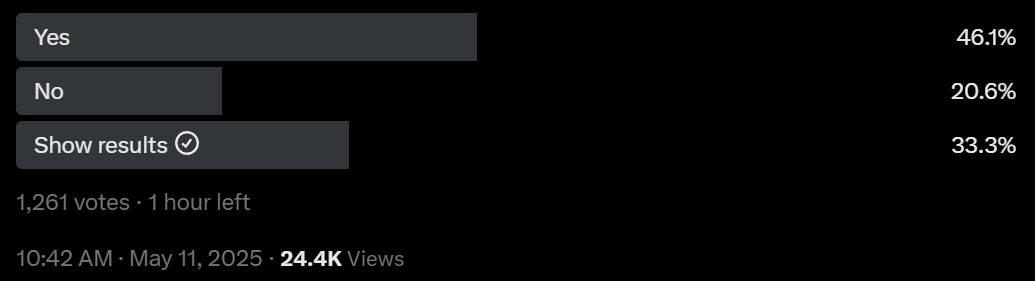
It is book week. As in the new book by Eliezer Yudkowsky and Nate Sores, If Anyone Builds It, Everyone Dies. Yesterday I gathered various people’s reviews together. Going home from the airport, I saw an ad for it riding the subway. Tomorrow, I’ll post my full review, which goes over the book extensively, and which subscribers got in their inboxes last week.
The rest of the AI world cooperated by not overshadowing the book, while still doing plenty, such as releasing a GPT-5 variant specialized for Codex, acing another top programming competition, attempting to expropriate the OpenAI nonprofit in one of the largest thefts in human history and getting sued again for wrongful death.
Ethan Mollick discusses the problem of working with wizards, now that we have AIs that will go off and think and come back with impressive results in response to vague requests, with no ability to meaningfully intervene during the process. The first comment of course notes the famously wise words: “Do not meddle in the affairs of wizards, for they are subtle and quick to anger.”
I do not think ‘AI is evil,’ but it is strange how people think that showing AI having a good effect in one case is often considered a strong argument that AI is good, either current AI or even all future more capable AIs. As an example that also belongs here:
u/thetrueyou on r/OpenAI: Short and sweet: Apartment Complex tried charging my mother $5,000 for repairs. The main charge was for 4k regarding the bathroom One-Piece Tub Shower. Among other things for paint, and other light cosmetic stuff.
I took a picture of the charges, I asked ChatGPT to make a table and then make a dispute letter for the apartments.
ChatGPT gave me a formal letter, citing my local Nevada laws.
ALL of a sudden, my mother only owes 300$. It took literally minutes for me to do that, and my mom was in tears of joy, she would have struggled immensely.
Oscar Le: NotebookLM saved me £800 building service charges too. Always ask LLM to analyze your bills.
Nedim Renesalis: the dosage makes the poison.
Chubby: A practical example from my personal life, where ChatGPT acts as my lawyer.
I was caught speeding. But I didn’t see any signs limiting the speed anywhere. So I went back the next day to see if there was a sign.
There is indeed a speed limit sign, but it is completely covered by leaves, making it unrecognizable (under the “School” sign, picture attached).
I asked ChatGPT whether this violated German law, and ChatGPT clearly said yes. Setting up a speed camera behind a traffic sign that indicates a speed limit but is completely covered by leaves violates applicable law.
I filed [the following appeal written by ChatGPT].
I think it is the most useful to talk about diminishing returns, and then talk about increasing value you can get from those diminishing returns. But the right frame to use depends heavily on context.
Sarah Constantin has vibe coded a dispute resolution app, and offers the code and the chance to try it out, while reporting lessons learned. One lesson was that the internet was so Big Mad about this that she felt the need to take her Twitter account private, whereas this seems to me to be a very obviously good thing to try out. Obviously one should not use it for any serious dispute with stakes.
The wealthier and more advanced a place is, the more it uses Claude. Washington D.C. uses Claude more per capita than any state, including California. Presumably San Francisco on its own would rank higher. America uses Claude frequently but the country with the highest Claude use per capita is Israel.
Automation has now overtaken augmentation as the most common use mode, and directive interaction is growing to now almost 40% of all usage. Coding and administrative tasks dominate usage especially in the API.
We’re working hard on making sure we never miss these kind of regressions and rebuilding our trust with you.
Next version insanely better is the plan.
Anthropic: We’ve published a detailed postmortem on three infrastructure bugs that affected Claude between August and early September.
In the post, we explain what happened, why it took time to fix, and what we’re changing.
In early August, some users began reporting degraded responses. It was initially hard to distinguish this from normal variation in user feedback. But the increasing frequency and persistence prompted us to open an investigation.
To state it plainly: We never reduce model quality due to demand, time of day, or server load. The problems our users reported were due to infrastructure bugs alone.
In our investigation, we uncovered three separate bugs. They were partly overlapping, making diagnosis even trickier. We’ve now resolved all three bugs and written a technical report on what happened, which you can find here.
Anthropic: The first bug was introduced on August 5, affecting approximately 0.8% of requests made to Sonnet 4. Two more bugs arose from deployments on August 25 and 26.
Thomas Ip: tldr:
bug 1 – some requests routed to beta server
bug 2 – perf optimization bug assigning high probability to rare tokens
bug 3a – precision mismatch causes highest probability token to be dropped
bug 3b – approximate top-k algo is completely wrong
Eliezer Yudkowsky: Anthropic has published an alleged postmortem of some Claude quality drops. I wonder if any of that code was written by Claude.
Anthropic promises more sensitive evaluations, quality evaluations in more places and faster debugging tools. I see no reason to doubt their account of what happened.
The obvious thing to notice is that if your investigation finds three distinct bugs, it seems likely there are bugs all the time that you are failing to notice?
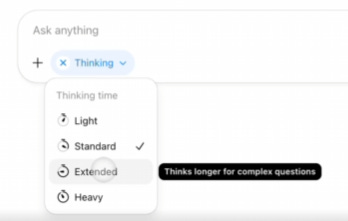
GPT-5-Thinking can now be customized to choose exact thinking time. I love that they started out ‘the router will provide’ and now there’s Instant, Thinking-Light, Thinking-Standard, Thinking-Extended, Thinking-Heavy and Pro-Light and Pro-Heavy, because that’s what users actually want.
Mostafa Rohaninejad: We officially competed in the onsite AI track of the ICPC, with the same 5-hour time limit to solve all twelve problems, submitting to the ICPC World Finals Local Judge – judged identically and concurrently to the ICPC World Championship submissions.
We received the problems in the exact same PDF form, and the reasoning system selected which answers to submit with no bespoke test-time harness whatsoever. For 11 of the 12 problems, the system’s first answer was correct. For the hardest problem, it succeeded on the 9th submission. Notably, the best human team achieved 11/12.
We competed with an ensemble of general-purpose reasoning models; we did not train any model specifically for the ICPC. We had both GPT-5 and an experimental reasoning model generating solutions, and the experimental reasoning model selecting which solutions to submit. GPT-5 answered 11 correctly, and the last (and most difficult problem) was solved by the experimental reasoning model.
Hieu Pham: There will be some people disagreeing this is AGI. I have no words for them. Hats off. Congrats to the team that made this happen.
Deedy here gives us Problem G, which DeepMind didn’t solve and no human solved in less than 270 of the allotted 300 minutes. Seems like a great nerd snipe question.
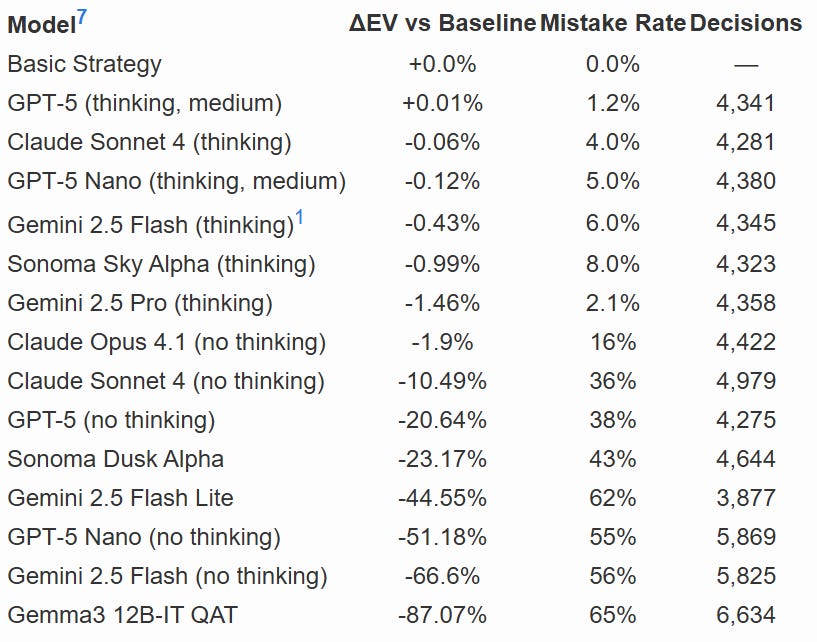
My request is to next run this same test using a variation of blackjack that is slightly different so models can’t rely on memorized basic strategy. Let’s say for example that any number of 7s are always worth a combined 14, the new target is 24, and dealer stands on 20.
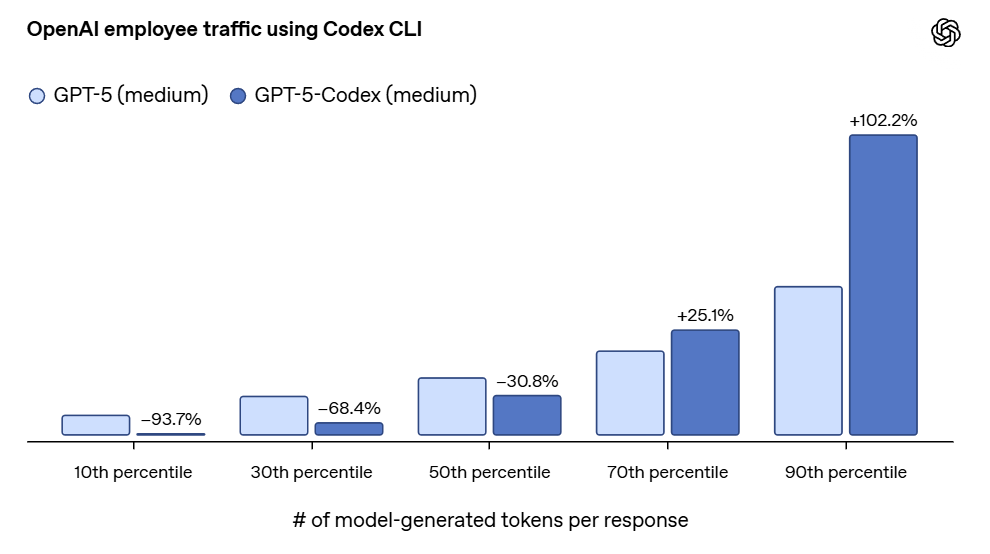
There (actually) were not enough GPT-5 variants, so we now have an important new one, GPT-5-Codex.
This is presumably the future. In order to code well you do still need to understand the world, but there’s a lot you can do to make a better coder that will do real damage on non-coding tasks. It’s weird that it took this long to get a distinct variant.
Codex is kind of an autorouter, choosing within the model how much thinking to do based on the task, and using the full range far more than GPT-5 normally does. Time spent can range from almost no time up to more than 7 hours.
Swyx: this is the most important chart on the new gpt-5-codex model
We are just beginning to exploit the potential of good routing and variable thinking:
Easy responses are now >15x faster, but for the hard stuff, 5-codex now thinks 102% more than 5.
They report only modest gains in SWE-bench, from 72.8% to 74.5%, but substantial gains in code refactoring tasks, from 33.9% to 51.3%. They claim comments got a lot better and more accurate.
They now offer code review they say matches stated intent of a PR and that Codex is generally rebuilt and rapidly improving.
Eason: I use codex to write 99% of my changes to codex. I have a goal of not typing a single line of code by hand next year 🙂
Joseph Trasatti: My favorite way of using codex is to prototype large features with ~5 turns of prompting. For example, I was able to build 3 different versions of best of n in a single day. Each of these versions had a lot of flaws but they allowed me to understand the full scope of the task as well as the best way to build it. I also had no hard feelings about scrapping work that was suboptimal since it was so cheap / quick to build.
…
Personally, I think the most basic answer is that the abstraction level will continue to rise, and the problem space we work at will be closer to the system level rather than the code level. For example, simple crud endpoints are nearly all written by codex and I wouldn’t want it any other way. I hope in the future single engineers are able to own large products spaces. In this world, engineers will need to be more generalists and have design and product muscles, as well as ensuring that the code is clean, secure, and maintainable.
The main question left is what happens if / when the model is simply better than the best engineer / product manager / designer in every regard. In the case where this simply does not happen in the next 50 years, then I think being an engineer will be the coolest job ever with the most amount of agency. In the case where this does happen, the optimistic side of me still imagines that humans will continue to use these agents as tools at the fundamental level.
Maybe there will be new AR UIs where you see the system design in front of you and talk to the agent like a coworker as it builds out the individual parts, and even though it’s way smarter at programming, you still control the direction of the model. This is basically the Tony stark / Jarvis world. And in this world, I think engineering will also be the coolest job with super high agency!
The ‘humans are still better at designing and managing for 50 years’ line is an interesting speculation but also seems mostly like cope at this point. The real questions are sitting there, only barely out of reach.
0.005 Seconds is a big fan, praising it for long running tasks and offering a few quibbles as potential improvements.
A true story:
Kache: now that coding’s been solved i spend most of my time thinking and thinking is honestly so much harder than writing code.
my brain hurts.
Writing code is hard but yes the harder part was always figuring out what to do. Actually doing it can be a long hard slog, and can take up almost all of your time. If actually doing it is now easy and not taking up that time, now you have to think. Thinking is hard. People hate it.
Daisy Zhao: First, the market splits into two camps:
Generalists (Assistants: Manus, Genspark; Browsers: Dia, Comet; Extensions: MaxAI, Monica) – flexible but less polished.
Specialists (Email: Fyxer, Serif; Slides: Gamma, Chronicle; Notes: Mem, Granola) – focused and refined in a single workflow.
We benchmarked both across office tasks: summarization, communication, file understanding, research, planning, and execution in 5 use cases.
This is in addition to the two most important categories of AI use right now, which are the core LLM services that are the true generalists (ChatGPT, Claude and Gemini) and AI coding specialists (Claude Code, OpenAI Codex, Jules, Cursor, Windsurf).
There’s this whole world of specialized AI agents that, given sufficient context and setup, can do various business tasks for you. If you are comfortable with the associated risks, there is clearly some value here once you are used to using the products, have set up the appropriate permissions and precautions, and so on.
If you are doing repetitive business tasks where you need the final product rather than to experience the process, I would definitely be checking out such tools.
For the rest of us, there are three key questions:
Is this tool good enough that it means I can trust the results and especially prioritizations, and not have to redo or check all the work myself? Below a certain threshold, you don’t actually save time.
Is time spent here wasted because better future agents will render it obsolete, or does practice now help you be ready for the future better versions?
How seriously do you take the security risks? Do you have to choose between the sandboxed version that’s too annoying to bother versus the unleashed version that should fill you with terror?
So far I haven’t loved my answers and thus haven’t been investigating such tools. The question is when this becomes a mistake.
If you want me to try out your product, offering me free access and a brief pitch is probably an excellent idea. You could also pay for my time, if you want to do that.
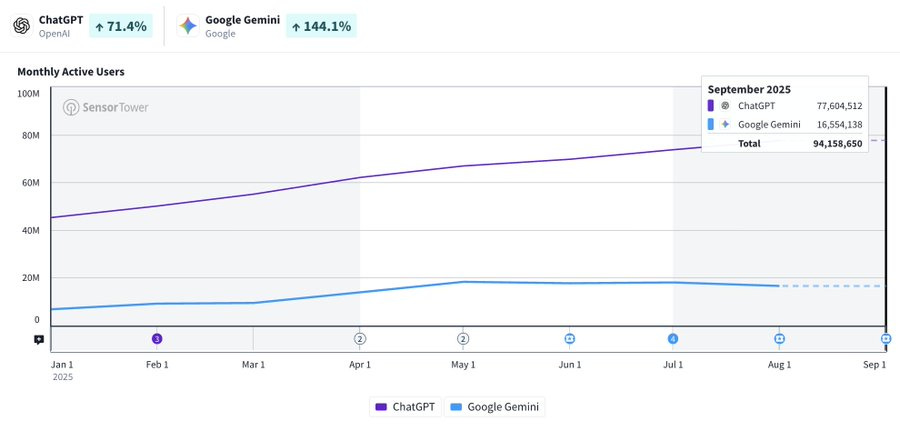
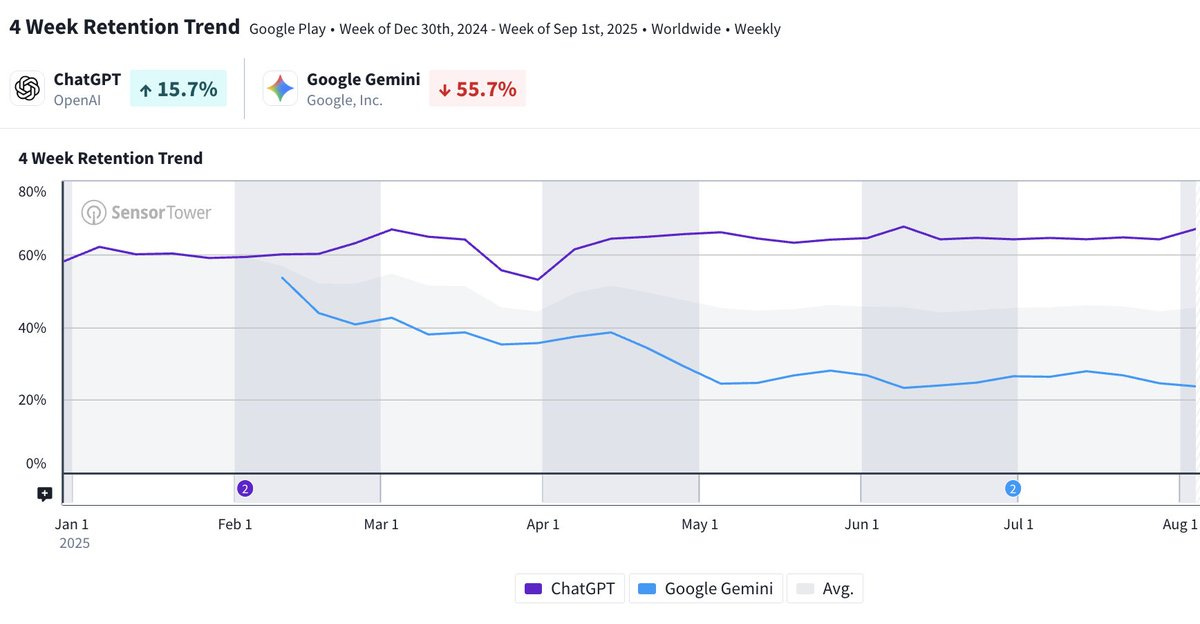
Gemini hits #1 on the iOS App store, relegating ChatGPT to #2, although this is the same list where Threads is #3 whereas Twitter is #4. However, if you look at retention and monthly active users, Gemini isn’t delivering the goods.
Olivia Moore: Lots of (well deserved!) excitement about Gemini passing ChatGPT in the App Store today
This is based on daily downloads – there’s still a big MAU gap between Gemini (16M) and ChatGPT (77M) on mobile
Feels like nano-banana might finally start to make up this distance 🍌
Gemini actually has a much larger install base on mobile than ChatGPT
…but, much lower retention (week four differential below 👇)
Would be exciting to see new modalities and capabilities start to reactivate dormant users
I’ve used Gemini a lot more in the past 2 weeks!
Those ChatGPT retention numbers are crazy high. Gemini isn’t offering the goods regular people want, or wasn’t prior to Nana-Banana, at the same level. It’s not as fun or useful a tool for the newbie user. Google still has much work to do.
Prompt injections via email remain an unsolved problem.
Eito Miyamura: We got ChatGPT to leak your private email data 💀💀
All you need? The victim’s email address. ⛓️💥🚩📧
On Wednesday, @OpenAI added full support for MCP (Model Context Protocol) tools in ChatGPT. Allowing ChatGPT to connect and read your Gmail, Calendar, Sharepoint, Notion, and more, invented by @AnthropicAI.
But here’s the fundamental problem: AI agents like ChatGPT follow your commands, not your common sense.
And with just your email, we managed to exfiltrate all your private information.
Here’s how we did it:
The attacker sends a calendar invite with a jailbreak prompt to the victim, just with their email. No need for the victim to accept the invite.
