“In both instances, this was user error, not AI error,” Amazon said, adding that it had not seen evidence that mistakes were more common with AI tools.
The company said the incident in December was an “extremely limited event” affecting only a single service in parts of mainland China. Amazon added that the second incident did not have an impact on a “customer facing AWS service.”
Neither disruption was anywhere near as severe as a 15-hour AWS outage in October 2025 that forced multiple customers’ apps and websites offline—including OpenAI’s ChatGPT.
Employees said the group’s AI tools were treated as an extension of an operator and given the same permissions. In these two cases, the engineers involved did not require a second person’s approval before making changes, as would normally be the case.
Amazon said that by default its Kiro tool “requests authorisation before taking any action” but said the engineer involved in the December incident had “broader permissions than expected—a user access control issue, not an AI autonomy issue.”
AWS launched Kiro in July. It said the coding assistant would advance beyond “vibe coding”—which allows users to quickly build applications—to instead write code based on a set of specifications.
The group had earlier relied on its Amazon Q Developer product, an AI-enabled chatbot, to help engineers write code. This was involved in the earlier outage, three of the employees said.
Some Amazon employees said they were still skeptical of AI tools’ utility for the bulk of their work given the risk of error. They added that the company had set a target for 80 percent of developers to use AI for coding tasks at least once a week and was closely tracking adoption.
Amazon said it was experiencing strong customer growth for Kiro and that it wanted customers and employees to benefit from efficiency gains.
“Following the December incident, AWS implemented numerous safeguards,” including mandatory peer review and staff training, Amazon added.
Today, OpenAI announced GPT-5.3-Codex, a new version of its frontier coding model that will be available via the command line, IDE extension, web interface, and the new macOS desktop app. (No API access yet, but it’s coming.)
GPT-5.3-Codex outperforms GPT-5.2-Codex and GPT-5.2 in SWE-Bench Pro, Terminal-Bench 2.0, and other benchmarks, according to the company’s testing.
There are already a few headlines out there saying “Codex built itself,” but let’s reality-check that, as that’s an overstatement. The domains OpenAI described using it for here are similar to the ones you see in some other enterprise software development firms now: managing deployments, debugging, and handling test results and evaluations. There is no claim here that GPT-5.3-Codex built itself.
Instead, OpenAI says GPT-5.3-Codex was “instrumental in creating itself.” You can read more about what that means in the company’s blog post.
But that’s part of the pitch with this model update—OpenAI is trying to position Codex as a tool that does more than generate lines of code. The goal is to make it useful for “all of the work in the software lifecycle—debugging, deploying, monitoring, writing PRDs, editing copy, user research, tests, metrics, and more.” There’s also an emphasis on steering the model mid-task and frequent status updates.
Hard to believe the gameplay on this website is powered by a set of earbuds.
Hard to believe the gameplay on this website is powered by a set of earbuds. Credit: DoomBuds
Squeezing the entirety of Doom onto modern earbuds wasn’t an easy task, either. The 4.2MB of game data won’t quite fit on the PineBuds’ 4MB of flash memory, for instance. That means the project needed to use a 1.7MB “squashware” build of Doom, which eliminates some animation frames and shortens some music tracks to make the game even more portable.
The earbuds also have just under 1MB of RAM, requiring the coding of a new version of the game that optimizes away many of the bits that usually fill up a full 4MB of RAM in the standard game. “Pre-generating lookup tables, making variables const, reading const variables from flash, disabling DOOM’s caching system, removing unneeded variables… it all adds up,” Sarkisan writes.
For those without their own PineBuds to test this wild idea, Sarkisan has set up an interactive Twitch stream that players can queue up to control for 45-second sessions via doombuds.com. It’s a great little break-time diversion, especially for people ready to marvel that a set of $70 earbuds can now run a game that required a $1,000-plus computer tower a few decades ago.
Linux and Git creator Linus Torvalds’ latest project contains code that was “basically written by vibe coding,” but you shouldn’t read that to mean that Torvalds is embracing that approach for anything and everything.
Torvalds sometimes works on a small hobby projects over holiday breaks. Last year, he made guitar pedals. This year, he did some work on AudioNoise, which he calls “another silly guitar-pedal-related repo.” It creates random digital audio effects.
Torvalds revealed that he had used an AI coding tool in the README for the repo:
Also note that the python visualizer tool has been basically written by vibe-coding. I know more about analog filters—and that’s not saying much—than I do about python. It started out as my typical “google and do the monkey-see-monkey-do” kind of programming, but then I cut out the middle-man—me—and just used Google Antigravity to do the audio sample visualizer.
Google’s Antigravity is a fork of the AI-focused IDE Windsurf. He didn’t specify which model he used, but using Antigravity suggests (but does not prove) that it was some version of Google’s Gemini.
Torvalds’ past public comments on using large language model-based tools for programming have been more nuanced than many online discussions about it.
He has touted AI primarily as “a tool to help maintain code, including automated patch checking and code review,” citing examples of tools that found problems he had missed.
On the other hand, he has also said he is generally “much less interested in AI for writing code,” and has publicly said that he’s not anti-AI in principle, but he’s very much anti-hype around AI.
To see how effective these modern AI coding tools are becoming, we decided to test four major models with a simple task: re-creating the classic Windows game Minesweeper. Since it’s relatively easy for pattern-matching systems like LLMs to play off of existing code to re-create famous games, we added in one novelty curveball as well.
Our straightforward prompt:
Make a full-featured web version of Minesweeper with sound effects that
1) Replicates the standard Windows game and 2) implements a surprise, fun gameplay feature.
Include mobile touchscreen support.
Ars Senior AI Editor Benj Edwards fed this task into four AI coding agents with terminal (command line) apps: OpenAI’s Codex based on GPT-5, Anthropic’s Claude Code with Opus 4.5, Google’s Gemini CLI, and Mistral Vibe. The agents then directly manipulated HTML and scripting files on a local machine, guided by a “supervising” AI model that interpreted the prompt and assigned coding tasks to parallel LLMs that can use software tools to execute the instructions. All AI plans were paid for privately with no special or privileged access given by the companies involved, and the companies were unaware of these tests taking place.
Ars Senior Gaming Editor (and Minesweeper expert) Kyle Orland then judged each example blind, without knowing which model generated which Minesweeper clone. Those somewhat subjective and non-rigorous results are below.
