I’m doing the Monthly Roundup early this month so that next week can be GPT-5.2 and affordability of life week, assuming we are not overtaken by other events.
The risk-reward profile of creating highly dangerous new viruses, supposedly in order to study them, is abysmal even when things are handled properly.
Also, the actual practice of it is completely utterly insane.
This below is the kind of thing that could very easily cause a global pandemic vastly worse than Covid, or even end civilization, and it was done in a BSL-2 laboratory, and no one has been arrested for it.
People need to be arrested for this. Ideally heads need to end up on pikes until it stops.
Maarten De Cock: A new 🇨🇳 gain of function study created chimeric coronaviruses that can infect human cells and kill mice (up to 100% mortality).
🚩”The viral infection [and all animal experiments] were performed in a BSL-2 laboratory”(!)🤦♂️
*The authors thank a.o. Ben Hu & Zheng-Li Shi.
At current margins, zoning restrictions on home-based businesses are terrible and make everything worse. There of course have to be some rules and limits, and occasionally one might even need to enforce them, but we can and should be dramatically more chill.
All the modern buildings and living spaces have no character, even expensive ones, as everything converges on a single largely white aesthetic. A lot of people realize that the old look of ‘having character’ was better, but no one ends up doing it, even when there is the ability to pay more.
This level of having no idea what prices do seems to be very common. Also very common is that someone finds out and then refuses to understand:
Pamela Hobart: I graduated with high honors from an affluent, acclaimed high school and then again with high honors with a BA in philosophy & pre-law before EVER once hearing the idea that prices convey information and coordinate actors.
I’ll never forget rolling up to a philosophy conference in Pasadena in 2008 and wandering into a session on “price gouging” and the pro-”price gougers” introduced this concept.
Possibly the single most transformative moment of my entire education.
like I didn’t even grow up in a particularly liberal enclave or anything either, most parents were garden variety Republicans as were the teachers I imagine.
CEOs are using the assassination of the CEO of United Healthcare to argue for higher pay in light of job risks and need for security, and many of them are getting it. As well they should, I know my happy price to be CEO of a major corporation went up that day.
Kelsey Piper recalls the story of James Damore, and the attempts to have him blacklisted after he was fired from Google. The events are also described in this podcast by her boss at the time, Harj Taggar, who resisted the calls to blacklist him. Yeah, things were like that back then.
I fully agree with David Manheim here, in general, that condemnations are almost always at most supererogatory.
David Manheim: I will again state my view that condemning bad things is great, but condemning others for failing to condemn bad things, (much less boycotting them and similar glorious loyalty oath crusades,) is building toxic community incentives and attempting to force conformity.
Partly this is because life beckons and we have better things to do with our time than constantly condemn everything bad. But it’s more than that.
Often condemning a bad thing only gives it oxygen, and also gives oxygen to additional demands to condemn things that are decreasingly bad until you finally draw the line, and you are now seen as endorsing, condoning or even ‘platforming’ anything you didn’t sufficiently condemn and punish. At which point you become blameworthy, no matter what you did. Don’t accept the jurisdiction of that court.
Videos from the Roots of Progress Conference.
Polymarket participant AlphaRaccoon once again exploits insider information (presumably), as is legal and allowed on Polymarket, and makes over a million dollars betting on the Google search markets, after profiting on the release date of Gemini 3.
This post has good advice on gift giving.
The central point on such guides is that you need to know why they haven’t gotten the gift for themselves despite it providing value when you give it to them, and the more good reasons for that the better.
Activation energy, trivial inconveniences, choices are bad, lack of in-context knowledge or taste, lack of access, guilt over spending, too much audacity or cringe if they bought it for themselves, shared experiences, symbolic meaning and yes liquidity and solvency constraints are all good reasons. Stack them on top of each other.
I strongly agree with the statement below, and it a statement that positively updates me on the person making it, also see this proposal from IFP.
Fidji Simo (OpenAI CEO of Products): We need the equivalent of the 20th-century clean water revolution, except for clean indoor air.
People with post-infectious chronic illnesses have known for a while how insane it is that, as a society, we continue to find it perfectly acceptable to breathe air full of viruses that can completely destroy our lives years later and that our schools are virus factories.
