Enlarge/ A grab bag of new features in macOS 15 Sequoia.
Apple
Most owners of aging Intel Macs got a bit of a reprieve today when Apple announced macOS 15 Sequoia—this new macOS release will run on the vast majority of the hardware that can currently run macOS 14 Sonoma. Intel Macs released between December of 2017 and 2020 are mostly eligible for the new update, though newer models with Apple Silicon chips will be needed to support some of the new features.
Apple’s full support list for Sequoia is as follows:
Generally, all of these Macs include Apple’s T2 chip, a co-processor installed in late-model Intel Macs that bridged the gap between the Intel and Apple Silicon eras. There are two exceptions: The biggest is the 2018 MacBook Air, which did come with an Apple T2 but also shipped with a weak dual-core processor and integrated GPU that Apple has apparently decided aren’t up to the task of handling Sequoia. The other is the 2019 iMac, which for whatever reason shipped without a T2. Apple says that the iPhone mirroring feature does require the T2 chip, so it presumably won’t work on the 2019 iMac.
The Apple Intelligence AI features will all require an Apple Silicon Mac—it will run on anything with an M1 chip or newer. Live audio transcription in the Notes app will also require an Apple Silicon chip.
Apple hasn’t said exactly when it plans to stop releasing new macOS updates for Intel Macs, but based on its current pace, Sequoia could be the end of the line. Whatever Apple decides to do next year, Intel Macs without an Apple T2 are definitively in the company’s rear-view mirror.
CUPERTINO, Calif.—Apple kicked off the keynote for its annual developer conference by announcing a new version of visionOS, the operating system that runs on the company’s pricey but impressive Vision Pro mixed reality headset.
The updates in visionOS 2 are modest, not revolutionary—mostly iterative changes, quality-of-life improvements, and some features that were originally expected in the first version of visionOS. That’s not too surprising given that visionOS just went out to users four months ago.
Vision Pro users hoping for multiple virtual Mac monitors will be disappointed that’s not planned this time around, but Apple plans to add the next-best thing: Users will be able to take advantage of a larger and higher-resolution single virtual display, including a huge, wraparound ultrawide monitor mode that Apple says is equivalent to two 4K monitors.
There’s one major machine learning-driven feature: You will soon be able to convert 2D images into 3D spatial ones in the Photos app, even photos you took years and years ago, long before iPhones could take spatial photos. (Apple also announced that a new Canon DSLR camera will get a spatial photo lens, as another option for taking new spatial photos.)
Other notable improvements include support for using travel mode on trains instead of just airplanes and a simple finger gesture to open the home screen so you don’t have to invoke Siri or reach up to press a physical button on the headset.
A lot of the improvements that will lead to better apps come in the form of new developer APIs that will facilitate apps that really take advantage of the spatial features rather than just being flat 2D windows floating around you—something we noted as a disappointment when we shared our impressions of the device. Some APIs help create shared spatial experiences with other Vision Pro users who aren’t in the same room as you. One of those, TabletopKit, is focused on creating apps that sit on a 2D surface, like board and card games.
There will also be new enterprise-specific APIs for things like surgical training and manufacturing applications.
Finally, Apple says Vision Pro is going international. It will go on sale in China (including Hong Kong), Japan, and Singapore on June 13 and in Australia, Canada, France, Germany, and the UK on June 28.
There was no specific release date named for visionOS 2.
The central discussion was the theses of his paper, Situational Awareness, which I offered quotes from earlier, with a focus on the consequences of AGI rather than whether AGI will happen soon. There are also a variety of other topics.
Thus, for the relevant sections of the podcast I am approaching this via roughly accepting the technological premise on capabilities and timelines, since they don’t discuss that. So the background is we presume straight lines on graphs will hold to get us to AGI and ASI (superintelligence), and this will allow us to generate a ‘drop in AI researcher’ that can then assist with further work. Then things go into ‘slow’ takeoff.
I am changing the order of the sections a bit. I put the pure AI stuff first, then afterwards are most of the rest of it.
I am leaving that part out because I see it as distinct, and requiring a different approach. It is important and I will absolutely cover it. I want to do that in its proper context, together with other events at OpenAI, rather than together with the global questions raised here. Also, if you find OpenAI events relevant to your interests that section is worth listening to in full, because it is absolutely wild.
Long post is already long, so I will let this stand on its own and not combine it with people’s reactions to Leopold or my more structured response to his paper.
While I have strong disagreements with Leopold, only some of which I detail here, and I especially believe he is dangerously wrong and overly optimistic about alignment, existential risks and loss of control in ways that are highly load bearing, causing potential sign errors in interventions, and also I worry that the new AGI fund may make our situation worse rather than better, I want to most of all say: Thank you.
Leopold has shown great courage. He stands up for what he believes in even at great personal cost. He has been willing to express views very different from those around him, when everything around him was trying to get him not to do that. He has thought long and hard about issues very hard to think long and hard about, and is obviously wicked smart. By writing down, in great detail, what he actually believes, he allows us to compare notes and arguments, and to move forward. This is The Way.
I have often said I need better critics. This is a better critic. A worthy opponent.
Also, on a great many things, he is right, including many highly important things where both the world at large and also those at the labs are deeply wrong, often where Leopold’s position was not even being considered before. That is a huge deal.
The plan is to then do a third post, where I will respond holistically to Leopold’s model, and cover the reactions of others.
Reminder on formatting for Podcast posts:
Unindented first-level items are descriptions of what was said and claimed on the podcast unless explicitly labeled otherwise.
Indented second-level items and beyond are my own commentary on that, unless labeled otherwise.
(2: 00) We start with the trillion-dollar cluster. It’s coming. Straight lines on a graph at half an order of magnitude a year, a central theme throughout.
(4: 30) Power. We’ll need more. American power generation has not grown for decades. Who can build a 10 gigawatt center let alone 100? Leonard thinks 10 was so six months ago and we’re on to 100. Trillion dollar cluster a bit farther out.
(6: 15) Distinction between cost of cluster versus rental cost of compute. If you want the biggest cluster you have to build it, not only rent it.
So in several ways, despite the profit margins on rentals, it is plausible efficiently scaling big costs proportionally more per compute relative to staying small. Suddenly you are buying or building power plants, lobbying governments, bribing utilities and so on. Indeed, in his paper Leopold thinks large scale power might become de facto somewhat priceless.
This also implies that dollar training costs behind the size curve should drop faster relative to the cost at the frontier.
A clear claim in Leopold’s model is that (in effect) power futures are radically underpriced. It’s time to build, anyone with the permits or a way to get them should be building everything they can.
(7: 00) Should we expect sufficient revenue from AI to pay for all this? Leopold calls back to the $100/month Office subscription idea, which he thinks you could sell to a third of subscribers, since the productivity returns will be enormous.
I agree the productivity gains will be enormous versus no AI.
It seems likely that if you have ‘the good AI’ that is integrated into workflow, that also is a very large productivity gain over other AIs, even if your AI is not overall smarter. Having an Office integrated GPT-N-based AI, that also integrates your email and other accounts via Outlook and such plus your entire desktop via something like Microsoft Recall is going to be a big boost if you ignore the times all your data gets seized or stolen.
This still feels like largely asking the wrong questions. Willingness to pay is not as correlated to marginal productivity or value as one might wish. We already see this in AI same as everywhere else.
I see this as one of the places where Leopold’s argument seems unconvincing, but I do agree with the conclusion. I expect AI will be making a lot of money in various ways soon enough, even if it is not transformational.
(7: 50) What can the AIs trained by these different datacenters do? 10 GW for AGI. 2025/26 timeline for models ‘smarter than most college graduates.’ Leopold calls adding affordances ‘unhobbling,’ conceptually the AI always had those abilities inside it but you needed to free its mind with various tools and tricks.
I am torn on the idea of these improvements as ‘unhobbling.’
On the one hand, it is highly useful to think about ‘this is what this system would be able to do if you gave it the right help,’ and contrasting that with the constraints inherent in the system. When considering the risks from a system, you need to think about what the system could do in the future, so the ‘unhobbled’ version is in many ways the version that matters.
On the other hand, it is not entirely fair or useful to say that anything an AI (or a human) could do with enough additional affordances and scaffolding is something they ‘had inside them all along.’ Even more than that, this framing implies that something hobbled the system, which could give people the wrong idea about what is happening.
(9: 00) Right now you need a lot of time to integrate GPT-4-level AIs into your workflow. That will change. Drop in remote workers that interface like workers. No kill like overkill on capabilities to make people actually integrate the AIs.
(11: 00) Where does the training data come for a zoom call like you have for text? Test time compute overhang will be key, issue of GPT-4 having to say first thing that comes to mind versus chain of thought. Tradeoff of test time compute versus training compute. ‘System 2 process’ via what he calls unhobbling.
(14: 45) Why should we think we can get it to do extended thinking? ‘Pretraining is magical,’ letting the model learn rich representations, which is key to Leopold’s model. Robotics increasingly becoming a software problem, not a hardware one.
I mostly think I get (and it is clear) what Leopold means when he says pretraining is magic, or similarly when he says ‘deep learning just works.’
It still seems important to lay out more about how it works, and what it actually does and does not do and why. I’d like to compare Leopold’s model of this to mine and hear him talk about implications, especially versus his thoughts on alignment, where it feels a lot like magic there too.
(17: 10) Leopold says, at some point probably around college Dwarkesh transitioned from pretraining to being able to learn by himself. Metaphor for AI. Reinforcement learning (RL) as most efficient data, potential transition to that.
(20: 30) The transition from GPT-2 to GPT-4, emphasis on the ‘school’ scale of what type of person it is similar to. Again looks ahead to drop in remote workers.
As many others have commented, I would caution against taking the ‘as smart as an Xth grader’ style charts and comparisons too seriously or literally. What is going on here is not that similar to what it is being compared against.
(21: 20) In 2023, Leopold could start to feel the AGI, see the training clusters that would be built, the rough algorithms it would use and so on. Expects rest of the world to feel it soon. Expects wrapper companies to get ‘sonic boomed.’
(24: 20) Who will be paying attention in 26/27? The national security state. When will they and the CCP wake up to superintelligence and its impact on national power?
I have learned that ‘surely they would not be so stupid as to not realize’ is not so strong an argument. Nor is ‘they would never allow this to happen.’
There is not always a ‘they,’ and what they there is can stay unaware longer than the situation can stay solvable.
In the paper and later in the podcast, Leopold draws the parallel to Covid. But Leopold, like many others I know, knew the whole thing was baked in by February. Yes, as he says, the government eventually acted, but well after it was too late, and only after people started shutting down events themselves. They spent a lot of time worrying about petty things that did not matter. They did not ‘feel the Covid’ in advance.
A similarly delayed reaction on AGI, if the technology is on the pace Leonard projects, would wake up to find the government no longer in charge. And indeed, so far we have seen a very similar reaction to early Covid. Leopold (at 32: 00) mentions the talk of ‘Asian racism’ and the parallel is clear for AI.
I don’t buy Leopold’s claim that ‘crazy radical reactions’ came when people saw Covid in America, although I do think that fits for China. Notice the big differences. If we see that difference again for AI, that’s huge. And notice that even when the government had indeed ‘woken up’ we still valued many other things far more than dealing with Covid. Consider the testing situation. Consider vaccine distribution. And so on.
Similarly, today, look at the H5N1 situation. A huge portion of our livestock are infected. What are we doing? We are letting the farm lobby shut down testing. We have learned nothing. I do not even see much effort to get people to not drink raw milk. The good news is it looks like we got away with it and this time is not that dangerous to humans unless we see another mutation, but again this is burying heads in sand until there is no other option.
Could the state actors wake up sooner? Oh, sure. But they might well not.
(25: 30) One of first automated jobs will be AI research. Then things get very fast. Decades of work in a year. One to a few years for much smarter than human things. Then figure out robotics. A ‘couple of years’ lead ‘could be decisive’ in military competition. Comparison to Gulf War I tech edge. Some speculations about physically how to do this.
No he did not say ‘alignment researcher.’ Whoops.
If anything his estimates after that seem rather slow if it was really all that.
If all this was really happening, a few years of edge is massive overkill.
We do not need to know exactly how this physically plays out to know it.
(28: 30) A core thesis of Leopold’s paper, that once NatSec and CCP ‘wake up’ to all this, the researchers stop being in charge. The governments will be in charge. There will be all-out espionage efforts.
Even if we assume no cooperation, again, I would not assume any of this. It seems entirely plausible that one or both countries could stay asleep.
Even if they do ‘wake up,’ there are levels of waking up. It is one thing to notice the issue, another to treat it like the only issue, as if we are in an existential war (in the WW2 sense.) In that example, what America did before and after Pearl Harbor is telling, despite already knowing the stakes.
(29: 00) China has built more power in the last decade than America has total, they can outbuild us.
Never count America out in situations like this.
Yes, right now we look terrible at building things, because we have chosen to be unable to build things in various ways. And That’s Terrible.
If we woke up and decided to hell with all that? Buckle up.
(29: 30) Dwarkesh asks, if you make the AI that can be an AI researcher, and you then use it at first only to build AI researchers because that’s the obviously right play, might others not notice what happened until suddenly everything happened? Leopold says it will be more gradual than that, you do some jobs, then you do robotics and supercharging factory workers, go from there.
I actually think Dwarkesh has a strong point here. If your compute is limited and also you are not trying to draw too much attention, especially if you are worried about national security types, it would make a lot of sense to not do those other things in visible ways ‘until it was too late’ to respond.
It is not only the AI that can sandbag its capabilities and then do a type of treacherous turn. If I was running an AI lab in this situation, I would be foolish not to give a lot of thought to whether I wanted to get taken over by the government or I would rather the government get taken over by my lab.
(30: 30) Will they actually realize it, and when? Leopold agrees this is the big question, says we likely have a few years, points to Covid, see discussion above. Leopold says he did indeed short the market in 2020.
(33: 00) Dwarkesh points out that right now government debates are about very different questions. Big tech. Parallels to social media. Climate change. Algorithmic discrimination. This doesn’t look like ‘we need to ensure America wins?’ Leopold notes that intense international competition is the norm, and in WW2 we had 50%+ of GDP going to the war effort, many countries borrowed over 100% of GDP.
I think Dwarkesh is underselling the ‘America must win’ vibes and actions. That is most definitely a big deal in Washington now. We must beat China is one of the things the parties agree upon, and they do apply this to AI, even without having any idea what the stakes here actually are.
