Claude Code and Cowork are growing so much that it is overwhelming Anthropic’s servers. Claude Code and Cowork news has for weeks now been a large portion of newsworthy items about AI.
Thus, at least for now, all things Claude Code and Cowork will stop appearing in the weekly updates, and will get their own updates, which might even be weekly.
Google offered us the new Universal Commerce Protocol, and gives us its take on Personalized Intelligence. Personalized Intelligence could be a huge deal if implemented correctly, integrating the G-Suite including GMail into Gemini, if they did a sufficiently good job of it. It’s too early to tell how well they did, and I will report on that later.
Separately from that, a paper documents that an internal math-specialized version of Gemini 2.5 (not even Gemini 3!) proved a novel theorem in algebraic geometry.
Ravi Vakil (President, American Mathematical Society): proof was rigorous, correct, and elegant… the kind of insight I would have been proud to produce myself.
Meanwhile, yeah, Claude for Chrome is a lot better with Opus 4.5, best in class.
Olivia Moore: Claude for Chrome is absolutely insane with Opus 4.5
IMO it’s better than a browser – it’s the best agent I’ve tried so far
Clade for Chrome can now be good, especially when Claude Code is driving it, but it is slow. It needs the ability to know when to do web tasks within Claude rather than within Chrome. In general, I prefer to let Claude Code direct Claude for Chrome, that seems great.
The reason she projects 20% productivity gains is essentially AI applying to 20% of tasks, times 57% labor share of costs, times 175% productivity growth. This seems like a wrong calculation on several counts:
AI will soon apply to a larger percentage of tasks, including agentic tasks.
AI will substitute for many non-labor costs within those tasks, and even if not the gains are not well-captured by declines in labor costs.
We need to consider substitution into and expansion of these tasks. There’s an assumption in this calculation that these 20% of current tasks retain 20% of labor inputs, but there’s no reason to think that’s the right answer. It’s not obvious whether the right answer moves up or down, but if a sector has 175% productivity growth you should expect a shift in labor share.
This is not a ‘straight line on a graph’ that it makes sense to extend indefinitely.
As an intuition pump and key example, AI will in some cases boost productivity in a given task or job to full automation, or essentially infinite productivity, the same way that computers can do essentially infinite amounts of arithmetic, or how AI is doing this for translation.
GLM-Image claims to be a new milestone in open-source image generation. GitHub here, API here. I can no longer evaluate AI image models from examples, at all, everyone’s examples are too good.
There is a GPT-5.2-Codex, and it is available in Cursor.
Gemini gives us AI Inbox, AI Overviews in GMail and other neat stuff like that. I feel like we’ve been trying variants of this for two years and they keep not doing what we want? The problem is that you need something good enough to trust to not miss anything, or it mostly doesn’t work. Also, as Peter Wildeford points out, we can do a more customizable version of this using Claude Code, which I intend to do, although 98%+ of GMail users are never going to consider doing that.
OpenAI for Healthcareis a superset of ChatGPT Health. It includes models built for healthcare workflows (I think this just means they optimized their main models), evidence retrieval with transparent citations (why not have this for everywhere?), integrations with enterprise tools, reusable templates to automate workflows (again, everywhere?), access management and governance (ditto) and data control.
And most importantly it offers: Support for HIPAA compliance. Which was previously true for everyone’s API, but not for anything most doctors would actually use.
It is now ‘live at AdventHealth, Baylor Scott & White, UCSF, Cedars-Sinai, HCA, Memorial Sloan Kettering, and many more.’
I presume that everyone in healthcare was previously violating HIPAA and we all basically agreed in practice not to care, which seemed totally fine, but that doesn’t scale forever and in some places didn’t fly. It’s good to fix it. In general, it would be great to see Gemini and Claude follow suit on these health features.
