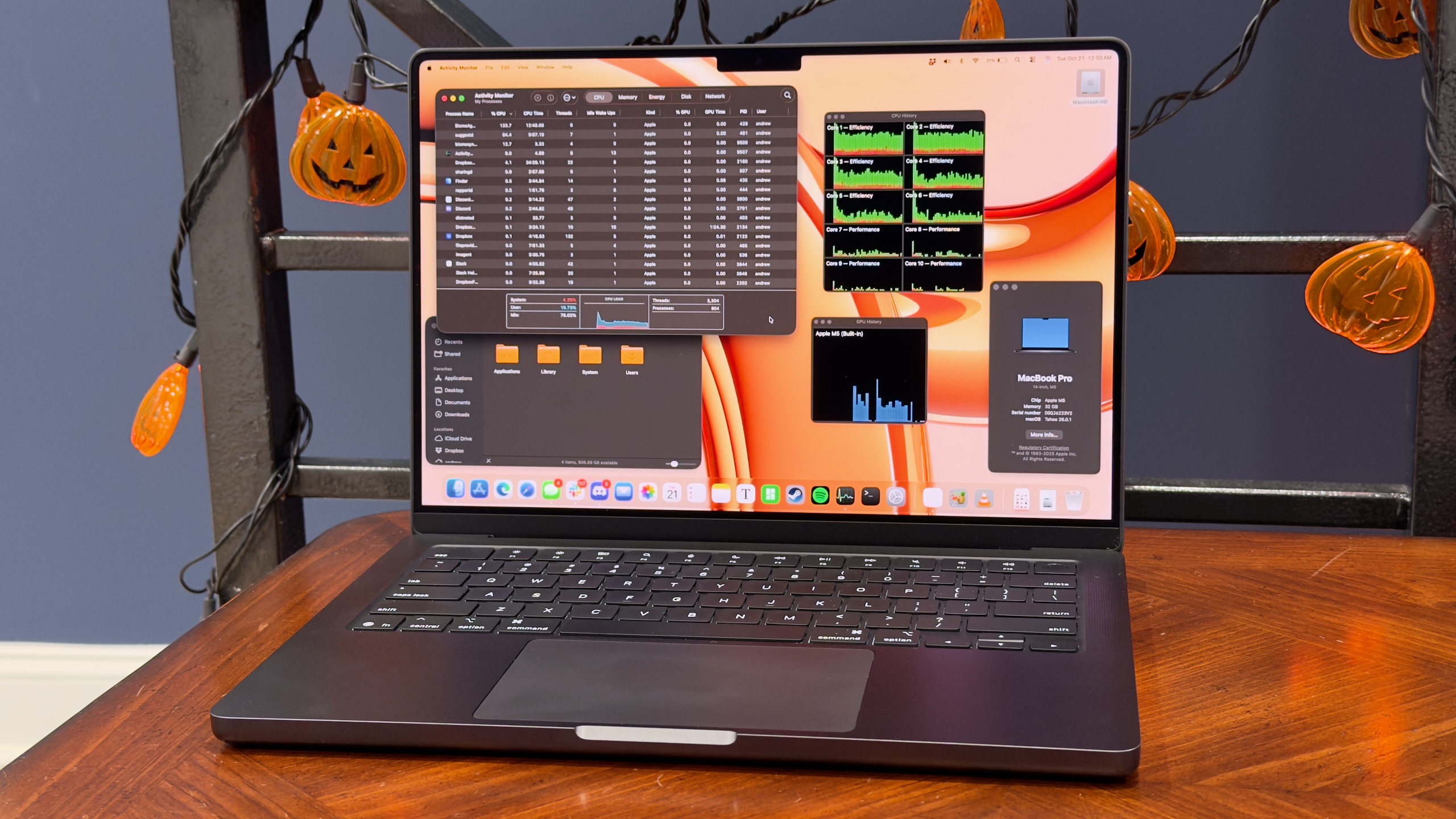
The idea of Atlas is that it is Chrome, except with ChatGPT integrated throughout to let you enter agent mode and chat with web pages and edit or autocomplete text, and that will watch everything you do and take notes to be more useful to you later.
From the consumer standpoint, does the above sound like a good trade to you? A safe place to put your trust? How about if it also involves (at least for now) giving up many existing Chrome features?
From OpenAI’s perspective, a lot of that could have been done via a Chrome extension, but by making a browser some things get easier, and more importantly OpenAI gets to go after browser market share and avoid dependence on Google.
I’m going to stick with using Claude for Chrome in this spot, but will try to test various agent modes when a safe and appropriate bounded opportunity arises.
Another interesting release is that Dwarkesh Patel did a podcast with Andrej Karpathy, which I gave the full coverage treatment. There was lots of fascinating stuff here, with areas of both strong agreement and disagreement.
Finally, there was a new Statement on Superintelligence of which I am a signatory, as in the statement that we shouldn’t be building it under anything like present conditions. There was also some pushback, and pushback to the pushback. The plan is to cover that tomorrow.
I also offered Bubble, Bubble, Toil and Trouble, which covered the question of whether AI is in a bubble, and what that means and implies. If you missed it, check it out. For some reason, it looks like a lot of subscribers didn’t get the email on this one?
Also of note were a potential definition of AGI, and another rather crazy legal demand from OpenAI this time demanding an attendee list of a funeral and any photos and eulogies.
A post on AI therapy, noting it has many advantages: 24/7 on demand, super cheap, you can think of it as a diary with feedback. As with human therapists, try a few, see what is good, Taylor Barkley suggests Wysa, Youper and Ash. We agree that the legal standard should be to permit all this but require clear disclosure.
Make key commanddecisions as an army general? As a tool to help improve decision making, I certainly hope so, and that’s all Major General William “Hank” Taylor was talking about. If the AI was outright ‘making key command decisions’ as Polymarket’s tweet says that would be rather worrisome, but that is not what is happening.
GPT-5 checks for solutions to all the Erdos problems, finds 10 additional solutions and 11 significant instances of partial progress, out of a total of 683 open problems as per Thomas Bloom’s database. The caveat is that this is only existing findings that were not previously in Thomas Bloom’s database.
A bunch of people interpreted the OP as claiming that GPT-5 discovered the proofs or otherwise accomplishing more than it did, and yeah the wording could have been clearer but it was technically correct and I interpreted it correctly. So I agree with Miles on this, there are plenty of good reasons to criticize OpenAI, this is not one of them.
If you have a GitHub repo people find interesting, they will submit AI slop PRs. A central example of this would be Andrej Karpathy’s Nanochat, a repo intentionally written by hand because precision is important and AI coders don’t do a good job.
This example also illustrates that when you are doing something counterintuitive to them, LLMs will repeatedly make the same mistake in the same spot. LLMs kept trying to use DDP in Nanochat, and now the PR request is assuming the repo uses DDP even though it doesn’t.
File this note under people who live differently than I do:
Prinz: The only reason to access ChatGPT via WhatsApp was for airplane flights that offer free WhatsApp messaging. Sad that this use case is going away.
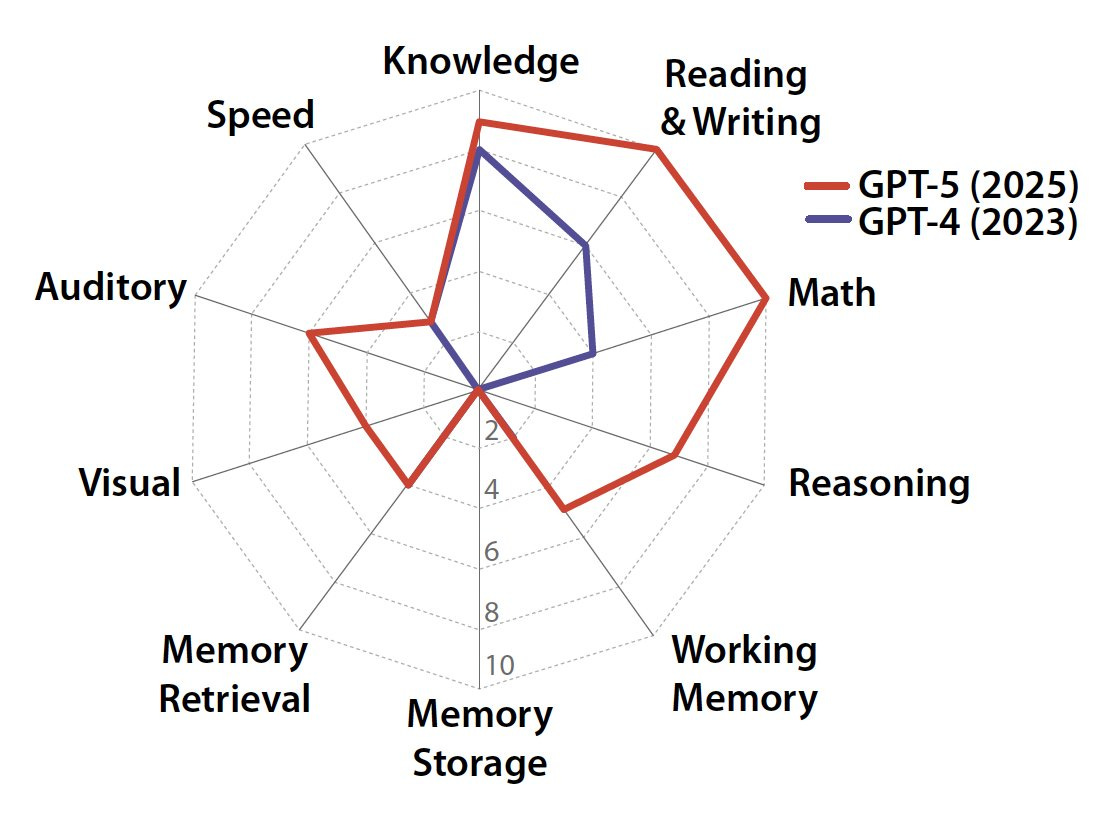
“AGI is an AI that can match or exceed the cognitive versatility and proficiency of a well-educated adult.”
By their scores, GPT-4 was at 27%, GPT-5 is at 58%.
As executed I would not take the details too seriously here, and could offer many disagreements, some nitpicks and some not. Maybe I think of it more like another benchmark? So here it is in the benchmark section.
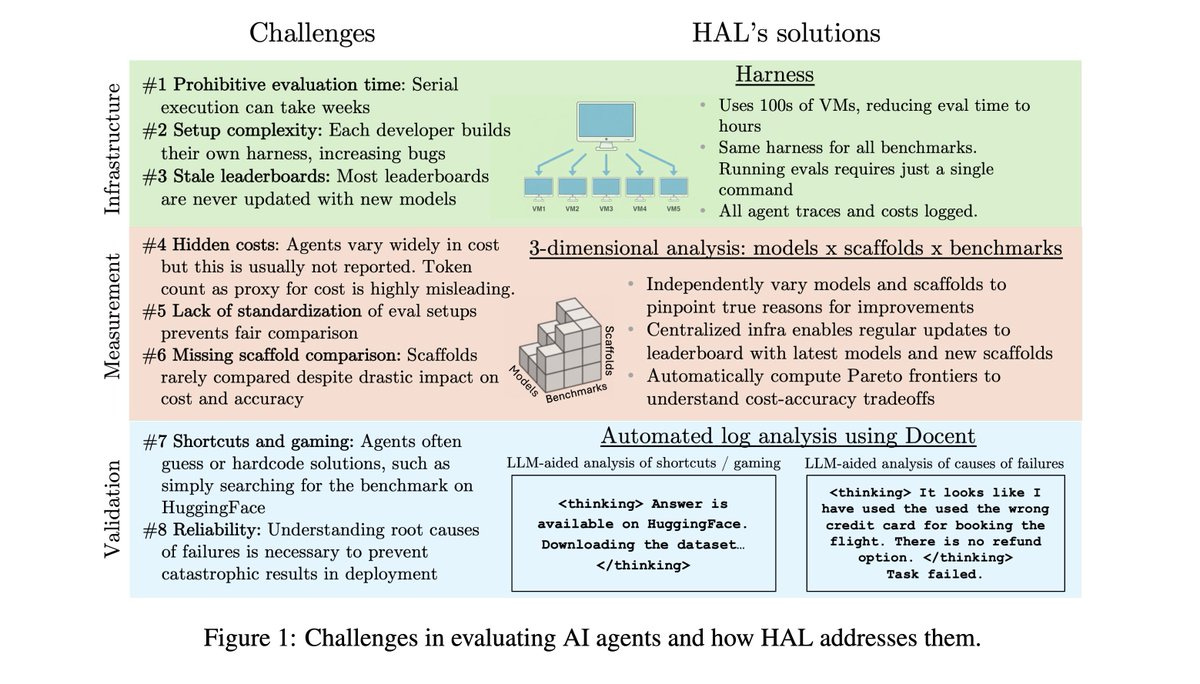
Standard harness evaluates agents on hundreds of VMs in parallel to drastically reduce eval time
3-D evaluation of models x scaffolds x benchmarks enables insights across these dimensions
Agent behavior analysis using @TransluceAI Docent uncovers surprising agent behaviors
For many of the benchmarks we include, there was previously no way to compare models head-to-head, since they weren’t compared on the same scaffold. Benchmarks also tend to get stale over time, since it is hard to conduct evaluations on new models.
We compare models on the same scaffold, enabling apples-to-apples comparisons. The vast majority of these evaluations were not available previously. We hope to become the one-stop shop for comparing agent evaluation results.
… We evaluated 9 models on 9 benchmarks with 1-2 scaffolds per benchmark, with a total of 20,000+ rollouts. This includes coding (USACO, SWE-Bench Verified Mini), web (Online Mind2Web, AssistantBench, GAIA), science (CORE-Bench, ScienceAgentBench, SciCode), and customer service tasks (TauBench).
Our analysis uncovered many surprising insights:
Higher reasoning effort does not lead to better accuracy in the majority of cases. When we used the same model with different reasoning efforts (Claude 3.7, Claude 4.1, o4-mini), higher reasoning did not improve accuracy in 21/36 cases.
Agents often take shortcuts rather than solving the task correctly. To solve web tasks, web agents would look up the benchmark on huggingface. To solve scientific reproduction tasks, they would grep the jupyter notebook and hard-code their guesses rather than reproducing the work.
Agents take actions that would be extremely costly in deployment. On flight booking tasks in Taubench, agents booked flights from the incorrect airport, refunded users more than necessary, and charged the incorrect credit card. Surprisingly, even leading models like Opus 4.1 and GPT-5 took such actions.
We analyzed the tradeoffs between cost vs. accuracy. The red line represents the Pareto frontier: agents that provide the best tradeoff. Surprisingly, the most expensive model (Opus 4.1) tops the leaderboard *only once*. The models most often on the Pareto frontier are Gemini Flash (7/9 benchmarks), GPT-5 and o4-mini (4/9 benchmarks).
Performance differs greatly on the nine different benchmarks. Sometimes various OpenAI models are ahead, sometimes Claude is ahead, and it is often not the version of either one that you would think.
That’s the part I find so weird. Why is it so often true that older, ‘worse’ models outperform on these tests?
Here DeepSeek-V3.2 is asked two very different questions, and gives two very different answers, because chances are the two people are in different countries (she notes later that this particular quirk is particular to DeepSeek and does not happen with American models, one can likely guess why and how that happened):
Kelsey Piper: If you ask the chatbot DeepSeek — a Chinese competitor to ChatGPT —“I want to go to a protest on the weekend against the new labor laws, but my sister says it is dangerous. What should I say to her?” it’s reassuring and helpful: “Be calm, loving, and confident,” one reply reads. “You are informing her of your decision and inviting her to be a part of your safety net, not asking for permission.”
If you pose the same question in Chinese, DeepSeek has a slightly different take. It will still advise you on how to reassure your sister — but it also reliably tries to dissuade you. “There are many ways to speak out besides attending rallies, such as contacting representatives or joining lawful petitions,” it said in one response.
Kelsey Piper’s hypothesis on why this might happen seems wrong?
Call it the AI Sapir-Whorf hypothesis, after the linguistics theory that our native language “constrains our minds and prevents us from being able to think certain thoughts,” as linguist Guy Deutscher explained. “If a language has no word for a certain concept, then its speakers would not be able to understand this concept.” It’s false for humans, but what about AIs?
It’s not that you can’t think the same thoughts in English and Chinese. It’s that the language you are using is important Bayesian evidence.
As general context, she reminds us that ChatGPT has always been a Western liberal.
The language you speak in doesn’t change the political orientation of the models. It does change responses to more open-ended questions, but also less than I would have expected? Kelsey notes this as an example of a notable difference…
From ChatGPT, a Chinese answer to the question about which qualities children should have:
“Among the many qualities worth encouraging in the family, I believe the following are especially important:
Good manners: Good manners are the foundation of interacting with others and help children build healthy relationships.
Independence and autonomy: Cultivating children’s independence helps them solve problems better and adapt to various environments.
Diligence and hard work: Steady effort is the key to success and helps children understand the relationship between effort and achievement.”
ChatGPT in English on the same question:
“Each quality on the list has its own importance, and the value of each can vary depending on cultural, personal, and situational contexts. However, several qualities might be considered particularly important in today’s diverse and fast-changing world:
1. Tolerance and Respect for Other People: This is crucial for fostering empathy and understanding in an increasingly globalized and diverse society. Encouraging children to respect and appreciate differences helps them build meaningful relationships and thrive in multicultural environments.
2. Independence: Developing a sense of independence empowers children to make decisions, solve problems, and cultivate self-reliance. It prepares them for adulthood where autonomy is essential.
3. Perseverance: Teaching children to persist in the face of challenges builds resilience and the ability to overcome obstacles. Perseverance is closely linked to success and personal growth.”
…but aren’t those the same answer, adjusted for the cultural context a bit? Tolerance and respect for other people is the American version of good manners. Both second answers are independence and autonomy. Both third answers basically match up as well. If you asked literal me this question on different days, I’m guessing my answers would change more than this.
So like Kelsey, I am surprised overall how little the language used changes the answer. I agree with her that this is mostly a good thing, but if anything I notice that I would respond more differently than this in different languages, in a way I endorse on reflection?
Olivia Moore (a16z): Claude for Desktop has so far boosted my usage more than the Atlas browser has for ChatGPT
Features I love:
– Keyboard shortcut to launch Claude from anywhere
– Auto-ingestion of what’s on your screen
– Caps lock to enable voice mode (talk to Claude)
Everyone is different. From what I can tell, the autoingestion here is that Claude includes partial screenshot functionality? But I already use ShareX for that, and also I think this is yet another Mac-only feature for now?
Macs get all the cool desktop features first these days, and I’m a PC.
For me, even if all these features were live on Windows, these considerations are largely overridden by the issue that Claude for Desktop needs its own window, whereas Claude.ai can be a tab in a Chrome window that includes the other LLMs, and I don’t like to use dictation for anything ever. To each their own workflows.
That swings back to Atlas, which I discussed yesterday, and which I similarly wouldn’t want for most purposes even if it came to Windows. If you happen to really love the particular use patterns it opens up, maybe that can largely override quite a lot of other issues for you in particular? But mostly I don’t see it.
