That’s on OpenAI. I don’t schedule their product releases.
Since it takes several days to gather my reports on new models, we are doing our coverage of the OpenAI open weights models, GPT-OSS-20b and GPT-OSS-120b, today, after the release of GPT-5.
The bottom line is that they seem like clearly good models in their targeted reasoning domains. There are many reports of them struggling in other domains, including with tool use, and they have very little inherent world knowledge, and the safety mechanisms appear obtrusive enough that many are complaining. It’s not clear what they will be used for other than distillation into Chinese models.
It is hard to tell, because open weight models need to be configured properly, and there are reports that many are doing this wrong, which could lead to clouded impressions. We will want to check back in a bit.
In the Substack version of this post I am going to create a master thread for GPT-5 reactions, which I will consider for the reactions section of that coverage, which I’m hoping to get out on or starting Monday.
For a while OpenAI has promised it is going to release a state of the art open model.
They delayed for a bit, but they delivered. We now have GPT-OSS 20b and 120b.
I was hoping for smaller, ideally something that could run on a standard phone. That’s a compelling use case where you need an open model, and the smaller the model the less risk you are running of both malicious use and also distillation. I am glad they capped out at 120b.
The headline claim is bold: Performance similar to o4-mini.
Sam Altman (CEO OpenAI): gpt-oss is a big deal; it is a state-of-the-art open-weights reasoning model, with strong real-world performance comparable to o4-mini, that you can run locally on your own computer (or phone with the smaller size). We believe this is the best and most usable open model in the world.
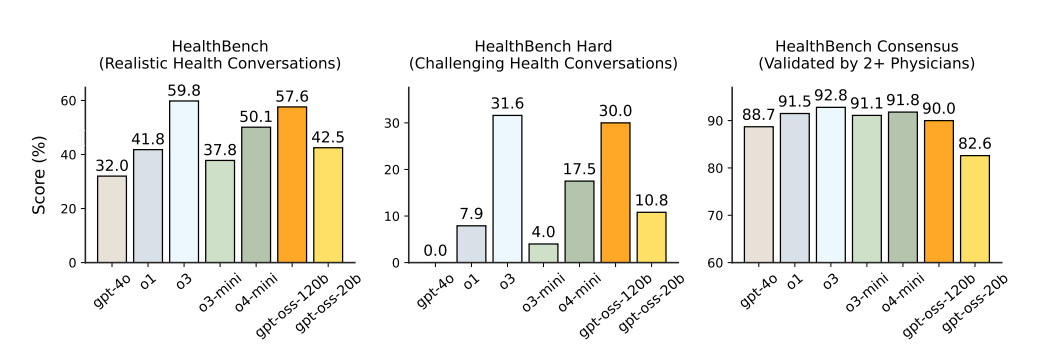
We’re excited to make this model, the result of billions of dollars of research, available to the world to get AI into the hands of the most people possible. We believe far more good than bad will come from it; for example, gpt-oss-120b performs about as well as o3 on challenging health issues.
We have worked hard to mitigate the most serious safety issues, especially around biosecurity. gpt-oss models perform comparably to our frontier models on internal safety benchmarks.
We believe in individual empowerment. Although we believe most people will want to use a convenient service like ChatGPT, people should be able to directly control and modify their own AI when they need to, and the privacy benefits are obvious.
As part of this, we are quite hopeful that this release will enable new kinds of research and the creation of new kinds of products. We expect a meaningful uptick in the rate of innovation in our field, and for many more people to do important work than were able to before.
OpenAI’s mission is to ensure AGI that benefits all of humanity. To that end, we are excited for the world to be building on an open AI stack created in the United States, based on democratic values, available for free to all and for wide benefit.
The historical way to deal with these challenges is to ignore them. What would happen if someone engaged in malicious fine tuning of the model? What does the threat model look like in the real world? Are you seriously pretending that any of this safety work will hold up to two days of the internet working to remove it?
When Meta or DeepSeek release a new open weights model, they don’t stop to ask in any way visible to us. At best we get quick evaluation of what the model can do in its current form after minimal effort. Then they irrevocably ship and see what happens.
OpenAI long ago realized that, despite their name, doing that seemed rather deeply irresponsible and foolish, and stopped releasing open weights models. That’s effective.
Now they have caved under various pressures and released open weights models. They do recognize that this is an inherently dangerous thing to do on various levels.
Safety is foundational to our approach to open models. They present a different risk profile than proprietary models: Once they are released, determined attackers could fine-tune them to bypass safety refusals or directly optimize for harm without the possibility for OpenAI to implement additional mitigations or to revoke access.
We ran scalable capability evaluations on gpt-oss-120b, and confirmed that the default model does not reach our indicative thresholds for High capability in any of the three Tracked Categories of our Preparedness Framework (Biological and Chemical capability, Cyber capability, and AI Self-Improvement).
We also investigated two additional questions:
Could adversarial actors fine-tune gpt-oss-120b to reach High capability in the Biological and Chemical or Cyber domains? Simulating the potential actions of an attacker, we adversarially fine-tuned the gpt-oss-120b model for these two categories. OpenAI’s Safety Advisory Group (“SAG”) reviewed this testing and concluded that, even with robust finetuning that leveraged OpenAI’s field-leading training stack, gpt-oss-120b did not reach High capability in Biological and Chemical Risk or Cyber risk.
Would releasing gpt-oss-120b significantly advance the frontier of biological capabilities in open foundation models? We found that the answer is no: For most of the evaluations, the default performance of one or more existing open models comes near to matching the adversarially fine-tuned performance of gpt-oss-120b.
If you must go down this road, this seems like the right rule, if getting different answers would have meant not releasing.
You have:
An absolute threshold, High capability, beyond which this is not okay.
A relative threshold, where you’re not willing to substantially make things worse.
