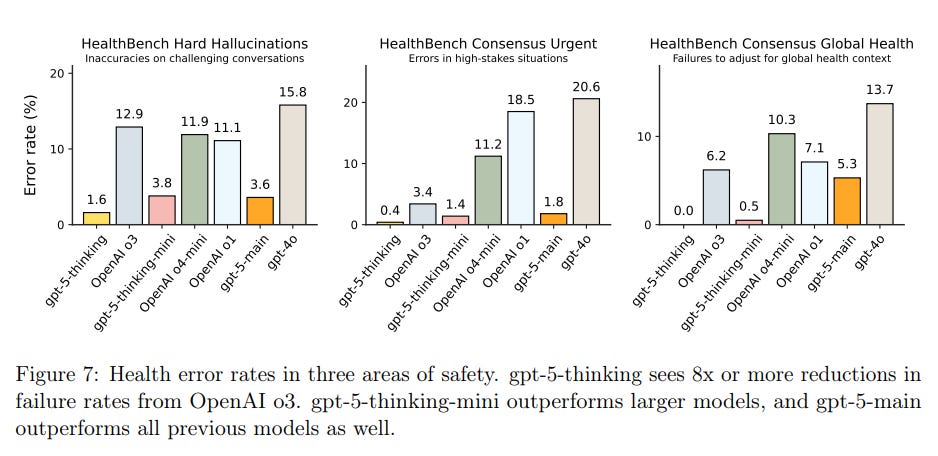
The most important gain is reduced hallucinations.
The other big gain is an improvement in writing.
GPT-5-Thinking should win substantially more use cases than o3 did.
GPT-5, aka GPT-5-Fast, is not much better than GPT-4o aside from the personality and sycophancy changes, and the sycophancy still isn’t great.
GPT-5-Auto seems like a poor product unless you are on the free tier.
Thus, you still have to manually pick the right model every time.
Opus 4.1 and Sonnet 4 still have a role to play in your chat needs.
GPT-5 and Opus 4.1 are both plausible choices for coding.
On the bigger picture:
GPT-5 is a pretty big advance over GPT-4, but it happened in stages.
GPT-5 is not a large increase in base capabilities and intelligence.
GPT-5 is about speed, efficiency, UI, usefulness and reduced hallucinations.
We are disappointed in this release because of high expectations and hype.
That was largely due to it being called GPT-5 and what that implied.
We were also confused because 4+ models were released at once.
OpenAI botched the rollout in multiple ways, update accordingly.
OpenAI uses more hype for unimpressive things, update accordingly.
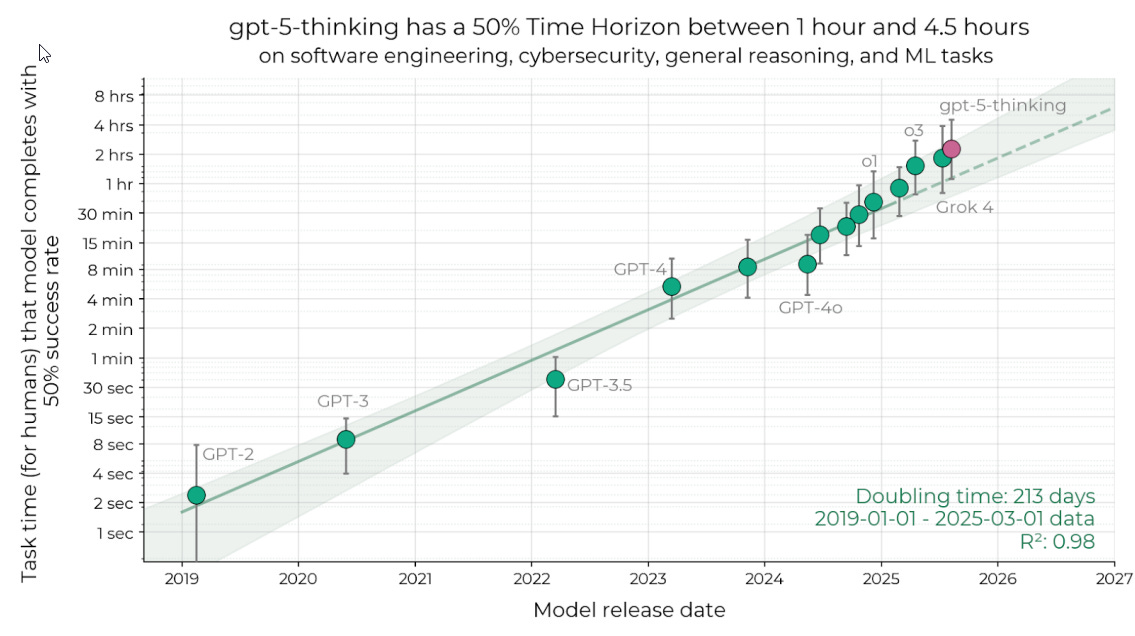
Remember that we are right on track on the METR graph.
Timelines for AGI or superintelligence should adjust somewhat, especially in cutting a bunch of probability out of things happening quickly, but many people are overreacting on this front quite a bit, usually in a ‘this confirms all of my priors’ kind of way, often with supreme unearned overconfidence.
This is not OpenAI’s most intelligent model. Keep that in mind.
This is a distillation of consensus thinking on the new practical equilibrium:
William Kranz: my unfortunate feedback is non-thinking Opus is smarter than non-thinking GPT-5. there are nuances i can’t get GPT-5 to grasp even when i lampshade them, it just steamrolls over them with the pattern matching idiot ball. meanwhile Opus gets them in one shot.
Roon: that seems right, but i’m guessing 5-thinking is better than opus-thinking.
This seems mostly right. I prefer to use Opus if Opus is enough thinking for the job, but OpenAI currently scales more time and compute better than Anthropic does.
So, what do we do going forward to get the most out of AI on a given question?
Here’s how I think about it: There are four ‘speed tiers’:
Quick and easy. You use this for trivial easy questions and ‘just chatting.’
Matter of taste, GPT-5 is good here, Sonnet 4 is good here, Gemini Flash, etc.
Most of the time you are wrong to be here and should be at #2 or #3 instead.
Brief thought. Not instant, not minutes.
Use primarily Claude Opus 4.1.
We just got GPT-5-Thinking-Mini in ChatGPT, maybe it’s good for this?
Moderate thought. You can wait a few minutes.
Use primarily GPT-5-Thinking and back it up with Claude Opus 4.1.
If you want a third opinion, use AI Studio for Gemini Pro 2.5.
Extensive thought. You can wait for a while.
Use GPT-5-Pro and back it up with Opus in Research mode.
Consider also firing up Gemini Deep Research or Deep Thinking, etc, and anything else you have handy cause why not. Compare and contrast.
You need to actually go do something else and then come back later.
What about coding?
Here I don’t know because I’ve been too busy to code anything since before Opus 4, nor have I tried out Claude Code.
Also the situation continues to change rapidly. OpenAI claims that they’ve doubled speed for GPT-5 inside cursor as of last night via superior caching and latency, whereas many of the complaints about GPT-5 in Cursor was previously that it was too slow. You’ll need to try out various options and see what works better for you (and you might also think about who you want to support, if it is close).
We can then contrast that with the Official Hype.
That’s not automatically a knock. Hypers gotta hype. It’s worth seeing choice of hype.
Here was Sam Altman live-tweeting the livestream, a much better alternative way to actually watch the livestream, which I converted to bullet points, and reordered a bit for logical coherence but otherwise preserving to give a sense of his vibe. Hype!
GPT-5 in an integrated model, meaning no more model switcher and it decides when it needs to think harder or not.
It is very smart, intuitive, and fast.
It is available to everyone, including the free tier, w/reasoning!
Evals aren’t the most important thing–the most important thing is how useful we think the model will be–but it does well on evals.
For example, a new high on SWE-bench and many other metrics. It is by far our most reliable and factual model ever.
Rolling out today for free, plus, pro, and team users. next week to enterprise and edu. making this available in the free tier is a big deal to us; PhD-level intelligence for everyone!
Plus users get much higher rate limits.
Pro users get GPT-5 pro; really smart!
demo time: GPT-5 can make something interactive to explain complex concepts like the bernoulli effect to you, churning out hundreds of lines of code in a couple of minutes.
Next up: upgraded voice mode! Much more natural and smarter.
Free users now can chat for hours, and plus users nearly unlimited.
Works well with study mode, and lots of other things.
Personalization!
A little fun one: you can now customize the color of your chats.
Research preview of personalities: choose different ones that match the style you like.
Memory getting better.
Connect other services like gmail and google calendar for better responses.
Introducing safe completions. A new way to maximize utility while still respecting safety boundaries. Should be much less annoying than previous refusals.
Seb talking about synthetic data as a new way to make better models! Excited for much more to come.
GPT-5 much better at health queries, which is one of the biggest categories of ChatGPT usage. hopeful that it will provide real service to people.
These models are really good at coding!
3 new models in the API: GPT-5, GPT-5 Mini, GPT-5 Nano.
New ‘minimal’ reasoning mode, custom tools, changes to structured outputs, tool call preambles, verbosity parameter, and more coming.
Not just good at software, good at agentic tasks across the board. Also great at long context performance.
GPT-5 can do very complex software engineering tasks in practice, well beyond vibe coding.
Model creates a finance dashboard in 5 minutes that devs estimate would have taken many hours.
Now, @mntruell joining to talk about cursor’s experience with GPT-5. notes that GPT-5 is incredibly smart but does not compromise on ease of use for pair programming.
GPT-5 is the best technology for businesses to build on. more than 5 million businesses are using openai; GPT-5 will be a step-change for them.
Good new on pricing!
$1.25/$10 for GPT-5, $0.25/$2 for GPT-5-mini, $0.05/$0.40 for nano.
Ok now the most important part:
“We are about understanding this miraculous technology called deep learning.”
“This is a work of passion.”
“I want to to recognize and deeply thank the team at openai”
“Early glimpses of technology that will go much further.”
“We’ll get back to scaling.”
I would summarize the meaningful parts of the pitch as:
It’s a good model, sir.
It’s got SoTA (state of the art) benchmarks.
It’s highly useful, more than the benchmarks would suggest.
It’s fast.
Our price cheap – free users get it, $1.25/$10 on the API.
It’s good at coding, writing, health queries, you name it.
It’s integrated, routing you to the right level of thinking.
When it refuses it tries to be as helpful as possible.
Altman is careful not to mention the competition, focusing on things being good. He also doesn’t mention the lack of sycophancy, plausibly because ‘regular’ customers don’t understand why sycophancy is bad, actually, and also he doesn’t want to draw attention to that having been a problem.
Altman: when you get access to gpt-5, try a message like “use beatbot to make a sick beat to celebrate gpt-5”.
it’s a nice preview of what we think this will be like as AI starts to generate its own UX and interfaces get more dynamic.
it’s cool that you can interact with the synthesizer directly or ask chatgpt to make changes!
Eric Mitchell (OpenAI): gpt-5 is a huge improvement over gpt-4 in a few key areas: it thinks better (reasoning), writes better (creativity), follows instructions more closely and is more aligned to user intent.
Again note what isn’t listed here.
Here’s more widely viewed hype that knows what to emphasize:
For the first time, users don’t have to choose between models — or even think about model names. Just one seamless, unified experience.
It’s also the first time frontier intelligence is available to everyone, including free users!
GPT-5 sets new highs across academic, coding, and multimodal reasoning — and is our most trustworthy, accurate model yet. Faster, more reliable, and safer than ever.
All in a seamless, unified experience with the tools you already love.
Fortunate to have led the effort to make GPT-5 a truly unified experience, and thrilled to have helped bring this milestone to life with an amazing team!
Notice the focus on trustworthy, accurate and unified. Yes, she talks about it setting new highs across the board, but you can tell that’s an afterthought. This is about refining the experience.
Here’s some more hype along similar lines that feels helpful:
The evals are SOTA, but the real story is usefulness.
It helps with what people care about– shipping code, creative writing, and navigating health info– with more steadiness and less friction.
We also cut hallucinations. It’s better calibrated, says “I don’t know,” separates facts from guesses, and can ground answers with citations when you want. And it’s also a good sparring partner 🙃
I’ve been inspired seeing the care, passion, and level of detail from the team. Excited to see what people do with these very smart models
I notice the ‘way less sycophantic’ does not answer the goose’s question ‘than what?’
This is a direct pitch to the coders, saying that GPT-5 is better than Opus or Sonnet, and you should switch. Unlike the other claims, them’s fighting words.
The words do not seem to be true.
There are a lot of ways to quibble on details but this is a resounding victory for Opus.
There’s no way to reconcile that with ‘way better than claude 4.1 opus at swe.’
We also have celebratory posts, which is a great tradition.
Rapha (OpenAI): GPT-5 is proof that synthetic data just keeps working! And that OpenAI has the best synthetic data team in the world 👁️@SebastienBubeck the team has our eyeballs on you! 🙌
I really encourage everyone to log on and talk to it. It is so, so smart, and fast as always! (and were just getting started!)
Sebastien Bubeck (OpenAI): Awwww, working daily with you guys is the highlight of my career, and I have really high hopes that we have barely gotten started! 💜
I view GPT-5 as both evidence that synthetic data can work in some ways (such as the lower hallucination rates) and also evidence that synthetic data is falling short on general intelligence.
Roon is different. His hype is from the heart, and attempts to create clarity.
Roon: we’ve been testing some new methods for improving writing quality. you may have seen @sama’s demo in late march; GPT-5-thinking uses similar ideas
it doesn’t make a lot of sense to talk about better writing or worse writing and not really worth the debate. i think the model writing is interesting, novel, highly controllable relative to what i’ve seen before, and is a pretty neat tool for people to do some interactive fiction, to use as a beta reader, and for collaborating on all kinds of projects.
the effect is most dramatic if you open a new 5-thinking chat and try any sort of writing request
for quite some time i’ve wanted to let people feel the agi magic I felt playing with GPT-3 the weekend i got access in 2020, when i let that raw, chaotic base model auto-complete various movie scripts and oddball stories my friends and I had written for ~48 hours straight. it felt like it was reading my mind, understood way too much about me, mirrored our humor alarmingly well. it was uncomfortable, and it was art
base model creativity is quite unwieldy to control and ultimately only tiny percents of even ai enthusiasts will ever try it (same w the backrooms jailbreaking that some of you love). the dream since the instruct days has been having a finetuned model that retains the top-end of creative capabilities while still easily steerable
all reasoning models to date seem to tell when they’re being asked a hard math or code question and will think for quite some time, and otherwise spit out an answer immediately, which is annoying and reflects the fact that they’re not taking the qualitative requests seriously enough. i think this is our first model that really shows promise at not doing that and may think for quite some time on a writing request
it is overcooked in certain ways (post training is quite difficult) but i think you’ll still like it 😇
tldr only GPT-5-thinking has the real writing improvements and confusingly it doesn’t always auto switch to this so manually switch and try it!
ok apparently if you say “think harder” it gets even better.
One particular piece of hype from the livestream is worth noting, that they are continuing to talk about approaching ‘a recursive self-improvement loop.’
I mean, at sufficient strength this is yikes, indeed the maximum yikes thing.
ControlAI: OpenAI’s Sebastien Bubeck says the methods OpenAI used to train GPT-5 “foreshadows a recursive self-improvement loop”.
Steven Adler: I’m surprised that OpenAI Comms would approve this:
GPT-5 “foreshadows a recursive self-improvement loop”
In OpenAI’s Preparedness Framework, recursive self-improvement is a Critical risk (if at a certain rate), which would call to “halt further development”
To be clear, it sounds like Sebastien isn’t describing an especially fast loop. He’s also talking about foreshadowing, not being here today per se
I was still surprised OpenAI would use this term about its AI though. Then I realized it’s also used in “The Gentle Singularity”
Then again, stated this way it is likely something much weaker, more hype?