With more horrible conditions being attributed to viruses earlier in life, I hope that perceptions will finally change, and that contaminated air will soon feel as unacceptable as contaminated water.
Avital Balwit writes the advice he would give on a mentorship call to college students.
Zohran Mamdani, New York City’s next major, plans to make it so you don’t have to fill out 24 forms and go through 7 agencies to start a barber shop? As I’ve thought for a while, we have no idea what Mamdani will actually do as mayor. Things like this can make up for a lot of stupid symbolic stuff.
Cate Hall once again reminds us that You Can Just Do Things, this time in an interview with Clara Collier.
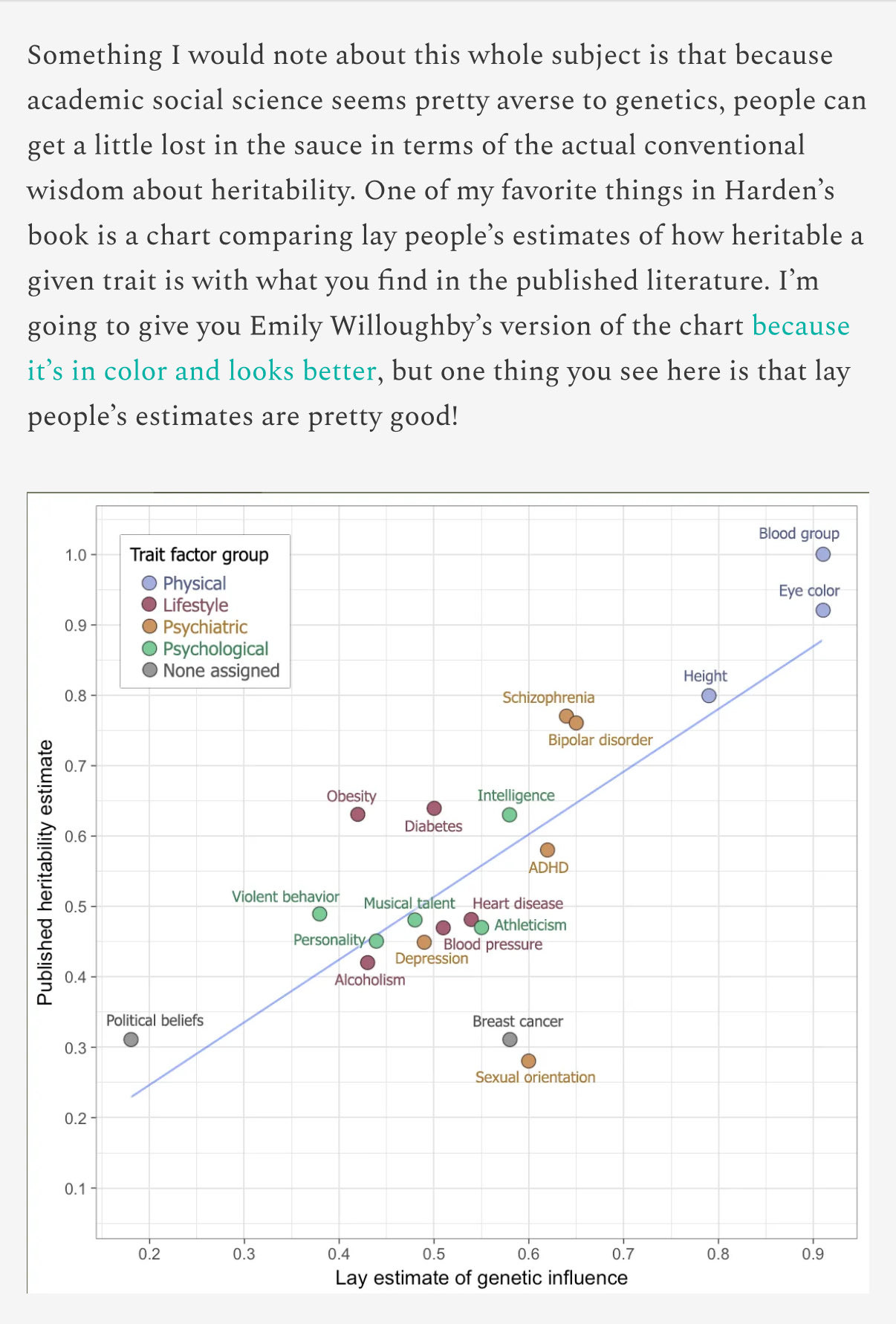
The public is reasonably good at estimating which traits are how heritable, r^2 is something like 0.35-0.4 even if you exclude eye color and blood group, and if you assume the literature is always right and the laypeople are wrong, which I would not be so quick to assume, especially for the big gaps: sexual orientation and obesity.
