The large language model-based coding assistant GitHub Copilot will switch from using exclusively OpenAI’s GPT models to a multi-model approach over the coming weeks, GitHub CEO Thomas Dohmke announced in a post on GitHub’s blog.
First, Anthropic’s Claude 3.5 Sonnet will roll out to Copilot Chat’s web and VS Code interfaces over the next few weeks. Google’s Gemini 1.5 Pro will come a bit later.
Additionally, GitHub will soon add support for a wider range of OpenAI models, including GPT o1-preview and o1-mini, which are intended to be stronger at advanced reasoning than GPT-4, which Copilot has used until now. Developers will be able to switch between the models (even mid-conversation) to tailor the model to fit their needs—and organizations will be able to choose which models will be usable by team members.
The new approach makes sense for users, as certain models are better at certain languages or types of tasks.
“There is no one model to rule every scenario,” wrote Dohmke. “It is clear the next phase of AI code generation will not only be defined by multi-model functionality, but by multi-model choice.”
It starts with the web-based and VS Code Copilot Chat interfaces, but it won’t stop there. “From Copilot Workspace to multi-file editing to code review, security autofix, and the CLI, we will bring multi-model choice across many of GitHub Copilot’s surface areas and functions soon,” Dohmke wrote.
There are a handful of additional changes coming to GitHub Copilot, too, including extensions, the ability to manipulate multiple files at once from a chat with VS Code, and a preview of Xcode support.
GitHub Spark promises natural language app development
In addition to the Copilot changes, GitHub announced Spark, a natural language tool for developing apps. Non-coders will be able to use a series of natural language prompts to create simple apps, while coders will be able to tweak more precisely as they go. In either use case, you’ll be able to take a conversational approach, requesting changes and iterating as you go, and comparing different iterations.
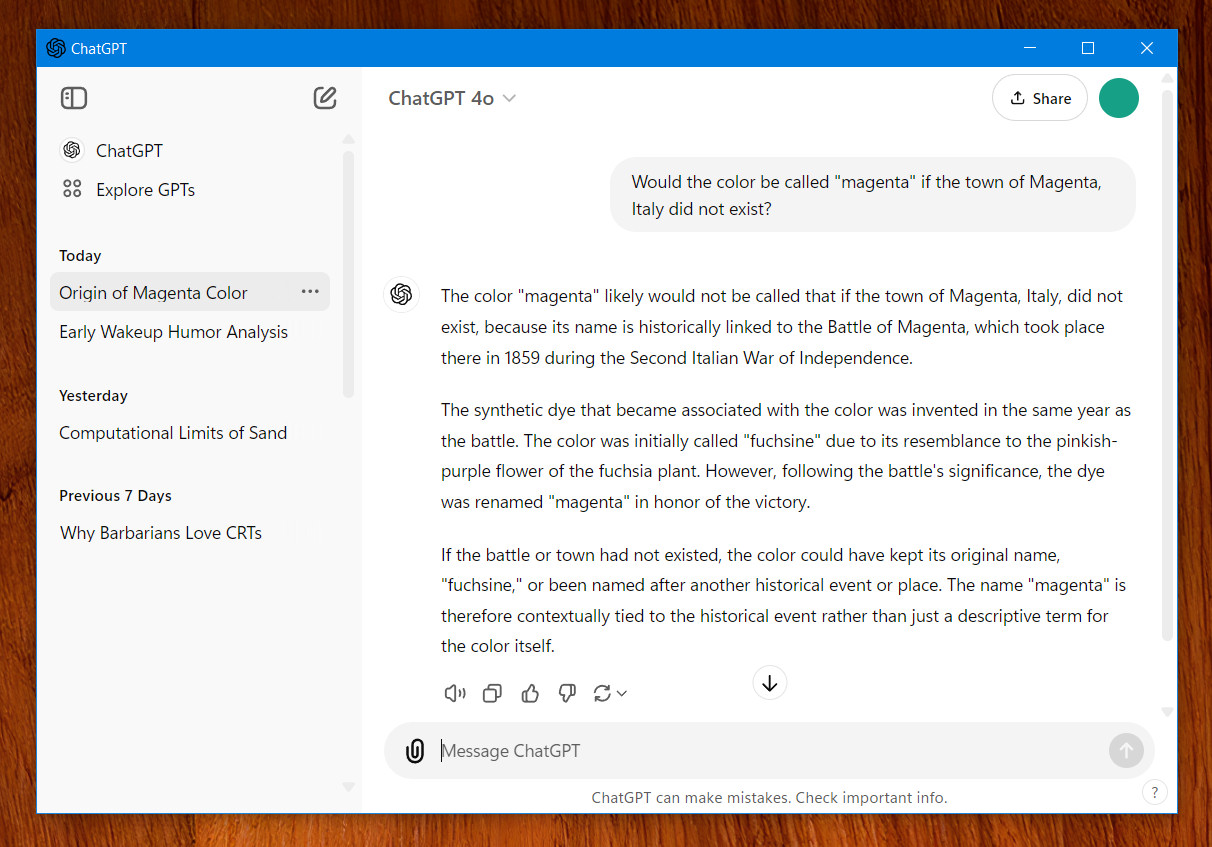
On Thursday, OpenAI released an early Windows version of its first ChatGPT app for Windows, following a Mac version that launched in May. Currently, it’s only available to subscribers of Plus, Team, Enterprise, and Edu versions of ChatGPT, and users can download it for free in the Microsoft Store for Windows.
OpenAI is positioning the release as a beta test. “This is an early version, and we plan to bring the full experience to all users later this year,” OpenAI writes on the Microsoft Store entry for the app. (Interestingly, ChatGPT shows up as being rated “T for Teen” by the ESRB in the Windows store, despite not being a video game.)
A screenshot of the new Windows ChatGPT app captured on October 18, 2024.
Credit: Benj Edwards
A screenshot of the new Windows ChatGPT app captured on October 18, 2024. Credit: Benj Edwards
Upon opening the app, OpenAI requires users to log into a paying ChatGPT account, and from there, the app is basically identical to the web browser version of ChatGPT. You can currently use it to access several models: GPT-4o, GPT-4o with Canvas, 01-preview, 01-mini, GPT-4o mini, and GPT-4. Also, it can generate images using DALL-E 3 or analyze uploaded files and images.
If you’re running Windows 11, you can instantly call up a small ChatGPT window when the app is open using an Alt+Space shortcut (it did not work in Windows 10 when we tried). That could be handy for asking ChatGPT a quick question at any time.
A screenshot of the new Windows ChatGPT app listing in the Microsoft Store captured on October 18, 2024.
Credit: Benj Edwards
A screenshot of the new Windows ChatGPT app listing in the Microsoft Store captured on October 18, 2024. Credit: Benj Edwards
And just like the web version, all the AI processing takes place in the cloud on OpenAI’s servers, which means an Internet connection is required.
So as usual, chat like somebody’s watching, and don’t rely on ChatGPT as a factual reference for important decisions—GPT-4o in particular is great at telling you what you want to hear, whether it’s correct or not. As OpenAI says in a small disclaimer at the bottom of the app window: “ChatGPT can make mistakes.”
