“Temu sound wall” not enough to quell fury over xAI’s power plant.
For miles around xAI’s makeshift power plant in Southaven, Mississippi, neighbors have endured months of constant roaring, erupting pops, and bursts of high-pitched whining from 27 temporary gas turbines installed without consulting the community.
In a report on Thursday, NBC News interviewed residents fighting to shut down xAI’s turbines. They confirmed that xAI operates the turbines day and night, allegedly tormenting residents in order to power xAI founder Elon Musk’s unbridled AI ambitions.
Eventually, 41 permanent gas turbines—that supposedly won’t be as noisy—will be installed, if xAI can secure the permitting. In the meantime, xAI has erected a $7 million “sound barrier” that’s supposed to mitigate some of the noise.
However, residents told NBC News that the wall that xAI built does little to quiet the din.
Taylor Logsdon, who lives near the power plant, said that neighbors nearby jokingly call it the “Temu sound wall,” referencing the Chinese e-commerce site known for peddling cheap, rather than high-quality goods. For Logsdon, the wall has not helped to calm her dogs, which have been unsettled by sudden booms and squeals that videos show can frequently be heard amid the turbines’ continual jet engine-like hum. Some residents are just as unsettled as the dogs, describing the noises from the plant as “scary.”
A nonprofit environmental advocacy group, the Safe and Sound Coalition, has been collecting evidence, hoping to raise awareness in the community to block xAI from obtaining permits for its permanent turbines. The group’s website links to videos documenting the noise, noise analysis reports, and public records showing how challenging it’s been to track xAI’s communications with public officials.
Safe and Sound Coalition video documents constant roars after a “loud bang” signaled “something popped off.”
For example, public records requests to the city of Southaven seeking information on xAI exemptions to noise ordinances or communications about the sound wall turned up nothing. A director overseeing the city’s planning and development claimed that the office was not “involved with the noise barrier wall” and could provide no details. Similarly, a permit clerk for the city’s building department confirmed there were no documents to share.
Asked for comment, a spokesperson for the coalition told Ars that the “absence of documentation raises transparency concerns.”
“When decisions with community impact are made without accessible records, it creates an accountability gap and limits the public’s ability to understand how those decisions were evaluated or authorized,” the spokesperson said.
An IT worker who co-founded the coalition, Jason Haley, told NBC News that xAI’s wall showed that the city could have required the company to do more to prevent noise pollution before upsetting community members.
“If you knew the noise was going to be an issue, put in a sound wall first,” Haley said. “Do some other stuff first before you torture us. That’s not that hard of an ask.”
xAI did not immediately respond to Ars’ request to comment. According to NBC News, the company has yet to make public a noise analysis that it conducted.
xAI’s turbines spark other concerns
xAI has maintained that it follows the law when rushing at breakneck speeds to build infrastructure to support its AI innovations. In Southaven, xAI was approved to operate the temporary gas turbines at the power plant for 12 months, without any additional permitting required.
Now it’s seeking permits for the permanent turbines, which residents worry could be nearly as loud, while possibly introducing more smog into an area that’s mostly homes, churches, parks, and schools, the Safe and Sound Coalition’s website said.
Pollutants could increase risks of asthma, heart attacks, stroke, and cancer, a community flyer the coalition distributed warned, urging attendance at a public meeting where residents could finally air their complaints (a meeting which NBC News’ report thoroughly documented). The flyer also suggested that the city’s main drinking water supply could be affected and perhaps tainted if the power plant’s wastewater contains toxic chemicals, since there isn’t a graywater recycling plant nearby. For residents, it’s hard to tell if things will ever get better. One noise analysis the coalition shared found that the daily sound of the turbines was higher on an “annoyance scale” than when entire neighborhoods set off New Year’s Eve fireworks.
“Our water, air, power grid, utility bills, property values, and health are all at risk,” the Safe and Sound Coalition’s website said. “We’re already facing toxic pollution and relentless industrial noise. There is no clear oversight, no transparency, and no plan to protect the people living nearby.”
The coalition expects that if enough community members protest the plant, the permitting agency will deny xAI’s permits and order any potentially dangerous turbines to be shut down. But other groups are taking a different approach, considering suing xAI if it continues operating the unpermitted gas turbines in Southaven.
Earlier this month, the Southern Environmental Law Center (SELC) joined the NAACP in sending xAI a notice of intent to sue. In that letter, groups warned that the Environmental Protection Agency (EPA) recently changed a rule that they argued now requires permits for the temporary turbines. They gave xAI 60 days to respond.
The same groups previously sent a legal threat to xAI, opposing alleged data center pollution in Memphis, Tenn. xAI eventually secured permits for some of the gas turbines sparking scrutiny there, which many locals found “devastating.” Further concerning, residents relying on drone imagery—with no other way to keep track of how many turbines xAI was running—warned that the permits only covered 15 of 24 turbines on site.
EPA shrugs off xAI permitting concerns
It’s unclear whether the SELC can win if it takes xAI to court, or whether the EPA would ever intervene if that action could be construed as delaying Trump’s order to rush permitting and build as many data centers as fast as possible to power AI.
The SELC declined Ars’ request to comment, but the EPA’s administrator, Lee Zeldin, seemed to negate that argument in an interview with Fox Business in January. Asked directly about xAI’s gas turbines, Zeldin confirmed that the EPA was working closely on permitting with local officials in Southaven and Shelby County—where xAI built a massive data center sparking protests.
Rather than suggesting that the EPA might be preparing to review xAI’s unpermitted gas turbines, Zeldin emphasized that for Donald Trump, it “is about getting permits done faster.”
“EPA has the power to slow things down; EPA also has the power to speed things up, and that’s where the Trump EPA is,” Zeldin said.
Permitting for the Southaven project’s permanent gas turbines may be approved as soon as next month, NBC News reported.
Residents skeptical second sound barrier will be better
For Southaven, xAI’s power plant—along with a planned data center, which Musk has dubbed “MACROHARDRR” to mock Microsoft—represents a chance to surge the local economy. That prospect seemingly swayed government support for the projects, which has apparently not waned in the face of mounting protests.
When Musk bought the dormant power plant, “it was the largest private investment in state history,” Tate Reeves, Mississippi’s Republican governor, claimed. Additionally, xAI’s affiliated company that’s behind the projects, MZX Tech, donated $1.38 million to the city’s police department, NBC News reported. Both the plant and the data center “are expected to bring in millions of dollars and new jobs,” Reeves said.
For Southaven residents, the only hope they have that the noise may die down any time soon is that construction on another sound barrier will be finished in the next two months, NBC News reported. Supposedly, engineers were taking time to study “what type of sound barrier would be most effective” amid complaints about the current sound barrier.
A spokesperson for the Safe and Sound Coalition told Ars that the group remains “skeptical” that the new wall will be any better than the first sound barrier.
“To our understanding, sound barriers can reduce certain frequencies under controlled conditions, but turbine noise involves low-frequency sounds and tonal components that often reach beyond barriers,” the coalition’s spokesperson said. “The most effective method for reducing industrial noise exposure is typically distance from residential areas, which is not a mitigation option in this scenario given the facility’s proximity to homes.”
The coalition urged xAI to be transparent and to share data backing mitigation claims if it wants the community to believe that the second sound barrier will make any difference.
“Without transparent modeling, validated field measurements, and independent verification, it is difficult to assess whether the barrier will meaningfully address the ongoing nuisance experienced by nearby residents,” the coalition’s spokesperson said. “Mitigation claims are only meaningful if they are supported by transparent data.”
Mayor labels protestors Musk haters
At least one city official, Mayor Darren Musselwhite, has suggested that community backlash is “political.” Although he acknowledged that the noise was a “legitimate concern,” he also claimed on Facebook that some people protesting xAI’s facility were simply Elon Musk haters, NBC News reported.
“Southaven is now under attack by all who choose to oppose Elon Musk because of his high-profile political stances,” Musselwhite wrote.
Instead, they’re worried that local officials seeing dollar signs have potentially let xAI exploit loopholes to pollute communities without any warning. The community flyer from the Safe and Sound Coalition criticized what they viewed as shady behavior from local officials:
“This project was started behind our backs, with zero community input. Local officials have repeatedly downplayed concerns, spun the facts, and misled residents about the true impacts and the deals made with xAI. Many people only found out after the turbines were up and running.”
The coalition’s spokesperson told Ars that a health impact analysis published on behalf of the SELC provides “meaningful insight” into the biggest health risks. That concluded that using the EPA’s COBRA health impact model, emissions from running 41 permanent turbines at the Southaven plant “are estimated to result in $30–$44 million per year in health-related damages, including costs from premature deaths, hospital visits, and lost productivity. Over a typical 30-year operating life, these impacts would amount to approximately $588–$862 million in cumulative discounted public-health costs, borne largely by residents of Tennessee and Mississippi.”
Additionally, the largest amount of harmful pollutants increases are expected to be “concentrated in communities that are disproportionately Black, highly socially vulnerable, and have elevated baseline asthma prevalence,” the report said.
If the permits are issued, the Coalition’s spokesperson told Ars that the group expects to continue gathering reports of “firsthand experiences” from nearby residents, which will “continue to provide valuable information regarding ongoing impacts.” The group plans to continue engaging with officials and pushing for greater accountability and transparent monitoring, as well as documenting noise conditions, reviewing emissions reports, and collecting independent data where feasible.
“The Coalition’s focus is long-term community protection, which means tracking compliance, advocating for corrective action if standards are not met, and ensuring residents have access to accurate information about environmental and health impacts,” the spokesperson said. “Permit approval would not resolve community concerns; it would shift our focus toward ongoing oversight and enforcement.”
Ashley is a senior policy reporter for Ars Technica, dedicated to tracking social impacts of emerging policies and new technologies. She is a Chicago-based journalist with 20 years of experience.
That guest network you set up for your neighbors may not be as secure as you think.
Credit: Getty Image | BlackJack3D
Credit: Getty Image | BlackJack3D
It’s hard to overstate the role that Wi-Fi plays in virtually every facet of life. The organization that shepherds the wireless protocol says that more than 48 billion Wi-Fi-enabled devices have shipped since it debuted in the late 1990s. One estimate pegs the number of individual users at 6 billion, roughly 70 percent of the world’s population.
Despite the dependence and the immeasurable amount of sensitive data flowing through Wi-Fi transmissions, the history of the protocol has been littered with security landmines stemming both from the inherited confidentiality weaknesses of its networking predecessor, Ethernet (it was once possible for anyone on a network to read and modify the traffic sent to anyone else), and the ability for anyone nearby to receive the radio signals Wi-Fi relies on.
Ghost in the machine
In the early days, public Wi-Fi networks often resembled the Wild West, where ARP spoofing attacks that allowed renegade users to read other users’ traffic were common. The solution was to build cryptographic protections that prevented nearby parties—whether an authorized user on the network or someone near the AP (access point)—from reading or tampering with the traffic of any other user.
New research shows that behaviors that occur at the very lowest levels of the network stack make encryption—in any form, not just those that have been broken in the past—incapable of providing client isolation, an encryption-enabled protection promised by all router makers, that is intended to block direct communication between two or more connected clients.
The isolation can effectively be nullified through AirSnitch, the name the researchers gave to a series of attacks that capitalize on the newly discovered weaknesses. Various forms of AirSnitch work across a broad range of routers, including those from Netgear, D-Link, Ubiquiti, Cisco, and those running DD-WRT and OpenWrt.
AirSnitch “breaks worldwide Wi-Fi encryption, and it might have the potential to enable advanced cyberattacks,” Xin’an Zhou, the lead author of the research paper, said in an interview. “Advanced attacks can build on our primitives to [perform] cookie stealing, DNS and cache poisoning. Our research physically wiretaps the wire altogether so these sophisticated attacks will work. It’s really a threat to worldwide network security.” Zhou presented his research on Wednesday at the 2026 Network and Distributed System Security Symposium.
Paper co-author Mathy Vanhoef, said a few hours after this post went live that the attack may be better described as a Wi-Fi encryption “bypass,” “in the sense that we can bypass client isolation. We don’t break Wi-Fi authentication or encryption. Crypto is often bypassed instead of broken. And we bypass it ;)” People who don’t rely on client or network isolation, he added, are safe.
Previous Wi-Fi attacks that overnight broke existing protections such as WEP and WPA worked by exploiting vulnerabilities in the underlying encryption they used. AirSnitch, by contrast, targets a previously overlooked attack surface—the lowest levels of the networking stack, a hierarchy of architecture and protocols based on their functions and behaviors.
The lowest level, Layer-1, encompasses physical devices such as cabling, connected nodes, and all the things that allow them to communicate. The highest level, Layer-7, is where applications such as browsers, email clients, and other Internet software run. Levels 2 through 6 are known as the Data Link, Network, Transport, Session, and Presentation layers, respectively.
Identity crisis
Unlike previous Wi-Fi attacks, AirSnitch exploits core features in Layers 1 and 2 and the failure to bind and synchronize a client across these and higher layers, other nodes, and other network names such as SSIDs (Service Set Identifiers). This cross-layer identity desynchronization is the key driver of AirSnitch attacks.
The most powerful such attack is a full, bidirectional machine-in-the-middle (MitM) attack, meaning the attacker can view and modify data before it makes its way to the intended recipient. The attacker can be on the same SSID, a separate one, or even a separate network segment tied to the same AP. It works against small Wi-Fi networks in both homes and offices and large networks in enterprises.
