The most important gain is reduced hallucinations.
The other big gain is an improvement in writing.
GPT-5-Thinking should win substantially more use cases than o3 did.
GPT-5, aka GPT-5-Fast, is not much better than GPT-4o aside from the personality and sycophancy changes, and the sycophancy still isn’t great.
GPT-5-Auto seems like a poor product unless you are on the free tier.
Thus, you still have to manually pick the right model every time.
Opus 4.1 and Sonnet 4 still have a role to play in your chat needs.
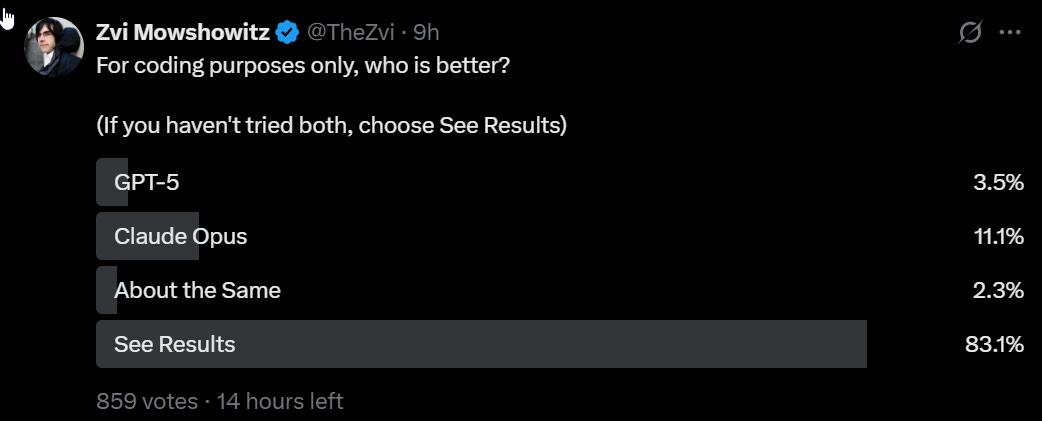
GPT-5 and Opus 4.1 are both plausible choices for coding.
On the bigger picture:
GPT-5 is a pretty big advance over GPT-4, but it happened in stages.
GPT-5 is not a large increase in base capabilities and intelligence.
GPT-5 is about speed, efficiency, UI, usefulness and reduced hallucinations.
We are disappointed in this release because of high expectations and hype.
That was largely due to it being called GPT-5 and what that implied.
We were also confused because 4+ models were released at once.
OpenAI botched the rollout in multiple ways, update accordingly.
OpenAI uses more hype for unimpressive things, update accordingly.
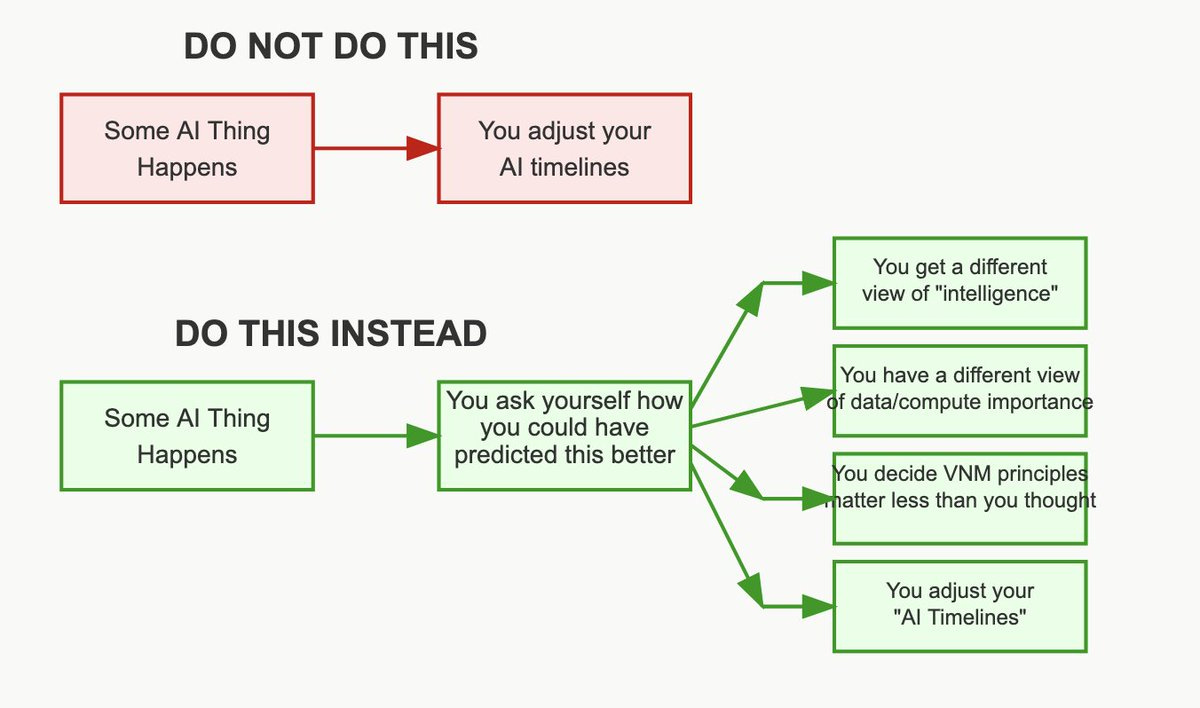
Remember that we are right on track on the METR graph.
Timelines for AGI or superintelligence should adjust somewhat, especially in cutting a bunch of probability out of things happening quickly, but many people are overreacting on this front quite a bit, usually in a ‘this confirms all of my priors’ kind of way, often with supreme unearned overconfidence.
This is not OpenAI’s most intelligent model. Keep that in mind.
This is a distillation of consensus thinking on the new practical equilibrium:
William Kranz: my unfortunate feedback is non-thinking Opus is smarter than non-thinking GPT-5. there are nuances i can’t get GPT-5 to grasp even when i lampshade them, it just steamrolls over them with the pattern matching idiot ball. meanwhile Opus gets them in one shot.
Roon: that seems right, but i’m guessing 5-thinking is better than opus-thinking.
This seems mostly right. I prefer to use Opus if Opus is enough thinking for the job, but OpenAI currently scales more time and compute better than Anthropic does.
So, what do we do going forward to get the most out of AI on a given question?
Here’s how I think about it: There are four ‘speed tiers’:
Quick and easy. You use this for trivial easy questions and ‘just chatting.’
Matter of taste, GPT-5 is good here, Sonnet 4 is good here, Gemini Flash, etc.
Most of the time you are wrong to be here and should be at #2 or #3 instead.
Brief thought. Not instant, not minutes.
Use primarily Claude Opus 4.1.
We just got GPT-5-Thinking-Mini in ChatGPT, maybe it’s good for this?
Moderate thought. You can wait a few minutes.