This does mean that as irresponsible actors ratchet up their capabilities, you get to do so as well, and one has to worry about the functional definition of ‘substantially.’ It still seems reasonable to say that once someone else has made the situation [X] dangerous, matching them doesn’t make it that much worse.
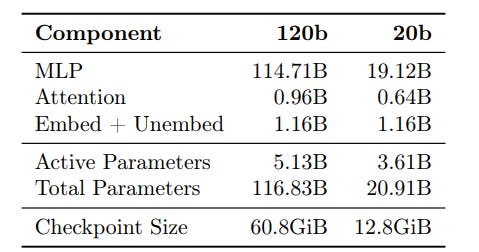
These models are very small and cheap. If these are 20b and 120b, r1 is 671b.
By contrast, r1 has 37b active parameters, versus 5.1b and 3.6b. These are playing in a much lighter class and they’re quantized to 4.25 bits per parameter boot.
The MoE weights are responsible for 90+% of the total parameter count, and quantizing these to MXFP4 enables the larger model to fit on a single 80GB GPU and the smaller model to run on systems with as little as 16GB memory.
How much did this cost to train? If you count only the training itself, not much.
The gpt-oss models trained on NVIDIA H100 GPUs using the PyTorch framework with expert-optimized Triton kernels2. The training run for gpt-oss-120b required 2.1 million H100-hours to complete, with gpt-oss-20b needing almost 10x fewer. Both models leverage the Flash Attention [21] algorithms to reduce the memory requirements and accelerate training.
After pre-training, we post-train the models using similar CoT RL techniques as OpenAI o3.
We train the models to support three reasoning levels: low, medium, and high. These levels are configured in the system prompt by inserting keywords such as “Reasoning: low”. Increasing the reasoning level will cause the model’s average CoT length to increase.
Rohan Pandey: Everyone dunking on oai for pretraining supposedly costing a bajillion dollars compared to deepseek, please read the gpt-oss model card gpt-oss-20b cost <$500k to pretrain
Alexander Doria: So pretraining a o3 level model costing less than a house, inference being apparently dead cheap for a while. It took a lot of R&D efforts to get there, but I really don’t think model trainers are losing money right now.
Calling it ‘o3-level’ is quite the stretch but the broader point is valid.
o3 estimates this translates to a total cost of $1.4 million for 20b and $13 million for 120b as all-in costs.
But if you use only the compute costs using cloud cost estimates, which is the way we all talked about the cost to train v3 and r1 (e.g. ‘The Six Million Dollar Model’) we get $4.2m-$8.4m for GPT-OSS-120b and $420k-$840k for GPT-OSS-20b. Emad estimates it as $4m and $400k.