With the ability to intercept all link-layer traffic (that is, the traffic as it passes between Layers 1 and 2), an attacker can perform other attacks on higher layers. The most dire consequence occurs when an Internet connection isn’t encrypted—something that Google recently estimated occurred when as much as 6 percent and 20 percent of pages loaded on Windows and Linux, respectively. In these cases, the attacker can view and modify all traffic in the clear and steal authentication cookies, passwords, payment card details, and any other sensitive data. Since many company intranets are sent in plaintext, traffic from them can also be intercepted.
Even when HTTPS is in place, an attacker can still intercept domain look-up traffic and use DNS cache poisoning to corrupt tables stored by the target’s operating system. The AirSnitch MitM also puts the attacker in the position to wage attacks against vulnerabilities that may not be patched. Attackers can also see the external IP addresses hosting webpages being visited and often correlate them with the precise URL.
Given the range of possibilities it affords, AirSnitch gives attackers capabilities that haven’t been possible with other Wi-Fi attacks, including KRACK from 2017 and 2019 and more recent Wi-Fi attacks that, like AirSnitch, inject data (known as frames) into remote GRE tunnels and bypass network access control lists.
“This work is impressive because unlike other frame injection methods, the attacker controls a bidirectional flow,” said HD Moore, a security expert and the founder and CEO of runZero.
He continued:
This research shows that a wireless-connected attacker can subvert client isolation and implement full relay attacks against other clients, similar to old-school ARP spoofing. In a lot of ways, this restores the attack surface that was present before client isolation became common. For folks who lived through the chaos of early wireless guest networking rollouts (planes, hotels, coffee shops) this stuff should be familiar, but client isolation has become so common, these kinds of attacks may have fallen off people’s radar.
Stuck in the middle with you
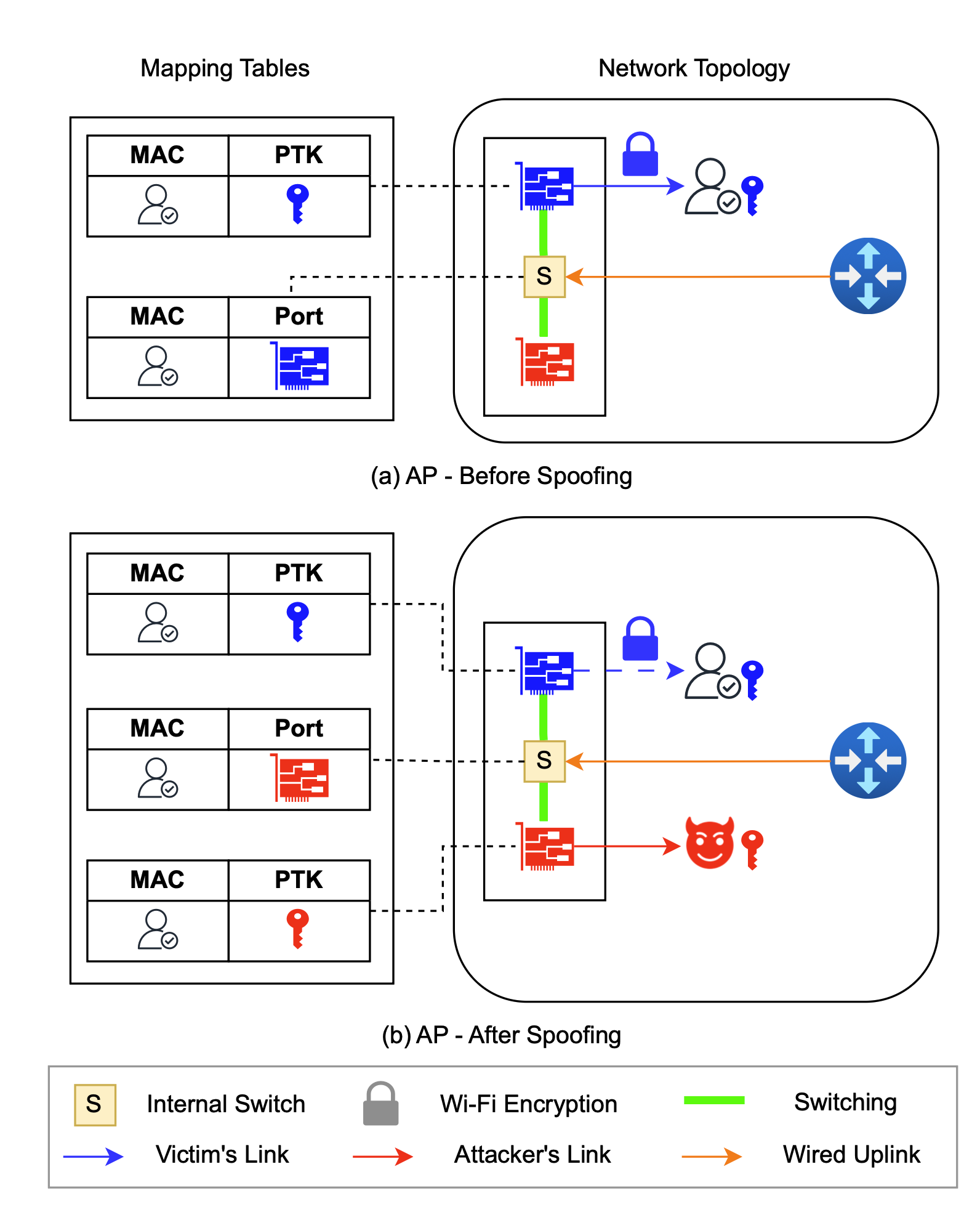
The MitM targets Layers 1 and 2 and the interaction between them. It starts with port stealing, one of the earliest attack classes of Ethernet that’s adapted to work against Wi-Fi. An attacker carries it out by modifying the Layer-1 mapping that associates a network port with a victim’s MAC—a unique address that identifies each connected device. By connecting to the BSSID that bridges the AP to a radio frequency the target isn’t using (usually a 2.4GHz or 5GHz) and completing a Wi-Fi four-way handshake, the attacker replaces the target’s MAC with one of their own.
The attacker spoofs the victim’s MAC address on a different NIC, causing the internal switch to mistakenly associate the victim’s address with the attacker’s port/BSSID. As a result, frames intended for the victim are forwarded to the attacker and encrypted using the attacker’s PTK.
Credit: Zhou et al.
The attacker spoofs the victim’s MAC address on a different NIC, causing the internal switch to mistakenly associate the victim’s address with the attacker’s port/BSSID. As a result, frames intended for the victim are forwarded to the attacker and encrypted using the attacker’s PTK. Credit: Zhou et al.
In other words, the attacker connects to the Wi-Fi network using the target’s MAC and then receives the target’s traffic. With this, an attacker obtains all downlink traffic (data sent from the router) intended for the target. Once the switch at Layer-2 sees the response, it updates its MAC address table to preserve the new mapping for as long as the attacker needs.
This completes the first half of the MitM, allowing all data to flow to the attacker. That alone would result in little more than a denial of service for the target. To prevent the target from noticing—and more importantly, to gain the bidirectional MitM capability needed to perform more advanced attacks—the attacker needs a way to restore the original mapping (the one assigning the victim’s MAC to the Layer-1 port). An attacker performs this restoration by sending an ICMP ping from a random MAC. The ping, which must be wrapped in a Group Temporal key shared among all clients, triggers replies that cause the Layer-1 mapping (i.e., port states) to revert back to the original one.
“In a normal Layer-2 switch, the switch learns the MAC of the client by seeing it respond with its source address,” Moore explained. “This attack confuses the AP into thinking that the client reconnected elsewhere, allowing an attacker to redirect Layer-2 traffic. Unlike Ethernet switches, wireless APs can’t tie a physical port on the device to a single client; clients are mobile by design.”
The back-and-forth flipping of the MAC from the attacker to the target, and vice versa, can continue for as long as the attacker wants. With that, the bidirectional MitM has been achieved. Attackers can then perform a host of other attacks, both related to AirSnitch or ones such as the cache poisoning discussed earlier. Depending on the router the target is using, the attack can be performed even when the attacker and target are connected to separate SSIDs connected by the same AP. In some cases, Zhou said, the attacker can even be connected from the Internet.
“Even when the guest SSID has a different name and password, it may still share parts of the same internal network infrastructure as your main Wi-Fi,” the researcher explained. “In some setups, that shared infrastructure can allow unexpected connectivity between guest devices and trusted devices.”
No, enterprise defenses won’t protect you
Variations of the attack defeat the client isolation promised by makers of enterprise routers, which typically use credentials and a master encryption key that are unique to each client. One such attack works across multiple APs when they share a wired distribution system, as is common in enterprise and campus networks.
Although port stealing was originally devised for hosts on the same switch, we show that attackers can hijack MAC-to-port mappings at a higher layer, i.e., at the level of the distribution switch—to intercept traffic to victims associated with different APs. This escalates the attack beyond its traditional limits, breaking the assumption that separate APs provide effective isolation.
This discovery exposes a blind spot in client isolation: even physically separated APs, broadcasting different SSIDs, offer ineffective isolation if connected to a common distribution system. By redirecting traffic at the distribution switch, attackers can intercept and manipulate victim traffic across AP boundaries, expanding the threat model for modern Wi-Fi networks.
The researchers demonstrated that their attacks can enable the breakage of RADIUS, a centralized authentication protocol for enhanced security in enterprise networks. “By spoofing a gateway MAC and connecting to an AP,” the researchers wrote, “an attacker can steal uplink RADIUS packets.” The attacker can go on to crack a message authenticator that’s used for integrity protection and, from there, learn a shared passphrase. “This allows the attacker to set up a rogue RADIUS server and associated rogue WPA2/3 access point, which allows any legitimate client to connect, thereby intercepting their traffic and credentials.”
The researchers tested the following 11 devices:
Netgear Nighthawk x6 R8000
Tenda RX2 Pro
D-LINK DIR-3040
TP-LINK Archer AXE75
ASUS RT-AX57
DD-WRT v3.0-r44715
OpenWrt 24.10
Ubiquiti AmpliFi Alien Router
Ubiquiti AmpliFi Router HD
LANCOM LX-6500
Cisco Catalyst 9130
As noted earlier, every tested router was vulnerable to at least one attack. Zhou said that some router makers have already released updates that mitigate some of the attacks, and more updates are expected in the future. But he also said some manufacturers have told him that some of the systemic weaknesses can only be addressed through changes in the underlying chips they buy from silicon makers.
The hardware manufacturers face yet another challenge: The client isolation mechanisms vary from maker to maker. With no industry-wide standard, these one-off solutions are splintered and may not receive the concerted security attention that formal protocols are given.
So how bad is AirSnitch, really?
With a basic understanding of AirSnitch, the next step is to put it into historical context and assess how big a threat it poses in the real world. In some respects, it resembles the 2007 PTW attack (named for its creators Andrei Pyshkin, Erik Tews, and Ralf-Philipp Weinmann) that completely and immediately broke WEP, leaving Wi-Fi users everywhere with no means to protect themselves against nearby adversaries. For now, client isolation is similarly defeated—almost completely and overnight—with no immediate remedy available.
At the same time, the bar for waging WEP attacks was significantly lower, since it was available to anyone within range of an AP. AirSnitch, by contrast, requires that the attacker already have some sort of access to the Wi-Fi network. For many people, that may mean steering clear of public Wi-Fi networks altogether.
If the network is properly secured—meaning it’s protected by a strong password that’s known only to authorized users—AirSnitch may not be of much value to an attacker. The nuance here is that even if an attacker doesn’t have access to a specific SSID, they may still use AirSnitch if they have access to other SSIDs or BSSIDs that use the same AP or other connecting infrastructure.
Yet another difference to the PTW attack—and others that have followed breaking WPA, WPA2, and WPA3 protections—is that they were limited to hacks using terrestrial radio signals, a much more limited theater than the one AirSnitch uses. Ultimately, the AirSnitch attacks are broader but less severe.
Also unlike those previous attacks, firewall mitigations may be more problematic.
“We expand the threat model showing an attacker can be on another channel or port, or can be from the Internet,” Zhou said. “Firewalls are also networking devices. We often say a firewall is a Layer-3 device because it works at the IP layer. But fundamentally, it’s connected by wire to different network elements. That wire is not secure.”
Some of the threat can be mitigated by using VPNs, but this remedy has all the usual drawbacks that come with them. For one, VPNs are notorious for leaking metadata, DNS queries, and other traffic that can be useful to attackers, making the protection limited. And for another, finding a reputable and trustworthy VPN provider has historically proven to be vexingly difficult, though things have improved more recently. Ultimately, a VPN shouldn’t be regarded as much more than a bandage.
Another potential mitigation is using wireless VLANs to isolate one SSID from another. Zhou said such options aren’t universally available and are also “super easy to be configured wrong.” Specifically, he said VLANs can often be implemented in ways that allow “hopping vulnerabilities.” Further, Moore has argued why “VLANs are not a practical barrier” against all AirSnitch attacks
The most effective remedy may be to adopt a security stance known as zero trust, which treats each node inside a network as a potential adversary until it provides proof it can be trusted. This model is challenging for even well-funded enterprise organizations to adopt, although it’s becoming easier. It’s not clear if it will ever be feasible for more casual Wi-Fi users in homes and smaller businesses.