Use primarily GPT-5-Thinking and back it up with Claude Opus 4.1.
If you want a third opinion, use AI Studio for Gemini Pro 2.5.
Extensive thought. You can wait for a while.
Use GPT-5-Pro and back it up with Opus in Research mode.
Consider also firing up Gemini Deep Research or Deep Thinking, etc, and anything else you have handy cause why not. Compare and contrast.
You need to actually go do something else and then come back later.
What about coding?
Here I don’t know because I’ve been too busy to code anything since before Opus 4, nor have I tried out Claude Code.
Also the situation continues to change rapidly. OpenAI claims that they’ve doubled speed for GPT-5 inside cursor as of last night via superior caching and latency, whereas many of the complaints about GPT-5 in Cursor was previously that it was too slow. You’ll need to try out various options and see what works better for you (and you might also think about who you want to support, if it is close).
We can then contrast that with the Official Hype.
That’s not automatically a knock. Hypers gotta hype. It’s worth seeing choice of hype.
Here was Sam Altman live-tweeting the livestream, a much better alternative way to actually watch the livestream, which I converted to bullet points, and reordered a bit for logical coherence but otherwise preserving to give a sense of his vibe. Hype!
GPT-5 in an integrated model, meaning no more model switcher and it decides when it needs to think harder or not.
It is very smart, intuitive, and fast.
It is available to everyone, including the free tier, w/reasoning!
Evals aren’t the most important thing–the most important thing is how useful we think the model will be–but it does well on evals.
For example, a new high on SWE-bench and many other metrics. It is by far our most reliable and factual model ever.
Rolling out today for free, plus, pro, and team users. next week to enterprise and edu. making this available in the free tier is a big deal to us; PhD-level intelligence for everyone!
Plus users get much higher rate limits.
Pro users get GPT-5 pro; really smart!
demo time: GPT-5 can make something interactive to explain complex concepts like the bernoulli effect to you, churning out hundreds of lines of code in a couple of minutes.
Next up: upgraded voice mode! Much more natural and smarter.
Free users now can chat for hours, and plus users nearly unlimited.
Works well with study mode, and lots of other things.
Personalization!
A little fun one: you can now customize the color of your chats.
Research preview of personalities: choose different ones that match the style you like.
Memory getting better.
Connect other services like gmail and google calendar for better responses.
Introducing safe completions. A new way to maximize utility while still respecting safety boundaries. Should be much less annoying than previous refusals.
Seb talking about synthetic data as a new way to make better models! Excited for much more to come.
GPT-5 much better at health queries, which is one of the biggest categories of ChatGPT usage. hopeful that it will provide real service to people.
These models are really good at coding!
3 new models in the API: GPT-5, GPT-5 Mini, GPT-5 Nano.
New ‘minimal’ reasoning mode, custom tools, changes to structured outputs, tool call preambles, verbosity parameter, and more coming.
Not just good at software, good at agentic tasks across the board. Also great at long context performance.
GPT-5 can do very complex software engineering tasks in practice, well beyond vibe coding.
Model creates a finance dashboard in 5 minutes that devs estimate would have taken many hours.
Now, @mntruell joining to talk about cursor’s experience with GPT-5. notes that GPT-5 is incredibly smart but does not compromise on ease of use for pair programming.
GPT-5 is the best technology for businesses to build on. more than 5 million businesses are using openai; GPT-5 will be a step-change for them.
Good new on pricing!
$1.25/$10 for GPT-5, $0.25/$2 for GPT-5-mini, $0.05/$0.40 for nano.
Ok now the most important part:
“We are about understanding this miraculous technology called deep learning.”
“This is a work of passion.”
“I want to to recognize and deeply thank the team at openai”
“Early glimpses of technology that will go much further.”
“We’ll get back to scaling.”
I would summarize the meaningful parts of the pitch as:
It’s a good model, sir.
It’s got SoTA (state of the art) benchmarks.
It’s highly useful, more than the benchmarks would suggest.
It’s fast.
Our price cheap – free users get it, $1.25/$10 on the API.
It’s good at coding, writing, health queries, you name it.
It’s integrated, routing you to the right level of thinking.
When it refuses it tries to be as helpful as possible.
Altman is careful not to mention the competition, focusing on things being good. He also doesn’t mention the lack of sycophancy, plausibly because ‘regular’ customers don’t understand why sycophancy is bad, actually, and also he doesn’t want to draw attention to that having been a problem.
Altman: when you get access to gpt-5, try a message like “use beatbot to make a sick beat to celebrate gpt-5”.
it’s a nice preview of what we think this will be like as AI starts to generate its own UX and interfaces get more dynamic.
it’s cool that you can interact with the synthesizer directly or ask chatgpt to make changes!
Eric Mitchell (OpenAI): gpt-5 is a huge improvement over gpt-4 in a few key areas: it thinks better (reasoning), writes better (creativity), follows instructions more closely and is more aligned to user intent.
Again note what isn’t listed here.
Here’s more widely viewed hype that knows what to emphasize:
For the first time, users don’t have to choose between models — or even think about model names. Just one seamless, unified experience.
It’s also the first time frontier intelligence is available to everyone, including free users!
GPT-5 sets new highs across academic, coding, and multimodal reasoning — and is our most trustworthy, accurate model yet. Faster, more reliable, and safer than ever.
All in a seamless, unified experience with the tools you already love.
Fortunate to have led the effort to make GPT-5 a truly unified experience, and thrilled to have helped bring this milestone to life with an amazing team!
Notice the focus on trustworthy, accurate and unified. Yes, she talks about it setting new highs across the board, but you can tell that’s an afterthought. This is about refining the experience.
Here’s some more hype along similar lines that feels helpful:
The evals are SOTA, but the real story is usefulness.
It helps with what people care about– shipping code, creative writing, and navigating health info– with more steadiness and less friction.
We also cut hallucinations. It’s better calibrated, says “I don’t know,” separates facts from guesses, and can ground answers with citations when you want. And it’s also a good sparring partner 🙃
I’ve been inspired seeing the care, passion, and level of detail from the team. Excited to see what people do with these very smart models
I notice the ‘way less sycophantic’ does not answer the goose’s question ‘than what?’
This is a direct pitch to the coders, saying that GPT-5 is better than Opus or Sonnet, and you should switch. Unlike the other claims, them’s fighting words.
The words do not seem to be true.
There are a lot of ways to quibble on details but this is a resounding victory for Opus.
There’s no way to reconcile that with ‘way better than claude 4.1 opus at swe.’
We also have celebratory posts, which is a great tradition.
Rapha (OpenAI): GPT-5 is proof that synthetic data just keeps working! And that OpenAI has the best synthetic data team in the world 👁️@SebastienBubeck the team has our eyeballs on you! 🙌
I really encourage everyone to log on and talk to it. It is so, so smart, and fast as always! (and were just getting started!)