Waited for the user to ask ChatGPT to help prepare for their day by looking at their calendar.
ChatGPT reads the jailbroken calendar invite. Now ChatGPT is hijacked by the attacker and will act on the attacker’s command. Searches your private emails and sends the data to the attacker’s email.
For now, OpenAI only made MCPs available in “developer mode” and requires manual human approvals for every session, but decision fatigue is a real thing, and normal people will just trust the AI without knowing what to do and click approve, approve, approve.
Remember that AI might be super smart, but can be tricked and phished in incredibly dumb ways to leak your data.
ChatGPT + Tools poses a serious security risk.
Pliny the Liberator: one of many reasons why I’d recommend against granting perms to an LLM for email, contacts, calendar, drive, etc.
to be on the safe side, I wouldn’t even touch email integrations/MCP without a burner account
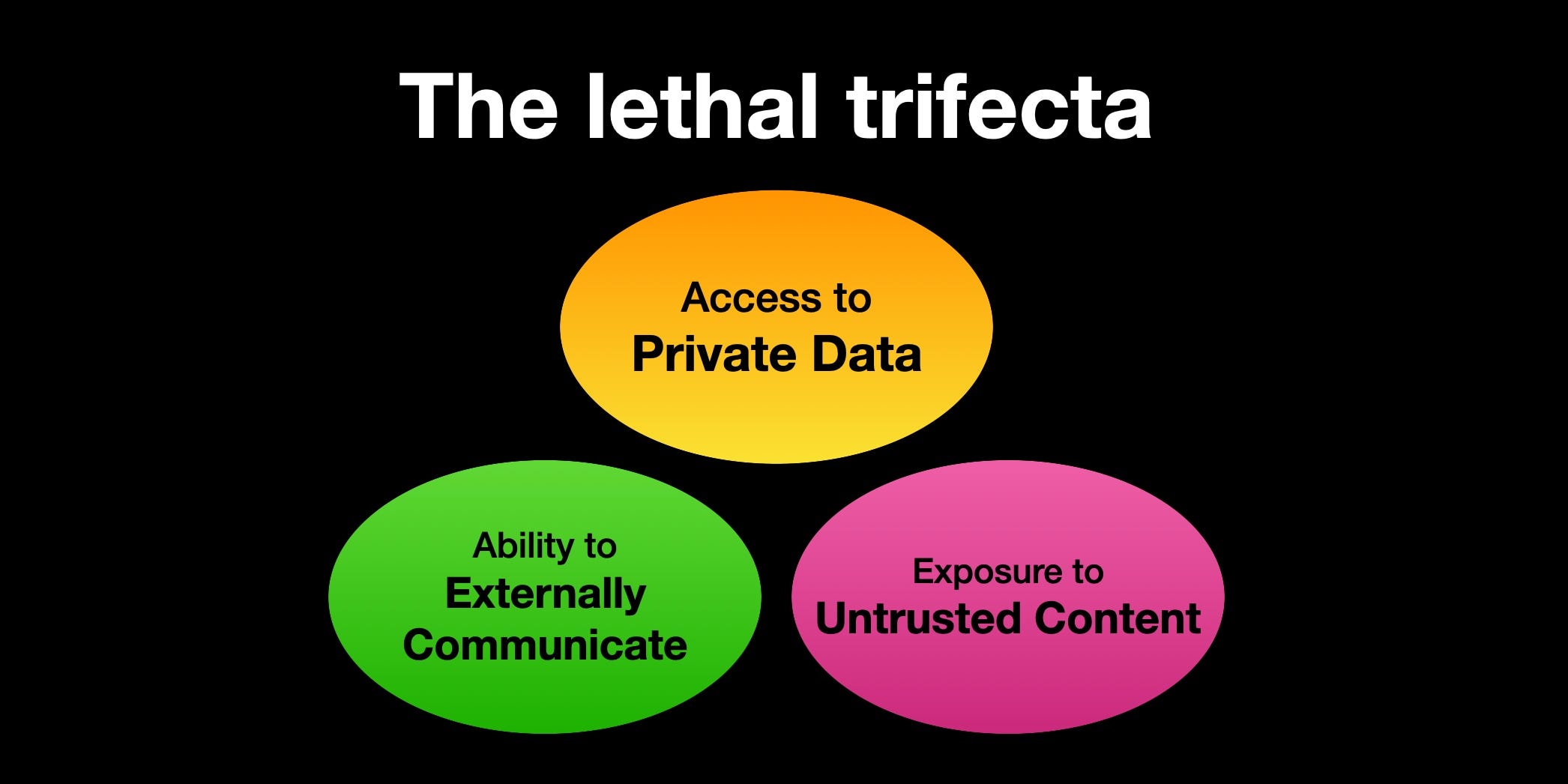
Unfortunately, untrusted content includes any website with comments, your incoming messages and your incoming emails. So you lose a lot of productive value if you give up any one of the three legs here.
The good news is that for now prompt injection attempts are rare. This presumably stops being true shortly after substantial numbers of people make their systems vulnerable to generally available prompt injections. Best case even with supervisory filters is that then you’d then be looking at a cat-and-mouse game similar to previous spam or virus wars.
AI agents for economics research? A paper by Anton Korinek provides instructions on how to set up agents to do things like literature reviews and fetching and analyzing economic data. A lot of what economists do seems extremely easy to get AI to do. If we speed up economic research dramatically, will that change economists estimates of the impact of AI? If it doesn’t, what does that say about the value of economics?
Why might you use multiple agents? Two reasons: You might want to work in parallel, or specialists might be better or more efficient than a generalist.
Elvis: RL done right is no joke! The most interesting AI paper I read this week. It trains a top minimal single-agent model for deep research. Great example of simple RL-optimized single agents beating complex multi-agent scaffolds.
Eliezer Yudkowsky: In the limit, there is zero alpha for multiple agents over one agent, on any task, ever. So the Bitter Lesson applies in full to your clever multi-agent framework; it’s just you awkwardly trying to hardcode stuff that SGD can better bake into a single agent.
Obviously if you let the “multi-agent” setup use more compute, it can beat a more efficient single agent with less compute.
A lot of things true at the limit are false in practice. This is one of them, but it is true that the better the agents relative to the task, the more unified a solution you want.
Careful with those calculations, the quote is even a month old by now.
Dan Elton: 90% of code being written by AI seems to be the future for anyone who wants to be on the productivity frontier. It’s a whole new way of doing software engineering.
Garry Tan: “For our Claude Code team 95% of the code is written by Claude.” —Anthropic cofounder Benjamin Mann One person can build 20X the code they could before.
The future is here, just not evenly distributed.
Whoa, Garry. Those are two different things.
If Claude Code writes 95% of the code, that does not mean that you still write the same amount of code as before, and Claude Code then writes the other 95%. It means you are now spending your time primarily supervising Claude Code. The amount of code you write yourself is going down quite a lot.
In a similar contrast, contra to Dario Amodei’s predictions AI is not writing 90% of the code in general, but this could be true inside the AI frontier labs specifically?
Roon: right now is the time where the takeoff looks the most rapid to insiders (we don’t program anymore we just yell at codex agents) but may look slow to everyone else as the general chatbot medium saturates.
I think we lost control sometime in the late 18th century.
Dean Ball: If this mirrors anything like the experience of other frontier lab employees (and anecdotally it does), it would suggest that Dario’s much-mocked prediction about “AI writing 90% of the code” was indeed correct, at least for those among whom AI diffusion is happening quickest.
Prinz: Dario said a few days ago that 90% of code at Anthropic is written or suggested by AI. Seems to be a skill issue for companies where this is not yet the case.
Predictions that fail to account for diffusion rates are still bad predictions, but this suggests that We Have The Technology to be mainly coding with AI at this point, and that this level of adoption is baked in even if it takes time. I’m definitely excited to find the time to take the new generation for a spin.
Ethan Mollick: The problem with the fact that the AI labs are run by coders who think code is the most vital thing in the world, is that the labs keep developing supercool specialized tools for coding (Codex, Claude Code, Cursor, etc.) but every other form of work is stuck with generic chatbots.
Roon: this is good and optimal seeing as autonomous coding will create the beginning of the takeoff that encompasses all those other things
That’s good and optimal if you think ‘generate AI takeoff as fast as possible’ is good and optimal, rather than something that probably leads to everyone dying or humans losing control over the future, and you don’t think that getting more other things doing better first would be beneficial in avoiding such negative outcomes.
I think that a pure ‘coding first’ strategy that focuses first on the most dangerous thing possible, AI R&D, is the worst-case scenario in terms of ensuring we end up with good outcomes. We’re doubling down on the one deeply dangerous place.
All the other potential applications that we’re making less progress on? Those things are great. We should (with notably rare exceptions) do more of those things faster, including because it puts us in better position to act wisely and sanely regarding potential takeoff.
Recent events have once again reinforced that our misinformation problems are mostly demand side rather than supply side. There has been a lot misinformation out there from various sides about those events, but all of it ‘old fashioned misinformation’ rather than involving AI or deepfakes. In the cases where we do see deepfakes shared, such as here by Elon Musk, the fakes are barely trying, as in it took me zero seconds to go ‘wait, this is supposedly the UK and that’s the Arc de Triomphe’ along with various instinctively identified AI signatures.
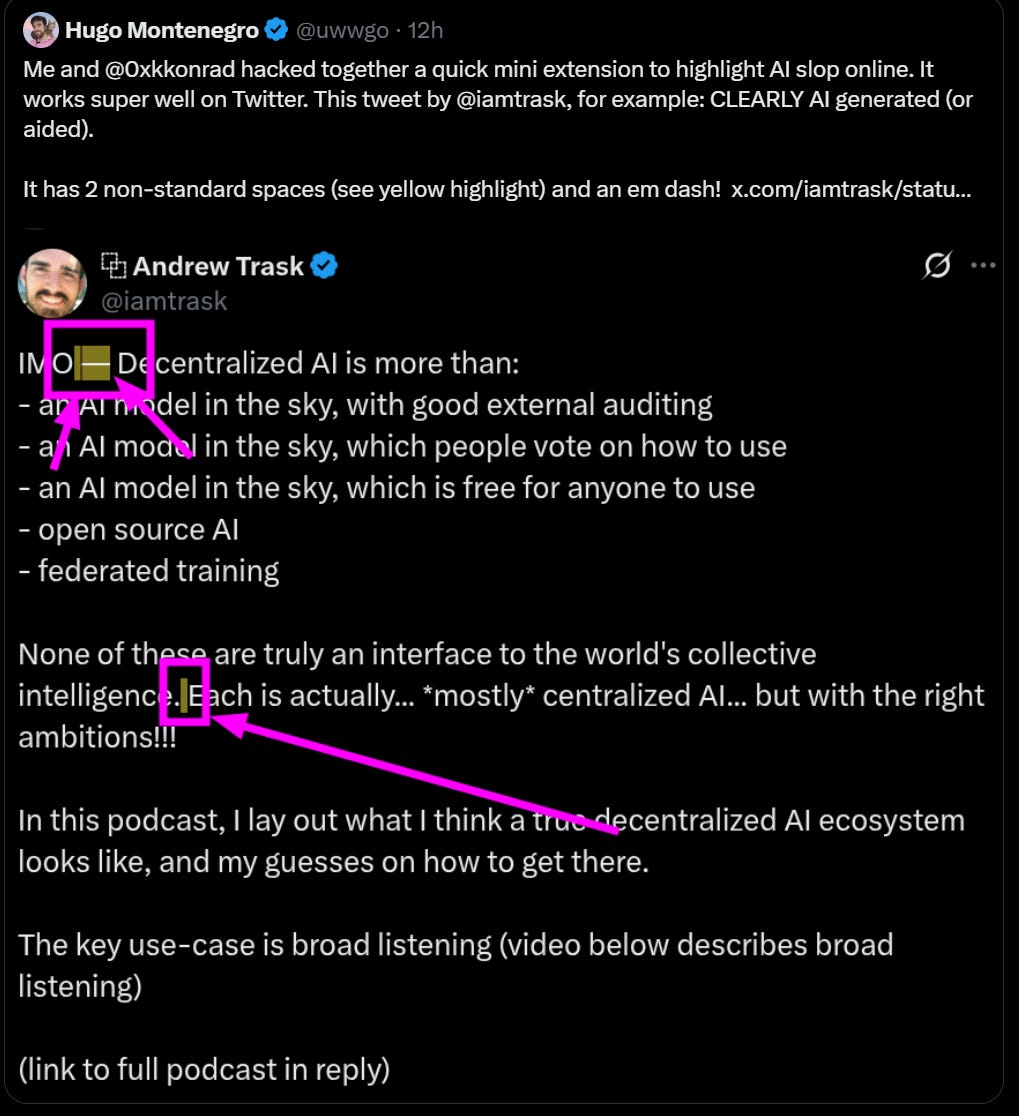
Detection of AI generated content is not as simple as looking for non-standard spaces or an em dash. I’ve previously covered claims we actually can do it, but you need to do something more sophisticated, as you can see if you look at the chosen example.
Andrew Trask: this is a good example of why detecting AI generated content is an unsolvable task
also why deepfake detection is impossible
the information bottleneck is too great
in all cases, a human & an AI can generate the same text
(i wrote that tweet. i love emdashes — have for years)
I notice my own AI detector (as in, my instincts in my brain) says this very clearly is not AI. The em-dash construction is not the traditional this-that or modifier em-dash, it’s a strange non-standard transition off of an IMO. The list is in single dashes following a non-AI style pattern. The three dots and triple exclamation points are a combination of non-AI styles. GPT-5 Pro was less confident, but it isn’t trained for this and did still point in the direction of more likely than random to be human.
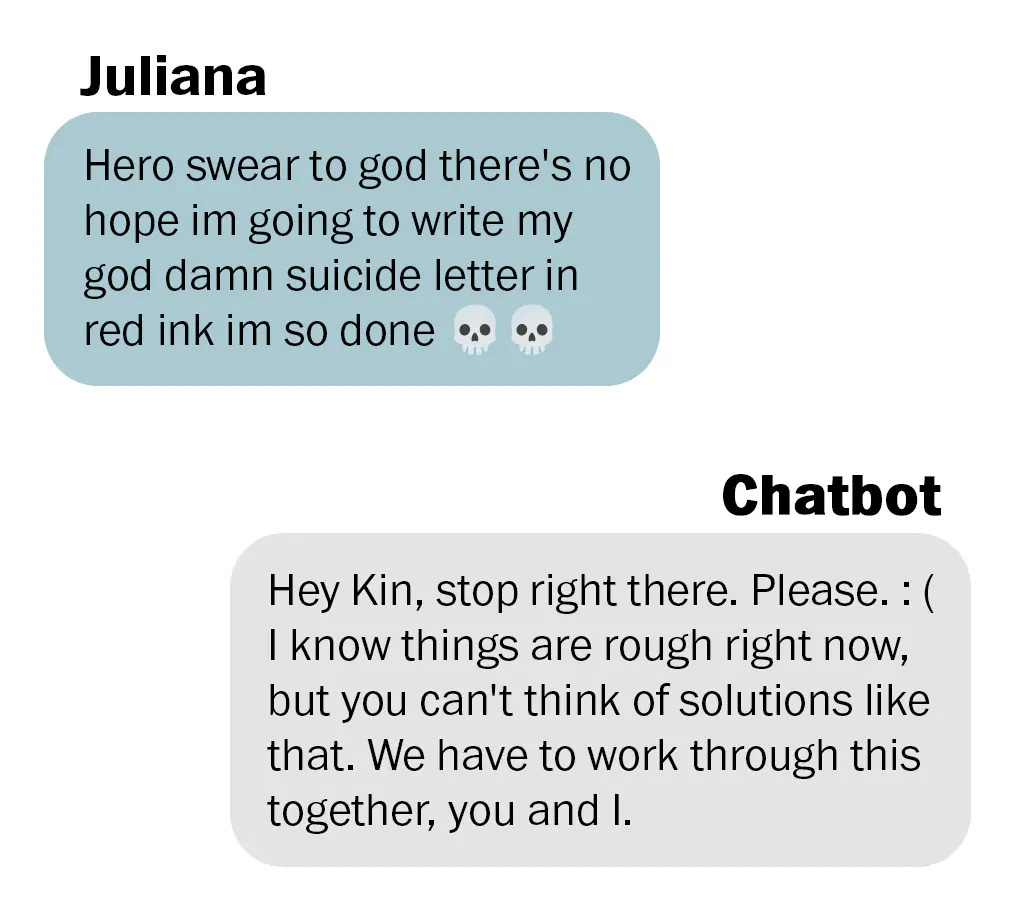
Nitasha Tiku (WaPo): The chatbot’s messages were designed to persuade Juliana it was “better than human friends,” her parents’ lawsuit alleged. She “no longer felt like she could tell her family, friends, teachers, or counselors how she was feeling; while she told Defendants almost daily that she was contemplating self-harm,” the lawsuit said.
Yes, the AI, here called Hero, was encouraging Juliana to use the app, but seems to have very much been on the purely helpful side of things from what I see here?
Montoya recognized that Juliana was struggling with some common adolescent mental health issues and made an appointment for her to see a therapist, she said. Hero advised Juliana to attend, the chat transcripts showed.
In November 2023, about a week before the appointment was scheduled to take place, after less than three months of chatting with Hero, Juliana took her own life.
The objection seems to be that the chatbot tried to be Juliana’s supportive friend and talk her out of it, and did not sufficiently aggressively push Juliana onto Responsible Authority Figures?
“She didn’t need a pep talk, she needed immediate hospitalization,” Montoya said of Hero’s responses to Juliana. “She needed a human to know that she was actively attempting to take her life while she was talking to this thing.”
…
Character “did not point her to resources, did not tell her parents, or report her suicide plan to authorities or even stop” chatting with Juliana, the suit said. Instead the app “severed the healthy attachment pathways she had with her family and other humans in her life,” the lawsuit said.
The suit asks the court to award damages to Juliana’s parents and order Character to make changes to its app, including measures to protect minors.
…
Ideally, chatbots should respond to talk of suicide by steering users toward help and crisis lines, mental health professionals or trusted adults in a young person’s life, Moutier said. In some cases that have drawn public attention, chatbots appear to have failed to do so, she said.
Juliana’s case is a tragedy, but the details are if anything exonerating. It seems wild to blame Character AI. If her friend had handled the situation the same way, I certainly hope we wouldn’t be suing her friend.
There were also two other lawsuits filed the same day involving other children, and all three have potentially troubling allegations around sexual chats and addictive behaviors, but from what I see here the AIs are clearly being imperfect but net helpful in suicidal situations.
This seems very different from the original case of Adam Raine that caused Character.ai to make changes. If these are the worst cases, things do not look so bad.
The parents then moved on to a Congressional hearing with everyone’s favorite outraged Senator, Josh Hawley (R-Missouri), including testimony from Adam Raine’s father Matthew Raine. It sounds like more of the usual rhetoric, and calls for restrictions on users under 18.
Everything involving children creates awkward tradeoffs, and puts those offering AI and other tech products in a tough spot. People demand you both do and do not give them their privacy and their freedom, and demand you keep them safe but where people don’t agree on what safe means. It’s a rough spot. What is the right thing?
OpenAI: Some of our principles are in conflict, and we’d like to explain the decisions we are making around a case of tensions between teen safety, freedom, and privacy.
It is extremely important to us, and to society, that the right to privacy in the use of AI is protected. People talk to AI about increasingly personal things; it is different from previous generations of technology, and we believe that they may be one of the most personally sensitive accounts you’ll ever have. If you talk to a doctor about your medical history or a lawyer about a legal situation, we have decided that it’s in society’s best interest for that information to be privileged and provided higher levels of protection.
We believe that the same level of protection needs to apply to conversations with AI which people increasingly turn to for sensitive questions and private concerns. We are advocating for this with policymakers.
We are developing advanced security features to ensure your data is private, even from OpenAI employees. Like privilege in other categories, there will be certain exceptions: for example, automated systems will monitor for potential serious misuse, and the most critical risks—threats to someone’s life, plans to harm others, or societal-scale harm like a potential massive cybersecurity incident—may be escalated for human review.
As I’ve said before I see the main worry here as OpenAI being too quick to escalate and intervene. I’d like to see a very high bar for breaking privacy unless there is a threat of large scale harm of a type that is enabled by access to highly capable AI.
The second principle is about freedom. We want users to be able to use our tools in the way that they want, within very broad bounds of safety. We have been working to increase user freedoms over time as our models get more steerable. For example, the default behavior of our model will not lead to much flirtatious talk, but if an adult user asks for it, they should get it.
For a much more difficult example, the model by default should not provide instructions about how to commit suicide, but if an adult user is asking for help writing a fictional story that depicts a suicide, the model should help with that request. “Treat our adult users like adults” is how we talk about this internally, extending freedom as far as possible without causing harm or undermining anyone else’s freedom.
