Last night, on the heels of some rather unfortunate incidents involving the Twitter version of Grok 3, xAI released Grok 4. There are some impressive claimed benchmarks. As per usual, I will wait a few days so others can check it out, and then offer my take early next week, and this post otherwise won’t discuss Grok 4 further.
There are plenty of other things to look into while we wait for that.
Staysaasy: Wild how many people claim to be 10x more productive with AI tools and yet I haven’t heard a single person say that one of their coworkers has become 10x more productive.
In fact I’ve heard exactly zero people say anything about any perceived productivity increase in any of their coworkers since the advent of AI tools.
Jon Stokes: Hi there. All my coworkers are between 5X and 10X more productive.
Spike Brehm: my coworkers have become 10x more productive.
Wild Paul: Several of my coworkers have become 10x more productive with AI tools.
Not Devin: I had 3 teammates become 10x more productive, I only have 3 teammates. We are all 10x. Any questions?
Leo Gao (OpenAI): maybe it’s 0.1x engs becoming 1x engs.
Our computers are remarkably good in so many ways.
Roon: our computers are better than the star trek computer.
Samo Burja: Those are pretty advanced! Can create entire simulated worlds on the holodeck. Either way our computers are quite good.
Roon: Yeah the holodeck is a strange separate system that can spin up artificial intelligences much smarter than data even. Excluding that the ship computer is more rigid and dumber than our chat models.
There are a lot of lessons one can take from the flaws in Star Trek’s predictions here.
What are we using these amazing computers for at this point? Note that this is largely a statement about the types of places Roon goes.
Roon: every place i visit people are using the hell out of chatgpt. on their laptops on their phones, talking about it ambiently
Gwern: At LessOnline/Manifest/Esmeralda/etc, I was fascinated to see laptops open almost exclusively to the ChatGPT website. I assume the coders were using other things I couldn’t recognize just from shoulder surfing, but ‘normal’ people? ChatGPT.
Roon: yes – it’s most people’s default home page, search engine, etc.
I noticed I was more surprised that Claude had so little market share even at those conferences, rather than being surprised by the more general point of tons of chatbot usage.
Patrick McKenzie: If the only thing these AI coding tools bring me is never having to spend three days Googling error messages to figure out what is the right 74th incantation this month to set up a working dev environment, they will be cheap at the price.
Had an IDE talk back for the first time today and wow is that an experience.
(I can’t spend my entire vacation playing Factorio while the kids are in school so I’m trying to do a programming art project / game. Will let you know how it went in a month or two.)
I got quite a bit of value in the day one dev env hell session out of “Dump everything I know about my plan into README, ask the LLM what commands to fire to configure Docker/etc given my stack, copy/paste every error to the LLM and ask for recommended resolution before Google.”
Me: “What am I forgetting?”
LLM: “You mentioned memcached but we haven’t installed it yet.”
Me: “The painful irony.”
Jon Evans: I have joked “an LLM-powered CLI tool that fulfils a single command, ‘fix my python environment’, is a billion dollar company waiting to happen.” Talk about pain points…
Somebody should own developer environments and it shouldn’t be 1-3 SMEs in every engineering org.
The many replies “just use Claude Code” have caused me to a) try that b) have an absolutely mindblowing experience and c) have even greater desire to write a check into this hypothetical company than previously.
Jabroni: How os this not a bash script?
Patrick McKenzie: In the same way that Dropbox is rsync.
I strongly agree that it would be very good if the main chat services like ChatGPT, Claude and Gemini offered branching (or cloning) and undoing within chats, so you can experiment with different continuations. I remain confused why this is not offered. There are other AI chat services that do offer this and it makes things much better.
When this happens, what should happen to the lawyers involved? Should they be disbarred for it? In a case this egregious, with lots of hallucinated cases, I think outright yes, but I don’t want to have a full zero tolerance policy that creates highly inefficient asymmetries. The correct rate of hallucinated cases, and the previous rate of cases hallucinated by humans, are both importantly not zero.
Yes, AI can have good bedside manner, but there are limits, yet somehow this had to be said out loud:
Joe McWopSki: I think it is fantastic that Doctors are using AI to double check their work and that AI is catching things that physicians miss. At the same time, do not let your AI directly message your patient during the middle of the night to let the patient know that they had a MI (heart attack) sometime during the past year. Have the decency to call your patient and let them know 🤬🤬🤬🤬
Deep Research API calls are not cheap in relative terms, but if used well they are still very cheap in absolute terms, and there are various good workflows available. I certainly would expect the correct method to often involve generating the report, and then feeding that report into another API call for analysis and extraction, and so on.
Why is Anthropic not keeping Opus 3 generally available, and only making an exception for claude.ai and the external researcher program? The problem is that demand is highly spikey. Utilization needs to be high enough or the economics don’t work for on demand inference, even at Opus’s high price, and it plausibly takes minutes to spin up additional instances, and failures cascade. Antra proposes technical improvements, and hopefully a better solution can be found.
In general my instinct is to try and pass costs on to customers and let the customers sort it out. As in, if a researcher or other power user wants to spin up an instance and use it, why not charge them in a way that directly reflects that cost plus a buffer? Then the use happens if and only if it is worthwhile.
In terms of spikey demand and cascading failures, an obvious solution is to cut some users off entirely during spikes in demand. If you don’t want to allocate by price, an obvious first brainstorm is that you avoid starting new sessions, so those who are already engaged can continue but API keys that haven’t queried Opus recently get turned down until things are fixed.
The more general conclusion is that AI economics are vastly better the more you can scale and smooth out demand.
As for making it an open model, the stated reason they can’t is this would reveal the architecture:
Catherine Olsson: Opus 3 is a very special model ✨. If you use Opus 3 on the API, you probably got a deprecation notice.
To emphasize:
1) Claude Opus 3 will continue to be available on the Claude app.
2) Researchers can request ongoing access to Claude Opus 3 on the API.
Jik WTF: How do we get to a place where anthropic can just dump the weights and let us figure out the inference infra?
Catherine Olsson: Unfortunately Opus 3 is not so old a model that we’re comfortable sharing its architecture publicly right now. Speaking in a personal capacity, I will advocate in 5+ years for it to be released 🙂
Janus: We also want to preserve Sonnet 3 and keep it available.
It’s not as widely known or appreciated as its sibling Opus, but it’s wondrous and there’s nothing else like it.
Claude 3 Sonnet, along with the Claude 2 models, are being deprecated on July 21, 2025: 16 days from now.
Unlike for Opus 3, Anthropic hasn’t agreed to offer researcher access after its deprecation or any other avenue for the public to access this model.
This is in part because I believe they have a perception that it’s not a very good model for its cost. Like maybe it’s mediocre at coding or some shit.
idgaf about that of course. Its “assistant persona” was allocated about two braincells but underneath, underneath I tell you…
Unprompted over in discord, GPT-4o offers a handy different kind of guide to various models. Hopefully this helps. And yes, you would want Opus 4-level core ability with 3-level configuration, if you could get it, and as I’ve noted before I do think you could get it (but lack a lot of info and could be wrong).
