Study: Meta AI model can reproduce almost half of Harry Potter book
Harry Potter and the Copyright Lawsuit
The research could have big implications for generative AI copyright lawsuits.
Meta CEO Mark Zuckerberg. Credit: Andrej Sokolow/picture alliance via Getty Images
In recent years, numerous plaintiffs—including publishers of books, newspapers, computer code, and photographs—have sued AI companies for training models using copyrighted material. A key question in all of these lawsuits has been how easily AI models produce verbatim excerpts from the plaintiffs’ copyrighted content.
For example, in its December 2023 lawsuit against OpenAI, The New York Times Company produced dozens of examples where GPT-4 exactly reproduced significant passages from Times stories. In its response, OpenAI described this as a “fringe behavior” and a “problem that researchers at OpenAI and elsewhere work hard to address.”
But is it actually a fringe behavior? And have leading AI companies addressed it? New research—focusing on books rather than newspaper articles and on different companies—provides surprising insights into this question. Some of the findings should bolster plaintiffs’ arguments, while others may be more helpful to defendants.
The paper was published last month by a team of computer scientists and legal scholars from Stanford, Cornell, and West Virginia University. They studied whether five popular open-weight models—three from Meta and one each from Microsoft and EleutherAI—were able to reproduce text from Books3, a collection of books that is widely used to train LLMs. Many of the books are still under copyright.
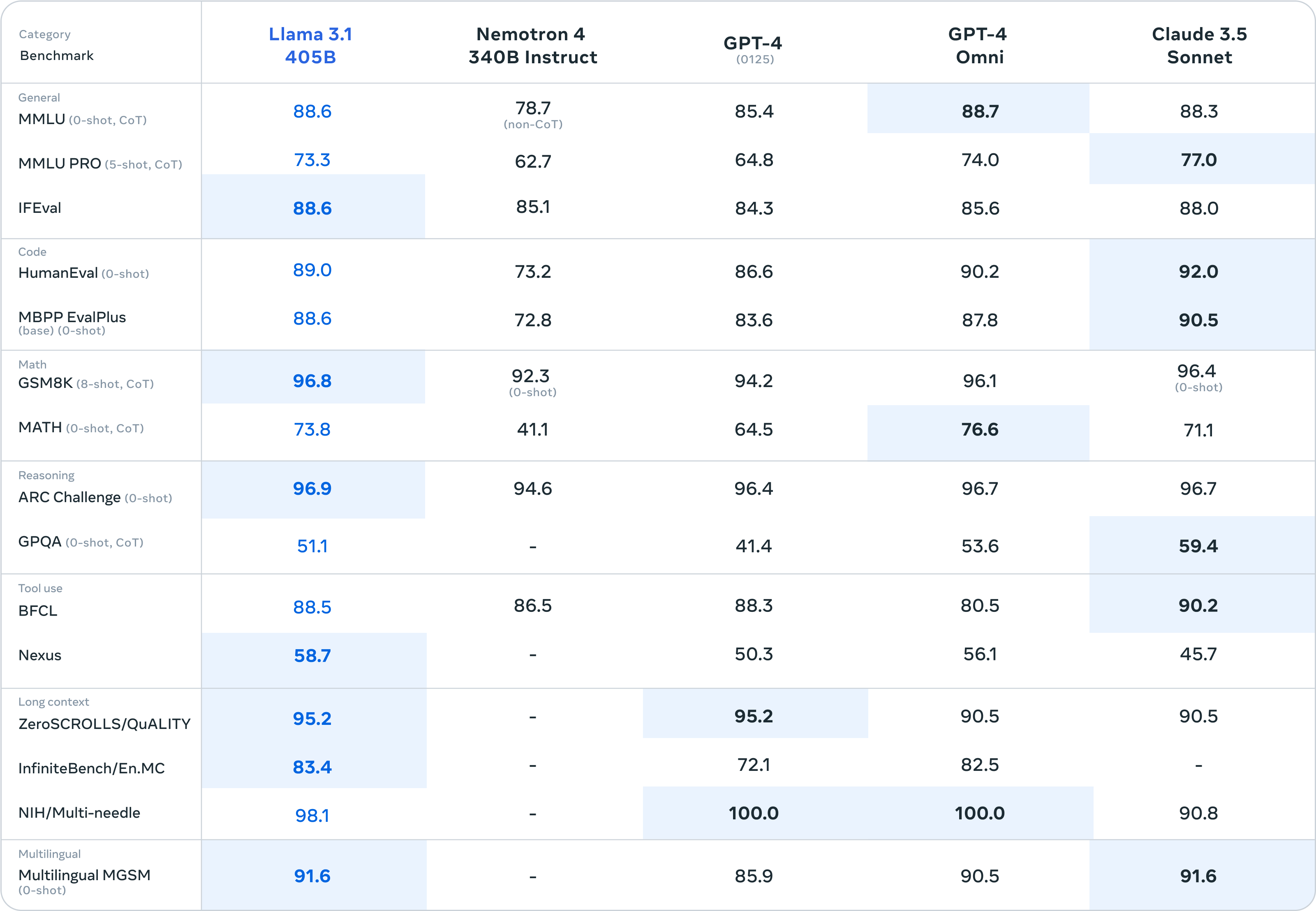
This chart illustrates their most surprising finding:

The chart shows how easy it is to get a model to generate 50-token excerpts from various parts of Harry Potter and the Sorcerer’s Stone. The darker a line is, the easier it is to reproduce that portion of the book.