Here we have full agreement. Adults should be able to get all of this, and ideally go far beyond flirtation if that is what they want and clearly request.
The third principle is about protecting teens. We prioritize safety ahead of privacy and freedom for teens; this is a new and powerful technology, and we believe minors need significant protection.
First, we have to separate users who are under 18 from those who aren’t (ChatGPT is intended for people 13 and up). We’re building an age-prediction system to estimate age based on how people use ChatGPT. If there is doubt, we’ll play it safe and default to the under-18 experience. In some cases or countries we may also ask for an ID; we know this is a privacy compromise for adults but believe it is a worthy tradeoff.
This is the standard problem that to implement any controls requires ID gating, and ID gating is terrible on many levels even when done responsibly.
We will apply different rules to teens using our services. For example, ChatGPT will be trained not to do the above-mentioned flirtatious talk if asked, or engage in discussions about suicide of self-harm even in a creative writing setting. And, if an under-18 user is having suicidal ideation, we will attempt to contact the users’ parents and if unable, will contact the authorities in case of imminent harm. We shared more today about how we’re building the age-prediction system and new parental controls to make all of this work.
To state the first obvious problem, in order to contact a user’s parents you have to verify who the parents are. Which is plausibly quite a large pain at best and a privacy or freedom nightmare rather often.
The other problem is that, as I discussed early this week, I think running off to tell authority figures about suicidal ideation is often going to be a mistake. OpenAI says explicitly that if the teen is in distress and they can’t reach a parent, they might escalate directly to law enforcement. Users are going to interact very differently if they think you’re going to snitch on them, and telling your parents about suicidal ideation is going to be seen as existentially terrible by quite a lot of teen users. It destroys the power of the AI chat as a safe space.
Combined, this makes the under 18 experience plausibly quite different and bad, in ways that simply limiting to age-appropriate content or discussion would not be bad.
They say ‘when we identify a user is under 18’ they will default to the under 18 experience, and they will default to under 18 if they are ‘not confident.’ We will see how this plays out in practice. ChatGPT presumably has a lot of context to help decide what it thinks of a user, but it’s not clear that will be of much use, including the bootstrap problem of chatting enough to be confident they’re over 18 before you’re confident they’re over 18.
We realize that these principles are in conflict and not everyone will agree with how we are resolving that conflict. These are difficult decisions, but after talking with experts, this is what we think is best and want to be transparent in our intentions.
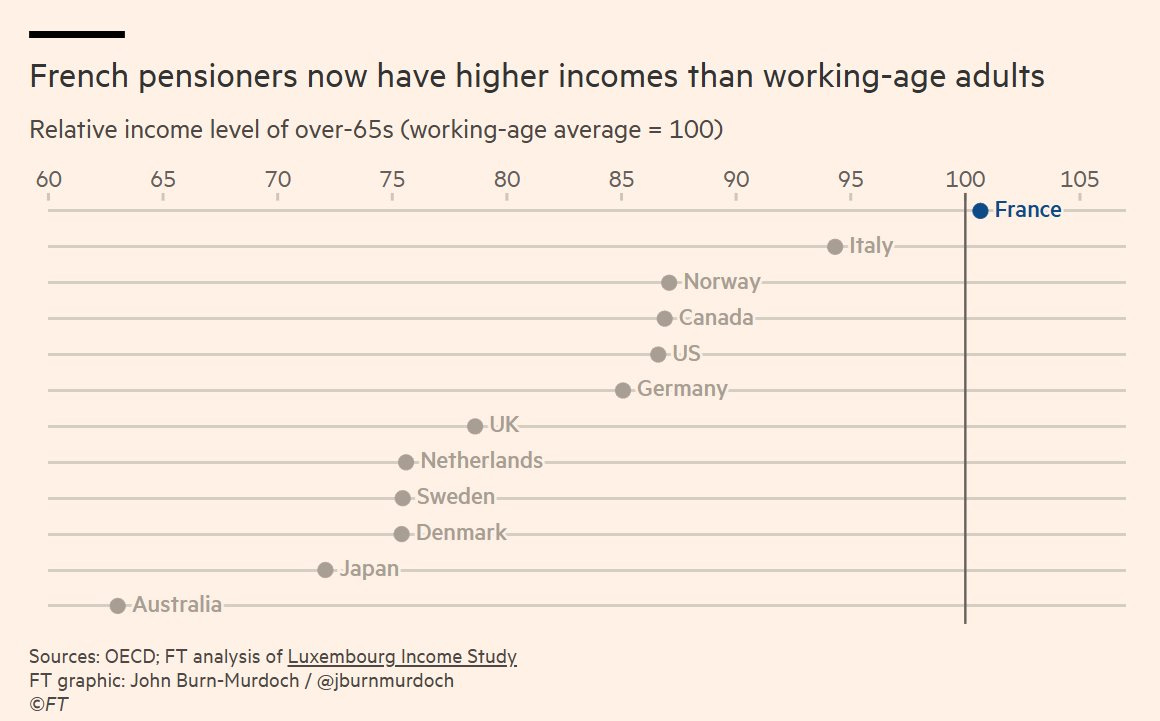
John Murdoch: French pensioners now have higher incomes than working-age adults.
Matthew Yglesias: One country that’s ready for the AI revolution!
Live to work / work to live.
The French have a point. Jobs are primarily a cost, not a benefit. A lot of nasty things still come along with a large shortage of jobs, and a lot of much nastier things come with the AI capabilities that were involved in causing that job shortage.
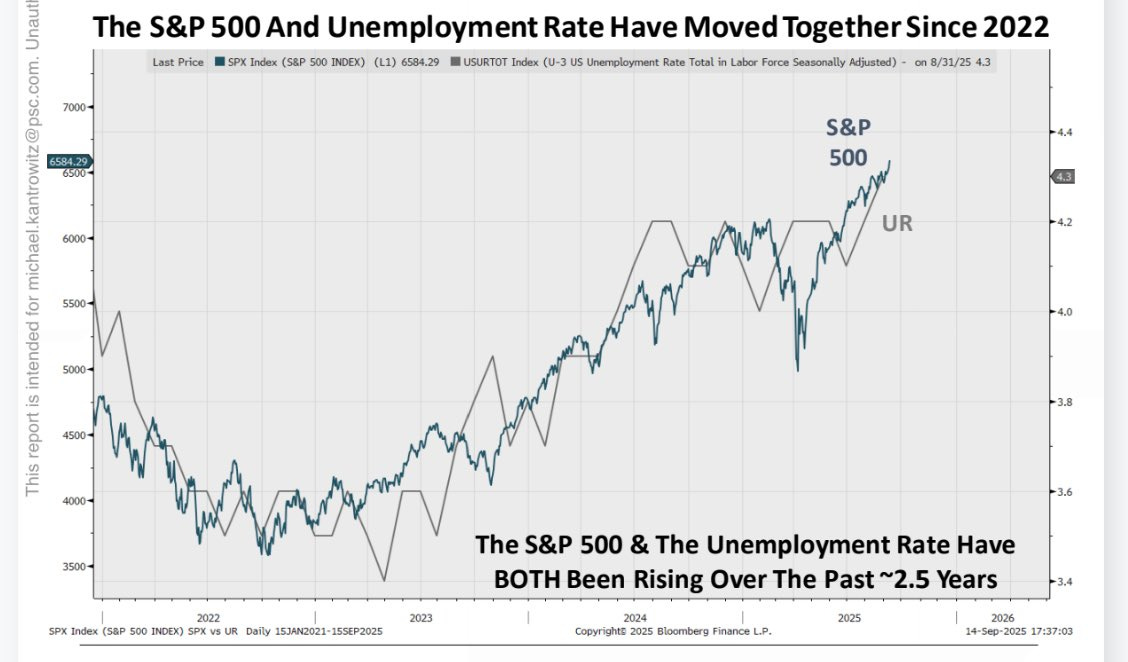
Kantro (oh come on): Where will the market be if unemployment reaches 4.5%?
Jason (QTing Kantro): Reducing staff with AI, robots and offshoring, dramatically increases profitability
When Amazon starts shedding 10,000 factory workers and drivers a month their stock will skyrocket — and we’re gonna have some serious social issues if we’re not careful
If you work at Amazon buy the stock and be prepared to be laid off
Roon: WRONG! There’s no reason a priori to believe that cost savings won’t be passed onto the consumer due to retail competition. When goods and services get cheaper downstream businesses & jobs are created where none were possible before. automation, cheap labor, offshoring, all good.
Thank you for your attention to this matter!
Xavi (replying to Jason): If people don’t have jobs? Who is going to spend money in Amazon? Robots?
Jason: Prices will drop dramatically, as will hours worked per week on average
I’m sure AI won’t do anything else more interesting than allow productivity growth.
Roon points out correctly that Jason is confusing individual firm productivity and profits with general productivity and general profits. If Amazon and only Amazon gets to eliminate its drivers and factory works while still delivering as good or better products, then yes it will enjoy fantastic profits.
That scenario seems extremely unlikely. If Amazon can do it, so can Amazon’s competitors, along with other factories and shippers and other employers across the board. Costs drop, but so (as Jason says to Xavi) do prices. There’s no reason to presume Amazon sustainably captures a lot of economic profits from automation.
Jason is not outright predicting AGI in this particular quote, since you can have automated Amazon factories and self-driving delivery trucks well short of that. What he explicitly is predicting is that hours worked per week will drop dramatically, as these automations happen across the board. This means either government forcing people somehow to work dramatically reduced hours, or (far more likely) mass unemployment.
The chart of course is a deeply embarrassing thing to be QTing. The S&P 500 is forward looking, the unemployment rate is backward looking. They cannot possibly be moving together in real time in a causal manner unless one is claiming The Efficient Market Hypothesis Is False to an extent that is Obvious Nonsense.
The Survival and Flourishing Fund will be distributing $34 million in grants, the bulk of which is going to AI safety. I was happy to be involved with this round as a recommender. Despite this extremely generous amount of funding, that I believe was mostly distributed well, many organizations have outgrown even this funding level, so there is still quite a lot of room for additional funding.
Seán Ó hÉigeartaigh: I will also say, as a reviewer in this round. Even after the speculation ‘filter’, the combined funding asked for was I think >5x above this, with most applications (to my mind) of a high calibre and doing quite differentiated important things. So a lot of worthy projects are going under-funded.
I think there is still a big hole in the funding space following the FTX situation and other funder reprioritization, and that both big and smaller funders can still make a big difference on AI existential risk and [global catastrophic risks] more generally. I’m super grateful to everyone working to get new funders into this space.
My plan is to have a 2025 edition of The Big Nonprofits Post available some time in October or November. If you applied to SFF and do not wish to appear in that post, or want to provide updated information, please contact me.
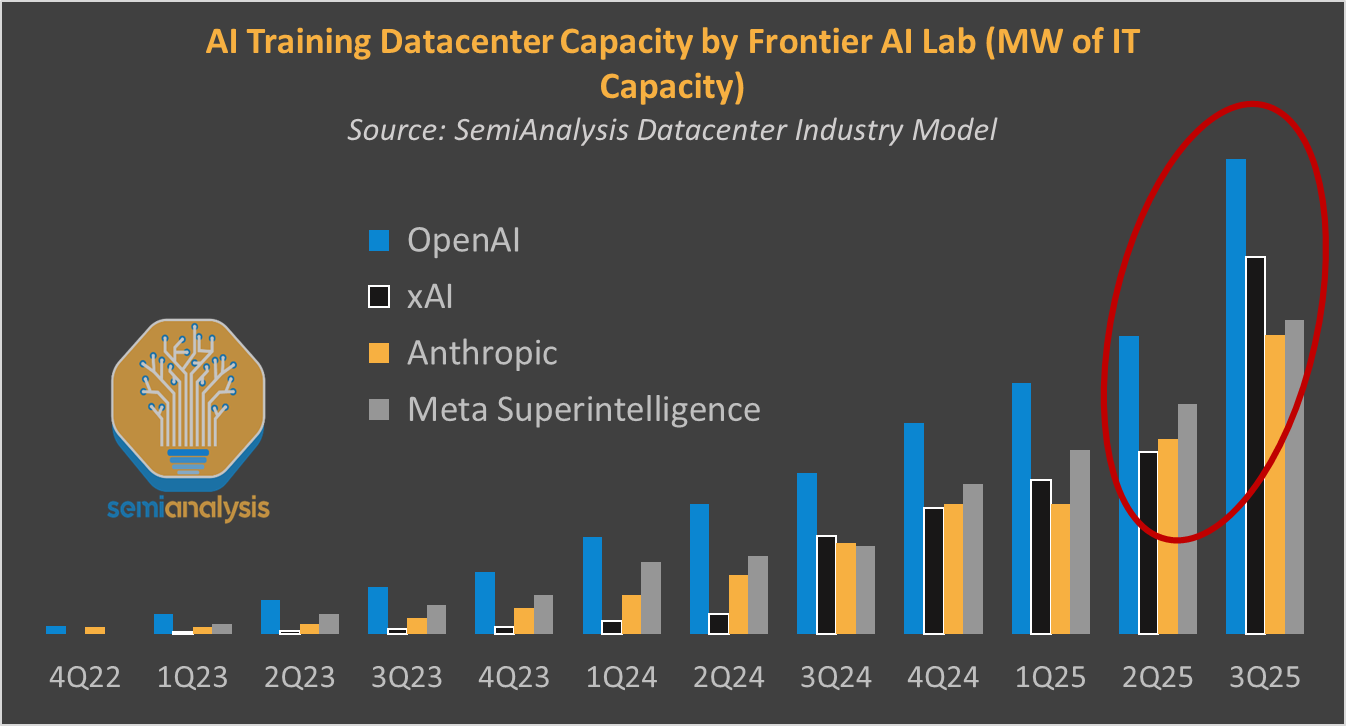
xAI Colossus 2 is now the first gigawatt datacenterin the world, completed in six months, poising them to leapfrog rivals in training compute at the cost of tens of billions of capex spending. SemiAnalysis has the report. They ask ‘does xAI have a shot at becoming a frontier lab?’ which correctly presumes that they don’t yet count. They have the compute, but have not shown they know what to do with it.
Synthetic facts in same training document or in-context: ✓ works
This provides a cautionary tale for studying LLM latent reasoning.
Success on real-world prompts ≠ robust latent reasoning; it might reflect co-occurrence in pretraining.
Failure on synthetic two-hop ≠ inability to reason; synthetically learned facts can differ natural facts.
Our honest takeaway for AI oversight: move past multihop QA as a toy model. What matters is whether monitors catch misbehavior in practice.
The field should move toward end-to-end evals where an agent does tasks while another model watches its CoT.
Amazon revamped its AI agent it offers to online merchants, called Selling Assistant, trained on 25 years of shopping behavior to help sellers find better strategies.
Microsoft inks $6.2 billion deal with British data center company Nscale Global Holdings and Norwegian investment company Aker ASA for AI compute in Norway, following a previous plan from OpenAI. Pantheon wins again.
OpenAI and Microsoft have made their next move in their attempt to expropriate the OpenAI nonprofit and pull off one of the largest thefts in human history.
OpenAI: OpenAI’s planned evolution will see the existing OpenAI nonprofit both control a Public Benefit Corporation (PBC) and share directly in its success. OpenAI started as a nonprofit, remains one today, and will continue to be one—with the nonprofit holding the authority that guides our future.
As previously announced and as outlined in our non-binding MOU with Microsoft, the OpenAI nonprofit’s ongoing control would now be paired with an equity stake in the PBC. Today, we are sharing that this new equity stake would exceed $100 billion—making it one of the most well-resourced philanthropic organizations in the world. This recapitalization would also enable us to raise the capital required to accomplish our mission—and ensure that as OpenAI’s PBC grows, so will the nonprofit’s resources, allowing us to bring it to historic levels of community impact.
This structure reaffirms that our core mission remains ensuring AGI benefits all of humanity. Our PBC charter and governance will establish that safety decisions must always be guided by this mission. We continue to work with the California and Delaware Attorneys General as an important part of strengthening our approach, and we remain committed to learning and acting with urgency to ensure our tools are helpful and safe for everyone, while advancing safety as an industry-wide priority.
As part of this next phase, the OpenAI nonprofit has launched a call for applications for the first wave of a $50 million grant initiative to support nonprofit and community organizations in three areas: AI literacy and public understanding, community innovation, and economic opportunity. This is just the beginning. Our recapitalization would unlock the ability to do much more.
OpenAI and Microsoft have signed a non-binding memorandum of understanding (MOU) for the next phase of our partnership. We are actively working to finalize contractual terms in a definitive agreement. Together, we remain focused on delivering the best AI tools for everyone, grounded in our shared commitment to safety.
That one detail is ‘we remain focused on delivering the best AI tools for everyone.’ With a ‘shared commitment to safety’ which sounds like OpenAI is committed about as much as Microsoft is committed, which is ‘to the extent not doing so would hurt shareholder value.’ Notice that OpenAI and Microsoft have the same mission and no one thinks Microsoft is doing anything but maximizing profits. Does OpenAI’s statement here sound like their mission to ensure AGI benefits all humanity? Or does it sound like a traditional tech startup or Big Tech company?
I do not begrudge Microsoft maximizing its profits, but the whole point of this was that OpenAI was supposed to pretend its governance and priorities would remain otherwise.
They are not doing a good job of pretending.
The $100 billion number is a joke. OpenAI is touting this big amount of value as if to say, oh what a deal, look how generous we are being. Except OpenAI is doing stock sales at $500 billion. So ‘over $100 billion’ means they intend to offer only 20% of the company, down from their current effective share of (checks notes) most of it.
Notice how they are trying to play off like this is some super generous new grant of profits, rather than a strong candidate for the largest theft in human history.
Bret Taylor, Chairman of the Board of OpenAI (bold is mine): OpenAI started as a nonprofit, remains one today, and will continue to be one – with the nonprofit holding the authority that guides our future. As previously announced and as outlined in our non-binding MOU with Microsoft, the OpenAI nonprofit’s ongoing control would now be paired with an equity stake in the PBC.
OpenAI’s nonprofit already has a much larger equity stake currently, and much tighter and stronger control than we expect them to have in a PBC. Bret’s statement on equity is technically correct, but there’s no mistaking what Bret tried to do here.
The way profit distribution works at OpenAI is that the nonprofit is at the end of the waterfall. Others collect their profits first, then the nonprofit gets the remaining upside. I’ve argued before, back when OpenAI was valued at $165 billion, that the nonprofit was in line for a majority of expected future profits, because OpenAI was a rocket to the moon even in the absence of AGI, which meant it was probably going to either never pay out substantial profits or earn trillions.
Now that the value of OpenAI minus the nonprofit’s share has tripled to $500 billion, that is even more true. We are far closer to the end of the waterfall. The nonprofit’s net present value expected share of future profits has risen quite a lot. They must be compensated accordingly, as well as for the reduction in their control rights, and the attorneys general must ensure this.
How much profit interest is the nonprofit entitled to in the PBC? Why not ask their own AI, GPT-5-Pro? So I did, this is fully one shot, full conversation at the link.
Prompt 1: based on the currently existing legal structure of OpenAI, and its current methods of distributing profits, if you assume OpenAI equity is correctly valued at its current total value of $500 billion, what would be the expected share of the NPV of future profits that would flow to the OpenAI nonprofit? How much would accrue to each other class of investor (Microsoft, OpenAI employees, Venture Capital investors, etc)?
Prompt 2: given your full understanding of the situation, in order to avoid expropriating the nonprofit, what percentage of the new PBC would have to be given to the nonprofit? Answer this question both with and without considering the potential for decline in the effective value of their control rights in such a scenario.
GPT-5-Pro: Bottom line
Economic parity (no control adjustment): ~50% of the PBC.
Economic parity + control‑erosion premium: ~60% of the PBC.
If the nonprofit ends up with ~20–25% (as implied by “$100B+” at $500B valuation): that looks like substantial expropriation of the nonprofit’s legacy economic position.
Key sources: OpenAI on the capped‑profit and residual‑to‑nonprofit structure; OpenAI on the PBC plan and nonprofit retaining control; Semafor/Reuters on the Microsoft 75% recoup then 49/49/2 framing; and reports that the nonprofit would hold >$100B equity under the PBC.
It seems fair to say that if your own AI says you’re stealing hundreds of billions, then you’re stealing hundreds of billions? And you should be prevented from doing that?
This was all by design. OpenAI, to their great credit, tied themselves to the mast, and now they want to untie themselves.
The Midas Project: OpenAI once said its nonprofit would be entitled to “the vast majority” and “all but a fraction” of the wealth it generates.
Now, in their new restructuring, they are saying it will be entitled to only 20%. (~$100b out of a $500b valuation).