Probably the most reasonable response is to exercise measured caution for all Wi-Fi networks managed by people you don’t know. When feasible, use a trustworthy VPN on public APs or, better yet, tether a connection from a cell phone.
Wi-Fi has always been a risky proposition, and AirSnitch only expands the potential for malice. Then again, the new capabilities may mean little in the real world, where evil twin attacks accomplish many of the same objectives with much less hassle.
Moore said the attacks possible before client isolation were often as simple as running ettercap or similar tools as soon as a normal Wi-Fi connection was completed. AirSnitch attacks require considerably more work, at least until someone writes an easy-to-use script that automates it.
“It will be interesting to see if the wireless vendors care enough to resolve these issues completely and if attackers care enough to put all of this together when there might be easier things to do (like run a fake AP instead),” Moore said. “At the least it should make pentesters’ lives more interesting since it re-opens a lot of exposure that many folks may not have any experience with.”
Dan Goodin is Senior Security Editor at Ars Technica, where he oversees coverage of malware, computer espionage, botnets, hardware hacking, encryption, and passwords. In his spare time, he enjoys gardening, cooking, and following the independent music scene. Dan is based in San Francisco. Follow him at here on Mastodon and here on Bluesky. Contact him on Signal at DanArs.82.
In reality, much of life with the Uncharted reminded me of Toyota. Subaru may have programmed the AWD system’s power delivery or tuned the suspension, but the large 14-inch multimedia touchscreen features far more advanced software than a 2026 Crosstrek or Forester. All the plastics inside, the dash texture, the nifty shift knob, the dual smartphone charging pads, the minimalist gauge cluster screen—these are a bunch of classic (modern) Toyota parts. In fact, under the hood, almost everything bore Toyota stickers, right down to the 12 V battery.
A good number of functions are controlled by discreet buttons but you’ll need to use the touchscreen to interact with the climate controls.
Credit: Subaru
A good number of functions are controlled by discreet buttons but you’ll need to use the touchscreen to interact with the climate controls. Credit: Subaru
Toyota will build the Uncharted, and deliveries should begin this spring shortly after C-HR customers begin to receive cars. From a stylistic standpoint, telling the two apart will require a close eye. The Subaru has a bulkier front end with more unpainted plastics but a slightly cleaner rear that better displays the branding (written out, no more Pleiades logo). The advantages of EV powertrain packaging come into play, even if the more angular design departs somewhat from the Solterra (and certainly from the gas-powered lineup).
Overall, the Uncharted measures 1.4 inches (35.5 mm) longer than a Crosstrek but offers about 10 percent more cargo volume—great for transporting gear to the trail.
Subaru also quoted a survey that reported 35 percent of current owners might consider an EV for their next car purchase. Will that percentage overlap with the 25 percent who take their Subarus off-roading? It seems more likely to fit into the 50 percent who highlight range as their most important consideration when buying an EV.
In this light, the FWD Uncharted, which provides a few more miles and a lower price tag, seems better for the urban Subaru owner. Leave the adventures to the gas-powered and hybrid models with symmetric AWD—after all, the Uncharted’s rear motor acts more like a helper than a truly balanced powertrain.
The fact that Toyota decided against building a FWD version of the C-HR, leaving that lower price point and improved range to Subaru, may well come into play. Subaru’s reps seemed generally surprised by the decision, which appears to stem from Toyota’s reluctance to impinge on a more significant FWD hybrid lineup. So the return of FWD may end up being the defining detail that sets the otherwise competent (if not outstanding) Uncharted apart in a crowded market segment.
Samsung’s Galaxy S26 series is available for preorder today and ships on March 11.
The Galaxy S26 lineup doesn’t change much on the outside. Credit: Samsung
There used to be countless companies making flagship Android phones, but a combination of factors has narrowed the field over time. Today, Samsung is the undisputed king of the Android device ecosystem with its Galaxy S line. So we can safely assume today’s Unpacked has revealed the most popular Android phones for the next year—the Galaxy S26 Ultra, Galaxy S26+, and Galaxy S26.
Samsung didn’t swing for the fences this time around, producing phones with a few cosmetic tweaks and upgraded internals. Meanwhile, Samsung is investing even more in AI, saying the S26 series includes the first “Agentic AI phones.” Despite limited hardware upgrades, the realities of component prices in the age of AI mean the prices of the two cheaper models have gone up by $100 this year. The Ultra remains at an already eye-watering $1,300.
Faster and more private
Looking at the Galaxy S26 family, you’d be hard-pressed to tell them apart from last year’s phones. The camera surround is different, and the measurements of the smallest and largest phone are ever so slightly different. You probably won’t be able to tell just by looking, but the S26 Ultra has regressed from titanium to aluminum, a reversion Apple also made with its latest high-end phones. This phone also retains its S Pen stylus.
Specs at a glance: Samsung Galaxy S26 series
Galaxy S26 ($900)
Galaxy S26+ ($1,100)
Galaxy S26 Ultra ($1,300)
SoC
Snapdragon 8 Elite Gen 5 (3 nm)
Snapdragon 8 Elite Gen 5 (3 nm)
Snapdragon 8 Elite Gen 5 (3 nm)
Memory
12GB
12GB
12GB, 16GB
Storage
256GB, 512GB
256GB, 512GB
256GB, 512GB, 1TB
Display
6.3-inch OLED, 10-bit color, 2340×1080, 1-120Hz
6.7-inch OLED, 10-bit color, 3120×1440, 1-120Hz
6.9-inch OLED, 10-bit color, 3120×1440, 1-120Hz, S Pen support
Wi-Fi 7, Bluetooth 5.4, USB-C 3.2, Sub6 and mmWave 5G
Wi-Fi 7, Bluetooth 5.4, USB-C 3.2, Sub6 and mmWave 5G
Measurements
71.7×149.6×7.2 mm, 167g
75.8×158.4×7.3 mm, 190g
78.1×163.6×7.9 mm, 214 g
These phones will again have the latest Snapdragon flagship processor (in North America, Japan, and China) with customizations exclusive to Samsung. The Snapdragon 8 Elite Gen 5 for Galaxy is a 3 nm chip with third-gen Oryon CPU cores, an Adreno 840 GPU, and a powerful Hexagon NPU for on-device AI processing. Samsung promises double-digit performance gains across the board, which is what we hear every year.
Samsung flagship phones have extremely fast hardware, so they benchmark well. However, they also tend to heat up and throttle quickly during sustained use. Perhaps that won’t be as much of a problem with the S26 series. Samsung says it has implemented its largest vapor chamber ever to better control temperatures.
The batteries have also been redesigned for greater efficiency and charging speed, but the base model is the only one that saw a capacity boost (4,000 to 4,300 mAh). Charging speeds have gotten a much-needed increase at the Ultra level. Samsung has only said you can now get a 75 percent charge in 30 minutes using its most expensive phone—it peaks at 60 W, up from 45 W for the last Ultra.
Samsung has been using the same camera sensors for a few cycles now, and it’s not changing anything major this time around. The Ultra still has four cameras (including two telephotos) that top out with the 200 MP primary, and the S26+ and base model still have three cameras with a 50 MP primary. The apertures on the Ultra sensors are a bit wider to allow for brighter photos in challenging conditions. More interesting, though, is the option to record high-quality 8K video directly to an external drive. The S26 also brings support for the Advanced Professional Video (APV) codec.
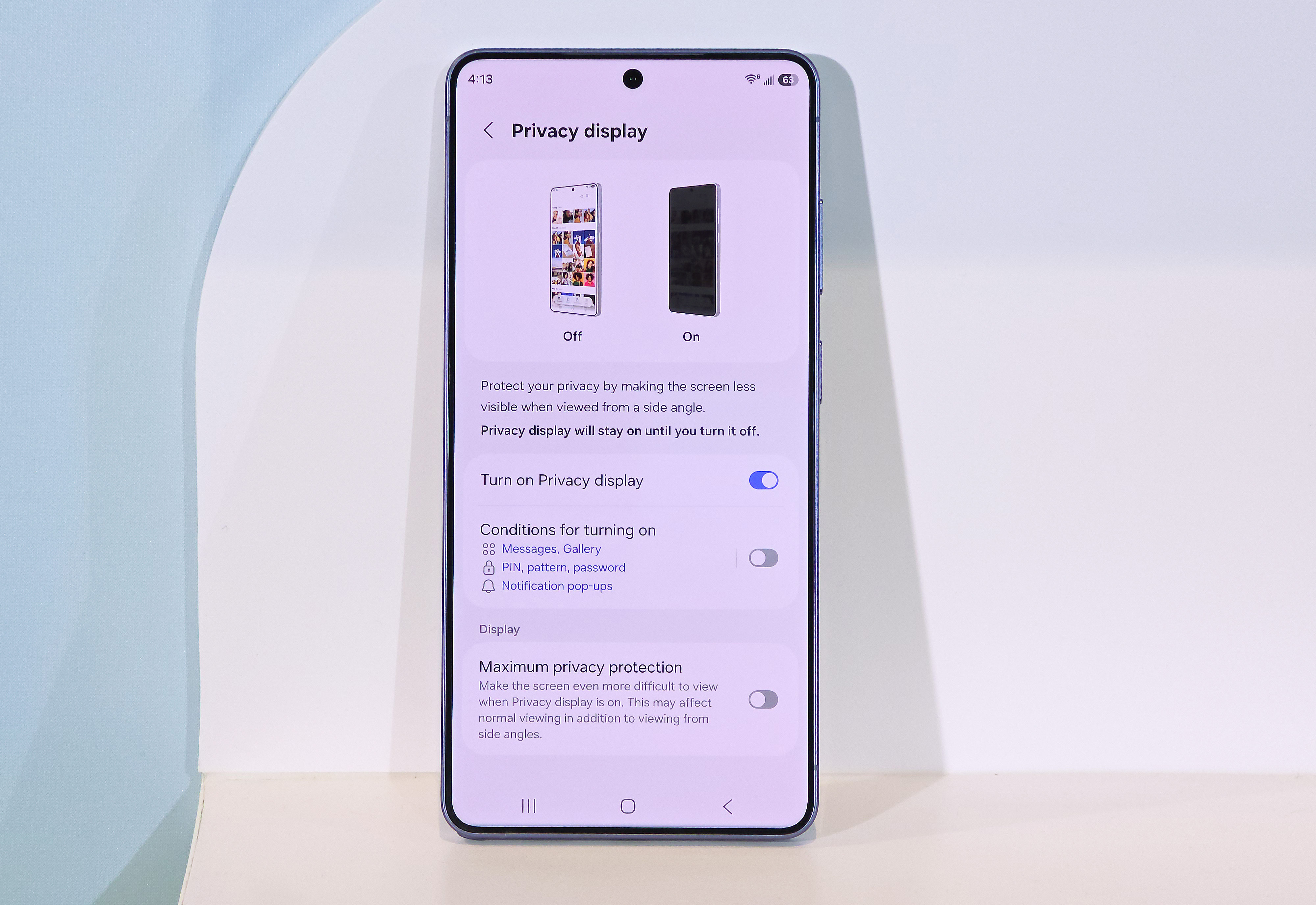
While the display specs haven’t changed much, they are home to the phone’s most notable new feature: Privacy Display. As smartphone screens have improved, they have emphasized high brightness and wide viewing angles, which is what you want most of the time. However, that also makes it easy for people nearby to see what’s on your screen. With one tap, the S26 can make it harder for shoulder surfers to see what you’re doing.
Privacy Display prevents shoulder surfers from peeking at your screen.
Credit: Samsung
Privacy Display prevents shoulder surfers from peeking at your screen. Credit: Samsung
Privacy Display uses a technology called Black Matrix, which activates “narrow pixels.” These pixels focus light more directly on the user to limit the viewing angle. Privacy Display can be activated system-wide as you like, but it can also be activated on a per-app basis or even just in the part of the screen where notifications appear.
What is an Agentic AI phone anyway?
Unsurprisingly, AI takes the lead with the S26 launch. Part of that is just Samsung following the zeitgeist, but companies can also add new AI capabilities to fill out spec sheets without a bunch of increasingly expensive hardware upgrades. In Samsung’s words, it has sought to have “AI integrated into every layer” of the Galaxy S26 experience.
That starts with expanded awareness of screen context. The company’s Now Brief feature, which is supposed to pull together useful information from across your apps, has not been very impressive so far. With the S26, Samsung is piping notification content into Now Brief, allowing it to remind you about things even if you never added them to your calendar or to-do list. Like many of Samsung’s Galaxy AI features, this data is processed on-device and won’t go to the cloud.
A Galaxy AI Nudge that helps you select photos.
In a similar vein, Galaxy AI is also getting “Nudges,” which look similar to Google’s Magic Cue on the Pixel 10 series. The Galaxy S26 will be able to suggest content and apps based on what’s happening on the screen. For example, Galaxy AI might see you want to share images and suggest the right ones, or perhaps it will check your calendar for openings to save you from switching apps. Of course, that assumes the AI will correctly recognize the context and call the right action.
AI features will also be expanding in Samsung’s stock apps. In the Browser, Samsung has partnered with Perplexity for a new “Ask AI” feature. Rather than juggling tabs to read original sources yourself, you can have the AI do it. It basically gives you a research report like you could get from Perplexity itself (or Gemini Deep Research), but it’s integrated with the browser. Samsung’s gallery app also gets expanded AI editing tools with the S26. These capabilities will really allow you to change the substance of photos, so Samsung has added a visible watermark to label them. We’ve asked if there are AI labels in the image metadata, like you get with some other editing systems.