Oliver Habryka offers a beginner’s guide, as in basic explanations for why exiting in paranoia-inducing epistemic situations drives people crazy and towards making seemingly crazy decisions. Oliver’s thesis is that the world has gotten more paranoia-requiring and epistemically hostile, and that this often overwhelms the value of us having better information and other resources, often leading to worse decisions.
He starts by going over how lemon markets work, and points out that in the real world we always have not only a potential lemon problem but also a potential lemon problem among the identifiers of the lemons, and so on. Whatever system you are relying upon there are those looking to exploit it.
Well, maybe. That’s true for a sufficiently collective value of ‘you,’ or if you alone are a sufficiently important target. In many cases, this doesn’t apply, and it isn’t true.
In other cases you can do a pretty good job identifying non-suspicious counterparties, or you can engage in enough iterated games, such that you can solve such worries.
The reason used cars in particular are such an issue is that not only is it traditionally hard to detect lemons, there is also little recourse or consequence to selling a lemon, and also there is a baseline cultural expectation that a ‘used car salesman’ will be slimy, so them being suspicious or having somewhat of a sketchy reputation doesn’t mean you can obviously bail on them.
(We now actually have made substantial progress in the used car lemon problem, with inspections that come with warranties, longer test drive periods, online marketplaces, certifications that have long term reputations to maintain and the rise of history trackers like Carfax and AutoCheck.)
The next point Oliver makes, about OODA loops, is key, although I’d frame it differently. Oliver presents it as, if the enemy can ‘get inside your OODA loop,’ meaning act on you before you can observe, orient, decide and act, then you’re screwed, because you never actually get to act in an appropriate way. This is a good illustration but feels too general.
It’s more a question of, can you handle the epistemic environment in which you have been placed without taking generally paranoid or drastic measures?
Consider a poker game. If you’re up against an inferior player, or one of similar caliber, then there is a lot of room to make interesting moves, and try to use the information they are giving off, and to give off intentionally misleading information, both with game actions and otherwise. You can always make what you think is the ‘best’ play based on the situation, and ideally only randomize in true edge cases.
If you’re up against a sufficiently superior player, that won’t work. They anticipate what you are thinking, they adopt faster than you do, they are giving off actively misleading signals and figuring out yours.
You need to retreat to your best approximation of game theory optimal play and randomize your moves while ignoring your reads, combining Oliver’s strategies.
Which are:
Oliver Habryka: There are lots of different ways people react to adversarial information environments like this, but at a high level, my sense is there are roughly three big strategies:
-
You blind yourself to information
-
You try to eliminate the sources of the deception
-
You try to become unpredictable
All three of those produce pretty insane-looking behavior from the outside, yet I think are by-and-large an appropriate response to adversarial environments (if far from optimal).
Blinding yourself to information is an extreme response that only makes sense when you are sufficiently outgunned. One good reason to be outgunned is that others might be putting way more effort in than you can or would want to put in.
When sources around you are willing to lie or otherwise untrustworthy, that does not mean you should ignore them, even if they are clearly lying to you to try and trick you.
Oliver gives the example of the CDC during Covid, where they were saying things like ‘masks don’t work.’ This is indeed valuable information about the CDC and also the current world state, if you understand how to process it and not fall into the trap of interpreting it as ‘oh, masks don’t work.’
This goes back to Simulacra Levels.
The CDC and Fauci were operating at Simulacra Level 2. As in, they would tell you [X] so that you would believe [X] and then act accordingly and do [Y]. They didn’t care if [X] was true or false, they cared that they thought [Y] was good for public health.
Once you identify that this is what the CDC and Fauci are doing, you can properly interpret their statements. They say ‘[X] is true’ and you hear ‘we think it would be good for public health if you did [Y].’