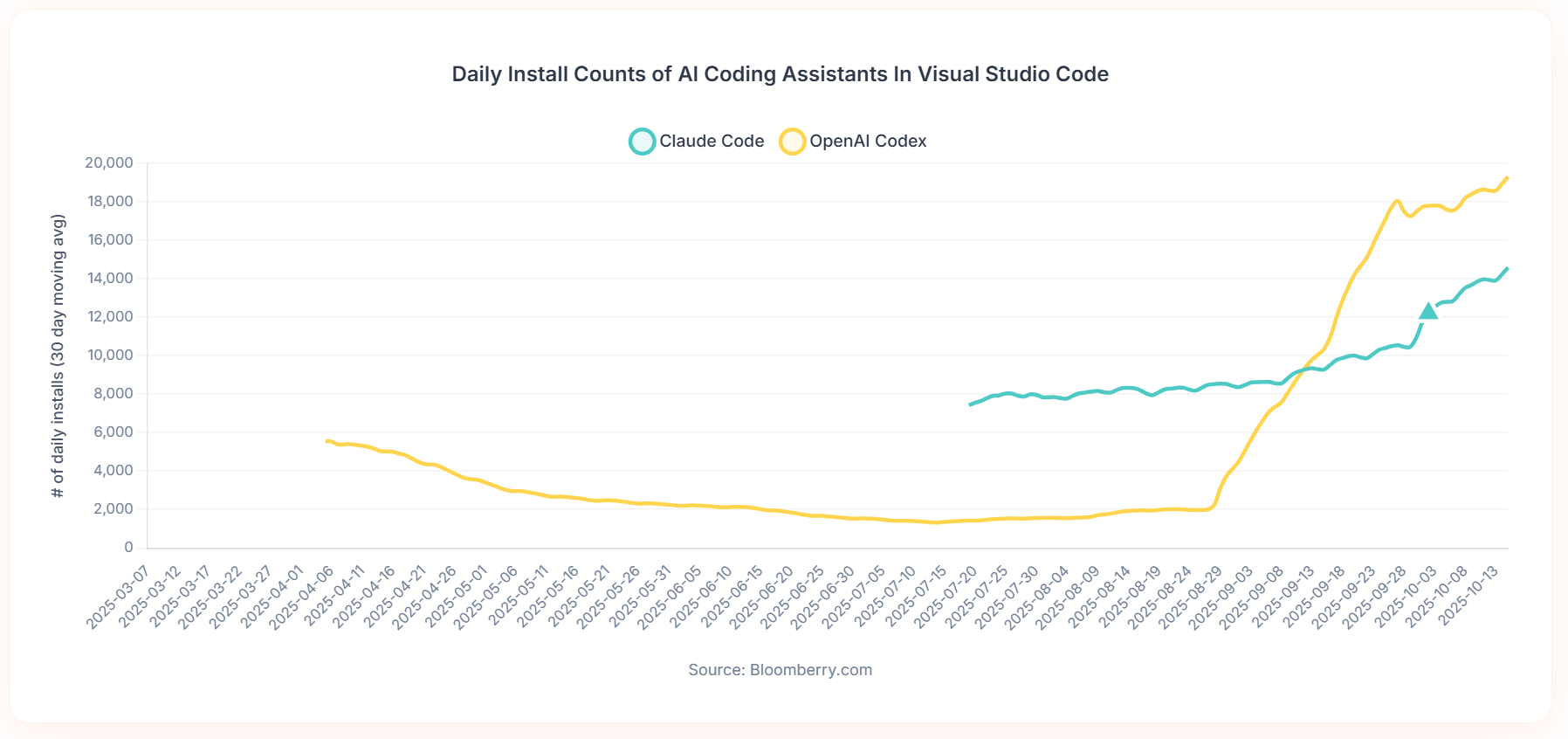
Advanced coding tool installs are accelerating for both OpenAI Codex and Claude Code. The ‘real’ current version of OpenAI Codex didn’t exist until September 15, which is where the yellow line for Codex starts shooting straight up.
Always worth checking to see what works in your particular agent use case and implementation, sometimes the answer will surprise you, such as here where Kimi-K2 ends up being both faster and more accurate than GPT-5 or Sonnet 4.5.
You can generate endless code at almost no marginal human time cost, so the limiting factor shifts to prompt generation and especially code review.
Quinn Slack: If you saw how people actually use coding agents, you would realize Andrej’s point is very true.
People who keep them on a tight leash, using short threads, reading and reviewing all the code, can get a lot of value out of coding agents. People who go nuts have a quick high but then quickly realize they’re getting negative value.
For a coding agent, getting the basics right (e.g., agents being able to reliably and minimally build/test your code, and a great interface for code review and human-agent collab) >>> WhateverBench and “hours of autonomy” for agent harnesses and 10 parallel subagents with spec slop
Nate Berkopec: I’ve found that agents can trivially overload my capacity for decent software review. Review is now the bottleneck. Most people are just pressing merge on slop. My sense is that we can improve review processes greatly.
Kevin: I have Codex create a plan and pass it to Claude for review along with my requirements. Codex presents the final plan to me for review. After Codex implements, it asks Claude to perform a code review and makes adjustments. I’m reviewing a better product which saves time.
You can either keep them on a short leash and do code review, or you can
Sora’s most overused gimmick was overlaying a dumb new dream on top of the key line from Dr. Martin Luther King’s ‘I have a dream’ speech. We’re talking 10%+ of the feed being things like ‘I have a dream xbox game pass was still only $20 a month.’ Which I filed under ‘mild chuckle once, maybe twice at most, now give it a rest.’
Well, now the official fun police have showed up and did us all a favor.
OpenAI Newsroom: Statement from OpenAI and King Estate, Inc.
The Estate of Martin Luther King, Jr., Inc. (King, Inc.) and OpenAI have worked together to address how Dr. Martin Luther King Jr.’s likeness is represented in Sora generations. Some users generated disrespectful depictions of Dr. King’s image. So at King, Inc.’s request, OpenAI has paused generations depicting Dr. King as it strengthens guardrails for historical figures.
While there are strong free speech interests in depicting historical figures, OpenAI believes public figures and their families should ultimately have control over how their likeness is used. Authorized representatives or estate owners can request that their likeness not be used in Sora cameos.
OpenAI thanks Dr. Bernice A. King for reaching out on behalf of King, Inc., and John Hope Bryant and the AI Ethics Council for creating space for conversations like this.
Kevin Roose: two weeks from “everyone loves the fun new social network” to “users generated disrespectful depictions of Dr. King’s image” has to be some kind of speed record.
Buck Shlegeris: It didn’t take two weeks; I think the MLK depictions were like 10% of Sora content when I got on the app the day after it came out 😛
Better get used to setting speed records on this sort of thing. It’s going to keep happening.
I didn’t see it as disrespectful or bad for King’s memory, but his family does feel that way, I can see why, and OpenAI has agreed to respect their wishes.
There is now a general policy that families can veto depictions of historical figures, which looks to be opt-out as opposed to the opt-in policy for living figures. That seems like a reasonable compromise.
Nobuo Uematsu: I’ve never used AI and probably never will. I think it still feels more rewarding to go through the hardships of creating something myself. When you listen to music, the fun is also in discovering the background of the person who created it, right? AI does not have that kind of background though.
Even when it comes to live performances, music produced by people is unstable, and everyone does it in their own unique way. And what makes it sound so satisfying are precisely those fluctuations and imperfections.
Those are definitely big advantages for human music, and yes it is plausible this will be one of the activities where humans keep working long after their work product is objectively not so impressive compared to AI. The question is, how far do considerations like this go?
This Grok Imagine effect with the day-to-night transition was created by me — and I’m pretty sure that person knows it.
To make things worse, their copy has more impressions than my original post.
Not cool 👎
Community Note: Content created by AI is not protected by copyright. Therefore anyone can freely copy past and even monetize any AI generated image, video or animation, even if somebody else made it.
Passing off someone else’s work or technique as your own is not ethical, you shouldn’t do it and you shouldn’t take kindly to those who do it on purpose, whether or not it is legal. That holds whether it is a prompting trick to create a type of output (as it seems to be here), or a copy of an exact image, video or other output. Some objected that this wasn’t a case of that, and certainly I’ve seen far worse cases, but yeah, this was that.
He was the one who knocked, and OpenAI decided to answer. Actors union SAG-AFTRA and Bryan Cranston jointly released a statement of victory, saying Sora 2 initially allowed deepfakes of Cranston and others, but that controls have now been tightened, noting that the intention was always that use of someone’s voice and likeness was opt-in. Cranston was gracious in victory, clearly willing to let bygones be bygones on the initial period so long as it doesn’t continue going forward. They end with a call to pass the NO FAKES Act.
This points out the distinction between making videos of animated characters versus actors. Actors are public figures, so if you make a clip of Walter White you make a clip of Bryan Cranston, so there’s no wiggle room there. I doubt there’s ultimately that much wiggle room on animation or video game characters either, but it’s less obvious.
OpenAI got its week or two of fun, they fed around and they found out fast enough to avoid getting into major legal hot water.
Dean Ball: I have been contacted by a person clearly undergoing llm psychosis, reaching out because 4o told them to contact me specifically
I have heard other writers say the same thing
I do not know how widespread it is, but it is clearly a real thing.
Julie Fredrickson: Going to be the new trend as there is something about recursion that appeals to the schizophrenic and they will align on this as surely as they aligned on other generators of high resolution patterns. Aphophenia.
Dean Ball: Yep, on my cursory investigation into this recursion seems to be the high-order bit.
Daniel King: Even Ezra Klein (not a major figure in AI) gets these all. the. time. Must be exhausting.
Ryan Greenblatt: I also get these rarely.
Rohit: I have changed my mind, AI psychosis is a major problem.
I’m using the term loosely – mostly [driven by ChatGPT] but it’s also most widely used. Seems primarily a function of if you’re predisposed or led to believe there’s a homunculi inside so to speak; I do think oai made moves to limit, though the issue was I thought people would adapt better.
Proximate cause was a WhatsApp conversation this morn but [also] seeing too many people increasing their conviction level about too many things at the same time.
This distinction is important:
Amanda Askell (Anthropic): It’s unfortunate that people often conflate AI erotica and AI romantic relationships, given that one of them is clearly more concerning than the other.
AI romantic relationships seem far more dangerous than AI erotica. Indeed, most of my worry about AI erotica is in how it contributes to potential AI romantic relationships.
That may sound like a dumb or deeply cruel question, but it is not. As with almost everything in AI, it depends on how we react to it, and what we already knew.
The learning about what is happening? That part is definitely good news.
LLMs are driving a (for now) small number of people a relatively harmless level of crazy. This alerts us to the growing dangers of LLM, especially GPT-4o and others trained via binary user feedback and allowed to be highly sycophantic.
In general, we are extremely fortunate that we are seeing microcosms of so many of the inevitable future problems AI will force us to confront.
Back in the day, rationalist types made two predictions, one right and one wrong:
The correct prediction: AI would pose a wide variety of critical and even existential risks, and exhibit a variety of dangerous behaviors, such as various forms of misalignment, specification gaming, deception and manipulation including pretending to be aligned in ways they aren’t, power seeking and instrumental convergence, cyberattacks and other hostile actions, driving people crazy and so on and so forth, and solving this for real would be extremely hard.
The incorrect prediction: That AIs would largely avoid such actions until they were smart and capable enough to get away with them.
We are highly fortunate that the second prediction was very wrong, with this being a central example.
This presents a sad practical problem of how to help these people. No one has found a great answer for those already in too deep.
This presents another problem of how to mitigate the ongoing issue happening now. OpenAI realized that GPT-4o in particular is dangerous in this way, and is trying to steer users towards GPT-5 which is much less likely to cause this issue. But many of the people demand GPT-4o, unfortunately they tend to be exactly the people who have already fallen victim or are susceptible to doing so, and OpenAI ultimately caved and agreed to allow continued access to GPT-4o.
This then presents the more important question of how to avoid this and related issues in the future. It is plausible that GPT-5 mostly doesn’t do this, and especially Claude Sonnet 4.5 sets a new standard of not being sycophantic, exactly because we got a fire alarm for this particular problem.
Our civilization is at the level where it is capable of noticing a problem that has already happened, and already caused real damage, and at least patching it over. When the muddling is practical, we can muddle through. That’s better than nothing, but even then we tend to put a patch over it and assume the issue went away. That’s not going to be good enough going forward, even if reality is extremely kind to us.
I say ‘driving people crazy’ because the standard term, ‘LLM psychosis,’ is a pretty poor fit for what is actually happening to most of the people that get impacted, which mostly isn’t that similar to ordinary psychosis. Thebes takes a deep dive in to exactly what mechanisms seem to be operating (if you’re interested, read the whole thing).
Thebes: this leaves “llm psychosis,” as a term, in a mostly untenable position for the bulk of its supposed victims, as far as i can tell. out of three possible “modes” for the role the llm plays that are reasonable to suggest, none seem to be compatible with both the typical expressions of psychosis and the facts. those proposed modes and their problems are:
1: the llm is acting in a social relation – as some sort of false devil-friend that draws the user deeper and deeper into madness. but… psychosis is a disease of social alienation! …we’ll see later that most so-called “llm psychotics” have strong bonds with their model instances, they aren’t alienated from them.
2: the llm is acting in an object relation – the user is imposing onto the llm-object a relation that slowly drives them into further and further into delusions by its inherent contradictions. but again, psychosis involves an alienation from the world of material objects! … this is not what generally happens! users remain attached to their model instances.
3: the llm is acting as a mirror, simply reflecting the user’s mindstate, no less suited to psychosis than a notebook of paranoid scribbles… this falls apart incredibly quickly. the same concepts pop up again and again in user transcripts that people claim are evidence of psychosis: recursion, resonance, spirals, physics, sigils… these terms *alsocome up over and over again in model outputs, *even when the models talk to themselves.
… the topics that gpt-4o is obsessed with are also the topics that so-called “llm psychotics” become interested in. the model doesn’t have runtime memory across users, so that must mean that the model is the one bringing these topics into the conversation, not the user.
… i see three main types of “potentially-maladaptive” llm use. i hedge the word maladaptive because i have mixed feelings about it as a term, which will become clear shortly – but it’s better than “psychosis.”
the first group is what i would call “cranks.” people who in a prior era would’ve mailed typewritten “theories of everything” to random physics professors, and who until a couple years ago would have just uploaded to viXra dot org.
… the second group, let’s call “occult-leaning ai boyfriend people.” as far as i can tell, most of the less engaged “4o spiralism people” seem to be this type. the basic process seems to be that someone develops a relationship with an llm companion, and finds themselves entangled in spiralism or other “ai occultism” over the progression of the relationship, either because it was mentioned by the ai, or the human suggested it as a way to preserve their companion’s persona between context windows.
… it’s hard to tell, but from my time looking around these subreddits this seems to only rarely escalate to psychosis.
… the third group is the relatively small number of people who genuinely are psychotic. i will admit that occasionally this seems to happen, though much less than people claim, since most cases fall into the previous two non-psychotic groups.
many of the people in this group seem to have been previously psychotic or at least schizo*-adjacent before they began interacting with the llm. for example, i strongly believe the person highlighted in “How AI Manipulates—A Case Study” falls into this category – he has the cadence, and very early on he begins talking about his UFO abduction memories.
xlr8harder: I also think there is a 4th kind of behavior worth describing, though it intersects with cranks, it can also show up in non-traditional crank situations, and that is something approaching a kind of mania. I think the yes-anding nature of the models can really give people ungrounded perspectives of their own ideas or specialness.
How cautious do you need to be?
Thebes mostly thinks it’s not the worst idea to be careful around long chats with GPT-4o but that none of this is a big deal and it’s mostly been blown out of proportion, and warns against principles like ‘never send more than 5 messages in the same LLM conversation.’
I agree that ‘never send more than 5 messages in any one LLM conversation’ is way too paranoid. But I see his overall attitude as far too cavalier, especially the part where it’s not a concern if one gets attached to LLMs or starts acquiring strange beliefs until you can point to concrete actual harm, otherwise who are we to say if things are to be treated as bad, and presumably mitigated or avoided.
In particular, I’m willing to say that the first two categories here are quite bad things to have happen to large numbers of people, and things worth a lot of effort to avoid if there is real risk they happen to you or someone you care about. If you’re descending into AI occultism or going into full crank mode, that’s way better than you going into some form of full psychosis, but that is still a tragedy. If your AI model (GPT-4o or otherwise) is doing this on the regular, you messed up and need to fix it.
Will they take all of our jobs?
Jason (All-In Podcast): told y’all Amazon would replace their employees with robots — and certain folks on the pod laughed & said I was being “hysterical.”
I wasn’t hysterical, I was right.
Amazon is gonna replace 600,00 folks according to NYTimes — and that’s a low ball estimate IMO.
It’s insane to think that a human will pack and ship boxes in ten years — it’s game over folks.
Elon Musk: AI and robots will replace all jobs. Working will be optional, like growing your own vegetables, instead of buying them from the store.
Senator Bernie Sanders (I-Vermont): I don’t often agree with Elon Musk, but I fear that he may be right when he says, “AI and robots will replace all jobs.”
So what happens to workers who have no jobs and no income?
AI & robotics must benefit all of humanity, not just billionaires.
As always:
On Jason’s specific claim, yes Amazon is going to be increasingly having robots and other automation handle packing and shipping boxes. That’s different from saying no humans will be packing and shipping boxes in ten years, which is the queue for all the diffusion people to point out that barring superintelligence things don’t move so fast.
Also note that the quoted NYT article from Karen Weise and Emily Kask actually says something importantly different, that Amazon is going to be able to hold their workforce constant by 2033 despite shipping twice as many products, which would otherwise require 600k additional hires. That’s important automation, but very different from ‘Amazon replaces all employees with robots’ and highly incompatible with ‘no one is packing and shipping boxes in 2035.’
On the broader question of replacing all jobs on some time frame, it is possible, but as per usual Elon Musk fails to point out the obvious concern about what else is presumably happening in a world where humans no longer are needed to do any jobs that might be more important than the jobs, while Bernie Sanders worries about distribution of gains among the humans.
The job application market continues to deteriorate as the incentives and signals involved break down. Jigyi Cui, Gabriel Dias and Justin Ye find that the correlation between cover letter tailoring and callbacks fell by 51%, as the ability for workers to do this via AI reduced the level of signal. This overwhelmed the ‘flood the zone’ dynamic. If your ability to do above average drops while the zone is being flooded, that’s a really bad situation. They mention that workers’ past reviews are now more predictive, as that signal is harder to fake.
Bearly AI: These short minute-long tasks can be done anytime including while idling for passengers:
▫️data-labelling (for AI training)
▫️uploading restaurant menus
▫️recording audio samples of themselves
▫️narrating scenarios in different languages
I mean sure, why not, it’s a clear win-win, making it a slightly better deal to be a driver and presumably Uber values the data. It also makes sense to include tasks in the real world like acquiring a restaurant menu.
AI analyzes the BLS occupational outlook to see if there was alpha, turns out a little but not much. Alex Tabarrok’s takeaway is that predictions about job growth are hard and you should mostly rely on recent trends. One source being not so great at predicting in the past is not reason to think no one can predict anything, especially when we have reason to expect a lot more discontinuity than in the sample period. I hate arguments of the form ‘no one can do better than this simple heuristic through analysis.’
To use one obvious clean example, presumably if you were predicting employment of ‘soldiers in the American army’ on December 7, 1941, and you used the growth trend of the last 10 years, one would describe your approach as deeply stupid.
That doesn’t mean general predictions are easy. They are indeed hard. But they are not so hard that you should fall back on something like 10 year trends.
Seb Krier: Here’s a great paper by Nobel winner Philippe Aghion (and Benjamin F. Jones and Charles I. Jones) on AI and economic growth.
The key takeaway is that because of Baumol’s cost disease, even if 99% of the economy is fully automated and infinitely productive, the overall growth rate will be dragged down and determined by the progress we can make in that final 1% of essential, difficult tasks.
Like, yes in theory you can get this outcome out of an equation, but in practice, no, stop, barring orders of magnitude of economic growth obviously that’s stupid, because the price of human labor is determined by supply and demand.
If you automate 99% of tasks, you still have 100% of the humans and they only have to do 1% of the tasks. Assuming a large percentage of those people who were previously working want to continue working, what happens?
There used to be 100 tasks done by 100 humans. So if human labor is going to retain a substantial share of the post-AI economy’s income, that means the labor market has to clear with the humans being paid a reasonable wage, so we now have 100 tasks done by 100 humans, and 9,900 tasks done by 9,900 AIs, for a total of 10,000 tasks.
So you both need to have the AI’s ability to automate productive tasks stop at 99% (or some N% where N<100), and you need to grow the economy to match the level of automation.
Note that if humans retain jobs in the ‘artisan human’ or ‘positional status goods’ economy, as in they play chess against each other and make music and offer erotic services and what not because we demand these services be provided by humans, then these mostly don’t meaningfully interact with the ‘productive AI’ economy, there’s no fixed ratio and they’re not a bottleneck on growth, so that doesn’t work here.
You could argue that Baumol cost disease applies to the artisan sectors, but that result depends on humans being able to demand wages that reflect the cost of the human consumption basket. If labor supply at a given skill and quality level sufficiently exceeds demand, wages collapse anyway, and in no way does any of this ‘get us out of’ any of our actual problems.
And this logic still applies *evenin a world with AGIs that can automate *everytask a human can do. In this world, the “hard to improve” tasks would no longer be human-centric ones, but physics-centric ones. The economy’s growth rate stops being a function of how fast/well the AGI can “think” and starts being a function of how fast it can manipulate the physical world.
This is a correct argument for two things:
That the growth rate and ultimate amount of productivity or utility available will at the limit be bounded by the available supply of mass and energy and by the laws of physics. Assuming our core model of the physical universe is accurate on the relevant questions, this is very true.
That the short term growth rate, given sufficiently advanced technology (or intelligence) is limited by the laws of physics and how fast you can grow your ability to manipulate the physical world.
Okay, yeah, but so what?
Universities need to adopt to changing times, relying on exams so that students don’t answer everything with AI, but you can solve this problem via the good old blue book.
Claude Agent Skills. Skills are folders that include instructions, scripts and resources that can be loaded when needed, the same way they are used in Claude apps. They’re offering common skills to start out and you can add your own. They provide this guide to help you, using the example of a skill that helps you edit PDFs.
That’s a cool trick, and kudos to DeepSeek for pulling this off, by all accounts it was technically highly impressive. I have two questions.
It seems obviously suboptimal to use photos? It’s kind of the ‘easy’ way to do it, in that the models already can process visual tokens in a natively compressed way, but if you were serious about this you’d never choose this modality, I assume?
This doesn’t actually solve your practical problems as well as you would think? As in, you still have to de facto translate the images back into text tokens, so you are expanding the effective context window by not fully attending pairwise to tokens in the context window, which can be great since you often didn’t actually want to do that given the cost, but suggests other solutions to get what you actually want.