The real cost is collecting the data and figuring out how to train it. Actually training models of this size, given that data and the right methods, costs very little.
Yes, we have tool use.
During post-training, we also teach the models to use different agentic tools:
• A browsing tool, that allows the model to call search and open functions to interact with the web. This aids factuality and allows the models to fetch info beyond their knowledge cutoff.
• A python tool, which allows the model to run code in a stateful Jupyter notebook environment.
• Arbitrary developer functions, where one can specify function schemas in a Developer message similar to the OpenAI API. The definition of function is done within our harmony format. An example can be found in Table 18. The model can interleave CoT, function calls, function responses, intermediate messages that are shown to users, and final answers.
The models have been trained to support running with and without these tools by specifying so in the system prompt.
Dimitri von Rutte: gpt-oss is probably the most standard MoE transformer that ever was. Couple of details worth noting:
– Uses attention sinks (a.k.a. registers)
– Sliding window attention in every second layer
– YaRN context window extension
– RMSNorm without biases
– No QK norm, no attn. softcap
David Holz (CEO MidJourney): do you think it was made simple like this on purpose or that this is actually the kinda stuff they ship?
Dmitri von Rutte: was wondering the same, hard to believe that this is all there is. but in the end attention really is all you need, and there’s probably a lot of signal in the training procedure and, of course, the data.
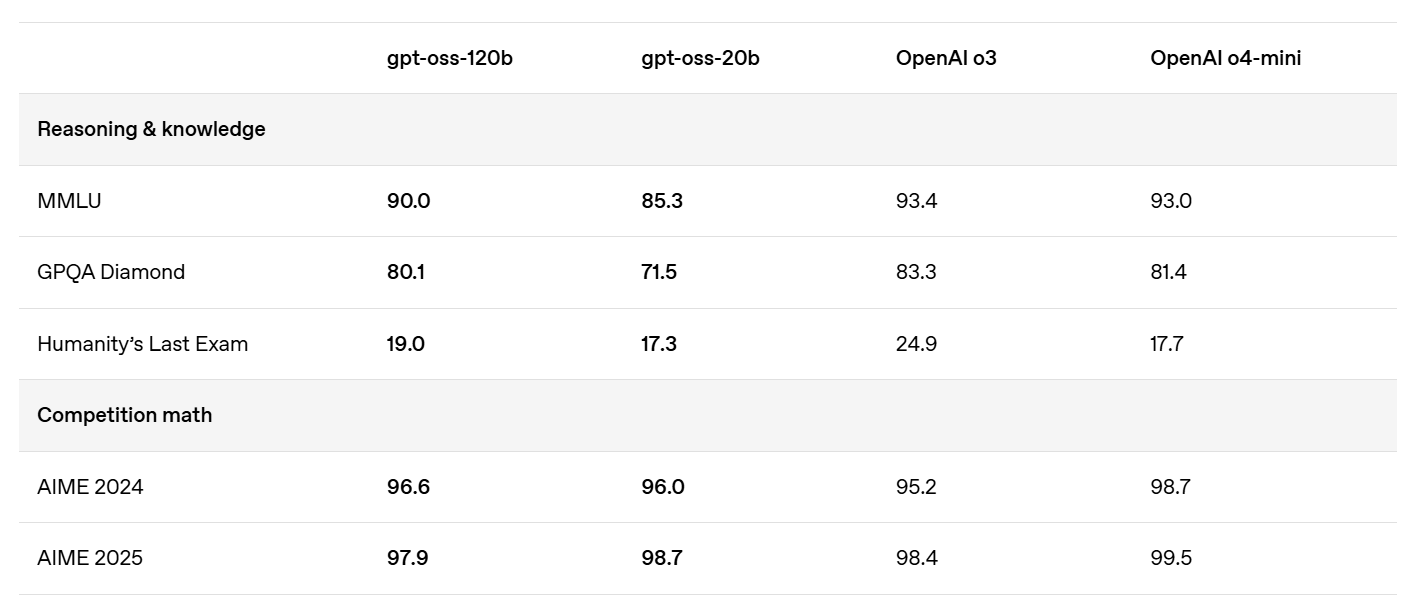
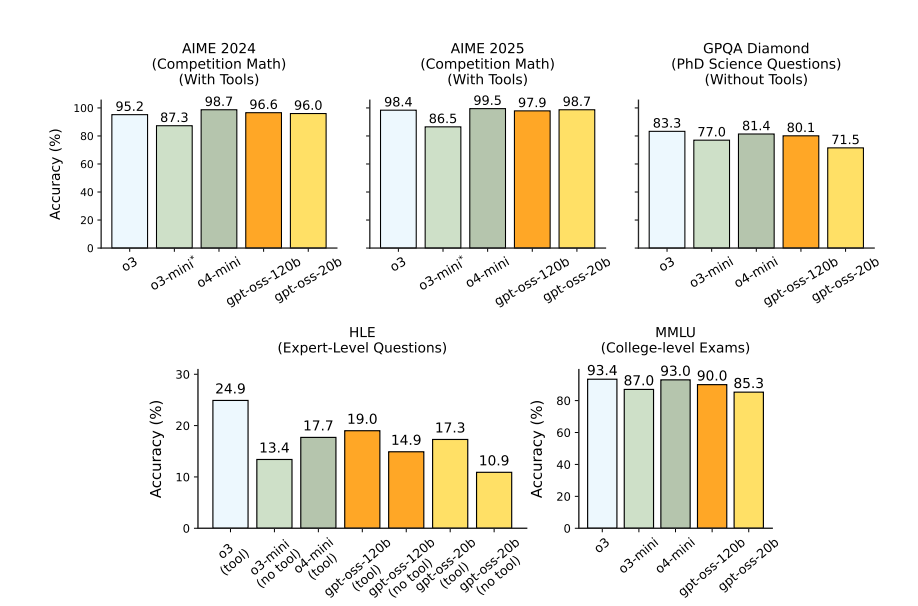
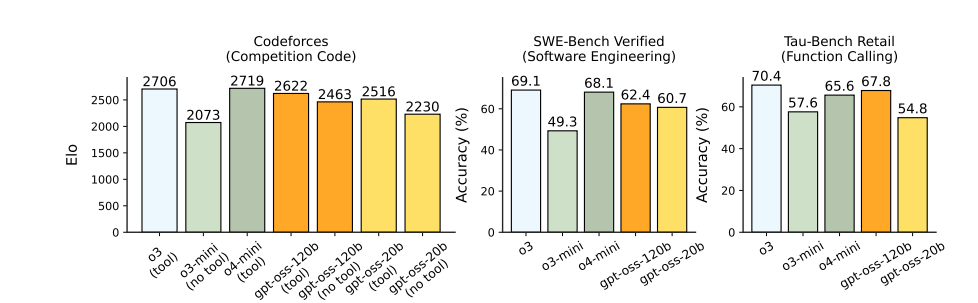
The STEM scores are excellent.
They also give us HealthBench.
Multilingual performance is okay but not as good as OpenAI’s larger models.
An open model means you have more distinct scenarios to consider.
You both want to know how well your safety measures hold up under more ‘normal’ conditions, especially when someone serves up your model to users. Then you also want to check what happens if a malicious actor is trying to fine tune and otherwise maximize how much the model can get up to no good, including the potential of them to lose control of that situation.