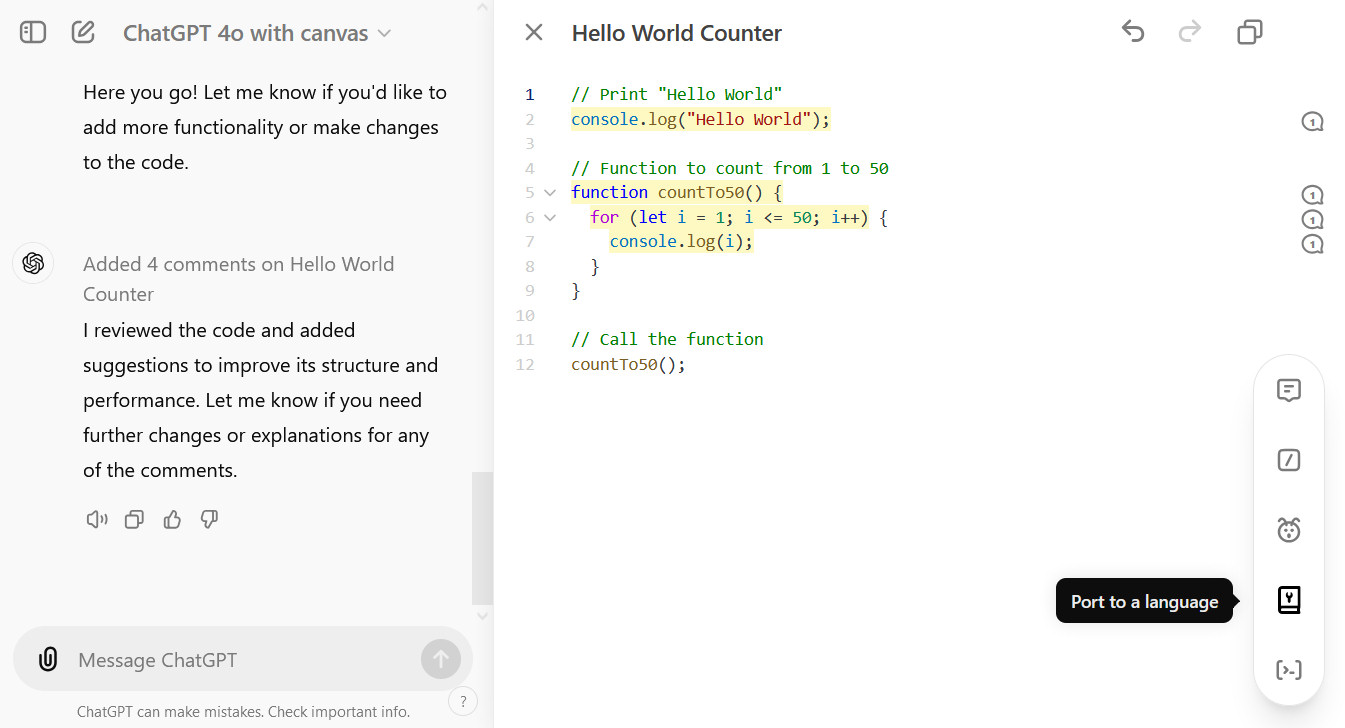
Coding shortcuts in canvas include reviewing code, adding logs for debugging, inserting comments, fixing bugs, and porting code to different programming languages. For example, if your code is JavaScript, with a few clicks it can become PHP, TypeScript, Python, C++, or Java. As with GPT-4o by itself, you’ll probably still have to check it for mistakes.
A screenshot of coding using ChatGPT with Canvas captured on October 4, 2024.
Credit: Benj Edwards
A screenshot of coding using ChatGPT with Canvas captured on October 4, 2024. Credit: Benj Edwards
Also, users can highlight specific sections to direct ChatGPT’s focus, and the AI model can provide inline feedback and suggestions while considering the entire project, much like a copy editor or code reviewer. And the interface makes it easy to restore previous versions of a working document using a back button in the Canvas interface.
A new AI model
OpenAI says its research team developed new core behaviors for GPT-4o to support Canvas, including triggering the canvas for appropriate tasks, generating certain content types, making targeted edits, rewriting documents, and providing inline critique.
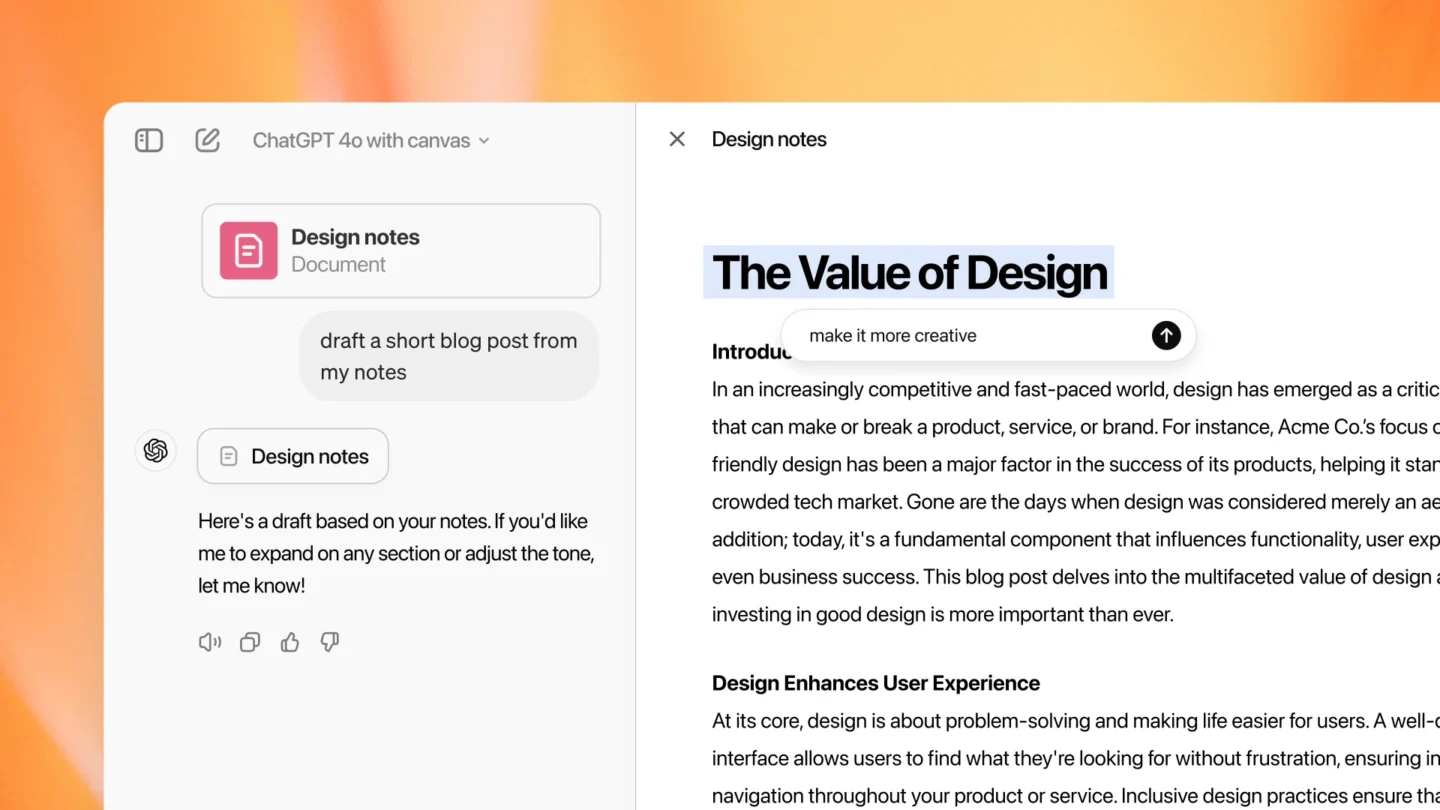
An image of OpenAI’s Canvas in action.
An image of OpenAI’s Canvas in action. Credit: OpenAI
One key challenge in development, according to OpenAI, was defining when to trigger a canvas. In an example on the Canvas blog post, the team says it taught the model to open a canvas for prompts like “Write a blog post about the history of coffee beans” while avoiding triggering Canvas for general Q&A tasks like “Help me cook a new recipe for dinner.”
Another challenge involved tuning the model’s editing behavior once canvas was triggered, specifically deciding between targeted edits and full rewrites. The team trained the model to perform targeted edits when users specifically select text through the interface, otherwise favoring rewrites.
The company noted that canvas represents the first major update to ChatGPT’s visual interface since its launch two years ago. While canvas is still in early beta, OpenAI plans to improve its capabilities based on user feedback over time.
On Saturday, a YouTube creator called “ChromaLock” published a video detailing how he modified a Texas Instruments TI-84 graphing calculator to connect to the Internet and access OpenAI’s ChatGPT, potentially enabling students to cheat on tests. The video, titled “I Made The Ultimate Cheating Device,” demonstrates a custom hardware modification that allows users of the graphing calculator to type in problems sent to ChatGPT using the keypad and receive live responses on the screen.
ChromaLock began by exploring the calculator’s link port, typically used for transferring educational programs between devices. He then designed a custom circuit board he calls “TI-32” that incorporates a tiny Wi-Fi-enabled microcontroller, the Seed Studio ESP32-C3 (which costs about $5), along with other components to interface with the calculator’s systems.
It’s worth noting that the TI-32 hack isn’t a commercial project. Replicating ChromaLock’s work would involve purchasing a TI-84 calculator, a Seed Studio ESP32-C3 microcontroller, and various electronic components, and fabricating a custom PCB based on ChromaLock’s design, which is available online.
The creator says he encountered several engineering challenges during development, including voltage incompatibilities and signal integrity issues. After developing multiple versions, ChromaLock successfully installed the custom board into the calculator’s housing without any visible signs of modifications from the outside.
“I Made The Ultimate Cheating Device” YouTube Video.
To accompany the hardware, ChromaLock developed custom software for the microcontroller and the calculator, which is available open source on GitHub. The system simulates another TI-84, allowing people to use the calculator’s built-in “send” and “get” commands to transfer files. This allows a user to easily download a launcher program that provides access to various “applets” designed for cheating.
