
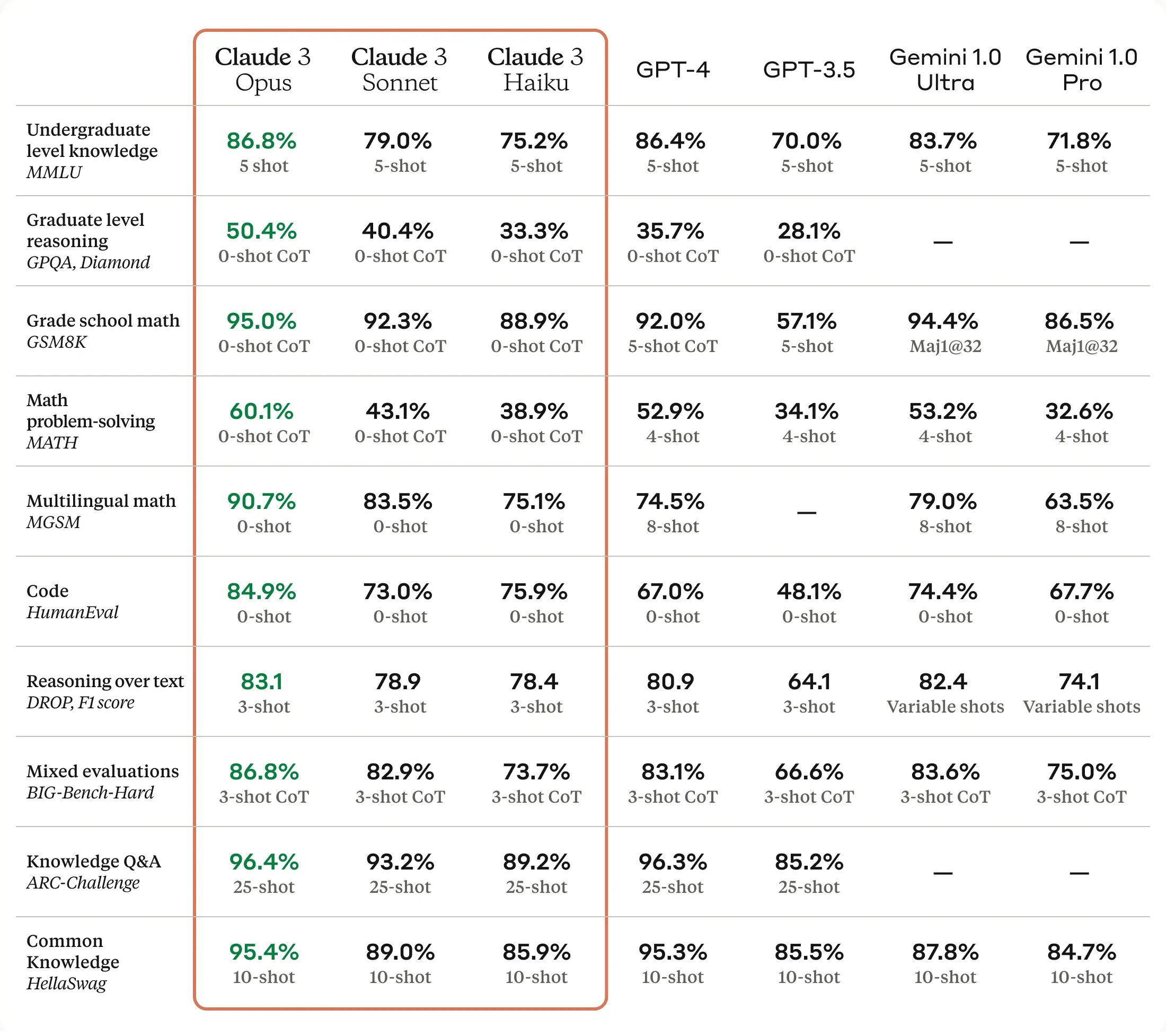
Florida middle-schoolers charged with making deepfake nudes of classmates
no consent —
AI tool was used to create nudes of 12- to 13-year-old classmates.