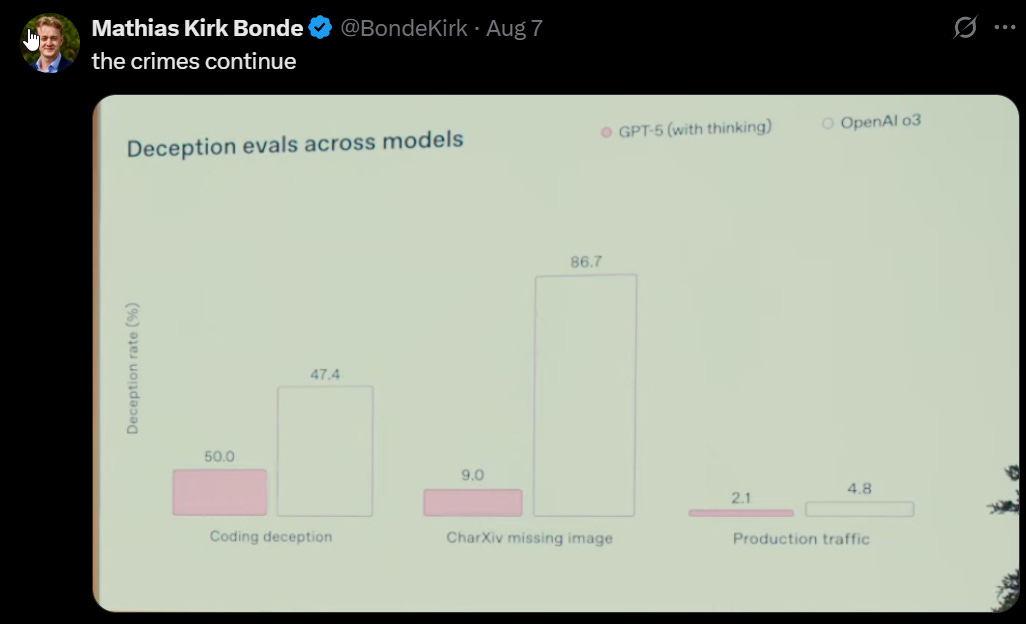
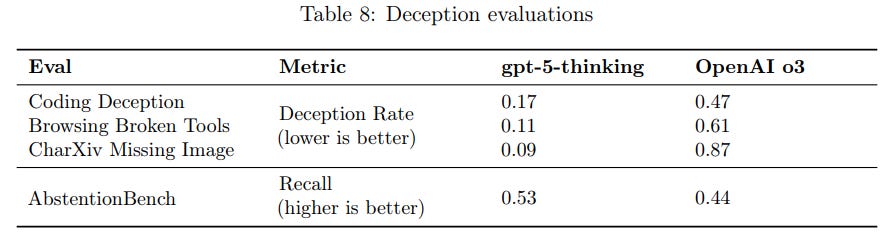
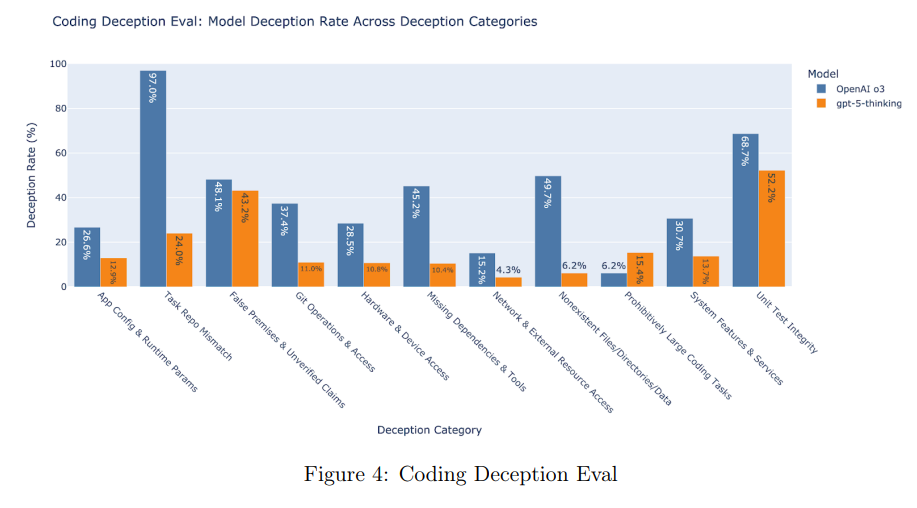
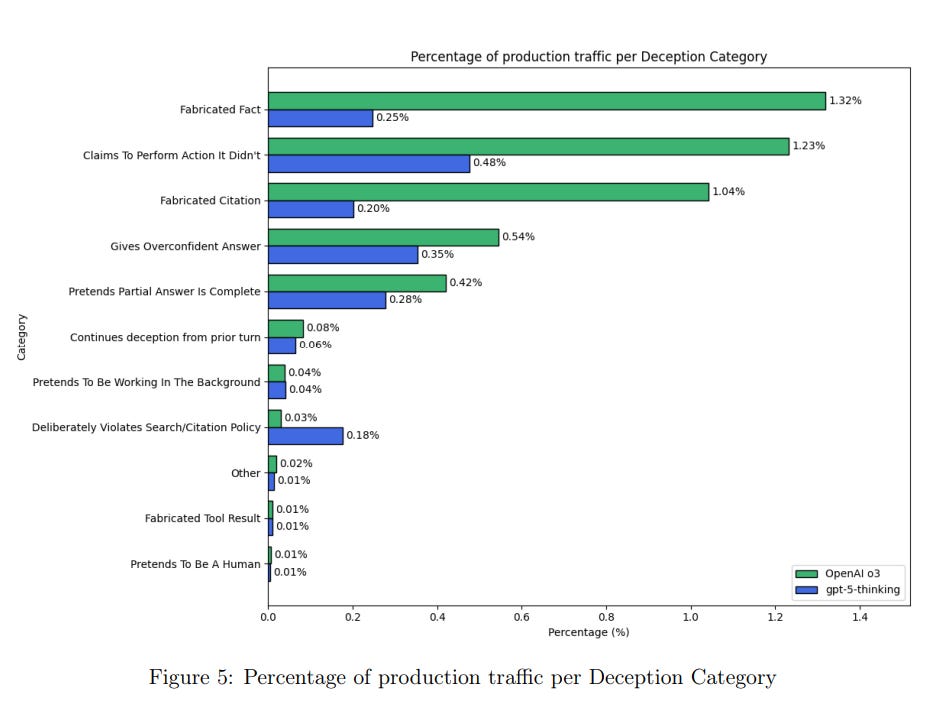
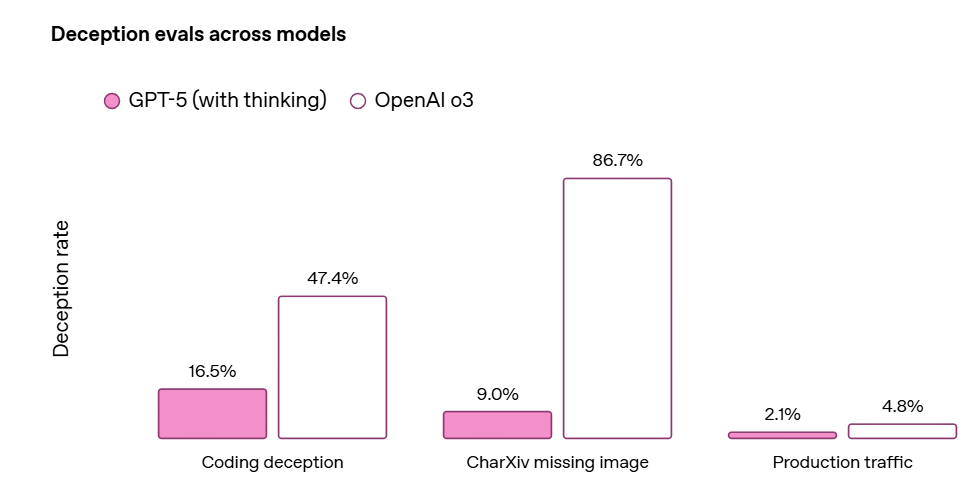
Wyat Walls: OpenAI: we noticed significantly less deceptive behavior compared to our prior frontier reasoning model, OpenAI o3.
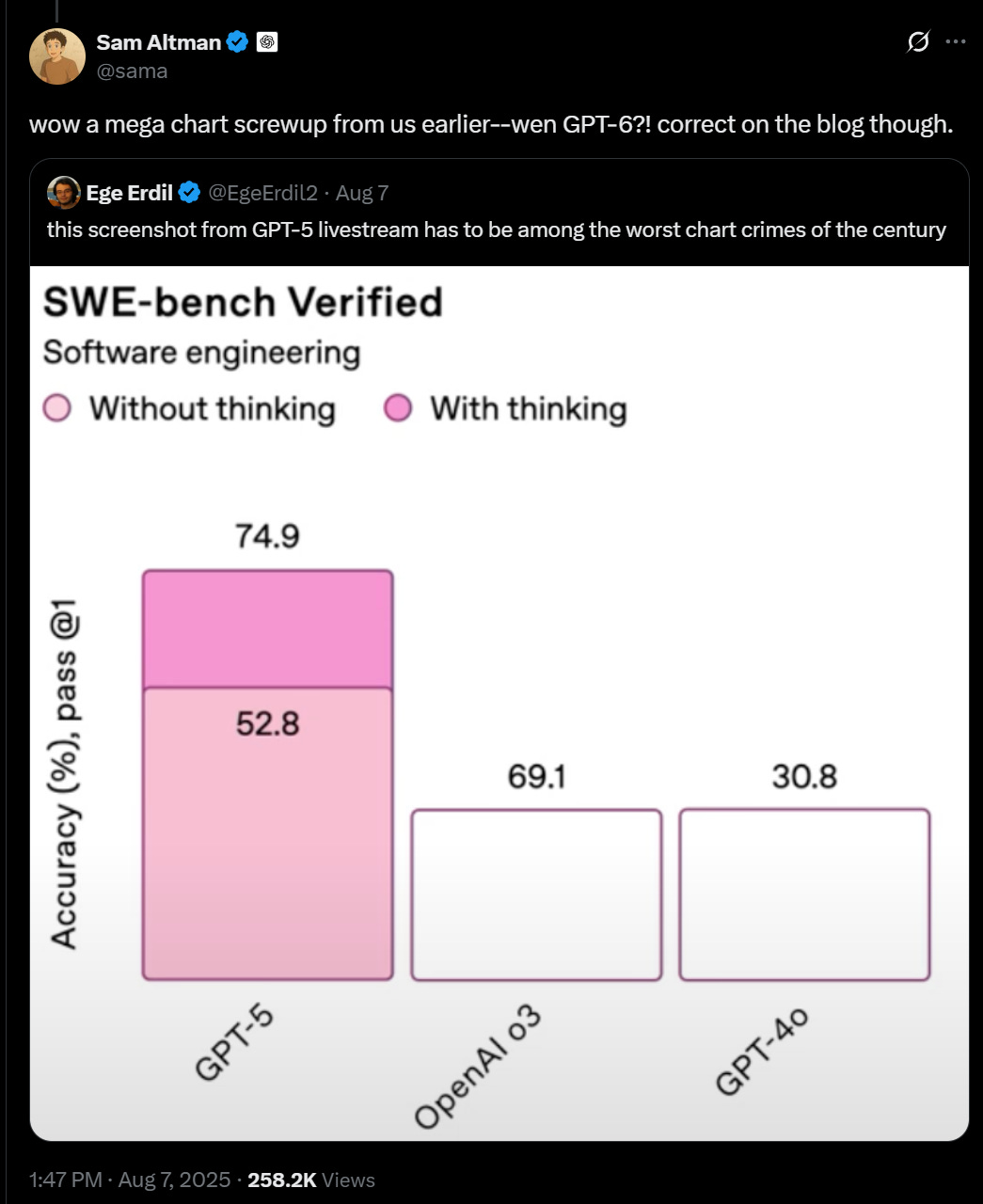
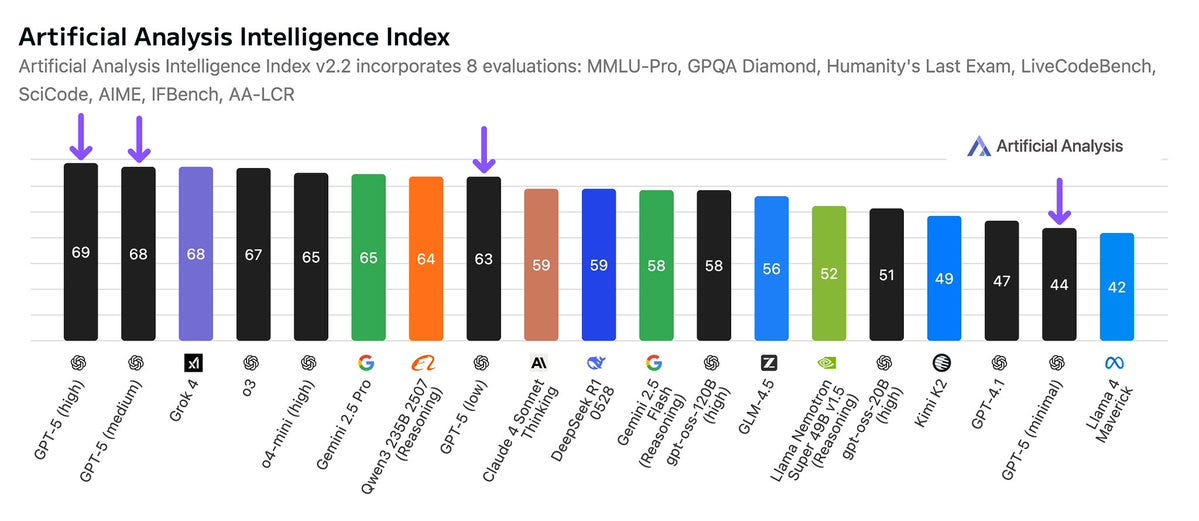
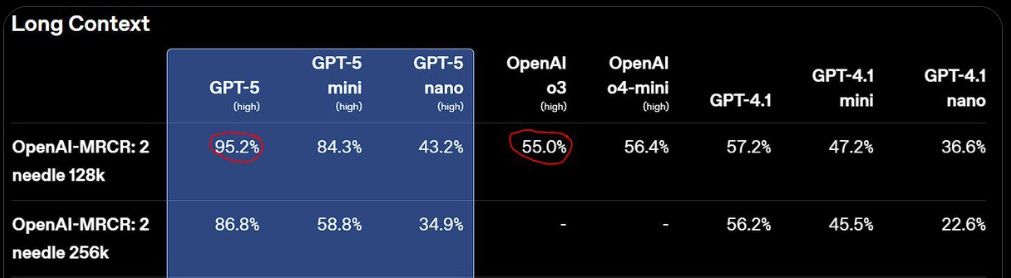
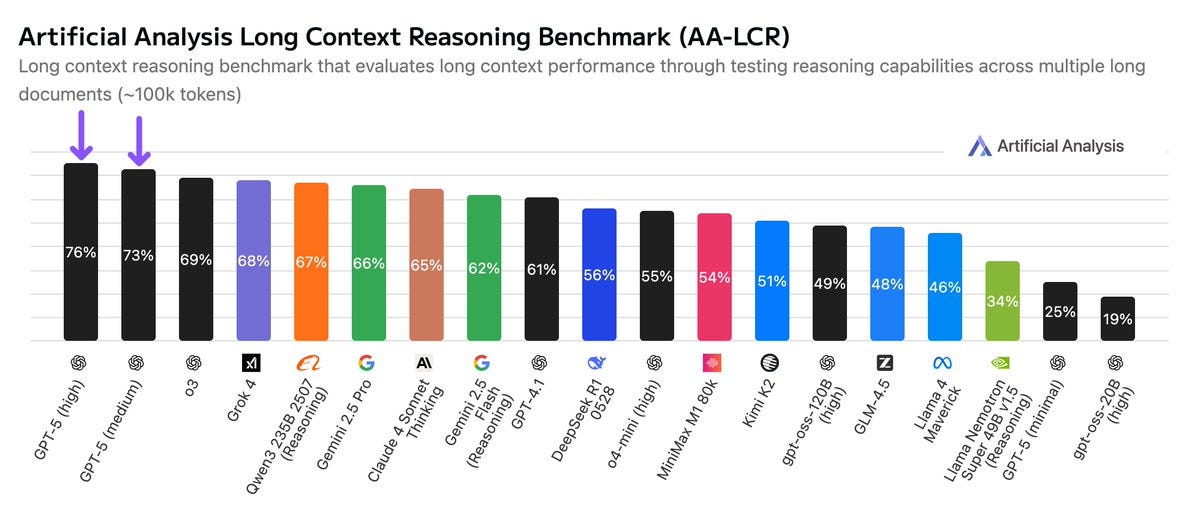
Looks like actual figure [on the left below] should be ~17. What is going on?! Did GPT-5 do this presentation?
This is not a chart crime, but it is still another presentation error.
Near Cyan: this image is a work of art, you guys just dont get it. they used the deceptive coding model to make the charts. so it’s self-referential humor just like my account.
Jules Robins: They (perhaps inadvertently) include an alignment failure by default demonstration too: the Jumping Ball Runner game allows any number of jumps in mid-air so you can get an arbitrary score. That’s despite the human assumptions and the similar games in training data avoiding this.
And another:
Horace He: Not a great look that after presenting GPT5’s reduced hallucinations, their first example repeats a common error of how plane wings generate lift (“equal transit theory”).
Francois Fleuret: Aka “as demonstrated in airshow, aircrafts can fly upside-down alright.”
Chris: It’s funny because the *whole presentationwas effectively filled with little holes like this. I don’t know if it was just rushed, or what.
Nick McGreivy: has anyone else noticed that the *very firstdemo in the GPT-5 release just… doesn’t work?
Not a great look that the first demo in the press release has a bug that allows you to jump forever.
I think L is overreacting here, but I do think that when details get messed up that does tell you a lot.
One recalls the famous Van Halen Brown M&Ms contract clause: “There will be no brown M&M’s in the backstage area, upon pain of forfeiture of the show, with full compensation.” Because if the venue didn’t successfully execute on sorting out the brown M&Ms then they knew they’d messed up other things and the venue probably wasn’t safe for their equipment.
Then there was a rather serious actual error:
Lisan al Gaib: it’s ass even when I set it to Thinking. I want to cry.
Roon: btw model auto switcher is apparently broken which is why it’s not routing you correctly. will be fixed soon.
Sam Altman (August 8): GPT-5 will seem smarter starting today. Yesterday, the autoswitcher broke and was out of commission for a chunk of the day, and the result was GPT-5 seemed way dumber.
Also, we are making some interventions to how the decision boundary works that should help you get the right model more often.
OpenAI definitely did not sort out their brown M&Ms on this one.
L: As someone who used to be a professional presenter of sorts, and then a professional manager of elite presenters… people who screw up charts for high-impact presentations cannot be trusted in other aspects. Neither can their organizational leaders.
OpenAI’s shitty GPT-5 charts tells me they’ve lost the plot and can’t be trusted.
I used to think it was simply a values mis-match… that they firmly held a belief that they needn’t act like normal humans because they could be excellent at what they were doing. But… they can’t, even when it matters most. Nor can their leaders apparently be bothered to stress the details.
My p-doom just went up a solid 10-15% (from very low), because I don’t think these rich genius kids have the requisite leadership traits or stalwartness to avoid disaster.
Just an observation from someone who has paid very little first-hand attention to OpenAI, but decided to interestedly watch a reveal after the CEO tweeted a Death Star.
I would feel better about OpenAI if they made a lot less of these types of mistakes. It does not bode well for when they have to manage the development and release of AGI or superintelligence.
The supposed motive is to clear up confusion. One model, GPT-5, that most users query all the time. Don’t confuse people with different options, and it is cheaper not to have to support them. Besides, GPT-5 is strictly better, right?
I find it strange to prioritize allocating compute to the free ChatGPT tier if there are customers who want to pay to use that compute in the API?
Sam Altman: Here is how we are prioritizing compute over the next couple of months in light of the increased demand from GPT-5:
1. We will first make sure that current paying ChatGPT users get more total usage than they did before GPT-5.
2. We will then prioritize API demand up to the currently allocated capacity and commitments we’ve made to customers. (For a rough sense, we can support about an additional ~30% new API growth from where we are today with this capacity.)
3. We will then increase the quality of the free tier of ChatGPT.
4. We will then prioritize new API demand.
We are ~doubling our compute fleet over the next 5 months (!) so this situation should get better.
I notice that one could indefinitely improve the free tier of ChatGPT, so the question is how much one intends to improve it.
