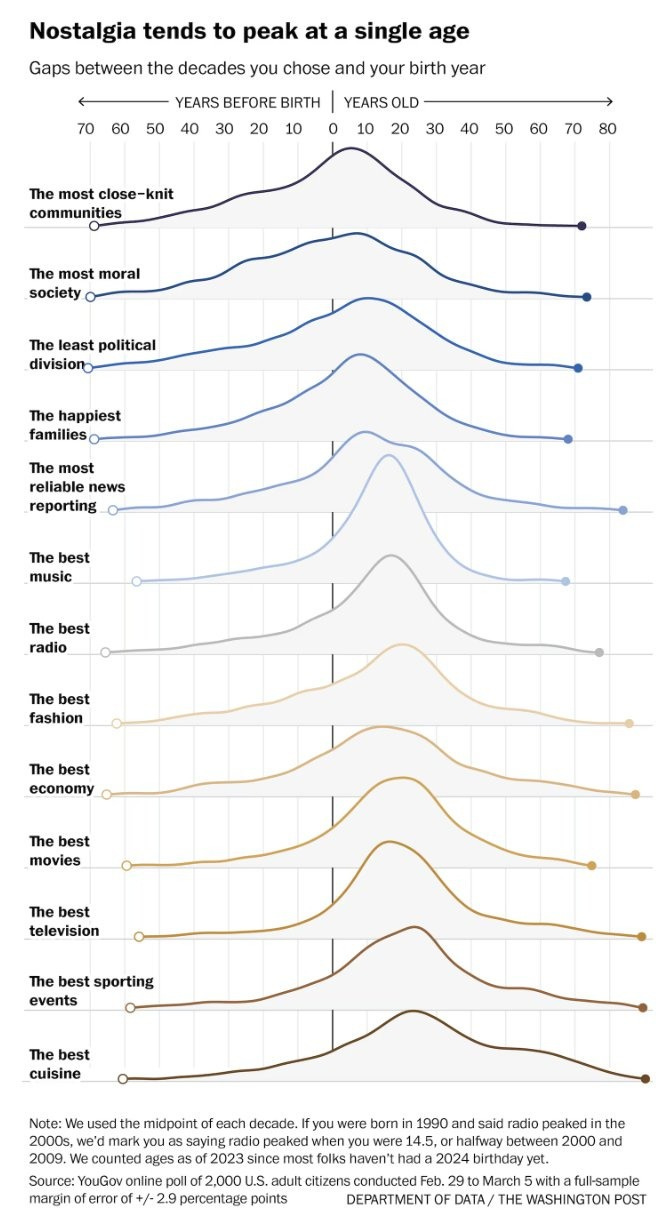
People remember their childhood world too fondly.
You adapt to it. You forget the parts that sucked, many of which sucked rather really badly. It resonates with you and sticks with you. You think it was better.
This is famously true for music, but also in general, including places it makes no sense like ‘most reliable news reporting.’
Matthew Yglesias: Regardless of how old they are, people tend to think that things were better when they were young.
As a result, you’d expect more negativity as the median age goes up and up.
Very obviously these views are not objective.
As a fun and also useful exercise, as part of the affordability sequence, now that we’ve looked at claims of modern impoverishment and asked when things were cheaper, it’s time to ask ourselves: When were various things really at their best?
In some aspects, yes, the past was better, and those aspects are an important part of the picture. But in many others today is the day and people are wrong about this.
I’ll start with the things on the above graph, in order, include some claims from another source, and also include a few important other considerations that help set up the main thesis of the sequence.
Far in the past. You wouldn’t like how they accomplished it, but they accomplished it.
The top candidates for specific such communities are either:
-
Hunter-gatherer bands.
-
Isolated low-tech villages that all share an intense mandatory religion.
-
Religious minority ethnic enclave communities under severe external threat.
You’re not going to match that without making intensive other sacrifices. Nor should you want to. Those communities were too close-knit for our taste.
In terms of on average most close knit communities in America, it’s probably right after we closed the frontier, so around 1900?
Close-knit communities, on a lesser level that is now rare, are valuable and important, but require large continuous investments and opportunity costs. You have to frequently choose engagement with a contained group over alternatives, including when those alternatives are otherwise far superior. You also, to do this today, have to engineer conditions to make the community possible, because you’re not going to be able to form one with whoever happens to live in your neighborhood.
Intentional communities are underrated, as is simply coordinating to live near your friends. I highly recommend such things, but coordination is hard, and they are going to remain rare.
