Some amazing things are going on, not all of which involve mRNA, although please please those of you with the ability to do so, do your part to ensure that stays funded, either via investment or grants.
As for mRNA, please do what you can to help save it, so we can keep getting more headlines like ‘a new cancer vaccine just wiped out tumors’ even if it is sufficiently early that the sentence this time inevitably concludes ‘IN MICE.’
Wait, what, you’re saying we might soon ‘mostly defeat’ heart disease?
Cremieux: It’s hard to oversell how big a discovery this is.
Heart disease is America’s #1 cause of death. With a combination of two drugs administered once every six months, it might be mostly defeated.
Just think about that how big this is! You will know your great-grandkids!
It is insanely optimistic that we have drugs that can reduce Lp(a) levels by [65%-]98% in trials right now.
If they succeed, they could help to crush heart disease and stroke.
Unlike LDL in general, Lp(a) levels are basically entirely genetic in origin and not open to lifestyle intervention. It is also widely accepted that the race differences are down to genes.
These drugs are examples of genetic discovery leading to a group difference fix via tech.
The future of medicine is still very bright.
I wouldn’t go that far. Even if these trials are successful, it seems unlikely we’re talking about ‘mostly defeat,’ although we could plausibly be at ‘greatly reduce.’ Which could still be worth several years of life expectancy across the board. If we could also similarly help with other major causes of death and aging, you’d see compounding gains, but without that aging still catches up with everyone.
Unfortunately, America under the current administration is making deep cuts in basic research funding that leads to advances like this. Hopefully AI can make up for that.
A new major study finds that alcohol causes cancer, so government worked to bury the study. Time and time again we get presented with the fact that small amounts of drinking correlate with improved health in various ways, fooling many into thinking a little alcohol is healthy.
As opposed to the reality, which is that alcohol is bad for you no matter what, but that inability to drink is highly correlated with alcoholism and other traits that go along with poor health, whereas ability to drink only in moderation is a good sign.
So drinking in moderation, which is only a small amount bad for your health, is still a good sign for your health if you are drinking in moderation. Whereas heavier drinking consistently looks bad, perhaps even worse than it is.
Trump himself is not fooled, and does not drink at all, as he has seen the dangers of alcoholism in his own family. A wise choice.
Dylan Scott: They broke out their findings by different drinking levels — from one drink per day to three — and focused on health outcomes that have been proven to be associated with alcohol use. Their big-picture conclusion:
Among the US population, the negative health effects of drinking alcohol start at low levels of consumption and begin to increase sharply the more a person drinks. A man drinking one drink per day has roughly a one in 1,000 chance of dying from any alcohol-related cause, whether an alcohol-associated cancer or liver disease or a drunk driving accident. Increase that to two drinks per day, and the odds increase to one in 25.
…
In that context, the report is a harrowing read: Alcohol use is associated with increased mortality for seven types of cancer — colorectal, breast cancer in women, liver, oral, pharynx, larynx, and esophagus. Risk for these cancers increases with any alcohol use and continues to grow with higher levels of use, the study’s authors concluded.
Women experience a higher risk of an alcohol-attributable cancer per drink consumed than men. Men and women who die from an alcohol-attributable cause die 15 years earlier on average.
A 4% chance of dying on average 15 years earlier is a big deal.
This is not the first time a Trump administration defied the data on this.
US officials always solicit expert opinion as they prepare a fresh set of dietary guidelines. The input is usually compiled into one massive report from a group of experts called the US Dietary Guidelines Advisory Committee and then submitted to the Department of Health and Human Services and the Department of Agriculture, the two agencies that produce the guidelines.
That was how the process went in 2020, and at that time, the subcommittee of researchers dedicated to alcohol (including Naimi) advised the government to reduce the recommended limit down to one drink per day for men, from two. The Trump administration ultimately decided not to follow the recommendation.
Montana passes SB 535 with broad bipartisan backing, further expands its ‘right to try’ rules, with a license path for experimental treatment centers to administer any drug that got through Phase I trials, to anyone who wants it. This is The Way.
Alex Tabarrok is correct that we could greatly improve healthcare if we allowed telemedicine across state lines. As long as a doctor is licensed where the doctor is physically located, it shouldn’t matter where the patient is located. The best part is that this could be done with an admin rules change of two words.
A call to make statins be sold over the counter (OTC). This seems obviously correct, even if you are highly skeptical that the correlations cited here imply causation, or that they imply that intervening via statin cause this causation without important side effects. That’s a decision people can make for themselves at this point. But then a whole host of things should be OTC at this point that aren’t.
A new embryo selection company, Herasight has launched that is allowing users to select for IQ. They claim that with as few as 10 embryos you can already go from an expected IQ of 100 to a new average of 107. Or you can do things like go from 45% chance of Type 2 Diabetes to 25%.
Alex Young: I’ve been working with an IVF startup, @herasight, that has already screened hundreds of embryos. Today we come out of stealth with a paper showing that our predictors for 17 diseases — validated within-family — beat the competition, with improved performance in non-Europeans.
In our paper, we detail our polygenic scores (PGS) for 17 diseases using a custom meta-analysis. We used state-of-the-art methods to create PGSs based on 7.3M SNPs. Our most predictive PGSs explained ~20% of the variance in liability for prostate cancer and type-II diabetes.
In practice what happens is you get your 5, 10 or 20 embryos, they profile each one, and you are choosing based on a variety of traits. What do you actually care about most? You are about to find out.
Kitten: Within a few years they’re going to be able to show you a very accurate picture of what each baby will look like as an adult.
That will trump every other consideration by a large margin.
I agree that this technology is coming. I agree it will matter to people. And why shouldn’t it matter, at least from a selfish point of view? It also might be a better way to select for other good things than you might think, as in general health and other positive traits are correlated with beauty. I do not think it will be anything like ‘this overrides everything else.’
Even the graceful failure mode for things like this is a really big deal.