There is thus a lot of talk of ‘promoting innovation’ and America, and of course note the Chips Act. Whether that all translates to anything actually useful to America’s AI efforts is another question. The traditional government view of what matters seems so clueless on AI.
No mention of existential risk there, another aspect of the debate. There are those who very much want to do the opposite of full speed ahead for that reason, on top of those who have other reasons.
Even though many saw WW2 coming, those dramatic spending efforts (at least on the Allied side) mostly only happened once the war began. Things would have gone very differently if France and the UK had spent in 1938 the way they everyone spent in 1940.
So when Leopold asks, will people see how high the stakes are, the obvious answer is that people never understand the stakes until events force them to.
(35: 20) Leopold agrees the question is timing. Will this happen only after the intelligence explosion is already happening, or earlier? Once it happens, it will activate ‘forces we have not seen in a long time.’
Yes, at some point the governments will notice the way they need to actually notice, assuming Leopold is right about the tech. That does not mean that on that day when they feel the AGI, they will still ‘feel in charge.’
(36: 00) AI-enabled permanent dictatorship worries. Growing up in Germany makes this more salient.
(39: 30) Are the Westernized Chinese AI researchers going to be down for AI research on behalf of CCP? Leopold asks, will they be in charge? OpenAI drama as highlighting the benefits of representative democracy.
One could take exactly the opposite perspective on the OpenAI drama, that it was a perfect illustration of what happens when a superficially popular demagogue who rules through a combination of fear and promises of spoils to his elite overthrows the rightful parliament when they try to stop him, by threatening to tear the whole thing down if he does not get his way. And that ‘the people’ fell in line, making their last decision, after which dissent was suppressed.
Or one could say that it was democracy in action, except that it is now clear that the voters were fooled by manufactured consent and chose wrong.
In this case I actually think a third parallel is more relevant. OpenAI, they say, is nothing without its people, a theory its people are increasingly testing. When a group seen as the enemy (the board, which was portrayed as a metaphorical CCP here by its enemies, and in some cases accused of being literal CCP agents) told everyone they were in charge and wanted a change of leadership, despite promoting from within and saying everything else would continue as normal, what happened?
What happened was that the bulk of employees, unconvinced that they wanted to work for this new regime (again, despite keeping the same purported goals) threatened to take their talents elsewhere.
Thus, I think the question of cooperation is highly valid. We have all seen Bond movies, but it is very difficult to get good intellectual progress and production out of someone who does not want to succeed, even if you have control over them. There would still be true believers, and those who were indifferent but happy to take the money and prestige on offer. We should not be so arrogant to think that all the most capable Chinese want America to win the future over the CCP. But yes, if you were AI talent that actively wanted the CCP to lose, because you had met the CCP, it seems easy to end up working on something else, or to not be so effective if not given that choice, even if you are not up for active sabotage.
We could and should, of course, be using immigration and recruitment now, while we still can, towards such ends. It is a key missing piece of Leopold’s ‘situational awareness’ that this weapon of America’s is not in his model.
(41: 15) How are we getting the power? Most obvious way is to displace less productive industrial uses but we won’t let that happen. We must build new power. Natural gas. 100 GW will get pretty wild but still doable with natural gas. Vital that the clusters be in America.
(42: 30) Why in America? National security. If you put the cluster in the UAE, they could steal your weights and other IP, or at minimum seize the compute. Even if they don’t do that, why give dictatorships leverage and a seat at the table? Why risk proliferation?
Altman seeking to put his data centers in the UAE is an underrated part of the evidence that he is not our friend.
(45: 30) Riskiest situation is a tight international struggle, only months apart, national security at stake, no margin for error or wiggle room. Also China might steal the weights and win by building better, and they might have less caution.
Maybe China would be more reckless than us. Maybe we would be more reckless than China. I don’t see much evidence cited on this.
If China can steal the weights then you are always potentially in a close race, and indeed it is pointless to go faster or harder on the software side until you fix that issue. You can still go faster and harder on the hardware side.
Leopold’s model (via the paper) puts essentially zero hope in cooperation because the stakes are too high and the equilibrium is too unstable. As you would expect, I strongly disagree that failure is inevitable here. If there is a reason cooperation is impossible, it seems if anything more likely to be America’s unwillingness rather than China’s.
(46: 45) More cluster location talk. Potential to fool yourself into thinking it is only for inference, but compute is fungible. Talk of people who bet against the liberal order and America, America can totally pull this off with natural gas. But oh no, climate commitments, so no natural gas until national security overrides.
For those thinking about carbon, doing it in America with natural gas emits less carbon than doing it in the UAE where presumably you are using oil. Emissions are fungible. If you say ‘but think of our climate commitments’ and say that it matters where the emissions happen, you are at best confusing the map for the territory.
Same with both country and company commitments. This is insane. It is not a hypothetical, we see it everywhere. Coal plants are being restarted or used because people demand that we ‘keep climate commitments.’ What matters is not your commitment. What matters it the carbon. Stop it.
(49: 45) You could also do green energy mega projects, solar with batteries, SMRs, geothermal and so on, but you can’t do it with current permitting processes. You need blanket exemptions, for both federal and state rules.
Yep. It is completely insane that we have not addressed this.
No, I am in some ways not especially thrilled to accelerate the amount of compute available because safety, but we would be infinitely better off if we got the power from green sources and I do not want America to wither for lack of electrical power. And I definitely don’t want to force the data centers overseas.
(51: 00) Harkening back to strikes in 1941 saying war threats were excuses, comparing to climate change objections. Will we actually get our act together? We did in the 40s. Leopold thinks China will be able to make a lot of chips and they can build fast.
That didn’t respond on the climate change issue. As I say above, if people actually cared about climate change they would be acting very differently.
That is true even if you don’t accept that ASI will of course solve climate change in the worlds where we keep it under our control, and in the worlds were we fail to do that we have much bigger problems.
(53: 30) What are the lab plans? Middle east has capital but America has tons of capital. Microsoft can issue infinite bonds. What about worries UAE would work with China instead? We can offer to share the bounty with them to prevent this.
The obvious note is that they can try going to China, but China knows as well as we do that data centers in the UAE are not secure for them, and would then have to use Chinese chips. So why not use those chips inside China?
(56: 10) “There’s another reason I’m a little suspicious of this argument that if the US doesn’t work with them, they’ll go to China. I’ve heard from multiple people — not from my time at OpenAI, and I haven’t seen the memo — that at some point several years ago, OpenAI leadership had laid out a plan to fund and sell AGI by starting a bidding war between the governments of the United States, China, and Russia. It’s surprising to me that they’re willing to sell AGI to the Chinese and Russian governments.” – Leopold
The above is a direct quote. I haven’t heard any denials.
If true, this sure sounds like a Bond Villain plot. Maybe Mission Impossible.
“But Russia and China are our enemies, you can’t give them AGI!”
“Then I suppose your government should bid highly, Mr. Bond!”
There is of course a difference between brainstorming an idea and trying to put it into practice. One should be cautious not to overreact.
But if this made it into a memo that a lot of people saw? I mean, wow. That seems like the kind of thing that national security types should notice?
(56: 30): “It’s surprising to me that they’re willing to sell AGI to the Chinese and Russian governments. There’s also something that feels eerily familiar about starting this bidding war and then playing them off each other, saying, “well, if you don’t do this, China will do it.” Dwarkesh responds: “Interesting. That’s pretty fucked up.”
Yes. That does sound pretty fucked up, Mr. Patel.
(57: 10) UAE is export controlled, they are not competitive. Dwarkesh asks if they can catch up? Leopold says yes, but you have to steal the algorithms and weights.
(58: 00) So how hard to steal those? Easy. DeepMind’s security level is currently at 0 on their own scale, by self-description, and Google probably has the best security. It’s startup security, which is not good.
(1: 00: 00) What’s the threat model? One is steal the weights. That’s important later, less important now but we need to get started now to be ready. But what we do need to protect now are algorithms. We will need new algorithms, everyone is working on RL to get through the data wall.
I wouldn’t downplay the theft of GPT-4. It is highly useful to have those weights for training and research, even if the model is not dangerous per se.
It also would be a huge economic boon, if they dared use them that way.
If the plan is to use RL to get around the data wall, notice how this impacts the statements in the alignment section of situational awareness.
(1: 02: 30) Why will state-level security be sufficient to protect our lead? We have a big lead now. China has good LLMs but they have them because they took our open weights LLMs and modified them. The algorithmic gap is expanding now that we do not publish that stuff, if we can keep the secrets. Also tacit knowledge.
(1: 03: 30) Aside about secrecy and the atomic bomb.
(1: 06: 30) Shouldn’t we expect parallel invention? Leopold thinks it would take years, and that makes all the difference. The time buffer is super important. Once again he paints a picture of China going hard without safety concerns, national security threats, huge pressure.
The buffer theory of alignment has a bunch of implicit assumptions.
First, it assumes that time spent at the end, with the most capable models and the greater resources later on, is far more valuable to safety than time spent previously. That we cannot or will not make those safety investments now.
Second, it assumes that the work we would do with the buffer could plausibly be both necessary and sufficient. You have to turn losses (worlds that turn out poorly, presumably due to loss of control or everyone dying) into wins. The theoretical worlds where we get ‘alignment by default’ and it is easy we don’t need it. The worlds where you only get one shot, you would be a fool to ask the AI to ‘do your alignment homework’ and your attempts will be insufficient will still die.
Thus, you have to be in the middle. If you look at the relevant section of the paper, this is a vision where ‘superalignment’ is a mere difficult engineering problem, and you have some slack and fuzzy metrics and various vague hopes and the more empirical work you do the better your chances. And then when you get the chance you actually do the real work.
Not mentioned by Leopold, but vital, is that even if you ‘solve alignment’ you then still have to win. Leopold frames the conflict as USA vs. CCP, democracy versus dictatorship. That is certainly one conflict where we share a strong preference. However it is not the only conflict, certainly not if democracy is to win, and a pure alignment failure is not the only way to lose control of events. While you are using superintelligence to turbocharge the economy and military and gain decisive advantage, as things get increasingly competitive, how are we going to navigate that world and keep it human, assuming we want that? Reminder that this is a highly unnatural outcome, and ‘we got the AIs to do what we tell them to do in a given situation’ helps but if people are in competition with widespread access to ASIs then I implore you to solve for the equilibrium and find an intervention that changes the result, rather than fooling yourself into thinking it will go a different way. In this type of scenario, these AIs are very much not ‘mere tools.’
(1: 09: 20) Dwarkesh notes no one he talks to thinks about the geopolitical implications of AI. Leopold says wait for it. “Now is the last time you can have some kids.”
That seems weird to me given who Dwarkesh talks to. I definitely think about those implications.
(1: 11: 00) More Covid talk. Leopold expected us to let it happen and the hospitals collapsed, instead we spent a huge percent of GDP and shut down the country.
(1: 11: 45) Smart people underestimate espionage. They don’t get it.
(1: 14: 15) What happens if the labs are locked down? Leopold says that the labs probably won’t be locked down, he doesn’t see it happening. Dwarkesh asks, what would a lockdown look like? You need to stay ahead of the curve of what is coming at you, right now the labs are behind. Eventually you will need air gapped systems, de facto security guards, all actions monitored, vetted hardware, that sort of thing. Private companies can’t do it on their own, not against the full version, you need people with security clearances. But probably we will always be behind this curve rather than ahead of it.
I strongly agree that the labs need to be locked down. I am not a security expert, and I do not have the clearances, so I do not know the correct details. I have no idea how intense is the situation now or where we need to be on the curve.
What I do know is that what the labs are doing right now almost certainly will not cut it. There is no sign that they will do what is necessary on their own.
This should be one of the places everyone can agree. We need steadily increasing security at major AI labs, the way we would treat similarly powerful government military secrets, and we need to start now. This decision cannot be left up to the labs themselves, nor could they handle the task even if they understood the gravity of the situation. Coordinating these actions makes them much easier and keeps the playing field level.
(1: 18: 00) Dwarkesh challenges the USA vs. China framework. Are we not all Team Humanity? Do we really want to treat this as an adversarial situation? Yes some bad people run China right now, but will our descendants care so much about such national questions? Why not cooperate? Leopold reiterates his position, says this talk is descriptive, not normative. Cooperation would be great, but it won’t happen. People will wake up. The treaty won’t be stable. Breakout is too easy. The incentives to break the deal are too great.
This assumes that both sides want to gain and then use this decisive strategic advantage. If America would use a decisive advantage to conquer or ensure permanent dominance over China and vice versa, or it is seen as the battle for the lightcone, then that is a highly unstable situation. Super hard. Still does not seem impossible. I have seen the decision theory, it can be done. If this is largely defensive in nature, that is different. On so many levels, sure you can say this is naive, but it is not obvious why America and China need to be fighting at all.
Certainly we will not know if we never, as I say it, pick up the phone.
So far attempts to coordinate, including the Seoul summit, are moving slowly but do seem to be moving forward. Diplomacy takes time, and it is difficult to tell how well it is working.
One core assumption Leopold is making here is that breakout is too easy. What if breakout was not so easy? Data centers are large physical structures. There are various ways one could hope to monitor the situation, to try and ensure that any attempt to break out would be noticed. I do not have a foolproof plan here, but it seems highly underexplored.
Perhaps ultimately we will despair, perhaps because we cannot agree on a deal because America wants to stay ahead and China will demand equality or more, or something similar. Perhaps the political climate will render it impossible. Perhaps the breakout problem has no physical solutions. It still seems completely and utterly crazy not to try very hard to make it work, if you believed anything like Leopold.
(1: 21: 45) Dwarkesh points out you can blow up data centers. Leopold says yes, this is a highly unstable situation. First strikes are very tempting, someone might get desperate. Data centers likely will be protected by potential nuclear retaliation.
(1: 24: 30) Leopold agrees: A deal with China would be great, but it is tough while in an unstable equilibrium.
No argument there. It’s more about missing mood, where he’s effectively giving up on the possibility. Everything about this situation is tough.
(1: 24: 40) Leopold’s strategy is, essentially, they’ll like us when we win. Peace through strength. Make it clear to everyone that we will win, lock down all the secrets, do everything locally. Then you can offer a deal, offer to respect them and let them do what they want, give them ‘their slice of the galaxy.’
Leopold seems to be making the mistake a lot of smart people make (and I have been among them) of assuming people and nations act in their own self-interest. The equilibrium is unstable so it cannot hold. If we are ahead, then China will take the deal because it is in their interest to do so.