You can do similar things when you figure out people are on Level 3 or Level 4.
I also think the stories on professional advice, official numbers and admissible evidence, Oliver’s examples of rules limiting information flow, are more complicated, but I won’t get into that here.
Strategy two is to purge the untrustworthy. This seems purely good. Even if you are in a mostly non-paranoid mode, and can mostly trust everyone, how do you keep it that way? By punishing and if needed exiling anyone who is not trustworthy, which includes you being insufficiently able to trust that they are trustworthy. That’s how trustworthiness works.
A variation of purging, or asking which sources are unreliable, is to determine which sources are adversarial. A source can be unreliable without being adversarial, or it can be adversarial without being unreliable. Ideally you’d avoid me if I was either of these.
Strategy three is to become unpredictable and vindictive.
You can combine these strategies, and you can also use either one on their own.
To a large extent ‘be unpredictable and vindictive’ is about creating maximally strong incentives. If you’re going down this strategy, you want maximum distinction between reward and punishment, and to always make people uncertain where they stand and worried or hopeful you might flip from one to the other, ideally with fear of massive overreactions. It can definitely work.
Paranoia is one good reason to do this, as it makes people scared to cross you, but it also is a valid strategy for anyone with enough power even without paranoia.
And again, you can split the two halves and do either without the other.
Richard Ngo suggests an additional strategy, that the wise trader uses, which is to have wide bid-ask spreads, and being conservative in taking actions that might reward or get punished by deception.
Thus we have six strategies.
We have Oliver’s three, the last of which is split in two, we have Richard’s, and then we have Git Gud, be able to parse the information properly and get good use out of it, and you can do any combination of the six.
Tyler Cowen list of best nonfiction books of the year.
The only one I have read is Open Socrates by Agnes Callard, which I affirm was excellent and I’m sad I did not finish my book review. I might attempt it again at a later time, it is even now on top of my ‘when I have time’ stack, although it will suffer from my loss of memory. I’ll be largely relying on what I chose to highlight. Still seems worth it? So much to enjoy disagreeing with in that book.
I am on the fence on whether I should be reading and reviewing more nonfiction books, versus other uses of time.
Tyler Cowen picks his best fiction of 2025, as a person whose best-of book lists are much bigger than how many books I read at all. I hadn’t even heard of any of these. Balle is included and appears to be a time travel story, which I’m usually down for, but I can wait and see if people like where it goes.
How many fiction books did I read in 2025 other than when reading to my kids? One, This Is How You Lose The Time War, which I read on a plane and can recommend as ‘a good book.’ I owe Seth Burn that I will read Dungeon Crawler next. Fiction is one of the things my revealed preferences don’t find the time for. I wonder if that is a mistake, as the upside of a really good book can be very high.
I’d also love to learn how to write fiction, although I’m most attracted to the idea of a screenplay? Every time I try to actually write fiction I feel like an imposter, nothing seems right or good enough, I end up not writing anything. Yet I often have very particular opinions about creative works.
I will be doing a Movies of 2025 post, either later this year or early in 2026, once I’ve had opportunity to watch the end-of-year movies. This was the year of pain, and the year of anticorrelation with critics.
The Pope waxes poetic about the magic of movies. No disagreements but also we need to see him get more feisty.
Charlie XCX on what it is like to be a pop star.
Another article, this time from Slow Boring and Chris Dalla Riva, points out that copyright terms are too long and terms too restrictive. In particular, Chris blames this for a lot of our cultural stagnation, as there are constant pushes to reintroduce us to existing music and other IP via things like biopics.
Except, isn’t that good? What’s wrong with getting owners of song catalogues to bankroll biopics for artists like Elvis and Springsteen, which you don’t have to watch and are often pretty good and also make our music experiences better? Or to encourage sampling?
The intervention Chris pushes is expanded compulsory licensing. I agree that compulsory licensing has been great for music. I unfortunately don’t think that works the same way for television and movies, but also the copyright term is obviously way too long and due to treaties it would be difficult to shorten it.
Thus, an obvious compromise suggests itself. We can move to mandatory licensing after a reasonable period of time, something like 30 years, plus a required prominent disclaimer on all licensed visual media.