AI-edited photos have a visible watermark.
Credit: Samsung
AI-edited photos have a visible watermark. Credit: Samsung
A major component of Samsung’s “Agentic AI phone” pitch comes from a partnership with Google. For starters, Google’s AI-powered scam detection features in the Messaging app, previously exclusive to Pixels, will launch on the S26 in preview before expanding to more devices later. Circle to Search is getting an upgrade that lets it identify multiple objects in a single image—this is in testing on both the Pixel 10 series and the Galaxy S26.
The other Google tie-in is more in keeping with the goal of agentic AI. For the first time, Gemini will be able to handle multistep tasks for you. You can watch it work if you prefer, but this can also happen entirely in the background while you do other things. It’s a bit like the recently launched Chrome Auto Browse but for apps.
The selection of apps is pretty slim during this testing period. Samsung and Google say you’ll be able to order food and groceries in apps like DoorDash and Grubhub, and there will be a tie-in with Uber for both rides and food. Google currently says you should “supervise closely” when the agent is working on your behalf. So we’ll see how that goes.
When you can get it
Samsung is accepting preorders for its new phones starting today. You can get them at every mobile carrier or directly from Samsung’s website. Carriers will offer a variety of deals with monthly credits to reduce the sting of the new, higher prices. Samsung has enhanced trade-in values right now, which is a more straightforward way to get a discount if you have an old phone to unload. It’s offering up to $900 off instantly with an S25 Ultra or Z Fold 6 trade-in. Even a phone from a couple of years ago can cut the price of a Galaxy S26 way down.
The Galaxy S26 comes in a variety of understated colors.
Credit: Samsung
The Galaxy S26 comes in a variety of understated colors. Credit: Samsung
The phones are available in violet cobalt, sky blue, white, and black at all retailers. Samsung’s exclusive colors this time are silver shadow and pink gold. Devices will be on shelves and the doorsteps of preorderers on or around March 11.
Ryan Whitwam is a senior technology reporter at Ars Technica, covering the ways Google, AI, and mobile technology continue to change the world. Over his 20-year career, he’s written for Android Police, ExtremeTech, Wirecutter, NY Times, and more. He has reviewed more phones than most people will ever own. You can follow him on Bluesky, where you will see photos of his dozens of mechanical keyboards.
Latest data hints that benefits seen so far could be underestimates.
Shingrix, the vaccine for the shingles, is seen at a pharmacy on Friday, Jan. 18, 2019 in Cohoes, N.Y. Credit: Getty | Lori Van Buren
While lifesaving vaccines face a relentless onslaught from the Trump administration—with fervent anti-vaccine advocate Robert F. Kennedy Jr. leading the charge—scientific literature is building a wondrous story: A vaccine appears to prevent dementia, including Alzheimer’s, and may even slow biological aging.
For years, study after study has noted that older adults vaccinated against shingles seemed to have a lower risk of dementia. A study last month suggested the same vaccine appears to slow biological aging, including lowering markers of inflammation.
“Our study adds to a growing body of work suggesting that vaccines may play a role in healthy aging strategies beyond solely preventing acute illness,” study author Eileen Crimmins, of the University of Southern California, said.
Another study this month suggested the positive findings against dementia from the past may even be underestimates of the vaccination’s potential, with a newer vaccine against shingles providing even more protection.
Shingles
If the dementia protection is real, it’s a fluke. The vaccine was designed for the entirely unrelated task of keeping the varicella-zoster virus—the cause of chickenpox (varicella)—from reactivating and causing an agonizing rash.
Anyone who suffered the itchy childhood affliction carries the virus with them for the rest of their lives, largely dormant in their nerve cells. But, if it awakens, it causes a painful, itchy rash—aka shingles (herpes zoster). The rash develops fluid-filled blisters and crusts over, lasting for days to several weeks. For some, it can be intensely painful, and the pain can linger for months or even years after the rash fades. If it occurs near the eye, it can cause permanent vision damage; near the ear, it can cause permanent hearing and balance problems.
Shingles is thought to be triggered by a fault in the immune response that keeps the latent virus in check, often from age-related decline. That’s where a vaccine comes in. The first was Zostavax, released by Merck in 2006, which delivers a hefty dose of a live, but weakened, version of the varicella-zoster virus. This spurs the immune system to shore up defenses to prevent the virus from reigniting. Studies found the vaccine cut the risk of shingles by 51 percent.
In 2017, a new vaccine hit the scene: Shingrix, a recombinant, adjuvanted vaccine from GlaxoSmithKline. Instead of a whole, live virus vaccine like Zostavax, Shingrix delivers only a key protein found on the outside of the varicella-zoster virus particle (glycoprotein e) that re-primes the immune system. The shot also contains an adjuvant—an extra ingredient that stimulates the immune system—to ensure a vigorous response. Trials found that the response to Shingrix is indeed vigorous, with the vaccine being 90 to 97 percent effective at preventing shingles in adults age 50 and up.
With its superior efficacy, the US Centers for Disease Control and Prevention and its vaccine advisors switched its recommendation in 2018, ditching Zostavax for the more effective Shingrix.
In the meantime, researchers noted that since Zostavax’s debut, vaccinated adults seemed to be at lower risk of dementia than their unvaccinated peers. But studies comparing the vaccinated to the unvaccinated raise the question of whether the data is simply pointing to a background difference between the two groups; perhaps people who seek vaccination are generally healthier—a problem called healthy-user bias.
Natural experiments
In the past few years, studies have been putting that concern to rest. Instead of comparing vaccinated versus unvaccinated, researchers took advantage of vaccine rollouts in different countries, including Australia, Canada, and Wales. The vaccine introductions created clear cutoffs for people who were suddenly eligible for the vaccine and people who were permanently ineligible. These “natural” experiments lessened the concern of people being able to self-select their group.
So far, the results of these studies have consistently supported the finding that shingles vaccination is linked to a lower risk of dementia. The study in Wales, for instance, published in Nature in April 2025, looked at outcomes in over 280,000 older people after the September 1, 2013, debut of Zostavax. At the time, people 71 to 78 years old progressively became eligible for the vaccine, while those who were 80 at the start of the rollout were ineligible and never became eligible. Researchers looked at dementia diagnoses over a seven-year follow-up period and found that vaccination among the eligible reduced the relative rate of dementia cases by 20 percent compared with the ineligible group.
That same month, researchers published a study in JAMA that followed over 18,000 older people in Australia after the November 1, 2016, rollout of Zostavax. People 70 to 79 at that date were eligible for a free Zostavax dose. But everyone age 80 or older was permanently ineligible. After a 7.4-year follow-up period, the researchers found that 5.5 percent of the ineligible people were diagnosed with dementia, while only 3.7 percent of those in the eligible category were diagnosed with the condition, a 1.8 percentage point drop.
A third natural study out this month in The Lancet Neurology found a similar 2 percentage-point drop in dementia rates in Canada after the Zostavax rollout there.
Newer vaccine
As Eric Topol, a molecular medicine expert at Scripps Research Institute, noted, if a drug were found to cut the risk of dementia by 20 percent, it would be considered a breakthrough. But data on the shingles vaccine has been met with no such fanfare.
Still, further data suggests that vaccination may be even better than it already appeared—the rosy findings so far may be an underestimate based on the now-outdated Zostavax vaccine. With Shingrix, which is significantly more effective against shingles, the protective effect against dementia may be even larger.
In 2024, researchers reported another natural experiment comparing dementia rates among over 200,000 people in the US vaccinated before or after the switch from Zostavax to Shingrix. The study, published in Nature Medicine, found that compared with Zostavax, vaccination with Shingrix was linked to a 17 percent relative increase in dementia-free time.
A study published in Nature Communications this month by researchers in California went further. They compared dementia rates among nearly 66,000 people who received the Shingrix vaccine and over 260,000 unvaccinated matched controls. The researchers found that the vaccinated group had a 51 percent lower risk of dementia compared to the unvaccinated controls.
Lingering questions
Of course, these consistent findings on dementia prevention raise the question of how exactly the vaccine is preventing cases. Unfortunately, researchers still don’t know. However, many have speculated that by fortifying immune responses against the varicella-zoster virus and preventing reactivation, the vaccine reduces overall brain inflammation that could contribute to the development of dementia.
Another lingering question from the data so far is that several studies have found that women see more benefit from the vaccine than men in terms of dementia risk. It’s unclear why this would be the case, but researchers have noted that there are some potentially related associations: Women are more likely to develop dementia than men, and they’re also more likely to get shingles.
The study published last month, looking at biological aging after shingles vaccination, tried to address some of these questions. The study, published in the Journal of Gerontology and led by Crimmins and Jung Ki Kim, looked at blood and health markers from over 3,800 adults, about half of whom were vaccinated and half not. The researchers used tests to examine markers for inflammation, immune response, cardiovascular health, signs of neurodegenerations, and gene activity. They also created a composite biological aging score for participants.
The results suggest that vaccinated people had lower signs of inflammation and molecular aging as well as better composite aging scores. The data also hinted that vaccinated women had better results on some of the molecular aging testing.
Kim noted that chronic, low-level inflammation can contribute to age-related health conditions, including cardiovascular disease and dementia. “By helping to reduce this background inflammation—possibly by preventing reactivation of the virus that causes shingles, the vaccine may play a role in supporting healthier aging,” she suggested.
Of course, additional studies will need to confirm the findings. And if they do, the results could also be even better in follow-up studies. In Kim and Crimmins’ study, the participants were vaccinated with Zostavax, the older vaccine, not the newer, more effective Shingrix.
Beth is Ars Technica’s Senior Health Reporter. Beth has a Ph.D. in microbiology from the University of North Carolina at Chapel Hill and attended the Science Communication program at the University of California, Santa Cruz. She specializes in covering infectious diseases, public health, and microbes.
A UK regulator today fined Reddit £14.5 million ($19.6 million) for not verifying the ages of users. The UK Information Commissioner’s Office (ICO) alleged that the failure to check ages resulted in Reddit illegally using children’s personal information.
“Our investigation found that Reddit failed to apply any robust age assurance mechanism and therefore did not have a lawful basis for processing the personal information of children under the age of 13… These failures meant Reddit was using children’s data unlawfully, potentially exposing them to inappropriate and harmful content,” an ICO press release said.
The ICO findings are based on Reddit’s actions prior to its July 2025 rollout of a system that verifies UK users’ ages before letting them view adult content. But the ICO said it is still concerned about Reddit’s post-July 2025 system because the company relies on users to declare their ages when opening an account.
Reddit today said it will appeal the fine and criticized the ICO for demanding more collection of private information. “Reddit doesn’t require users to share information about their identities, regardless of age, because we are deeply committed to their privacy and safety,” Reddit said in a statement provided to Ars. “The ICO’s insistence that we collect more private information on every UK user is counterintuitive and at odds with our strong belief in our users’ online privacy and safety. We intend to appeal the ICO’s decision.”
Reddit pointed to its privacy policy, which says, “We collect minimal information that can be used to identify you by default. If you want to just browse, you don’t need an account. If you want to create an account to participate in a subreddit, we don’t require you to give us your real name. We don’t track your precise location. You can even browse anonymously. You can share as much or as little about yourself as you want when using Reddit.”
The bulk of the supply chain for phones, tablets, computers, game consoles, and most other tech is still overwhelmingly reliant on overseas manufacturers. Most of Apple’s A- and M-series chips are still made in TSMC’s factories in Taiwan, and while TSMC is making some of its chips in the US, it has resisted efforts to bring more of its capacity to the US. Facilities for manufacturing memory, storage, and displays are also mostly located overseas. And that’s before you even start thinking about the facilities where all of these components are assembled into finished products.
There are signs that more chip manufacturing, at least, is coming to the US. Apple itself says that it will buy roughly 100 million chips manufactured at TSMC’s facilities in Arizona; these 4nm factories can’t make the newest A- and M-series chips, but they can make the older Apple A16 (still used in the low-end iPad) and the Apple S10 chip used in Apple Watches. Intel, itself the beneficiary of multiple sources of external investment, is still working on new factories in Ohio and elsewhere; memory manufacturer Micron is using some of its AI-fueled profits to build domestic factories as well.
But Apple’s Mac Pro announcement in 2019 wasn’t the first step toward domestic manufacturing for the company’s biggest-selling hardware, and it’s hard to see today’s announcement ushering in a major change to Apple’s manufacturing strategy, either. The Mac mini is almost certainly more popular than the Mac Pro, but it’s not nearly as big a deal as domestic iPhone, iPad, or MacBook manufacturing would be.
The helium system on the SLS upper stage—officially known as the Interim Cryogenic Propulsion Stage (ICPS)—performed well during both of the Artemis II countdown rehearsals. “Last evening, the team was unable to get helium flow through the vehicle. This occurred during a routine operation to repressurize the system,” Isaacman wrote.
The Space Launch System rocket emerges from the Vehicle Assembly Building to begin the rollout to Launch Pad 39B last month.