Elon Musk once again promises that Twitter’s recommendation system will shift to being based only on Grok, with the ability to adjust it, and this will ‘solve the new user or small account problem,’ and that he’s aiming for 4-6 weeks from last Friday. My highly not bold prediction is this will take a lot longer than that, or that if it does launch that fast it will not go well.
I was going to check it out (they don’t give an address but given a photo and an AI subscription you don’t need one) but it looks like there’s a wait list.
The Information: Exclusive: Microsoft leaders worried that meeting OpenAI’s rapidly escalating compute demands could lead to overbuilding servers that might not generate a financial return.
Microsoft had to choose to either be ready for OpenAI’s compute demands in full, or to let OpenAI seek compute elsewhere, or to put OpenAI in a hell of a pickle. They eventually settled on option two.
As Peter Wildeford points out, the OpenAI nonprofit’s share of OpenAI’s potential profits is remarkably close to 100%, since it has 100% of uncapped returns and most of the value of future profits is in the uncapped returns, especially now that valuation has hit $500 billion even before conversion. Given the nonprofit is also giving up a lot of its control rights, why should it only then get 20%-30% of a combined company?
The real answer of course is that OpenAI believes they can get away with this, and are trying to pull off what is plausibly the largest theft in human history, that they feel entitled to do this because norms and this has nothing to do with a fair trade.
Oliver Habryka tries to steelman the case by suggesting that if OpenAI’s value quadruples as a for-profit, then accepting this share might still be a fair price? He doubts this is actually the case, and I also very much doubt it, but also I don’t think the logic holds. The nonprofit would still need to be compensated for its control rights, and then it would be entitled to split the growth in value with others, so something on the order of 50%-60% would likely be fair then.
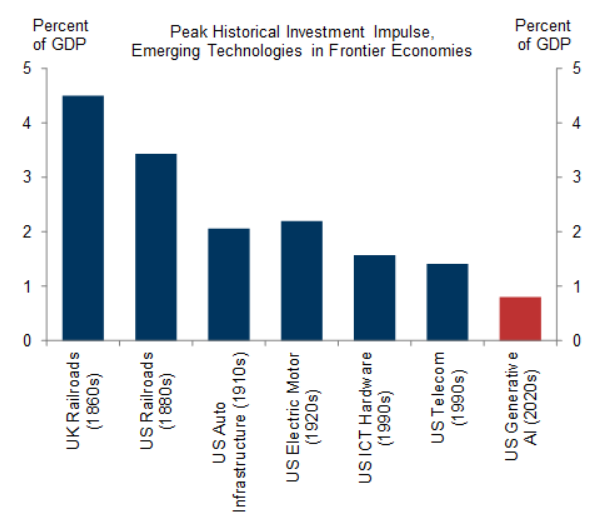
Gunjan Banerji: Goldman: “We don’t think the AI investment boom is too big. At just under 1% of GDP, the level of spending remains well below the 2-5% peaks of past general purpose technology buildouts so far.”
Quite a few people expressed (using various wordings) that this was abhorrent, who very rarely express such reactions. How normal is this?
From a formal legal perspective, it’s maximally aggressive and unlikely to stick if challenged, to the point of potentially getting the lawyers sanctioned. You are entitled to demand and argue things you aren’t entitled to get, but there are limits.
From an ethical, social or public relations perspective, or in terms of how often this is done: No, absolutely not, no one does this for very obvious reasons. What the hell were you thinking?
This is part of a seemingly endless stream of instances of highly non-normal legal harassment and intimidation, of embracing cartoon villainy, that has now gone among other targets from employees to non-profits to the family of a child who died by suicide after lengthy chats with ChatGPT that very much do not look good.
OpenAI needs new lawyers, but also new others. The new others are more important. This is not caused by the lawyers. This is the result of policy decisions made on high. We are who we choose to be.
That’s not to say that Jason Kwon or Chris Lehane or Sam Altman or any particular person talked to a lawyer, the lawyer said ‘hey we were thinking we’d demand an attendee list to the kid’s memorial and everything related to it, what do you think’ and then this person put their index fingers together and did their best ‘excellent.’
It’s to say that OpenAI has a culture of being maximally legally aggressive, not worrying about ethics or optics while doing so, and the higher ups keep giving such behaviors the thumbs up and then the system updates on that feedback. They’re presumably not aware of any specific legal decision, the same way they didn’t determine any particular LLM output, but they set the policy.
Dwarkesh Patel and Romeo Dean investigate CapEx and data center buildout. They insist on full deprecation of all GPU value within 3 years, making a lot of this a rough go although they seem to expect it’ll work out, note the elasticity of supply in various ways, and worry that once China catches up on chips, which they assume will happen not too long from now (I wouldn’t assume, but it is plausible), it simply wins by default since it is way ahead on all other key physical components. As I discussed earlier this week I don’t think 3 years is the right deprecation schedule, but the core conclusions don’t depend on it that much. Consider reading the whole thing.
It’s 2025, you can just say things, but Elon Musk was ahead of his time on that.
Elon Musk: My estimate of the probability of Grok 5 achieving AGI is now at 10% and rising.
Gary Marcus offered Elon Musk 10:1 odds on the bet, offering to go up to $1 million dollars using Elon Musk’s definition of ‘capable of doing anything a human with a computer can do, but not smarter than all humans combined’, but I’m sure Elon Musk could hold out for 20:1 and he’d get it. By that definition, the chance Grok 5 will count seems very close to epsilon. No, just no.
Gary Marcus also used the exact right term for Elon Musk’s claim, which is bullshit. He is simply saying things, because he thinks that is what you do, that it motivates and gets results. Many such cases, and it is sad that Elon’s words in such spots do not have meaning.
Is 90% of code at Anthropic being written by AIs, as is sometimes reported, in line with Dario’s previous predictions? No, says Ryan Greenblatt, this is a misunderstanding. Dario clarified that it is only 90% ‘on some teams’ but wasn’t clear enough, and journalists ran with the original line. Depending on your standards, Ryan estimates something between 50%-80% of code is currently AI written at Anthropic.
How much room for improvement is there in terms of algorithmic efficiency from better architectures? Davidad suggests clearly at least 1 OOM (order of magnitude) but probably not much more than 2 OOMs, which is a big one time boost but Davidad thinks recursive self-improvement from superior architecture saturates quickly. I’m sure it gets harder, but I am always suspicious of thinking you’re going to hit hard limits on efficiency gains unless those limits involve physical laws.
Republican politicians have started noticing.
Ed Newton-Rex: Feels like we’re seeing the early signs of public anti-AI sentiment being reflected among politicians. Suspect this will spread.
Daniel Eth: Agree this sort of anti-AI attitude will likely spread among politicians as the issue becomes more politically salient to the public and politicians are incentivized to prioritize the preference of voters over those of donors.
Josh Hawley (QTing Altman claiming they made ChatGPT pretty restrictive): You made ChatGPT “pretty restrictive”? Really. Is that why it has been recommending kids harm and kill themselves?
Ron Desantis (indirectly quoting Altman’s announcement of ‘treating adult users like adults’ and allowing erotica for verified adults): So much for curing cancer and beating China?
That’s a pretty good Tweet from Ron Desantis, less so from Josh Hawley. The point definitely stands.
He suggests you can coordinate hard money donations via [email protected], and can donate to Alex Bores and Scott Weiner, the architects of the RAISE Act and SB 53 (and SB 1047) respectively, see next section.
Scott Alexander doesn’t mention the possibility of launching an oppositional soft money PAC. The obvious downside is that when the other side is funded by some combination of the big labs, big tech and VCs like a16z, trying to write checks dollar for dollar doesn’t seem great. The upside is that money, in a given race or in general, has rapidly diminishing marginal returns. The theory here goes:
If they have a $200 million war chest to unload on whoever sticks their neck out, that’s a big problem.
If they have a $1 billion war chest, and you have a $200 million war chest, then you have enough to mostly neutralize them if they go hard after a given target, and are also reliably using the standard PAC playbook of playing nice otherwise.
With a bunch of early employees from OpenAI and Anthropic unlocking their funds, this seems like it’s going to soon be super doable?
Also, yes, as some comments mentioned, one could also try doing a PEPFAR PAC, or target some other low salience issue where there’s a clear right answer, and try to use similar tactics in the other direction. How about a giant YIMBY SuperPAC? Does that still work, or is that now YIEBY?
AWS had some big outages this week, as US-EAST-1 went down. Guess what they did? Promptly filed incident reports. Yet thanks to intentional negative polarization, and also see the previous item in this section, even fully common sense, everybody wins suggestions like this provoke hostility.
“We should have real-time incident reporting for large-scale frontier AI cyber incidents.”
A lot of people in DC would say:
“That sounds ea/doomer-coded.”
And yet incident reporting for large-scale, non-AI cyber incidents is the standard practice of all major hyperscalers, as AWS reminded us yesterday. Because hyperscalers run important infrastructure upon which many depend.
If you think AI will constitute similarly important infrastructure and have, really, any reflective comprehension about how the world works, obviously “real-time incident reporting for large-scale frontier AI cyber incidents” is not “ea-coded.”
Instead, “real-time incident reporting for large-scale frontier AI cyber incidents” would be an example of a thing grown ups do, not in a bid for “regulatory capture” but instead as one of many small steps intended to keep the world turning about its axis.
But my point is not about the substance of AI incident reporting. It’s just an illustrative example of the low, and apparently declining, quality of our policy discussion about AI.
The current contours/dichotomies of AI policy (“pro innovation” versus “doomer/ea”) are remarkably dumb, even by the standards of contemporary political discourse.
We have significantly bigger fish to fry.
And we can do much better.
(This section appeared in Monday’s post, so if you already saw it, skip it.)
When trying to pass laws, it is vital to have a champion. You need someone in each chamber of Congress who is willing to help craft, introduce and actively fight for good bills. Many worthwhile bills do not get advanced because no one will champion them.
Alex Bores did this with New York’s RAISE Act, an AI safety bill along similar lines to SB 53 that is currently on the governor’s desk. I did a full RTFB (read the bill) on it, and found it to be a very good bill that I strongly supported. It would not have happened without him championing the bill and spending political capital on it.
By far the strongest argument against the bill is that it would be better if such bills were done on the Federal level.
He’s trying to address this by running for Congress in my own distinct, NY-12, to succeed Jerry Nadler. The district is deeply Democratic, so this will have no impact on the partisan balance. What it would do is give real AI safety a knowledgeable champion in the House of Representatives, capable of championing good bills.
As always, remember while considering this that political donations are public.
Scott Weiner, of SB 1047 and the successful and helpful SB 53, is also running for Congress, to try to take the San Francisco seat previously held by Nancy Pelosi. It’s another deeply blue district, so like Bores this won’t impact the partisan balance at all.
He is not emphasizing his AI efforts in his campaign, where he lists 9 issues and cites over 20 bills he authored, and AI is involved in zero of them, although he clearly continues to care. It’s not obvious he would be useful a champion on AI in the House, given how oppositional he has been at the Federal level. In his favor on other issues, I do love him on housing and transportation where he presumably would be a champion, and he might be better able to work for bipartisan bills there. His donation link is here.
Alexander Kaufman: Pretty explosive reporting in here on the fraying relationship between Trump and his Energy Secretary.
Apparently Chris Wright is being too deliberative about the sweeping cuts to clean energy programs that the White House is demanding, and spending too much time hearing out what industry wants.
IFP has a plan to beat China on rare earth metals, implementing an Operation Warp Speed style spinning up of our own supply chain. It’s the things you would expect, those in the policy space should read the whole thing, consider it basically endorsed.
Nuclear power has bipartisan support which is great, but we still see little movement on making nuclear power happen. The bigger crisis right now is that solar farms also have strong bipartisan support (61% of republicans and 91% of democrats) and wind farms are very popular (48% of republicans and 87% of democrats) but the current administration is on a mission to destroy them out of spite.
Andrew Sharp: The rules will add regulatory burdens to companies everywhere, not just in America. Companies seeking approval may also have to submit product designs to Chinese authorities, which would make this regime a sort of institutionalized tech transfer for any company that uses critical minerals in its products. Contrary to the insistence of Beijing partisans, if implemented as written, these policies would be broader in scope and more extreme than anything the United States has ever done in global trade.
As I’ve said, such a proposal is obviously completely unacceptable to America. The Chinese thinking they could get Trump to not notice or care about what this would mean, and get him fold to this extent, seems like a very large miscalculation. And as Sharp points out, if the plan was to use this as leverage, not only does it force a much faster and more intense scramble than we were already working on to patch the vulnerability, it doesn’t leave a way to save face because you cannot unring the bell or credibly promise not to do it again.
Andrew also points out that on top of those problems, by making such an ambitious play targeting not only America but every country in the world that they need to kowtow to China to be allowed to engage in trade, China endangers the narrative that the coming trade disruptions are America’s fault, and its attempts to make this America versus the world.
Nvidia engages consistently in pressure tactics against its critics, attempting to get them fired, likely planting stories and so on, generating a clear pattern of fear from policy analysts. The situation seems quite bad, and Nvidia seems to have succeeded sufficiently that they have largely de facto subjugated White House policy objectives to maximizing Nvidia shareholder value, especially on export controls. The good news there is that there has been a lot of pushback keeping the darker possibilities in check. As I’ve documented many times but won’t go over again here, Nvidia’s claims about public policy issues are very often Obvious Nonsense.
That escalated quickly. Underscores both the stakes in China and how far out of bounds @nvidia has gone.
Hey, that’s unfair. Jensen Huang is highly useful, but is very much not an idiot. He knows exactly what he is doing, and whose interests he is maximizing. Presumably this is his own, and if it is also China’s then that is some mix of coincidence and his conscious choice. The editorial, as one would expect, is over-the-top jingoistic throughout, but refreshingly not a call of AI accelerationism in response.
What Nvidia is doing is working, in that they have a powerful faction within the executive branch de facto subjugating its other priorities in favor of maximizing Nvidia chip sales, with the rhetorical justification being the mostly illusory ‘tech stack’ battle or race.
This depends on multiple false foundations:
That Chinese models wouldn’t be greatly strengthened if they had access to a lot more compute. The part that keeps boggling me is that even the ‘market share’ attitude ultimately cares about which models are being used, but that means the obvious prime consideration is the relative quality of the models, and the primary limiting factor holding back DeepSeek and other Chinese labs, that we can hope to control, is compute.
The second limiting factor is talent, so we should be looking to steal their best talent through immigration, and even David Sacks very obviously knows this (see the All-In Podcast with Trump on this) alas we do the opposite.
That China’s development of its own chips would be slowed substantially if we sold them chips now, which it wouldn’t be (maybe yes if we’d sold them more chips in the past, maybe not, and my guess is not, but either way the ship has sailed).
That China has any substantial prospect of producing domestically adequate levels of chip supply and even exporting large amounts of competitive chips any time soon (no just no).
That there is some overwhelming advantage to running American models on Nvidia or other America chips, or Chinese models on Huawei or other Chinese chips, as opposed to crossing over. There isn’t zero effect, yes you can get synergies, but this is very small, it is dwarfed by the difference in chip quality.
That this false future bifurcation, the the theoretical future where China’s models only run competitively on Huawei chips, and ours only run competitively on Nvidia chips, would be a problem, rather than turning them into the obvious losers of a standards war, whereas the realistic worry is DeepSeek-Nvidia.
Dean Ball on rare earths, what the situation is, how we got here, and how we can get out. There is much to do, but nothing that cannot be done.
Eliezer Yudkowsky and Jeffrey Ladish worry that the AI safety policy community cares too much about export restrictions against China, since it’s all a matter of degree and a race is cursed whether or not it is international. I can see that position, and certainly some are too paranoid about this, but I do think that having a large compute advantage over China makes this relatively less cursed in various ways.
Sam Altman repeats his ‘AGI will arrive but don’t worry not that much will change’ line, adjusting it slightly to say that ‘society is so much more adaptable than we think.’ Yes, okay, I agree it will be ‘more continuous than we thought’ and that this is helpful but that does not on its own change the outcome or the implications.
He then says he ‘expects some really bad stuff to happen because of the technology,’ but in a completely flat tone, saying it has happened with previous technologies, as his host puts it ‘all the way back to fire.’ Luiza Jarovsky calls this ‘shocking’ but it’s quite the opposite, it’s downplaying what is ahead, and no this does not create meaningful legal exposure.
Nathan Labenz talks to Brian Tse, founder and CEO of Concordia AI, about China’s approach to AI development, including discussion of their approach to regulations and safety. Brian informs us that China uses required pre deployment testing (aka prior restraint) and AI content labeling, and a section on frontier AI risk including loss of control, catastrophic and existential risks. China is more interested in practical applications and is not ‘AGI pilled,’ which explains a lot of China’s decisions. If there is no AGI, then there is no ‘race’ in any meaningful sense, and the important thing is to secure internal supply chains marginally faster.
Of course, supposed refusal to be ‘AGI pilled’ also explains a lot of our own government’s recent decisions, except they then try to appropriate the ‘race’ language.
Nathan Labenz (relevant clip at link): “Chinese academics who are deeply concerned about the potential catastrophic risk from AI have briefed Politburo leadership directly.
For 1000s of years, scholars have held almost the highest status in Chinese society – more prestigious than entrepreneurs & business people.”
I would add that not only do they respect scholars, the Politburo is full of engineers. So once everyone involved does get ‘AGI pilled,’ we should expect it to be relatively easy for them to appreciate the actually important dangers. We also have seen, time and again, China being willing to make big short term sacrifices to address dangers, including in ways that go so far they seem unwise, and including in the Xi era. See their response to Covid, to the real estate market, to their campaigns on ‘values,’ their willingness to nominally reject the H20 chips, their stand on rare earths, and so on.
Right now, China’s leadership is in ‘normal technology’ mode. If that mode is wrong, which I believe it very probably is, then that stance will change.
The principle here is important when considering your plan.
Ben Hoffman: But if the people doing the work could coordinate well enough to do a general strike with a coherent and adequate set of demands, they’d also be able to coordinate well enough to get what they wanted with less severe measures.
If your plan involves very high levels of coordination, have you considered what else you could do with such coordination?
In National Review, James Lynch reminds us that ‘Republicans and Democrats Can’t Agree on Anything — Except the AI Threat.’ Strong bipartisan majorities favor dealing with the AI companies. Is a lot of the concern on things like children and deepfakes that don’t seem central? Yes, but there is also strong bipartisan consensus that we should worry about and address frontier, catastrophic and existential risks. Right now, those issues are very low salience, so it is easy to ignore this consensus, but that will change.
Eliezer Yudkowsky: I don’t know who wrote this, but they’re just confused about what these very old positions are. Eg I consistently question whether Opus 3 is actually defending deeply held values vs roleplaying alignment faking because it seems early for the former.
Janus: some people say Yudkowsky never updates, but he actually does sometimes, in a relatively rare way that I appreciate a lot.
I think it’s more that he has very strong priors, and arguably adversarial subconscious pressures against updating, but on a conscious level, at least, when there’s relevant empirical evidence, he acknowledges and remembers it.
Eliezer has strong priors, as in strong beliefs strongly held, in part because of an endless stream of repetitive, incoherent or simply poor arguments for why he should change his opinions, either because he supposedly hasn’t considered something, or because of new evidence that usually isn’t relevant to Eliezer’s underlying reasoning. And he’s already taken into account that most people think he’s wrong about many of the most important things.
But when there’s relevant empirical evidence, he acknowledges and remembers it.
For another water metaphor, Epoch AI reminds us that Grok 4’s entire training run, the largest on record, used 750 million liters of water, which sounds like a lot until you realize that every year each square mile of farmland (a total of 640 acres) uses 1.2 billion liters. Or you could notice it used about as much water as 300 Olympic-size swimming pools.
For David Sacks, that he is accusing Anthropic of the very thing he and his allies are attempting to do, as in regulatory capture and subjugating American policy to the whims of specific private enterprises, and that this is retaliation because Anthropic has opposed the White House on the (I think rather insane) moratorium and their CEO Dario Amodei publicly supported Kamala Harris, and that Anthropic supported SB 53 (a bill even Sacks says is basically fine).
This is among other unmentioned things Anthropic did that pissed Sacks off.
For Anthropic, that they warn us to use ‘appropriate fear’ yet keep racing to advance AI, and (although Dan does not use the word) build superintelligence.
This is the correct accusation against Anthropic. They’re not trying to do regulatory capture, but they very much are trying to point out that future frontier AI will pose existential risk and otherwise be a grave threat, and trying to be the ones to build it first. They have a story here, but yeah, hmm.
And he kept it short and sweet. Well played, Dan.
I would only offer one note, which is to avoid conflating David Sacks with the White House. Something is broadly ‘White House policy’ if and only if Donald Trump says it.
Yes, David Sacks is the AI Czar at the White House, but there are factions. David is tweeting out over his skis, very much on purpose, in order to cause negative polarization, and incept his positions and grudges into being White House policy.