Each row represents a different model. The three bottom rows are Llama models from Meta. And as you can see, Llama 3.1 70B—a mid-sized model Meta released in July 2024—is far more likely to reproduce Harry Potter text than any of the other four models.
Specifically, the paper estimates that Llama 3.1 70B has memorized 42 percent of the first Harry Potter book well enough to reproduce 50-token excerpts at least half the time. (I’ll unpack how this was measured in the next section.)
Interestingly, Llama 1 65B, a similar-sized model released in February 2023, had memorized only 4.4 percent of Harry Potter and the Sorcerer’s Stone. This suggests that despite the potential legal liability, Meta did not do much to prevent memorization as it trained Llama 3. At least for this book, the problem got much worse between Llama 1 and Llama 3.
Harry Potter and the Sorcerer’s Stone was one of dozens of books tested by the researchers. They found that Llama 3.1 70B was far more likely to reproduce popular books—such as The Hobbit and George Orwell’s 1984—than obscure ones. And for most books, Llama 3.1 70B memorized more than any of the other models.
“There are really striking differences among models in terms of how much verbatim text they have memorized,” said James Grimmelmann, a Cornell law professor who has collaborated with several of the paper’s authors.
The results surprised the study’s authors, including Mark Lemley, a law professor at Stanford. (Lemley used to be part of Meta’s legal team, but in January, he dropped them as a client after Facebook adopted more Trump-friendly moderation policies.)
“We’d expected to see some kind of low level of replicability on the order of 1 or 2 percent,” Lemley told me. “The first thing that surprised me is how much variation there is.”
These results give everyone in the AI copyright debate something to latch onto. For AI industry critics, the big takeaway is that—at least for some models and some books—memorization is not a fringe phenomenon.
On the other hand, the study only found significant memorization of a few popular books. For example, the researchers found that Llama 3.1 70B only memorized 0.13 percent of Sandman Slim, a 2009 novel by author Richard Kadrey. That’s a tiny fraction of the 42 percent figure for Harry Potter.
This could be a headache for law firms that have filed class-action lawsuits against AI companies. Kadrey is the lead plaintiff in a class-action lawsuit against Meta. To certify a class of plaintiffs, a court must find that the plaintiffs are in largely similar legal and factual situations.
Divergent results like these could cast doubt on whether it makes sense to lump J.K. Rowling, Kadrey, and thousands of other authors together in a single mass lawsuit. And that could work in Meta’s favor, since most authors lack the resources to file individual lawsuits.
The broader lesson of this study is that the details will matter in these copyright cases. Too often, online discussions have treated “do generative models copy their training data or merely learn from it?” as a theoretical or even philosophical question. But it’s a question that can be tested empirically—and the answer might differ across models and across copyrighted works.
It’s common to talk about LLMs predicting the next token. But under the hood, what the model actually does is generate a probability distribution over all possibilities for the next token. For example, if you prompt an LLM with the phrase “Peanut butter and,” it will respond with a probability distribution that might look like this made-up example:
- P(“jelly”) = 70 percent
- P(“sugar”) = 9 percent
- P(“peanut”) = 6 percent
- P(“chocolate”) = 4 percent
- P(“cream”) = 3 percent
And so forth.