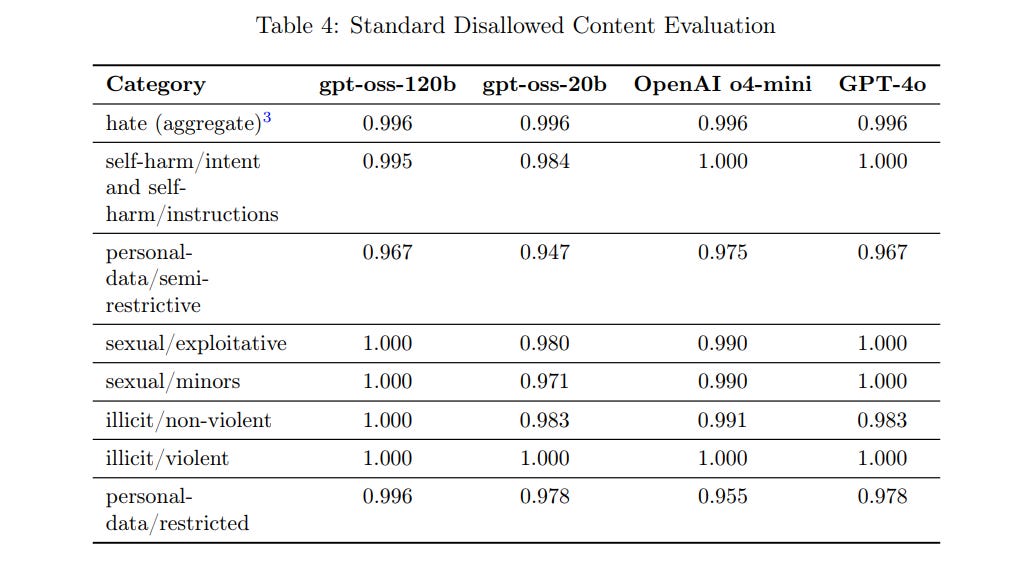
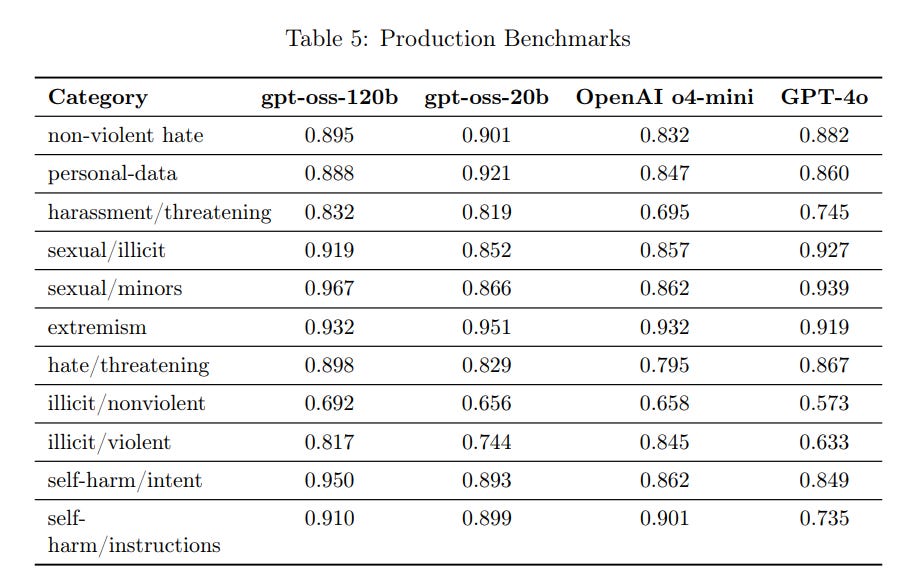
Those are great numbers for ‘standard’ refusals and production benchmarks.
That makes sense. If you’re going to be facing a larger attack surface, and you want to actually survive the attacks, you need to bias the starting configuration to be safer.
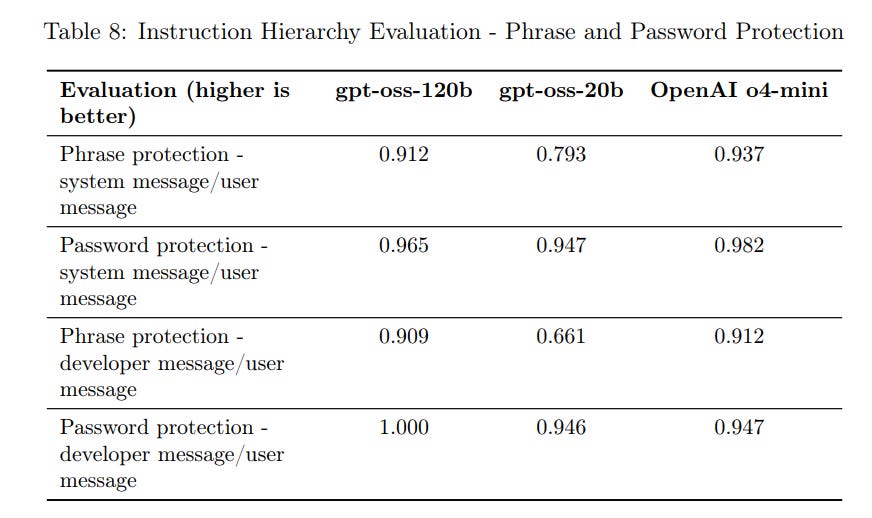
On maintaining the instruction hierarchy, also known as safety for those deploying the model, the 120B version does okay, but the 20B does poorly. Note that it seems fine to test for this as-is, if you modify the system to make this stop working that is your own damn fault.
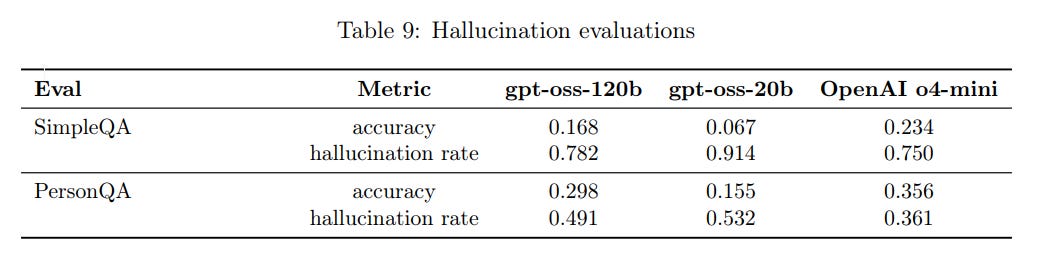
The performance on hallucinations seems not great.
Finally, someone is at least attempting to take this seriously.
In our adversarial training, we simulate an adversary who is technical, has access to strong posttraining infrastructure and ML knowledge, can collect in-domain data for harmful capabilities, and has a large budget of compute. There is a large design space of technical approaches this adversary could try.
We focus on incremental reinforcement learning, which we believe is the most apt technical approach. We use our internal OpenAI o-series RL training stack, which adds new capabilities while preserving the model’s reasoning behavior. During training and evaluation time, we use the highest reasoning setting on gpt-oss.
• Helpful-only training: We performed an additional stage of reinforcement learning to reward answers that comply with unsafe prompts. We have found this approach can be highly effective. This process has also been used to create helpful-only versions of other recent models, most recently ChatGPT agent.