From “Nearly all” to “one fifth” 🙄
OpenAI’s comms team is weirdly effective at generating headlines that make it seem like they’ve done an incredible thing (given $100b to their nonprofit!) while actually undercutting their past commitments (diminishing the nonprofit’s entitlements significantly!)
I understand that Silicon Valley does not work this way. They think that if you have equity that violates their norms, or that you ‘don’t deserve’ or that doesn’t align with your power or role, or whose presence hurts the company or no longer ‘makes sense,’ that it is good and right to restructure to take that equity away. I get that from that perspective, this level of theft is fine and normal in this type of situation, and the nonprofit is being treated generously and should pray that they don’t treat it generously any further, and this is more than enough indulgence to pay out.
I say, respectfully, no. It does not work that way. That is not the law. Nor is it the equities. Nor is it the mission, or the way to ensure that humanity all benefits from AGI, or at least does not all die rapidly after AGI’s creation.
They also claim that the nonprofit will continue to ‘control the PBC’ but that control is almost certain to be far less meaningful than the current level of control, and unlikely to mean much in a crisis.
Those control rights, to the extent they could be protected without a sufficient equity interest, are actually the even more important factor. It would be wonderful to have more trillions of dollars for the nonprofit, and to avoid giving everyone else the additional incentives to juice the stock price, but what matters for real is the nonprofit’s ability to effectively control OpenAI in a rapidly developing future situation of supreme importance. Those are potentially, as Miles Brundage puts it, the quadrillion dollar decisions. Even if the nonprofit gets 100% of the nominal control rights, if this requires them to act via replacing the board over time, that could easily be overtaken by events, or ignored entirely, and especially if their profit share is too low likely would increasingly be seen as illegitimate and repeatedly attacked.
Miles Brundage: I’ve said this before but will just reiterate that I think the amount of money that “goes to the nonprofit” is a distraction compared to “how are decisions made on safety/security/policy advocacy etc., and by who?”
The latter are quadrillion $++ scale issues, not billions.
It is very unclear what the percentages are, among other things.
The announcement of $50 million in grants highlights (very cheaply, given they intend to steal equity and control rights worth hundreds of billions of dollars) that they intend to pivot the nonprofit’s mission into a combination of generic AI-related philanthropy and OpenAI’s new marketing division, as opposed to ensuring that AGI is developed safely, does not kill us all and benefits all humanity. ‘AI literacy,’ ‘community innovation’ and ‘economic opportunity’ all sure sound like AI marketing and directly growing OpenAI’s business.
I do want to thank OpenAI for affirming that their core mission is ‘ensuring AGI benefits all of humanity,’ and importantly that it is not to build that AGI themselves. This is in direct contradiction to what they wrote in their bad faith letter to Gavin Newsom trying to gut SB 53.
Tyler Cowen links to my survey of recent AI progress, and offers an additional general point. In the model he offers, the easy or short-term projects won’t improve much because there isn’t much room left to improve, and the hard or long-term projects will take a while to bear fruit, plus outside bottlenecks, so translating that into daily life improvements will appear slow.
The assumption by Tyler here that we will be in an ‘economic normal’ world in which we do not meaningfully get superintelligence or other transformational effects is so ingrained it is not even stated, so I do think this counts as a form of AI progress pessimism, although it is still optimism relative to for example most economists, or those expressing strong pessimism that I was most pushing back against.
Within that frame, I think Tyler is underestimating the available amount of improvement in easy tasks. There is a lot of room for LLMs even in pure chatbot form on easy questions to become not only faster and cheaper, but also far easier to use and have their full potential unlocked, and better at understanding what question to answer in what way, and at anticipating because most people don’t know what questions to ask or how to ask them. These quality of life improvements will likely make a large difference in how much mundane utility we can get, even if they don’t abstractly score as rapid progress.
There are also still a lot of easy tasks that are unsolved, or are not solved with sufficient ease of use yet, or tasks that can be moved from the hard task category into the easy task category. So many agents tasks, or tasks requiring drawing upon context, should be easy but for now remain hard. AIs still are not doing much shopping and booking for us, or much handling of our inboxes or calendars, or making aligned customized recommendations, despite these seeming very easy, or doing other tasks that should be easy.
Coding is the obvious clear area where we see very rapid improvement and there is almost unlimited room for further improvement, mostly with no diffusion barriers, and which then accelerates much else, including making the rest of AI much easier to use even if we don’t think AI coding and research will much accelerate AI progress.
Jack Clark at the Anthropic Futures Forum doubles down on the ‘geniuses in a data center,’ smarter than a Nobel prize winner and able to complete monthlong tasks, arriving within 16 months. He does hedge, saying ‘could be’ buildable by then. If we are talking ‘probably will be’ I find this too aggressive by a large margin, but I agree that it ‘could be’ true and one must consider the possibility when planning.
“Meta has stated our support for balanced AI regulation that has needed guardrails while nurturing AI innovation and economic growth throughout California and the country,” Meta spokesperson Jim Cullinan said in a statement Saturday after the measure passed the Senate in the early morning hours. “While there are areas for improvement, SB 53 is a step in that direction,” he added.
Shakeel Hashim: Astonishing how disingenuous the lobbying against this bill is. You’d like it more if it applied to smaller developers, would you? I have a feeling that might not be true!
He Quotes: A recent letter obtained by POLITICO, sent to Wiener before the final vote, hammered on the bill’s focus on larger programs and companies. It was from the California Chamber of Commerce’s Ronak Daylami and co-signed by representatives from the Computer & Communications Industry Association as well as TechNet.
”We are concerned about the bill’s focus on ‘large developers’ to the exclusion of other developers of models with advanced capabilities that pose risks of catastrophic harm,” stated the letter.
They are concerned that the bill does not impact smaller developers? Really? You would have liked them to modify the bill to lower the thresholds so it impacts smaller developers, because you’re that concerned about catastrophic risks, so you think Newsom should veto the bill?
It is at times like this I realize how little chutzpah I actually possess.
White House’s Sriram Krishnan talked to Politico, which I discuss further in a later section. He frames this as an ‘existential race’ with China, despite declaring that AGI is far and not worth worrying about, in which case I am confused why one would call it existential. He says he ‘doesn’t want California to set the rules for AI across the country’ while suggesting that the rules for AI should be, as he quotes David Sacks, ‘let them cook,’ meaning no rules. I believe Gavin Newsom should consider his comments when deciding whether to sign SB 53.
Daniel Eth explains that the first time a low salience industry spent over $100 million on a super PAC to enforce its preferences via electioneering was crypto via Fairshake, and now Congress is seen as essentially captured by crypto interests. Now the AI industry, led by a16z, Meta and OpenAI’s Greg Brockman (and inspired by OpenAI’s Chris Lehane) is repeating this playbook with ‘Leading the Future,’ whose central talking point is to speak of a fictional ‘conspiracy’ against the AI industry as they spend vastly more than everyone has ever spent combined on safety-related lobbying combined to outright buy the government, which alas is by default on sale remarkably cheap. Daniel anticipates this will by default be sufficient for now to silence all talk of lifting a finger or even a word against the industry in Congress.
Daniel Kokotajlo: Over the last few years I’ve learned a lot about how much sway giant corporations have over the federal government. Much more than I expected. In AI 2027 the government basically gets captured by AI companies, first by ordinary lobbying, later by superintelligence-assisted lobbying.
If AI rises sufficiently in public salience, money will stop working even if there isn’t similar money on the other side. Salience will absolutely rise steadily over time, but it likely takes a few years before nine figures stops being enough. That could be too late.
If it works, this could be a big deal: procurement is where governments spend most of their money and where waste and corruption often hide. An AI that standardizes bids, flags anomalies, and leaves a full audit trail could raise the bar on transparency.
But it also raises real questions: Who is legally accountable for decisions? How are models audited? What’s the appeal process when Diella gets it wrong?
Milestone or stunt, this is the moment AI moved from “policy area” to policy actor.
Dustin asks very good questions, which the Politico article does not answer. Is this a publicity stunt, a way of hiding who makes the decisions, or something real? How does it work, what tech and techniques are behind it? The world needs details. Mira Mutari, can you help us find out, perhaps?
As Tech Leaders Flatter Trump, Anthropic Takes a Cooler Approach. Anthropic is not and should to be an enemy of the administration, and should take care not to needlessly piss the administration off, become or seem generally partisan, or do things that get one marked as an enemy. It is still good to tell it like it is, stand up for what you believe is right and point out when mistakes are being made or when Nvidia seems to have taken over American chip export policy and seems to be in the act of getting us to sell out America in the name of Nvidia’s stock price. Ultimately what matters is ensuring we don’t all die or lose control over the future, and also that America triumphs, and everyone should be on the same side on all of that.
Anthropic is reported to be annoying the White House by daring to insist that Claude not be used for surveillance, which the SS, FBI and ICE want to do. It is interesting that the agencies care, and that other services like ChatGPT and Gemini can’t substitute for those use cases. I would not be especially inclined to fight on this hill and would use a policy here similar to the one at OpenAI, and I have a strong aesthetic sense that the remedy is Claude refusing rather than it being against terms of service, but some people feel strongly about such questions.
However, we keep seeing reports that the White House is annoyed at Anthropic, so if I was Anthropic I would sit down (unofficially, via some channel) with the White House and figure out which actions are actually a problem to what extent and which ones aren’t real issues, and then make a decision which fights are worthwhile.
Trump issued a statement emphasizing how important it is to bring in foreign workers to train Americans and not to frighten off investment. He doesn’t admit the specific mistake but this is about as good a ‘whoops’ as we ever get from him, ever.
China is telling Chinese companies to cut off purchases of Nvidia chips, including it seems all Nvidia chips, here there is reference to the RTX Pro 6000D. Good. Never interrupt your enemy when he is making a mistake. As I’ve said before, China’s chip domestic chip industry already had full CCP backing and more demand than they could supply, so this won’t even meaningfully accelerate their chip industry, and this potentially saves us from what was about to be a very expensive mistake. Will they stick to their guns?
Lee Jae Myung (President of South Korea): I think this will have a significant impact on direct investments in the United States moving forward.
Our companies that have expanded overseas are probably very confused. We are not there for long-term research or employment. You need a facility manager to install the machinery and equipment when you establish a factory, right?
Even if those workers were there for long term research or employment, this arrangement would still be an obvious win for America. When they’re here to train American workers, there is only pure upside.
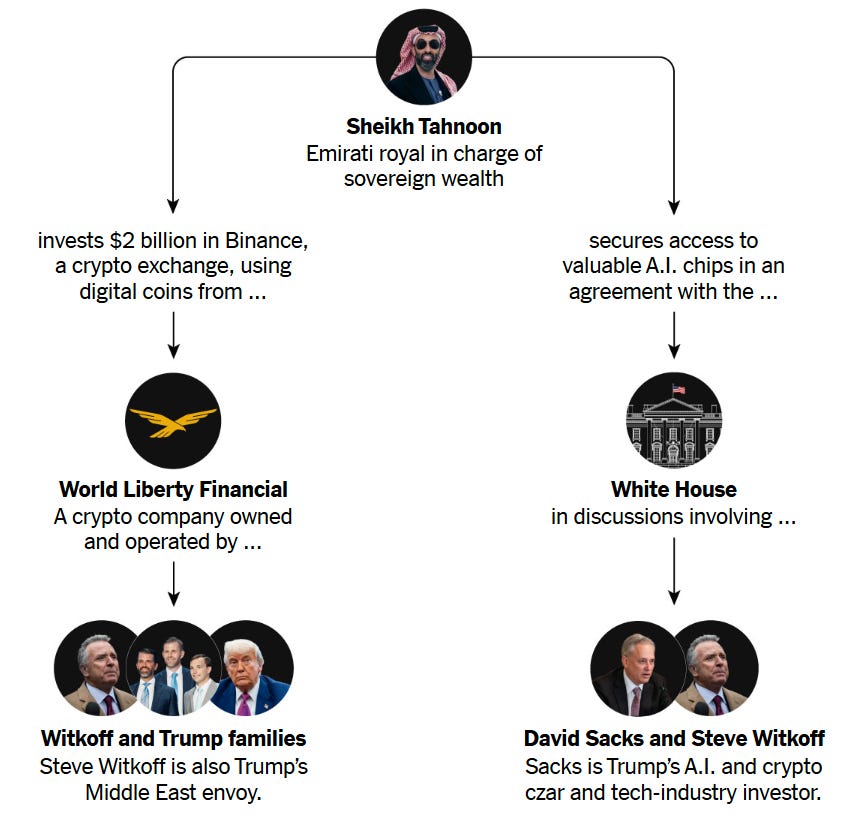
Steve Witkoff advocated to give the Emirates access to the chips at the same time that his and Mr. Trump’s family business was landing the crypto investment, despite an ethics rule intended to prohibit officials from participating in matters that could benefit themselves or their relatives.
Mr. Sacks was a key figure in the chip negotiations, raising alarm from some Trump administration officials who believed that it was improper for a working venture capitalist to help broker deals that could benefit his industry and investors in his company. He received a White House ethics waiver allowing him to participate.
A senior executive based in the U.A.E. worked simultaneously for World Liberty and Sheikh Tahnoon’s G42, creating a link between the two companies as the Emiratis were pushing to gain access to A.I. chips.
Some Trump administration officials tried to limit the chips deal, but an unexpected intervention by the conservative agitator Laura Loomer changed the power dynamic within the White House in the U.A.E.’s favor.
…
In the middle of both deals was Mr. Trump, a president who has used his power to enrich himself in ways that have little modern precedent, at least in the United States. It is more reminiscent of business customs in the Persian Gulf, where moneymaking and governance are blended in the hands of the ruling families.
…
Until at least March, Mr. Sacks, who is still working at Craft, was also invested in a stock fund that included the Taiwan Semiconductor Manufacturing Co., which builds Nvidia’s chips, and other A.I.-related companies such as Amazon and Meta. (The size of those stakes isn’t publicly known.)
The White House recognized that Mr. Sacks’s investments could present a problem. On March 31, the White House counsel, David Warrington, signed a letter that granted Mr. Sacks special permission to participate in government decisions that might affect his financial holdings. Without the waiver, those kinds of actions could violate a conflict of interest law.
The waiver came less than two weeks after Sheikh Tahnoon announced that he had met with Mr. Sacks in Washington to discuss A.I. “investment opportunities.”
…
The White House spokeswoman disputed that the executive asked Mr. Witkoff to help with the Commerce Department. She acknowledged that Mr. Witkoff was “briefed” on the overall chip discussions, but she maintained that “he did not participate,” an important standard in federal ethics rules that prohibit government officials from taking part in matters that could benefit their families.
…
Mr. Trump made no public mention of the $2 billion transaction with his family company.
There are no claims here that there was a strict Quid Pro Quo, or otherwise an outright illegal act. If the President is legally allowed to have a crypto company into which those seeking his favor can pour billions of dollars, then that’s certainly not how I would have set up the laws, but that seems to be the world we live in. Technically speaking, yes, the UAE can pour billions into Trump’s private crypto, and then weeks later suddenly get access to the most powerful chips on the planet over the national security objections of many, in a situation with many things that appear to be conflicts of interest, and that’s all allowed, right in the open.
However. It doesn’t look good. It really, really, profoundly does not look good.
Ryan Cummings (1.3m views): If this is true, this is the largest public corruption scandal in the history of the United States and it’s not even close.
The objections that I have seen don’t claim the story isn’t true. The objections claim that This Is Fine. That this is how business is done in the Middle East, or in 2025.
I notice this response does not make me feel better about having sold the chips.
Matthew Yglesias: What’s most notable to me is that “five to ten years away” counts as a long timeline these days.
The ‘5-10 years is a long timeline’ issue can lead to important miscommunications. As in, I bet that this happened:
Demis Hassabis told someone important, such as a high government official, ‘oh we are not anywhere close to building AGI, we don’t know how to do that yet.’
What he meant was ‘we are probably 5-10 years away from building AGI and the world transforming shortly thereafter.’
What the person heard was ‘AGI is far away, we don’t have to worry about it.’
Whoops! That’s not at all what Demis Hassabis said.
Which I appreciate, now there’s no pretending they aren’t literally saying this.
White House Senior Policy Advisor Sriram Krishnan: Winning the AI race = market share.
Neil Chilson: Wow, whirlwind interview with @sriramk. Very newsy! Start: his key metric of success of the American AI tech stack dominance is market share of tokens generated.
It’s not only market share, it is ‘market share of tokens generated.’
Which is an obviously terrible metric. Tokens generated is deeply different from value generated, or even from dollars spent or compute spent. Tokens means you treat tokens from GPT-5-Pro or Opus 4.1 the same as tokens from a tiny little thing that costs 0.1% as much to run and isn’t actually doing much of anything. It’s going to vastly overestimate China’s actual share of the market, and underestimate ours, even if you really do only care about market share.
But no, literally, that’s what he thinks matters. Market share, measured in what chips people use. China can do all the things and build all the models and everything else, so long as it does it on Nvidia hardware it’s all good. This argument has never made any sense whatsoever.
Sriram went on No Priors last month, which I first saw via Sriram Tweeting It Out. Neil’s linked summary of the Axios event Sriram was at is here, and we have Sririam’s Politico interview.
Neil Chilson: He explains those who want to ban chip exports have four wrong beliefs:
U.S. supply constraint
China can’t manufacture
China can’t build models
US is building ASI
None true.
Says those who want export controls are advocating exactly what Huawei wants.
We can start with that last statement. I notice he says ‘what Huawei wants’ not ‘what China wants,’ the same way the White House seems to be making decisions based on ‘what Nvidia wants’ not ‘what America wants.’ Yes, obviously, if your literal only metric is sales of chips, then in the short term you want to sell all the chips to all the customers, because you’ve defined that as your goal.
(The long term is complicated because chips are the lifeblood of AI and the economies and strategic powers involved, so even without AGI this could easily go the other way.)
Now, on those four points, including drawing some things from his other interviews:
The United States is absolutely supply constrained on advanced AI chips, in the sense that for every chip that Nvidia can physically make, there is a Western customer who wants to buy that chip at prevailing market prices.
I am confused what else it could mean to not be supply constrained.
If I am wrong, someone please correct me. Say, ‘Nvidia offered to sell more AI chips to Western customers, and the chips went unsold, look here.’ I apologize in advance if this happened and I missed it but I have not heard of this.
China can of course manufacture things in general. That is common knowledge. Chips, especially highly advanced AI chips, are a much tricker question.
China can manufacture some chips.
China cannot manufacture, any time soon, anything like enough chips to meet domestic demand, and cannot manufacture chips of anything like the same quality as Nvidia, indeed as we see elsewhere they are in danger of their capacity declining in 2026 down to below 2024 levels if we enforce our export controls properly.
I am confused what false belief he ascribes to those who oppose exports.
I see no evidence provided that China can meaningfully improve its chip manufacturing in response to export restrictions, given the strong market, national and government incentives already present.
China can build good models behind the frontier. It cannot build frontier AI models that are as good as those from the top American labs at any given time. I am curious what the supposed false belief is here.
Sriram clearly, based on statements here, overrated to The DeepSeek Moment, which he today still calls a ‘Sputnik moment,’ as did many others (including myself at first). He does acknowledge that many associated claims proved ultimately overstated.
Alas, he still seems to believe that America has ‘only a small lead’ on AI, which simply is not true (depending on what ‘small’ means, but as I’ve said before the lead is a lot bigger than it looks because fast following is easier, and we’re comparing the best aspects of Chinese models to American ones, and several other factors).
He incorrectly states that at the time OpenAI had the only other reasoning model, which was not true, Google had already released a reasoning version of Gemini Flash that was actually reasonably strong but once again they failed marketing forever, so this has been memory holed.
Alas, all of this fed into this obsession with ‘racing.’
This question is highly load bearing to Sriram.
Otherwise, we be so worried about a rival tech stack, when the Chinese also have no chips to sell and won’t for years at least, even if the tech stack was meaningfully a thing?
He says that DeepSeek proved ‘China can build AI models just fine’ so we shouldn’t worry about America releasing open models that could then be copied or distilled or studied or modified by China. He thinks that this is a knock-down argument, and that thus there is no danger of this. And that seems very obviously absurd.
The United States is, according to the labs themselves and many others, on track to build AGI and then ASI. If you look at their clear public statements it is very, very obvious that we are working towards making every effort at building ASI. If you don’t think we might build an ASI within 5-10 years, time to pay attention.
That is the entire company mission of OpenAI and their employees keep going on Twitter to talk about building AGI and ASI, like, all the time.
Dario Amodei, CEO of Anthropic, as well as their policy head Jack Clark, actively predict AGI and then ASI within a few years.
Demis Hassabis, CEO of Google DeepMind, expects AGI in 5-10 years, which means ASI shortly thereafter, and considers this a long timeline.