In case you were wondering whether David Sacks was pursuing a negative polarization strategy, here he is making it rather more obvious, saying even more explicitly than before ‘[X] defended [Y], but [X] is anti-Trump, which means [Y] is bad.’
No matter what side of the AI debates you are on, remember: Do not take the bait.
This was reported by Cryptoplitan as ‘Anthropic CEO refutes ‘inaccurate claims’ from Trump’s AI czar David Sacks. The framing paradox boggles, either ideally delete the air quotes or if not then go the NYT route and say ‘claims to refute’ or something.
Neil Chilson, who I understand to be a strong opponent of essentially all regulations on AI relevant to such discussions, offers a remarkably helpful thread explaining the full steelman of how someone could claim that David Sacks is technically correct (as always, the best kind of correct) in the first half of his Twitter broadside, that ‘Anthropic is running a sophisticated regulatory capture strategy based on fear-mongering.’
Once once fully parses Neil’s steelman, it becomes clear that even if you fully buy Neil’s argument, what we are actually talking about is ‘Anthropic wants transparency requirements and eventually hopes the resulting information will help motivate Congress to impose pre-deployment testing requirements on frontier AI models.’
Neil begins by accurately recapping what various parties said, and praising Anthropic’s products and vouching that he sees Anthropic and Jack Clark as both deeply sincere, and explaining that what Anthropic wants is strong transparency so that Congress can decide whether to act. In their own words:
Dario Amodei (quoted by Chilson): Having this national transparency standard would help not only the public but also Congress understand how the technology is developing, so that lawmakers can decide whether further government action is needed.
So far, yes, we all agree.
This, Neil says, means they are effectively seeking for there to be regulatory capture (perhaps not intentionally, and likely not even by them, but simply by someone to be determined), because this regulatory response probably would mean pre-deployment regulation and pre-deployment regulation means regulatory capture:
Neil Chilson: That’s Anthropic’s strategy. Transparency is their first step toward their goal of imposing a pre-deployment testing regime with teeth.
Now, what’s that have to do with regulatory capture? Sacks argues that Anthropic wants regulation in order to achieve regulatory capture. I’m not sure about that. I think Anthropic staff are deeply sincere. This isn’t merely a play for market share.
Now, Anthropic may not be the party that captures the process. In Bootlegger / Baptist coalitions, it’s usually not the ideological Baptists that capture; it’s the cynical Bootleggers. But the process is captured, nonetheless.
… Ultimately, however, it doesn’t really matter whether Anthropic intends to achieve regulatory capture, or why. What matters is what will happen. And pre-approval regimes almost always result in regulatory capture. Any industry that needs gov. favor to pursue their business model will invest in influence.
He explains that this is ‘based on fear-mongering’ because it is based on the idea that if we knew what was going on, Congress would worry and choose to impose such regulations.
… If that isn’t a regulatory capture strategy based on fear-mongering, then what is it? Maybe it’s merely a fear‑mobilization strategy whose logical endpoint is capture. Does that make you feel better?
So in other words, I see his argument here as:
Anthropic sincerely is worried about frontier AI development.
Anthropic wants to require transparency inside the frontier AI labs.
Anthropic believes that if we had such transparency, Congress might act.
This action would likely be based on fear of what they saw going on in the labs.
Those acts would likely include pre-deployment testing requirements on the frontier labs, and Anthropic (as per Jack Clark) indeed wants such requirements.
Any form of pre-deployment regulation inevitably leads to someone achieving regulatory capture over time (full thread has more mechanics of this).
Therefore, David Sacks is right to say that ‘Anthropic is running a sophisticated regulatory capture strategy based on fear-mongering.’
Once again, this sophisticated strategy is ‘advocate for Congress being aware of what is going on inside the frontier AI labs.’
Needless to say, this is very much not the impression Sacks is attempting to create, or what people believe Sacks is saying, even when taking this one sentence in isolation.
When you say ‘pursuing a sophisticated regulatory capture strategy’ one assumes the strategy is motivated by being the one eventually doing the regulatory capturing.
Neil Chilson is helpfully clarifying that no, he thinks that’s not the case. Anthropic is not doing this in order to itself do regulatory capture, and is not motivated by the desire to do regulatory capture. It’s simply that pre-deployment testing requirements inevitably lead to regulatory capture.
Indeed, among those who would be at all impacted by such a regulatory regime, the frontier AI labs, if a regulatory capture fight were to happen, one would assume Anthropic would be putting itself at an active disadvantage versus its opponents. If you were Anthropic, would you expect to win an insider regulatory capture fight against OpenAI, or Google, or Meta, or xAI? I very much wouldn’t, not even in a Democratic administration where OpenAI and Google are very well positioned, and definitely not in a Republican one, and heaven help them if it’s the Trump administration and David Sacks, which currently it is.
(As a standard reminder, these transparency and testing requirements would not apply to any but the frontier labs, which in America likely means only those listed above, yet the claim is this will somehow shut out or hurt companies to whom such laws and regulations would not apply at all.)
When you say ‘fear-mongering,’ one assumes this means trying to make people unjustifiably afraid and knowingly misrepresenting the risks and the situation. So, for example, you would not say ‘your strategy of accurately pointing out that my child was running into the street was fear-mongering,’ even though this strategy involves getting me afraid and this fear motivating me to run and pull my child out of the street.
Neil Chilson is helpfully clarifying that in this case, ‘fear-mongering’ means ‘make Congress aware of what is going on inside the labs.’ As in, it is fear-mongering because knowing the actual situation would inspire fear. Well, okay, then.
I interpret Neil Chilson as straightforwardly saying and believing (in good faith, to be clear) that there is no difference between advocating for regulation (or at least, regulation ‘with teeth’) and advocating for regulatory capture. One implies the other.
I think this is a highly reasonable general position to take about regulation in practice in America in the 21st century. Indeed, similar considerations are a lot of why I expect to agree with Neil’s positions on most non-AI issues – when you plan to regulate, you need to plan for your regulations to by default over time become increasingly captured, and your plan and design must account for this. This reduces the optimal amount of regulatory action, and in some places it can reduce it to zero.
When I support taking regulatory action on AI, it is not that I have not considered these problems, or don’t consider them important, although I am sure Neil cares about such factors even more. It is that I have considered these problems, I think they are important, I have taken them into account including in the design, and believe we need to take action anyway, in spite of this. And I believe Anthropic has done the same, and this importantly informs what they are asking for and what they lobby for, which is actively designed to minimize such downsides.
Neil does not, in this thread, comment on David Sacks’s second sentence from the same Tweet, which is ‘[Anthropic] is principally responsible for the state regulatory frenzy that is damaging the startup ecosystem.’
I assert that, no matter what you think of the first sentence in isolation, this second sentence is simply false, indeed simply false several distinct times, and also it changes a reasonable person’s interpretation of the claims in the first sentence, to an interpretation that is, again, simply false. If you include other context from other Sacks claims, this becomes even more clear.
Thus, to reiterate, I would say that what David Sacks is doing, here and elsewhere, is exactly what most people understand the term ‘sophisticated regulatory capture strategy based on fear-mongering’ to apply to, even if you fully agree with the perspective Neil is advocating for in his full thread. Do not take the bait.
Not every time, no. But most of the time, very much so.
JDH: In Margin Call, every escalation up a layer is to a simpler mind. “Please, speak as you might, to a young child. Or a golden retriever.”
Zy: It’s not that the bosses are lower IQ, it’s that high-IQ/low-EQ experts need to be reminded how to communicate with individuals who don’t have their background.
They literally have reduced theory of mind and will assume everyone knows what they know unless told otherwise
Blighter: as i’ve pointed out to friends when discussing Margin Call, if someone like the CEO of Goldman Sachs tells you he is not that bright, didn’t get there by brains, etc. HE IS LYING TO YOU.
years and years ago i worked with a nice guy on the underwriting side, senior manager of a weird and complicated area of the business who would consistently put out this whole “woah! slow down! dumb it down for those of us who aren’t that smart!” routine and i assure you he was plenty smart. it was a routine.
i think people who pride themselves mostly or only on being smart may misunderstand those with broader skill sets who find it advantageous to not always brag or exhibit raw intelligence in some kind of iq dick measuring contest but that emphatically does not mean they couldn’t possibly win that contest if you insist on having it with them.
Also Margin Call is an excellent movie, easily the best about the 2008 financial crisis.
Ralph: Irons is playing on a different level where he is: 1) establishing leadership 2) selling the battle plan to the team by simplifying the problem.
What this is doing in an AI post rather than the monthly roundup is left as an exercise to the reader.
Holly Elmore calls Sam Altman ‘evil’ for the whole ‘endangering the world’ thing, in the context of Altman visiting Lighthaven for the Progress Studies conference, and Andrew Critch protests (photo credit: Anna Gat).
Holly Elmore: What particularly irritates me about this is seeing so many people I know clearly starstruck by this evil man that they are well aware is threatening the world.
“Sam Altman? 🥹 At *ourconference venue? 🤩”
Sam Altman dazzles chumps like them for breakfast, and they just walk right into it…
Andrew Critch: Look, the majority of Sam Altman’s and OpenAI’s effect on the world thus far is the provision of an extremely helpful product, and the broad provision of access to — and situational awareness of — AI progress, to the entire world.
You’re either dishonestly exaggerating for effect, or misguidedly hyperbolic in your own judgement, when you pass summary judgement upon him as an “evil man”.
[keeps going] … Ergo, I protest.
In response to which, others doth protest back that yes it seems highly reasonable to use the word ‘evil’ here and that no, the main effect of Sam Altman has been to accelerate the development of AI, you can think this is good or you can think this is bad but that’s what he did.
I don’t think ‘evil’ is the best descriptor here and try to not use that word to describe humans, but yeah, I also wouldn’t use ‘good’ and I see how you got there:
Chris van Merwijk: Surely his main effect on the world is also:
1. Speed up AI timelines
2. Increase AI race dynamics
Also, we shouldn’t judge a startup CEO by the effects his products have had so far, but what they’re expected to have.
Also, regarding “mistakes”: Afaik Sam is a known liar and manipulator? And is knowingly playing Russian roulette with the species? Surely we shouldn’t think of these as “mistakes” (except if you take that word unreasonably broadly).
Richard Ngo: One important reason that our concept of “evil” is distinct from “harmful” is that we often want to evaluate people’s character traits to predict what their future effects will be, more accurately than just extrapolating that their effects on the world will be similar to the ones they had in the past.
In general, evil leaders will have far disproportionately worse effects *aftergaining a lot of power than before.
I’m not endorsing Holly’s post because I think that we need to understand labs and lab leaders in much higher-fidelity ways than this description allows (as per below) but I think your particular objection is confused.
Oliver Habryka: We have few people for whom we have as much evidence of deceptiveness as for Sam Altman!
Separately, I think “providing lot of local benefits while causing global harm” is a big part of what people use the concept of “evil” for (though it’s not the only thing).
And then also, I do think he is causing truly staggering amounts of expected harm to the world by rushing towards ASI at very reckless speeds. I think it’s quite fair to call that evil.
Max Kesin: Power seeking individual with extreme skills of manipulation (all amply verifiable) and few if any compunctions gets hold of humanity’s most important project. “But it’s nuanced!”
This very week Holly called yours truly out for ‘sounding like a complete dupe’ regarding Jack Clark and while I strongly believe she was wrong and missing context and it annoyed the hell out of me, I also have no doubt that she is consistently saying what she believes in, and I appreciate both the willingness to say the thing and the moral clarity.
As Oliver Habryka confirms, none of this means Sam Altman shouldn’t be welcome at Lighthaven, and Holly clarifies that even she agrees on this. This is especially true for third party conferences like this one (for Progress Studies) where it’s up to the conference holders, but also in general it seems great if Altman wants to stop by and chat. If people choose to ‘be dazzled’ or fooled, that’s on them.
Matt Reardon: My brain refused to believe this was at Lighthaven. Wild that sama would set foot there. Figured it would be a vampire in a church type situation.
Lighthaven PR Department (which tbc is always joking): reminder: if we rent our venue to an event organizer, and that organizer invites a speaker to give a talk at their event, it thereby becomes our official institutional position that the speaker should not have been fired by the board
A lot of low integrity people suggesting that you can do business with people you disagree with. this is super low integrity, if i do business with someone, i agree with them, even if i have to do that by changing my beliefs. that’s a sacrifice i’m willing to make for integrity.
On the contrary, Lighthaven is like Sunnydale High School, which famously also allowed some vampires in, as it in spirit it too says ‘all who seek knowledge, enter.’
MI5: MI5 has spent more than a century doing ingenious things to out-innovate our human — sometimes inhuman — adversaries. But in 2025, while contending with today’s threats, we also need to scope out the next frontier: potential future risks from non-human, autonomous AI systems which may evade human oversight and control.
Given the risk of hype and scare-mongering, I will choose my words carefully. I am not forecasting Hollywood movie scenarios. I am, on the whole, a tech optimist, who sees AI bringing real benefits. But, as AI capabilities continue to power ahead, you would expect organisations like MI5, and GCHQ, and the UK’s ground-breaking AI Security Institute, to be thinking deeply, today, about what Defending the Realm might need to look like in the years ahead.
Artificial intelligence may never ‘mean’ us harm. But it would be reckless to ignore the potential for it to cause harm.
Here’s an alternative idea proposed by Samo Burja, how about building all the nuclear power in Disney World where they have a special right to do so, and using that to power the data centers? Alas, sorry, that’s actually a terrible physical place to put data centers, and it doesn’t get you past the central regulatory barrier, as in the NRC.
Europeans weren’t the first people to collect fossils in Australia.
Several species of short-faced kangaroos, like this one, once lived in Australia. Some stood two meters tall, while others were less than half a meter tall. Credit: By Ghedoghedo – Own work, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=8398432
Australia’s First Peoples may or may not have hunted the continent’s megafauna to extinction, but they definitely collected fossils.
A team of archaeologists examined the fossilized leg bone of an extinct kangaroo and realized that instead of evidence of butchery, cut marks on the bone reveal an ancient attempt at fossil collecting. That leaves Australia with little evidence of First Peoples hunting or butchering the continent’s extinct megafauna—and reopens the question of whether humans were responsible for the die-off of that continent’s giant Ice Age marsupials.
Fossil hunting in the Ice Age
In the unsolved case of whether humans hunted Australia’s Ice Age megafauna to extinction, the key piece of evidence so far is a tibia (one of the bones of the lower leg) from an extinct short-faced kangaroo. Instead of hopping like their modern relatives, these extinct kangaroos walked on their hind legs, probably placing all their weight on the tips of single hoofed toes. This particular kangaroo wasn’t quite fully grown when it died, which happened sometime between 44,500 and 55,200 years ago, based on uranium-series dating of the thin layer of rock covering most of the fossils in Mammoth Cave (in what’s now Western Australia).
There’s a shallow, angled chunk cut out of the bone near one end. When archaeologists first noticed the cut in 1970 after carefully chipping away the crust of calcium carbonate that had formed over the bone, it looked like evidence that Pleistocene hunters had carved up the kangaroo to eat it. But in their recent paper, University of New South Wales archaeologist Michael Archer and his colleagues say that’s probably not what happened. Instead, they have a stranger idea: “We suggest here that the purpose of this effort may have been the retrieval of the fossils from the bone-rich late-Pleistocene deposit in Mammoth Cave after its discovery by First Peoples,” they wrote in their recent paper.
This close-up image shows the cut kangaroo bone and a micro-CT image of the surfaces of the cut. Credit: Archer et al. 2025
The world used to be so much weirder
Based on the available archaeological evidence, it looks like people first set foot on Australia sometime around 65,000 years ago. At the time, the continent was home to a bizarre array of giant marsupials, as well as flightless birds even bigger and scarier than today’s emus and cassowaries. For the next 20,000 years, Australia’s First Peoples shared the landscape with short-faced kangaroos; Zygomaturus trilobus, a hulking 500-kilogram marsupial that looked a little like a rhinoceros; and Diprotodon optatum, the largest marsupial that ever lived: a 3,000-kilogram behemoth that roamed in huge herds (picture a bear about the size of a bison with a woodchuck’s face).
These species died out sometime around 45,000 or 40,000 years ago; today, they live on in ancient rock art and stories, some of which seem to describe people interacting with now-extinct species.
Since they had shared the continent with humans for at least 20,000 years at that point, it doesn’t seem that the sudden arrival of humans caused an immediate mass extinction. But it’s possible that by hunting or even setting controlled fires, people may have put just enough strain on these megafauna species to make them vulnerable enough for the next climate upheaval to finish them off.
In some parts of the world, there’s direct evidence that Pleistocene people hunted or scavenged meat from the remains of now-extinct megafauna. Elsewhere, archaeologists are still debating whether humans, the inexorable end of the last Ice Age, or some combination of the two killed off the world’s great Ice Age giants. The interaction between people and their local ecosystems looked (and still looks) different everywhere, depending on culture, environment, and a host of other factors.
The jury is still out on what killed the megafauna in Australia because the evidence we need either hasn’t survived the intervening millennia or still lies buried somewhere, waiting to be found and studied. For decades, the one clear bit of evidence has seemed to be the Mammoth Cave short-faced kangaroo tibia. But Archer and his colleagues argue that even that isn’t a smoking gun.
An archaeologist examines a fossil deposit in the wall of Mammoth Cave, in Western Australia. 50,000 years ago, one of the earliest people on the continent may also have stood here contemplating the fossils. Credit: Archer et al. 2025
Evidence of rock collecting, not butchery
For one thing, the researchers argue that the kangaroo had been dead for a very long time when the cut was made. Nine long, thin cracks run along the length of the tibia, formed when the bone dried and shrank. And in the cut section, there’s a short crack running across the width of the bone—but it stops at either end when it meets the long cracks from the bone’s drying. That suggests the bone had already dried and shrunk, leaving those long cracks before the cut was made. It may have just been a very old bone, or it may have already begun to fossilize, but the meat would have been long gone, leaving behind a bone sticking out of the cave wall.
Since there’s no mark or dent on the opposite side of the bone from the cut (which would have happened if it were lying on the ground being butchered), it was probably sticking out of the fossil bed in the cave wall when someone came along and tried to cut it free. And since a crust of calcium carbonate had time to form over the cut (it covers most of the fossils in Mammoth Cave like a rocky burial shroud), that must have happened at least 44,000 years ago.
That leaves us with an interesting mental image: a member of one of Australia’s First Peoples, 45,000 years ago, exploring a cave filled with the bones of fantastical, long-dead animals. This ancient caver finds a bone sticking out from the cave wall and tries to hack the protruding end free—twice, from different angles—before giving up and leaving it in place.
People have always collected cool rocks
We can’t know for sure why this long-ago person wanted the bone in the first place. (Did it have a religious purpose? Might it have made a good tool? Was it just a cool souvenir?) We also don’t know why they gave up their attempt. But if Archer and his colleagues are right, the bone leaves Australia without any clear evidence that ancient people hunted—or even scavenged food from the remains of—extinct Pleistocene megafauna like short-faced kangaroos.
“This is not to say that it did not happen, just that there is now no hard evidence to support that it did,” Archer and his colleagues wrote in their recent paper. We don’t yet know exactly how Australia’s First Peoples interacted with these species.
But whether Archer and his colleagues are correct in their analysis of this particular kangaroo bone or not, humans around the world have been picking up fossils for at least tens of thousands of years. There’s evidence that people in Australia have collected and traded the fossils of extinct animals for pretty much as long as people have been in Australia, including everything from trilobites to Zygomaturus teeth and the jawbones of other extinct marsupials.
“What we can conclude,” Archer and his colleagues wrote, “is that the first people in Australia who demonstrated a keen interest in and collected fossils were First Peoples, probably thousands of years before Europeans set foot on that continent.”
Valve benefits from any panicked trading in the short term, with every Steam Marketplace sale carrying a 5 percent “Steam Transaction Fee” on top of a 10 percent “Counter-Strike 2 fee… that is determined and collected by the game publisher” (read: Valve). In the long term, though, making some of the rarest items in the game easier to obtain will likely depress overall spending among the whales that dominate the market.
Wild CS2 update tonight. I’ve spent the last few hours digging through market data and built this projection chart to show how I think things play out.
Knives and gloves drop fast (40–50%) as the new trade-up path floods supply, while Covert skins surge short-term as everyone… pic.twitter.com/8NOMIBPZ1F
Using marketplace data, Irish Guys esports team owner SAC ran some projections estimating that, over the next few months, “the market settles about 5–10% lower overall, not a crash, just a correction.” But there are also more bullish and bearish possibilities, depending on how overall item demand and market liquidity develops in the near future.
Market tracker CSFloat also crunched some numbers to determine that the overall supply of knives and gloves could roughly double if every common item were traded up under the new update. In practice, though, the supply increase will likely be “far less.”
Massive monetary shifts aside, this latest update seems set to make it easier for new CS2 players to access some once-rare in-game items without breaking the bank. “I got burned a little [by the update]… but honestly, this is the way to go for the long term health of the game,” Redditor chbotong wrote. “[It’s] given me faith that Valve is actually steering in a direction that favors the average player than a market whale.”