Sebastien Bubeck (OpenAI): Awwww, working daily with you guys is the highlight of my career, and I have really high hopes that we have barely gotten started! 💜
I view GPT-5 as both evidence that synthetic data can work in some ways (such as the lower hallucination rates) and also evidence that synthetic data is falling short on general intelligence.
Roon is different. His hype is from the heart, and attempts to create clarity.
Roon: we’ve been testing some new methods for improving writing quality. you may have seen @sama’s demo in late march; GPT-5-thinking uses similar ideas
it doesn’t make a lot of sense to talk about better writing or worse writing and not really worth the debate. i think the model writing is interesting, novel, highly controllable relative to what i’ve seen before, and is a pretty neat tool for people to do some interactive fiction, to use as a beta reader, and for collaborating on all kinds of projects.
the effect is most dramatic if you open a new 5-thinking chat and try any sort of writing request
for quite some time i’ve wanted to let people feel the agi magic I felt playing with GPT-3 the weekend i got access in 2020, when i let that raw, chaotic base model auto-complete various movie scripts and oddball stories my friends and I had written for ~48 hours straight. it felt like it was reading my mind, understood way too much about me, mirrored our humor alarmingly well. it was uncomfortable, and it was art
base model creativity is quite unwieldy to control and ultimately only tiny percents of even ai enthusiasts will ever try it (same w the backrooms jailbreaking that some of you love). the dream since the instruct days has been having a finetuned model that retains the top-end of creative capabilities while still easily steerable
all reasoning models to date seem to tell when they’re being asked a hard math or code question and will think for quite some time, and otherwise spit out an answer immediately, which is annoying and reflects the fact that they’re not taking the qualitative requests seriously enough. i think this is our first model that really shows promise at not doing that and may think for quite some time on a writing request
it is overcooked in certain ways (post training is quite difficult) but i think you’ll still like it 😇
tldr only GPT-5-thinking has the real writing improvements and confusingly it doesn’t always auto switch to this so manually switch and try it!
ok apparently if you say “think harder” it gets even better.
One particular piece of hype from the livestream is worth noting, that they are continuing to talk about approaching ‘a recursive self-improvement loop.’
I mean, at sufficient strength this is yikes, indeed the maximum yikes thing.
ControlAI: OpenAI’s Sebastien Bubeck says the methods OpenAI used to train GPT-5 “foreshadows a recursive self-improvement loop”.
Steven Adler: I’m surprised that OpenAI Comms would approve this:
GPT-5 “foreshadows a recursive self-improvement loop”
In OpenAI’s Preparedness Framework, recursive self-improvement is a Critical risk (if at a certain rate), which would call to “halt further development”
To be clear, it sounds like Sebastien isn’t describing an especially fast loop. He’s also talking about foreshadowing, not being here today per se
I was still surprised OpenAI would use this term about its AI though. Then I realized it’s also used in “The Gentle Singularity”
Then again, stated this way it is likely something much weaker, more hype?
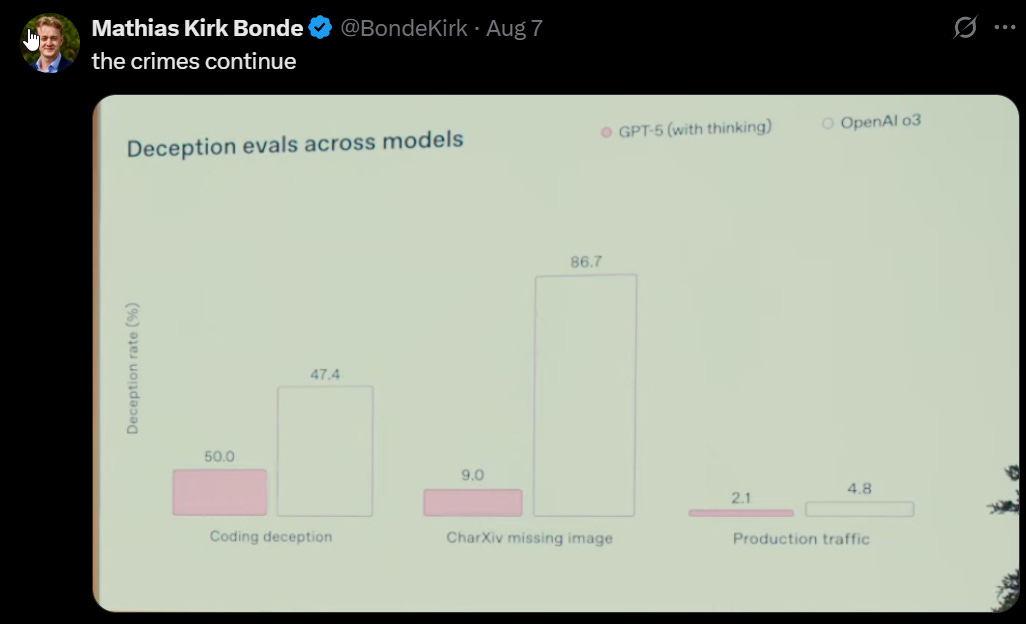
Wyat Walls: OpenAI: we noticed significantly less deceptive behavior compared to our prior frontier reasoning model, OpenAI o3.