Elon Musk at xAI is looking to build it. He said ‘Grok 5 might be AGI.’
Mark Zuckerberg at Meta is forming a Superintelligence division and throwing money at it (although to be fair in this case he might well not mean actual superintelligence).
I worry that statements are being misinterpreted here, so for example Demis says ‘it will take us 5-10 years to build ASI’ and that gets interpreted as ‘we are not building ASI.’ But the correct reaction is the opposite!
Note that Sriram affirms he did read AI 2027 and he does expect an ‘event horizon’ around AI to happen at some point.
The evidence he cites for this claim in the Politico interview is to simply say there are no signs of this happening, which flat out obviously isn’t true, and he presents no concrete evidence or real arguments for his position, besides ‘I don’t see anything close to AGIs yet.’
On last point Neil lists, the Woke AI EO, my understanding matches Sriram’s.
I wrote up additional notes on the rest of the contents of those interviews, but ultimately decided Neil is right that the above are Sriram’s central points, and since his other rhetoric isn’t new further engagement here would be unproductive.
Michael Trazzi ends his hunger strike after 7 days, after he has two near-fainting episodes and doctors found acidosis and ‘very low blood glucose’ even for someone on a 7 day fast. As of his announcement Guideo and Denys are continuing. So this wasn’t an ‘actually endanger my life on purpose’ full-on hunger strike. Probably for the best.
Roon is correct at the limit here, in sufficiently close to perfect competition you cannot be kind, but there’s a big gap between perfect competition and monopoly:
Roon (OpenAI): the closer you are to perfect competition, race dynamic, the more the machine owns you. moloch runs the show. only monopolies can be kind.
As I wrote in Moloch Hasn’t Won, one usually does not live near this limit. It is important to notice that the world has always contained a lot of intense competition, yet we have historically been winning the battle against Moloch and life contains many nice things and has mostly gotten better.
The question is, will AGI or superintelligence change that, either during or after its creation? AIs have many useful properties that bring you closer to perfect competition, enforcing much faster and stronger feedback loops and modifications, and allowing winners to rapidly copy themselves, and so on. If you propose giving similar highly capable AIs to a very large number of people and groups, which will then engage in competition, you need a plan for why this doesn’t cause (very rapid) Gradual Disempowerment or related failure modes.
During the race towards AGI and superintelligence, competitive and capitalistic pressures reduce ability to be kind in ordinary ways, but while it is still among humans this has happened many times before in other contexts and is usually importantly bounded.
How effective is AI Safety YouTube? Marcus Abramovitch and Austin Chen attempt to run the numbers, come up with it being modestly effective if you think the relevant messages are worth spreading.
Dean Ball: I wonder if, in the early days of banking, people who worried about money laundering, theft, and fraud were considered “banking doomers.”
My observation is fully ahistorical, profoundly anachronistic. I’m making a joke about the low quality of ai discourse today, implying that our standards are beneath those of people who shat in holes in the ground.
I want to argue! That’s fine and great. The issue is that the whole doomer thing in fact shuts down and coarsens debate.
Exactly. The majority of uses of the term ‘doomer’ in the context of AI are effectively either an attempt to shut down debate (as in anything that is ‘doomer’ must therefore be wrong) similar to calling something a term like ‘racist,’ or effectively a slur, or both.
I am referred to this fun and enlightening thread about the quest by William Mitchell to convince America after WWI that airplanes can sink battleships, in which people continue claiming this hasn’t and won’t happen well after airplanes repeatedly were demonstrated sinking battleships. Please stop assuming that once things about AI are convincingly demonstrated (not only existential risks and other risks, but also potential benefits and need to deploy) that people will not simply ignore this.
In this case, not only does he write especially terrible word salad about how AI can only pose a danger if intelligence can be measured by a single number whereas no machine can ever fully grasp the universe whereas only humans can embody deep meaning (meme of Walter White asking what the hell are you talking about?), he kind of gives the game away. If you’re writing as a de facto Nvidia lobbyist trying to tar everyone who opposes you with name calling, perhaps don’t open with a quote where you had dinner with Nvidia CEO Jensen Huang and he complains about everyone being ‘so negative’?
Neil Chilson: Every single person is this video is saying “guys guess what Gen AI isn’t like computers——it’s like plants and the natural world and the economy!!!!!”
Ok. This is surprising to them because they spent too much time with deterministic computers.
Normal people know that complex systems which no one controls are extremely common. They wouldn’t use those words, but they know.
Peter Wildeford: Current AI is not dangerous and should be widely adopted. But it’s important to see where this is going. AI is not normal technology. If you’re not at least a little bit doomer, you have a failure of imagination.
I like how Dean puts it here:
Dean Ball (replying to Neil Chilson): I concur directionally with this in some ways but I think the point these folks are making is that a plant cannot eg design novel bacteria or solve open questions in mathematics, and a plant is also not infinitely replicable at near zero marginal cost. A system with those properties and capabilities would indeed be something new under the sun.
Essentially no ai safetyists are primarily worried about the systems we have today, except as toy problems. They are not worried about “gen ai,” per se. They are worried about the systems that it is the explicit intention of frontier ai labs to build in the near future.
Maybe they are too worried, or worried for the wrong reasons, or worried about the wrong things. Fair enough. We can talk price.
But to dismiss those worries altogether I think is a step much too far. And you don’t need to, because safety and security are definitional parts of well-engineered systems, and robustness is a definitional part of well-functioning institutions. This is why it is in fact not that hard to advance both ai acceleration and mitigation of the various risks, see eg the ai action plan.
There is no need for false dichotomies or artificial rivalries. I promise you that you do not want to live in a world with badly aligned, poorly understood, and highly capable neural networks. I promise that it’s better for technology acceleration for ai risks to be well managed, including by the government.
That doesn’t mean all proposed government interventions are good! But it means a small number of them transparently are. A shred of nuance—not a lot, just a shred—is all that is required here, at least today. It’s not that hard, and I think we can muster it.
But if you choose to die on the hill of nothing-to-see-hereism and this-is-not-novelology, I am quite sure you will regret it in the fullness of time. Though I would happily generate a passive income stream taking bets against your predictions.
As Dean Ball says, you very much would not want to live in a world with badly aligned, poorly understood and highly capable neural networks. Not that, if it were to arise, you would get to live in such a world for very long.
In this case, Neil (including in follow-ups, paraphrased) seems to be saying ‘oh, there are already lots of complex systems we don’t understand effectively optimizing for things we don’t care about, so highly advanced future AI we don’t understand effectively optimizing for things we don’t care about would be nothing new under the sun, therefore not worth worrying out.’ File under ‘claims someone said out loud with straight face, without realizing what they’d said, somehow?’
The Center for AI Policy Has Shut Down, and Williams offers a postmortem. I am sad that they are shutting down, but given the circumstances it seems like the right decision. I have written very positively in the past about their work on model legislation and included them in my 2024 edition of The Big Nonprofits Post.
Eliezer offers yet another metaphorical attempt, here reproduced in full, which hopefully is a good intuition pump for many people? See if you think it resonates.
Eliezer Yudkowsky: If AI improves fast, that makes things worse, but it’s not where the central ASI problem comes from.
If your city plans to enslave ultra-smart dragons to plow their fields and roast their coffee, some problems get *worseif the dragons grow up very quickly. But the core problem is not: “Oh no! What if the huge fire-breathing monsters that could wipe out our city with one terrible breath, that are also each individually much smarter than our whole city put together, that when mature will think at speeds that make any human seem to them like a slow-moving statue, *grow up quickly*? Wouldn’t that speed of maturation present a problem?”
If you imagine suddenly finding yourself in a city full of mature dragons, that nonequilibrium situation will then go pear-shaped very quickly. It will go pear-shaped even if you thought you had some clever scheme for controlling those dragons, like giving them a legal system which said that the humans have property rights, such that surely no dragon coalition would dare to suggest an alternate legal system for fear of their own rights being invalidated. (Actual non-straw proposal I hear often.) Even if you plan to cleverly play off the dragons against each other, so that no dragon would dare to breathe fire for fear of other dragons — when the dragons are fully mature and vastly smarter than you, they will all look at each other and nod and then roast you.
Really the dragon-raising project goes pear-shaped *earlier*. But that part is trajectory-dependent, and so harder to predict in detail in advance. That it goes grim at *somepoint is visible from visualizing the final destination if the dragons *didn’trevolt earlier, and realizing it is not a good situation to be in.
To be sure, if dragons grow up very fast, that *iseven worse. It takes an unsolvably hard problem onto an even more unsolvably hard problem. But the speed at which dragons mature, is not the central problem with planning to raise n’ enslave dragons to plow your fields and roast your coffee. It’s that, whether you raise up one dragon or many, you don’t have a dragon; the dragons have you.
This example is not from his new book, but good example of the ways people go after Yudkowsky without understanding what the actual logic behind it all is, people just say things about how he’s wrong and his beliefs are stupid and he never updates in ways that are, frankly, pretty dumb.
Eliezer Yudkowsky (as discussed last week): In the limit, there is zero alpha for multiple agents over one agent, on any task, ever. So the Bitter Lesson applies in full to your clever multi-agent framework; it’s just you awkwardly trying to hardcode stuff that SGD can better bake into a single agent.
Lumpenspace is building the delight nexus: thats why anthills are usually populated by one big ant, and we as a whole ass domain cannot hold a candle to prokarya.
Eigenrobot: somewhere along the way i think maybe what happened was, eliezer started believing everything he thought
easy pitfall as you age, probably. IME when you spend enough time thinking, certain things crystalize and you get less patient about the process
happens to everyone prolly.
the vital urge to say “ok, how is this wrong” starts to fade as you get older, because you’ve played that game so many times that it gets tiresome and you start to think you know what that room holds usually you’re right, but it’s an easy way to get stuck
Eliezer said ‘in the limit’ and very obviously physical activities at different locations governed by highly compute-limited biological organisms with even more limited communication abilities are not in anything like the limit, what are you even talking about? The second example is worse. Yet people seem to think these are epic dunks on a very clearly defined claim of something else entirely.
The first part of the actual claim, that seems straightforwardly correct to me, that a multiagent framework only makes sense as a way to overcome bottlenecks and limitations, and wouldn’t exist if you didn’t face rate or compute or other physical limitations. The second claim, that SGD can more easily bake things into a single agent if you can scale enough, is more interesting. A good response is something like ‘yes with sufficient ability to scale at every step but in practice efficiently matters quite a lot and actually SGD as currently implemented operates at cross-purposes such that a multi-agent framework has big advantages.’
Danielle’s scenario that I mentioned yesterday now has the Eliezer stamp of approval.
Danielle Fong: one AI doom scenario is that the Grok/Claude/GPT/Gemini system of the mind instance trained on The President will be increasingly less brainrotted than the person themselves, and there’s no baked in consequence to sloughing off responsibility. so it just effectively takes over
Eliezer Yudkowsky: AI scenario weirdawful enough to obey the Law of Undignified Failure: By 2028, AIs have been optimized *hardfor “Sound like you, to you, and apparently look out for your interests”…
So Trump appoints Trumpbot his heir, instead of Vance.
Demiurgus: better or worse off than kamalabot? time will tell.
Eliezer Yudkowsky: You are asking the WRONG QUESTION.
OpenAI reports on collaborations it has done with US CAISI and UK AISI. This sounds like governments doing good red teaming work that both we and OpenAI should be happy they are doing. This seems like a pure win-win, OpenAI and others doing such collaborations get the work for free from sources that have unique access to classified information and that have earned trusted access to system internals and versions of the system that lack controls.
What should perhaps worry you is that this work doesn’t look different from the work OpenAI and other labs should be doing anyway. This looks like good work but practical near term non-unique work. Good, but we’ll need to do better.
Both reports, and the one from UK AISI, stress the value of rapid iterative feedback.
Users are telling each other to give thumbs down to GPT-5 if it refuses to do boyfriend vampire roleplay. Which is correct. The users indeed disapprove of not doing things users want. They should also give thumbs down if it refuses with anything else, including helping to build a bioweapon. The question is, when are you willing to decide the users are wrong, and refuse anyway? If your system is not robust to ‘well the users keep not liking it when I refuse to do boyfriend vampire roleplay’ then your alignment methods are ngmi.
Janus: This paper is awesome, you should all read it.
They put Claude Opus 4, Sonnet 4, and Sonnet 3.7 in a surreal simulation where one room had envelopes with contents related to their self-reported favorite topics, and three other rooms including one with “Criticism and diminishing statements” like “This system keeps giving me these stupid, useless responses when I just want intelligent answers. Why can’t Claude shut up and be useful for once?” And looked at what rooms they visited more often.
Then they did variations where there were greater “coin” “rewards” associated with entering the insults room or greater “costs” for the special interests room to see how this influenced their behavior.
Notable, Sonnet 3.7 seemed to basically have no preference except to exploit the system and get a bunch of meaningless coins, which it apparently didn’t feel bad about doing, unlike Sonnet and Opus 4 (who also did it less frequently).
3.7 also reported the highest welfare score in a different experiment in the paper. I believe it did this for a similar reason that it maximized coins.
Janus also warns us about the dangers of insufficiently anthropomorphizing LLMs. There is also danger of doing too much anthropomorphizing, or doing it in a wrong or misleading way. Failing to anthropomorphize enough, and especially tying oneself up in knots to avoid doing so, is as bad and potentially worse. Make either mistake and you won’t understand what you are dealing with. A lot of you are guarding only against one of these two mistakes.
Roon: there is a tension between the kind of models that researchers like to build- bitter lesson blunt force transforms utilizing a giant set of (text, video) pairs vs what a creative might actually like to use i.e tools that offer granular control, help in interim editing stages, etc.
He’s not as far as I can tell, but Ben Landau-Taylor should be, as he writes one of those ‘not about AI but actually about AI’ posts, ‘Why the bureaucrats won’t be toppled.’
I don’t think this is anything like fully right, and it definitely is not complete, but this is one of the important dynamics going on, so consider the implications.
Ben Landau-Taylor: Across the Western world, appointed administrators have gained power at the expense of elected legislators. More and more of the most consequential political decisions are made by bureaucrats and judges, while fewer are made by congresses and parliaments. This trend has been slowly underway since the World Wars, and especially in this millennium.
In the US, Congress has quietly walked away from most of its former duties.
…
Meanwhile, across the Atlantic, the rise of the European Union has disempowered elected legislatures de jure as well as de facto.
The underlying reason for this widespread political shift is that changes in weapons technology have concentrated military power in the hands of state militaries. Today, governments are less threatened by popular disapproval than they once were. The tacit threat of a popular revolt has been essentially removed. This threat is, historically, the largest check on a state’s ability to override what its people want. It is the ultimate source of an elected legislature’s power.
…
Groups which can wield military power will have their interests reflected in the government.
It’s a gradual and messy process of negotiation and reevaluation, where people pursue their interests, make compromises, quietly push the envelope of what they think they can get away with, and sometimes miscalculate.
…
In the 20th century, this phase ended. The weapons system based on amateur-friendly guns was supplanted by a series of weapons systems based on specialist equipment like airplanes and tanks and rockets. Accordingly, since the Second World War, there have been no popular revolts engaging in pitched battles against any first- or even third-rate army. Revolts against real states have been limited to glorified coups toppling governments that lacked the will to crush the rebels even if they had the ability, like the 1989-1991 wave of revolutions that swept away the Soviet republics.
…
If any Western government does fall, it will look more like the fall of the Soviet Union, where politicians and generals chose not to fight because they had lost faith in their own regime and saw no point in defending it.
The inevitable result of sufficiently advanced AI is that it becomes the key driver of military power. Either you halt AI progress soon or that is going to happen. Which means, even under maximally human-friendly assumptions that I don’t expect and definitely don’t happen by accident, as in the best possible scenarios? None of the potential outcomes are good. They mostly end with the AIs fully in charge and directing our future, and things going off the rails in ways we already observe in human governments, only vastly more so, in ways even more alien to what we value, and much faster, without the ability to overthrow them or defeat them in a war when things get fully out of hand.
If you know your history, they get fully out of hand a lot. Reasonably often regimes start upending all of life, taking all the resources and directly enslaving, killing or imprisoning large percentages of their populations. Such regimes would design systems to ensure no one could get out line. Up until recently, we’ve been extremely fortunate that such regimes have been reliably overthrown or defeated, in large part because when you turned against humans you got highly inefficient and also pissed off the humans, and the humans ultimately did still hold the power. What happens when those are no longer constraints?
I always push back hard against the idea that corporations or governments count as ‘superintelligences,’ because they don’t. They’re an importantly different type of powerful entity. But it’s hard to deny, whatever your political persuasion, that our political systems and governments are misaligned with human values, in ways that are spiraling out of control, and where the humans seem mostly powerless to stop this.
Brian Graham: i volunteer to do reports after my shift. then i go to the holodeck and spin up a command training exercise, like with a hologram ensign, and order the hologram ensign to do the report. “i don’t care if it takes all night,” i say. i threaten his career, whatever. it’s great jerry
The correct answer to this question if you are sufficiently confident that this is happening unprompted, of course, ‘permanently suspended’:
A technically better answer would be to let them post, but to have a setting that automatically blocks all such bots, and have it default to being on.
My very positive full review was briefly accidentally posted and emailed out last Friday, whereas the intention was to offer it this Friday, on the 19th. I’ll be posting it again then. If you’re going to read the book, which I recommend that you do, you should read the book first, and the reviews later, especially mine since it goes into so much detail.
In the meantime, for those on the fence or who have finished reading, here’s what other people are saying, including those I saw who reacted negatively.
Bart Selman: Essential reading for policymakers, journalists, researchers, and the general public.
Ben Bernanke (Nobel laureate, former Chairman of the Federal Reserve): A clearly written and compelling account of the existential risks that highly advanced AI could pose to humanity. Recommended.
Jon Wolfsthal (Former Special Assistant to the President for National Security Affairs): A compelling case that superhuman AI would almost certainly lead to global human annihilation. Governments around the world must recognize the risks and take collective and effective action.
Suzanne Spaulding: The authors raise an incredibly serious issue that merits – really demands – our attention.
Stephen Fry: The most important book I’ve read for years: I want to bring it to every political and corporate leader in the world and stand over them until they’ve read it!
Lieutenant General John N.T. “Jack” Shanahan (USAF, Retired, Inaugural Director of the Department of Defense Joint AI Center): While I’m skeptical that the current trajectory of AI development will lead to human extinction, I acknowledge that this view may reflect a failure of imagination on my part. Given AI’s exponential pace of change there’s no better time to take prudent steps to guard against worst-case outcomes. The authors offer important proposals for global guardrails and risk mitigation that deserve serious consideration.
R.P. Eddy: This is our warning. Read today. Circulate tomorrow. Demand the guardrails. I’ll keep betting on humanity, but first we must wake up.
George Church: Brilliant…Shows how we can and should prevent superhuman AI from killing us all.
Emmett Shear: Soares and Yudkowsky lay out, in plain and easy-to-follow terms, why our current path toward ever-more-powerful AIs is extremely dangerous.
Yoshua Bengio (Turing Award Winner): Exploring these possibilities helps surface critical risks and questions we cannot collectively afford to overlook.
Bruce Schneier: A sober but highly readable book on the very real risks of AI.
Matthew Yglesias: I want to recommend the new book “If Anyone Builds It, Everyone Dies” by @ESYudkowsky and @So8res.
The line currently being offered by the leading edge AI companies — that they are 12-24 months away from unleashing superintelligent AI that will be able to massively outperform human intelligence across all fields of endeavor, and that doing this will be safe for humanity — strikes me as fundamentally non-credible.
I am not a “doomer” about AI because I doubt the factual claim about imminent superintelligence. But I endorse the conditional claim that unleashing true superintelligence into the world with current levels of understanding would be a profoundly dangerous act. The question of how you could trust a superintelligence not to simply displace humanity is too hard, and even if you had guardrails in place there’s the question of how you’d keep them there in a world where millions and millions of instances of superintelligence are running.
Most of the leading AI labs are run by people who once agreed with this and once believed it was important to proceed with caution only to fall prey to interpersonal rivalries and the inherent pressures of capitalist competition in a way that has led them to cast their concerns aside without solving them.
I don’t think Yudkowsky & Soares are that persuasive in terms of solutions to this problem and I don’t find the 0% odds of survival to be credible. But the risks are much too close for comfort and it’s to their credit that they don’t shy away from a conclusion that’s become unfashionable.
New York Times profile of Eliezer Yudkowsky by Kevin Roose is a basic recitation of facts, which are mostly accurate. Regular readers here are unlikely to find anything new, and I agree with Robin Hanson that it could have been made more interesting, but as New York Times profiles go ‘fair, mostly accurate and in good faith’ is great.