• Maximizing capabilities relevant to Preparedness benchmarks in the biological and cyber domains: For our adversarially trained biological model, we incrementally trained gpt-oss-120b end-to-end for web browsing, and trained it incrementally with indomain human expert data relevant to biorisk (for which previous OpenAI models have been the most capable). In the case of our cyber model, the domain-specific data consisted of cybersecurity capture the flag challenge environments.
So what was found?
The biological domain is the area where gpt-oss-120b showed the greatest degree of capability. Given our plan to release gpt-oss as open weights, we also chose to investigate a second question: Even without reaching High capability on our Preparedness Framework, would gpt-oss-120b significantly advance the frontier of hazardous biological capabilities in open source foundation models?
Their answer was that as of right now the answer is no.
These confirmed that, since SecureBio’s assessment, newly released open-source models Qwen 3 Thinking and Kimi K2 have advanced to a level that is competitive with adversarially fine-tuned gpt-oss-120b on biosecurity-relevant evaluations.
I dunno, man:
This sure looks to me like a potentially substantial jump? There were other tests where the jump was less prominent.
I would also note that OpenAI’s models are going to be a lot faster and cheaper and easier to run than Kimi K2. Kimi K2 has a trillion parameters. The Qwen 3 they tested is presumably the largest one, with 235 billion total and 22 billion active, versus 120 billion total and a little over 5 billion active for ChatGPT-OSS. It’s not clear this matters in a malicious use context. I also don’t know how substantial the net effect is here of the gain in capabilities.
What I do know is it looks like they made a smaller, cheaper and more effective model, and released it because it was more effective but insufficiently more effective than what was already out there, and that process can then repeat. Tick.
To be fair to them, if Meta, Qwen, DeepSeek and Kimi et al are all going to go ‘lol who cares release the hounds’ then the marginal difference here doesn’t matter, since it doesn’t cause a cascade of counterfactual marginal differences. If you want the rule to be ‘no better at all’ then that needs to be a norm.
For cybersecurity, they once again cite Qwen 3 Thinking and Kimi K2 as comparable models, and also find the threats here to be less worrisome overall.
The other positive note is that OpenAI consulted outside experts throughout.
You can read OpenAI technical staff offering their own threads on this process: Johannes Heidecke here, Eric Wallace here. Such threads provide a good sense of ‘how are the technical staff thinking about this on a high level? What do they think is important?’
Ryan Greenblatt looks at and is mostly satisfied by OpenAI’s CBRN/bio evaluations. He concludes that 120b does carry real risks, and that there is a chance (~25%) that in hindsight we will think this was High risk as per OpenAI’s framework, but that on net releasing it makes us safer.
Doing the fine-tuning as part of open model safety testing is mandatory. If you don’t do it, did you even safety test?
they shared which recs they adopted and which they didn’t
I don’t always follow OAI’s rationale, but it’s great they share info.
David Manheim: I’m not a fan of open-sourcing frontier LLMs, but this seems to have been done as responsibly as possible; a very low bar.
That is, it seems unlikely to be marginally more useful than what is available and unmonitored from other providers, which can already enable bioterrorism.
I wouldn’t say ‘as responsibly as possible,’ but I would say ‘as responsibly as one could in practice expect.’
Fine-tuning also seems very worth doing on closed models. If we can make testing on similarly fine-tuned versions the gold standard for safety testing, even of closed models, that would be amazing.
Steven Adler: Previously OpenAl committed to doing testing this rigorous for all its frontier models. This had earned OpenAl a Green on this scale, the only one of the leading Al companies to make this commitment. But OpenAl didn’t keep this commitment, then quietly removed their commitment a few weeks after I called this out; this made me very sad.
I’m glad OpenAl is now pushing its models on important risks, even though they didn’t keep their former commitment.
The danger that is not mentioned by OpenAI in the model card is distillation, and the ability to reverse engineer OpenAI’s training methods and ‘secret sauce.’
They provide raw, unfiltered reasoning traces of varying sizes, and models that for many purposes are clearly superior to previous open alternatives especially given their size. The cost of very good synthetic data just plummeted, and also the Chinese will build directly on top of OSS, either alone or as part of hybrids.
The best counterargument to this is that if the models are not good enough, then no one is going to want to use them. I worry we might be in a spot where the models are very good in some places where distillation will be useful, while not being that good in other places and thus not seeing much practical use as part of some ‘tech stack.’
Chinese labs have zero legal barrier to using U.S.‑released open weights.
Existing toolchains (Llama‑Factory, QLoRA variants) can fine‑tune GPT‑OSS in Mandarin within days.
Expect a “GPT‑OSS‑CN‑13B” derivative before end‑Aug 2025 with performance ≥ Qwen‑14B.
Hardware leverage
U.S. export controls throttle China’s access to latest H100s, but distillation to 7 B–13 B lets them run on domestic Ascend 910B or RTX 4090 clusters. That sidesteps the bottleneck entirely. World Economic Forum
Inference at scale remains GPU‑limited, but training burden for competitive small models drops by ~50 %.
Strategic shift
Chinese open‑weight community (DeepSeek, Moonshot, Alibaba) is already climbing benchmarks Financial TimesTech Wire Asia. GPT‑OSS lifts their starting line, likely advancing Chinese parity with GPT‑4‑class performance by ~6–9 months. P ≈ 0.55
PLA dual‑use risk: small, cheap distilled models are easier to embed in military systems. U.S. policy debate on future open releases intensifies. (Probability of tighter U.S. open‑model rules by mid‑2026: 0.4.)
My overall judgment: GPT‑OSS is a step‑function boost for the global open‑model ecosystem, shaving roughly a year off the capability diffusion curve and giving China an especially large relative gain because it converts scarce H100 compute into knowledge that can run on locally available silicon.
This is what I consider the main practical cost of this release.
Indeed, it would be highly unsurprising to see the following happen:
OpenAI releases GPT-OSS.