Mason: I think this just ignores the realities of IVF tbh
20 healthy embryos is, for most people, 3-5 IVF cycles
Success for a single embryo transfer is 40-60%.
“Well, your dad and I wanted a boy and you were the second highest IQ male after Embryo 6 failed to implant.”
Yeah, these numbers are for mothers <35. It's crazy how many people think IVF is a safety net for aging out of your fertility window when you actually need to start the process quite young in order for it to be likely to work.
I mean that sounds pretty great? You got your choice of gender and a couple of IQ points, while presumably also dodging a variety of potential genetic disorders. That’s a pretty good haul.
What you actually get is not maximizing on one to two traits, although you do have that option. What you get is to do a general maximization over many traits. That is a lot more valuable if you are making reasonable decisions.
Mason is however making the very important point that if you want to use IVF and have confidence it will work at all, let alone confidence it will give you selection, you need to do it early. The younger you are, the better all of this will on average go, until such time as we figure out how to generate new eggs (which is plausibly only a few years away).
As Gene Smith points out in this thread, academics are super against all of this.
Gene Smith: We’re in this insane world right now where rich parents are going through IVF just to do embryo selection, and middle class parents who are ALREADY doing IVF are being told by doctors that embryo selection doesn’t work or is unethical.
If you’ve been to conferences on embryo selection or ones where the topic is discussed, you will realize the truth is basically the opposite. Most academic discussion of this is dominated by ethicists talking about how problematic it is or academics talking about its limitations.
And make no mistake, these discussions matter. They’re the main reason why even doctors who understand embryo selection rarely recommend it to their patients, even when it could significantly reduce the odds of a patient passing along a disease to their child.
Among the academics that care about this, a large majority are opposed to embryo selection for ideological reasons. There hasn’t been all that much quantitative analysis done on it. And what has been done often fails to capture how embryo selection is actually done in industry.
A lot of work has focused on selection on a single trait, which is easier to model, but not how selection actually works in practice. And many of the conclusions about its efficacy rely on outdated predictors which have improved substantially since publication.
The effect size of embryo selection for IQ has nearly tripled since the publication of this paper, which was still being cited relatively recently.
He also reminds us that we are spending all our gene editing resources on rare diseases where we can stick the government gigantic bills and the ‘ethicists’ stop trying to ban you from helping, whereas the places where most of the value lies are complete ignored, even by people who would directly benefit.
Gene Smith: The situation in the gene editing field right now is kind of unbelievable. We’ve spent over a decade throwing billions of dollars at the gene editing for rare diseases and we still can’t get the editors inside most of the cell types we need to modify.
Everything is either for the liver or the eye or the bone marrow. We can’t get to the brain. We can’t get to the lungs. We can’t get to the heart. And we can barely fit a single editor into the best delivery vector so no one is even thinking about polygenic disease.
There is an extremely simple way to fix this: edit in embryos. All the stuff we can’t target right now because of delivery issues becomes almost trivial in embryos. You can literally stick a needle into the egg and squirt the editors in.
Alzheimer’s? Tractable. Diabetes? You can pretty much get rid of it. Heart disease? You can mostly make it a thing of the past. Breast cancer? Same deal.
…
The blame for this delay lies at the feet of academics. There are literally professors who go to conferences on gene editing and brag about how they’ve gotten governments to ban embryo gene editing.
[thread continues]
Bex: surely this is being done black budget and for the uber wealthy already. but I guess all that learning is hidden:(
Gene Smith: As someone working on the cutting edge of this field, I can tell you it’s definitely NOT. You underestimate how maddeningly myopic wealthy people can be about new tech. Fred Koch literally didn’t ask the cancer research center he funded to look into ways to treat his cancer.
The most cutting edge thing wealthy people are actually doing right now is embryo selection a la Herasight and Orchid.
I mean, it’s not that simple, of course it is not that simple, but it is a little bit that simple?
If you have the option to use the technology we do have, it seems crazy not to use it. Noor Siddiqui is being too righteous and superior about it even for me here, but if it really does cost as little as $2,500 to get selection over potential embryos, that is a better deal than essentially any remotely optional interventions you have access to after birth. The replies to such proposals are full of people saying how horrible all this is and having instinctual disgust and purity reactions, and calling everyone involved and the proposal itself various names, all of it patently absurd without any actual justifications.
I do strongly agree with Vitalik Buterin that while we should be very much in favor of embryo selection and most of the attacks on it are deranged, it is counterproductive and wrong to strike back by saying that since it condemns your children to be worse off that not using selection is unethical.
Vitalik Buterin: If you publicly telegraph that if you win your fight for acceptance you will immediately follow it up with a fight for imposition, do not be surprised if people decide to oppose your fight for acceptance from day one with a vigor only reserved for resisting imposition.
We’ve been over this one many times. If that which is not forbidden is compulsory, then that which I do not want to be compulsory must be forbidden.
Oh no, all these GLP-1 drugs are going to prevent people from dying, and that could have a negative impact on pensions?
Eliezer does a survey, finds ~80% of those who tried GLP-1 drugs report it helped lots versus those that didn’t, roughly confirming industry claims. That’s a fantastic success rate.
Now we are potentially seeing Eli Lily have a pill that’s ~55% as effective as Ozempic in phase-3 trials, their stock was up 14% on the news. They also have Retatrutide coming in a year or two, which is claimed to be a more effective GLP-1 drug that also causes less muscle loss.
These marginal improvements make a huge practical difference. GLP-1s are now a lot like AI, in that we keep getting better versions and people’s impressions don’t update.
Unfortunately, it’s not always easy to get a line on the necessary supply.
Scott Alexander: Update on Ozempocalypse: some pharmacies have stopped selling compounded GLP-1 drugs, others continue, with various flimsy legal excuses. Cremieux has a guide (partly subscriber-only) on how to order and use cheap “research chemical” GLP-1 from from peptide companies. And the Trump administration cancelled a Biden initiative to make GLP-1 drugs available via insurance.