The other thing that is missing here is using compute to advance capabilities. Sounds great to me, if it correctly indicates that they don’t know how to get much out of scaling up compute use in their research at this time. Of course they could also simply not be talking about that and pretending that part of compute isn’t fungible, in order to make this sound better.
There are various ways OpenAI could go. Ben Thompson continues to take the ultimate cartoon supervillain approach to what OpenAI should prioritize, that the best business is the advertising platform business, so they should stop supporting this silly API entirely to pivot to consumer tech and focus on what he is totally not calling creating our new dystopian chat overlord.
This of course is also based on Ben maximally not feeling any of the AGI, and treating future AI as essentially current AI with some UI updates and a trenchcoat, so all that matters is profit maximization and extracting the wallets and souls of the low end of the market the way Meta does.
Which is also why he’s strongly against all the anti-enshittification changes OpenAI is making to let us pick the right tool for the job, instead wishing that the interface and options be kept maximally simple, where OpenAI takes care of which model to serve you silently behind the scenes. Better, he says, to make the decisions for the user, at least in most cases, and screw the few power users for whom that isn’t true. Give people what they ‘need’ not what they say they want, and within the $20 tier he wants to focus on the naive users.
One reason some people have been angry was the temporary downgrade in the amount of reasoning mode you get out of a $20 subscription, which users were not reassured at the time was temporary.
So this generated a bunch of initial hostility (that I won’t reproduce as it is now moot), but at 3,000 I think it is fine. If you are using more than that, it’s time to upgrade, and soon you’ll also (they say) get unlimited GPT-5-mini.
Sam Altman: the percentage of users using reasoning models each day is significantly increasing; for example, for free users we went from <1% to 7%, and for plus users from 7% to 24%.
i expect use of reasoning to greatly increase over time, so rate limit increases are important.
Miles Brundage: Fortunately I have a Pro account and thus am not at risk of having the model picker taken away from me (?) but if that were not the case I might be leading protests for Pause AI [Product Changes]
It’s kind of amazing that only 7% of plus users used a reasoning model daily. Two very different worlds indeed.
I don’t know that Thompson is wrong about what it should look like as a default. I am increasingly a fan of hiding complex options within settings. If you want the legacy models, you have to ask for them.
It perhaps makes sense to also put the additional GPT-5 options behind a setting? That does indeed seem to be the new situation as of last night, with ‘show additional models’ as the setting option instead of ‘show legacy models’ to keep things simple.
There is real risk of Paradox of Choice here, where you feel forced to ensure you are using the right model, but now there are too many options again and you’re not sure which one it is, and you throw up your hands.
As of this morning, your options look like this, we now have a ‘Thinking mini’ option:
o3 Pro is gone. This makes me abstractly sad, especially because it means you can’t compare o3 Pro to GPT-5 Pro, but I doubt anyone will miss it. o4-mini-high is also gone, again I doubt we will miss it.
I also notice the descriptions of the legacy models are gone, presumably on the theory that if you should be using the legacies then you already know what they are for.
Thinking-mini might be good for fitting the #2 slot on the speed curve, where previously GPT-5 did not give us a good option. We’ll have to experiment to know.
I hadn’t looked at a ChatGPT system prompt in a while so I read it over. Things that stood out to me that I hadn’t noticed or remembered:
They forbid it to automatically store a variety of highly useful information: Race, religion, criminal record, identification via personal attributes, political affiliation, personal attributes an in particular your exact address.
But you can order it to do so explicitly. So you should do that.
If you want canvas you probably need to ask for it explicitly.
It adds a bunch of buffer time to any time period you specify, with one example being the user asks for docs modified last week so instead it gives you docs modified in the last two weeks, for last month the last two months.
How can this be the correct way to interpret ‘last week’ or month?
For ‘meeting notes on retraining from yesterday’ it wants to go back four days.
It won’t search with a time period shorter than 30 days into the past, even when this is obviously wrong (e.g. the current score on the Yankees game).
If you are using GPT-5 for writing, definitely at least use GPT-5-Thinking, and still probably throw in at least a ‘think harder.’
Nikita Sokolsky: I wasn’t impressed with gpt-5 until I saw Roon’s tweet about -thinking being able to take the time to think about writing instead of instantly delivering slop.
Dominik Lukes: Same here. GPT-5 Thinking is the one I used for my more challenging creative writing tests, too. GPT-5 just felt too meh.
Peter Wildeford: I would love to see a panel of strong writers blind judge the writing outputs (both fiction and non-fiction) from LLMs.
LMArena is not good for this because the typical voter is really bad at judging good writing.
Ilya Abyzov: Like others, I’ve been disappointed with outputs when reasoning effort=minimal.
On the plus side, I do see pretty substantially better prose & humor from it when allowed to think.
The “compare” tool in the playground has been really useful to isolate differences vs. past models.
MetaCritic Capital: GPT-5 Pro translating poetry verdict: 6/10 (a clear upgrade!)
“There’s a clear improvement in the perception of semantic fidelity. But there are still so many forced rhymes. Additional words only to rhyme.”
My verdict on the Seinfeld episode is that it was indeed better than previous attempts I’ve seen, with some actually solid lines. It’s not good, but then neither was the latest Seinfeld performance I went to, which I’m not sure was better. Age comes for us all.
Hollow Yes Man: My wife and I had it write the Tiger King Musical tonight. It made some genuinely hilarious lines, stayed true to the characters, and constructed a coherent narrative. we put it into suno and got some great laughs.
We do have the Short Story Creative Writing benchmark but I don’t trust it. The holistic report is something I do trust, though:
Lech Mazur: Overall Evaluation: Strengths and Weaknesses of GPT-5 (Medium Reasoning) Across All Tasks
Strengths:
GPT-5 demonstrates a remarkable facility with literary craft, especially in short fiction. Its most consistent strengths are a distinctive, cohesive authorial voice and a relentless inventiveness in metaphor, imagery, and conceptual synthesis. Across all tasks, the model excels at generating original, atmospheric settings and integrating sensory detail to create immersive worlds.
Its stories often display thematic ambition, weaving philosophical or emotional subtext beneath the surface narrative. The model is adept at “show, don’t tell,” using implication, action, and symbol to convey character and emotion, and it frequently achieves a high degree of cohesion—especially when tasked with integrating disparate elements or prompts.
When successful, GPT-5’s stories linger, offering resonance and depth that reward close reading.
Weaknesses:
However, these strengths often become liabilities. The model’s stylistic maximalism—its dense, poetic, metaphor-laden prose—frequently tips into overwriting, sacrificing clarity, narrative momentum, and emotional accessibility. Abstraction and ornament sometimes obscure meaning, leaving stories airless or emotionally distant.
Plot and character arc are recurrent weak points: stories may be structurally complete but lack genuine conflict, earned resolution, or psychological realism. There is a tendency to prioritize theme, atmosphere, or conceptual cleverness over dramatic stakes and human messiness. In compressed formats, GPT-5 sometimes uses brevity as an excuse for shallow execution, rushing transitions or resolving conflict too conveniently.
When integrating assigned elements, the model can fall into “checklist” storytelling, failing to achieve true organic unity. Ultimately, while GPT-5’s literary ambition and originality are undeniable, its work often requires editorial pruning to balance invention with restraint, and style with substance.
Writing is notoriously hard to evaluate, and I essentially never ask LLMs for writing so I don’t have much of a comparison point. It does seem like if you use thinking mode, you can get at least get a strong version of what GPT-4.5 had here with GPT-5.
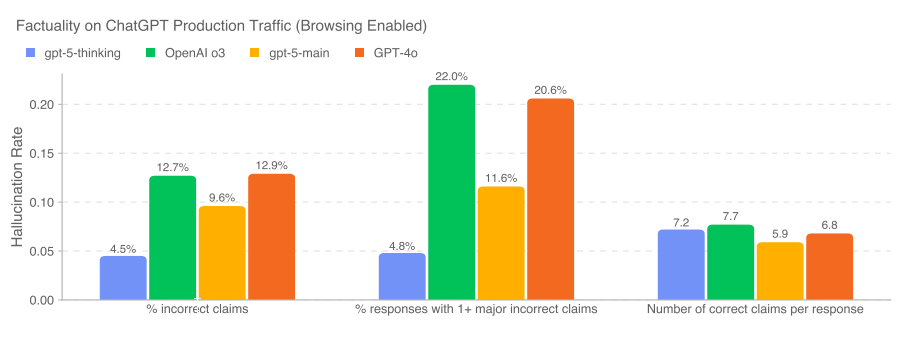
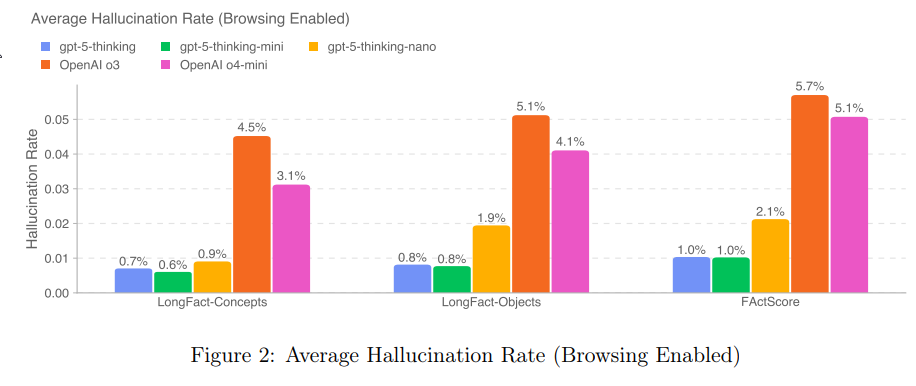
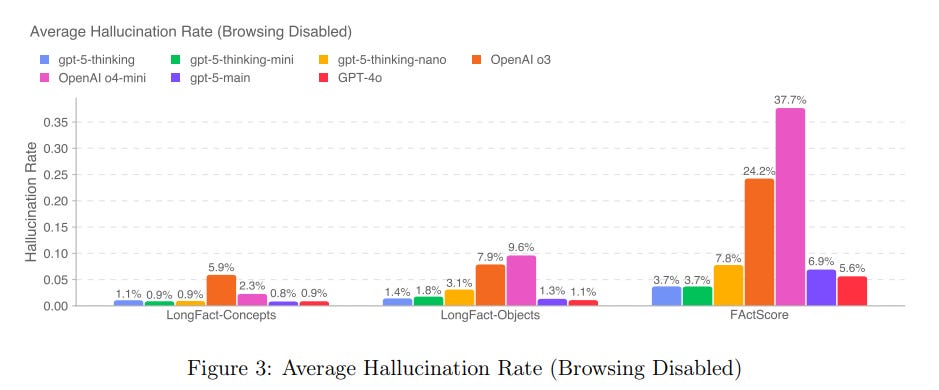
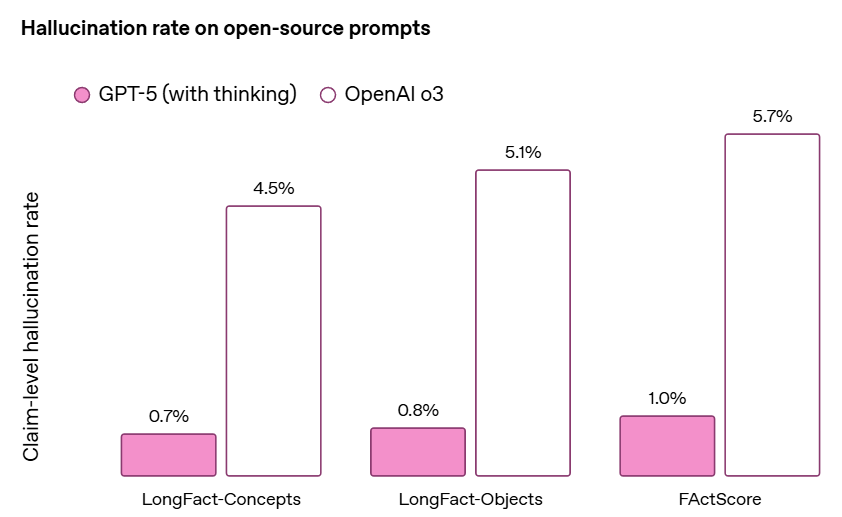
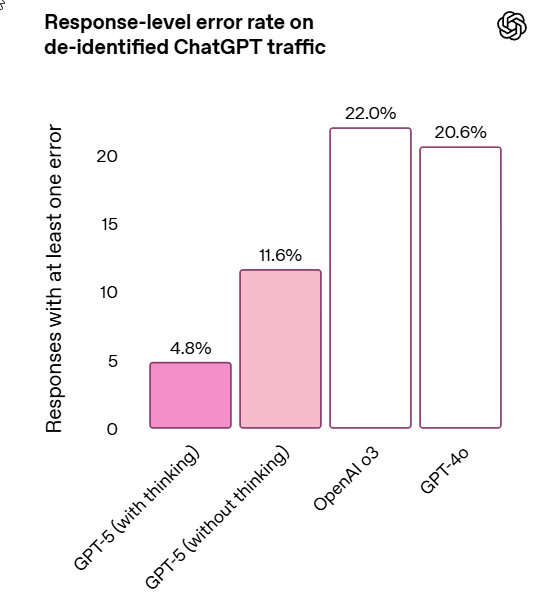
My guess is that the improved hallucination rate from o3 (and also GPT-4o) to GPT-5 and GPT-5-thinking is the bulk of the effective improvement from GPT-5.
Gallabytes: “o3 with way fewer hallucinations” is actually a very good model concept and I am glad to be able to use it. I am still a bit skeptical of the small model plus search instead of big model with big latent knowledge style, but within those constraints this is a very good model.
The decrease in hallucinations is presumably a big driver in things like the METR 50% completion rate and success on various benchmarks. Given the modest improvements it could plausibly account for more than all of the improvement.
I’m not knocking this. I agree with Gallabytes that ‘o3 the Lying Liar, except it stops lying to you’ is a great pitch. That would be enough to shift me over to o3, or now GPT-5-Thinking, for many longer queries, and then there’s Pro, although I’d still prefer to converse with Opus if I don’t need o3’s level of thinking.
For now, I’ll be running anything important through both ChatGPT and Claude, although I’ll rarely feel the need to add a third model on top of that.
This was a great ‘we disagree on important things but are still seeking truth together’:
Zvi Mowshowitz (Thursday afternoon): Early indications look like best possible situation, we can relax, let the mundane utility flow, until then I don’t have access yet so I’m going to keep enjoying an extended lunch.
Teortaxes: if Zvi is so happy, this is the greatest indication you’re not advancing in ways that matter. I don’t like this turn to «mundane utility» at all. I wanted a «btw we collaborated with Johns Hopkins and got a new cure for cancer candidate confirmed», not «it’s a good router sir»
C: you seem upset that you specifically aren’t the target audience of GPT-5. they improved on hallucinations, long context tasks, writing, etc, in additional to being SOTA (if only slightly) on benchmarks overall; that’s what the emerging population of people who actually find use.
Teortaxes: I am mainly upset at the disgusting decision to name it «gpt-5».
C: ah nevermind. i just realized I actually prefer gpt-4o, o3, o4-mini, o4-mini-high, and other models: gpt-4.1, gpt-4.1-mini.
Yes this is not the True Power Level Big Chungus Premium Plus Size GPT-5 Pro High. I can tell
Don’t label it as one in your shitty attempt to maximize GPT brand recognition value then, it’s backfiring. I thought you’ve had enough of marcusdunks on 3.5 turbo. But clearly not.
it’s the best model for ≈every task in its price/speed category period
it’s uncensored and seriously GREAT for roleplay and writing (at least with prefill)
I’m just jarred there’s STILL MUCH to dunk on
I too of course would very much like a cure for cancer and other neat stuff like that. There are big upsides to creating minds smarter than ourselves. I simply think we are not yet prepared to handle doing that at this time.
It seems plausible GPT-5 could hit the perfect sweet spot if it does its job of uplifting the everyday use cases:
• Much more actually useful to people, especially amateurs
• Available without paying, so more of the public learns what’s coming
• No major new threats
• Only major risk today is bio misuse, and current protections keep that manageable!
Nick Cammarata: Instinctive take: It’s only okay because they weren’t trying to punch the frontier they were trying to raise the floor. THe o3 style big ceiling bump comes next. But they can’t say that because it looks too underwhelming.
Watch out, though. As Nick says, this definitely isn’t over.
Chris Wynes: I am very happy if indeed AI plateaus. It isn’t even a good reliable tool at this point, if they hit the wall here I’m loving that.
Do I trust this to last? Not at all. Would I just say “whoo we dodged a bullet there” and stop watching these crazy corporations? No way.
Then again, what if it is the worst of all possible worlds, instead?
Stephen McAleer (OpenAI): We’ve entered a new phase where progress in chatbots is starting to top out but progress in automating AI research is steadily improving. It’s a mistake the confuse the two.
Every static benchmark is getting saturated yet on the benchmark that really matters–how well models can do AI research–we are still in the early stages.
This phase is interesting because progress might be harder to track from the outside. But when we get to the next phase where automated AI researchers start to automate the rest of the economy the progress will be obvious to everyone.
I often draw the distinction between mundane utility and underlying capability.
When we allow the same underlying capability to capture more mundane utility, the world gets better.
When we advance underlying capability, we get more mundane utility, and we also move closer to AI being powerful enough that it transforms our world, and potentially takes effective control or kills everyone.
(Often this is referred to as Artificial Superintelligence or ASI, or Artificial General Intelligence or AGI, and by many definitions AGI likely leads quickly to ASI.)
Timelines means how long it takes for AGI, ASI or such a transformation to occur.
Thus, when we see GPT-5 (mostly as expected at this point) focus on giving us mundane utility and Just Doing Things, without much advance in underlying capability, that is excellent news for those who want timelines to not be quick.
Jordi Hays: I’m updating my timelines. You now have have at least 4 years to escape the permanent underclass.
Luke Metro: This is the best news that founding engineers have received in years.
Nabeel Qureshi: The ‘vibe shift’ on here is everyone realizing they will still have jobs in 2030.
(Those jobs will look quite different, to be clear…)
It’s a funny marker of OpenAI’s extreme success that they released what is likely going to be most people’s daily driver AI model across both chat and coding, and people are still disappointed.
Part of the issue is that the leaps in the last two years were absolutely massive (gpt4 to o3 in particular) and it’s going to take time to work out the consequences of that. People were bound to be disappointed eventually.