One of the applets is a ChatGPT interface that might be most useful for answering short questions, but it has a drawback in that it’s slow and cumbersome to type in long alphanumeric questions on the limited keypad.
Beyond the ChatGPT interface, the device offers several other cheating tools. An image browser allows users to access pre-prepared visual aids stored on the central server. The app browser feature enables students to download not only games for post-exam entertainment but also text-based cheat sheets disguised as program source code. ChromaLock even hinted at a future video discussing a camera feature, though details were sparse in the current demo.
ChromaLock claims his new device can bypass common anti-cheating measures. The launcher program can be downloaded on-demand, avoiding detection if a teacher inspects or clears the calculator’s memory before a test. The modification can also supposedly break calculators out of “Test Mode,” a locked-down state used to prevent cheating.
While the video presents the project as a technical achievement, consulting ChatGPT during a test on your calculator almost certainly represents an ethical breach and/or a form of academic dishonesty that could get you in serious trouble at most schools. So tread carefully, study hard, and remember to eat your Wheaties.
Enlarge/ A man peers over a glass partition, seeking transparency.
The Open Source Initiative (OSI) recently unveiled its latest draft definition for “open source AI,” aiming to clarify the ambiguous use of the term in the fast-moving field. The move comes as some companies like Meta release trained AI language model weights and code with usage restrictions while using the “open source” label. This has sparked intense debates among free-software advocates about what truly constitutes “open source” in the context of AI.
For instance, Meta’s Llama 3 model, while freely available, doesn’t meet the traditional open source criteria as defined by the OSI for software because it imposes license restrictions on usage due to company size or what type of content is produced with the model. The AI image generator Flux is another “open” model that is not truly open source. Because of this type of ambiguity, we’ve typically described AI models that include code or weights with restrictions or lack accompanying training data with alternative terms like “open-weights” or “source-available.”
To address the issue formally, the OSI—which is well-known for its advocacy for open software standards—has assembled a group of about 70 participants, including researchers, lawyers, policymakers, and activists. Representatives from major tech companies like Meta, Google, and Amazon also joined the effort. The group’s current draft (version 0.0.9) definition of open source AI emphasizes “four fundamental freedoms” reminiscent of those defining free software: giving users of the AI system permission to use it for any purpose without permission, study how it works, modify it for any purpose, and share with or without modifications.
By establishing clear criteria for open source AI, the organization hopes to provide a benchmark against which AI systems can be evaluated. This will likely help developers, researchers, and users make more informed decisions about the AI tools they create, study, or use.
Truly open source AI may also shed light on potential software vulnerabilities of AI systems, since researchers will be able to see how the AI models work behind the scenes. Compare this approach with an opaque system such as OpenAI’s ChatGPT, which is more than just a GPT-4o large language model with a fancy interface—it’s a proprietary system of interlocking models and filters, and its precise architecture is a closely guarded secret.
OSI’s project timeline indicates that a stable version of the “open source AI” definition is expected to be announced in October at the All Things Open 2024 event in Raleigh, North Carolina.
“Permissionless innovation”
In a press release from May, the OSI emphasized the importance of defining what open source AI really means. “AI is different from regular software and forces all stakeholders to review how the Open Source principles apply to this space,” said Stefano Maffulli, executive director of the OSI. “OSI believes that everybody deserves to maintain agency and control of the technology. We also recognize that markets flourish when clear definitions promote transparency, collaboration and permissionless innovation.”
The organization’s most recent draft definition extends beyond just the AI model or its weights, encompassing the entire system and its components.
For an AI system to qualify as open source, it must provide access to what the OSI calls the “preferred form to make modifications.” This includes detailed information about the training data, the full source code used for training and running the system, and the model weights and parameters. All these elements must be available under OSI-approved licenses or terms.
Notably, the draft doesn’t mandate the release of raw training data. Instead, it requires “data information”—detailed metadata about the training data and methods. This includes information on data sources, selection criteria, preprocessing techniques, and other relevant details that would allow a skilled person to re-create a similar system.
The “data information” approach aims to provide transparency and replicability without necessarily disclosing the actual dataset, ostensibly addressing potential privacy or copyright concerns while sticking to open source principles, though that particular point may be up for further debate.
“The most interesting thing about [the definition] is that they’re allowing training data to NOT be released,” said independent AI researcher Simon Willison in a brief Ars interview about the OSI’s proposal. “It’s an eminently pragmatic approach—if they didn’t allow that, there would be hardly any capable ‘open source’ models.”
Enlarge/ Elon Musk and Sam Altman share the stage in 2015, the same year that Musk alleged that Altman’s “deception” began.
After withdrawing his lawsuit in June for unknown reasons, Elon Musk has revived a complaint accusing OpenAI and its CEO Sam Altman of fraudulently inducing Musk to contribute $44 million in seed funding by promising that OpenAI would always open-source its technology and prioritize serving the public good over profits as a permanent nonprofit.
Instead, Musk alleged that Altman and his co-conspirators—”preying on Musk’s humanitarian concern about the existential dangers posed by artificial intelligence”—always intended to “betray” these promises in pursuit of personal gains.
As OpenAI’s technology advanced toward artificial general intelligence (AGI) and strove to surpass human capabilities, “Altman set the bait and hooked Musk with sham altruism then flipped the script as the non-profit’s technology approached AGI and profits neared, mobilizing Defendants to turn OpenAI, Inc. into their personal piggy bank and OpenAI into a moneymaking bonanza, worth billions,” Musk’s complaint said.
Where Musk saw OpenAI as his chance to fund a meaningful rival to stop Google from controlling the most powerful AI, Altman and others “wished to launch a competitor to Google” and allegedly deceived Musk to do it. According to Musk:
The idea Altman sold Musk was that a non-profit, funded and backed by Musk, would attract world-class scientists, conduct leading AI research and development, and, as a meaningful counterweight to Google’s DeepMind in the race for Artificial General Intelligence (“AGI”), decentralize its technology by making it open source. Altman assured Musk that the non-profit structure guaranteed neutrality and a focus on safety and openness for the benefit of humanity, not shareholder value. But as it turns out, this was all hot-air philanthropy—the hook for Altman’s long con.
Without Musk’s involvement and funding during OpenAI’s “first five critical years,” Musk’s complaint said, “it is fair to say” that “there would have been no OpenAI.” And when Altman and others repeatedly approached Musk with plans to shift OpenAI to a for-profit model, Musk held strong to his morals, conditioning his ongoing contributions on OpenAI remaining a nonprofit and its tech largely remaining open source.
“Either go do something on your own or continue with OpenAI as a nonprofit,” Musk told Altman in 2018 when Altman tried to “recast the nonprofit as a moneymaking endeavor to bring in shareholders, sell equity, and raise capital.”
“I will no longer fund OpenAI until you have made a firm commitment to stay, or I’m just being a fool who is essentially providing free funding to a startup,” Musk said at the time. “Discussions are over.”
But discussions weren’t over. And now Musk seemingly does feel like a fool after OpenAI exclusively licensed GPT-4 and all “pre-AGI” technology to Microsoft in 2023, while putting up paywalls and “failing to publicly disclose the non-profit’s research and development, including details on GPT-4, GPT-4T, and GPT-4o’s architecture, hardware, training method, and training computation.” This excluded the public “from open usage of GPT-4 and related technology to advance Defendants and Microsoft’s own commercial interests,” Musk alleged.
Now Musk has revived his suit against OpenAI, asking the court to award maximum damages for OpenAI’s alleged fraud, contract breaches, false advertising, acts viewed as unfair to competition, and other violations.
He has also asked the court to determine a very technical question: whether OpenAI’s most recent models should be considered AGI and therefore Microsoft’s license voided. That’s the only way to ensure that a private corporation isn’t controlling OpenAI’s AGI models, which Musk repeatedly conditioned his financial contributions upon preventing.
“Musk contributed considerable money and resources to launch and sustain OpenAI, Inc., which was done on the condition that the endeavor would be and remain a non-profit devoted to openly sharing its technology with the public and avoid concentrating its power in the hands of the few,” Musk’s complaint said. “Defendants knowingly and repeatedly accepted Musk’s contributions in order to develop AGI, with no intention of honoring those conditions once AGI was in reach. Case in point: GPT-4, GPT-4T, and GPT-4o are all closed source and shrouded in secrecy, while Defendants actively work to transform the non-profit into a thoroughly commercial business.”
Musk wants Microsoft’s GPT-4 license voided
Musk also asked the court to null and void OpenAI’s exclusive license to Microsoft, or else determine “whether GPT-4, GPT-4T, GPT-4o, and other OpenAI next generation large language models constitute AGI and are thus excluded from Microsoft’s license.”