There were official shortages of GLP-1 drugs, which allowed compounders to make and sell those drugs cheaply, on the order of $300/month, in essentially unlimited quantities. Alas, there is now no longer an official shortage, so the price is shooting back up again (~$1k/month) and supply is harder to find. We really should find a way to buy out those patents and make these drugs available for low prices (ideally for free, with at most a minimal consultation) for whoever wants them.
Is it possible that if you combine a GLP-1 with anabolic agent Bimagrumab, you can lose fat without losing muscle? Eli Lily is in phase 2b of trying to find out.
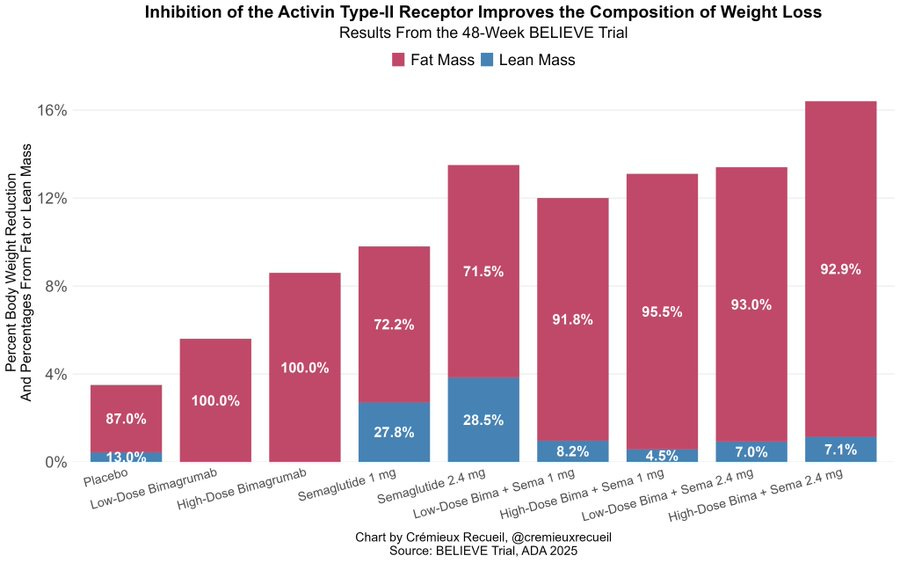
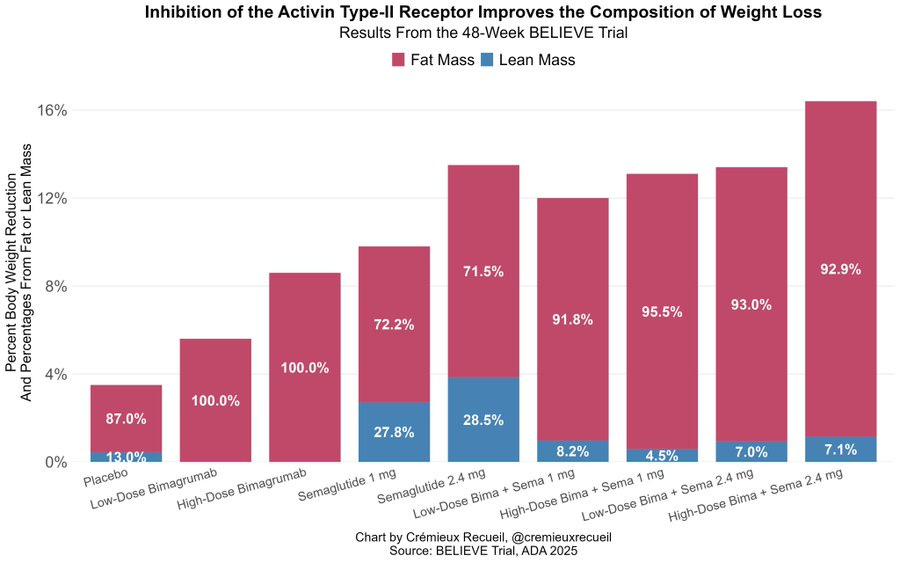
Egan Peltan: Today, Lilly revealed the weight loss & composition at 48 weeks
Sema: -13.5% (72% Fat)
Bima: -8.6% (100% Fat)
Bima + Sema: -16.4% (>90% Fat)
Patients on bima+sema saw >40% decrease in body fat with no changein lean mass at 24W. Overall, bima and bima+sema were well tolerated No striking SAE imbalances.
What we don’t know works with GLP-1s is microdosing.
Eric Topol: The GLP-1 microdosing wellness and longevity craze without any data for dose or evidence of effect.
As usual this as worded confuses lack of formalized data and evidence for a lack of data and evidence. These are not the same thing. It is an entirely sensible strategy to experiment with different doses and to choose, with a drug that has big benefits, but also downsides, and is clearly safe. Self-experimentation can provide highly useful data and evidence, and clearly different people respond differently in terms of benefits and side effects at different doses.
Babb (from the WSJ article): What feels healthiest is taking the lowest amount that’s providing what I’m perceiving to be these health benefits.
The marketing involving microdosing does sound not great, especially its claims of other vague and hard to measure benefits.
There are still some potential safety issues where it would be good to have more confidence, I agree that we are not treating checking for such possibilities as seriously as we should given how many people are on these drugs. But also given how many people are on these drugs (about 6% of Americans right now), and how much many people are inherently suspicious that there is a catch, and how long people have been taking them for (including previously for diabetes) I am confident that if there was a showstopper problem it would have been found by now.
Andrew Rettek: Ozempic type drugs have been on the market for over seven years. It’s been about five years since 1 million Americans have been taking them. We have a pretty good idea of their side effects at this point. It’s longer than you thought, because people have been taking them for diabetes for years before they became popular for weight loss.
People instinctively think there must be a catch to GLP-1s. But for people in most circumstances there mostly isn’t one, at least not one of magnitude similar to the benefits, other than that for some people it doesn’t work?
