Microsoft’s new AI agent can control software and robots

The researchers’ explanations about how “Set-of-Mark” and “Trace-of-Mark” work. Credit: Microsoft Research
The Magma model introduces two technical components: Set-of-Mark, which identifies objects that can be manipulated in an environment by assigning numeric labels to interactive elements, such as clickable buttons in a UI or graspable objects in a robotic workspace, and Trace-of-Mark, which learns movement patterns from video data. Microsoft says those features allow the model to complete tasks like navigating user interfaces or directing robotic arms to grasp objects.
Microsoft Magma researcher Jianwei Yang wrote in a Hacker News comment that the name “Magma” stands for “M(ultimodal) Ag(entic) M(odel) at Microsoft (Rese)A(rch),” after some people noted that “Magma” already belongs to an existing matrix algebra library, which could create some confusion in technical discussions.
Reported improvements over previous models
In its Magma write-up, Microsoft claims Magma-8B performs competitively across benchmarks, showing strong results in UI navigation and robot manipulation tasks.
For example, it scored 80.0 on the VQAv2 visual question-answering benchmark—higher than GPT-4V’s 77.2 but lower than LLaVA-Next’s 81.8. Its POPE score of 87.4 leads all models in the comparison. In robot manipulation, Magma reportedly outperforms OpenVLA, an open source vision-language-action model, in multiple robot manipulation tasks.
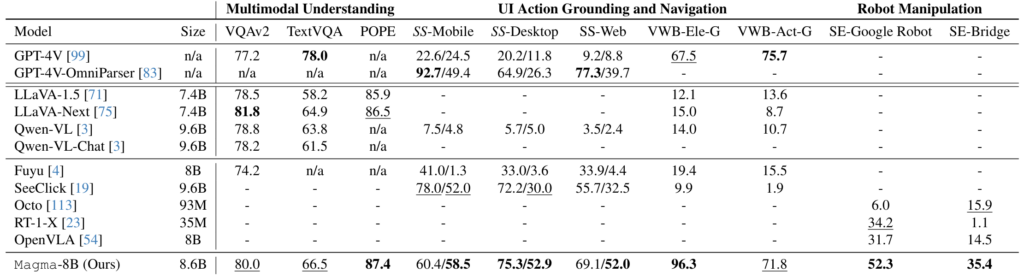
Magma’s agentic benchmarks, as reported by the researchers. Credit: Microsoft Research
As always, we take AI benchmarks with a grain of salt since many have not been scientifically validated as being able to measure useful properties of AI models. External verification of Microsoft’s benchmark results will become possible once other researchers can access the public code release.
Like all AI models, Magma is not perfect. It still faces technical limitations in complex step-by-step decision-making that requires multiple steps over time, according to Microsoft’s documentation. The company says it continues to work on improving these capabilities through ongoing research.
Yang says Microsoft will release Magma’s training and inference code on GitHub next week, allowing external researchers to build on the work. If Magma delivers on its promise, it could push Microsoft’s AI assistants beyond limited text interactions, enabling them to operate software autonomously and execute real-world tasks through robotics.
Magma is also a sign of how quickly the culture around AI can change. Just a few years ago, this kind of agentic talk scared many people who feared it might lead to AI taking over the world. While some people still fear that outcome, in 2025, AI agents are a common topic of mainstream AI research that regularly takes place without triggering calls to pause all of AI development.
Microsoft’s new AI agent can control software and robots Read More »