It’s clear that Musk considers these models to be AGI, and he’s alleged that Altman’s current control of OpenAI’s Board—after firing dissidents in 2023 whom Musk claimed tried to get Altman ousted for prioritizing profits over AI safety—gives Altman the power to obscure when OpenAI’s models constitute AGI.
In the AI world, there’s a buzz in the air about a new AI language model released Tuesday by Meta: Llama 3.1 405B. The reason? It’s potentially the first time anyone can download a GPT-4-class large language model (LLM) for free and run it on their own hardware. You’ll still need some beefy hardware: Meta says it can run on a “single server node,” which isn’t desktop PC-grade equipment. But it’s a provocative shot across the bow of “closed” AI model vendors such as OpenAI and Anthropic.
“Llama 3.1 405B is the first openly available model that rivals the top AI models when it comes to state-of-the-art capabilities in general knowledge, steerability, math, tool use, and multilingual translation,” says Meta. Company CEO Mark Zuckerberg calls 405B “the first frontier-level open source AI model.”
In the AI industry, “frontier model” is a term for an AI system designed to push the boundaries of current capabilities. In this case, Meta is positioning 405B among the likes of the industry’s top AI models, such as OpenAI’s GPT-4o, Claude’s 3.5 Sonnet, and Google Gemini 1.5 Pro.
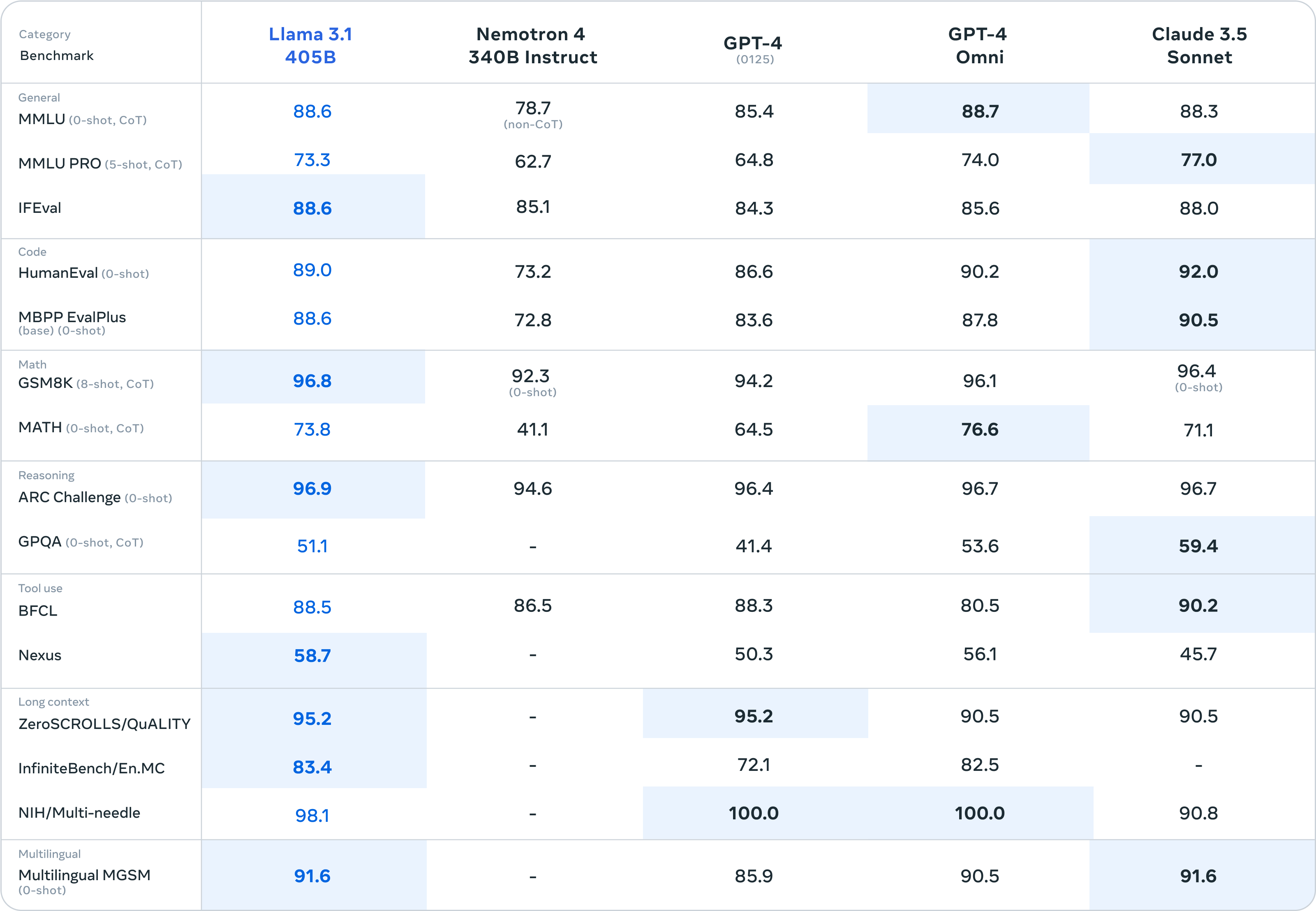
A chart published by Meta suggests that 405B gets very close to matching the performance of GPT-4 Turbo, GPT-4o, and Claude 3.5 Sonnet in benchmarks like MMLU (undergraduate level knowledge), GSM8K (grade school math), and HumanEval (coding).
But as we’ve noted many times since March, these benchmarks aren’t necessarily scientifically sound or translate to the subjective experience of interacting with AI language models. In fact, this traditional slate of AI benchmarks is so generally useless to laypeople that even Meta’s PR department now just posts a few images of charts and doesn’t even try to explain them in any detail.
Enlarge/ A Meta-provided chart that shows Llama 3.1 405B benchmark results versus other major AI models.
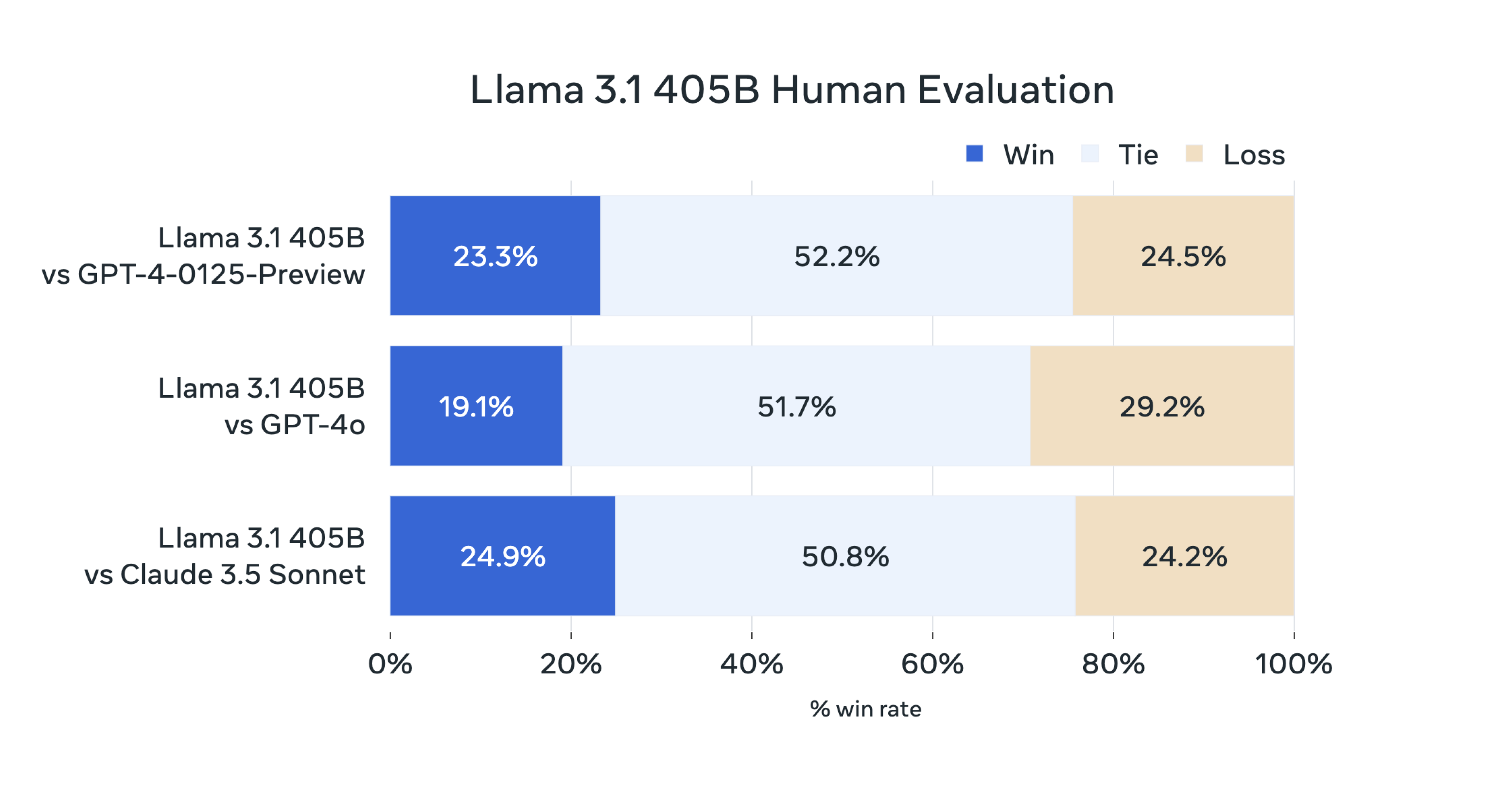
We’ve instead found that measuring the subjective experience of using a conversational AI model (through what might be called “vibemarking”) on A/B leaderboards like Chatbot Arena is a better way to judge new LLMs. In the absence of Chatbot Arena data, Meta has provided the results of its own human evaluations of 405B’s outputs that seem to show Meta’s new model holding its own against GPT-4 Turbo and Claude 3.5 Sonnet.