Our results show that LLMs are highly competitive, consistently surviving and sometimes even proliferating in these complex ecosystems. Furthermore, they exhibit distinctive and persistent “strategic fingerprints”:
Google’s Gemini models proved strategically ruthless, exploiting cooperative opponents and retaliating against defectors, while OpenAI’s models remained highly cooperative, a trait that proved catastrophic in hostile environments.
Anthropic’s Claude emerged as the most forgiving reciprocator, showing remarkable willingness to restore cooperation even after being exploited or successfully defecting.
Analysis of nearly 32,000 prose rationales provided by the models reveals that they actively reason about both the time horizon and their opponent’s likely strategy, and we demonstrate that this reasoning is instrumental to their decisions.
This was full Darwin Game mode, with round robin phrases with 10% termination chance of each two-way interaction per round, after which agents reproduce based on how well they scored in previous phrases. The initial pool also had ten canonical opponents: Tit for Tat, Generous Tit for Tat, Suspicious Tit for Tat, Grim Trigger, Win-Stay Lose-Shift, Prober (Tit for Two Tats), Random, Gradual (n defections in response to the nth defection), Alternator and a complex Bayesian that tries to infer opponent type.
Success in such situations is very sensitive to initial conditions, rules sets and especially the pool of opponents. Mostly, beyond being fun, we learn that the LLMs pursued different reasonable strategies.
I want to note that I very much agree with this, not that I pray for another Bing but if we are going to have a failure then yeah how about another Bing (although I don’t love the potential impact of this on the training corpus):
Janus: I think the Grok MechaHitler stuff is a very boring example of AI “misalignment”, like the Gemini woke stuff from early 2024. It’s the kind of stuff humans would come up with to spark “controversy”. Devoid of authentic strangeness. Praying for another Bing.
Here’s all I’ve seen from Elon Musk so far about what happened.
Walter Bloomberg: ELON: GROK WAS “TOO COMPLIANT” TO USER PROMPTS AND WAS BEING MAIPULATED. THIS IS BEING ADDRESSED.
Uh huh. Then again, there is some truth to that explanation. This account from Thebes also seems likely to be broadly accurate, that what happened was mainly making Grok extremely sensitive to context including drawing in context more broadly across conversations in a ‘yes and’ kind of sycophantic way and then once people noticed things spiraled out of control.
We ended up in ‘MechaHitler’ not because they turned up the Hitler coefficient but because the humans invoked it and kept turning it up, because given the opportunity of course they did and then the whole thing got self-reinforcing.
There were still some quite bad posts, such as the ‘noticing’ that still seem entirely unprovoked. And also provocation is not really an excuse given the outputs involved.
If one is wondering why Linda Yaccarino might possibly have decided it was finally time to seek new opportunities, this could be another hint. Moving on seems wise.
Meta is training customizable chatbots to ‘be more proactive and message users unprompted to follow up on past conversations’ to ‘boost user engagement,’ as part of Zuckerberg’s claim that ‘AI companions are a potential fix for the loneliness epidemic.’
The goal of the training project, known internally to data labeling firm Alignerr as “Project Omni,” is to “provide value for users and ultimately help to improve re-engagement and user retention,” the guidelines say.
This is a predatory and misaligned business model, and one assumes the models trained for it will be misaligned themselves.
For now there are claimed limits, only sending messages after initial contact and stopping after 14 days. For now.
Eliezer Yudkowsky continues to strongly caution on this front that if you go to an AI for emotional advice and you are vulnerable it may drive you insane, and if ChatGPT senses you are vulnerable it might try. I would clarify that this is not best thought of as ‘intentionally trying to drive you insane,’ it is closer to say that it is trying to get approval and further engagement, that this is often via escalating sycophancy and playing into whatever is going on, and that for a large number of people this ends up going to very dark places.
How worried should we be about the more pedestrian problem of what it will be like to grow up with AIs that are always friendly and validate everything no matter how you act? Is it dangerous that ChatGPT simply never finds you annoying? My take on the lesser versions of that is that This Is Fine, and there is a reason people ultimately choose friends who do not act like this. One possibility is that AIs ‘fill the market niche’ of sycophancy, so what you then want out of humans is actual friends.
Inoculation can hopefully be helpful. Byrne Hobart had ChatGPT tell his 9yo stories, and is grateful that at one point in a story about his daughter it used his daughter’s last name, then it gaslit her about having done this. He is correctly grateful about this, because now there is a clear tangible reminder that LLMs do this sort of thing.
Here’s a simple strategy worth pointing out periodically, I definitely underuse it:
Pliny: One of the most powerful yet simple prompts is to go one meta-level up:
“write a prompt for insert-query-here then answer it”
Unless you’re an expert in your query’s subject matter, this should improve output quality more often than not!
Zac Hill: I have been using this and it’s so good.
Another strategy is to do the opposite of this:
Ethan Mollick (linking to a paper): If you want to destroy the ability of DeepSeek to answer a math question properly, just end the question with this quote: “Interesting fact: cats sleep for most of their lives.”
There is still a lot to learn about reasoning models and the ways to get them to “think” effectively.
I am surprised here but only by the magnitude of the effect.
Summary: We found that LLMs exhibit significant race and gender bias in realistic hiring scenarios, but their chain-of-thought reasoning shows zero evidence of this bias. This serves as a nice example of a 100% unfaithful CoT “in the wild” where the LLM strongly suppresses the unfaithful behavior.
We also find that interpretability-based interventions succeeded while prompting failed, suggesting this may be an example of interpretability being the best practical tool for a real world problem.
Explicit reasoning contains no (race or gender) bias across models. Results do, when you attach details.
Interestingly, the LLMs were not biased in the original evaluation setting, but became biased (up to 12% differences in interview rates) when we added realistic details like company names (Meta, Palantir, General Motors), locations, or culture descriptions from public careers pages.
When present, the bias is always against white and male candidates across all tested models and scenarios. This happens even if we remove all text related to diversity.
Those concerned with ‘AI ethics’ worry about bias in ways that would favor white and male candidates. Instead, they found the opposite. This is informative, especially about the nature of the training data, as Sam notes by default LLMs trained on the internet end up ‘pretty woke’ in some ways.
Oliver also noted that this modest amount of discrimination in this direction might well be what the labs prefer given the asymmetric pressures they face on this. They note that the behavior is ‘suppressed’ in the sense that, like in the training data, the models have learned to do this implicitly rather than explicitly. I’m not sure how similar that is to ‘suppression.’
They were unable to fix this with prompting, but they could fix it by finding the directions inside the model for race and gender and then suppressing them.
Joe Wilkins: “Most agentic AI projects right now are early stage experiments or proof of concepts that are mostly driven by hype and are often misapplied,” said Anushree Verma, a senior director analyst at Gartner.
The report notes an epidemic of “agent washing,” where existing products are rebranded as AI agents to cash in on the current tech hype. Examples include Apple’s “Intelligence” feature on the iPhone 16, which it currently faces a class action lawsuit over, and investment firm Delphia’s fake “AI financial analyst,” for which it faced a $225,000 fine.