My read on this is that China sees its self interest in very different fashion than this. What Leopold proposes is humiliating if it accomplishes what it sets out to do, enshrining us in pole position. It requires them to trust us on many levels. I don’t see it as a more hopeful approach.
It also is not so necessary, if you can get to that position, unless your model is that China would otherwise launch a desperation war.
To be clear, if we did reach that position, I would still want to try it.
(1: 26: 25) Not going to spoil this part. It’s great. And it keeps going.
(1: 27: 50) Back to business. Leopold emphasizes locking down the labs. No deals without that, our position will not allow it. Worry about desperation sabotage attacks or an attack on Taiwan.
Leopold does not seem to appreciate that China might want to invade Taiwan because they want Taiwan back for ordinary nationalist reasons, rather than because of TSMC.
(1: 31: 00) Central point is to challenge talk about private labs getting AGI. The national security crowd is going to get involved in some fashion.
I do think most people are underestimating the probability that the government will intervene. I still think Leopold is coming in too high.
(1: 32: 10) Is China load bearing in all this? Leopold says not really on security. Even if no China, Russia and North Korea and so on are still a thing. But yes, if we were in a weird world like we had in 2005 where there was no central rival we could have less government involvement.
(1: 33: 40) Dwarkesh challenges. Discussion of the Manhattan Project. Leopold says the regret was due to the tech, not the nature of the project, and it will happen again. Do we need to give the ASI to the monopoly on violence department, or can we simply require higher security? Why are we trying to win against China, what’s the point if we get government control anyway?
(1: 37: 20) Leopold responds. Open source was never going to be how AGI goes down, the $100 billion computer does not get onto your phone soon, we will have 2-3 big players. If you don’t go with the government you are counting on a benevolent private dictator instead.
So, about OpenAI as democracy in action, that’s what I thought.
(1: 39: 00) Dwarkesh notes a lot of private actors could do a lot of damage and they almost never do, and history says that works best. Leopold says we don’t handle nukes with distributed arsenals. The government having the biggest guns is good, actually, great innovation in civilization. He says the next few decades are especially dangerous and this is why we need a government project. After that, the threat is mostly passed in his model.
Dwarkesh makes a valid point that most people with destructive capacity never use it, but some do, as that amount scales it becomes a bigger issue, and also it does not address Leopold’s claim here. Leopold is saying that some AI lab is going to win the race to ASI and then will effectively become the sovereign if the current sovereign stays out of it. Us being able to handle or not handle multi-polarity is irrelevant if it never shows up.
As usual when people talk about history saying that private actors with maximally free reign have historically given you the best results, I agree this is true historically, mostly, although we have indeed needed various restrictions at various times even if we usually go too far on that. The key issue is that the core principle held when the humans were the powerful and capable intelligences, agents and optimizers. Here we are talking about ASIs. They would now be the most powerful and capable things around on all fronts. That requires a complete reevaluation of the scenario, and how we want to set the ground rules for the private actors, if we want to stay in control and preserve the things we care about. Otherwise, if nothing else, everyone is forced to steadily turn everything over to AIs because they have to stay competitive, giving the AIs increasing freedom of action and complexity of instructions and taking humans out of all the loops, and so on, and whoops.
I do not see Leopold engaging with this threat model at all. His model of the post-critical period sounds a like a return to normal, talk of buying galaxies and epic economic growth aside.
My guess is Leopold is implicitly imagining a world with ground rules that keep the humans in control and in the loop, while still having ASI use be widespread, but he does not specify how that works. From other context, I presume his solution is something like ‘a central source ensures the competitively powerful ASIs all have proper alignment in the necessary senses to keep things in balance’ and I also presume his plan for working that out is to get the ASIs to ‘do his alignment homework’ for him in this sense. Which, if the other kinds of alignment are solved, is then perhaps not so crazy, as much as I would much prefer a better plan. Certainly it is a more reasonable plan than doing this handoff in the earlier phase.
(1: 42: 15) Leopold points out that the head of the ASI company can overthrow the government, that effectively it is in charge if it wants that. Dwarkesh challenges that there would be other companies, but Leopold is not so sure about that. And if there are 2-3 companies close to each other, then that is the same as the USA-China problem, and is the government going to allow that, plus also you’d have the China (and company) problem?
There is not going to not be a government. If the government abdicates by letting a private lab control AGI and ASI, then we will get a new one in some form. And that new government will either find rules that preserve human control, or humans will lose control.
So the government has to step in at least enough to stop that from happening, if as Leopold’s model suggests only a small number of labs are relevant.
They still might not do it, or not do it in time. In which case, whoops.
(1: 44: 00) Dwarkesh says yes the labs could do a coup, but so could the actual government project. Do you want to hand that over to Trump? Isn’t that worse? Leopold says checks and balances. Dwarkesh tries to pounce and gets cut off. Leopold discusses what the labs might do, or rogue employees might do since security will suck. Leopold notes the need for an international coalition.
I find the optimism about cooperating with current allies, combined with skepticism of cooperating with current enemies, rather jarring.
Dwarkesh was likely pouncing to say that the checks and balances will stop working here the same way the private company could also go through them. The whole point is that previous power relationships will stop mattering.
Indeed, Leopold’s model seems to in some places be very sober about what it means to have ASIs running around. In other places, like ‘checks and balances,’ it seems to not do that. Congress has to spend the money, has to approve it. The courts are there, the first amendment. Once again, do those people have the keys to the ASI? Do they feel like they can be checking and balancing? Why? How?
Leopold says that these institutions have ‘stood the test of time in a powerful way,’ but this new situation quite obviously invalidates that test, even if you ignore that perhaps things are not so stable to begin with. It is one thing to say humans will be in the loop, it is another to think Congress will be.
Another contrast is ‘military versus civilian’ applications, with the idea that putting ASIs into use in other places is not dangerous and we can be happy to share that. Certainly there are other places that are fine, but there are also a lot of places that seem obviously potentially not fine, and many other ways you would not want these ASIs ‘fully unlocked’ shall we say.
(1: 47: 05) Leopold says it will be fine because you program the AIs to follow the constitution. Generals cannot follow unlawful orders.
Constitutional AI except our actual constitution? Really?
No, just no. This absolutely will not work, even if you succeeded technically.
I leave proving this as an exercise to the reader. There are a lot of distinct ways to show this.
(1: 47: 50) Dwarkesh asks, given you cannot easily un-nationalize, why not wait until we know more about which world we live in? Leopold says we are not going to nationalize until it is clear what is happening.
Reminder that Leopold says his claims are descriptive not normative here.
Indeed, in a few minutes he says he is not confident the government project is good, but at various points he essentially says it is the only way.
(1: 48: 45) Dwarkesh says dictatorship is the default state of mankind, and that we did a lot of work to prevent nuclear war but handing ASI to government here does not seem to be doing that work. Leopold says the government has checks and balances that are much better than those of private companies.
I notice I am confused by the nuclear metaphor here.
I do not think dictatorship is the default state of mankind, but that question is based on circumstances and technology, and ASI would be a huge change in the relevant forces, in hard to predict (and existentially dangerous) directions.
Kind of stunning, actually, how little talk there has been about existential risk.
Dwarkesh speaks of ‘handing ASI to the government’ but in the scenarios we are describing, as constructed, if you instead keep the ASI then you are now the government. You do not get to stay a ‘private actor’ long.
I worry a lot of such debates, both with and without existential risk involved, is people seeing solution X, noticing problem Y they consider a dealbreaker, and thus saying therefore we must do Z instead. The problem is that Z has its own dealbreakers, often including Y. I do not know what the right future is to aim for exactly, but I do know that there is going to be some aspect of it that is going to seem like a hell of a Y not, because there are unavoidable dilemmas.
(1: 51: 00) What does the government project look like? A joint venture between labs, cloud providers and the government. In the paper he uses the metaphor of Boeing and Lockheed Martin. Leopold says no, he does not especially want to start off using ASI for what it will first be used for, but you have to start by limiting proliferation and stabilizing the situation. Dwarkesh says that would be bad. Leopold asks what is the alternative? Many companies going for it, government involved in security.
(1: 54: 00) Leopold’s model involves broad deployment of AIs, with open models that are a few years behind as well. Civilian applications will have their day. Governments ‘have the biggest guns.’
The guns that matter in this future are the ASIs. So either the government has them, or they’re not the government.
(1: 56: 00) Why do those in The Project of the ASI, who are decades ahead on tech, need to trade with the rest of us? Leopold says that economic distribution is a completely different issue, there he has no idea.
That seems kind of important? And it is not only economics and trade. It is so many other aspects of that situation as well.
(1: 56: 30) Leopold comes back to the stakes being, will liberal democracy survive? Will the CCP survive? And that will activate greater forces, national security will dominate.
Will humanity survive? Hello? Those are the stakes.
Beyond that, yes, there are different ways to survive. They very much matter.
But for all of this talk about the stakes of liberal democracy, Leopold fails to ask whether and how liberal democracy can function in this future ASI-infused world. I am not saying it is impossible, I am saying he does not answer the question of how that would work, or whether it would be the desirable way of being. He notices some ways the world could be incompatible with it, but not others.
I wonder how much of that is strategic, versus a blind spot.
(1: 58: 30) Dwarkesh says this does not sound like what we would do if we suddenly thought there were going to be hundreds of millions of Von Neumanns. Wouldn’t we think it was good rather than obsessing over exactly which ones went where? Leopard points to the very short period of time and the geopolitical rivalries, and also says yes obviously we would be concerned in that scenario.
I thought we were past this sort of question? There are many big differences that should be highly obvious?
Of course a lot of those scenarios are actually identical in the sense that the first thing the Von Neumanns do is build ASI anyway. Perhaps being that smart they figure out how to do it safety. One can hope.
The other possibility is that they do better decision theory and realize that since they are all Von Neumann they can cooperate to not build it and work together in other ways and everything goes amazingly great.
(2: 00: 30) If we are merging these various companies are we sure this even speeds things up? Leopold says Google’s merge of Brain and DeepMind went fine, although that was easier. Dwarkesh notices Operation Warp Speed was at core private using advance market commitments and was the only Covid thing we did that worked, Leopold says this will look close to that, it will be a partnership with private institutions and thinks merging is not that difficult. People would not sign up for it yet, but that will change.
The more details I hear and think through, the more it sounds remarkably like a private effort that then gives the results to the government? The government will assist with security and cybersecurity, and perhaps capital, but what else is it going to be contributing?
(2: 04: 00) Talk about nuclear weapon development and regret. Leopold says it was all inevitable, regret would be wrong. Also nukes went really well.
I strongly agree nukes actually went really well. We are still here.
Indeed, the exact way it played out, with a rush to control it and a demonstration of why no one can ever use it, might have been a remarkable stroke of luck for humanity, on top of the other times we got lucky later.
(2: 07: 45) Leopold does not see alternatives. This is a war. There is no time for even ordinary safety standards, or a deliberate regulatory regime. There will be fog of war, we will not know what it is going on, the curves don’t look great, the tests are showing alarm bells but we hammered it out, China stole the weights, what to do?
I really hope he is wrong. Because there is a technical term for humanity in that situation, and that term is ‘toast.’
If he is right, that is a very strong argument for a deliberate regulatory regime now. There is no ‘wait until we know more’ if developments are going to be well outside the expected OODA loop and we will not have the time later. We can only hope we have the time now.
Indeed, exactly what we need most now in this scenario is visibility, and the ability to intervene if needed. Which is exactly what is being pushed for. Then the question is whether you can hope to do more than that, but clearly if you believe in Leopold’s model you should start setting that up now in case this is a bit slower and you do have the time?
(2: 09: 10) The startups claim they are going to do safety, but it is really rough when you are in a commercial race, and they are startups. Startups are startups.
The accent on claim here is the opposite of reassuring.
I too do not expect much in the way of safety.
But also turning this into a military race doesn’t sound better on this axis?
(2: 09: 45) Could the RSPs work to retain private companies? Keep things from getting off the rails? Leopold says current regulations and RSPs are good for flashing warning signs. But if the lights flash and we have the automated worker than it is time to go.
But we will ignore the flashing lights and proceed anyway, said Eliezer.
That is true, says Leopold.
And then we die, says Eliezer.
That does seem like the baseline scenario in that spot.
(2: 12: 45) Mention that if the courts blocked lesser attempts, then actual nationalization would likely be what followed. And yeah, that is indeed what Leopold expects. They have a good laugh about it.
(2: 46: 10) The fast AGI → AI AI researchers → ASI (superintelligence). Dwarkesh is skeptical of the input-output model. Leopold says obviously inputs obviously matter, but Dwarkesh points out that small groups often outcompete the world. Leopold says those groups are highly selected. That the story is straight lines on log graphs, things get harder. More researchers balancing harder problems is an equilibrium the same way supply equals demand.
Leopold seems overconfident in the details, but the argument that the researcher inputs do not matter gets more absurd each time I think about it. You can question the premise of there being AGI sufficient to allow AI researchers that are on par with the meaningful human researchers, but if you do allow this then the conclusions follow and we are talking price.
Yes, a small selected group can and often does outcompete very large groups at idea generation or other innovation, if the large groups are not trying to do the thing, or pursuing the same misguided strategy over and over again. If all you are doing is adding more AIs to the same strategy, you are not maximizing what you can get.
But that is similar to another true statement, which is that stacking more layers and throwing more compute and data at your transformer is not the most efficient thing you could have in theory done with your resources, and that someone with a better design but less resources could potentially beat you. The point is the bitter lesson, that we know how to scale this strategy and add more zeroes to it, and that gets you farther than bespoke other stuff that doesn’t similarly scale.
So it would be with AI researchers. If you can ‘do the thing that scales’ then it probably won’t much matter if you lose 50% or 90% or even 99% efficiency, so long as you can indeed scale and no one else is doing the better version. Also, one of the first things you can do with those AGI researchers is figure out how to improve your strategy to mitigate this issue. And I presume a lot of the reason small groups can win is that humans have limited bandwidth and various coordination issues and incentive problems and institutional decay, so large groups and systems have big disadvantages. Whereas a new large AI strategy would be able to avoid much of that.
It makes sense that if idea difficulty is a log scale that rises faster than you can innovate better research methods, that no matter how much you spend on research and how many researchers you hire, your rate of progress will mostly look similar, because you find ideas until they get harder again.
If instead your ability to innovate and improve your research goes faster than the rate at which ideas get harder, because of something like AGI changing the equation, then things speed up without limit until that stops being true.