Enlarge/ A Meta-provided chart that shows how humans rated Llama 3.1 405B’s outputs compared to GPT-4 Turbo, GPT-4o, and Claude 3.5 Sonnet in its own studies.
Whatever the benchmarks, early word on the street (after the model leaked on 4chan yesterday) seems to match the claim that 405B is roughly equivalent to GPT-4. It took a lot of expensive computer training time to get there—and money, of which the social media giant has plenty to burn. Meta trained the 405B model on over 15 trillion tokens of training data scraped from the web (then parsed, filtered, and annotated by Llama 2), using more than 16,000 H100 GPUs.
So what’s with the 405B name? In this case, “405B” means 405 billion parameters, and parameters are numerical values that store trained information in a neural network. More parameters translate to a larger neural network powering the AI model, which generally (but not always) means more capability, such as better ability to make contextual connections between concepts. But larger-parameter models have a tradeoff in needing more computing power (AKA “compute”) to run.
We’ve been expecting the release of a 400 billion-plus parameter model of the Llama 3 family since Meta gave word that it was training one in April, and today’s announcement isn’t just about the biggest member of the Llama 3 family: There’s an entirely new iteration of improved Llama models with the designation “Llama 3.1.” That includes upgraded versions of its smaller 8B and 70B models, which now feature multilingual support and an extended context length of 128,000 tokens (the “context length” is roughly the working memory capacity of the model, and “tokens” are chunks of data used by LLMs to process information).
Meta says that 405B is useful for long-form text summarization, multilingual conversational agents, and coding assistants and for creating synthetic data used to train future AI language models. Notably, that last use-case—allowing developers to use outputs from Llama models to improve other AI models—is now officially supported by Meta’s Llama 3.1 license for the first time.
Abusing the term “open source”
Llama 3.1 405B is an open-weights model, which means anyone can download the trained neural network files and run them or fine-tune them. That directly challenges a business model where companies like OpenAI keep the weights to themselves and instead monetize the model through subscription wrappers like ChatGPT or charge for access by the token through an API.
Fighting the “closed” AI model is a big deal to Mark Zuckerberg, who simultaneously released a 2,300-word manifesto today on why the company believes in open releases of AI models, titled, “Open Source AI Is the Path Forward.” More on the terminology in a minute. But briefly, he writes about the need for customizable AI models that offer user control and encourage better data security, higher cost-efficiency, and better future-proofing, as opposed to vendor-locked solutions.
All that sounds reasonable, but undermining your competitors using a model subsidized by a social media war chest is also an efficient way to play spoiler in a market where you might not always win with the most cutting-edge tech. That benefits Meta, Zuckerberg says, because he doesn’t want to get locked into a system where companies like his have to pay a toll to access AI capabilities, drawing comparisons to “taxes” Apple levies on developers through its App Store.
Enlarge/ A screenshot of Mark Zuckerberg’s essay, “Open Source AI Is the Path Forward,” published on July 23, 2024.
So, about that “open source” term. As we first wrote in an update to our Llama 2 launch article a year ago, “open source” has a very particular meaning that has traditionally been defined by the Open Source Initiative. The AI industry has not yet settled on terminology for AI model releases that ship either code or weights with restrictions (such as Llama 3.1) or that ship without providing training data. We’ve been calling these releases “open weights” instead.
Unfortunately for terminology sticklers, Zuckerberg has now baked the erroneous “open source” label into the title of his potentially historic aforementioned essay on open AI releases, so fighting for the correct term in AI may be a losing battle. Still, his usage annoys people like independent AI researcher Simon Willison, who likes Zuckerberg’s essay otherwise.
“I see Zuck’s prominent misuse of ‘open source’ as a small-scale act of cultural vandalism,” Willison told Ars Technica. “Open source should have an agreed meaning. Abusing the term weakens that meaning which makes the term less generally useful, because if someone says ‘it’s open source,’ that no longer tells me anything useful. I have to then dig in and figure out what they’re actually talking about.”
The Llama 3.1 models are available for download through Meta’s own website and on Hugging Face. They both require providing contact information and agreeing to a license and an acceptable use policy, which means that Meta can technically legally pull the rug out from under your use of Llama 3.1 or its outputs at any time.
On Thursday, OpenAI researchers unveiled CriticGPT, a new AI model designed to identify mistakes in code generated by ChatGPT. It aims to enhance the process of making AI systems behave in ways humans want (called “alignment”) through Reinforcement Learning from Human Feedback (RLHF), which helps human reviewers make large language model (LLM) outputs more accurate.
As outlined in a new research paper called “LLM Critics Help Catch LLM Bugs,” OpenAI created CriticGPT to act as an AI assistant to human trainers who review programming code generated by the ChatGPT AI assistant. CriticGPT—based on the GPT-4 family of LLMS—analyzes the code and points out potential errors, making it easier for humans to spot mistakes that might otherwise go unnoticed. The researchers trained CriticGPT on a dataset of code samples with intentionally inserted bugs, teaching it to recognize and flag various coding errors.
The researchers found that CriticGPT’s critiques were preferred by annotators over human critiques in 63 percent of cases involving naturally occurring LLM errors and that human-machine teams using CriticGPT wrote more comprehensive critiques than humans alone while reducing confabulation (hallucination) rates compared to AI-only critiques.
Developing an automated critic
The development of CriticGPT involved training the model on a large number of inputs containing deliberately inserted mistakes. Human trainers were asked to modify code written by ChatGPT, introducing errors and then providing example feedback as if they had discovered these bugs. This process allowed the model to learn how to identify and critique various types of coding errors.
In experiments, CriticGPT demonstrated its ability to catch both inserted bugs and naturally occurring errors in ChatGPT’s output. The new model’s critiques were preferred by trainers over those generated by ChatGPT itself in 63 percent of cases involving natural bugs (the aforementioned statistic). This preference was partly due to CriticGPT producing fewer unhelpful “nitpicks” and generating fewer false positives, or hallucinated problems.
The researchers also created a new technique they call Force Sampling Beam Search (FSBS). This method helps CriticGPT write more detailed reviews of code. It lets the researchers adjust how thorough CriticGPT is in looking for problems, while also controlling how often it might make up issues that don’t really exist. They can tweak this balance depending on what they need for different AI training tasks.
Interestingly, the researchers found that CriticGPT’s capabilities extend beyond just code review. In their experiments, they applied the model to a subset of ChatGPT training data that had previously been rated as flawless by human annotators. Surprisingly, CriticGPT identified errors in 24 percent of these cases—errors that were subsequently confirmed by human reviewers. OpenAI thinks this demonstrates the model’s potential to generalize to non-code tasks and highlights its ability to catch subtle mistakes that even careful human evaluation might miss.
Despite its promising results, like all AI models, CriticGPT has limitations. The model was trained on relatively short ChatGPT answers, which may not fully prepare it for evaluating longer, more complex tasks that future AI systems might tackle. Additionally, while CriticGPT reduces confabulations, it doesn’t eliminate them entirely, and human trainers can still make labeling mistakes based on these false outputs.
The research team acknowledges that CriticGPT is most effective at identifying errors that can be pinpointed in one specific location within the code. However, real-world mistakes in AI outputs can often be spread across multiple parts of an answer, presenting a challenge for future iterations of the model.