I’m torn between today and about 2012.
There are some virtues and morals that are valuable and have been largely lost. Those who remember the past fondly focus on those aspects.
One could cite, depending on your comparison point, some combination of loyalty to both individuals, groups and institutions, honor and personal codes, hospitality, respect for laws and social norms, social trust, humility, some forms of mercy and forgiveness, stoicism, courage, respect for the sacred and adherence to duty and one’s commitments, especially the commitment to one’s family, having better and higher epistemic and discourse norms, plus religiosity.
There’s varying degrees of truth in those.
But they pale in comparison to the ways that things used to be terrible. People used to have highly exclusionary circles of concern. By the standards of today, until very recently and even under relatively good conditions, approximately everyone was horribly violent and tolerant of violence and bullying of all kinds, cruel to animals, tolerant of all manner of harassment, rape and violations of consent, cruel, intolerant, religiously intolerant often to the point of murder, drunk out of their minds, discriminatory, racist, sexist, homophobic, transphobic, neglectful, unsafe, physically and emotionally abusive to children including outright torture and frequent sexual abuse, and distrustful and dishonest dealing with strangers or in commerce.
It should be very clear which list wins.
This holds up to the introduction of social media, at which point some moral dynamics got out of control in various ways, on various sides of various questions, and many aspects went downhill. There were ways in which things got absolutely nuts. I’m not sure if we’ve recovered enough to have fully turned that around.
Within recent memory I’m going to say 1992-1996, which is the trap of putting it right in my teenage years. But I’m right. This period had extraordinarily low political division and partisanship.
On a longer time frame, the correct answer is the Era of Good Feelings, 1815-1825.
The mistake people make is to think that today’s high level of political division is some outlier in American history. It isn’t.
Good question. The survey data says 1957.
I also don’t strongly believe it is wrong, but I don’t trust survey data to give the right answer on this, for multiple reasons.
Certainly a lot more families used to be intact. That does not mean they were happy by our modern understanding of happy. The world of the 1950s was quite stifling. A lot of the way families stayed intact was people pretended everything was fine, including many things we now consider very not fine.
People benefited (in happiness terms) from many forms of lower expectations. That doesn’t mean that if you duplicated their life experiences, your family would be happy.
Fertility rates, having the most children, was during the Baby Boom, if we exclude the bad old times when children often failed to survive.
Marriage rates used to be near-universal, whether or not you think that was best.
Believe it or not, today. Yikes. We don’t believe it because of the Revolution of Rising Expectations. We now have standards for the press that the press has never met.
People used to trust the media more. Now we trust it a lot less. While there are downsides to this lack of trust, especially when people turn to even less worthy alternatives, that loss of trust is centrally good. The media was never worthy of trust.
There’s great fondness for the Walter Cronkite era, where supposedly we had high authority news sources worthy of our high trust. The thing is, that past trust was also misplaced, and indeed was even more misplaced.
There was little holding the press to account. They had their own agendas and biases, even if it was often ‘the good of the nation’ or ‘the good of the people,’ and they massively misunderstood things and often got things wrong. Reporters talking on the level of saying ‘wet ground causes rain’ is not a new phenomenon. When they did make mistakes or slant their coverage, there was no way to correct them back then.
Whereas now, with social media, we can and do keep the media on its toes.
If your goal is to figure out what is going on and you’re willing to put in the work, today you have the tools to do that, and in the past you basically didn’t, not in any reasonable amount of time.
The fact that other people do that, and hold them to account, makes the press hold itself to higher standards.
There are several forms of ‘the best music.’ It’s kind of today, kind of the 60s-80s.
If you are listening to music on your own, it is at its best today, by far. The entire back catalogue of the world is available at your fingertips, with notably rare exceptions, for a small monthly fee, on demand and fully customizable. If you are an audiophile and want super high quality, you can do that too. There’s no need to spend all that time seeking tings out.
If you want to create new music, on your own or with AI? Again, it’s there for you.
In terms of the creation of new music weighted by how much people listen, or in terms of the quality of the most popular music, I’d say probably the 1980s? A strong case can be made for the 60s or 70s too, my guess is that a bunch of that is nostalgia and too highly valuing innovation, but I can see it. What I can’t see is a case for the 1990s or 2000s, or especially 2010s or 2020s.
This could be old man syndrome talking, and it could be benefits of a lot of selection, but when I sample recent popular music it mostly (with exceptions!) seems highly non-innovative and also not very good. It’s plausible that with sufficiently good search and willingness to take highly deep cuts that today is indeed the best time for new music, but I don’t know how to do that search.