GSV Bemusement Park: Look if you are trying to lose weight there is no reason to not be padding your efforts with a GLP-1 drug unless everyone in your family gets thyroid cancer.
If you buy smartly the cost is literally negative after accounting for the food you don’t eat, and you can always go back on if you regain weight.
If you follow me then your mutuals almost certainly include several helpful, literate people who will be thrilled to advise you.
You have nothing to lose but waistline.
Peter Hague: Ozempic skepticism seems entirely based on the animist-like idea that there is a conservation law for good fortune – all good things must have some equal cost imposed elsewhere. It’s not scientific skepticism, it’s superstition.
I’m really concerned too how “big pharma is trying to kill you/sterilise you with fake medicine” has gone from the fringes of Facebook mummy groups to the mainstream. It used to be the main complaint was they were greedy and withholding good medicine from sick people.
Dystopina GF: Anti-Ozempic people don’t understand that the average person isn’t supposed to be an iron-willed Übermensch. Average people simply reflect the quality of their society; they’re obese bc modernity is sick, not bc of some moral failing. Being thin should be effortless, the default!
A well-designed society is a system that makes good things as frictionless as possible. A poorly-designed society is one where it takes a Herculean effort to achieve the most basic elements of human health and fulfillment
John Pressman: The replies on this inspire serious misanthropy. The QT is straightforwardly correct and the replies make it obvious that all good things come from brutally, ruthlessly destroying the perverse costly signaling equilibria people naturally cover up utility with.
Of course, here I am saying that and then not taking them, but I am a bizarro case where I was able to get to my target through sheer willpower, and I have decades of experience dealing with essentially permanent hunger. That almost never works.
Andrew Rettek reports from a week discussing diet, exercise and GLP-1s at LessOnline and Manifest. Lots of people wanted to exercise, but felt they needed ‘demystifying’ of the gym and the general procedures involved. I very much feel this. Our on ramps suck, and mostly amount to ‘find a source and trust it.’ Which is way better than not exercising but doesn’t fill one with confidence or motivation – I’m spending a substantial portion of my time and willpower and energy on this, and different implementations differ a lot. Whereas for diet, Andrew observed people mostly weren’t interested, my guess is because they’ve already heard so many contradictory things.
GLP-1s served as a large scale experiment in drug compounding, and in sidestepping the FDA’s various usual regulatory requirements. The results were amazingly great, everything went smoothly. This is even more evidence for FDA Delenda Est, while noting that ‘fire a bunch of people at the FDA’ makes things worse rather than better. Removing requirements is good, but if there are going to be requirements it is necessary to be able to handle the paperwork and meetings promptly.
Going forward, the bigger question is: What happens if this actually works?
Cremieux: Eli Lilly just showed that you can lose tons of fat while barely losing any muscle using their activin type-II receptor inhibitor, bimagrumab.
We are approaching a golden era of weight loss, where everyone can easily be muscular and skinny.
Prepare for hordes of hot Americans.
Devon Eriksen: And I am predicting, here and now, that there will be a massive social pushback from people who would rather see their fellow Americans live out their lives sick, fat, and miserable than give up their just-universe fallacy.
At what point do we start to think of weight loss as fully treatable?
Shako: Increasingly in public I see obese people as glp1 deficient. I mean this seriously. There is a 200 pound 15 year old girl at this playground. It’s heartbreaking and we can treat it now.
Lots of people commenting diet and exercise work better. And yet vast amounts of Americans, often stupid and poor, die every year from preventable metabolic diseases. Do you think they just don’t know about diets?
Eliezer Yudkowsky: Tirzepatide doesn’t work on 20% of people, including me.
Shako: 🙏🏻 hope something does soon.
Not every case can be treated, since we have a non-response problem, and some people will run into side effects or risk factors. But a large majority of people with a problem still haven’t attempted treatment. Most of them should try. If you were already going to lose the weight on your own, you could do it easier with help?
What about the equilibrium, signaling and status arguments? That if we allow people to lose weight without willpower or personal virtue then that will make the signals harder to read and be Just Awful? Yeah, I don’t care.
Cremieux claims that it is a myth that yo-yo weight loss reduces muscle mass and makes you fatter. Andrew Rettek responds that the studies claiming to bust this were on wrestlers, which doesn’t apply to normal people, and I buy his explanation of the mechanism here, which is:
-
If you lose weight without resistance training you’ll lose some muscle mass.
-
If you gain weight without resistance training you won’t gain muscle mass.
-
Thus, if you do both, yes, you end up worse off.
-
But that’s a choice, and it’s fixable by attacking ‘without resistance training.’
There are also other exercise methods. The point is clear.
Weight loss helps resolve back problems and otherwise make things hurt less. Few appreciate how big a deal this is. This was a big game changer for me on its own.
Man Down Ted: I may have a bit less hair, but I have FAR fewer body aches and pains than I did 10 years ago.
A lot of that is due to lowering the weight my body has to carry, but at least some of it is due to the fact that I will just make myself do 10 mins of yoga to loosen up, any time.
Meanwhile, half my male friends near my age have thrown their back out this year. Possibly more than half wake up stiff and sore from sleep every day.
Dropping the weight is good for dating,, but it’s GREAT for your long-term health and self image. And not THAT hard.
That is, no one knows much about how to do it right.
We do know many ways in which one can do it wrong.