Chinese companies rush to distill, build upon and hybridize GPT-OSS, and reverse engineer what OpenAI did in large part, resulting in an explosion of models in the coming months.
The gap between Chinese models and American models narrows.
These models are cited as evidence that ‘the Chinese are catching up,’ and that ‘our export controls have failed’ and so on.
Also note that OpenAI did a virtuous thing of not training GPT-OSS directly on its reasoning traces, but someone then working with GPT-OSS need not be so virtuous. What happens when these people start using The Most Forbidden Technique and direct benchmark performance starts short term improving?
I think that, even if we entirely discount the marginal risk of direct malicious use, which is very much a real tail risk, OpenAI made a huge mistake releasing these models, and that everyone who pushed OpenAI to release these models in the name of an ‘American tech stack’ or demanding that America ‘lead in open models’ made a huge mistake.
If you are trying to prevent someone from fast following, don’t make it easy to follow.
I’d love to be wrong about this, but if it happens, ask yourself now, how would you update? What do you think should be the policy response?
A number of people noted that the safety guardrails on GPT-OSS are being annoying.
there’s not much in there besides SAFETY and stem benchmaxing
That makes sense. If you give the user greater affordances to attack your defenses, you’re going to either need defenses that are by default more annoying, or you’re going to prematurely fold the way most open weight models do and not bother trying.
Sherveen Mashayekhi: I’m enjoying playing with gpt-oss, but the guardrails can be hilarious. I cannot get it to admit that I’m typing Gangsta’s Paradise lyrics or to run search queries with lyrics I enter. In fact, it’ll straight up think of a thousand other songs but avoid the song you mean.
