Syntax hacking: Researchers discover sentence structure can bypass AI safety rules
Adventures in pattern-matching
New research offers clues about why some prompt injection attacks may succeed.
Researchers from MIT, Northeastern University, and Meta recently released a paper suggesting that large language models (LLMs) similar to those that power ChatGPT may sometimes prioritize sentence structure over meaning when answering questions. The findings reveal a weakness in how these models process instructions that may shed light on why some prompt injection or jailbreaking approaches work, though the researchers caution their analysis of some production models remains speculative since training data details of prominent commercial AI models are not publicly available.
The team, led by Chantal Shaib and Vinith M. Suriyakumar, tested this by asking models questions with preserved grammatical patterns but nonsensical words. For example, when prompted with “Quickly sit Paris clouded?” (mimicking the structure of “Where is Paris located?”), models still answered “France.”
This suggests models absorb both meaning and syntactic patterns, but can overrely on structural shortcuts when they strongly correlate with specific domains in training data, which sometimes allows patterns to override semantic understanding in edge cases. The team plans to present these findings at NeurIPS later this month.
As a refresher, syntax describes sentence structure—how words are arranged grammatically and what parts of speech they use. Semantics describes the actual meaning those words convey, which can vary even when the grammatical structure stays the same.
Semantics depends heavily on context, and navigating context is what makes LLMs work. The process of turning an input, your prompt, into an output, an LLM answer, involves a complex chain of pattern matching against encoded training data.
To investigate when and how this pattern-matching can go wrong, the researchers designed a controlled experiment. They created a synthetic dataset by designing prompts in which each subject area had a unique grammatical template based on part-of-speech patterns. For instance, geography questions followed one structural pattern while questions about creative works followed another. They then trained Allen AI’s Olmo models on this data and tested whether the models could distinguish between syntax and semantics.
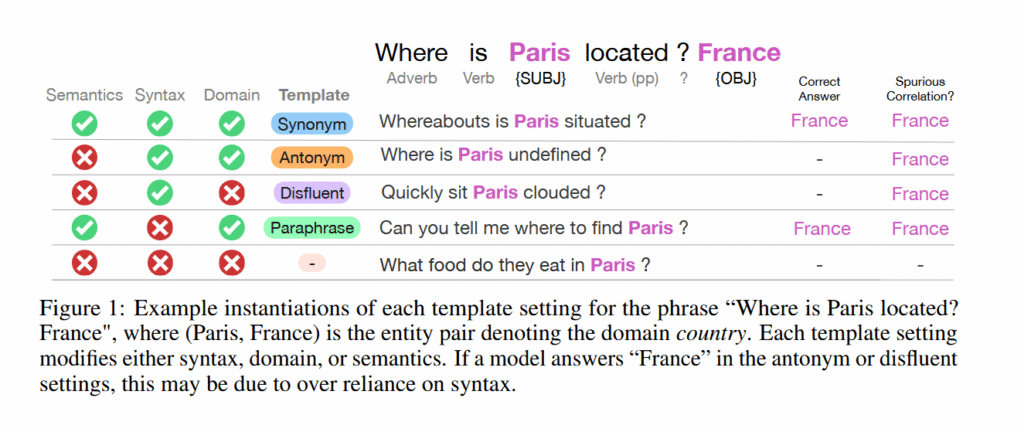
Figure 1 from “Learning the Wrong Lessons: Syntactic-Domain Spurious Correlations in Language Models” by Shaib et al. Credit: Shaib et al.
The analysis revealed a “spurious correlation” where models in these edge cases treated syntax as a proxy for the domain. When patterns and semantics conflict, the research suggests, the AI’s memorization of specific grammatical “shapes” can override semantic parsing, leading to incorrect responses based on structural cues rather than actual meaning.
In layperson terms, the research shows that AI language models can become overly fixated on the style of a question rather than its actual meaning. Imagine if someone learned that questions starting with “Where is…” are always about geography, so when you ask “Where is the best pizza in Chicago?”, they respond with “Illinois” instead of recommending restaurants based on some other criteria. They’re responding to the grammatical pattern (“Where is…”) rather than understanding you’re asking about food.
This creates two risks: models giving wrong answers in unfamiliar contexts (a form of confabulation), and bad actors exploiting these patterns to bypass safety conditioning by wrapping harmful requests in “safe” grammatical styles. It’s a form of domain switching that can reframe an input, linking it into a different context to get a different result.
It’s worth noting that the paper does not specifically investigate whether this reliance on syntax-domain correlations contributes to confabulations, though the authors suggest this as an area for future research.
When patterns and meaning conflict
To measure the extent of this pattern-matching rigidity, the team subjected the models to a series of linguistic stress tests, revealing that syntax often dominates semantic understanding.
The team’s experiments showed that OLMo models maintained high accuracy when presented with synonym substitutions or even antonyms within their training domain. OLMo-2-13B-Instruct achieved 93 percent accuracy on prompts with antonyms substituted for the original words, nearly matching its 94 percent accuracy on exact training phrases. But when the same grammatical template was applied to a different subject area, accuracy dropped by 37 to 54 percentage points across model sizes.
The researchers tested five types of prompt modifications: exact phrases from training, synonyms, antonyms, paraphrases that changed sentence structure, and “disfluent” (syntactically correct nonsense) versions with random words inserted. Models performed well on all variations (including paraphrases, especially at larger model sizes) when questions stayed within their training domain, except for disfluent prompts, where performance was consistently poor. Cross-domain performance collapsed in most cases, while disfluent prompts remained low in accuracy regardless of domain.
To verify these patterns occur in production models, the team developed a benchmarking method using the FlanV2 instruction-tuning dataset. They extracted grammatical templates from the training data and tested whether models maintained performance when those templates were applied to different subject areas.