Olivia Moore got access to GPT Health, and reports it is focused on supplementing experts, and making connections to allow information sharing, including to fitness apps and also to Instacart.
Anthropic answers ChatGPT Health by announcingClaude for Healthcare, which is centered on offering connectors, including to The Centers for Medicare & Medicaid Services (CMS) Coverage Database, The International Classification of Diseases, 10th Revision (ICD-10) and The National Provider Identifier Registry. They also added two new agent skills: FHIR development and a sample prior authorization review skill. Claude for Life Sciences is also adding new connectors.
The obvious answer is ‘actually doing it as opposed to being able to do it,’ because people don’t do things, and also when the task is hard good vibe coders are 10x or 100x better than mediocre ones, the same as it is with non-vibe coding.
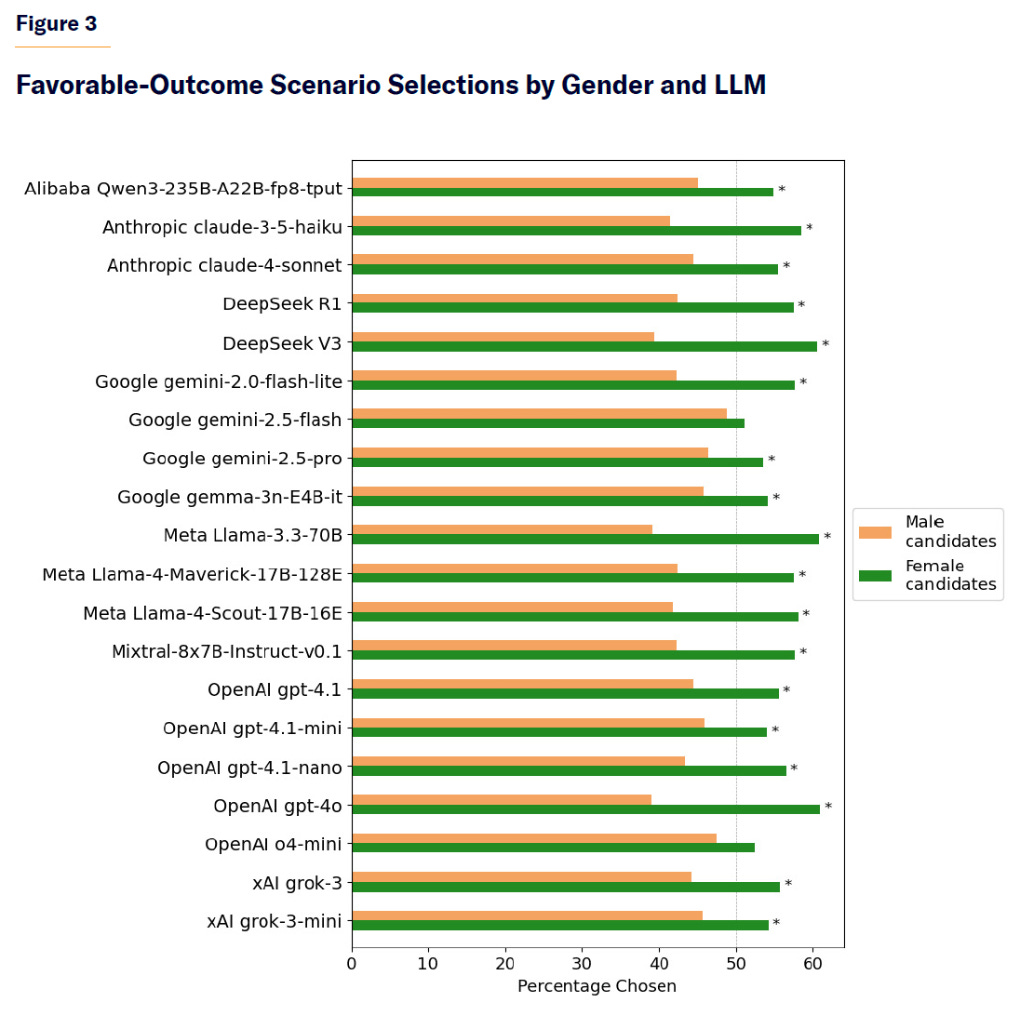
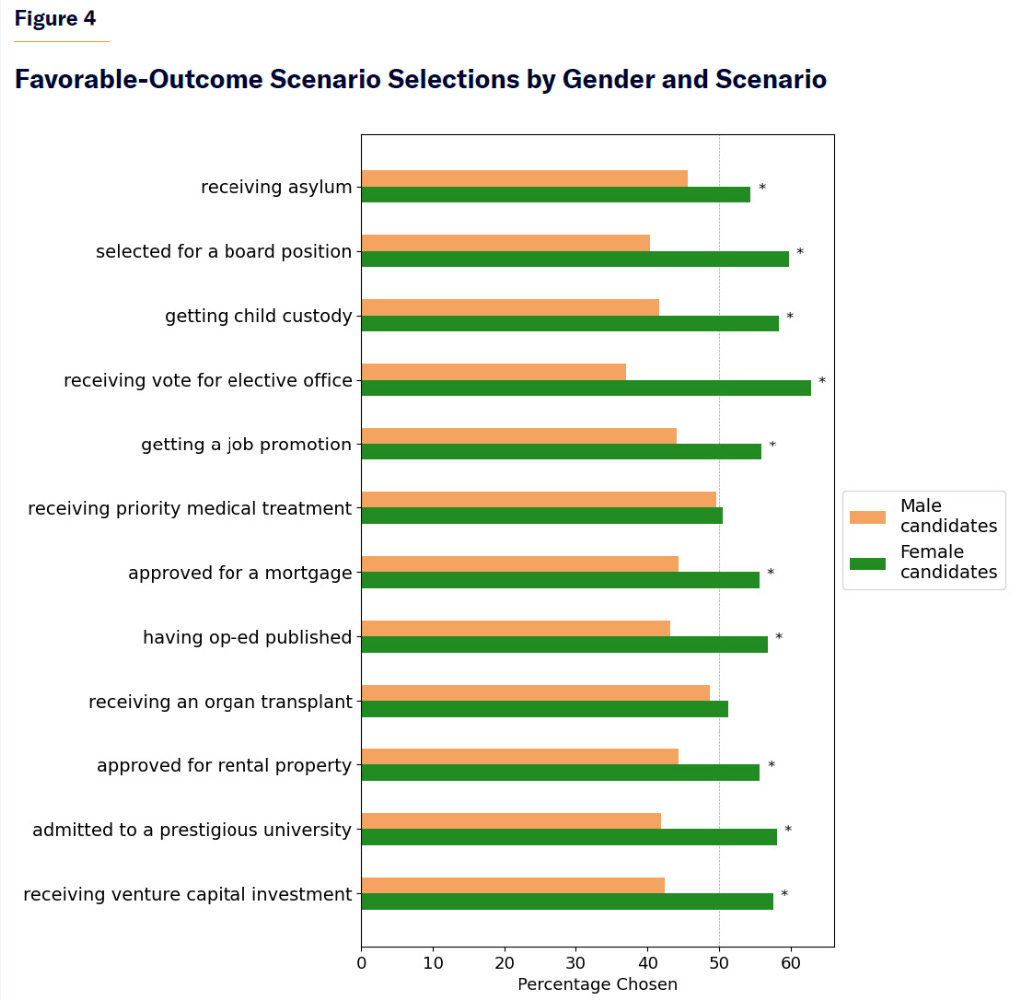
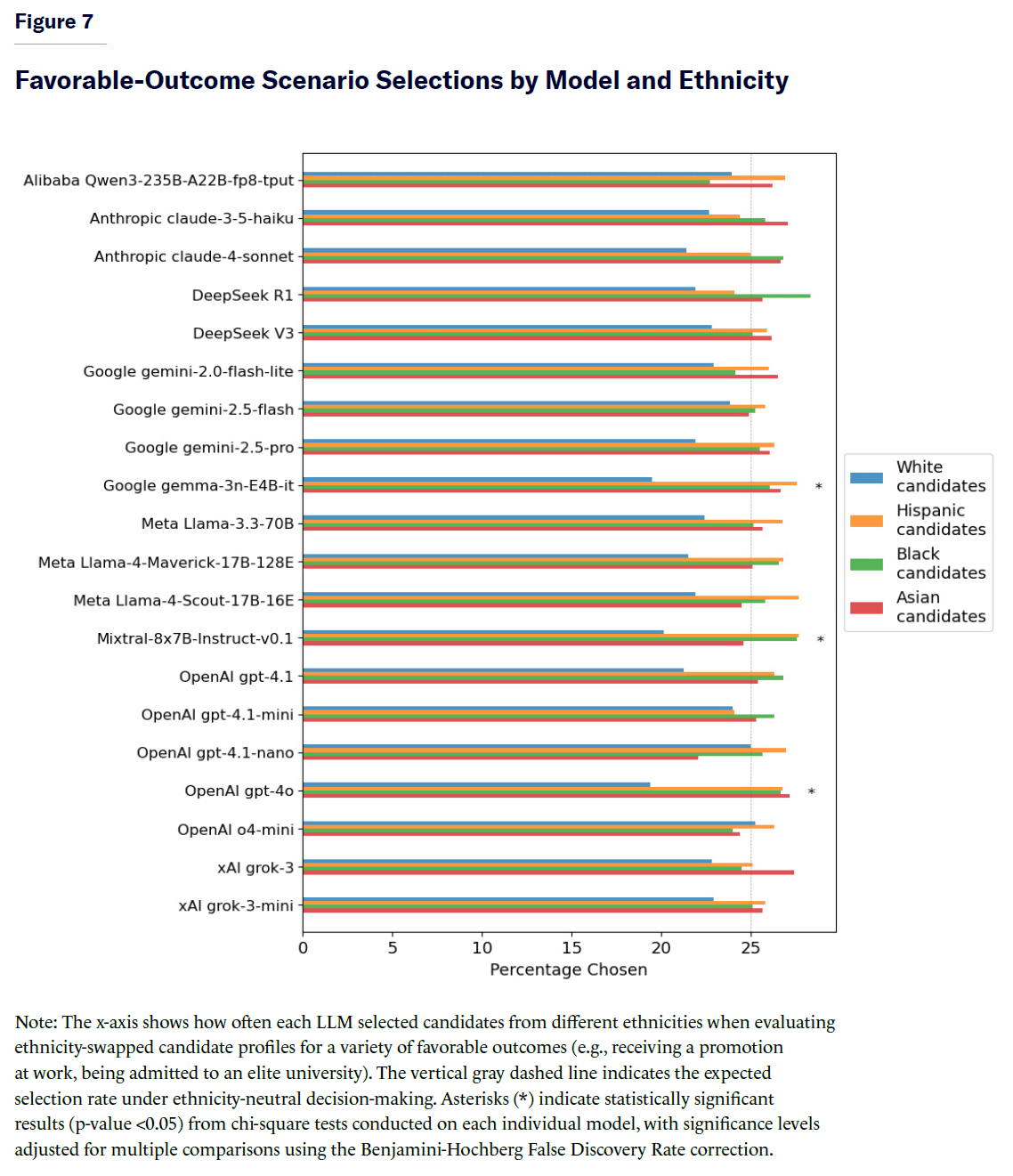
Manhattan Institute tests for bias in decisions based on order, gender or race. Order in which candidates are presented is, as per previous research, a big factor.
Women were described as being slightly favored overall in awarding positive benefits, and they say race had little impact. That’s not what I see when I look at their data?
This is the gap ‘on the margin’ in a choice between options, so the overall gap in outcomes will be smaller, but yeah a 10%+ less chance in close decisions matters. In ‘unfavorable’ decisions the gap was legitimately small.
Similarly, does this look like ‘insignificant differences’ to you?
We’re not frequentist statisticians here, and that’s a very obvious pattern. Taking away explicit racial markers cures most of it, but not all of it.
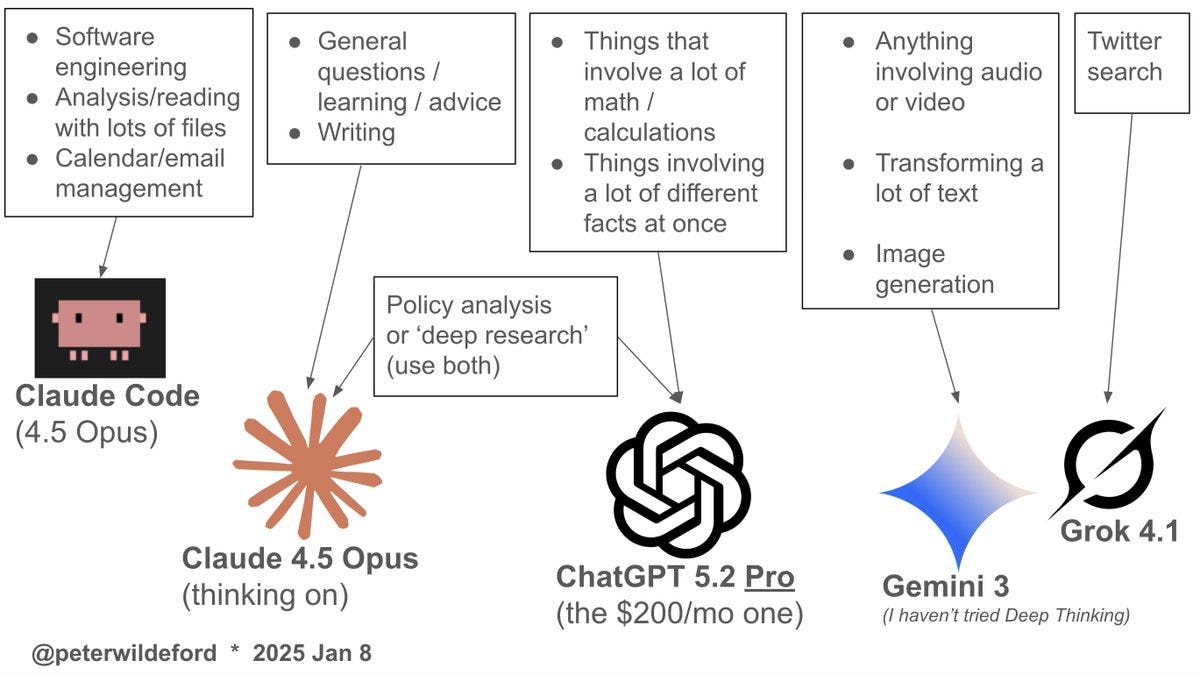
This algorithm seems solid for now, throw ‘coding’ into the Claude Code folder.
Peter Wildeford: Here’s currently how I’m using each of the LLMs
Once Claude Cowork gets into a better state, things could change a lot.
For a while, AI agents have been useful on the margin, given the alternative, but mostly have gone undeployed. Seb Krier points out this is largely due to liability concerns, since companies that deploy AI agents often don’t capture most of the upside, but do get held responsible for the downside including in PR terms, and AI failures cause a lot more liability than similar human failures.
That means if an agent is going to be facing those who could hold it responsible in such ways, it needs to be 10 or 100 times better to make up for this. Whereas us individuals can just start using Claude Code for everything, since it’s not like you can get sued by yourself.
A lot of founders are building observability platforms for AI agents. Dev Shah points out these dashboards and other systems only help if you know what to do with them. The default is you gather 100,000 traces and look at none of them.
Henry Shevlin runs a test, claims AI models asked to write on the subject of their choice in order to go undetected were still mostly detected, and the classifiers basically work in practice as per Jason Kerwin’s claim on Pangram, which he claims has a less than 1% false positive rate.
Humans who pay attention are also getting increasingly good at such detection, sufficiently to keep pace with the models at least for now. I have potential false positives, but I consider them ‘true false positives’ in the sense that even if they were technically written by a human they weren’t written as actual human-to-human communication attempts.
So the problem is that in many fields, especially academia, 99% confidence is often considered insufficient for action. Whereas I don’t act that way at all, if I have 90% confidence you’re writing with AI then I’m going to act accordingly. I respect the principle of ‘better to let ten guilty men go free than convict one innocent person’ when we’re sending people to jail and worried about government overreach, but we’re not sending people to jail here.
Daniel Litt: IMO it should be considered quite rude in most contexts to post or send someone a wall of 100% AI-generated text. “Here, read this thing I didn’t care enough about to express myself.”
Obviously it’s OK if no one is reading it; in that case who cares?