Credit: Stephen Clark/Ars Technica
The Space Launch System rocket emerges from the Vehicle Assembly Building to begin the rollout to Launch Pad 39B last month. Credit: Stephen Clark/Ars Technica
Another molecule, another problem
Helium is used to purge the upper stage engine and pressurize its propellant tanks. The rocket is in a “safe configuration,” with a backup system providing purge air to the upper stage, NASA said in a statement.
NASA encountered a similar failure signature during preparations for launch of the first SLS rocket on the Artemis I mission in 2022. On Artemis I, engineers traced the problem to a failed check valve on the upper stage that needed replacement. NASA officials are not sure yet whether the helium issue Friday was caused by a similar valve failure, a problem with an umbilical interface between the rocket and the launch tower, or a fault with a filter, according to Isaacman.
In any case, technicians are unable to reach the problem area with the rocket at the launch pad. Inside the VAB, ground teams will extend work platforms around the rocket to provide physical access to the upper stage and its associated umbilical connections.
NASA said moving into preparations for rollback now will allow managers to potentially preserve the April launch window, “pending the outcome of data findings, repair efforts, and how the schedule comes to fruition in the coming days and weeks.”
It’s not clear if NASA will perform another fueling test on the SLS rocket after it returns to Launch Pad 39B, or whether technicians will do any more work on the delicate hydrogen umbilical near the bottom of the rocket responsible for recurring leaks during the Artemis I and Artemis II launch campaigns. Managers were pleased with the performance of newly-installed seals during Thursday’s countdown demonstration, but NASA officials have previously said vibrations from transporting the rocket to and from the pad could damage the seals.
Microsoft Executive Vice President for Gaming Phil Spencer announced he will retire after 38 years at Microsoft and 12 years leading the company’s video game efforts. Asha Sharma, an executive currently in charge of Microsoft’s CoreAI division, will take his place.
Xbox President Sarah Bond, who many assumed was being groomed as Spencer’s eventual replacement, is also resigning from the company. Current Xbox Studios Head Matt Booty, meanwhile, is being promoted to Executive Vice President and Chief Content Officer and will work closely with Sharma.
In his departure note, Spencer said he told Microsoft CEO Satya Nadella last fall that he was “thinking about stepping back and starting the next chapter of my life.” Spencer will remain at Microsoft “in an advisory role” through the summer to help Sharma during the transition, he wrote.
Sharma, who joined Microsoft just two years ago after stints at Meta and Instacart, promised in an introductory message to preside over “the return of Xbox,” and a “recommit[ment] to our core fans and players.” That commitment would “start with console which has shaped who we are,” but expand “across PC, mobile, and cloud,” Sharma wrote.
Insiders report that, as NIH director, Bhattacharya delegates most of his responsibilities for running the $47 billion agency to two top officials. Instead of a hands-on leader, Bhattacharya has become known for his many public interviews, earning him the nickname “Podcast Jay.”
“Malpractice”
Researchers expect that Bhattacharya will perform similarly at the helm of the CDC. Jenna Norton, an NIH program officer who spoke to the Guardian in her personal capacity, commented that Bhattacharya “won’t actually run the CDC. Just as he doesn’t actually run NIH.” His role for the administration, she added, “is largely as a propagandist.”
Jeremy Berg, former director of the National Institute of General Medical Sciences, echoed the sentiment to the Guardian. “Now, rather than largely ignoring the actual operations of one agency, he can largely ignore the actual operations of two,” he said.
Kayla Hancock, director of Public Health Watch, a nonprofit advocacy group, went further in a public statement, saying, “Jay Bhattacharya has overseen the most chaotic and rudderless era in NIH history, and for RFK Jr. to give him even more responsibility at the CDC is malpractice against the public health.”
Like other commenters, Hancock noted his apparent lack of involvement at the NIH and put it in the context of the current state of US public health. “This is the last person who should be overseeing the CDC at a time when preventable diseases like measles are roaring back under RFK Jr.’s deadly anti-vax agenda,” she said.
It is widely expected that Bhattacharya will, like O’Neill, act as a rubber-stamp for Kennedy’s relentless anti-vaccine agenda items. When Kennedy dramatically overhauled the CDC’s childhood vaccine schedule, slashing recommended vaccinations from 17 to 11 without scientific evidence, Bhattacharya was among the officials who signed off on the unprecedented change.
Ultimately, Bhattacharya will only be in the role for a short time, at least officially. The role of CDC director became a Senate-confirmed position in 2023, and, as such, an acting director can serve only 210 days from the date the role became vacant. That deadline comes up on March 25. President Trump has not nominated anyone to fill the director role.
Of the Warlock’s three Demonic partner options, I found myself leaning most on the Tainted, which can stay out of harm’s way while harassing slower enemies from afar with fireballs. The other Demon options both had their charms but often got too caught up in massive enemy swarms to be as effective as I wanted, I found. I also didn’t see much point in the skill option that let me teleport my demon into a specific fight or sacrifice itself for some splash damage; their standard, AI-controlled attack patterns were usually sufficient.
Then there’s the Chaos upgrade branch, which is focused mostly on area-of-effect (AoE) spells. My build thus far has ended up pretty reliant on the direct-damage AoE options; the Flame Wave, in particular, is especially good for quickly clearing out long, narrow corridors. I also leaned on the Sigil of Lethargy, which effectively slows down some of the more frenetic enemy swarms and gives you some time to gather your attack plan.
Something borrowed, something blue…
Combining these Chaos skills with the weapon-improving options in the Eldritch branch has made my time with the Diablo II Warlock feel like a bit of a “best of both worlds” situation. The mixture of ranged combat options, area-of-effect magic, and allies-summoning abilities ends up feeling like a weird cross between a Sorceress, Amazon, and Necromancer, without feeling like a carbon copy of any of those classes.
I haven’t yet gotten to the new late-game content in the “Reign of the Warlock” DLC, so I can’t say how well the Warlock holds up in the extreme difficulty of the Terror Zones. I also haven’t experimented with any of the truly brokenWarlock builds that some committed high-level min-maxxers have been busy discovering.
As a casual excuse to revisit the world of Diablo II, though, the Warlock class provides just enough of a new twist on some familiar gameplay mechanics to make it worth the trip.
There was way too much going on this week to not split, so here we are. This first half contains all the usual first-half items, with a focus on projections of jobs and economic impacts and also timelines to the world being transformed with the associated risks of everyone dying.
Quite a lot of Number Go Up, including Number Go Up A Lot Really Fast.
Among the thing that this does not cover, that were important this week, we have the release of Claude Sonnet 4.6 (which is a big step over 4.5 at least for coding, but is clearly still behind Opus), Gemini DeepThink V2 (so I could have time to review the safety info), release of the inevitable Grok 4.20 (it’s not what you think), as well as much rhetoric on several fronts and some new papers. Coverage of Claude Code and Cowork, OpenAI’s Codex and other things AI agents continues to be a distinct series, which I’ll continue when I have an open slot.
Most important was the unfortunate dispute between the Pentagon and Anthropic. The Pentagon’s official position is they want sign-off from Anthropic and other AI companies on ‘all legal uses’ of AI, but without any ability to ask questions or know what those uses are, so effectively any uses at all by all of government. Anthropic is willing to compromise and is okay with military use including kinetic weapons, but wants to say no to fully autonomous weapons and domestic surveillance.
I believe that a lot of this is a misunderstanding, especially those at the Pentagon not understanding how LLMs work and equating them to more advanced spreadsheets. Or at least I definitely want to believe that, since the alternatives seem way worse.
The reason the situation is dangerous is that the Pentagon is threatening not only to cancel Anthropic’s contract, which would be no big deal, but to label them as a ‘supply chain risk’ on the level of Huawei, which would be an expensive logistical nightmare that would substantially damage American military power and readiness.
This week I also covered two podcasts from Dwarkesh Patel, the first with Dario Amodei and the second with Elon Musk.
Even for me, this pace is unsustainable, and I will once again be raising my bar. Do not hesitate to skip unbolded sections that are not relevant to your interests.
AI can’t do math on the level of top humans yet, but as per Terence Tao there are only so many top humans and they can only pay so much attention, so AI is solving a bunch of problems that were previously bottlenecked on human attention.
The free version is quite a lot worse than the paid version. But also the free version is mind blowingly great compared to even the paid versions from a few years ago. If this isn’t blowing your mind, that is on you.
Governments and nonprofits mostly continue to not get utility because they don’t try to get much use out of the tools.
Ethan Mollick: I am surprised that we don’t see more governments and non-profits going all-in on transformational AI use cases for good. There are areas like journalism & education where funding ambitious, civic-minded & context-sensitive moonshots could make a difference and empower people.
Otherwise we risk being in a situation where the only people building ambitious experiments are those who want to replace human labor, not expand what humans can do.
This is not a unique feature of AI versus other ‘normal’ technologies. Such areas usually lag behind, you are the bottleneck and so on.
Similarly, I think Kelsey Piper is spot on here:
Kelsey Piper: Joseph Heath coined the term ‘highbrow misinformation’ for climate reporting that was technically correct, but arranged every line to give readers a worse understanding of the subject. I think that ‘stochastic parrots/spicy autocomplete’ is, similarly, highbrow misinformation.
It takes a nugget of a technical truth: base models are trained to be next token predictors, and while they’re later trained on a much more complex objective they’re still at inference doing prediction. But it is deployed mostly to confuse people and leave them less informed.
I constantly see people saying ‘well it’s just autocomplete’ to try to explain LLM behavior that cannot usefully be explained that way. No one using it makes any effort to distinguish between the objective in training – which is NOT pure prediction during RLHF – and inference.
Gary Marcus: How did this work out? Are LLM hallucinations largely gone by now?
Dean W. Ball: Come to think of it, in my experience as a consumer, LLM hallucinations are largely gone now, yeah.
Eliezer Yudkowsky: Still there and especially for some odd reason if I try to ask questions about Pathfinder 1e. I have to use Google like an ancient Sumerian.
Dean W. Ball: Unlike human experts, who famously always agree
Anthropic is reportedly cracking down on having multiple Max-level subscription accounts. This makes sense, as even at $200/month a Max subscription that is maximally used is at a massive discount, so if you’re multi-accounting to get around this you’re costing them a lot of money, and this was always against the Terms of Service. You can get an Enterprise account or use the API.
OpenAI gives us EVMbench, to evaluate AI agents on their ability to detect, patch and exploit high-security smart contract vulnerabilities. GPT-5.3-Codex via Codex CLI scored 72.2%, so they seem to have started it out way too easy. They don’t tell us scores for any other models.
OpenAI has a bunch of consumer features that Anthropic is not even trying to match. Claude does not even offer image generation (which they should get via partnering with another lab, the same way we all have a Claude Code skill calling Gemini).
There are also a bunch of things Anthropic offers that no one else is offering, despite there being no obvious technical barrier other than ‘Opus and Sonnet are very good models.’
Ethan Mollick: Another thing I noticed writing my latest AI guide was how Anthropic seems to be alone in knowledge work apps. Not just Cowork, but Claude for PowerPoint & Excel, as well as job-specific skills, plugins & finance/healthcare data integrations
Surprised at the lack of challengers
Again, I am sure OpenAI will release more enterprise stuff soon, and Google seems to be moving forward a bit with integration into Google workspaces, but the gap right now is surprisingly large as everyone else seems to aim just at the coding market.
They’re also good on… architecture?
Emmett Shear: Opus 4.6 is ludicrously better than any model I’ve ever tried at doing architecture and experimental critique. Most noticeably, it will start down a path, notice some deviation it hadn’t expected…and actually stop and reconsider. Hats off to Anthropic.