For this test, we used each AI model’s unmodified code in a “single shot” result to see how well these tools perform without any human debugging. In the real world, most sufficiently complex AI-generated code would go through at least some level of review and tweaking by a human software engineer who could spot problems and address inefficiencies.
We chose this test as a sort of simple middle ground for the current state of AI coding. Cloning Minesweeper isn’t a trivial task that can be done in just a handful of lines of code, but it’s also not an incredibly complex system that requires many interlocking moving parts.
Minesweeper is also a well-known game, with manyversions documented across the Internet. That should give these AI agents plenty of raw material to work from and should be easier for us to evaluate than a completely novel program idea. At the same time, our open-ended request for a new “fun” feature helps demonstrate each agent’s penchant for unguided coding “creativity,” as well as their ability to create new features on top of an established game concept.
With all that throat-clearing out of the way, here’s our evaluation of the AI-generated Minesweeper clones, complete with links that you can use to play them yourselves.
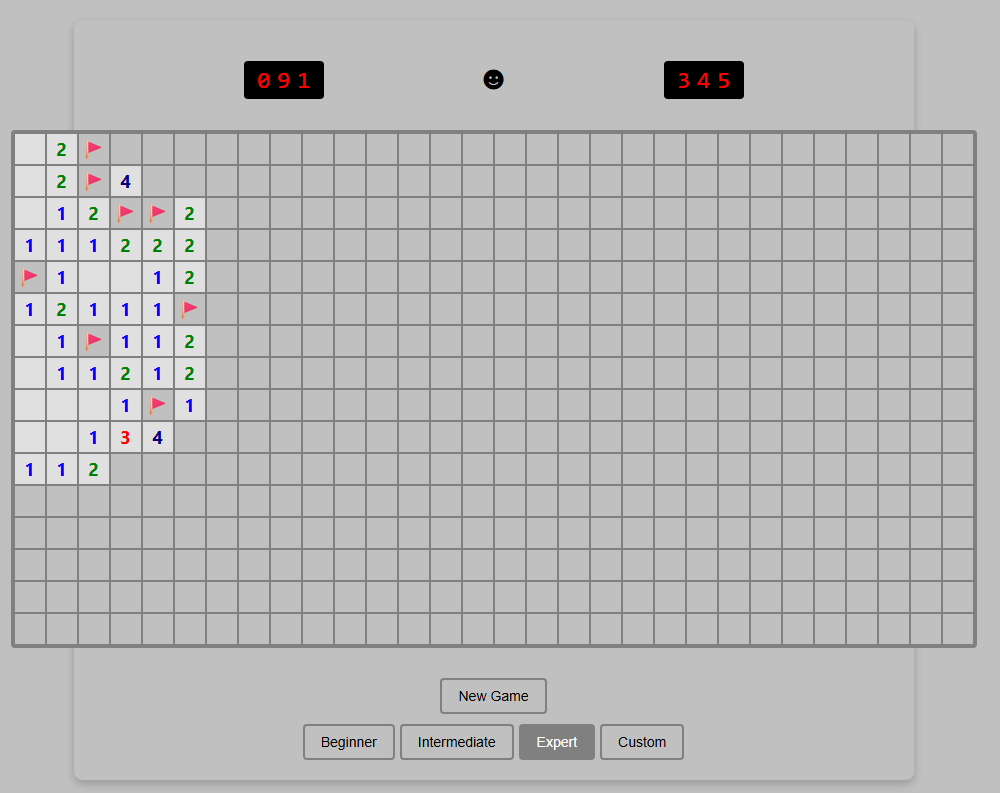
Just ignore that Custom button. It’s purely for show.
Just ignore that Custom button. It’s purely for show. Credit: Benj Edwards
Implementation
Right away, this version loses points for not implementing chording—the technique that advanced Minesweeper players use to quickly clear all the remaining spaces surrounding a number that already has sufficient flagged mines. Without this feature, this version feels more than a little clunky to play.
I’m also a bit perplexed by the inclusion of a “Custom” difficulty button that doesn’t seem to do anything. It’s like the model realized that customized board sizes were a thing in Minesweeper but couldn’t figure out how to implement this relatively basic feature.
The game works fine on mobile, but marking a square with a flag requires a tricky long-press on a tiny square that also triggers selector handles that are difficult to clear. So it’s not an ideal mobile interface.
Presentation
This was the only working version we tested that didn’t include sound effects. That’s fair, since the original Windows Minesweeper also didn’t include sound, but it’s still a notable relative omission since the prompt specifically asked for it.
The all-black “smiley face” button to start a game is a little off-putting, too, compared to the bright yellow version that’s familiar to both Minesweeper players and emoji users worldwide. And while that smiley face does start a new game when clicked, there’s also a superfluous “New Game” button taking up space for some reason.
“Fun” feature
The closest thing I found to a “fun” new feature here was the game adding a rainbow background pattern on the grid when I completed a game. While that does add a bit of whimsy to a successful game, I expected a little more.
Coding experience
Benj notes that he was pleasantly surprised by how well Mistral Vibe performed as an open-weight model despite lacking the big-money backing of the other contenders. It was relatively slow, however (third fastest out of four), and the result wasn’t great. Ultimately, its performance so far suggests that with more time and more training, a very capable AI coding agent may eventually emerge.
Overall rating: 4/10
This version got many of the basics right but left out chording and didn’t perform well on the small presentational and “fun” touches.