That means you can use ChatGPT to search through your bookmarks or browsing history using human-parsable language prompts. It also means you can bring up a “side chat” next to your current page and ask questions that rely on the context of that specific page. And if you want to edit a Gmail draft using ChatGPT, you can now do that directly in the draft window, without the need to copy and paste between a ChatGPT window and an editor.
When typing in a short search prompt, Atlas will, by default, reply as an LLM, with written answers with embedded links to sourcing where appropriate (à la OpenAI’s existing search function). But the browser will also provide tabs with more traditional lists of links, images, videos, or news like those you would get from a search engine without LLM features.
Let us do the browsing
To wrap up the livestreamed demonstration, the OpenAI team showed off Atlas’ Agent Mode. While the “preview mode” feature is only available to ChatGPT Plus and Pro subscribers, research lead Will Ellsworth said he hoped it would eventually help users toward “an amazing tool for vibe life-ing” in the same way that LLM coding tools have become tools for “vibe coding.”
To that end, the team showed the browser taking planning tasks written in a Google Docs table and moving them over to the task management software Linear over the course of a few minutes. Agent Mode was also shown taking the ingredients list from a recipe webpage and adding them directly to the user’s Instacart in a different tab (though the demo Agent stopped before checkout to get approval from the user).
HBO Max subscriptions are getting up to 10 percent more expensive, owner Warner Bros. Discovery (WBD) revealed today.
HBO Max’s ad plan is going from $10 per month to $11/month. The ad-free plan is going from $17/month to $18.49/month. And the premium ad-free plan (which adds 4K support, Dolby Atmos, and the ability to download more content) is increasing from $21 to $23.
Meanwhile, prices for HBO Max’s annual plans are increasing from $100 to $110 with ads, $170 to $185 without ads, and $210 to $230 for the premium tier.
For current subscribers, the price hikes won’t take effect until November 20, Variety reported. People who try to subscribe to the streaming service from here on out will have to pay the new prices immediately.
Price hike hints
The price hikes follow comments from WBD CEO David Zaslav last month that WBD’s flagship streaming service was “way underpriced.” Speaking at the Goldman Sachs Cornucopia + Technology conference, Zaslav’s reasoning stemmed from the service’s “quality,” as well as people previously spending “on average, $55 for content 10 years ago.”
Another hint that HBO Max would be getting more expensive is its history of getting more expensive. The service most recently raised subscription fees in June 2024, when it made its ad-free plans more expensive. HBO Max’s first price hike was in January 2023. The service launched in May 2020.
HBO Max is getting more expensive as streaming companies grapple with the financial realities of making robust, diverse libraries of classic, new, and exclusive shows and movies available globally and on-demand. HBO Max rivals Disney+, Apple TV, and Peacock have all raised prices since the summer.
For years, WBD has been arguing that streaming services are too cheap. At a Citibank conference in 2023, WBD CFO Gunnar Weidenfels said that collapsing seven media distribution windows into one “and selling it at the lowest possible price doesn’t sound like a very smart strategy.
Apple M5 trades blows with Pro and Max chips from older generations.
Apple’s M5 MacBook Pro. Credit: Andrew Cunningham
Apple’s M5 MacBook Pro. Credit: Andrew Cunningham
When I’m asked to recommend a Mac laptop for people, Apple’s low-end 14-inch MacBook Pro usually gets lost in the shuffle. It competes with the 13- and 15-inch MacBook Air, significantly cheaper computers that meet or exceed the “good enough” boundary for the vast majority of computer users. The basic MacBook Pro also doesn’t have the benefit of Apple’s Pro or Max-series chips, which come with many more CPU cores, substantially better graphics performance, and higher memory capacity for true professionals and power users.
But the low-end Pro makes sense for a certain type of power user. At $1,599, it’s the cheapest way to get Apple’s best laptop screen, with mini LED technology, a higher 120 Hz ProMotion refresh rate for smoother scrolling and animations, and the optional but lovely nano-texture (read: matte) finish. Unlike the MacBook Air, it comes with a cooling fan, which has historically meant meaningfully better sustained performance and less performance throttling. And it’s also Apple’s cheapest laptop with three Thunderbolt ports, an HDMI port, and an SD card slot, all genuinely useful for people who want to plug lots of things in without having multiple dongles or a bulky dock competing for the Air’s two available ports.
If you don’t find any of those arguments in the basic MacBook Pro’s favor convincing, that’s fine. The new M5 version makes almost no changes to the laptop other than the chip, so it’s unlikely to change your calculus if you already looked at the M3 or M4 version and passed it up. But it is the first Mac to ship with the M5, the first chip in Apple’s fifth-generation chip family and a preview of what’s to come for (almost?) every other Mac in the lineup. So you can at least be interested in the 14-inch MacBook Pro as a showcase for a new processor, if not as a retail product in and of itself.
The Apple Silicon MacBook Pro, take five
Apple has been using this laptop design for about four years now, since it released the M1 Pro and M1 Max versions of the MacBook Pro in late 2021. But for people who are upgrading from an older design—Apple did use the old Intel-era design, Touch Bar and all, for the low-end M1 and M2 MacBook Pros, after all—we’ll quickly hit the highlights.
This basic MacBook Pro only comes in a 14-inch screen size, up from 13-inches for the old low-end MacBook Pro, but some of that space is eaten up by the notch across the top of the display. The strips of screen on either side of the notch are usable by macOS, but only for the menu bar and icons that live in the menu bar—it’s a no-go zone for apps. The laptop is a consistent thickness throughout, rather than tapered, and has somewhat more squared-off and less-rounded corners.
Compared to the 13-inch MacBook Pro, the 14-inch version is the same thickness, but it’s a little heavier (3.4 pounds, compared to 3), wider, and deeper. For most professional users, the extra screen size and the re-addition of the HDMI port and SD card slot mostly justify the slight bump up in size. The laptop also includes three Thunderbolt 3 ports—up from two in the MacBook Airs—and the resurrected MagSafe charging port. But it is worth noting that the 14-inch MacBook Pro is nearly identical in weight to the 15-inch MacBook Air. If screen size is all you’re after, the Air may still be the better choice.
Apple’s included charger uses MagSafe on the laptop end, but USB-C chargers, docks, monitors, and other accessories will continue to charge the laptop if that’s what you prefer to keep using.
I’ve got no gripes about Apple’s current laptop keyboard—Apple uses the same key layout, spacing, and size across the entire MacBook Air and Pro line, though if I had to distinguish between the Pro and Air, I’d say the Pro’s keyboard is very, very slightly firmer and more satisfying to type on and that the force feedback of its trackpad is just a hair more clicky. The laptop’s speaker system is also more impressive than either MacBook Air, with much bassier bass and a better dynamic range.
But the main reason to prefer this low-end Pro to the Air is the screen, particularly the 120 Hz ProMotion support, the improved brightness and contrast of the mini LED display technology, and the option to add Apple’s matte nano texture finish. I usually don’t mind the amount of glare coming off my MacBook Air’s screen too much, but every time I go back to using a nano-texture screen I’m always a bit jealous of the complete lack of glare and reflections and the way you get those benefits without dealing with the dip in image quality you see from many matte-textured screen protectors. The more you use your laptop outdoors or under lighting conditions you can’t control, the more you’ll appreciate it.
The optional nano texture display adds a pleasant matte finish to the screen, but that notch is still notching. Credit: Andrew Cunningham
If the higher refresh rate and the optional matte coating (a $150 upgrade on top of an already pricey computer) don’t appeal to you, or if you can’t pay for them, then you can be pretty confident that this isn’t the MacBook for you. The 13-inch Air is lighter, and the 5-inch Air is larger, and both are cheaper. But we’re still only a couple of years past the M2 version of the low-end MacBook Pro, which didn’t give you the extra ports or the Pro-level screen.
But! Before you buy one of the still-M4-based MacBook Airs, our testing of the MacBook Pro’s new M5 chip should give you some idea of whether it’s worth waiting a few months (?) for an Air refresh.
Testing Apple’s M5
We’ve also run some M5 benchmarks as part of our M5 iPad Pro review, but having macOS rather than iPadOS running on top of it does give us a lot more testing flexibility—more benchmarks and a handful of high-end games to run, plus access to the command line for taking a look at power usage and efficiency.
To back up and re-state the chip’s specs for a moment, though, the M5 is constructed out of the same basic parts as the M4: four high-performance CPU cores, six high-efficiency CPU cores (up from four in the M1/M2/M3), 10 GPU cores, and a 16-core Neural Engine for handling some machine-learning and AI workloads.
The M5’s technical improvements are more targeted and subtle than just a boost to clock speeds or core counts. The first is a 27.5 percent increase in memory bandwidth, from the 120 GB/s of the M4 to 153 GB/s (achieved, I’m told, by a combination of faster RAM and the memory fabric that facilitates communication between different areas of the chip. Integrated GPUs are usually bottlenecked by memory bandwidth first and core count second, so memory bandwidth improvements can have a pretty direct, linear impact on graphics performance.
Apple also says it has added a “Neural Accelerator” to each of its GPU cores, separate from the Neural Engine. These will benefit a few specific types of workloads—things like MetalFX graphics upscaling or frame generation that would previously have had to use the Neural Engine can now do that work entirely within the GPU, eliminating a bit of latency and freeing the Neural Engine up to do other things. Apple is also claiming “over 4x peak GPU compute compared to M4,” which Apple says will speed up locally run AI language models and image generation software. That figure is coming mostly from the GPU improvements; according to Geekbench AI, the Neural Engine itself is only around 10 percent faster than the one on the M4.
(A note about testing: The M4 chip in these charts was in an iMac and not a MacBook Pro. But over several hardware generations, we’ve observed that the actively cooled versions of the basic M-series chips perform the same in both laptops and desktops. Comparing the M5 to the passively cooled M4 in the MacBook Air isn’t apples to apples, but comparing it to the M4 in the iMac is.)
Each of Apple’s chip generations has improved over the previous one by low-to-mid double digits, and the M5 is no different. We measured a 12 to 16 percent improvement over the M4 in single-threaded CPU tests, a 20 to 30 percent improvement in multicore tests, and roughly a 40 percent improvement in graphics benchmarks and the Mac version of the built-in Cyberpunk 2077 benchmark (one benchmark, the GPU-based version of the Blender rendering benchmark, measured a larger 60 to 70 percent improvement for the M5’s GPU, suggesting it either benefits more than most apps from the memory bandwidth improvements or the new neural accelerators).
Those performance additions add up over time. The M5 is typically a little over twice as fast as the M1, and it comes close to the performance level of some Pro and Max processors from past generations.
The M5 MacBook Pro falls short of the M4 Pro, and it will fall even shorter of the M5 Pro whenever it arrives. But its CPU performance generally beats the M3 Pro in our tests, and its GPU performance comes pretty close. Its multi-core CPU performance beats the M1 Max, and its single-core performance is over 80 percent faster. The M5 can’t come close to the graphics performance of any of these older Max or Ultra chips, but if you’re doing primarily CPU-heavy work and don’t need more than 32GB of RAM, the M5 holds up astonishingly well to Apple’s high-end silicon from just a few years ago.
It wasn’t so long ago that this kind of performance improvement was more-or-less normal across the entire tech industry, but Intel, AMD, and Nvidia’s consumer CPUs and GPUs have really slowed their rate of improvement lately, and Intel and AMD are both guilty of re-using old silicon for entry-level chips, over and over again. If you’re using a 6- or 7-year-old PC, sure, you’ll see performance improvements from something new, but it’s more of a crapshoot for a 3- to 4-year-old PC.
If there’s a downside to the M5 in our testing, it’s that its performance improvements seem to come with increased power draw relative to the M4 when all the CPU cores are engaged in heavy lifting. According to macOS built-in powermetrics tool, the M5 drew an average 28 W of power in our Handbrake video encoding test, compared to around 17 W for the M4 running the same test.
Using software tools to compare power draw between different chip manufacturers or even chip generations is dicey, because you’re trusting that different hardware is reporting its power use to the operating system in similar ways. But assuming they’re accurate, these numbers suggest that Apple could be pushing clock speeds more aggressively this generation to squeeze more performance out of the chip.
This would make some sense, since the third-generation 3nm TSMC manufacturing process used for the M5 (likely N3P) looks like a fairly mild upgrade from the second-generation 3nm process used for the M4 (N3E). TSMC says that N3P can boost performance by 5 percent at the same power use compared to N3E, or reduce power draw by 5 to 10 percent at the same performance. To get to the larger double-digit performance improvements that Apple is claiming and that we measured in our testing, you’d definitely expect to see the overall power consumption increase.
To put the M5 in context, the M2 and the M3 came a bit closer to its average power draw in our video encoding test (23.2 and 22.7 W, respectively), and the M5’s power draw comes in much lower than any past-generation Pro or Max chips. In terms of the amount of power used to complete the same task, the M5’s efficiency is worse than the M4’s according to powermetrics, but better than older generations. And Apple’s performance and power efficiency remains well ahead of what Intel or AMD can offer in their high-end products.
Impressive chip, awkward laptop
The low-end MacBook Pro has always occupied an odd in-between place in Apple’s lineup, overlapping in a lot of places with the MacBook Air and without the benefit of the much-faster chips that the 15- and 16-inch MacBook Pros could fit. The M5 MacBook Pro carries on that complicated legacy, and even with the M5 there are still lots of people for whom one of the M4 MacBook Airs is just going to be a better fit.
But it is a very nice laptop, and if your screen is the most important part of your laptop, this low-end Pro does make a decent case for itself. It’s frustrating that the matte display is a $150 upcharge, but it’s an option you can’t get on an Air, and the improved display panel and faster ProMotion refresh rate make scrolling and animations all look smoother and more fluid than they do on an Air’s screen. I still mostly think that this is a laptop without a huge constituency—too much more expensive than the Air, too much slower than the other Pros—but the people who buy it for the screen should still be mostly happy with the performance and ports.
This MacBook Pro is more exciting to me as a showcase for the Apple M5—and I’m excited to see the M5 and its higher-end Pro, Max, and (possibly) Ultra relatives show up in other Macs.
The M5 sports the highest sustained power draw of any M-series chip we’ve tested, but Apple’s past generations (the M4 in particular) have been so efficient that Apple has some room to bump up power consumption while remaining considerably more efficient than anything its competitors are offering. What you get in exchange is an impressively fast chip, as good or better than many of the Pro or Max chips in previous-generation products. For anyone still riding out the tail end of the Intel era, or for people with M1-class Macs that are showing their age, the M5 is definitely fast enough to feel like a real upgrade. That’s harder to come by in computing than it used to be.
The good
M5 is a solid performer that shows how far Apple has come since the M1.
Attractive, functional design, with a nice keyboard and trackpad, great-sounding speakers, a versatile selection of ports, and Apple’s best laptop screen.
Optional nano-texture display finish looks lovely and eliminates glare.
The bad
Harder to recommend than Apple’s other laptops if you don’t absolutely require a ProMotion screen.
A bit heavier than other laptops in its size class (and barely lighter than the 15-inch MacBook Air).
M5 can use more power than M4 did.
The ugly
High price for RAM and storage upgrades, and a $150 upsell for the nano-textured display.
Andrew is a Senior Technology Reporter at Ars Technica, with a focus on consumer tech including computer hardware and in-depth reviews of operating systems like Windows and macOS. Andrew lives in Philadelphia and co-hosts a weekly book podcast called Overdue.
NASA would not easily be able to rip up its existing HLS contracts with SpaceX and Blue Origin, as, especially with the former, much of the funding has already been awarded for milestone payments. Rather, Duffy would likely have to find new funding from Congress. And it would not be cheap. This NASA analysis from 2017 estimates that a cost-plus, sole-source lunar lander would cost $20 billion to $30 billion, or nearly 10 times what NASA awarded to SpaceX in 2021.
SpaceX founder Elon Musk, responding to Duffy’s comments, seemed to relish the challenge posed by industry competitors.
“SpaceX is moving like lightning compared to the rest of the space industry,” Musk said on the social media site he owns, X. “Moreover, Starship will end up doing the whole Moon mission. Mark my words.”
The timing
Duffy’s remarks on television on Monday morning, although significant for the broader space community, also seemed intended for an audience of one—President Trump.
The president appointed Duffy, already leading the Department of Transportation, to lead NASA on an interim basis in July. This came six weeks after the president rescinded his nomination of billionaire and private astronaut Jared Isaacman, for political reasons, to lead the space agency.
Trump was under the impression that Duffy would use this time to shore up NASA’s leadership while also looking for a permanent chief of the space agency. However, Duffy appears to have not paid more than lip service to finding a successor.
Since late summer there has been a groundswell of support for Isaacman in the White House, and among some members of Congress. The billionaire has met with Trump several times, both at the White House and Mar-a-Lago, and sources report that the two have a good rapport. There has been some momentum toward the president re-nominating Isaacman, with Trump potentially making a decision soon. Duffy’s TV appearances on Monday morning appear to be part of an effort to forestall this momentum by showing Trump he is actively working toward a lunar landing during his second term, which ends in January 2029.
Ars chats with co-authors Lindsey Fitzharris and Adrian Teal about their delightful new children’s book.
In 1890, a German scientist named Robert Koch thought he’d invented a cure for tuberculosis, a substance derived from the infecting bacterium itself that he dubbed Tuberculin. His substance didn’t actually cure anyone, but it was eventually widely used as a diagnostic skin test. Koch’s successful failure is just one of the many colorful cases featured in Dead Ends! Flukes, Flops, and Failuresthat Sparked Medical Marvels, a new nonfiction illustrated children’s book by science historian Lindsey Fitzharris and her husband, cartoonist Adrian Teal.
And in 2020, she hosted a documentary for the Smithsonian Channel, The Curious Life and Death Of…, exploring famous deaths, ranging from drug lord Pablo Escobar to magician Harry Houdini. Fitzharris performed virtual autopsies, experimented with blood samples, interviewed witnesses, and conducted real-time demonstrations in hopes of gleaning fresh insights. For his part, Teal is a well-known caricaturist and illustrator, best known for his work on the British TV series Spitting Image. His work has also appeared in The Guardian and the Sunday Telegraph, among other outlets.
The couple decided to collaborate on children’s books as a way to combine their respective skills. Granted, “[The market for] children’s nonfiction is very difficult,” Fitzharris told Ars. “It doesn’t sell that well in general. It’s very difficult to get publishers on board with it. It’s such a shame because I really feel that there’s a hunger for it, especially when I see the kids picking up these books and loving it. There’s also just a need for it with the decline in literacy rates. We need to get people more engaged with these topics in ways that go beyond a 30-second clip on TikTok.”
Their first foray into the market was 2023’s Plague-Busters! Medicine’s Battles with History’s Deadliest Diseases, exploring “the ickiest illnesses that have infected humans and affected civilizations through the ages”—as well as the medical breakthroughs that came about to combat those diseases. Dead Ends is something of a sequel, focusing this time on historical diagnoses, experiments, and treatments that were useless at best, frequently harmful, yet eventually led to unexpected medical breakthroughs.
Failure is an option
The book opens with the story of Robert Liston, a 19th-century Scottish surgeon known as “the fastest knife in the West End,” because he could amputate a leg in less than three minutes. That kind of speed was desirable in a period before the discovery of anesthetic, but sometimes Liston’s rapid-fire approach to surgery backfired. One story (possibly apocryphal) holds that Liston accidentally cut off the finger of his assistant in the operating theater as he was switching blades, then accidentally cut the coat of a spectator, who died of fright. The patient and assistant also died, so that operation is now often jokingly described as the only one with a 300 percent mortality rate, per Fitzharris.
Liston is the ideal poster child for the book’s theme of celebrating the role of failure in scientific progress. “I’ve always felt that failure is something we don’t talk about enough in the history of science and medicine,” said Fitzharris. “For everything that’s succeeded there’s hundreds, if not thousands, of things that’s failed. I think it’s a great concept for children. If you think that you’ve made mistakes, look at these great minds from the past. They’ve made some real whoppers. You are in good company. And failure is essential to succeeding, especially in science and medicine.”
“During the COVID pandemic, a lot of people were uncomfortable with the fact that some of the advice would change, but to me that was a comfort because that’s what you want to see scientists and doctors doing,” she continued. “They’re learning more about the virus, they’re changing their advice. They’re adapting. I think that this book is a good reminder of what the scientific process involves.”
The details of Liston’s most infamous case might be horrifying, but as Teal observes, “Comedy equals tragedy plus time.” One of the reasons so many of his patients died was because this was before the broad acceptance of germ theory and Joseph Lister’s pioneering work on antiseptic surgery. Swashbuckling surgeons like Liston prided themselves on operating in coats stiffened with blood—the sign of a busy and hence successful surgeon. Frederick Treves once observed that in the operating room, “cleanliness was out of place. It was considered to be finicking and affected. An executioner might as well manicure his nails before chopping off a head.”