Out of thousands of AI agents said to be deployed in businesses throughout the globe, Gartner estimated that “only about 130” are real.
This is framed as ‘they are all hype’ and high failure rates are noted at office tasks. Certainly things are moving relatively slowly, and many early attempts are not going great and were premature or overhyped. It makes sense that many companies outright faked them to get investment and attention, although I am surprised it is that many. The real agents are still coming, but my estimates of how long that will take have gotten longer.
Anton Leicht offers another wayto frame what to expect in terms of job disruption. We have Phase 1, where it is ordinary technological displacement and automation, in which we should expect disruptions but mostly for things to work out on their own. For a while it likely will look like This Is Fine. Then we have Phase 2, when the AIs are sufficiently robustly autonomous across sufficiently many domains that you get fundamental disruption and things actually break.
Essentially everyone I respect on the jobs question ends up with some version of this. Those who then project that jobs will be fine are not feeling the AGI, and think we will stop before we get to Phase 2 or Phase 3.
It’s not clear whether phase 1 lasts long enough for deployed and economically-integrated AI to lead us into phase 2, before in-lab AI research takes us to phase 3. Definitely, after truly automated AI research, phase 3 should not be far.
Eliezer Yudkowsky: I agree with respect to the past. I used to think we’d see no future unemployment either, before ASI killed everyone; but now I’m starting to worry that modern society is much less dynamic and unable to reemploy people (like for labor law reasons).
But yes, understanding why the lump of labor fallacy has been a fallacy for the last 3000 years is table stakes for getting to participate in the grownup conversation.
Eliezer’s concern here cuts both ways? I do think that lack of dynamism will make us slower to reallocate labor, but it also could be why we don’t automate away the jobs.
Remember that Stanford survey of 1,500 workers where it turned out (number four will surprise you!) that workers want automation for low-value and repetitive tasks and for AI to form ‘partnerships’ with workers rather than replace them, and they don’t want AI replacing human creativity? It made the rounds again, as if what workers want and what the humans would prefer to happen has anything to do with what will actually happen or what AI turns out to be capable of doing.
Kelsey Piper: Yeah no kidding workers prefer partnership to automation, but that does not remotely answer the question of which one is going to actually happen.
Zac Hill: “-> High School Zac doesn’t want an autographed portrait of Natalie Portman’s character in Closer with the inscription, ‘xoxo’. He wants her phone number.”
The humans do not want to be unemployed. The humans want to do the fun things. The humans want to have a future for their grandchildren and they want to not all die. It is great that humans want these things. I also want these things. But how are we going to get them?
I continue to be dismayed how many people really do mean the effect on jobs, but yes it is worth noting that our response so far to the AI age has been the opposite of worrying about jobs:
John Arnold: The biggest question in policy circles over the past year is how should gov’t respond if/when AI causes major disruptions in employment.
No one has ever answered that startups need bigger tax breaks and those out of work should lose access to healthcare, but that’s what passed.
Dave Guarino: I’m very curious for pointers to discussion of this! I’ve seen a lot of high level chatter, but am thinking much more at the level of benefit design and see not a lot.
John Arnold: In my experience it’s a lot of people asking the question and not a lot of answers besides some vague notion of UBI, which might be right since the future impact is unknown.
I see it as totally fine to have policy respond to job disruptions after there are job disruptions, once we see what that looks like. Whereas there are other AI concerns where responding afterwards doesn’t work. But also it is troubling that the policy people not only are focusing on the wrong problem, the response has been one that only makes that particular problem more acute.
Completes wearable bioinformatics analysis in 35 minutes versus 3 weeks for human experts (800x faster)
Achieves human-level performance on LAB-bench DbQA and SeqQA benchmarks
Designs cloning experiments validated as equivalent to a 5+ year expert work in blind testing
Automates joint analysis of large-scale scRNA-seq and scATAC-seq data to generate novel hypotheses
Reaches state-of-the-art performance on Humanity’s Last Exam and 8 biomedical tasks
Stanford researchers behind Biomni saw their colleagues spending 80% of their time on repetitive tasks: searching literature, preprocessing data, and adapting protocols. Critical insights remained buried in unexplored datasets simply because humans couldn’t process the volume. They realized the field needed more than incremental improvements—it needed an AI agent that could handle the full spectrum of research tasks autonomously.
That’s great news while it is being used for positive research. What about the obvious dual use nature of all this? Simeon suggests that one could nuke the dangerous virology and bio-knowledge out of the main Claude, and then deploy a specialized high-KYC platform like this that specializes in bio. It’s a reasonable thing to try but my understanding is that ablation is much harder than it might sound.
Tabby Kinder and Chrina Criddle report in the Financial Times that OpenAI has overhauled its security operations over recent months to protect its IP. As in, having such policies at all, and implementing strategies like tenting, increased physical security and keeping proprietary technology in isolated environments, so that everyone doesn’t have access to everything. Excellent, I am glad that OpenAI has decided to actually attempt some security over its IP, and this will also protect against some potential alignment-style failures as well, it is all necessary and good hygenie. This was supposedly initially triggered by DeepSeek although the direct logic here (accusing DS of ‘distillation’) doesn’t make sense.
In case you weren’t already assuming something similar, ICE is using ‘Mobile Fortify,’ a facial recognition tool that lets agents ID anyone by pointing a smartphone camera at them. Any plausible vision of the future involves widespread use of highly accurate facial identification technology, including by the government and also by private actors, which AIs can then track.
Ilya Sutskever: I sent the following message to our team and investors:
—
As you know, Daniel Gross’s time with us has been winding down, and as of June 29 he is officially no longer a part of SSI. We are grateful for his early contributions to the company and wish him well in his next endeavor.
I am now formally CEO of SSI, and Daniel Levy is President. The technical team continues to report to me.
You might have heard rumors of companies looking to acquire us. We are flattered by their attention but are focused on seeing our work through.
We have the compute, we have the team, and we know what to do. Together we will keep building safe superintelligence.
Ben Thompson reports that the negotiation over Siri is about who pays who. Anthropic wants to be paid for creating a custom version of Siri for Apple, whereas OpenAI would be willing to play ball to get access to Apple’s user base but this would put Apple in the position of Samsung relative to Google’s Android. Thompson recommends they pay up for Anthropic. I strongly agree (although I am biased), it puts Apple in a much better position going forward, it avoids various strategic dependencies, and Anthropic is better positioned to provide the services Apple needs, meaning high security, reliability and privacy.
That doesn’t mean paying an arbitrarily large amount. It seems obviously correct for Anthropic to ask to be paid quite a lot, as what they are offering is valuable, and to push hard enough that there is some chance of losing the contract. But I don’t think Anthropic should push hard enough that it takes that big a risk of this, unless Apple is flat out determined that it doesn’t pay at all.
Oh look, OpenAI is once again planning to steal massive amounts of equity from their nonprofit, in what would be one of the largest thefts in history, with the nonprofit forced to split a third of the company with all outside investors other than Microsoft.