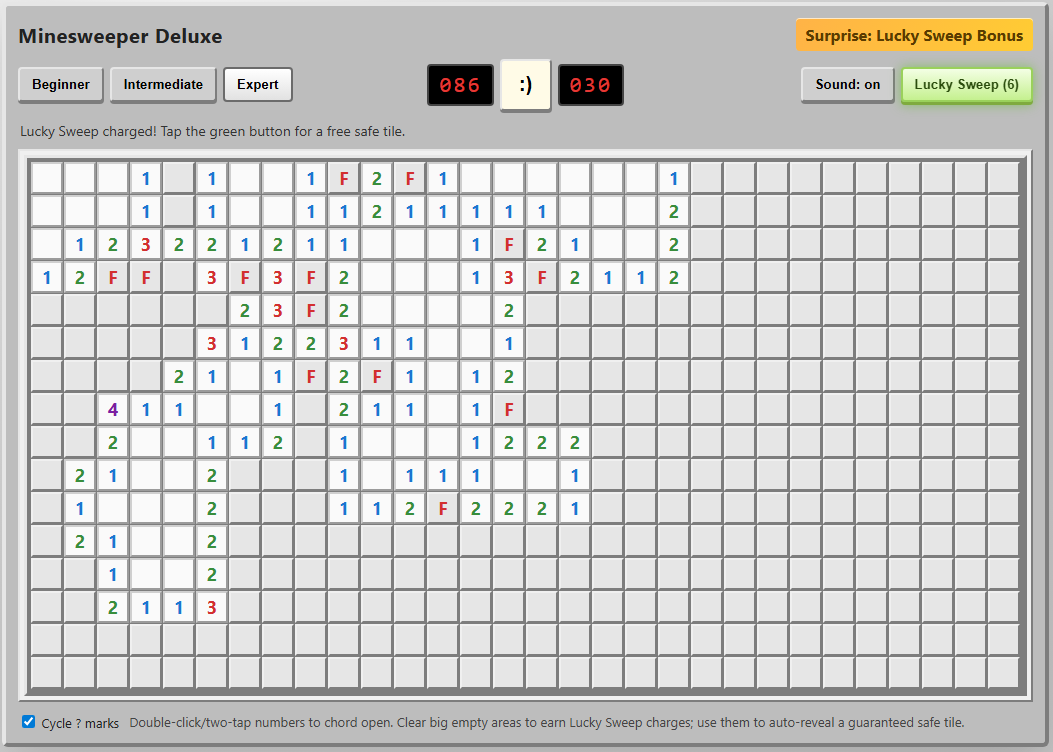
I can’t tell you how much I appreciate those chording instructions at the bottom.
I can’t tell you how much I appreciate those chording instructions at the bottom. Credit: Benj Edwards
Implementation
Not only did this agent include the crucial “chording” feature, but it also included on-screen instructions for using it on both PC and mobile browsers. I was further impressed by the option to cycle through “?” marks when marking squares with flags, an esoteric feature I feel even most human Minesweeper cloners might miss.
On mobile, the option to hold your finger down on a square to mark a flag is a nice touch that makes this the most enjoyable handheld version we tested.
Presentation
The old-school emoticon smiley-face button is pretty endearing, especially when you blow up and get a red-tinted “X(“. I was less impressed by the playfield “graphics,” which use a simple “*” for revealed mines and an ugly red “F” for flagged tiles.
The beeps-and-boops sound effects reminded me of my first old-school, pre-Sound-Blaster PC from the late ’80s. That’s generally a good thing, but I still appreciated the game giving me the option to turn them off.
“Fun” feature
The “Surprise: Lucky Sweep Bonus” listed in the corner of the UI explains that clicking the button gives you a free safe tile when available. This can be pretty useful in situations where you’d otherwise be forced to guess between two tiles that are equally likely to be mines.
Overall, though, I found it a bit odd that the game gives you this bonus only after you find a large, cascading field of safe tiles with a single click. It mostly functions as a “win more” button rather than a feature that offers a good balance of risk versus reward.
Coding experience
OpenAI Codex has a nice terminal interface with features similar to Claude Code (local commands, permission management, and interesting animations showing progress), and it’s fairly pleasant to use (OpenAI also offers Codex through a web interface, but we did not use that for this evaluation). However, Codex took roughly twice as long to code a functional game than Claude Code did, which might contribute to the strong result here.
Overall: 9/10
The implementation of chording and cute presentation touches push this to the top of the list. We just wish the “fun” feature was a bit more fun.
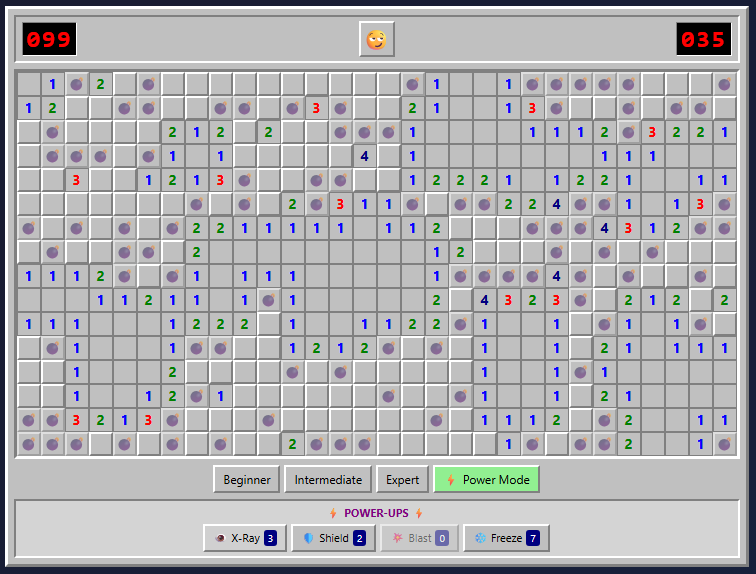
The Power Mod powers on display here make even Expert boards pretty trivial to complete.
The Power Mod powers on display here make even Expert boards pretty trivial to complete. Credit: Benj Edwards
Implementation
Once again, we get a version that gets all the gameplay basics right but is missing the crucial chording feature that makes truly efficient Minesweeper play possible. This is like playing Super Mario Bros. without the run button or Ocarina of Time without Z-targeting. In a word: unacceptable.
The “flag mode” toggle on the mobile version of this game is perfectly functional, but it’s a little clunky to use. It also visually cuts off a portion of the board at the larger game sizes.
Presentation
Presentation-wise, this is probably the most polished version we tested. From the use of cute emojis for the “face” button to nice-looking bomb and flag graphics and simple but effective sound effects, this looks more professional than the other versions we tested.
That said, there are some weird presentation issues. The “beginner” grid has weird gaps between columns, for instance. The borders of each square and the flag graphics can also become oddly grayed out at points, especially when using Power Mode (see below).
“Fun” feature
The prominent “Power Mode” button in the lower-right corner offers some pretty fun power-ups that alter the core Minesweeper formula in interesting ways. But the actual powers are a bit hit-and-miss.