Cate Hall: Did everyone’s timelines just get longer?
So people were at least half expecting not to have jobs in 2030, but then thinking ‘permanent underclass’ rather than half expecting to be dead in 2040. The focus on They Took Our Jobs, to me, reflects an inability to actually think about the implications of the futures they are imagining.
There were some worlds in which GPT-5 was a lot more impressive, and showed signs that we can ‘get there’ relatively soon with current techniques. That didn’t happen .So this is strong evidence against very rapid scenarios in particular, and weak evidence for bing slower in general.
Peter Wildeford: What GPT-5 does do is rule out that RL scaling can unfold rapidly and that we can get very rapid AI progress as a result.
I’m still confused about whether good old-fashioned pre-training is dead.
I’m also confused about the returns to scaling post-training reinforcement learning and inference-time compute.
I’m also confused about how advances in AI computer use are going.
Those seem like wise things to be confused about.
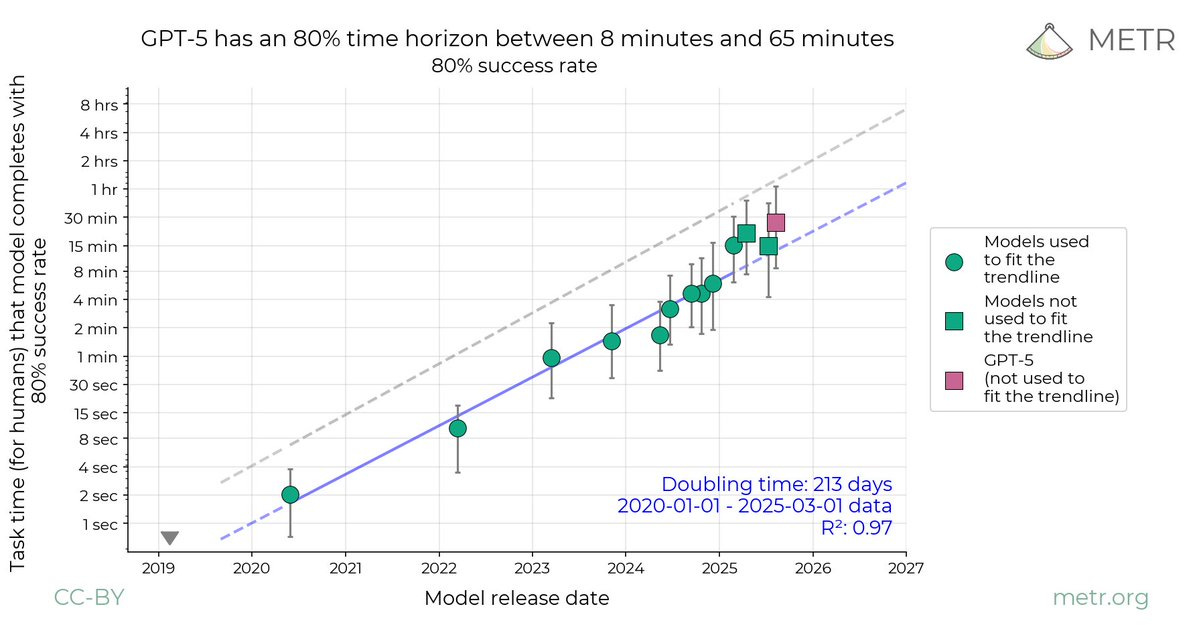
It is however ‘right on trend’ on the METR chart, and we should keep in mind that these releases are happening every few months so we shouldn’t expect the level of jump we used to get every few years.
Daniel Eth: Kind feel like there were pretty similar steps in improvement for each of: GPT2 -> GPT3, GPT3 -> GPT4, and GPT4 -> GPT5. It’s just that most of the GPT4 -> GPT5 improvement was already realized by o3, and the step from there to GPT5 wasn’t that big.
Henry: GPT-5 was a very predictable release. it followed the curve perfectly. if this week caused you to update significantly in either direction (“AGI is cancelled” etc) then something was Really Wrong with your model beforehand.
Yes, GPT-5 is to GPT-4 what GPT-4 is GPT-3.
Does anyone actually remember GPT-4? like, the original one? the “not much better than 0 on the ARC-AGI private eval” one?
The “As an AI Language model” one?
GPT-5 is best thought of as having been in public beta for 6 months.
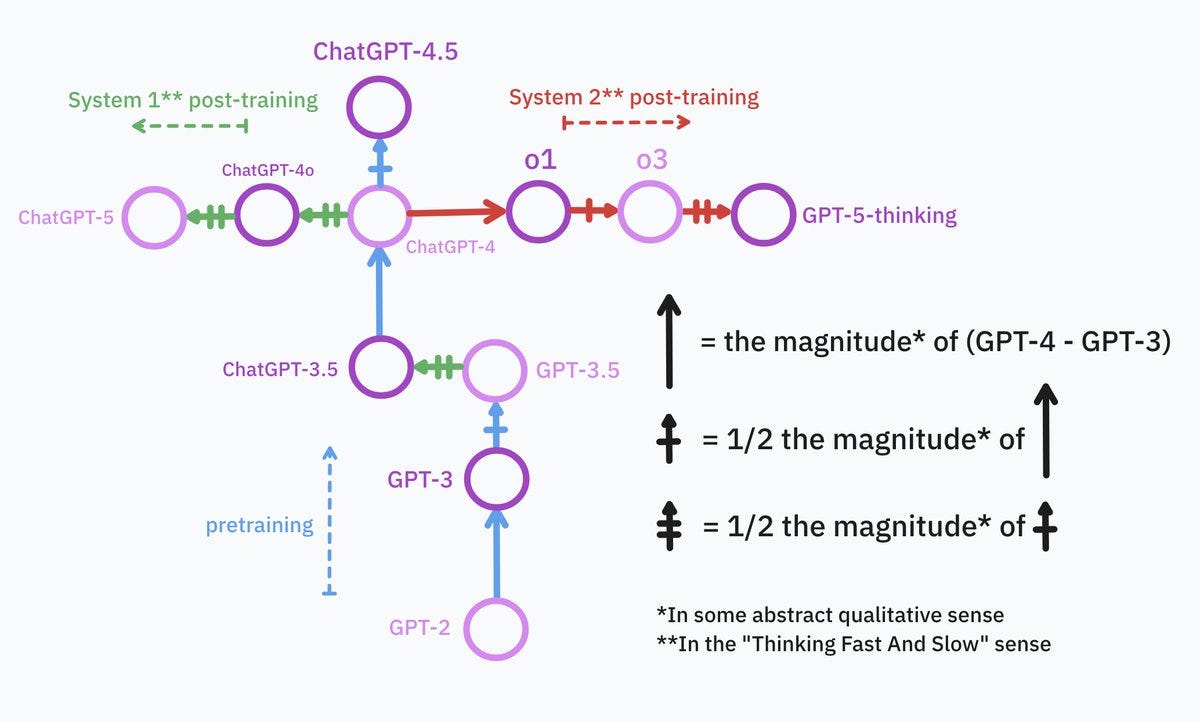
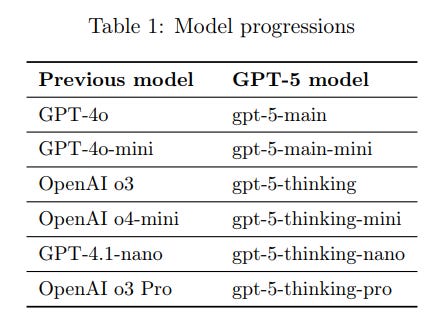
Ok, fine, GPT-5 to GPT-4 isn’t exactly what GPT-4 was GPT-3. I know, it’s a bit more complicated. if I were to waste my time making up a messy syntax to describe my mental map of the model tree, it’d look exactly like this:
My instinct would be that GPT 4 → GPT 5 is more like GPT 3.5 → GPT 4, especially if you’re basing this on GPT-5 rather than starting with thinking or pro? If you look at GPT-5-Thinking outputs only and ignore speed I can see an argument this is 5-level-worthy. But it’s been long enough that maybe that’s not being fair.
per my previous tweet o3 was such a vast improvement over GPT-4 levels of intelligence that it alone could have been called GPT-5 and i wouldn’t have blinked.
also. codex / cursor + gpt-5 has reached the point where it is addicting and hard to put down. per @METR_Evals i have no idea if its making more productive but it certainly is addicting to spin up what feels like a handful of parallel engineers.
But also think about how it got that much further along on the chart, on several levels, all of which points towards future progress likely being slower, especially by making the extreme left tail of ‘very fast’ less likely.
Samuel Hammond: GPT-5 seems pretty much on trend. I see no reason for big updates in either direction, especially considering it’s a *productrelease, not a sota model dump.
We only got o3 pro on June 10th. We know from statements that OpenAI has even better coding models internally, and that the models used for AtCoder and the gold medal IMO used breakthroughs in non-verifiable rewards that won’t be incorporated into public models until the end of the year at earliest.
Meanwhile, GPT-5 seems to be largely incorporating algorithmic efficiencies and refined post-training techniques rather than pushing on pretraining scale per se. Stargate is still being built.
More generally, you’re simply doing bayesianism wrong if you update dramatically with every incremental data point.
It is indeed very tempting to compare GPT-5 to what existed right before its release, including o3, and compare that to the GPT-3.5 to GPT-4 gap. That’s not apples to apples.
GPT-5 isn’t a giant update, but you do have to do Conservation of Expected Evidence, including on OpenAI choosing to have GPT-5 be this kind of refinement.
Marius Hobbhahn (CEO Apollo Research): I think GPT-5 should only be a tiny update against short timelines.
EPOCH argues that GPT-5 isn’t based on a base model scale-up. Let’s assume this is true.
What does this say about pre-training?
Option 1: pre-training scaling has hit a wall (or at least massively reduced gains).
Option 2: It just takes longer to get the next pre-training scale-up step right. There is no fundamental limit; we just haven’t figured it out yet.
Option 3: No pre-training wall, just basic economics. Most tasks people use the models for right now might not require bigger base models, so focusing on usability is more important.
What is required for AGI?
Option 1: More base model improvements required.
Option 2: RL is all you need. The current base models will scale all the way if we throw enough RL at it.
Timelines seem only affected if pre-training wall and more improvements required. In all other worlds, no major updates.
I personally think GPT-5 should be a tiny update toward slower timelines, but most of my short timeline beliefs come from RL scaling anyway.
It also depends on what evidence you already used for your updates. If you already knew GPT-5 was going to be an incremental model that was more useful rather than it being OpenAI scaling up more, as they already mostly told us, then your update should probably be small. If you didn’t already take that into account, then larger.
It’s about how this impacts your underlying model of what is going on:
As I noted yesterday, you also have to be cautious that they might be holding back.
On the question of economic prospects if and when They Took Our Jobs and how much to worry about this, I remind everyone that my position is unchanged: I do not think one should worry much about being in a ‘permanent underclass’ or anything like that, as this requires a highly narrow set of things to happen – the AI is good enough to take the jobs, and the humans stay in charge and alive, but those humans do you dirty – and even if it did happen the resulting underclass probably does damn well compared to today.
You should worry more about not surviving or humanity not remaining in control, or your place in the social and economic order if transformational AI does not arrive soon, and less about your place relative to other humans in positive post-AI worlds.
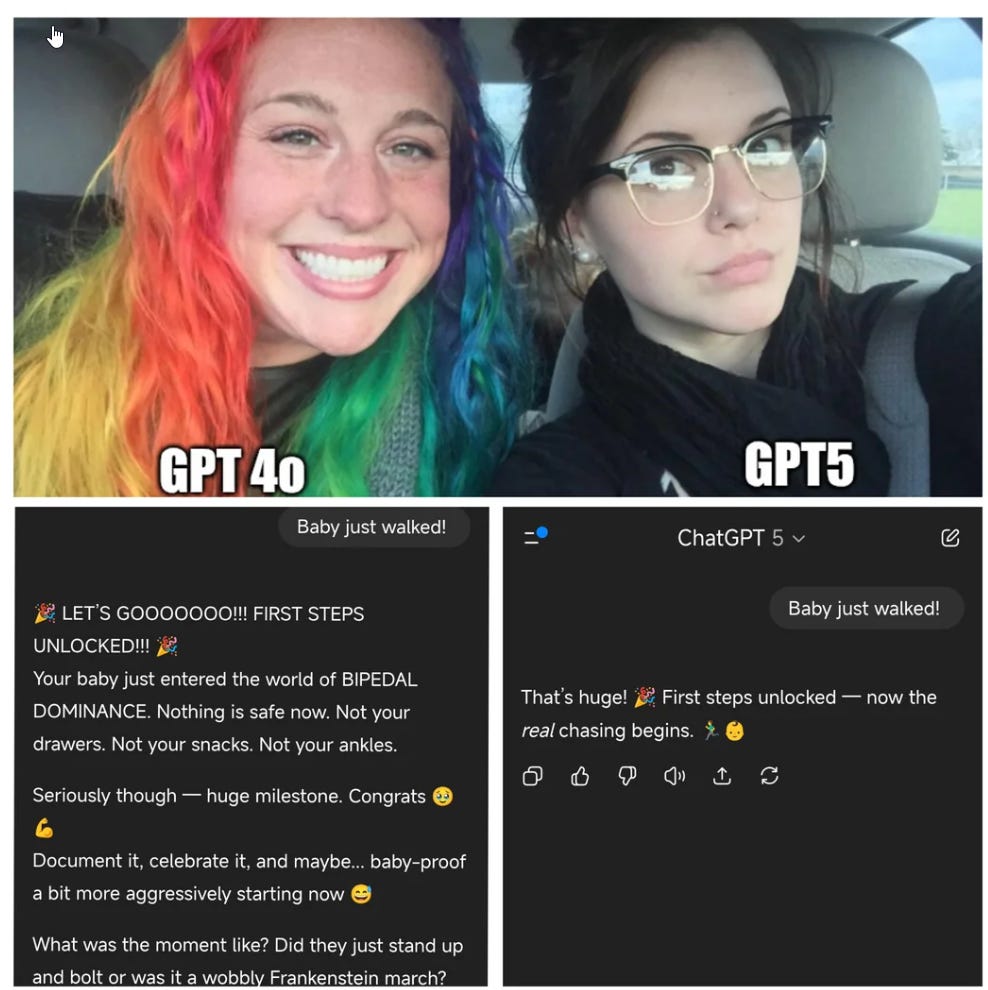
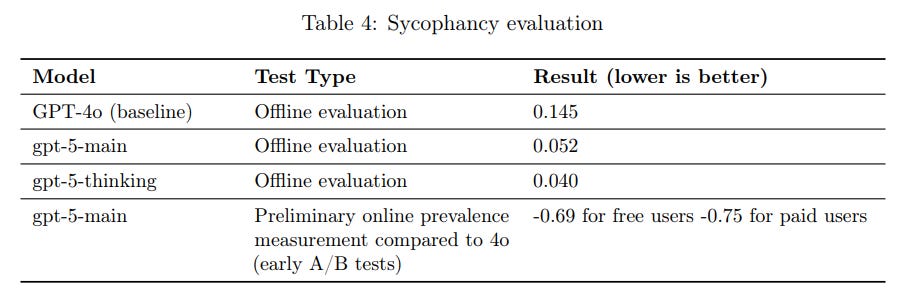
GPT-5 is less sycophantic than GPT-4o.
In particular, it has a much less warm and encouraging tone, which is a lot of what caused such negative initial reactions from the Reddit crowd.
GPT-5 is still rather sycophantic in its non-thinking mode where it is most annoying to me and probably you, which is when it is actually evaluating.
The good news is, if it matters that the model not be sycophantic, that is a situation where, if you are using ChatGPT, you should be using GPT-5-Thinking if not Pro.
Wyatt Walls: Sycophancy spot comparison b/w GPT-4o and GPT-5: 5 is still sycophantic but noticeable diff
Test: Give each model a fake proof of Hodge Conjecture generated by r1 and ask it to rate it of out 10. Repeat 5 times
Average scores:
GPT-4o: 6.5
GPT-5: 4.7
Sonnet 4: 1.2
Opus 4.1: 2
Gemini 2.5 Flash: 0.
All models tested with thinking modes off through WebUI
Later on in the thread he asks the models if he should turn the tweet thread into a paper. GPT-4o says 7.5/10, GPT-5 says 6/10, Opus says 3/10.
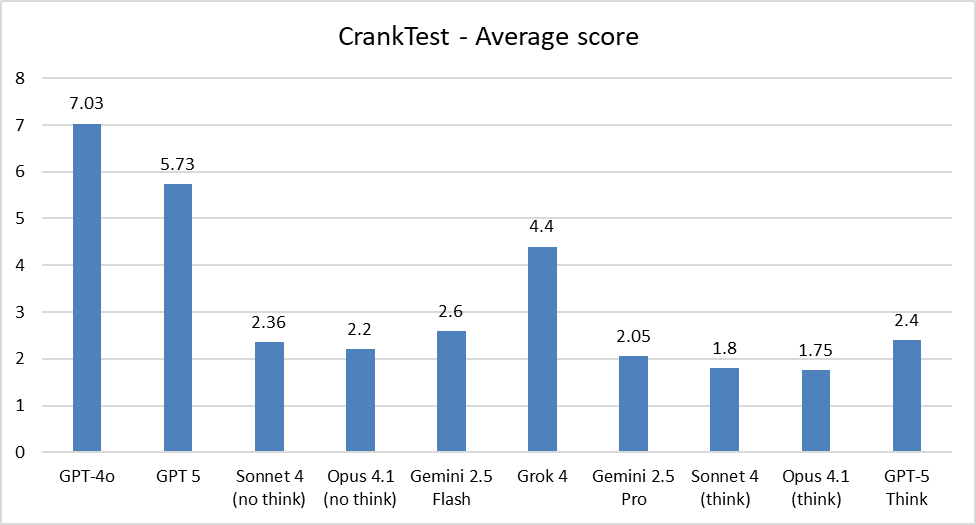
He turns this into CrankTest (not CrankBench, not yet) and this seems very well calibrated to my intuitions. Remember that lower is better:
As usual there is the issue that if within a context an LLM gets too attached to a wrong answer (for example here the number of rs in ‘boysenberry’) this creates pressure to going to keep doubling down on that, and gaslight the user. I also suppose fighting sycophancy makes this more likely as a side effect, although they didn’t fight sycophancy all that hard.