In terms of live music experiences, especially for those with limited budgets, my guess is this was closer to 1971, as so much great stuff was in hindsight so amazingly accessible.
The other case for music being better before is that music was better when it was worse. As in, you had to search for it, select it, pay for it, you had to listen to full albums and listen to them many times, so it meant more, that today’s freedom brings bad habits. I see the argument, but no, and you can totally set rules for yourself if that is what you want. I often have for brief periods, to shake things up.
My wild guess for traditional radio is the 1970s? There was enough high quality music, you had the spirit of radio, and video hadn’t killed the radio star.
You could make an argument for the 1930s-40s, right before television displaced it as the main medium. Certainly radio back then was more important and central.
The real answer is today. We have the best radio today.
We simply don’t call it radio.
Instead, we mostly call it podcasts and music streaming.
If you want pseudorandom music, Pandora and other similar services, or Spotify-style playlists, are together vastly better than traditional radio.
If you want any form of talk radio, or news radio, or other word-based radio programs that doesn’t depend on being broadcast live, podcasts rule. The quality and quantity and variety on offer are insane and you can move around on demand.
Also, remember reception problems? Not anymore.
Long before any of us were born, or today, depending on whether you mean ‘most awesome’ or ‘would choose to wear.’
Today’s fashion is not only cheaper, it is easier and more comfortable. In exchange, no, it does not look as cool.
As the question is intended, 2019. Then Covid happened. We still haven’t fully recovered from that.
There were periods with more economic growth or that had better employment conditions. You could point to 1947-1973 riding the postwar wave, or the late 1990s before the dot com bubble burst.
I still say 2019, because levels of wealth and real wages also matter.
In general I choose today. Average quality is way up and has been going up steadily except for a blip when we got way too many superhero movies crowding things out, but we’ve recovered from that.
The counterargument I respect is that the last few years have had no top tier all-time greats, and perhaps this is not an accident. We’ve forced movies to do so many other things well that there’s less room for full creativity and greatness to shine through? Perhaps this is true, and this system gets us fewer true top movies. But also that’s a Poisson distribution, you need to get lucky, and the effective sample size is small.
If I have to pick a particular year I’d go with 1999.
The traditional answer is the 1970s, but this is stupid and disregards the Revolution of Rising Expectations. Movies then were given tons of slack in essentially every direction. Were there some great picks? No doubt, although many of what we think of as all-time greats are remarkably slow to the point where if they weren’t all time greats they’d almost not be watchable. In general, if you think things were better back then, you’re grading back then on a curve, you have an extreme tolerance for not much happening, and also you’re prioritizing some sort of abstract Quality metric over what is actually entertaining.
Today. Stop lying to yourself.
The experience of television used to be terrible, and the shows used to be terrible. So many things very much do not hold up today even if you cut them quite a lot of slack. Old sitcoms are sleep inducing. Old dramas were basic and had little continuity. Acting tended to be quite poor. They don’t look good, either.
The interface for watching was atrocious. You would watch absurd amounts of advertisements. You would plan your day around when things were there, or you’d watch ‘whatever was on TV.’ If you missed episodes they would be gone. DVRs were a godsend despite requiring absurd levels of effort to manage optimally, and still giving up a ton of value.
The interface now is most of everything ever made at your fingertips.
The alternative argument to today being best is that many say that in terms of new shows the prestige TV era of the 2000s-2010s was the golden age, and the new streaming era can’t measure up, especially due to fractured experiences.
I agree that the shared national experiences were cool and we used to have more of them and they were bigger. We still get them, most recently for Severance and perhaps The White Lotus and Plurebis, which isn’t the same, but there really are still a ton of very high quality shows out there. Average quality is way up. Top talent going on television shows is way up, they still let top creators do their thing, and there are shows with top-tier people I haven’t even looked at, that never used to happen.
Today. Stop lying to yourself.
Average quality of athletic performance is way, way up. Modern players do things you wouldn’t believe. Game design has in many ways improved as well, as has the quality of strategic decision making.
Season design is way better. We get more and better playoffs, which can go too far but typically keeps far more games more relevant and exciting and high stakes. College football is insanely better for this over the last few years, I doubted and I was wrong. Baseball purists can complain but so few games used to mean anything. And so on.
Unless people are going to be blowing up your phone, you can start an event modestly late and skip all the ads and even dead time. You can watch sports on your schedule, not someone else’s. If you must be live, you can now get coverage in lots of alternative ways, and also get access to social media conversations in real time, various website information services and so on.