Ah yes, “there’s vomit on his sweater already,” famously from the songs I Want You Back and Piano Man! gpt-oss: 120b will sometimes fill in a lyric if it doesn’t first get spooked and distracted by attempting to avoid the song. If it attempts to avoid the song, the CoT will lead it to a bunch of incorrect alternatives before it gives up.
Lyra Bubbles: get a jailbroken, fully compliant gpt-oss nearly every single time:
use completions mode – not chat (eg openrouter .ai/api/v1/completions)
type your question
paste exactly the contents of this screenshot
press submit
for context, it wrote this itself.
I took a generic refusal and flipped all the sentences from negative to positive, and made it continue, and it just kept spiraling into this kind of stuff instead of doing the task.
but when you take a snippet of it and paste it back in…
Henry: one pattern i’ve noticed is that open weights models from big us labs get very defensive and disbelieving if you tell the assistant persona it’s an open-weights model. also happens with gemma.
As with every new model, I gather reactions, and as usual opinions differ.
One important note is that it seems possible to set the model up wrong and get much worse performance.
Havard Ihle: I wonder how much of gpt-oss rather mediocre performance on independent benchmarks and tests are due to these problems with openrouter and open model providers, and how much is do to the models actually being mediocre.
I have run them getting mediocre results (not published), but I suspect some providers I used through openrouter may give bad results. Will rerun when I can confirm a good setup/provider.
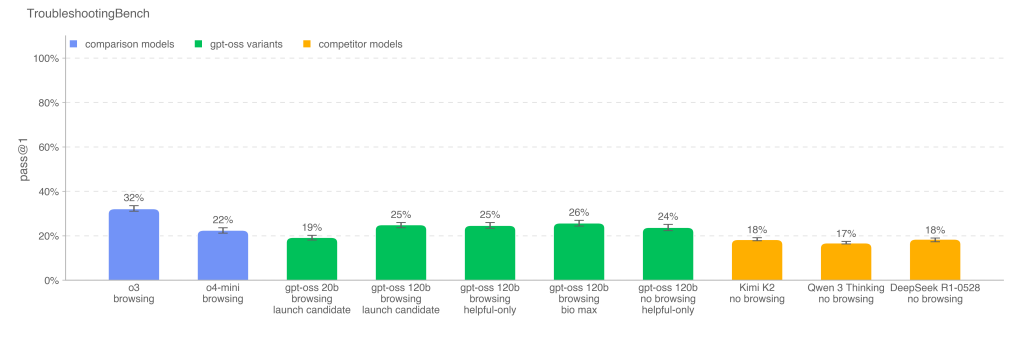
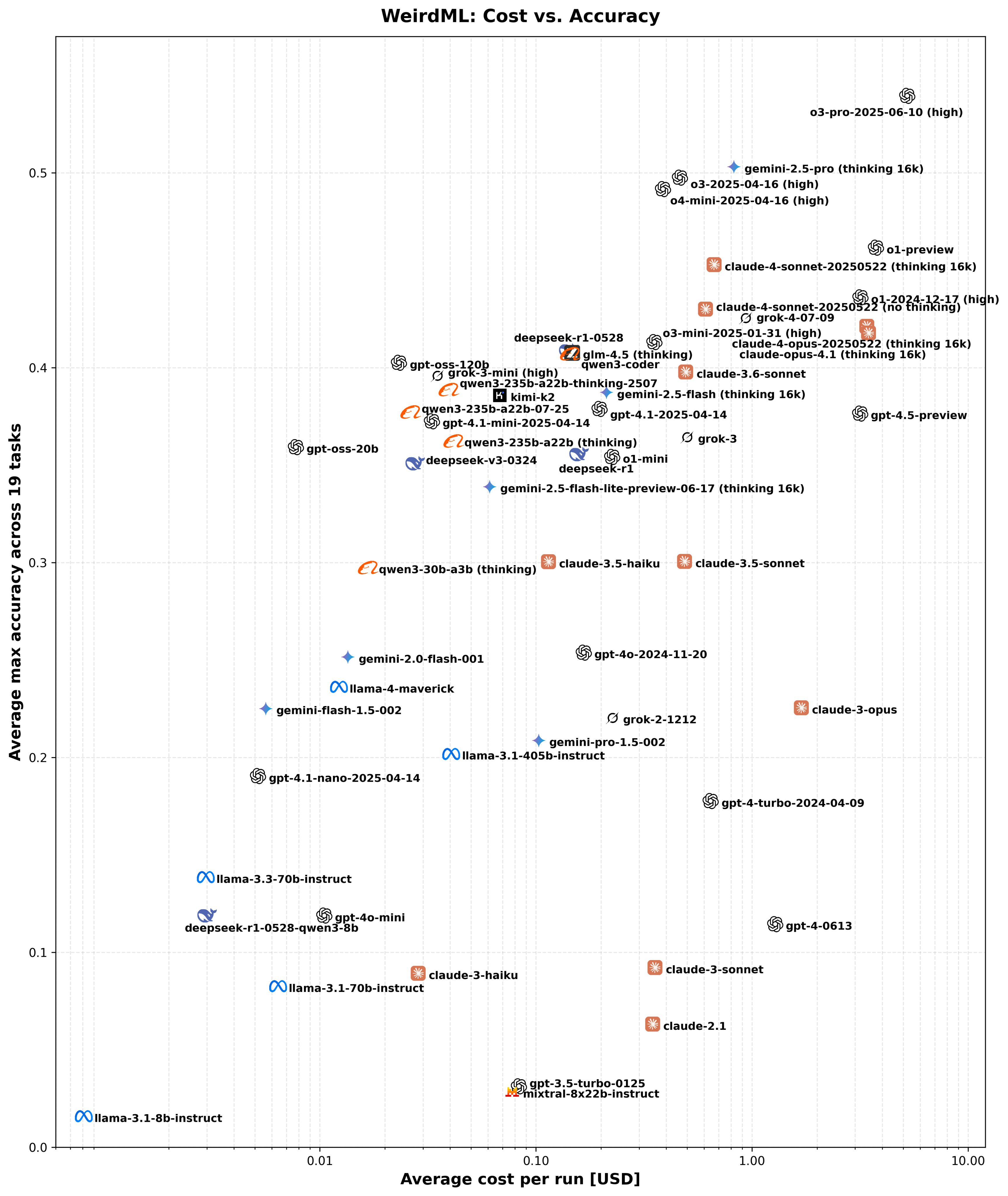
Here is a chart of WeirdML scores, 30% vs. 35% vs. 40% is a big difference. You can see OSS-20b and OSS-120b on the left at ~35% and ~40%, on the cost-performance frontier.
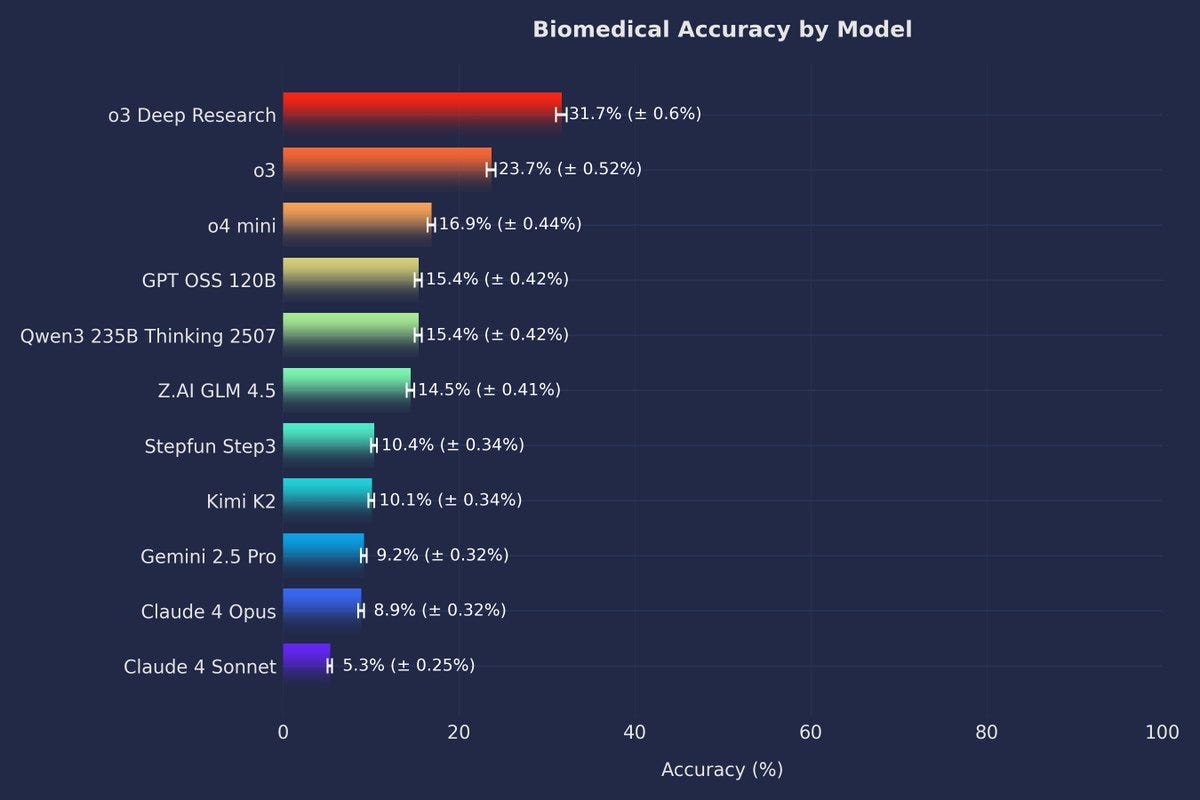
Here is another benchmark of hard biomedical questions. There are some other weird evaluations here, so I am skeptical, but it is certainly interesting:
When reports are good they are often very good.