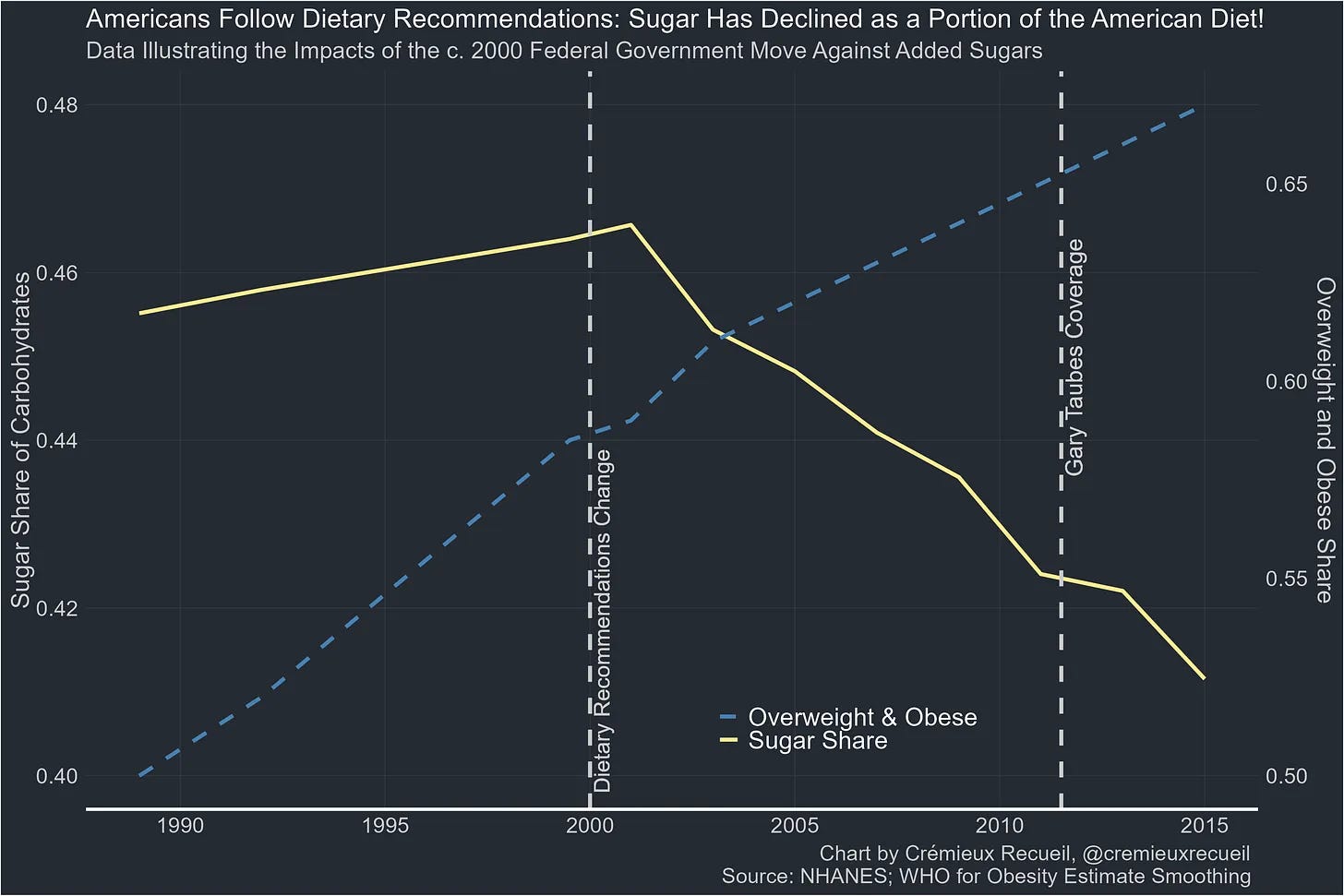
Cremieux points out that in general ‘nutrition beliefs are just-so stories.’
If there were two concrete specific things I would have said I was confident about, one of them would have been ‘vegetables mostly good’ and the other would be ‘sugar bad.’ I don’t think it’s bad enough to stop me all that much on either front, but I do buy that sugar is bad on the margin.
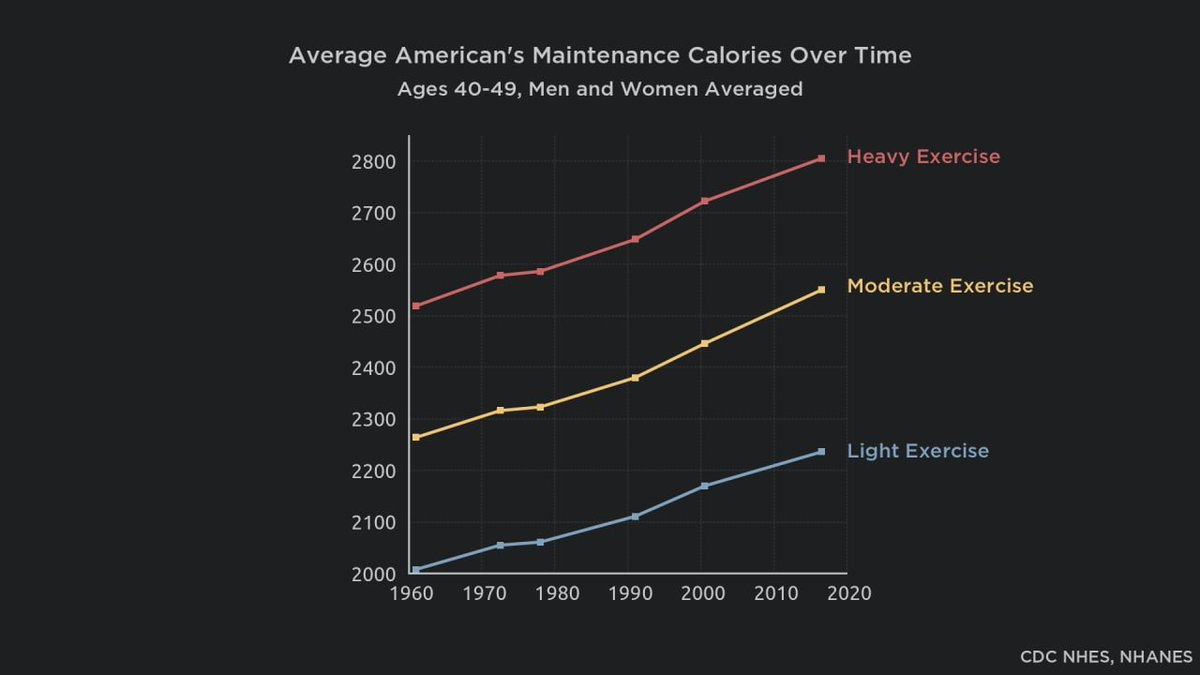
And yet when Americans cut sugar consumption (modestly by ~10%, note the y-axis) the obesity rate still mostly kept moving up.