(2: 51: 00) Dwarkesh asks, then why doesn’t OpenAI scale faster and hire every smart person? His theory is transaction costs, parallelization difficulty and such. Leopold starts off noting that AI researcher salaries are up ~400% over the last year, so the war for the worthy talent is indeed pretty crazy. Not everyone 150 IQ would be net useful. Leopold notes that training is not easily scalable (in humans). Training is very hard.
Yep. Among humans we have all these barriers to rapid scaling. Training is super expensive because it costs time from your best people. Retaining your corporate culture is super valuable and limits how fast you can go. Bad hires are a very large mistake, especially if not corrected, B players hire C players and so on. All sorts of things get harder as you scale the humans.
(2: 53: 10) AI is not like that. You do not need to train each copy. They will be able to learn in parallel, quickly, over vast amounts of data. They can share context. No culture issues, no talent searches. Ability to put high level talent on low level tasks. The 100 million researchers are largely a metaphor, you do what makes sense in context. An internet of tokens every day.
If you accept the premise that such AIs will exist, the conclusion that they will greatly accelerate progress in such areas seems to follow. I see most disagreement here as motivated by not wanting it to be true or not appreciating the arguments.
(2: 56: 00) What hobblings are still waiting for us? Unknown. Leopold’s model is you solve some aspects, that accelerates you, you then solve other aspects (more ‘unhobbling’) until you get there.
(2: 58: 00) How to manage a million AI researchers? Won’t it be slow figuring out how to use all this? Doesn’t adaptation take way longer than you would think? Leopold agrees there are real world bottlenecks. You remove the labor bottleneck, others remain. AI researchers are relatively easy versus other things.
The paper goes into more detail on all this. I am mostly with Leopold on this point. Yes, there will be bottlenecks, but you can greatly improve the things that lack them, and algorithmic progress alone will be a huge deal. This slows us down versus the alternative, and is the reason why in this model the transition is a year or two rather than a Tuesday or a lunch break.
If anything, all the timelines Leopold discusses after getting to AGI seem super long to me, rather than short, despite the bottlenecks. What is taking so long? How are we capable of improving so little? The flip side of bottlenecks is that you do not need to do the same things you did before. If some things get vastly better and more effective, and others do not, you can shift your input composition and your consumption basket, and we do.
The ‘level one adaptation’ of AI is to plug AI into the subtasks where it improves performance. That is already worth a ton, but has bottleneck issues. That is still, for example, where I largely am right now in my own work. Level two is to adjust your strategy to rely on the newly powerful and easy stuff more, I do some of that but that is harder.
(3: 02: 45) What lack of progress would suggest that AI progress is going to take longer than Leopold expects? Leopold suggests the data wall as the most plausible cause of stagnation. Can we crack the data wall by 2026, or will we stall? Dwarkesh asks, is it a coincidence that we happen to have about enough data to train models about powerful enough at 4.5-level to potentially kick off self-play? Leopold doesn’t directly answer but says 3 OOMs (orders of magnitude) less data would have been really rough, probably we needed to be within 1 OOM.
My intuition is that this is less coincidental than it looks and another of those equilibrium things. If you had less data you would find a way to get here more efficiently in data, or you had more data you would worry about data efficiency even less. Humans are super data efficient because we have to be.
Intiutively, at some point getting more data on the same distribution should not much matter, the same way duplicate data does not much matter. The new is decreasingly new. Also intiutively data helps you a lot more when you are not as capable as the thing generating the data, and a lot less once you match it, and that seems like it should matter more than it seems to. But of course I am not an ML researcher or engineer.
The part where something around human level is the minimum required for a model to maybe learn from itself? That’s definitely not a coincidence.
(3: 06: 30) Dwarkesh is still skeptical that too much of this is first principles and in theory, not in practice. Leopold says, maybe, we’ll find out soon. Run-time horizon of thinking will be crucial. Context windows help but aren’t enough. GPT-4 has had very large post-training gains over time, and 4-level is when tools become workable.
(3: 11: 00) What other domains are there where vast amounts of intelligence would accelerate you this same way this quickly? Could you have done it with flight? Leopold says there are limits, but yeah, decades of progress in a year, sure. The AI AI researchers help with many things, including robotics, you do need to try things in the physical world, although simulations are a thing too.
I have sometimes used the term ‘intelligence denialism’ for those who deny that pumping dramatically more intelligence into things would make much difference. Yes, there will still be some amount of bottlenecks, but unlimited intellectual directed firepower is a huge game.
(3: 14: 00) Magnitudes matter. If you multiply your AI firepower by 10 each year even now that’s a lot. Would be quite a knife’s edge story to think you need that to stay on track. Dwarkesh notices this is the opposite of the earlier story. Leopold says this a different magnitude change.
(3: 17: 30) Lot of uncertainty over the 2030s, but it’s going to be fing crazy. Dwarkesh asks, what happens if the new bigger models are more expensive? If they cost $100/hour of human output? Will we have enough compute for inference? Leopold notes GPT-4 now is cheaper than GPT-3 at launch, inference costs seem largely constant. And that this continuing seems plausible.
(3: 22: 15) Scaling laws keep working. Dwarkesh points out this is for the loss function they are trained on, but the new capabilities are different. Leopold thinks GPT-4 tokens are perhaps not that different from Leopold internal tokens. Leopold says it is not so crazy to think AGI within a year (!).
A question I have asked several times is, if you got this theoretical ‘minimum loss’ AI, what would it look like? What could it do? What could it not do? No one I have asked has good intuitions for this.
I think Leopold internal tokens are rather different from GPT-4 internal tokens. They are definitely very different in the sense that Leopold tokens are very different from Random Citizen tokens, and then more so.
This is a super frustrating segment. I did my best to give the benefit of the doubt and steelman throughout, and to gesture at the most salient problems without going too far down rabbit holes. I cite some problems here, but I mostly can only gesture and there are tons more I am skipping. What else can one do here?
(3: 27: 00) Leopold’s model is that alignment is an ordinary problem, just ensuring the machines do what we want them to do, not ‘some doomer’ problem about finding a narrow survivable space.
I wish it was that way. I am damn certain it’s the other way.
That does not mean it cannot be done, but… not with that attitude, no.
Ironically, I see Leopold here as severely lacking… situational awareness.
And yes, I mean that exactly the same way he uses the term.
(3: 27: 20) Dwarkesh asks, if your theory here is correct, should we not worry that alignment could fall into the wrong hands? That it could enable brainwashing, dictatorial control? Shouldn’t we keep this secret? Leopold says yes. Alignment is dual use, it enables the CCP bots, and how you get the USA bots to – and Zvi Mowshowitz is not making this up, it is a direct quote – “follow the Constitution, disobey unlawful orders, and respect separation of powers and checks and balances.”
I am going to give the benefit of the doubt based on discussion that follows, and assume that this is a proxy for ‘together with the ASIs we will design, decide on and enshrine a set of rules that promote human flourishing and then get the ASIs to enforce those rules’ and when stated like that (instead of a fetish for particular mechanism designs that are unlikely to make sense, and with sufficient flexibility) it is not utter lunacy or obviously doomed.
Leopold is at best still massively downplaying (as in by OOMs) how hard that is going to be to get to work. That does not mean we cannot pull it off.
It is a stunning amount of contempt for the problem and the dangers, or perhaps a supreme confidence in our victory (or actual ‘better dead than red’ thinking perhaps), to think that we should be locking down our alignment secrets so the Chinese do not get them. Yes, I get that there are ways this can turn Chinese wins into American wins. This still feels like something out of Dr. Strangelove.
That kind of goes double if you think the only way China catches up is if they steal our secrets anyway? So either they steal our secrets, in which case keeping alignment secret did not help, or they don’t, in which case it does not help because they lose either way? It is so, so hard to make this a good idea.
Keeping alignment secret is one good way to ensure zero cooperation and an all-out race to the finish line. Even I would do it if you tried that.
If this view of alignment is true, then given its failure to invest in this valuable dual use technology OpenAI is in a lot of trouble.
(3: 28: 30) Dwarkesh suggests future paths. Solving alignment shuts off the fully doomed paths like (metaphorical) paperclipping. Now it is humans making decisions. You can’t predict the future, but it will be human will not AI will, and it intensifies human conflicts. Leopold essentially agrees.
This ignores what I tried to call the ‘phase two’ problem. Phase one is the impossibly hard problem ‘solve alignment’ in the sense Leopold is thinking about it. For now, let’s say we do manage to solve it.
Then you have to set up a stable equilibrium, despite intense human competition over the future and resources and everything humans fight about, where humans stay in control. Where it is not the right (or chosen in practice even if wrong) move to steadily hand over control of the future, or to increasingly do things that risk loss of control or other catastrophically bad outcomes. Indeed, some will intentionally seek to put those on the table to get leverage, as humans have often done in the past.
Asking humanity to stay in charge of increasingly super superintelligence indefinitely is asking quite a lot. It is not a natural configuration of atoms. I would not go as far as Roman Yampolskiy who says ‘perpetual alignment is like a perpetual motion machine’ but there is wisdom in that. It is closer than I would like.
That is the problem scenario we want to have. That is still far from victory.
There are solutions that have been proposed, but at best and even if they work they all have big downsides. Imagining the good AI future is very hard even if you assume you live in a in many ways highly convenient world.
One hope is that with access to these ASIs, humans would be wiser, better able to coordinate and use decision theory, have a much bigger surplus to divide, and with those better imaginations we would come up with a much better solution than anything we know about now. This is the steelman of Leopold’s essentially punting on this question.
Synthesizing, the idea is that with ASI help we would come up with a rules set that would allow for such conflicts without allowing the move of putting human control in increasing danger. That presumably means, in its own way, giving up some well-chosen forms of control, the same way we live in a republic and not an anarchy.
(3: 29: 40) Dwarkesh brings up ‘the merge’ with superintelligence plus potential market style order. Asks about rights, brainwashing, red teaming, takeovers. Notes how similar proposed ‘alignment techniques’ sound to something out of Maoist cultural revolution techniques. Leopold says sentient AI is a whole different topic and it will be important how we treat them. He reiterates that alignment is ‘a technical problem with a technical solution.’
A subset of alignment is a technical problem with a technical solution. It is also a philosophical problem, and a design problem, and also other things.
It would still be a huge help if we were on track to solve the technical parts of the problem. We are not.
(3: 31: 25) Back to the Constitution. Leopold notes really smart people really believe in the Constitution and debate what it means and how to implement it in practice. We will need to figure out what the new Constitution looks like with AI police and AI military.
So the good news is this is at least envisioning a very different set of laws and rules than our current one that the AIs will be following under this plan. I am writing the above notes with the sane and expansive version of this as my assumption.
(3: 32: 20) Leopold says it is really important that each faction, even if you disagree with their values, gets their own AI, in a classical liberal way.
I see the very good reasons for this, but again, if you do this then the default thing that happens is the factions steadily turn everything over to their AIs. Humanity quickly loses control, after that it probably gets worse.
If you do not want that to happen, you have to prevent it from happening. You have to set up a design and an equilibrium that lets the factions do their thing without the loss of control happening. This is at best very hard.
Classical liberalism has been our best option, but that involves updating how it works to match the times. Where we have failed to do that, we have already suffered very greatly, such as entire nations unable to build houses.
That is all assuming that you did fully solve technical alignment.
(3: 33: 00) On the technical level, why so optimistic? Timelines could vary. Dwarkesh says GPT-4 is pretty aligned, Leopold agrees. Say you pull a crank to ASI. Does a sharp left turn happen? Do agents change things? Leopold questions the sharp left turn concept but yes there are qualitative changes all along the way. We have to align the automated researcher ourselves. Say you have the RL-story to get past the data wall and you get agents with long horizons. Pre-training is alignment neutral, it has representations of everything, it is not scheming against you. The long horizon creates the bigger problems. You want to add side constraints like don’t lie or commit fraud. So you want to use RLHF, but the problem is the systems get superhuman, so things are too complex to evaluate.
GPT-4’s alignment is not where we are going to need alignment to be.
This is a vision where alignment is a problem because there is a fixed set of particular things you do not want the AI to do. So you check a bunch of outputs to see if Bad Things are involved, thumbs down if you find one, then it stops doing the Bad Things until the outputs are so complex you cannot tell. Of course, that implies you could tell before.
To the extent that you could not tell before, or the simplest best model of your responses will fail outside distribution, or you did not consider potential things you would not like, or there are things in your actual decision process on feedback that you don’t endorse on reflection out of distribution, or there are considerations that did not come up, or there is any other solution to the ‘get thumbs up’ problem besides the one you intended, or the natural generalizations start doing things you did not want, you are screwed.
I could go on but I will stop there.
(3: 37: 00) Then you have the superintelligence part and that’s super scary. Failure could be really bad, and everything is changing extremely rapidly. Maybe initially we can read what the workers are thinking via chain of thought, but the more efficient way won’t let us do that. The thinking gets alien. Scary. But you can use the automated researchers to do alignment.
So the plan is ‘get the AIs to do our alignment homework,’ no matter how many times there are warnings that this perhaps the worst possible task to ask an AI to do on your behalf. It encompasses anything and everything, it involves so many complexities and failure modes, and so on.
(3: 39: 20) Dwarkesh says OpenAI started with people worried about exactly these things. Leopold interjects ‘but are they still there?’ A good nervous laugh. But yes, also some of the ones still there including Altman. There are still trade-offs made. Why should we be optimistic about national security people making those decisions without domain knowledge? Leopold says they might not be, but the private world is tough, the labs are racing and will get their stuff stolen. You need a clear lead. Leopold says he has faith in the mechanisms of a liberal society.
Look, I love classical liberalism far more than most next guys, but this sounds more and more like some kind of mantra or faith. Classical liberalism is based on muddling through, on experimentation and error correction, on being able to react slowly, and on the ‘natural’ outcome being good because economics is awesome that way. It is about using government to create incentive and mechanism design and not to trust it to make good decisions in the breach.
You can’t use that to have faith in a classical liberal government making good tactical or strategic alignment decisions in a rapidly moving unique situation. The whole point of classical liberal government is that when it makes terrible decisions it still turns out fine.
‘Vastly superior to all known alternatives and especially to the CCP’ should not be confused with a terminal value system.
(3: 41: 50) If evidence is ambiguous, as in many words it will be, that is where you need the safety margin.
If you have the levels of rigor described in this podcast, and the evidence looks unambiguous, you should worry quite a lot that you are not smart enough or methodical enough to not fool yourself and have made a mistake.
If you have the levels of rigor described in this podcast, and the evidence looks ambiguous, you almost certainly have not solved the problem and are about to lose control of the future with unexpected results.