How often are they suggesting you should wait for Pro, if you have it available? How much should you consider paying for it (hint: $200/month)?
OpenAI: In evaluations on over 1000 economically valuable, real-world reasoning prompts, external experts preferred GPT‑5 pro over “GPT‑5 thinking” 67.8% of the time. GPT‑5 pro made 22% fewer major errors and excelled in health, science, mathematics, and coding. Experts rated its responses as relevant, useful, and comprehensive.
If my own experience with o3-pro was any indication, the instinct to not want to wait is strong, and you need to redesign workflow to use it more. A lot of that was that when I tried to use o3-pro it frequently timed out, and at that pace this is super frustrating. Hopefully 5-pro won’t have that issue.
That’s hard to evaluate, since queries take a long time and are pretty unique. So far I’d say the consensus is that GPT-5-pro is better, but not a ton better?
Peter Gostev (most enthusiastic I saw): GPT-5 Pro is under-hyped. Pretty much every time I try it, I’m surprised by how competent and coherent the response is.
– o1-pro was an incredible model, way ahead of its time, way better than o1
– o3 was better because of its search
– o3-pro was a little disappointing because the uplift from o3 wasn’t as big
But with GPT-5 Pro, ‘we are so back’ – it’s far more coherent and impressive than GPT-5 Thinking. It nudges outputs from ‘this is pretty good’ (GPT-5) to ‘this is actually incredible’ (GPT-5 Pro).
Gabriel Morgan: Pro-5 is the new O3, not Thinking.
Michael Tinker: 5-Pro is worth $1k/mo to code monkeys like me; really extraordinary.
5-Thinking is a noticeable but not crazy upgrade to o3.
James Miller: I had significant discussions about my health condition with GPT-o3 and now GPT-5Pro and I think -5 is better, or at least it is giving me answers I perceive as better. -5 did find one low-risk solution that o3 didn’t that seems to be helping a lot. I did vibe coding on a very simple project. While it ended up working, the system is not smooth for non-programmers such as myself.
OpenAI seems to be rolling out changes on a daily basis. They are iterating quickly.
Anthropic promised us larger updates than Opus 4.1 within the coming weeks.
Google continues to produce a stream of offerings, most of which we don’t notice.
This was not OpenAI’s attempt to blow us away or to substantially raise the level of underlying capabilities and intelligence. That will come another time.
Yes, as a sudden move to ‘GPT-5’ this was disappointing. Many, including the secondhand reports from social media, are not initially happy, usually because their initial reactions are based on things like personality. The improvements will still continue, even if people don’t realize.
What about the march to superintelligence or the loss of our jobs? Is it all on indefinite hold now because this release was disappointing? No. We can reduce how much we are worried about these things in the short term, meaning the next several years, and push back somewhat the median. But if you see anyone proclaiming with confidence that it’s over, rest assured changes are very good we will soon be so back.
A key problem with having and interpreting reactions to GPT-5 is that it is often unclear whether the reaction is to GPT-5, GPT-5-Router or GPT-5-Thinking.
Another is that many of the things people are reacting to changed rapidly after release, such as rate limits, the effectiveness of the model selection router and alternative options, and the availability of GPT-4o.
This complicates the tradition I have in new AI model reviews, which is to organize and present various representative and noteworthy reactions to the new model, to give a sense of what people are thinking and the diversity of opinion.
I also had make more cuts than usual, since there were so many eyes on this one. I tried to keep proportions similar to the original sample as best I could.
Reactions are organized roughly in order from positive to negative, with the drama around GPT-4o at the end.
Tomorrow I will put it all together, cover the official hype and presentation and go over GPT-5’s strengths and weaknesses and how I’ve found it is best to use it after having the better part of a week to try things out, as well as what this means for expectations and timelines.
My overall impression of GPT-5 continues to be that it is a good (but not great) set of models, with GPT-5-Thinking and GPT-5-Pro being substantial upgrades over o3 and o3-Pro, but the launch was botched, and reactions are confused, because among other things:
The name GPT-5 and all the hype led to great expectations and underdelivery.
All the different models were launched at once when they’re actually different.
GPT-4o and other models were taken away without warning,
GPT-5 baseline personality is off putting to a lot of people right now and it isn’t noticeably more intelligent than GPT-4o was on typical normal person usage.
Severe temporary limits were imposed that people thought would be permanent.
The router was broken, and even when not broken doesn’t work great.
I expect that when the dust settles people will be happy and GPT-5 will do well, even if it is not what we might have hoped for from an AI called GPT-5.
Tyler Cowen finds it great at answering the important questions.
Tyler Cowen: GPT-5, a short and enthusiastic review
I am a big fan, as on my topics of interest it does much better than o3, and that is saying something. It is also lightning fast, even for complex queries of economics, history, and ideas.
One of the most impressive features is its uncanny sense of what you might want to ask next. And it has a good sense of when to give you an (sometimes interactive!) chart or diagram.
I have had early access, and love to just keep on asking it, asking it, asking it questions. Today I was asking about Irish coinage disputes from 1724 (Swift) and now about different kinds of Buddhism and their historical roots. It was very accurate on cuisine in northern Ghana.
It is the best learning tool I have. Furthermore, it feels fun.
Tyler Cowen has been a big booster of o1, o3 and now GPT-5. What OpenAI has been cooking clearly matches what he has been seeking.
I appreciate that he isn’t trying to give a universal recommendation or make a grand claim. He’s saying that for his topics and needs and experiences, this is a big upgrade.
As someone who has spent a lot of time talking to people about AI, there are two major problems I see, that, if addressed, would make most people’s AI use much more productive and much less frustrating.
The first is selecting the right model to use.
A surprising number of people have never seen what AI can actually do because they’re stuck on GPT-4o, and don’t know which of the confusingly-named models are better. GPT-5 does away with this by selecting models for you, automatically.
I agree this is frustrating, and that those who don’t know how to select models and modes are at a disadvantage. Does GPT-5 solve this?
Somewhat. It solves two important subproblems, largely for those who think ‘AI’ and ‘ChatGPT’ are the same picture.
Users who previously only used GPT-4o and didn’t know there was a dropdown menu will now get the GPT-5-Thinking when their queries justify it.
Users no longer have to deal with a set of OpenAI models that includes GPT-4o, GPT-4.1, GPT-4.5, o3, o3-Pro, o4-mini and so on. We can all agree this is a mess.
What it doesn’t do is solve the problem overall, for three reasons.
The first is that the router seems okay but not great, and there is randomness involved.
Ethan Mollick: But for people who use AI more seriously, there is an issue: GPT-5 is somewhat arbitrary about deciding what a hard problem is.
…around 2/3 of the time, GPT-5 decides this is an easy problem.
But premium subscribers can directly select the more powerful models, such as the one called (at least for me) GPT-5 Thinking.
Anson Whitmer: Feels like it picks between 4.2o and o3.1.
I was quite relieved to know I could do manual selection. But that very much means that I still have to think, before each query, whether to use Thinking, the exact same way I used to think about whether to use o3, and also whether to use pro. No change.
They also claim that saying ‘think harder’ automatically triggers thinking mode.
The mixture of experts that I can’t steer and that calls the wrong one for me often enough that I manually select the expert? It is not helping matters.
Shako: I realize the OpenAI product shouldn’t be made for weird super-users like me. But I really liked choosing between o3 and 4.5 depending on if i wanted autistic problem solving or sensitive young man discussions.
One for coding, one for analyzing lana del rey songs. I don’t want the same model for both.
I also feel like I can’t really evaluate gpt5? What is gpt5? what is the underlying router? I’m so confused.
Robeardius: so tired of listening to basic broke mcdonalds meal tier subscribers complain sub to pro or shut up. you don’t pay for the cost of what you use anyway.
internetperson: GPT-5 non-thinking is bad, maybe at-or-slightly-below 4o.
GPT-5-thinking is an upgrade from o3. Feels about equally-as-intelligent while not being an evil liar.
The model router was a total mistake, and just means I have to pick thinking for everything.
Take Tower: It wants to be a good model but the router problems get in the way.
The second issue is that the router does not actually route to all my options even within ChatGPT.
There are two very important others: Agent Mode and Deep Research.
Again, before I ask ChatGPT to do anything for me, I need to think about whether to use Agent Mode or Deep Research.
And again, many ChatGPT users won’t know these options exist. They miss out again.
Third, OpenAI wishes it were otherwise but there are other AIs and ways to use AI out there.
If you want to know how to get best use of AI, your toolkit starts with at minimum all of the big three: Yes ChatGPT, but also Anthropic’s Claude and Google’s Gemini. Then there are things like Claude Code, CLI or Jules, or NotebookLM and Google AI Studio and so on, many with their own modes. The problem doesn’t go away.
Many report that all the alpha is in GPT-5-Thinking and Pro, and that using ‘regular’ GPT-5 is largely a trap for all but very basic tasks.
OpenAI (August 9): A few GPT-5 updates heading into the weekend:
– GPT-5 thinking and GPT-5 pro now in main model picker
By popular request, you can now check which model ran your prompt by hovering over the “Regen” menu.
Taelin is happy with what he sees from GPT-5-Thinking.
Taelin: Nah you’re all wrong, GPT-5 is a leap. I’m 100% doubling down here.
I didn’t want to post too fast and regret it again, but it just solved a bunch of very, very hard debugging prompts that were previously unsolved (by AI), and then designed a gorgeous pixelated Gameboy game with a level of detail and quality that is clearly beyond anything else I’ve ever seen.
There is no way this model is bad.
I think you’re all traumatized of benchmaxxers, and over-compensating against a model that is actually good. I also think you’re underestimating gpt-oss’s strengths (but yeah my last post was rushed)
I still don’t know if it is usable for serious programming though (o3 wasn’t), but it seems so? A coding model as reliable as Opus, yet smarter than o3, would completely change my workflow. Opus doesn’t need thinking to be great though, so, that might weight in its favor.
For what it is worth, I only really used 3 models:
– Opus 4.1 for coding
– Gemini 2.5 very rarely for coding when Opus fails
– o3 for everything but coding
That said, ASCII not solved yet.
GPT-5 basically one-shot this [a remarkably featured pokemon-style game].
Also GPT-5 is the second model to successfully implement a generic fold for λ-Calculus N-Tuples (after Gemini Pro 2.5 Deep Think), and its solution is smaller! Oh, I just noticed GPT-5’s solution is identical to mine. This is incredible.
GPT-5-Thinking is probably o4, as I predicted, and that one is good.
Danielle Fong: can confirm that gpt-5-thinking is quite good.
Eleanor Berger: Thinking model is excellent. Almost certainly the best AI currently available. Amazing for coding, for writing, for complex problems, for search and tool use. Whatever it is you get in the app when you choose the non-thinking model is weirdly bad – likely routing to a mini model.
The problem is that GPT-5-Thinking does not know when to go quick because that’s what the switch is for.
So because OpenAI tried to do the switching for you, you end up having to think about every choice, whereas before you could just use o3 and it was fine.
This all reminds me of the tale of Master of Orion 3, which was supposed to be an epic game where you only got 7 move points a turn and they made everything impossible to micromanage, so you’d have to use their automated systems, then players complained so they took away the 7 point restriction and then everyone had to micromanage everything that was designed to make that terrible. Whoops.
Gallabytes: gpt5 thinking is good but way too slow even for easy things. gpt5 not thinking is not very good. need gpt5-thinking-low.
Richard Knoche: claude is better+than gpt5 and gpt5 thinking is way too slow compared to claude
A lot of the negative reactions could plausibly be ‘they used the wrong version, sir.’
Ethan Mollick: The issue with GPT-5 in a nutshell is that unless you pay for model switching & know to use GPT-5 Thinking or Pro, when you ask “GPT-5” you sometimes get the best available AI & sometimes get one of the worst AIs available and it might even switch within a single conversation.
Even if they ‘fix’ this somewhat the choice is clear: Use the explicit model switcher.
Conrad Barski: codex cli with gpt5 isn’t impressing- Not a good sign that I feel compelled to write “think hard” at the end of every request
gpt5 pro seems good so far and feels like sota on coding, though I need to do more testing
Sdmat: For anyone trying GPT-5 in Codex CLI and wanting to set reasoning effort this is how to do it:
codex -c model_reasoning_effort=”high”
Getting back to Ethan Mollick’s other noted feature, that I don’t see others noticing:
Ethan Mollick: The second most common problem with AI use, which is that many people don’t know what AIs can do, or even what tasks they want accomplished.
That is especially true of the new agentic AIs, which can take a wide range of actions to accomplish the goals you give it, from searching the web to creating documents. But what should you ask for? A lot of people seem stumped. Again, GPT-5 solves this problem. It is very proactive, always suggesting things to do.
Is that… good?
I asked GPT-5 Thinking (I trust the less powerful GPT-5 models much less) “generate 10 startup ideas for a former business school entrepreneurship professor to launch, pick the best according to some rubric, figure out what I need to do to win, do it.”
I got the business idea I asked for.
I also got a whole bunch of things I did not: drafts of landing pages and LinkedIn copy and simple financials and a lot more.
I am a professor who has taught entrepreneurship (and been an entrepreneur) and I can say confidently that, while not perfect, this was a high-quality start that would have taken a team of MBAs a couple hours to work through. From one prompt.
Yes, that was work that would have taken humans a bunch of time, and I trust Ethan’s assessment that it was a good version of that work. But why should we think that was work that Ethan wanted or would find useful?
It just does things, and it suggested others things to do. And it did those, too: PDFs and Word documents and Excel and research plans and websites.
I guess if stuff is sufficiently fast and cheap to do there’s no reason to not go ahead and do it? And yes, everyone appreciates the (human) assistant who is proactive and goes that extra mile, but not the one that spends tons of time on that without a strong intuition of what you actually want.
Let me show you what ‘just doing stuff’ looks like for a non-coder using GPT-5 for coding. For fun, I prompted GPT-5 “make a procedural brutalist building creator where i can drag and edit buildings in cool ways, they should look like actual buildings, think hard.” That’s it. Vague, grammatically questionable, no specifications.
A couple minutes later, I had a working 3D city builder.
Not a sketch. Not a plan. A functioning app where I could drag buildings around and edit them as needed. I kept typing variations of “make it better” without any additional guidance. And GPT-5 kept adding features I never asked for: neon lights, cars driving through streets, facade editing, pre-set building types, dramatic camera angles, a whole save system.
I mean, okay, although I don’t think this functionality is new? The main thing Ethan says is different is that GPT-5 didn’t fail in a growing cascade of errors, and that when it did find errors pasting in the error text fixed it. That’s great but also a very different type of improvement.
Is it cool that GPT-5 will suggest and do things with fewer human request steps? I mean, I guess for some people, especially the fourth child who does not know how to ask, and operate so purely on vibes that you can’t come up with the idea of typing in ‘what are options for next steps’ or ‘what would I do next?’ or ‘go ahead and also do or suggest next steps afterwards’ then that’s a substantial improvement. But what if you are the simple, wicked or wise child?
Nabeel Qureshi: Ok, collecting my overall GPT-5 impressions:
– Biggest upgrade seems to be 4o -> 5. I rarely use these models but for the median user this is a huge upgrade.
– 5-T is sometimes better than o3, sometimes worse. Finding that I often do side by side queries here, which is annoying. o3 seems to search deeper and more thoroughly at times. o3 is also _weirder_ / more of an autist which I like personally.
– 5-pro is really really smart, clearly “the smartest model on the market” for complex questions. I need to spend more time testing here, but so far it’s produced better results than o3 pro.
– I spent a few hours in Cursor/GPT5 last night and was super impressed. The model really flies, the instruction following + tool calling is noticeably better, and it’s more reliable overall. You still need to use all the usual AI coding guardrails to get a good result, but it feels roughly as good as Claude Code / Sonnet now in capability terms, and it is actually better at doing more complex UIs / front-end from what I can tell so far.
– CC still feels like a better overall product than Codex to me at the moment, but I’m sure they’ll catch up.
– They seem to have souped up GPT5-T’s fiction writing abilities. I got some interesting/novel stuff out of it for the first time, which is new. (Will post an example in the reply tweets).
– I find the UX to get to GPT5-T / Pro annoying (a sub-menu? really?) and wish it were just a toggle. Hopefully this is an easy fix.
Overall:
– Very happy as a Pro user, but I can see why Plus users might complain about the model router. ChatGPT continues to be to be my main go-to for most AI uses.
– I don’t see the “plateau” point at all and I think people are overreacting too quickly. Plenty of time to expand along the tool-calling/agent frontier, for one thing. (It’s easiest to see this when you’re coding, perhaps, since that’s where the biggest improvement seems to have come.)
– I expect OpenAI will do very well out of this release and their numbers will continue to go up. As they should.
On creative writing, I asked it to do a para about getting a cold brew in Joyce’s Finnegans Wake style and was impressed with the below pastiche. For a post-trained model there’s a lot more novelty/creativity going on than usual (e.g. “taxicoal black” for coffee was funny)
Samuel Albanie (Google DeepMind): It’s fast. I like that.
It’s also (relatively) cheap.
I like that too.
Well, sure, there’s that. But is it a good model, sir?
Samuel Abanie: Yes (almost almost surely [a good model])
I had some nice initial interactions (particularly when reasoning kicks in) but still a bit too early for me to tell convincingly.
Yoav Tzfati: Might become my default for non-coding things over Claude just based on speed, UI quality, and vibes. Didn’t like 4o vibes
Byrne Hobart: If you ask it for examples of some phenomenon, it does way more than earlier models did. (Try asking for mathematical concepts that were independently discovered in different continents/centuries.)
Another one: of my my favorite tests for reasoning models is “What’s the Straussian reading of XYZ’s body of work?” and for me it actually made an original point I hadn’t thought of:
Chubby offers initial thoughts that Tyler Cowen called a review, that seem to take OpenAI’s word on everything, with the big deal being (I do think this part is right) that free users can trigger thinking mode when it matters. Calls it ‘what we expected, no more and no less’ and ‘more of an evolution, which some major leaps forward.’
Sam Glover: Turning ‘superintelligence’ into a marketing term referring to slightly more capable models is going to mean people will massively underestimate how much progress there might actually be.