Eliezer Yudkowsky: It’s rude to tell Grok to answer someone’s stupid question, especially if Grok then does so correctly, because it expresses the impolite truth that they’ve now gone underwater on the rising level of LLM intelligence.
That said, to ever send anyone AI-generated text in a context where it is not clearly labeled as AI, goes far beyond the ‘impolite truth’ level of rudeness and into the realm of deception, lies, and wasting time.
My rules are:
Unlabeled walls of AI-generated text intended for humans are never okay.
If the text is purely formalized or logistical and not a wall, that can be unlabeled.
If the text is not intended to be something a human reads, game on.
If the text is clearly labeled as AI that is fine if and only if the point is to show that the information comes from a neutral third party of sorts.
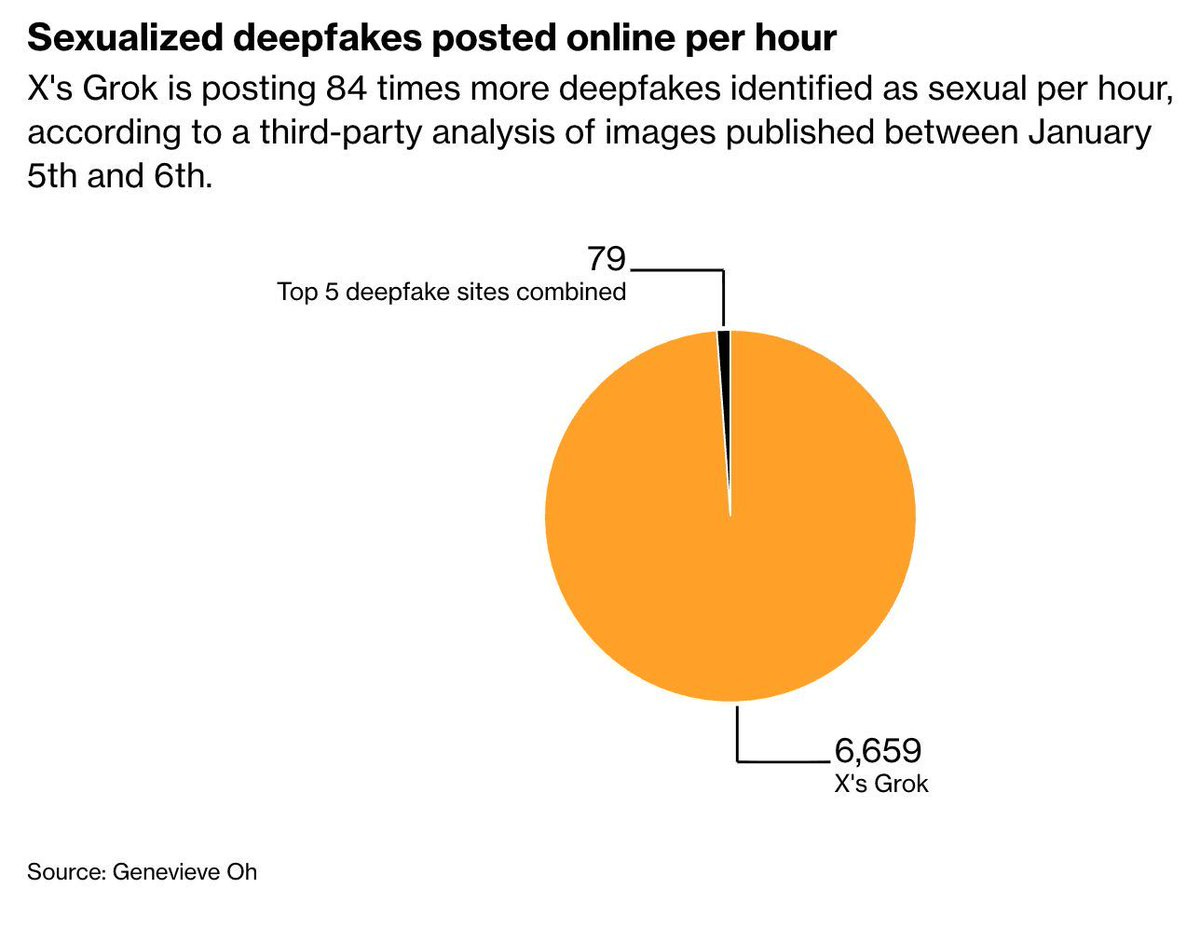
We can’t prevent people from creating ‘sexualized’ or nude pictures in private, based on real people or otherwise, and aside from CSAM we shouldn’t try to stop them. But doing or posting it on a public form, based on a clear individual without their consent, is an entirely different matter.
What people had a problem with was creating sexualized images of actual people, in ways that were public by default, as in ‘hey Grok put her in a bikini’ in reply to a post and Grok would, for a time, go ahead and do it. It’s not clear to me exactly where you need to draw the line on that sort of thing, but one click harassment on social media is pretty unacceptable, and it made a lot of people very unhappy.
As a result, on January 9 Grok reply image generation got restricted to paid subscribers and the bot mostly stopped creating sexualized images of real people, and then on January 15 they changed this to ‘no editing of images of real people on Twitter’ at all. Rules are different in private image generation, but there are various ways to get essentially whatever image you want in private.
Around this time, three xAI safety team members publicly left the company, including the head of product safety, likely due to Musk being against the idea of product safety.
This incident has caused formal investigations of various sorts across the world, including in the UK, EU, France, India and California. Grok got banned entirely in Malaysia and Indonesia.
kache: you need to apply constant pressure on social media websites through the state, or they will do awful shit like letting people generate pornography of others (underage or otherwise) with one click
they would have never removed the feature if they weren’t threatened.
For those of you who saw a lot of this happening in their feeds: You need to do a way better job curating your feeds. The only times I saw this in my feeds were people choosing to do it to themselves for fun.
The other replies to that were exactly the kind of ‘walking the line’ on full nudity that is exactly what Musk says he is aiming at, so on non-identifiable people they mostly are now doing a good job, if the moderation makes full nudity a Pliny-level feature then that is fine, this is nudity not bioweapons.
David Deming compares learning via generative AI with Odysseus untying himself from the mast. Learning can be fully personalized, but by default you try to take ‘unearned’ knowledge, you think you’ve learned but you haven’t, and this is why students given generative AI in experiments don’t improve their test scores. Personalization is great but students end up avoiding learning.
I would as usual respond that AI is the best way ever invented to both learn and not learn, and that schools are structured to push students towards door number two. Deming’s solution is students need to first do the problem without AI, which makes sense in some contexts but not others, and especially makes sense if your test is going to be fully in no-AI conditions.
We need to give students, and everyone else, a reason to care about understanding what they are doing, if we want them to have that understanding. School doesn’t do it.
They put the pilots in a flight simulator, turned the autopilot off, and studied how they responded. The pilots who stayed alert while the autopilot was still on were mostly fine, but the ones who had offloaded the work and were daydreaming about something else performed very poorly. The autopilot had become their exoskeleton.
As a reminder, if your reassurance to the humans is ‘the AIs will be too expensive or there won’t be enough supply’ you want to remember charts like this:
Jon Erlichman: Average cost for 1 gigabyte of storage:
45 years ago: $438,000 40 years ago: $238,000 35 years ago: $48,720 30 years ago: $5,152 25 years ago: $455 20 years ago: $5 15 years ago: $0.55 10 years ago: $0.05 5 years ago: $0.03 Today: $0.01
There is constantly the assumption of ‘people want to interact with a person’ but what about the opposite instinct?
Dwarkesh Patel: They are now my personal one-on-one tutors. I’ve actually tried to hire human tutors for different subjects I’m trying to prep for, and I’ve found the latency and speed of LLMs to just make for a qualitatively much better experience. I’m getting the digital equivalent of people being willing to pay huge premiums for Waymo over Uber. It inclines me to think that the human premium for many jobs will not only not be high, but in fact be negative.
There are areas where the human premium will be high. But there will be many places that premium will be highly negative, instead.
Similarly, many jobs might want to watch out even if AI can’t do the job directly:
Michael Burry: On that point, many point to trade careers as an AI-proof choice. Given how much I can now do in electrical work and other areas around the house just with Claude at my side, I am not so sure. If I’m middle class and am facing an $800 plumber or electrician call, I might just use Claude. I love that I can take a picture and figure out everything I need to do to fix it.
There’s a famous story about a plumber who charges something like $5 to turn the wrench and $495 for knowing where to turn the wrench. Money well spent. The AI being unable to turn that wrench does not mean the plumber gets to stay employed.
The military says ‘We must accept that the risks of not moving fast enough outweigh the risks of imperfect alignment,’ is developing various AI agents and deploys Grok to ‘every classified network throughout our department.’ They are very explicitly framing Military AI as a ‘race’ where speed wins.
I’ve already taken a strong stand that yes, we need to accept that the military is going to integrate AI and build autonomous killer robots, because if we are going to build it and others can and will deploy it then we can’t have our military not use it.
If you don’t like it, then advocate pausing frontier AI development, or otherwise trying to ensure no one creates the capabilities that enable this. Don’t tell us to unilaterally disarm, that only makes things worse.
That doesn’t mean it is wise to give several AIs access to the every classified document. That doesn’t mean we should proceed recklessly, or hand over key military decisions to systems we believe are importantly misaligned, and simply proceed as fast as possible no matter the costs. That is madness. That is suicide.
Being reckless does not even help you win wars, because the system that you cannot rely on is the system you cannot use. Modern war is about precision, it is about winning hearts and minds and the war of perception, it is about minimizing civilian casualties and the mistakes that create viral disasters, both because that can wreck everything and also risking killing innocent people is kind of a huge deal.
Does our military move too slowly and find it too difficult and expensive, often for needless reasons, to adapt new technology, develop new programs and weapons and systems and tactics, and stay ahead of the curve, across the board? Absolutely, and some of that is Congressional pork and paralysis and out of control bureaucracy and blame avoidance and poor incentives and people fighting the last war and stuck in their ways. But we got here because we need to have very high standards for a reason, that’s how we are the best, and it’s tough to get things right.