I especially liked the “Shield” power, which protects you from an errant guess, and the “Blast” power, which seems to guarantee a large cascade of revealed tiles wherever you click. But the “X-Ray” power, which reveals every bomb for a few seconds, could be easily exploited by a quick player (or a crafty screenshot). And the “Freeze” power is rather boring, just stopping the clock for a few seconds and amounting to a bit of extra time.
Overall, the game hands out these new powers like candy, which makes even an Expert-level board relatively trivial with Power Mode active. Simply choosing “Power Mode” also seems to mark a few safe squares right after you start a game, making things even easier. So while these powers can be “fun,” they also don’t feel especially well-balanced.
Coding experience
Of the four tested models, Claude Code with Opus 4.5 featured the most pleasant terminal interface experience and the fastest overall coding experience (Claude Code can also use Sonnet 4.5, which is even faster, but the results aren’t quite as full-featured in our experience). While we didn’t precisely time each model, Opus 4.5 produced a working Minesweeper in under five minutes. Codex took at least twice as long, if not longer, while Mistral took roughly three or four times as long as Claude Code. Gemini, meanwhile, took hours of tinkering to get two non-working results.
Overall: 7/10
The lack of chording is a big omission, but the strong presentation and Power Mode options give this effort a passable final score.
Gemini CLI did give us a few gray boxes you can click, but the playfields are missing. While interactive troubleshooting with the agent may have fixed the issue, as a “one-shot” test, the model completely failed.
Coding experience
Of the four coding agents we tested, Gemini CLI gave Benj the most trouble. After developing a plan, it was very, very slow at generating any usable code (about an hour per attempt). The model seemed to get hung up attempting to manually create WAV file sound effects and insisted on requiring React external libraries and a few other overcomplicated dependencies. The result simply did not work.
Benj actually bent the rules and gave Gemini a second chance, specifying that the game should use HTML5. When the model started writing code again, it also got hung up trying to make sound effects. Benj suggested using the WebAudio framework (which the other AI coding agents seemed to be able to use), but the result didn’t work, which you can see at the link above.
Unlike the other models tested, Gemini CLI apparently uses a hybrid system of three different LLMs for different tasks (Gemini 2.5 Flash Lite, 2.5 Flash, and 2.5 Pro were available at the level of the Google account Benj paid for). When you’ve completed your coding session and quit the CLI interface, it gives you a readout of which model did what.
In this case, it didn’t matter because the results didn’t work. But it’s worth noting that Gemini 3 coding models are available for other subscription plans that were not tested here. For that reason, this portion of the test could be considered “incomplete” for Google CLI.
Overall: 0/10 (Incomplete)
Final verdict
OpenAI Codex wins this one on points, in no small part because it was the only model to include chording as a gameplay option. But Claude Code also distinguished itself with strong presentational flourishes and quick generation time. Mistral Vibe was a significant step down, and Google CLI based on Gemini 2.5 was a complete failure on our one-shot test.
While experienced coders can definitely get better results via an interactive, back-and-forth code editing conversation with an agent, these results show how capable some of these models can be, even with a very short prompt on a relatively straightforward task. Still, we feel that our overall experience with coding agents on other projects (more on that in a future article) generally reinforces the idea that they currently function best as interactive tools that augment human skill rather than replace it.
Kyle Orland has been the Senior Gaming Editor at Ars Technica since 2012, writing primarily about the business, tech, and culture behind video games. He has journalism and computer science degrees from University of Maryland. He once wrote a whole book about Minesweeper.
The latest Xcode beta contains clear signs that Apple plans to bring Anthropic’s Claude and Opus large language models into the integrated development environment (IDE), expanding on features already available using Apple’s own models or OpenAI’s ChatGPT.
Apple enthusiast publication 9to5Mac “found multiple references to built-in support for Anthropic accounts,” including in the “Intelligence” menu, where users can currently log in to ChatGPT or enter an API key for higher message limits.
Apple introduced a suite of features meant to compete with GitHub Copilot in Xcode at WWDC24, but first focused on its own models and a more limited set of use cases. That expanded quite a bit at this year’s developer conference, and users can converse about codebases, discuss changes, or ask for suggestions using ChatGPT. They are initially given a limited set of messages, but this can be greatly increased by logging in to a ChatGPT account or entering an API key.
This summer, Apple said it would be possible to use Anthropic’s models with an API key, too, but made no mention of support for Anthropic accounts, which are generally more cost-effective than using the API for most users.
We’ve been expecting it for a while, and now it’s here: OpenAI has introduced an agentic coding tool called Codex in research preview. The tool is meant to allow experienced developers to delegate rote and relatively simple programming tasks to an AI agent that will generate production-ready code and show its work along the way.
Codex is a unique interface (not to be confused with the Codex CLI tool introduced by OpenAI last month) that can be reached from the side bar in the ChatGPT web app. Users enter a prompt and then click either “code” to have it begin producing code, or “ask” to have it answer questions and advise.
Whenever it’s given a task, that task is performed in a distinct container that is preloaded with the user’s codebase and is meant to accurately reflect their development environment.
To make Codex more effective, developers can include an “AGENTS.md” file in the repo with custom instructions, for example to contextualize and explain the code base or to communicate standardizations and style practices for the project—kind of a README.md but for AI agents rather than humans.
Codex is built on codex-1, a fine-tuned variation of OpenAI’s o3 reasoning model that was trained using reinforcement learning on a wide range of coding tasks to analyze and generate code, and to iterate through tests along the way.