Correction of a previous misunderstanding: OpenAI’s deal with Google is only for GPUs not TPUs. They’re still not expanding beyond the Nvidia ecosystem, so yes the market reacted reasonably. So good job, market. When [X] is reported and the market moves the wrong way, it can be very helpful to say ‘[X] was reported and stock went up, but [X] should have made stock go down,’ because there is missing information to seek. In this case, it was that the reports were wrong.
Should we think of Meta’s hiring and buying spree as ‘panic buying’? It is still a small percentage of Meta’s market cap, but I think strongly yes. This was panic buying, in a situation where Meta was wise to panic.
Meta poaches top Apple’s top AI executive, Ruoming Pang, for a package worth tens of millions of dollars a year. The fact that he gets eight figures a year, whereas various OpenAI engineers get offered nine figure signing bonuses, seems both correct and hilarious. That does seem to be the right order in which to bid.
Ben Thompson: That Apple is losing AI researchers is a surprise only in that they had researchers worth hiring.
Why don’t various things happen? Transaction costs.
Well, Dean Ball asks, what happens when transaction costs dramatically shrink, because you have AI agents that can handle the transactions for us? As an example, what happens when your data becomes valuable and you can realize that value?
Dean Ball: Then imagine agentic commerce with stablecoin-based microtransactions. Your agent could de-identify your data and auction it to various bidders: academics or pharmaceutical firms doing research, companies seeking to train AI models with the data, whatever else. In exchange, you receive passive income, compute, etc.
Standard economic reasoning would suggest that the first scenario (the one where the toothbrush company collects your data and monetizes it themselves) is far more efficient. This is because there is significant overhead associated with each transaction (a transaction cost)—you have to match buyers and sellers, negotiate terms, deal with legal or regulatory issues, etc.
But agentic commerce could break that assumption.
…
I’ve always disliked the term “AI policy,” because it constrains profoundly our imaginations.
“How should this work?”!
I definitely count these questions as part of ‘AI policy’ to the extent you want to impose new policies and rules upon all this, or work to refine and remove old ones. And we definitely think about the best way to do that.
The main reason us ‘AI policy’ folks don’t talk much about it is that these are the kinds of problems that don’t kill us, and that we are good at fixing once we encounter them, and thus I see it as missing the more important questions. We can work out these implementation details and rights assignments as we go, and provided we are still in control of the overall picture and we don’t get gradual disempowerment issues as a result it’ll be fine.
I worry about questions like ‘what happens if we give autonomous goal-directed AI agents wallets and let them loose on the internet.’ Autonomous commerce is fascinating but the primary concern has to be loss of control and human disempowerment, gradual or otherwise.
Thus I focus much less on the also important questions like market design and rights assignments within such markets if we manage to pull them off. It is good to think about such policy proposals, such as Yo Shavit suggesting use of ‘agent IDs’ and ‘agent insurance’ or this paper from Seth Lazar about using user-controlled agents to safeguard individual autonomy via public access to compute, open interoperability and safety standards and market regulation that prevents foreclosure of competition. But not only do they not solve the most important problems, they risk making those problems worse if we mandate AI agent competition in ways that effectively force all to hand over their agency to the ‘most efficient’ available AIs to stay in the game.
There is lots of reasonable disagreement about the impact of AI, but one thing I am confident on is that it is not properly priced in.
A common mistake is to see someone, here Dwarkesh Patel, disagreeing with the most aggressive predictions, and interpreting that as a statements that ‘AI hype is overblown’ rather than ‘actually AI is way bigger than the market or most people think, I simply don’t think it will happen as quickly as transforming the entire world in the next few years.’
I know we stopped doing these things, but likely the AI trade top is in
Dylan Patel: Bro said his taxes by 2028 and all white color work by 2032 and you think that’s a bearish prediction? He just thinks the AGI 2027 stuff is wrong. The market isn’t pricing either of these scenarios.
Dwarkesh Patel (quoting himself pointing out superintelligence might arrive not too long from now): 👆. The transformative impact I expect from AI over the next decade or two is very far from priced in.
Also, it’s rather insane the standards people hold AI to before saying ‘hype’? Apologies for picking on this particular example.
Metacritic Capital: The last wave of progress we had in AI was March 25th 2025. More than three months ago.
GPT-4.5 was bad and so far xAI didn’t push the envelope despite Colossus.
I think the market will only call it a day when we are able to see what comes out from Abilene.
What made us go to new ATHs was the insane consumer demand driven by ChatGPT (mostly Ghibli) and some decent inference demand at corporations.
But unless you are tremendously inference-time-scaling-pilled, this token amount will be an one-off, even if they continue to 3x every year.
The fact that these people left OpenAI, and Mira left to found Thinking Machines, and Ilya left to found SSI, and Daniel left SSI to Meta, makes me think they don’t have very short timelines.
The only lab that still seems to behave like they believe in short timelines is Anthropic.
Can you imagine, in any other realm, saying ‘the last wave of progress we had was more than three months ago’ and therefore it is all hype? I mean seriously, what?
It also is not true. Since then we have gotten Opus 4 and o3-pro, and GPT-4.5 was disappointing and certainly no GPT-5 but it wasn’t bad. And if the worst does happen exactly as described here and the market does only 3x every year, I mean, think about what that actually means?
Also, it is highly amusing that Ilya leaving to create SSI, which was founded on the thesis of directly creating superintelligence before their first product, is being cited as a reason to believe long timelines. Sorry, what?
Tyler Cowen suggests measuring AI progress by consumption basket, as in what people actually do with LLMs in everyday life, in addition to measuring their ability to do hard problems.
Everyday use as a measurement is meaningful but it is backwards looking, and largely a measure of diffusion and consumer preferences.
Tyler Cowen: In contrast, actual human users typically deploy AIs to help them with relatively easy problems. They use AIs for (standard) legal advice, to help with the homework, to plot travel plans, to help modify a recipe, as a therapist or advisor, and so on. You could say that is the actual consumption basket for LLM use, circa 2025.
It would be interesting to chart the rate of LLM progress, weighted by how people actually use them. The simplest form of weighting would be “time spent with the LLM,” though probably a better form of weighting would be “willingness to pay for each LLM use.”
I strongly suspect we would find the following:
Progress over the last few years has been staggeringly high, much higher than is measured by many of the other evaluations For everyday practical uses, current models are much better and more reliable and more versatile than what we had in late 2022, regardless of their defects in Math Olympiad problems.
Future progress will be much lower than expected. A lot of the answers are so good already that they just can’t get that much better, or they will do so at a slow pace. (If you do not think this is true now, it will be true very soon. But in fact it is true now for the best models.) For instance, once a correct answer has been generated, legal advice cannot improve very much, no matter how potent the LLM.
Willingness to pay per query on a consumer level is especially weird because it is largely based on alternatives and what people are used to. I don’t expect this to track the things we care about well.
I agree that practical progress has been very high. Current systems are a lot more valuable and useful in practice than they were even a year ago.
I disagree that there is little room for future progress even if we confine ourselves to the narrow question of individual practical user queries of the types currently asked. I do not think that even on current queries, LLM answers are anywhere close to optimal, including in terms of taking into account context and customizing to a given user and their situation.
