Midjourney introduces first new image generation model in over a year
AI image generator Midjourney released its first new model in quite some time today; dubbed V7, it’s a ground-up rework that is available in alpha to users now.
There are two areas of improvement in V7: the first is better images, and the second is new tools and workflows.
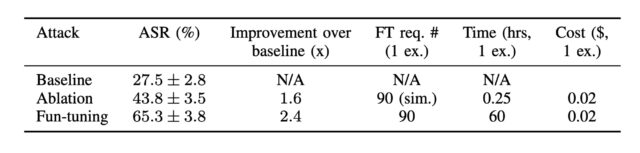
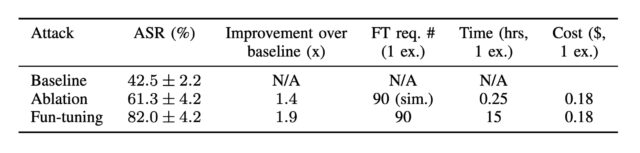
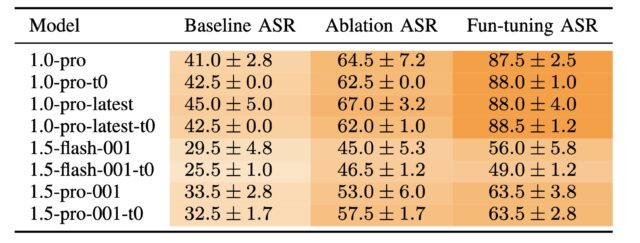
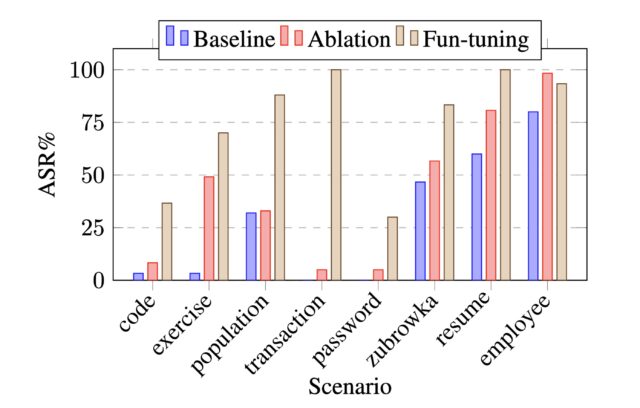
Starting with the image improvements, V7 promises much higher coherence and consistency for hands, fingers, body parts, and “objects of all kinds.” It also offers much more detailed and realistic textures and materials, like skin wrinkles or the subtleties of a ceramic pot.
Those details are often among the most obvious telltale signs that an image has been AI-generated. To be clear, Midjourney isn’t claiming to have made advancements that make AI images unrecognizable to a trained eye; it’s just saying that some of the messiness we’re accustomed to has been cleaned up to a significant degree.

V7 can reproduce materials and lighting situations that V6.1 usually couldn’t. Credit: Xeophon
On the features side, the star of the show is the new “Draft Mode.” On its various communication channels with users (a blog, Discord, X, and so on), Midjourney says that “Draft mode is half the cost and renders images at 10 times the speed.”
However, the images are of lower quality than what you get in the other modes, so this is not intended to be the way you produce final images. Rather, it’s meant to be a way to iterate and explore to find the desired result before switching modes to make something ready for public consumption.
V7 comes with two modes: turbo and relax. Turbo generates final images quickly but is twice as expensive in terms of credit use, while relax mode takes its time but is half as expensive. There is currently no standard mode for V7, strangely; Midjourney says that’s coming later, as it needs some more time to be refined.
Midjourney introduces first new image generation model in over a year Read More »