Jacqui VanLiew; Getty Images
Two teenage boys from Miami, Florida, were arrested in December for allegedly creating and sharing AI-generated nude images of male and female classmates without consent, according to police reports obtained by WIRED via public record request.
The arrest reports say the boys, aged 13 and 14, created the images of the students who were “between the ages of 12 and 13.”
![]()
The Florida case appears to be the first arrests and criminal charges as a result of alleged sharing of AI-generated nude images to come to light. The boys were charged with third-degree felonies—the same level of crimes as grand theft auto or false imprisonment—under a state law passed in 2022 which makes it a felony to share “any altered sexual depiction” of a person without their consent.
The parent of one of the boys arrested did not respond to a request for comment in time for publication. The parent of the other boy said that he had “no comment.” The detective assigned to the case, and the state attorney handling the case, did not respond for comment in time for publication.
As AI image-making tools have become more widely available, there have been several high-profile incidents in which minors allegedly created AI-generated nude images of classmates and shared them without consent. No arrests have been disclosed in the publicly reported cases—at Issaquah High School in Washington, Westfield High School in New Jersey, and Beverly Vista Middle School in California—even though police reports were filed. At Issaquah High School, police opted not to press charges.
The first media reports of the Florida case appeared in December, saying that the two boys were suspended from Pinecrest Cove Academy in Miami for 10 days after school administrators learned of allegations that they created and shared fake nude images without consent. After parents of the victims learned about the incident, several began publicly urging the school to expel the boys.
Nadia Khan-Roberts, the mother of one of the victims, told NBC Miami in December that for all of the families whose children were victimized the incident was traumatizing. “Our daughters do not feel comfortable walking the same hallways with these boys,” she said. “It makes me feel violated, I feel taken advantage [of] and I feel used,” one victim, who asked to remain anonymous, told the TV station.
WIRED obtained arrest records this week that say the incident was reported to police on December 6, 2023, and that the two boys were arrested on December 22. The records accuse the pair of using “an artificial intelligence application” to make the fake explicit images. The name of the app was not specified and the reports claim the boys shared the pictures between each other.
“The incident was reported to a school administrator,” the reports say, without specifying who reported it, or how that person found out about the images. After the school administrator “obtained copies of the altered images” the administrator interviewed the victims depicted in them, the reports say, who said that they did not consent to the images being created.
After their arrest, the two boys accused of making the images were transported to the Juvenile Service Department “without incident,” the reports say.
A handful of states have laws on the books that target fake, nonconsensual nude images. There’s no federal law targeting the practice, but a group of US senators recently introduced a bill to combat the problem after fake nude images of Taylor Swift were created and distributed widely on X.
The boys were charged under a Florida law passed in 2022 that state legislators designed to curb harassment involving deepfake images made using AI-powered tools.
Stephanie Cagnet Myron, a Florida lawyer who represents victims of nonconsensually shared nude images, tells WIRED that anyone who creates fake nude images of a minor would be in possession of child sexual abuse material, or CSAM. However, she claims it’s likely that the two boys accused of making and sharing the material were not charged with CSAM possession due to their age.
“There’s specifically several crimes that you can charge in a case, and you really have to evaluate what’s the strongest chance of winning, what has the highest likelihood of success, and if you include too many charges, is it just going to confuse the jury?” Cagnet Myron added.
Mary Anne Franks, a professor at the George Washington University School of Law and a lawyer who has studied the problem of nonconsensual explicit imagery, says it’s “odd” that Florida’s revenge porn law, which predates the 2022 statute under which the boys were charged, only makes the offense a misdemeanor, while this situation represented a felony.
“It is really strange to me that you impose heftier penalties for fake nude photos than for real ones,” she says.
Franks adds that although she believes distributing nonconsensual fake explicit images should be a criminal offense, thus creating a deterrent effect, she doesn’t believe offenders should be incarcerated, especially not juveniles.
“The first thing I think about is how young the victims are and worried about the kind of impact on them,” Franks says. “But then [I] also question whether or not throwing the book at kids is actually going to be effective here.”
This story originally appeared on wired.com.
Florida middle-schoolers charged with making deepfake nudes of classmates Read More »




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}