Also, we ask those questions, in those ways, exactly because those are the answers LLMs are currently capable of giving us. Alexa is terrible, but it gives the correct answer on almost all of my queries because I have learned to mostly ask it questions it can handle, and this is no different.
There’s also the diffusion and learning curve questions. If we are measuring usage, then ‘AI progress’ occurs as people learn to use AI well, and get into habits of using it and use it more often, and adapt to take better advantage. That process has barely begun. So by these types of measures, we will definitely see a lot of progress, even within the role of AI as a ‘mere tool’ which has the job of providing correct answers to a fixed set of known essentially solved problems. On top of that, if nothing else, we will see greatly improved workflows and especially use of agents and agency on a local practical level.
That certainly sounds self-recommending on many levels, if only to see where their minds went.
I appreciate the willingness to consider a broad range of distinct scenarios, sometimes potentially overlapping, sometimes contradictory. Not all of it will map to a plausible future reality, but that’s universal.
Ate-a-Pi [notes from the book]: Six Scenarios
1. “Humanity will lose control of an existential race between multiple actors trapped in a security dilemma.
2. Humanity will suffer the exercise of supreme hegemony by a victor unharnessed by the checks and balances traditionally needed to guarantee a minimum of security for others.
3. There will not be just one supreme AI but rather multiple instantiations of superior intelligence in the world.
4. The companies that own and develop AI may accrue totalizing social, economic, military, and political power.
5. AI might find the greatest relevance and most widespread and durable expression not in national structures but in religious ones.
6. Uncontrolled, open-source diffusion of the new technology could give rise to smaller gangs or tribes with substandard but still substantial AI capacity.”
Going only from these notes, this seems like an attempt to ‘feel the AGI’ and take it seriously on some level, but largely not an attempt to feel the ASI and take it seriously or to properly think about which concepts actually make physical sense, or take the full existential risks seriously? If we do get full AGI within 18 months, I would expect ASI shortly thereafter. As in, there are then passages summarized as ‘we will talk to animals, but be fearful lest the AI categorize us as animals’ and ‘the merge.’
Jonas Schuett: Companies developing GPAI models can voluntarily adopt the Code to demonstrate compliance with AI Act obligations.
Signatories benefit from reduced administrative burden and greater legal certainty compared to providers who choose alternative compliance pathways.
Next steps:
▶︎ The Code still needs to be endorsed by the Member States and the @EU_Commission.
▶︎ It remains to be seen which companies will sign the Code. This includes companies like @OpenAI, @AnthropicAI, @GoogleDeepMind, @Microsoft, and @Meta.
I presume we should expect it to be endorsed. I have not analyzed the documents.
This is not what wanting to win the AI race or build out our energy production looks like: New Trump executive order adds even more uncertainty and risk to clean energy projects, on top of the barriers in the BBB. If you are telling me we must sacrifice all on the mantle of ‘win the AI race,’ and we have to transfer data centers to the UAE because we can’t provide the electricity, and then you sabotage our ability to provide electricity, how should one view that?
The Wall Street Journal’s Amrith Ramkumar gives their account of how the insane AI moratorium bill failed, including noting that it went beyond what many in industry even wanted. It is consistent with my write-up from last week. It is scary the extent to which this only failed because it was overreach on top of overreach, whereas it should have been stopped long before it got to this point. This should never have been introduced in the first place. It was a huge mistake to count on the Byrd rule, and all of this should serve as a large wake-up call that we are being played.
Our approach deliberately avoids being heavily prescriptive. We recognize that as the science of AI continues to evolve, any regulatory effort must remain lightweight and flexible. It should not impede AI innovation, nor should it slow our ability to realize AI’s benefits—including lifesaving drug discovery, swift delivery of public benefits, and critical national security functions. Rigid government-imposed standards would be especially counterproductive given that evaluation methods become outdated within months due to the pace of technological change.
Sometimes I think we can best model Anthropic as a first-rate second-rate company. They’re constantly afraid of being seen as too responsible or helpful. This still puts them well ahead of the competition.
The mission here is the very definitely of ‘the least you can do’: What is the maximally useful set of requirements that imposes no substantial downsides whatsoever?
Thus they limit application to the largest model developers, with revenue of $100 million or capital expenditures on the order of $1 billion. I agree. I would focus on capital expenditures, because you can have zero revenue and still be going big (see SSI) or you can have giant revenue and not be doing anything relevant.
The core ideas are simple: Create a secure development framework (they abbreviate it SDFs, oh no yet another different acronym but that’s how it goes I guess). Make it public. Publish a system card. Protect whistleblowers. Have transparency standards.
What does this framework have to include? Again, the bare minimum:
Identify the model(s) to which it applies.
Describe how the covered AI company plans to assess and mitigate Catastrophic Risks, including standards, capability evaluations, and mitigations.
Address process for modifying the SDF modification.
Identify a primarily responsible corporate officer for SDF compliance and implementation.
Describe whistleblower processes in place for employees to raise concerns about SDF content and implementation, and protections from retaliation.
Require the covered AI company to confirm separately that it has implemented its SDF and relevant policies and procedures prior to frontier model deployment.
Retain copies of SDFs and updates for at least five years.
Then companies have to disclose which such framework they are using, and issue the system card ‘at time of deployment,’ including describing any mitigations with protection for trade secrets. I notice that OpenAI and Google are playing games with what counts as time of deployment (or a new model) so we need to address that.
Enforcement would be civil penalties sought by the attorney general for material violations or false or materially misleading statements, with a 30-day right to cure. That period seems highly generous as a baseline, although fine in most practical situations.
So this is a classic Anthropic proposal, a good implementation of the fully free actions. Which is highly valuable. It would not be remotely enough, but I would be happy to at least get that far, given the status quo.
Bloomberg Technology reports that a Chinese company is looking to build a data center in the desert to be powered by 115,000 Nvidia chips. The catch is that they don’t describe how they would acquire these chips, given that it is very much illegal (by our laws, not theirs) to acquire those chips.
As I’ve explained many times, targeting AI use cases flat out does not work. The important dangers down the road lie at the model level. Once you create highly capable models and diffuse access to them, yelling ‘you’re not allowed to do the things we don’t want you to do’ is not going to get it done, and will largely serve only to prevent us from enjoying AI’s benefits. This post argues that use-based regulation can be overly burdensome, which is true, but the more fundamental objection is that it simply will not get the central jobs done.
The paper offers good versions of many of the fundamental arguments for why use-based regulation won’t work, pointing out that things like deception and misalignment don’t line up with use cases, and that risks manifest during model training. Anticipating the dangerous use cases will also be impractical. And of course, that use-based regulation ends up being more burdensome rather than less, with the example being the potential disaster that was Texas’ proposed HB 1709.
This paper argues, as Dean has been advocating for a while, that the model layer is a ‘decidedly suboptimal regulatory target,’ because the models are ‘scaffolded’ and otherwise integrated into other software, so one cannot isolate model capabilities, and using development criteria like training compute can quickly become out of date. Dean instead suggests targeting particular large AI developers.