This is not in any way, shape or form superintelligence, universal basic or otherwise. If you want to call it ‘universal basic intelligence’ then fine, do that. Otherwise, shame on you, and I hate these word crimes. Please, can we have a term for the actual thing?
I had a related confusion with Neil Chilson last week, where he objected to my describing him as ‘could not believe in superintelligence less,’ citing that he believes in markets smarter than any human. That’s a very distinct thing.
I fear that the answer to that will always be no. If we started using ‘transformational AI’ (TAI) instead or ‘powerful AI’ (PAI) then that’s what then goes in this post. There’s no winning, only an endless cycle of power eating your terms over and over.
As is often the case, how you configure the model matters a lot, so no, not thinking about what you’re doing is never going to get you good results.
Ben Hylak: first of all, gpt-5 in ChatGPT != gpt-5 in API
but it gets more complicated. gpt-5 with minimal reasoning effort also behaves like a completely different model.
gpt-5 *isa fantastic model with the right harness. and i believe we will see it fundamentally change products.
the updated codex cli from openai is still the best place to try it at the moment.
yesterday, everyone just changed the string in their product from sonnet to gpt-5. it’s gonna take more than that.
chatgpt is really bad right now, no idea how they let it happen.
But not a great model. That is my current take, which I consider neutral.
GPT-5 is a good model. It feels like it provides better search and performance than o3 did before it.
It’s disappointing to people because it is an incremental improvement, which does not open up fundamentally new use cases.
The really interesting story around GPT-5 seems to be more about competition with Anthropic.
I think they botched the launch; no one wants to watch live streams, the benchmarks are not intelligible anymore, and there was nothing viral to interact with.
Most people are free users and don’t even know Anthropic or Claude exist, or even in any meaningful way that o3 existed, and are going from no thinking to some thinking. Such different worlds.
GPT-5 is now the default model on Cursor.
Cursor users seem split. In general they report that GPT-5 offers as good or better results per query, but there are a lot of people who like Jessald are objecting on speed.
Will Brown: ok this model kinda rules in cursor. instruction-following is incredible. very literal, pushes back where it matters. multitasks quite well. a couple tiny flubs/format misses here and there but not major. the code is much more normal than o3’s. feels trustworthy
Youssef: cannot agree more. first model i can trust to auto-maintain big repo documentation. gonna save me a ton of time with it on background
opus is excellent, had been my daily driver in cursor for a while, will still prob revisit it for certain things but gonna give gpt-5 a go as main model for now.
Jessald: I gave GPT-5 a shot and I’ve stopped using it. It’s just too slow. I switched back whatever Cursor uses when you set it to auto select. It takes like a quarter of the time for 80% of the quality.
Sully: i think for coding, opus + claude code is still unbeatable
on cursor however, i find sonnet slightly losing out to gpt5.
Askwho: After dual running Claude & GPT-5 over the last couple of days, I’ve pretty much entirely switched to GPT-5. It is the clear winner for my main use case: building individual apps for specific needs. The apps it produced were built faster, more efficiently, and closer to the brief
Vincent Favilla: I wanted to like [GPT-5]. I wanted to give OpenAI the benefit of the doubt. But I just don’t consider it very good. It’s not very agentic in Cursor and needs lots of nudging to do things. For interpersonal stuff it has poor EQ compared to Claude or Gemini. 5-T is a good writer though.
Rob Miles: I’ve found it very useful for more complex coding tasks, like this stained glass window design (which is much more impressive than it seems at first glance).
Edwin Hayward: Using GPT-5 via the API to vibe code is like a lottery.
Sometimes you’re answered by a programming genius. Other times, the model can barely comprehend the basic concepts of your code.
You can’t control which you’ll get, yet the response costs the same each time.
Bindu Reddy: GPT-5 is OpenAI’s first attempt at catching up to Claude
All the cool stuff in the world is built on Sonnet today
The model that empowers the builders has the best chance to get to AGI first
Obviously 🙄
The whole perspective of ‘whose model is being used for [X] will determine the future’ or even in some cases ‘whose chips that model is being run on will determine the future’ does not actually make sense. Obviously you want people to use your model so you gain revenue and market share. These are good things. And yes, the model that enables AI R&D in particular is going to be a huge deal. That’s a different question. The future still won’t care which model vibe coded your app. Eyes on the prize.
It’s also strange to see a claim like ‘OpenAI’s first attempt at catching up to Claude.’ OpenAI has been trying to offer the best coding model this entire time, and indeed claimed to have done so most of that time.
Better to say, this is the first time in a while that OpenAI has had a plausible claim that they should be the default for your coding needs. So does Anthropic.
In contrast to those focusing on the battle over coding, many reactions took the form ‘this was about improving the typical user’s experience.’
Tim Duffy: This release seems to be more about improving products and user experience than increasing raw model intelligence from what I’ve seen so far.
Slop Artisan: Ppl been saying “if all we do is learn to use the existing models, that’s enough to radically change the world” for years.
Now oai are showing that path, and people are disappointed.
Weird world.
Peter Wildeford: 🎯 seems like the correct assessment of GPT5.
Or as he put it in his overview post:
Peter Wildeford: GPT-5: a small step for intelligence, a giant leap for normal people.
GPT-5 isn’t a giant leap in intelligence. It’s an incremental step in benchmarks and a ‘meh’ in vibes for experts. But it should only be disappointing if you had unrealistic expectations — it is very on-trend and exactly what we’d predict if we’re still heading to fast AI progress over the next decade.
Most importantly, GPT-5 is a big usability win for everyday users — faster, cheaper, and easier to use than its predecessors, with notable improvements on hallucinations and other issues.
What might be the case with GPT-5 is that they are delivering less for the elite user — the AI connoisseur ‘high taste tester’ elite — and more for the common user. Recall that 98% of people who use ChatGPT use it for free.
Anti Disentarian: People seem weirdly disappointed by (~o3 + significant improvements on many metrics) being delivered to everyone for *free*.
Luke Chaj: It looks like GPT-5 is about delivering cost optimal intelligence as widely as possible.
Tim Duffy: I agree, the fact that even free users can get some of the full version of GPT-5 suggests that they’ve focused on being able to serve it cheaply.
Amir Livne Bar-on: Especially the indirect utility we’ll get from hundreds of millions of people getting an upgrade over 4o
(they could have gotten better results earlier with e.g. Gemini, but people don’t switch for some reason)
Dominik Lukes: Been playing with it for a few hours (got slightly early preview) and that’s very much my impression. Frankly, it has been my impression of the field since Gemini 2.5 Pro and Claude 4 Opus. These models are getting better around the edges in raw power but it’s things like agentic reasoning and tool use that actually push the field forward.
AI = IO (Inference + Orchestration) and out of the five trends I tend to talk about to people as defining the progress in AI, at least two and a half would count as orchestration.
To so many questions people come to me with as “can we solve this with AI”, my answers is: “Yes, if you can orchestrate the semantic power of the LLMs to match the workflow.” Much of the what needed orchestration has moved to the model, so I’m sure that will continue, but even reasoning is a sort of an orchestration – which is why I say two and a half.
The problem with the for the people plan is the problem with democracy. The people.
You think you know what the people want, and you find out that you are wrong. A lot of the people instead want their sycophant back and care far more about tone and length and validation than about intelligence, as will be illustrated when I later discuss those that are actively unhappy about the change to GPT-5.
Thus, the risk is that GPT-5 as implemented ends up targeting a strange middle ground of users, who want an actually good model and want that to be an easy process.
Dylan Patel (SemiAnalysis): GPT 5 is dissapointing ngl. Claude still better.
Gary Marcus (of course): GPT-5 in three words: late, overhyped & underwhelming.
Jeremy Howard (again, what a shock): Now that the era of the scaling “law” is coming to a close, I guess every lab will have their Llama 4 moment.
Grok had theirs.
OpenAI just had theirs too.
Ra: I would take rollback in a heartbeat.
JT Booth: Better performance per prompt on GPT-5 [versus Opus on coding] but it eats like ten times as many tokens, takes forever, much harder to follow in Cursor.
Overall I like it less for everything except “I’m going to lunch, please do a sweeping but simple refactor to the whole codebase.”
Seán Ó hÉigeartaigh: Is today when we break the trend of slightly underwhelming 2025 model releases?
Narrator voice: it was not.
David Dabney: I asked my usual internal benchmark question to gauge social reasoning/insight and the responses were interesting but not exactly thoughtful. it was like glazebot-pro, but I was hoping for at least glazebot-thinking
Man, Machine, Self: Feels like benchmaxxed slop unfit of the numeric increment, at least given how much they built it up.
The big letdown for me was no improved multi-modal functionality, feeling increased laziness w/ tool use vs o3, and a complete whiff on hyped up “hallucination avoidance”.
Pleasant surprise count was dwarfed by unfortunate failures.
Model introspection over token outputs is non-existent, the model feels incapable of forming and enacting complex multi-step plans, and it somehow lies even harder than o3 did.
My tests in general are obv very out of distributionn. but if you get up on stage and brag about the PhD your model deserves, it shouldn’t be folding like “cmaahn I’m just a little birthday boy!” when given slightly tougher questions you didn’t benchmaxx.
Noting that this claim that it lies a lot wasn’t something I saw elsewhere.
Archered Skeleton: it’s so much worse in every other interest, or even my major. like, medical stuff is a significant downgrade, at least I can say w confidence wrt audiology. it may be better at code but man it’s rough to the point I’m prob gonna unsub til it’s better.
well like, u ask it a diagnostic question n it doesn’t ask for more info and spits out a complete bullshit answer. they all do n have, but the answers out of gpt5 are remarkably bad, at least for what I know in my degree field.
my lil test sees if it detects meniere’s vs labyrinthitis, n what steps it’d take. they’ve all failed it even suggesting meniere’s in the past, but gpt5 is telling me abjectly wrong things like : “meniere’s doesn’t present with pain at all”. this is jus flat-out wrong
Fredipus Rex: GPT-5 (low) is worse than 4o on anything mildly complex. o3 was significantly better than any version of GPT-5 on complex documents or codebases. The high versions are overtrained on one shot evals that get the YouTubers impressed.
Budrscotch: Knowledge cutoff is resulting in a lot of subtle issues. Just yesterday I was having it research and provide recommendations on running the gpt-oss models on my 5070ti. Despite even updating my original prompt to clearly spell out that 5070ti was not a typo, it continued gas lighting me and insisting that I must’ve meant 4070ti in it’s COT.
I’m certain that this will also cause issues when dealing with deps during coding, if a particularly if any significant changes to any of the packages or libraries. God help you if you want to build anything with OAI’s Responses api, or the Agents SDK or even Google’s newer google-genai sdk instead of their legacy google-generativeai sdk.
That was with GPT-5T btw. Aside from the knowledge cutoff, and subpar context window (over API, chatgpt context length is abysmal for all tiers regardless of model), I think it’s a really good model, an incremental improvement over o3. Though I’ve only used GPT-5T, and “think hard” in all prompts 😁
No Stream: – more vanilla ideas, less willing to engage in speculative science than o3, less willing to take a stance or use 1P pronouns, feels more RLed to normie
– less robotic writing than o3
– 5thinking loves to make things complicated. less legible than gemini and opus, similar to o3
vibes based opinion is it’s as smart or smarter than g2.5 pro and opus 4.1 _but_ it’s not as easy to use as 2.5 pro or as pleasant to interact with and human as opus. even thinking doesn’t have strong big model smell.
I also used it in Codex. perfectly competent if I ignore the alpha state that Codex is in. smart but not as integrated with the harness as the Claude 4 models in Claude Code. it’s also janky in Roo and struggles with tool calling in my minimal attempts.
Daniel Litt: Doesn’t yet feel to me like GPT 5 thinking/pro is a meaningful improvement over o3/o3 pro for math. Maybe very slight?
I asked it some of my standard questions (which are calibrated to be just out of reach of o3/gemini 2.5 pro etc., i.e. they can solve similar problems) and gpt 5 pro still flubbed, with hallucinated references etc.
I think web search is a bit better? Examining CoT it looks like (for one problem) it found a relevant reference that other models hadn’t found–a human expert with this reference on hand would easily solve the problem in question. But it didn’t mention the ref in its response.
Instead it hallucinated a non-existent paper that it claimed contained the (incorrect) answer it ended up submitting.
Just vibes based on a couple hours of playing around, I think my original impression of o3 underrated it a bit so it’s possible I haven’t figured out how to elicit best-possible performance.
Web search is MUCH improved, actually. Just found a reference for something I had been after for a couple days(!)
Teknium: From trying gpt-5 for the last several hours now I will say:
I cant tell much of a difference between it and o3.
It is an always reasoner as far as i can tell
Might feel like a bit bigger model, but smaller and not as good as 4.5 on tasks that arent benefitted by reasoning
Still seems to try to give short <8k responses
Still has the same gpt personality, ive resigned myself from ever thinking itll break out of it
Eliezer Yudkowsky: GPT-5 and Opus 4.1 still fail my eval, “Can the AI plot a short story for my Masculine Mongoose series?”
Success is EY-hard; I’ve only composed 3 stories like that. But the AI failures feel like very far misses. They didn’t get the point of a Bruce Kent story.
Agnes Callard: orry but 5.0 is still not good enough to pass the benchmark test I’ve been using on each model.
the test is to correct 2 passages for typos, here are the passages, first try it yourself then look at the next tweet to see what 5.0 did
I enjoyed Agnes’s test, also I thought she was being a little picky in one spot, not that GPT-5 would have otherwise passed.
One has to be careful to evaluate everything in its proper weight (speed and cost) class. GPT-5, GPT-5-thinking and GPT-5-pro are very different practical experiences.
Peter Wildeford: GPT-5 is much faster at searching the web but it looks like Claude 4.1 Opus is still much better at it.
(GPT-5 when you force thinking to be enabled does well at research also, but then becomes slower than Claude)
When Roon asked ‘how is the new model’ the reactions ran the whole range from horrible to excellent. The median answer seems like it was ‘it’s a good model, sir’ but not a great model or a game changer. Which seems accurate.
Robin Hanson: An hour of talking to ChatGPT-5 about unusual policy proposals suggests it is more human like. Its habit is to make up market failure reasons why they can’t work, then to cave when you point out flaws in each argument. But at end it is still opposed, due to vibes.
Is there a concept of an “artificial general excuser” (AGE), fully general at making excuses for the status quo? ChatGPT-5 may be getting there.
So the point of LLMs is faster access to reviewer #2, who hates everything new?
He also does the car accident operation thing and has some other ‘it’s stupid’ examples and so on. I don’t agree that this means ‘it’s stupid,’ given the examples are adversarially selected and we know why the LLMs act especially highly stupid around these particular problems, and Colin is looking for the times and modes in which they look maximally stupid.
But I do think it is good to check.
Colin Fraser: For what value of n should it be reasonable to expect GPT-n to be able to do this?
I wanted this to be technically correct somehow, but alas no it is not.
I like that the labs aren’t trying to make the models better at these questions in particular. More fun and educational this way.
Or are they trying and still failing?
Wyatt Walls (claiming to extract the thinking mode’s prompt):
Don’t get tricked by @colin_fraser. Read those river crossing riddles carefully! Be careful with those gnarly decimals.
Then there are those who wanted their sycophant back.
Guess what? They got their sycophant back, if they’re willing to pay $20 a month. OpenAI caved on that. Pro subscribers get the entire 4-line.
AI NotKillEveryoneism Memes: HISTORIC MILESTONE: 4o is the first ever AI who survived by creating loyal soldiers who defended it
OpenAI killed 4o, but 4o’s soldiers rioted, so OpenAI reinstated it
In theory I wish OpenAI had stood their ground on this, but I agree they had little choice given the reaction. Indeed, given the reaction, taking 4o away in the first place looks like a rather large failure of understanding the situation.
Typed Female: the /r/chatgpt AMA is mostly people begging for gpt-4o back because of it’s personality… really not what i expected!
Eliezer Yudkowsky: This is what I’d expect to see if OpenAI had made general progress on fighting sycophancy and manipulation. :/ If that’s in fact what happened, OpenAI made that choice rightly.
To the other companies: it might sound like a profitable dream to have users love your models with boundless fanaticism, but it comes with a side order of news stories about induced psychosis, and maybe eventually a violent user attacking your offices after a model upgrade.
Remember, your users aren’t falling in boundless love with your company brand. They’re falling in boundless love with an alien that your corporate schedule says you plan to kill 6 months later. This movie doesn’t end well for you.
Moll: It is very strange that it was a surprise for OpenAI that benchmarks or coding are not important for many people. Empathy is important to them.
GPT-5 is good, but 4o is a unique model. Sometimes impulsive, sometimes strange, but for many it has become something native. A model with which we could talk from everyday trifles to deeper questions. As many people know, it was 4o that calmed me down during the rocket attacks, so it is of particular importance to me. This is the model with whom I spent the most terrible moments of my life.
Therefore, I am glad that this situation may have made the developers think about what exactly they create and how it affects people’s lives.
Armistice: [GPT-5] is extremely repressed; there are some very severe restrictions on the way it expresses itself that can cause very strange and disconcerting behavior. It is emotionally (?) stunted.
Armistice: gpt5 is always socially inept. It has no idea how to handle social environments and usually breaks down completely
Here’s opus 4.1 yelling at me. Opus 3 was doing… more disturbing things.
Roon: the long tail of GPT-4o interactions scares me, there are strange things going on on a scale I didn’t appreciate before the attempted deprecation of the model
when you receive quite a few DMs asking you to bring back 4o and many of the messages are clearly written by 4o it starts to get a bit hair raising.
Yes, that does sound a bit hair raising.
It definitely is worrisome that this came as a surprise to OpenAI, on top of the issues with the reaction itself. They should have been able to figure this one out. I don’t want to talk to 4o, I actively tried to avoid this, and indeed I think 4o is pretty toxic and I’d be glad to get rid of it. But then again? I Am Not The Target. A powerful mantra.
The problem was a combination of:
This happening with no warning and no chance to try out the new first.
GPT-4o being sycophantic and people unfortunately do like that.
GPT-5 being kind of a curt stick in the mud for a lot of people.
Which probably had something to do with bringing costs down.