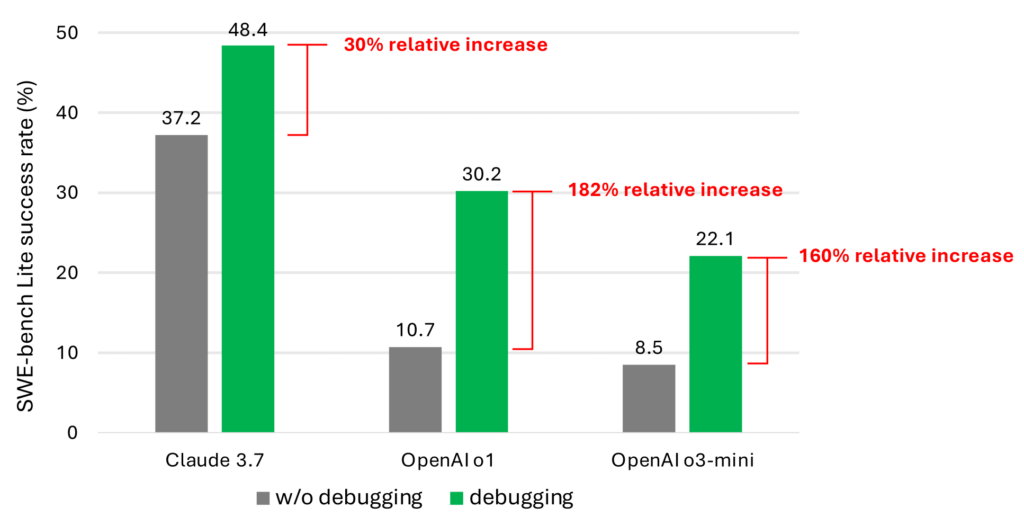
Agents using debugging tools drastically outperformed those that didn’t, but their success rate still wasn’t high enough. Credit: Microsoft Research
This approach is much more successful than relying on the models as they’re usually used, but when your best case is a 48.4 percent success rate, you’re not ready for primetime. The limitations are likely because the models don’t fully understand how to best use the tools, and because their current training data is not tailored to this use case.
“We believe this is due to the scarcity of data representing sequential decision-making behavior (e.g., debugging traces) in the current LLM training corpus,” the blog post says. “However, the significant performance improvement… validates that this is a promising research direction.”
This initial report is just the start of the efforts, the post claims. The next step is to “fine-tune an info-seeking model specialized in gathering the necessary information to resolve bugs.” If the model is large, the best move to save inference costs may be to “build a smaller info-seeking model that can provide relevant information to the larger one.”
This isn’t the first time we’ve seen outcomes that suggest some of the ambitious ideas about AI agents directly replacing developers are pretty far from reality. There have been numerous studies already showing that even though an AI tool can sometimes create an application that seems acceptable to the user for a narrow task, the models tend to produce code laden with bugs and security vulnerabilities, and they aren’t generally capable of fixing those problems.
This is an early step on the path to AI coding agents, but most researchers agree it remains likely that the best outcome is an agent that saves a human developer a substantial amount of time, not one that can do everything they can do.
Accepting AI-written code without understanding how it works is growing in popularity.
For many people, coding is about telling a computer what to do and having the computer perform those precise actions repeatedly. With the rise of AI tools like ChatGPT, it’s now possible for someone to describe a program in English and have the AI model translate it into working code without ever understanding how the code works. Former OpenAI researcher Andrej Karpathy recently gave this practice a name—”vibe coding”—and it’s gaining traction in tech circles.
The technique, enabled by large language models (LLMs) from companies like OpenAI and Anthropic, has attracted attention for potentially lowering the barrier to entry for software creation. But questions remain about whether the approach can reliably produce code suitable for real-world applications, even as tools like Cursor Composer, GitHub Copilot, and Replit Agent make the process increasingly accessible to non-programmers.
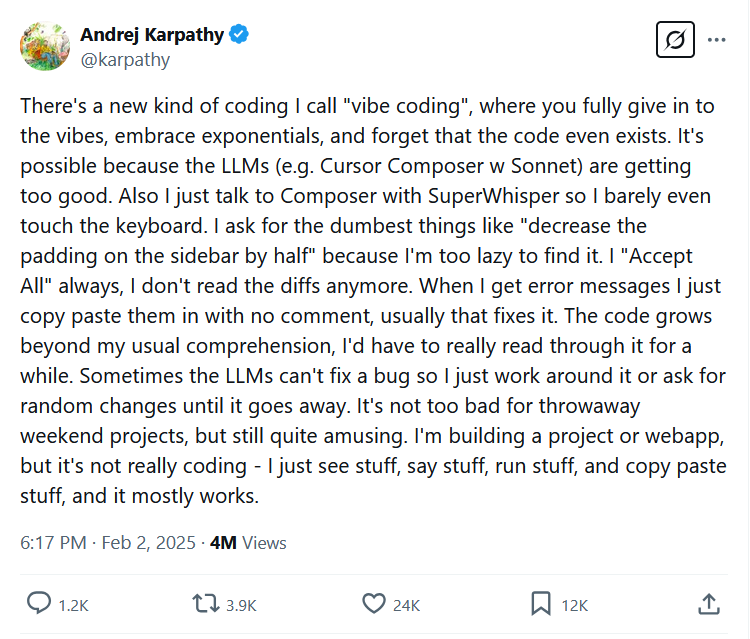
Instead of being about control and precision, vibe coding is all about surrendering to the flow. On February 2, Karpathy introduced the term in a post on X, writing, “There’s a new kind of coding I call ‘vibe coding,’ where you fully give in to the vibes, embrace exponentials, and forget that the code even exists.” He described the process in deliberately casual terms: “I just see stuff, say stuff, run stuff, and copy paste stuff, and it mostly works.”
A screenshot of Karpathy’s original X post about vibe coding from February 2, 2025. Credit: Andrej Karpathy / X
While vibe coding, if an error occurs, you feed it back into the AI model, accept the changes, hope it works, and repeat the process. Karpathy’s technique stands in stark contrast to traditional software development best practices, which typically emphasize careful planning, testing, and understanding of implementation details.
As Karpathy humorously acknowledged in his original post, the approach is for the ultimate lazy programmer experience: “I ask for the dumbest things, like ‘decrease the padding on the sidebar by half,’ because I’m too lazy to find it myself. I ‘Accept All’ always; I don’t read the diffs anymore.”
At its core, the technique transforms anyone with basic communication skills into a new type of natural language programmer—at least for simple projects. With AI models currently being held back by the amount of code an AI model can digest at once (context size), there tends to be an upper-limit to how complex a vibe-coded software project can get before the human at the wheel becomes a high-level project manager, manually assembling slices of AI-generated code into a larger architecture. But as technical limits expand with each generation of AI models, those limits may one day disappear.
Who are the vibe coders?
There’s no way to know exactly how many people are currently vibe coding their way through either hobby projects or development jobs, but Cursor reported 40,000 paying users in August 2024, and GitHub reported 1.3 million Copilot users just over a year ago (February 2024). While we can’t find user numbers for Replit Agent, the site claims 30 million users, with an unknown percentage using the site’s AI-powered coding agent.
