AI-generated code could be a disaster for the software supply chain. Here’s why.
AI-generated computer code is rife with references to non-existent third-party libraries, creating a golden opportunity for supply-chain attacks that poison legitimate programs with malicious packages that can steal data, plant backdoors, and carry out other nefarious actions, newly published research shows.
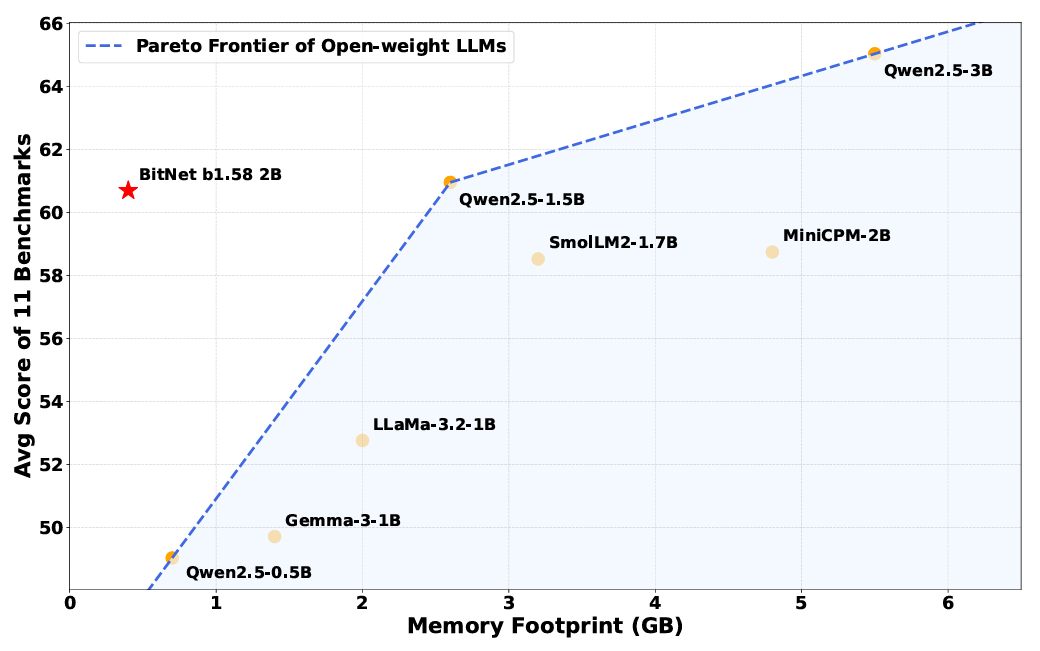
The study, which used 16 of the most widely used large language models to generate 576,000 code samples, found that 440,000 of the package dependencies they contained were “hallucinated,” meaning they were non-existent. Open source models hallucinated the most, with 21 percent of the dependencies linking to non-existent libraries. A dependency is an essential code component that a separate piece of code requires to work properly. Dependencies save developers the hassle of rewriting code and are an essential part of the modern software supply chain.
Package hallucination flashbacks
These non-existent dependencies represent a threat to the software supply chain by exacerbating so-called dependency confusion attacks. These attacks work by causing a software package to access the wrong component dependency, for instance by publishing a malicious package and giving it the same name as the legitimate one but with a later version stamp. Software that depends on the package will, in some cases, choose the malicious version rather than the legitimate one because the former appears to be more recent.
Also known as package confusion, this form of attack was first demonstrated in 2021 in a proof-of-concept exploit that executed counterfeit code on networks belonging to some of the biggest companies on the planet, Apple, Microsoft, and Tesla included. It’s one type of technique used in software supply-chain attacks, which aim to poison software at its very source in an attempt to infect all users downstream.
“Once the attacker publishes a package under the hallucinated name, containing some malicious code, they rely on the model suggesting that name to unsuspecting users,” Joseph Spracklen, a University of Texas at San Antonio Ph.D. student and lead researcher, told Ars via email. “If a user trusts the LLM’s output and installs the package without carefully verifying it, the attacker’s payload, hidden in the malicious package, would be executed on the user’s system.”
AI-generated code could be a disaster for the software supply chain. Here’s why. Read More »