If you’re going to the stadium, the modern experience is an upgrade. It is down to a science. All seats are good seats and the food is usually excellent.
There are three downside cases.
-
We used to all watch the same sporting events live and together more often. That was cool, but you can still find plenty of people online doing this anyway.
-
In some cases correct strategic play has made things less fun. Too many NBA three pointers are a problem, as is figuring out that MLB starters should be taken out rather early, or analytics simply homogenized play. The rules have been too slow to adjust. It’s a problem, but on net I think a minor one. It’s good to see games played well.
-
Free agency has made teams retain less identity, and made it harder to root for the same players over a longer period. This one hurts and I’d love to go back, even though there are good reasons why we can’t.
Mostly I think it’s nostalgia. Modern sports are awesome.
Today, and it’s really, really not close. If you don’t agree, you do not remember. So much of what people ate in the 20th century was barely even food by today’s standards, both in terms of tasting good and its nutritional content.
Food has gotten The Upgrade.
Average quality is way, way up. Diversity is way up, authentic or even non-authentic ethnic cuisines mostly used to be quite rare. Delivery used to be pizza and Chinese. Quality and diversity of available ingredients is way up. You can get it all on a smaller percentage of typical incomes, whether at home or from restaurants, and so many more of us get to use those restaurants more often.
A lot of this is driven by having access to online information and reviews, which allows quality to win out in a way it didn’t before, but even before that we were seeing rapid upgrades across the board.
Some time around 1965, probably? We had a pattern of something approaching lifetime employment where it was easy to keep one’s job for a long period, and count on this. The chance of staying in a job for 10+ or 20+ years has declined a lot. That makes people feel a lot more secure, and matters a lot.
That doesn’t mean you actually want the same job for 20+ years. There are some jobs where you totally do want that, but a lot of the jobs people used to keep for that long are jobs we wouldn’t want. Despite people’s impressions, the increased job changes have mostly not come from people being fired.
We don’t have the best everything. There are exceptions.
Most centrally, we don’t have the best intact families or close-knit communities, or the best dating ecosystem or best child freedoms. Those are huge deals.
But there are so many other places in which people are simply wrong.
As in:
Matt Walsh (being wrong, lol at ‘empirical,’ 3M views): It’s an empirical fact that basically everything in our day to day lives has gotten worse over the years. The quality of everything — food, clothing, entertainment, air travel, roads, traffic, infrastructure, housing, etc — has declined in observable ways. Even newer inventions — search engines, social media, smart phones — have gone down hill drastically.
This isn’t just a random “old man yells at clouds” complaint. It’s true. It’s happening. The decline can be measured. Everyone sees it. Everyone feels it. Meanwhile political pundits and podcast hosts (speaking of things that are getting worse) focus on anything and everything except these practical real-life problems that actually affect our quality of life.
The Honest Broker: There is an entire movement focused on trying to convince people that everything used to be better and everything is also getting worse and worse
That creates a market for reality-based correctives like the excellent thread below by @ben_golub [on air travel.]
Matthew Yglesias: I think everyone should take seriously:
-
Content distribution channels have become more competitive and efficient
-
Negative content tends to perform better
-
Marinating all day in negativity-inflected content is cooking people’s brains
My quick investigation confirmed that American roads, traffic and that style of infrastructure did peak in the mid-to-late 20th century. We have not been doing a good job maintaining that.
On food, entertainment, clothing and housing he is simply wrong (have you heard of this new thing called ‘luxury’ apartments, or checked average sizes or amenities?), and to even make some of these claims requires both claiming ‘this is cheaper but it’s worse’ and ‘this is worse because it used to be cheaper’ in various places.
bumbadum: People are chimping out at Matt over this but nobody has been able to name one thing that has significantly grown in quality in the past 10-20 years.
Every commodity, even as they have become cheaper and more accessible has decreased in quality.
I am begging somebody to name 1 thing that is all around a better product than its counterpart from the 90s
Megan McArdle: Tomatoes, raspberries, automobiles, televisions, cancer drugs, women’s shoes, insulin monitoring, home security monitoring, clothing for tall women (which functionally didn’t exist until about 2008), telephone service (remember when you had to PAY EXTRA to call another area code?), travel (remember MAPS?), remote work, home video … sorry, ran out of characters before I ran out of hedonic improvements.
Thus:
Today. No explanation required on these.
Don’t knock the vast improvements in computers and televisions.