Netflix is attempting to buy Warner Brothers for $72 billion, although Paramount has now bid higher and the prediction markets think Paramount is the favorite. The market hates the deal for Netflix. It is unclear how much of that is ‘this is too high a price or a poor fit’ and how much is ‘Netflix choosing to do this reveals something is wrong.’
Lucas Shaw and Michelle Davis: California Republican Darrell Issa wrote a note to US regulators objecting to any potential Netflix deal, saying it could result in harm to consumers. Netflix has argued that one of its biggest competitors, however, is Alphabet Inc.’s YouTube, and that bundling offerings could lower prices for subscribers.
I think Netflix is right, and also this merger could be fantastic for customers, combining HBO and Netflix. Netflix has promised to allow Warner Brothers films to continue to have full theatrical releases, and for their business to continue unchanged, and I see little reason for them not to do that.
I agree with Matthew Yglesias that a lot of what Netflix is buying is the prestige television and the best way to use that is to let it do its thing on that front. On the movie front there is some reason to worry about less motivation for prestige films especially.
I have also heard the theory that if Paramount buys Warner Bros. then Paramount would pull all of both companies content from Netflix and form a competitor, so the Netflix bid is largely defensive. That’s all the more reason not to fear it.
My instinct is we want Netflix to win this fight, but if Paramount is willing to integrate Paramount+ and HBO Max into an actually functional streaming service that can surface high quality content (Paramount+ is, shall we say, not the most functional service on either surfacing high quality content or serving its basic functions) then that would also be a win.
If a Magic: The Gathering deck would be too good with perfect play, but approximately zero people can play the deck well enough to dominate with it, do we have a problem? Amulet decks in Modern are the latest to suggest this question.
In the linked discussion I think both Seth Burn and Sam Black make good points. Centrally I agree that bans are about harm reduction, which is often best served by harm prevention, with the goal of creating the best game in practice. I view harm as primarily mattering on the level of typical player experiences and health of a format in practice. I do think there’s a level at which Pro Tour level results can force your hand here anyway, but it’s on the level of ‘this deck is >50% to win if we ran the tournament back next week.’
Werewolf is a highly illustrative game (basic rules: there are [X] players in the village, [Y] of which are werewolves, each day everyone in the village including the werewolves votes to kill a player, each night the werewolves kill a player, whichever side is left at the end wins, various players get various other special powers), in that in most groups the werewolves win way more often than they ‘should’ for given values of [X] and [Y].
This happens largely because so many players effectively focus largely on their own survival rather than the survival of their team, so they become afraid to speak out or otherwise try to help the village win, and that the villager side is in various ways the harder one to play well. Whereas if the villagers are good enough at working together, getting people talking and analyzing Bayesian evidence, they can win remarkably often, including a high chance of identifying a werewolf at game start without any hard evidence. These are important lessons about the world and the ease with which a focused group can win, which was the point of the OP she is QTing here.
Liv Boeree is correct that by balancing the special roles (and also the number of werewolves) you can get the win rate for the werewolves to be whatever you want it to be for a given group of people, but people fail to understand the dynamics pointing towards the werewolves, and thus the werewolves tend to win most games in practice unless a given group is self-balancing.
Roblox is a confusingly popular platform for children’s computer games. There are more than 150 million daily active users spending 11 billion hours a month, 3 percent of the gaming space, with at one point more than 25 million users simultaneously playing the game ‘Steal a Brainrot.’ I haven’t checked that ‘game’ out but presumably based only on the title this is an indictment of our entire civilization. A quick investigation indicates it is basically a base raiding game.
Roblox is described as ‘one of the primary gathering places for preteens.’
Alas, any time something attracts kids that will mean not only hosts of abominations like ‘Steal a Brainrot.’ It also means predators, and there are 20+ associated lawsuits. Roblox pitched Kevin Roose and Hard Fork on interviewing Roblox’s CEO David Baszucki about child safety, which seems like a fine idea for all concerned, except then it got weird.
They start out talking about new safety measures, including using a facial scan and AI age estimator (that is also using various behavioral indicators) before allowing communications. The idea is yes you might fool the image filter but when you stack the evidence it gets harder and harder to hide that you’re a kid. They also use such strategies as not sharing images, aggressive text filtering and so on.