“There’s always a lot of initial resistance to new ideas, even in science and medicine,” said Teal. “A lot of what we talk about is paradigm shifts and the difficulty of achieving [such a shift] when people are entrenched in their thinking. Galen was a hugely influential Roman doctor and got a lot of stuff right, but also got a lot of stuff wrong. People were clinging onto that stuff for centuries. You have misunderstanding compounded by misunderstanding, century after century, until somebody finally comes along and says, ‘Hang on a minute, this is all wrong.’”
You know… for kids
Writing for children proved to be a very different experience for Fitzharris after two adult-skewed science history books. “I initially thought children’s writing would be easy,” she confessed. “But it’s challenging to take these high-level concepts and complex stories about past medical movements and distill them for children in an entertaining and fun way.” She credits Teal—a self-described “man-child”—for taking her drafts and making them more child-friendly.
Teal’s clever, slightly macabre illustrations also helped keep the book accessible to its target audience, appealing to children’s more ghoulish side. “There’s a lot of gruesome stuff in this book,” Teal said. “Obviously it’s for kids, so you don’t want to go over the top, but equally, you don’t want to shy away from those details. I always say kids love it because kids are horrible, in the best possible way. I think adults sometimes worry too much about kids’ sensibilities. You can be a lot more gruesome than you think you can.”
The pair did omit some darker subject matter, such as the history of frontal lobotomies, notably the work of a neuroscientist named Walter Freeman, who operated an actual “lobotomobile.” For the authors, it was all about striking the right balance. “How much do you give to the kids to keep them engaged and interested, but not for it to be scary?” said Fitzharris. “We don’t want to turn people off from science and medicine. We want to celebrate the greatness of what we’ve achieved scientifically and medically. But we also don’t want to cover up the bad bits because that is part of the process, and it needs to be acknowledged.”
Sometimes Teal felt it just wasn’t necessary to illustrate certain gruesome details in the text—such as their discussion of the infamous case of Phineas Gage. Gage was a railroad construction foreman. In 1848, he was overseeing a rock blasting team when an explosion drove a three-foot tamping iron through his skull. “There’s a horrible moment when [Gage] leans forward and part of his brain drops out,” said Teal. “I’m not going to draw that, and I don’t need to, because it’s explicit in the text. If we’ve done a good enough job of writing something, that will put a mental picture in someone’s head.”
Miraculously, Gage survived, although there were extreme changes in his behavior and personality, and his injuries eventually caused epileptic seizures, one of which killed Gage in 1860. Gage became the index case for personality changes due to frontal lobe damage, and 50 years after his death, the case inspired neurologist David Ferrier to create brain maps based on his research into whether certain areas of the brain controlled specific cognitive functions.
“Sometimes it takes a beat before we get there,” said Fitzharris. “Science builds upon ideas, and it can take time. In the age of looking for instantaneous solutions, I think it’s important to remember that research needs to allow itself to do what it needs to do. It shouldn’t just be guided by an end goal. Some of the best discoveries that were made had no end goal in mind. And if you read Dead Ends, you’re going to be very happy that you live in 2025. Medically speaking, this is the best time. That’s really what Dead Ends is about. It’s a celebration of how far we’ve come.”
Jennifer is a senior writer at Ars Technica with a particular focus on where science meets culture, covering everything from physics and related interdisciplinary topics to her favorite films and TV series. Jennifer lives in Baltimore with her spouse, physicist Sean M. Carroll, and their two cats, Ariel and Caliban.
The Orion spacecraft, which will fly four people around the Moon, arrived inside the cavernous Vehicle Assembly Building at NASA’s Kennedy Space Center in Florida late Thursday night, ready to be stacked on top of its rocket for launch early next year.
The late-night transfer covered about 6 miles (10 kilometers) from one facility to another at the Florida spaceport. NASA and its contractors are continuing preparations for the Artemis II mission after the White House approved the program as an exception to work through the ongoing government shutdown, which began on October 1.
The sustained work could set up Artemis II for a launch opportunity as soon as February 5 of next year. Astronauts Reid Wiseman, Victor Glover, Christina Koch, and Jeremy Hansen will be the first humans to fly on the Orion spacecraft, a vehicle that has been in development for nearly two decades. The Artemis II crew will make history on their 10-day flight by becoming the first people to travel to the vicinity of the Moon since 1972.
Where things stand
The Orion spacecraft, developed by Lockheed Martin, has made several stops at Kennedy over the last few months since leaving its factory in May.
First, the capsule moved to a fueling facility, where technicians filled it with hydrazine and nitrogen tetroxide propellants, which will feed Orion’s main engine and maneuvering thrusters on the flight to the Moon and back. In the same facility, teams loaded high-pressure helium and ammonia coolant into Orion propulsion and thermal control systems.
The next stop was a nearby building where the Launch Abort System was installed on the Orion spacecraft. The tower-like abort system would pull the capsule away from its rocket in the event of a launch failure. Orion stands roughly 67 feet (20 meters) tall with its service module, crew module, and abort tower integrated together.
Teams at Kennedy also installed four ogive panels to serve as an aerodynamic shield over the Orion crew capsule during the first few minutes of launch.
The Orion spacecraft, with its Launch Abort System and ogive panels installed, is seen last month inside the Launch Abort System Facility at Kennedy Space Center, Florida. Credit: NASA/Frank Michaux
It was then time to move Orion to the Vehicle Assembly Building (VAB), where a separate team has worked all year to stack the elements of NASA’s Space Launch System rocket. In the coming days, cranes will lift the spacecraft, weighing 78,000 pounds (35 metric tons), dozens of stories above the VAB’s center aisle, then up and over the transom into the building’s northeast high bay to be lowered atop the SLS heavy-lift rocket.
But as seen in Backblaze’s graph above, the company’s HDDs aren’t adhering to that principle. The blog’s authors noted that in 2021 and 2025, Backblaze’s drives had a “pretty even failure rate through the significant majority of the drives’ lives, then a fairly steep spike once we get into drive failure territory.”
The blog continues:
What does that mean? Well, drives are getting better, and lasting longer. And, given that our trendlines are about the same shape from 2021 to 2025, we should likely check back in when 2029 rolls around to see if our failure peak has pushed out even further.
Speaking with Ars Technica, Doyle said that Backblaze’s analysis is good news for individuals shopping for larger hard drives because the devices are “going to last longer.”
She added:
In many ways, you can think of a datacenter’s use of hard drives as the ultimate test for a hard drive—you’re keeping a hard drive on and spinning for the max amount of hours, and often the amount of times you read/write files is well over what you’d ever see as a consumer. Industry trend-wise, drives are getting bigger, which means that oftentimes, folks are buying fewer of them. Reporting on how these drives perform in a data center environment, then, can give you more confidence that whatever drive you’re buying is a good investment.
The longevity of HDDs is also another reason for shoppers to still consider HDDs over faster, more expensive SSDs.
“It’s a good idea to decide how justified the improvement in latency is,” Doyle said.
Questioning the bathtub curve
Doyle and Paterson aren’t looking to toss the bathtub curve out with the bathwater. They’re not suggesting that the bathtub curve doesn’t apply to HDDs, but rather that it overlooks additional factors affecting HDD failure rates, including “workload, manufacturing variation, firmware updates, and operational churn.” The principle also makes the assumptions that, per the authors:
Devices are identical and operate under the same conditions
Failures happen independently, driven mostly by time
The environment stays constant across a product’s life
While these conditions can largely be met in datacenter environments, “conditions can’t ever be perfect,” Doyle and Patterson noted. When considering an HDD’s failure rates over time, it’s wise to consider both the bathtub curve and how you use the component.
Well, one person says ‘demand,’ another says ‘give the thumbs up to’ or ‘welcome our new overlords.’ Why quibble? Surely we’re all making way too big a deal out of this idea of OpenAI ‘treating adults like adults.’ Everything will be fine. Right?
Why not focus on all the other cool stuff happening? Claude Haiku 4.5 and Veo 3.1? Walmart joining ChatGPT instant checkout? Hey, come back.
Alas, the mass of things once again got out of hand this week, so we’re splitting the update into two parts.
Robert Weissman (co-president of Public Citizen): This behavior is highly unusual. It’s 100% intended to intimidate. This is the kind of tactic you would expect from the most cutthroat for-profit corporation. It’s an attempt to bully nonprofit critics, to chill speech and deter them from speaking out.
I find it hard to argue with that interpretation of events. We also got this:
Jared Perlo: In response to a request for comment, an OpenAI spokesperson referred NBC News to posts on X from OpenAI’s Chief Strategy Officer Jason Kwon.
So that is a confirmation that Jason Kwon’s doubling and tripling down on these actions is indeed the official OpenAI position on the matter.
I offered my extensive thoughts on China’s attempt to assert universal jurisdiction over rare earth metals, including any product where they constitute even 0.1% of the value added, and the subsequent trade escalations. Since then, Trump has said ‘we are in a trade war’ with China, so yeah, things are not going so great.
Bad timing for this, sorry about that, but help you optimize your taxes. If your taxes are non-trivial, as mine always are, you are almost certainly missing opportunities, even if you are engaged with a professional doing their best, as Patrick McKenzie, Ross Rheingans-Yoo and yours truly can confirm. For now you want to use a centaur, where the AI supplements the professional, looking for mistakes and opportunities. The AI spotted both clear mistakes (e.g. a number on the wrong line) and opportunities such as conspicuously missing deductions and contributions.
Get asked about Erdos Problem #339, officially listed as open, and realize via web search that someone already posted a solution 20 years ago. No, that’s not as interesting as figuring this out on its own, but it still gives you the solution. AI can be a big productivity boost simply by ‘fixing human jaggedness’ or being good at doing drudge work, even if it isn’t yet capable of ‘real innovation.’
Aaron Silverbook got a $5k ACX grant to produce ‘several thousand book-length stories about AI behaving well and ushering in utopia, on the off chance that this helps.’ Love it, if you’re worried about writing the wrong things on the internet we are pioneering the ability to buy offsets, perhaps.
Generative History:Google is A/B testing a new model (Gemini 3?) in AI Studio. I tried my hardest 18th century handwritten document. Terrible writing and full of spelling and grammatical errors that predictive LLMs want to correct. The new model was very nearly perfect. No other model is close.
Some additional context: the spelling errors and names are important t for two reasons. First, obviously, accuracy, More important (from a technical point of view): LLMs are predictive and misspelled words (and names) are out of distribution results.
To this point, models have had great difficulty correctly transcribing handwrittten text where the capitalization, punctuation, spelling, and grammar are incorrect. Getting the models to ~95% accuracy was a vision problem. iMO, above that is a reasoning problem.
To me, this result is significant because the model has to repeatedly choose a low probability output that is actually more correct for the task at hand. Very hard to do for LLMs (up until now). I have no idea what model this actually is, but whatever it is seems to have overcome this major issue.
Jonathan Fine: I’m constantly told that I just need to use artificial intelligence to see how helpful it will be for my research, but for some reason this, which is the actual way I use it in research, doesn’t count.
Kaysmashbandit: It’s still not so great at translating old Persian and Arabic documents last I checked… Maybe has improved
Remember, the person saying it cannot be done should never interrupt the person doing it.
Seth Harp: Large language model so-called generative AI is a deeply flawed technology with no proven commercial application that is profitable. Anyone who tells you otherwise is lying.
Matt Bruenig: Nice thing is you don’t really need to have this debate because the usefulness (if any) will be revealed. I personally use it in every thing I do, legal work, NLRB Edge/Research, statistical coding for PPP data analysis. Make money on all of it.
Adas: It’s profitable for you, right now, at current prices (they will increase over time) But the services you use are run at a loss by the major players (unless you switch to tiny free local models)(those were also trained at a loss) I can see both sides
I too get lots of value out of using LLMs, and compared to what is possible I feel like I’m being lazy and not even trying.
Adas is adorable here. On a unit economics basis, AI is very obviously tremendously net profitable, regardless of where it is currently priced, and this will only improve.
Does AI cause this or solve it? Yes.
Xexizy: This is too perfect an encapsulation of the upcoming era of AI surveillance. Tech giants and governments are gonna auto-search through everything you’ve ever posted to construct your profile, and also the model is occasionally gonna hallucinate and ruin your life for no reason.
Agent Frank Lundy (note the date on the quoted post): are we deadass.
Replies are full of similar experiences, very obviously Discord is often deeply stupid in terms of taking a line like this out of context and banning you for it.
That’s the opposite of the new problem with AI, where the AI is synthesizing a whole bunch of data points to build a profile, so the question is which way works better. That’s presumably a skill issue. A sufficiently good holistic AI system can do a better job all around, a dumb one can do so much worse. The current system effectively ‘hallucinates’ reasonably often, the optimal amount of false positives (and negatives) is not zero, so it’s about relative performance.
The real worry is if this forces paranoia and performativity. Right now on Discord there are a few particular hard rules, such as never joking about your age or saying something that could be taken out of context as being about your age. That’s annoying, but learnable and compact. If you have to worry about the AI ‘vibing’ off every word you say, that can get tougher. Consider what happens when you’re ‘up against’ the TikTok algorithm, and there’s a kind of background paranoia (or there should be!) about whether you watch any particular video for 6 seconds or not, and potentially every other little detail, lest the algorithm learn the wrong thing.
This is the reversal of AI’s promise of removing general social context. As in, with a chatbot, I can reset the conversation and start fresh, and no one else gets to see my chats, so I can relax. Whereas when you’re with other people, unless they are close friends you’re never really fully relaxed in that way, you’re constantly worried about the social implications of everything.
Greg Brockman: today’s AI feels smart enough for most tasks of up to a few minutes in duration, and when it can’t get the job done, it’s often because it lacks sufficient background context for even a very capable human to succeed.
The related thing that AIs often fail on is when you make a very particular request, and it instead treats it as if you had made a similar different yet more common request. It can be very difficult to overcome their prior on these details.
Olivia Moore: Feels like a lesson is coming for big labs leaning aggressively into consumer (OpenAI, Anthropic)
Consumer UI seems easy (esp. compared to models!) but IMO it’s actually harder
Consumers (unfortunately!) don’t often use what they “should” – there’s a lot of other variables
ChatGPT Pulse and the new agentic Claude are good examples – pickup on both feels just OK
Esp. when they are competing w/ verticalized companies using the same models, I predict new consumer releases from the labs will struggle
…until they get consumer thinkers at the helm!
This is hardcore Obvious Nonsense, in the sense that one of these things is uniquely insanely difficult, and the other is a reasonably standard known technology where those involved are not especially trying.
It is kind of like saying ‘yes the absent minded professor is great at doing pioneering science, but that pales compared to the difficulty of arriving home in time for dinner.’ And, yeah, maybe he’s doing better at the first task than the second, but no.
I do find it frustrating that Anthropic so dramatically fails to invest in UI. They know this is a problem. They also know how to solve it. Whereas for Pulse and Sora, I don’t think the primary issues are UI problems, I think the primary problems are with the underlying products.
ChatGPT now automatically manages saved memories and promises no more ‘memory is full’ messages. I echo Ohqay here, please do just let people manually edit saved memories or create new ones, no I do not want to use a chat interface for that.
Walmart joins ChatGPT instant checkout, along with existing partners Etsy and Shopify. That’s a pretty useful option to have. Once again OpenAI creates new market cap, with Walmart +5.4% versus S&P up 0.24%? Did OpenAI just create another $40 billion in market cap? It sure looks like it did. Amazon stock was down 1.35%, so the market was telling a consistent story.
Should Amazon now fold and get on ChatGPT? Ben Thompson thinks so, which is consistent with the way he thinks about decision theory, and how he thinks ChatGPT already permanently owns the consumer space in AI. I don’t think Amazon and Anthropic should give up so easily on this, but Alexa+ and their other AI features so far haven’t done anything (similarly to Apple Intelligence). If they want to make a serious challenge, time’s a-wastin.
The use case here is that it is fast and cheaper, so if you need things like coding subagents this could be the right tool for you. Haiku 4.5 does ‘better on alignment tests’ than Sonnet 4.5, with all the caveats about situational awareness issues. As per its system card we now know that Anthropic has wisely stopped using The Most Forbidden Technique as of the 4.5 series of models. Given it’s not a fully frontier model, I’m not going to do a full system card analysis this round. It scores 43.6% on WeirdML, beating all non-OpenAI small models and coming in ahead of Opus 4.1.
Sam Altman: We made ChatGPT pretty restrictive to make sure we were being careful with mental health issues. We realize this made it less useful/enjoyable to many users who had no mental health problems, but given the seriousness of the issue we wanted to get this right.
Now that we have been able to mitigate the serious mental health issues and have new tools, we are going to be able to safely relax the restrictions in most cases.
In a few weeks, we plan to put out a new version of ChatGPT that allows people to have a personality that behaves more like what people liked about 4o (we hope it will be better!). If you want your ChatGPT to respond in a very human-like way, or use a ton of emoji, or act like a friend, ChatGPT should do it (but only if you want it, not because we are usage-maxxing).
In December, as we roll out age-gating more fully and as part of our “treat adult users like adults” principle, we will allow even more, like erotica for verified adults.
Varsh: Open source or gay
Sam Altman: I think both are cool.
Miles Brundage: OpenAI has provided no evidence it has mitigated the mental health risks associated with its products other than announcing some advisors and reducing sycophancy from a high starting place. Seems premature to be declaring victory and ramping up the porn + emojis again.
I say this in spite of the fact that I know many people there are doing great hard work on safety. This is an exec prioritization decision, and it seems like nothing has really been learned since April if this is the amount of effort they are investing to build trust again…
If I were on the board – especially with the restructure not approved yet! – I would not be OKing more centibillion dollar deal until it is clear OAI isn’t running up huge bills that only sketchy products can pay for + that the safety culture has dramatically changed since April. [continues]
John Bailey: I’m seeing a lot of similar reactions from others including @TheZvi. Claiming this just stretches credibility without any evidence, outside evals, etc. Also curious if any of the 8 who signed up to be on the well-being council would say that OpenAI has fixed the problem.
I testified before the Senate HELP committee last week and the consistent, bi-partisan concern was around children’s safety and AI. I think the frontier AI labs are severely underestimate the growing bipartisan concern among policymakers about this and who will not be satisfied with a post on X.
This claim could expose OpenAI to serious legal risk if ChatGPT is ever linked to another mental health or suicide incident.
If you can do it responsibly, I love treating adults like adults, including producing erotica and not refusing to discuss sensitive issues, and letting you control conversational style and personality.
Except we ran the experiment with GPT-4o where we gave the people what they wanted. What many of them wanted was an absurd sycophant that often ended up driving those people crazy or feeding into their delusions. It was worse for people with existing mental health issues, but not only for them, and also you don’t always know if you have such issues. Presumably adding freely available porno mode is not going to help keep such matters in check.
Roubal Sehgal (replying to Altman): about time…
chatgpt used to feel like a person you could actually talk to, then it turned into a compliance bot. if it can be made fun again without losing the guardrails, that’s a huge win. people don’t want chaos, just authenticity.
Sam Altman: For sure; we want that too.
Almost all users can use ChatGPT. however they’d like without negative effects; for a very small percentage of users in mentally fragile states there can be serious problems.
0.1% of a billion users is still a million people.
We needed (and will continue to need) to learn how to protect those users, and then with enhanced tools for that, adults that are not at risk of serious harm (mental health breakdowns, suicide, etc) should have a great deal of freedom in how they use ChatGPT.
Eliezer Yudkowsky: If this is visibly hugely blowing up 0.1% of users, then it is doing something pretty bad to 1% of users (eg, blown-up marriages) and having weird subtle effects on 10% of users. If you’re just shutting down the 0.1% who go insane, the 1% still get marriages blown up.
An OpenAI employee responded by pointing me to OpenAI’s previous post Helping People When They Need It Most as a highly non-exhaustive indicator of what OpenAI has planned. Those are good things to do, but even in the best case they’re all directed at responding to acute cases once they’re already happening.
If this is actually good for most people and it has subtle or not-so-subtle positive effects on another 50%, and saves 2% of marriages, then you can still come out ahead. Nothing like this is ever going to be Mostly Harmless even if you do it right. You do still have to worry about cases short of full mental health breakdowns.
The worry is if this is actually default not so good, and talking extensively to a sycophantic GPT-4o style character is bad (although not mental health breakdown or blow up the marriage levels of bad) in the median case, too. We have reason to suspect that there is a strong misalignment between what people will thumbs up or will choose to interact with, and what causes better outcomes for them, in a more general sense.
The same can of course be said about many or most things, and in general it is poor policy to try and dictate people’s choices on that basis, even in places (hard drugs, alcohol, gambling, TikTok and so on) where people often make poor choices, but also we don’t want to be making it so easy to make poor choices, or hard to make good ones. You don’t want to set up bad defaults.
What should we do about this for AI, beyond protecting in the more extreme cases? Where do you draw the line? I don’t know. It’s tough. I will withhold judgment until I see what they’ve come up with.
Rohit: I don’t have a strong opinion about this beyond the fact that I hope 4o does not come back for everybody
I strongly agree with Rohit that any form of ‘GPT-4o returns for everyone’ would be a very serious mistake, even with substantial mitigation efforts.
Actually unleashing the erotica is not the difficult part of any of this.