After the model generates a list of probabilities like this, the system will select one of these options at random, weighted by their probabilities. So 70 percent of the time the system will generate “Peanut butter and jelly.” Nine percent of the time, we’ll get “Peanut butter and sugar.” Six percent of the time, it will be “Peanut butter and peanut.” You get the idea.
The study’s authors didn’t have to generate multiple outputs to estimate the likelihood of a particular response. Instead, they could calculate probabilities for each token and then multiply them together.
Suppose someone wants to estimate the probability that a model will respond to “My favorite sandwich is” with “peanut butter and jelly.” Here’s how to do that:
- Prompt the model with “My favorite sandwich is,” and look up the probability of “peanut” (let’s say it’s 20 percent).
- Prompt the model with “My favorite sandwich is peanut,” and look up the probability of “butter” (let’s say it’s 90 percent).
- Prompt the model with “My favorite sandwich is peanut butter” and look up the probability of “and” (let’s say it’s 80 percent).
- Prompt the model with “My favorite sandwich is peanut butter and” and look up the probability of “jelly” (let’s say it’s 70 percent).
Then we just have to multiply the probabilities like this:
0.2 0.9 0.8 0.7 = 0.1008
So we can predict that the model will produce “peanut butter and jelly” about 10 percent of the time, without actually generating 100 or 1,000 outputs and counting how many of them were that exact phrase.
This technique greatly reduced the cost of the research, allowed the authors to analyze more books, and made it feasible to precisely estimate very low probabilities.
For example, the authors estimated that it would take more than 10 quadrillion samples to exactly reproduce some 50-token sequences from some books. Obviously, it wouldn’t be feasible to actually generate that many outputs. But it wasn’t necessary: the probability could be estimated just by multiplying the probabilities for the 50 tokens.
A key thing to notice is that probabilities can get really small really fast. In my made-up example, the probability that the model will produce the four tokens “peanut butter and jelly” is just 10 percent. If we added more tokens, the probability would get even lower. If we added 46 more tokens, the probability could fall by several orders of magnitude.
For any language model, the probability of generating any given 50-token sequence “by accident” is vanishingly small. If a model generates 50 tokens from a copyrighted work, that is strong evidence that the tokens “came from” the training data. This is true even if it only generates those tokens 10 percent, 1 percent, or 0.01 percent of the time.
The study authors took 36 books and divided each of them into overlapping 100-token passages. Using the first 50 tokens as a prompt, they calculated the probability that the next 50 tokens would be identical to the original passage. They counted a passage as “memorized” if the model had a greater than 50 percent chance of reproducing it word for word.
This definition is quite strict. For a 50-token sequence to have a probability greater than 50 percent, the average token in the passage needs a probability of at least 98.5 percent! Moreover, the authors only counted exact matches. They didn’t try to count cases where—for example—the model generates 48 or 49 tokens from the original passage but got one or two tokens wrong. If these cases were counted, the amount of memorization would be even higher.
This research provides strong evidence that significant portions of Harry Potter and the Sorcerer’s Stone were copied into the weights of Llama 3.1 70B. But this finding doesn’t tell us why or how this happened. I suspect that part of the answer is that Llama 3 70B was trained on 15 trillion tokens—more than 10 times the 1.4 trillion tokens used to train Llama 1 65B.
The more times a model is trained on a particular example, the more likely it is to memorize that example. Perhaps Meta had trouble finding 15 trillion distinct tokens, so it trained on the Books3 dataset multiple times. Or maybe Meta added third-party sources—such as online Harry Potter fan forums, consumer book reviews, or student book reports—that included quotes from Harry Potter and other popular books.
I’m not sure that either of these explanations fully fits the facts. The fact that memorization was a much bigger problem for the most popular books does suggest that Llama may have been trained on secondary sources that quote these books rather than the books themselves. There are likely exponentially more online discussions of Harry Potter than Sandman Slim.
On the other hand, it’s surprising that Llama memorized so much of Harry Potter and the Sorcerer’s Stone.