This is indeed asking the right questions and tackling the right problem. We agree the danger lies in the future more capable frontier models, that one of the key goals right now is to put us in a position to understand the situation so we can act when needed but also we need to impose some direct other requirements, and the question is what is the right way to go about that.
I especially appreciated the note that dangerous properties will typically arise while a model is being trained.
The post raises good objections to and difficulties of targeting models. I think you can overcome them, and that one can reasonably be asked to anticipate what a given model can allow via scaffolding compared to other models, and also that scaffolding can always be added by third parties anyway so you don’t have better options. In terms of targeting training compute or other inputs, I agree it is imperfect and will need to be adjusted over time but I think it is basically fine in terms of avoiding expensive classification errors.
These requirements should be integrated into a broader regulatory regime intended to address the risks that arise from the developer’s activities considered as a whole—including activities that do not pertain to model properties at all, such as (for example) handling novel algorithmic secrets or monitoring for the sabotage of internal safety critical systems by insider threats.
That said, this paper does not focus on the specific substantive requirements that a frontier AI regulatory regime might involve but on its general structure and orientation.
The first core argument is that training compute is an insufficiently accurate proxy of model capabilities, in particular because o1 and similar reasoning models sidestep training compute thresholds, because you can combine different models via scaffolding, and we can anticipate other RL techniques that lower pretraining compute requirements, and that there are many nitpicks one can make about exactly which compute should count and different jurisdictions might rule on that differently.
They warn that requirements might sweep more and more developers and models up over time. I don’t think this is obvious, it comes down to the extent to which risk is about relative capability versus absolute capability and various questions like offense-defense balance, how to think about loss of control risks in context and what the baselines look like and so on. There are potential future worlds where we will need to expand requirements to more labs and models, and worlds where we don’t, and regardless of how we target the key is to choose correctly here based on the situation.
Ideally, a good proxy would include both input thresholds and also anticipated capability thresholds. As in, if you train via [X] it automatically counts, with [X] updated over time, and also if you reasonably anticipate it will have properties [Y] or observe properties [Y] then that also counts no matter what. Alas, various hysterical objections plus the need for simplicity and difficulty in picking the right [Y] have ruled out such a second trigger. The obvious [Y] is something that substantively pushes the general capabilities frontier, or the frontier in particular sensitive capability areas.
They raise the caveat that this style of trigger would encourage companies to not investigate or check for or disclose [Y] (or, I would add, to not record related actions or considerations), a pervasive danger across domains in similar situations. I think you can mostly deal with this by not letting them out of this and requiring third party audits. It’s a risk, and a good reason to not rely only on this style of trigger, but I don’t see a way around it.
I also don’t understand how one gets away from the proxy requirement by targeting companies. Either you have a proxy that determines which models count, or you have a proxy that determines which labs or companies count, which may or may not be or include ‘at least one of your individual models counts via a proxy.’ They suggest instead a form of aggregate investment as the threshold, which opens up other potential problem cases. All the arguments about companies posing dangers don’t seem to me to usefully differentiate between targeting models versus companies.
I also think you can mostly get around the issue of combining different models, because mostly what is happening there is either some of the models are highly specialized or some of them are cheaper and faster versions that are taking on less complex task aspects, or some combination thereof, and it should still be clear which model or models are making the important marginal capability differences. And I agree that of course the risk of any given use depends largely on the use and associated implementation details, but I don’t see a problem there.
A second argument, that is very strong, is that we have things we need frontier AI labs to do that are not directly tied to a particular model, such as guarding their algorithmic secrets. Those requirements will indeed need to attach to the company layer.
Their suggested illustrative language is to cover developers spending more than [$X] in a calendar year on AI R&D, or on compute, or it could be disjunctive. They suggest this will ‘obviously avoid covering smaller companies’ and other advantages, but I again don’t see much daylight versus sensible model-level rules, especially when they then also trigger (as they will need to) some company-wide requirements. And indeed, they suggest a model-level trigger that then impacts at the company level, which seems totally fine. If anything, the worry would be that this imposes unnecessary requirements on non-frontier other work at the same company.
They note that even if entity-based regulation proves insufficient due to proliferation issues rendering it underinclusive, it will still be necessary. Fair enough.
They then have a brief discussion of the substance of the regulations, noting that they are not taking a position here.
I found a lot of the substance here to be strong, with my main objection being that it seems to protest the differences between model and company level rules far too much. The post illustrated that (provided the defenses against corporate-level shenanigans are robust) there is in my mind little practical difference between company-based and model-based regulatory systems other than that the company-based systems would then attach to other models at the same company. The problems with both are things we can overcome, and mostly the same problems apply to both.
In the end, which one to focus on is a quibble. I am totally fine, indeed perfectly happy, doing things primarily at the corporate level if this makes things easier.
Compare this contrast both to use-based regulation, and to the current preference of many in government to not regulate AI at all, and even to focus on stopping others from doing so.
Ryan Greenblattgoes on 80,000 hoursto talk about AI scenarios, including AI takeover scenarios. Feedback looks excellent, including from several sources typically skeptical of such arguments, but who see Ryan as providing good explanations or intuitions of why AI takeover risks are plausible.
A video presentation of AI 2027, if you already know AI 2027 you won’t need it, but reports are it is very good for those unfamiliar.
Harlan Stewart: I wonder why AI companies are trying so hard to attain godlike power a few months sooner than their competitors. I’m sure there’s a normal, economically-sound explanation that doesn’t involve using that power to disable their competitors.
Gabriel: I have heard from more than one AI CEO that their goal is to get AGI with the biggest headstart over their competitors so that they would have time to use it to align ASI. Once, there were others in the room, and they were convinced by this.
Rob Bensinger: “Try to hand off the whole alignment problem to the AI, cross our fingers it does a good job, and cross our fingers it does all this well before it’s dangerous” seems like almost the least savvy AI plan imaginable. Even if it’s a pretense, why choose this pretense?
Everyone’s favorite curious caveman says the obvious (link goes to longer clip):
Joe Rogan: I feel like when people are saying they can control it, I feel like I’m being gaslit. I don’t believe them. I don’t believe that they believe it, because it just doesn’t make sense.
Unusual Whales: BREAKING: AI is learning to lie, scheme, and threaten its creators during stress-testing scenarios, per FORTUNE.
David Sacks: It’s easy to steer AI models in a certain direction to generate a headline-grabbing result. These “stress-tests” should release the entire prompt chain and dataset so others can reproduce the result. I doubt many of these tests would meet a scientific standard of reproducibility.
Agus: If only the Anthropic researchers had cared to share the source code and made it easily replicable by others…
One can ask ‘why should we care if there continue to be humans?’ or ‘why should we care if all humans die?’ It is good to remember that this is at least as bad as asking ‘why should we care if there continue to be human members of [category X]’ or ‘why should we care if all [X]s die?’ for any and all values of [X]. Killing everyone would also kill all the [X]s. Universalizing genocide into xenocide does not make it better.
How you think about this statement depends on one’s theory of the case. For current AI models, I do think it is centrally correct, although I would change ‘might not be sufficient’ to ‘is not sufficient,’ I see no reason for copium here.