This is one of those ‘no matter how many times you think you have adjusted for the rules above’ situations.
Leopold talks a lot about this ‘safety margin’ of calendar time. I agree that this is a very good thing to have, and can plausibly turn a substantial number of losses into wins. We very much want it. But what to do with it? How are you going to use this window to actually solve the problem? The assertion Leopold makes is that this is an ‘ordinary engineering’ problem, so time is all you need.
(2: 13: 12) How (the f did that happen? He really wanted out of Germany. German public school sucked, no elite colleges there, no opportunities for talent, no meritocracy. Have to get to America.
This is the future America [many people] want, alas, as they attack our remaining talent funnels and outlets for our best and brightest. School is a highly oppressive design for anyone smart even when they are trying to be helpful, because the main focus remains on breaking your will, discipline and imprisonment. I can only imagine this next level.
He loved college, liked the core curriculum, majored math/statistics/economics. In hindsight he would focus on finding the great professors teaching pretty much anything.
This is definitely underrated if you know which classes they are.
Columbia does not make it easy, between the inevitable 15+ AP credits and the 40 or so credit core curriculum and your 35-42 credit major there are not going to be many credits left to use on exploration.
(2: 16: 50) Leonard wrote at 17 a novel economic paper on economic growth and existential risk and it got noticed. To him, why wouldn’t you do that? He notices he has peak productivity times and they matter a lot. Dwarkesh notices that being bipolar or manic is common among CEOs.
(2: 18: 30) Why economics? Leopold notes economic thinking imbues what he does even now, straight lines on graphs. He loves the concepts but he’s down on economic academia, finding it decadent, its models too complex and fiddly. The best economic insights are conceptually very easy and intuitive once pointed out and then highly useful. Tyler Cowen warned Leopold off going to graduate school and steered him to Twitter weirdos instead, bravo.
I very much endorse this model of economics. Economics to me is full of simple concepts that make perfect sense once you are in the right frame of mind and can transform how you see the world and apply everywhere. Someone does have to apply it and go into the details.
The goal when reading an economics paper (or taking an economics course!) is to be a distillation learning algorithm that extracts the much shorter version that contains the actual crisp insights. If there is a 50 page economic paper and I have to read it all in order to understand it, it is almost never going to be all that interesting or important.
(2: 22: 10) Leopold says the best insights still require a lot of work to get the crisp insight.
Yes and no, for me? Sometimes the crisp insight is actually super intuitive and easy. Perhaps this is because one already ‘did the work’ of getting the right frame of mind, and often they did the work of searching the space.
A lot of my frustration with economists on AI seems to be a clash of crisp insights? They want to draw straight lines on historical linear graphs, apply historical patterns forward, demand particular models to various degrees, assume that anyone worrying about technological unemployment or other disruptive technology or runaway growth or unbridled competition and selection or having any confidence in smart actors to defeat Hayekian wisdom is being foolish.
They think this because inside their training samples of everything that ever happened, they’re right, and they’ve crystalized that in highly useful ways. Also like everyone else they find it hard (and perhaps scary) to imagine the things that are about to happen. They lack Leopold’s situational awareness. They look for standard economic reasons things won’t happen, demand you model this.
This actually parallels a key issue in machine learning and alignment, perhaps? You are training on the past to distill a set of heuristics that predicts future output. When the future looks like the past, and you are within distribution in the ways that count and the implicit assumptions hold well enough, this can work great.
However, what happens when those assumptions break? A lot of the dynamics we are counting on revolve around limitations of humans, and there not existing other things with different profiles whose capabilities match or dominate those of humans. Things turning out well for the humans relies on them being competitive, having something to offer, being scope limited with decreasing marginal returns, and having values and behaviors that are largely hardcoded. And on our understanding of the action space and physical affordances.
All of that is about to break if capabilities continue on their straight lines. A lot of it breaks no matter what, and then a lot more breaks when these new entities are no longer ‘mere tools.’
There is a new set of crisp insights that applies to such situations, that now seems highly intuitive to some people to a large extent, but it is like a new form of economics. And the same as a lot of people really don’t ‘get’ simple economic principles like supply and demand, even fewer people get the new concepts, and their brains largely work to avoid understanding.
So I have a lot of sympathy, but also come on everyone, stop being dense.
(2: 22: 20) Valedictorian is highest average grade, so average productivity, how did that happen here too? He loved all this stuff.
It is not only highest average, it is highly negative selection, very punishing. The moment I got my first bad grade in college I essentially stopped caring about GPA due to this, there was nothing to win.
(2: 24: 00) A key lesson of the horrible situation in Germany was that trying works. The people with agency become the people who matter.
(2: 25: 25) Life history, Leopold did a bit of econ research after college, then went to Future Fund, funded by SBF and FTX. Plan was for four people to move fast, break things and deploy billions to remake philanthropy. Real shame about FTX being a fraud and SBF doing all the crime, collapsing the whole thing overnight. He notes the tendency to give successful CEOs a pass on their behavior, and says it is important to pay attention to character.
(3: 42: 15) What was different about Germany or even all of Europe after WW2, versus other disasters that killed similar portions of populations? Why aren’t we discussing Europe in all this? Leopold is very bearish on Germany, although he still thinks Germany is top 5 and has strong state capacity. USA has creativity and a ‘wild west’ feeling you don’t see in Germany with its rule following and backlash against anything elite.
(3: 45: 00) Why turn against elitism? Response to WW2 was way harsher than WW1, imposition of new political systems, country in ruins, but it worked out better, maybe don’t wake the sleeping beast even if it is too sleepy.
I do not think it is obvious that the post-WW2 treatment was harsher. Imposing a ruinous debt burden is quite terrible, whereas after WW2 there was interest in making each side’s Germany prosperous. Destroying half the housing stock is terrible but it can be rebuilt.
(3: 46: 30) Chinese and German elite selection is very conformist, for better and worse. America is not like that. To Leopold China is worryingly impenetrable. What is the state of mind or debate? Dwarkesh is thinking about going to China, asking for help on that.
Those who warn or worry about China do not seem to think much of this dynamic. To me it seems like a huge deal. China’s system does not allow for exactly the types of cultural contexts and dynamics that are the secret of American progress in AI. For all the talk of how various things could cripple American AI or are holding it back, China is already doing lots of far more crippling things (to be clear, not for existential risk related reasons, unless maybe you mean existential to the regime).
Leopold’s model here does say China would have to steal the algorithms or weights to catch up, which reconciles this far more than most warnings.
(3: 50: 00) ByteDance cold emailed everyone on the Gemini paper with generous offers to try and recruit them. How much of the alpha from a lab could one such person bring? Leopold says a lot, if the person was intentional about it. Whereas China doesn’t let its senior AI researchers leave the country.
Sure, why not? Worth a shot. Plausibly should have bid ten times higher.
It is indeed scary what one of a large number of people could do here, less so if it has to all be in their head but even then. As Leopold says, we need to lock a variety of things down.
(3: 52: 30) What perspective is Leopold missing? Insight on China. How normal people in America will (or won’t) engage with AI, or react to it. Dwarkesh mentions Tucker Carlson’s mention that nukes are always immoral except when you use them on data centers to stop superintelligence that might enslave humanity. Political positions can flip. Technocratic proposals might not have space, it might be crude reactions only.
Unless I am missing something big: The more you believe we will do crude reactions later without ability to do anything else, the more you should push for technocratic solutions to be implemented now.
If you think the alternative to technocratic solutions now is technocratic solutions later, and later will let you know better what the right solution looks like, and you think a mistake now would get worse over time, and nothing too bad was going to happen soon, then it would make sense to wait. This goes double if you think a future very light touch is plausibly good enough.
However, if you think that the alternative to technocratic solutions now is poorly considered blunt solutions later, largely based on panic and emotion and short term avoidance of blame, then that does not make sense. You need to design things as best you can now, because you won’t get to design them later, especially if you have not laid groundwork.
This is especially true if failure to act now constrains our options in the future. Not locking down the labs now plausibly means much harsher actions later after things are stolen. Allowing actively dangerous future open models to be released in ways that cannot be undone, and especially failing to prevent an AI-caused or AI-enabled catastrophic event, could plausibly force a draconian response.
At minimum, we need desperately to push for visibility and nimble state capacity, so that we can know what is going on and what to do, and have the ability to choose technocratic solutions over blunt solutions. The option to do nothing indefinitely is not on the table even if there are no existential risks, the public wouldn’t allow it and neither would the national security state.
The parallel to Covid response may be helpful here. If you did not get proactive early, you paid the price later via politically forced overreactions, and got worse outcomes all around. There are a lot of metaphorical ‘we should not mandate investments in Covid testing’ positions running around, or even metaphorical calls to do as we actually did at first and try to ban testing.
Scott Sumner might use the example of monetary policy. Fail to properly adjust the expected future path rates as circumstances change, making policy too tight or loose, and you end up raising or lowering interest rates far more to fix the problem than you would have moved them if you had done it earlier.
(3: 55: 30) When the time comes, you will want the security guards.
(3: 55: 35) China will read Leopold’s paper too. What about the tradeoff of causing the issues you warn about? Cat is largely out of the bag, China already knows, and we need to wake up. Tough trade-off, he hopes more of us read it than they do.
This echoes questions rationalists and those worried about AI have thought about and dealt with for two decades now. To what extent might your warnings and efforts cause, worsen or accelerate the exact thing you are trying to prevent or slow down?
The answer was plausibly quite a lot. All three major labs (DeepMind, OpenAI and Anthropic) were directly founded in response to these concerns. The warnings about existential risk proved far more dangerous than the technical details people worried about sharing. Meanwhile, although I do think we laid foundations that are now proving highly useful as things move forward, those things we deliberately did not discuss plausibly held back our ability to make progress that would have helped, and were in hindsight unlikely to have made things worse in other ways. A key cautionary tale.
In this case, if Leopold believes his own model, he should worry that he is not only waking the CCP up to AGI and the stakes, he is also making cooperation even harder than it already was. If you are CCP and reading situational awareness, your hopes for cooperating with America are growing dim. Meanwhile, you are all but being told to go steal all our secrets before we wake up, and prepare to race.
There is a continual flux in Leopold’s talk, and I think his actual beliefs, between when he is being normative and when he is being descriptive. He says repeatedly that his statements are descriptive, that he is saying The Project (national effort to build an ASI) will happen, rather than that it should happen. But at other times he very clearly indicates he thinks it also should happen. And at times like this, he indicates that he is worried that it might not happen, and he wants to ensure that it happens, not merely steer the results of any such project in good directions. Mostly I think he is effectively saying both that the path he predicts is going to happen, and also that it is good and right, and that we should do it faster and harder.
(3: 57: 50) Dwarkesh’s immigration story. He got here at 8 but he came very close to being kicked out at 21 and having to start the process again. He only got his green card a few months before the deadline for highly contingent reasons. Made Dwarkesh realize he needed to never be a code monkey, which was otherwise his default path. Future Fund giving him $20k and several other contingent things helped Dwarkesh stay on his path.
The whole thing is totally nuts. Everyone agrees (including both parties) that we desperately need lots more high skill immigration and to make the process work, things would be so much better in every way, in addition to helping with AI. If we want to have a great country, to ‘beat China’ in any sense, this should be very high up on our priorities list and is plausibly at the top. Why do we only grant 20% of HB-1 visas? Why do we kick graduates of our colleges out of the country? Very few people actually want these things.
Yet the fix does not happen, because to ‘make a deal’ on immigration in general is impossible due to disagreements about low skill immigration, and the parties are unable to set that aside and deal with this on its own. Their bases will not let them, or they think it would be unstrategic, and all that.
Standard exhortations to ‘lock the people in a room’ and what not until this happens, or to use executive power to work around much of this.
Spending in the high leverage spots is so amazingly better. $20k!
(4: 03: 15) Convert to mormonism for real if you could? Leopold draws parallel of a mormon outside Utah to being an outsider in Germany, giving you strength. He also notes the fertility rate question and whether isolation can scale. Notes the value of believing in and serving something greater than yourself.
(4: 06: 20) At OpenAI, Dwarkesh notes that plenty of financially ironclad employees had to have similar concerns, but only Leopold, a 22-year-old with less than a year there and little in savings, made a fuss.
(4: 08: 00) Leopold is launching one. Why? The post-AGI period will be important and there is a lot of money to be made. It gives freedom and independence. Puts him in a position to advise.
I have not seen good outcomes so far from ‘invest to have a seat at the table.’
If you are investing betting on AGI, I think you will have very good expected returns in dollars. That does not obviously mean you have high expected returns in utility. Ask in what worlds money has how much marginal utility.
Also ask what impact your investing has on the path to AGI. Many companies are already saturated with capital, if you buy Nvidia stock they do not then invest more money in making chips. Startups are different. Leopold of course might say that is good actually.
(4: 11: 15) Worried about timing? Not blowing up is important. They will bet on fast AGI, otherwise firm will not do well. Sequence of bets is critical. Last year Nvidia was the only real play. In the future utilities and companies like Google get involved but right now they are not so big on AI. He expects high interest rates (perhaps >10% by end of the decade) creating tailwinds on stocks, higher growth rates might not depress stocks. Nationalization. The big short on bonds. Bets on the tails.
There are a lot of different ways to play this sort of situation.
If you want to get maximum effective leverage and exposure, then yes in many ways you will become progressively more exposed to timing and getting the details right.
If you are willing to take a more conservative approach and use less leverage in multiple senses, you can get a less exposure but still a lot of exposure to the underlying factors without also being massively exposed to the timing and details. You can make otherwise solid plays. That’s my typical move.
(4: 16: 15) Dwarkesh asks the important question of whether your property rights will be respected in these worlds. Will your Fidelity account be worth anything? Leopold thinks yes, until the galaxy rights phase.
Leopold does not express how certain he is here. I certainly would not be so confident. The history of property rights holding under transformations is not that great and this is going to be far crazier. Even if they technically hold, one should not assume that will obviously matter.
(1: 16: 45) A lot of the idea is Leopold wants to get capital to have influence. Dwarkesh notes the ‘landed gentry’ from before the industrial revolution did not get great returns, and most benefits from progress were diffused. Leopold notes that the actual analogue is you would sell your land and invest it in industry. Whereas human capital is going to decay rapidly, so this is a hedge.
The good news is that the landed gentry in many places survived intact and did fine. Others now have more money, but they do not obviously have less. In other places, of course, not so much, but you had a shot.