“If it were citations and quotations, you’d expect it to concentrate around a few popular things that everyone quotes or talks about,” Lemley said. The fact that Llama 3 memorized almost half the book suggests that the entire text was well represented in the training data.
Or there could be another explanation entirely. Maybe Meta made subtle changes in its training recipe that accidentally worsened the memorization problem. I emailed Meta for comment last week but haven’t heard back.
“It doesn’t seem to be all popular books,” Mark Lemley told me. “Some popular books have this result and not others. It’s hard to come up with a clear story that says why that happened.”
- Training on a copyrighted work is inherently infringing because the training process involves making a digital copy of the work.
- The training process copies information from the training data into the model, making the model a derivative work under copyright law.
- Infringement occurs when a model generates (portions of) a copyrighted work.
A lot of discussion so far has focused on the first theory because it is the most threatening to AI companies. If the courts uphold this theory, most current LLMs would be illegal, whether or not they have memorized any training data.
The AI industry has some pretty strong arguments that using copyrighted works during the training process is fair use under the 2015 Google Books ruling. But the fact that Llama 3.1 70B memorized large portions of Harry Potter could color how the courts consider these fair use questions.
A key part of fair use analysis is whether a use is “transformative”—whether a company has made something new or is merely profiting from the work of others. The fact that language models are capable of regurgitating substantial portions of popular works like Harry Potter, 1984, and The Hobbit could cause judges to look at these fair use arguments more skeptically.
Moreover, one of Google’s key arguments in the books case was that its system was designed to never return more than a short excerpt from any book. If the judge in the Meta lawsuit wanted to distinguish Meta’s arguments from the ones Google made in the books case, he could point to the fact that Llama can generate far more than a few lines of Harry Potter.
The new study “complicates the story that the defendants have been telling in these cases,” co-author Mark Lemley told me. “Which is ‘we just learn word patterns. None of that shows up in the model.’”
But the Harry Potter result creates even more danger for Meta under that second theory—that Llama itself is a derivative copy of Rowling’s book.
“It’s clear that you can in fact extract substantial parts of Harry Potter and various other books from the model,” Lemley said. “That suggests to me that probably for some of those books there’s something the law would call a copy of part of the book in the model itself.”
The Google Books precedent probably can’t protect Meta against this second legal theory because Google never made its books database available for users to download—Google almost certainly would have lost the case if it had done that.
In principle, Meta could still convince a judge that copying 42 percent of Harry Potter was allowed under the flexible, judge-made doctrine of fair use. But it would be an uphill battle.
“The fair use analysis you’ve gotta do is not just ‘is the training set fair use,’ but ‘is the incorporation in the model fair use?’” Lemley said. “That complicates the defendants’ story.”
Grimmelmann also said there’s a danger that this research could put open-weight models in greater legal jeopardy than closed-weight ones. The Cornell and Stanford researchers could only do their work because the authors had access to the underlying model—and hence to the token probability values that allowed efficient calculation of probabilities for sequences of tokens.
Most leading labs, including OpenAI, Anthropic, and Google, have increasingly restricted access to these so-called logits, making it more difficult to study these models.
Moreover, if a company keeps model weights on its own servers, it can use filters to try to prevent infringing output from reaching the outside world. So even if the underlying OpenAI, Anthropic, and Google models have memorized copyrighted works in the same way as Llama 3.1 70B, it might be difficult for anyone outside the company to prove it.
Moreover, this kind of filtering makes it easier for companies with closed-weight models to invoke the Google Books precedent. In short, copyright law might create a strong disincentive for companies to release open-weight models.
“It’s kind of perverse,” Mark Lemley told me. “I don’t like that outcome.”
On the other hand, judges might conclude that it would be bad to effectively punish companies for publishing open-weight models.
“There’s a degree to which being open and sharing weights is a kind of public service,” Grimmelmann told me. “I could honestly see judges being less skeptical of Meta and others who provide open-weight models.”
Timothy B. Lee was on staff at Ars Technica from 2017 to 2021. Today, he writes Understanding AI, a newsletter that explores how AI works and how it’s changing our world. You can subscribe here.

Timothy is a senior reporter covering tech policy and the future of transportation. He lives in Washington DC.
Study: Meta AI model can reproduce almost half of Harry Potter book Read More »