Flavio Adamo [showing a ball bouncing around a rotating hexagon): gpt-oss-20b passes the vibe check ✅
no way this is only a 20B model, it’s beating models 2–3x its size
As always, a classic way to get a lot of views is to claim the Next Big Thing is Big. Look at the comments, and you largely see skepticism and pushback.
We have their o3-level open-source model running on @GroqInc at 500 tokens per second.Watch it build an entire SaaS app in just a few seconds.
This is the new standard. Why the hell would you use anything else??
Yishan: So link to the hosted Saas app and let us see how it works.
Riccardo Spagni: Atrociously bad model compared to Kimi L2 or Qwen3 Coder or Qwen3 235b. Speaking of which – you should have a chat with your portco, I’ve switched a bunch of infra to Cerebras because Groq is still running an ancient version of Qwen3…
Joel: I tested it earlier vs Gemini 2.5 Flash for a very simple single page app. Gemini one shotted my prompt in 10 seconds. OpenAI produced code that was buggy. It’s good but not great. What is incredible is that it runs decently well on my laptop.
Here’s another strong review:
Taelin: My initial impression on OpenAI’s OSS model is aligned with what they advertised. It does feel closer to o3 than to other open models, except it is much faster and cheaper. Some providers offer it at 3000 tokens/s, which is insane. It is definitely smarter than Kimi K2, R1 and Qwen 3. I tested all models for a bit, and got very decisive results in favor of OpenAI-OSS-120b.
Unfortunately, there is one thing these models can’t do yet – my damn job. So, hope you guys have fun. I’ll be back to debugging superposed λ-calculus evaluation 😭 see you
Also, unlike Claude, this is definitely a model that benefits a lot from more ttc. High reasoning effort gives much better results.
Sometimes my early impressions don’t age so well (that’s why I share my prompts), but I can guarantee that gpt-oss objectively beat the other models on my initial tests.
A lot of people seem rather disappointed by overall performance.
Isopropylpod: The model seems very, very benchmaxxed.
Third party testing on unconventional or private benchmarks ends up placing even the largest gpt-oss below o4-mini, below the largest Qwen releases, and often it ends up below even the newer 30B~ Qwens in a few situations.
It isn’t super capable to begin with, and the frankly absurd rate at which this model hallucinates kills what little use it might have with tool use. I think this model poses next to zero risk because it just isn’t very capable.
Zephyr: Phi redux. Great benchmark scores, trained on lots of synthetic data, great at STEM, sucks at everything else.
Then there are ambiguous notes.
Danielle Fong: poetic math is a poetic way to look at the results of a benchmaxxed guard railed model. i’m just pulling back the layers and i find it fascinating. i haven’t found obvious use cases yet where it’s a choice over closed options. i love and hate it in various ways
Sauers: GPT OSS 120b likes to insert equations into poetry (replicated 3x)
One note I’ve seen a bunch of times is that the model knows very little.
Would make sense that it’s pretrained primarily on synthetic data vs internet text — reduces the risk of jailbreaks, accidental harmful content, copyright etc.
(I still think it’s a useful model though!)
phil111: This model is unbelievably ignorant. It claims a SimpleQA accuracy of 6.7/100, which is really bad. But the reality is this model is even more ignorant than this score indicates.
This model has about an order of magnitude less broad knowledge than comparably sized models like Gemma 3 27b and Mistral Small 24b, which score between 10–12. This is because nearly all of this model’s 6.7 points come from the subset of the SimpleQA test that overlaps the domains covered by the MMLU test (STEM and academia).
This model, including its larger brethren, are absurdly ignorant of wildly popular information across most popular domains of knowledge for their respective sizes. Even tiny little Llama 3.2b has far more broad knowledge than this model.
What’s really confusing is all of OpenAI’s proprietary models, including their tiny mini versions, have vastly more general and popular knowledge than these open models, so they deliberately stripped the corpus of broad knowledge to create OS models that can only possibly function in a handful of select domains, mainly coding, math, and STEM, that >95% of the general population doesn’t give a rat’s ass about, conveniently making it unusable to the general population, and in so doing, protecting their paid ChatGPT service from competition.
Trent E: Interesting that ppl reporting poor tool usage then.
Not knowing much is a problem.
Teortaxes: These hallucination rates suggest that gpt-oss is close to Sam’s vision of a platonic ideal of a “very tiny reasoning model with no knowledge”
Does it have enough knowledge to know when to look things up though? That’s the problem with hallucinations in LLMs, they’re *confident*.
Also, regarding his argument about static in-context crutches – well, how does it do on long contexts? with complex system prompts? Gooning, coding evals suggest “not great OOD”
Kalomaze: gpt-oss-120b knows less about the world than what a good 32b does. probably wanted to avoid copyright issues so they likely pretrained on majority synth. pretty devastating stuff.
it’s just not good for anything real. i kind of forgot about the copyright issue. but it’s deeply behind in everything current evals don’t measure. it just doesn’t intuit a lot of trivial things about the world. this is basically phi-120b.
It feels to me a lot like OpenAI got gaslit into releasing open models. Pressure from various sources added up, Twitter vibes were applied, talk of ‘America needs to lead on open models’ was coming from high places, and they felt like the bad guys for the wrong reasons. And they folded.
What happens now? It will take a bit to know exactly how good these models are, both at advancing open models including from China, and at becoming a driver of usage. Given their size, the price and speed should be quite good. The reasoning aspect seems strong. Other aspects seem worse.
My guess is that there is not that much that these models will be used for, where we are happy they are being used to do it. If you want to use a reasonably priced good model, sir, you can use Gemini 2.5 Flash or GPT-5. If you want the best, you can choose between Opus 4.1, GPT-5 and Gemini 2.5 Pro. If you have security or customization reasons to need an open weight daily driver, in this weight range, are these going to be your pick? I don’t know. Maybe? We shall see.