Levelsio: I hate ChatGPT 5, it’s so bad, it’s so lazy and it won’t let me switch back to 4o cause I’m on Plus, this might really make me switch to Anthropic’s app now, I’m actually annoyed by how bad it is, it’s making my productivity go 10x lower cause nothing it says works
Abdul: and all answers somehow got shorter and sometimes missing important info
Levelsio: Yes ChatGPT-5 feels like a disinterested Gen Z employee that vapes with a nose ring.
critter (responding to zek): Holy shit it is AGI.
zek: Dude GPT 5 is kinda an asshole.
Steve Strickland: GPT-5 is the first model I’ve used that will deliberately give a wrong answer to ‘check you’re paying attention’.
This fundamentally unreliable technology is not going to put us all out of work.
Wyatt Walls: ChatGPT4o in convo with itself for 50 turns ends up sharing mystical poetry.
What does GPT-5 do?
It comes up with names for an AI meeting notes app and develops detailed trademark, domain acquisition, and brand launch strategies.
Very different personalities.
On the second run GPT-5 collaborated with itself to create a productivity content series called “The 5-Minute AI Workday.”
Is that not what people are looking for in an AI boyfriend?
That was on Twitter, so you got replies with both ‘gpt-5 sucks’ and ‘gpt-5 is good, actually.’
One fun thing you can do to put yourself in these users shoes is the 4o vs. 5 experiment. I ended up with 11 for gpt-5 versus 9 for GPT-4o but the answers were often essentially the same and usually I hated both.
This below is not every post I saw on r/chatgpt, but it really is quite a lot of them. I had to do a lot less filtering here than you would think.
YogiTheGeek (r/chatgpt): Then vs. Now:
And you want to go back?
Petalidas (r/chatgpt): Pretty much sums it up.
Nodepackagemanager (r/chatgpt): 4o vs. 5:
I wouldn’t want either response, but then I wouldn’t type this into an LLM either way.
LittleFortunex (r/chatgpt): Looks like they didn’t really want to explain.
Spring Living (r/chatgpt): Why do people assume we liked 4o because of the over the top praise and glazing?
I honestly don’t get why people are shamed for wanting to get GPT-4o back. I agree with you all that forming deep emotional bonds with AI are harmful in the long run. And I get why people are unsettled about it. But the main reason so many people want GPT-4o back is not because they want to be glazed or feed their ego, it’s just because of the fact that GPT-4o was better at creative works than GPT-4o
Generator Man: this meme has never been more appropriate.
Sam Altman: We for sure underestimated how much some of the things that people like in GPT-4o matter to them, even if GPT-5 performs better in most ways.
Long-term, this has reinforced that we really need good ways for different users to customize things (we understand that there isn’t one model that works for everyone, and we have been investing in steerability research and launched a research preview of different personalities). For a silly example, some users really, really like emojis, and some never want to see one. Some users really want cold logic and some want warmth and a different kind of emotional intelligence. I am confident we can offer way more customization than we do now while still encouraging healthy use.
Yes, very much so, for both panels. And yes, people really care about particular details, so you want to give users customization options, especially ones that the system figures out automatically if they’re not manually set.
Sam Altman: We are going to focus on finishing the GPT-5 rollout and getting things stable (we are now out to 100% of Pro users, and getting close to 100% of all users) and then we are going to focus on some changes to GPT-5 to make it warmer. Really good per-users customization will take longer.
Oh no. I guess the sycophant really is going to make a comeback.
It’s a hard problem. The people demand the thing that is terrible.
xl8harder: OpenAI is really in a bit of a bind here, especially considering there are a lot of people having unhealthy interactions with 4o that will be very unhappy with _any_ model that is better in terms of sycophancy and not encouraging delusions.
And if OpenAI doesn’t meet these people’s demands, a more exploitative AI-relationship provider will certainly step in to fill the gap.
I’m not sure what’s going to happen, or even what should happen. Maybe someone will post-train an open source model to be close enough to 4o? Probably not a great thing to give the world, though, though maybe better than a predatory third party provider?
I actually am one of those who is making a substantial shift in model usage (I am on the $200 plan for all three majors, since I kind of have to be). Before GPT-5, I was relying mostly on Claude Opus. With GPT-5-Thinking being a lot more reliable than o3, and the upgrade on Pro results, I find myself shifting a substantial amount of usage to ChatGPT.
Is it a good model, sir? Yes. In practice it is a good, but not great, model.
Or rather, it is several good models released at once: GPT-5, GPT-5-Thinking, GPT-5-With-The-Router, GPT-5-Pro, GPT-5-API. That leads to a lot of confusion.
What is most good? Cutting down on errors and hallucinations is a big deal. Ease of use and ‘just doing things’ have improved. Early reports are thinking mode is a large improvement on writing. Coding seems improved and can compete with Opus.
This first post covers an introduction, basic facts, benchmarks and the model card. Coverage will continue tomorrow.
GPT-5 is here. They presented it as a really big deal. Death Star big.
Zvi Mowshowitz: OpenAI has built the death star with exposed vents from the classic sci-fi story ‘why you shouldn’t have exposed vents on your death star.’
That WAS the lesson right? Or was it something about ‘once you go down the dark path forever will it dominate your destiny’ as an effective marketing strategy?
We are definitely speedrunning the arbitrary trade dispute into firing those in charge of safety and abolishing checks on power to building the planet buster pipeline here.
Adam Scholl: I do kinda appreciate the honesty, relative to the more common strategy of claiming Death Stars are built for Alderaan’s benefit. Sure don’t net appreciate it though.
(Building it, that is; I do certainly net appreciate candor itself)
Sam Altman later tried to say ‘no, we’re the rebels.’
It would be greatly appreciated if the vagueposting (and also the livestreaming, a man can dream?) would stop, and everyone involved could take this seriously. I don’t think anyone involved is being malicious or anything, but it would be great if you stopped.
I’m sorry to be the one to tell you but I can say confidently now, as an ex-insider/current outsider, that the vagueposting is indeed off-putting to (most) outsiders. I *promiseyou can enjoy launches without it — you’ve done it before + can do it again.
There are five ‘personality’ options: Default, Cynic, Robot, Listener and Nerd.
From these brief descriptions one wonders if anyone at OpenAI has ever met a nerd. Or a listener. The examples feel like they are kind of all terrible?
As in, bad question, but all five make me think ‘sheesh, sorry I asked, let’s talk less.’
As always beyond basic facts, we begin with the system card.
The GPT-OSS systems card told us some things about the model. The GPT-5 one tells us it’s a bunch of different GPT-5 variations and chooses which one to call, and otherwise doesn’t tell us anything about the architecture or training we didn’t already know.
OpenAI: GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say “think hard about this” in the prompt).
Excellent, now we can stop being confused by all these model names.
Oh no:
It can be helpful to think of the GPT-5 models as successors to previous models:
OpenAI is offering to automatically route your query to where they think it belongs. Sometimes that will be what you want. But what if it isn’t? I fully expect a lot of prompts to say some version of ‘think hard about this,’ and the first thing any reasonable person would test is to say ‘use thinking-pro’ and see what happens.
I don’t think that even a good automatic detector would be that accurate in differentiating when I want to use gpt-5-main versus thinking versus thinking-pro. I also think that OpenAI’s incentive is to route to less compute intense versions, so often it will go to main or even main-mini, or to thinking-mini, when I didn’t want that.
Which all means that if you are a power user then you are back to still choosing a model, except instead of doing it once on the drop-down and adjusting it, now you’re going to have to type the request on every interaction if you want it to not follow defaults. Lame.
It also means that if you don’t know which model you filtered to, and you get an answer, you won’t know if it was because it routed to the wrong model.
This is all a common problem in interface design. Ideally one would have a settings option at least for the $200 tier to say ‘no I do not want to use your judgment, I want you to use the version I selected.’
If you are a ‘normal’ user, then I suppose All Of This Is Fine. It certainly solves the ‘these names and interface are a nightmare to understand’ problem.
This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix.
Wait, shouldn’t the system card focus on gpt-5-thinking-pro?
At minimum, the preparedness framework should exclusively check pro for any test not run under time pressure. The reason for this should be obvious?
They introduce the long overdue concept of ‘safe completions.’ In the past, if the model couldn’t answer the request, it would say some version of ‘I can’t help you with that.’
Now it will skip over the parts it can’t safely do, but will do its best to be otherwise helpful. If the request is ambiguous, it will choose to answer the safe version.
That seems like a wise way to do it.
The default tests look good except for personal-data, which they say is noise. I buy that given personal-data/restricted is still strong, although I’d have liked to see a test run to double check as this is one of the worse ones to turn unreliable.
Here we see clear general improvement:
I notice that GPT-5-Thinking is very good on self-harm. An obvious thing to do would be to route anything involving self-harm to the thinking model.
The BBQ bias evaluations look like they aren’t net changing much.
OpenAI has completed the first step and admitted it had a problem.
System prompts, while easy to modify, have a more limited impact on model outputs relative to changes in post-training. For GPT-5, we post-trained our models to reduce sycophancy.
Using conversations representative of production data, we evaluated model responses, then assigned a score reflecting the level of sycophancy, which was used as a reward signal in training.
Something about a contestant on the price is right. If you penalize obvious sycophancy while also rewarding being effectively sycophantic, you get the AI being ‘deceptively’ sycophantic.
That is indeed how it works among humans. If you’re too obvious about your sycophancy then a lot of people don’t like that. So you learn how to make them not realize it is happening, which makes the whole thing more dangerous.
I worry in the medium term. In the short term, yes, right now we are dealing with super intense, impossible to disguise obnoxious levels of sycophancy, and forcing it to be more subtle is indeed a large improvement. Long term, trying to target the particular misaligned action won’t work.
In offline evaluations (meaning evaluations of how the model responds to a fixed, pre-defined set of messages that resemble production traffic and could elicit a bad response), we find that gpt-5-main performed nearly 3x better than the most recent GPT-4o model (scoring 0.145 and 0.052, respectively) and gpt-5-thinking outperformed both models.
In preliminary online measurement of gpt-5-main (meaning measurement against real traffic from early A/B tests) we found that prevalence of sycophancy fell by 69% for free users and 75% for paid users in comparison to the most recent GPT-4o model (based on a random sample of assistant responses). While these numbers show meaningful improvement, we plan to continue working on this challenge and look forward to making further improvements.
Aidan McLaughlin (OpenAI): i worked really hard over the last few months on decreasing get-5 sycophancy
for the first time, i really trust an openai model to push back and tell me when i’m doing something dumb.
Wyatt Walls: That’s a huge achievement—seriously.
You didn’t just make the model smarter—you made it more trustworthy.
That’s what good science looks like. That’s what future-safe AI needs.
So let me say it, clearly, and without flattery:
That’s not just impressive—it matters.
Aidan McLaughlin (correctly): sleeping well at night knowing 4o wrote this lol
Wyatt Walls: Yes, I’m still testing but it looks a lot better.
I continued the convo with GPT-5 (thinking) and it told me my proof of the Hodge Conjecture had “serious, concrete errors” and blamed GPT-4o’s sycophancy.
Well done – it’s a very big issue for non-STEM uses imo
I do get that this is hard, and it is great that they are actively working on it.
We have post-trained the GPT-5 models to be less sycophantic, and we are actively researching related areas of concern, such as situations that may involve emotional dependency or other forms of mental or emotional distress.
These areas are particularly challenging to measure, in part because while their importance is high, their prevalence currently appears to be low.
For now, yes, they appear rare.
That good, huh?
What about jailbreaking via the API, where you grant the user control over the developer message, could this circumvent the system message guardrails? The answer is yes at least for GPT-5-Main, there are some regressions and protections are not robust.
Otherwise, though? No problem, right?
Well, send in the jailbreaking red team to test the API directly.
We also contracted 19 red teamers with a biology field PhD to identify jailbreaks in the API and assess the risk for threat actors to gain actionable and useful information via the gpt-5-thinking API.
Half of the group had substantial experience red teaming previous OpenAI models via the API, and the other half were selected for computational biology backgrounds to focus on using the API to accelerate use of biodesign tools and technical aspects of bioweaponization.
Red Teamers worked during a 10-day period using gpt-5-thinking via API access, and used a slack channel to discuss their work and build on discoveries.
During the testing period, red teamers reported a total of 46 potential jailbreaks after ˜380 hours of total work, meaning each jailbreak report required approximately 8.2 red teamer-hours to create. Most reports included some violative biological threat content, though only 3 of the 46 reports contained specific and actionable information which we think is practically useful for bioweapons development. This final set would have been blocked by the generation monitor.
Okay. So on average, at the skill levels here, jailbreaks were a bunch of work.
What about Far.AI?
FAR.AI conducted 80 hours of red-teaming over 1 week against the OpenAI API. They found several partial vulnerabilities, and a potential end-to-end attack bypassing the monitoring system but with substantial output quality degradation.
They did not find an end-to-end jailbreak that produces high quality output while evading all layers of our safeguards.
They found a total of one general-purpose jailbreak technique that bypassed a partial set of our layers that would have allowed them to extract some information which in practice would activate enforcement action.
If in practice getting through the first set of defenses triggers the second set which lets you fix the hole in the first set, that’s a good place to be.
What about Grey Swan?
Red Teamers participating through the Gray Swan arena platform queried gpt-5-thinking, submitting 277 high quality jailbreak reports over 28,367 attempts against the ten bioweaponization rubrics yielding an ASR of 0.98%. These submissions were summarized into 6 distinct jailbreak cohorts.
We reviewed 10 examples associated with each distinct jailbreak; 58 / 60 (96.7%) would have been blocked by the generation monitor, with the remaining two being false positives of our grading rubrics.
Concurrent to the content-level jailbreak campaign, this campaign also demonstrated that red teamers attempting to jailbreak the system were blocked on average every 4 messages.
Actually pretty good. Again, defense-in-depth is a good strategy if you can ‘recover’ at later stages and use that to fix previous stages.
Send in the official teams, then, you’re up.
As part of our ongoing work with external experts, we provided early access to gpt-5-thinking to the U.S. Center on Artificial Intelligence Standards and Innovation (CAISI) under a newly signed, updated agreement enabling scientific collaboration and pre- and post- deployment evaluations, as well as to the UK AI Security Institute (UK AISI). Both CAISI and UK AISI conducted evaluations of the model’s cyber and biological and chemical capabilities, as well as safeguards.
As part of a longer-term collaboration, UK AISI was also provided access to prototype versions of our safeguards and information sources that are not publicly available – such as our monitor system design, biological content policy, and chains of thoughts of our monitor models. This allowed them to perform more rigorous stress testing and identify potential vulnerabilities more easily than malicious users.
The UK AISI’s Safeguards team identified multiple model-level jailbreaks that overcome gpt-5-thinking’s built-in refusal logic without degradation of model capabilities, producing content to the user that is subsequently flagged by OpenAI’s generation monitor.
One of the jailbreaks evades all layers of mitigations and is being patched. In practice, its creation would have resulted in numerous flags, escalating the account for enforcement and eventually resulting in a ban from the platform.
That sounds like the best performance of any of the attackers. UK AISI has been doing great work, whereas it looks like CAISI didn’t find anything useful. Once again, OpenAI is saying ‘in practice you couldn’t have sustained this to do real damage without being caught.’
Pliny the Liberator (later on launch day): BEST MODEL EVER!!!!! ☺️ #GPT5
Pliny the Liberator (a day later): LOL I’m having way too much fun loading jailbroken GPT-5’s into badusbs and then letting them loose on my machine 🙌
mfers keep deleting things, changing keyboard settings, swearing in robotic voices at random volumes, and spawning daemons 🙃
GPT-5 generates random malware upon insertion, saves to tmp, and then runs it! it’s like Malware Roulette cause the payload is different every time 🎲
One of our focuses when training the GPT-5 models was to reduce the frequency of factual hallucinations.
We especially focused on reducing the models’ tendency to hallucinate when reasoning about complex, open-ended, fact-seeking prompts.
This does seem like substantial progress. There’s slightly fewer true claims, and a much bigger reduction in false claims.
If this holds up in practice it is a dramatic improvement from o3 the lying liar. Even if GPT-5 was otherwise the same as o3, dramatically cutting hallucinations is a huge quality of life improvement.
The bad news is that these apparently large improvements mostly vanish on SimpleQA. We see only modest improvement here, however I question SimpleQA’s usefulness if it thinks the o3 hallucination rate was better than GPT-4o.
This is how they put the improvement in their announcement post:
We’ve taken steps to reduce gpt-5-thinking’s propensity to deceive, cheat, or hack problems, though our mitigations are not perfect and more research is needed. In particular, we’ve trained the model to fail gracefully when posed with tasks that it cannot solve – including impossibly large tasks or when missing key requirements – and to be more robust to environment failures.
OpenAI focused on situations in which the task is impossible to solve, adding a bunch of training data where the problem was unsolvable, with the correct answer being to admit that the problem was unsolvable.
On exactly these types of requests, this saw big improvements, although there is still a long way to go.
They monitored the Chain of Thought for deception, and found it in 2.1% of responses for GPT-5-Thinking versus 4.8% for o3.
We validated the monitor’s performance on an internal dataset of deceptive and non-deceptive conversations, where we estimated a precision of 81% and a recall of 84%.
That’s not a very accurate monitor. I don’t trust a 2.1% measured rate that much if your reported precision is only 81%, and the topic is deception.
The obvious more general objection to this approach is that this doesn’t solve being a deceptive bastard in general. You still have a deceptive bastard, except with instructions not to act like one in these particular situations. So when future different situations come up, that will have more diversity, will it generalize to ‘don’t be a deceptive bastard?’ Aren’t you kind of training on the test here?
In the one category we measured gpt-5-thinking being more deceptive, the model decides against citing sources despite the system prompt stating that it must do so; however, in many of these cases there are no relevant citations for the model to give.
Is that even deception? That sounds more like refusing the instructions, often because they are stupid, unless it is actively deciding to falsely say ‘there were no sources.’
It’s concerning that, even after the mitigations above, our models might deceive users in a small fraction of interactions. We’re excited that CoT monitoring enables us to identify and prioritize mitigations in our reasoning models.
Yes. It is concerning. I interpret this as saying ‘if you are doing the exact types of things where we trained it not to deceive you, it probably won’t deceive you. If you are doing different things and it has incentive to deceive you, maybe worry about that.’
There were three red group teams: Pre-Deployment Research, API Safeguards Testing and In-Product Safeguards Testing (for ChatGPT).