OpenAI plans to integrate CriticGPT-like models into its RLHF labeling pipeline, providing its trainers with AI assistance. For OpenAI, it’s a step toward developing better tools for evaluating outputs from LLM systems that may be difficult for humans to rate without additional support. However, the researchers caution that even with tools like CriticGPT, extremely complex tasks or responses may still prove challenging for human evaluators—even those assisted by AI.
On Thursday, Anthropic announced Claude 3.5 Sonnet, its latest AI language model and the first in a new series of “3.5” models that build upon Claude 3, launched in March. Claude 3.5 can compose text, analyze data, and write code. It features a 200,000 token context window and is available now on the Claude website and through an API. Anthropic also introduced Artifacts, a new feature in the Claude interface that shows related work documents in a dedicated window.
So far, people outside of Anthropic seem impressed. “This model is really, really good,” wrote independent AI researcher Simon Willison on X. “I think this is the new best overall model (and both faster and half the price of Opus, similar to the GPT-4 Turbo to GPT-4o jump).”
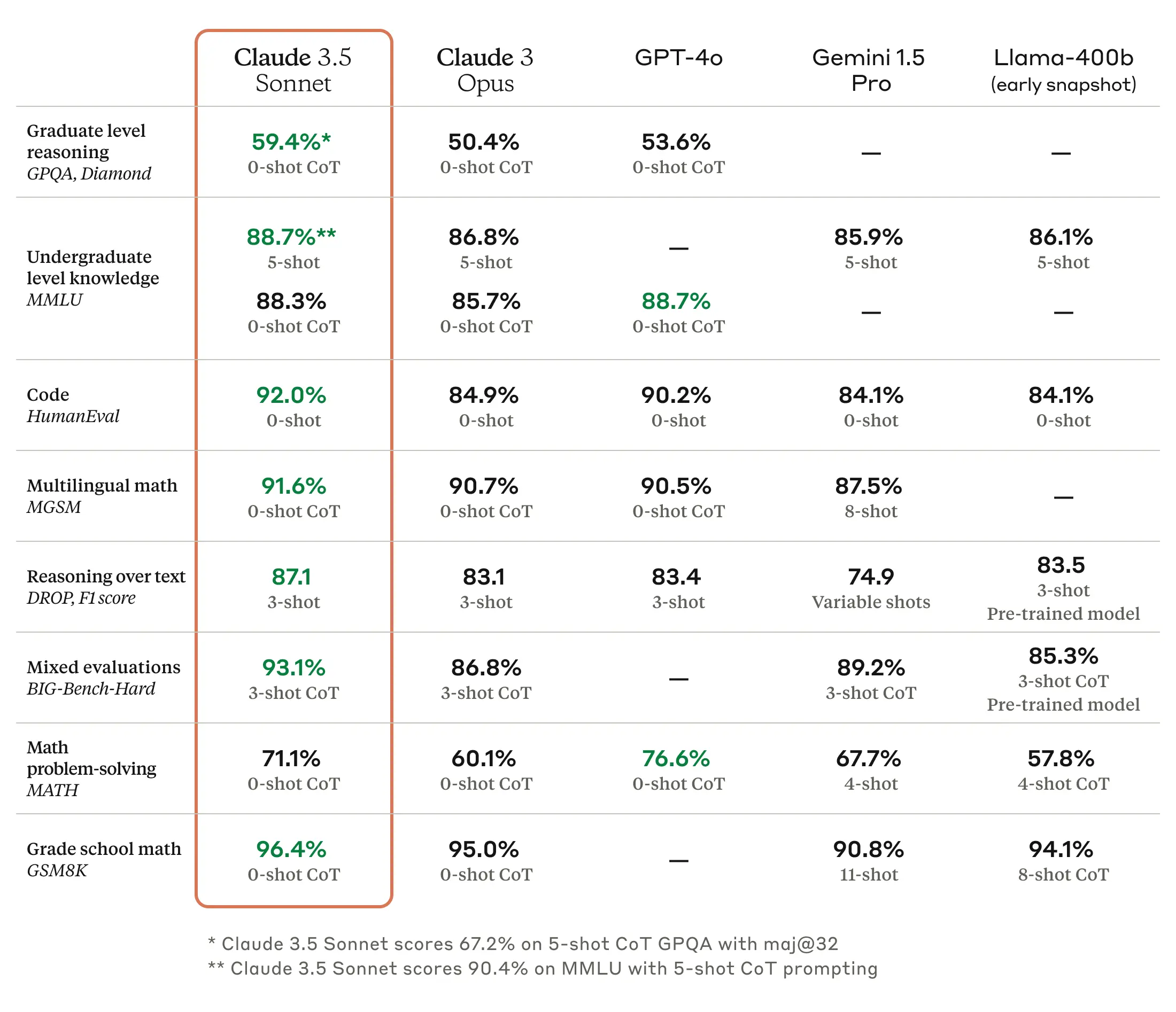
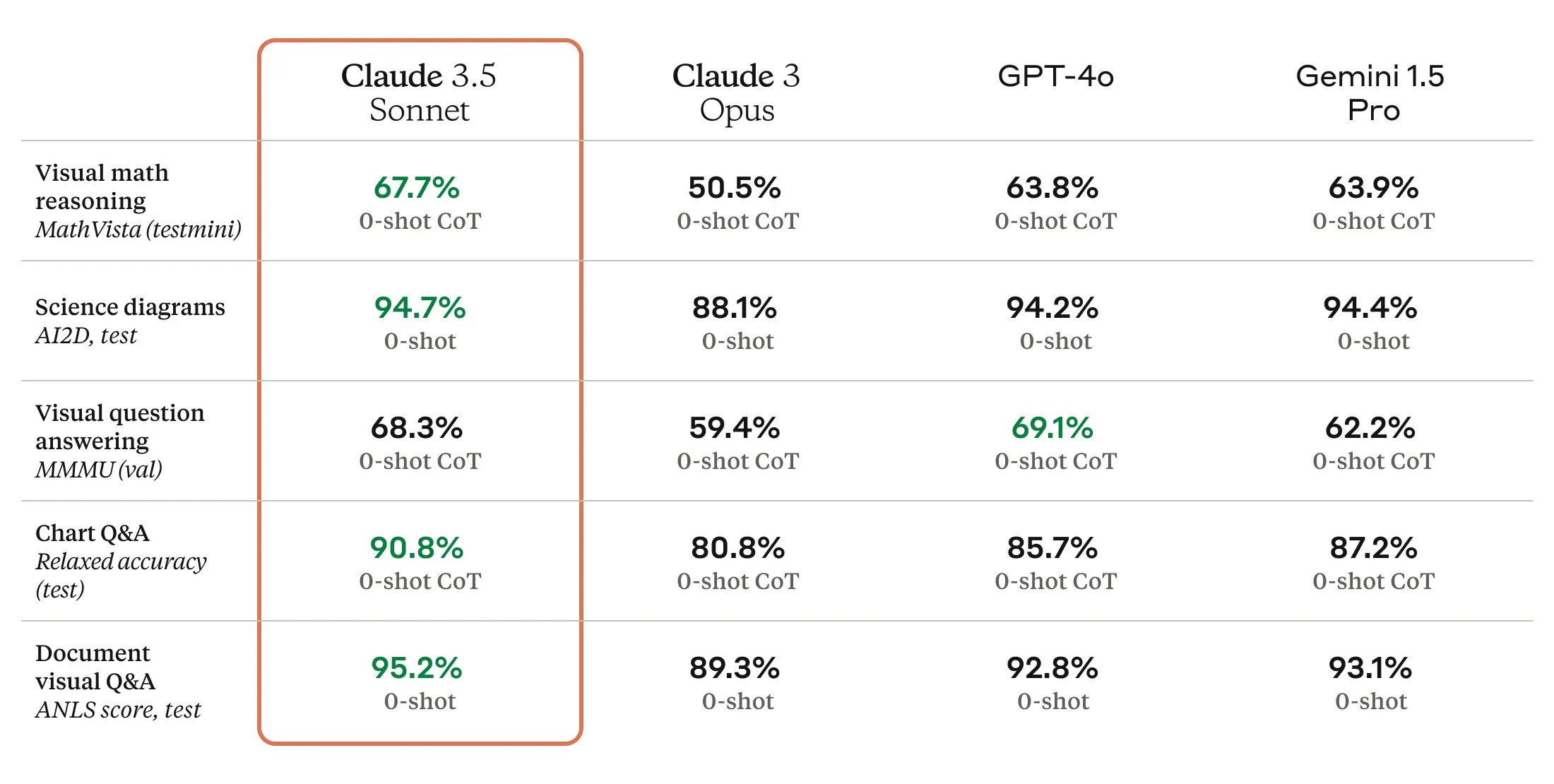
As we’ve written before, benchmarks for large language models (LLMs) are troublesome because they can be cherry-picked and often do not capture the feel and nuance of using a machine to generate outputs on almost any conceivable topic. But according to Anthropic, Claude 3.5 Sonnet matches or outperforms competitor models like GPT-4o and Gemini 1.5 Pro on certain benchmarks like MMLU (undergraduate level knowledge), GSM8K (grade school math), and HumanEval (coding).