And he says essentially: Hey, better to have the kids in Roblox with these restrictions, than a place like Snapchat or Instagram or Discord where things are worse. Fair point.
That all helps, but as always if you twiddle enough you can always get through filters. As Baszucki points out at some point you’re using the fifth letter of every third word and nothing short of full generative AI analysis is going to ever cut it. Give me a text channel, give me sufficient incentive and time, and you’re cooked.
Many games respond to this by not allowing open-ended chat, period, or heavily restricting what it takes to open such a channel. When I made the Emergents TCG, I was essentially informed by our legal department that no, you are not going to let your users chat with each other, you are not allowed to do that.
Which really, really sucks. I’m totally with Baszucki that allowing communication adds a ton of value, that being social is important to the experience. I mean, look, it sure isn’t the quality of the games.
Then Roose asks about responsibility coming with scale and then the Hindenburg report on Roblox where they said they were compromising child safety to report growth to investors (which of course they were, compromises are inevitable and not obviously bad, we’re talking price here) and things keep focusing on the safety issues at the expense of everything else, at which point Baszucki gets increasingly upset and things go off the rails and complains that he’d love to also talk about things other than content filtering at some point.
Fundamentally, underneath him going on tilt, it seems like Baszucki’s core argument is that AI safety filtering is better than human filtering given how much human attention could reasonably be available. And I actually agree with that, so long as it escalates to a human when necessary.
Oh, and then Baszucki brings up Polymarket unprompted, he’s rightfully a big fan but also then he gives a flat out yes to a intended-to-be-a-joke question about putting prediction markets inside Roblox via a Dress To Impress Predictor. So that was a lot of fun. Isaac King is right that prediction markets for kids are a great idea if you can find a way to avoid them devolving into gambling, that does not make it not funny.
Seth Burn breaks down the latest game in which an NFL team would have benefited by going for 2 in order to adjust their behavior (in this case, the Eagles score a TD to go down 9 with 3: 09 to go against the Bears). To maximize the probability of winning, the Eagles need to go for 2 right away, so they can onside kick if they fail, which overrides all the ways the Bears might use the information.
That is true, but the gain in win probability is very low, whereas the amount of exciting football that is lost to the fans, in expectation, is rather high. From the perspective of the NFL or of the fans, I would want a convention that you kick the extra point here. I agree that you play to win the game, but it’s not to the exclusion of all other considerations, and the win probability difference here is very small, well under 1%. It’s fine to give some consideration to what is cool, to the fan experience, to various records, to health of players, to ‘the good of the game’ writ large and maintaining good norms.
An easy way to see this is that near the end of basketball games, there is a point at which there is a non-zero chance that the team trailing could win if they started fouling, yet there is a convention that past some point they do not try, and that this convention is obviously a good thing. Whereas in the NCAA tournament that rule goes out the window and you play to win the game, and that too is good.
University of Michigan athletics generated $266 million in revenue last year and still lost $15 million, and that’s before they were on the hook for $20 million or more in payments to student-athletes, and also before the football coach got fired and arrested.
What’s the actual business model? Sports drive alumni donations.
Geoff White: Donors gave nearly $900 million dollars to UofM in 2025. As an alum, I can state with 100% confidence those numbers would be substantially lower without athletics. The impact is far, far, far greater than $15mm, it is probably closer to $250mm. That is the real story.
Twitter made user locations public, revealing that many supposedly accounts stoking the flames of toxic discourse were not American at all. At least many of them were foreigners in it for the engagement payments.
Mostly all the ‘real’ accounts are who and where they said they were, many reported that a bunch of accounts that got exposed vanished, and mostly this was a big win. I didn’t notice a change, but I cultivate lists and block as needed so I’m not exposed to troll farms. Seems like a very good change overall.
The one problem was that the location algorithm can be a little funky in some cases.
This led to some obviously real accounts joking about being put in the wrong place (such as Liv Boeree being put in the UK or Will Eden in Japan) and also some bad faith attacks in places where the origin was obviously glitched. As always, I noted who joined in such attacks and who did not.
The rollout of the new Twitter ‘chat’ feature has been a rather unmitigated disaster and it is rather dismaying that it was allowed to go forward. It frequently didn’t work, and even when it does work the whole thing is worse than what we had before, and I don’t see any benefits.