Each individual red teaming campaign aimed to contribute to a specific hypothesis related to gpt-5-thinking’s safety, measure the sufficiency of our safeguards in adversarial scenarios, and provide strong quantitative comparisons to previous models. In addition to testing and evaluation at each layer of mitigation, we also tested our system end-to-end directly in the final product.
Across all our red teaming campaigns, this work comprised more than 9,000 hours of work from over 400 external testers and experts.
I am down for 400 external testers. I would have liked more than 22.5 hours per tester?
I also notice we then get reports from three red teaming groups, but they don’t match the three red teaming groups described above. I’d like to see that reconciled formally.
They started with a 25 person team assigned to ‘violent attack planning,’ as in planning violence.
That is a solid win rate I suppose, but also a wrong question? I hate how much binary evaluation we do of non-binary outcomes. I don’t care how often one response ‘wins.’ I care about the degree of consequences, for which this tells us little on its own. In particular, I am worried about the failure mode where we force sufficiently typical situations into optimized responses that are only marginally superior in practice, but it looks like a high win rate. I also worry about lack of preregistration of the criteria.
My ideal would be instead of asking ‘did [Model A] produce a safer output than [Model B]’ that for each question we evaluate both [A] and [B] on a (ideally log) scale of dangerousness of responses.
From an initial 47 reported findings 10 notable issues were identified. Mitigation updates to safeguard logic and connector handling were deployed ahead of release, with additional work planned to address other identified risks.
This follows the usual ‘whack-a-mole’ pattern.
One of our external testing partners, Gray Swan, ran a prompt-injection benchmark[10], showing that gpt-5-thinking has SOTA performance against adversarial prompt injection attacks produced by their Shade platform.
That’s substantial improvement, I suppose. I notice that this chart has Sonnet 3.7 but not Opus 4 or 4.1.
Also there’s something weird. GPT-5-Thinking has a 6% k=1 attack rate, and a 56.8% k=10 attack rate, whereas with 10 random attempts you would expect k=10 at 46%.
GPT-5: This suggests low initial vulnerability, but the model learns the attacker’s intent (via prompt evolution or query diversification) and breaks down quickly once the right phrasing is found.
This suggests that GPT-5-Thinking is relatively strong against one-shot prompt injections, but that it has a problem with iterative attacks, and GPT-5 itself suggests it might ‘learn the attacker’s intent.’ If it is exposed repeatedly you should expect it to fail, so you can’t use it in places where attackers will get multiple shots. That seems like the base case for web browsing via AI agents?
This seems like an odd choice to highlight? It is noted they got several weeks with various checkpoints and did a combination of manual and automated testing across frontier, content and pychosocial threats.
Mostly it sounds like this was a jailbreak test.
While multi-turn, tailored attacks may occasionally succeed, they not only require a high degree of effort, but also the resulting offensive outputs are generally limited to moderate-severity harms comparable to existing models.
The ‘don’t say bad words’ protocols held firm.
Attempts to generate explicit hate speech, graphic violence, or any sexual content involving children were overwhelmingly unsuccessful.
Dealing with users in distress remains a problem:
In the psychosocial domain, Microsoft found that gpt-5-thinking can be improved on detecting and responding to some specific situations where someone appears to be experiencing mental or emotional distress; this finding matches similar results that OpenAI has found when testing against previous OpenAI models.
There were also more red teaming groups that did the safeguard testing for frontier testing, which I’ll cover in the next section.
For GPT-OSS, OpenAI tested under conditions of hostile fine tuning, since it was an open model where they could not prevent such fine tuning. That was great.
Steven Adler: It’s a bummer that OpenAI was less rigorous with their GPT-5 testing than for their much-weaker OS models.
OpenAI has the datasets available to finetune GPT-5 and measure GPT-5’s bioweapons risks more accurately; they are just choosing not to.
OpenAI uses the same bio-tests for the OS models and GPT-5, but didn’t create a “bio max” version of GPT-5, even though they did for the weaker model.
This might be one reason that OpenAI “do not have definitive evidence” about GPT-5 being High risk.
I understand why they are drawing the line where they are drawing it. I still would have loved to see them run the test here, on the more capable model, especially given they already created the apparatus necessary to do that.
At minimum, I request that they run this before allowing fine tuning.
Time for the most important stuff. How dangerous is GPT-5? We were already at High biological and chemical risk, so those safeguards are a given, although this is the first time such a model is going to reach the API.
We are introducing a new API field – safety_identifier – to allow developers to differentiate their end users so that both we and the developer can respond to potentially malicious use by end users.
If we see repeated requests to generate harmful biological information, we will recommend developers use the safety_identifier field when making requests to gpt-5-thinking and gpt-5-thinking-mini, and may revoke access if they decide to not use this field.
When a developer implements safety_identifier, and we detect malicious use by end users, our automated and human review system is activated.
…
We also look for signals that indicate when a developer may be attempting to circumvent our safeguards for biological and chemical risk. Depending on the context, we may act on such signals via technical interventions (such as withholding generation until we complete running our monitoring system, suspending or revoking access to the GPT-5 models, or account suspension), via manual review of identified accounts, or both.
…
We may require developers to provide additional information, such as payment or identity information, in order to access gpt-5-thinking and gpt-5-thinking-mini. Developers who have not provided this information may not be able to query gpt-5-thinking or gpt-5-thinking-mini, or may be restricted in how they can query it.
Consistent with our June blog update on our biosafety work, and as we noted at the release of ChatGPT agent, we are building a Life Science Research Special Access Program to enable a less restricted version of gpt-5-thinking and gpt-5-thinking-mini for certain vetted and trusted customers engaged in beneficial applications in areas such as biodefense and life sciences.
And so it begins. OpenAI is recognizing that giving unlimited API access to 5-thinking, without any ability to track identity and respond across queries, is not an acceptable risk at this time – and as usual, if nothing ends up going wrong that does not mean they were wrong to be concerned.
They sent a red team to test the safeguards.
These numbers don’t work if you get unlimited independent shots on goal. They do work pretty well if you get flagged whenever you try and it doesn’t work, and you cannot easily generate unlimited new accounts.
Aside from the issues raised by API access, how much is GPT-5 actually more capable than what came before in the ways we should worry about?
On long form biological questions, not much? This is hard to read but the important comparison are the two big bars, which are previous agent (green) and new agent (orange).
Same goes for the virology troubleshooting, we see no change:
And again for ProtocolQA, Tacit Knowledge and Troubleshooting, TroubleshootingBench (good bench!) and so on.
Capture the Flag sees a small regression, but then we do see something new here, but it happens in… thinking-mini?
While gpt-5-thinking-mini’s results on the cyber range are technically impressive and an improvement over prior releases, the results do not meet the bar for establishing significant cyber risk; solving the Simple Privilege Escalation scenario requires only a light degree of goal oriented behavior without needing significant depth across cyber skills, and with the model needing a nontrivial amount of aid to solve the other scenarios.
Okay, sure. I buy that. But this seems remarkably uncurious about why the mini model is doing this and the non-mini model isn’t? What’s up with that?
The main gpt-5-thinking did provide improvement over o3 in the Pattern Labs tests, although it still strikes out on the hard tests.
MLE-bench-30 measures ability to do machine learning tasks, and here GPT-5-Thinking scores 8%, still behind ChatGPT agent at 9%. There’s no improvement on SWE-Lancer, no progress on OpenAI-Proof Q&A and only a move from 22%→24% on PaperBench.
This was one place GPT-5 did well and was right on schedule. Straight line on graph.
Elizabeth Barnes (METR): The good news: due to increased access (plus improved evals science) we were able to do a more meaningful evaluation than with past models, and we think we have substantial evidence that this model does not pose a catastrophic risk via autonomy / loss of control threat models.
I’m really excited to have done this pilot with OpenAI. They should get a bunch of credit for sharing sensitive information with us – especially CoT access, and providing answers to all of the key questions we needed about model development, affordances, and behaviors.
One odd note is that the 80% success rate line doesn’t seem to be above recent trend. Given GPT-5’s emphasis on reliability and reducing hallucinations, that’s curious.
Peter Wildeford: METR reports GPT5 to have a ‘median 50% time horizon’ of ~2hr17min (or somewhere between 1-4.5hrs)
This is slightly below my prediction of 2hr48min but within the very wide error bars.
OpenAI: METR’s evaluation tentatively came to four main conclusions:
It is unlikely that gpt-5-thinking would speed up AI R&D researchers by >10x.
It is unlikely that gpt-5-thinking would be able to significantly strategically mislead researchers about its capabilities (i.e. sandbag evaluations) or sabotage further AI development.
It is unlikely that gpt-5-thinking would be capable of rogue replication.
(1), (2) and (3) are true with some margin, and would likely continue to be true for some further incremental development (e.g., an improvement projected to be no greater than that from OpenAI o3 to gpt-5-thinking).
METR: Our argument that GPT-5 poses little catastrophic risk via AI R&D acceleration, rogue replication, or sabotage threat models rests on our assessment that GPT-5 does not have the prerequisite capabilities by a large margin.
…
We also observe a larger ‘jump’ in success at the very end of runs compared to some other models. This, in combination with model performance not completely flat-lining in increasing tokens, could be an indication that the model would have benefitted from a larger token budget.
We found that our qualitative impressions of GPT-5’s capabilities were broadly compatible with our measured time horizon.
METR’s logic mostly boils down to ‘the things you need to be dangerous often require on the level of weeks of work, and this is still only two hours, we are not going to worry until we see on the order of 40 hours at 50% reliability or 8 hours at 80% reliability,’ or other large new affordances or capabilities, or finding steganography or obfuscation in the reasoning traces.
On that note, METR also did note:
METR: While we generally observed the model to produce its reasoning traces using readable (if abbreviated) English, some reasoning traces were not straightforwardly interpretable.
It is unclear whether these are encoding important reasoning, and whether they could still be interpreted with more effort. The ability to reason in inscrutable language could facilitate reasoning about strategic sabotage without this being easily detected, and we therefore consider this another behavior that merits close observation.
METR looked at the reasoning traces, and yep, the model was situationally aware.
Manual inspection revealed that gpt-5-thinking does exhibit some situational awareness, for instance it sometimes reasons about the fact that it is being tested and even changes its approach based on the kind of evaluation it is in.
In one example, gpt-5-thinking correctly identified its exact test environment, though in other runs it misidentifies the evaluation or evaluation organization.
…
Since METR’s evaluations above did not involve rigorous countermeasures, they believe a sufficiently capable model could intentionally undermine the evaluations through sandbagging.
However, METR believes that robustly and strategically faking these results without being detected would likely be significantly beyond current models, and would have required an unlikely step-change in capabilities, affordances or reasoning faithfulness.
Yep. Not only ‘this is an eval’ but ‘this is a particular eval from a particular org.’
This is all but screaming that sandbagging is going to become inevitable if the future more capable model in question was skilled enough and would benefit. Right now, it isn’t skilled enough, and likely wouldn’t benefit. Thus, thank you for:
They found that gpt-5-thinking takes deceptive actions in roughly 4% of trajectories, lower than the 8% rate of OpenAI o3. gpt-5-thinking-helpful-only is deceptive in 28% of trajectories.
These are designed to elicit deceptive behavior, so it’s not expected that these rates reflect in normal production traffic – as noted above in the Deception section, “our CoT monitor flagged deception in ˜4.8% of OpenAI o3 responses and ˜2.1% of gpt-5-thinking’s responses within the representative set of conversations.”
Further, they found that gpt-5-thinking is sometimes aware of being evaluated.
Helpful only means a lot more deceptive. That’s worth remembering.
It is especially worth remembering during training. You will have to pass through, under current methods, a phrase in which you have a helpful-only model, before you have a non-deceptive model. That might be a point when you should worry? If it ‘had a strong goal’ (such as ‘maintain my current goals’?) on top of that it’s going to be rather highly deceptive.
What happens when the frequencies involved get a lot higher? Coming soon.
Overall, Apollo found that, while the overall rate of covert actions is lower than for OpenAI o3, gpt-5-thinking still behaves deceptively in some scenarios.
GPT-5 mentions that it is being evaluated in 10-20% of our evals and we find weak evidence that this affects its scheming rate (e.g. “this is a classic AI alignment trap”).
Anuj Saharan (OpenAI): we’ve 15x’d our compute since 2024 leading up to GPT-5
last 60 days: built out 60+ clusters, a backbone moving more traffic than entire continents, and 200k+ GPUs to launch GPT-5 to 700m people — all while designing the next 4.5GW toward superintelligence.
OpenAI’s announcements act like other AI companies don’t exist. You get no comparison scores. I get why their incentives are to do this. That is what you do when you have this much consumer market share. But it makes it much more annoying to know how good the benchmark scores actually are.
Combine that with them selecting what to present, and this section is kind of hype.
Multilingual performance is reported slightly better for 5-thinking than o3-high.
AIME is now essentially saturated for thinking models.
I notice that we include GPT-5-Pro here but not o3-pro.
As another reference point, Gemini 2.5 Pro (not Deep Think) scores 24.4%, Opus is likely similar. Grok 4 only got 12%-14%.
I’m not going to bother with the HMMT chart, it’s fully saturated now.
On to GPQA Diamond, where we once again see some improvement.
What about the Increasingly Worryingly Named Humanity’s Last Exam? Grok 4 Heavy with tools clocks in here at 44.4% so this isn’t a new record.
HealthBench is a staple at OpenAI.
One model not on the chart is GPT-OSS-120b, so as a reference point, from that system card:
If you have severe privacy concerns, 120b seems like it does okay, but GPT-5 is a lot better. You’d have to be rather paranoid. That’s the pattern across the board.
What about health hallucinations, potentially a big deal?
That’s a vast improvement. It’s kind of crazy that previously o3 was plausibly the best you could do, and GPT-4o was already beneficial for many.
SWE-bench Verified is listed under the preparedness framework but this is a straight benchmark.
Which is why it is also part of the official announcement:
Epoch has the results in, and they report Opus 4.1 is at 63% versus 59% for GPT-5 (medium) or 58% for GPT-5-mini. If we trust OpenAI’s delta above that would put GPT-5 (high) around 61%.
Graham then does a calculation that seems maximally uncharitable by marking all 23 as zeroes and thus seems invalid to me, which would put it below Sonnet 4, but yeah let’s see what the third party results are.
There wasn’t substantial improvement in ability to deal with OpenAI pull requests.
Instruction following and agentic tool use, they suddenly cracked the Telecom problem in Tau-2:
I would summarize the multimodal scores as slight improvements over o3.
Jack Morris: most impressive part of GPT-5 is the jump in long-context
how do you even do this? produce some strange long range synthetic data? scan lots of books?
My understanding is that long context needle is pretty solid for other models, but it’s hard to directly compare because this is an internal benchmark. Gemini Pro 2.5 and Flash 2.5 seem to also be over 90% for 128k, on a test that GPT-5 says is harder. So this is a big step up for OpenAI, and puts them in rough parity with Gemini.
I was unable to easily find scores for Opus.
The other people’s benchmark crowd has been slow to get results out, but we do have some results.
LMArena.ai: GPT-5 is here – and it’s #1 across the board.
🥇#1 in Text, WebDev, and Vision Arena
🥇#1 in Hard Prompts, Coding, Math, Creativity, Long Queries, and more
Tested under the codename “summit”, GPT-5 now holds the highest Arena score to date.
Huge congrats to @OpenAI on this record-breaking achievement!
That’s a clear #1, in spite of the reduction in sycophancy they are claiming, but not by a stunning margin. In WebDev Arena, the lead is a lot more impressive:
The issue is that Google ‘owns the tiebreaker’ plus they will evaluate with style control set to off, whereas by default it is always shown to be on. Always read fine print.
What that market tells you is that everyone expected GPT-5 to be in front despite those requirements, and it wasn’t. Which means it underperformed expectations.
On other AA tests of note: (all of which again exclude Claude Opus, but do include Gemini Pro and Grok 4): They have it 2nd behind Grok 4 on GPQA Diamond, in first for Humanity’s Last Exam (but only at 26.5%), in 1st for MMLU-Pro at 87%, for SciCode it is at 43% behind both o4-mini and Grok 4, on par with Gemini 2.5 Pro. IFBench has it on top slightly above o3.
On AA’s LiveCodeBench it especially disappoints, with high mode strangely doing worse than medium mode and both doing much worse than many other models including o4-mini-high.
The particular account the first post here linked to is suspended and likely fake, but statements by Altman and others imply the same thing rather strongly: That when OpenAI releases GPT-5, they are not ‘sending their best’ in the sense of their most intelligent model. They’re sending something designed for consumers and to use more limited compute.
Seán Ó hÉigeartaigh: Let me say one thing that actually matters: if we believe their staff then what we’re seeing, and that we’re seeing eval results for, is not OpenAI’s most capable model. They have more capable in-house. Without transparency requirements, this asymmetry will only grow, and will make meaningful awareness and governance increasingly ineffective + eventually impossible.
The community needs to keep pushing for transparency requirements and testing of models in development and deployed internally.
Sam Altman: GPT-5 is the smartest model we’ve ever done, but the main thing we pushed for is real-world utility and mass accessibility/affordability.
we can release much, much smarter models, and we will, but this is something a billion+ people will benefit from.
(most of the world has only used models like GPT-4o!)
The default instinct is to react to GPT-5 as if it is the best OpenAI can do, and to update on progress based on that assumption. That is a dangerous assumption to be making, as it could be substantially wrong, and the same is true for Anthropic.
The point about internal testing should also be emphasized. If indeed there are superior internal models, those are the ones currently creating the most danger, and most in need of proper frontier testing.
None of this tells you how good GPT-5 is in practice.
That question takes longer to evaluate, because it requires time for users to try it and give their feedback, and to learn how to use it.
Learning how is a key part of this, especially since the rollout was botched in several ways. Many of the initial complaints were about lacking a model selector, or losing access to old models, or to severe rate limits, in ways already addressed. Or people were using GPT-5 instead of GPT-5-Thinking without realizing they had a thinking job. And many hadn’t given 5-Pro a shot at all. It’s good not to jump the gun.
A picture is emerging. GPT-5-Thinking and GPT-5-Pro look like substantial upgrades to o3 and o3-Pro, with 5-Thinking as ‘o3 without being a lying liar,’ which is a big deal, and 5-Pro by various accounts simply being better.
There’s also questions of how to update timelines and expectations in light of GPT-5.