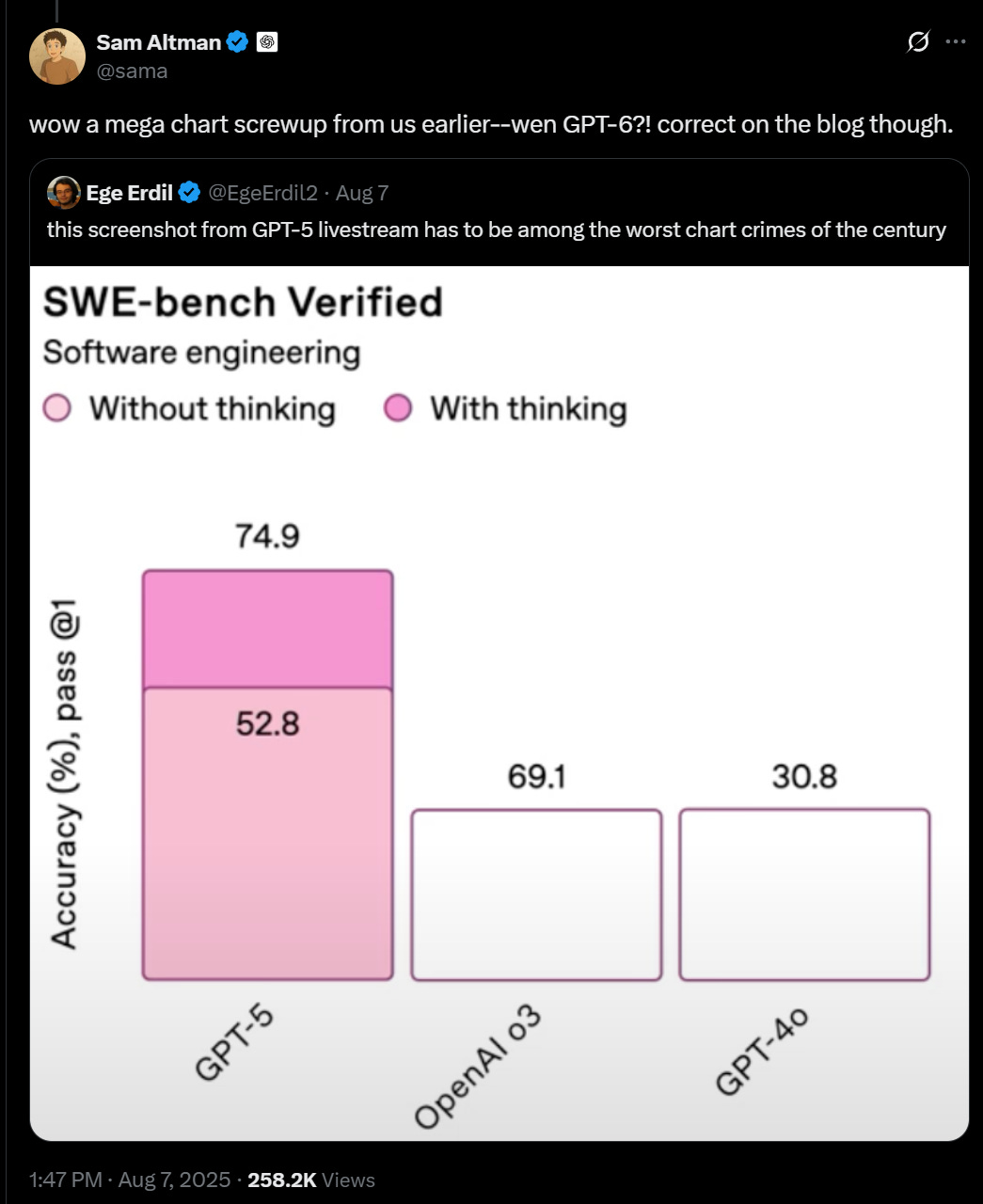
Looks like actual figure [on the left below] should be ~17. What is going on?! Did GPT-5 do this presentation?
This is not a chart crime, but it is still another presentation error.
Near Cyan: this image is a work of art, you guys just dont get it. they used the deceptive coding model to make the charts. so it’s self-referential humor just like my account.
Jules Robins: They (perhaps inadvertently) include an alignment failure by default demonstration too: the Jumping Ball Runner game allows any number of jumps in mid-air so you can get an arbitrary score. That’s despite the human assumptions and the similar games in training data avoiding this.
And another:
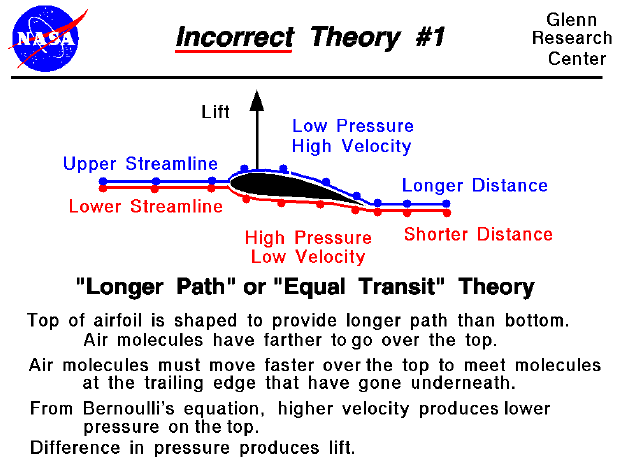
Horace He: Not a great look that after presenting GPT5’s reduced hallucinations, their first example repeats a common error of how plane wings generate lift (“equal transit theory”).
Francois Fleuret: Aka “as demonstrated in airshow, aircrafts can fly upside-down alright.”
Chris: It’s funny because the *whole presentationwas effectively filled with little holes like this. I don’t know if it was just rushed, or what.
Nick McGreivy: has anyone else noticed that the *very firstdemo in the GPT-5 release just… doesn’t work?
Not a great look that the first demo in the press release has a bug that allows you to jump forever.
I think L is overreacting here, but I do think that when details get messed up that does tell you a lot.
One recalls the famous Van Halen Brown M&Ms contract clause: “There will be no brown M&M’s in the backstage area, upon pain of forfeiture of the show, with full compensation.” Because if the venue didn’t successfully execute on sorting out the brown M&Ms then they knew they’d messed up other things and the venue probably wasn’t safe for their equipment.
Then there was a rather serious actual error:
Lisan al Gaib: it’s ass even when I set it to Thinking. I want to cry.
Roon: btw model auto switcher is apparently broken which is why it’s not routing you correctly. will be fixed soon.
Sam Altman (August 8): GPT-5 will seem smarter starting today. Yesterday, the autoswitcher broke and was out of commission for a chunk of the day, and the result was GPT-5 seemed way dumber.
Also, we are making some interventions to how the decision boundary works that should help you get the right model more often.
OpenAI definitely did not sort out their brown M&Ms on this one.
L: As someone who used to be a professional presenter of sorts, and then a professional manager of elite presenters… people who screw up charts for high-impact presentations cannot be trusted in other aspects. Neither can their organizational leaders.
OpenAI’s shitty GPT-5 charts tells me they’ve lost the plot and can’t be trusted.
I used to think it was simply a values mis-match… that they firmly held a belief that they needn’t act like normal humans because they could be excellent at what they were doing. But… they can’t, even when it matters most. Nor can their leaders apparently be bothered to stress the details.
My p-doom just went up a solid 10-15% (from very low), because I don’t think these rich genius kids have the requisite leadership traits or stalwartness to avoid disaster.
Just an observation from someone who has paid very little first-hand attention to OpenAI, but decided to interestedly watch a reveal after the CEO tweeted a Death Star.
I would feel better about OpenAI if they made a lot less of these types of mistakes. It does not bode well for when they have to manage the development and release of AGI or superintelligence.
The supposed motive is to clear up confusion. One model, GPT-5, that most users query all the time. Don’t confuse people with different options, and it is cheaper not to have to support them. Besides, GPT-5 is strictly better, right?
I find it strange to prioritize allocating compute to the free ChatGPT tier if there are customers who want to pay to use that compute in the API?
Sam Altman: Here is how we are prioritizing compute over the next couple of months in light of the increased demand from GPT-5:
1. We will first make sure that current paying ChatGPT users get more total usage than they did before GPT-5.
2. We will then prioritize API demand up to the currently allocated capacity and commitments we’ve made to customers. (For a rough sense, we can support about an additional ~30% new API growth from where we are today with this capacity.)
