Cheap AI “video scraping” can now extract data from any screen recording
Researcher feeds screen recordings into Gemini to extract accurate information with ease.

Recently, AI researcher Simon Willison wanted to add up his charges from using a cloud service, but the payment values and dates he needed were scattered among a dozen separate emails. Inputting them manually would have been tedious, so he turned to a technique he calls “video scraping,” which involves feeding a screen recording video into an AI model, similar to ChatGPT, for data extraction purposes.
What he discovered seems simple on its surface, but the quality of the result has deeper implications for the future of AI assistants, which may soon be able to see and interact with what we’re doing on our computer screens.
“The other day I found myself needing to add up some numeric values that were scattered across twelve different emails,” Willison wrote in a detailed post on his blog. He recorded a 35-second video scrolling through the relevant emails, then fed that video into Google’s AI Studio tool, which allows people to experiment with several versions of Google’s Gemini 1.5 Pro and Gemini 1.5 Flash AI models.
Willison then asked Gemini to pull the price data from the video and arrange it into a special data format called JSON (JavaScript Object Notation) that included dates and dollar amounts. The AI model successfully extracted the data, which Willison then formatted as CSV (comma-separated values) table for spreadsheet use. After double-checking for errors as part of his experiment, the accuracy of the results—and what the video analysis cost to run—surprised him.
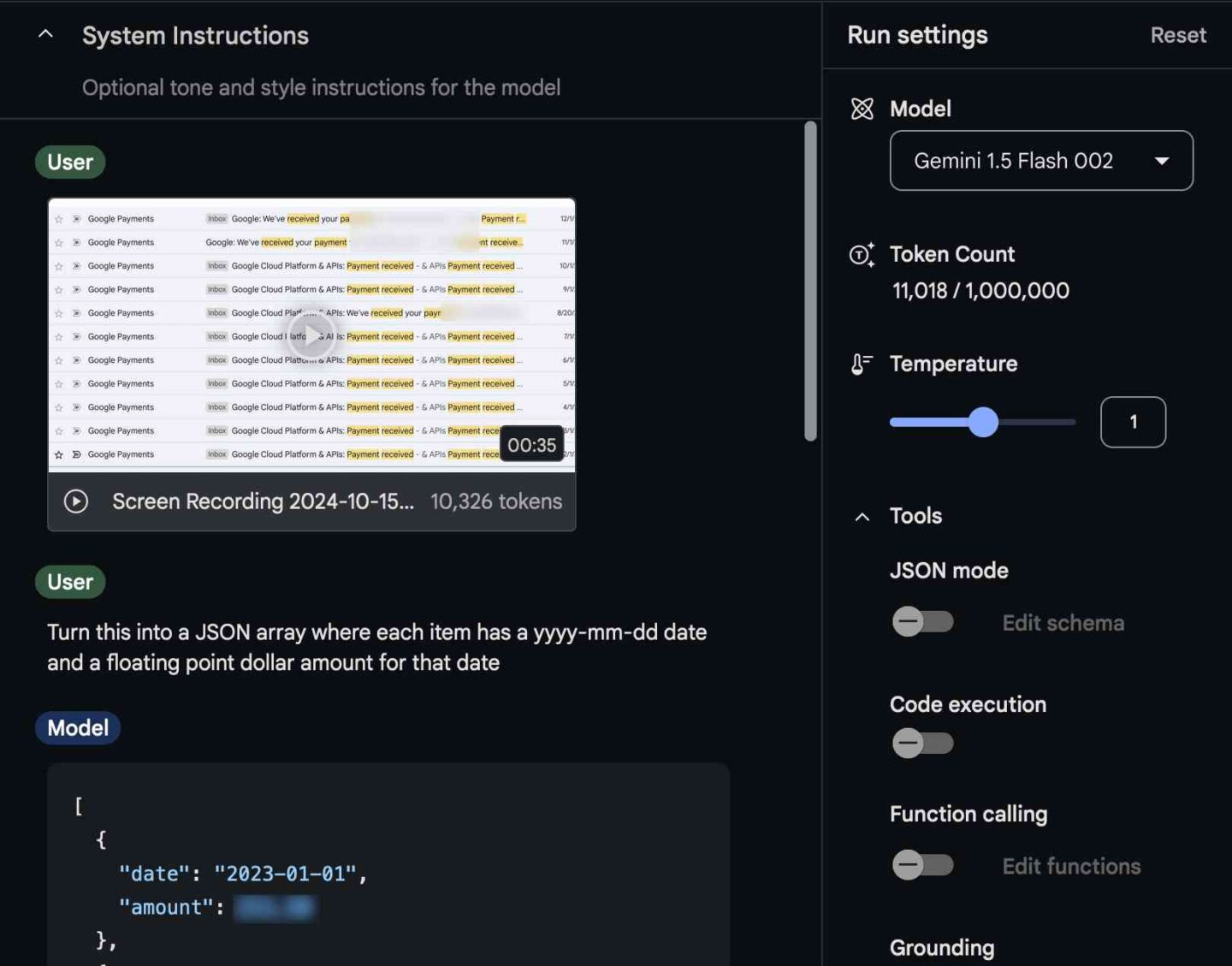
A screenshot of Simon Willison using Google Gemini to extract data from a screen capture video.
A screenshot of Simon Willison using Google Gemini to extract data from a screen capture video. Credit: Simon Willison
“The cost [of running the video model] is so low that I had to re-run my calculations three times to make sure I hadn’t made a mistake,” he wrote. Willison says the entire video analysis process ostensibly cost less than one-tenth of a cent, using just 11,018 tokens on the Gemini 1.5 Flash 002 model. In the end, he actually paid nothing because Google AI Studio is currently free for some types of use.
Video scraping is just one of many new tricks possible when the latest large language models (LLMs), such as Google’s Gemini and GPT-4o, are actually “multimodal” models, allowing audio, video, image, and text input. These models translate any multimedia input into tokens (chunks of data), which they use to make predictions about which tokens should come next in a sequence.
A term like “token prediction model” (TPM) might be more accurate than “LLM” these days for AI models with multimodal inputs and outputs, but a generalized alternative term hasn’t really taken off yet. But no matter what you call it, having an AI model that can take video inputs has interesting implications, both good and potentially bad.
Breaking down input barriers
Willison is far from the first person to feed video into AI models to achieve interesting results (more on that below, and here’s a 2015 paper that uses the “video scraping” term), but as soon as Gemini launched its video input capability, he began to experiment with it in earnest.
In February, Willison demonstrated another early application of AI video scraping on his blog, where he took a seven-second video of the books on his bookshelves, then got Gemini 1.5 Pro to extract all of the book titles it saw in the video and put them in a structured, or organized, list.
Converting unstructured data into structured data is important to Willison, because he’s also a data journalist. Willison has created tools for data journalists in the past, such as the Datasette project, which lets anyone publish data as an interactive website.
To every data journalist’s frustration, some sources of data prove resistant to scraping (capturing data for analysis) due to how the data is formatted, stored, or presented. In these cases, Willison delights in the potential for AI video scraping because it bypasses these traditional barriers to data extraction.
“There’s no level of website authentication or anti-scraping technology that can stop me from recording a video of my screen while I manually click around inside a web application,” Willison noted on his blog. His method works for any visible on-screen content.
Video is the new text