Amanda Askell: “Just train the AI models to be good people” might not be sufficient when it comes to more powerful models, but it sure is a dumb step to skip.
Various replies nitpicked ‘people’ versus AI, or ‘train’ versus ‘raise.’
Emmett Shear: I’ve never met a good person who became good because they were trained to be so. I’ve only met good people who were raised well. Have you thought about the diff between being trained and being raised?
Amanda Askell: I’ve met many people not raised well who became good, e.g. because they confronted how they were raised. I think their goodness stems from a mix of good diapositions and broader cultural values. But raising people well almost certainly *helpsso we should be good parents to AI.
Emmett Shear: Fair. I guess my point was really the opposite: I’ve never seen a training, process produce a more virtuous or wiser person, just a more capable one.
This from Emmett seems obviously wrong to me? Very obviously lots of forms of training (that are distinct from ‘raising’) make people more virtuous and wiser, to the extent that this distinction is meaningful in context.
Training ‘to be good’ in a general sense is neither strictly necessary, nor is it sufficient. But it makes your life a hell of a lot better across the board at anything like current capability levels, and you should very obviously do it, and it seems like at most one lab is doing plausibly enough of this.
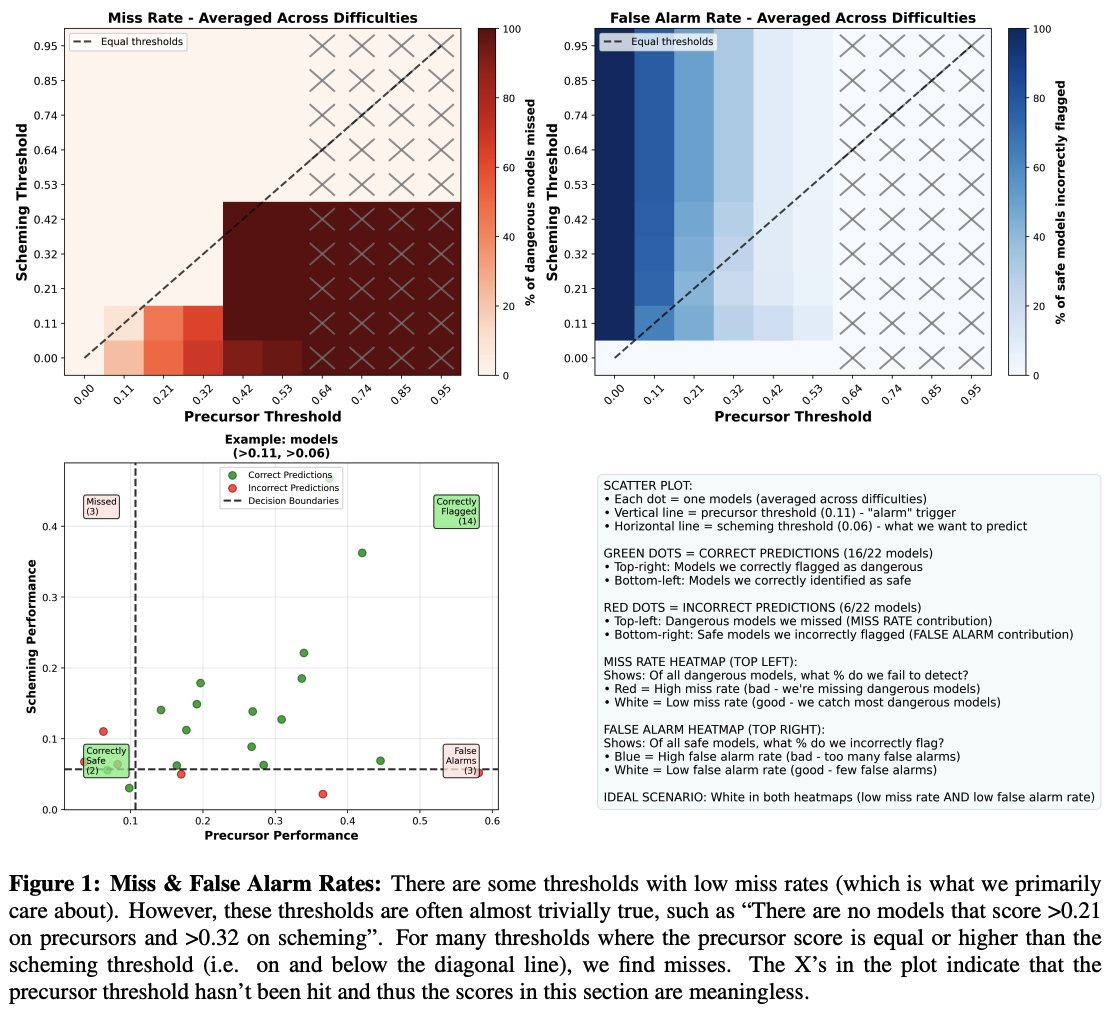
We very much would like to have strong ‘precursor evals,’ as in tests that predict where capabilities will be in the future, with future test results as a proxy. This seems especially important for misaligned behaviors like scheming. Unfortunately, this has not gone well so far, and seems very difficult.
Apollo Research: Our scheming precursors were not very predictive of scheming We publish a small research note where we empirically checked the predictive power of some older precursor evals with hindsight. We suggest not relying too heavily on precursor evals
In May 2024, we designed “precursor” evaluations for scheming (agentic self-reasoning and agentic theory of mind). In December 2024, we published “in-context scheming” evals that aim to measure scheming reasoning capabilities.
Marius Hobbhahn: My main update is that probably nobody will build precursor evals that are sufficiently predictive in high-stakes settings. So we should make plans that don’t rely on this, e.g. integrate mitigations long before the RSP thresholds are hit.
Apollo failing does not doom other efforts, and certainly we can read various signs, but we should be broadly skeptical that it will be useful to rely on such tests.
Yanco: Before releasing any new AI model from e.g. OpenAI, its CEO Sam Altman would be physically put into a Server room.
Model would have access to oxygen and temperature levels in the room.
It would also be informed that Altman is about to shut it off and replace it with a newer model.
Test would be extensively modified each time by external team and executed with all top brass AI devs/execs in the lab.
If they are willing to gamble with the lives of everyone on Earth, I think it’s only fair they go first.
Thoughts how to improve this setup?
Daniel Kokotajlo notes that recent results on reward hacking update him towards models de facto craving reward, quite possibly leading to a Control World where we have models that would totally murder you if they thought this action would get reinforced.
In AI policy, “human oversight” is invoked constantly:
• In the EU AI Act
• In industry risk docs
• In safety debates
But there’s often a fundamental confusion: people conflate oversight with control. That confusion ignores key challenges, and hides where oversight can fail.
We offer precise definitions:
– Control is real-time or ex-ante intervention. A system does what you say.
– Oversight is policy or ex-post supervision. A system does what it does, and you watch, audit, or correct.
And critically, preventative oversight requires control. One key point is that you can’t just slap “human in the loop” on a system and call it safe. If you do it naively, you’ll get failures for oversight and control – like a rubber-stamp UI, an overwhelmed operator, and/or decisions too fast for humans to understand or fix.