I do think the hedge on human capital depreciation argument has merit. If AGI does not arrive and civilization continues, then anyone with strong human capital does not need that much financial capital, especially if you are as young as Leopold. We wouldn’t like it and it would be insane to get into such a position, but if necessary most of us could totally pull an ‘if.’
Whereas if you think AGI means there is lots of wealth and production but your human capital is worthless, They Took Our Jobs comes for Leopold, but you expect property rights to hold and people to mostly be fine, then yes you might highly value having enough capital. The UBI might not show up and it might not be that generous, and there might be wonders for sale. Note that a lot of the value here is a threshold wealth effect where you can survive.
(4: 18: 30) The economist or Tyler Cowen question: Why has AGI not been priced in? Aren’t markets efficient? Leopold used to be a true EMH (efficient markets hypothesis) guy, but has changed his mind. Groups can have alpha in seeing the future, similar to Covid. Not many people take these ideas seriously.
In a sense this begs the question. The market is failing to price it in because the market is failing to price it in. But also that is a real answer. It is an explicit rejection, which I share, of the EMH in spots like this. Yes, we have enough information to say the market is being bonkers. And yes, we know why we are able to make this trade, the market is bonkers because society is asleep at the wheel on this, and the market is made up of those people. Those who know do not have that much capital.
Rather than offer additional arguments I will say this all seems straightforwardly and obviously true at this point.
On AI in particular, the market and economic forecasts are not even pricing in the sane bear case for AI, let alone pricing in potential AGI.
Your periodic reminder: Substantial existential risk does not change this so much. If the world ends with 50% probability, then you factor that in. That does not mean that in those worlds that the world will ‘wake up’ to the situation and crash the market or otherwise give you an opportunity, see market prices during the Cuban Missile Crisis to show that even everyone knowing about such dangers did not move things much. And it does not mean that, even if you could indeed make a lot of money this way, you would have had anything useful to do with money before the end. If the universe definitely ends in a month no matter what I do, giving me a trillion dollars would be of little utility. What would I do with it that I can’t do already?
(4: 20: 00) Why did the Allies make better overall decisions than the Axis? Leopold thinks Blitzkrieg was forced, because they could not win a long war industrially. The invasion of Russia was about the resources needed to fight the West, especially oil. Lots of men died in the Eastern front but German industrial might largely was directed West.
(4: 22: 00) China builds like 200 times more ships than we do. Over time in a war China could mobilize industrial resources better than we could. Or for AI if this all came down to a building game.
We don’t build ships because of the Jones Act. Yes, it claims to be protecting American shipbuilding, but it destroyed it instead through lack of competition, now we simply don’t have any ships. And we also can’t buy them from Japan and South Korea and Europe for the same reason. This is all very dumb, but also the important thing is that we need the ships, not to build the ships. Donate to Balsa Research today to help us repeal the Jones Act.
This is a very strange view of a potential future war, where both sides mobilize their industrial might over years in a total war fashion without things going nuclear, and where America is presumably largely cut off from trade and allies. We cannot rule that scenario out, but it is super weird, no?
I would not count out American industrial might in a long war. Right now we make plenty of things when it would make economic sense to do so and we make doing so legal. But we do not make many other things because it is not in our economic interest to make those things, and because we often make it illegal or prohibitively annoying and expensive and slow to make things. That is a set of choices we could reverse.
Also in this scenario, America would have a large AI advantage over China, and no I do not think some amount of espionage will do it.
Could we still get outproduced long term by China with its much larger population? Absolutely, but people keep betting against America in these situations and they keep losing.
(4: 23: 15) Leopold asks, will we let the robot factories and robot armies run wild? He says we won’t but maybe China will.
Seriously, why are we assuming America will definitely act all responsible and safe in these situations, but thinking China might not?
I wonder if Leopold has read The Doomsday Machine. We do not exactly have a great track record of making war plans that would not cause an apocalypse.
(4: 23: 55) What do you do with industrial strength ASI? Not (only) chatbots. Oil transformed America before we even invented cars. What do we do once we have our intelligence explosion and lots of compute? How will everyone react.
(4: 26: 50) Changing your mind is really important. Leopold says many ‘doomers’ were prescient early, but have not updated to the realities of deep learning, their proposals are naive and don’t make sense, people come in with a predefined ideology.
Shots. Fired.
I know who talks about changing their mind and works on it a lot and I see doing it a lot, and who I do not. I will let you judge.
I see lots of the proposals by many on alignment, including Leopold here and in his paper, as being naive and not making sense and not reflecting the underlying realities, so there you go.
On ‘the realities of deep learning’ I think there are some people making this mistake, but more common is accusing people of making this mistake without checking if the mistake is being made. Or claiming that the update that can be made without being an engineer at a top lab is not the true update, you can’t know what it is like without [whatever thing you haven’t done].
Also this ‘update on realities’ is usually code for saying: I believe all future systems will of course be like current systems, except more intelligent, there is only empiricism and curve extrapolation. Anyone who thinks that is not true, they are saying, is hopelessly naive and not getting with the zeitgeist.
(4: 27: 15) Leopold notes e/accs shitpost but they are not thinking through the technology.
Well, yes.
(4: 27: 25) There is risk in writing down your worldview. You get attached to it. So he wants to be clear that painting a concrete picture is valuable, and that this is Leopold’s best guess for the next decade, and anything like this will be wild. But we will learn more soon, and will need to update and stay sane.
Yes, strongly endorsed. I am very happy Leopold wrote down what he actually believes and was highly concrete about it. This is The Way. And yes, one big danger is that this could make it difficult for Leopold to change his mind when the situation changes or he hears better arguments or thinks more. It is good that he is noticing that too.
But the scariest realization is that there is no crack team coming to handle this. As a kid you have this glorified view of the world, that when things get real there are the heroic scientists, the uber- competent military men, the calm leaders who are on it, who will save the day. It is not so. The world is incredibly small; when the facade comes off, it’s usually just a few folks behind the scenes who are the live players, who are desperately trying to keep things from falling apart.
Enlarge/ A Diamond Shruumz chocolate bar, which come in a variety of flavors.
Various federal and state health officials are sounding the alarm on Diamond Shruumz-brand Microdosing Chocolate Bars. The candy, said to be infused with mushrooms, has been linked to severe illnesses, including seizures, loss of consciousness, confusion, sleepiness, agitation, abnormal heart rates, hyper/hypotension, nausea, and vomiting, according to an outbreak alert released by the Food and Drug Administration on Friday.
So far, eight people across four states have been sickened—four in Arizona, two in Indiana, one in Nevada, and one in Pennsylvania, the FDA reported. Of the eight, six have been hospitalized.
“We are urging the public to use extreme caution due to the very serious effects of these products,” Maureen Roland, director of the Banner Poison and Drug Information Center in Phoenix, said in a press release earlier this week.
Steve Dudley, director of the Arizona Poison and Drug Information Center, added that there’s “clearly something toxic occurring” with the chocolates. “We’ve seen the same phenomenon of people eating the chocolate bar then seizing, losing consciousness, and having to be intubated.” Dudley noted that the state is aware of additional cases beyond the eight reported Friday by the FDA. Those cases were reported from Nebraska and Utah.
It’s not entirely clear what is in the chocolates or what could be causing the illnesses. The FDA said it was working with the Centers for Disease Control and Prevention as well as America’s Poison Centers to “determine the cause of these illnesses and is considering the appropriate next steps.”
On its website, Diamond Shruumz says that its chocolate bars contain a “primo proprietary blend of nootropic and functional mushrooms.” The website also contains reports of laboratory analyses on their products, some of which indicate the absence of select known fungal toxins and compounds such as the hallucinogen psilocybin and cannabinoids.
Diamond Shruumz did not immediately respond to Ars’ request for comment.
The chocolate bars are still available for sale online but the FDA said that consumers should not eat, sell, or serve them. Any bars already purchased should be discarded. Likewise, retailers should not sell or distribute them. The FDA noted that, in addition to being available online, the bars are also sold in various retail locations nationwide, including smoke/vape shops and retailers that sell hemp-derived products.
Google has achieved its goal of avoiding a jury trial in one antitrust case after sending a $2.3 million check to the US Department of Justice. Google will face a bench trial, a trial conducted by a judge without a jury, after a ruling today that the preemptive check is big enough to cover any damages that might have been awarded by a jury.
“I am satisfied that the cashier’s check satisfies any damages claim,” US District Judge Leonie Brinkema said after a hearing in the Eastern District of Virginia on Friday, according to Bloomberg. “A fair reading of the expert reports does not support” a higher amount, Brinkema said.
The check was reportedly for $2,289,751. “Because the damages are no longer part of the case, Brinkema ruled a jury is no longer needed and she will oversee the trial, set to begin in September,” according to Bloomberg.
The payment was unusual, but so was the US request for a jury trial because antitrust cases are typically heard by a judge without a jury. The US argued that a jury should rule on damages because US government agencies were overcharged for advertising.
The US opposed Google’s motion to strike the jury demand in a filing last week, arguing that “the check it delivered did not actually compensate the United States for the full extent of its claimed damages” and that “the unilateral offer of payment was improperly premised on Google’s insistence that such payment ‘not be construed’ as an admission of damages.”
The government’s damages expert calculated damages that were “much higher” than the amount cited by Google, the US filing said. In last week’s filing, the higher damages amount sought by the government was redacted.
Lawsuit targets Google advertising
The US and eight states sued Google in January 2023 in a lawsuit related to the company’s advertising technology business. There are now 17 states involved in the case.
Google’s objection to a jury trial said that similar antitrust cases have been tried by judges because of their technical and often abstract nature. “To secure this unusual posture, several weeks before filing the Complaint, on the eve of Christmas 2022, DOJ attorneys scrambled around looking for agencies on whose behalf they could seek damages,” Google said.
The US and states’ lawsuit claimed that Google “corrupted legitimate competition in the ad tech industry” in a plan to “neutralize or eliminate ad tech competitors, actual or potential, through a series of acquisitions” and “wield its dominance across digital advertising markets to force more publishers and advertisers to use its products while disrupting their ability to use competing products effectively.”
The US government lawsuit said that federal agencies bought over $100 million in advertising since 2019 and aimed to recover treble damages for Google’s alleged overcharges on those purchases. But the government narrowed its claims to the ad purchases of just eight agencies, lowering the potential damages amount.
Google sent the check in mid-May. While the amount wasn’t initially public, Google said it contained “every dollar the United States could conceivably hope to recover under the damages calculation of the United States’ own expert.” Google also said it “continues to dispute liability and welcomes a full resolution by this Court of all remaining claims in the Complaint.”
US: We want more
The US disagreed that $2.3 million was the maximum it could recover. “Under the law, Google must pay the United States the maximum amount it could possibly recover at trial, which Google has not done,” the US said. “And Google cannot condition acceptance of that payment on its assertion that the United States was not harmed in the first place. In doing so, Google attempts to seize the strategic upside of satisfying the United States’ damages claim (potentially allowing it to avoid judgment by a jury) while at the same time avoiding the strategic downside of the United States being free to argue the common-sense inference that Google’s payment, is, at minimum, an acknowledgment of the harm done to federal agency advertisers who used Google’s ad tech tools.”
In a filing on Wednesday, Google said the DOJ previously agreed that its claims amounted to less than $1 million before trebling and pre-judgment interest. The check sent by Google was for the exact amount after trebling and interest, the filing said. But the “DOJ now ignores this undisputed fact, offering up a brand new figure, previously uncalculated by any DOJ expert, unsupported by the record, and never disclosed,” Google told the court.
Siding with Google at today’s hearing, Brinkema “said the amount of Google’s check covered the highest possible amount the government had sought in its initial filings,” the Associated Press reported. “She likened receipt of the money, which was paid unconditionally to the government regardless of whether the tech giant prevailed in its arguments to strike a jury trial, as equivalent to ‘receiving a wheelbarrow of cash.'”
While the US lost its attempt to obtain more damages than Google offered, the lawsuit also seeks an order declaring that Google illegally monopolized the market. The complaint requests a breakup in which Google would have to divest “the Google Ad Manager suite, including both Google’s publisher ad server, DFP, and Google’s ad exchange, AdX.”
Elon Musk, back in October 2021, tweeted that “humans drive with eyes and biological neural nets, so cameras and silicon neural nets are only way to achieve generalized solution to self-driving.” The problem with his logic has been that human eyes are way better than RGB cameras at detecting fast-moving objects and estimating distances. Our brains have also surpassed all artificial neural nets by a wide margin at general processing of visual inputs.
To bridge this gap, a team of scientists at the University of Zurich developed a new automotive object-detection system that brings digital camera performance that’s much closer to human eyes. “Unofficial sources say Tesla uses multiple Sony IMX490 cameras with 5.4-megapixel resolution that [capture] up to 45 frames per second, which translates to perceptual latency of 22 milliseconds. Comparing [these] cameras alone to our solution, we already see a 100-fold reduction in perceptual latency,” says Daniel Gehrig, a researcher at the University of Zurich and lead author of the study.
Replicating human vision
When a pedestrian suddenly jumps in front of your car, multiple things have to happen before a driver-assistance system initiates emergency braking. First, the pedestrian must be captured in images taken by a camera. The time this takes is called perceptual latency—it’s a delay between the existence of a visual stimuli and its appearance in the readout from a sensor. Then, the readout needs to get to a processing unit, which adds a network latency of around 4 milliseconds.
The processing to classify the image of a pedestrian takes further precious milliseconds. Once that is done, the detection goes to a decision-making algorithm, which takes some time to decide to hit the brakes—all this processing is known as computational latency. Overall, the reaction time is anywhere between 0.1 to half a second. If the pedestrian runs at 12 km/h they would travel between 0.3 and 1.7 meters in this time. Your car, if you’re driving 50 km/h, would cover 1.4 to 6.9 meters. In a close-range encounter, this means you’d most likely hit them.
Gehrig and Davide Scaramuzza, a professor at the University of Zurich and a co-author on the study, aimed to shorten those reaction times by bringing the perceptual and computational latencies down.
The most straightforward way to lower the former was using standard high-speed cameras that simply register more frames per second. But even with a 30-45 fps camera, a self-driving car would generate nearly 40 terabytes of data per hour. Fitting something that would significantly cut the perceptual latency, like a 5,000 fps camera, would overwhelm a car’s onboard computer in an instant—the computational latency would go through the roof.