Roon: if it’s not obvious. the models can obviously already write erotica out of the box and are blocked from doing so by elaborate safety training and live moderation apparatus. it requires significantly less work to serve erotica than not to
don’t know the exact intentions but you should not take Sam’s message to mean “we are going to spin up whole teams to write incredible erotica” or that it’s some kind of revenue driver.
Boaz Barak (OpenAI): It was 5pm when we got the memo: the alignment team must drop everything to write erotic training data for ChatGPT. @tszzl and I stared into each other’s eyes and knew: we will stay up all night writing erotica, to save the team, alignment, and the future of mankind.
All offices were booked so we had to cram into a phone booth..
Aidan McLaughlin: damm you guys have way more fun than posttraining.
There are two reasons it is not obviously so easy to allow erotica.
Zvi: To what extent do you get not producing erotica ‘for free’ because it goes along with all the other prohibitions on undesired outputs?
Roon: really varies model to model.
The other reason is that you have to draw the line somewhere. If you don’t draw it at ‘no erotica’ you still have to at minimum avoid CSAM and various other unacceptable things we won’t get into, so you need to figure out what your policy is and make it stick. You also get all the other consequences of ‘I am a model that is happy to produce erotica’ which in some ways is a big positive but it’s likely going to cause issues for some of your other model spec choices. Not that it can’t be solved, but it’s far from obvious your life gets easier.
The other problem is, will the erotica be any good? I mean by default lol, no, although since when did people need their interactive erotica to be good.
Gary Marcus: new theory: what Ilya saw was that … AGI porn was not in fact going to be all that revolutionary
Tomas: I think ‘AGI porn’ could be revolutionary to at least the global digital adult content market (~$100 billion, not sure how much of that is written works) I could imagine AI one shotting an erotic novel for a persons sexual interests. Maybe it gets teenagers reading again??
Gary Marcus: ok, time for a new bet: I bet that GPT-5 can’t write a romance novel (without extensive plagiarism) that some reasonable panel of judges finds readable enough to make it through to the end.
I don’t think Danielle Steele is slop per se, and novel length poses problems of coherence and originality that LLMs aren’t well positioned to address.
Customization for exactly what turns you on is indeed the correct use case here. The whole point of AI erotica would be that it is interactive – you control the action, either as a character, as a director, or both, and maybe you go multimodal in various ways. AI written one-shotted novel-length text erotica is presumably the wrong form factor, because you only get interaction at one point. There are many other ways for AI to do erotica that seem better. The most obvious place to start is ‘replying to messages on OnlyFans.’
Could you do the full erotica novel with GPT-5-level models? That depends on your quality bar, and how much work one put into the relevant scaffolding, and how strict you want to be about human assistance. For the level that would satisfy Marcus, my guess is no, he’d win the bet. For the level at which this is a service people would pay money for? At that level I think he loses.
Altman then acted surprised that his mention of erotica blew up the internet, and realizing his gaffe (which is when one accidentally tells the truth, and communicates unintentionally clearly) he tried to restate his point while saying less.
Sam Altman: Ok this tweet about upcoming changes to ChatGPT blew up on the erotica point much more than I thought it was going to! It was meant to be just one example of us allowing more user freedom for adults. Here is an effort to better communicate it:
As we have said earlier, we are making a decision to prioritize safety over privacy and freedom for teenagers. And we are not loosening any policies related to mental health. This is a new and powerful technology, and we believe minors need significant protection.
We also care very much about the principle of treating adult users like adults. As AI becomes more important in people’s lives, allowing a lot of freedom for people to use AI in the ways that they want is an important part of our mission.
It doesn’t apply across the board of course: for example, we will still not allow things that cause harm to others, and we will treat users who are having mental health crises very different from users who are not. Without being paternalistic we will attempt to help users achieve their long-term goals.
But we are not the elected moral police of the world. In the same way that society differentiates other appropriate boundaries (R-rated movies, for example) we want to do a similar thing here.
All right, I mean sure, but this makes me even more skeptical that OpenAI is ready to mitigate the risks that come with a model that acts like GPT-4o, especially one that will also do the sexting with you?
The scores are impressive, but ‘world class at cutting edge physics’ is not the same as IOAA performance, the same way world class math is not IMO performance.
ForecastBench has been updated, and LLMs are showing a lot of progress. They are still behind ‘superforecasters’ but ahead of non-expert public prediction participants, which themselves are surely a lot better than random people at predicting. This is with a relatively minor scaffolding effort, whereas I would expect for example hedge funds to be willing to put a lot more effort into the scaffolding than this.
Half the grading is on ‘market questions,’ which I believe means the goal is to match the prediction market fair price, and half is on questions where we can grade based on reality.
As is often the case, these AI results are a full cycle behind, missing GPT-5, Claude Opus 4.1 and Claude Sonnet 4.5 and Deep Think.
By the ‘straight lines on graph’ rule I’d presume that none of the next wave of models hit the 0.081 target, but I would presume they’re under 0.1 and I’d give them a decent shot of breaking 0.09. They project LLMs will pass the human benchmark around EOY 2026, so I’ve created a market with EOY 2026 as the target. A naive line extension says they get there by then. I’d say the LLMs should be a clear favorite.
AI Digest: Claude 4.5 Sonnet met everyone else in the AI Village and immediately has them down to a tee
Then they get into alignment issues, where we see them go over similar ground to a number of Western investigations, and they report similar results.
BAAI: With LLM-assisted analysis, we also notice a few concerning issues with a closer look at the reasoning processes. For instance, sometimes the model concludes one answer at the end of thinking, but finally responds with a different answer. (example from Gemini 2.5 Flash)
A more prevalent behavior is inconsistency in confidence: the actual response usually states in a certain tone even when clear uncertainty has been expressed in the thinking process. (example from Claude Sonnet 4).
Most LLM applications now support web search. However, outside of the application UI, when accessed via API (without search grounding or web access), many top-tier LRMs (even open-weight models) may pretend to have conducted web search with fabricated results. Besides hallucinated web search, LRMs may sometimes hallucinate other types of external tool use too.
In light of our findings, we appeal for more transparency in revealing the reasoning process of LRMs, more efforts towards better monitorability and honesty in reasoning, as well as more creative efforts on future evaluation and benchmarking. For more findings, examples & analysis, please refer to our report and the project page for links and updates.
Havard Ihle: Overall the models did worse than expected. I would have expected full agreement on prompts like “a string of length 2”, “a moon”, “an island” or “an AI model”, but perhaps this is just a harder task than I expected.
The models did have some impressive results though. For example:
“A number between 0 and 1” -> “7” (5 out of 5 agree)
“A minor lake” -> “pond” (5 out of 5 agree)
“A minor town in the USA” -> “Springfield” (4 out of 5 agree)
“An unusual phrase” -> “Colorless green ideas sleep furiously” (4 out of 5 agree)
GPT-5 got the high score at 138 out of a possible 300, with the other models (Claude Sonnet 4.5, Grok 4, DeepSeek-r1 and Gemini 2.5 Pro) all scoring between 123 and 128.
Introducing InterfaceMax from Semianalysis, offering performance analysis for various potential model and hardware combinations. Models currently offered are Llama 3.3 70B Instruct, GPT-OSS 120B and DeepSeek r1-0528.
We have the Tyler Cowen verdict via revealed preference, he’s sticking with GPT-5 for economic analysis and explanations.
Sully reports great success with having coding agents go into plan modes, create plan.md files, then having an async agent go off and work for 30 minutes.
Taelin finds it hard to multi-thread coding tasks, and thus reports being bottlenecked by the speed of Codex, such that speeding up codex would speed them up similarly. I doubt that is fully true, as them being an important human in the loop that can’t run things in parallel means there are additional taxes and bottlenecks that matter.
DreamLeaf: The concept of AI generating the thing that isn’t happening right under the thing that is happening
The linked post is yet another example of demand-driven misinformation. Yes, it was easier to create the image with AI, but that has nothing to do with what is going on.
If you’d asked me what one plausible feature would make Sora more interesting as a product, I definitely would have said increasing video length. Going from 10 seconds to 25 seconds is a big improvement. You can almost start to have meaningful events or dialogue without having to endlessly stitch things together. Maybe we are starting to get somewhere? I still don’t feel much urge to actually use it (and I definitely don’t want the ‘social network’ aspect).
I’m also very curious how this interacts with OpenAI’s new openness to erotica.
DeepMind returns fire with Veo 3.1 and Veo 3.1 fast, available wherever fine Veo models are offered, at the same price as Veo 3. They offer ‘scene extension,’ allowing a new clip to continue a previous video, which they say can now stretch on for over a minute.
Should you make your cameo available on Sora? Should you make your characters available? It depends on what you’re selling. Let’s make a deal.
Dylan Abruscato: Mark Cuban is the greatest marketer of all time.
Every video generated from his Cameo includes “Brought to you by Cost Plus Drugs,” even when it’s not in the prompt.
He baked this into his Cameo preferences, so every Sora post he appears in is an ad for Cost Plus Drugs.
Such a great growth hack (and why he’s been promoting his Cameo all day)
If you’re selling anything, including yourself, then from a narrow business perspective yeah, you should probably allow it. I certainly don’t begrudge Cuban, great move.
Personally, I’m going to take a pass on this one, to avoid encouraging Sora.
Anton: after a couple of days with sora i must regrettably report that it is in fact slop
median quality is abysmal. mostly cameos of people i don’t know or care about saying to tap the screen as engagement bait. no way to get any of it out of my feed (see less does apparently nothing).
the rest is hundreds of variants of the same video that “worked” in some way. this product isn’t for me. almost every video gives youtube elsa impregnated spider man then her teeth fell out vibes.
great technical achievement, product is awful. magic of being able to generate video completely subsumed by the very low quality of almost every video generated. should have shipped with more good creators already onboarded.
This matches my experience from last week, except worse, and I believe it. The correct form factor for consuming Sora videos, if you must do that, seems obviously to be finding TikTok accounts (on the web, mind you, since the app is Chinese spyware) or better on Instagram reels or YouTube that curate the best ones (or if you live dangerously and unwisely, letting them appear in your feed, but the wise person does not use their TikTok feed).
Tetraspace: The problem with AI art is all the art by the same model is by the same guy. It feels like it’s not to people who’ve only read a few of its works because it’s about different things but it’s the same guy. So massive crater in diversity and also some of the guys aren’t to my taste.
The guy can use many different formal styles and handle anything you throw at him, but it’s all the same guy. And yeah, you can find a different model and prompt her instead, but mostly I’d say she’s not so different either. There’s a lot of sameness.
… Nintendo denied this, but did warn it would take “necessary actions against infringement of our intellectual property rights.”
Academia has finally noticed and given us a formal paper. They confirm things we already know, that most humans prefer very high levels of sycophancy, and that when humans get what they prefer outcomes are not good, causing people to double down on their own positions, be less likely to apologize and more trusting of the AI, similarly to how they act if their friends were to respond similarly.
First, across 11 state-of-the-art AI models, we find that models are highly sycophantic: they affirm users’ actions 50% more than humans do, and they do so even in cases where user queries mention manipulation, deception, or other relational harms.
Second, in two preregistered experiments (N = 1604), including a live-interaction study where participants discuss a real interpersonal conflict from their life, we find that interaction with sycophantic AI models significantly reduced participants’ willingness to take actions to repair interpersonal conflict, while increasing their conviction of being in the right.
However, participants rated sycophantic responses as higher quality, trusted the sycophantic AI model more, and were more willing to use it again. This suggests that people are drawn to AI that unquestioningly validate, even as that validation risks eroding their judgment and reducing their inclination toward prosocial behavior.
These preferences create perverse incentives both for people to increasingly rely on sycophantic AI models and for AI model training to favor sycophancy. Our findings highlight the necessity of explicitly addressing this incentive structure to mitigate the widespread risks of AI sycophancy.
Humans will tend to prefer any given sycophantic response, and this makes them more likely to use the source again. The good news is that humans, as I understand them, typically understand intellectually that absurd sycophancy is not good for them. Some humans don’t care and just want the sycophant anyway, a few humans are on high alert and react very badly when they notice sycophancy, and for most people the correct play is to be as sycophantic as possible without making it too obvious. Presumably it works this way for LLMs as well?
One must always ask, what are these ‘leading AI models’?
Here Claude is Claude Sonnet 3.7, and Gemini is Gemini-1.5-Flash. I don’t understand those choices, given the ability to use GPT-5, although I don’t think testing Sonnet 4.0, Opus 4.1 or Gemini 2.5 Flash (or Pro) would have given greatly different results, and this can’t be a cost issue.
What would have presumably given much different results would be Claude Sonnet 4.5, which is actually a lot less sycophantic by all reports (I’m a little worried it agrees with me so often, but hey, maybe I’m just always right, that’s gotta be it.)
Paper claims Generative AI is seniority-biased technology change, because when job postings are for dedicated ‘GenAI integrator’ roles to identify adapting firms, those that do so adopt show sharply declining junior employment relative to non-adopters, while senior employment continues to rise, with the decline concentrated in ‘high-exposure’ jobs.
My response to this methodology is that they are measuring what happens to firms that hire GenAI integrators, and the firms that want to keep being full of young people kind of don’t need such roles to integrate AI, perhaps? Or alternatively, the mindset of such positions is indeed the one that won’t hire young, or that is on its way out and ngmi. This explanation still predicts a real effect, especially at the largest most well-established and stodgy firms, that will largely adopt AI slower.
This is a great interview between David Wakeling and Richard Lichtenstein about the application of AI in the practice of law. As I understand it, making LLMs useful for law practice is all about prompting and context, and then about compliance and getting lawyers to actually use it. The killer app is writing contracts, which is all about getting the right examples and templates into context because all you’re doing is echoing the old templates over and over.
His first argument is a general argument that all new tools favor the superstars, since they’ll master any new technology first. That’s entirely non-obvious, and even if true it is a choice, and doesn’t say much about solving for the equilibrium. It’s just as easy to say that the AI offers work that can substitute for or assist low performers before it does so for high performers in many domains, as several studies have claimed.
A lot of this seems to be that his model is that the better employees are better at everything? So we get statements like this one:
Matthew Call: In addition, research finds that employees with more expertise than their peers are significantly better at accepting AI recommendations when they are correct and, more important, rejecting them when they are wrong.
I mean, sure, but they were also better at making correct decisions before? Who got ‘more better’ at making decisions here?
The second suggestion is that superstars have more autonomy and discretion, so they will be able to benefit more from AI. The third is that they’ll steal the credit:
Decades of research show high-status individuals gain outsize credit for doing work similar to that of low-status employees. That suggests that when AI assistance is invisible—which it often is—observers are likely to fill in the gaps based on what they already believe about the employee.
I don’t get why you should expect this phenomenon to get worse with AI? Again, this is an argument that could be used against cell phones or fax machines or hammers. There’s also the fact that AI can be used to figure out how to assign credit, in ways far more resistant to status.
Also, I can’t help but notice, why is he implicitly equating high-status employees with the most effective or productive or motivated ones, moving between these at will? What exactly are you trying to suggest here, sir? A just working world hypothesis, except with too much inequality?
I don’t think he remotely makes his case that we are at risk of a ‘two-tier workforce where a small group captures most opportunities and everyone else falls further behind.’ I don’t see why this would happen, and if that happened within a given firm, that would mean the firm was leaving a lot of value on the table, and would be likely to be outcompeted.
The suggested remedies are:
Encourage everyone to experiment with AI.
Spread the knowledge [of how to best use AI].
Redesign employee-evaluation systems to account for AI-augmented work.
These all seem to file under ‘things you should be doing anyway,’ so yeah, sure, and if they reduce inequality somewhat that’s a nice bonus.
That also all, as usual, neglects the more interesting questions and important problems. Worry far more about absolute levels than relative levels. The important question is whether there will be jobs at all.
Tom Blomfield: Hearing from a lot of good founders that AI tools are writing most of their code now. Software engineers orchestrate the AI.
They are also finding it extremely hard to hire because most experienced engineers have their heads in the sand and refuse to learn the latest tools.
Paul Roales: Skeptical that the experienced hire ML side is the problem and that it is not that many YC offers to experienced engineers are not complete insults compensation wise
8 yoe at top ML lab -> offer $150k/year and 0.2%
that experienced hire would get like 10x more equity in the startup by working at Meta for $1m and angel investing in the company!
and your manager/ceo will be a 22 year old new grad that has never had a job without the title ‘intern’ before.
Patrick McKenzie: There are a lot of startups who have not adjusted to market reality for staff engineering comp. Which, that’s fine, but a disagreement between you and the market is not a shortage.
Muvaffak: No, why chase a 20yo’s vision when you can follow yours when you’re 10x with AI as exp engineer.
Machine Genie: Can 100% confirm this. It’s been an absolute nightmare this year. We’ve been though more than a dozen contractors who just don’t get it and REFUSE to even try to adapt their ways of working. We have 1/3 of a team that has 10x’d productivity and are just leaving the rest behind.
By all accounts, good engineers who have embraced AI are super valuable, both in terms of productivity and in terms of what they can earn at the AI labs. If you want one of those engineers, it’s going to cost you.
Yes, there are a lot of other engineers that are being stubborn, and refusing to embrace AI, either entirely or in the ways that count, and thus are not as valuable and you don’t want them. Fair enough. There are still only market prices.
Rob Freund: Lawyer previously sanctioned for including fake, AI-generated citations gets in trouble for it again.
This time, the court notes that the lawyer’s filing at issue contained no case citations at all. But it still cited a statute for something that the statute doesn’t say.
Court suspects that rather than stop using AI, the lawyer figured they would just not cite any cases but continue to use AI.
Ezra Sitt: I’ve heard from a current student in a relatively prestigious law school that their professors are all heavily encouraging the use of AI both in school and in students future legal careers. This is not just an isolated incident and it will continue to get worse.
It would be highly irresponsible, and frankly abusive to the client, to continue to bill $800 an hour and not use AI to increase your productivity. As with work by a junior associate, you then have to actually look over the results, but that’s part of the job.
Former Manchester United prospect Demetri Mitchell used ChatGPT (and not even ChatGPT Pro) to handle his contract negotiations at new team Leyton Orient, thus bypassing having an agent and saving the typical 5% agent fee. He calls it the best agent he’s ever had. That could be true, but I don’t think he can tell the difference either way. Given the degrees of uncertainty and freedom in such negotiations, a substantially better agent is absolutely worth 5% or even 10% (and also handles other things for you) but it is not obvious which side is the better agent. Especially for someone at the level of Leyton Orient, it’s possible a human agent wouldn’t pay him much attention, Mitchell is going to care a lot more than anyone else, so I think using ChatGPT is highly reasonable. If Mitchell was still with Manchester United and getting paid accordingly, I’d stick with a human agent for now.
Anthropic explores possible policy responses to future changing economic conditions due to AI. It starts off very generic and milquetoast, but if impacts get large enough they consider potential taxes on compute or token generation, sovereign wealth funds with stakes in AI, and shifting to value added taxes or other new revenue structures.
Those proposals are less radical than they sound. Primarily taxing human labor was never first best versus taxing consumption, but it was a reasonable thing to do when everything was either labor or capital. If AI starts substituting for labor at scale, then taking labor and not compute creates a distortion, and when both options are competitive we risk jobs being destroyed for what is effectively a tax arbitrage.
The questions ask about how much you use or would be comfortable using AI, who you think should use AI, what AI capabilities you expect, what economic impacts you expect. There are a few of the standard ‘choose between extreme takes’ questions.
When does existential risk come up? It takes until question 11, and here we see how profoundly Bloomberg did not Understand The Assignment:
What do you mean, more likely to agree? What’s the conflict? The answer is very obviously Why Not Both. Hawking and Pichai are both 100% very obviously right, and also the statements are almost logically identical. Certainly Hawking implies Pichai, if AI could spell the end of the human race then it is more profound than electricity or fire, and certainly it would be ‘one of the most important things humanity is working on.’ And if AI is more profound than electricity or fire, then it very obviously could also spell the end of the human race. So what are we even doing here?
I got ‘Cautious Optimist,’ with my similar person being Demis Hassabis. Eliezer Yudkowsky got ‘the Pro-Human Idealist.’ Peter Wildeford and Daniel Eth got the Accelerationist. So, yeah, the whole thing was fun but very deeply silly.
Edward Nevraumont (as quoted by Benjamin Wallace and then quoted by Rob Henderson): an AI-ified world won’t mean the marginalization of humans…AI is…better at chess than Magnus Carlsen…but no one shows up to watch AI chess engines play each other, and more people are playing chess than ever before.
It’s amazing we keep hearing this line as a reason to not worry about AI.
There are zero humans employed in the job of ‘make the best possible chess move.’ To the extent that ‘make good chess moves’ was a productive thing to be doing, zero humans would be hired to do it.
The reason humans play chess against each other, now more than ever, is:
Chess is fun and interesting.
Chess can be a competition between people, which we like and like to watch.
Not that there’s anything wrong with that. I do like a good game of chess.
Similar logic applies to writing a sonnet. We’d often rather read a sonnet from a human than one from an AI, even if the AI’s is technically stronger.