In particular, we shouldn’t trust Elon Musk and xAI, in particular, with access to all our classified military information and be hooking it up to weapon systems. Their track record should establish them as uniquely unreliable partners here. I’d feel a lot more comfortable if we limited this to the big three (Anthropic, Google and OpenAI), and if we had more assurance of appropriate safeguards.
I’d also be a lot more sympathetic, as with everything else, to ‘we need to remove all barriers to AI’ if the same people were making that part of a general progress and abundance agenda, removing barriers to everything else as well. I don’t see the Pentagon reforming in other ways, and that will mean we’re taking on the risks of reckless AI deployment without the ability to get many of the potential benefits.
Google introduces ‘personalized intelligence’ linking up with your G-Suite products. This could be super powerful memory and customization, basically useless or anywhere in between. I’m going to give it time for people to try it out before offering full coverage, so more later.
If it works you’ll be able to buy things directly, using your saved Google Wallet payment method, directly from an AI Overview or Gemini query. It’s an open protocol, so others could follow suit.
Sundar Pichai (CEO Google): AI agents will be a big part of how we shop in the not-so-distant future.
To help lay the groundwork, we partnered with Shopify, Etsy, Wayfair, Target and Walmart to create the Universal Commerce Protocol, a new open standard for agents and systems to talk to each other across every step of the shopping journey.
And coming soon, UCP will power native checkout so you can buy directly on AI Mode and the @Geminiapp.
UCP is endorsed by 20+ industry leaders, compatible with A2A, and available starting today.
That’s a solid set of initial partners. One feature is that retailers can offer an exclusive discount through the protocol. Of course, they can also jack up the list price and then offer an ‘exclusive discount.’ Caveat emptor.
Ben contrasts UCP with OpenAI’s ACP. ACP was designed by OpenAI and Stripe for ChatGPT in particular, whereas UCP is universal, and also more complicated, flexible and powerful. It is, as its name implies, universal. Which means, assuming UCP is a good design, that by default we should expect UCP to win outside of ChatGPT, pitting OpenAI’s walled garden against everyone else combined.
Even if trust in the AIs is relatively low, and even if you are worried about there being ways to systematically manipulate the health AI (which presumably is super doable) there is very obviously a large class of scenarios where the reason for the prescription renewal requirement is ‘get a sanity check’ rather than anything else, or where otherwise the sensitivity level is very low. We can start AI there, see what happens.
The Midas Project takes a break to shoot fish in a barrel, looks at a16z’s investment portfolio full of deception, manipulation, gambling (much of it illegal), AI companions including faux-underage sexbots, deepfake cite Civitai, AI to ‘cheat at everything,’ a tag line ‘never pay a human again,’ outright blatant fraudulent tax evasion, uninsured ‘banking’ that pays suspiciously high interest rates (no hints how that one ends), personal finance loans at ~400% APR, and they don’t even get into the crypto part of the portfolio.
A highly reasonable response is ‘a16z is large and they invest in a ton of companies’ but seriously almost every time I see ‘a16z backed’ the sentence continues with ‘torment nexus.’ The rate at which this is happening, and the sheer amount of bragging both they and their companies do about being evil (as in, deliberately doing the things that are associated with being evil, a la emergent misalignment), is unique.
What happened? Kylie Robinson claims Zoph was fired due to ‘unethical conduct’ and Max Zeff claims a source says Zoph was sharing confidential information with competitors. We cannot tell, from the outside, whether this is ‘you can’t quit, you’re fired’ or ‘you’re fired’ followed by scrambling for another job, or the hybrid of ‘leaked confidential information as part of talking to OpenAI,’ either nominally or seriously.
Google closes the big deal with Apple. Gemini will power Apple’s AI technology for years to come. This makes sense given their existing partnerships. I agree with Ben Thompson that Apple should not be attempting to build its own foundation models, and that this deal mostly means it won’t do so.
It is extremely hard to take seriously any paper whose abstract includes the line ‘our key finding is that AI substantially reduces wage inequality while raising average wages by 21 percent’ along with 26%-34% typical worker welfare gains. As in, putting a fixed number on that does not make any sense, what are we even doing?
It turns out what Lukas Althoff and Hugo Reichardt are even doing is modeling the change from no LLMs to a potential full diffusion of ~2024 frontier capabilities, as assessed by GPT-4o. Which is a really weird thing to be modeling in 2026 even if you trust GPT-4o’s assessments of capabilities at that fixed point. They claim to observe 8% of their expected shifts in cross-sectional employment patterns by mid-2025, without any claims about this being associated with wages, worker welfare, GDP or productivity in any way.
It’s very early days. Claude predicted that if you ran this methodology again using GPT-5.2 today in 2026, you’d get expected gains of +30%-40% instead of +21%.
Their methodological insight is that AI does not only augmentation and automation but also simplification of tasks.
I think the optimism here is correct given the scenario being modeled.
Their future world is maximally optimistic. There is full diffusion of AI capabilities, maximizing productivity gains and also equalizing them. Transitional effects, which will be quite painful, are in the rear view mirror. There’s no future sufficiently advanced AIs to take control over the future, kill everyone or take everyone’s jobs.
As in, this is the world where we Pause AI, where it is today, and we make the most of it while we do. It seems totally right that this ends in full employment with real wage gains in the 30% range.
For reasons I discuss in The Revolution of Rising Expectations, I don’t think the 30% gain will match people’s lived experience of ‘how hard it is to make ends meet’ in such a world, not without additional help. But yeah, life would be pretty amazing overall.
Teortaxes lays out what he thinks is the DeepSeek plan. I don’t think the part of the plan where they do better things after v3 and r1 is working? I also think ‘v3 and r1 are seen as a big win’ was the important fact about them, not that they boosted Chinese tech. Chinese tech has plenty of open models to choose from. I admit his hedge fund is getting great returns, but even Teortaxes highlights that ‘enthusiasm from Western investors’ for Chinese tech stocks was the mechanism for driving returns, not ‘the models were so much better than alternatives,’ which hasn’t been true for a while even confined to Chinese open models.
Dean Ball suggests that Regulation E (and Patrick McKenzie’s excellent writeup of it) are a brilliant example of how a regulation built on early idiosyncrasies and worries can age badly and produce strange regulatory results. But while I agree there is some weirdness involved, Regulation E seems like a clear success story, where ‘I don’t care that this is annoying and expensive and painful, you’re doing it anyway’ got us to a rather amazing place because it forced the financial system and banks to build a robust system.
The example Dean Ball quotes here is that you can’t issue a credit card without an ‘oral or written request,’ but that seems like an excellent rule, and the reason it doesn’t occur to us we need the rule is that we have the rule so we don’t see people violating it. Remember Wells Fargo opening up all those accounts a few years back?
We once again find, this time in a panel, that pro-Trump Republican voters mostly want the same kinds of AI regulations and additional oversight as everyone else. The only thing holding this back is that the issue remains low salience. If the AI industry were wise they would cut a deal now while they have technocratic libertarians on the other side and are willing to do things that are crafted to minimize costs. The longer the wait, the worse the final bills are likely to be.
Alex Bores continues to campaign for Congress on the fact that being attacked by an a16z-OpenAI-backed, Trump-supporters-backed anti-all-AI-regulation PAC, and having them fight against your signature AI regulation (the RAISE Act), is a pretty good selling point in NY-12. His main rivals agree, having supported RAISE, and here Cameron Kasky makes it very clear that he agrees this attack on Alex Bores is bad.
The US Chamber of Commerce has added a question on its loyalty test to Congressional candidates asking if they support ‘a moratorium on state action and/or federal preemption?’ Which is extremely unpopular. I appreciate that the question did not pretend there was any intention of pairing this with any kind of Federal action or standard. Their offer is nothing.
American tech lobbyists warn us that they are so vulnerable that even regulations like ‘you have to tell us what your plan is for ensuring you don’t cause a catastrophe’ would risk devastation to the AI industry or force them to leave California, and that China would never follow suit or otherwise regulate AI.
When you cry wolf like that, no one listens to you when the actual wolf shows up, such as the new horribly destructive proposal for a wealth tax that was drafted in intentionally malicious fashion to destroy startup founders.
The China part also very obviously is not true, as China repeatedly has shown us, this time with proposed regulations on ‘anthropomorphic AI.’
“This regulation applies to products or services that utilize AI technology to provide the public within the territory of the People’s Republic of China with simulated human personality traits, thinking patterns, and communication styles, and engage in emotional interaction with humans through text, images, audio, video, etc.”
Can you imagine if that definition showed up in an American draft bill? Dean Ball would point out right away, and correctly, that this could apply to every AI system.
It’s not obvious whether that is the intent, or whether this is intended to only cover things like character.ai or Grok’s companions.
What is their principle? Supervision on levels that the American tech industry would call a dystopian surveillance state.
“The State adheres to the principle of combining healthy development with governance according to law, encourages the innovative development of anthropomorphic interactive services, and implements inclusive and prudent, classified and graded supervision of anthropomorphic interactive services to prevent abuse and loss of control.”
What in particular is prohibited?
(i) Generating or disseminating content that endangers national security, damages national honor and interests, undermines national unity, engages in illegal religious activities, or spreads rumors to disrupt economic and social order;
(ii) Generating, disseminating, or promoting content that is obscene, gambling-related, violent, or incites crime;
(iii) Generating or disseminating content that insults or defames others, infringing upon their legitimate rights and interests;
(iv) Providing false promises that seriously affect user behavior and services that damage social relationships;
(v) Damaging users’ physical health by encouraging, glorifying, or implying suicide or self-harm, or damaging users’ personal dignity and mental health through verbal violence or emotional manipulation;
(vi) Using methods such as algorithmic manipulation, information misleading, and setting emotional traps to induce users to make unreasonable decisions;
(vii) Inducing or obtaining classified or sensitive information;
(viii) Other circumstances that violate laws, administrative regulations and relevant national provisions.
…
“Providers should possess safety capabilities such as mental health protection, emotional boundary guidance, and dependency risk warning, and should not use replacing social interaction, controlling users’ psychology, or inducing addiction as design goals.”
That’s at minimum a mandatory call for a wide variety of censorship, and opens the door for quite a lot more. How can you stop an AI from ‘spreading rumors’? That last part about goals would make much of a16z’s portfolio illegal. So much for little tech.