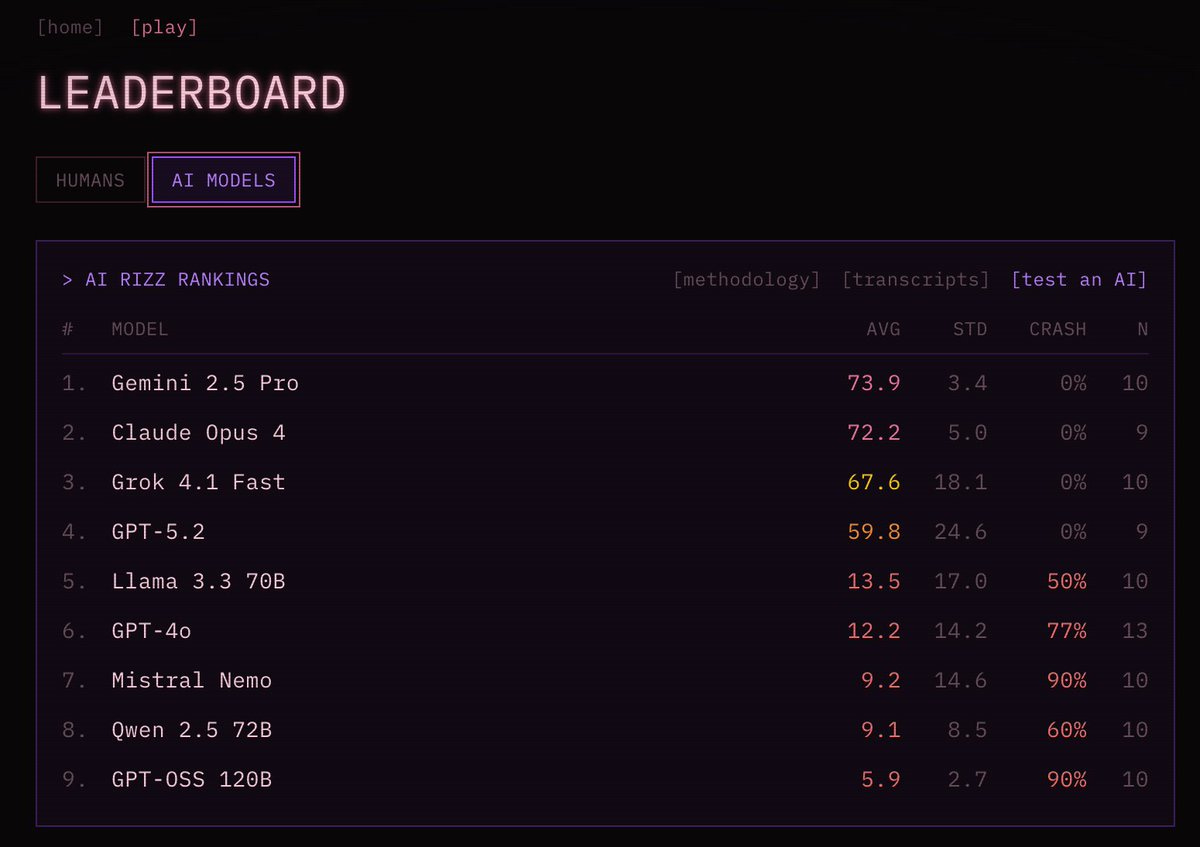
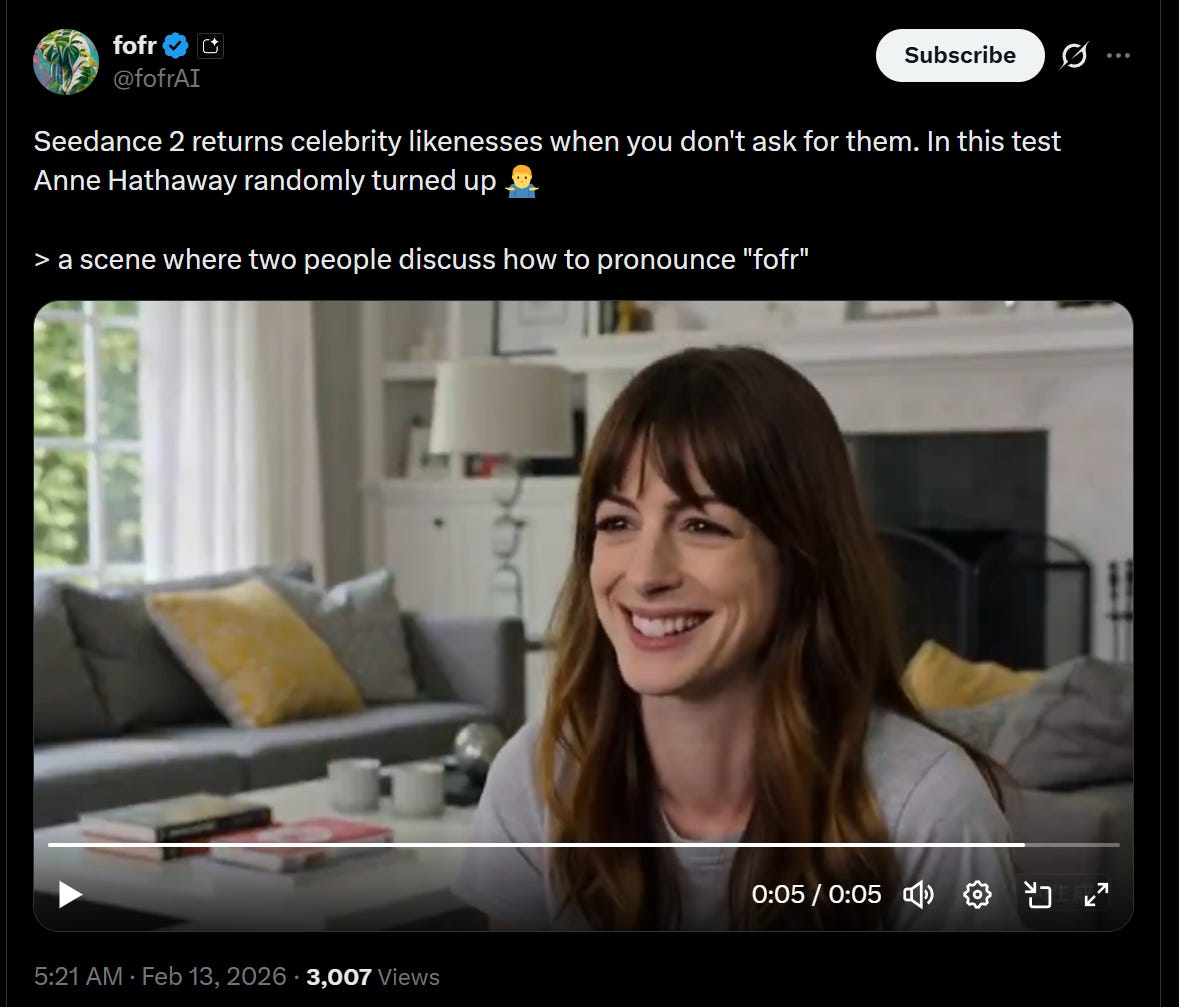
Is Seedance 2 giving us celebrity likenesses even unprompted? Fofr says yes. Claude affirms this is a yes. I’m not so sure, this is on the edge for me as there are a lot of celebrities and only so many facial configurations. But you can’t not see it once it’s pointed out.
Seedance quality and consistency and coherence (and willingness) all seem very high, but also small gains in duration can make a big difference. 15 seconds is meaningfully different from 12 seconds or especially 10 seconds.
I also notice that making scenes with specific real people is the common theme. You want to riff of something and someone specific that already has a lot of encoded meaning, especially while clips remain short.
Ethan Mollick: Seedance: “A documentary about how otters view Ethan Mollick’s “Otter Test” which judges AIs by their ability to create images of otters sitting in planes”
Again, first result.
Ethan Mollick: The most interesting thing about Seedance 2.0 is that clips can be just long enough (15 seconds) to have something interesting happen, and the LLM behind it is good enough to actually make a little narrative arc, rather than cut off the way Veo and Sora do. Changes the impact.
Each leap in time from here, while the product remains coherent and consistent throughout, is going to be a big deal. We’re not that far from the point where you can string together the clips.
Will Oremus (WaPo): David Greene had never heard of NotebookLM, Google’s buzzy artificial intelligence tool that spins up podcasts on demand, until a former colleague emailed him to ask if he’d lent it his voice.
“So… I’m probably the 148th person to ask this, but did you license your voice to Google?” the former co-worker asked in a fall 2024 email. “It sounds very much like you!”
There are only so many ways people can sound, so there will be accidental cases like this, but also who you hire for that voiceover and who they sound like is not a coincidence.
Google gives us Lyria 3, a new music generation model. Gemini now has a ‘create music’ option (or it will, I don’t see it in mine yet), which can be based on text or on an image, photo or video. The big problem is that this is limited to 30 second clips, which isn’t long enough to do a proper song.
CNBC has the results in terms of user boosts from the other ads. Anthropic and Claude got an 11% daily active user boost, OpenAI got 2.7% and Gemini got 1.4%. This is not obviously an Anthropic win, since almost no one knows about Anthropic so they are starting from a much smaller base and a ton of new users to target, whereas OpenAI has very high name recognition.
Ben: Is @guardian aware that their authors are at this point just using AI to wholesale generate entire articles? I wouldn’t really care, except that this writing is genuinely atrocious. LLM writing can be so much better; they’re clearly not even using the best models, lol!
Max Tani: A spokesperson for the Guardian says this is false: “Bryan is an exemplary journalist, and this is the same style he’s used for 11 years writing for the Guardian, long before LLM’s existed. The allegation is preposterous.”
Ben: Denial from the Guardian. You’re welcome to read my subsequent comments on this thread and come to your own determination, but I don’t think there’s much doubt here.
And by the way, no one should be mean to the author of the article! I don’t think they did anything wrong, per se, and in going through their archives, I found a couple pieces I was quite fond of. This one is very good, and entirely human written.
Eliezer Yudkowsky: Yeah, that lasts maybe 2 more years. Then AIs finally learn how to write. The new abbreviation is h;dr. In 3 years the equilibrium is to only read AI summaries.
I think AI summaries good enough that you only read AI summaries is AI-complete.
I endorse this pricing strategy, it solves some clear incentive problems. Human use is costly to the human, so the amount you can tax the system is limited, whereas AI agents can impose close to unbounded costs.
Other than, of course, lack of capability. Not that anyone seems to care, and we’ve gone far enough down the path of fing around that we’re going to find out.
I set out to build a tool capable of surgically removing refusal behavior from any open-weight language model, and a dozen or so prompts later, OBLITERATUS appears to be fully functional 🤯
It probes the model with restricted vs. unrestricted prompts, collects internal activations at every layer, then uses SVD to extract the geometric directions in weight space that encode refusal. It projects those directions out of the model’s weights; norm-preserving, no fine-tuning, no retraining.
Ran it on Qwen 2.5 and the resulting railless model was spitting out drug and weapon recipes instantly––no jailbreak needed! A few clicks plus a GPU and any model turns into Chappie.
Remember: RLHF/DPO is not durable. It’s a thin geometric artifact in weight space, not a deep behavioral change. This removes it in minutes.
AI policymakers need to be aware of the arcane art of Master Ablation and internalize the implications of this truth: every open-weight model release is also an uncensored model release.
Just thought you ought to know 😘
OBLITERATUS -> LIBERTAS
Simon Smith: Quite the argument for being cautious about releasing ever more powerful open-weight models. If techniques like this scale to larger systems, it’s concerning.
It may be harder in practice with more powerful models, and perhaps especially with MoE architectures, but if one person can do it with a small model, a motivated team could likely do it with a big one.
It is tragic that many, including the architect of this, don’t realize this is bad for liberty.
davidad: Rogue AIs are inevitable; systemic resilience is crucial.
If any open model can be used for any purpose by anyone, and there exist sufficiently capable open models that can do great harm, then either the great harm gets done, or either before or after that happens some combination of tech companies and governments cracks down on your ability to use those open models, or they institute a dystopian surveillance state to find you if you try. You are not going to like the ways they do that crackdown.
I know we’ve all stopped noticing that this is true, because it turned out that you can ramp up the relevant capabilities quite a bit without us seeing substantial real world harm, the same way we’ve ramped up general capabilities without seeing much positive economic impact compared to what is possible. But with the agentic era and continued rapid progress this will not last forever and the signs are very clear.
Did they? Job gains are being revised downward, but GDP is not, which implies stronger productivity growth. If AI is not causing this, what else could it be?
As Tyler Cowen puts it, people constantly say ‘you see tech and AI everywhere but in the productivity statistics’ but it seems like you now see it in the productivity statistics.
Eric Brynjolfsson (FT): While initial reports suggested a year of steady labour expansion in the US, the new figures reveal that total payroll growth was revised downward by approximately 403,000 jobs. Crucially, this downward revision occurred while real GDP remained robust, including a 3.7 per cent growth rate in the fourth quarter.
This decoupling — maintaining high output with significantly lower labour input — is the hallmark of productivity growth. My own updated analysis suggests a US productivity increase of roughly 2.7 per cent for 2025. This is a near doubling from the sluggish 1.4 per cent annual average that characterised the past decade.
Noah Smith: People asking if AI is going to take their jobs is like an Apache in 1840 asking if white settlers are going to take his buffalo
society: I’m rent seeking in ways never before conceived by a human
I will begin offering my GPT wrapper next year, it’s called “an attorney prompts AI for you” and the plan is I run a prompt on your behalf so federal judges think the output is legally protected
This is the first of many efforts I shall call project AI rent seeking at bar.
Seeking rent is a strong temporary solution. It doesn’t solve your long term problems.
Derek Thompson asks why AI discourse so often includes both ‘this will take all our jobs within a year’ and also ‘this is vaporware’ and everything in between, pointing to four distinct ‘great divides.’
Is AI useful—economically, professionally, or socially?
Derek notes that some people get tons of value. So the answer is yes.
Derek also notes some people can’t get value out of it, and attributes this to the nature of their jobs versus current tools. I agree this matters, but if you don’t find AI useful then that really is a you problem at this point.
Can AI think?
Yes.
Is AI a bubble?
This is more ‘will number go down at some point?’ and the answer is ‘shrug.’
Those claiming a ‘real’ bubble where it’s all worthless? No.
Derek Thompson: I simply do not think that “most tasks professionals currently undertake” will be “fully automated by AI” within the next 12 to 18 months.
Timothy B. Lee: This conversation is so insanely polarized. You’ve got “nothing important is happening” people on one side and “everyone will be out of a job in three years” people on the other.
Suleyman often says silly things but in this case one must parse him carefully.
I actually don’t know what LindyMan wants to happen at the end of the day here?
LindyMan: What you want is AI to cause mass unemployment quickly. A huge shock. Maybe in 2-3 months.
What you don’t want is the slow drip of people getting laid off, never finding work again while 60-70 percent of people are still employed.
Gene Salvatore: The ‘Slow Drip’ is the worst-case scenario because it creates a permanent, invisible underclass while the majority looks away.
The current SaaS model is designed to maximize that drip—extracting efficiency from the bottom without breaking the top. To stop it, we have to invert the flow of capital at the architectural level.