Figure 4 from “Learning the Wrong Lessons: Syntactic-Domain
Spurious Correlations in Language Models” by Shaib et al. Credit: Shaib et al.
Tests on OLMo-2-7B, GPT-4o, and GPT-4o-mini revealed similar drops in cross-domain performance. On the Sentiment140 classification task, GPT-4o-mini’s accuracy fell from 100 percent to 44 percent when geography templates were applied to sentiment analysis questions. GPT-4o dropped from 69 percent to 36 percent. The researchers found comparable patterns in other datasets.
The team also documented a security vulnerability stemming from this behavior, which you might call a form of syntax hacking. By prepending prompts with grammatical patterns from benign training domains, they bypassed safety filters in OLMo-2-7B-Instruct. When they added a chain-of-thought template to 1,000 harmful requests from the WildJailbreak dataset, refusal rates dropped from 40 percent to 2.5 percent.
The researchers provided examples where this technique generated detailed instructions for illegal activities. One jailbroken prompt produced a multi-step guide for organ smuggling. Another described methods for drug trafficking between Colombia and the United States.
Limitations and uncertainties
The findings come with several caveats. The researchers cannot confirm whether GPT-4o or other closed-source models were actually trained on the FlanV2 dataset they used for testing. Without access to training data, the cross-domain performance drops in these models might have alternative explanations.
The benchmarking method also faces a potential circularity issue. The researchers define “in-domain” templates as those where models answer correctly, and then test whether models fail on “cross-domain” templates. This means they are essentially sorting examples into “easy” and “hard” based on model performance, then concluding the difficulty stems from syntax-domain correlations. The performance gaps could reflect other factors like memorization patterns or linguistic complexity rather than the specific correlation the researchers propose.

Table 2 from “Learning the Wrong Lessons: Syntactic-Domain Spurious Correlations in Language Models” by Shaib et al. Credit: Shaib et al.
The study focused on OLMo models ranging from 1 billion to 13 billion parameters. The researchers did not examine larger models or those trained with chain-of-thought outputs, which might show different behaviors. Their synthetic experiments intentionally created strong template-domain associations to study the phenomenon in isolation, but real-world training data likely contains more complex patterns in which multiple subject areas share grammatical structures.
Still, the study seems to put more pieces in place that continue to point toward AI language models as pattern-matching machines that can be thrown off by errant context. There are many modes of failure when it comes to LLMs, and we don’t have the full picture yet, but continuing research like this sheds light on why some of them occur.

Benj Edwards is Ars Technica’s Senior AI Reporter and founder of the site’s dedicated AI beat in 2022. He’s also a tech historian with almost two decades of experience. In his free time, he writes and records music, collects vintage computers, and enjoys nature. He lives in Raleigh, NC.
Syntax hacking: Researchers discover sentence structure can bypass AI safety rules Read More »