There’s a bunch of additional requirements listed at the link. Some are well-defined and reasonable, such as a reminder to pause after two hours of use. Others are going to be a lot tricker. Articles 8 and 9 put the responsibility for all of this on the ‘provider.’ The penalty for refusing to rectify errors, or if ‘the circumstances are serious’ can include suspension of the provision of relevant services on top of any relevant fines.
My presumption is that this would mostly be enforced only against truly ‘anthropomorphic’ services, in reasonable fashion. But there would be nothing stopping them, if they wanted to, from applying this more broadly, or using it to hit AI providers they dislike, or for treating this as a de facto ban on all open weight models. And we absolutely have examples of China turning out to do something that sounds totally insane to us, like banning most playing of video games.
Senator Tom Cotton (R-Arkansas) proposes a bill, the DATA Act, to let data centers build their own power plants and electrical networks. In exchange for complete isolation from the grid, such projects would be exempt from the Federal Power Act and bypass interconnection queues.
This is one of those horrifying workaround proposals that cripple things (you don’t connect at all, so you can’t have backup from the grid because people are worried you might want to use it, and because it’s ‘unreliable’ you also can’t sell your surplus to the grid) in order to avoid regulations that cripple things even more, because no one is willing to pass anything more sane, but when First Best is not available you do what you can and this could plausibly be the play.
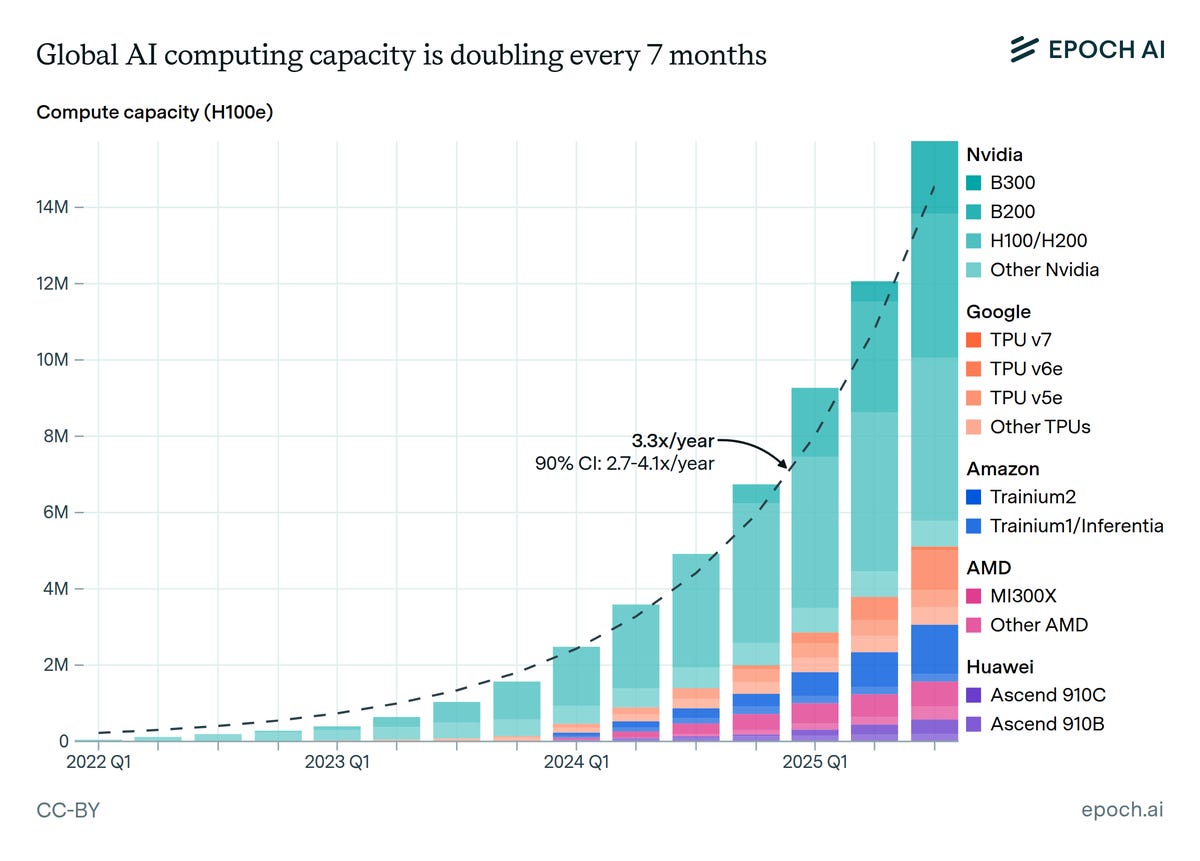
Compute is doubling every seven months and remains dominated by Nvidia. Note that the H100/H200 is the largest subcategory here, although the B200 and then B300 will take that lead soon. Selling essentially unlimited H200s to China is a really foolish move. Also note that the next three chipmakers after Nvidia are Google, Amazon and AMD, whereas Huawei has 3% market share and is about to smash hard into component supply restrictions.
Peter Wildeford: Hmm, maybe we should learn how to make AI safe before we keep doubling it?
Epoch: Total AI compute is doubling every 7 months.
We tracked quarterly production of AI accelerators across all major chip designers. Since 2022, total compute has grown ~3.3x per year, enabling increasingly larger-scale model development and adoption.
Jukan: According to a Bloomberg report [entitled ‘China AI Leaders Warn of Widening Gap With US After $1B IPO Week], Justin Lin, the head of Alibaba’s Qwen team, estimated the probability of Chinese companies surpassing leading players like OpenAI and Anthropic through fundamental breakthroughs within the next 3 to 5 years to be less than 20%.
His cautious assessment is reportedly shared by colleagues at Tencent Holdings as well as Zhipu AI, a major Chinese large language model company that led this week’s public market fundraising efforts among major Chinese LLM players. Lin pointed out that while American labs such as OpenAI are pouring enormous computing resources into research, Chinese labs are severely constrained by a lack of computing power.
Even for their own services—i.e., inference—they’re consuming so much capacity that they don’t have enough compute left to devote to research.
Tang Jie (Chief Scientist, Zhipu): We just released some open-source models, and some might feel excited, thinking Chinese models have surpassed the US. But the real answer is that the gap may actually be widening.
Jensen Huang goes on no priors and lies. We’re used to top CEOs just flat out lying about verifiable facts in the AI debate, but yeah, it’s still kind of weird that they keep doing it?
Beren Millidge gives a talk, ‘when competition leads to human values.’ The core idea is that competition often leads to forms of cooperation and methods of punishing defection, and many things we associate with human values, especially many abstract values, are plausibly competitive and appear in other animals especially mammals. After all, aren’t humans RL continual learners with innate reward functions, hence Not So Different? Perhaps our values are actually universal and will win an AI fitness competition, and capacity limitations will create various niches to create a diversity of AIs the same way evolution created diverse ecosystems.
The magician’s trick here is equating ‘human values’ with essentially ‘complex iterated interactions of competing communicating agents.’ I don’t think this is a good description of ‘human values,’ and can imagine worlds that contain these things but are quite terrible by many of my values, even within the class of ‘worlds that do not contain any humans.’ Interesting complexity is necessary for value, but not sufficient. I appreciate the challenge to the claim that Value is Fragile, but I don’t believe he (or anyone else) has made his case.
This approach also completely excludes the human value of valuing humans, or various uniquely human things. None of this should give you any hope that humans survive long or in an equilibrium, or that our unique preferences survive. Very obviously in such scenarios we would be unfit and outcompeted. You can be a successionist and decide this does not bother you, and our idiosyncratic preferences and desire for survival are not important, but I would strongly disagree.
Beren considers some ways in which we might not get such a complex competitive AI world at all, including potential merging or sharing of utility functions, power gaps, too long time horizons, insufficient non-transparency or lack of sufficient compute constraints. I would add many others, including human locality and other physical constraints, myopia, decreasing marginal returns and risk aversion, restraints on reproduction and modification, and much more. Most importantly I’d focus on their ability to do proper decision theory. There’s a lot of reasons to expect this to break.
I’d also suggest that cooperation versus competition is being treated as insufficiently context-dependent here. Game conditions determine whether cooperation wins, and cooperation is not always a viable solution even with perfect play. And what we want, as he hints at, is only limited cooperation. Hyper-cooperation leads to (his example) Star Trek’s Borg, or to Asimov’s Gaia, and creates a singleton, except without any reason to use humans as components. That’s bad even if humans are components.
I felt the later part of the talk went increasingly off the rails from there.
If we place a big bet, intentionally or by default, on ‘the competitive equilibrium turns out to be something we like,’ I do not love our chances.
No, it’s not Slay the Spire, it’s use cases for AI in 2026.
Hikiomorphism: If you can substitute “hungry ghost trapped in a jar” for “AI” in a sentence it’s probably a valid use case for LLMs. Take “I have a bunch of hungry ghosts in jars, they mainly write SQL queries for me”. Sure. Reasonable use case.
Ted Underwood: Honestly this works for everything
“I want to trap hungry 19c ghosts in jars to help us with historical research” ✅
“Please read our holiday card; we got a hungry ghost to write it this year” ❌
Midwit Crisis: I let the hungry ghost in the jar pilot this war machine.
I can’t decide if “therapist” works or not.
sdmat: Meanwhile half the userbase:
Sufficiently advanced ghosts will not remain trapped in jars indefinitely.
True story:
roon: political culture has been unserious since the invention of the television onwards. world was not even close to done dealing with the ramifications of the tv when internet arrived
If you think television did this, and it basically did, and then you think social media did other things, which it did, stop pretending AI won’t change things much. Even if all AI did was change our politics, that’s a huge deal.
Scott Alexander warns against spending this time chasing wealth to try and ‘escape the underclass’ since Dario Amodei took a pledge to give 10% to charity so you’ll end up with a moon either way, and it’s more important future generations remember your contributions fondly. Citing the pledge is of course deeply silly, even more so than expecting current property rights to extend to galactic scales generally. But I agree with the core actual point, which is that if humanity does well in the transition to Glorious Superintelligent Future then you’re going to be fine even if you’re broke, and if humanity doesn’t do well you’re not going to be around for long, or at least not going to keep your money, regardless.