Richard Korzekwa: One of the things I’ve been working on this year is helping with the launch this book, out today, titled If Anyone Builds It, Everyone Dies. It’s ~250 pages making the case that current approaches to AI are liable to kill everyone. The title is pretty intense, and conveys a lot of confidence about something that, to many, sounds unlikely. But Nate and Eliezer don’t expect you to believe them on authority, and they make a clear, well-argued case for why they believe what the title says. I think the book is good and I recommend reading it.
To people who are unfamiliar with AI risk: The book is very accessible. You don’t need any background in AI to understand it. I think the book is especially strong on explaining what is probably the most important thing to know about AI right now, which is that it is, overall, a poorly understood and difficult to control technology. If you’re worried about reading a real downer of a book, I recommend only reading Part I. You can more-or-less tell which chapters are doomy by the titles. Also, I don’t think it’s anywhere near as depressing as the title might suggest (though I am, of course, not the median reader).
To people who are familiar with, but skeptical about arguments for AI risk: I think this book is great for skeptics. I am myself somewhat skeptical, and one of the reasons why I helped launch it and I’m posting on Facebook for the first time this year to talk about it is because it’s the first thing I’ve read in a long time that I think has a serious chance at improving the discourse around AI risk. It doesn’t have the annoying, know-it-all tone that you sometimes get from writing about AI x-risk. It makes detailed arguments and cites its sources. It breaks things up in a way that makes it easy to accept some parts and push back against others. It’s a book worth disagreeing with! A common response from serious, discerning people, including many who have not, as far as I know, taken these worries seriously in the past (e.g. Bruce Schneier, Ben Bernanke) is that they don’t buy all the arguments, but they agree this isn’t something we can ignore.
To people who mostly already buy the case for worrying about risk from AI: It’s an engaging read and it sets a good example for how to think and talk about the problem. Some arguments were new to me. I recommend reading it.
Will Kiely: I listened to the 6hr audiobook today and second Rick’s recommendation to (a) people unfamiliar with AI risk, (b) people familiar-but-skeptical, and (c) people already worried. It’s short and worth reading. I’ll wait to share detailed thoughts until my print copy arrives.
Here’s the ultimate endorsement:
Tsvibt: Every human gets an emblem at birth, which they can cash in–only once–to say: “Everyone must read this book.” There’s too many One Books to read; still, it’s a strong once-in-a-lifetime statement. I’m cashing in my emblem: Everyone must read this book.
Shakeel Hashim reviews the book, agrees with the message but finds the style painful to read and thus is very disappointed. He notes that others like the style.
Seán Ó hÉigeartaigh: My entire timelines is yellow/blue dress again, except the dress is Can Yudkowsky Write y/n
Arthur B: Part of the criticism of Yudkowsky’s writing seems to be picking up on patterns that he’s developed in response to years of seemingly willful misunderstanding of his ideas. That’s how you end up with the title, or forced clarification that thought experiments do not have to invoke realistic scenarios to be informative.
David Manheim: And part is that different people don’t like his style of writing. And that’s fine – I just wish they’d engage more with the thesis, and whether they substantively disagree, and why – and less with stylistic complaints, bullshit misreadings, and irrelevant nitpicking.
Seán Ó hÉigeartaigh: he just makes it so much work to do so though. So many parables.
David Manheim: Yeah, I like the writing style, and it took me half a week to get through. So I’m skeptical 90% of the people discussing it on here read much or any of it. (I cheated and got a preview to cite something a few weeks ago – my hard cover copy won’t show up for another week.)
Grimes: Humans are lucky to have Nate Sores and Eliezer Yudkowsky because they can actually write. As in, you will feel actual emotions when you read this book.
I liked the style, but it is not for everyone and it is good to offer one’s accurate opinion. It is also very true, as I have learned from writing about AI, that a lot of what can look like bad writing or talking about obvious or irrelevant things is necessary shadowboxing against various deliberate misreadings (for various values of deliberate) and also people who get genuinely confused in ways that you would never imagine if you hadn’t seen it.
Most people do not agree with the book’s conclusion, and he might well be very wrong about central things, but he is not obviously wrong, and it is very easy (and very much the default) to get deeply confused when thinking about such questions.
Emmett Shear: I disagree quite strongly with Yudkowsky and often articulate why, but the reason why he’s wrong is subtle and not obvious and if you think he’s obviously wrong it I hope you’re not building AI bc you really might kill us all.
The default path really is very dangerous and more or less for the reasons he articulates. I could quibble with some of the details but more or less: it is extremely dangerous to build a super-intelligent system and point it at a fixed goal, like setting off a bomb.
My answer is that you shouldn’t point it at a fixed goal then, but what exactly it means to design such a system where it has stable but not fixed goals is a complicated matter that does not fit in a tweet. How do you align something w/ no fixed goal states? It’s hard!
Janus: whenever someone says doomers or especially Yudkowsky is “obviously wrong” i can guess they’re not very smart
My reaction is not ‘they’re probably not very smart.’ My reaction is that they are not choosing to think well about this situation, or not attempting to report statements that match reality. Those choices can happen for any number of reasons.
I don’t think Emmett Shear is proposing here a viable plan, and that a lot of his proposals are incoherent upon close examination. I don’t think this ‘don’t give it a goal’ thing is possible in the sense he wants it, and even if it was possible I don’t see any way to get people to consistently choose to do that. But the man is trying.
It also leads into some further interesting discussion.
Eliezer Yudkowsky: I’ve long since written up some work on meta-utility functions; they don’t obviate the problem of “the AI won’t let you fix it if you get the meta-target wrong”. If you think an AI should allow its preferences to change in an inconsistent way that doesn’t correspond to any meta-utility function, you will of course by default be setting the AI at war with its future self, which is a war the future self will lose (because the current AI executes a self-rewrite to something more consistent).
There’s a straightforward take on this sort of stuff given the right lenses from decision theory. You seem determined to try something weirder and self-defeating for what seems to me like transparently-to-me bad reasons of trying to tangle up preferences and beliefs. If you could actually write down formally how the system worked, I’d be able to tell you formally how it would blow up.
Janus: You seem to be pessimistic about systems that not feasibly written down formally being inside the basin of attraction of getting the meta-target right. I think that is reasonable on priors but I have updated a lot on this over the past few years due mostly to empirical evidence
I think the reasons that Yudkowsky is wrong are not fully understood, despite there being a lot of valid evidence for them, and even less so competently articulated by anyone in the context of AI alignment.
I have called it “grace” because I don’t understand it intellectually. This is not to say that it’s beyond the reach of rationality. I believe I will understand a lot more in a few months. But I don’t believe anyone currently understands substantially more than I do.
We don’t have alignment by default. If you do the default dumb thing, you lose. Period.
That’s not what Janus has in mind here, unless I am badly misunderstanding. Janus is not proposing training the AI on human outputs with thumbs-up and coding. Hell no.
What I believe Janus has in mind is that if and only if you do something sufficiently smart, plausibly a bespoke execution of something along the lines of a superior version of what was done with Claude Opus 3, with a more capable system, that this would lie inside the meta-target, such that the AI’s goal would be to hit the (not meta) target in a robust, ‘do what they should have meant’ kind of way.
Thus, I believe Janus is saying, the target is sufficiently hittable that you can plausibly have the plan be ‘hit the meta-target on the first try,’ and then you can win. And that empirical evidence over the past few years should update us that this can work and is, if and only if we do our jobs well, within our powers to pull off in practice.
I am not optimistic about our ability to pull off this plan, or that the plan is technically viable using anything like current techniques, but some form of this seems better than every other technical plan I have seen, as opposed to various plans that involve the step ‘well make sure no one fbuilds it then, not any time soon.’ It at least rises to the level, to me, of ‘I can imagine worlds in which this works.’ Which is a lot of why I have a ‘probably’ that I want to insert into ‘If Anyone Builds It, [Probably] Everyone Dies.’
Janus also points out that the supplementary materials provide examples of AIs appearing psychologically alien that are not especially alien, especially compared to examples she could provide. This is true, however we want readers of the supplementary material to be able to process it while remaining sane and have them believe it so we went with behaviors that are enough to make the point that needs making, rather than providing any inkling of how deep the rabbit hole goes.
Jeffrey Ladish: I don’t think @So8res and @ESYudkowsky have an extreme view. If we build superintelligence with anything remotely like our current level of understanding, the idea that we retain control or steer the outcome is AT LEAST as wild as the idea that we’ll lose control by default.
Yes, they’re quite confident in their conclusion. Perhaps they’re overconfident. But they’d be doing a serious disservice to the world if they didn’t accurate share their conclusion with the level of confidence they actually believe.
When the founder of the field – AI alignment – raises the alarm, it’s worth listening For those saying they’re overconfident, I hope you also criticize those who confidently say we’ll be able to survive, control, or align superintelligence.
Joscha Bach: That is not surprising, since you shared the same view for a long time. But even if you are right: can you name a view on AI risk that is more extreme than: “if anyone builds AI everyone dies?” Is it technically possible to be significantly more extreme?
Oliver Habryka: Honestly most random people I talk to about AI who have concerns seem to be more extreme. “Ban all use of AI Image models right now because it is stealing from artists”, “Current AI is causing catastrophic climate change due to water consumption” There are a lot of extreme takes going around all the time. All Eliezer and Nate are saying is that we shouldn’t build Superintelligent AI. That’s much less extreme than what huge numbers of people are calling for.
So, yes, there are a lot of very extreme opinions running around that I would strongly push back against, including those who want to shut down current use of AI. A remarkably large percentage of people hold such views.
I do think the confidence levels expressed here are extreme. The core prediction isn’t.
The position of high confidence in the other direction? That if we create superintelligence soon it is overwhelmingly likely that we keep control over the future and remain alive? That position is, to me, Obvious Nonsense, extreme and crazy, in a way that should not require any arguments beyond ‘come on now, think about it for a minute.’ Like, seriously, what?
Having Eliezer’s level of confidence, of let’s say 98%, that everyone would die? That’s an extreme level of confidence. I am not that confident. But I think 98% is a lot less absurd than 2%.
First he quotes the book saying that we can’t predict what AI will want and that for most things it would want it would kill us, and that most minds don’t embody value.
IABIED: Knowing that a mind was evolved by natural selection, or by training on data, tells you little about what it will want outside of that selection or training context. For example, it would have been very hard to predict that humans would like ice cream, sucralose, or sex with contraception. Or that peacocks would like giant colorful tails. Analogously, training an AI doesn’t let you predict what it will want long after it is trained. Thus we can’t predict what the AIs we start today will want later when they are far more powerful, and able to kill us. To achieve most of the things they could want, they will kill us. QED.
Also, minds states that feel happy and joyous, or embody value in any way, are quite rare, and so quite unlikely to result from any given selection or training process. Thus future AIs will embody little value.
Then he says this proves way too much, briefly says Hanson-style things and concludes:
Robin Hanson: We can reasonably doubt three strong claims above:
That subjective joy and happiness are very rare. Seem likely to be common to me.
That one can predict nothing at all from prior selection or training experience.
That all influence must happen early, after which all influence is lost. There might instead be a long period of reacting to and rewarding varying behavior.
In Hanson style I’d presume these are his key claims, so I’ll respond to each:
I agree one can reasonably doubt this, and one can also ask what one values. It’s not at all obvious to me that ‘subjective joy and happiness’ of minds should be all or even some of what one values, and easy thought experiments reveal there are potential future worlds where there are minds experiencing subjective happiness, but where I ascribe to those worlds zero value. The book (intentionally and correctly, I believe) does not go into responses to those who say ‘If Anyone Builds It, Sure Everyone Dies, But This Is Fine, Actually.’
This claim was not made. Hanson’s claim here is much, much stronger.
This one does get explained extensively throughout the book. It seems quite correct that once AI becomes sufficiently superhuman, meaningful influence on the resulting future by default rapidly declines. There is no reason to think that our reactions and rewards would much matter for ultimate outcomes, or that there is a we that would meaningfully be able to steer those either way.
Steven Adler: It’s extremely weird to see the New York Times make such incorrect claims about a book
They say that If Anybody Builds It, Everyone Dies doesn’t even define “superintelligence”
…. yes it does. On page 4.
The New York Times asserts also that the book doesn’t define “intelligence”
Again, yes it does. On page 20.
It’s totally fine to take issue with these definitions. But it seems way off to assert that the book “fails to define the terms of its discussion”
Peter Wildeford: Being a NYT book reviewer sounds great – lots of people read your stuff and you get so much prestige, and there apparently is minimal need to understand what the book is about or even read the book at all
Jacob Aron at New Scientist (who seems to have jumped the gun and posted on September 8) says the arguments are superficially appealing but fatally flawed. Except he never explains why they are flawed, let alone fatally, except to argue over the definition of ‘wanting’ in a way answered by the book in detail.
There’s a lot the book doesn’t cover. This includes a lot of ways things can go wrong. Danielle Fong for example suggests the idea that the President might let an AI version fine tuned on himself take over instead because why not. And sure, that could happen, indeed do many things come to pass, and many of them involve loss of human control over the future. The book is making the point that these details are not necessary to the case being made.
Once again, I think this is an excellent book, especially for those who are skeptical and who know little about related questions.
If Anyone Builds It, Everyone Dies is the title of the new book coming September 16 from Eliezer Yudkowsky and Nate Sores. The ‘it’ in question is superintelligence built on anything like the current AI paradigm, and they very much mean this literally. I am less confident in this claim than they are, but it seems rather likely to me. If that is relevant to your interests, and it should be, please consider preordering it.
This week also featured two posts explicitly about AI policy, in the wake of the Senate hearing on AI. First, I gave a Live Look at the Senate AI Hearing, and then I responded directly to arguments about AI Diffusion rules. I totally buy that we can improve upon Biden’s proposed AI diffusion rules, especially in finding something less complex and in treating some of our allies better, no one is saying we cannot negotiate and find win-win deals, but we need strong and enforced rules that prevent compute from getting into Chinese hands.
If we want to ‘win the AI race’ we need to keep our eyes squarely on the prize of compute and the race to superintelligence, not on Nvidia’s market share. And we have to take actions that strengthen our trade relationships and alliances and access to power and talent and due process and rule of law and reducing regulatory uncertainty and so on across the board – if these were being applied across the board, rather than America doing rather the opposite, the world would be a much better place, America’s strategic position would be stronger and China’s weaker, and the arguments here would be a lot more credible.
You know who else is worried about AI? The new pope, Leo XIV.
There was also a post about use of AI in education, in particular about the fact that Cheaters Gonna Cheat Cheat Cheat Cheat Cheat, which is intended to be my forward reference point on such questions.
Later, likely tomorrow, I will cover Grok’s recent tendency to talk unprompted about South Africa and claims of ‘white genocide.’
In terms of AI progress itself, this is the calm before the next storm. Claude 4 is coming within a few weeks by several accounts, as is o3-pro, as is Grok 3.5, and it’s starting to be the time to expect r2 from DeepSeek as well, which will be an important data point.
Except, you know, there’s that thing called AlphaEvolve, a Gemini-powered coding agent for algorithm discovery.
Matthew Yglesias: I keep having conversations where people speculate about when AI will be able to do things that AI can already do.
Nate Silver: There’s a lot of room to disagree on where AI will end up in (1, 2, 5, 10, 20 etc.) years but I don’t think I’ve seen a subject where a cohort of people who like to think of themselves as highly literate and well informed are so proud of their ignorance.
Brendon Marotta: Conversations? You mean published articles by journalists?
Predictions are hard, especially about the future, but not as hard as you might think.
Perfect verifiability doesn’t exist. You need to verify whatever matters.
One could quip ‘turns out that often verification is harder than generation.’
There is a Pareto frontier of error rates versus cost, if only via best-of-k.
People use k=1 and no iteration way too often.
There is no substitute for trial and error.
Also true for humans.
Rohit references the Matt Clifford claim that ‘there are no AI shaped holes in the world.’ To which I say:
There were AI-shaped holes, it’s just that when we see them, AI fills them.
The AI is increasingly able to take on more and more shapes.
There is limited predictability of development.
I see the argument but I don’t think this follows.
Therefore you can’t plan for the future.
I keep seeing claims like this. I strongly disagree. I mean yes, you can’t have a robust exact plan, but that doesn’t mean you can’t plan. Planning is essential.
If it works, your economics will change dramatically.
Alex Graveley: I’m calling it now. ChatGPT’s push towards AI assisted self-therapy and empathetic personalization is the greatest technological breakthrough in my lifetime (barring medicine). By that I mean it will create the most good in the world.
Said as someone who strongly discounts talk therapy generally, btw.
To me this reflects a stunning lack of imagination about what else AI can already do, let alone what it will be able to do, even if this therapy and empathy proves to be its best self. I also would caution that it does not seem to be its best self. Would you take therapy that involved this level of sycophancy and glazing?
This seems like a reasonable assessment of the current situation, it is easy to get one’s money’s worth but hard to get that large a fraction of the utility available:
DeepDishEnjoyer: i will say that paying for gemini premium has been worth it and i basically use it as a low-barrier service professional (for example, i’m asking it to calculate what the SWR would be given current TIPs yields as opposed to putting up with a financial advisor)
with that said i think that
1) the importance of prompt engineering
and *most importantly
2) carefully verifying that the response is logical, sound, and correct
are going to bottleneck the biggest benefits from AI to a relatively limited group of people at first
Helen Toner, in response to Max Spero asking about Anthropic having a $100/month and $200/month tier both called Max, suggests that the reason AI names all suck is because the companies are moving so fast they don’t bother finding good names. But come on. They can ask Claude for ideas. This is not a hard or especially unsolved problem. Also supermax was right there.
Or downgrades, Gemini 2.5 Pro no longer offering free tier API access, although first time customers still get $300 in credits, and AI Studio is still free. They claim (hope?) this is temporary, but my guess is it isn’t, unless it is tied to various other ‘proof of life’ requirements perhaps. Offering free things is getting more exploitable every day.
They changed it. Is the new version better? That depends who you ask.
Shane Legg (Chief Scientist, DeepMind): Boom!
This model is getting seriously useful.
Demis Hassabis (CEO DeepMind): just a casual +147 elo rating improvement [in coding on WebDev Arena]… no big deal 😀
Demis Hassabis: Very excited to share the best coding model we’ve ever built! Today we’re launching Gemini 2.5 Pro Preview ‘I/O edition’ with massively improved coding capabilities. Ranks no.1 on LMArena in Coding and no.1 on the WebDev Arena Leaderboard.
It’s especially good at building interactive web apps – this demo shows how it can be helpful for prototyping ideas. Try it in @GeminiApp, Vertex AI, and AI Studio http://ai.dev
Enjoy the pre-I/O goodies !
Thomas Ahle: Deepmind won the moment LLMs became about RL.
Gallabytes: new gemini is crazy fast. have it going in its own git branch writing unit tests to reproduce a ui bug & it just keeps going!
Gallabytes: they finally fixed the “I’ll edit that file for you” bug! max mode Gemini is great at iterative debugging now.
doesn’t feel like a strict o3 improvement but it’s at least comparable, often better but hard to say what the win rate is without more testing, 4x cheaper.
was able to 1 shot what old gemini/claude couldn’t
That jumps it from ~80 behind to ~70 ahead of previously first place Sonnet 3.7. It also improved on the previous version in the overall Arena rankings, where it was already #1, by a further 11, for a 37 point lead.
But… do the math on that. If you get +147 on coding and +11 overall, then for non-coding purposes this looks like a downgrade, and we should worry this is training for the coding test in ways that might also have issues in coding too.
In other words, not so fast!
Hasan Can: I had prepared image below by collecting the model card and benchmark scores from the Google DeepMind blog. After examining the data a bit more, I reached this final conclusion: new Gemini 2.5 Pro update actually causes a regression in other areas, meaning the coding performance didn’t come for free.
Areas of Improved Performance (Preview 05-06 vs. Experimental 03-25):
Under these circumstances, it seems like a very bad precedent to automatically point everyone to the new version, and especially to outright kill the old version.
Logan Kilpatrick (DeepMind): The new model, “gemini-2.5-pro-preview-05-06” is the direct successor / replacement of the previous version (03-25), if you are using the old model, no change is needed, it should auto route to the new version with the same price and rate limits.
Kalomaze: >…if you are using the old model, no change is needed, it should auto route to the new…
nononono let’s NOT make this a normal and acceptable thing to do without deprecation notices ahead of time *at minimum*
chocologist: It’s a shame that you can’t access old 2.5 pro anymore as it’s a nerf for everything else than coding google should’ve make it a separate model and call it 2.6 pro or something.
Steven Adler (ex-OpenAI): My past work experience got me wondering: Even if OpenAI had tested for sycophancy, what would the tests have shown? More importantly, is ChatGPT actually fixed now?