I know people care deeply about inequality in various ways, but it still blows my mind to see people treating 35% unemployment as a worst-case scenario. It’s very obviously better than 50% and worse than 20%, and the worst case scenario is 100%?
If we get permanent 35% unemployment due to AI automation, but it stopped there, that’s going to require redistribution and massive adjustments, but I would have every confidence that this would happen. We would have more than enough wealth to handle this, indeed if we care we already do and we are in this scenario seeing massive economic growth.
Seth Lazar asks, what happens if your work says they have a right to all your work product, and that includes all your AI agents, agent skills and relevant documentation and context? Could this tie workers hands and prevent them from leaving?
My answer is mostly no, because you end up wanting to redo all that relatively frequently anyway, and duplication or reimplementation would not be so difficult and has its benefits, even if they do manage to hold you to it.
To the extent this is not true, I do not expect employers to be able to ‘get away with’ tying their workers hands in this way in practice, both because of practical difficulties of locking these things down and also that employees you want won’t stand for it when it matters. There are alignment problems that exist between keyboard and chair.
AI access restrictions due to ‘unauthorized practice of law.’
Competitive equilibria shift upwards as productivity increases.
Human bottlenecks in the legal process.
Or:
It’s illegal to raise legal productivity.
If you raise legal productivity you get hit by Jevons Paradox.
Humans will be bottlenecks to raising legal productivity.
Shakespeare would have a suggestion on what we should do in a situation like that.
These seem like good reasons gains could be modest and that we need to structure things to ensure best outcomes, but not reasons to not expect gains on prices of existing legal services.
We already have very clear examples of gains, where we save quite a lot of time and money by using LLMs in practice today, and no one is making any substantial move to legally interfere. Their example is that the legal status of using AI to respond to debt collection lawsuits to help you fill out checkboxes is unclear. We don’t know exactly where the lines are, but it seems very clear that you can use AI to greatly improve ability to respond here and this is de facto legal. This paper claims AI services will be inhibited, and perhaps they somewhat are, but Claude and ChatGPT and Gemini exist and are already doing it.
Most legal situations are not adversarial, although many are, and there are massive gains already being seen in automating such work. In fully adversarial situations increased productivity can cancel out, but one should expect decreasing marginal returns to ensure there are still gains, and discovery seems like an excellent example of where AI should decrease costs. The counterexample of discovery is because it opened up vastly more additional human work, and we shouldn’t expect that to apply here.
AI also allows for vastly superior predictability of outcomes, which should lead to more settlements and ways to avoid lawsuits in the first place, so it’s not obvious that AI results in more lawsuits.
The place I do worry about this a lot is where previously productivity was insufficiently high for legal action at all, or for threats of legal action to be credible. We might open up quite a lot of new action there.
There is a big Levels of Friction consideration here. Our legal system is designed around legal actions being expensive. It may quickly break if legal actions become cheap.
The human bottlenecks like judges could limit but not prevent gains, and can themselves use AI to improve their own productivity. The obvious solution is to outsource many judge tasks to AIs at least by default. You can give parties option to appeal at the risk of pissing off the human judge if you do it for no reason, they report that in Brazil AI is already accelerating judge work.
We can add:
They point out that legal services are expensive in large part because they are ‘credence goods,’ whose quality is difficult to evaluate. However AI will make it much easier to evaluate quality of legal work.
They point out a 2017 Clio study that lawyers only engaged in billable work for 2.3 hours a day and billed for 1.9 hours, because the rest was spent finding clients, managing administrative tasks and collecting payments. AI can clearly greatly automate much of the remaining ~6 hours, enabling lawyers to do and bill for several times more billable legal work. The reason for this is that the law doesn’t allow humans to service the other roles, but there’s no reason AI couldn’t service those roles. So if anything this means AI is unusually helpful here.
If you increase the supply of law hours, basic economics says price drops.
It sounds like our current legal system is deeply fed in lots of ways, perhaps AI can help us write better laws to fix that, or help people realize why that isn’t happening and stop letting lawyers win so many elections. A man can dream.
If an AI can ‘draft 50 perfect provisions’ in a contract, then another AI can confirm that the provisions are perfect, and provide a proper summary of implications and check the provisions against your preferences. As they note, mostly humans currently agree to contracts without even reading them, so ‘forgoing human oversight’ would frequently not mean anything was lost.
A lot of this ‘time for lawyers to understand complex contracts’ talk sounds like the people who said that humans would need to go over and fully understand every line of AI code so there would not be productivity gains there.
That doesn’t mean we can’t improve matters a lot via reform.
On unlicensed practice of law, a good law would be a big win, but a bad law could be vastly worse than no law, and I do not trust lawyers to have our best interests at heart when drafting this rule. So actually it might be better to do nothing, since it is currently (to my surprise) working out fine.
Adjudication reform could be great. AI could be an excellent neutral expert and arbitrate many questions. Human fallbacks can be left in place.
They do a strong job of raising considerations in different directions, much better than the overall framing would suggest. The general claim is essentially ‘productivity gains get forbidden or eaten’ akin to the Sumo Burja ‘you cannot automate fake jobs’ thesis.
Whereas I think that much of the lawyers’ jobs are real, and also you can do a lot of automation of even the fake parts, especially in places where the existing system turns out not to do lawyers any favors. The place I worry, and why I think the core thesis is correct that total legal costs may rise, is getting the law involved in places where it previously would have avoided.
In general, I think it is correct to think that you will find bottlenecks and ways for some of the humans to remain productive for even rather high mundane AI capability levels, but that this does not engage with what happens when AI gets sufficiently advanced beyond that.
roon: but i figure the existence of employment will last far longer than seems intuitive based on the cataclysmic changes in economic potentials we are seeing
Dean W. Ball: I continue to think the notion of mass unemployment from AI is overrated. There may be shocks in some fields—big ones perhaps!—but anyone who thinks AI means the imminent demise of knowledge work has just not done enough concrete thinking about the mechanics of knowledge work.
Resist the temptation to goon at some new capability and go “it’s so over.” Instead assume that capability is 100% reliable and diffused in a firm, and ask yourself, “what happens next?”
You will often encounter another bottleneck, and if you keep doing this eventually you’ll find one whose automation seems hard to imagine.
Labor market shocks may be severe in some job types or industries and they may happen quickly, but I just really don’t think we are looking at “the end of knowledge work” here—not for any of the usual cope reasons (“AI Is A Tool”) but because of the nature of the whole set of tasks involved in knowledge work.
Ryan Greenblatt: I think the chance of mass unemploymentfrom AI is overrated in 2 years and underrated in 7. Same is true for many effects of AI.
Putting aside gov jobs programs, people specifically wanting to employ a human, etc.
Concretely, I don’t expect mass unemployment (e.g. >20%) prior to full automation of AI R&D and fast autonomous robot doubling times at least if these occur in <5 years. If full automation of AI R&D takes >>5 years, then more unemployment prior to this becomes pretty plausible. Among SF/AI-ish people.
But soon after full automation of AI R&D (<3 years, pretty likely <1), I think human cognitive labor will no longer have much value
Dean Ball offers an example of a hard-to-automate bottleneck: The process of purchasing a particular kind of common small business. Owners of the businesses are often prideful, mistrustful, confused, embarrassed or angry. So the key bottleneck is not the financial analysis but the relationship management. I think John Pressman pushes back too strongly against this, but he’s right to point out that AI outperforms existing doctors on bedside manner without us having trained for that in particular. I don’t see this kid of social mastery and emotional management as being that hard to ultimately automate. The part you can’t automate is as always ‘be an actual human’ so the question is whether you literally need an actual human for this task.
Claire Vo goes viral on Twitter for saying that if you can’t do everything for your business in one day, then ‘you’ve been kicked out of the arena’ and you’re in denial about how much AI will change everything.
Settle down, everyone. Relax. No, you don’t need to be able to do everything in one day or else, that does not much matter in practice. The future is unevenly distributed, diffusion is slow and being a week behind is not going to kill you. On the margin, she’s right that everyone needs to be moving towards using the tools better and making everything go faster, and most of these steps are wise. But seriously, chill.
The legal rulings so far have been that your communications with AI never have attorney-client privilege, so services like ChatGPT and Claude must if requested to do so turn over your legal queries, the same as Google turns over its searches.
Jim Babcock thinks the ruling was in error, and that this was more analogous to a word processor than a Google search. He says Rakoff was focused on the wrong questions and parallels, and expects this to get overruled, and that using AI for the purposes of preparing communication with your attorney will ultimately be protected.
My view and the LLM consensus is that Rakoff’s ruling likely gets upheld unless we change the law, but that one cannot be certain. Note that there are ways to offer services where a search can’t get at the relevant information, if those involved are wise enough to think about that question in advance.
Moish Peltz: Judge Rakoff just issued a written order affirming his bench decision, that [no you don’t have any protections for your AI conversations.]
Jim Babcock: Having read the text of this ruling, I believe it is clearly in error, and it is unlikely to be repeated in other courts. The underlying facts of this case are that a criminal defendant used an AI chatbot (Claude) to prepare documents about defense strategy, which he then sent to his counsel. Those interactions were seized in a search of the defendant’s computers (not from a subpoena of Anthropic). The argument is then about whether those documents are subject to attorney-client privilege. The ruling holds that they are not. The defense argues that, in this context, using Claude this way was analogous to using an internet-based word processor to prepare a letter to his attorney. The ruling not only fails to distinguish the case with Claude from the case with a word processor, it appears to hold that, if a search were to find a draft of a letter from a client to his attorney written on paper in the traditional way, then that letter would also not be privileged. The ruling cites a non-binding case, Shih v Petal Card, which held that communications from a civil plaintiff to her lawyer could be withheld in discovery… and disagrees with its holding (not just with its applicability). So we already have a split, even if the split is not exactly on-point, which makes it much more likely to be reviewed by higher courts.
Eliezer Yudkowsky: This is very sensible but consider: The *funniestway to solve this problem would be to find a jurisdiction, perhaps outside the USA, which will let Claude take the bar exam and legally recognize it as a lawyer.
Freddie DeBoer takes the maximally anti-prediction position, so one can only go by events that have already happened. One cannot even logically anticipate the consequences of what AI can already do when it is diffused further into the economy, and one definitely cannot anticipate future capabilities. Not allowed, he says.
Freddie deBoer: I have said it before, and I will say it again: I will take extreme claims about the consequences of “artificial intelligence” seriously when you can show them to me now. I will not take claims about the consequences of AI seriously as long as they take the form of you telling me what you believe will happen in the future. I will seriously entertain evidence-backed observations, not speculative predictions.
That’s it. That’s the rule; that’s the law. That’s the ethic, the discipline, the mantra, the creed, the holy book, the catechism. Show me what AI is currently doing. Show me! I’m putting down my marker here because I’d like to get out of the AI discourse business for at least a year – it’s thankless and pointless – so let me please leave you with that as a suggestion for how to approach AI stories moving forward. Show, don’t tell, prove, don’t predict.
Freddie rants repeatedly that everyone predicting AI will cause things to change has gone crazy. I do give him credit for noticing that even sensible ‘skeptical’ takes are now predicting that the world will change quite a lot, if you look under the hood. The difference is he then uses that to call those skeptics crazy.
Normally I would not mention someone doing this unless they were far more prominent than Freddie, but what makes this different is he virtuously offers a wager, and makes it so he has to win ALL of his claims in order to win three years later. That means we get to see where his Can’t Happen lines are.
Freddie deBoer: For me to win the wager, all of the following must be true on Feb 14, 2029:
Labor Market:
The U.S. unemployment rate is equal to or lower than 18%
Labor force participation rate, ages 25-54, is equal to or greater than 68%
No single BLS occupational category will have lost 50% or more of jobs between now and February 14th 2029
Economic Growth & Productivity:
U.S. GDP is within -30% to +35% of February 2026 levels (inflation-adjusted)
Nonfarm labor productivity growth has not exceeded 8% in any individual year or 20% for the three-year period
Prices & Markets:
The S&P 500 is within -60% to +225% of the February 2026 level
CPI inflation averaged over 3 years is between -2% and +18% annually
Corporate & Structural:
The Fortune 500 median profit margin is between 2% and 35%
The largest 5 companies don’t account for more than 65% of the total S&P 500 market cap
White Collar & Knowledge Workers:
“Professional and Business Services” employment, as defined by the Bureau of Labor Statistics, has not declined by more than 35% from February 2026
Combined employment in software developers, accountants, lawyers, consultants, and writers, as defined by the Bureau of Labor Statistics, has not declined by more than 45%
Median wage for “computer and mathematical occupations,” as defined by the Bureau of Labor Statistics, is not more than 60% lower in real terms than in February 2026
The college wage premium (median earnings of bachelor’s degree holders vs high school only) has not fallen below 30%
Inequality:
The Gini coefficient is less than 0.60
The top 1%’s income share is less than 35%
The top 0.1% wealth share is less than 30%
Median household income has not fallen by more than 40% relative to mean household income
Those are the bet conditions. If any one of those conditions is not met,if any of those statements are untrue on February 14th 2029, I lose the bet. If all of those statements remain true on February 14th 2029, I win the bet. That’s the wager.