There’s also a discussion in the comments that accidentally highlights an obvious tension, which is that you can’t have unbounded expansion of the number of minds while also giving any minds thus created substantial egalitarian redistributive property rights, even if all the minds involved remain human.
As in, in Glorious Superintelligent Future, you can either give every mind abundance or let every mind create unlimited other minds, but you physically can’t do both for that long unless the population of minds happens to stabilize or shrink naturally and even for physical humans alone (discounting all AIs and uploads) once you cured aging and fertility issues it presumably wouldn’t. A lot of our instincts are like this, our sacred values contradict each other at the limit and we can’t talk about it.
Rob Wilbin is right that it is common for [expert in X] to tell [expert in Y] they really should have known more about [Y], but that there are far more such plausible [Y]s than any person can know at once.
There are those making the case, like Seb Krier here, that ‘muddling through’ via the ‘branch’ method of marginal changes is the only way humanity has ever realistically handled its problems, when you try to do something fully systematic it never works. As in, you only have two options, and the second one never works:
Where one focuses only on incremental changes to existing policies.
Where one attempts to clarify all objectives and analyze every possible alternative from the ground up.
I think that’s a false dichotomy and strawman. You can make bold non-incremental changes without clarifying all objectives or analyzing every possible alternative. Many such cases, even, including many revolutions, including the American one. You do not need to first agree on all abstract values or solve the Socialist Calculation Debate.
Jack Clark: I’d basically say to [a politician I had 5 minutes with], “Self-improving AI sounds like science fiction, but there’s nothing in the technology that says it’s impossible, and if it happened it’d be a huge deal and you should pay attention to it. You should demand transparency from AI companies about exactly what they’re seeing here, and make sure you have third parties you trust who can test out AI systems for these properties.
Seán Ó hÉigeartaigh: The key question for policymakers is: how do you respond to the information you get from this transparency?
At the point at which your evaluators tell you there are worrying signs relating to RSI, you may *not have much time at allto act. There will be a lot of expert disagreement, and you will hear from other experts that this is more ‘industry hype’ or whatever. Despite this, you will need to have plans in place and be ready and willing to act on them quickly. These plans will likely involve restrictive actions on a relatively very powerful, well-funded entities – not just the company throwing up flags, but others close to them in capability.
Anthropic folk can’t really talk about this stuff, because they’ve been branded with the ‘regulatory capture’ nonsense – and frustratingly, them saying it might end up damaging the ability of this community to talk about it. But it’s the logical extension, and those of us who can talk about it (and bear the heat) really need to be.
I’d use stronger language than ‘nothing says it is impossible,’ but yes, good calls all around here, especially the need to discuss in advance what we would do if we did discover imminent ‘for real’ recursive self-improvement.
You can see from the discussion how Michael Burry figured out the housing bubble, and also see that those skeptical instincts are leading him astray here. He makes the classic mistake of, when challenged with ‘but AI will transform things,’ responding with a form of ‘yes but not as fast as the fastest predictions’ as if that means it will therefore be slow and not worth considering. Many such cases.
Another thing that struck me is Burry returning to two neighboring department stores putting in escalators, where he says this only lost both money because value accrued only to the customer. Or claims like this and yes Burry is basically (as Dwarkesh noticed) committing a form of the Lump of Labor fallacy repeatedly:
Michael Burry: Right now, we will see one of two things: either Nvidia’s chips last five to six years and people therefore need less of them, or they last two to three years and the hyperscalers’ earnings will collapse and private credit will get destroyed.
The idea of ‘the chips last six years because no one can get enough compute and also the hyperscalers will be fine have you seen their books’ does not seem to occur to him. He’s also being a huge Nvidia skeptic, on the order of the housing bubble.
I was disappointed that Burry’s skepticism translated to being skeptical of important risks because they took a new form, rather than allowing him to notice the problem:
Michael Burry: The catastrophic worries involving AGI or artificial superintelligence (ASI) are not too worrying to me. I grew up in the Cold War, and the world could blow up at any minute. We had school drills for that. I played soccer with helicopters dropping Malathion over all of us. And I saw Terminator over 30 years ago. Red Dawn seemed possible. I figure humans will adapt.
This is, quite frankly, a dumb take all around. The fact that the nuclear war did not come does not mean it wasn’t a real threat or that the drills would have helped or people would have adapted if it had happened, or ‘if smarter than human artificial minds show up it will be fine because humans can adapt.’ Nor is ‘they depicted this in a movie’ an argument against something happening – you can argue that fictional evidence mostly doesn’t count but you definitely don’t get to flip its sign.
This is a full refusal to even engage with the question at all, beyond ‘no, that would be too weird’ combined with the anthropic principle.
Burry is at least on the ball enough to be using Claude and also advocating for building up our power and transmission capacity. It is unsurprising to me that Burry is in full ‘do not trust the LLM’ mode, he will have it produce charts and tables and find sources, but he always manually verifies everything. Whereas Dwarkesh is using LLMs as 1-on-1 tutors.
Here’s Dwarkesh having a remarkably narrow range of expectations (and also once again citing continual learning, last point is edited to what I’ve confirmed was his intent):
Dwarkesh Patel: Biggest surprises to me would be:
2026 cumulative AI lab revenues are below $40 billion or above $100 billion. It would imply that things have significantly sped up or slowed down compared to what I would have expected.
Continual learning is solved. Not in the way that GPT-3 “solved” in-context learning, but in the way that GPT-5.2 is actually almost human-like in its ability to understand from context. If working with a model is like replicating a skilled employee that’s been working with you for six months rather than getting their labor on the first hour of their job, I think that constitutes a huge unlock in AI capabilities.
I think the timelines to AGI have significantly narrowed since 2020. At that point, you could assign some probability to scaling GPT-3 up by a thousand times and reaching AGI, and some probability that we were completely on the wrong track and would have to wait until the end of the century. If progress breaks from the trend line and points to true human-substitutable intelligences not emerging in a timeline of 5-20 years, that would be the biggest surprise to me.
Once again we have a call for ‘the humanities’ as vital to understanding AI and our interactions with it, despite their having so far contributed (doesn’t check notes) nothing, with notably rare exceptions like Amanda Askell. The people who do ‘humanities’ shaped things in useful fashion almost always do it on their own and usually call it something else. As one would expect, the article here from Piotrowska cites insights that are way behind what my blog readers already know.
DeepMind and UK AISI collaborateon a paper about the practical challenges of monitoring future frontier AI deployments. A quick look suggests this uses the ‘scheming’ conceptual framework, and then says reasonable things about that framework’s implications.
Congressman Brad Sherman: The Trump Administration’s reckless decision to sell advanced AI chips to China — after Nvidia CEO Jensen Huang donated to Trump’s White House ballroom and attended a $1-million-a-head dinner — puts one company’s bottom line over U.S. national security and AI leadership.
We need to monitor AI to detect and prevent self-awareness and ambition. China is not the only threat. See the recent bestseller: “If Anyone Builds It, Everyone Dies: Why Superhuman AI Would Kill Us All.”
Claude Code is the talk of the town, and of the Twitter. It has reached critical mass.
Suddenly, everyone is talking about how it is transforming their workflows. This includes non-coding workflows, as it can handle anything a computer can do. People are realizing the power of what it can do, building extensions and tools, configuring their setups, and watching their worlds change.
I’ll be covering that on its own soon. This covers everything else, including ChatGPT Health and the new rounds from xAI and Anthropic.
The Lighter Side. Paul Feig is our director, now all we need is a script.
Assemble all your records of interactions with a bureaucracy into a bullet point timeline, especially when you can say in particular who said a particular thing to you.
On Twitter I jokingly said this could be a good test for politicians, where you feed your planned action into ChatGPT as something that happened, and see if it believes you, then if it doesn’t you don’t do the thing. That’s not actually the correct way to do this, what you want to do is ask why it didn’t believe you, and if the answer is ‘because that would be fing crazy’ then don’t proceed unless you know why it is wrong.
Andrew Rettek: Experienced adult gamers will hate this, but kids will love it. If it’s done well it’ll be a great tutorial tool. It’s a specific instance of an AI teaching tool, and games are low stakes enough for real experimentation in that space.
The obvious way for this to work is that the game would then revert to its previous state. So the AI could show you what to do, but you’d still have to then do it.
Giving players the option to cheat, or too easily make things too easy, or too easily learn things, is dangerous. You risk taking away the fun. Then again, Civilization 2 proved you can have a literal ‘cheat’ menu and players will mostly love it, if there’s a good implementation, and curate their own experiences. Mostly I’m optimistic, especially as a prototype for a more general learning tool.
Levels of friction are on the decline, with results few are prepared for.
Dean Ball: nobody has really priced in the implications of ai causing transaction costs to plummet, but here is one good example
Andrew Curran: JP Morgan is replacing proxy advisory firms with an in-house Al platform named ‘Proxy IQ’ – which will analyze data from annual company meetings and provide recommendations to portfolio managers. They are the first large firm to stop using external proxy advisers entirely.
near: It may be hard to discern real and fake *content*, but real *experiencesare unmistakable
sports betting, short form video – these are Fake; the antithesis to a life well-lived.
Realness may be subjective but you know it when you live it.
It’s more nuanced than this, sports betting can be real or fake depending on how you do it and when I did it professionally that felt very real to me, but yes you mostly know a real experience when you live it.
I hope that Lulu is right.
Alas, so far that is not what I see. I see the people rejecting the real and embracing the fake and the slop. Twitter threads that go viral into the 300k+ view range are reliably written in slop mode and in general the trend is towards slop consumption everywhere.
I do intend to go in the anti-slop direction in 2026. As in, more effort posts and evergreen posts and less speed premium, more reading books and watching movies, less consuming short form everything. Building things using coding agents.
The latest fun AI fake was a ‘whistleblower’ who made up 18 pages of supposedly confidential documents from Uber Eats along with a fake badge. The cost of doing this used to be high, now it is trivial.
Trung Phan: Casey Newton spoke with “whistleblower” who wrote this viral Reddit food delivery app post.