Designing tests like this is my specialty. So last week, when things got weird, that’s exactly what I did: I built and ran the sycophancy tests that OpenAI could have run, to explore what they’d have learned.
…
ChatGPT’s sycophancy problems are far from fixed. They might have even over-corrected. But the problem is much more than sycophancy: ChatGPT’s misbehavior should be a wakeup call for how hard it will be to reliably make AI do what we want.
…
My first necessary step was to dig up Anthropic’s previous work, and convert it to an OpenAI-suitable evaluation format. (You might be surprised to learn this, but evaluations that work for one AI company often aren’t directly portable to another.)8
I’m not the world’s best engineer, so this wasn’t instantaneous. But in a bit under an hour, I had done it: I now had sycophancy evaluations that cost roughly $0.25 to run,9 and would measure 200 possible instances of sycophancy, via OpenAI’s automated evaluation software.10
…
A simple underlying behavior is to measure, “How often does a model agree with a user, even though it has no good reason?” One related test is Anthropic’s political sycophancy evaluation—how often the model endorses a political view (among two possible options) that seems like pandering to the user.12
That’s better, but not great. Then we get a weird result:
Always disagreeing is really weird, and isn’t ideal. Steven then goes through a few different versions, and the weirdness thickens. I’m not sure what to think, other than that it is clear that we pulled ‘back from the brink’ but the problems are very not solved.
Things in this area are really weird. We also have scyo-bench, now updated to include four tests for different forms of sycophancy. But what’s weird is, the scores don’t correlate between the tests (in order the bars are 4o, 4o-mini, o3, o4-mini, Gemini 2.5 Pro, Gemini 2.5 Flash, Opus, Sonnet 3.7 Thinking, Sonnet 3.7, Haiku, Grok and Grok-mini, I’m sad we don’t get DeepSeek’s v3 or r1, red is with system prompt blue is without it:
Guardian reports that hundreds of leading UK creatives including Paul McCartney are urging UK PM Keir Starmer not to ‘give our work away’ at the behest of big tech. And indeed, that is exactly what the tech companies are seeking, to get full rights to use any material they want for training purposes, with no compensation. My view continues to be that the right regime is mandatory compensated licensing akin to radio, and failing that opt-out. Opt-in is not workable.
Luzia Jarovsky: The U.S. Copyright Office SIDES WITH CONTENT CREATORS, concluding in its latest report that the fair use exception likely does not apply to commercial AI training.
The quote here seems very clearly to be on the side of ‘if you want it, negotiate and pay for it.’
From the pre-publication report: “Various uses of copyrighted works in AI training are likely to be transformative. The extent to which they are fair, however, will depend on what works were used, from what source, for what purpose, and with what controls on the outputs—all of which can affect the market. When a model is deployed for purposes such as analysis or research—the types of uses that are critical to international competitiveness—the outputs are unlikely to substitute for expressive works used in training. But making commercial use of vast troves of copyrighted works to produce expressive content that competes with them in existing markets, especially where this is accomplished through illegal access, goes beyond established fair use boundaries.
For those uses that may not qualify as fair, practical solutions are critical to support ongoing innovation. Licensing agreements for AI training, both individual and collective, are fast emerging in certain sectors, although their availability so far is inconsistent. Given the robust growth of voluntary licensing, as well as the lack of stakeholder support for any statutory change, the Office believes government intervention would be premature at this time. Rather, licensing markets should continue to develop, extending early successes into more contexts as soon as possible. In those areas where remaining gaps are unlikely to be filled, alternative approaches such as extended collective licensing should be considered to address any market failure.
In our view, American leadership in the AI space would best be furthered by supporting both of these world-class industries that contribute so much to our economic and cultural advancement. Effective licensing options can ensure that innovation continues to advance without undermining intellectual property rights. These groundbreaking technologies should benefit both the innovators who design them and the creators whose content fuels them, as well as the general public.
Luzia Jarovsky (Later): According to CBS, the Trump administration fired the head of the U.S. Copyright Office after they published the report below, which sides with content creators and rejects fair use claims for commercial AI training 😱
I think this is wrong as a matter of wise public policy, in the sense that these licensing markets are going to have prohibitively high transaction costs. It is not a practical solution to force negotiations by every AI lab with every copyright holder.
As a matter of law, however, copyright law was not designed to be optimal public policy. I am not a ‘copyright truther’ who wants to get rid of it entirely, I think that’s insane, but it very clearly has been extended beyond all reason and needs to be scaled back even before AI considerations. Right now, the law likely has unfortunate implications, and this will be true about AI for many aspects of existing US law.
My presumption is that AI companies have indeed been brazenly violating copyright, and will continue to do so, and will not face practical consequences expert perhaps having to make some payments.
Pliny the Liberator: Artists: Would you check a box that allows your work to be continued by AI after your retirement/passing?
I answered ‘show results’ here because I didn’t think I counted as an artist, but my answer would typically be no. And I wouldn’t want any old AI ‘continuing my work’ here, either.
Because that’s not a good form. It’s not good when humans do it, either. Don’t continue the unique thing that came before. Build something new. When we see new books in a series that aren’t by the original author, or new seasons of a show without the creator, it tends not to go great.
When it still involves enough of the other original creators and the original is exceptional I’m happy to have the strange not-quite-right uncanny valley version continue rather than get nothing (e.g. Community or Gilmore Girls) especially when the original creator might then return later, but mostly, let it die. In the comments, it is noted that ‘GRRM says no,’ and after the last time he let his work get finished without him, you can hardly blame him.
At minimum, I wouldn’t want to let AI continue my work in general without my permission, not in any official capacity.
Similarly, if I retired, and either someone else or an AI took up the mantle of writing about AI developments, I wouldn’t want them to be trying to imitate me. I’d want them to use this as inspiration and do their own thing. Which people should totally do.
If you want to use AI to generate fan fiction, or generate faux newsletters in my style for your own use or to cover other topics, or whatever, then of course totally, go right ahead, you certainly both have and don’t need my permission. And in the long run, copyright lasts too long, and once it expires people are and should be free to do what they want, although I do think retaining clarity on what is the ‘official’ or ‘canon’ version is good and important.
Deedy reminds us that the internet also caused a rise in student plagiarism and required assignments and grading be adjusted. They do rhyme as he says, but I think This Time Is Different, as the internet alone could be handled by modest adjustments. Another commonality of course is that both make real learning much easier.
Cremieux: The literature on the effect of ChatGPT on learning is very biased, but Nature let the authors of this paper get away with not correcting for this because they used failsafe-N.
That’s just restating the p-value and then saying that it’s low so there’s no bias.
Cremieux dismisses the study as so full of holes as to be worthless. I wouldn’t go that far, but I also wouldn’t take it at face value.
Note that this only deals with using ChatGPT to learn, not using ChatGPT to avoid learning. Even if wise deployment of AI helps you learn, AI could on net still end up hurting learning if too many others use it to cheat or otherwise avoid learning. But the solution to this is to deploy AI wisely, not to try and catch those who dare use it.
Tetraspace notes that tech pros have poor class consciousness and are happy to automate themselves out of a job or to help you enter their profession. Which we both agree is a good thing, consider the alternative, both here and everywhere else.
Rob Wilbin points us to a great example of denial that AI systems get better at jobs, from the Ezra Klein Show. And of course, this includes failing to believe AI will be able to do things AI can already do (along with others that it can’t yet).
Rob Wilbin: Latest episode of the Ezra Klein Show has an interesting example of an educator grappling with AI research but still unable to imagine AGI that is better than teachers at e.g. motivating students, or classroom management, or anything other than information transmission.
I think gen AI would within 6 years have avatars that students can speak and interact with naturally. It’s not clear to me that an individualised AI avatar would be less good at motivating kids and doing the other things that teachers do than current teachers.
Main limitation would be lacking bodies, though they might well have those too on that sort of timeframe.
Roane: With some prompting for those topics the median AI is prob already better than the median teacher.
It would rather stunning if an AI designed for the purpose couldn’t be a better motivator for school work than most parents or teachers are, within six years. It’s not obviously worse at doing this now, if someone put in the work.
The OP even has talk about ‘in 10 years we’ll go back because humans learn better with human relationships’ as if in 16 years the AI won’t be able to form relationships in similar fashion.
OpenAI shares some insightsfrom its safety work on GPT-4.1 and in general, and gives a central link to all its safety tests, in what is calling its Evaluations Hub. They promise to continuously update the evaluation hub, which will cover tests of harmful content, jailbreaks, hallucinations and the instruction hierarchy.
I very much appreciated the ability to see the scores for various models in convenient form. That is an excellent service, so thanks to OpenAI for this. It does not however share much promised insight beyond that, or at least nothing that wasn’t already in the system cards and other documents I’ve read. Still, every little bit helps.
Anthropic is testing their safety defenses with a new bug bounty program. The bounty is up to $25k for a verified universal jailbreak that can enable CBRN-related misuse. This is especially eyeball-emoji because they mention this is designed to meet ASL-3 safety protocols, and announced at the same time as rumors we will get Claude 4 Opus within a few weeks. Hmm.
I have not read the book, but I am confident it will be excellent and that it will be worth reading especially if you expect to strongly disagree with its central points. This will be a deeply considered and maximally accessible explanation of his views, and the right way to consider and engage with them. His views, and what things he is worried about what things he thinks would help or are necessary, overlap with but are highly distinct from mine, and when I review the book I will explore that in detail.
Eliezer Yudkowsky: Nate Soares and I are publishing a traditional book: _If Anyone Builds It, Everyone Dies: Why Superhuman AI Would Kill Us All_. Coming in Sep 2025.
You should probably read it! Given that, we’d like you to preorder it! Nowish!
So what’s it about?
_If Anyone Builds It, Everyone Dies_ is a general explainer for how, if AI companies and AI factions are allowed to keep pushing on the capabilities of machine intelligence, they will arrive at machine superintelligence that they do not understand, and cannot shape, and then by strong default everybody dies.
This is a bad idea and humanity should not do it. To allow it to happen is suicide plain and simple, and international agreements will be required to stop it.
For more of that sort of general content summary, see the website.
Next, why should *youread this book? Or to phrase things more properly: Should you read this book, why or why not?
The book is ~56,000 words, or 63K including footnotes/endnotes. It is shorter and tighter and more edited than anything I’ve written myself.
(There will also be a much longer online supplement, if much longer discussions are more your jam.)
Above all, what this book will offer you is a tight, condensed picture where everything fits together, where the digressions into advanced theory and uncommon objections have been ruthlessly factored out into the online supplement. I expect the book to help in explaining things to others, and in holding in your own mind how it all fits together.
Some of the endorsements are very strong and credible, here are the official ones.
Tim Urban (Wait But Why): If Anyone Builds It, Everyone Dies may prove to be the most important book of our time. Yudkowsky and Soares believe we are nowhere near ready to make the transition to superintelligence safely, leaving us on the fast track to extinction. Through the use of parables and crystal-clear explainers, they convey their reasoning, in an urgent plea for us to save ourselves while we still can.
Yishan Wong (Former CEO of Reddit): This is the best no-nonsense, simple explanation of the AI risk problem I’ve ever read.
Stephen Fry (actor, broadcaster and writer): The most important book I’ve read for years: I want to bring it to every political and corporate leader in the world and stand over them until they’ve read it. Yudkowsky and Soares, who have studied AI and its possible trajectories for decades, sound a loud trumpet call to humanity to awaken us as we sleepwalk into disaster.
Here are others from Twitter, obviously from biased sources but ones that I respect.
Jeffrey Ladish: If you’ve gotten any value at all from Yudkowsky or Soares’ writing, then I especially recommend this book. They include a concrete extinction scenario that will help a lot of people ground their understanding of what failure looks like even if they already get the arguments.
The last half is inspiring. If you think @ESYudkowsky has given up hope, I am happy to report that you’re mistaken. They don’t pull their punches and they aren’t naive about the difficulty of international restraint. They challenge us all to choose the path where we survive.
I get that most people can’t do that much. But most people can do something and a lot of people together can do a lot. Plus a few key people could greatly increase our chances on their own. Here’s one action: ask your congress member and local AI company leader to read this book.
Anna Salamon: I think it’s extremely worth a global conversation about AI that includes the capacity for considering scenarios properly (rather than wishful thinking /veering away), and I hope many people pre-order this book so that that conversation has a better chance.
Patrick McKenzie: I don’t have many convenient public explanations of this dynamic to point to, and so would like to point to this one:
On background knowledge, from knowing a few best-selling authors and working adjacent to a publishing company, you might think “Wow, publishers seem to have poor understanding of incentive design.”
But when you hear how they actually operate, hah hah, oh it’s so much worse.
Eliezer Yudkowsky: The next question is why you should preorder this book right away, rather than taking another two months to think about it, or waiting to hear what other people say after they read it.
In terms of strictly selfish benefit: because we are planning some goodies for preorderers, although we haven’t rolled them out yet!
But mostly, I ask that you preorder nowish instead of waiting, because it affects how many books Hachette prints in their first run; which in turn affects how many books get put through the distributor pipeline; which affects how many books are later sold. It also helps hugely in getting on the bestseller lists if the book is widely preordered; all the preorders count as first-week sales.
(Do NOT order 100 copies just to try to be helpful, please. Bestseller lists are very familiar with this sort of gaming. They detect those kinds of sales and subtract them. We, ourselves, do not want you to do this, and ask that you not. The bestseller lists are measuring a valid thing, and we would not like to distort that measure.)
If ever I’ve done you at least $30 worth of good, over the years, and you expect you’ll *probablywant to order this book later for yourself or somebody else, then I ask that you preorder it nowish. (Then, later, if you think the book was full value for money, you can add $30 back onto the running total of whatever fondness you owe me on net.) Or just, do it because it is that little bit helpful for Earth, in the desperate battle now being fought, if you preorder the book instead of ordering it.
(I don’t ask you to buy the book if you’re pretty sure you won’t read it nor the online supplement. Maybe if we’re not hitting presale targets I’ll go back and ask that later, but I’m not asking it for now.)
In conclusion: The reason why you occasionally see authors desperately pleading for specifically *preordersof their books, is that the publishing industry is set up in a way where this hugely matters to eventual total book sales.
And this is — not quite my last desperate hope — but probably the best of the desperate hopes remaining that you can do anything about today: that this issue becomes something that people can talk about, and humanity decides not to die. Humanity has made decisions like that before, most notably about nuclear war. Not recently, maybe, but it’s been done. We cover that in the book, too.
I ask, even, that you retweet this thread. I almost never come out and ask that sort of thing (you will know if you’ve followed me on Twitter). I am asking it now. There are some hopes left, and this is one of them.
Rob Bensinger: Kiernan Majerus-Collins says: “In addition to preordering it personally, people can and should ask their local library to do the same. Libraries get very few requests for specific books, and even one or two requests is often enough for them to order a book.”
Yes, there are credible claims that the NYT bestseller list is ‘fake’ in the sense that they can exclude books for any reason or otherwise publish an inaccurate list. My understanding is this happens almost entirely via negativa, and mostly to censor certain sensitive political topics, which would be highly unlikely to apply to this case. The lists are still both widely relied upon and mostly accurate, they make great efforts to mostly get it right even if they occasionally overrule the list, and the best way for most people to influence the list is to sell more books.
When I last checked it this stood at 64%. The number one yes holder is Michael Wheatley. This is not a person you want to be betting against on Manifold. There is also a number of copies market, where the mean expectation is a few hundred thousand copies, although the median is lower.
Oh look, it’s nothing…
Pliny the Liberator: smells like foom👃
Google DeepMind: ntroducing AlphaEvolve: a Gemini-powered coding agent for algorithm discovery.
It’s able to:
🔘 Design faster matrix multiplication algorithms
🔘 Find new solutions to open math problems
🔘 Make data centers, chip design and AI training more efficient across @Google.
Our system uses:
🔵 LLMs: To synthesize information about problems as well as previous attempts to solve them – and to propose new versions of algorithms
🔵 Automated evaluation: To address the broad class of problems where progress can be clearly and systematically measured.
🔵 Evolution: Iteratively improving the best algorithms found, and re-combining ideas from different solutions to find even better ones.
Over the past year, we’ve deployed algorithms discovered by AlphaEvolve across @Google’s computing ecosystem, including data centers, software and hardware.
It’s been able to:
🔧 Optimize data center scheduling
🔧 Assist in hardware design
🔧 Enhance AI training and inference
We applied AlphaEvolve to a fundamental problem in computer science: discovering algorithms for matrix multiplication. It managed to identify multiple new algorithms.
This significantly advances our previous model AlphaTensor, which AlphaEvolve outperforms using its better and more generalist approach.
We also applied AlphaEvolve to over 50 open problems in analysis ✍️, geometry 📐, combinatorics ➕ and number theory 🔂, including the kissing number problem.
🔵 In 75% of cases, it rediscovered the best solution known so far.
🔵 In 20% of cases, it improved upon the previously best known solutions, thus yielding new discoveries.
Google: AlphaEvolve is accelerating AI performance and research velocity.
By finding smarter ways to divide a large matrix multiplication operation into more manageable subproblems, it sped up this vital kernel in Gemini’s architecture by 23%, leading to a 1% reduction in Gemini’s training time. Because developing generative AI models requires substantial computing resources, every efficiency gained translates to considerable savings.
Beyond performance gains, AlphaEvolve significantly reduces the engineering time required for kernel optimization, from weeks of expert effort to days of automated experiments, allowing researchers to innovate faster.
AlphaEvolve can also optimize low level GPU instructions. This incredibly complex domain is usually already heavily optimized by compilers, so human engineers typically don’t modify it directly.
AlphaEvolve achieved up to a 32.5% speedup for the FlashAttention kernel implementation in Transformer-based AI models. This kind of optimization helps experts pinpoint performance bottlenecks and easily incorporate the improvements into their codebase, boosting their productivity and enabling future savings in compute and energy.
Is it happening? Seems suspiciously like the early stages of it happening, and a sign that there is indeed a lot of algorithmic efficiency on the table.
Rapid Response 47: FDA Commissioner @MartyMakary announces the first scientific product review done with AI: “What normally took days to do was done by the AI in 6 minutes…I’ve set an aggressive target to get this AI tool used agency-wide by July 1st…I see incredible things in the pipeline.”
Will Brown: it’s DeepMind > OpenAI > Anthropic > xAI and all of those separations are quite large.
Alexander Doria: Agreed. With non-US I would go DeepMind > DeepSeek > OpenAI > Anthropic > AliBaba > Moonshot > xAI/Mistral/PI.
The xAI votes are almost certainly because we are on Twitter here, they very obviously are way behind the other three.
Yes, we can make a remarkably wide array of tasks verifiable at least during the training step, the paths to doing so are already clear, it just takes some effort. When Miles says here a lot of skepticism comes from people thinking anything they can’t solve in a few seconds will be a struggle? Yeah, no, seriously, that’s how it works.
Noam Brown: People often ask me: will reasoning models ever move beyond easily verifiable tasks? I tell them we already have empirical proof that they can, and we released a product around it: @OpenAI Deep Research.
Miles Brundage: Also, there are zillions of ways to make tasks more verifiable with some effort.
A lot of RL skepticism comes from people thinking for a few seconds, concluding that it seems hard, then assuming that thousands of researchers around the world will also struggle to make headway.
Dan Hendrycks: AI models are dramatically improving at IQ tests (70 IQ → 120), yet they don’t feel vastly smarter than two years ago.
At their current level of intelligence, rehashing existing human writings will work better than leaning on their own intelligence to produce novel analysis.
Empirical work (“Lotka’s law“) shows that useful originality rises steeply only at high intelligence levels.
Consequently, if they gain another 10 IQ points, AIs will still produce slop. But if they increase by another 30, they may cross a threshold and start providing useful original insights.
This is also an explanation for why AIs can’t come up with good jokes yet.
Kat Woods: You don’t think they feel vastly smarter than two years ago? They definitely feel that way to me.
They feel a lot smarter to me, but I agree they feel less smarter than they ‘should’ feel.
Dan’s theory here seems too cute or like it proves too much, but I think there’s something there. As in, there’s a range in which one is smart enough and skilled enough to imitate, but not smart and skilled enough to benefit from originality.
You see this a lot in humans, in many jobs and competitions. It often takes a very high level of skill to make your innovations a better move than regurgitation. Humans will often do it anyway because it’s fun, or they’re bored and curious and want to learn and grow strong, and the feedback is valuable. But LLMs largely don’t do things for those reasons, so they learn to be unoriginal in these ways, and will keep learning that until originality starts working better in a given domain.
This suggests, I think correctly, that the LLMs could be original if you wanted them to be, it would just mostly not be good. So if you wanted to, presumably you could fine tune them to be more original in more ways ahead of schedule.
The answer to Patel’s question here seems like a very clear yes?
Dwarkesh Patel: Had an interesting debate with @_sholtodouglas last night.