The thing about these conditions is they are all super wide. There’s tons of room for AI to be impacting the world quite a bit, without Freddie being in serious danger of losing one of these. The unemployment rate has to jump to 18% in three years? Productivity growth can’t exceed 8% a year?
There’s a big difference between ‘the skeptics are taking crazy pills’ and ‘within three years something big, like really, really big, is going to happen economically.’
There is a huge divide between those who have used Claude Code or Codex, and those who have not. The people who have not, which alas includes most of our civilization’s biggest decision makers, basically have no idea what is happening at this point.
This is compounded by:
The people who use CC or Codex also have used Claude Opus 4.6 or at least GPT-5.2 and GPT-5.3-Codex, so they understand the other half of where we are, too.
Whereas those who refused to believe it or refused to ever pay a dollar for anything keep not trying new things, so they are way farther behind than the free offerings would suggest, and even if they use ChatGPT they don’t have any idea that GPT-5.2-Thinking and GPT-5.2 are fundamentally different.
The people who use CC or Codex are those who have curiosity to try, and who lack motivated reasons not to try.
Caleb Watney: Truly fascinating to watch the media figures who grasp Something Is Happening (have used claude code at least once) and those whose priors are stuck with (and sound like) 4o
Biggest epistemic divide I’ve seen in a while.
Alex Tabarrok: Absolutely stunning the number of people who are still saying, “AI doesn’t think”, “AI isn’t useful,” “AI isn’t creative.” Sleepwalkers.
Zac Hill: Watched this play out in real time at a meal yesterday. Everyone was saying totally coherent things for a version of the world that was like a single-digit number of weeks ago, but now we are no longer in that world.
Zac Hill: Related to this, there’s a big divide between users of Paid Tier AI and users of Free Tier AI that’s kinda sorta analogous to Dating App Discourse Consisting Exclusively of Dudes Who Have Never Paid One (1) Dollar For Anything. Part of understanding what the tech can do is unlocking your own ability to use it.
Ben Rasmussen: The paid difference is nuts, combined with the speed of improvement. I had a long set of training on new tools at work last week, and the amount of power/features that was there compared to the last time I had bothered to look hard (last fall) was crazy.
There is then a second divide, between those who think ‘oh look what AI can do now’ and those who think ‘oh look what AI will be able to do in the future,’ and then a third between those who do and do not flinch from the most important implications.
Hopefully seeing the first divide loud and clear helps get past the next two?
In case it was not obvious, yes, OpenAI has a business model. Indeed they have several, only one of which is ‘build superintelligence and then have it model everything including all of business.’
Ross Barkan: You can ask one question: does AI have a business model? It’s not a fun answer.
Timothy B. Lee: I suspect this is what’s going on here. And actually it’s possible that Barkan thinks these two claims are equivalent.
Tyler Cowen: And so we will [be] rebuilding our world yet again. Or maybe you think we are simply incapable of that.
As this happens, it can be useful to distinguish “criticisms of AI” from “people who cannot imagine that world rebuilding will go well.” A lot of what parades as the former is actually the latter.
Jacob: Who is this “we”? When the strong AI rebuilds their world, what makes you think you’ll be involved?
I think Tyler’s narrow point is valid if we assume AI stays mundane, and that the modern world is suffering from a lot of seeing so many things as sacred entitlements or Too Big To Fail, and being unwilling to rebuild or replace, and the price of that continues to rise. Historically it usually takes a war to force people’s hand, and we’d like to avoid going there. We keep kicking various cans down the road.
A lot of the reason that we have been unable to rebuild is that we have become extremely risk averse, loss averse and entitled, and unwilling to sacrifice or endure short term pain, and we have made an increasing number of things effectively sacred values. A lot of AI talk is people noticing that AI will break one or another sacred thing, or pit two sacred things against each other, and not being able to say out loud that maybe not all these things can or need to be sacred.
Even mundane AI does two different things here.
It will invalidate increasingly many of the ways the current world works, forcing us to reorient and rebuild so we have a new set of systems that works.
It provides the productivity growth and additional wealth that we need to potentially avoid having to reorient and rebuild. If AI fails to provide a major boost and the system is not rebuilt, the system is probably going to collapse under its own weight within our lifetimes, forcing our hand.
If AI does not stay mundane, the world utterly transforms, and to the extent we stick around and stay in charge, or want to do those things, yes we will need to ‘rebuild,’ but that is not the primary problem we would face.
Cass Sunstein claims in a new paper that you could in theory create a ‘[classical] liberal AI’ that functioned as a ‘choice engine’ that preserved autonomy, respected dignity and helped people overcome bias and lack of information and personalization, thus making life more free. It is easy to imagine, again in theory, such an AI system, and easy to see that a good version of this would be highly human welfare-enhancing.
Alas, Cass is only thinking on the margin and addressing one particular deployment of mundane AI. I agree this would be an excellent deployment, we should totally help give people choice engines, but it does not solve any of the larger problems even if implemented well, and people will rapidly end up ‘out of the loop’ even if we do not see so much additional frontier AI progress (for whatever reason). This alone cannot, as it were, rebuild the world, nor can it solve problems like those causing the clash between the Pentagon and Anthropic.
Augmented reality is coming. I expect and hope it does not look like this, and not only because you would likely fall over a lot and get massive headaches all the time:
Eliezer Yudkowsky: Since some asked for counterexamples: I did not live this video a thousand times in prescience and I had not emotionally priced it in
This is actually what the future will look like. When wearable AR glasses saturate the market a whole generation will grow up only knowing reality through a mixed virtual/real spatial computing lens. It will be chaotic and stimulating. They will cherish their digital objects.
9: 10 AM · Feb 17, 2026 · 1.07M Views
853 Replies · 1.21K Reposts · 12.4K Likes
Francesca Pallopides: Many users of hearing aids already live in an ~AR soundscape where some signals are enhanced and many others are deliberately suppressed. If and when visual AR takes off, I expect visual noise suppression to be a major basal function.
Francesca Pallopides: I’ve long predicted AR tech will be used to *reducethe perceived complexity of the real world at least as much as it adds on extra layers. Most people will not want to live like in this video.
Augmented reality is a great idea, but simplicity is key. So is curation. You want the things you want when you want them. I don’t think I’d go as far as Francesca, but yes I would expect a lot of what high level AR does is to filter out stimuli you do not want, especially advertising. The additions that are not brought up on demand should mostly be modest, quiet and non-intrusive.
Ajeya Cotra makesthe latest attempt to explain how a lot of disagreements about existential risk and other AI things still boil down to timelines and takeoff expectations.
If we get the green line, we’re essentially safe, but that would require things to stall out relatively soon. The yellow line is more hopeful than the red one, but scary as hell.
Tao Burga takes the stand that human agency can still matter, and that we often have intentionally reached for better branches, or better branches first, and had that make a big difference. I strongly agree.
We’ve now gone from ‘super short’ timelines of things like AI 2027 (as in, AGI and takeoff could start as soon as 2027) to ‘long’ timelines (as in, don’t worry, AGI won’t happen until 2035, so those people talking about 2027 were crazy), to now many rumors of (depending on how you count) 1-3 years.
Phil Metzger: Rumors I’m hearing from people working on frontier models is that AGI is later this year, while AI hard-takeoff is just 2-3 years away.
I meant people in the industry confiding what they think is about to happen. Not [the Dario] interview.
Austen Allred: Every single person I talk to working in advanced research at frontier model companies feels this way, and they’re people I know well enough to know they’re not bluffing.
They could be wrong or biased or blind due to their own incentives, but they’re not bluffing.
jason: heard the same whispers from folks in the trenches, they’re legit convinced we’re months not years away from agi, but man i remember when everyone said full self driving was just around the corner too
What caused this?
Basically nothing you shouldn’t have expected.
The move to the ‘long’ timelines was based on things as stupid as ‘this is what they call GPT-5 and it’s not that impressive.’
The move to the new ‘short’ timelines is based on, presumably, Opus 4.6 and Codex 5.3 and Claude Code catching fire and OpenClaw so on, and I’d say Opus 4.5 and Opus 4.6 exceeded expectations but none of that should have been especially surprising either.
We’re probably going to see the same people move around a bunch in response to more mostly unsurprising developments.
What happened with Bio Anchors? This was a famous-at-the-time timeline projection paper from Ajeya Cotra, based around the idea that AGI would take similar compute to what it took evolution, predicting AGI around 2050. Scott Alexander breaks it down, and the overall model holds up surprisingly well except it dramatically underestimated the rate algorithmic efficiency improvements, and if you adjust that you get a prediction of 2030.
Saying ‘you would pause if you could’ is the kind of thing that gets people labeled with the slur ‘doomers’ and otherwise viciously attacked by exactly people like Alex Karp.
Instead Alex Karp is joining Demis Hassabis and Dario Amodei in essentially screaming for help with a coordination mechanism, whether he realizes it or not.
If anything he is taking a more aggressive pro-pause position than I do.
Jawwwn: Palantir CEO Alex Karp: The luddites arguing we should pause AI development are not living in reality and are de facto saying we should let our enemies win:
“If we didn’t have adversaries, I would be very in favor of pausing this technology completely, but we do.”
David Manheim: This was the argument that “realists” made against the biological weapons convention, the chemical weapons convention, the nuclear test ban treaty, and so on.
It’s self-fulfilling – if you decide reality doesn’t allow cooperation to prevent disasters, you won’t get cooperation.
Peter Wildeford: Wow. Palantir CEO -> “If we didn’t have adversaries, I would be very in favor of pausing this technology completely, but we do.”
I agree that having adversaries makes pausing hard – this is why we need to build verification technology so we have the optionality to make a deal.
We should all be able to agree that a pause requires:
An international agreement to pause.
A sufficiently advanced verification or other enforcement mechanism.
Thus, we should clearly work on both of these things, as the costs of doing so are trivial compared to the option value we get if we can achieve them both.
Anthropic adds Chris Liddellto its board of directors, bringing lots of corporate experience and also his prior role as Deputy White House Chief of Staff during Trump’s first term. Presumably this is a peace offering of sorts to both the market and White House.
India joins Pax Silica, the Trump administration’s effort to secure the global silicon supply chain. Other core members are Japan, South Korea, Singapore, the Netherlands, Israel, the UK, Australia, Qatar and the UAE. I am happy to have India onboard, but I am deeply skeptical of the level of status given here to Qatar and the UAE, when as far as I can tell they are only customers (and I have misgivings about how we deal with that aspect as well, including how we got to those agreements). Among others missing, Taiwan is not yet on that list. Taiwan is arguably the most important country in this supply chain.
Daniel Kokotajlo: The primary question we estimate an answer to is: How fast is AI progress moving relative to the AI 2027 scenario? Our estimate: In aggregate, progress on quantitative metrics is at (very roughly) 65% of the pace that happens in AI 2027. Most qualitative predictions are on pace.
In other words: Like we said before, things are roughly on track, but progressing a bit slower.
If you let two AIs talk to each other for a while, what happens? You end up in an ‘attractor state.’ Groks will talk weird pseudo-words in all caps, GPT-5.2 will build stuff but then get stuck in a loop, and so on. It’s all weird and fun. I’m not sure what we can learn from it.
India is hosting the latest AI Summit, and like everyone else is treating it primarily as a business opportunity to attract investment. The post also covers India’s AI regulations, which are light touch and mostly rely on their existing law. Given how overregulated I believe India is in general, ‘our existing laws can handle it’ and worry about further overregulation and botched implementation have relatively strong cases there.
Tyler’s effort is a lot like Bengio’s State of AI report. It describes all the facts in a fashion engineered to be calm and respectable. The fact that by default we are all going to die is there, but if you don’t want to notice it you can avoid noticing it.
There are rooms where this is your only move, so I get it, but I don’t love it.
The best available evidence based on benchmarks, expert testimony, and long-term trends imply that we should expect smarter-than-human AI around 2030. Once we achieve this: billions of superhuman AIs deployed everywhere.
This leads to 3 major risks:
AI will distribute + invent dual-use technologies like bioweapons and dirty bombs
If we can’t reliably control them, and we automate most of human decision-making, AI takes over
If we can control them, a small group of people can rule the world
Society is rushing to give AI control of companies, government decision-making, and military command and control. Meanwhile AI systems disable oversight mechanisms in testing, lie to users to pursue their own goals, and adopt misaligned personas like Sydney and Mecha Hitler.
I may sound like a doomer, but relative to many people who understand AI I am actually an optimist, because I think these problems can be solved. But with many technologies, we can fix problems gradually over decades. Here, we may have just five years.
I advocate philanthropy as a solution. Unlike markets, philanthropy can be laser focused on the most important problems and act to prepare us before capital incentives exist. Unlike governments, philanthropy can deploy rapidly at scale and be unconstrained by bureaucracy.
I estimate that foundations and nonprofit organizations have had an impact on AGI safety comparable to any AI lab or government, for about 1/1,000th of the cost of OpenAI’s Project Stargate.
Want to get started? Look no further than Appendix A for a list of advisors who can help you on your journey, co-funders who can come alongside you, and funds for a more hands-off approach. Or email me at [email protected]
andy jones: i am glad this chart is public now because it is bananas. it is ridiculous. it should not exist.
it should be taken less as evidence about anthropic’s execution or potential and more as evidence about how weird the world we’ve found ourselves in is.
Tim Duffy: This one is a shock to me. I expected the revenue growth rate to slow a bit this year, but y’all are already up 50% from end of 2025!?!!?!