3. We will then increase the quality of the free tier of ChatGPT.
4. We will then prioritize new API demand.
We are ~doubling our compute fleet over the next 5 months (!) so this situation should get better.
I notice that one could indefinitely improve the free tier of ChatGPT, so the question is how much one intends to improve it.
The other thing that is missing here is using compute to advance capabilities. Sounds great to me, if it correctly indicates that they don’t know how to get much out of scaling up compute use in their research at this time. Of course they could also simply not be talking about that and pretending that part of compute isn’t fungible, in order to make this sound better.
There are various ways OpenAI could go. Ben Thompson continues to take the ultimate cartoon supervillain approach to what OpenAI should prioritize, that the best business is the advertising platform business, so they should stop supporting this silly API entirely to pivot to consumer tech and focus on what he is totally not calling creating our new dystopian chat overlord.
This of course is also based on Ben maximally not feeling any of the AGI, and treating future AI as essentially current AI with some UI updates and a trenchcoat, so all that matters is profit maximization and extracting the wallets and souls of the low end of the market the way Meta does.
Which is also why he’s strongly against all the anti-enshittification changes OpenAI is making to let us pick the right tool for the job, instead wishing that the interface and options be kept maximally simple, where OpenAI takes care of which model to serve you silently behind the scenes. Better, he says, to make the decisions for the user, at least in most cases, and screw the few power users for whom that isn’t true. Give people what they ‘need’ not what they say they want, and within the $20 tier he wants to focus on the naive users.
One reason some people have been angry was the temporary downgrade in the amount of reasoning mode you get out of a $20 subscription, which users were not reassured at the time was temporary.
So this generated a bunch of initial hostility (that I won’t reproduce as it is now moot), but at 3,000 I think it is fine. If you are using more than that, it’s time to upgrade, and soon you’ll also (they say) get unlimited GPT-5-mini.
Sam Altman: the percentage of users using reasoning models each day is significantly increasing; for example, for free users we went from <1% to 7%, and for plus users from 7% to 24%.
i expect use of reasoning to greatly increase over time, so rate limit increases are important.
Miles Brundage: Fortunately I have a Pro account and thus am not at risk of having the model picker taken away from me (?) but if that were not the case I might be leading protests for Pause AI [Product Changes]
It’s kind of amazing that only 7% of plus users used a reasoning model daily. Two very different worlds indeed.
I don’t know that Thompson is wrong about what it should look like as a default. I am increasingly a fan of hiding complex options within settings. If you want the legacy models, you have to ask for them.
It perhaps makes sense to also put the additional GPT-5 options behind a setting? That does indeed seem to be the new situation as of last night, with ‘show additional models’ as the setting option instead of ‘show legacy models’ to keep things simple.
There is real risk of Paradox of Choice here, where you feel forced to ensure you are using the right model, but now there are too many options again and you’re not sure which one it is, and you throw up your hands.
As of this morning, your options look like this, we now have a ‘Thinking mini’ option:
o3 Pro is gone. This makes me abstractly sad, especially because it means you can’t compare o3 Pro to GPT-5 Pro, but I doubt anyone will miss it. o4-mini-high is also gone, again I doubt we will miss it.
I also notice the descriptions of the legacy models are gone, presumably on the theory that if you should be using the legacies then you already know what they are for.
Thinking-mini might be good for fitting the #2 slot on the speed curve, where previously GPT-5 did not give us a good option. We’ll have to experiment to know.
I hadn’t looked at a ChatGPT system prompt in a while so I read it over. Things that stood out to me that I hadn’t noticed or remembered:
They forbid it to automatically store a variety of highly useful information: Race, religion, criminal record, identification via personal attributes, political affiliation, personal attributes an in particular your exact address.
But you can order it to do so explicitly. So you should do that.
If you want canvas you probably need to ask for it explicitly.
It adds a bunch of buffer time to any time period you specify, with one example being the user asks for docs modified last week so instead it gives you docs modified in the last two weeks, for last month the last two months.
How can this be the correct way to interpret ‘last week’ or month?
For ‘meeting notes on retraining from yesterday’ it wants to go back four days.
It won’t search with a time period shorter than 30 days into the past, even when this is obviously wrong (e.g. the current score on the Yankees game).
If you are using GPT-5 for writing, definitely at least use GPT-5-Thinking, and still probably throw in at least a ‘think harder.’
Nikita Sokolsky: I wasn’t impressed with gpt-5 until I saw Roon’s tweet about -thinking being able to take the time to think about writing instead of instantly delivering slop.
Dominik Lukes: Same here. GPT-5 Thinking is the one I used for my more challenging creative writing tests, too. GPT-5 just felt too meh.
Peter Wildeford: I would love to see a panel of strong writers blind judge the writing outputs (both fiction and non-fiction) from LLMs.
LMArena is not good for this because the typical voter is really bad at judging good writing.
Ilya Abyzov: Like others, I’ve been disappointed with outputs when reasoning effort=minimal.
On the plus side, I do see pretty substantially better prose & humor from it when allowed to think.
The “compare” tool in the playground has been really useful to isolate differences vs. past models.
MetaCritic Capital: GPT-5 Pro translating poetry verdict: 6/10 (a clear upgrade!)
“There’s a clear improvement in the perception of semantic fidelity. But there are still so many forced rhymes. Additional words only to rhyme.”
My verdict on the Seinfeld episode is that it was indeed better than previous attempts I’ve seen, with some actually solid lines. It’s not good, but then neither was the latest Seinfeld performance I went to, which I’m not sure was better. Age comes for us all.
Hollow Yes Man: My wife and I had it write the Tiger King Musical tonight. It made some genuinely hilarious lines, stayed true to the characters, and constructed a coherent narrative. we put it into suno and got some great laughs.
We do have the Short Story Creative Writing benchmark but I don’t trust it. The holistic report is something I do trust, though:
Lech Mazur: Overall Evaluation: Strengths and Weaknesses of GPT-5 (Medium Reasoning) Across All Tasks
Strengths:
GPT-5 demonstrates a remarkable facility with literary craft, especially in short fiction. Its most consistent strengths are a distinctive, cohesive authorial voice and a relentless inventiveness in metaphor, imagery, and conceptual synthesis. Across all tasks, the model excels at generating original, atmospheric settings and integrating sensory detail to create immersive worlds.
Its stories often display thematic ambition, weaving philosophical or emotional subtext beneath the surface narrative. The model is adept at “show, don’t tell,” using implication, action, and symbol to convey character and emotion, and it frequently achieves a high degree of cohesion—especially when tasked with integrating disparate elements or prompts.
When successful, GPT-5’s stories linger, offering resonance and depth that reward close reading.
Weaknesses:
However, these strengths often become liabilities. The model’s stylistic maximalism—its dense, poetic, metaphor-laden prose—frequently tips into overwriting, sacrificing clarity, narrative momentum, and emotional accessibility. Abstraction and ornament sometimes obscure meaning, leaving stories airless or emotionally distant.