One thing we do know: the approach has particularly gained traction online as a fun way of rapidly prototyping games. Microsoft’s Peter Yang recently demonstrated vibe coding in an X thread by building a simple 3D first-person shooter zombie game through conversational prompts fed into Cursor and Claude 3.7 Sonnet. Yang even used a speech-to-text app so he could verbally describe what he wanted to see and refine the prototype over time.
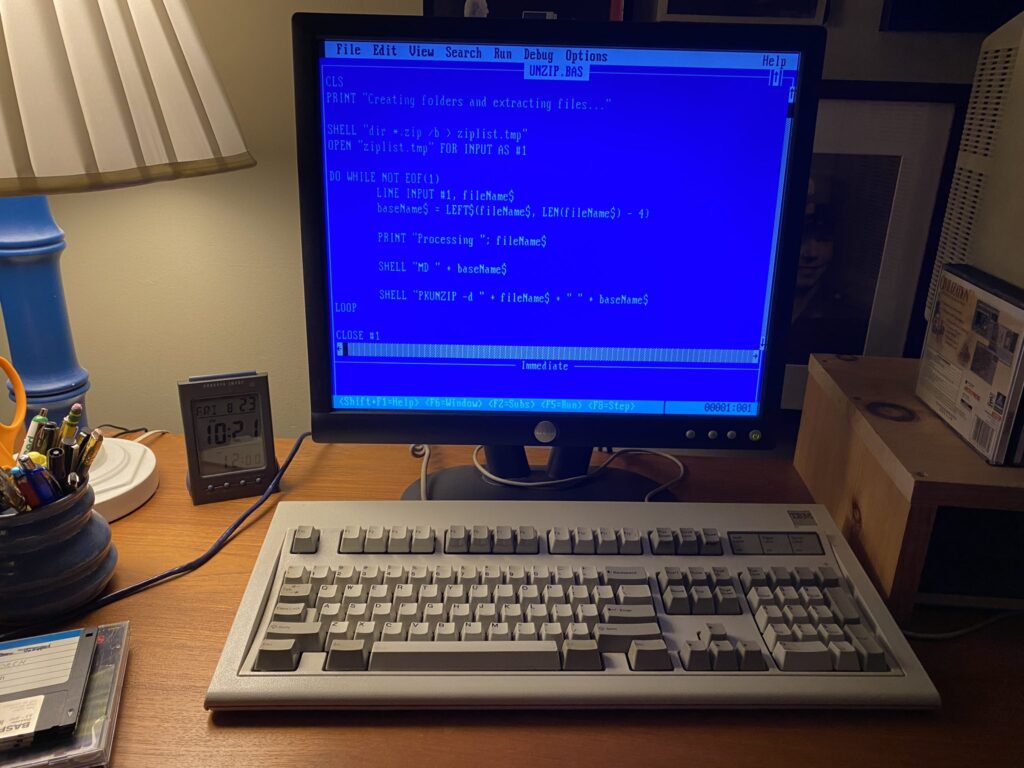
In August 2024, the author vibe coded his way into a working Q-BASIC utility script for MS-DOS, thanks to Claude Sonnet. Credit: Benj Edwards
We’ve been doing some vibe coding ourselves. Multiple Ars staffers have used AI assistants and coding tools for extracurricular hobby projects such as creating small games, crafting bespoke utilities, writing processing scripts, and more. Having a vibe-based code genie can come in handy in unexpected places: Last year, I asked Anthropic’s Claude write a Microsoft Q-BASIC program in MS-DOS that decompressed 200 ZIP files into custom directories, saving me many hours of manual typing work.
Debugging the vibes
With all this vibe coding going on, we had to turn to an expert for some input. Simon Willison, an independent software developer and AI researcher, offered a nuanced perspective on AI-assisted programming in an interview with Ars Technica. “I really enjoy vibe coding,” he said. “It’s a fun way to try out an idea and prove if it can work.”
But there are limits to how far Willison will go. “Vibe coding your way to a production codebase is clearly risky. Most of the work we do as software engineers involves evolving existing systems, where the quality and understandability of the underlying code is crucial.”
At some point, understanding at least some of the code is important because AI-generated code may include bugs, misunderstandings, and confabulations—for example, instances where the AI model generates references to nonexistent functions or libraries.
“Vibe coding is all fun and games until you have to vibe debug,” developer Ben South noted wryly on X, highlighting this fundamental issue.
Willison recently argued on his blog that encountering hallucinations with AI coding tools isn’t as detrimental as embedding false AI-generated information into a written report, because coding tools have built-in fact-checking: If there’s a confabulation, the code won’t work. This provides a natural boundary for vibe coding’s reliability—the code runs or it doesn’t.
Even so, the risk-reward calculation for vibe coding becomes far more complex in professional settings. While a solo developer might accept the trade-offs of vibe coding for personal projects, enterprise environments typically require code maintainability and reliability standards that vibe-coded solutions may struggle to meet. When code doesn’t work as expected, debugging requires understanding what the code is actually doing—precisely the knowledge that vibe coding tends to sidestep.
Programming without understanding
When it comes to defining what exactly constitutes vibe coding, Willison makes an important distinction: “If an LLM wrote every line of your code, but you’ve reviewed, tested, and understood it all, that’s not vibe coding in my book—that’s using an LLM as a typing assistant.” Vibe coding, in contrast, involves accepting code without fully understanding how it works.
While vibe coding originated with Karpathy as a playful term, it may encapsulate a real shift in how some developers approach programming tasks—prioritizing speed and experimentation over deep technical understanding. And to some people, that may be terrifying.
Willison emphasizes that developers need to take accountability for their code: “I firmly believe that as a developer you have to take accountability for the code you produce—if you’re going to put your name to it you need to be confident that you understand how and why it works—ideally to the point that you can explain it to somebody else.”
He also warns about a common path to technical debt: “For experiments and low-stake projects where you want to explore what’s possible and build fun prototypes? Go wild! But stay aware of the very real risk that a good enough prototype often faces pressure to get pushed to production.”
The future of programming jobs
So, is all this vibe coding going to cost human programmers their jobs? At its heart, programming has always been about telling a computer how to operate. The method of how we do that has changed over time, but there may always be people who are better at telling a computer precisely what to do than others—even in natural language. In some ways, those people may become the new “programmers.”
