
Google goes “open AI” with Gemma, a free, open-weights chatbot family
Free hallucinations for all —
Gemma chatbots can run locally, and they reportedly outperform Meta’s Llama 2.

On Wednesday, Google announced a new family of AI language models called Gemma, which are free, open-weights models built on technology similar to the more powerful but closed Gemini models. Unlike Gemini, Gemma models can run locally on a desktop or laptop computer. It’s Google’s first significant open large language model (LLM) release since OpenAI’s ChatGPT started a frenzy for AI chatbots in 2022.
Gemma models come in two sizes: Gemma 2B (2 billion parameters) and Gemma 7B (7 billion parameters), each available in pre-trained and instruction-tuned variants. In AI, parameters are values in a neural network that determine AI model behavior, and weights are a subset of these parameters stored in a file.
Developed by Google DeepMind and other Google AI teams, Gemma pulls from techniques learned during the development of Gemini, which is the family name for Google’s most capable (public-facing) commercial LLMs, including the ones that power its Gemini AI assistant. Google says the name comes from the Latin gemma, which means “precious stone.”
While Gemma is Google’s first major open LLM since the launch of ChatGPT (it has released smaller research models such as FLAN-T5 in the past), it’s not Google’s first contribution to open AI research. The company cites the development of the Transformer architecture, as well as releases like TensorFlow, BERT, T5, and JAX as key contributions, and it would not be controversial to say that those have been important to the field.
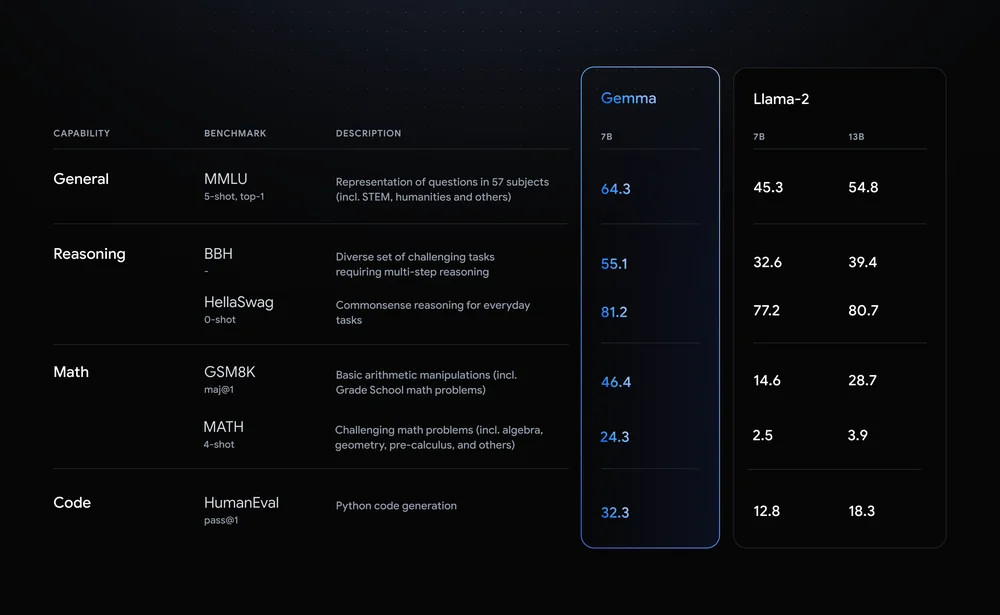
Enlarge / A chart of Gemma performance provided by Google. Google says that Gemma outperforms Meta’s Llama 2 on several benchmarks.
Owing to lesser capability and high confabulation rates, smaller open-weights LLMs have been more like tech demos until recently, as some larger ones have begun to match GPT-3.5 performance levels. Still, experts see source-available and open-weights AI models as essential steps in ensuring transparency and privacy in chatbots. Google Gemma is not “open source” however, since that term usually refers to a specific type of software license with few restrictions attached.
In reality, Gemma feels like a conspicuous play to match Meta, which has made a big deal out of releasing open-weights models (such as LLaMA and Llama 2) since February of last year. That technique stands in opposition to AI models like OpenAI’s GPT-4 Turbo, which is only available through the ChatGPT application and a cloud API and cannot be run locally. A Reuters report on Gemma focuses on the Meta angle and surmises that Google hopes to attract more developers to its Vertex AI cloud platform.
We have not used Gemma yet; however, Google claims the 7B model outperforms Meta’s Llama 2 7B and 13B models on several benchmarks for math, Python code generation, general knowledge, and commonsense reasoning tasks. It’s available today through Kaggle, a machine-learning community platform, and Hugging Face.
In other news, Google paired the Gemma release with a “Responsible Generative AI Toolkit,” which Google hopes will offer guidance and tools for developing what the company calls “safe and responsible” AI applications.
Google goes “open AI” with Gemma, a free, open-weights chatbot family Read More »


{kind=link}