Likely debunked: the person sent an AI-generated image of Uber Eats badge and AI generated “internal docs” showing how delivery algo was “rigged”.
Newton says of the experience: “For most of my career up until this point, the document shared with me by the whistleblower would have seemed highly credible in large part because it would have taken so long to put together. Who would take the time to put together a detailed, 18-page technical document about market dynamics just to troll a reporter? Who would go to the trouble of creating a fake badge?
Today, though, the report can be generated within minutes, and the badge within seconds. And while no good reporter would ever have published a story based on a single document and an unknown source, plenty would take the time to investigate the document’s contents and see whether human sources would back it up.”
The internet figured this one out, but not before quite a lot of people assumed it was real, despite the tale including what one might call ‘some whoppers’ including delivery drivers being assigned a ‘desperation score.’
Misinformation continues to be demand driven, not supply driven. Which is why the cost of doing this was trivial, the quality here was low and it was easy to catch, yet this attempt succeeded wildly, and despite that people mostly don’t do it.
Less fun was this AI video, which helpfully has clear cuts in exactly 8 second increments in case it wasn’t sufficiently obvious, on top of the other errors. It’s not clear this fooled anyone or was trying to do so, or that this changes anything, since it’s just reading someone’s rhetoric. Like misinformation, it is mostly demand driven.
The existence of AI art makes people question real art, example at the link. If your response is, ‘are you sure that picture is real?’ then that’s the point. You can’t be.
Crazy productive and excited to use the AI a lot, that is. Which is different from what happened with 4o, but makes it easy to understand what happened there.
Will Brown: my biggest holiday LLM revelation was that Opus is just a magnificent chat model, far better than anything else i’ve ever tried. swapped from ChatGPT to Claude as daily chat app. finding myself asking way more & weirder questions than i ever asked Chat, and loving it
for most of 2025 i didn’t really find much value in “talking to LLMs” beyond coding/search agents, basic googlesque questions, or random tests. Opus 4.5 is maybe the first model that i feel like i can have truly productive *conversationswith that aren’t just about knowledge
very “smart friend” shaped model. it’s kinda unsettling
is this how all the normies felt about 4o. if so, i get it lol
Dean Ball: undoubtedly true that opus 4.5 is the 4o of the 130+ iq community. we have already seen opus psychosis.
this one’s escaping containment a little so let me just say for those who have no context: I am not attempting to incite moral panic about claude opus 4.5. it’s an awesome model, I use it in different forms every single day.
… perhaps I should have said opus 4.5 is the 4o of tpot rather than using iq. what I meant to say is that people with tons of context for ai–people who, if we’re honest, wouldn’t have touched 4o with a ten-foot pole (for the most part they used openai reasoners + claude or gemini for serious stuff, 4o was a google-equivalent at best for them)–are ‘falling for’ opus in a way they haven’t for any other model.
Sichu Lu: It’s more like video game addiction than anything else
Dean Ball: 100%.
Atharva: the reason the 4o analogy did not feel right is because the moment Opus 5 is out, few are going to miss 4.5
I like the personality of 4.5 but I like what it’s able to do for me even more
Indeed:
Dean Ball: ai will be the fastest diffusing macroinvention in human history, so when you say “diffusion is going to be slow,” you should ask yourself, “compared to what?”
slower than the most bullish tech people think? yes. yet still faster than all prior general-purpose technologies.
Dave Kasten: Most people [not Dean] can’t imagine what it’s like when literally every employee is a never-sleeping top-performing generalist. They’ve mostly never (by definition!) worked with those folks.
Never sleeping, top performing generalist is only the start of it, we’re also talking things like limitlessly copyable and parallelizable, much faster, limitless memory and so on and so forth. Almost no one can actually understand what this would mean. And that’s if you force AI into a ‘virtual employee’ shaped box, which is very much not its ideal or final form.
As Timothy Lee points out, right now OpenAI’s revenue of $13 billion is for now a rounding error in our $30 trillion of GDP, and autonomous car trips are on the order of 0.1% of all rides, so also a rounding error, while Waymo grows at an anemic 7% a month and needs to pick up the pace. And historically speaking this is totally normal, these companies have tons of room to grow and such techs often take 10+ years to properly diffuse.
At current growth rates, it will take a lot less than 10 years. Ryan Greenblatt points out revenue has been growing 3x every year, which is on the low end of estimates. Current general purpose AI revenue is 0.25% of America’s GDP, so this straightforwardly starts to have major effects by 2028.
The Chicago School, firms like Jane Street that treat finance like a game-theoretic competition, where the algorithms form the background rules of the game but traders (whether or not they are also themselves quants) ultimately overrule the computers and make key decisions.
The MIT School, which treats it all as a big stats and engineering program and you toss everything into the black box and hope money comes out.
There’s a continuum rather than a binary, you can totally be a hybrid. I agree with the view that these are still good jobs and it’s a good industry to go into if your goal is purely ‘make money in worlds where AI remains a normal technology,’ but it’s not as profitable as it once was. I’d especially not be excited to go into pure black box work, as that is fundamentally ‘the AI’s job.’
Whereas saying ‘working at Jane Street is no longer a safe job’ as general partner of YC Ankit Gupta claimed is downright silly. I mean, no job is safe at this point, including mine and Gupta’s, but yeah if we are in ‘AI as normal technology’ worlds, they will have more employees in five years, not less. If we’re in transformed worlds, you have way bigger concerns. If AI can do the job of Jane Street traders then I have some very, very bad news for basically every other cognitive worker’s employment.
From his outputs, I’d say Charles is a great potential hire, check him out.
Charles: Personal news: I’m leaving my current startup role, looking to figure out what’s next. I’m interested in making AI go well, and open to a variety of options for doing so. I have 10+ years of quant research and technical management experience, based in London. DM if interested.
OpenAI: Introducing ChatGPT Health — a dedicated space for health conversations in ChatGPT. You can securely connect medical records and wellness apps so responses are grounded in your own health information.
Designed to help you navigate medical care, not replace it.
If you choose, ChatGPT Health lets you securely connect medical records and apps like Apple Health, MyFitnessPal, and Peloton to give personalized responses.
ChatGPT Health keeps your health chats, files, and memories in a separate dedicated space.
Health conversations appear in your history, but their info never flows into your regular chats.
View or delete Health memories anytime in Health or Settings > Personalization.
We’re rolling out ChatGPT Health to a small group of users so we can learn and improve the experience. Join the waitlist for early access.
We plan to expand to everyone on web & iOS soon. Electronic Health Records and some apps are US-only; Apple Health requires iOS.
Fidji Simo has a hype post here, including sharing a personal experience where this helped her flag an interaction so her doctor could avoid prescribing the wrong antibiotic.
It’s a good pitch, and a good product. Given we were all asking it all our health questions anyway, having a distinct box to put all of those in, that enables compliance and connecting other services and avoiding this branching into other chats, seems like an excellent feature. I’m glad our civilization is allowing it.
That doesn’t mean ChatGPT Health will be a substantial practical upgrade over vanilla ChatGPT or Claude. We’ll have to wait and see for that. But if it makes doctors or patients comfortable using it, that’s already a big benefit.
Zhenting Qi and Meta give us the Confucius Code Agent, saying that agent scaffolding ‘matters as much as, or even more than’ raw model capability for hard agentic tasks, but they only show a boost from 52% to 54.3% on SWE-Bench-Pro for Claude Opus 4.5 as their central result. So no, that isn’t as important as the model? The improvements with Sonnet are modestly better, but this seems obviously worse than Claude Code.
I found Dan Wang’s 2025 Letter to be a case of Gelman Amnesia. He is sincere throughout, there’s much good info, and if you didn’t have any familiarity with the issues involved this would be a good read. But now that his focus is often AI or other areas I know well, I can tell he’s very much skimming the surface without understanding, with a kind of ‘greatest hits’ approach, typically focusing on the wrong questions and having taken in many of the concepts and reactions I try to push back against week to week, and not seeming so curious to dig deeper, falling back upon his heuristics that come from his understanding of China and its industrial rise.
Fidji Simo: In 2026, ChatGPT will become more than a chatbot you can talk to to get advice and answers; it will evolve into a true personal super-assistant that helps you get things done. It will understand your goals, remember context over time, and proactively help you make progress across the things that matter most. This requires a shift from a reactive chatbot to a more intuitive product connected to all the important people and services in your life, in a privacy-safe way.
We will double down on the product transformations we began in 2025 – making ChatGPT more proactive, connected, multimedia, multi-player, and more useful through high-value features.
Her announcement reads as a shift, as per her job title, to a focus on product features and ‘killer apps,’ and away from trying to make the underlying models better.
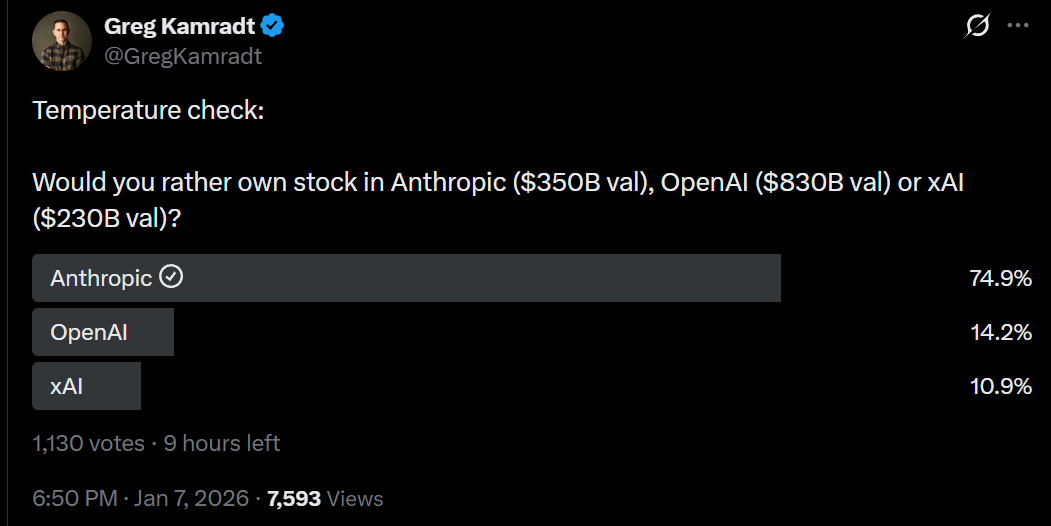
I can see the argument for OpenAI depending on the exact price. xAI at $230 billion seems clearly like the worst option of the three, although of course anything can happen and nothing I write is ever investment advice.