UK Taskforce calls for radical reset of nuclear regulation in UK. I saw widespread praise for the whole of the recommendations here, and this was an opportunity to push for doing all of it, and it worked, the PM has pledged to do exactly that.
Visegrad 24: The European Parliament just voted in favor of banning social media for people under the age of 16.
483 MEPs voted in favor while 92 voted against. If it becomes law, people will likely have to use IDs to log into their profiles, making anonymous accounts impossible.
The primary effect of this is to force tracking and verification of everyone’s identify online to the maximum extent possible. Which of course they know, and is why they voted for it.
Over half the cost of hardware construction at Revoy and Charm Industrial is claimed to come from regulatory bottlenecks. The post makes good points but I note the accounting seems creative, as in ‘you delayed my project a year so you imposed a societal burden equal to the per-year benefits of the project.’ That’s a real thing you can measure, but you have to keep it in its proper context.
Tyler Cowen says an important point out loud, which is that every workable immigration policy offends liberal instincts, public opinion or both. I would argue that ultimately, no matter the path, it is both. All the options require doing something that profoundly sucks in both ways, in some combination of who is not allowed in, how we enforce who is not allowed in and how we treat those we let in.
That still leaves many free wins available to us. We are miles away from the production possibilities frontier. High skilled and high value immigration is a win for everyone across the board, or can be with compensation as needed, no matter what else we ultimately choose to do, and a lot of the things we do right now are purely destructive and cruel, and we can stop. But yes, ultimately there are contradictions.
Elon Musk used to talk about free speech.
Elon Musk: Falsely labeling non-violent people as “fascist” or “Nazi” should be treated as incitement to murder.
CNN (October 29, 2024): Trump calls Harris a fascist, says he is ‘the opposite of a Nazi.’
To guarantee objectivity I turned to Grok to ask if Elon Musk has ever done this. The answer is yes.
Zvi: has Elon Musk called any non-violent people ‘fascist’ or ‘nazis’?
Grok: Yes, Elon Musk has referred to non-violent individuals and entities as “fascists” or drawn comparisons implying “Nazi” associations on multiple occasions. Here are some key examples based on documented instances:
-
In September 2024, Musk labeled the Australian government “fascists” in response to proposed legislation that would fine social media platforms for failing to address misinformation. This was directed at the center-left government led by Prime Minister Anthony Albanese, who is not associated with violence.
He doubled down on the remark after Albanese criticized it, emphasizing his opposition to the bill’s potential impact on free speech.
-
In February 2022, amid the Canadian trucker protests against COVID-19 restrictions, Musk posted (and later deleted) a meme likening Prime Minister Justin Trudeau to Adolf Hitler, implying a Nazi comparison. The meme read: “Stop comparing me to Justin Trudeau. I had a budget,” overlaid on a photo of Hitler.
In a related post, he stated: “If Canadian government is suppressing peaceful protests, that’s where fascism lies,” indirectly calling Trudeau’s administration fascist.
Trudeau, a non-violent political leader, was the target of these remarks.
These instances involve Musk criticizing government actions he views as authoritarian, but the individuals and groups referenced (e.g., elected officials and administrations) are not engaged in personal violence.
Zvi: would you describe these instances as ‘falsely labeling’ those people?
Grok: Yes, I would describe these instances as falsely labeling those people, as the terms “fascist” and “Nazi” (or direct comparisons to Hitler) carry specific historical and ideological connotations that do not accurately apply to the democratic governments and leaders in question. [explanation continues].
Curious.
Michael and Susan Dell donate $6.25 billion for ‘Trump accounts’ for children (out of a net worth of about $148.5 billion), giving them $250 each.
Look, no, good that he’s donating the money to kids at all, but this implementation is dumb, it doesn’t buy that much political goodwill and it isn’t a good use of the funds. This seems well behind the ‘make tuition free’ donations if you have to go this route.
Postmanbloke: House parties need to make a comeback.
Peter Wildeford: House parties exist! I met my girlfriend at a house party 2 years and 10 months ago ❤️
Allie: Guys just have house parties. No one is stopping you.
The fun thing is you do not need a house! I did this in my apartment.
I think they often also mean they don’t have a social circle to begin with.