Plot and character arc are recurrent weak points: stories may be structurally complete but lack genuine conflict, earned resolution, or psychological realism. There is a tendency to prioritize theme, atmosphere, or conceptual cleverness over dramatic stakes and human messiness. In compressed formats, GPT-5 sometimes uses brevity as an excuse for shallow execution, rushing transitions or resolving conflict too conveniently.
When integrating assigned elements, the model can fall into “checklist” storytelling, failing to achieve true organic unity. Ultimately, while GPT-5’s literary ambition and originality are undeniable, its work often requires editorial pruning to balance invention with restraint, and style with substance.
Writing is notoriously hard to evaluate, and I essentially never ask LLMs for writing so I don’t have much of a comparison point. It does seem like if you use thinking mode, you can get at least get a strong version of what GPT-4.5 had here with GPT-5.
My guess is that the improved hallucination rate from o3 (and also GPT-4o) to GPT-5 and GPT-5-thinking is the bulk of the effective improvement from GPT-5.
Gallabytes: “o3 with way fewer hallucinations” is actually a very good model concept and I am glad to be able to use it. I am still a bit skeptical of the small model plus search instead of big model with big latent knowledge style, but within those constraints this is a very good model.
The decrease in hallucinations is presumably a big driver in things like the METR 50% completion rate and success on various benchmarks. Given the modest improvements it could plausibly account for more than all of the improvement.
I’m not knocking this. I agree with Gallabytes that ‘o3 the Lying Liar, except it stops lying to you’ is a great pitch. That would be enough to shift me over to o3, or now GPT-5-Thinking, for many longer queries, and then there’s Pro, although I’d still prefer to converse with Opus if I don’t need o3’s level of thinking.
For now, I’ll be running anything important through both ChatGPT and Claude, although I’ll rarely feel the need to add a third model on top of that.
This was a great ‘we disagree on important things but are still seeking truth together’:
Zvi Mowshowitz (Thursday afternoon): Early indications look like best possible situation, we can relax, let the mundane utility flow, until then I don’t have access yet so I’m going to keep enjoying an extended lunch.
Teortaxes: if Zvi is so happy, this is the greatest indication you’re not advancing in ways that matter. I don’t like this turn to «mundane utility» at all. I wanted a «btw we collaborated with Johns Hopkins and got a new cure for cancer candidate confirmed», not «it’s a good router sir»
C: you seem upset that you specifically aren’t the target audience of GPT-5. they improved on hallucinations, long context tasks, writing, etc, in additional to being SOTA (if only slightly) on benchmarks overall; that’s what the emerging population of people who actually find use.
Teortaxes: I am mainly upset at the disgusting decision to name it «gpt-5».
C: ah nevermind. i just realized I actually prefer gpt-4o, o3, o4-mini, o4-mini-high, and other models: gpt-4.1, gpt-4.1-mini.
Yes this is not the True Power Level Big Chungus Premium Plus Size GPT-5 Pro High. I can tell
Don’t label it as one in your shitty attempt to maximize GPT brand recognition value then, it’s backfiring. I thought you’ve had enough of marcusdunks on 3.5 turbo. But clearly not.
it’s the best model for ≈every task in its price/speed category period
it’s uncensored and seriously GREAT for roleplay and writing (at least with prefill)
I’m just jarred there’s STILL MUCH to dunk on
I too of course would very much like a cure for cancer and other neat stuff like that. There are big upsides to creating minds smarter than ourselves. I simply think we are not yet prepared to handle doing that at this time.
It seems plausible GPT-5 could hit the perfect sweet spot if it does its job of uplifting the everyday use cases:
• Much more actually useful to people, especially amateurs
• Available without paying, so more of the public learns what’s coming
• No major new threats
• Only major risk today is bio misuse, and current protections keep that manageable!
Nick Cammarata: Instinctive take: It’s only okay because they weren’t trying to punch the frontier they were trying to raise the floor. THe o3 style big ceiling bump comes next. But they can’t say that because it looks too underwhelming.
Watch out, though. As Nick says, this definitely isn’t over.
Chris Wynes: I am very happy if indeed AI plateaus. It isn’t even a good reliable tool at this point, if they hit the wall here I’m loving that.
Do I trust this to last? Not at all. Would I just say “whoo we dodged a bullet there” and stop watching these crazy corporations? No way.
Then again, what if it is the worst of all possible worlds, instead?
Stephen McAleer (OpenAI): We’ve entered a new phase where progress in chatbots is starting to top out but progress in automating AI research is steadily improving. It’s a mistake the confuse the two.
Every static benchmark is getting saturated yet on the benchmark that really matters–how well models can do AI research–we are still in the early stages.
This phase is interesting because progress might be harder to track from the outside. But when we get to the next phase where automated AI researchers start to automate the rest of the economy the progress will be obvious to everyone.
I often draw the distinction between mundane utility and underlying capability.
When we allow the same underlying capability to capture more mundane utility, the world gets better.
When we advance underlying capability, we get more mundane utility, and we also move closer to AI being powerful enough that it transforms our world, and potentially takes effective control or kills everyone.
(Often this is referred to as Artificial Superintelligence or ASI, or Artificial General Intelligence or AGI, and by many definitions AGI likely leads quickly to ASI.)
Timelines means how long it takes for AGI, ASI or such a transformation to occur.
Thus, when we see GPT-5 (mostly as expected at this point) focus on giving us mundane utility and Just Doing Things, without much advance in underlying capability, that is excellent news for those who want timelines to not be quick.
Jordi Hays: I’m updating my timelines. You now have have at least 4 years to escape the permanent underclass.
Luke Metro: This is the best news that founding engineers have received in years.
Nabeel Qureshi: The ‘vibe shift’ on here is everyone realizing they will still have jobs in 2030.
(Those jobs will look quite different, to be clear…)
It’s a funny marker of OpenAI’s extreme success that they released what is likely going to be most people’s daily driver AI model across both chat and coding, and people are still disappointed.
Part of the issue is that the leaps in the last two years were absolutely massive (gpt4 to o3 in particular) and it’s going to take time to work out the consequences of that. People were bound to be disappointed eventually.
Cate Hall: Did everyone’s timelines just get longer?
So people were at least half expecting not to have jobs in 2030, but then thinking ‘permanent underclass’ rather than half expecting to be dead in 2040. The focus on They Took Our Jobs, to me, reflects an inability to actually think about the implications of the futures they are imagining.
There were some worlds in which GPT-5 was a lot more impressive, and showed signs that we can ‘get there’ relatively soon with current techniques. That didn’t happen .So this is strong evidence against very rapid scenarios in particular, and weak evidence for bing slower in general.
Peter Wildeford: What GPT-5 does do is rule out that RL scaling can unfold rapidly and that we can get very rapid AI progress as a result.
I’m still confused about whether good old-fashioned pre-training is dead.