An illustration of a cybernetic eyeball.
An illustration of a cybernetic eyeball. Credit: Getty Images
The ease and effectiveness of Willison’s technique reflect a noteworthy shift now underway in how some users will interact with token prediction models. Rather than requiring a user to manually paste or type in data in a chat dialog—or detail every scenario to a chatbot as text—some AI applications increasingly work with visual data captured directly on the screen. For example, if you’re having trouble navigating a pizza website’s terrible interface, an AI model could step in and perform the necessary mouse clicks to order the pizza for you.
In fact, video scraping is already on the radar of every major AI lab, although they are not likely to call it that at the moment. Instead, tech companies typically refer to these techniques as “video understanding” or simply “vision.”
In May, OpenAI demonstrated a prototype version of its ChatGPT Mac App with an option that allowed ChatGPT to see and interact with what is on your screen, but that feature has not yet shipped. Microsoft demonstrated a similar “Copilot Vision” prototype concept earlier this month (based on OpenAI’s technology) that will be able to “watch” your screen and help you extract data and interact with applications you’re running.
Despite these research previews, OpenAI’s ChatGPT and Anthropic’s Claude have not yet implemented a public video input feature for their models, possibly because it is relatively computationally expensive for them to process the extra tokens from a “tokenized” video stream.
For the moment, Google is heavily subsidizing user AI costs with its war chest from Search revenue and a massive fleet of data centers (to be fair, OpenAI is subsidizing, too, but with investor dollars and help from Microsoft). But costs of AI compute in general are dropping by the day, which will open up new capabilities of the technology to a broader user base over time.
Countering privacy issues
As you might imagine, having an AI model see what you do on your computer screen can have downsides. For now, video scraping is great for Willison, who will undoubtedly use the captured data in positive and helpful ways. But it’s also a preview of a capability that could later be used to invade privacy or autonomously spy on computer users on a scale that was once impossible.
A different form of video scraping caused a massive wave of controversy recently for that exact reason. Apps such as the third-party Rewind AI on the Mac and Microsoft’s Recall, which is being built into Windows 11, operate by feeding on-screen video into an AI model that stores extracted data into a database for later AI recall. Unfortunately, that approach also introduces potential privacy issues because it records everything you do on your machine and puts it in a single place that could later be hacked.

To that point, although Willison’s technique currently involves uploading a video of his data to Google for processing, he is pleased that he can still decide what the AI model sees and when.
“The great thing about this video scraping technique is that it works with anything that you can see on your screen… and it puts you in total control of what you end up exposing to the AI model,” Willison explained in his blog post.
It’s also possible in the future that a locally run open-weights AI model could pull off the same video analysis method without the need for a cloud connection at all. Microsoft Recall runs locally on supported devices, but it still demands a great deal of unearned trust. For now, Willison is perfectly content to selectively feed video data to AI models when the need arises.
“I expect I’ll be using this technique a whole lot more in the future,” he wrote, and perhaps many others will, too, in different forms. If the past is any indication, Willison—who coined the term “prompt injection” in 2022—seems to always be a few steps ahead in exploring novel applications of AI tools. Right now, his attention is on the new implications of AI and video, and yours probably should be, too.

Benj Edwards is Ars Technica’s Senior AI Reporter and founder of the site’s dedicated AI beat in 2022. He’s also a widely-cited tech historian. In his free time, he writes and records music, collects vintage computers, and enjoys nature. He lives in Raleigh, NC.
Cheap AI “video scraping” can now extract data from any screen recording Read More »