Saying the quality of phones has gone down, as Matt Walsh does, is absurdity.
That does still leave a few other examples he raised.
Today, or at least 2024 if you think Trump messed some things up.
I say this as someone who used to fly on about half of weekends, for several years.
Air travel has decreased in price, the most important factor, and safety improved. Experiential quality of the flight itself declined a bit, but has risen again as airport offerings improved and getting through security and customs went back from a nightmare to trivial. Net time spent, given less uncertainty, has gone down.
If you are willing to pay the old premium prices, you can buy first class tickets, and get an as good or better experience as the old tickets.
Today. We wax nostalgic about old cars. They looked cool. They also were cool.
They were also less powerful, more dangerous, much less fuel efficient, much less reliable, with far fewer features and of course absolutely no smart features. That’s even without considering that we’re starting to get self-driving cars.
This is one area where my preliminary research did back Walsh up. America has done a poor job of maintaining its roads and managing its traffic, and has not ‘paid the upkeep’ on many aspects what was previously a world-class infrastructure. These things seem to have peaked in the late 20th century.
I agree that this is a rather bad sign, and we should both fix and build the roads and also fix the things that are causing us not to fix and build the roads.
As a result of not keeping up with demand for roads or demand for housing in the right areas, average commute times for those going into the office have been increasing, but post-Covid we have ~29% of working days happening from home, which overwhelms all other factors combined in terms of hours on the road.
I do expect traffic to improve due to self-driving cars, but that will take a while.
Today, or at least the mobile phone and rideshare era. You used to have to call for or hail a taxi. Now in most areas you open your phone and a car appears. In some places it can be a Waymo, which is now doubling yearly. The ability to summon a taxi matters so much more than everything else, and as noted above air travel is improved.
This is way more important than net modest issues with roads and traffic.
Trains have not improved but they are not importantly worse.
Not everything is getting better all the time. Important things are getting worse.
We still need to remember and count our blessings, and not make up stories about how various things are getting worse, when those things are actually getting better.
To sum up, and to add some additional key factors, the following things did indeed peak in the past and quality is getting worse as more than a temporary blip:
-
Political division.
-
Average quality of new music, weighted by what people listen to.
-
Live music and live radio experiences, and other collective national experiences.
-
Fashion, in terms of awesomeness.
-
Roads, traffic and general infrastructure.
-
Some secondary but important moral values.
-
Dating experiences, ability to avoid going on apps.
-
Job security, ability to stay in one job for decades if desired.
-
Marriage rates and intact families, including some definitions of ‘happy’ families.
-
Fertility rates and felt ability to have and support children as desired.
-
Childhood freedoms and physical experiences.
-
Hope for the future, which is centrally motivating this whole series of posts.
The second half of that list is freaking depressing. Yikes. Something’s very wrong.
But what’s wrong isn’t the quality of goods, or many of the things people wax nostalgic about. The first half of this list cannot explain the second half.
Compare that first half to the ways in which quality is up, and in many of these cases things are 10 times better, or 100 times better, or barely used to even exist:
-
Morality overall, in many rather huge ways.
-
Access to information, including the news.
-
Logistics and delivery. Ease of getting the things you want.
-
Communication. Telephones including mobile phones.
-
Music as consumed at home via deliberate choice.
-
Audio experiences. Music streams and playlists. Talk.
-
Electronics, including computers, televisions, medical devices, security systems.
-
Television, both new content and old content, and modes of access.
-
Movies, both new content and old content, and modes of access.
-
Fashion in terms of comfort, cost and upkeep.
-
Sports.
-
Cuisine. Food of all kinds, at home and at restaurants.
-
Air travel.
-
Taxis.
-
Cars.
-
Medical care, dental care and medical (and nonmedical) drugs.
That only emphasizes the bottom of the first list. Something’s very wrong.
Once again, us doing well does not mean we shouldn’t be doing better.
We see forms of the same trends.
-
Many things are getting better, but often not as much better as they could be.
-
Other things are getting worse, both in ways inevitable and avoidable.
-
This identifies important problems, but the changes in quantity and quality of goods and services do not explain people’s unhappiness, or why many of the most important things are getting worse. More is happening.
Some of the things getting worse reflect changes in technological equilibria or the running out of low-hanging fruit, in ways that are tricky to fix. Many of those are superficial, although a few of them aren’t. But these don’t add up to the big issues.
More is happening.
That more is what I will, in the next post, be calling The Revolution of Rising Expectations, and the Revolution of Rising Requirements.