A large meteor is visible from much of Ohio and parts of neighboring states
A large meteor crashed through the sound barrier above northern Ohio on Tuesday morning, producing a large fireball and what local residents described as an extremely loud “boom.”
According to various eyewitness reports, the meteor’s bright streak through the morning sky was visible across a wide area. A National Weather Service meteorologist in Pennsylvania, Jared Rackley, captured video of the meteor passing through the atmosphere and creating a large fireball. So far, there have been no reports of impacts on the ground.
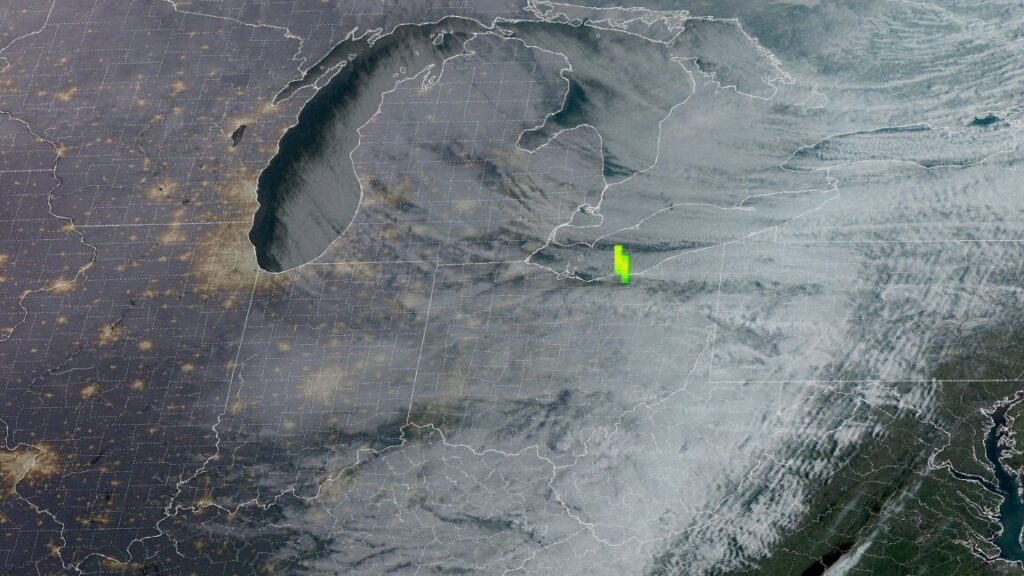
The precise location of the fireball was pinpointed by a near-infrared optical detector on a geostationary satellite at 9: 01 am ET (13: 01 UTC). This “geostationary lightning mapper” revealed that the meteor traversed through the atmosphere in northern Ohio, just west of Cleveland, and over Lake Erie.
A meteoroid—a small body moving through space—is called a meteor when it encounters a planet’s atmosphere and subsequently produces a bright streak of light. This occurs because the meteoroid is traveling many times faster than the speed of sound.
In this case, the “boom” was not due to breaking the sound barrier, like a supersonic aircraft, but rather to the hypersonic meteoroid generating a powerful shockwave as it moved through the atmosphere. This shockwave compresses the air, producing a series of sonic booms or even a rumbling sound.
No further information was available about the size and impacts of the meteor as of mid-morning on Tuesday. This story will be updated if additional information becomes available.
A large meteor is visible from much of Ohio and parts of neighboring states Read More »