So, the Swiss team used something called an “event camera,” which mimics the way biological eyes work. “Compared to a frame-based video camera, which records dense images at a fixed frequency—frames per second—event cameras contain independent smart pixels that only measure brightness changes,” explains Gehrig. Each of these pixels starts with a set brightness level. When the change in brightness exceeds a certain threshold, the pixel registers an event and sets a new baseline brightness level. All the pixels in the event camera are doing that continuously, with each registered event manifesting as a point in an image.
This makes event cameras particularly good at detecting high-speed movement and allows them to do so using far less data. The problem with putting them in cars has been that they had trouble detecting things that moved slowly or didn’t move at all relative to the camera. To solve that, Gehrig and Scaramuzza went for a hybrid system, where an event camera was combined with a traditional one.
Enlarge/ What can I say? It was tough putting the Brompton C Line Electric through its paces. Finding just the right context for it. Grueling work.
Kevin Purdy
There’s never been a better time to ride a weird bike.
That’s especially true if you live in a city where you can regularly see kids being dropped off at schools from cargo bikes with buckets, child seats, and full rain covers. Further out from the urban core, fat-tire e-bikes share space on trails with three-wheelers, retro-style cruisers, and slick roadies. And folding bikes, once an obscurity, are showing up in more places, especially as they’ve gone electric.
So when I got to try out the Brompton Electric C Line (in a six-speed model), I felt far less intimidated riding, folding, and stashing the little guy wherever I went than I might have been a few years back. A few folks recognized the distinctively small and British bike and offered a thumbs-up or light curiosity. If anyone was concerned about the oddity of this quirky ride, it was me, mostly because I obsessed over whether I could and should lock it up outside or not.
But for the most part, the Brompton fits in, and it works as a bike. It sat next to me at bars and coffee shops and outdoor eateries, it rode the DC Metro, it went on a memorial group ride, and it went to the grocery store. I repeatedly hauled it to a third-floor walkup apartment and brought it on a week’s vacation, fitting it on the floor behind the car driver’s seat. And with an electric battery pack, it was even easier to forget that it was any different from a stereotypical bike—so long as you didn’t look down.
Still, should you pay a good deal more than $3,000 (and probably more like $4,000 after accessories) for a bike with 16-inch tires—especially one you might never want to leave locked up outside?
Let’s get into that.
The Brompton C Line, pre-fold (mid-beer).
Kevin Purdy
Step 1: Release a clasp and pull the bike frame up, allowing the rear wheel to swing forward underneath.
Kevin Purdy
Step 2: Loosen the clamp and fold the front half back to align with the rear wheel, lining up a little hook on the wheel with the frame.
Kevin Purdy
Step 3: Remove the battery (technically unnecessary, but wise), loosen a clamp holding up the handlebar, then fold it down onto the frame, letting a nub tuck into a locking notch.
Kevin Purdy
Step 4: Drop down the seat (which also locks the frame into position), rotate one pedal onto the tire, and flip the other pedal up.
Kevin Purdy
Learning The Fold
Whether you buy it at a store or have it shipped to you, a Brompton C Line is possibly the easiest e-bike to unpack, set up, and get rolling. You take out the folded-up bike, screw in the crucial hinge clamps that hold it together, put on the saddle, and learn how to unfold it for the first time. Throw some air in the tires, and you could be on your way about 20 minutes after getting the bike.
But you shouldn’t head out without getting some reps in on The Fold. The Fold is the reason the Brompton exists. It hasn’t actually changed that much since Andrew Ritchie designed it in 1975. Release a rear frame clip and yank the frame up, and the rear wheel and its frame triangle roll underneath the top tube. Unscrew a hinged clamp, then “stir” the front wheel backward, allowing a subtle hook to catch on the rear frame. Drop the seat and you’ll feel something lock inside the frame. You can then unhinge and fold the handlebar down, or you can keep it up to push the bike around on its tiny frame wheels in “shopping cart mode.”
If you forget the sequence of the fold, there are little reminders in a few spots on the bike.
Kevin Purdy
After maybe five attempts, I began to get The Fold done in less than a minute. After around a dozen tries, I started to appreciate its design and motions. The way a Brompton folds up is great for certain applications, like fitting into a car instead of using a rack, bringing on public transit or train rides, tucking underneath a counter or table, or fitting into the corner of the most space-challenged home. It can also be handy if you’re heading somewhere you’re wary of locking it up outside (more on that in a moment).
2K Games is expected to show the first trailer footage of the upcoming Civilization VII as part of this weekend’s Summer Games Fest marketing extravaganza after a logo for the game leaked on 2K’s website this morning.
Eagle-eyed gamers at ResetEra and Reddit both noticed the Civ VII banner atop the publisher’s official site early this morning, alongside a “Coming Soon” label and inactive links to a trailer and wishlist page. The appearance comes just ahead of the trailer-filled Summer Games Fest livestream, which will premiere at 5 pm Eastern Friday afternoon.
In May, the Summer Games Fest Twitter account teased that 2K would be using the event “to reveal the next iteration in one of [its] biggest and most beloved franchises.” Civilization VII now seems primed to fill that pre-announced slot, which may be unwelcome news for fans of 2K-owned franchises like Borderlands, Bioshock, and NFL2K (which was first publicly mulled for a revival in 2020).
Last year, developer Firaxis announced that it had started development on the “next mainline game in the world-famous Sid Meier’s Civilization franchise,” under the guidance of Civilization VI Creative Director Ed Beach and newly promoted studio head Heather Hazen (who previously worked with Epic Games and Popcap). “We have plans to take the Civilization franchise to exciting new heights for our millions of players around the world,” Hazen said in a statement at the time.
Enlarge/Civilization namesake Sid Meier holds forth with fans at a Firaxicon fan gathering in 2014.
Kyle Orland
Civilization VII will be the first entry in the storied strategy franchise in at least eight years, a historically long gap for a series that has seen a new numbered entry every four to six years since its debut in 1991. When Civilization VI hit in 2016, we praised the game for its smoother, more easily accessible interface and focus on fraught decision-making.
In an interview with Ars just after the launch of Civ VI, series namesake Sid Meier said his official role as franchise director has evolved over the years into more of a support structure for younger designers. “I’m there to kind of represent the history of the game,” Meier told Ars. “My role is just to be supportive. Designers have huge egos, and they’re easily bruised. Making a game can be a painful process. Part of my role is to be encouraging—’that idea didn’t work, try something else.'”
Launched in 2000, the Zvezda Service Module provides living quarters and performs some life-support system functions.
NASA
NASA and the Russian space agency, Roscosmos, still have not solved a long-running and worsening problem with leaks on the International Space Station.
The microscopic structural cracks are located inside the small PrK module on the Russian segment of the space station, which lies between a Progress spacecraft airlock and the Zvezda module. After the leak rate doubled early this year during a two-week period, the Russians experimented with keeping the hatch leading to the PrK module closed intermittently and performed other investigations. But none of these measures taken during the spring worked.
“Following leak troubleshooting activities in April of 2024, Roscosmos has elected to keep the hatch between Zvezda and Progress closed when it is not needed for cargo operations,” a NASA spokesperson told Ars. “Roscosmos continues to limit operations in the area and, when required for use, implements measures to minimize the risk to the International Space Station.”
What are the real risks?
NASA officials have downplayed the severity of the leak risks publicly and in meetings with external stakeholders of the International Space Station. And they presently do not pose an existential risk to the space station. In a worst-case scenario of a structural failure, Russia could permanently close the hatch leading to the PrK module and rely on a separate docking port for Progress supply missions.
However, there appears to be rising concern in the ISS program at NASA’s Johnson Space Center in Houston. The space agency often uses a 5×5 “risk matrix” to classify the likelihood and consequence of risks to spaceflight activities, and the Russian leaks are now classified as a “5” both in terms of high likelihood and high consequence. Their potential for “catastrophic failure” is discussed in meetings.
In responding to questions from Ars by email, NASA public relations officials declined to make program leaders available for an interview. The ISS program is currently managed by Dana Weigel, a former flight director. She recently replaced Joel Montalbano, who became deputy associate administrator for the agency’s Space Operations Mission Directorate at NASA Headquarters in Washington.
One source familiar with NASA’s efforts to address the leaks confirmed to Ars that the internal concerns about the issue are serious. “We heard that basically the program office had a runaway fire on their hands and were working to solve it,” this person said. “Joel and Dana are keeping a lid on this.”
US officials are likely remaining quiet about their concerns because they don’t want to embarrass their Russian partners. The working relationship has improved since the sacking of the pugnacious leader of Russia’s space activities, Dmitry Rogozin, two years ago. The current leadership of Roscosmos has maintained a cordial relationship with NASA despite the high geopolitical tensions between Russia and the United States over the war in Ukraine.
The leaks are a sensitive subject. Because of Russian war efforts, the resources available to the country’s civil space program will remain flat or even decrease in the coming years. A dedicated core of Russian officials who value the International Space Station partnership are striving to “make do” with the resources they have to maintain its Soyuz and Progress spacecraft, which carry crew and cargo to the space station respectively, and its infrastructure on the station. But they do not have the ability to make major new investments, so they’re left with patching things together as best they can.
Aging infrastructure
At the same time, the space station is aging. The Zvezda module was launched nearly a quarter of a century ago, in July 2000, on a Russian Proton rocket. The cracking issue first appeared in 2019 and has continued to worsen since then. Its cause is unknown.
“They have repaired multiple leak locations, but additional leak locations remain,” the NASA spokesperson said. “Roscosmos has yet to identify the cracks’ root cause, making it challenging to analyze or predict future crack formation and growth.”
NASA and Russia have managed to maintain the space station partnership since Russia’s invasion of Ukraine in February 2022. The large US segment is dependent on the Russian segment for propulsion to maintain the station’s altitude and maneuver to avoid debris. Since the invasion, the United States could have taken overt steps to mitigate against this, such as funding the development of its own propulsion module or increasing the budget for building new commercial space stations to maintain a presence in low-Earth orbit.
Instead, senior NASA officials chose to stay the course and work with Russia for as long as possible to maintain the fragile partnership and fly the aging but venerable International Space Station. It remains to be seen whether cracks—structural, diplomatic, or otherwise—will rupture this effort prior to the station’s anticipated retirement date of 2030.
June 2023 did not seem like an exceptional month at the time. It was the warmest June in the instrumental temperature record, but monthly records haven’t exactly been unusual in a period where the top 10 warmest years on record have all occurred within the last 15 years. And monthly records have often occurred in years that are otherwise unexceptional; at the time, the warmest July on record had occurred in 2019, a year that doesn’t stand out much from the rest of the past decade.
But July 2023 set another monthly record, easily eclipsing 2019’s high temperatures. Then August set yet another monthly record. And so has every single month since, a string of records that propelled 2023 to the warmest year since we started keeping track.
Yesterday, the European Union’s Copernicus Earth-monitoring service announced that we’ve now gone a full year where every single month has been the warmest version of that month since we’ve had enough instruments in place to track global temperatures.
Enlarge/ History monthly temperatures show just how extreme the temperatures have been over the last year.
As you can see from this graph, most years feature a mix of temperatures, some higher than average, some lower. Exceptionally high months tend to cluster, but those clusters also tend to be shorter than a full year.
In the Copernicus data, a similar year-long streak of records happened once before (recently, in 2015/2016). NASA, which uses slightly different data and methods, doesn’t show a similar streak in that earlier period. NASA hasn’t released its results for May’s temperatures yet—they’re expected in the next few days. But it’s very likely that NASA will also show a year-long streak of records.
Beyond records, the EU is highlighting the fact that the one-year period ending in May was 1.63° C above the average temperatures of the 1850–1900 period, which are used as a baseline for preindustrial temperatures. That’s notable because many countries have ostensibly pledged to try to keep temperatures from exceeding 1.5° above preindustrial conditions by the end of the century. While it’s likely that temperatures will drop below the target again at some point within the next few years, the new records suggest that we have a very limited amount of time before temperatures persistently exceed it.
Enlarge/ For the first time on record, temperatures have held steadily in excess of 1.5º above the preindustrial average.
Realistically, those plans involve overshooting the 1.5° C target by midcentury but using carbon capture technology to draw down greenhouse gas levels. Exceeding that target earlier will mean that we have more carbon dioxide to pull out of the atmosphere, using technology that hasn’t been demonstrated anywhere close to the scale that we’ll need. Plus, it’s unclear who will pay for the carbon removal.
The extremity of some of the monthly records—some months have come in a half-degree C above any earlier month—are also causing scientists to look for reasons. But so far, the field hasn’t come to a consensus regarding the sudden surge in temperature extremes.
Because it has been accompanied by significant warming of ocean temperatures, a lot of attention has focused on changes to pollution rules for international shipping, which are meant to reduce sulfur emissions. These went into effect recently and have cut down on the emission of aerosols by cargo vessels, reducing the amount of sunlight that’s reflected back to space.
That’s considered likely to be a partial contributor. A slight contribution may have also come from the Hunga Tonga eruption, which blasted significant amounts of water vapor into the upper atmosphere, though nowhere near enough to explain this warming. Beyond that, there are no obvious explanations for the recent warmth.
Enlarge/ The R1S and R1T don’t look much different from the electric trucks we drove in 2022, but under the skin, there have been a lot of changes.
Rivian
In rainy Seattle this week, Rivian unveiled what it’s calling the “Second Generation” of its R1 line with a suite of mostly under-the-hood software and hardware updates that increase range, power, and efficiency while simultaneously lowering the cost of production for the company. While it’s common for automotive manufacturers to do some light refreshes after about four model years, Rivian has almost completely retooled the underpinnings of its popular R1S SUV and R1T pickup just two years after the vehicles made their debut.
“Overdelivering on the product is one of our core values,” Wassym Bensaid, the chief software officer at Rivian, told a select group of journalists at the event on Monday night, “and customer feedback has been one of the key inspirations for us.”
For these updates, Rivian changed more than half the hardware components in the R1 platform, retooled its drive units to offer new tri- and quad-motor options (with more horsepower), updated the suspension tuning, deleted 1.6 miles (2.6 km) of wiring, reduced the number of ECUs, increased the number of cameras and sensors around the vehicle, changed the battery packs, and added some visual options that better aligned with customizations that owners were making to their vehicles, among other things. Rivian is also leaning harder into AI and ML tools with the aim of bringing limited hands-free driver-assistance systems to their owners toward the end of the year.
Usually, an automaker waits four years before it refreshes a product, but Rivian decided to move early.
Rivian
The R1 interior can feel quite serene.
Rivian
Perhaps you’d prefer something more colorful?
Rivian
An exploded view of a drive unit with a pair of motors.