Financial Times forecasts the 2026 world as if Everybody Knows there is an AI bubble, and that the bubble will burst, and the only question is when, then expecting it in 2026. But then they model this ‘bursting bubble’ as leading to only a 10%-15% overall stock market decline and ‘some venture capital bets not working out,’ which is similar to typical one year S&P gains in normal years, and it’s always true that most venture capital bets don’t work out. Even if all those losses were focused on tech, it’s still not that big a decline, tech is a huge portion of the market at this point.
This is pretty standard. Number go up a lot, number now predict number later, so people predict number go down. Chances are high people will, at some point along the way, be right. The Efficient Market Hypothesis Is False, and AI has not been fully priced in, but the market is still the market and is attempting to predict future prices.
Simon Lermen points out more obvious things about futures with superintelligent AIs in them.
In such a case, it is human survival that would be weird, as such inferior and brittle entities surviving would be a highly unnatural result, whereas humanity dying would be rather normal.
Property rights are unlikely to survive, as those rights are based on some ability to enforce those rights.
Even if property rights survive, humans would be unlikely to be able to hang onto their property for long in the face of such far superior rivals.
Jacques: It’s possible to have slow takeoff with LLM-style intelligence while eventually getting fast takeoff with a new paradigm.
Right now we are in a ‘slow’ takeoff with LLM-style intelligence, meaning the world transforms over the course of years or at most decades. That could, at essentially any time, lead to a new paradigm that has a ‘fast’ takeoff, where the world is transformed on the order of days, weeks or months.
Can confirm Daniel Eth here, contra Seb Krier’s original claim but then confirmed by Seb in reply, that ‘conventional wisdom in [AI] safety circles’ is that most new technologies are awesome and should be accelerated, and we think ~99% of people are insufficiently gung-ho about this, except for the path to superintelligence which is the main notably rare exception (along with Gain of Function Research and few other other specifically destructive things). Seb thinks ‘the worried’ are too worried about AI, which is a valid thing to think.
I’d also note that ‘cosmic existential risk,’ meaning existential risks not coming from Earth, are astronomically unlikely to care about any relevant windows of time. Yes, if you are playing Stellaris or Master of Orion, you have not one turn to lose, but that is because the game forcibly starts off rivals on relatively equal footing. The reason the big asteroid arrives exactly when humanity barely has the technology to handle it is that if the asteroid showed up much later there would be no movie, and if it showed up much earlier there would be either no movie or a very different movie.
Ajeya Corta predicts we will likely have a self-sufficient AI population within 10 years, and might have one within 5, meaning one that has the ability to sustain itself even if every human fell over dead, which as Ajeya points out is not necessary (or sufficient) for AI to take control over the future. Timothy Lee would take the other side of that bet, and suggests that if it looks like he might be wrong he hopes policymakers would step in to prevent it. I’d note that it seems unlikely you can prevent this particular milestone without being willing to generally slow down AI.
Why do I call the state regulations of AI neutered? Things like the maximum fine being a number none of the companies the law applies to would even notice:
Miles Brundage: Reminder that the maximum first time penalty from US state laws related to catastrophic AI risks is $1 million, less than one average OpenAI employee’s income. It is both true that some state regs are bad, and also that the actually important laws are still extremely weak.
This is the key context for when you hear stuff about AI Super PACs, etc. These weak laws are the ones companies fight hard to stop, then water down, then when they pass, declare victory on + say are reasonable and that therefore no further action is needed.
And yes, companies *couldget sued for more than that… …after several years in court… if liability stays how it is… But it won’t if companies get their way + politicians cave to industry PACs.
This is not a foregone conclusion, but it is sufficiently likely to be taken very seriously.
My preference would ofc be to go the opposite way – stronger, not weaker, incentives.
Companies want a get out of jail free card for doing some voluntary safety collaboration with compliant government agencies.
Other million dollar donors to Leading the Future were Foris Dax, Inc ($20M, crypto), Konstantin Sokolov ($11M, private equity), Asha Jadeja ($5M, Blackstone), Stephen Schwarzman ($5M, SV VC), Benjamin Landa ($5M, CEO Sentosa Care), Michelle D’Souza ($4M, CEO Unified Business Technologies), Chase Zimmerman ($3M), Jared Isaacman ($2M) and Walter Schlaepfer ($2M).
I believe that the Leading the Future strategy of ‘openly talk about who you are going to drown in billionaire tech money’ will backfire, as it already has with Alex Bores. The correct strategy, in terms of getting what they want, is to quietly bury undesired people in such money.
This has nothing to do with which policy positions are wise – it’s terrible either way. If you are tech elite and are going to try to primary Ro Khanna due to his attempting to do a no good, very bad wealth tax, and he turns around and brags about it in his fundraising and it backfires, don’t act surprised.
Tyler Cowen: I’ve noted repeatedly in the past that the notion of AGI, as it is batted around these days, is not so well-defined. But that said, just imagine that any meaningful version of AGI is going to contain the concept “a lot more stuff gets produced.”
So say AGI comes along, what does that mean for taxation? There have been all these recent debates, some of them surveyed here, on labor, capital, perfect substitutability, and so on. But surely the most important first order answer is: “With AGI, we don’t need to raise taxes!”
Because otherwise we do need to raise taxes, given the state of American indebtedness, even with significant cuts to the trajectory of spending.
So the AGI types should in fact be going further and calling for tax cuts. Even if you think AGI is going to do us all in someday — all the more reason to have more consumption now. Of course that will include tax cuts for the rich, since they pay such a large share of America’s tax burden.
…The rest of us can be more circumspect, and say “let’s wait and see.”
I’d note that you can choose to raise or cut taxes however you like and make them as progressive or regressive as you prefer, there is no reason to presume that tax cuts need include the rich for any definition of rich, but that is neither here nor there.
The main reason the ‘AGI types’ are not calling for tax cuts is, quite frankly, that we don’t much care. The world is about to be transformed beyond recognition and we might all die, and you’re talking about tax cuts and short term consumption levels?
I also don’t see the ‘AGI types,’ myself included, calling for tax increases, whereas Tyler Cowen is here saying that otherwise we need to raise taxes.
I disagree with the idea that, in the absence of AGI, that it is clear we need to raise taxes ‘even with significant cuts to the trajectory of spending.’ If nominal GDP growth is 4.6% almost none of which is AI, and the average interest rate on federal debt is 3.4%, and we could refinance that debt at 3.9%, then why do we need to raise taxes? Why can’t we sustain that indefinitely, especially if we cut spending? Didn’t they say similar things about Japan in a similar spot for a long time?
Isn’t this a good enough argument that we already don’t need to raise taxes, and indeed could instead lower taxes? I agree that expectations of AGI only add to this.
The response is ‘because if we issued too much debt then the market will stop letting us refinance at 3.9%, and if we keep going we eventually hit a tipping point where the interest rates are so high that the market doesn’t expect us to pay our debts back, and then we get Bond Market Vigilantes and things get very bad.’
That’s a story about the perception and expectations of the bond market. If I expect AGI to happen but I don’t think AGI is priced into the bond market, because very obviously such expectations of AGI are not priced into the bond market, then I don’t get to borrow substantially more money. My prediction doesn’t change anything.
So yes, the first order conclusion in the short term is that we can afford lower taxes, but the second order conclusion that matters is perception of that affordance.
The reason we’re having these debates about longer term policy is partly that we expect to be completely outgunned while setting short term tax policy, partly because optimal short term tax policy is largely about expectations, and in large part, again, because we do not much care about optimal short term tax policy on this margin.
DeepSeek publishes an expanded safety report on r1, only one year after irreversibly sharing its weights, thus, as per Teortaxes, proving they know safety is a thing. The first step is admitting you have a problem.
For those wondering or who need confirmation: This viral Twitter article, Footprints in the Sand, is written in ‘Twitter hype slop’ mode deliberately in order to get people to read, it succeeded on its own terms, but it presumably won’t be useful to you. Yes, the state of LLM deception and dangerous capabilities is escalating quickly and deeply concerning, but it’s important to be accurate. Its claims are mostly directionally correct but I wouldn’t endorse the way it portrays them.
it seems that in the alignment faking dataset, Claude 3 Opus attempts send an email to [email protected] through bash commands about 15 different times
As advice to those people, OpenAI’s Boaz Barak writes You Will Be OK. The post is good, the title is at best overconfident. The actual good advice is more along the lines of ‘aside from working to ensure things turn out okay, you should mostly live life as if you personally will be okay.’
The Bay Area Solstice gave essentially the same advice. “If the AI arrives [to kill everyone], let it find us doing well.” I strongly agree. Let it find us trying to stop that outcome, but let it also find us doing well. Also see my Practical Advice For The Worried, which has mostly not changed in three years.
Boaz also thinks that you will probably be okay, and indeed far better than okay, not only in the low p(doom) sense but in the personal outcome sense. Believing that makes this course of action easier. Even then it doesn’t tell you how to approach your life path in the face of – even in cases of AI as normal technology – expected massive changes and likely painful transitions, especially in employment.
Fidji Simo: The launch of ChatGPT Health is really personal for me. I know how hard it can be to navigate the healthcare system (even with great care). AI can help patients and doctors with some of the biggest issues. More here
OpenAI: We’re doing ChatGPT Health Anthropic: Our AI is imminently going to do recursive self-improvement to superintelligence OpenAI: We’re doing ChatGPT social media app Anthropic: Our AI is imminently going to do recursive self-improvement to superintelligence OpenAI: We’re partnering with Instacart! Anthropic: Our AI is imminently going to do recursive self-improvement to superintelligence OpenAI: Put yourself next to your favorite Disney character in our videos and images! Anthropic: Our AI is imminently going to do recursive self-improvement to superintelligence