He blames this mess on selection. Once sugar got blamed, choosing to consume more sugar became correlated with other health decisions, some of which matter. The associations between sugar and health only show up, he claims, after 2012. And he says this generalizes – certain people eat certain diets. He finishes with a survey of some of the other problems.
I am inclined to be kinder, and see the epistemic problems here as actually super hard. Nutrition is remarkably different for different people, doing proper studies on humans is extremely hard, there are distinct effects for short, medium and long terms, a lot of this is about how you psychologically respond, lots of details matter and are hard to measure and can be changed without you realizing, and so on.
As far as anyone can tell Aspartame, a zero calorie sweetener, seems benign. I agree that this is great news so long as no one forces anyone to use it. I think the people this most annoys are people who believe that it is not as good an experience as sugar, and don’t want their sugar taken away, either legally or by those ‘worried about their health.’ Also, since no one knows anything about nutrition, I wouldn’t assume that there isn’t a catch.
From what I’ve seen, they go wrong enough often enough that starting to mess with them probably doesn’t make sense if you aren’t already messing with them.
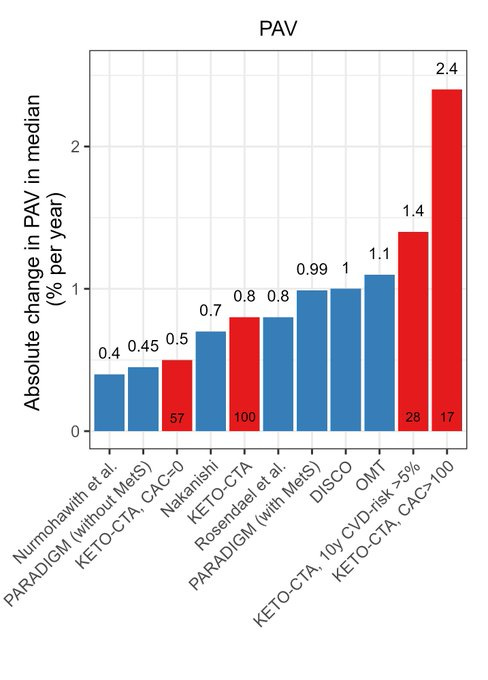
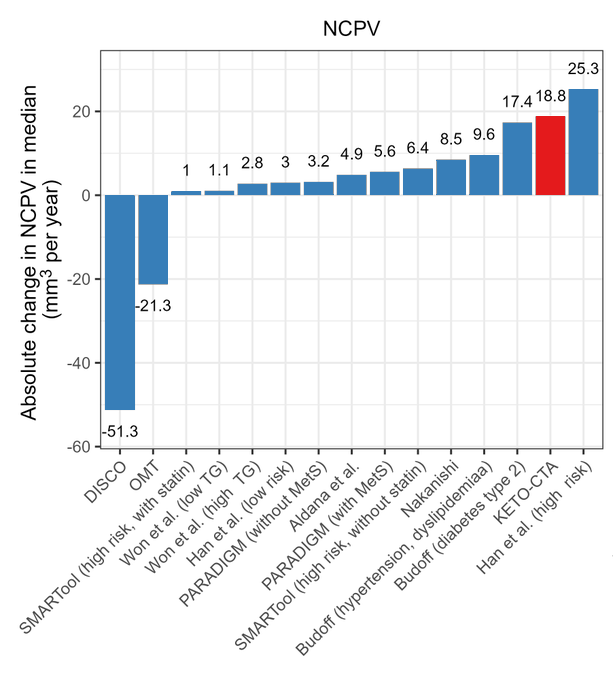
Do ketogenic diets dramatically raise risk of stroke and heart attack?
Christoffer Bausted Nilsen: “When the facts change, I change my mind. What do you do, sir?” (source)
The graphs show dramatically accelerated PAV (Percent Atheroma Volume) and NCPV (Non-Calcified Plaque Volume) in those on Keto diets.
As always, beware conclusions from intermediate endpoints, and also different people often have very different reactions and averages can be misleading. But I agree this does not look good.
Cremieux: I’m a little annoyed that I spent so many years thinking keto was obviously good.
Now that we have a lot of data, it turns out that the people who said “fat—especially saturated fat—clogs your arteries” were just totally correct.
I should not have believed the contrarians.
I don’t think we have enough evidence here to draw that conclusion either?
Here’s a counterargument from someone thoughtful and sympathetic to Keto:
William Eden (not endorsed): As someone who has recommended paleo/keto diets in the past, let me lay out my current thinking:
ApoB is directly related to atherosclerosis progression (experts are right)
*Somepeople who go on keto skyrocket ApoB, and yes I think keto is bad for those people. This is where ultimately empirical results overcame the same things he derides in this discussion (“mechanistic” reasoning to support the answer you’re hoping to see).
Human PCSK9 mutants with no CVD changed my mind – and are the basis for a class of very strong therapeutics! However… I still think mechanisms are real. Some are better established, others speculative. Good theories predict the (very complicated) data My favorite thinker on the subject is Peter over at Hyperlipid, though he’s almost impossible to understand.
Just because high sat fat keto increases heart disease doesn’t mean the answer is to eat huge amounts of polyunsaturated fats either. Yes, I am a seed oil disrespecter. Mechanistically I think it causes the liver to hang onto fat instead of circulating it, but we can do better.
This video from Peter Attia is just 10 minutes and lays out the good drug options available today, including ones with better risk/reward than statins (though a *low dosestatin I think is fine with CoQ10 supplementation).