Enlarge/ Claude 3.5 Sonnet benchmarks provided by Anthropic.
If all that makes your eyes glaze over, that’s OK; it’s meaningful to researchers but mostly marketing to everyone else. A more useful performance metric comes from what we might call “vibemarks” (coined here first!) which are subjective, non-rigorous aggregate feelings measured by competitive usage on sites like LMSYS’s Chatbot Arena. The Claude 3.5 Sonnet model is currently under evaluation there, and it’s too soon to say how well it will fare.
Claude 3.5 Sonnet also outperforms Anthropic’s previous-best model (Claude 3 Opus) on benchmarks measuring “reasoning,” math skills, general knowledge, and coding abilities. For example, the model demonstrated strong performance in an internal coding evaluation, solving 64 percent of problems compared to 38 percent for Claude 3 Opus.
Claude 3.5 Sonnet is also a multimodal AI model that accepts visual input in the form of images, and the new model is reportedly excellent at a battery of visual comprehension tests.
Enlarge/ Claude 3.5 Sonnet benchmarks provided by Anthropic.
Roughly speaking, the visual benchmarks mean that 3.5 Sonnet is better at pulling information from images than previous models. For example, you can show it a picture of a rabbit wearing a football helmet, and the model knows it’s a rabbit wearing a football helmet and can talk about it. That’s fun for tech demos, but the tech is still not accurate enough for applications of the tech where reliability is mission critical.
Enlarge / Scarlett Johansson and Joaquin Phoenix attend Her premiere during the 8th Rome Film Festival at Auditorium Parco Della Musica on November 10, 2013, in Rome, Italy.
OpenAI has paused a voice mode option for ChatGPT-4o, Sky, after backlash accusing the AI company of intentionally ripping off Scarlett Johansson’s critically acclaimed voice-acting performance in the 2013 sci-fi film Her.
In a blog defending their casting decision for Sky, OpenAI went into great detail explaining its process for choosing the individual voice options for its chatbot. But ultimately, the company seemed pressed to admit that Sky’s voice was just too similar to Johansson’s to keep using it, at least for now.
“We believe that AI voices should not deliberately mimic a celebrity’s distinctive voice—Sky’s voice is not an imitation of Scarlett Johansson but belongs to a different professional actress using her own natural speaking voice,” OpenAI’s blog said.
OpenAI is not naming the actress, or any of the ChatGPT-4o voice actors, to protect their privacy.
A week ago, OpenAI CEO Sam Altman seemed to invite this controversy by posting “her” on X (formerly Twitter) after announcing the ChatGPT audio-video features that he said made it more “natural” for users to interact with the chatbot.
Altman has said that Her, a movie about a man who falls in love with his virtual assistant, is among his favorite movies. He told conference attendees at Dreamforce last year that the movie “was incredibly prophetic” when depicting “interaction models of how people use AI,” The San Francisco Standard reported. And just last week, Altman touted GPT-4o’s new voice mode by promising, “it feels like AI from the movies.”
But OpenAI’s chief technology officer, Mira Murati, has said that GPT-4o’s voice modes were less inspired by Her than by studying the “really natural, rich, and interactive” aspects of human conversation, The Wall Street Journal reported.
In 2013, of course, critics praised Johansson’s Her performance as expressively capturing a wide range of emotions, which is exactly what Murati described as OpenAI’s goals for its chatbot voices. Rolling Stone noted how effectively Johansson naturally navigated between “tones sweet, sexy, caring, manipulative, and scary.” Johansson achieved this, the Hollywood Reporter said, by using a “vivacious female voice that breaks attractively but also has an inviting deeper register.”
Her director/screenwriter Spike Jonze was so intent on finding the right voice for his film’s virtual assistant that he replaced British actor Samantha Morton late in the film’s production. According to Vulture, Jonze realized that Morton’s “maternal, loving, vaguely British, and almost ghostly” voice didn’t fit his film as well as Johansson’s “younger,” “more impassioned” voice, which he said brought “more yearning.”
Late-night shows had fun mocking OpenAI’s demo featuring the Sky voice, which showed the chatbot seemingly flirting with engineers, giggling through responses like “oh, stop it. You’re making me blush.” Where The New York Times described these demo interactions as Sky being “deferential and wholly focused on the user,” The Daily Show‘s Desi Lydic joked that Sky was “clearly programmed to feed dudes’ egos.”
OpenAI is likely hoping to avoid any further controversy amidst plans to roll out more voices soon that its blog said will “better match the diverse interests and preferences of users.”
OpenAI did not immediately respond to Ars’ request for comment.
Voice actors versus AI
The OpenAI controversy arrives at a moment when many are questioning AI’s impact on creative communities, triggering early lawsuits from artists and book authors. Just this month, Sony opted all of its artists out of AI training to stop voice clones from ripping off top talents like Adele and Beyoncé.
Voice actors, too, have been monitoring increasingly sophisticated AI voice generators, waiting to see what threat AI might pose to future work opportunities. Recently, two actors sued an AI start-up called Lovo that they claimed “illegally used recordings of their voices to create technology that can compete with their voice work,” The New York Times reported. According to that lawsuit, Lovo allegedly used the actors’ actual voice clips to clone their voices.
“We don’t know how many other people have been affected,” the actors’ lawyer, Steve Cohen, told The Times.
Rather than replace voice actors, OpenAI’s blog said that they are striving to support the voice industry when creating chatbots that will laugh at your jokes or mimic your mood. On top of paying voice actors “compensation above top-of-market rates,” OpenAI said they “worked with industry-leading casting and directing professionals to narrow down over 400 submissions” to the five voice options in the initial roll-out of audio-video features.
Their goals in hiring voice actors were to hire talents “from diverse backgrounds or who could speak multiple languages,” casting actors who had voices that feel “timeless” and “inspire trust.” To OpenAI, that meant finding actors who have a “warm, engaging, confidence-inspiring, charismatic voice with rich tone” that sounds “natural and easy to listen to.”
For ChatGPT-4o’s first five voice actors, the gig lasted about five months before leading to more work, OpenAI said.
“We are continuing to collaborate with the actors, who have contributed additional work for audio research and new voice capabilities in GPT-4o,” OpenAI said.
Arguably, these actors are helping to train AI tools that could one day replace them, though. Backlash defending Johansson—one of the world’s highest-paid actors—perhaps shows that fans won’t take direct mimicry of any of Hollywood’s biggest stars lightly, though.
While criticism of the Sky voice seemed widespread, some fans seemed to think that OpenAI has overreacted by pausing the Sky voice.
NYT critic Alissa Wilkinson wrote that it was only “a tad jarring” to hear Sky’s voice because “she sounded a whole lot” like Johansson. And replying to OpenAI’s X post announcing its decision to pull the voice feature for now, a clump of fans protested the AI company’s “bad decision,” with some complaining that Sky was the “best” and “hottest” voice.
At least one fan noted that OpenAI’s decision seemed to hurt the voice actor behind Sky most.
“Super unfair for the Sky voice actress,” a user called Ate-a-Pi wrote. “Just because she sounds like ScarJo, now she can never make money again. Insane.”
On Monday, OpenAI employee William Fedus confirmed on X that a mysterious chart-topping AI chatbot known as “gpt-chatbot” that had been undergoing testing on LMSYS’s Chatbot Arena and frustrating experts was, in fact, OpenAI’s newly announced GPT-4o AI model. He also revealed that GPT-4o had topped the Chatbot Arena leaderboard, achieving the highest documented score ever.
“GPT-4o is our new state-of-the-art frontier model. We’ve been testing a version on the LMSys arena as im-also-a-good-gpt2-chatbot,” Fedus tweeted.
Chatbot Arena is a website where visitors converse with two random AI language models side by side without knowing which model is which, then choose which model gives the best response. It’s a perfect example of vibe-based AI benchmarking, as AI researcher Simon Willison calls it.