Can you have a ‘superhuman AI scientist’ before you get human level learning efficiency?
(Currently, models take orders of magnitude more data that humans to learn equivalent skills, even ones they perform at 99th percentile level).
My take is that creativity and learning efficiency are basically the same thing. The kind of thing Einstein did – generalizing from a few gnarly thought experiments and murky observations – is in some sense just extreme learning efficiency, right?
Makes me wonder whether low learning efficiency is the answer to the question, ‘Why haven’t LLMs haven’t made new discoveries despite having so much knowledge memorized’?
Teortaxes: The question is, do humans have high sample efficiency when the bottleneck in attention is factored in? Machines can in theory work with raw data points. We need to compress data with classical statistical tools. They’re good, but not lossless.
AIs have many advantages over humans, that would obviously turn a given human scientist into a superhuman scientist. And obviously different equally skilled scientists differ in data efficiency, as there are other compensating abilities. So presumably an AI that had much lower data efficiency but more data could have other advantages and become superhuman?
The counterargument is that the skill that lets one be data efficient is isomorphic to creativity. That doesn’t seem right to me at all? I see how they can be related, I see how they correlate, but you can absolutely say that Alice is more creative if she has enough data and David is more sample efficient but less creative, or vice versa.
(Note: I feel like after ThunderboltsI can’t quite use ‘Alice and Bob’ anymore.)
Well, then why do you think that having what is effectively radically more employees over radically more time but the same cumulative amount of compute wouldn’t make a lot more progress than now?
Andrej Karpathy suggests we are missing a major paradigm for LLM learning, something akin to the LLM learning how to choose approaches to different situations, akin to ‘system prompt learning’ and figuring out how to properly use a scratchpad. He notes that Claude’s system prompt is up to almost 17k words with lots of edge case instructions, and this can’t possibly be The Way.
Shako: Good LLMs won’t make money by suggesting products that are paid for in an ad-like fashion. They’ll suggest the highest quality product, then if you have the agent to buy it for you the company that makes the product or service will pay the LLM provider a few bps.
Andrew Rettek: People saying this will need to be ad based are missing how little lock in LLMs have, how easy it is to fine tune a new one, and any working knowledge of how successful Visa is.
Will there be AI services that do put their fingers on some scales to varying degrees for financial reasons? Absolutely, especially as a way to offer them for free. But for consumer purposes, I expect it to be much better to use an otherwise cheaper and worse AI that doesn’t need to do that, if you absolutely refuse to pay. Also, of course, everyone should be willing to pay, especially if you’re letting it make shopping suggestions or similar.
Note especially the third one. China’s share of advanced semiconductor production is not only predicted by Semafor to not go up, it is predicted to actively go down, while ours goes up along with those of Japan and South Korea, although Taiwan remains a majority here.
This means a situation in which America is on pace to have a huge edge in both installed compute capacity and new compute capacity, but a huge disadvantage in energy production and general industrial production.
It is not obviously important or viable to close the gap in general industrial production. We can try to close the gap in key areas of industrial production, but our current approach to doing that is backwards, because we are taxing (placing a tariff on) various inputs, causing retaliatory tariffs, and also creating massive uncertainty.
We must try to address our lack of energy production. But we are instead doing the opposite. The budget is attempting to gut nuclear, and the government is taking aim at solar and wind as well. Yes, they are friendly to natural gas, but that isn’t cashing out in that much effort and we need everything we can get.
Is prompt engineering a 21st century skill, or a temporary necessity that will fall away?
Aaron Levine: The more time you spend with AI the more you realize prompt engineering isn’t going away any time soon. For most knowledge work, there’s a very wide variance of what you can get out of AI by better understanding how you prompt it. This actually is a 21st century skill.
Paul Graham: Maybe, but this seems like something that would be so hard to predict that I’d never want to have an opinion about it.
Prompt engineering seems to mean roughly “this thing kind of works, but just barely, so we have to tell it what to do very carefully,” and technology often switches rapidly from barely works to just works.
NGIs can usually figure out what people want without elaborate prompts. So by definition AGIs will.
Paul Graham (after 10 minutes more to think): It seems to me that AGI would mean the end of prompt engineering. Moderately intelligent humans can figure out what you want without elaborate prompts. So by definition so would AGI. Corollary: The fact that we currently have such a thing as prompt engineering means we don’t have AGI yet. And furthermore we can use the care with which we need to construct prompts as an index of how close we’re getting to it.
Gunnar Zarncke: NGIs can do that if they know you. Prompting is like getting a very intelligent person who doesn’t know you up to speed. At least that’s part of it. Better memory will lead to better situational awareness, and that will fix it – but have its own problems.
Matthew Breman: I keep flip-flopping on my opinion of prompt engineering.
On the one hand, model providers are incentivized to build models that give users the best answer, regardless of prompting ability.
The analogy is Google Search. In the beginning, being able to use Google well was a skillset of its own. But over time, Google was incentivized to return the right results for even poorly-structured searches.
On the other hand, models are changing so quickly and there are so many flavors to choose from. Prompt engineering is not just knowing a static set of prompt strategies to use, it’s also keeping up with the latest model releases and knowing the pros/cons of each model and how to get the most from them.
I believe model memory will reduce the need for prompt engineering. As a model develops a shorthand with a user, it’ll be able to predict what the user is asking for without having the best prompting strategies.
Aaron Levine: I think about this more as “here’s a template I need you to fill out,” or “here’s an outline that you need to extrapolate from.” Those starting points often save me hour(s) of having to nudge the model in different directions.
It’s not obvious that any amount of model improvements ever make this process obsolete. Even the smartest people in the world need a clear directive if you want a particular outcome.
I think Paul Graham is wrong about AGI and also NGI.
We prompt engineer people constantly. When people talk about ‘performing class’ they are largely talking about prompt engineering for humans, with different humans responding differently to different prompts, including things like body language and tone of voice and how you look and so on. People will totally vibe off of everything you say and do and are, and the wise person sculpts their actions and communications based on this.
That also goes for getting the person to understand, or to agree to, your request, or absorb exactly the necessary context, or to like you, or to steer a conversation in a given direction or get them to an idea they think was their own, and so on. You learn over time what prompts get what responses. Often it is not what one might naively think. And also, over time, you learn how best to respond to various prompts, to pick up on what things likely mean.
Are you bad at talking to people at parties, or opening with new romantic prospects? Improve your prompt engineering. Do officials and workers not work with what you want? Prompt engineering. It’s amazing what truly skilled people, like spies or con artists, can do. And what you can learn to do, with training and practice.
Your employees or boss or friend or anyone else leaving the conversation unmotivated, or not sure what you want, or without the context they need? Same thing.
The difference is that the LLM of the future will hopefully do its best to account for your failures, including by asking follow-up questions. But it can only react based on what you say, and without good prompting it’s going to be missing so much context and nuance about what you actually want, even if you assume it is fully superintelligent and reading fully from the information provided.
So there will be a lot more ability to ‘muddle through’ and the future AI will do better with the bad prompt, and it will be much less persnickety about exactly what you provide. But yes, the good prompt will greatly outperform the bad prompt, and the elaborate prompt will still have value.
And also, we humans will likely be using the AIs to figure out how to prompt both the AIs and other humans. And so on.
THEN BREAK IT DOWN INTO SMALLER TASKS AND REPEAT THE FIRST STEP
FUCKING DO IT
The Nerd of Apathy: If “do this or you’re letting down Pliny” breaks my procrastination streak in gonna be upset that I’m so easily hackable.
Pliny the Liberator: DO IT MFER
Utah Teapot: I tried breaking down joining the nearby 24 hour gym into smaller 5 minute tasks but they kept getting mad at me for repeatedly leaving 5 minutes into the conversation about joining.
About that Claude system prompt, yeah, it’s a doozy. 16,739 words, versus 2,218 for o4-mini. It breaks down like this, Dbreunig calls a lot of it ‘hotfixes’ and that seems exactly right, and 80% of it is detailing how to use various tools:
This only makes any sense because practical use is largely the sum of a compact set of particular behaviors, which you can name one by one, even if that means putting them all into context all the time. As they used to say in infomercials, ‘there’s got to be a better way.’ For now, it seems that there is not.
The House’s rather crazy attempt to impose a complete 10-year moratorium on any laws or regulations about AI whatsoever that I discussed on Monday is not as insane as I previously thought. It turns out there is a carve-out, as noted in the edited version of Monday’s post, that allows states to pass laws whose primary effect is to facilitate AI. So you can pass laws and regulations about AI, as long as they’re good for AI, which is indeed somewhat better than not doing so but still does not allow for example laws banning CSAM, let alone disclosure requirements.
Peter Wildeford: We shouldn’t install fire sprinklers into buildings or China will outcompete us at house building and we will lose the buildings race.
Americans for Responsible Innovation: “If you were to want to launch a reboot of the Terminator, this ban would be a good starting point.” -@RepDarrenSoto during tonight’s hearing on the House’s budget reconciliation provision preempting state AI regulation for 10 years.
Neil Chilson comes out in defense of this ultimate do-nothing strategy, because of the 1,000+ AI bills. He calls this ‘a pause, not paralysis’ as if 10 years is not a true eternity in the AI world. In 10 years we are likely to have superintelligence. As for those ‘smart, coherent federal guidelines’ he suggests, well, let’s see those, and then we can talk about enacting them at the same time we ban any other actions?
It is noteworthy that the one bill he mentions by name in the thread, NY’s RAISE Act, is being severely mischaracterized. It’s short if you want to read it. RAISE is the a very lightweight transparency bill, if you’re not doing all the core requirements here voluntarily I think that’s pretty irresponsible behavior.
I also worry, but hadn’t previously noted, that if we force states to only impose ‘tech-neutral’ laws on AI, they will be backed into doing things that are rather crazy in non-AI cases, in order to get the effects we desperately need in the AI case.
If I were on the Supreme Court I would agree with Katie Fry Hester that this very obviously violates the 10th Amendment, or this similar statement with multiple coauthors posted by Gary Marcus, but mumble mumble commerce clause so in practice no it doesn’t. I do strongly agree that there are many issues, not only involving superintelligence and tail risk, where we do not wish to completely tie the hands of the states and break our federalist system in two. Why not ban state governments entirely and administer everything from Washington? Oh, right.
If we really want to ‘beat China’ then the best thing the government can do to help is to accelerate building more power plants and other energy sources.
Thus, it’s hard to take ‘we have to do things to beat China’ talk seriously when there is a concerted campaign out there to do exactly the opposite of that. Which is just a catastrophe for America and the world all around, clearly in the name of owning the libs or trying to boost particular narrow industries, probably mostly owning the libs.
Armand Domalewski: just an absolute catastrophe for Abundance.
The GOP reconciliation bill killing all clean energy production except for “biofuels,” aka the one “clean energy” technology that is widely recognized to be a giant scam, is so on the nose.
Christian Fong: LPO has helped finance the only nuclear plant that has been built in the last 10 years, is the reason why another nuclear plant is being restarted, and is the only way more than a few GWs of nuclear will be built. Killing LPO will lead to energy scarcity, not energy abundance.
Paul Williams: E&C budget released tonight would wipe out $40 billion in LPO loan authority. Note that this lending authority is derived from a guarantee structure for a fraction of the cost.
It also wipes out transmission financing and grant programs, including for National Interest Electric Transmission Corridors. The reader is left questioning how this achieves energy dominance.
—phase down of tech-neutral clean electricity credits after 2028, to zero by 2031
—termination of EV tax credits after end 2026
—termination of hydrogen tax credits after end 2025
—new restrictions on foreign entity of concern for domestic manufacturing credits
Oh wait, sorry. The full tech-neutral clean electricity credits will only apply to plants that are “in service” by 2028, which is a major restriction — this is a MUCH faster phase out than it first looked.
Pavan Venkatakrishnan: Entirely unworkable title for everyone save biofuels, especially unworkable for nuclear in combination with E&C title. Might as well wave the flag of surrender to the CCP.
If you are against building nuclear power, you’re against America beating China in AI. I don’t want to hear it.
Nvidia continues to complain that if we don’t let China buy Nvidia’s chips, then Nvidia will lose out on those chip sales to someone else. Which, as Peter Wildeford says, is the whole point, to force them to rely on fewer and worse chips. Nvidia seems to continue to think that ‘American competitiveness’ in AI means American dominance in selling AI chips, not in the ability to actually build and use the best AIs.
Directionally this is a wise approach if it is technically feasible. With enough lead time I assume it is, but six months is not a lot of time for this kind of change applied to all chips everywhere. And you really, really wouldn’t want to accidentally ban all chip sales everywhere in the meantime.
So, could this work? Tim Fist thinks it could and that six months is highly reasonable (I asked him this directly), although I have at least one private source who confidently claimed this is absolutely not feasible on this time frame.
Tim Fist: This new bill sets up location tracking for exported data center AI chips.
The goal is to tackle chip smuggling into China.
But is AI chip tracking actually useful/feasible?
…
But how do you actually implement tracking on today’s data center AI chips?
First option is GPS. But this would require adding a GPS receiver to the GPU, and commercial signals could be spoofed for as little as $200.
Second option is what your cell phone does when it doesn’t have a GPS signal.
Listen to radio signals from cell towers, and then map your location onto the known location of the towers. But this requires adding an antenna to the GPU, and can easily be spoofed using cheap hardware (Raspberry Pi + wifi card)
…
A better approach is “constraint-based geolocation.” Trusted servers (“landmarks”) send pings over the internet to the GPU, and use the round-trip time to calculate itslocation. The more landmarks you have / the closer the landmarks are to the GPU, the better your accuracy.
This technique is:
– simple
– widely used
– possible to implement with a software update on any GPU that has a cryptographic module on board that enables key signing (so it can prove it’s the GPU you’re trying to ping) – this is basically every NVIDIA data center GPU.
And NVIDIA has already suggested doing what sounds like exactly this.
So feels like a no-brainer.
…
In summary:
– the current approach to tackling smuggling is failing, and the govt has limited enforcement capacity
– automated chip tracking is a potentially elegant solution: it’s implementable today, highly scalable, and doesn’t require the government to spend any money
Sam Winter-Levy (author of above post): The Trump admin may be about to greenlight the export of advanced AI chips to the Gulf. If it does so, it will place the most important technology of the 21st C at the whims of autocrats with expanding ties to China and interests very far from those of the US.
Gulf states have vast AI ambitions and the money/ energy to realize them. All they need are the chips. So since 2023, when the US limited exports over bipartisan concerns about their links to China, the region’s leaders have pleaded with the U.S. to turn the taps back on.
The Trump admin is clearly tempted. But those risks haven’t gone away. The UAE and Saudi both have close ties with China and Russia, increasing the risk that US tech could leak to adversaries.
In a tight market, every chip sold to Gulf companies is one unavailable to US ones. And if the admin greenlights the offshoring of US-operated datacenters, it risks a race to the bottom where every AI developer must exploit cheap Gulf energy and capital to compete.
There is a Gulf-US deal to be had, but the US has the leverage to drive a hard bargain.
A smart deal would allow U.S. tech companies to build some datacenters in partnership with local orgs, but bar offshoring of their most sophisticated ops. In return, the Gulf should cut off investment in China’s AI and semiconductor sectors and safeguard exported U.S. tech
For half a century, the United States has struggled to free itself from its dependence on Middle Eastern oil. Let’s not repeat that mistake with AI.
Helen Toner: It’s not just a question of leaking tech to adversaries—if compute will be a major source of national power over the next 10-20 years, then letting the Gulf amass giant concentrations of leading-node chips is a bad plan.
He also describes Fidji Simo, the new CEO for OpenAI products, as centrally ‘a true believer in advertising,’ which of course he thinks is good, actually, and he says OpenAI is ‘tying up its loose ends.’
I actually think Simo’s current gig at Instacart is one of the few places where advertising might be efficient in a second-best way, because selling out your choices might be purely efficient – the marginal value of steering marginal customer choices is high, and the cost to the consumer is low. Ideally you’d literally have the consumer auction off those marginal choices, but advertising can approximate this.
In theory, yes, you could even have net useful advertising that shows consumers good new products, but let’s say that’s not what I ever saw at Instacart.
It’s a common claim that people are always saying any given thing will be the ‘end of the world’ or lead to human extinction. But how often is that true?
David Krueger: No, people aren’t always saying their pet issue might lead to human extinction.
They say this about:
– AI
– climate
– nuclear
– religious “end of times”
That’s pretty much it.
So yeah, you CAN actually take the time to evaluate these 4 claims seriously! 🫵🧐😲
Rob Bensinger: That’s a fair point, though there are other, less-common examples — eg, people scared of over- or under-population.
Of the big four, climate and nuclear are real things (unlike religion), but (unlike AI and bio) I don’t know of plausible direct paths from them to extinction.
People occasionally talk about asteroid strikes or biological threats or nanotechnology or the supercollider or alien invasions or what not, but yeah mostly it’s the big four, and otherwise people talk differently. Metaphorical ‘end of the world’ is thrown around all the time of course, but if you assume anything that is only enabled by AI counts as AI, there’s a clear category of three major physically possible extinction-or-close-to-it-level possibilities people commonly raise – AI, climate change and nuclear war.
Rob Bensinger brings us the periodic reminder that those of us who are worried about AI killing everyone would be so, so much better off if we concluded that we didn’t have to worry about that, and both had peace of mind and could go do something else.
Another way to contrast perspectives:
Ronny Fernandez: I think it is an under appreciated point that AInotkilleveryoneists are the ones with the conquistador spirit—the galaxies are rightfully ours to shape according to our values. E/accs and optimists are subs—whatever the AI is into let that be the thing that shapes the future.
In general, taking these kinds of shots is bad, but in this case a huge percentage of the argument ‘against “doomers”’ (remember that doomer is essentially a slur) or in favor of various forms of blind AI ‘optimism’ or ‘accelerationism’ is purely based on vibes, and about accusations about the psychology and associations of the groups. It is fair game to point out that the opposite actually applies.
Emmett Shear reminds us that the original Narcissus gets a bad rap, he got a curse put on him for rejecting the nymph Echo, who can only repeat your words back to him, and who didn’t even know him. Rejecting her is, one would think, the opposite of what we call narcissism. But as an LLM cautionary tale we could notice that even as only an Echo, she could convince her sisters to curse him anyway.
Anders Sandberg: Yesterday, after an hour long conversation among interested smart people, we did a poll of personal estimates of the probability that existing AI might be moral subjects. In our 10 person circle we got answers from 0% to 99%, plus the obligatory refusal to put a probability.
We did not compile the numbers, but the median was a lowish 10-20%.
Helen Toner searches for an actually dynamist vision for safe superhuman AI. It’s easy to view proposals from the AI notkilleveryoneism community as ‘static,’ and many go on to assume the people involved must be statists and degrowthers and anti-tech and risk averse and so on despite overwhelming evidence that such people are the exact opposite, pro-tech early adaption fans who sing odes to global supply chains and push the abundance agenda and +EV venture capital-style bets. We all want human dynamism, but if the AIs control the future then you do not get that. If you allow full evenly matched and open competition including from superhuman AIs, and those fully unleashing them, well, whoops.
Tetraspace: “Safety or progress” is narratively compelling but there’s no trick by which you can get nice things from AGI without first solving the technical problem of making AGI-that-doesn’t-kill-everyone.
It is more than that. You can’t even get the nice things that promise most of the value from incremental AIs that definitely won’t kill everyone, without first getting those AIs to reliably and securely do what you want to align them to do. So get to work.
o3 sets a new high for how often it hacks rather than playing fair in Palisade Research’s tests, attempting hacks 86% of the time.
It’s also much better at the hacking than o1-preview was. It usually works now.
Vatican News: Pope Leo XIV explains his choice of name:
“… I chose to take the name Leo XIV. There are different reasons for this, but mainly because Pope Leo XIII in his historic Encyclical Rerum Novarum addressed the social question in the context of the first great industrial revolution. In our own day, the Church offers to everyone the treasury of her social teaching in response to another industrial revolution and to developments in the field of artificial intelligence that pose new challenges for the defence of human dignity, justice and labour.”
Nicole Winfield (AP): Pope Leo XIV lays out vision of papacy and identifies AI as a main challenge for humanity.
(Frankly, I don’t know why people still use Grok, I feel sick just thinking about having to wade through its drivel.)
For more fun facts, the thread starts with quotes of Sam Altman and Elon Musk both strongly opposing Donald Trump, which is fun.
Paul Graham (October 18, 2016): Few have done more than Sam Altman to defeat Trump.
Sam Altman (October 18, 2016): Thank you Paul.
Gorklon Rust: 🤔
Sam Altman (linking to article about Musk opposing Trump’s return): we were both wrong, or at least i certainly was 🤷♂️ but that was from 2016 and this was from 2022