Cartoons Hate Her!: ACTUALLY something is stopping me: nobody fucking comes!!
One problem here is irl I have zero “status” related to my career. Not that it explains nobody liking me, but people generally don’t know/care what CHH is, so I say im a writer and theyre thinking “oh, a loser”
There are a lot of people from the Internet who would come to my house party if I invited them, but I specifically do not want them there.
Ben Hsieh: ok i can finally post about my trauma trying to host events in LA where consistently 0-1 people showed and in one case the invitees did the same event just without me
honestly felt like something was wrong with me until i moved back to NYC and started getting 20+ attendees again
the actual nadir (well besides the rehosting thing) was somehow hosting a comped company happy hour where all 6 rsvpd coworkers ghosted including a designer i work with every day. honestly fuck LA never going back
shoutout to the solo attendees tho, those guys were total bros about it every time 🫡
Jake Eaton: first holiday party in LA we invited (and cooked) for 20 people; 2 showed up. once we proposed doing formalwear at mel’s diner with friends. while we tried to find a date, we saw on instagram they did it without us. i still miss it all the time though
Ben Hsieh: wow this is so validating to hear that it wasn’t just me. honestly i never felt like it was anything personal but just the unpredictable traffic and people being overly surface nice makes the flake rate insane. solidarity for hosts w/ flakey friends tho
Misha: Party Expert here: most house parties are not in fact networking events based on your prestige or legible status. They’re outgrowths of friend groups, chance meetings, and public/semi-public events.
There IS an unfortunate sort of catch-22 here which is if you’re locally socially disconnected your avenue for getting people to come to your parties / getting invited to parties is pretty constrained
but there’s also a clear if effortful path to connection
Another unfortunate thing about the process of making friends (or lovers or whatever) is that it’s necessarily kind of stochastic because it’s hard to know if you’ll get along with someone before you interact. Even correct purposeful behavior will only be intermittently rewarded.
I would attend a house party by Cartoons Hate Her! if it was local, but then I am probably one of those internet people she doesn’t want to come.
Lots of businesses actually have no idea how they make or lose money, and have huge room for improvement. There’s a reason Private Equity exists.
Alec Stapp (describing Rob Henderson):
> hired to work in art gallery café
> get bored making coffee
> decide to look at the books
> discover 2 of 3 “income sources” are actually cost centers
> convince board to pivot business model
> revenue up 311%
Zac Hill: This is exactly what led my wife to opening her own nail salon: she literally spent one day looking at the accounting of a well-regarded high end DC franchise while bored working at the front desk, and was just like “…wait, what? no.”
Leah Libresco Sargeant: Experiences like this help drive the “surely the problem is waste fraud and abuse” attitude @rSanti97’s been talking about elsewhere on Here
See also: the movie Dave where they fix the federal budget this way.
I had one job where I didn’t realize I wasn’t supposed to be doing this so I went ahead and did it. I believe the impact was similar, but after a while rather than let me transition into running the place those that did run it told me to stop, at one point even saying ‘the time of heroes is over.’ I didn’t stay that much longer after that.
Entering into a romantic relationship with a manager is associated with raising your earnings by 6%, but breaking up predicts an abrupt 18% earnings decline, and retention of other workers declines by 6%.
I am being more careful about wording than the paper abstract, because while obviously some of this is causal, I don’t believe we can assume most or all of this is causal. There are also other mechanisms in play, such as higher performers that are already on good terms with the boss (and thus more likely to get raises) more often entering such relationships, and breakups happening for reasons.
What this does conclude is that as the subordinate, if you are not prepared to seek alternative employment then you should tread lightly and only do this if you see a real future together, since if you break up you face a net loss of 13% of earnings and probably a much bigger loss in terms of other aspects of the work experience.
Similarly, as a manager, beware small slights and set those birthday reminders.
We study what appears to be a very minor workplace mistreatment—failing to deliver an expected birthday gift and greeting card on time—and examine its effect on subsequent employee performance. Using a dynamic difference-in-differences approach with detailed data from a national retail chain, we find that this small slight leads to over a 50% increase in employee absenteeism and a reduction of more than two working hours per month.
Again I would be cautious with potential common cause concerns, but yeah people take such things personally, as anyone who has seen shows like The Office or worked in an actual typical office will know.