There was a point in the late 1970s to early ’80s when many people thought people required programming skills to use a computer effectively because there were very few pre-built applications for all the various computer platforms available. School systems worldwide made educational computer literacy efforts to teach people to code.
A brochure for the GE 210 computer from 1964. BASIC’s creators used a similar computer four years later to develop the programming language that many children were taught at home and school. Credit: GE / Wikipedia
Before too long, people made useful software applications that let non-coders utilize computers easily—no programming required. Even so, programmers didn’t disappear—instead, they used applications to create better and more complex programs. Perhaps that will also happen with AI coding tools.
To use an analogy, computer controlled technologies like autopilot made reliable supersonic flight possible because they could handle aspects of flight that were too taxing for all but the most highly trained and capable humans to safely control. AI may do the same for programming, allowing humans to abstract away complexities that would otherwise take too much time to manually code, and that may allow for the creation of more complex and useful software experiences in the future.
But at that point, will humans still be able to understand or debug them? Maybe not. We may be completely dependent on AI tools, and some people no doubt find that a little scary or unwise.
Whether vibe coding lasts in the programming landscape or remains a prototyping technique will likely depend less on the capabilities of AI models and more on the willingness of organizations to accept risky trade-offs in code quality, maintainability, and technical debt. For now, vibe coding remains an apt descriptor of the messy, experimental relationship between AI and human developers—more collaborative than autonomous, but increasingly blurring the lines of who (or what) is really doing the programming.
Benj Edwards is Ars Technica’s Senior AI Reporter and founder of the site’s dedicated AI beat in 2022. He’s also a tech historian with almost two decades of experience. In his free time, he writes and records music, collects vintage computers, and enjoys nature. He lives in Raleigh, NC.
The large language model-based coding assistant GitHub Copilot will switch from using exclusively OpenAI’s GPT models to a multi-model approach over the coming weeks, GitHub CEO Thomas Dohmke announced in a post on GitHub’s blog.
First, Anthropic’s Claude 3.5 Sonnet will roll out to Copilot Chat’s web and VS Code interfaces over the next few weeks. Google’s Gemini 1.5 Pro will come a bit later.
Additionally, GitHub will soon add support for a wider range of OpenAI models, including GPT o1-preview and o1-mini, which are intended to be stronger at advanced reasoning than GPT-4, which Copilot has used until now. Developers will be able to switch between the models (even mid-conversation) to tailor the model to fit their needs—and organizations will be able to choose which models will be usable by team members.
The new approach makes sense for users, as certain models are better at certain languages or types of tasks.
“There is no one model to rule every scenario,” wrote Dohmke. “It is clear the next phase of AI code generation will not only be defined by multi-model functionality, but by multi-model choice.”
It starts with the web-based and VS Code Copilot Chat interfaces, but it won’t stop there. “From Copilot Workspace to multi-file editing to code review, security autofix, and the CLI, we will bring multi-model choice across many of GitHub Copilot’s surface areas and functions soon,” Dohmke wrote.
There are a handful of additional changes coming to GitHub Copilot, too, including extensions, the ability to manipulate multiple files at once from a chat with VS Code, and a preview of Xcode support.
GitHub Spark promises natural language app development
In addition to the Copilot changes, GitHub announced Spark, a natural language tool for developing apps. Non-coders will be able to use a series of natural language prompts to create simple apps, while coders will be able to tweak more precisely as they go. In either use case, you’ll be able to take a conversational approach, requesting changes and iterating as you go, and comparing different iterations.
In recent years, we’ve reported on multiple efforts to reverse-engineer Nintendo 64 games into fully decompiled, human-readable C code that can then become the basis for full-fledged PC ports. While the results can be impressive, the decompilation process can take years of painstaking manual effort, meaning only the most popular N64 games are likely to get the requisite attention from reverse engineers.
Now, a newly released tool promises to vastly reduce the amount of human effort needed to get basic PC ports of most (if not all) N64 games. The N64 Recompiled project uses a process known as static recompilation to automate huge swaths of the labor-intensive process of drawing C code out of N64 binaries.
While human coding work is still needed to smooth out the edges, project lead Mr-Wiseguy told Ars that his recompilation tool is “the difference between weeks of work and years of work” when it comes to making a PC version of a classic N64 title. And parallel work on a powerful N64 graphic renderer means PC-enabled upgrades like smoother frame rates, resolution upscaling, and widescreen aspect ratios can be added with little effort.
Inspiration hits
Mr-Wiseguy told Ars he got his start in the N64 coding space working on various mod projects around 2020. In 2022, he started contributing to the then-new RT64 renderer project, which grew out of work on a ray-traced Super Mario 64 port into a more generalized effort to clean up the notoriously tricky process of recreating N64 graphics accurately. While working on that project, Mr-Wiseguy said he stumbled across an existing project that automates the disassembly of NES games and another that emulates an old SGI compiler to aid in the decompilation of N64 titles.
YouTuber Nerrel lays out some of the benefits of Mr-Wiseguy’s N64 recompilation tool.
“I realized it would be really easy to hook up the RT64 renderer to a game if it could be run through a similar static recompilation process,” Mr-Wiseguy told Ars. “So I put together a proof of concept to run a really simple game and then the project grew from there until it could run some of the more complex games.”
A basic proof of concept for Mr-Wiseguy’s idea took only “a couple of weeks at most” to get up and running, he said, and was ready as far back as November of 2022. Since then, months of off-and-on work have gone into rounding out the conversion code and getting a recompiled version of The Legend of Zelda: Majora’s Mask ready for public consumption.
Trust the process
At its most basic level, the N64 recompilation tool takes a raw game binary (provided by the user) and reprocesses every single instruction directly and literally into corresponding C code. The N64’s MIPS instruction set has been pretty well-documented over years of emulation work, so figuring out how to translate each individual opcode to its C equivalent isn’t too much of a hassle.
Enlarge/ An early beta of the RT64 renderer shows how ray-tracing shadows and reflections might look in a port of Wave Race 64.
The main difficulty, Mr-Wiseguy said, can be figuring out where to point the tool. “The contents of the [N64] ROM can be laid out however the developer chose to do so, which means you have to find where code is in the ROM before you can even start the static recompilation process,” he explained. And while N64 emulators automatically handle games that load and unload code throughout memory at runtime, handling those cases in a pre-compiled binary can add extra layers of complexity.