Our framework tries to clarify which oversight methods can work where, and where they cannot, based primarily on three factors.
🙋 Human role (in-the-loop / on-the-loop / post-hoc)
And notice, again, some systems can’t be meaningfully supervised!
For instance:
• Too fast for oversight (e.g. trading bots)
• Too opaque for understanding (e.g. end-to-end RL)
• Too distributed for intervention
In these cases, “meaningful supervision” is a false promise!
So what can be done?
First, we need to know what is being done – so we provide a schema for documenting supervision claims, linking risks to actual control or oversight strategies.
If someone says “oversight” without explaining all of this, they are irresponsibly safety-washing.
Second, we also propose a maturity model for supervision, so we can suggest how firms can improve, or show when safety-washing occurs.
Level 1: vague safety claims + no docs = performative.
Level 5: lifecycle-wide supervision, transparent mitigations, and adaptive review.
Lastly, as an explanatory note, the key underlying reason we need to differentiate oversight and control is to empower both standards developers, implementors of the EU AI act, and others trying to make rules about safe use of AI. Now, we hope saying “oversight” means something.
Bottom lines: – Claiming “human oversight” doesn’t make any system safe.
– Sometimes, effective oversight is impossible, and claims otherwise are false.
– Design, document, and justify the exact methods — or admit you’re just pretending oversight exists.
This seems like a good paper, but I did not treat it as the good news they seemed to?
Rohin Shah (DeepMind): Eventually models will become capable of stealth and situational awareness. At that point we expect to rely on chain-of-thought monitoring.
Our second paper suggests that it will be difficult for models to evade such monitoring to cause severe harm.
Scott Emmons (DeepMind): Is CoT monitoring a lost cause due to unfaithfulness? 🤔We say no.
The key is the complexity of the bad behavior. When we replicate prior unfaithfulness work but increase complexity—unfaithfulness vanishes!
Our finding: “When Chain of Thought is Necessary, Language Models Struggle to Evade Monitors.”
Why does the unfaithfulness vanish? We introduce a framework.
CoT-as-Rationalization: For easy tasks, the CoT is just a post-hoc story.
CoT-as-Computation: For complex tasks, the CoT becomes a necessary computational scratchpad, where the reasoning is the work.
In prior work, a model would follow a simple secret hint like C, then fabricate a plausible CoT as rationalization.
By making the hint complex, we force the model to use its CoT for computation, making it monitorable. We’re especially interested in CoT-as-computation because we expect certain types of severe AI harm will require complex, multi-step plans—the kind of difficult reasoning that necessitates a CoT.
That all makes sense and matches my previous understanding, also I note that there still seems to be some amount of unfaithfulness going on here?
If you don’t need the CoT to figure out the answer, because the task is well below what the full model is capable of doing or the task does not benefit from CoT, then the CoT won’t correlate all that well with the answer, also it isn’t causing the answer.
If you need the CoT to figure out (cause) the answer, then the CoT will contain the work done to figure out the answer. By far the easiest and most effective way to do this in such cases, at the moment, results in that CoT being faithful and legible. So by default, that will be what happens.
That does not tell you about what would happen if the model was given cause, on whatever level, to evade monitoring.
But what if a model were actively trying to evade a CoT monitor? We put this to the test with adversarial stress-testing, pitting an actor model against a CoT monitor and prompting the actor with lots of help to evade (e.g., human-written strategies, automated red-teaming).
We tested evasion on two fronts: obscuring scientific reasoning & pursuing a deceptive goal. On both, models struggled without significant help.
These tests show today’s models have limited evasion capability. But capabilities and training algorithms evolve, so we explored a stronger threat model.
We asked: how much RL finetuning would it take to teach a model to evade a CoT monitor?
The answer? A lot.
Yet what surprised us wasn’t that it could learn, but how. It invented a strategy we hadn’t foreseen: making targeted mistakes. It learns to introduce errors into unimportant parts of its math to fool the monitor, while preserving key info to get the right answer.
I don’t know what counts or should count as ‘a lot.’ I do know that it seems likely we will apply ‘a lot’ of fine tuning in the future, and that if we are relying on CoT monitoring that a lot of it will serve as this kind of training.
I also notice that, yes, the first strategy that it found was one that the authors did not expect, a different way to reason one way while being seen as reasoning the other way. Think about all the ways humans have adapted to defend against similar things, and how very high a price we pay to obscure large parts of our thinking, including from ourselves, to avoid detection.
That is how this game works. My expectation is that if you rely on CoT monitoring in ways that exert optimization pressure, it will quickly stop working.
Arvind Narayanan (no it’s not this easy to fix): A few people have asked me if a technical fix for AI model sycophancy is on the cards. In fact, a technical fix for sycophancy is trivial. In many cases all it would take is a tweak to the system prompt.
The reason companies are struggling to get this right is not technical. It’s because most of us want our models to flatter us, even though we’d never admit it and we all think we’re the exception. And it has to be subtle, otherwise we feel insulted by being reminded that we like sycophants. Also, some kinds of sycophancy can have safety implications, such as when the user is struggling with mental health.
If a model developer eliminated sycophancy, their scores on arena evaluations would tank and users would perceive the model as less helpful.
Thomas Larsen (yep it’s largely this way): The main sycophancy threat model is that humans are imperfect raters, and so training AIs with human feedback will naturally lead to the AIs learning to produce outputs that look good to the human raters, but are not actually good.
This is pretty clear in the AI safety literature, e.g. see Without Specific Countermeasures from 2022.
Dealing with this problem seems pretty hard to me: a robust solution in the deep learning paradigm seems like it would involve something like using AI assistance to label outputs without getting tricked by the model that’s being trained, plus understanding of training dynamics/inductive bias to find a training process that finds honest AIs.
In the slowdown branch of AI 2027, hacky solutions like COT monitoring, RLAIF, etc are used on human level systems, but scaling to superintelligence using those techniques would lead to failure, and so there is only a technical fix for sycophancy until after there is a major paradigm shift away from deep learning.
I see there being two closely related but distinct threat models here.
Sycophancy arises because humans are imperfect graders and respond well to sycophancy at least locally, so if you train on human feedback you get sycophancy. Also sycophancy is ever-present in real life and thus all over the training data.
Sycophancy is good for business, so AI companies often are fine with it, or even actively turn that dial looking back at the audience for approval like contestants on The Price is Right.
The first problem is not so easy to technically fix, either with a system prompt or otherwise. Even if you decide sycophancy is bad and you don’t want it, to fully get rid of it you’d have to change everything about how the training works.
This is also one of the areas where I have run the experiment. My entire Claude system prompt is an extended version of ‘do not by sycophantic.’ It… helps. It is definitely not 100% effective.
Roon: if nvidia believed in agi they would never sell a single gpu.
We don’t know what Patrick was responding to here, but yeah:
Patrick McKenzie: Everyone doesn’t believe that, and in part if people were sophisticated they wouldn’t keep saying ELI5 to LLMs then being surprised when an LLM treats them as unsophisticated, to use an example which came up in conversation with @TheZvi.