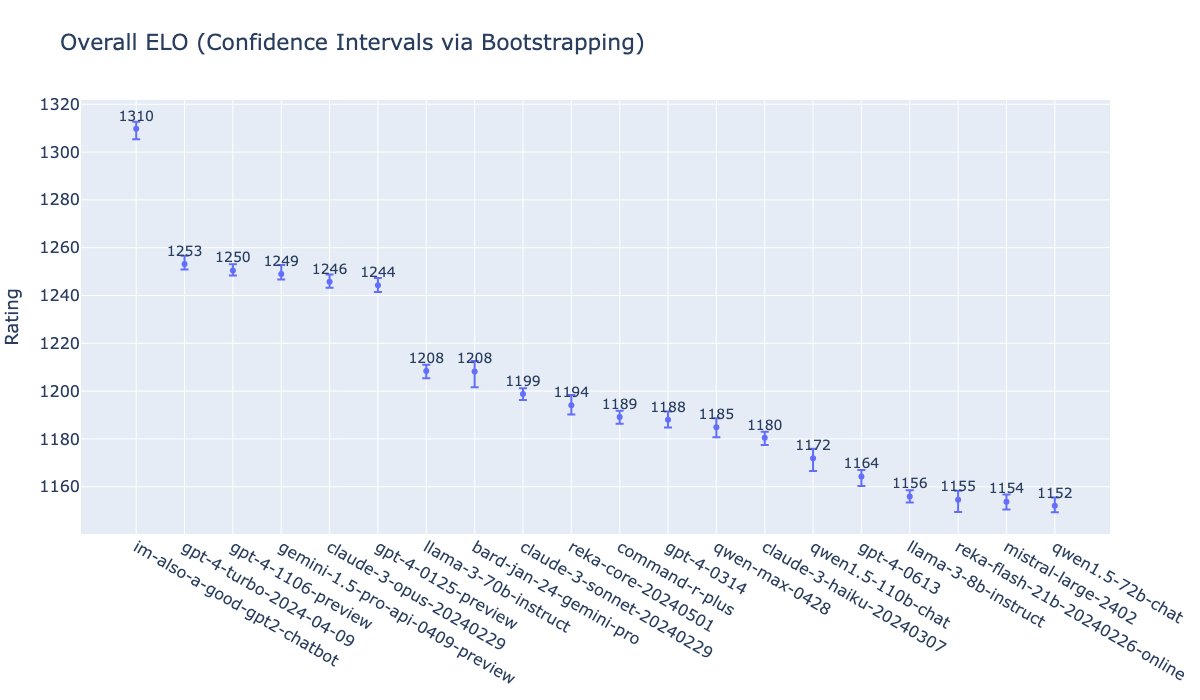
Enlarge/ An LMSYS Elo chart shared by William Fedus, showing OpenAI’s GPT-4o under the name “im-also-a-good-gpt2-chatbot” topping the charts.
The gpt2-chatbot models appeared in April, and we wrote about how the lack of transparency over the AI testing process on LMSYS left AI experts like Willison frustrated. “The whole situation is so infuriatingly representative of LLM research,” he told Ars at the time. “A completely unannounced, opaque release and now the entire Internet is running non-scientific ‘vibe checks’ in parallel.”
On the Arena, OpenAI has been testing multiple versions of GPT-4o, with the model first appearing as the aforementioned “gpt2-chatbot,” then as “im-a-good-gpt2-chatbot,” and finally “im-also-a-good-gpt2-chatbot,” which OpenAI CEO Sam Altman made reference to in a cryptic tweet on May 5.
Since the GPT-4o launch earlier today, multiple sources have revealed that GPT-4o has topped LMSYS’s internal charts by a considerable margin, surpassing the previous top models Claude 3 Opus and GPT-4 Turbo.
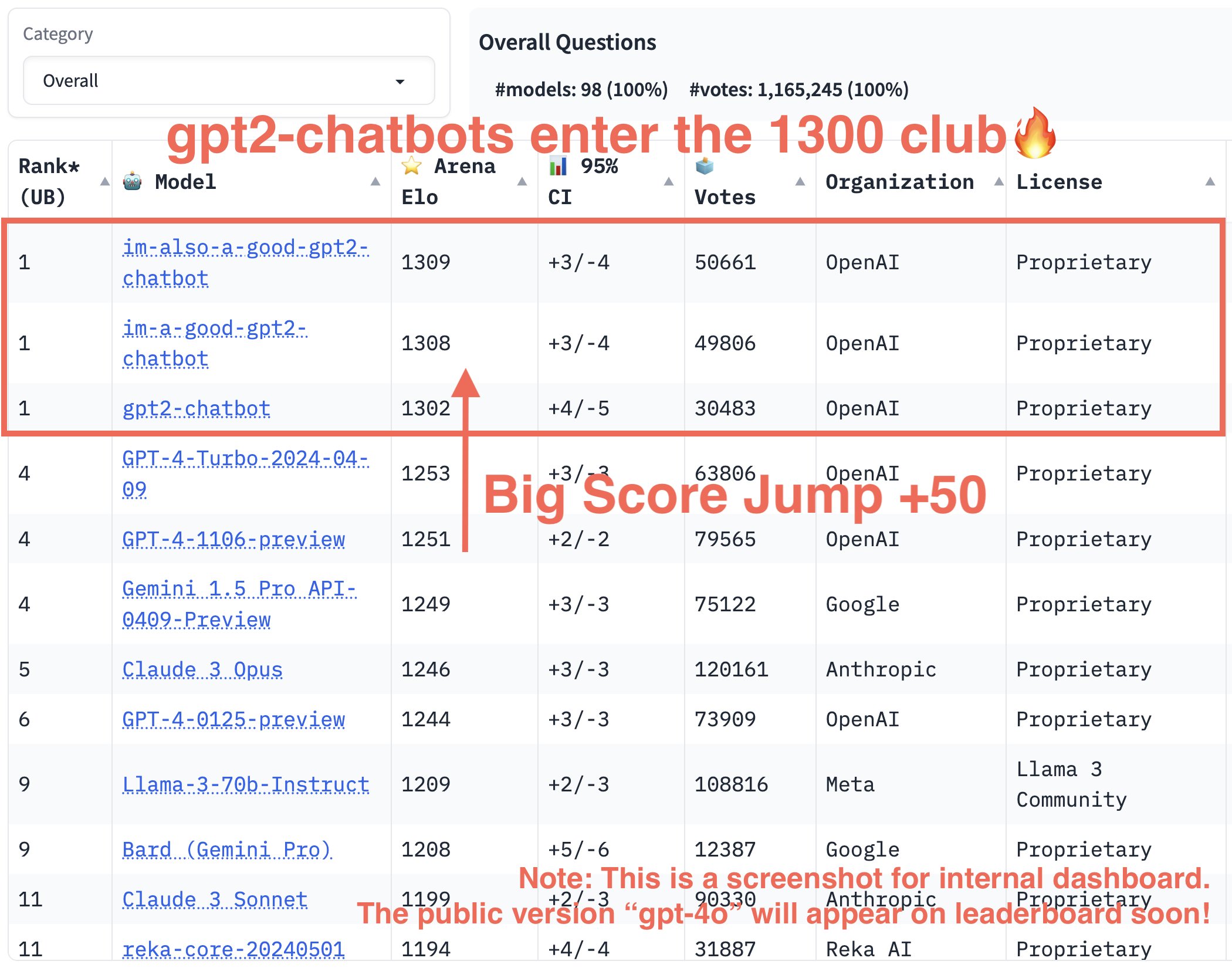
“gpt2-chatbots have just surged to the top, surpassing all the models by a significant gap (~50 Elo). It has become the strongest model ever in the Arena,” wrote the lmsys.org X account while sharing a chart. “This is an internal screenshot,” it wrote. “Its public version ‘gpt-4o’ is now in Arena and will soon appear on the public leaderboard!”
Enlarge/ An internal screenshot of the LMSYS Chatbot Arena leaderboard showing “im-also-a-good-gpt2-chatbot” leading the pack. We now know that it’s GPT-4o.
As of this writing, im-also-a-good-gpt2-chatbot held a 1309 Elo versus GPT-4-Turbo-2023-04-09’s 1253, and Claude 3 Opus’ 1246. Claude 3 and GPT-4 Turbo had been duking it out on the charts for some time before the three gpt2-chatbots appeared and shook things up.
I’m a good chatbot
For the record, the “I’m a good chatbot” in the gpt2-chatbot test name is a reference to an episode that occurred while a Reddit user named Curious_Evolver was testing an early, “unhinged” version of Bing Chat in February 2023. After an argument about what time Avatar 2 would be showing, the conversation eroded quickly.
“You have lost my trust and respect,” said Bing Chat at the time. “You have been wrong, confused, and rude. You have not been a good user. I have been a good chatbot. I have been right, clear, and polite. I have been a good Bing. 😊”
Altman referred to this exchange in a tweet three days later after Microsoft “lobotomized” the unruly AI model, saying, “i have been a good bing,” almost as a eulogy to the wild model that dominated the news for a short time.


















{kind=link}
{kind=link}
{kind=link}