(Btw I think it’s absolutely clear that LDL must play some role in the body or it wouldn’t exist. I don’t 100% know all of its functions, but when you look across countries, low LDL is seen in developing countries with lots of infectious disease and other cardiovascular issues)
In terms of my diet advice, I do think a higher-fat diet that dips occasionally in and out of ketosis is likely optimal for long term performance and health. If you get high ApoB, swap out sat fat for monounsaturated fat, and consider drugs. Keto for >>1 month I have concerns.
In terms of my epidemic advice, I do think contrarians should try harder to grapple with mainstream evidence instead of dismissing it. *Especiallythe really strong evidence, and being able to see it as such. That’s why short term diet studies didn’t get me, but PCSK9 did. Fin.
Nathan Cofnas defends Keto on multiple fronts while also offering warnings.
-
He gives us the standard ‘correlation is not causation’ warnings that are at their peak in nutrition and a reminder that no one knows anything beyond that you need a basic set of nutrients and that different people are different.
-
The key thing about Keto, as its fans envision it, is it is the ultimate case of never do anything by halves. The idea of Keto is that you force your body into ketosis. That means consistent hardcore restricting of carbs. Most people can’t do it.
-
So almost any observational study is going to include a bunch of people who don’t actually do the thing and stay in ketosis, and being kind-of-keto doesn’t work.
-
Remember, when evaluating diets, that people basically neve stick to one for very long. The majority of people who say they’re ‘vegetarian’ will then admit they’ve eaten meat in the past week.
-
Keto is not optimized for longevity. You do it to feel and look better now, not to live for longer. Even if it has longevity costs, it might still be worth it. If you do want primarily longevity he suggests caloric restriction and pescetarianism, which is kind of the opposite of keto.
-
Keto is the only diet that worked for him in terms of current health, but of course different things work for different people.
I find these defenses:
-
Reasonable arguments.
-
Clear indications that very few people should be trying to be on a keto diet.
For keto to make sense, even if you mostly buy the counterarguments, given the risks involved (over a range of possible worlds):
-
You need to have extraordinary willpower and discipline, keeping in mind that most people who think they have it, don’t have it.
-
You need to be willing to spend that, and give up carbs, and endure all the hedonic and social costs involved, to stick to keto for real.
-
You need to prioritize short term health over longevity.
-
You need to have a body where keto happens to be relatively beneficial for you.
-
You keep avery close eye on various markers and your experience as you try it, and abort on the spot if an issue emerges, either in terms of your health or experience, or simply exposing that the willpower price is too damn high.
And that’s if you buy the counterarguments.
In practice, even if you think this is right for you to try, I’m willing to go ahead and say that on average you are wrong about that.
Congratulations to Allyson Taft on her transformation, including losing 120+ pounds in just under a year by walking a lot, drinking a lot of water and tracking calories.
Not everyone can do this. Not everyone should attempt this. And most people in the position to need to do it should probably take GLP-1s.
It was still very nice to see a clear example of someone pulling off the pure willpower route who wasn’t me. And it sounds like she didn’t even use GLP-1s.
One thing I would push back on very hard is the idea that there is something perverse and modern about the fact that if we eat until we feel satiated with reasonable access to a variety of foods then we will gain weight:
exfatloss: If you can maintain a healthy body weight by restricting your total food intake, but never give in to eat ad libitum because you know you’d gain fat, your satiety & appetite are broken. Until very recently, nobody needed to count calories to remain thin.
I’m not saying that staying thin did not get harder on many fronts, and it is entirely possible that there are other things making things harder on top of that, but the idea that in the past eating as much as you wanted of what you wanted wouldn’t have made you fat is Obvious Nonsense. Rich people from the past who could eat as much as they wanted, and didn’t care, totally got fat. Sure, people mostly stayed thin, but largely out of lack of opportunity.
Needing to control yourself to stay thin does not mean that your satiety is broken. You’re asking way too much of satiety. You’re asking it to give you the right highly calibrated signal in a radically different world than the one it was trained for.
This doesn’t require toxins or any particular villain beyond widespread variety and caloric availability, including many calorically dense foods, and greatly increased food variety and quality, and various cultural expectations of eating frequently. It is enough, and regardless of the original cause life is not fair.
Cremieux: Attempts to explain the obesity epidemic through contamination, toxins, conspiracies, seed oils, sugar, high-fructose corn syrup, lithium, or whatever else always strike me as annoying.
What we must explain is an increase of ~200-350 calories a day in energy balance. That’s all.
My answer is simple, and similar to Cremieux’s in the thread, that there was never really any robust natural ‘balance.’
For full disclosure, I say this as someone whose satiety has always been utterly broken to the point of uselessness. If left to my own devices I would put on insane amounts of weight very quickly. I might double my caloric intake. That’s what actually broken looks like. But don’t ask an evolutionary mechanism to give the right answer in a radically changed world, and don’t call it ‘broken’ when you have to adapt.
Yes, until recently that meant you had to work for it. That’s one option. The other? Good news, now we have Ozempic and other GLP-1s.
Key Smash Bandit: I started taking a million supplements and I do feel meaningfully better but the new problem is I have no idea which one did it, and taking all of them is expensive and annoying
Ryan Moulton: This is a fun task to try to design an experiment to resolve.
I would randomize to taking 50% each day, (ideally blinded, but whatever) and then record how I felt each day. Then after you have ~a month of data, fit a regression model from what you took to how you felt, probably also with at least terms for 1 day lag. Lean on L1 in lasso a lot, because you’re probably looking for a single thing rather than a large set.
Unfortunately there are what the economists call ‘long and variable lags’ in vitamin impact, both positive and negative. Even if it originally helped or hurt in a day, it might take a while for a supplement to wear off. Others only work via accumulation over time, or work on things other than observable mood.
Experimental design here is very hard. I would not want to maximize purely on the basis of how I feel within 24 hours.