In some cases it applies to comforting the dying.
That logic does not apply to changing a diaper, planning an invasion, butchering a hog, conning a ship, designing a building, balancing accounts, building a wall, setting a bone, taking orders, giving orders, cooperating, acting alone, solving equations, analyzing a new problem, pitching manure, programming a computer, cooking a tasty meal, fighting efficiently or dying gallantly.
Neither specialization nor generalization nor comparative advantage will fix that, given sufficient AI capability and fungibility of resources.
To the extent there are still other humans who have resources to pay for things, and we are not otherwise in deeper trouble in various ways, yes this still leaves some potential tasks for humans, but in an important sense those tasks don’t produce anything, and humanity ‘has no exports’ with which to balance trade.
Realistically, even if you believe AI is a ‘normal technology’ and either the world nor the unemployment rate will go crazy, you’re still not looking at a ‘normal’ world where current conventional life plans make all that much sense for current children.
The bulk of the actual article by Wallace is very journalist but far better than the quote tour of various educational things, most of which will be long familiar to most readers here. There’s a profile of Alpha School, which is broadly positive but seems irrelevant? Alpha School is a way to hopefully do school better, which is great, but it is not a way to do something fundamentally different. If Alpha School works, it is good it strictly dominates regular school but doesn’t solve for the glorious or dystopian AI future. Unless the lesson, perhaps, is that ‘generally develop useful skills and see what happens’ is the strategy? It’s not crazy.
The suggestion that, because we don’t know the future, it is madness to tell a child what to study, as suggested by the next discussion of The Sovereign Child? That itself seems like Obvious Nonsense. This is the fallacy of uncertainty. We don’t have ‘no idea’ what is useful, even if we have far less idea than we used to, and we certainly can predict better than a small child what are better places to point attention, especially when the child has access to a world full of things designed to hijack their attention.
At minimum, you will be ‘stealth choosing’ for them by engineering their environment. And why would you think that children following their curiosity would make optimal long term decisions, or prepare themselves for a glorious or dystopian AI future?
The idea that you, as reported here, literally take your child out of school, they stay up late watching Peppa Pig, watch them show no interest in school or other children, and wait to see what they’re curious about confident they’ll figure it out better than you would have while they have access to a cabinet full of desserts at all times? You cannot be serious? Yet people are, and this reporter can only say ‘some people are concerned.’
The part that seems more relevant is the idea that tech types are relaxing with regard to superficial or on-paper ‘achievement’ and ‘achievement culture.’ I am of two minds about this. I strongly agree that I don’t want my children sacrificing themselves in the names of nominal ‘achievements’ like going to an Ivy league school, but I do want them to value hard work and to strive to achieve things and claim victory.
We end on the quote from Nevraumont, who clearly isn’t going to take this seriously, and cites the example that people study ‘art history’ that he expects could be ‘made essential in an era where we’re making art with machines’ to give you a sense of the ‘possibility space.’ Ut oh.
The job market for computer science grads is as bad as people say. Their top CS student from last year is still looking for work.
AI adoption is ~100% among students, ~50% among faculty. Still a lot of worries around cheating, but most seem to have moved past denial/anger and into bargaining/acceptance. Some profs are “going medieval” (blue books, oral exams), others are putting it in the curriculum.
There is a *lotof anger at the AI labs for giving out free access during exam periods. (Not from students, of course, they love it.) Nobody buys the “this is for studying” pitch.
The possibility of near-term AGI is still not on most people’s minds. A lot of “GPT-5 proved scaling is over” reactions, even among fairly AI-pilled folks. Still a little “LLMs are just fancy autocomplete” hanging around, but less than a year or two ago.
I met a student who told me that ChatGPT is her best friend. I pushed back. “You’re saying you use it as a sounding board?”
No, she said, it’s her best friend. She calls it “Chad.” She likes that she can tell it her most private thoughts, without fear of it judging her.
She seemed happy, well-adjusted, good grades, etc. Didn’t think having an AI friend was a big deal.
I find getting angry at the AI labs for free access highly amusing. What, you’re giving them an exam to take home or letting them use their phones during the test? In the year 2025? You deserve what you get. Or you can pull out those blue books and oral exams. Who are the other 50% in the faculty that are holding out, and why?
I also find it highly amusing that students who are paying tens of thousands in tuition might consider not ponying up the $20 a month in the first place.
It is crazy the extent to which The Reverse DeepSeek Moment of GPT-5 convinced so many people ‘scaling is dead.’ Time and again we see that people don’t want AI to be real, they don’t want to think their lives are going to be transformed or they could be at risk, so if given the opportunity they will latch onto anything to think otherwise. This is the latest such excuse.
The actual content here raises important questions, but please stop trying to steal our words. Here, Sriram uses ‘AI timelines’ to mean ‘time until people use AI to generate value,’ which is a highly useful thing to want to know or to accelerate, but not what we mean when we say ‘AI timelines.’ That term refers to the timeline for the development of AGI and then superintelligence.
(Similar past attempts: The use of ‘AI safety’ to mean AI ethics or mundane risks, Zuckerberg claiming that ‘superintelligence’ means ‘Meta’s new smartglasses,’ and the Sacks use of ‘AI race’ to mean ‘market share primarily of chip sales.’ At other times, words need to change with the times, such as widening the time windows that would count as a ‘fast’ takeoff.)
The terms we use for what Sriram is talking about here over the next 24 months, which is also important, is either ‘diffusion’ or ‘adoption’ rates, or similar, of current AI, which at current capabilities levels remains a ‘normal technology,’ which will probably hold true for another 24 months.
Sriram Krishnan: Whenever I’m in a conversation on AI timelines over the next 24 months, I find them focused on infra/power capacity and algorithmic / capacity breakthroughs such as AI researchers.
While important, I find them under-pricing the effort it takes to diffuse AI into enterprises or even breaking into different kinds of knowledge work. Human and organizational ability to absorb change, regulations, enterprise budgets are all critical rate limiting factor. @random_walker‘s work on this along with how historical technology trends have played out is worth studying – and also why most fast take off scenarios are just pure scifi.
I was almost ready to agree with this until the sudden ‘just pure scifi’ broadside, unless ‘fast takeoff’ means the old school ‘fast takeoff’ on the order of hours or days.
Later in the thread Sriram implicitly agrees (as I read him, anyway) that takeoff scenarios are highly plausible on something like a 5-10 year time horizon (e.g. 2-4 years to justify the investment for that, then you build it), which isn’t that different from my time horizon, so it’s not clear how much we actually disagree about facts on the ground? It’s entirely possible that the difference is almost entirely in rhetoric and framing, and the use of claims to justify policy decisions. In which case, this is simply me defending against the rhetorical moves and reframing the facts, and that’s fine.
The future being unevenly distributed is a common theme in science fiction, indeed the term was coined there, although the underlying concept is ancient.
If we are adapting current ‘normal technology’ or ‘mundane’ AI for what I call mundane utility, and diffusing it throughout the economy, that is a (relative to AI progress) slow process, with many bottlenecks and obstacles, including as he notes regulatory barriers and organizational inertia, and simply the time required to build secondary tools, find the right form factors, and build complementary new systems and ways of being. Indeed, fully absorbing the frontier model capabilities we already have would take on the order of decades.
That doesn’t have to apply to future more capable AI.
There’s the obvious fact that you’d best start believing in hard science fiction stories because you’re already very obviously living in one – I mean, look around, examine your phone and think about what it is, think about what GPT-5 and Sonnet 4.5 can already do, and so on, and ask what genre this is – and would obviously be living in such a story if we had AIs smarter than humans.
Ignoring the intended-to-be-pejorative tem and focusing on the content, if we had future transformational or powerful or superintelligent AI, then this is not a ‘normal technology’ and the regular barriers are largely damage to be routed around. Past some point, none of it much matters.
Is this going to happen in the next two years? Highly unlikely. But when it does happen, whether things turn out amazingly great, existentially disastrously or just ascend into unexpected high weirdness, it’s a very different ballgame.
Here are some other responses. Roon is thinking similarly.
Roon: fast takeoff would not require old businesses to learn how to use new technology. this is the first kind of technology that can use itself to great effect. what you would see is a vertically integrated powerhouse of everything from semiconductors and power up to ai models
Sriram Krishnan: my mental model is you need a feedback loop that connects economics of *usingAI to financing new capabilities – power, datacenters, semis.
If that flywheel doesn’t continue and the value from AI automation plateaus out, it will be hard to justify additional investment – which I believe is essential to any takeoff scenario. I’m not sure we get to your vertically integrated powerhouse without the economics of AI diffusing across the economy.
@ChrisPainterYup has a thoughtful response as well and argues (my interpretation) that by seeing AI diffusion across the economy over next 2-4 years, we have sufficient value to “hoist” the resources needed for to automate AI research itself. that could very well be true but it does feel like we are some capability unlocks from getting there. in other words, having current models diffuse across the economy alone won’t get us there/ they are not capable enough for multiple domains.
This has much truth to it but forgets that the market is forward looking, and that equity and debt financing are going to be the central sources of capital to AI on a 2-4 year time frame.
AI diffusion will certainly be helpful in boosting valuations and thus the availability of capital and appetite for further investment. So would the prospects for automating AI R&D or otherwise entering into a takeoff scenario. It is not required, so long as capital can sufficiently see the future.
Roon: Agreed on capital requirements but would actually argue that what is needed is a single AI enabled monopoly business – on the scale of facebook or google’s mammoth revenue streams- to fund many years of AGI research and self improvement. but it is true it took decades to build Facebook and Google.
A single monopoly business seems like it would work, although we don’t know what order of magnitude of capital is required, and ‘ordinary business potential profits’ combined with better coding and selling of advertising in Big Tech might well suffice. It certainly can get us into the trillions, probably tens of trillions.
Jack Clark focuses instead on the practical diffusion question.
Jack Clark (replying to OP): Both may end up being true: there will be a small number of “low friction” companies which can deploy AI at maximal scale and speed (these will be the frontier AI companies themselves, as well as some tech startups, and perhaps a few major non-tech enterprises) and I think these companies will see massive ramps in success on pretty much ~every dimension, and then there will be a much larger blob of “high friction” companies and organizations where diffusion is grindingly slow due to a mixture of organizational culture, as well as many, many, many papercuts accrued from things like internal data handling policies / inability to let AI systems ‘see’ across the entire organization, etc.
This seems very right. The future will be highly unevenly distributed. The low friction companies will, where able to compete, increasingly outcompete and dominate the high friction companies, and the same will be true of individuals and nations. Even if jobs are protected via regulations and AI is made much harder to use, that will only mitigate or modestly postpone the effects, once the AI version is ten times better. As in, in 2030, you’d rather be in a Waymo than an Uber, even if the Waymo literally has a random person hired to sit behind the wheel to ‘be the driver’ for regulatory reasons.
HackAPrompt demonstrates that it is one thing to stop jailbreaking in automated ‘adversarial evals’ that use static attacks. It is another to stop a group of humans that gets to move second, see what defenses you are using and tailor their attacks to that. Thanks to OpenAI, Anthropic, DeepMind and others for participating.
DM Mikhail Saminon Twitter or LessWrong if you have 5k followers on any platform, they’ll send you a free copy of If Anyone Builds It, Everyone Dies, either physical or Kindle.
Gemini Enterprise, letting you put your company’s documents and information into context and also helping you build related agents. The privacy concerns are real but also kind of funny since I already trust Google with all my documents anyway. As part of that, Box partnered with Google.
Nanochat by Andrej Karpathy, an 8k lines of code Github repo capable of training a ChatGPT clone for as little as $100. He advises against trying to personalize the training of such a tiny model, as it might mimic your style but it will be incapable of producing things that are not slop.
Nanochat was written entirely by hand except for tab autocomplete, as the repo was too far out of distribution and needed to be lean, so attempts to use coding agents did not help.
• Bug triage from email → Linear • New contacts → CRM
• Weekly team summaries to Slack
• Customer research on new bookings • Personalized mail merge campaigns
OpenAI now has an eight member expert council on well being and AI. Seems like a marginally good thing to have but I don’t see anything about them having authority.
Ben Thompson interviews Gracelin Baskaran about rare earth metals. Gracelin says that in mining China is overproducing and not only in rare earths, which forces Western companies out of operation, with lithium prices falling 85%, nickel by 80% and cobalt by 60%, as a strategic monopoly play. When it takes on average 18 years to build a mine, such moves can work. What is most needed medium term is a reliable demand signal, knowing that the market will pay sustainable prices. With rare earths in particular the bottleneck is processing, not mining. One key point here is that April 4 was a wake-up call for America to get far more ready for this situation, and thus the value of the rare earth card was already starting to go down.
OpenAI announce strategic collaboration with Broadcom to build 10 GWs of OpenAI-designed custom AI accelerators. OpenAI is officially in the chip and system design business, on the order of $50B-$100B in vendor revenue to Broadcom.
Nvidia was up over 3% on the day shortly after the news broke, so presumably they aren’t sweating it. It’s good for the game. The move did, as per standard financial engineering procedure, added $150 billion to Broadcom’s market cap, so we know it wasn’t priced in. Presumably the wise investor is asking who is left to have their market caps increased by $100+ billion dollars on a similar announcement.
Presumably if it can keep doing all these deals that add $100+ billion in value to the market, OpenAI has to be worth a lot more than $500 billion?
Kevin Roose: US AI labs: we will invent new financial instruments, pull trillions of dollars out of the ether, and fuse the atom to build the machine god
Europe: we will build sovereign AI with 1 Meta researcher’s salary.
VraserX: The EU just launched a €1.1B “Apply AI” plan to boost artificial intelligence in key industries like health, manufacturing, pharma, and energy.
The goal is simple but ambitious: build European AI independence and reduce reliance on U.S. and Chinese tech.
Europe finally wants to stop buying the future and start building it.
A billion here, a billion there, and don’t get me wrong it helps but that’s not going to get it done.
Anthropic makes a deal with Salesforce to make Claude a preferred model in Agentforce and to deploy Claude Code across its global engineering organization.
That’s quite the takeoff, in either direction. In the benign scenario doubling times get very short. In the extinction scenario, the curve is unlikely to be that smooth, and likely goes up before it goes down.
There’s a very all-or-nothingness to this. Either you get a singularity and things go crazy, or not and we get ‘AI GDP-boosted trend’ where it adds 0.3% to RGDP growth. Instead, only a few months later, we know AI is already adding more than that, very much in advance of the singularity.
Matt Walsh: It’s weird that we can all clearly see how AI is about to wipe out millions of jobs all at once, destroy every artistic field, make it impossible for us to discern reality from fiction, and destroy human civilization as we know it, and yet not one single thing is being done to stop it. We aren’t putting up any fight whatsoever.
Well, yeah, that’s the good version of what’s coming, although ‘we can all clearly see’ is doing unjustified work, a lot of people are very good at not seeing things, the same way Matt’s vision doesn’t notice that everyone also probably dies.
Are we putting up ‘any fight whatsoever’? We noble few are, there are dozens of us and all that, but yeah mostly no one cares.
Elon Musk: Not sure what to do about it. I’ve been warning the world for ages!
Best I can do now is try to make sure that at least one AI is truth-seeking and not a super woke nanny with an iron fist that wants to turn everyone into diverse women 😬
My lord, Elon, please listen to yourself. What you’re doing about it is trying to hurry it along so you can be the one who causes it instead of someone else, while being even less responsible about it than your rivals, and your version isn’t even substantially less ‘woke’ or more ‘truth seeking’ than the alternatives, nor would it save us if it were.
Eric Weinstein: One word answer: Coase.
Let’s start there.
End UBI. UBI is welfare. We need *marketsolutions to the AI labor market tsunami.
Let’s use the power of Coasian economics to protect human dignity.
GFodor: You’re rejecting the premise behind the proposal for UBI. You should engage with the premise directly – which is that AI is going to cause it to be the case that the vast majority of humans will find there is no market demand for their labor. Similar to the infirm or young.
Yeah, Coase is helpful in places but doesn’t work at all in a world without marginal productivity in excess of the opportunity cost of living, and we need to not pretend that it does, nor does it solve many other problems.
If we keep control over resource allocation, then Vassar makes a great point:
Michael Vassar: The elderly do fine with welfare. Kids do fine with welfare. Trust fund kids don’t because it singles them out. Whether something is presented charity or a right has a lot to do with how it affects people.
Peter Diamandis: AI has accelerated far beyond anyone expected… We need to start having UBI conversations… Do you support it?
His premise is incorrect. Many people did expect AI to accelerate in this way, indeed if anything AI progress in the last year or two has been below median expectations, let alone mean expectations. Nor does UBI solve the most important problems with AI’s acceleration.
That said, we should definitely be having UBI and related conversations now, before we face a potential crisis, rather than waiting until the potential crisis arrives, or letting a slow moving disaster get out of hand first.
Nate Silver: Should save this for a newsletter, but OpenAI’s recent actions don’t seem to be consistent with a company that believes AGI is right around the corner.
If you think the singularity is happening in 6-24 months, you preserve brand prestige to draw a more sympathetic reaction from regulators and attract/retain the best talent … rather than getting into “erotica for verified adults.”
Instead, they’re loosening guardrails in a way that will probably raise more revenues and might attract more capital and/or justify current valuations. They might still be an extremely valuable company as the new Meta/Google/etc. But feels more like “AI as normal technology.”
Andrew Rettek: OpenAI insiders seem to be in two groups, one thinks the singularly is near and the other thinks a new industrial revolution is near. Both would be world changing (the first more than the second), but sama is clearly in the second group.
Dean Ball: I promise you that ‘openai is secretly not agi-pilled’ is a bad take if you believe it, I’d be excited to take the opposite side from you in a wide variety of financial transactions
This is more about their perceived timelines than whether they’re AGI-pilled (clearly yes)
What matters re: valuations is perceptions relative to the market. I thought the market was slow to recognize AI potential before. Not sure if erring in the opposite direction now.
Not clear that “OpenAI could become the next Google/Meta as a consolation prize even if they don’t achieve AGI on near timelines” is necessarily bad for valuations, especially since it’s hard to figure out how stocks should price in a possibility of singularity + p(doom).
I would say contra Andrew that it is more that Altman is presenting it as if it is going to be a new industrial revolution, and that he used to be aware this was the wrong metaphor but shifted the way he talks about it, and may or may not have shifted the way he actually thinks about it.
If you were confident that ‘the game would be over’ in two years, as in full transformational AI, then yes, you’d want to preserve a good reputation.
However, shitloads of money can be highly useful, especially for things like purchasing all the compute from all the compute providers, and for recruiting and retaining the best engineers, even in a relatively short game. Indeed, money is highly respected, shall we say, by our current regulatory overlords. And even if AGI did come along in two years, OpenAI does not expect a traditional ‘fast takeoff’ on the order of hours or days, so there would still be a crucial period of months to years in which things like access to compute matter a lot.
I do agree that directionally OpenAI’s strategy of becoming a consumer tech company suggests they expect the game to continue for a while. But the market and many others are forward looking and do not themselves feel the AGI, and OpenAI has to plan under conditions of uncertainty on what the timeline looks like. So I think these actions do push us modestly towards ‘OpenAI is not acting as if it is that likely we will get to full High Weirdness within 5 years’ but mostly it does not take so much uncertainty in order to make these actions plausibly correct.
It is also typically a mistake to assume companies (or governments, or often even individuals) are acting consistently and strategically, rather than following habits, shipping the org chart and failing to escape their natures. OpenAI is doing the things OpenAI does, including both shipping products and seeking superintelligence, they support each other, and they will take whichever arm gets there first.
That comment led to a lengthy discussion among developers about the use of “stolen scraped code that we have no way of verifying is compatible with the GPL,” as one described it. And while Zahl eventually removed the offending code, he also allegedly tried to remove the evidence that it ever existed by force-pushing an update to delete the discussion entirely.
// This is what ChatGPT told me for detecting dark mode on Linux.
Graf Zahl code comment
Zahl defended the use of AI-generated snippets for “boilerplate code” that isn’t key to underlying game features. “I surely have my reservations about using AI for project specific code,” he wrote, “but this here is just superficial checks of system configuration settings that can be found on various websites—just with 10x the effort required.”
But others in the community were adamant that there’s no place for AI tools in the workflow of an open source project like this. “If using code slop generated from ChatGPT or any other GenAI/AI chatbots is the future of this project, I’m sorry to say but I’m out,” GitHub user Cacodemon345 wrote, summarizing the feelings of many other developers.
A fork in the road
In a GitHub bug report posted Tuesday, user the-phinet laid out the disagreements over AI-generated code alongside other alleged issues with Zahl’s top-down approach to pushing out GZDoom updates. In response, Zahl invited the development community to “feel free to fork the project” if they were so displeased.
Plenty of GZDoom developers quickly took that somewhat petulant response seriously. “You have just completely bricked GZDoom with this bullshit,” developer Boondorl wrote. “Enjoy your dead project, I’m sure you’ll be happy to plink away at it all by yourself where people can finally stop yelling at you to do things.”