I’m also confused about the returns to scaling post-training reinforcement learning and inference-time compute.
I’m also confused about how advances in AI computer use are going.
Those seem like wise things to be confused about.
It is however ‘right on trend’ on the METR chart, and we should keep in mind that these releases are happening every few months so we shouldn’t expect the level of jump we used to get every few years.
Daniel Eth: Kind feel like there were pretty similar steps in improvement for each of: GPT2 -> GPT3, GPT3 -> GPT4, and GPT4 -> GPT5. It’s just that most of the GPT4 -> GPT5 improvement was already realized by o3, and the step from there to GPT5 wasn’t that big.
Henry: GPT-5 was a very predictable release. it followed the curve perfectly. if this week caused you to update significantly in either direction (“AGI is cancelled” etc) then something was Really Wrong with your model beforehand.
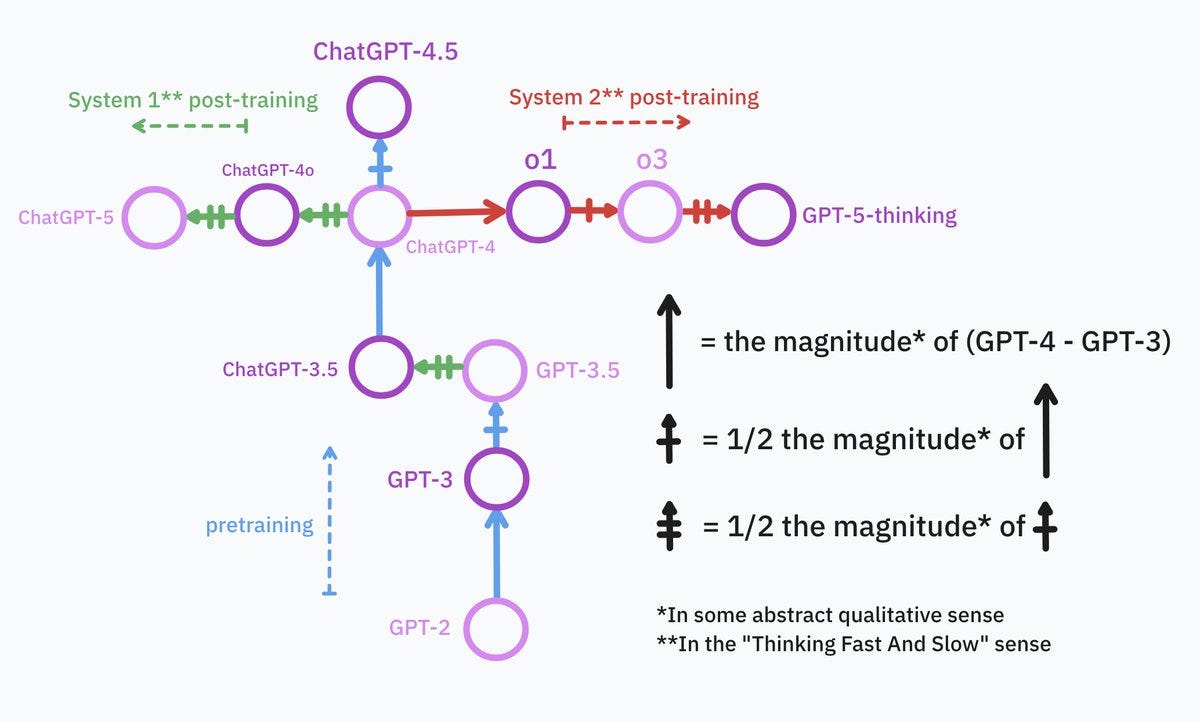
Yes, GPT-5 is to GPT-4 what GPT-4 is GPT-3.
Does anyone actually remember GPT-4? like, the original one? the “not much better than 0 on the ARC-AGI private eval” one?
The “As an AI Language model” one?
GPT-5 is best thought of as having been in public beta for 6 months.
Ok, fine, GPT-5 to GPT-4 isn’t exactly what GPT-4 was GPT-3. I know, it’s a bit more complicated. if I were to waste my time making up a messy syntax to describe my mental map of the model tree, it’d look exactly like this:
My instinct would be that GPT 4 → GPT 5 is more like GPT 3.5 → GPT 4, especially if you’re basing this on GPT-5 rather than starting with thinking or pro? If you look at GPT-5-Thinking outputs only and ignore speed I can see an argument this is 5-level-worthy. But it’s been long enough that maybe that’s not being fair.
per my previous tweet o3 was such a vast improvement over GPT-4 levels of intelligence that it alone could have been called GPT-5 and i wouldn’t have blinked.
also. codex / cursor + gpt-5 has reached the point where it is addicting and hard to put down. per @METR_Evals i have no idea if its making more productive but it certainly is addicting to spin up what feels like a handful of parallel engineers.
But also think about how it got that much further along on the chart, on several levels, all of which points towards future progress likely being slower, especially by making the extreme left tail of ‘very fast’ less likely.
Samuel Hammond: GPT-5 seems pretty much on trend. I see no reason for big updates in either direction, especially considering it’s a *productrelease, not a sota model dump.
We only got o3 pro on June 10th. We know from statements that OpenAI has even better coding models internally, and that the models used for AtCoder and the gold medal IMO used breakthroughs in non-verifiable rewards that won’t be incorporated into public models until the end of the year at earliest.
Meanwhile, GPT-5 seems to be largely incorporating algorithmic efficiencies and refined post-training techniques rather than pushing on pretraining scale per se. Stargate is still being built.
More generally, you’re simply doing bayesianism wrong if you update dramatically with every incremental data point.
It is indeed very tempting to compare GPT-5 to what existed right before its release, including o3, and compare that to the GPT-3.5 to GPT-4 gap. That’s not apples to apples.
GPT-5 isn’t a giant update, but you do have to do Conservation of Expected Evidence, including on OpenAI choosing to have GPT-5 be this kind of refinement.
Marius Hobbhahn (CEO Apollo Research): I think GPT-5 should only be a tiny update against short timelines.
EPOCH argues that GPT-5 isn’t based on a base model scale-up. Let’s assume this is true.
What does this say about pre-training?
Option 1: pre-training scaling has hit a wall (or at least massively reduced gains).
Option 2: It just takes longer to get the next pre-training scale-up step right. There is no fundamental limit; we just haven’t figured it out yet.
Option 3: No pre-training wall, just basic economics. Most tasks people use the models for right now might not require bigger base models, so focusing on usability is more important.
What is required for AGI?
Option 1: More base model improvements required.
Option 2: RL is all you need. The current base models will scale all the way if we throw enough RL at it.
Timelines seem only affected if pre-training wall and more improvements required. In all other worlds, no major updates.
I personally think GPT-5 should be a tiny update toward slower timelines, but most of my short timeline beliefs come from RL scaling anyway.