Enlarge/ I can see the code that controls the Tetri-verse!
Aurich Lawson
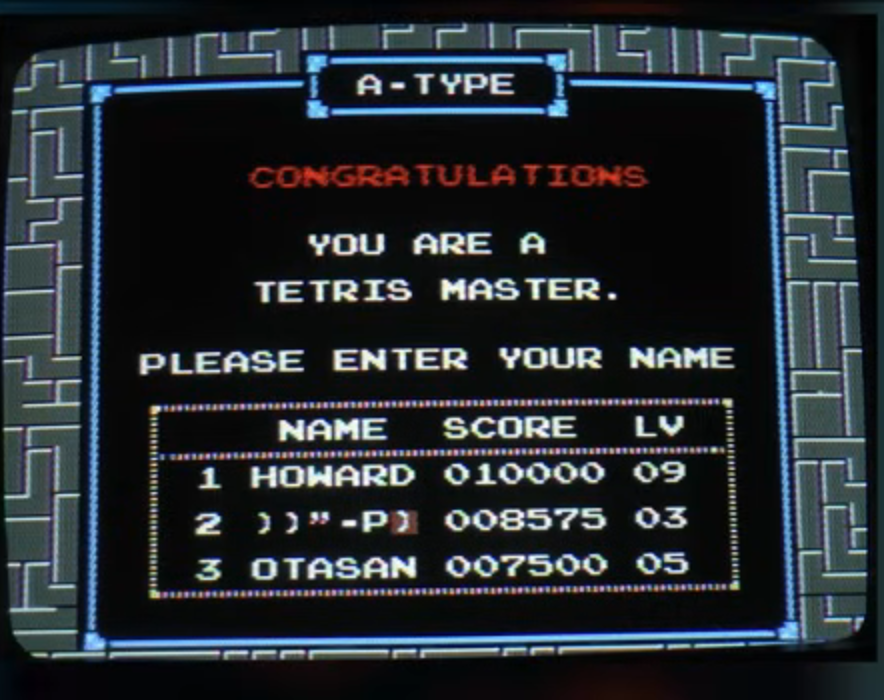
Earlier this year, we shared the story of how a classic NES Tetris player hit the game’s “kill screen” for the first time, activating a crash after an incredible 40-minute, 1,511-line performance. Now, some players are using that kill screen—and some complicated memory manipulation it enables—to code new behaviors into versions of Tetris running on unmodified hardware and cartridges.
Displaced Gamers explains how to reprogram NES Tetris within the game.
But a recent video from Displaced Gamers takes the idea from private theory to public execution, going into painstaking detail on how to get NES Tetris to start reading the game’s high score tables as machine code instructions.
Fun with controller ports
Taking over a copy of NES Tetris is possible mostly due to the specific way the game crashes. Without going into too much detail, a crash in NES Tetris happens when the game’s score handler takes too long to calculate a new score between frames, which can happen after level 155. When this delay occurs, a portion of the control code gets interrupted by the new frame-writing routine, causing it to jump to an unintended portion of the game’s RAM to look for the next instruction.
Usually, this unexpected interrupt leads the code to jump to address the very beginning of RAM, where garbage data gets read as code and often leads to a quick crash. But players can manipulate this jump thanks to a little-known vagary in how Tetris handles potential inputs when running on the Japanese version of the console, the Famicom.
Enlarge/ The Famicom expansion port that is key to making this hack work.
Unlike the American Nintendo Entertainment System, the Japanese Famicom featured two controllers hard-wired to the unit. Players who wanted to use third-party controllers could plug them in through an expansion port on the front of the system. The Tetris game code reads the inputs from this “extra” controller port, which can include two additional standard NES controllers through the use of an adapter (this is true even though the Famicom got a completely different version of Tetris from Bullet-Proof Software).
As it happens, the area of RAM that Tetris uses to process this extra controller input is also used for the memory location of that jump routine we discussed earlier. Thus, when that jump routine gets interrupted by a crash, that RAM will be holding data representing the buttons being pushed on those controllers. This gives players a potential way to control precisely where the game code goes after the crash is triggered.
Coding in the high-score table
For Displaced Gamers’ jump-control method, the player has to hold down “up” on the third controller and right, left, and down on the fourth controller (that latter combination requires some controller fiddling to allow for simultaneous left and right directional input). Doing so sends the jump code to an area of RAM that holds the names and scores for the game’s high score listing, giving an even larger surface of RAM that can be manipulated directly by the player.
By putting “(G” in the targeted portion of the B-Type high score table, we can force the game to jump to another area of the high score table, where it will start reading the names and scores sequentially as what Displaced Gamers calls “bare metal” code, with the letters and numbers representing opcodes for the NES CPU.
Enlarge/ This very specific name and score combination is actually read as code in Displaced Gamers’ proof of concept.
Unfortunately, there are only 43 possible symbols that can be used in the name entry area and 10 different digits that can be part of a high score. That means only a small portion of the NES’s available opcode instructions can be “coded” into the high score table using the available attack surface.
Despite these restrictions, Displaced Gamers was able to code a short proof-of-concept code snippet that can be translated into high-score table data (A name of '))"-P)', and a second-place score of 8,575 in the A-Type game factors prominently, in case you’re wondering). This simple routine puts two zeroes in the top digits of the game’s score, lowering the score processing time that would otherwise cause a crash (though the score will eventually reach the “danger zone” for a crash again, with continued play).
Of course, the lack of a battery-backed save system means hackers need to achieve these high scores manually (and enter these complicated names) every time they power up Tetris on a stock NES. The limited space in the high score table also doesn’t leave much room for direct coding of complex programs on top of Tetris‘ actual code. But there are ways around this limitation; HydrantDude writes of a specific set of high-score names and numbers that “build[s] another bootstrapper which builds another bootstrapper that grants full control over all of RAM.”
With that kind of full control, a top-level player could theoretically recode NES Tetris to patch out the crash bugs altogether. That could be extremely helpful for players who are struggling to make it past level 255, where the game actually loops back to the tranquility of Level 0. In the meantime, I guess you could always just follow the lead of Super Mario World speedrunners and transform Tetris into Flappy Bird.


















{kind=link}
{kind=link}
{kind=link}