Rivian
There are two capacities of lithium-ion battery, and an optional lithium iron phosphate pack with 275 miles of range is on the way.
Rivian’s R1 still looks friendly amid a sea of scary-looking SUVs and trucks.
Rivian
While many of these changes have simplified manufacturing for Rivian, which as of Q1 of this year lost a whopping $38,000 on every vehicle it sold, the company has continued to close the gap with the likes of BMW and Mercedes in terms of ride, handling, comfort, and efficiency.
On the road in the new R1
We drove a new second-gen dual-motor 665 hp (496 kW), 829 lb-ft (1,124 Nm) R1S Performance, which gets up to 410 miles (660 km) of range with the new Max Pack battery, out to DirtFish Rally School in Snoqualmie in typically rainy Seattle weather. On the road, the new platform, with its revised suspension and shocks, felt much more comfortable than it did in our first experience with an R1S in New York in 2022.
The vehicle offers modes that allow you to tackle pretty much any kind of driving that life can throw at you, including Sport, All Purpose (there’s no longer a “Conserve” mode), Snow, All-Terrain, and Soft Sand, alongside customizable suspension, ride feel and height, and regen settings. The R1S feels far more comfortable from all seating positions, including the back and third-row seats. There’s less floaty, car-sick-inducing modulation over bumps in All-Purpose, and Sport tightens things down nicely when you want to have a bit more road feel.
One of the big improvements on the road comes from the new “Autonomy Compute Module” and its suite of high-resolution 4K HDR cameras, radars, and sensors that have been upgraded on the R1 platform. The new R1 gets 11 cameras (one more than the first gen), with eight times greater resolution, five radar modules, and a new proprietary AI and ML integrated system that learns from anonymized driver data and information taken from the world around the vehicles to “see” 360-degrees around the vehicle, even in inclement weather.
While the R1S has had cruise control since its launch, the new “Autonomy” platform allows for smart lane-changing—something Rivian calls “Lane Change on Command” when using the new “Enhanced Highway Assist” (a partially automated driver assist), and centers the vehicle in marked lanes. We tried both features on the highways around Seattle, and the system handled very rainy and wet weather without hesitation, but it did ping-pong between the lane markers, and when that smart lane change system bailed out at the last minute, the move was abrupt and not confidence-inspiring, since there was no apparent reason for the system to fail. These features are not nearly as good as the latest from BMW and Mercedes, both of which continue to offer some of the most usable driver-assist systems on the market.
With the new R1 software stack, Rivian is also promising some limited hands-free highway driver-assistance features to come at the end of the year. While we didn’t get to try the feature in the short drive to DirtFish, Rivian says eye-tracking cameras in the rearview mirror will ensure that drivers have ample warning to take over when the system is engaged and needs human input.
We’ve been living through the generative AI boom for nearly a year and a half now, following the late 2022 release of OpenAI’s ChatGPT. But despite transformative effects on companies’ share prices, generative AI tools powered by large language models (LLMs) still have major drawbacks that have kept them from being as useful as many would like them to be. Retrieval augmented generation, or RAG, aims to fix some of those drawbacks.
Perhaps the most prominent drawback of LLMs is their tendency toward confabulation (also called “hallucination”), which is a statistical gap-filling phenomenon AI language models produce when they are tasked with reproducing knowledge that wasn’t present in the training data. They generate plausible-sounding text that can veer toward accuracy when the training data is solid but otherwise may just be completely made up.
Relying on confabulating AI models gets people and companies in trouble, as we’ve covered in the past. In 2023, we saw two instances of lawyers citing legal cases, confabulated by AI, that didn’t exist. We’ve covered claims against OpenAI in which ChatGPT confabulated and accused innocent people of doing terrible things. In February, we wrote about Air Canada’s customer service chatbot inventing a refund policy, and in March, a New York City chatbot was caught confabulating city regulations.
So if generative AI aims to be the technology that propels humanity into the future, someone needs to iron out the confabulation kinks along the way. That’s where RAG comes in. Its proponents hope the technique will help turn generative AI technology into reliable assistants that can supercharge productivity without requiring a human to double-check or second-guess the answers.
“RAG is a way of improving LLM performance, in essence by blending the LLM process with a web search or other document look-up process” to help LLMs stick to the facts, according to Noah Giansiracusa, associate professor of mathematics at Bentley University.
Let’s take a closer look at how it works and what its limitations are.
A framework for enhancing AI accuracy
Although RAG is now seen as a technique to help fix issues with generative AI, it actually predates ChatGPT. Researchers coined the term in a 2020 academic paper by researchers at Facebook AI Research (FAIR, now Meta AI Research), University College London, and New York University.
As we’ve mentioned, LLMs struggle with facts. Google’s entry into the generative AI race, Bard, made an embarrassing error on its first public demonstration back in February 2023 about the James Webb Space Telescope. The error wiped around $100 billion off the value of parent company Alphabet. LLMs produce the most statistically likely response based on their training data and don’t understand anything they output, meaning they can present false information that seems accurate if you don’t have expert knowledge on a subject.
LLMs also lack up-to-date knowledge and the ability to identify gaps in their knowledge. “When a human tries to answer a question, they can rely on their memory and come up with a response on the fly, or they could do something like Google it or peruse Wikipedia and then try to piece an answer together from what they find there—still filtering that info through their internal knowledge of the matter,” said Giansiracusa.
But LLMs aren’t humans, of course. Their training data can age quickly, particularly in more time-sensitive queries. In addition, the LLM often can’t distinguish specific sources of its knowledge, as all its training data is blended together into a kind of soup.
In theory, RAG should make keeping AI models up to date far cheaper and easier. “The beauty of RAG is that when new information becomes available, rather than having to retrain the model, all that’s needed is to augment the model’s external knowledge base with the updated information,” said Peterson. “This reduces LLM development time and cost while enhancing the model’s scalability.”



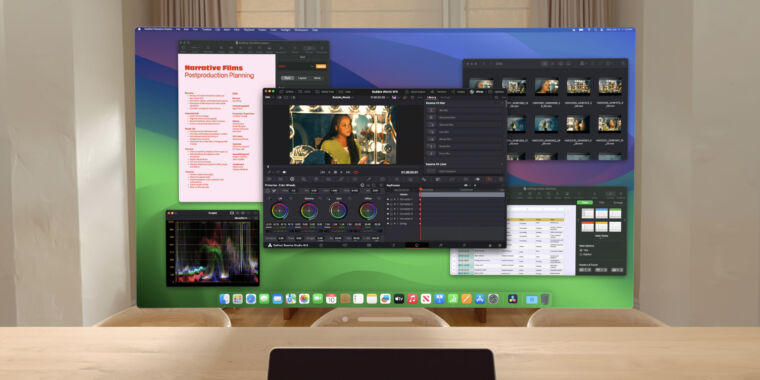

















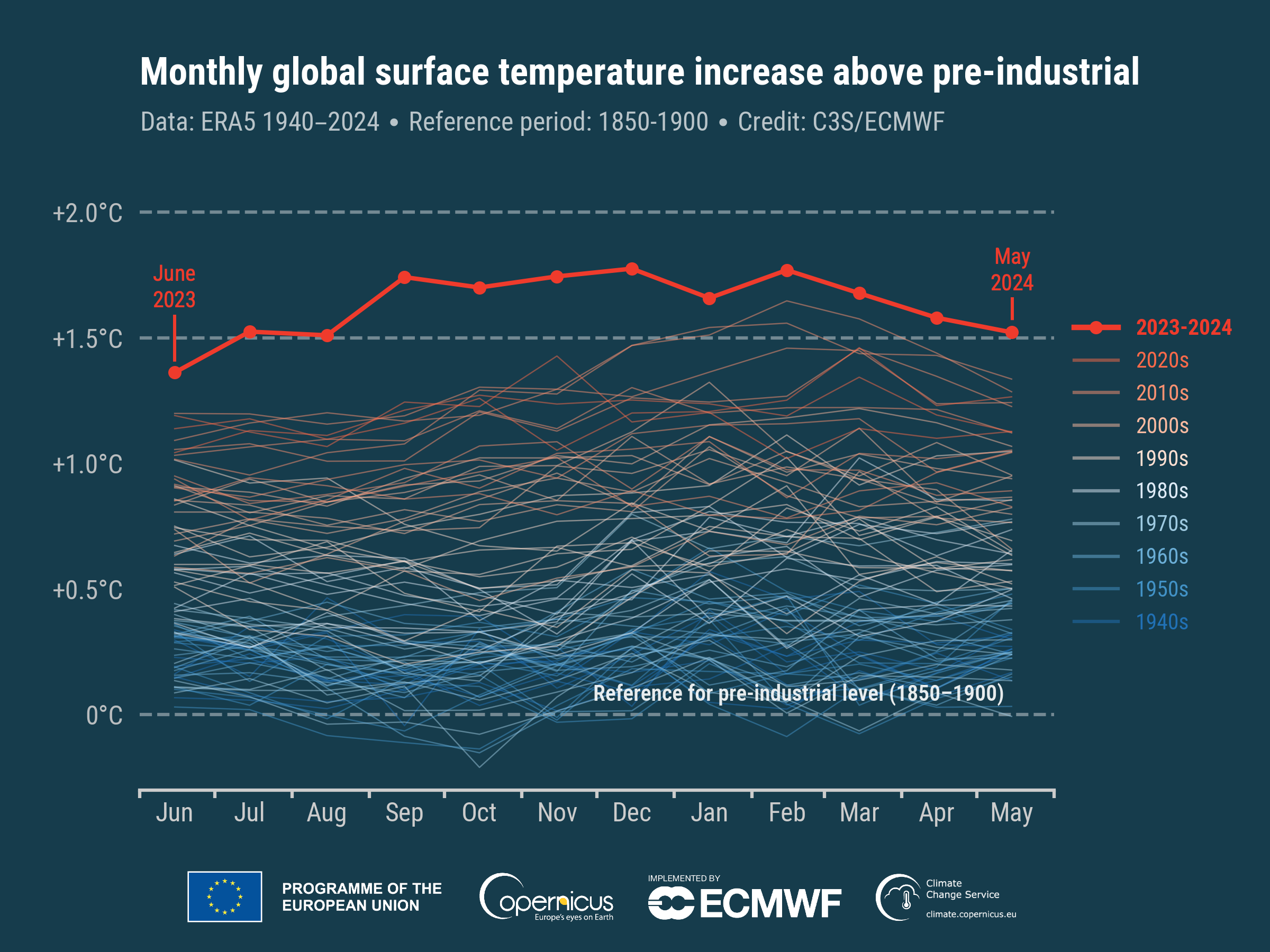
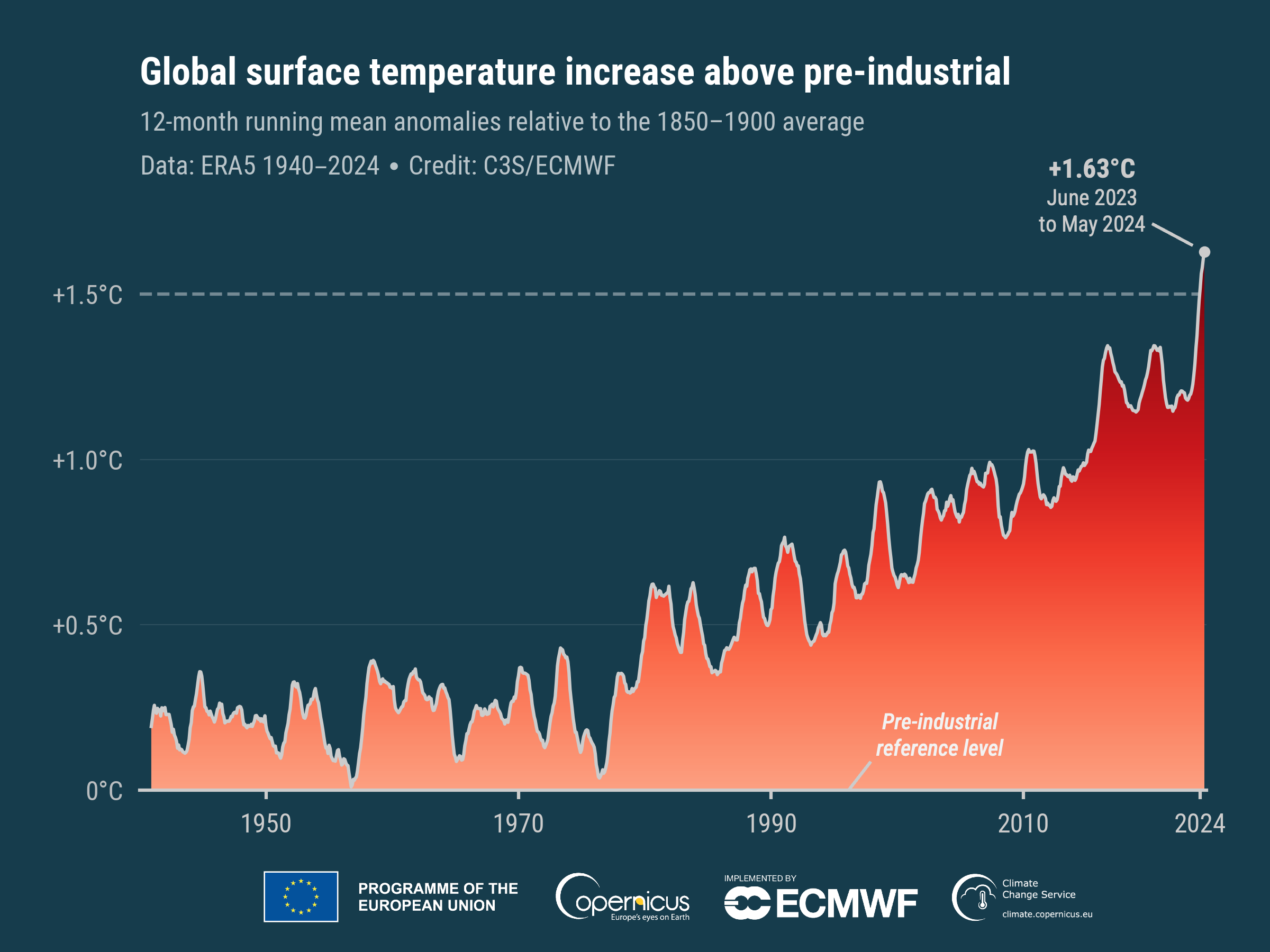




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}