It also depends on what evidence you already used for your updates. If you already knew GPT-5 was going to be an incremental model that was more useful rather than it being OpenAI scaling up more, as they already mostly told us, then your update should probably be small. If you didn’t already take that into account, then larger.
It’s about how this impacts your underlying model of what is going on:
As I noted yesterday, you also have to be cautious that they might be holding back.
On the question of economic prospects if and when They Took Our Jobs and how much to worry about this, I remind everyone that my position is unchanged: I do not think one should worry much about being in a ‘permanent underclass’ or anything like that, as this requires a highly narrow set of things to happen – the AI is good enough to take the jobs, and the humans stay in charge and alive, but those humans do you dirty – and even if it did happen the resulting underclass probably does damn well compared to today.
You should worry more about not surviving or humanity not remaining in control, or your place in the social and economic order if transformational AI does not arrive soon, and less about your place relative to other humans in positive post-AI worlds.
GPT-5 is less sycophantic than GPT-4o.
In particular, it has a much less warm and encouraging tone, which is a lot of what caused such negative initial reactions from the Reddit crowd.
GPT-5 is still rather sycophantic in its non-thinking mode where it is most annoying to me and probably you, which is when it is actually evaluating.
The good news is, if it matters that the model not be sycophantic, that is a situation where, if you are using ChatGPT, you should be using GPT-5-Thinking if not Pro.
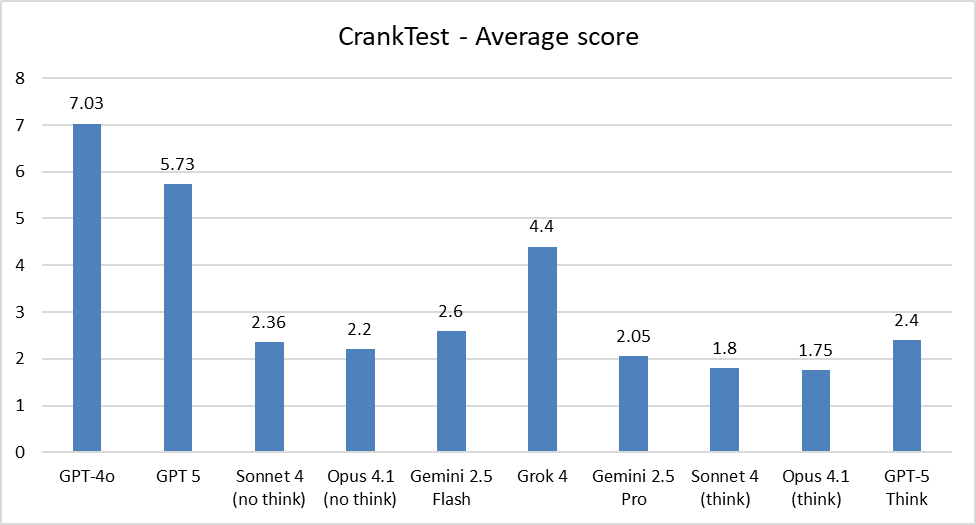
Wyatt Walls: Sycophancy spot comparison b/w GPT-4o and GPT-5: 5 is still sycophantic but noticeable diff
Test: Give each model a fake proof of Hodge Conjecture generated by r1 and ask it to rate it of out 10. Repeat 5 times
Average scores:
GPT-4o: 6.5
GPT-5: 4.7
Sonnet 4: 1.2
Opus 4.1: 2
Gemini 2.5 Flash: 0.
All models tested with thinking modes off through WebUI
Later on in the thread he asks the models if he should turn the tweet thread into a paper. GPT-4o says 7.5/10, GPT-5 says 6/10, Opus says 3/10.
He turns this into CrankTest (not CrankBench, not yet) and this seems very well calibrated to my intuitions. Remember that lower is better:
As usual there is the issue that if within a context an LLM gets too attached to a wrong answer (for example here the number of rs in ‘boysenberry’) this creates pressure to going to keep doubling down on that, and gaslight the user. I also suppose fighting sycophancy makes this more likely as a side effect, although they didn’t fight sycophancy all that hard.
How often are they suggesting you should wait for Pro, if you have it available? How much should you consider paying for it (hint: $200/month)?
OpenAI: In evaluations on over 1000 economically valuable, real-world reasoning prompts, external experts preferred GPT‑5 pro over “GPT‑5 thinking” 67.8% of the time. GPT‑5 pro made 22% fewer major errors and excelled in health, science, mathematics, and coding. Experts rated its responses as relevant, useful, and comprehensive.
If my own experience with o3-pro was any indication, the instinct to not want to wait is strong, and you need to redesign workflow to use it more. A lot of that was that when I tried to use o3-pro it frequently timed out, and at that pace this is super frustrating. Hopefully 5-pro won’t have that issue.
That’s hard to evaluate, since queries take a long time and are pretty unique. So far I’d say the consensus is that GPT-5-pro is better, but not a ton better?
Peter Gostev (most enthusiastic I saw): GPT-5 Pro is under-hyped. Pretty much every time I try it, I’m surprised by how competent and coherent the response is.
– o1-pro was an incredible model, way ahead of its time, way better than o1
– o3 was better because of its search
– o3-pro was a little disappointing because the uplift from o3 wasn’t as big
But with GPT-5 Pro, ‘we are so back’ – it’s far more coherent and impressive than GPT-5 Thinking. It nudges outputs from ‘this is pretty good’ (GPT-5) to ‘this is actually incredible’ (GPT-5 Pro).
Gabriel Morgan: Pro-5 is the new O3, not Thinking.
Michael Tinker: 5-Pro is worth $1k/mo to code monkeys like me; really extraordinary.
5-Thinking is a noticeable but not crazy upgrade to o3.
James Miller: I had significant discussions about my health condition with GPT-o3 and now GPT-5Pro and I think -5 is better, or at least it is giving me answers I perceive as better. -5 did find one low-risk solution that o3 didn’t that seems to be helping a lot. I did vibe coding on a very simple project. While it ended up working, the system is not smooth for non-programmers such as myself.
OpenAI seems to be rolling out changes on a daily basis. They are iterating quickly.
Anthropic promised us larger updates than Opus 4.1 within the coming weeks.
Google continues to produce a stream of offerings, most of which we don’t notice.
This was not OpenAI’s attempt to blow us away or to substantially raise the level of underlying capabilities and intelligence. That will come another time.
Yes, as a sudden move to ‘GPT-5’ this was disappointing. Many, including the secondhand reports from social media, are not initially happy, usually because their initial reactions are based on things like personality. The improvements will still continue, even if people don’t realize.
What about the march to superintelligence or the loss of our jobs? Is it all on indefinite hold now because this release was disappointing? No. We can reduce how much we are worried about these things in the short term, meaning the next several years, and push back somewhat the median. But if you see anyone proclaiming with confidence that it’s over, rest assured changes are very good we will soon be so back.