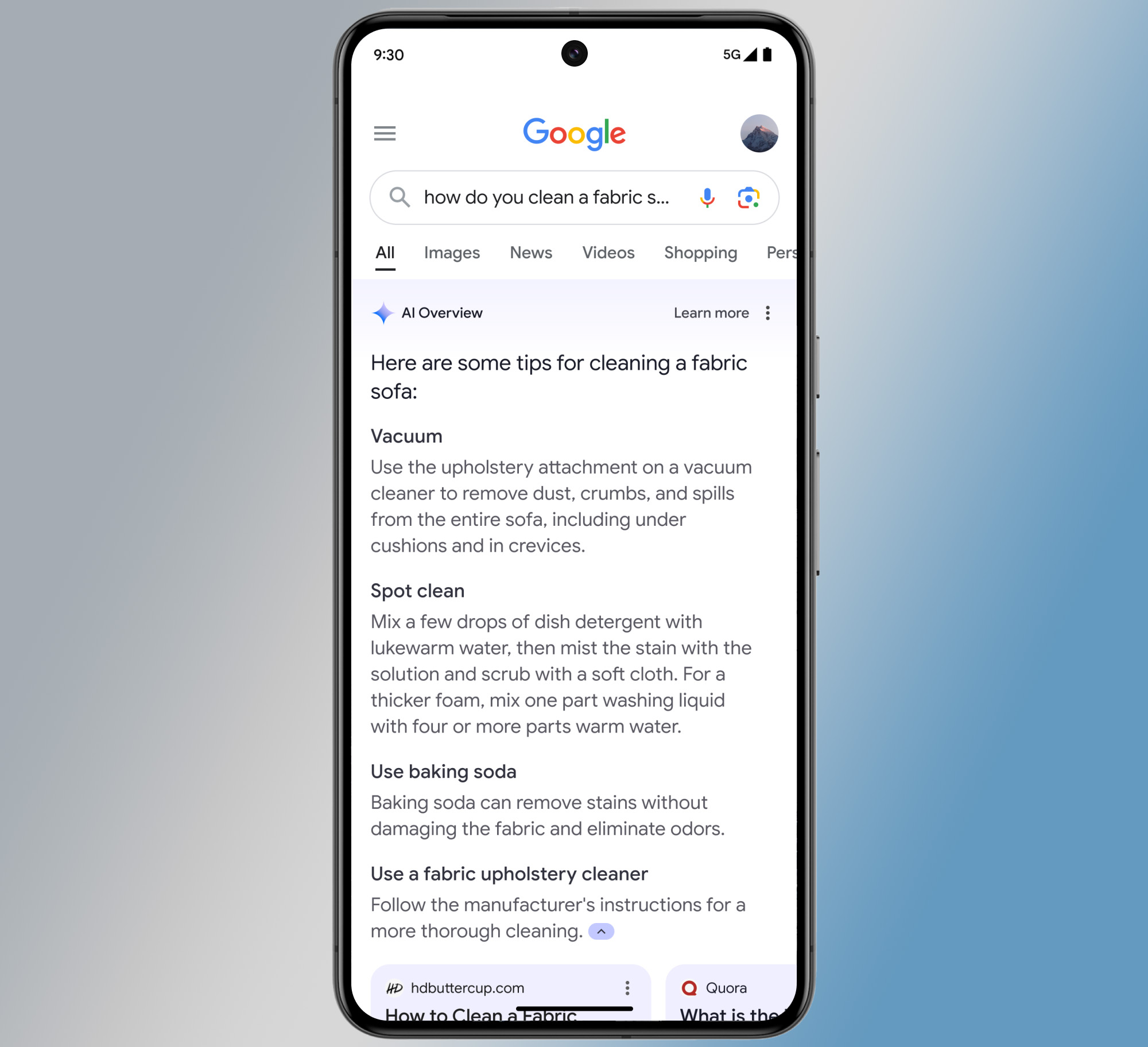
Chicago Sun-Times prints summer reading list full of fake books

Photo of the Chicago Sun-Times “Summer reading list for 2025” supplement. Credit: Rachel King / Bluesky
Novelist Rachael King initially called attention to the error on Bluesky Tuesday morning. “The Chicago Sun-Times obviously gets ChatGPT to write a ‘summer reads’ feature almost entirely made up of real authors but completely fake books. What are we coming to?” King wrote.
So far, community reaction to the list has been largely negative online, but others have expressed sympathy for the publication. Freelance journalist Joshua J. Friedman noted on Bluesky that the reading list was “part of a ~60-page summer supplement” published on May 18, suggesting it might be “transparent filler” possibly created by “the lone freelancer apparently saddled with producing it.”
The staffing connection
The reading list appeared in a 64-page supplement called “Heat Index,” which was a promotional section not specific to Chicago. Buscaglia told 404 Media the content was meant to be “generic and national” and would be inserted into newspapers around the country. “We never get a list of where things ran,” he said.
The publication error comes two months after the Chicago Sun-Times lost 20 percent of its staff through a buyout program. In March, the newspaper’s nonprofit owner, Chicago Public Media, announced that 30 Sun-Times employees—including 23 from the newsroom—had accepted buyout offers amid financial struggles.
A March report on the buyout in the Sun-Times described the staff reduction as “the most drastic the oft-imperiled Sun-Times has faced in several years.” The departures included columnists, editorial writers, and editors with decades of experience.
Melissa Bell, CEO of Chicago Public Media, stated at the time that the exits would save the company $4.2 million annually. The company offered buyouts as it prepared for an expected expiration of grant support at the end of 2026.
Even with those pressures in the media, one Reddit user expressed disapproval of the apparent use of AI in the newspaper, even in a supplement that might not have been produced by staff. “As a subscriber, I am livid! What is the point of subscribing to a hard copy paper if they are just going to include AI slop too!?” wrote Reddit user xxxlovelit, who shared the reading list. “The Sun Times needs to answer for this, and there should be a reporter fired.”
This article was updated on May 20, 2025 at 11: 02 AM to include information on Marco Buscaglia from 404 Media.
Chicago Sun-Times prints summer reading list full of fake books Read More »