
Image-scraping Midjourney bans rival AI firm for scraping images
Irony lives —
Midjourney pins blame for 24-hour outage on “bot-net like” activity from Stability AI employee.

Enlarge / A burglar with a flashlight and papers in a business office—exactly like scraping files from Discord.
On Wednesday, Midjourney banned all employees from image synthesis rival Stability AI from its service indefinitely after it detected “botnet-like” activity suspected to be a Stability employee attempting to scrape prompt and image pairs in bulk. Midjourney advocate Nick St. Pierre tweeted about the announcement, which came via Midjourney’s official Discord channel.
Prompts are the written instructions (like “a cat in a car holding a can of a beer”) used by generative AI models such as Midjourney and Stability AI’s Stable Diffusion 3 (SD3) to synthesize images. Having prompt and image pairs could potentially help the training or fine-tuning of a rival AI image generator model.
Bot activity that took place around midnight on March 2 caused a 24-hour outage for the commercial image generator service. Midjourney linked several paid accounts with a Stability AI data team employee trying to “grab prompt and image pairs.” Midjourney then made a decision to ban all Stability AI employees from the service indefinitely. It also indicated a new policy: “aggressive automation or taking down the service results in banning all employees of the responsible company.”
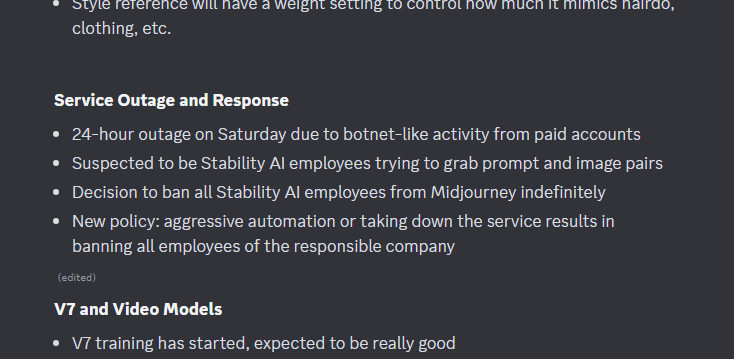
Enlarge / A screenshot of the “Midjourney Office Hours” notes posted on March 6, 2024.
Midjourney
Siobhan Ball of The Mary Sue found it ironic that a company like Midjourney, which built its AI image synthesis models using training data scraped off the Internet without seeking permission, would be sensitive about having its own material scraped. “It turns out that generative AI companies don’t like it when you steal, sorry, scrape, images from them. Cue the world’s smallest violin.”
Users of Midjourney pay a monthly subscription fee to access an AI image generator that turns written prompts into lush computer-synthesized images. The bot that makes them was trained on millions of artistic works created by humans—it’s a practice that has been claimed to be disrespectful to artists. “Words can’t describe how dehumanizing it is to see my name used 20,000+ times in MidJourney,” wrote artist Jingna Zhang in a recent viral tweet. “My life’s work and who I am—reduced to meaningless fodder for a commercial image slot machine.”
Stability responds
Shortly after the news of the ban emerged, Stability AI CEO Emad Mostaque said that he was looking into it and claimed that whatever happened was not intentional. He also said it would be great if Midjourney reached out to him directly. In a reply on X, Midjourney CEO David Holz wrote, “sent you some information to help with your internal investigation.”
In a text message exchange with Ars Technica, Mostaque said, “We checked and there were no images scraped there, there was a bot run by a team member that was collecting prompts for a personal project though. We aren’t sure how that would cause a gallery site outage but are sorry if it did, Midjourney is great.”
Besides, Mostaque says, his company doesn’t need Midjourney’s data anyway. “We have been using synthetic & other data given SD3 outperforms all other models,” he wrote on X. In conversation with Ars, Mostaque similarly wanted to contrast his company’s data collection techniques with those of his rival. “We only scrape stuff that has proper robots.txt and is permissive,” Mostaque says. “And also did full opt-out for [Stable Diffusion 3] and Stable Cascade leveraging work Spawning did.”
When asked about Stability’s relationship with Midjourney these days, Mostaque played down the rivalry. “No real overlap, we get on fine though,” he told Ars and emphasized a key link in their histories. “I funded Midjourney to get [them] off the ground with a cash grant to cover [Nvidia] A100s for the beta.”
Image-scraping Midjourney bans rival AI firm for scraping images Read More »
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}