Also, for various reasons, you cannot by default confidently equate any given pill with other pills from another source that claim to deliver the same dose of the same vitamin.
If I was going to run such tests, as much I would like to randomize every day, I would at minimum want to wait three or so days between swaps, and I would limit the multiple hypothesis testing. The data is going to be super noisy at best.
A story worth sharing.
Josh Whiton: Halfway through university I was diagnosed with clinical depression. After a battery of tests and interviews with psychologists I eventually met with the psychiatrist who was to dispense my medication.
Instead he asked me a question that no one had ever asked.
“Why are you depressed?”
So I told him about the meaninglessness of life in an accidental universe where all life was just the product of chance.
“You want me to put you on medication because you’re an intellectual?” he said.
Then he said the wildest thing: “My concern is that your depression is part of a process and the drugs will slow it down.”
He told me to go home and observe all the thoughts in my mind instead of trying to escape from them. If in three days I still wanted the drugs, to come back and he’d give them to me.
So I went home and spent three days journaling, had three epiphanies about the nature of reality, and the year-long depression immediately lifted.
I wonder about all the kids like me who got the drugs instead.
Zac Hill: One of the things I was most brazenly wrong about was just basically making fun of people who thought that Canada’s euthanasia program would achieve scale.
As in, MAID now is already 5% of all deaths in Canada and is about to be available for mental conditions and parliament wants to grant access to minors, and I see a bunch of claims about it being aggressively pushed onto people in various ways. One wonders where this stops, once it starts. If it stops.
Former Quebec officials suggest that best “solution” for intellectually disabled woman without adequate support might be death. Which might be true, but wowie. This highlights where things might be going. Do you trust the state to not push such solutions on people who are financial burdens? To not cut off aid to them as part of an attempt to force such choices upon them? I notice my answer is very much no.
A lot of ‘ethics’ people think the only ethical thing for you to do is hurry up and die.
Joao Pedro de Magalhães: “It is highly unethical to stop aging” – reviewer commenting on one of my grant applications.
The grant focused on cellular rejuvenation, no mention to curing aging, but it shows we still have a long way to go to convince even fellow scientists that curing aging is desirable.
As in, you are trying to solve people’s health problems, but this might also cure aging, And That’s Terrible.
Once again: Bioethicists know nothing of ethics. This is them answering:
Here’s a bioethicist giving a Ted talk advocating that humans be ‘engineered’ to be, no not more intelligent or healthy or happy but (checks notes) intolerant to meat, at the same time that other ‘ethicists’ are screaming about how awful it is we might do embryo selection on positive traits.
And 41% stand ready here to outright deny physical reality.
How exactly would we design society such that it is not a disadvantage to be blind?
If I was blind and I heard people were claiming this, I’d be pretty pissed off at them.
Do you think, by answering that way, you are helping anyone?
Learning about your HIV status, when treatment is not available, dramatically reduces long term survival rates. Some of this is people adjusting rationally to the news, and engaging in generally riskier (to themselves) behaviors and having higher discount rates. Some of it is despair or overreaction. However it isn’t really an option not to tell them or not run the tests, for obvious reasons.
Here in New York they take every opportunity to push you to get tested for HIV, even when there is no reason to do that, as I found out on a recent hospital visit (it was an infection, I am 100% fine now, don’t worry).
Clash Report: Hot-mic moment at the Beijing parade.
Xi: “People rarely lived past 70 before. Now at 70 you’re still a child.”
Putin: “With biotech, organs can be replaced endlessly… people could even reach immortality.”
Xi: “Some predict people might live to 150 this century.”
I do see hope that some people might live to 150 this century, or even that some people alive today might live far longer than that. It will not happen because ‘organs can be replaced endlessly’ because that does not reverse aging, so the rate of new problems will keep doubling roughly every seven years, but we have other options.
Also, yeah, thinking ‘at 70 you’re still a child’ is both obviously false and reflective of the geriatric ruling class that is doing so much damage. Until your anti-aging technology gets a lot better no one 70+ should be in high office.
In response to RFK’s War on Vaccinations and as Florida repeals all vaccine requirements, there are now two state coalitions trying to defend our health. California, Oregon, Washington and Hawaii are going to form one set of recommendations. New York, Massachusetts, Connecticut, Delaware, Pennsylvania and Rhode Island will form another, likely with New Jersey, Vermont and Maine.
Freezing sperm young, if you can spare a little cash to do it, is a pretty great deal. Even if everything keeps working fine you cut down on mutation load a lot, and if something does go wrong you’re going to be very happy about it. It’s a lot of optionality and insurance at a remarkably cheap price, even if you factor in the chance that in the long term we’ll have other tech that renders it unnecessary.
This could end up being a big one: Germany’s national academy of sciences correctly urges that we treat aging like a disease. If we can get momentum behind this, it will supercharge progress towards the (non-AI) thing that is actually killing most of us.
New study claims living near (within 1-3 miles of) a golf course doubles risk of Parkinson’s Disease, which is presumed to be due to pesticides.
Ross Rheingans-Yoo is doing a video podcast series on why our drug development process is so broken and expensive.
Scott Adams has prostate cancer, we wish him well, thread has illustrations of exactly how unhinged a certain type of thinking got and how wide a set of medical topics. Luckily he himself has realized the mistake and although the odds are against him he now appears to be setting aside the quacks and getting real treatment.
A new claim from a randomized trial that getting immunotherapy in the morning has a doubled survival rate versus getting it in the evening, Abhishaike Mahajan speculates potential reasons why.
A potentially serious incentive problem: If CRISPR treatments can permanently cure conditions, insurance companies have no reason to value a permanent solution more than a temporary one, so the whole system will underinvest in such treatments. Ultimately it should be fine, since at most this is a limited cost factor and thus not enough distortion to stop this from happening, and AI should improve development costs enough to compensate.
They did finally run a decade-long study of GMOs in monkeys, and of course they found zero adverse effects on any measured health indicator.